#amazon redshift data warehouse
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
70% of Tumblr users say the Dashboard is their favorite place to spend time online.
Text
Best Practices for a Smooth Data Warehouse Migration to Amazon Redshift
In the era of big data, many organizations find themselves outgrowing traditional on-premise data warehouses. Moving to a scalable, cloud-based solution like Amazon Redshift is an attractive solution for companies looking to improve performance, cut costs, and gain flexibility in their data operations. However, data warehouse migration to AWS, particularly to Amazon Redshift, can be complex, involving careful planning and precise execution to ensure a smooth transition. In this article, we’ll explore best practices for a seamless Redshift migration, covering essential steps from planning to optimization.
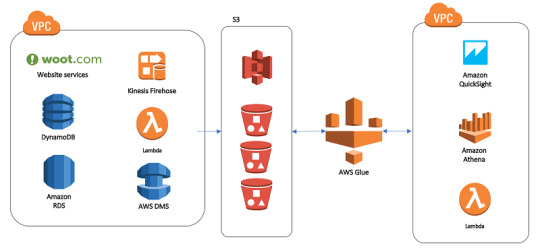
1. Establish Clear Objectives for Migration
Before diving into the technical process, it’s essential to define clear objectives for your data warehouse migration to AWS. Are you primarily looking to improve performance, reduce operational costs, or increase scalability? Understanding the ‘why’ behind your migration will help guide the entire process, from the tools you select to the migration approach.
For instance, if your main goal is to reduce costs, you’ll want to explore Amazon Redshift’s pay-as-you-go model or even Reserved Instances for predictable workloads. On the other hand, if performance is your focus, configuring the right nodes and optimizing queries will become a priority.
2. Assess and Prepare Your Data
Data assessment is a critical step in ensuring that your Redshift data warehouse can support your needs post-migration. Start by categorizing your data to determine what should be migrated and what can be archived or discarded. AWS provides tools like the AWS Schema Conversion Tool (SCT), which helps assess and convert your existing data schema for compatibility with Amazon Redshift.
For structured data that fits into Redshift’s SQL-based architecture, SCT can automatically convert schema from various sources, including Oracle and SQL Server, into a Redshift-compatible format. However, data with more complex structures might require custom ETL (Extract, Transform, Load) processes to maintain data integrity.
3. Choose the Right Migration Strategy
Amazon Redshift offers several migration strategies, each suited to different scenarios:
Lift and Shift: This approach involves migrating your data with minimal adjustments. It’s quick but may require optimization post-migration to achieve the best performance.
Re-architecting for Redshift: This strategy involves redesigning data models to leverage Redshift’s capabilities, such as columnar storage and distribution keys. Although more complex, it ensures optimal performance and scalability.
Hybrid Migration: In some cases, you may choose to keep certain workloads on-premises while migrating only specific data to Redshift. This strategy can help reduce risk and maintain critical workloads while testing Redshift’s performance.
Each strategy has its pros and cons, and selecting the best one depends on your unique business needs and resources. For a fast-tracked, low-cost migration, lift-and-shift works well, while those seeking high-performance gains should consider re-architecting.
4. Leverage Amazon’s Native Tools
Amazon Redshift provides a suite of tools that streamline and enhance the migration process:
AWS Database Migration Service (DMS): This service facilitates seamless data migration by enabling continuous data replication with minimal downtime. It’s particularly helpful for organizations that need to keep their data warehouse running during migration.
AWS Glue: Glue is a serverless data integration service that can help you prepare, transform, and load data into Redshift. It’s particularly valuable when dealing with unstructured or semi-structured data that needs to be transformed before migrating.
Using these tools allows for a smoother, more efficient migration while reducing the risk of data inconsistencies and downtime.
5. Optimize for Performance on Amazon Redshift
Once the migration is complete, it’s essential to take advantage of Redshift’s optimization features:
Use Sort and Distribution Keys: Redshift relies on distribution keys to define how data is stored across nodes. Selecting the right key can significantly improve query performance. Sort keys, on the other hand, help speed up query execution by reducing disk I/O.
Analyze and Tune Queries: Post-migration, analyze your queries to identify potential bottlenecks. Redshift’s query optimizer can help tune performance based on your specific workloads, reducing processing time for complex queries.
Compression and Encoding: Amazon Redshift offers automatic compression, reducing the size of your data and enhancing performance. Using columnar storage, Redshift efficiently compresses data, so be sure to implement optimal compression settings to save storage costs and boost query speed.
6. Plan for Security and Compliance
Data security and regulatory compliance are top priorities when migrating sensitive data to the cloud. Amazon Redshift includes various security features such as:
Data Encryption: Use encryption options, including encryption at rest using AWS Key Management Service (KMS) and encryption in transit with SSL, to protect your data during migration and beyond.
Access Control: Amazon Redshift supports AWS Identity and Access Management (IAM) roles, allowing you to define user permissions precisely, ensuring that only authorized personnel can access sensitive data.
Audit Logging: Redshift’s logging features provide transparency and traceability, allowing you to monitor all actions taken on your data warehouse. This helps meet compliance requirements and secures sensitive information.
7. Monitor and Adjust Post-Migration
Once the migration is complete, establish a monitoring routine to track the performance and health of your Redshift data warehouse. Amazon Redshift offers built-in monitoring features through Amazon CloudWatch, which can alert you to anomalies and allow for quick adjustments.
Additionally, be prepared to make adjustments as you observe user patterns and workloads. Regularly review your queries, data loads, and performance metrics, fine-tuning configurations as needed to maintain optimal performance.
Final Thoughts: Migrating to Amazon Redshift with Confidence
Migrating your data warehouse to Amazon Redshift can bring substantial advantages, but it requires careful planning, robust tools, and continuous optimization to unlock its full potential. By defining clear objectives, preparing your data, selecting the right migration strategy, and optimizing for performance, you can ensure a seamless transition to Redshift. Leveraging Amazon’s suite of tools and Redshift’s powerful features will empower your team to harness the full potential of a cloud-based data warehouse, boosting scalability, performance, and cost-efficiency.
Whether your goal is improved analytics or lower operating costs, following these best practices will help you make the most of your Amazon Redshift data warehouse, enabling your organization to thrive in a data-driven world.
#data warehouse migration to aws#redshift data warehouse#amazon redshift data warehouse#redshift migration#data warehouse to aws migration#data warehouse#aws migration
0 notes
Text

Learn how Amazon Redshift handles massive datasets and complex queries, and when it's best suited for tasks like Mortgage Portfolio Analysis or Real-Time Fraud Detection. Explore AWS QuickSight's integration with AWS data sources and its strengths in Business Intelligence and Data Exploration. Get actionable insights to make informed decisions for your projects and use cases.
#fintech#technology#finance#data analytics#redshift#quicksight#aws#amazon web services#technology videos#learning videos#data management#data warehouse#mortgage services#mortgage finance#data transformation
0 notes
Text
Discover practical strategies and expert tips on optimizing your data warehouse to scale efficiently without spending more money. Learn how to save costs while expanding your data infrastructure, ensuring maximum performance.
0 notes
Text
"Unlocking Business Intelligence with Data Warehouse Solutions"
Data Warehouse Solution: Boosting Business Intelligence

A data warehouse (DW) is an organized space that enables companies to organize and assess large volumes of information through multiple locations in a consistent way. This is intended to assist with tracking, company analytics, and choices. The data warehouse's primary purpose was to render it possible to efficiently analyze past and present information, offering important conclusions for management as a business strategy.
A data warehouse normally employs procedures (Take, convert, load) for combining information coming from several sources, including business tables, operations, and outside data flows.This allows for an advanced level of scrutiny by ensuring data reliability and precision. The information's structure enables complicated searches, which are often achieved using the aid of SQL-based tools, BI (Business Intelligence) software, or information display systems.
Regarding activities requiring extensive research, data storage centers were ideal since they could provide executives with rapid and precise conclusions. Common application cases include accounting, provider direction, customer statistics, and projections of sales. Systems provide connectivity, speed, and easy control of networks, but as cloud computing gained popularity, data warehouses like Amazon's Redshift, Google's Large SEARCH, and Snowflake have remained famous.
In conclusion, managing information systems is essential for companies that want to make the most out of their information. Gathering information collected in one center allows firms to better understand how they operate and introduce decisions that promote inventiveness and originality.
2 notes
·
View notes
Text
I wish I lived in a beautiful world where googling “redshift” returned the wikipedia article on the astronomical phenomenon as the first result instead of amazon’s data warehouse and “ads” redirected me to the astrophysics data system instead of suggesting a linkedin page with careers in advertising
#gonna be real for a moment. the amazon redshift thing is pissing me OFF.#1. it’s a stupid name and 2. it’s a pain in my ass and 3. WHY is it the first result.#astroposting
4 notes
·
View notes
Text
Data Engineering Concepts, Tools, and Projects
All the associations in the world have large amounts of data. If not worked upon and anatomized, this data does not amount to anything. Data masterminds are the ones. who make this data pure for consideration. Data Engineering can nominate the process of developing, operating, and maintaining software systems that collect, dissect, and store the association’s data. In modern data analytics, data masterminds produce data channels, which are the structure armature.
How to become a data engineer:
While there is no specific degree requirement for data engineering, a bachelor's or master's degree in computer science, software engineering, information systems, or a related field can provide a solid foundation. Courses in databases, programming, data structures, algorithms, and statistics are particularly beneficial. Data engineers should have strong programming skills. Focus on languages commonly used in data engineering, such as Python, SQL, and Scala. Learn the basics of data manipulation, scripting, and querying databases.
Familiarize yourself with various database systems like MySQL, PostgreSQL, and NoSQL databases such as MongoDB or Apache Cassandra.Knowledge of data warehousing concepts, including schema design, indexing, and optimization techniques.
Data engineering tools recommendations:
Data Engineering makes sure to use a variety of languages and tools to negotiate its objects. These tools allow data masterminds to apply tasks like creating channels and algorithms in a much easier as well as effective manner.
1. Amazon Redshift: A widely used cloud data warehouse built by Amazon, Redshift is the go-to choice for many teams and businesses. It is a comprehensive tool that enables the setup and scaling of data warehouses, making it incredibly easy to use.
One of the most popular tools used for businesses purpose is Amazon Redshift, which provides a powerful platform for managing large amounts of data. It allows users to quickly analyze complex datasets, build models that can be used for predictive analytics, and create visualizations that make it easier to interpret results. With its scalability and flexibility, Amazon Redshift has become one of the go-to solutions when it comes to data engineering tasks.
2. Big Query: Just like Redshift, Big Query is a cloud data warehouse fully managed by Google. It's especially favored by companies that have experience with the Google Cloud Platform. BigQuery not only can scale but also has robust machine learning features that make data analysis much easier. 3. Tableau: A powerful BI tool, Tableau is the second most popular one from our survey. It helps extract and gather data stored in multiple locations and comes with an intuitive drag-and-drop interface. Tableau makes data across departments readily available for data engineers and managers to create useful dashboards. 4. Looker: An essential BI software, Looker helps visualize data more effectively. Unlike traditional BI tools, Looker has developed a LookML layer, which is a language for explaining data, aggregates, calculations, and relationships in a SQL database. A spectacle is a newly-released tool that assists in deploying the LookML layer, ensuring non-technical personnel have a much simpler time when utilizing company data.
5. Apache Spark: An open-source unified analytics engine, Apache Spark is excellent for processing large data sets. It also offers great distribution and runs easily alongside other distributed computing programs, making it essential for data mining and machine learning. 6. Airflow: With Airflow, programming, and scheduling can be done quickly and accurately, and users can keep an eye on it through the built-in UI. It is the most used workflow solution, as 25% of data teams reported using it. 7. Apache Hive: Another data warehouse project on Apache Hadoop, Hive simplifies data queries and analysis with its SQL-like interface. This language enables MapReduce tasks to be executed on Hadoop and is mainly used for data summarization, analysis, and query. 8. Segment: An efficient and comprehensive tool, Segment assists in collecting and using data from digital properties. It transforms, sends, and archives customer data, and also makes the entire process much more manageable. 9. Snowflake: This cloud data warehouse has become very popular lately due to its capabilities in storing and computing data. Snowflake’s unique shared data architecture allows for a wide range of applications, making it an ideal choice for large-scale data storage, data engineering, and data science. 10. DBT: A command-line tool that uses SQL to transform data, DBT is the perfect choice for data engineers and analysts. DBT streamlines the entire transformation process and is highly praised by many data engineers.
Data Engineering Projects:
Data engineering is an important process for businesses to understand and utilize to gain insights from their data. It involves designing, constructing, maintaining, and troubleshooting databases to ensure they are running optimally. There are many tools available for data engineers to use in their work such as My SQL, SQL server, oracle RDBMS, Open Refine, TRIFACTA, Data Ladder, Keras, Watson, TensorFlow, etc. Each tool has its strengths and weaknesses so it’s important to research each one thoroughly before making recommendations about which ones should be used for specific tasks or projects.
Smart IoT Infrastructure:
As the IoT continues to develop, the measure of data consumed with high haste is growing at an intimidating rate. It creates challenges for companies regarding storehouses, analysis, and visualization.
Data Ingestion:
Data ingestion is moving data from one or further sources to a target point for further preparation and analysis. This target point is generally a data storehouse, a unique database designed for effective reporting.
Data Quality and Testing:
Understand the importance of data quality and testing in data engineering projects. Learn about techniques and tools to ensure data accuracy and consistency.
Streaming Data:
Familiarize yourself with real-time data processing and streaming frameworks like Apache Kafka and Apache Flink. Develop your problem-solving skills through practical exercises and challenges.
Conclusion:
Data engineers are using these tools for building data systems. My SQL, SQL server and Oracle RDBMS involve collecting, storing, managing, transforming, and analyzing large amounts of data to gain insights. Data engineers are responsible for designing efficient solutions that can handle high volumes of data while ensuring accuracy and reliability. They use a variety of technologies including databases, programming languages, machine learning algorithms, and more to create powerful applications that help businesses make better decisions based on their collected data.
6 notes
·
View notes
Text
Navigating the Cloud Landscape: Unleashing Amazon Web Services (AWS) Potential
In the ever-evolving tech landscape, businesses are in a constant quest for innovation, scalability, and operational optimization. Enter Amazon Web Services (AWS), a robust cloud computing juggernaut offering a versatile suite of services tailored to diverse business requirements. This blog explores the myriad applications of AWS across various sectors, providing a transformative journey through the cloud.

Harnessing Computational Agility with Amazon EC2
Central to the AWS ecosystem is Amazon EC2 (Elastic Compute Cloud), a pivotal player reshaping the cloud computing paradigm. Offering scalable virtual servers, EC2 empowers users to seamlessly run applications and manage computing resources. This adaptability enables businesses to dynamically adjust computational capacity, ensuring optimal performance and cost-effectiveness.
Redefining Storage Solutions
AWS addresses the critical need for scalable and secure storage through services such as Amazon S3 (Simple Storage Service) and Amazon EBS (Elastic Block Store). S3 acts as a dependable object storage solution for data backup, archiving, and content distribution. Meanwhile, EBS provides persistent block-level storage designed for EC2 instances, guaranteeing data integrity and accessibility.
Streamlined Database Management: Amazon RDS and DynamoDB
Database management undergoes a transformation with Amazon RDS, simplifying the setup, operation, and scaling of relational databases. Be it MySQL, PostgreSQL, or SQL Server, RDS provides a frictionless environment for managing diverse database workloads. For enthusiasts of NoSQL, Amazon DynamoDB steps in as a swift and flexible solution for document and key-value data storage.
Networking Mastery: Amazon VPC and Route 53
AWS empowers users to construct a virtual sanctuary for their resources through Amazon VPC (Virtual Private Cloud). This virtual network facilitates the launch of AWS resources within a user-defined space, enhancing security and control. Simultaneously, Amazon Route 53, a scalable DNS web service, ensures seamless routing of end-user requests to globally distributed endpoints.
Global Content Delivery Excellence with Amazon CloudFront
Amazon CloudFront emerges as a dynamic content delivery network (CDN) service, securely delivering data, videos, applications, and APIs on a global scale. This ensures low latency and high transfer speeds, elevating user experiences across diverse geographical locations.
AI and ML Prowess Unleashed
AWS propels businesses into the future with advanced machine learning and artificial intelligence services. Amazon SageMaker, a fully managed service, enables developers to rapidly build, train, and deploy machine learning models. Additionally, Amazon Rekognition provides sophisticated image and video analysis, supporting applications in facial recognition, object detection, and content moderation.
Big Data Mastery: Amazon Redshift and Athena
For organizations grappling with massive datasets, AWS offers Amazon Redshift, a fully managed data warehouse service. It facilitates the execution of complex queries on large datasets, empowering informed decision-making. Simultaneously, Amazon Athena allows users to analyze data in Amazon S3 using standard SQL queries, unlocking invaluable insights.
In conclusion, Amazon Web Services (AWS) stands as an all-encompassing cloud computing platform, empowering businesses to innovate, scale, and optimize operations. From adaptable compute power and secure storage solutions to cutting-edge AI and ML capabilities, AWS serves as a robust foundation for organizations navigating the digital frontier. Embrace the limitless potential of cloud computing with AWS – where innovation knows no bounds.
3 notes
·
View notes
Text
Best Data Warehousing Tools: Top Solutions for Modern Data Management
In today’s data-driven world, businesses are generating massive amounts of data from various sources—websites, CRMs, IoT devices, social platforms, and more. To store, manage, and analyze this data effectively, companies need reliable and scalable data warehousing tools. These tools not only store large volumes of structured and semi-structured data but also support fast querying, reporting, and analytics.
Choosing the best data warehousing tools is essential for building a future-ready data infrastructure. In this blog, we’ll explore some of the top tools in the market, their key features, pros and cons, and what makes them stand out.
What is a Data Warehouse?
A data warehouse is a centralized repository designed to store, manage, and analyze data from multiple sources. It is optimized for read-heavy operations and supports business intelligence (BI), analytics, and reporting functions.
Unlike transactional databases, data warehouses are designed for complex queries and historical data analysis, making them ideal for strategic decision-making.
Key Features to Look for in Data Warehousing Tools
When selecting a data warehousing solution, here are some features you should consider:
Scalability: Can the tool handle growing data volumes?
Performance: Does it provide fast query and report generation?
Data Integration: Can it ingest data from various sources like databases, APIs, and third-party platforms?
Cloud or On-Premise: Does it support hybrid or fully cloud-native architectures?
Security and Compliance: Does it meet your industry’s regulatory standards?
Best Data Warehousing Tools in 2025
1. Amazon Redshift
Amazon Redshift is one of the most widely used cloud data warehousing tools. It is fully managed and designed for high-speed analytics on large datasets.
Key Features:
Columnar storage and parallel query execution
Integrates easily with AWS ecosystem (e.g., S3, Glue, QuickSight)
Advanced security and compliance tools
Pros:
Scalable and cost-effective
Easy integration with BI tools like Tableau and Looker
Cons:
Performance can degrade with large complex joins
May require tuning for optimal performance
2. Google BigQuery
BigQuery is Google Cloud’s serverless, highly scalable data warehouse that excels in handling large-scale analytics.
Key Features:
Serverless—no infrastructure to manage
Real-time analytics with built-in machine learning
SQL-compatible querying engine
Pros:
Blazing-fast query performance
Seamless integration with Google Workspace and Looker
Cons:
Query costs can be high if not optimized
Limited support for certain complex transformations
3. Snowflake
Snowflake is a cloud-native data platform that supports multi-cloud deployment (AWS, Azure, GCP). It separates storage from compute, allowing dynamic scalability.
Key Features:
Time Travel & Fail-safe for data recovery
Automatic scaling and workload isolation
Supports both structured and semi-structured data
Pros:
Excellent concurrency and performance
No infrastructure management needed
Cons:
Pricing can become complex as usage grows
Learning curve for new users
4. Microsoft Azure Synapse Analytics
Formerly known as Azure SQL Data Warehouse, Azure Synapse Analytics is an integrated analytics service combining data warehousing with big data analytics.
Key Features:
Deep integration with Power BI and Azure Machine Learning
Hybrid transactional and analytical processing
Built-in data lake integration
Pros:
Unified experience for ingestion, preparation, and visualization
Good for organizations already in the Azure ecosystem
Cons:
UI can be overwhelming for beginners
Complex to configure initially
5. Oracle Autonomous Data Warehouse
Oracle Autonomous Data Warehouse is a cloud-based, self-driving data warehouse that uses machine learning for optimization and automation.
Key Features:
Automated tuning, backup, and patching
Built-in analytics and data visualizations
High performance with Oracle Exadata infrastructure
Pros:
Minimal administrative overhead
Robust enterprise-grade features
Cons:
Premium pricing
Better suited for existing Oracle users
6. Teradata Vantage
Teradata Vantage is an enterprise-grade data analytics platform that offers scalable cloud and hybrid solutions.
Key Features:
Cross-platform analytics
Integrates with AWS, Azure, and GCP
Unified data lake and warehouse management
Pros:
Excellent for complex analytics at scale
Proven performance in large enterprises
Cons:
Higher cost of ownership
May be too advanced for small businesses
7. Century Software
Century Software is an emerging name in data warehousing, offering tailored solutions for mid-sized businesses and enterprises. It combines ETL, data lake, and warehousing capabilities under one platform.
Key Features:
Simple UI and fast deployment
Built-in connectors for CRM, ERP, and marketing tools
Real-time sync and custom dashboards
Pros:
Easy to use and cost-effective
Excellent customer support
Cons:
Still growing in market maturity
Limited community and third-party integrations (as of now)
Conclusion: Choose What Fits Your Business
The best data warehousing tools are those that align with your current infrastructure, scale with your growth, and support your analytical needs. For businesses deep into AWS, Redshift might be the natural choice. For a serverless, low-maintenance option, BigQuery is ideal. Snowflake offers cross-cloud flexibility, while Azure Synapse is best for Microsoft-centric ecosystems.
Emerging platforms like Century Software offer simpler, more affordable alternatives without compromising on essential features.
The future of data warehousing is in flexibility, scalability, and real-time insights. Choose a platform that doesn’t just meet today’s needs, but prepares you for tomorrow’s data challenges.
0 notes
Text
Struggling to Manage Data Volumes? Discover How Data Warehouse Consulting Can Help
Our expert data warehouse consulting services help businesses navigate complex data management. We specialize in architecting scalable and secure cloud data warehouse solutions tailored to meet your performance, compliance, and growth needs. Whether you’re migrating from legacy systems or starting fresh in the cloud, our team ensures a seamless transition with minimal downtime and maximum efficiency.
Why Modern Businesses Are Drowning in Data
Today’s enterprises generate more data than ever before from customer interactions and sales reports to real-time operations and third-party integrations. Without the right architecture, this data becomes fragmented, slow, and difficult to manage.
The Role of Data Warehouse Consulting
Data warehouse consulting is important for businesses that need to store, manage, and analyze large volumes of data efficiently. Experts help design and implement scalable systems that consolidate data from multiple sources into a centralized platform, enabling faster and smarter decision-making.
Benefits of Cloud Data Warehouse Solutions
By using cloud data warehouse solutions, businesses can:
Scale storage and computing power on-demand
Eliminate the need for costly on-prem infrastructure
Integrate seamlessly with analytics and BI tools
Improve security, backup, and disaster recovery protocols
Platforms like Snowflake, Google BigQuery, and Amazon Redshift offer powerful foundations for cloud-based analytics when guided by the right consulting team.
Dataplatr’s Expertise in Cloud Data Warehouse Services
We deliver end-to-end cloud data warehouse services from initial strategy and migration to optimization and ongoing support. Our team work closely with your teams to:
Assess current data architecture
Recommend best-fit cloud platforms
Ensure high-performance data pipelines
Optimize cost and performance continuously
Customized Cloud Data Warehouse Consulting Services
Every business is not the same which is why our cloud data warehouse consulting services are fully customized. Whether you need real time analytics, system migration, or multi-cloud data balance, Dataplatr helps your solution to align with your goals.
0 notes
Text
Efficient Data Management for Predictive Models – The Role of Databases in Handling Large Datasets for Machine Learning
Predictive modelling thrives on data—lots of it. Whether you are forecasting demand, detecting fraud, or personalising recommendations, the calibre of your machine-learning (ML) solutions depends on how efficiently you store, organise, and serve vast amounts of information. Databases—relational, NoSQL, and cloud-native—form the backbone of this process, transforming raw inputs into ready-to-learn datasets. Understanding how to architect and operate these systems is, therefore, a core competency for every aspiring data professional and hence, a part of every data science course curriculum.
Why Databases Matter to Machine Learning
An ML workflow usually spans three data-intensive stages:
Ingestion and Storage – Collecting data from transactional systems, IoT devices, logs, or third-party APIs and landing it in a durable store.
Preparation and Feature Engineering – Cleaning, joining, aggregating, and reshaping data to create meaningful variables.
Model Training and Serving – Feeding training sets to algorithms, then delivering real-time or batch predictions back to applications.
Databases underpin each stage by enforcing structure, supporting fast queries, and ensuring consistency, and hence form the core module of any data science course in Mumbai. Without a well-designed data layer, even the most sophisticated model will suffer from long training times, stale features, or unreliable predictions.
Scaling Strategies for Large Datasets
Horizontal vs. Vertical Scaling Traditional relational databases scale vertically—adding more CPU, RAM, or storage to a single machine. Modern workloads often outgrow this approach, prompting a shift to horizontally scalable architectures such as distributed SQL (e.g., Google Spanner) or NoSQL clusters (e.g., Cassandra, MongoDB). Sharding and replication distribute data across nodes, supporting petabyte-scale storage and parallel processing.
Columnar Storage for Analytics Column-oriented formats (Parquet, ORC) and columnar databases (Amazon Redshift, ClickHouse) accelerate analytical queries by scanning only the relevant columns. This is especially valuable when feature engineering requires aggregations across billions of rows but only a handful of columns.
Data Lakes and Lakehouses Data lakes offer schema-on-read flexibility, letting teams ingest semi-structured or unstructured data without upfront modelling. Lakehouse architectures (Delta Lake, Apache Iceberg) layer ACID transactions and optimised metadata on top, blending the reliability of warehouses with the openness of lakes—ideal for iterative ML workflows.
Integrating Databases with ML Pipelines
Feature Stores To avoid re-computing features for every experiment, organisations adopt feature stores—specialised databases that store versioned, reusable features. They supply offline batches for training and low-latency look-ups for online inference, guaranteeing training-serving consistency.
Streaming and Real-Time Data Frameworks like Apache Kafka and Flink pair with databases to capture event streams and update features in near real time. This is crucial for applications such as dynamic pricing or anomaly detection, where stale inputs degrade model performance.
MLOps and Automation Infrastructure-as-code tools (Terraform, Kubernetes) and workflow orchestrators (Airflow, Dagster) automate database provisioning, data validation, and retraining schedules. By codifying these steps, teams reduce manual errors and accelerate model deployment cycles.
Governance, Quality, and Cost
As datasets balloon, so do risks:
Data Quality – Referential integrity, constraints, and automatic checks catch nulls, duplicates, and outliers early.
Security and Compliance – Role-based access, encryption, and audit logs protect sensitive attributes and meet regulations such as GDPR or HIPAA.
Cost Management – Partitioning, compression, and lifecycle policies curb storage expenses, while query optimisers and materialised views minimise compute costs.
A modern data science course walks students through these best practices, combining theory with labs on indexing strategies, query tuning, and cloud-cost optimisation.
Local Relevance and Hands-On Learning
For learners taking a data science course in Mumbai, capstone projects frequently mirror the city’s fintech, media, and logistics sectors. Students might design a scalable order-prediction pipeline: ingesting transaction data into a distributed warehouse, engineering temporal features via SQL window functions, and serving predictions through a feature store exposed by REST APIs. Such end-to-end experience cements the role of databases as the silent engine behind successful ML products.
Conclusion
Efficient data management is not an afterthought—it is the foundation upon which predictive models are built and maintained. By mastering database design, scaling techniques, and MLOps integration, data professionals ensure that their models train faster, score accurately, and deliver value continuously. As organisations double down on AI investments, those who can marry machine learning expertise with robust database skills will remain at the forefront of innovation.
Business Name: ExcelR- Data Science, Data Analytics, Business Analyst Course Training Mumbai Address: Unit no. 302, 03rd Floor, Ashok Premises, Old Nagardas Rd, Nicolas Wadi Rd, Mogra Village, Gundavali Gaothan, Andheri E, Mumbai, Maharashtra 400069, Phone: 09108238354, Email: [email protected].
0 notes
Text
AWS Kinesis: Guides, Pricing, Cost Optimization

AWS Kinesis isn't just one service; it's a family of services, each tailored for different streaming data needs:
Amazon Kinesis Data Streams (KDS):
What it is: The foundational service. KDS allows you to capture, store, and process large streams of data records in real-time. It provides durable storage for up to 365 days (default 24 hours), enabling multiple applications to process the same data concurrently and independently.
Use Cases: Real-time analytics, log and event data collection, IoT data ingestion, real-time dashboards, application monitoring, and streaming ETL.
Key Concept: Shards. KDS capacity is measured in shards. Each shard provides a fixed unit of capacity (1 MB/s ingress, 1,000 records/s ingress, 2 MB/s egress per shard, shared among consumers).
Amazon Kinesis Data Firehose:
What it is: A fully managed service for delivering real-time streaming data to destinations like Amazon S3, Amazon Redshift, Amazon OpenSearch Service, Splunk, and generic HTTP endpoints. It automatically scales to match your data throughput and requires no administration.
Use Cases: Loading streaming data into data lakes (S3), data warehouses (Redshift), and analytics tools with minimal effort. It handles batching, compression, and encryption.
Amazon Kinesis Data Analytics:
What it is: The easiest way to process and analyze streaming data in real-time with Apache Flink or standard SQL. It allows you to build sophisticated streaming applications to transform and enrich data, perform real-time aggregations, and derive insights as data arrives.
Use Cases: Real-time anomaly detection, interactive analytics, streaming ETL, and building real-time dashboards.
Amazon Kinesis Video Streams:
What it is: A service that makes it easy to securely stream video from connected devices to AWS for analytics, machine learning (ML), and other processing. It automatically provisions and scales all the necessary infrastructure.
Use Cases: IoT video streaming, smart home security, drone video analytics, and integrating with ML services like Amazon Rekognition.
Understanding Kinesis Pricing Models
Kinesis pricing is "pay-as-you-go," meaning you only pay for what you use, with no upfront costs or minimum fees. However, the billing components vary significantly per service:
1. Kinesis Data Streams (KDS) Pricing:
KDS pricing revolves around shards and data throughput. There are two capacity modes:
Provisioned Capacity Mode:
Shard Hours: You pay for each shard-hour. This is the base cost.
PUT Payload Units: You are charged per million "PUT payload units." Each record ingested is rounded up to the nearest 25 KB. So, a 1 KB record and a 20 KB record both consume one 25 KB payload unit.
Data Retrieval: Standard data retrieval is included in shard hours up to 2MB/s per shard shared among consumers.
Extended Data Retention: Extra cost per shard-hour for retaining data beyond 24 hours, up to 7 days. Beyond 7 days (up to 365 days), it's priced per GB-month.
Enhanced Fan-Out (EFO): An additional cost per consumer-shard-hour for dedicated read throughput (2 MB/s per shard per consumer) and per GB of data retrieved via EFO. This is ideal for multiple, high-throughput consumers.
On-Demand Capacity Mode:
Per GB of Data Written: Simpler billing based on the volume of data ingested (rounded up to the nearest 1 KB per record).
Per GB of Data Read: Charged for the volume of data retrieved (no rounding).
Per Stream Hour: A fixed hourly charge for each stream operating in on-demand mode.
Optional Features: Extended data retention and Enhanced Fan-Out incur additional charges, similar to provisioned mode but with different rates.
Automatic Scaling: KDS automatically scales capacity based on your traffic, doubling the peak write throughput of the previous 30 days.
2. Kinesis Data Firehose Pricing:
Data Ingestion: Charged per GB of data ingested into the delivery stream. Records are rounded up to the nearest 5 KB.
Format Conversion: Optional charge per GB if you convert data (e.g., JSON to Parquet/ORC).
VPC Delivery: Additional cost per GB if delivering data to a private VPC endpoint.
No charges for delivery to destinations, but standard charges for S3 storage, Redshift compute, etc., apply at the destination.
3. Kinesis Data Analytics Pricing:
Kinesis Processing Units (KPUs): Billed hourly per KPU. A KPU is a combination of compute (vCPU), memory, and runtime environment (e.g., Apache Flink).
Running Application Storage: Charged per GB-month for stateful processing features.
Developer/Interactive Mode: Additional KPUs may be charged for interactive development.
4. Kinesis Video Streams Pricing:
Data Ingestion: Charged per GB of video data ingested.
Data Storage: Charged per GB-month for stored video data.
Data Retrieval & Playback: Charged per GB for data retrieved, and additional costs for specific features like HLS (HTTP Live Streaming) or WebRTC streaming minutes.
Cost Optimization Strategies for AWS Kinesis
Optimizing your Kinesis costs requires a deep understanding of your workload and the various pricing components. Here are key strategies:
Choose the Right Kinesis Service:
Firehose for simplicity & delivery: If your primary goal is to load streaming data into a data lake or warehouse without complex real-time processing, Firehose is often the most cost-effective and easiest solution.
KDS for complex processing & multiple consumers: Use Data Streams if you need multiple applications to consume the same data independently, require precise record ordering, or need custom real-time processing logic with Kinesis Data Analytics or custom consumers.
Data Analytics for real-time insights: Use Kinesis Data Analytics when you need to perform real-time aggregations, transformations, or anomaly detection on your streams.
Optimize Kinesis Data Streams (KDS) Capacity Mode:
On-Demand for unpredictable/new workloads: Start with On-Demand if your traffic patterns are unknown, highly spiky, or if you prefer a fully managed, hands-off approach to capacity. It's generally more expensive for predictable, sustained workloads but eliminates throttling risks.
Provisioned for predictable workloads: Once your traffic patterns are stable and predictable, switch to Provisioned mode. It is often significantly cheaper for consistent, high-utilization streams.
Dynamic Switching: For very variable workloads, you can technically switch between Provisioned and On-Demand modes (up to twice every 24 hours) using automation (e.g., Lambda functions) to align with known peak and off-peak periods, maximizing cost savings.
Right-Size Your Shards (Provisioned KDS):
Monitor relentlessly: Use Amazon CloudWatch metrics (IncomingBytes, IncomingRecords, GetRecords.Bytes) to understand your stream's actual throughput.
Reshard dynamically: Continuously evaluate if your current shard count matches your data volume. Scale up (split shards) when throughput needs increase and scale down (merge shards) during low periods to avoid over-provisioning. Automate this with Lambda functions and CloudWatch alarms.
Beware of "Hot Shards": Ensure your partition keys distribute data evenly across shards. If a single key (or a few keys) sends too much data to one shard, that "hot shard" can become a bottleneck and impact performance, potentially requiring more shards than technically necessary for the overall throughput.
Optimize Data Ingestion:
Batching & Aggregation: For KDS, aggregate smaller records into larger batches (up to 1 MB per PutRecord call) before sending them. For Provisioned mode, records are billed in 25KB increments, so aim for record sizes that are multiples of 25KB to avoid wasted capacity. For Firehose, ingestion is billed in 5KB increments.
Pre-process Data: Use AWS Lambda or other processing before ingesting into Kinesis to filter out unnecessary data, reduce record size, or transform data to a more efficient format.
Manage Data Retention:
Default 24 Hours: KDS retains data for 24 hours by default, which is free. Only extend retention (up to 7 days or 365 days) if your downstream applications truly need to re-process historical data or have compliance requirements. Extended retention incurs additional costs.
Long-Term Storage: For archival or long-term analytics, deliver data to cost-effective storage like Amazon S3 via Firehose or a custom KDS consumer, rather than relying on KDS's extended retention.
Smart Consumer Design (KDS):
Enhanced Fan-Out (EFO): Use EFO judiciously. While it provides dedicated throughput and low latency per consumer, it incurs additional per-consumer-shard-hour and data retrieval costs. If you have fewer than three consumers or latency isn't critical, standard (shared) throughput might be sufficient.
Kinesis Client Library (KCL): For custom consumers, use the latest KCL versions (e.g., KCL 3.0) which offer improved load balancing across workers, potentially allowing you to process the same data with fewer compute resources (e.g., EC2 instances or Lambda concurrency).
Leverage Firehose Features:
Compression: Enable data compression (e.g., GZIP, Snappy, ZIP) within Firehose before delivery to S3 or other destinations to save on storage and transfer costs.
Format Conversion: Convert data to columnar formats like Apache Parquet or ORC using Firehose's built-in conversion. This can significantly reduce storage costs in S3 and improve query performance for analytics services like Athena or Redshift Spectrum.
Buffering: Adjust buffer size and buffer interval settings in Firehose to optimize for delivery costs and destination performance, balancing real-time needs with batching efficiency.
Conclusion
AWS Kinesis is an indispensable suite of services for building robust, real-time data streaming architectures. However, its power comes with complexity, especially in pricing. By understanding the unique billing models of each Kinesis service and implementing thoughtful optimization strategies – from choosing the right capacity mode and right-sizing shards to optimizing data ingestion and consumer patterns – you can harness the full potential of real-time data processing on AWS while keeping your cloud costs in check. Continuous monitoring and a proactive approach to resource management will be your best guides on this journey.
0 notes
Text
Data Lakehouse

Data Lakehouse: революция в мире данных, о которой вы не знали. Представьте себе мир, где вам больше не нужно выбирать между хранилищем структурированных данных и озером неструктурированной информации.
Data Lakehouse — это как швейцарский нож в мире данных, объединяющий лучшее из двух подходов. Давайте разберёмся, почему 75% компаний уже перешли на эту архитектуру и как она может изменить ваш бизнес.
Что такое Data Lakehouse на самом деле?
Data Lakehouse — это не просто модное словечко. Это принципиально новый подход к работе с данными, который ломает традиционные барьеры. В отличие от старых систем, где данные приходилось постоянно перемещать между разными хранилищами, здесь всё живёт в одной экосистеме. Почему это прорыв? - Больше никакой головной боли с ETL — данные доступны сразу после поступления. - Один источник правды — все отделы работают с одинаковыми данными. - Масштабируемость без ограничений — растёт бизнес, растёт и ваше хранилище.
Как работает эта магия?
Секрет Data Lakehouse в трёх китах. Единый слой хранения Вместо разделения на data lakes и warehouses — общее хранилище для всех типов данных. Apache Iceberg (тот самый, за который Databricks выложили $1 млрд) — это лишь один из примеров технологий, делающих это возможным.
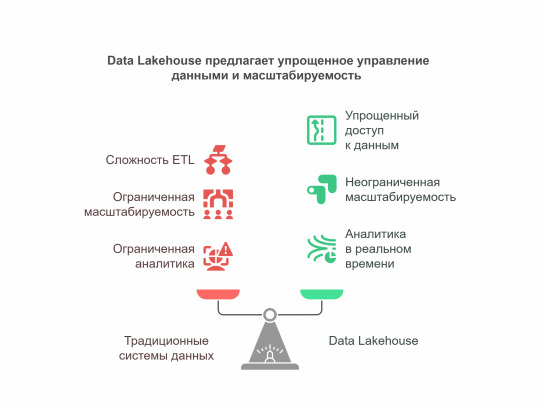
Революция в мире данных, о которой вы не знали Реальное время — не просто слова 56% IT-директоров подтверждают: аналитика в реальном времени сокращает их расходы вдвое. Финансовые операции, маркетинговые кампании, обнаружение мошенничества — всё это теперь можно делать мгновенно. SQL и не только Старые добрые запросы работают бок о бок с машинным обучением и сложной аналитикой. Никаких "или-или" — только "и то, и другое".
Кто двигает этот рынок?
Три компании, за которыми стоит следить: - SingleStore — анализирует петабайты данных за миллисекунды ($464 млн инвестиций). - dbt Labs — превращает сырые данные в готовые для анализа без перемещения (60 тыс. клиентов). - Tinybird — создание приложений для работы с данными в реальном времени ($70 млн финансирования).
Почему вам стоит задуматься об этом уже сегодня?
70% технологических лидеров называют доступность данных для реальной аналитики критически важной. Data Lakehouse — это не будущее, это настоящее. Компании, которые внедряют эти решения сейчас, получа��т: - Конкурентное преимущество — быстрее принимают решения. - Экономию — до 50% на инфраструктуре. - Гибкость — работа с любыми данными в любом формате.
Динамика тренда С чего начать? Попробуйте облачные решения от Databricks или Amazon Redshift. Начните с малого — одного проекта или отдела. Убедитесь сами, как это работает, прежде чем масштабировать на всю компанию. Data Lakehouse — это не просто технология. Это новый образ мышления о данных. Как вы планируете использовать этот подход в своем бизнесе?
Часто задаваемые вопросы (ЧаВо)
Что такое Data Lakehouse и чем он отличается от традиционных хранилищ данных? Data Lakehouse — это современная архитектура данных, объединяющая преимущества Data Lakes (хранение неструктурированных данных) и Data Warehouses (структурированная аналитика). В отличие от традиционных систем, он обеспечивает единое хранилище для всех типов данных с поддержкой SQL-запросов, машинного обучения и аналитики в реальном времени без необходимости перемещения данных между системами. Какие ключевые преимущества Data Lakehouse для бизнеса? Основные преимущества включают: 1) Снижение затрат на инфраструктуру до 50% 2) Возможность аналитики в реальном времени 3) Устранение необходимости сложных ETL-процессов 4) Поддержка всех типов данных (структурированных, полуструктурированных и неструктурированных) 5) Единый источник данных для всей организации. Какие технологии лежат в основе Data Lakehouse? Ключевые технологии включают: 1) Apache Iceberg, Delta Lake и Apache Hudi для управления таблицами 2) Облачные хранилища (S3, ADLS) 3) Вычислительные движки (Spark, Presto) 4) SQL-интерфейсы 5) Инструменты машинного обучения. Эти технологии обеспечивают ACID-транзакции, версионность данных и высокую производительность. Как начать внедрение Data Lakehouse в моей компании? Рекомендуется начинать с пилотного проекта: 1) Выберите одну бизнес-задачу или отдел 2) Оцените облачные решения (Databricks, Snowflake, Amazon Redshift) 3) Начните с миграции части данных 4) Обучите команду 5) Измерьте результаты перед масштабированием. Многие провайдеры предлагают бесплатные пробные версии. Какие компании являются лидерами в области Data Lakehouse? Ключевые игроки ры��ка: 1) Databricks (Delta Lake) 2) Snowflake 3) AWS (Redshift, Athena) 4) Google (BigQuery) 5) Microsoft (Fabric). Также стоит обратить внимание на инновационные стартапы: SingleStore для аналитики в реальном времени, dbt Labs для трансформации данных и Tinybird для приложений реального времени. Какие проблемы решает Data Lakehouse? Data Lakehouse решает ключевые проблемы: 1) Фрагментация данных между разными системами 2) Задержки в аналитике из-за ETL 3) Высокая стоимость содержания отдельных хранилищ и озер данных 4) Сложность работы с неструктурированными данными 5) Ограничения масштабируемости традиционных решений. Каковы основные варианты использования Data Lakehouse? Типичные сценарии: 1) Аналитика в реальном времени (финансы, маркетинг) 2) Обнаружение мошенничества 3) Персонализация клиентского опыта 4) IoT и обработка потоковых данных 5) Машинное обучение и AI 6) Консолидация корпоративных данных 7) Управление клиентскими данными (CDP). Read the full article
0 notes
Text
7 Practical Benefits of Data Warehousing

In today’s competitive, data-driven world, organizations of all sizes are seeking efficient ways to manage, analyze, and utilize the growing volumes of data they generate. A data warehouse serves as the foundation for strategic decision-making by centralizing information from various sources into a single, reliable repository. Here are 7 practical benefits of data warehousing that demonstrate why this technology is essential for business success.
1. Seamless Data Integration Across Multiple Sources
Businesses typically rely on multiple data systems — CRM platforms, marketing software, ERP solutions, and more. A data warehouse integrates all of this data into a single system, ensuring that users have access to a unified, consistent view of business information.
This allows stakeholders to avoid the complications of data silos and disparate formats, making cross-departmental analysis faster and more accurate.
2. High-Performance Data Retrieval and Reporting
One of the most noticeable benefits of a data warehouse is the speed of data retrieval. Unlike transactional databases, which are optimized for day-to-day operations, data warehouses are built for complex queries and analysis.
Whether it’s generating sales reports, forecasting inventory needs, or analyzing marketing campaign performance, a data warehouse can deliver insights in seconds—without disrupting daily operations.
3. Enhanced Data Quality and Accuracy
Before being loaded into the warehouse, data goes through a rigorous ETL (Extract, Transform, Load) process. During this stage, data is:
Cleansed of inconsistencies
Standardized into a uniform structure
Validated for accuracy
The result is high-quality, trustworthy data that forms the foundation of reliable analytics and reporting.
4. Advanced Decision-Making and Predictive Analytics
Data warehousing empowers organizations to make better decisions by supporting real-time analytics, historical trend analysis, and even predictive modeling.
With a centralized and accessible data environment, executives and analysts can ask complex “what-if” questions and simulate various business scenarios to inform their next move—reducing risks and identifying opportunities faster.
5. Long-Term Historical Data Storage
Unlike operational systems that often overwrite old data, a data warehouse stores information over long periods. This historical data is vital for:
Trend analysis
KPI tracking
Seasonal forecasting
Customer lifetime value analysis
Having access to a comprehensive timeline allows businesses to uncover patterns that may go unnoticed in short-term data snapshots.
6. Better Compliance and Data Governance
With data regulations like GDPR, CCPA, and HIPAA, organizations must ensure their data is stored, managed, and accessed responsibly. Data warehouses offer:
Role-based access control
Audit logs
Data lineage tracking
This structured environment improves regulatory compliance and supports a culture of responsible data use across the organization.
7. Scalability and Cost Efficiency
Modern data warehouses, especially cloud-based platforms like Amazon Redshift, Google BigQuery, or Snowflake, are designed to scale effortlessly as your data and business grow.
You pay only for the storage and compute resources you use, making data warehousing a cost-effective solution for both startups and large enterprises. There's no need for hefty upfront investments in hardware, and system upgrades are handled by the cloud provider.
Final Thoughts
Implementing a data warehouse isn’t just a technical upgrade—it’s a strategic investment that enhances how your organization thinks, plans, and operates. From better reporting to faster decision-making, the practical benefits of data warehousing touch every part of the business.
0 notes
Text
In an era where data reigns supreme, businesses are scrambling to make the most of the mountains of information they collect. Enter reverse ETL - a hip, savvy, and somewhat enigmatic superhero of the data world, swooping in to save the day. But what exactly is reverse ETL? How does it differ from its more traditional counterpart, ETL? The ABCs of Reverse ETL: Data Warehouses, ETL, and More Before we dive headfirst into the realm of reverse ETL, let's take a step back and familiarize ourselves with the basics: data warehouses and the traditional ETL process. Data Warehouses: The Vaults of Digital Treasure Data warehouses are expansive, centralized repositories for all types of structured and semi-structured data. Think of it as the Fort Knox of your company's digital assets. Popular data warehouse providers include Google BigQuery, Amazon Redshift, and Snowflake. Without these repositories, it would be next to impossible to accurately analyze data, generate comprehensive reports and make informed decisions. Nevertheless, one must take into account that not all data warehouses offer the same features and functionality. For example, the capabilities of Snowflake and Databricks can differ greatly. Therefore, it is essential to have a comprehensive understanding of the data warehouse ecosystem before deciding on a provider. This will ensure that you make an informed decision and leverage all available resources. Extraction, Transformation, and Loading (ETL): The Classic Data Pipeline ETL is the traditional process of extracting data from various sources, transforming it into a standardized format, and loading it into a data warehouse. It's like a data assembly line, taking raw materials and refining them into something shiny and valuable. However, while ETL has served us well for years, it has its limitations. Once the data is safely stored in the warehouse, it often becomes siloed and disconnected from other business applications, making it difficult to leverage for practical purposes. Reverse ETL: A Modern Spin on an Old Classic Reverse ETL flips the script by taking the refined, transformed data from the warehouse and pushing it back into other business applications. It's like a data-driven boomerang, sending valuable information back to where it can be most useful. Key features and benefits of reverse ETL include: Integration: Connecting the dots between data warehouses and operational systems to ensure that data flows seamlessly between them. Enrichment: Improving business applications by providing them with more accurate, up-to-date, and comprehensive data. This will increase their efficacy and make your business operations more efficient. Automation: Reducing manual data entry and transfer tasks, freeing up valuable time and resources for other strategic initiatives. Real-World Examples: Reverse ETL in Action Now that we've covered the theory, let's delve into some real-world examples of reverse ETL, showcasing its potential to revolutionize the way businesses leverage their data. Customer Relationship Management (CRM) Integration: The Perfect Data Marriage Reverse ETL can be a matchmaker, marrying data from your warehouse with your CRM system to create a harmonious union. By synchronizing data between the two systems, sales, and marketing teams gain access to a more complete and accurate view of customer interactions, preferences, and history. Benefits of CRM integration include: Improved sales efficiency: With access to enriched customer profiles, sales representatives can better target prospects and tailor their pitches to address specific needs and pain points. Enhanced marketing campaigns: By combining historical customer data with real-time insights, marketing teams can design more effective and personalized campaigns, driving higher conversion rates and customer satisfaction. Business Intelligence (BI) Tool Enrichment: Turbocharging Your Analytics Imagine being able to supercharge your tools with the power of enriched data from your warehouse.
Reverse ETL makes this possible, supplying your analytics platform with a treasure trove of information to slice, dice, and analyze. The benefits of BI tool enrichment include: Deeper insights: With access to a broader and more accurate dataset, businesses can uncover hidden patterns, trends, and opportunities that might otherwise go unnoticed. Data-driven decision-making: By feeding analytics platforms with up-to-date, high-quality data, businesses can make more informed decisions, backed by solid evidence. Marketing Automation and Personalization: Hit the Bullseye Every Time A well-executed marketing campaign is like a perfectly aimed arrow, striking right at the heart of your target audience's desires. Reverse ETL can help fine-tune your aim by supplying your marketing automation tools with rich, up-to-date customer data. The benefits of this integration include: Targeted marketing campaigns: By leveraging customer data from the warehouse, marketers can create laser-focused campaigns that resonate with specific audience segments. Improved customer experiences: Tailoring experiences to individual customers is the key to creating an unforgettable experience.. Reverse ETL enables businesses to tailor content, offers, and interactions based on individual preferences, resulting in happier, more loyal customers. Overcoming Obstacles: Challenges and Solutions in Reverse ETL Implementation As with any great tool, the world of reverse ETL comes with its fair share of challenges. Let's explore two of the common obstacles (and their solutions). Data Quality and Consistency Reverse ETL is only as good as the data it works with. Ensuring data quality and consistency is paramount for reaping the full benefits of this process. To achieve this, consider the following techniques: Data validation: Implement checks and controls to ensure that only accurate and complete data enters your warehouse. Data cleansing: Regularly review and clean up your warehouse data to eliminate duplicates, inconsistencies, and inaccuracies. Data Security and Compliance Data is a valuable commodity, and with great value comes great responsibility. Ensuring the security and compliance of your data is a top priority when implementing reverse ETL. Consider these best practices for data protection: Encryption: Use strong encryption methods to safeguard data both in transit and at rest. Access control: Implement strict access controls to prevent unauthorized access to sensitive data. Auditing: Regularly audit your data management processes and systems to identify and address potential vulnerabilities. The Takeaway Reverse ETL is a powerful tool that can unlock the hidden potential of data stored in warehouses. By making this data readily available to various business applications, organizations can drive better decision-making, improve operational efficiency, and create more personalized experiences for their customers. By staying mindful of data security and accuracy, you will be primed to experience the full advantages reverse ETL has to offer.
0 notes
Text
Transforming the Digital Future with Kadel Labs: Pioneers in Data Engineering Services and Solutions
In today’s data-driven world, businesses are continuously challenged to transform vast amounts of raw data into actionable insights. The companies that succeed are those that effectively harness the power of modern data engineering. As the demand for real-time analytics, data governance, and scalable architecture grows, businesses increasingly turn to experts for support. This is where Kadel Labs emerges as a frontrunner—offering comprehensive Data Engineering Services and forward-thinking Data Engineering Solutions tailored to meet the evolving needs of modern enterprises.
The Role of Data Engineering in Modern Business
Data engineering is the foundation upon which data science, analytics, and artificial intelligence thrive. It involves designing and building systems for collecting, storing, and analyzing data at scale. Businesses rely on data engineers to ensure data is clean, accessible, and usable for downstream processing.
The rapid growth in data volumes, combined with the proliferation of IoT devices, cloud computing, and artificial intelligence, makes robust data pipelines and architectures more important than ever. Without a solid data infrastructure, even the most sophisticated analytics tools are rendered ineffective.
Why Data Engineering Services Are Essential
To keep up with today’s digital pace, businesses need more than just data scientists. They need a reliable team of data engineers to:
Build scalable ETL (Extract, Transform, Load) pipelines
Integrate disparate data sources into a unified data ecosystem
Ensure data quality and governance
Optimize data storage and retrieval
Facilitate real-time data processing
Enable machine learning workflows through effective data provisioning
This is where Kadel Labs stands out with their extensive suite of Data Engineering Services.
Who Is Kadel Labs?
Kadel Labs is a technology consultancy and innovation-driven company dedicated to enabling digital transformation across industries. Headquartered in a rapidly growing tech hub, Kadel Labs leverages cutting-edge tools and technologies to offer end-to-end digital solutions. Among its flagship offerings, its Data Engineering Solutions have earned it a reputation as a trusted partner for organizations looking to capitalize on the full potential of their data.
Kadel Labs’ mission is to empower businesses to become data-first by building modern data platforms, implementing scalable architectures, and ensuring high data reliability.
Comprehensive Data Engineering Services by Kadel Labs
Kadel Labs offers a full spectrum of Data Engineering Services, helping organizations modernize their data infrastructure and make data a strategic asset. Their core offerings include:
1. Data Architecture & Platform Engineering
Kadel Labs designs and implements robust data architectures that support both batch and real-time data processing. Their engineers build scalable cloud-native data platforms using technologies like AWS, Azure, Google Cloud, Apache Spark, and Kubernetes. These platforms enable companies to handle terabytes or even petabytes of data with ease.
2. ETL and ELT Pipeline Development
Efficient data pipelines are at the heart of every modern data system. Kadel Labs specializes in creating optimized ETL and ELT pipelines that move data seamlessly across environments while maintaining high performance and data integrity.
3. Data Lake and Data Warehouse Integration
Whether clients are looking to implement a data lake for unstructured data or a data warehouse for structured analytics, Kadel Labs delivers tailored solutions. Their team works with platforms like Snowflake, Amazon Redshift, BigQuery, and Azure Synapse to meet diverse client needs.
4. Data Governance and Quality Assurance
Data without governance is a liability. Kadel Labs integrates strong data governance frameworks, ensuring compliance, security, and accuracy. They implement metadata management, data lineage tracking, and quality checks to give businesses confidence in their data.
5. Real-Time Data Streaming
Today’s business decisions often require real-time insights. Kadel Labs enables real-time analytics through tools like Apache Kafka, Apache Flink, and Spark Streaming. These technologies allow businesses to respond immediately to customer behavior, market trends, and operational anomalies.
6. Machine Learning Data Pipelines
For AI initiatives to succeed, data needs to be properly prepared and delivered. Kadel Labs builds ML-ready pipelines that feed consistent, high-quality data into machine learning models, accelerating time-to-value for AI projects.
Strategic Data Engineering Solutions for Competitive Advantage
Kadel Labs doesn’t offer one-size-fits-all services. Their Data Engineering Solutions are customized based on each client’s industry, data maturity, and business goals. Here’s how they approach problem-solving:
1. Industry-Centric Frameworks
From finance and healthcare to retail and manufacturing, Kadel Labs brings domain-specific expertise to each project. They understand the unique challenges of each industry—be it HIPAA compliance in healthcare or real-time analytics in e-commerce—and craft solutions accordingly.
2. Cloud-Native and Hybrid Architectures
As cloud adoption accelerates, Kadel Labs supports clients in transitioning from on-premises systems to cloud-native or hybrid models. They focus on building flexible architectures that allow seamless scaling and easy integration with third-party systems.
3. End-to-End Automation
Manual data processes are error-prone and slow. Kadel Labs integrates automation across the data lifecycle—from ingestion and transformation to validation and reporting—boosting efficiency and reliability.
4. Agile Delivery Model
With an agile and collaborative approach, Kadel Labs ensures quick iterations, continuous feedback, and timely delivery. Their clients remain actively involved, which leads to greater alignment between business goals and technical execution.
5. Data Democratization
Kadel Labs believes in making data accessible to everyone within the organization—not just data scientists. Through intuitive dashboards, self-service tools, and data catalogs, they empower business users to make data-driven decisions without needing to write code.
Success Stories: Kadel Labs in Action
Case Study 1: Optimizing Retail Supply Chain
A leading retail chain was struggling with fragmented data across multiple vendors and regions. Kadel Labs developed a centralized data platform that integrated supply chain data in real time. With better visibility, the company reduced inventory costs by 20% and improved delivery timelines.
Case Study 2: Accelerating Financial Reporting
A financial services client needed to automate monthly compliance reporting. Kadel Labs implemented a data warehouse and built ETL pipelines that pulled data from 15+ sources. Reports that previously took 5 days to compile were now generated within hours, with higher accuracy.
Case Study 3: Powering Predictive Analytics in Healthcare
Kadel Labs partnered with a healthcare provider to create ML pipelines for patient readmission prediction. By streamlining data engineering workflows, they helped the organization deploy predictive models that reduced readmission rates by 12%.
The Kadel Labs Difference
What truly sets Kadel Labs apart is not just their technical expertise, but their commitment to innovation, quality, and partnership. They approach each engagement with a focus on long-term value creation. Their clients see them not just as vendors, but as strategic allies in the data transformation journey.
Key Strengths
Expert Team: Data engineers, architects, cloud specialists, and domain experts under one roof
Technology Agnostic: Proficiency across a wide range of tools and platforms
Scalability: Solutions that grow with your business
Security First: Emphasis on data privacy, compliance, and governance
Customer-Centric: Transparent communication and dedicated support
Preparing for the Data-Driven Future
As businesses brace for a future where data is the new currency, the importance of reliable Data Engineering Solutions cannot be overstated. Companies must be equipped not only to gather data but to transform it into meaningful insights at scale. Partnering with a forward-thinking firm like Kadel Labs ensures that your organization is prepared for what lies ahead.
Whether you're just beginning your data journey or looking to modernize legacy systems, Kadel Labs provides the technical depth and strategic guidance to make your vision a reality.
Final Thoughts
The modern enterprise’s success hinges on its ability to leverage data intelligently. With the right infrastructure, architecture, and processes, organizations can gain a competitive edge, unlock innovation, and deliver superior customer experiences.
Kadel Labs, through its industry-leading Data Engineering Services and custom-built Data Engineering Solutions, empowers businesses to achieve exactly that. By transforming raw data into strategic insights, Kadel Labs is not just enabling digital transformation—it’s driving the future of data excellence.
0 notes
Text
How AWS Transforms Raw Data into Actionable Insights

Introduction
Businesses generate vast amounts of data daily, from customer interactions to product performance. However, without transforming this raw data into actionable insights, it’s difficult to make informed decisions. AWS Data Analytics offers a powerful suite of tools to simplify data collection, organization, and analysis. By leveraging AWS, companies can convert fragmented data into meaningful insights, driving smarter decisions and fostering business growth.
1. Data Collection and Integration
AWS makes it simple to collect data from various sources — whether from internal systems, cloud applications, or IoT devices. Services like AWS Glue and Amazon Kinesis help automate data collection, ensuring seamless integration of multiple data streams into a unified pipeline.
Data Sources AWS can pull data from internal systems (ERP, CRM, POS), websites, apps, IoT devices, and more.
Key Services
AWS Glue: Automates data discovery, cataloging, and preparation.
Amazon Kinesis: Captures real-time data streams for immediate analysis.
AWS Data Migration Services: Facilitates seamless migration of databases to the cloud.
By automating these processes, AWS ensures businesses have a unified, consistent view of their data.
2. Data Storage at Scale
AWS offers flexible, secure storage solutions to handle both structured and unstructured data. With services Amazon S3, Redshift, and RDS, businesses can scale storage without worrying about hardware costs.
Storage Options
Amazon S3: Ideal for storing large volumes of unstructured data.
Amazon Redshift: A data warehouse solution for quick analytics on structured data.
Amazon RDS & Aurora: Managed relational databases for handling transactional data.
AWS’s tiered storage options ensure businesses only pay for what they use, whether they need real-time analytics or long-term archiving.
3. Data Cleaning and Preparation
Raw data is often inconsistent and incomplete. AWS Data Analytics tools like AWS Glue DataBrew and AWS Lambda allow users to clean and format data without extensive coding, ensuring that your analytics processes work with high-quality data.
Data Wrangling Tools
AWS Glue DataBrew: A visual tool for easy data cleaning and transformation.
AWS Lambda: Run custom cleaning scripts in real-time.
By leveraging these tools, businesses can ensure that only accurate, trustworthy data is used for analysis.
4. Data Exploration and Analysis
Before diving into advanced modeling, it’s crucial to explore and understand the data. Amazon Athena and Amazon SageMaker Data Wrangler make it easy to run SQL queries, visualize datasets, and uncover trends and patterns in data.
Exploratory Tools
Amazon Athena: Query data directly from S3 using SQL.
Amazon Redshift Spectrum: Query S3 data alongside Redshift’s warehouse.
Amazon SageMaker Data Wrangler: Explore and visualize data features before modeling.
These tools help teams identify key trends and opportunities within their data, enabling more focused and efficient analysis.
5. Advanced Analytics & Machine Learning
AWS Data Analytics moves beyond traditional reporting by offering powerful AI/ML capabilities through services Amazon SageMaker and Amazon Forecast. These tools help businesses predict future outcomes, uncover anomalies, and gain actionable intelligence.
Key AI/ML Tools
Amazon SageMaker: An end-to-end platform for building and deploying machine learning models.
Amazon Forecast: Predicts business outcomes based on historical data.
Amazon Comprehend: Uses NLP to analyze and extract meaning from text data.
Amazon Lookout for Metrics: Detects anomalies in your data automatically.
These AI-driven services provide predictive and prescriptive insights, enabling proactive decision-making.
6. Visualization and Reporting
AWS’s Amazon QuickSight helps transform complex datasets into easily digestible dashboards and reports. With interactive charts and graphs, QuickSight allows businesses to visualize their data and make real-time decisions based on up-to-date information.
Powerful Visualization Tools
Amazon QuickSight: Creates customizable dashboards with interactive charts.
Integration with BI Tools: Easily integrates with third-party tools like Tableau and Power BI.
With these tools, stakeholders at all levels can easily interpret and act on data insights.
7. Data Security and Governance
AWS places a strong emphasis on data security with services AWS Identity and Access Management (IAM) and AWS Key Management Service (KMS). These tools provide robust encryption, access controls, and compliance features to ensure sensitive data remains protected while still being accessible for analysis.
Security Features
AWS IAM: Controls access to data based on user roles.
AWS KMS: Provides encryption for data both at rest and in transit.
Audit Tools: Services like AWS CloudTrail and AWS Config help track data usage and ensure compliance.
AWS also supports industry-specific data governance standards, making it suitable for regulated industries like finance and healthcare.
8. Real-World Example: Retail Company
Retailers are using AWS to combine data from physical stores, eCommerce platforms, and CRMs to optimize operations. By analyzing sales patterns, forecasting demand, and visualizing performance through AWS Data Analytics, they can make data-driven decisions that improve inventory management, marketing, and customer service.
For example, a retail chain might:
Use AWS Glue to integrate data from stores and eCommerce platforms.
Store data in S3 and query it using Athena.
Analyze sales data in Redshift to optimize product stocking.
Use SageMaker to forecast seasonal demand.
Visualize performance with QuickSight dashboards for daily decision-making.
This example illustrates how AWS Data Analytics turns raw data into actionable insights for improved business performance.
9. Why Choose AWS for Data Transformation?
AWS Data Analytics stands out due to its scalability, flexibility, and comprehensive service offering. Here’s what makes AWS the ideal choice:
Scalability: Grows with your business needs, from startups to large enterprises.
Cost-Efficiency: Pay only for the services you use, making it accessible for businesses of all sizes.
Automation: Reduces manual errors by automating data workflows.
Real-Time Insights: Provides near-instant data processing for quick decision-making.
Security: Offers enterprise-grade protection for sensitive data.
Global Reach: AWS’s infrastructure spans across regions, ensuring seamless access to data.
10. Getting Started with AWS Data Analytics
Partnering with a company, OneData, can help streamline the process of implementing AWS-powered data analytics solutions. With their expertise, businesses can quickly set up real-time dashboards, implement machine learning models, and get full support during the data transformation journey.
Conclusion
Raw data is everywhere, but actionable insights are rare. AWS bridges that gap by providing businesses with the tools to ingest, clean, analyze, and act on data at scale.
From real-time dashboards and forecasting to machine learning and anomaly detection, AWS enables you to see the full story your data is telling. With partners OneData, even complex data initiatives can be launched with ease.
Ready to transform your data into business intelligence? Start your journey with AWS today.
0 notes