#apache cassandra consulting
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was created by web developers David Karp and Marco Arment.
Text
Real-Time Data Streaming: How Apache Kafka is Changing the Game
Introduction
In today’s fast-paced digital world, real-time data streaming has become more essential than ever because businesses now rely on instant data processing to make data-driven and informed decision-making. Apache Kafka, i.e., a distributed streaming platform for handling data in real time, is at the heart of this revolution. Whether you are an Apache Kafka developer or exploring Apache Kafka on AWS, this emerging technology can change the game of managing data streams. Let’s dive deep and understand how exactly Apache Kafka is changing the game.
Rise of Real-Time Data Streaming
The vast amount of data with businesses in the modern world has created a need for systems to process and analyze as it is produced. This amount of data has emerged due to the interconnections of business with other devices like social media, IoT, and cloud computing. Real-time data streaming enables businesses to use that data to unlock vast business opportunities and act accordingly.
However, traditional methods fall short here and are no longer sufficient for organizations that need real-time data insights for data-driven decision-making. Real-time data streaming requires a continuous flow of data from sources to the final destinations, allowing systems to analyze that information in less than milliseconds and generate data-driven patterns. However, building a scalable, reliable, and efficient real-time data streaming system is no small feat. This is where Apache Kafka comes into play.
About Apache Kafka
Apache Kafka is an open-source distributed event streaming platform that can handle large real-time data volumes. It is an open-source platform developed by the Apache Software Foundation. LinkedIn initially introduced the platform; later, in 2011, it became open-source.
Apache Kafka creates data pipelines and systems to manage massive volumes of data. It is designed to manage low-latency, high-throughput data streams. Kafka allows for the injection, processing, and storage of real-time data in a scalable and fault-tolerant way.
Kafka uses a publish-subscribe method in which:
Data (events/messages) are published to Kafka topics by producers.
Consumers read and process data from these subjects.
The servers that oversee Kafka's message dissemination are known as brokers.
ZooKeeper facilitates the management of Kafka's leader election and cluster metadata.
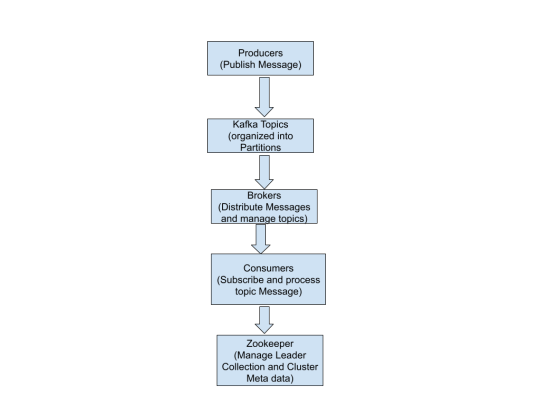
With its distributed architecture, fault tolerance, and scalability, Kafka is a reliable backbone for real-time data streaming and event-driven applications, ensuring seamless data flow across systems.
Why Apache Kafka Is A Game Changer
Real-time data processing helps organizations collect, process, and even deliver the data as it is generated while immediately ensuring the utmost insights and actions. Let’s understand the reasons why Kafka stands out in the competitive business world:
Real-Time Data Processing
Organizations generate vast amounts of data due to their interconnection with social media, IoT, the cloud, and more. This has raised the need for systems and tools that can react instantly and provide timely results. Kafka is a game-changer in this regard. It helps organizations use that data to track user behavior and take action accordingly.
Scalability and Fault Tolerance
Kafka's distributed architecture guarantees data availability and dependability even in the case of network or hardware failures. It is a reliable solution for mission-critical applications because it ensures data durability and recovery through replication and persistent storage.
Easy Integration
Kafka seamlessly connects with a variety of systems, such as databases, analytics platforms, and cloud services. Its ability to integrate effortlessly with these tools makes it an ideal solution for constructing sophisticated data pipelines.
Less Costly Solution
Kafka helps in reducing the cost of data processing and analyzing efficiently and ensures high performance of the businesses. By handling large volumes of data, Kafka also enhances scalability and reliability across distributed systems.
Apache Kafka on AWS: Unlocking Cloud Potential
Using Apache Kafka on ASW has recently become more popular because of the cloud’s advantages, like scalability, flexibility, and cost efficiency. Here, Kafka can be deployed in a number of ways, such as:
Amazon MSK (Managed Streaming for Apache Kafka): A fully managed service helps to make the deployment and management of Kafka very easy. Additionally, it handles infrastructure provisioning, scaling, and even maintenance and allows Apache Kafka developers to focus on building applications.
Self-Managed Kafka on EC2: This is apt for organizations that prefer full control of their Kafka clusters, as AWS EC2 provides the flexibility to deploy and manage Kafka instances.
The benefits of Apache Kafka on ASW are as follows:
Easy scaling of Kafka clusters as per the demand.
Ensures high availability and enables disaster recovery
Less costly because it uses a pay-as-you-go pricing model
The Future of Apache Kafka
Kafka’s role in the technology ecosystem will definitely grow with the increase in the demand for real-time data processing. Innovations like Kafka Streams and Kafka Connect are already expanding the role of Kafka and making real-time processing quite easy. Moreover, integrations with cloud platforms like AWS continuously drive the industry to adopt Kafka within different industries and expand its role.
Conclusion
Apache Kafka is continuously revolutionizing the organizations of modern times that are handling real-time data streaming and changing the actual game of businesses around the world by providing capabilities like flexibility, scalability, and seamless integration. Whether you are deploying Apache Kafka on AWS or working as an Apache Kafka developer, this technology can offer enormous possibilities for innovation in the digitally enabled business landscape.
Do you want to harness the full potential of your Apache Kafka systems? Look no further than Ksolves, where a team of seasoned Apache Kafka experts and developers stands out as a leading Apache Kafka development company with their client-centric approach and a commitment to excellence. With our extensive experience and expertise, we specialize in offering top-notch solutions tailored to your needs.
Do not let your data streams go untapped. Partner with leading partners like Ksolves today!
Visit Ksolves and get started!
#kafka apache#apache kafka on aws#apache kafka developer#apache cassandra consulting#certified developer for apache kafka
0 notes
Text
Big Data Technologies You’ll Master in IIT Jodhpur’s PG Diploma

In today’s digital-first economy, data is more than just information—it's power. Successful businesses are set apart by their ability to collect, process, and interpret massive datasets. For professionals aspiring to enter this transformative domain, the IIT Jodhpur PG Diploma offers a rigorous, hands-on learning experience focused on mastering cutting-edge big data technologies.
Whether you're already in the tech field or looking to transition, this program equips you with the tools and skills needed to thrive in data-centric roles.
Understanding the Scope of Big Data
Big data is defined not just by volume but also by velocity, variety, and veracity. With businesses generating terabytes of data every day, there's a pressing need for experts who can handle real-time data streams, unstructured information, and massive storage demands. IIT Jodhpur's diploma program dives deep into these complexities, offering a structured pathway to becoming a future-ready data professional.
Also, read this blog: AI Data Analyst: Job Role and Scope
Core Big Data Technologies Covered in the Program
Here’s an overview of the major tools and technologies you’ll gain hands-on experience with during the program:
1. Hadoop Ecosystem
The foundation of big data processing, Hadoop offers distributed storage and computing capabilities. You'll explore tools such as:
HDFS (Hadoop Distributed File System) for scalable storage
MapReduce for parallel data processing
YARN for resource management
2. Apache Spark
Spark is a game-changer in big data analytics, known for its speed and versatility. The course will teach you how to:
Run large-scale data processing jobs
Perform in-memory computation
Use Spark Streaming for real-time analytics
3. NoSQL Databases
Traditional databases fall short when handling unstructured or semi-structured data. You’ll gain hands-on knowledge of:
MongoDB and Cassandra for scalable document and column-based storage
Schema design, querying, and performance optimization
4. Data Warehousing and ETL Tools
Managing the flow of data is crucial. Learn how to:
Use tools like Apache NiFi, Airflow, and Talend
Design effective ETL pipelines
Manage metadata and data lineage
5. Cloud-Based Data Solutions
Big data increasingly lives on the cloud. The program explores:
Cloud platforms like AWS, Azure, and Google Cloud
Services such as Amazon EMR, BigQuery, and Azure Synapse
6. Data Visualization and Reporting
Raw data must be translated into insights. You'll work with:
Tableau, Power BI, and Apache Superset
Custom dashboards for interactive analytics
Real-World Applications and Projects
Learning isn't just about tools—it's about how you apply them. The curriculum emphasizes:
Capstone Projects simulating real-world business challenges
Case Studies from domains like finance, healthcare, and e-commerce
Collaborative work to mirror real tech teams
Industry-Driven Curriculum and Mentorship
The diploma is curated in collaboration with industry experts to ensure relevance and applicability. Students get the opportunity to:
Attend expert-led sessions and webinars
Receive guidance from mentors working in top-tier data roles
Gain exposure to the expectations and workflows of data-driven organizations
Career Pathways After the Program
Graduates from this program can explore roles such as:
Data Engineer
Big Data Analyst
Cloud Data Engineer
ETL Developer
Analytics Consultant
With its robust training and project-based approach, the program serves as a launchpad for aspiring professionals.
Why Choose This Program for Data Engineering?
The Data Engineering course at IIT Jodhpur is tailored to meet the growing demand for skilled professionals in the big data industry. With a perfect blend of theory and practical exposure, students are equipped to take on complex data challenges from day one.
Moreover, this is more than just academic training. It is IIT Jodhpur BS./BSc. in Applied AI and Data Science, designed with a focus on the practical, day-to-day responsibilities you'll encounter in real job roles. You won’t just understand how technologies work—you’ll know how to implement and optimize them in dynamic environments.
Conclusion
In a data-driven world, staying ahead means being fluent in the tools that power tomorrow’s innovation. The IIT Jodhpur Data Engineering program offers the in-depth, real-world training you need to stand out in this competitive field. Whether you're upskilling or starting fresh, this diploma lays the groundwork for a thriving career in data engineering.
Take the next step toward your future with “Futurense”, your trusted partner in building a career shaped by innovation, expertise, and industry readiness.
Source URL: www.lasttrumpnews.com/big-data-technologies-iit-jodhpur-pg-diploma
0 notes
Text
Data Engineering’s Key Role in Delivering AI Solutions

In recent years, artificial intelligence has accelerated the tech industry; however, this transformation is heavily dependent on big data and AI. Gazing to draw an effective solution can only be possible with high-quality unstructured details, which need to be meticulously managed. In this trait, the term “data engineering” ensures the vast amount of information is well-collected, cleansed, and then structured by meaningfully enabling ML models to perform the task accurately. Without a robust solution, deep learning systems can falter because of poor data quality, which leads to unreliable outcomes. This guide comprehends the overall journey of artificial intelligence powering your business and how data engineering helps to covertly drive success for businesses. Read on to discuss the realm of AI-driven success.
Also Read: Why Your Data Integration Strategy Needs a Check-Up
Data Engineering Key Role in Delivering Impactful Solutions
Artificial intelligence has changed the landscape from recommendation engines to predictive analytics. Executing the ELT process of massive raw information collections automates ML’s advanced algorithms and models. However, it has its exponential growth; a structured system is required to gain knowledge, accuracy, and real-time solutions. Big data technologies serve as the foundation, providing the raw information that algorithms are going to work with to learn, forecast, and decide. Big data & AI work hand in hand—gathering, filtering, and storing this information to make it available for next-generation applications. That connection is the reason that we need professional consultants such as Spiral Mantra. Typical systems are incapable of processing such volumes of information in the amount of time and scale that impose real-time managerial needs.
Let’s Discuss the Significant Role of Data in Forecasting Solutions
It starts with scraping information from sources, cleaning it, making it available in usable form, and feeding it to ML models.
Acquisition and Merge of Raw Details
Algorithms of AI use varied sets of information from sources like social media and IoT devices. This way, the Spiral Mantra developers create pipelines to automate the acquisition of raw details and integrate them into the different sources to form an aggregate report. This step involves using tools such as Apache Kafka and Apache Nifi, which are scalable frameworks to collect information at high speed.
Navigating to Important Storage Technologies
Storing and processing huge sets of details is a very important task. Big Data and AI major techs such as Hadoop Distributed File System, Apache Cassandra, and Amazon Redshift allow you to store your information scalable and have professionals easily work with it across clusters. Then there are things such as Apache Spark, which focuses on processing and allows engineers to create pipelines that can compute workloads.
Data Importance for ETL
Structured and unstructured details must be processed into ML algorithms; structured details cannot be interpreted without being parsed by AI models. That’s called ETL (Extract, Transform, Load), where Spiral Mantra’s professionals convert, normalize, and transform raw details to eradicate inconsistencies and errors that may be biased or inaccurate in the AI predictions.
Cleaning and Transformation of Data
The process of cleaning and transformation is mandatory to be fulfilled, as it comprehends the data that needs to be formatted suitable for further analysis. This majorly includes removing inaccuracies and encoding the prompt information into numerical formats.
Factors That Makeup Data Engineering in AI Workflows
Successful applications don’t just need big data technologies but also well-structured workflows executed by professionals. These are some of the most important parts of data engineering and AI workflows:
Data Pipeline Development: It is identified as a process of creating pipelines that automatically pull, sift, and write data information to storage. These pipelines automatically foster the flow with the accessible details pushed from the source to the AI models for batch processing.
Managing the ETL Workflows: ETL is one of the most prominent functions, which converts unstructured details into a manageable form. When the raw details are structured this way, ETL jobs make it easier for AI algorithms to pull out the final information they want to predict.
Validity and Consistency: Quality and consistency matter a lot to machine learning models, as they contain error detection and fixing processes to ensure a high-quality feed for the AI algorithms.
Data Governance & Compliance: In the wake of new regulations, being compliant and up-to-date is a key to survival. That is why Spiral Mantra ensures the details used for AI models are compliant with regulations, so you don’t risk sensitive information.
Why Companies Need Data Engineering AI-Powered Solutions
If an organization wants to deploy deep learning, then reaching out to leading data engineering companies like us is the must-have solution. Understanding its core concepts, from information flow management to its advanced technologies, we, being the leaders of the industry, develop the infrastructure for AI to be successful. In addition, as AI applications have evolved, the need for engineers who can manage large volumes of information and help optimize business information pipelines has skyrocketed. Big data analytics companies offer development and AI collaborations by leveraging skilled teams to collect, cleanse, and combine details from multiple sources. Considering the future of collaboration then both industries will soon be involved;
Real-time analytics for a large volume of information monitoring to produce predictive results.
Enhanced security and culture by using advanced measures and data compliance guidelines.
Automated process for cleansing and data transformation.
Spiral Mantra, the leading digital transformation company, can help you by offering expertise in data engineering. Contact us today to learn how we can support your business and journey.
0 notes
Text

Big Data Software Development & Consulting Services
At SynapseIndia, our expert team propels businesses toward data-driven success by employing diverse tools such as Apache Hadoop, Spark, MongoDB, Cassandra, Apache Flink, Kafka, and Elasticsearch. We specialize in real-time analytics and advanced data visualization, ensuring your business benefits from the transformative power of Big Data. Know more at https://posts.gle/N3nmPx
0 notes
Text
The conversation of Cassandra vs MySQL can extend further but it’s your requirement that will help you to choose the best. Share your requirements with Ksolves to get the best out of the difference between Cassandra and MySQL. Our expertise in the Cassandra Consulting Services will ensure that your requirements are kept at priority. Contact us to explore more about the same!
1 note
·
View note
Link
apache cassandra consulting company in noida
0 notes
Text
Choosing New Tools and Technology for Your Web Projects

Are you planning to create a website or mobile app for your business but don’t know how to start? Choosing a technology is simultaneously one of the most exciting and dreaded tasks when building a software product.
Creating a product is about stability, security, and maintainability. In order to select the right technology, you should answer the following questions:
Who will use my product and in what context?
Who will buy my product and what will they pay?
What third party systems will my product need to interoperate with?
Selecting an appropriate technology for your software is critical. You must understand the implications of that technology landscape to make relevant decisions.
So, with no further ado, let’s get straight to the point. How do you figure out which technology is the most suitable for you? To make your choice a little easier, here some factors to consider when choosing your tools.
Requirements of your project
Technologies are heavily dependent on each other. The type of app you’re developing influences the technology you should select.
It’s common practice to rely on your developers for technology suggestions. However, it’s important to take into account all the important features that will be implemented.
Project size
The complexity of your project will affect the choice of technology.
Small projects include single page sites, portfolios, presentations, and other small web solutions
Medium-sized projects, such as online stores, financial, and enterprise apps require more complex tools and technologies.
Large projects, such as marketplaces require much more scalability, speed, and serviceability.
Time to market
It's all about being the first to hit the market. Use technologies that can help you to get your web solution to the market in the shortest time.
Security of the tools
Security is crucial for web applications. Ensure that you're using technologies with no known vulnerabilities.
Maintenance
When selecting technologies for your web app, think about how you’ll support the app in the long run. Your team must be able to maintain the application after it is released.
Cost
Cost is important as a constraint, not as an objective. There is a delicate balance between price and value. Thriving in today’s competitive environment requires understanding the trends in software development. There are open-source IT frameworks and tools that are free. However, some tech stacks come with subscription fees and demand a high salary for developers.
Scalability
When you're choosing the technology, ensure that the components are scalable.
Top 6 technology stacks
Just like building a house, there are different “building materials” and tools, to build a solid ground for your software you need a finely selected technology stack.
What is a technology stack? It is a set of tools, programming languages, and technologies that work together to build digital products. A technology stack consists of two equally important elements:
Frontend (client-side) is the way we see web pages.
Backend (server-side) is responsible for how web and mobile applications function and how the internal processes are interconnected.
It’s absolutely essential to choose the right technology stack that will let you build solid ground for your software. For example, Facebook’s tech stack includes PHP, React, GraphQL, Cassandra, Hadoop, Swift, and other frameworks.
So, what are the leading stacks of software development in 2021?
1. The MEAN stack
MEAN stack is a combination of four major modules, namely:
MongoDB
Express.js
AngularJS
Node.js
Being an end-to-end JavaScript stack, you use a single language throughout your stack. You can reuse code across the entire application and avoid multiple issues that usually occur with the client and server-side matching.
Companies using MEAN stack: YouTube, Flickr, Paytm, Tumblr
2. The MERN stack
MERN is nearly identical to MEAN with a bit of technological change – the difference is that React is used instead of Angular.js. React is known for its flexibility in developing interactive user interfaces.
Companies using MERN stack: Facebook, Instagram, Forbes, Tumblr
3. The MEVN Stack
MEVN is another variation of MEAN. It uses Vue.js as a front-end framework instead of Angular.js.
Vue.js combines the best features of Angular and React and offers a rich set of tools. It is fast and easy to learn.
Companies using MEVN stack: Alibaba, Grammarly, Behance, TrustPilot
4. The LAMP stack
LAMP is industry standard when it comes to tech stack models. It is a time-tested stack of technologies that includes:
Linux
Apache
MySQL
PHP
Apps developed using the LAMP stack run smoothly on multiple operating systems. LAMP is the preferred choice for large-scale web applications.
Companies using LAMP stack: Facebook, Google, Wikipedia, and Amazon
5. The Serverless Stack
Developing applications on cloud infrastructure is a popular web development trend. Up to hundreds of thousands of users can quickly be scaled overnight with serverless computing systems. AWS Lambda and Google cloud are among significant providers of serverless services.
Companies using Serverless stack: Coca-Cola, Netflix
6. Flutter
Flutter is a revolutionary stack for cross-platform development. Flutter employs the same UI and business logic on all platforms.
Companies using Flutter stack: Delivery Hero, Nubank
What is left is finding the right assistant on this journey
The choice of the right tool depends on what requirements you face. When selecting a technology, consider the short and long-term goals of your project. For instance, web applications need different sets of tools from mobile apps. Even within mobile applications, you need different technologies for Android and iOS development.
While the prospect of a new project can create a buzz around your team like nothing else can, it can also cause a lot of anxiety. There is no one-size-fits-all solution in web development. Finally, when in doubt, it’s always better to consult a web design company near you for a second opionion.
We feel you. The technological building blocks of your software product are of course fundamentally important. Technology selection could be overwhelming, but you have to keep up to keep ahead.
0 notes
Photo

New Post has been published on https://techcrunchapp.com/tech-mn-faq-friday-blockchain/
tech.mn – FAQ Friday — Blockchain
Welcome to our latest FAQ Friday — blockchain FAQ — where industry experts answer your burning technology and startup questions. We’ve gathered top Minnesota authorities on topics from software development to accounting to talent acquisition and everything in between. Check in each week, and submit your questions here.
This week’s FAQ Friday is sponsored by Coherent Solutions. Coherent Solutions is a software product development and consulting company that solves customer business problems by bringing together global expertise, innovation, and creativity. The business helps companies tap into the technology expertise and operational efficiencies made possible by their global delivery model.
Meet Our FAQ Expert
Max Belov, CTO of Coherent Solutions
Max Belov
Max Belov has been with Coherent Solutions since 1998 and became CTO in 2001. He is an accomplished architect and an expert in distributed systems design and implementation. He’s responsible for guiding the strategic direction of the company’s technology services, which include custom software development, data services, DevOps & cloud, quality assurance, and Salesforce.
Max also heads innovation initiatives within Coherent’s R&D lab to develop emerging technology solutions. These initiatives provide customers with top notch technology solutions IoT, blockchain, and AI, among others. Find out more about these solutions and view client videos on the Coherent Solutions YouTube channel.
Max holds a master’s degree in Theoretical Computer Science from Moscow State University. When he isn’t working, he enjoys spending time with his family, on a racetrack, and playing competitive team handball.
What is blockchain?
Blockchain is a technology that … yes, we can ask Google for a definition of any given word, but you can get confused and lost in thousands of the suggested results when it comes to googling technologies, especially one as multi-faceted as blockchain. The best way to understand the technology is to refer to the history of its development where the starting point was a problem that could be solved by applying the technology.
Consider the following situation. Your friend has a painting that costs $10,000. We can say that the painting is unique and valuable because the friend has the required documentation that proves it. You decide that you really want that painting and want to buy it from your friend. So, you give your friend $10,000, and after that, the friend gives you the painting. That was simple, right? Now imagine your friend has a unique and valuable digital picture. The friend sends it to you by email, and you transfer $10,000 to their bank account. Now it is getting interesting. How do you know that the picture belongs to only you? Maybe your friend made a couple of copies. We assume that your friend is an honest person, but how do we check the picture’s uniqueness in case your friend got the picture from someone else?
If we have some digital information, there are many cases when we need to be sure that the data is valid and that third parties like hackers have not modified the information, and the history of valid changes is verifiable.
Let us consider a business case where organizations need to manage and transact such assets as finances, real property, medical records, physical goods, etc. It is essential to enable the following features for involved parties:
If an asset’s information changes, it should be transparent for all parties.
It is impossible to change and update an asset’s information without the owner’s acknowledgment and approval.
The history of changes is transparent and verifiable.
To implement such a scenario, there should be a database that accurately records the required assets information. As practice shows, typical databases with one logical owner (centralized relational databases like MySQL or distributed non-relational databases like Apache Cassandra) do not meet our requirements. In 2016, hackers attempted to steal $951 million from Bangladesh bank and succeeded in getting $101 million. The same year, 57 million users’ personal information was breached at Uber and Facebook faced a database data leak of 419 million users in 2019. In all these cases, the central database that stores all of the information about various assets proved to be vulnerable to an attack despite all the precautions taken by its owners.
But in 2008, a new type of data storage technology was invented, and it was called blockchain. This technology took enough time to overcome initial challenges and obstacles to wide adoption and it is an excellent alternative data management solution today. Blockchain is based on Distributed Ledger Technology (DLT) technology. Its key components are:
Information is stored across a distributed network of servers owned by different entities.
All proposals to update and change information are done by applying respective actions called “transactions.”
Transaction integrity is maintained based on digital signatures.
To apply proposed changes, transactions are verified by a specific algorithm called a “consensus algorithm.”
All transactions that have been successfully applied are stored in “blocks” linked using cryptography and enable the verifiable history of changes.
There are no single points of failure or single data owner.
Blockchain makes digital representation of any asset unalterable and transparent using decentralization and cryptographic hashing.
What benefits to business and client privacy does blockchain offer?
Greater transparency
The beauty of blockchain lies in the fact that it creates trust out of mistrust. Transactions must be agreed upon before they are recorded. Think of a large group of people with their own ledgers or record books. These people can and will only add to the ledger if most of the people agree upon the authenticity of the proposed addition. This group action or “distribution” is incredibly powerful and can provide businesses with peace of mind, and customers as well.
Enhanced security
The biggest problem with any centralized ledger or a handful of centralized ledgers is vulnerability to corruption and manipulation. Blockchain transactions and blocks are linked using cryptography, and all information is stored across a network of computers instead of on a single server. That makes it difficult for hackers to compromise the data.
Improved traceability
Given that all blocks of transactions from the very beginning of the ledger are linked, it brings one more significant feature of blockchain — immutability. Here’s how
Increased efficiency and speed
Due to its decentralized nature, blockchain removes the need for intermediaries in many processes that are prone to human errors. Asset management processes are made more efficient with a unified system of an ownership record and smart contracts that automate agreements.
Reduced costs
Today, most businesses spend significant efforts to bring trust, transparency, security and efficiency. We can see this in the form of intermediaries or specialized companies that provide these services to other businesses at a cost. However, because of blockchain’s nature, businesses can massively decrease their overhead costs and direct those cost benefits to customers or other initiatives.
What are some use cases of blockchain that startups and smaller businesses could take advantage of?
Now that you have seen how blockchain technology can benefit your business and clients, let us look at how startups and small businesses could take advantage of it. From payments (by decreasing time and fees of money transfer) to smart contracts enabling new and innovative business models by processing transactions via a protocol that automatically executes, controls or documents legally relevant events and actions according to the terms in a contract or agreement. Organizations collaborate easier and more securely. Here are just a few of the use cases.
Supply chain
In most cases, it requires intermediaries that slow down procurement process and makes records susceptible to errors that are not uncommon. Another challenge is the fraud that is made possible by the lack of transparency. This is where blockchain technology steps in. It cannot be corrupted, nor can it lose any document/information along the chain of custody. All deals are transparent and auditable.
Healthcare
The application of blockchain technology is intended to be incredibly valuable in the context of Digital Health services. Personal health records management could be significantly improved to enable more effective and customized healthcare by:
Patient Data Management – Gives patients full data ownership over their medical records.
Clinical Adjudication – Supports in the validation, coordination and maintenance of consistent adherence to approved clinical trial protocols.
Claims Adjudication – Offers clear and transparent communication of patient billing through smart contracts that do not lead to over-billing the patient
Drug Supply Chain – Allows to reliably check a drug’s origin and manufacturing history, thus identifying a counterfeit medication or prescription.
Cloud storage
Cloud storage was a hit when it first appeared, but the system is not bulletproof. Since companies store user data in centralized servers, this means that cloud storage has central points of failure that make the whole system vulnerable. By using blockchain technology, decentralized cloud storage makes your files unhackable.
How long does it take to incorporate blockchain into business operations?
It really depends on your business and use case. Here are the key steps you need to take to incorporate blockchain into your business.
Identify a relevant use case
There are a lot of different valid use cases across multiple industries, including: banking & finances, retail, digital identity, healthcare, supply chain, notary, ad tech, music, and video, etc. If we abstract all use-cases to a higher level, we find that the most use cases fall under one or more of the following categories: asset management, authentication & verification, and smart contracts.
Research legal/Regulatory requirements
Many countries are still very skeptical about this technology, especially when applied in the financial industry, and are therefore taking stringent measures to regulate it or even ban it altogether. Since blockchain is still an emerging technology (yet to go mainstream), the laws governing its applications are either not there at all or are very poorly defined.
Identify the consensus mechanism
A consensus algorithm is what determines if a transaction is valid and can be added to the blockchain. There are many different consensus algorithms available: Proof of Work (PoW), Proof of Stake (PoS), Byzantine Fault Tolerance (BFT), Proof of Elapsed Time (PoET), Proof of Authority (PoA), Delegated PoS (DPoS), etc. Each consensus algorithm has its pros and cons, so there is no “best’ consensus algorithm. The algorithm should be chosen depending upon the use case. Generally, there is a trade-off between decentralization, security, transparency, cost of executing the algorithm and system performance.
Selecting a blockchain platform
Just the way there are multiple consensus algorithms at our disposal, there are numerous platforms on which we can implement blockchain solutions: public, private and consortium blockchains. Many of them are free and open source. The selection of the ideal platform depends upon the use case and consensus algorithm. The differences between public, non-permissioned blockchain networks and private, permissioned networks are straightforward and understanding the differences is crucial for deciding what best suits your needs.
Need more information on blockchain? Check out this blog from Coherent Solutions.
Still curious? Ask Max and the Coherent Solutions team questions on Twitter at @CoherentTweets.
Don’t stop learning! Get the scoop on a ton of valuable topics from Max Belov and Coherent Solutions in our FAQ Friday archive.
FAQ Friday — Digital Apps
FAQ Friday — eCommerce
FAQ Friday – Security and Working Remotely
FAQ Friday – Machine Learning
0 notes
Text
Data Engineering’s Key Role in Delivering AI Solutions

In recent years, artificial intelligence has accelerated the tech industry; however, this transformation is heavily dependent on big data and AI. Gazing to draw an effective solution can only be possible with high-quality unstructured details, which need to be meticulously managed. In this trait, the term “data engineering” ensures the vast amount of information is well-collected, cleansed, and then structured by meaningfully enabling ML models to perform the task accurately. Without a robust solution, deep learning systems can falter because of poor data quality, which leads to unreliable outcomes. This guide comprehends the overall journey of artificial intelligence powering your business and how data engineering helps to covertly drive success for businesses. Read on to discuss the realm of AI-driven success.
Also Read: Why Your Data Integration Strategy Needs a Check-Up
Data Engineering Key Role in Delivering Impactful Solutions
Artificial intelligence has changed the landscape from recommendation engines to predictive analytics. Executing the ELT process of massive raw information collections automates ML’s advanced algorithms and models. However, it has its exponential growth; a structured system is required to gain knowledge, accuracy, and real-time solutions. Big data technologies serve as the foundation, providing the raw information that algorithms are going to work with to learn, forecast, and decide. Big data & AI work hand in hand—gathering, filtering, and storing this information to make it available for next-generation applications. That connection is the reason that we need professional consultants such as Spiral Mantra. Typical systems are incapable of processing such volumes of information in the amount of time and scale that impose real-time managerial needs.
Let’s Discuss the Significant Role of Data in Forecasting Solutions
It starts with scraping information from sources, cleaning it, making it available in usable form, and feeding it to ML models.
Acquisition and Merge of Raw Details
Algorithms of AI use varied sets of information from sources like social media and IoT devices. This way, the Spiral Mantra developers create pipelines to automate the acquisition of raw details and integrate them into the different sources to form an aggregate report. This step involves using tools such as Apache Kafka and Apache Nifi, which are scalable frameworks to collect information at high speed.
Navigating to Important Storage Technologies
Storing and processing huge sets of details is a very important task. Big Data and AI major techs such as Hadoop Distributed File System, Apache Cassandra, and Amazon Redshift allow you to store your information scalable and have professionals easily work with it across clusters. Then there are things such as Apache Spark, which focuses on processing and allows engineers to create pipelines that can compute workloads.
Data Importance for ETL
Structured and unstructured details must be processed into ML algorithms; structured details cannot be interpreted without being parsed by AI models. That’s called ETL (Extract, Transform, Load), where Spiral Mantra’s professionals convert, normalize, and transform raw details to eradicate inconsistencies and errors that may be biased or inaccurate in the AI predictions.
Cleaning and Transformation of Data
The process of cleaning and transformation is mandatory to be fulfilled, as it comprehends the data that needs to be formatted suitable for further analysis. This majorly includes removing inaccuracies and encoding the prompt information into numerical formats.
Factors That Makeup Data Engineering in AI Workflows
Successful applications don’t just need big data technologies but also well-structured workflows executed by professionals. These are some of the most important parts of data engineering and AI workflows:
Data Pipeline Development: It is identified as a process of creating pipelines that automatically pull, sift, and write data information to storage. These pipelines automatically foster the flow with the accessible details pushed from the source to the AI models for batch processing.
Managing the ETL Workflows: ETL is one of the most prominent functions, which converts unstructured details into a manageable form. When the raw details are structured this way, ETL jobs make it easier for AI algorithms to pull out the final information they want to predict.
Validity and Consistency: Quality and consistency matter a lot to machine learning models, as they contain error detection and fixing processes to ensure a high-quality feed for the AI algorithms.
Data Governance & Compliance: In the wake of new regulations, being compliant and up-to-date is a key to survival. That is why Spiral Mantra ensures the details used for AI models are compliant with regulations, so you don’t risk sensitive information.
Why Companies Need Data Engineering AI-Powered Solutions
If an organization wants to deploy deep learning, then reaching out to leading data engineering companies like us is the must-have solution. Understanding its core concepts, from information flow management to its advanced technologies, we, being the leaders of the industry, develop the infrastructure for AI to be successful. In addition, as AI applications have evolved, the need for engineers who can manage large volumes of information and help optimize business information pipelines has skyrocketed. Big data analytics companies offer development and AI collaborations by leveraging skilled teams to collect, cleanse, and combine details from multiple sources. Considering the future of collaboration then both industries will soon be involved;
Real-time analytics for a large volume of information monitoring to produce predictive results.
Enhanced security and culture by using advanced measures and data compliance guidelines.
Automated process for cleansing and data transformation.
Spiral Mantra, the leading digital transformation company, can help you by offering expertise in data engineering. Contact us today to learn how we can support your business and journey.
0 notes
Text
Datastax acquires The Last Pickle
Datastax acquires The Last Pickle
Data management company Datastax, one of the largest contributors to the Apache Cassandra project, today announced that it has acquired The Last Pickle (and no, I don’t know what’s up with that name either), a New Zealand-based Cassandra consulting and services firm that’s behind a number of popular open-source tools for the distributed NoSQL database.
As Datastax Chief Strategy Officer Sam…
View On WordPress
#apache#apache cassandra#Apigee#AT&T#Autodesk#cassandra#ceo#Cloud#Cloud Foundry Foundation#COMPUTING#data#data management#datastax#Developer#Enterprise#Google#Kubernetes#New Zealand#nosql#PREMIER#Sam Ramji#Spotify#T-Mobile#TC#WETA
0 notes
Photo
Why Ksolves Provides Best Apache Cassandra Services?
#ksolves#apache cassandra#apache cassandra development company in usa#apache cassandra service#apache cassandra strategy#apache cassandra developers#Apache Cassandra Development Company#Apache Cassandra Development Services#Apache Cassandra Development Company in India#apache cassandra consulting#apache cassandra consulting company in usa#apache cassandra consulting company in noida#Apache Cassandra Consulting Services#apache cassandra consulting company in India#apache cassandra expert#apache cassandra experts in noida#apache cassandra experts in india#apache cassandra experts#apache cassandra experts in usa
1 note
·
View note
Photo

Apache Cassandra Consulting Services
0 notes
Text
Datastax acquires The Last Pickle
Data management company Datastax, one of the largest contributors to the Apache Cassandra project, today announced that it has acquired The Last Pickle (and no, I don’t know what’s up with that name either), a New Zealand-based Cassandra consulting and services firm that’s behind a number of popular open-source tools for the distributed NoSQL database.
As Datastax Chief Strategy Officer Sam Ramji, who you may remember from his recent tenure at Apigee, the Cloud Foundry Foundation, Google and Autodesk, told me, The Last Pickle is one of the premier Apache Cassandra consulting and services companies. The team there has been building Cassandra-based open source solutions for the likes of Spotify, T Mobile and AT&T since it was founded back in 2012. And while The Last Pickle is based in New Zealand, the company has engineers all over the world that do the heavy lifting and help these companies successfully implement the Cassandra database technology.
It’s worth mentioning that Last Pickle CEO Aaron Morton first discovered Cassandra when he worked for WETA Digital on the special effects for Avatar, where the team used Cassandra to allow the VFX artists to store their data.
“There’s two parts to what they do,” Ramji explained. “One is the very visible consulting, which has led them to become world experts in the operation of Cassandra. So as we automate Cassandra and as we improve the operability of the project with enterprises, their embodied wisdom about how to operate and scale Apache Cassandra is as good as it gets — the best in the world.” And The Last Pickle’s experience in building systems with tens of thousands of nodes — and the challenges that its customers face — is something Datastax can then offer to its customers as well.
And Datastax, of course, also plans to productize The Last Pickle’s open-source tools like the automated repair tool Reaper and the Medusa backup and restore system.
As both Ramji and Datastax VP of Engineering Josh McKenzie stressed, Cassandra has seen a lot of commercial development in recent years, with the likes of AWS now offering a managed Cassandra service, for example, but there wasn’t all that much hype around the project anymore. But they argue that’s a good thing. Now that it is over ten years old, Cassandra has been battle-hardened. For the last ten years, Ramji argues, the industry tried to figure out what the de factor standard for scale-out computing should be. By 2019, it became clear that Kubernetes was the answer to that.
“This next decade is about what is the de facto standard for scale-out data? We think that’s got certain affordances, certain structural needs and we think that the decades that Cassandra has spent getting harden puts it in a position to be data for that wave.”
McKenzie also noted that Cassandra provides users with a number of built-in features like support for mutiple data centers and geo-replication, rolling updates and live scaling, as well as wide support across programming languages, give it a number of advantages over competing databases.
“It’s easy to forget how much Cassandra gives you for free just based on its architecture,” he said. “Losing the power in an entire datacenter, upgrading the version of the database, hardware failing every day? No problem. The cluster is 100 percent always still up and available. The tooling and expertise of The Last Pickle really help bring all this distributed and resilient power into the hands of the masses.”
The two companies did not disclose the price of the acquisition.
0 notes
Photo

New Post has been published on https://magzoso.com/tech/aiven-raises-40m-to-democratize-access-to-open-source-projects-through-managed-cloud-services/
Aiven raises $40M to democratize access to open-source projects through managed cloud services

The growing ubiquity of open-source software has been a big theme in the evolution of enterprise IT. But behind that facade of popularity lies another kind of truth: Companies may be interested in using more open-source technology, but because there is a learning curve with taking on an open-source project, not all of them have the time, money and expertise to adopt it. Today, a startup out of Finland that has built a platform specifically to target that group of users is announcing a big round of funding, underscoring not just demand for its products, but its growth to date.
Aiven — which provides managed, cloud-based services designed to make it easier for businesses to build services on top of open-source projects — is today announcing that it has raised $40 million in funding, a Series B being led by IVP (itself a major player in enterprise software, backing an illustrious list that includes Slack, Dropbox, Datadog, GitHub and HashiCorp).
Previous investors Earlybird VC, Lifeline Ventures and the family offices of Risto Siilasmaa (chairman of Nokia), and Olivier Pomel (founder of Datadog), also participated. The deal brings the total raised by Aiven to $50 million.
Oskari Saarenmaa, the CEO of Aiven who co-founded the company with Hannu Valtonen, Heikki Nousiainen and Mika Eloranta, said in an interview that the company is not disclosing its valuation at this time, but it comes in the wake of some big growth for the company.
It now has 500 companies as customers, including Atlassian, Comcast, OVO Energy and Toyota, and over the previous two years it doubled headcount and tripled its revenues.
“We are on track to do better than that this year,” Saarenmaa added.
It’s a surprising list, given the size of some of those companies. Indeed, Saarenmaa even said that originally he and the co-founders — who got the idea for the startup by first building such implementations for previous employers, which included Nokia and F-Secure — envisioned much smaller organisations using Aiven.
But in truth, the actual uptake speaks not just to the learning curve of open-source projects, but to the fact that even if you do have the talent to work with these, it makes more sense to apply that talent elsewhere and use implementations that have been tried and tested.
The company today provides services on top of eight different open-source projects — Apache Kafka, PostgreSQL, MySQL, Elasticsearch, Cassandra, Redis, InfluxDB and Grafana — which cover a variety of basic functions, from data streams to search and the handling of a variety of functions that involve ordering and managing vast quantities of data. It works across big public clouds, including Google, Azure, AWS, Digital Ocean and more.
The company is running two other open-source technologies in beta — M3 and Flink — which will also soon be added on general release, and the plan will be to add a few more over time, but only a few.
“We may want to have something to help with analytics and data visualisation,” Saarenmaa said, “but we’re not looking to become a collection of different open-source databases. We want to provide the most interesting and best to our customers. The idea is that we are future-proofing. If there is an interesting technology that comes up and starts to be adopted, our users can trust it will be available on Aiven.”
He says that today the company does not — and has no plans to — position itself as a system integrator or consultancy around open-source technologies. The work that it does do with customers, he said, is free and tends to be part of its pre- and after-sales care.
One primary use of the funding will be to expand its on-the-ground offices in different geographies — Aiven has offices in Helsinki, Berlin and Sydney today — with a specific focus on the U.S., in order to be closer to customers to continue to do precisely that.
But sometimes the mountain comes to Mohamed, so to speak. Saarenmaa said that he was first introduced to IVP at Slush, an annual tech conference in Helsinki held in November, and the deal came about quickly after that introduction.
“The increasing adoption of open-source infrastructure software and public cloud usage are among the incredibly powerful trends in enterprise technology and Aiven is making it possible for customers of all sizes to benefit from the advantages of open source infrastructure,” Eric Liaw, a general partner at IVP, said in a statement.
“In addition to their market potential and explosive yet capital-efficient growth, we were most impressed to hear from customer after customer that ‘Aiven just works.’ The overwhelmingly positive feedback from customers is a testament to their hiring practices and the strong engineering team they have built. We’re thrilled to partner with Aiven’s team and help them build their vision of a single open-source data cloud that serves the needs of customers of all sizes.”
Liaw is joining the board with this round.
0 notes
Text
How Can You Define the Big Data?
Big data is a term that describes very large or complex data sets involving both structured and unstructured data. The data is collected from a variety of sources including mobile devices, mobile apps, emails, servers, databases, and many other means. When formatted, captured, processed, manipulated and then analyzed, this data will help a business gain insight, maintain or get clients, increase revenue and enhance operations.

What Is Big Data?
Big data is defined as the name says, in brief, the massive volume of both structured and unstructured data. Mainly, that is so large and difficult to process using traditional database and software techniques.
For the most part, big data characteristics consist of five V’s, which include volume, velocity, variety, veracity, and value, which makes big data a huge business.
What Type of Data Is Big Data?
Big data refers to the data gathered from multiple sources, which include structured, unstructured, and semi-structured data.
While, for the data in the past, usually, data could only be collected from spreadsheets and databases.
Big Data Features
Big data analysis demand cost-effective, innovative forms of information processing for enhanced insight and decision making.
It includes the process of data mining, data storage, data analysis, data sharing, and data visualization.
One of the most significant advantages of big data is predictive analysis with the most accuracy.
In conclusion, big data analytics helps companies generate more sales leads. It would naturally mean a boost in revenue.
In short, with big data insights, you can always stay a step ahead of your competitors.
Big Data Tools
Namely, the tools for big data are as follows:
Hadoop
Apache Spark
Apache Storm
Cassandra
RapidMiner
MongoDB
R Programming Tool
Neo4j
Apache SAMOA
High-Performance Computing Cluster (HPCC)
The use and working of some tools are given below:
Hadoop:
Hadoop has enormous capability of large-scale processing data.
It can run on a cloud infrastructure.
It is an open-source framework.
Apache Spark:
Apache spark fills the gaps of Apache Hadoop concerning data processing.
It handle both batch data and real-time data.
Apache Spark processes data much faster than the traditional disk processing.
R Programming Tool:
R is used for statistical analysis.
R has its own public library Comprehensive R Archive Network (CRAN).
CRAN consists of more than 9000 modules and algorithms for statistical data analysis.
High-Performance Computing Cluster (HPCC):
HPCC helps in parallel data processing.
HPCC includes binary packages supported for Linux distributions.
It maintains code and data encapsulation.
Big Data Analysis Techniques
Association rule learning: It is a method for discovering interesting correlations between variables in large databases.
Classification tree analysis: It is the method of identifying categories that a new observation belongs to.
Genetic algorithms: Though, algorithms that are inspired in such a way evolution works, that is, adopting mechanisms such as inheritance, mutation, and natural selection.
Machine learning: Machine learning includes software that can learn from data.
Regression analysis: Data Analysis involves manipulating some independent variables to see how it influences a dependent variable.
Sentiment analysis: Data Analysis helps researchers, though with determining the sentiments of speakers or writers with respect to a topic.
Social network analysis: It is a technique that was first used in the telecommunications industry, and then quickly adopted by sociologists to study interpersonal relationships.
The Big Data Analysis Challenges
Getting data into a big data structure.
Syncing across data sources.
Conversely, extracting information from the data in big data integration.
Last, miscellaneous challenges. For instance, integration of data, skill availability, solution cost, the volume of data, the rate of transformation of data, veracity, and validity of data.
Dealing with data growth, as the quantity of data is increasing with time.
Big Data Analysis Usage
Various industries use big data analytics given as following:
Health care: By using predictive analytics, medical professionals and healthcare practitioners provide personalized healthcare services to individual patients.
Academia: Big data is providing the opportunity and helping enhance the education system today.
Banking: The banking sector relies on big data for fraud detection in real-time such as misuse of credit/debit cards, archival of inspection tracks, faulty alteration in customer stats, etc.
Manufacturing: It helps in manufacturing industries to improve the supply strategies and product quality.
IT: Companies around the globe are using big data to optimize their work functioning, enhance employee productivity, and minimizing the risks in business operations.
Future Scope of Big Data as in Career Choice
High demand for data analytics professionals.
Huge job opportunities around the globe.
The salary aspects are high.
After all, big data analytics is being a top priority in a lot of organizations.
It provides the key factor in decision making.
The adoption of big data analytics in industries is growing.
Outstanding the market forecast and predictions for big data analytics.
In conclusion, big data analytics is being used everywhere.
Conclusion
Therefore, the availability of big data in the industry, with the low-cost commodity hardware, and therefore, new information management, together with, the analytic software, has produced a unique moment in the history of data analysis.
In short, the age of big data is here, and these are truly revolutionary times.
So, in case you need any consultancy regarding data analytics you can get in touch with us at https://www.loginworks.com/web-scraping-services.
We serve our clients with quality work and as per their satisfaction.
Please feel free to share your feedback and opinion about this blog. We hope you enjoyed this post. It would be very great if you could share it with your friends or share it on social sites. Thank you!
0 notes
Text
Urgent Requirement Java Developer in Singapore
Company Overview:
Intellect Minds is a Singapore-based company since 2008, specializing in talent acquisition, application development, and training. We are the Best Job Recruitment Agency and consultancy in Singapore serve BIG MNCs and well-known clients in talent acquisition, application development, and training needs for Singapore, Malaysia, Brunei, Vietnam, and Thailand.
Job Responsibilities: • Hands on Design, Development, Deployment & Support of Software products • Interact with Product Owners to design and deliver technical solutions to support various business functions • Provide thought leadership and lead innovation by exploring, investigating, recommending, benchmarking and implementing tools and frameworks. • Work in a Globally Distributed Development team environment to enable successful delivery with a minimal supervision • Advocate, document, and follow best design and development practices
It is you, if: • You are passionate, creative and self-driven • You are curious and collaborative, and a believer in the power of teams and team work • You are flexible and have a broad set of capabilities to wear multiple hats • You thrive in a dynamic and a fast paced environment • You pursue speed and simplicity relentlessly • You are a natural leader in everything you do
Experience:
• BS/MS CS/SE/EE degree or equivalent with 8+ years of experience in the field of Software Engineering and Development using Java/JEE/JavaScript • Minimum 5+ years of strong hands-on development experience with Java (7.0/8.0), JEE and related technologies • Minimum 5+ years of experience in building Platforms, Frameworks & API’s using Open Source Java & JavaScript Frameworks (SpringBoot, Hibernate, Play, Akka, Netty.IO, Node.js etc.) • Strong working experience in micro services API first development • Experience in AWS is added advantage • Experience in large scale data management using Big Data, Elastic Search • Working Knowledge on Reactive/Functional Programming is highly desirable • Knowledge of NO-SQL technologies like Cassandra, MongoDB • Excellent understanding of Micro services based architectures, Service oriented design & architecture, Application Integration & Messaging, Security and Web 2.0. • Strong understanding of design patterns and best practices in Java/JEE platform including UI, Application & Frameworks development. • Extensive hands-on development experience with frameworks and tools including Apache Stack, Web Services. • Strong Experience/Knowledge on Data modeling (RDBMS, XSD, JSON), Database/XML interaction, SQL, Stored Procedure and ORM. • Experience with web servers & application servers such as Tomcat & JBoss • Must have prior experience in leading Technical deliverables. Must be able to effectively communicate & work with fellow team members and other functional team members to coordinate & meet deliverables. • Exceptional communication, organization and presentation skills • Experience working with Open Source API Gateway Frameworks, Mulesoft/Apigee API Gateway is a huge plus • Good understanding of CI/CD systems and Container based deployments on Docker.
All successful candidates can expect a very competitive remuneration package and a comprehensive range of benefits.
Interested Candidates, please submit your detailed resume online.
To your success!
The Recruitment Team
Intellect Minds Pte Ltd (Singapore)
https://www.intellect-minds.com/job/java-developer-5/

0 notes