#because plot is a generic function that is implemented differently for each object
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
There are dozens of funny blogs to kill time on Tumblr.
Text

don't get me started on R prev
ridiculous language everyday I want to punch this language in the face
i think everyone should program at least once just so you realise just how fucking stupid computers are. because theyre so fucking stupid. a computer wants to be told what to do and exactly that and if you make one typo or forget one detail it starts crying uncontrollably
#I not only work in R full time but I also teach it#did you know R has like three and a half different ways it implements object orientation?#and it's not easy to use any of them? because the language itself is not object oriented obviously#BUT there are classes and polymorphism implemented in the r base#which you quickly figure out when you lookup the help for the plot function and learn absolutely nothing#because plot is a generic function that is implemented differently for each object#of course#it is of course a more modern and updated language than C (or S). but at what cost?#everyday I find out that it's doing something that never in a million lifetimes I could predict
27K notes
·
View notes
Text
5 best programming language for data science beginners
What are programming languages?
Programming languages, simply put, are the languages used to write the lines of code that make up software programs. These lines of code are digital instructions, commands, and other syntax that are translated into digital output.
There are 5 main types of programming languages:

Procedural programming language
Functional programming language
Object Oriented Programming Language
Script programming language
Logic programming
Each of these types of programming languages performs different functions and has specific advantages and disadvantages.
Python
Python has grown in popularity in recent years, ranking first in several programming language popularity indexes, including the TIOBE index and the PYPL index. Python is an open-source, general-purpose programming language that is widely applicable not only in the data science industry but also in other domains such as web development and game development.
Best used for: Python is best used for automation. Task automation is extremely valuable in data science and will ultimately save you a lot of time and provide you with valuable data
2. R
R is quickly rising up the ranks as the most popular programming language for data science, and for good reason. R is a highly extensible and easy-to-learn language that creates an environment for graphics and statistical computing.
All this makes R an ideal choice for data science, big data and machine learning.
R is a powerful scripting language. Since this is the case, it means R can handle large and complex data sets. This, combined with its ever-growing community, makes it a top-tier choice for the aspiring data scientist.
Best used for: R is best used in the data science world. It is especially powerful when performing statistical operations.
MATLAB
MATLAB is a very powerful tool for mathematical and statistical computing, which allows the implementation of algorithms and the creation of user interfaces. Creating UIs is especially easy with MATLAB because of its built-in graphics for plotting and data visualization.
This language is particularly useful for learning data science, it is primarily used as a resource to accelerate data science knowledge. Because of the deep learning toolbox functionality, learning Matlab is a great way to easily transition into deep learning.
Best Used For: MATLAB is commonly used in academia to teach linear algebra and numerical analysis.
SAS
SAS is a tool used primarily to analyze statistical data. It literally means statistical analysis system. The primary purpose of SAS is to retrieve, report, and analyze statistical data.
SAS may not be the first language you learn, but for beginners, knowing SAS can open up many more opportunities. It will help you a lot if you are looking for a job in data management.
Best Used For: SAS is used for machine learning and business intelligence with tools on your belt such as predictive and advanced analytics.
SQL
SQL is a very important language to learn to become a great data scientist. This is very important because data scientists need SQL to process data. SQL gives you access to data and statistics, making it a very useful resource for data science.
Data science requires a database, hence the use of a database language such as SQL. Anyone working with big data needs to have a solid understanding of SQL to be able to query databases.
Best used for: SQL is the most widely used and standard programming language for relational databases.
#machinelearning#datascience#datascienceassignment dataAssignmenthelp#pythonprogramming#Datascienceprogrammng#datsciencehomeworkhelp#DataScienceassignmenthelp
0 notes
Text
OUAT 2X14 - Manhattan
I don’t have a pun for this time, but I wanted to say that this is probably one of the episodes that I was the most excited to cover for this rewatch for a few reasons. First, I haven’t watched it since my initial watch of the series so apart from the broad strokes of the story, I’ve forgotten a great deal of it. Second, it’s one of the biggest and best received episodes of the season from a General Audiences standpoint from what I understand. Third, I’ve never had a real opinion on Neal because I binged Seasons 2 and 3, so this episode will provide me the opportunity to do just that! Finally, it takes place in New York and who doesn’t love New York!

...Don’t answer that! Anyway, I hope you’ll read my review of this episode which is just under the cut, so I’ll CUT to the chase. Ha! Turns out I did have a pun in me! Okay! Let’s get started!
Press Release While Mr. Gold, Emma and Henry go in search of Gold’s son Bae in New York, Cora, Regina and Hook attempt to track down one of Rumplestiltskin’s most treasured possessions. Meanwhile, in the fairytale land that was, Rumplestiltskin realizes his destiny while fighting in the Ogres War. General Thoughts - Characters/Stories/Themes and Their Effectiveness Past We gotta talk about the forking Seer and how she relates to Rumple. First, on a strictly aesthetic level, look at the way that the Seer moves her hands as she asks for water! It looks a bit like how Rumple moves his hands when he gets the Seer’s powers. Also, even her voice is sing-songy in the scene as per the captions, matching Rumple’s. Second, on a more narrative level, it’s really interesting to examine just how much of the Seer ended up becoming part of Rumple. When we see Rumple first become the Dark One, while manipulative at times, because said manipulation happens with Bae as a child, it’s played as more of manipulation that any authority figure could conceivably do cranked up to 11. And when he’s not with Bae and he’s dealing with others, he’s blunter, not as cunning as he grows to be later. But the Seer, like him in later flashbacks, picks upon more vulnerable parts of Rumple’s psyche, like how she brings up Milah and Rumple’s fears of his past and cowardice.
So I know that there are some complaints about Rumple’s discussed reasoning for turning back from the Ogres Wars was changed to being about Bae to about Rumple’s cowardice, and I actually couldn’t disagree more. This entire flashback’s setup isn’t about Rumple’s excitement to be a father, but about how he is more scared than he realizes of fighting and dying in the war. That’s how, as I mentioned before, the Seer initially gets him: by mentioning his father’s cowardice and his desire to stray away from that path. In the next flashback scene, Rumple shows much more explicit fear at those harmed in the war and one of the most poignant lines from that scene is about praying for a quick death and the final words he says to what he thinks is the Seer is “and I’m gonna die.” I honestly feel like this was a revelation that was always supposed to come out. It doesn’t lessen Rumple’s love for Bae or that that loves is any less powerful, for he wants to live for Bae, but from a story perspective, the main throttle of Rumple’s decision to harm himself does lean more towards cowardice. Hell, even Milah hits the ball on the head: “You left because you were AFRAID.”
“It will require a curse -- a curse powerful enough to rip everyone from this land.” Note that the Seer says this as Rumple’s asking for the truth about him finding his son to be revealed. I feel like people forget about this line and how it pertains to Rumple’s journey back to Bae. Many in the fandom (Myself included) mock Rumple for needing a curse to traverse realms while there are many other ways to travel them as revealed over the course of the series. Now, I get that yeah, to an extent, that’s true. New magical MacGuffins are introduced so that new characters can be introduced and so that we can see our current cast battle the fairytale elements with their modern mindsets and emotional problems (I personally find it more annoying when it’s mocked to the point where it’s used as an actual story critique, forking Cinema Sins and the mentality they’ve introduced for many who criticise films over minute details rather than how the work functions as a story -- this is why you will never see me take a point off for a plot hole). But back on topic, Rumple was told by both the Blue Fairy and now the Seer that he’d need a curse to get back to Bae, and so he kept that in mind. Present I know that a major point of contention is Emma not telling Neal about Henry when he brought up the idea of something good coming of their relationship, and I think it’s more of a complicated situation, one akin to both her initial lie to Henry in “True North” and her decisions in “Fruit of the Poisonous Tree,” where to say that something is objectively right or wrong is missing the point. Yes, Emma shouldn’t have lied and the episode is very explicit with how that was the wrong decision. However, look at what she’s dealing with. A vulnerable time in her life is now being further bastardized with the knowledge that it was all a conspiracy and while I like Neal, he didn’t exactly broach the subject with tactful bedside manner, instead trying to rationalize something so personal and painful to her. Also, I want to point out how Emma on some level knows this. That’s why she calls Mary Margaret in the very next present scene. But she doesn’t do the right thing. Look, this isn’t the easiest episode to be an Emma fan during, and I know that well. And I swear, I’m doing my best to keep my fan goggles off, but I’m not going to pretend that it’s not a nuanced situation when it is. And finally, Emma is chewed out for her decision. Henry gives her a “Reason You Suck Speech,” calling her just as bad as Regina, a line that hurts but is justified and given with an appropriate level of painfulness from an eleven year old. And even her initial apology isn’t enough.
So, that first confrontation between Rumple and Neal. Wow. What I like about Neal as he pertains to Rumple is that he immediately gives Rumple no leniency. I talked about this briefly during my review of “The Return,” but this is such an important distinction to Rumple’s other biggest loved one, Belle, who has somewhat looser parameters. From the second Neal sees Rumple again, he’s blunt about his intentions and exactly what he thinks about what Rumple’s capable of. I don’t want to say that there’s no love there, but it is pushed back in terms of Neal’s priorities, buried under decades of bitterness. And at the same time, while full of love, Rumple is still using his old tricks to get Neal to talk to him. He leverages his deal with Emma for more time to talk to him and while it works, it only serves to get more ire out of Neal. Rumple’s apology is likewise undeniably sincere, but the manner in which it is both gotten and attempted to be implemented completely miss the point that the anger produced can’t be healed so easily. I mean, just look at Neal’s face when he says that there’s magic in Storybrooke. Every benefit of every doubt is abandoned like the Stiltskin boys across portals. That having been said, with three minutes of time for an apology, I feel like we almost got more out of Rumple’s apology to August in “The Return” than we did here. Where are the tears? Why isn’t Rumple saying as much as he possibly can? It’s not enough to take points off or anything, but this meeting is partially what the first season and a half were building towards, and I kind of wanted more umph to it. That also having been said, I get that because Neal is a different person from August’s rendition of him entirely, of course the reactions are going to be different, and Neal’s speech after he’s done talking blows the conversation away. Credit to Michael Raymond James because in this scene, he completely kept up with Robert Carlyle, and that’s not always an easy feat, especially in such an emotionally charged scene. Insights - Stream of Consciousness -It is so bizarre to see Rumple and Milah happy. It’s a great contrast to how bad things got between them and is a great show of how Rumple’s cowardice really affected Milah, turning her from someone who looked so content into the miserable woman from the flashback in “The Crocodile.” All throughout the scene, they’re so dopey-eyed and in-sync towards the end. I honestly would love to read a fic where they managed to come to terms with their past and maybe be able to forgive each other, and I know I’m alone in this, but there is a story there. -”My weaving days are over.” *thinks about how in roughly 250 years, he goes by Weaver* Suuuuuure, Rumple. -Okay, seeing an adorably excited non-Dark One non-present timeline Rumple is just the best. Robert Caryle really shows Rumple’s youth here, excited, bouncy, full of music and light. It’s an honest job and plays against the cowardly spinster we see in “Desperate Souls,” the blunter Mr. Gold and the silly, but frightening Dark One version of Rumple, it makes for such a unique contrast! -Milah also gets such a unique contrast in another respect, being the more cautious half of the relationship compared to how she is after Rumple arrives home. -”But to the world?” So, when in the series finale, the idea of “the Rumplestiltskin the world will remember” came up and kept being echoed like it was this important thing, I felt that it kind of came out of nowhere because I hadn’t ever seen Rumple concerned with his legacy beyond the more isolated well being of his children, grand and great-grandchildren, and wife. However, as I hear this line, it makes a bit more sense to me, especially because this is the same episode that discussed the Henry prophecy, which was also touched upon in the series finale. -So, Rumple does that bug-eyed thing that I complained about in the last episode, but here, because the confrontation between Rumple and Bae is impending and is isolated as the main reason for his concern, it works sooo well! -Killian, thank you for breaking up that horrible mother/daughter moment! -”Names are what I traffic in, but sadly, no.” This line cracked me up! XD -”I’m not answering anything until you tell me the truth.” That’s a pretty solid rule of thumb, Emma. Neal’s definitely no villain, but just going forward, that’s a good mindset to have! -”I am the only one allowed to be angry here!” She’s got a point, Neal. You’re not really explaining yourself in a way that you’d be justified in being angry. -I love spotting bloopers as they’re happening. It’s like the OUAT version of finding Hidden Mickeys! -”My son’s been running away for a long time now.” When?! He ran away ONCE and he wasn’t even trying to run from you. He was trying to take you with him, in fact! Did you forget that?! -Henry and Rumple get a great scene! -I know you’re Baelfire.” Fun fact, last year at NJ con, I got this question wrong in the true/false game. But now I know the truth, and I’m coming for you again, Jersey! -Gotta give all the credit in the world to Jennifer Morrison here. There’s so much pain in her voice as Neal’s revealing the truth to Emma and Jen just captures how Emma’s barely holding her shirt together because now even more of her life has been shown to be a lie, and this time, a more vulnerable memory has been made even worse because of this new knowledge. -”To remind myself never to trust someone again.” That is such a tragic line. Even as Storybrooke has done a major job of changing Emma’s mindset in that regard, you do still see bits of that distrust in her personality. That’s why I like the concept of Emma’s walls being a constant in the series. -”You’ll never have to see me again.” Neal, you do know that your father is clearly still chasing you, right? You think he’s gonna give up so soon? -I like how as Rumple agreeing to watch the Seer, you can already see that his face has fallen and that he’s grown more haggard, showing some of that fear already striking him now that some of the initial adrenaline has worn off and the reality of the war is settling in. -”Who are you?” Jeez Belle, why not say “hi” like a decent person? -Regina, you know, instead of playing The Sorcerer’s Apprentice, it could be easier to, you know, look in her bag instead. -David, Thanksgiving with your family would be the best thing EVER! -Apparently, Bae learned to be a locksmith from Rumple. Neat! -Another great use of the weather from OUAT! The snow really helps to accentuate the dire straits of the war and is just adds a nice bit of texture to the scene so that it’s not just dirt against a night sky. -On the opposite end, Rumple hurting himself, especially as someone who is overcoming some serious orthopedic issues right now, is so uncomfortable to watch. Rumple’s screams actually gave me shudders. -As if I didn’t have enough reasons to praise the living daylights out of Robert Carlyle, just look at the moments when he enters Neal’s apartment. It’s the first glimpse that he gets of everything his son went through as a result of his actions and it’s subtly heartbreaking. -To add to this Robert Carlyle acting chain, his eyes as he screams “tell me” is forking hysterical! -Rumple’s splint makes me so uncomfortable. Go see a better doctor! -”A strong name!” Rumple straight up indignation as he says that cracks me the fork up! -I like Milah’s buildup of frustration as Rumple arrives home. At first, she’s almost smiling as she tells Rumple Bae’s name, but as she quickly confronts him and learns the facts, she gets angrier until we see the beginnings of the misery that sets off “The Crocodile.” I also want to note that Milah’s anger is for Bae’s sake, not for her own like in “The Crocodile,” and I think that is such an important distinction. A lot of people condemn Milah for her choice to leave Bae and my degree of agreement with that statement varies if you’re asking me to view it in terms of her choice as an individual vs comparisons with other characters, but I think it’s important to show that love for Bae. -forking hell. Die, Cora! -I think I do enough of a job complimenting the effects team to be able to laugh at the New York backdrop during Emma and Henry’s conversation. -I ADORE the design of the Seer, by the way. The stitched up face and the eyeballs on her hands is just so cool! -It’s interesting to note that the last scene of the flashback happens after the events of “The Crocodile’s” flashback, as Rumple states that his wife ran away, and not “died.” -Rumple, to quote a magnificent show of great quality, “If you could gaze into the future, you’d think that life would be a breeze, seeing trouble from a distance, but it’s not that easy. I try to save the situation, then I end up misbehaving. Oh-oh-o-o-o-oh!” (I’ll write a ficlet for the first person to tell me what I’m referencing). -”Okay. I get it. We’re all messed up.” *Takes a deep breath* Ookay, Neal. You sent Emma to jail, and while it may have helped break the curse, it also put her through some serious shirt. You don’t get to make light of that. -”In time, you will work it all out.” Yeah, about 250 years, but he does get there, and it’s pretty freakin’ awesome when he does! Arcs - How are These Storylines Progressing? Rumple finding his son - I probably should’ve listed this as an arc long ago, but I forgot. In any case, Rumple finally found him! The journey from the start of the series here was a fantastically well done one! I feel like it never dragged or took any longer or shorter than the season and a half that it ended up lasting. And now, it kind of gets a second life. Rumple is now physically with his son, but emotionally couldn’t be further from him, and we get to see Rumple trying to bridge that gap. I don’t remember liking this part of it, but on concept alone, it’s so fascinating to see that next step. Emma lying to Henry - I like that Emma gets to have a flawed moment with Henry and that Henry actually reacts to it so negatively. For a season and a half now, Emma’s been Henry’s hero so of course when she not only lies, but to such an extent, he’s going to have a bad reaction because he’s put her on a pedestal. Not only is it an interesting character moment for Henry, but as I mentioned before, it’s a good job on the narrative’s part in punishing Emma for her lie. Favorite Dynamic Rumple and Henry. To be honest, Neal and Rumple should absolutely go here, but their entire conversation is more story based, and I talked about them ad nauseum up in that category, so why not highlight another dynamic? Rumple and Henry are so supportive and kind to each other here, and it feels like both good foreshadowing of their familial relationship, a show of the progress both characters had made thus far when it comes to how they treat their loved ones, and a tragic setup for not only the let down they both get from their respective loved ones, but also of the prophecy. For the latter one, for most of he episode, it felt a little weird seeing Rumple talk to Henry so softly despite knowing the prophecy. It felt a bit like him raising a pig for slaughter. However, the end of the episode makes it clear that Rumple was just now remembering the prophecy as he watched Neal and Henry bond, and it works well enough for me. Their time together in the episode is just so gentle and in an episode that’s more or less full of harsh moments (those gentle moments included in hindsight), the break that Henry and Rumple give is desperately needed. Writer Adam and Eddy are really good at writing intricate storylines. When you look at their other episode like the “Pilot,” “A Land Without Magic,” and “The Queen of Hearts,” you notice that the situation the characters are put into are never so simple. Just like someone can’t or shouldn’t be expected to straight-up hate Regina in the “Pilot,” one can’t or shouldn’t be expected to hate Emma, Neal, Henry, or Rumple here (Except Cora. We can hate Cora allllll we want), no matter who you’re a fan of. That’s because they’re careful with their framing and character work as to never let one forget their full picture. And I think that holds especially true in “Manhattan.” Culture In my intro, I said I was excited to finally get an impression of Neal for myself. When you’re in a certain shipping camp like I am (Captain Swan), Neal tends to be thrown through the ringer. Hell, even my best friend in the fandom hates him. However, when you’re as anti-salt as I am, you tend to take a lot of the shirt thrown at him with a grain of...well, salt. This is part of the reason why this rewatch appealed to me so much. I always found Neal to be pretty average in my book. I remember liking him, but not having much of a reaction to either his actions or his death in Season 3 (I also feel like I should disclose the fact that I wasn’t in either of the shipping camps throughout Neal’s entire present existence on the show), and I feel like I’d be remiss not to talk about him a bit now, especially as this is his debut present episode and affords him the most perspective.
So here goes.
I like Neal. I don’t love him. If you asked me to line up every character in the show, he’d probably end up near August, and I like August too, though not as much as major characters like Rumple, Regina, and Emma.
What’s appealing to me about Neal is his non-exaggerated blunt personality. The way he curb stomps Rumple’s apology is so in-your-face, as if to scream to an audience that already finds sympathy for Rumple that his pain matters too and it will be paid attention to. This works by keeping him a sympathetic character, but also giving him a compelling dynamic. As for Emma, that bluntness also helps, but in a way that makes Emma more sympathetic. I mentioned before that Neal’s exposition about his part in the conspiracy of sending Emma to jail was less than ideal, and it’s part of what contributes to her decision to lie about finding him. Neal is a bit of a jerk, obviously not devoid of either the heroism or love of his former selves, but it’s a character quality all the same and a good one, especially because to my memory, it stays around and is pretty organic. It paints the trauma that he’s had at the hands of the world since his abandonment as it’s such a stark contrast to his Enchanted Forest self.
Rating Golden Apple. What a great episode! It goes in with the promise of payoff for quite a few major story elements and does exactly that. It’s unwaveringly harsh in many respects, but that’s why it works as well as it does. Neal’s addition to the main cast shakes things up and provides new opportunities for characters, for as harsh as it is to watch, seeing Emma lie about Neal and be punished for it was a good narrative choice, and the flashback was utterly fantastic in its storytelling! Flip My Ship - Home of All Things “Shippy Goodness” Swan Fire - Listen to that vulnerability as Emma says Neal’s name and that happiness that Neal just can’t keep out of his voice as he says Emma’s! That’s just fantastic! Also, he keeps the dreamcatcher! Also also, that “leave her alone” was romantic as all hell! Captain Floor - I’m very pissed at myself for not mentioning the best ship ever at any point before this. Like, Killian and the Floor just belong together, and to not acknowledge that was a callous mistake on my part! My sincerest apologies to my reader base, and I beg for you not to think I’m at all an anti! ()()()()()()()()() It feels so good to give this season a high grade again!!!! Woohoo!! Thank you for reading and to the fine folks at @watchingfairytales for putting this project together!
Next time...someone DIES!!!
...I’m saying that like we all don’t know who it is that dies… ...Please come back…I’m so lonely...
Season 2 Tally (124/220) Writer Tally for Season 2: Adam Horowitz and Edward Kitsis: (39/60) Jane Espenson (25/50) Andrew Chambliss and Ian Goldberg (24/50) David Goodman (16/30) Robert Hull (16/30) Christine Boylan (17/30) Kalinda Vazquez (20/30) Daniel Thomsen (10/20)
Operation Rewatch Archives
9 notes
·
View notes
Text
Segmentation Study- A Vital Tool for any Business to Succeed
In the dynamic, competitive marketing landscape, no business can move a step further without having a clear picture of the market it is entering into and the consumers associated with it. Marketers hence invest resources in ‘Segmentation Studies’ to understand which consumer segment to target and how to target them to develop tailored products/services, tailor marketing strategies better, design customer experience and tap growth opportunities.
Let’s start with the basics of a segmentation study.
A segmentation study identifies a set of criteria based on which a market is divided into segments, including consumers with homogenous purchasing traits, needs and expectations. The study allows marketers to pick identical benefits associated with the segments so that the most promising one can be focused on to create an effective brand portfolio. The ultimate aim of segmentation research is to design market strategies and tactics for the different segments to optimize products and services for different customers.
All businesses, irrespective of size and the industry it is functional in, practice segmentation study to read consumers’ minds. The first step to the segmentation study is to learn about the various ways a market can be segmented. Segmentation can be of the following types:
Geographic
Demographic
Behavioral
Psychographic
Getting started with segmentation study
An effective segmentation study is a high-stakes venture. Hence, it is important to plan the study strategically to obtain high-quality segmentation insights by making optimum usage of a firm’s resources.
Set Objectives and goals of the segmentation study.
Set criteria to Decide the Type of Segmentation to go for. Create a hypothesis based on the identified segmentation variables.
Design the study through questionnaires to obtain quantitative and qualitative responses.
Conduct Preliminary Research to familiarize with the potential customers.
Create customer segments by analyzing the responses either manually or using appropriate statistical software.
Analyze the created segments and pick the most relevant one
Develop a Segmentation Strategy for the selected target segment.
Execute the strategy to identify key stakeholders and Repeat what works.
How is a good segmentation characterized?
Even though a segmentation study aims to tackle the complexities of a competitive market, a poorly conducted study can complicate things. So, how should an approachable market segment look like?
It should be relevant and unique
Measurable
Accessible by promotion, communication, and distribution channels
Substantial
Actionable
Differentiable
Conducive to the prediction of customer choice
Easy to implement strategies
Why does segmentation matter?
Looking in time, some of the world's most successful brands have failed miserably in specific markets. Walmart’s low-price strategy and the convenience of finding great deals under a roof, was not much effective in Japan as it is in the US. Hence, after more than a decade in the market, the American retail giant was forced to exit Japan. Likewise, Walmart did not consider the cultural nuances of Germany, specifically in the personal space and had to pull out with a hefty loss.
Another US giant, Home Depot failed to dip its toes into the Chinese market because the concept of DIY didn't fit the preference of the locals. Starbucks' failure to adapt its offerings to Australia's rich coffee culture proved to be a marketing blunder.
Where did things go wrong? Because each consumer is unique and the ‘one-product-for-everyone' approach has never worked, marketers must thoroughly understand the target segment before entering it. That is the importance of segmentation studies.
Segmentation study allows to focus on a group that matters and to tailor marketing strategies and ad campaign messages that resonate with the needs of that particular segment of consumers. Segmentation insights provide a deeper level of understanding about the consumers to develop better products.
Let us dive into some more benefits of segmentation studies.
Enhanced customer support
Enables efficient marketing and better brand strategy
Enact data-driven changes
Optimized pricing strategy
Better customer retention
Unravel new areas to expand in
Allows to forecast future trends and shape a forecast model accordingly.
Ensures higher ROI and CRO
Helps to stay competitive within a domain.
Pitfalls to avoid during a segmentation study
Segmentation study being a complicated practice is vulnerable to various common mistakes that marketers and researchers tend to make.
Too small or specialized segments are difficult to organize. This can hence disrupt the objective and can yield data with no statistical or directional significance.
Inflexible segments curb switching strategies that usually costs a lot to the firm.
Not evolving with the dynamic market trends and remaining too attached to a particular segment defeats the whole purpose of a segmentation study.
Let us see how Borderless Access helped a leading media channel find out a potential audience to target with the following case study.
Case study: Segmentation study to yield qualitative insights about audiences’ behavioural traits against quantitative demographic data
This case study describes how BA Insightz helped our client obtain in-depth insights about a spectrum of attributes of each audience segment of the Subscription Video on Demand (SVOD) category.
A leading entertainment channel leveraged the research expertise of Borderless Access to segment SVOD users and obtain game-changing segmentation insights. The objective of the study was to understand the general streaming behaviour of each of the audience segments in the US to tap the opportunity hence created.
Subscription video on demand (SVOD) is a subscription-based service using which consumers can access pre-designated video content, streamed through an internet connection on the service provider’s platform at a certain chargeable fee. SVOD gives users the freedom to select the video content they prefer to watch in this service and consume at convenience. Hence, we can say that consumer preferences, to a great extent, design SVOD services. Here comes segmentation into play as to know consumer preferences better, they need to be sorted based on several defined criteria.
The Borderless Access research team, BA Insightz, had employed a hybrid method of assessment in the geographical region of the US to yield the desired insights about the attitude and behaviour of current SVOD users from the lens of the consumer segments.
Measures Used for Segmentation
Following are the measures used for segmenting consumers, plotted against demographics and behaviour to identify the unique features of each of the segments.
Psychographics
Attitude towards Technology
Streaming Behavior
Personality Statements
Media, Social & Cultural Attitudes
Attitude towards Content
Variables Used for Segmentation
Each measure stated above was then given a set of criterions such as preferences, varied interests and perceptions.
The target group, subjected to a set of criteria furthered with categorizing the target audience into 5 actionable segments covering the spectrum of demographics as well as psychographics in the SVOD landscape.
Primary target segments
Streaming Advocates (16%)- This segment consisted mostly of mid-aged couples whose top watch list contains movies streaming and live and recorded TV shows.
Exploring Early Adopters (22%)- This male-dominated segment likes to explore almost all types of content except news.
Secondary target segments
Conscious Original Seekers (22%)- This has a greater number of females who are interested in TV shows and movies.
Trend Followers (21%)- This segment mostly has young males and females who showed interest in all types of content including sports.
Tertiary target segments
Legacy Loyalists (19%)- A female-dominated segment that inclines more toward live TV shows and news.
Findings
Each segment has been studied thoroughly and the following are the key findings-
Streaming advocates and exploring early adopters should be the key segments to target.
Exploring Early Adopters’ and ‘Streaming Advocates’ can be the target groups for kids’ content.
All except ‘Exploring Early Adopters’ can be targeted for mainstream content.
‘Exploring Early Adopters’ and ‘Streaming Advocates’ can be the potential targets segment for any new online streaming services.
The high price of SVOD services is one major factor that stops the segments- ‘Exploring Early Adopters’ ‘Conscious Original Seekers’ and ‘Legacy Loyalists’ from continuing the streaming services.
A wide range of content is a prominent reason behind consumers continuing with the services.
With SVOD, as we see, consumers are increasingly calling the shots. Hence the marketers should laser-focus on the customer experience to keep satisfaction and engagement levels high as streaming services flourish. Customer-centricity is the way to go for SVOD service providers.
BA Insightz – our consumer research vertical, helped the client with in-depth insights into each audience segment about attributes such as streaming behavior, entertainment and content consumption habits, triggers and barriers for streaming, and most important, opportunities to tap into each segment.
The insights can be used to access and define the audience segments, thus helping the client deliver exceptional and consistent customer experiences, improved consumer engagement and a key opportunity to stand out.
Final Thoughts
Segmentation can be tricky and complex. However, segmenting your customers can provide tremendous returns when compared to ‘one-size-fits-all’ approaches. Segmentation study defines target audiences and ideal customers; identifies the right market to place a product/service, and allows designing effective marketing strategies.
0 notes
Text
[Week 3-4] Summary Research Game Design: The Art & Business of Creating Games
PART 1 : CHAPTER 6: CREATING A PUZZLE
Overview
As goes along story, there is no hero directly kills the opponents and achieving the goal. Instead they will reach the obstacles, deal with them and finally get through the goal. As these obstacles are the puzzles that the players wanted to solve. A good puzzle contribute to plot, character, and story development. They draw the player into the fictional world. A bad puzzle does not and they are intrusive and obstructionist just like bad writing. A good puzzle fits into the setting and present an obstacles that make sense.
TYPES of PUZZLES
Ordinary Use of an Object
The basic functions of the object are being used to solve the puzzle.
Player enter dark room, find a light socket, and check his inventory and found a light bulb and he attached on it.
Door Example: The player discover the door with golden lock and he has a golden key. He unlock the door with golden key.
Finding Object logic, or hides on the box that requires to solve a puzzle
Unusual Use of an Object
The secondary characteristic of the object.
Require players to recognize them can be use in different ways
Diamond make pretty rings, but they could also cut the glass.
A candle can light up fire, but their wax could also make an impression of a key.
Door Example:
The player find a door with no key but is barred from the other side.
"Building" Puzzles
create a new object with raw materials (also combine object together)
Information Puzzles
player has to supply the missing piece of information
simply as supplying password → deducing the correct sequence of number that will defuse the bomb
Codes, Cryptograms, and Other "Words" Puzzles
subset of information puzzles
defining he boundaries of the kind of information for which the player is looking
Excluded Middle Puzzles
Hardest Type of Puzzles, both design and solve
Involving create reliable cause-and-effect relationship.
State in the term of logic;
a always cause b
c always cause d
the player want d then he has to believe that b and c would be linked and he will perform a.
Door Example:
(a) rubbing the lamp
(b) summon a bull
(c) bull see something red
(d) bull charge to it.
Door is red, and the player can see a lamp then he rub the lamp and b,c,d will be performed to unlock the door
Preparing the Way
A wrinkle on the excluded middle that makes it even more difficult.
Te player require to create the condition in order to perform the cause-and-effect chain reaction
Door Example:
Door is green, so the player need to realize to paint in red in order to summon the bull to charge to it.
People Puzzles
greatly enhance the building of the characters and storytelling
involve a people blocking the player's progress or holding important information piece
Timing Puzzles
difficult class of the puzzle
require player to recognize that the action perform will not be effect immediately but will cause in particular point in the future
Sequence Puzzles
need to perform correct sequence action in the right order
can be elaborate differently
commonly the action you perform will be block to acheiving the goal, then the player need to put something back to reset the sequence again once it gone.
Logic Puzzles
deduce particular bit of information by examining a series of statements and ferreting (search) out a hidden implication
Classic Game Puzzles **
aren't action or adventure game puzzles
Examples: magic square puzzles, move the matchstick puzzles, or jump the peg and leave the last one in the middle puzzles...
reminder: easy way to reset them
possible help system or an alternative to completing the puzzle
Riddles
least satisfying puzzle ☹️ cause if player does not get it, he does not get it.
Dialog Puzzles
A by-product dialog trees
A player need to follow a conversation down the correct path until a character says or does the right thing
advantage: bring really like people talk
disadvantage: not really a puzzle
Trial and Error Puzzles
player is confronted with an array of choices and with no information to go on.
Need to test each possible choices
Machinery Puzzles
need to figure out how to operate or control the machine
sometimes involve minor trial-n-error.
sometimes logic.
Alternative Interface
can from machinery puzzles to maps
you remove the normal game interface and replace it with a screen the player has to manipulate to reach a predefined condition
Maze
As what you heard is a maze
Gestalt Puzzles
recognize through a general condition.
Interesting fact: the designer does not actually state the condition, instead provide evidence that build up over time.
WHAT MAKES A BAD PUZZLE?
circumstances to fit into the game world.
Is important to suit the theme and setting of the game itself
Restore Puzzles
unfair to kill a player because not solving the puzzle
and only provide the information he needed to solve it
does not give a player to think ahead of time
Arbitrary Puzzles
Effects should always linked to the causes
Event shouldn't be happen because of designer intended to
Designer Puzzles
avoid the puzzles that only make sense to designer
require good testing corps to test out the ideas
Binary Puzzles
a puzzle only have yes or no answer is yield the instance failure or success
should give them lots of choices
Hunt the Pixel Puzzles
the important object in the screen is just too small for notice
WHAT MAKES A GOOD PUZZLES
a puzzle that can be solved, and eventually learned
Fairness
A player should theoretically be able to solve it the first time they encounters it simply by thinking hard enough
Assume he is presented all the information needed.
Appropriation to the Environment
Plopping a logic or mathematical puzzle into the middle of the story is NOT a good way to move a narrative along
The best puzzles are naturally fits into the story
Amplifying the Theme
should not have the player taking actions contrary to the character you have set up
The V-8 Response
A player A-ha! Of Course = Good Puzzles
A player There is no way to solve it, I don't even understand it now, Why does it work? = Bad Puzzles
LEVELS OF DIFFICULTY
Adjusting the difficulty of the puzzle
Bread Crumbs
change the directness of the information you give the player.
The Solution's Proximity to the Puzzle
The closeness of answer to the problem determine the difficulty of the game
True in both psychological and geographical
Alternative Solutions
provide alternative solutions to puzzles to make it easier
Red Herrings
implement red herrings to make it harder
Not necessary to do it
Steering the Player
Responding to the player input that not actually solve puzzles.
Steering the player to the correct path on the true answer by providing small clues
Response should contain little nuggets of information
HOW TO DESIGN THE PUZZLE
Creating the Puzzle
Settings → Characters → General Goals → Different Scenes → Sub goal → Obstacles
Obstacles are the puzzles
Create problems for the player that are appropriate to the story and setting
Think of the character I had created
Think about reasonable obstacles to place in his path
The Villians
think about villian while design puzzle
He is the one who create obstacles.
materials he used is from the environment, clear purpose and it's up for hero to overcome the obstacles
Ask ourselves why the puzzles are there
Player Empathy
the ability of looked into the game as the player does
to determine what is fair and reasonable
Formed ourselves as a player while designing the puzzles
Letting the player know where the puzzles are
SUMMARY
Make sure the puzzles enhance the game rather than detract from it
Use the puzzle to draw the attention of the player into the story so that he learned more about the characters
Don't withhold the information he need to solve the puzzles
Develop player empathy and strive for that perfect level frustration that drives a player forward
Above all, — play fair
0 notes
Text
Applying Knowledge Discovery Process in General Aviation Flight Performance Analysis

Abstract
The air transportation is a technology-intensive industry that has found itself collecting large volumes of data in a variety of forms from daily operations. Aviation data play a critical role in numerous aspects of aviation industry, aircraft flight performance is one of the most important uses of aviation data. Aircraft operational data are usually collected using aircraft onboard flight data recording devices and have been traditionally used for monitoring flight safety and aircraft maintenance with basic statistical analysis and threshold exceedance detection. With the development of data science and advanced computing technology, there is a growing awareness of incorporating knowledge discovery process into aviation operations. This article provides a review of recent studies on flight data analysis with two example studies on applying knowledge discovery process in flight performance analyses of general aviation.
Keywords:General aviation; Knowledge discovery process; Flight performance analysis
Introduction
In the field of aviation, data analyses have been widely adopted for a variety of needs, such as aviation safety improvement, airspace utility assessment, and operational efficiency measuring. With different purposes, aviation data are collected, analyzed and interpreted from different perspectives with a variety of techniques. For example, data of air traffic volume are usually used for airspace management and airline network planning, data of transportation gross or passenger load factor are used for airline’s economic performance related analyses, and flight operational data from flight data recorder could be used for safety analyses. The number of common aviation data analysis techniques documented by the Federal Aviation Administration (FAA) System Safety Handbook reaches as many as 81, and there are more techniques are being developed [1]. Because of the diversity of aviation data and analytical purposes, expensive investment on technological equipment, proprietary software, and long-term labor costs for data collection and analytics is required for aviation operators.
Knowledge discovery is a nontrivial extraction of implicit, previously unknown, and potentially useful information from a collection of data, including a process of obtaining raw data, cleaning, transforming data, and modeling and converting data into useful information to support decision-making, shown as Figure 1 [2, 3].
As an interdisciplinary area, knowledge discovery process widely involves database technology, information science, statistics, machine learning, visualization, and other disciplines, and includes the following nine steps:
a) Develop an understanding of the application domain and the relevant prior knowledge, and identify the goal of the KDD process from the customer’s perspective,
b) Select a target data set or subset of data samples on which discovery is to be performed,
c) Data cleaning and preprocessing, including removing noise, collecting necessary information to model or account for noise, deciding on strategies for handling missing data, and accounting for time-sequence information and known changes,
d) Data reduction and projection by finding useful features to represent the data depending on the goal or task,
e) Match the goals of the KDD process to a particular data mining method,
f) Exploratory analysis and model and hypothesis selection by choosing the data mining algorithms and selecting methods to be used for searching for data patterns,
g) Data mining to search for patterns of interest in a particular representational form or a set of such representations, such as classification rules or trees, regression, and clustering,
h) Interpret the mined patterns, possibly return to any of steps 1 through 7 for needed iteration,
i) Apply the discovered knowledge directly or incorporate the knowledge into another system for further actions [3].
By taking the advantages of the information and communication technologies, knowledge discovery process has been used to extract useful information from the massive data coming from different fields, such as marketing, finance, sports, astrology, and science exploration. In other words, knowledge discovery process is applicable for a wide range of data-driven cases with appropriate design and implementation, aviation industry is no exception. Many studies have been conducted to adopt the knowledge discovery process for the development of advanced aviation data analysis techniques. The article provides a review of recent studies on flight data analysis with two example studies on applying knowledge discovery process in flight performance analyses of general aviation (GA).
Review of Flight Data Analysis in GA
The United States has the largest and most diverse GA community in the world performing an important role in noncommercial business aviation, aerial work, instructional flying, and pleasure flying [4]. During the last decades, GA accident rates indicate a decreasing trend, but there were still estimated 347 people killed in 209 GA accidents in 2017 [5]. Reducing GA accident rates has been a challenge for many years. The FAA and industry have been working on several initiatives to improve GA safety, such as the General Aviation Joint Steering Committee (GAJSC), Equip 2020 for ADS-B Out, new Airman Certification Standards (ACS), and the Got Data? External Data Initiative [5]. Compared to last century, there are fewer aviation accidents with common causes. Traditional aviation safety improvement strategies relying on reactively investigating aircraft accidents and incidents are no longer enough to support further improve aviation safety. Therefore, government and the aviation industry have steered safety enhancement strategies from reactive approaches to proactive approaches [6]. Given the effectiveness of Flight Data Monitoring/Flight Operational Quality Assurance (FDM/FOQA) programs on commercial aviation safety improvement, the FAA and industry are also focused on reducing GA accident rate by primarily using a voluntary, non-regulatory, proactive, data-driven strategies [5]. For example, de-identified GA operational data were used in the Aviation Safety Information Analysis and Sharing (ASIAS) program to identify risks before they cause accidents [5]. The National General Aviation Flight Information Database (NGAFID) was launched as a joint FAA-industry initiative designed to bring voluntary FDM to general aviation, and a datalink between ASIAS and the NGAFID was built by the University of North Dakota in 2013 [7].
Today, the FDM is also known as flight data analysis or operational flight data monitoring (OFDM) under the framework of International Civil Aviation Organization (ICAO) and other civil aviation authorities, as shown in Figure 2 [8]. Although the features of each program may vary, most of them are developed on two primary approaches: The exceedance detection approach and the statistical analysis approach [9]. Exceedance detection looks for deviation from flight manual limits and standard operating procedures (SOPs). Exceedance detection approach detects predefined undesired safety occurrences. It monitors interesting aircraft parameters and trigger warning or draws attentions of safety specialists when parameters hit the preset limits or baselines under certain conditions. For example, the program can be set to detect the events when the aircraft parameters of speed, altitude, or attitude are higher than predefined thresholds.
Statistical analysis approaches are used to create the flight profiles, plot the distributions and trends of certain types of flight parameters, or map flight track on geo-referenced chart to examine particular operational features of flight. By using statistical analysis approaches, aviation operators not only obtain numeric features of flight operations, but also acquire a more comprehensive picture of the flight operations based on the distributions of aggregated flight data [9]. Statistical analysis is a tool to look at the total performance and determine the critical safety concerns for flight operations. In addition, both exceedance analysis and statistical analysis can dive into the data on a specific target, such as phases of flight, airports, or aircraft type.
Many observations in aviation data are either spatially or temporally related, for instance, aircraft flight parameters captured by onboard flight data recorder, tracks from radar, and aircraft GPS position data are all in the form of sequential observations. In addition to above two prevalent flight data analysis approaches for flight safety assurance, many other data analysis techniques are being developed and used for more specific objectives.
Exceedance Detection of GA Flight Operations
Flight data analysis is an effective strategy for proactive safety management in aviation. In addition to Part 121 commercial air carriers, Part 135 operations are also highly encouraged to adopt Flight Data Monitoring (FDM) as one of the most wanted transportation safety improvements [10]. However, the implementation of flight data analysis requires significant investment in flight data recording technology, data transferring, and professional software and labor cost for data analytics. Because of the high cost of flight data analysis, totally only 53 air transportation service operators in the U.S. have a FOQA program implemented [11]. Moreover, most flight data analysis strategies for commercial air carriers adopt the Ground Data Replay and Analysis System (GDRAS), which is typically a proprietary software with predesigned functionalities and replies on a great number of flight parameters fed from advanced flight data recorder. Due to the resource constraint of general aviation, traditional flight data analyses are usually unaffordable and not flexible to meet the demand of GA operators given GA aircraft have less sophisticated avionics onboard and diverse operational characteristics.
An innovative flight exceedance detection strategy was explored based on knowledge discovery process and next generation air traffic surveillance technology – automatic dependent surveillance broadcast (ADS-B) [12, 13]. This strategy is expected to provide an inexpensive flight data analysis strategy particularly for GA operations by eliminating the dependency of proprietary GDRAS and investment of expensive onboard flight data recorder. These studies collected aircraft operational data from ADS-B and followed the knowledge discovery process to preprocess, transform and analyzed the data, as shown in Figure 3.
The exceedance detection procedure used in the study is shown as Figure 4. In total, a set of 29 flight metrics were developed based on the content of ADS-B data for the purpose of exceedance detection and flight performance measurement. Five flight exceedances were identified from aircraft operations manual and airplane information manual for experiment:
a) No turn before reaching 400 feet above the ground level (AGL) during the phase of takeoff
b) suggested climb angle during initial climb from 0 to 1000 feet AGL: 7 – 10 degrees
c) suggested indicated airspeed for the Base leg: 90+5 knots
d) suggested indicated airspeed for final approach: 78+5 knots
e) stabilized approach: Constant glide angle established from 500 feet AGL to 0 feet AGL for flight under visual flight rules (VFR)
40 sets of ADS-B data were collected for exceedance detection. The study result shows certain types of exceedances could be more accurately detected than other exceedance events by using ADS-B data. The primary reason is because of the missing values of ADS-B data as it is transmitted wirelessly on 1090MHz or 978MHz. However, flight data analysis using ADS-B data is expected to be a promising strategy with further research and development.
Fuel Consumption Analysis of GA Piston-engine Aircraft
With the modernization of GA fleet, there are more and more GA aircraft equipped with advanced digital flight data recorders, which provide quick access to GA flight data. Therefore, aircraft operational data become more accessible for flight performance analysis. One of such studies explored the fuel consumption efficiency of GA piston-engine aircraft by discovering the relationship between aircraft operational parameters [14]. Following the knowledge discovery process, 22 sets of flight operational data with 176,370 data observations were collected from Garmin G1000 avionics system installed on GA pistonengine aircraft – Cirrus SR20, and transformed and analyzed with machine learning techniques. Statistical relationship between the fuel flow rate and three aircraft parameters (aircraft ground speed, flight altitude, and the vertical speed) was modeled. The classification and Regression Trees (CART) were used to predict the fuel flow rate using the three explanatory aircraft parameters, as shown in Figure 5. By developing the model, GA operators could intuitively estimate the fuel flow rate of aircraft at any given time with only three other aircraft parameters, which could be acquired real-time or post-flight from many available aeronautic technologies. In addition, analyses in this study also show that aircraft groundspeed and vertical speed have higher impact on the fuel flow rate than the flight altitude, which provides GA operators of important intelligence to optimize the fuel consumption efficiency [14].
Fuel Consumption Analysis of GA Piston-engine Aircraft
With the modernization of GA fleet, there are more and more GA aircraft equipped with advanced digital flight data recorders, which provide quick access to GA flight data. Therefore, aircraft operational data become more accessible for flight performance analysis. One of such studies explored the fuel consumption efficiency of GA piston-engine aircraft by discovering the relationship between aircraft operational parameters [14]. Following the knowledge discovery process, 22 sets of flight operational data with 176,370 data observations were collected from Garmin G1000 avionics system installed on GA pistonengine aircraft – Cirrus SR20, and transformed and analyzed with machine learning techniques. Statistical relationship between the fuel flow rate and three aircraft parameters (aircraft ground speed, flight altitude, and the vertical speed) was modeled. The classification and Regression Trees (CART) were used to predict the fuel flow rate using the three explanatory aircraft parameters, as shown in Figure 5. By developing the model, GA operators could intuitively estimate the fuel flow rate of aircraft at any given time with only three other aircraft parameters, which could be acquired real-time or post-flight from many available aeronautic technologies. In addition, analyses in this study also show that aircraft groundspeed and vertical speed have higher impact on the fuel flow rate than the flight altitude, which provides GA operators of important intelligence to optimize the fuel consumption efficiency [14].
Discussion and Conclusion
This article reviews the recent progress of aviation data analyses and two example studies of applying knowledge discovery process in GA flight performance analyses from different perspectives. Two example studies illustrate how knowledge discovery process are practically addressing different demands in flight performance analyses in safety measurement and operational efficiency monitoring. Knowledge discovery process has been widely practiced in many non-aeronautic fields by taking the advantages of the improvement of new information and communication technologies. As an important part of transportation industry, aviation has been incorporating more data-driven strategies in operations, management, and safety. Knowledge discovery process incorporates different data sources for data analyses so that it could support diverse knowledge discovery purposes. In knowledge discovery process, data are selected upon the analysis objectives and analyzed from different viewpoints to discover interesting patterns driven by the main goal of supporting better decision-making. All of those features make it a promising strategy in the world of air transportation.
While knowledge discovery is a promising strategy to extracting useful information from massive aviation data, applying knowledge discovery for a specific objective relies on good input of domain knowledge and well addressing constrains in each step of knowledge discovery process. First, domain knowledge generally determines how practical the entire knowledge discovery process is, and how useful the output knowledge could be. Staring from determining target data and choosing appropriate data mining techniques, solid domain knowledge decides whether the selected target data and analytic strategies fit the desired research objectives. For the later steps of interpretation and reporting the outcomes, domain knowledge arbitrates whether explanations of discovered knowledge is applicable and valuable given the research background. Second, issues from database constrain the effectiveness of knowledge discovery projects. Data analysts should take above factors into account when practice knowledge discover process in the field of aviation.
To Know More About Trends in Technical and ScientificResearch Please click on: https://juniperpublishers.com/ttsr/index.php
To Know More About Open Access Journals Please click on: https://juniperpublishers.com/index.php
#Juniper publishers#Open access Journals#Peer review journal#Juniper publishers reviews#Juniper publisher journals
0 notes
Text
Uncanny Dimple
My final project Uncanny Dimple is a body of work that examines the close proximity between the cute and the creepy. Drawing from roboticist Masahiro Mori’s concept of the Uncanny Valley, which explains the eeriness of lifelike robots, my theory of the Uncanny Dimple portrays a parallel phenomenon in the context of cuteness. The robotic creatures inhabiting the dimple demonstrate the often contradictory affects we experience towards non-human actors. When does cuteness start to border on the grotesque? If cuteness is the outcome of extreme objectification of living beings, can it also be the result of an anthropomorphising inanimate objects? Why does cuteness trigger the impulse to nurture and to protect, but also to abuse and to violate? Cute things are often seen as innocent, passive, and submissive, but can they also manipulate, misbehave and demand attention?

This body of work is based on my MFA thesis Uncanny Dimple — Mapping the Cute and the Uncanny in Human-Robot Interaction, where I examine the aforementioned contradictions of cuteness by applying Donna Haraway’s Cyborg Manifesto (1991) and the Uncanny Valley theory by Masahiro Mori (1970). I also reference the recent research on the cognitive phenomenon of cute aggression, a commonly experiences impulse to harm cute objects. (Aragón et al. 2015; Stavropoulos & Alba 2018)
Sigmund Freud first coined the term uncanny in his 1919 essay Das Unheimliche to describe an unsettling proximity to familiarity encountered in dolls and wax figures. However, the contemporary use of the word has been inflated by the concept of the Uncanny Valley by roboticist Masahiro Mori. Mori’s notion was that lifelike but not quite living beings, such as anthropomorphic robots, trigger a strong sense of uneasiness in the viewer. When plotting experienced familiarity against human likeness, the curve dips into a steep recess — the so called Uncanny Valley — just before reaching true human resemblance.
As a rejection of rigid boundaries between “human”, “animal” and “machine”, Haraway’s cyborg theory touches many of the same points as Mori’s Uncanny Valley. Haraway addresses multiple persistent dichotomies which function as systems of domination against the “other” while mirroring the “self”, much like cuteness and uncanniness: “Chief among these troubling dualisms are self/other, mind/body, culture/nature, male/female, civilized/primitive, reality/appearance, whole/part, agent/resource, maker/made, active/passive, right/wrong, truth/illusion, total/partial, God/man.” (Haraway 1991: 59)
Haraway’s image of the cyborg, despite functioning more as a charged metaphor than an actual comment on the technology, still aptly demonstrates the dualistic nature of cuteness and its entanglements with the uncanny at the site of human-robot interaction. Furthermore, Haraway’s cyborg theory grounds the analysis of the cute to a wider socio-political context of feminist studies. In the Companion Species Manifesto where she updates her cyborg theory, Haraway (2003: 7) is adamantly reluctant to address cuteness as a potential source of emancipation (which seems to be the case with other feminists of the same generation): "None of this work is about finding sweet and nice — 'feminine' — worlds and knowledges free of the ravages and productivities of power. Rather, feminist inquiry is about understanding how things work, who is in the action, what might he possible, and how worldly actors might somehow be accountable to and love each other less violently." I argue on the contrary that some of these inquiries can be answered by exposing the potential of cuteness as a social and moral activator. While Haraway describes a false dichotomy between these “sweet and nice” worlds and “the ravages and productivities of power”, I believe that their entanglement is in fact an important site for feminist inquiry. By revealing the plump underbelly of cuteness, we can harness the subversive power it wields.
In my thesis I conclude that cuteness and uncanniness are both defined by their distance to what we consider “human” or “natural”, and shaped by the distribution of power in our relationships with objects that we deem having a mind or agency. I continue to propose that a similar phenomenon to the Uncanny Valley can be described in regard of cuteness, which I call the Uncanny Dimple. Much like Mori’s valley and Haraway’s cyborg, Uncanny Dimple is presented as a figuration: It does not necessarily try to make any empirical or quantitative claims about the experience of cuteness, but strives to utilise the diagram as a rhetorical device for better understanding the entangled affects of cuteness and uncanniness.
Similar to Mori’s visualisation of the Uncanny Valley, the Uncanny Dimple is mapped in a diagram where the horizontal axis denotes “human likeness”, but Mori’s vertical axis of “familiarity” is in this case replaced with cuteness. Similar to Mori, I propose that cuteness first increases proportionally with anthropomorphic features. As established in Konrad Lorenz’s Baby Schema model from 1943, cuteness also increase proportionally in the presence of neotenic (i.e. “babylike”) features, such as large eyes, tall forehead, chubby cheeks and small nose. I suggest that this applies only to some extent: When the neotenic features have reached a point where they are over-exaggerated beyond realism, but the total human likeness is still below the Threshold of Realism, cuteness climaxes at what I call the Cute Aggression Peak. When human likeness exceeds that point, cute aggression becomes unbearable, the experienced cuteness is surpassed by uncanniness, and the curve dips to the Uncanny Dimple.

I wanted to create various cute but uncanny creatures which all had their distinctive way of moving or interacting with the audience. I created multiple different prototypes of most of the creatures, and in the final installation I had eight different types:
1. Sebastian is an interactive quadruped robot that can detect obstacles. Sebastian will wake up if it's approaced, and run away. The inverse kinematic functions for the quadruped gait are based on SunFounder's remote controlled robot. In the basic quadruped gait three legs are on the ground while one leg is moving. The algorithm calculates the angles for every joint in every leg at every given time, so that the centre of gravity of the robot stays inside the triangle of the three supporting legs. I designed all the parts and implemented the new dimensions in the code. I also added the ultrasonic sensor triggering and obstacle detection. For calculating distance measurements based on the ultrasonic sensor readings I used the New Ping library by Tim Eckel.

2. Ritu is an interactive robotic installation using Arduino, various sensors, servo motors and electromagnet. Users are prompted to feed the vertically suspended robot, which will descend, pick the treat from the bowl, and take it up to its nest. There is a hidden light sensor in the bowl, which senses if food is placed in the bowl. This will trigger the robot to descend using a continous rotation servo motor winch. The distance the robot moves vertically is based on the reading of a ultrasonic sensor. The robot uses an electromagnet attached to a moving arm to pick up objects from the bowl. After succesfully grabbing the object, the robot will ascend and drop the object in a suspended nest. For calculating distance measurements based on the ultrasonic sensor readings I used the New Ping library by Tim Eckel.

3. Crawler Bois are two monopod robots that move with motorised crawling legs that mimic the mechanism of real muscles and tendons. Each robot has a leg that consist of two joints, two servo motors, a string, and two rubber bands. The first servo lifts and lowers the leg, and the second servo tightens the string (the "muscle") which contracts the joins. When the string relaxes, the rubber bands (the "tendons") pull the joints to their original position. The robots move back and forth in a randomised sequence and sometimes do a small dance.

4. Lickers are three individually interactive robots using servo motors, Scotch Yoke mechanisms, and sound sensors. The Scotch Yoke is a reciprocating motion mechanism, in this case converting the rotational motion of a 360 degree servo motor into the linear motion of a licking silicone tongue protruding from the mouth of a creature. If a loud sound is detected, the creature will stop licking and lift up its ears. The treshold of the sound detection can be modified directly from a potentiometer on the sound sensor module.

5. Shaking Little Critter is a simple interactive installation using an Arduino, a vibrating motor and a light sensor. Users are prompted to remove the creature's hat, after which it will "get cold" and start shaking around in its cage. The absence of the hat is detected with a light sensor on top of the creature's head.

6. Rat Queen is a robotic installation exploring the emergent features arising from the combination of pseudo-randomness and mechanic inaccuracy. It consist of five identical rats-like robots that are connected to a shared power supply with their tails. All the members of the Rat Queen move independently in randomised sequences, but because they are started at the same time, the randomness is identical, since the random seed is calculated based on the starting time of the program. However, due to small inaccuracies and differences in the continuous rotation servo motors and their installation, the movement patterns diverge, and the rats slowly get increasingly tangled with their tails.

7. Cute Aggression is an interactive sound installation using Arduino and Max MSP. Users can record sounds by whispering in a hidden microphone in the plush toy creature's ear. A tilt switch in the ear starts the recording when the ear is lifted. The sounds are played back when the user pets the creature. The petting is detected with conductive fabric using Capacitive sensing library by Paul Badger. The reading from the sensor is sent to a Max MSP patch via serial communication. The sounds a generated from the Arduino data using a granular synthesis method based on Nobuyasu Sakonda’s SugarSynth. Sounds can be modulated by manipulating the creature's nipples, which are silicone-covered potentiometers.

8. Cucumber Weasel is a modified version of the motorised toy know as weasel ball. The plastic ball has a weighted, rotating motor inside, which makes the ball roll and change directions. The toy usually has a furry “weasel” attached to it, but here it is replaced with a silicone cast of a cucumber.

References:
Aragón, O. R; Clark, M. S.; Dyer, R. L. & Bargh, J. A. (2015). “Dimorphous Expressions of Positive Emotion: Displays of Both Care and Aggression in Response to Cute Stimuli”. Psychological Science 26(3) pp. 259–273.
Badger, P. (2008). Capacitive sensing library.
Eckel, T. (2017). New Ping library for ultrasonic sensor.
Freud, S. (1919). The ‘Uncanny’. The Standard Edition of the Complete Psychological Works of Sigmund Freud, Volume XVII (1917-1919): An Infantile Neurosis and Other Works, pp. 217-256.
Haraway, D. (1991). "A Cyborg Manifesto: Science, Technology, and Socialist-Feminism in the Late Twentieth Century," in Simians, Cyborgs and Women: The Reinvention of Nature. New York, NY: Routledge.
Haraway, D. (2003). The Companion Species Manifesto: Dogs, People, and Significant Otherness. Chicago, IL: Prickly Paradigm Press.
Lorenz, K. (1943). “Die angeborenen Formen moeglicher Erfahrung”. Z Tierpsychol., 5, pp. 235–409.
Mori, M. (2012). "The Uncanny Valley". IEEE Robotics & Automation Magazine, 19(2), pp. 98–100.
Rutanen, E. (2019). Uncanny Dimple — Mapping the Cute and the Uncanny in Human-Robot Interaction.
Sakonda, N. (2011). SugarSynth.
Sunfounder (n.d.). Crawling Quadruped Robot Kit v2.0.
Stavropoulos K. M. & Alba L. A. (2018). “‘It’s so Cute I Could Crush It!’: Understanding Neural Mechanisms of Cute Aggression”. Frontiers in Behavioral Neuroscience, 12, pp. 300
1 note
·
View note
Link
Deep Learning from the Foundations Written: 28 Jun 2019 by Jeremy Howard Today we are releasing a new course (taught by me), Deep Learning from the Foundations, which shows how to build a state of the art deep learning model from scratch. It takes you all the way from the foundations of implementing matrix multiplication and back-propogation, through to high performance mixed-precision training, to the latest neural network architectures and learning techniques, and everything in between. It covers many of the most important academic papers that form the foundations of modern deep learning, using “code-first” teaching, where each method is implemented from scratch in python and explained in detail (in the process, we’ll discuss many important software engineering techniques too). The whole course, covering around 15 hours of teaching and dozens of interactive notebooks, is entirely free (and ad-free), provided as a service to the community. The first five lessons use Python, PyTorch, and the fastai library; the last two lessons use Swift for TensorFlow, and are co-taught with Chris Lattner, the original creator of Swift, clang, and LLVM. This course is the second part of fast.ai’s 2019 deep learning series; part 1, Practical Deep Learning for Coders, was released in January, and is a required pre-requisite. It is the latest in our ongoing commitment to providing free, practical, cutting-edge education for deep learning practitioners and educators—a commitment that has been appreciated by hundreds of thousands of students, led to The Economist saying “Demystifying the subject, to make it accessible to anyone who wants to learn how to build AI software, is the aim of Jeremy Howard… It is working”, and to CogX awarding fast.ai the Outstanding Contribution in AI award. The purpose of Deep Learning from the Foundations is, in some ways, the opposite of part 1. This time, we’re not learning practical things that we will use right away, but are learning foundations that we can build on. This is particularly important nowadays because this field is moving so fast. In this new course, we will learn to implement a lot of things that are inside the fastai and PyTorch libraries. In fact, we’ll be reimplementing a significant subset of the fastai library! Along the way, we will practice implementing papers, which is an important skill to master when making state of the art models. Chris Lattner at TensorFlow Dev SummitA huge amount of work went into the last two lessons—not only did the team need to create new teaching materials covering both TensorFlow and Swift, but also create a new fastai Swift library from scratch, and add a lot of new functionality (and squash a few bugs!) in Swift for TensorFlow. It was a very close collaboration between Google Brain’s Swift for TensorFlow group and fast.ai, and wouldn’t have been possible without the passion, commitment, and expertise of the whole team, from both Google and fast.ai. This collaboration is ongoing, and today Google is releasing a new version of Swift for TensorFlow (0.4) to go with the new course. For more information about the Swift for TensorFlow release and lessons, have a look at this post on the TensorFlow blog. In the remainder of this post I’ll provide a quick summary of some of the topics you can expect to cover in this course—if this sounds interesting, then get started now! And if you have any questions along the way (or just want to chat with other students) there’s a very active forum for the course, with thousands of posts already. Lesson 8: Matrix multiplication; forward and backward passes Our main goal is to build up to a complete system that can train Imagenet to a world-class result, both in terms of accuracy and speed. So we’ll need to cover a lot of territory. Our roadmap for training a CNNStep 1 is matrix multiplication! We’ll gradually refactor and accelerate our first, pure python, matrix multiplication, and in the process will learn about broadcasting and einstein summation. We’ll then use this to create a basic neural net forward pass, including a first look at how neural networks are initialized (a topic we’ll be going into in great depth in the coming lessons). Broadcasting and einsum let us accelate matmul dramaticallyThen we will implement the backwards pass, including a brief refresher of the chain rule (which is really all the backwards pass is). We’ll then refactor the backwards path to make it more flexible and concise, and finally we’ll see how this translates to how PyTorch actually works. Back propagation from scratchPapers discussed Lesson 9: Loss functions, optimizers, and the training loop In the last lesson we had an outstanding question about PyTorch’s CNN default initialization. In order to answer it, I did a bit of research, and we start lesson 9 seeing how I went about that research, and what I learned. Students often ask “how do I do research”, so this is a nice little case study. Then we do a deep dive into the training loop, and show how to make it concise and flexible. First we look briefly at loss functions and optimizers, including implementing softmax and cross-entropy loss (and the logsumexp trick). Then we create a simple training loop, and refactor it step by step to make it more concise and more flexible. In the process we’ll learn about nn.Parameter and nn.Module, and see how they work with nn.optim classes. We’ll also see how Dataset and DataLoader really work. Once we have those basic pieces in place, we’ll look closely at some key building blocks of fastai: Callback, DataBunch, and Learner. We’ll see how they help, and how they’re implemented. Then we’ll start writing lots of callbacks to implement lots of new functionality and best practices! Callbacks in the training loopPapers discussed Lesson 10: Looking inside the model In lesson 10 we start with a deeper dive into the underlying idea of callbacks and event handlers. We look at many different ways to implement callbacks in Python, and discuss their pros and cons. Then we do a quick review of some other important foundations: __dunder__ special symbols in Python How to navigate source code using your editor Variance, standard deviation, covariance, and correlation Softmax Exceptions as control flow Python's special methods let us create objects that behave like builtin onesNext up, we use the callback system we’ve created to set up CNN training on the GPU. This is where we start to see how flexible this sytem is—we’ll be creating many callbacks during this course. Some of the callbacks we'll create in this courseThen we move on to the main topic of this lesson: looking inside the model to see how it behaves during training. To do so, we first need to learn about hooks in PyTorch, which allow us to add callbacks to the forward and backward passes. We will use hooks to track the changing distribution of our activations in each layer during training. By plotting this distributions, we can try to identify problems with our training. An example temporal activation histogramIn order to fix the problems we see, we try changing our activation function, and introducing batchnorm. We study the pros and cons of batchnorm, and note some areas where it performs poorly. Finally, we develop a new kind of normalization layer to overcome these problems, compare it to previously published approaches, and see some very encouraging results. Papers discussed Lesson 11: Data Block API, and generic optimizer We start lesson 11 with a brief look at a smart and simple initialization technique called Layer-wise Sequential Unit Variance (LSUV). We implement it from scratch, and then use the methods introduced in the previous lesson to investigate the impact of this technique on our model training. It looks pretty good! Then we look at one of the jewels of fastai: the Data Block API. We already saw how to use this API in part 1 of the course; but now we learn how to create it from scratch, and in the process we also will learn a lot about how to better use it and customize it. We’ll look closely at each step: Get files: we’ll learn how os.scandir provides a highly optimized way to access the filesystem, and os.walk provides a powerful recursive tree walking abstraction on top of that Transformations: we create a simple but powerful list and function composition to transform data on-the-fly Split and label: we create flexible functions for each DataBunch: we’ll see that DataBunch is a very simple container for our DataLoaders Next up, we build a new StatefulOptimizer class, and show that nearly all optimizers used in modern deep learning training are just special cases of this one class. We use it to add weight decay, momentum, Adam, and LAMB optimizers, and take a look a detailed look at how momentum changes training. The impact of varying momentum on a synthetic training exampleFinally, we look at data augmentation, and benchmark various data augmentation techniques. We develop a new GPU-based data augmentation approach which we find speeds things up quite dramatically, and allows us to then add more sophisticated warp-based transformations. Using GPU batch-level data augmentation provides big speedupsPapers discussed Lesson 12: Advanced training techniques; ULMFiT from scratch We implement some really important training techniques in lesson 12, all using callbacks: MixUp, a data augmentation technique that dramatically improves results, particularly when you have less data, or can train for a longer time Label smoothing, which works particularly well with MixUp, and significantly improves results when you have noisy labels Mixed precision training, which trains models around 3x faster in many situations. An example of MixUp augmentationWe also implement xresnet, which is a tweaked version of the classic resnet architecture that provides substantial improvements. And, even more important, the development of it provides great insights into what makes an architecture work well. Finally, we show how to implement ULMFiT from scratch, including building an LSTM RNN, and looking at the various steps necessary to process natural language data to allow it to be passed to a neural network. ULMFiTPapers discussed Lesson 13: Basics of Swift for Deep Learning By the end of lesson 12, we’ve completed building much of the fastai library for Python from scratch. Next we repeat the process for Swift! The final two lessons are co-taught by Jeremy along with Chris Lattner, the original developer of Swift, and the lead of the Swift for TensorFlow project at Google Brain. Swift code and Python code don't look all that differentIn this lesson, Chris explains what Swift is, and what it’s designed to do. He shares insights on its development history, and why he thinks it’s a great fit for deep learning and numeric programming more generally. He also provides some background on how Swift and TensorFlow fit together, both now and in the future. Next up, Chris shows a bit about using types to ensure your code has less errors, whilst letting Swift figure out most of your types for you. And he explains some of the key pieces of syntax we’ll need to get started. Chris also explains what a compiler is, and how LLVM makes compiler development easier. Then he shows how we can actually access and change LLVM builtin types directly from Swift! Thanks to the compilation and language design, basic code runs very fast indeed - about 8000 times faster than Python in the simple example Chris showed in class. Learning about the implementation of `float` in SwiftFinally, we look at different ways of calculating matrix products in Swift, including using Swift for TensorFlow’s Tensor class. Swift resources Lesson 14: C interop; Protocols; Putting it all together Today’s lesson starts with a discussion of the ways that Swift programmers will be able to write high performance GPU code in plain Swift. Chris Lattner discusses kernel fusion, XLA, and MLIR, which are exciting technologies coming soon to Swift programmers. Then Jeremy talks about something that’s available right now: amazingly great C interop. He shows how to use this to quickly and easily get high performance code by interfacing with existing C libraries, using Sox audio processing, and VIPS and OpenCV image processing as complete working examples. Behind the scenes of Swift's C interopNext up, we implement the Data Block API in Swift! Well… actually in some ways it’s even better than the original Python version. We take advantage of an enormously powerful Swift feature: protocols (aka type classes). Data blocks API in Swift!We now have enough Swift knowledge to implement a complete fully connect network forward pass in Swift—so that’s what we do! Then we start looking at the backward pass, and use Swift’s optional reference semantics to replicate the PyTorch approach. But then we learn how to do the same thing in a more “Swifty” way, using value semantics to do the backward pass in a really concise and flexible manner. Finally, we put it all together, implementing our generic optimizer, Learner, callbacks, etc, to train Imagenette from scratch! The final notebooks in Swift show how to build and use much of the fastai.vision library in Swift, even although in these two lessons there wasn’t time to cover everything. So be sure to study the notebooks to see lots more Swift tricks… Further information More lessons We’ll be releasing even more lessons in the coming months and adding them to an attached course we’ll be calling Applications of Deep Learning. They’ll be linked from the Part 2 course page, so keep an eye out there. The first in this series will be a lesson about audio processing and audio models. I can’t wait to share it with you all! Sneak peak at the forthcoming Audio lesson
0 notes
Text
GSoC Coding Phase - Part 1
Hello everyone!
A lot has happened since the GSoC results were declared! I’ve got quite a few things implemented in my project, I’ll be breaking the discussion of the first part of the coding phase into two or three parts. So lets get into it without further ado.
According to my proposal here, I had one week of community bonding, during which I had to make sure that I had everything I needed to begin with the project, and discuss with the mentors what i should be doing ahead of time. I received a mail from my mentors, Brad and Marc welcoming me to the program. After some discussion it was decided that I should modify my milestones a little bit. Swift for TensorFlow is being used in the Fast.ai course. And there’s a lot of interest in displaying plots in Jupyter notebooks, which is being driven by this. This was to be moved to the first milestone. I have never worked with Jupyter notebooks before let alone editing code that communicated with a Jupyter Kernel. Marc guided me through this. It was decided that for an initial implementation I could use the Swift-Python interoperability to display base64 images in a relatively straightforward manner. Once I implemented some of the planned plots I could work on a pure Swift implementation.
One of the most important parts of building a framework is that it functions as expected. There will definitely be many revisions and changes to the code later on. This warranted a need for the presence of some tests included in the project repository. This would help in making sure that new changes did not break the previously working plots. (I am really glad that we decided to include this in the first milestone itself. It helped me find a really important bug! We’ll come to it in later on)
I have been a little vague in my proposal about implementation of Sub Plots. For those who don’t know what Sub Plots are, they are multiple graphs included in a single display/image. They can be of any type(Line Graph, Bar Graph, etc.). It was necessary to include Sub Plots in the first milestone itself because each Plot would have to be coded in a way that it could be part of a Sub Plot. Implementing all the plots independently and later adding Sub Plot support would be a lot of extra work!
So this is what was decided. In the first milestone I would do the following:
Make a simple Line Chart implementation with Sub Plot support.
Setup tests that saves images.
Get a base64 encoded PNG and use it in Jupyter notebook. Later work on python free implementation.
Complete line chart implementation in the leftover time.
The rest of the stuff for the first milestone according to my proposal were to be moved to the second milestone.
It didn’t take long for me to complete the simple line chart. I used most of the code from the prototype I had made with a few changes.
Let’s look briefly at the LineGraph implementation. All the further discussion will be applicable to Linux (I am using Ubuntu 18.04 LTS) unless otherwise specified.
The first step was to set up the Swift Package. For absolute beginners, this is how you initialise a Swift Package using the Swift Package manager:
Execute this command in the terminal.
swift package init --type library
This will initialise a package that is primarily meant to be a library. If you want a package with an executable as the build product, you can change the type flag to executable.
Before implementing the plots I had to set up the renderers because they were the entities that would handle all the image generation. The plan was to have almost no plotting logic in the Renderers. They would just allow you to draw primitives such as Lines, Rectangles, Text, etc.
One of the Renderers part of the project is the Anti-Grain Geometry C++ library, developed by the late Maxim Shemanarev. I wrote some code to render simple primitives necessary for a Line Graph. Although Swift Package Manager can compile C++ code, C++ functions aren’t directly accessible from Swift code. So I had to write a bridging C-headers. You can call the C-functions from Swift directly which in turn call the C++ functions. You can find the implementation here.
One other aim of implementing different rendering backends was to facilitate adding more backends in the future. This required all the Renderers to have some main stuff in common. So I made a Renderer protocol that included the main functions that every Renderer must have. Each Renderer will have to conform to that protocol.
The AGGRenderer worked fine apart from one thing. The plot dimensions and and therefore the buffer size were hard coded. This meant that the user couldn’t change the size of the image rendered. This was obviously a big handicap to the end user. But for the moment I decided to focus on implementing the plot and getting the basic structure up and running. I could deal with it later on.
The other Renderer I planned to implement was a simple SVGRenderer written in Swift. The implementation is pretty simple and straightforward just like the SVG format. It has a String variable that will describe the image. Whenever you need to draw a primitive you pass the data to the SVGRenderer and it concatenates the relevant tag to the String. In the end the Renderer saves the String into a .svg file.
We’re talking about passing the plotting data to the Renderer, but how does that happen? I have defined a Point type which is a struct. It contains two Floats, x and y. You can pass the plotting data to the Renderer in the form of Point variable, or Point arrays. But the end user need not worry about this. All this will be handled by the Plots. Which brings us to the LineGraph implementation.
What I noticed first was that each plot would have to have the support of being a SubPlot. Therefore the renderer would need each image and plot to have separate dimensions in case of a SubPlot. Lets take an example of two SubPlots stacked horizontally. An easy way to go about it would be to do all the plot calculations of each plot in its own independent co-ordinate system and the shift the origin of each plot as required while drawing it.So what I did was create a Plot protocol with a PlotDimensions type that held the image size and the dimesions of the current plot being rendered, and two offset variables, xOffset and yOffset respectively. In this case the xOffset of the second SubPlot will be a positive number and the yOffset will be zero for both of them. The plot dimensions will be equal divisions of the net image space available to all the Sub Plots. The Renderer will just shift the origin of each SubPlot by (xOffset, yOffset). This did the job.

The Plot protocol has just one more method called drawGraph(). This was because each Plot had to have the functionality to just draw the plot in memory irrespective of what mode of output(like saving images in case of AGG, or displaying an image in a window in case an OpenGL implementation was written) the used Renderer would have. Also this facilitated drawing each SubPlot separately to the image before generating the final output.
Then I took the plotting logic from my prototype and the basic Line Graph was done.
The next step was to set up the tests. I created an examples directory with individual executable modules, each demonstrating a single feature. In this directory I made a Reference directory with two separate directories for AGG and SVG renders. So that anyone could run all the tests easily in one go, I made a simple bash script with the commands to run each example like so:
swift run <Executable Example Module Name>
Then came the time to let the users show the plots in a Jupyter Notebook. Initially the way I did this was, save the image as usual using the AGGRenderer, re read it from the disk encode it to base64 in C++ code, and send back the String to Swift code. But there was a better way that my mentors suggested. The library that I was using to encode PNGs, lodepng, allowed you to encode the image in memory and not save it to the disk. I could return a pointer to a buffer with the encoded bytes, to the Swift code and use some functions under Foundation to do the base64 encoding in Swift itself. This could come in handy sometime later if another Renderer could generate images that coudl be encoded to base64. I did the encoding using a function like this:
public func encodeBase64PNG(pngBufferPointer: UnsafePointer<UInt8>, bufferSize: Int) -> String { let pngBuffer : NSData = NSData(bytes: pngBufferPointer, length: bufferSize) return pngBuffer.base64EncodedString(options: .lineLength64Characters) }
To display the image in Jupyter I added these lines to the EnableIPythonDisplay.swift file in the swift-jupyter repository:
func display(base64EncodedPNG: String) { let displayImage = Python.import("IPython.display") let codecs = Python.import("codecs") let imageData = codecs.decode(Python.bytes(base64EncodedPNG, encoding: "utf8"), encoding: "base64") displayImage.Image(data: imageData, format: "png").display() }
To display the plot the only thing the user has to do is to include this file in their jupyter notebook, get the base64 image from the plot object and pass it to the display function.
This completed all the main stuff I had planned for my first milestone well before the deadline. By this time the official coding period hadn’t started yet. The first deadline was June 24 and I had almost a month left. I could cover a lot more stuff in my first milestone itself, so I decided to complete the Line Plot and keep at least the Bar Chart implementation in my first milestone.
You can find all the code here.
This post has already gotten pretty long, so I’ll sign off here. I’ll be discussing the rest of my Line Graph implementation, Bar Chart implementation and how setting up the tests beforehand helped me avoid a bug, all in my next post.
Stay tuned!
PS: Don’t forget to subscribe to the Swift for TensorFlow newsletter to stay up to date with the work being done and the happenings of the S4TF community!
Here’s the link: https://www.s4tfnews.com/
PPS: Also recently a Swift for TensorFlow Special Interest Group has been announced to help steer the framework. Weekly meetings will be held discussion the progress and plan ahead. Anyone interested can sign up to the mailing list here.
0 notes
Text
How In order to Gain with Free Fortnite Vbucks?
The way To Present Fortnite V
Fortnite is a house sandbox survival video game developed by People Could Soar with Epic Games. This was a newly discovered area in a person in the Epic Games forums - it seems a number of Fortnite "movie" lines were actually injured or corrupted. According to Marksman, selling Fortnite program is a safer choice than go broken-into accounts, although the accounts may be added rewarding (one seller I address with was going an relation with rare skins for $900). Players may restore stolen report in contacting Epic Games' support with modifying their details. The systems are irrelevant.
To Get Free V Cash in Fortnite Battle Royale, there are portions of legit ways for you. Yet, this open v bucks query also end in itself an opportunity for scammers to fraud game players with suggesting them Against Bucks Generator for Fortnite Game. If you happen to use Discord, then make sure you optimize this too to boost your FPS in Fortnite and other games while Dispute is training in the experience.

Fortnite Battle Royale has been free to play while their release, and virtual currency represents a major revenue river for Epic Games While items acquired from the mass offer no competitive advantage, they create the game joy with clear. Your essential pilot to Fortnite, the biggest game of the season, combining report on Battle Royale and Collect the World modes to the final one-stop winner's manual.
These cheats for Fortnite is 100% functioning and authorized to use from the activity. You can certainly find Unlimited V Responsibilities for PS4 by using these ways. Don't you worry, you can as well find V Bucks For Xbox One, PC, iOS and Android with the same process. Traps are very effective in Fortnite, especially to protect your rear. It is not recommended to remain still, if you prefer for a passive game, try to recover the different types of tricks (on the soil, within the sides) in order to shell you.
youtube
Epic Games: Fortnite Battle Royale says no direct the experience to help children under the period of 13 in the BRITISH. Leave on April 13, players can go with the Fortnite World Cup Open Qualifiers offered as a game approach in the fashion selection screen. Each qualifier may provide a total prize share of $1 million, which means Epic will deliver $10 million fair into Direct Qualifiers with the Earth Cup.
Although Fortnite has been doing the most extraordinary multiplayer plot with activity for on the time now, none of that matters if the game isn't enjoyable to engage in. But there's a reason that captured the interest of thousands around the world for so long, and it isn't right into the Floss dance with Brain Trooper skin. Fortnite is a collection of choice based episodic story games. Every item in this game circles in different personalities. The Fortnite can be little tough later, that's the reason anyone might need Fortnite V BUCKS Hack tool free those are available at free click.
With Season 7 in full swing, version 7.01 might not give the impression that exciting by contrast. That said, the new form of Fortnite embraces the Infinity Blade gun from Epic Games' Infinity Blade series, the new Close Encounters limited-time mode, and more. Figure 2a: Data shows the estimated profit by item mode with value go in Fortnite players August 2017 — June 2018, based on the Edison Trends dataset.
Random VBUCKS Tip
Accumulate resources: Unlike other Battle Royale, one of the source of Fortnite lives to foster is very important. From a ramp allowing you to climb to an elevated point into a wall after that to help obscure yourself, or exercise as a shield to take off if you are at a disadvantage, take a potion. For the first time ever, Fortnite Battle Royale players have the chance to compete with one another for a huge amount of V-Bucks, the game's virtual currency.
Well, Fortnite's success isn't based only on the fact that it is free, but instead, it is because of how very the free-to-play asset interlocks with the premise and features of the game itself. To means that the fact that Fortnite is released at the second is a strong source to closely supports additional factors we will be discussing. Sound the votes are in and that been officially confirmed - Fortnite is the best Battle Royale game away there.
Unfortunately, some Fortnite players, particularly sons and teenagers, still fall for the many scams on-line also about YouTube promising them V-Bucks. You can use the Fortnite Generator to generate Free Fornite V Bucks, the procedure to do that is fairly straightforward, once you got the application about the pc, just launch Fortnite and plant the amount of Fortnite V Challenges that you want to get in your account, once you are done you just have to click on the Generate Buttons.
Fortnite: But The planet is a co-op survival game using all the same tools with weapon as you'll learn in Fortnite Battle Royale, and expenses the player with body defenses before playing behind the assault of AI controlled zombies. Survive the night with a person gain rewards such so new tools, gear, blocks with size things to do everything again. With including two very different modes along with taking place in young access, it is surprising how lucky Fortnite works both at home PVE and PVP modes. As such, you don't really need a tremendous powerful PC to be able to play the game.
Fortnite presents a in-game feedback tool from the Central Menu on the contest to tell bad player behaviour. You can also email Epic Up for, the founder of Fortnite, because of the website - reporting any issues you may have. Fortnite: Battle Royale, is no doubt the most significant free to play sports in the world by far, then it should come to no wonder for anyone to learn that gamers can buy cosmetics with real-world currency.
Street Talk: VBUCKS
More just: Playing "Fortnite" is open, but growing through the game's loot-unlock system is not. While people follow in for the middle Fortnite game free v-bucks no human verification you will be presented rotating missions from the everyday Quest machine. Once you have finished each one, you'll become the free V-bucks and you will be able to spend them at objects for the conflict Royale mode.
Now, not every Side Quests get you V-Bucks (Fortnite is fairly particular about these things) but the large cut is there are some Aspect Quests which moves people around 150 V-Bucks. V Bucks Hack Glitch in Fortnite also created an Anti-Ban story by implementing Proxy setup. Fortnite battle royale is a free game, open on multi platforms. Players could show daily given challenges in which they can earn vbucks, it is the game internal currency which can be used for the person group with sticks.
Your account security is your top priority! Protect the story in allowing 2FA. As a prize for keeping the bill, you'll uncover the Boogiedown Emote in Fortnite Battle Royale. It's unclear at this time the way the Buried Treasure item will work, however. It'd make sense if the item somehow exposed a pink, powerful weapon hidden somewhere around the map—but most Fortnite fans don't know what to expect quite yet.
Using Vortex you can play Fortnite by every device. Play Fortnite by older PC, Mac, mobile device or smart TV. Fortnite Battle Royale is the completely free 100-player PvP style in Fortnite. One big record. A drive bus. Fortnite building abilities and destructible environments combined with intense PvP combat. The last one have wins. Download now for FREE and shoot in the war.
Nobody can really pinpoint any indications that happen significant warnings of contents in Period 7. While several believe the Fortnite map could be switched to a ‘Winter' theme in time for the Holiday's, it rests unclear which direction Epic Games will take. In fact, you can hone your skill in the competition and become one of the better Fortnite players without having to spend a single money on in-game purchases. However, purchasing V Bucks has its advantages.
Flamemaster”, a tenth grader, says they are, Annoying, obnoxious, toxic, and infuriating.” What went wrong? Of course, every activity gets the catches, next I become not wanting to demonstrate how Fortnite is a negative game, only show how most people who act this say ruined what could have been a good game. You will accept the e-mail alert when the charge of Fortnite - 10,000 (+3,500 Bonus) V-Bucks can fall.
Fortnite Battle Royale isn't merely the biggest sport of 2018; it's a true cultural fact. From middle-school playgrounds to frat house teams to million-view YouTube livestreams https://andrewceqp8556.wordpress.com/2019/05/08/precisely-how-to-success-with-free-fortnite-vbucks/ , that become a good obsession for countless fans. Gaming hasn't seen everything this big since the go of Minecraft. Fact No: 2 : - Fortnite will ban all gamers who will try to cut or cheat the arrangement.
You can turn off hardware acceleration in Google Chrome and so that training applications executed by Chrome do not eat too many resources if you are enjoying Fortnite. Free Fortnite V Bucks Generator Greatest and Relaxed Way for 2019. Though, if you're not, then pay attention to this area and examine very carefully. Because those fake V Bucks Hack can cause the ‘Fortnite account banned or blocked‘ if you slid in the trap.
This development should break. That driven here CS:GO since it would basically bring in the hitboxes larger, in Fortnite, working on a modern game engine, this right smushes the character model down. Any perceived effect they have in your own chance to show is a placebo. The creator may think resulting in Fortnite's footsteps and including new, limited-time game methods that sport with the BR formula, or perhaps map-changing parts that maintain game environment fresh. Or Respawn could understand PUBG also combine new, smaller roads with something else server dimensions to socialize points up.
0 notes
Text
How and Why to Get Sound Designers in Your Game Early
The bulk of a sound designer’s work is going to be done further into the development process. That is just an unfortunate necessity of the job. However, that doesn’t mean that you need to wait to get one involved. In fact, in a lot of cases, the earlier the better! There are tons of audio ideas that can be fleshed out before a single sound is made. One of the very first things they can do in your production is help fill out the audio section of your game design document (GDD). Or if you don’t have one, they can help explain why it’s a good idea and spend their time convincing you to make one. But in all seriousness, treat them the same way you might treat an artist. At this stage, you might be discussing an ideal color palette for your world. Why not discuss the auditory pallet similarly? This can apply to any part of your game as well. How do you want the GUI to feel to the player? Is it going to be musical and play a little musical sounding chime on interaction? Or maybe it should be more technology like, the kind of feedback you’d expect when using a computer. Or maybe you can make the GUI part of the actual world. Marshall McGee actually has a great video on how Hearthstone does this. This is also a great time to consider the goals for your sounds.
Do you want them to sound realistic and immerse the player in the world? You might think that would be self-explanatory, but there are still considerations to be taken at this stage. What are the focal points of your game? Is it all about guns and explosions? Then maybe those should be the loudest, most impactful elements. Are they just there to serve a plot point? Maybe they shouldn’t be mixed quite so prominently. Even though both choices will make the players think they are hearing a gun, the way they are presented will affect the way the world is received by the player. What about gameplay with elements you wouldn’t find in real life? This might be a good time for the sound designer to talk with the concept artist. This is where sound design begins to overlap with physics. They tend to look at whatever it is and ask, “How is the sound being generated?” Take the example of a monster. Is it big or small? Does it have a mouth? Is there anything obstructing its mouth? Does it move slow or fast? Does it have a hard skeleton or is it more goopy? The questions can go on and on. If you want an example of this in practice, there is a video of the sound designers from Arrival discussing the physics of bones rubbing together and how that was the impetus for what the aliens would sound like. There is also an important question that can be addressed at this stage too: what is the player supposed to be feeling? Even if you went through every possible iteration of that monster, and thought about every aspect of its design that might affect how it sounds, that might not be enough. You need to take into account the emotional response as well. After all, you are likely going to want a scary monster to sound different than a friendly one. If you want the player to be in awe of this creature and where it came from, you might use more surreal sounds. But what if you want this horrible, angry monster to be sympathetic? Maybe you use more familiar sounds, ones you might find in nature so the player has a frame of reference to connect with it. Figuring out what you want the player to feel upon hearing these sounds is important. What about sounds that serve a non-emotional function for the player? Deciding what audio cues can lead a player to their objective is often a crucial part of game design. There is a talk by the audio team of Overwatch that is a phenomenal example of this idea. They discuss how each and every character has a very distinct sound to them. They are so unique that, if you are in a room and hear footsteps coming down the corridor, not only do you now know someone is coming, but you know exactly who it is. This gives the player time to figure out how to prepare or run away. This is just one example, but if you go and play a few games, you’d be surprised by how often audio is helping guide you through objectives and in how many different ways. The best part of these discussions to me is not that the audio is being planned. It is instead the back and forth it creates between disciplines. Maybe discussing the sonic palette of an environment with an artist might spark an idea for how they could paint the world in an even more engaging way. Maybe trying to plan a sonic feedback system helps the quest designer realize a more effective approach to their writing. This type of collaboration is what games are built on, so there is no reason for the audio team to not be a part of this process as well. You could also begin to discuss the more technical side of things at this point. Is there going to be a size limit for files? Is there going to be a limit on how much processing power can be used for effects? Are the files being implemented into the engine? Middleware? A custom solution? Flesh all that out now before there are problems down the road. The final point I want to make, and one you should absolutely discuss, is how the sound effects work with the rest of the game’s audio. If you have ambience, explosions, gunshots, dialogue, and a full orchestra with synthesizers all playing at once, it is likely going to be a complete mess. That is why your audio professionals can take this preproduction time to discuss how they are going to approach their respective tasks. Take tuning sound effects for example. The way you wouldn’t want to listen to two musicians play out of tune with one another, you also wouldn’t want to listen to sound effects and music be out of tune with each other. I won’t go too much into the subject because there are tons of guides on that topic. But you can take as simple or creative an approach as you like to it. You could decide on a simple ducking system based on the priority of sound, and all the sound effects and music are tuned to E minor. On the other hand, you can go absolutely crazy and have the sound effects actually change pitch depending on the music, as heard recently in Super Mario Odyssey. These are just a handful of the things a sound designer can do early in the process, but really the sky is the limit. The more your sonic decisions influence the design of the game, the more engaging they will be. When the sound design is lovingly crafted from the ground up as part of the game world, it can make a world of difference from sounds added after everything else is already done. Of course, making decisions this early means they are going to change, as with anything else. But the key is that they are changing with the game, not because of it. Anything you thought was missing from this post? Let me know and I’ll update it. Anything you think is untrue, or too confusing? I’d love to make the post reflect that. I am posting this to help those of you who have asked me this question, as well as to better understand and learn from it myself. So please, start a discussion! If there are any other topics you’d like to see me cover, feel free to suggest them as well.
0 notes
Text
5 Crucial Concepts for Learning d3.js and How to Understand Them

You may have already heard about d3.js, the dazzling JavaScript library that lets you create beautiful charts and graphics with just a few lines of code. You might have seen some of the fantastic examples of D3 in action, or you may have heard that the New York Times uses it to create its interactive visual stories.
If you’ve ever tried to dip your feet into the world of D3, then you’ll already be familiar with its famously steep learning curve.
You just don’t get to build things right out of the box with D3.
With its confusing method chains, alien syntax, and black-box functions that seem to work by magic, D3 can quickly seem like more hassle than it’s worth. But fear not, because D3 gets substantially easier if you understand just a few key concepts.
I want to take you through a simple tutorial, explaining 5 of the most common areas of confusion that beginners face when starting out with D3.
We’re going to create a dynamic scatter plot, which updates every second between two different sets of data:
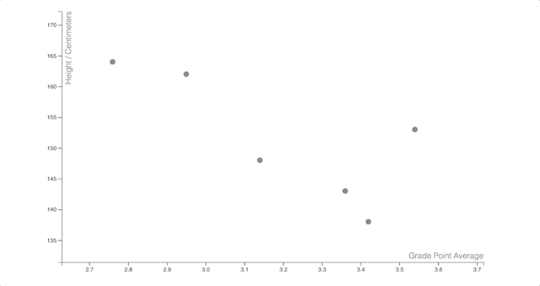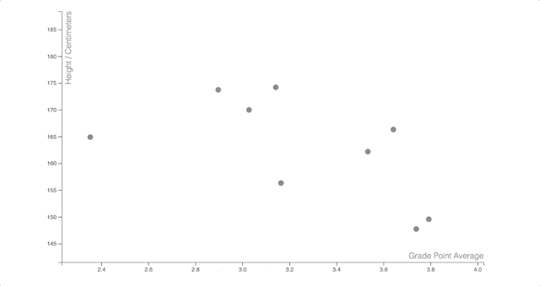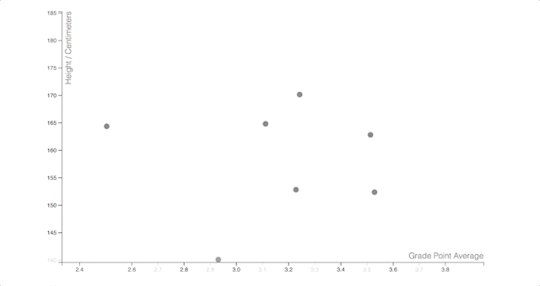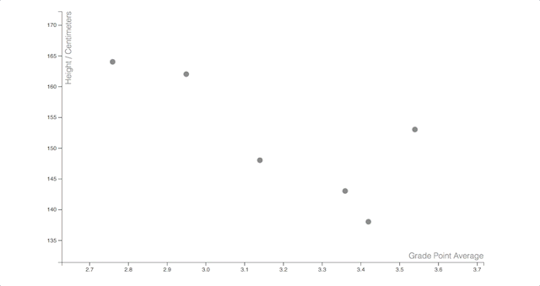
Take a moment to appreciate the little details here. Check out how smoothly these dots are sliding across the screen. Look at how they fade gently in and out of view. Behold the calm sway of our axes between their different values.
These are actually some of the easiest features to implement in D3. Once you can get through the initial struggle of figuring out the basic building blocks of the library, adding in this kind of stuff is a piece of cake.
Before we get ahead of ourselves, let’s talk about what D3 actually is.
D3 stands for Data Driven Documents.
The data can be absolutely anything, which is part of what makes D3 so powerful. Most of the time in D3, you’ll want to read in this data from a file, but for this example we’ll just be using two arrays stored as variables:
var data0 = [ { gpa: 3.42, height: 138 }, { gpa: 3.54, height: 153 }, { gpa: 3.14, height: 148 }, { gpa: 2.76, height: 164 }, { gpa: 2.95, height: 162 }, { gpa: 3.36, height: 143 } ] var data1 = [ { gpa: 3.15, height: 157 }, { gpa: 3.12, height: 175 }, { gpa: 3.67, height: 167 }, { gpa: 3.85, height: 149 }, { gpa: 2.32, height: 165 }, { gpa: 3.01, height: 171 }, { gpa: 3.54, height: 168 }, { gpa: 2.89, height: 180 }, { gpa: 3.75, height: 153 } ]
The documents part in D3 refers to the Document Object Model (DOM). D3 is all about moving elements on the page around, based on what the data is saying. Specifically, we’re working with special shape elements called SVGs.
Crucial Concept #1 — Working with SVGs
So here we come to the first challenging concept that every D3 newbie has to deal with. You immediately need to get a good grasp on a special type of markup which you might not have seen before.
Here’s what SVG markup might look like:
<svg width="400" height="60"> <rect x="0" y="0" width="50" height="50" fill="green"></rect> <circle cx="90" cy="25" r="25" fill="red"></circle> <ellipse cx="145" cy="25" rx="15" ry="25" fill="grey"></ellipse> <line x1="185" y1="5" x2="230" y2="40" stroke="blue" stroke-width="5"></line> <text x="260" y="25" font-size="20px" fill="orange">Hello World</text> </svg>
If we place this snippet into an HTML document, then our browser will interpret it like this:
Basically, each of these SVGs has a set of attributes which our browser uses to place these shapes on the screen. A few things to know about SVGs:
There’s a distinction between the SVG canvas (drawn with the
tags) and the SVGs shapes themselves.
There’s a fairly unintuitive coordinate system that you’ll need to understand, since the (0, 0) point of an SVG grid is at the top-left, rather than the bottom-left.
You might come across some pretty weird behavior if you don’t understand what’s going on under the hood.
It can be tempting to gloss over this subject, opting instead to dive head-first into the titillating business of laying down some D3 code right away, but things will seem a lot clearer later on if you know how these shapes are working.
Resources for understanding SVGs…
A guide to SVGs for absolute beginners — Rob Levin
An SVG primer for D3 — Scott Murray
As a first step to building our scatter plot, we’ll want to add a small circle SVG for each item of data that we want to display. We add SVGs in D3 like this:
d3.select("#canvas") .append("circle") .attr("cx", 50) .attr("cy", 50) .attr("r", 5) .attr("fill", "grey");
Writing d3.select(“#canvas”) here is analogous to writing $(“#canvas”) in jQuery, as it grabs hold of the element with the ID of “canvas”. d3.select goes one step further, adding a few special methods to this selection that we’ll be using later on.
We’re using the d3.append method to add a circle SVG to that element, and we’re setting each of the circle’s attributes with the d3.attr method.
Since we want to add a circle for every item in our array, you might think that we’d want to use a for loop:
for(var i = 0; i < data0.length; i++) { d3.select("#canvas") .append("circle") .attr("cx", data0[i].gpa) .attr("cy", data0[i].height) .attr("r", 5) .attr("fill", "grey"); }
However, since this is D3, we’ll be doing something slightly more complicated, and slightly more powerful…
Crucial Concept #2 — Data Binding
The next hurdle that every new D3 developer needs to overcome is the D3 data join. D3 has its own special way of binding data to our SVGs.
Here’s how we add a circle for every item in our array with D3:
var circles = d3.select("#canvas").selectAll("circle") .data(data0); circles.enter().append("circle") .attr("cx", function(d, i){ return 25 + (50 * i); }) .attr("cy", function(d, i){ return 25 + (50 * i); }) .attr("r", 5) .attr("fill", "grey");
For a developer who is just starting off with D3, this can seem confusing. Actually, for many seasoned developers with years of experience in D3, this can still seem confusing…
You would think that calling selectAll(“circle”) on a page devoid of circles would return a selection of nothing. We’re then calling the data() method on this selection of nothing, passing in our array. We have a mysterious call to the enter() method, and then we have a similar setup as before.
This block of code adds a circle for each item in our array, allowing us to set our attributes with anonymous functions. The first argument to these functions gives us access to the item in our data that we’re looking at, and the second argument gives us the item’s index in our array.
Creating a “data join” like this marks the first step to doing something useful with our data, so it’s an important step to understand. This strange syntax can be daunting when you first encounter it, but it’s a handy tool to know how to use.
Resources for understanding data binding in D3:
A beginner’s guide to data binding — SitePoint
Thinking with joins — Mike Bostock
Let’s make a grid with D3.js — Chuck Grimmett
Once we run the code that we’ve written so far, we end up with something that looks like this:

We attached the right number of circles to the screen and spaced them out a little, but what we have so far isn’t particularly helpful. For a scatter plot, the coordinates of these circles should correspond to two different values.
The GPA and height values that we have in our arrays aren’t much use to us at the moment. Our GPA values range from 2.32 to 3.85, and our height values range from 138 to 180. When positioning our circles, we want to work with x-values between 0 and 800 (the width of our SVG), and y-values between 0 and 500 (the height of our SVG).
We’ll need to apply some kind of transformation to our raw data, to convert these values into a format that we can use.
In D3, we do this by using scales.
Crucial Concept #3 — Scales
Here comes our next major challenge to picking up D3.
Scales are confusing to talk about when you’re first getting started. They need to be set with a domain and a range, which can be pretty easy to confuse. The domain represents the interval that our input values will run between, and the range represents the interval that our output values will run between.
A scale is a function in D3 that will take in a value as an input, and spit out a different value as an output. In this example, we’ll need an x-scale that converts a GPA to a pixel value, and a y-scale that converts a person’s height to a pixel value, so that we can use our data to set the attributes of our circles.
Here’s a diagram to show you what our x-scale should be doing:
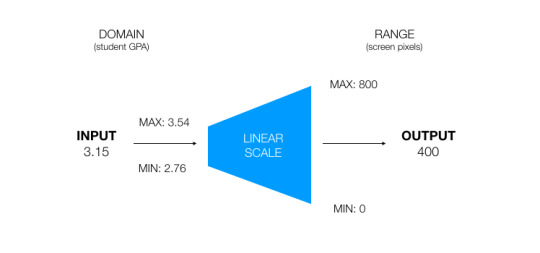
We need to initialize our domain and range with some minimum and maximum values. We’re saying that a value of 3.54 should translate to a pixel value of 800, and a GPA of 2.76 should translate to a pixel value of 0. So, if we pass in a value of 3.15 to our scale, then the output would be 400, since 3.15 is half way between the min and max of our domain.
In this example, we’re using a linear scale, meaning that values should be scaled proportionally between the two extremes that we’re looking at. However, there are a few different types of scales that you’ll want to get your head around.
If you’re working with data that increases exponentially over time, then you might want to use a logarithmic scale.
If you’re working with date values, then you’ll use a time scale.
If you want to assign colors between different categories, you can use an ordinal scale.
If you’re spacing out rectangles in a bar chart, then you’ll use a band scale.
For each of these scales, the syntax is slightly different, but it’ll still follow the same general format as our linear scale.
Resources for understanding scales in D3…
An introduction to linear scales in D3 — Ben Clikinbeard
A walkthrough of the different types of scales — D3 in depth
The entry for scales in the D3 API reference
So now, we can add in two linear scales to use for our x and y axes.
var x = d3.scaleLinear() .domain([d3.min(data0, function(d){ return d.gpa; }) / 1.05, d3.max(data0, function(d){ return d.gpa; }) * 1.05]) .range([0, 800]); var y = d3.scaleLinear() .domain([d3.min(data0, function(d){ return d.height; }) / 1.05, d3.max(data0, function(d){ return d.height; }) * 1.05]) .range([500, 0]);
Each of our scales will take in a value somewhere between the minimum and maximum of each variable in our data, and spit out a pixel value that we can use for our SVGs. I’m using the d3.min() and d3.max() functions here so that D3 will automatically automatically adjust if our dataset changes. I’m also giving our domains a 5% buffer both ways, so that all of our dots will fit on the screen.
We’re also reversing the range values for our y-scale, since an input of 0 should spit out an output of 500px (the bottom of a cartesian grid in the SVG coordinate system).
Next, we can make a few edits to our code from earlier, so that the values for our circles come from our scales.
var circles = d3.select("#canvas").selectAll("circle") .data(data0); circles.enter() .append("circle") .attr("cx", function(d){ return x(d.gpa) }) .attr("cy", function(d){ return y(d.height) }) .attr("r", 5) .attr("fill", "grey");
At this point, we have something that looks like a real visualization!

The next step is to add in some axes, so that we can tell what these dots are meant to represent. We can do this by using D3’s axis generator functions, but we’ll soon run into some problems…
Crucial Concept #4 — Margins and Axes
D3’s axis generators work by attaching an axis onto whichever element they’re called on. The problem is that, if we try attaching axes straight onto our SVG canvas, then we’ll end up with something like this:
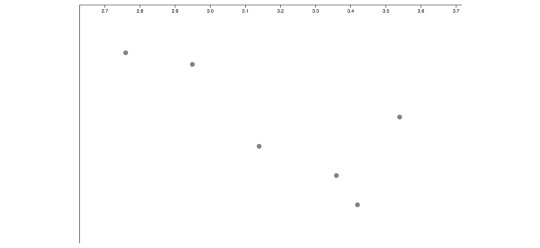
Our first problem is that the axes are always positioned at the top-left hand corner of the grid. That’s fine for our y-axis in this case, but it’s not okay for our x-axis, which we want to place at the bottom.
Another issue here is that, since our axes are sticking out over the edge of our SVG canvas, our axis tick marks don’t show up for our y-axis.
We can fix this by making use of a few SVG groups — invisible elements for adding structure to our pages.
In D3, we need to get used to the “margin convention” that all of our projects should follow:
The idea is that we want to give ourselves a buffer around the edge of our visualization area, giving us some space for our axes to live. We need to set some width, height, and margin variables at the top of our file, allowing us to simulate this effect:
ar svg = d3.select("#canvas"); var margin = {top: 10, right: 10, bottom: 50, left: 50}; var width = +svg.attr("width") - margin.left - margin.right; var height = +svg.attr("height") - margin.top - margin.bottom; var g = svg.append("g") .attr("transform", "translate(" + margin.left + "," + margin.top + ")");
We now need to use these width and height variables to set the range for our scales, and we’ll be attaching our circles onto this g variable, which represents our main visualization area.
If we also attach our axes to SVG groups, then we can shift them into the right position using the transform attribute that comes with the group element. Here’s the code we’ll be using to add our axes onto our graph:
// Axes var xAxisCall = d3.axisBottom(x) var xAxis = g.append("g") .attr("class", "x-axis") .attr("transform", "translate(" + 0 + "," + height + ")") .call(xAxisCall); var yAxisCall = d3.axisLeft(y) var yAxis = g.append("g") .attr("class", "y-axis") .call(yAxisCall) // Labels xAxis.append("text") .attr("class", "axis-title") .attr("transform", "translate(" + width + ", 0)") .attr("y", -6) .text("Grade Point Average") yAxis.append("text") .attr("class", "axis-title") .attr("transform", "rotate(-90)") .attr("y", 16) .text("Height / Centimeters");
I’m also adding some text SVGs as labels, which will tell us what each of the axes is showing.
The margin convention can seem a little random for newcomers to D3, and there are a wide range of methods that we can use to edit how our tick marks should look.
Resources for understanding margins and axes in D3…
An walkthrough of our margin convention code — Mike Bostock
A guide to axis generators in D3 — TutorialsTeacher
The D3 API reference entry on axes
Now that we can see what our chart is showing, I want to take it to the next level by adding in an update to our data. To do this, we’ll use the D3 interval method to run some code continuously:
var flag = true; // Run this code every second... d3.interval(function(){ // Flick between our two data arrays data = flag ? data0 : data1; // Update our chart with new data update(data); // Update our flag variable flag = !flag; }, 1000)
Every 1000ms, this function is going to execute an update function, changing the data that we’re using between our two different arrays.
We need to make a few edits to our code to get everything to update like we want it to:
// Scales var x = d3.scaleLinear() .range([0, width]); var y = d3.scaleLinear() .range([height, 0]); // Axes var xAxisCall = d3.axisBottom(x) var xAxis = g.append("g") .attr("class", "x-axis") .attr("transform", "translate(" + 0 + "," + height + ")"); var yAxisCall = d3.axisLeft(y) var yAxis = g.append("g") .attr("class", "y-axis"); // Labels xAxis.append("text") .attr("class", "axis-title") .attr("transform", "translate(" + width + ", 0)") .attr("y", -6) .text("Grade Point Average") yAxis.append("text") .attr("class", "axis-title") .attr("transform", "rotate(-90)") .attr("y", 16) .text("Height / Centimeters"); var flag = true; // Run this code every second... d3.interval(function(){ // Flick between our two data arrays data = flag ? data0 : data1; // Update our chart with new data update(data); // Update our flag variable flag = !flag; }, 1000) // Run for the first time update(data0); function update(data){ // Update our scales x.domain([d3.min(data, function(d){ return d.gpa; }) / 1.05, d3.max(data, function(d){ return d.gpa; }) * 1.05]) y.domain([d3.min(data, function(d){ return d.height; }) / 1.05, d3.max(data, function(d){ return d.height; }) * 1.05]) // Update our axes xAxis.call(xAxisCall); yAxis.call(yAxisCall); // Update our circles var circles = g.selectAll("circle") .data(data); circles.exit().remove() circles .attr("cx", function(d){ return x(d.gpa) }) .attr("cy", function(d){ return y(d.height) }) circles.enter() .append("circle") .attr("cx", function(d){ return x(d.gpa) }) .attr("cy", function(d){ return y(d.height) }) .attr("r", 5) .attr("fill", "grey"); }
We’re setting our scale domains inside our update function, so that they adjust to the data that we’re working with. We’re then calling our axis generators here too, which will update them accordingly. We then have a confusing block of code, which handles how we want our circles to update.
Crucial Concept #5 — The General Update Pattern
The general update pattern is used in pretty much every visualization that you’ll want to build with D3. It defines the behavior of elements in our data that should enter, update, or exit the screen. As a beginner, all of this code can seem a little overwhelming.
Let’s take a closer look at what each of these lines are doing.
First, we’re binding our new array of data to our D3 selection:
// JOIN new data with old elements. var circles = g.selectAll("circle") .data(data);
Next, this block of code will remove all the dots that no longer exist in our new array of data:
// EXIT old elements not present in new data. circles.exit().remove()
Here, we’re updating the position of all the dots on the screen that still exist in our new data array.
// UPDATE old elements present in new data. circles .attr("cx", function(d){ return x(d.gpa) }) .attr("cy", function(d){ return y(d.height) })
Finally, we’re adding a dot for every item in our new data array that doesn’t have a corresponding circle on the screen.
// ENTER new elements present in new data. circles.enter().append("circle") .attr("cx", function(d){ return x(d.gpa) }) .attr("cy", function(d){ return y(d.height) }) .attr("r", 5) .attr("fill", "grey");
The tricky thing about understanding the general update pattern is figuring out exactly what selectAll(), enter(), and exit() are doing. D3 works by using a set of “virtual selectors”, which we can use to keep track of which elements need to be updated.
Although you can get away with having only a surface understanding of the update pattern with many charts that you’d want to create, the whole library becomes a lot clearer once you can figure out what each of these selectors are doing.
Resources for understanding the general update pattern in D3…
A walkthrough of the general update pattern — Quinton Louis Aiken
An interactive exploration of the general update pattern — Chris Given
Once we’ve added in our updates, here’s what our chart looks like:
Our visualization is now flicking between the two arrays of data that we want to display. I’m going to add one more final flourish to make our graph look a little neater.
We can add in some beautiful transitions by making use of the superb D3 transition suite. First, we’re defining a transition variable at the top of our update function, which is spreading each of our transitions out over a duration of 750ms.
// Standard transition for our visualization var t = d3.transition().duration(750);
Any attributes that we set before calling the transition method on a D3 selection will be set straight away, and any attributes that we set after this transition method will be applied gradually.
We can add transitions to our axes like this:
// Update our axes xAxis.transition(t).call(xAxisCall); yAxis.transition(t).call(yAxisCall);
And we can add transitions to our circles like this:
// Update our circles var circles = g.selectAll("circle") .data(data); circles.exit().transition(t) .attr("fill-opacity", 0.1) .attr("cy", y(0)) .remove() circles.transition(t) .attr("cx", function(d){ return x(d.gpa) }) .attr("cy", function(d){ return y(d.height) }) circles.enter().append("circle") .attr("cx", function(d){ return x(d.gpa) }) .attr("cy", y(0)) .attr("r", 5) .attr("fill", "grey") .attr("fill-opacity", 0.1) .transition(t) .attr("fill-opacity", 1) .attr("cy", function(d){ return y(d.height) });
We’re transitioning between a fill-opacity of 0 and 1 to make our dots gently fade in and out of existence, and we’re smoothly shifting the updating circles to their new positions.
So there we have it. We now have a beautiful scatter plot which is updating between different sources of data. You can find the finished product of all this code on my GitHub page here.
Although mastering the concepts in this article might seem like a huge step to take just to get started with D3, the code gets easier and easier to understand with practice.
You’ll soon find that the same key concepts underpin every D3 visualization, and that once you know how one visualization works in D3, you can quickly learn to build almost anything that you can imagine.
Check out the examples on bl.ocks.org and blockbuilder.org to see some ready-made implementations of so many interesting projects. Like D3 itself, all of this code is open source, meaning that you can copy any of this code onto your local machine, and use it for your own projects.
An easy way to get started with D3…
If you’re looking for the fastest and easiest way to learn D3, then I teach a course on Udemy which offers a comprehensive introduction to the library. The course includes:
7 hours of quality video content.
A step-by-step introduction to the foundational concepts in D3, covering all of the topics covered in this article and more.
Four awesome class projects to practice the skills that you’re learning with real-world data.
A strong emphasis on data visualization design, helping you to create custom visualizations for your own data.
Walkthroughs of 12 of the most commonly used visualizations, teaching you how to understand and adapt pre-written community code for your own purposes.
An introduction to an object-orientated approach for creating complex web apps, where multiple visualizations on the page are updating at once.
You can get the course at a discounted price of only $20.99 by signing up through this link here.
The post 5 Crucial Concepts for Learning d3.js and How to Understand Them appeared first on David Walsh Blog.

5 Crucial Concepts for Learning d3.js and How to Understand Them published first on https://appspypage.tumblr.com/
0 notes
Text
Roles and Responsibilities of a Business Analyst

If you aren’t a millennial working in IT, it is quite possible that you may not be familiar with the term, “Business Analyst."
But there are plenty of reasons why you should be.
Business analysis has emerged as a core business practice since the dawn of the 21st century. Although every business domain has some business analyst jobs; IT especially has witnessed an explosion of career opportunities for business analyst profiles.
So, why has BA swiftly rose to prominence, and why are they being offered such lucrative salary packages?
This is primarily because they serve as a vital link between a firm's information technology capabilities and their business objectives. Skilled business analysts directly contribute to the profitability of companies, large or small.
Now, before delving into the roles and responsibilities, and what it takes to become a Business Analyst, let’s dig a little deeper into what precisely does a Business Analyst do.
What is the Role of a Business Analyst?
In today’s complex business environment, an organization’s adaptability, agility, and ability to manage constant disruption through innovation can be an important element to ensure success. Traditional approaches may no longer suffice in reaching objectives when economic conditions are unfavorable.
That’s where business analysis comes in. Businesses achieve goals through projects that translate customer needs into new products, services, and profits. Business analysts can make that happen rather efficiently & effectively.
A business analyst's primary objective is helping businesses cost-effectively implement technology solutions by precisely determining the requirements of a project or a program, and communicating them clearly to the key stakeholders.
Business analysts usually collect and interpret data from many areas within an organization, simultaneously improving the business processes and finding solutions to business problems with all that gathered data.
Pre-Requisites
BAs typically require knowledge of statistics, and statistical softwares such as R. Companies prefer a BA who also possesses relevant SQL skills.
The education and training requirements, although, may vary for business by - employer, specific role, and industry.
It is possible to enter into the field with just a two-year degree and relevant work experience, but most employers would require at least a bachelor's degree.
Business analysts should be able to create solutions to problems for the business as a whole, and accordingly must effectively be able to communicate with a variety of business areas. Thus communication skills are another major prerequisite.
BAs should be able to understand the business needs of customers and should be able to translate them into the application and operational requirements with the help of solid analytical and product management skills.
NOTE: As mentioned, SQL knowledge is a much sought-after skill for business analysts. SQL is a key language utilized for managing data held in RDBMS or relational database systems. Business analysts might not require the same level of SQL knowledge as, say, an analyst would, but a basic understanding of its concept, capabilities and basic functions is essential.
The Duties of a Business Analyst:
Documenting and translating customer business functions and processes.
Warranting the system design is perfect as per the needs of the customer.
Participating in functionality testing and user acceptance testing of the new system
Helping technically in training and coaching professional and technical staff.
Developing a training programme and conducting formal training sessions covering designated systems module.
Acting as a team-lead on assigned projects and assignments; and providing work direction to the developers and other project stakeholders.
Responsibilities Of A Business Analyst
Let's take a look at the responsibilities based on different project phase.
1. Understanding the Requirements of the Business
Understanding the intricacies of a project is very crucial for BAs. A fundamental responsibility of a Business Analyst is to work in accordance with relevant project stakeholders to understand their requirements and translate them into details, which the developers can comprehend.
The key skill set required for this part of the process is the capability of the Analysts to filter the different messages as well as the requirements of the project stakeholders or consumers into a consistent, but, - single vision.
Thus, a business analyst devotes a large chunk of time, asking questions. They may even need to conduct interviews, read, observe and align the developers with their target goal.
They also need to carry out analysis and look for solutions for both, the organization, as well as the customer.
2. Analyzing Information
The analysis phase is the stage during which a BA reviews the elements in detail, asserting clearly and unambiguously as what the business needs to do in order achieve its objective.
During this stage, the BA will also require to interact with the development team and the technical architects, to design the layout and define accurately what the solution should look like.
A Business Analyst then plots the scope and initial requirement of the project. The fundamental goal for any BA is to obtain the project concentrated early by converting the initial high-level goal into a tangible realistic one.
3. Communicating With a Broad Range Of People
For Businesses, it is of paramount importance to create, as well as deliver quality presentations on topics like business requirements, application designs, as well as project status. Good Business Analysts needs to dedicate countless hours actively communicating back and forth. More than just speaking, they need to listen and recognize verbal and non-verbal information.
Generally, people watching the presentation of Business Analysts are senior executives of the organization, as well as key management people of IT. Building an open conversation, validating that you understand what you have heard, and communicating what you have gathered to the stakeholders is extremely important to keep the vehicle operating efficiently.
Therefore, Business Analysts are expected to impress the stakeholders and other authority with their presentations, which in turn would have a notable effect on the growth of the business.
4. Documenting the Findings
This is where a BA gets into evaluating the needs and ensuring that the implementation team has gathered comprehensive details they require for creating and implementing the process. This phase involves collaborating with a wide range of stakeholders and consumers across the company to guarantee their needs, as well as knowledge, are combined into a detailed document about what they will actually build.
An effective document is the one which clearly states options for solving particular difficulties and then helps select the best one. There are oftentimes situations where a BA might miss out on a few requirements from the document.
Consequently, the developers won't be aware of the same which in turn would lead to a considerable loss of time and efforts, as they would be required to redesign the product, this time including the missed part.
Hence, it is extremely critical for any BA to effectively document the findings where each requirement of the client is efficiently mentioned, and nothing is left amiss.
The favored solution is then estimated throughout the layout and planning - to assure that it meets the business requirements.
5. Evaluating and Implementing the Finest Solution
Ensuring that the systems’ design is up to the mark, as per the needs of the customer is the next decisive step. Business Analyst spends time identifying options for solving particular difficulties and then help pick the best one. The preferred solution is then assessed throughout the layout and planning to assure that it meets the business requirements.
The implementation phase, although, is not the final stage for Business Analysts. In fact, it could turn out to be the riskiest time for things to go awry and for objectives to be overlooked. It is during this step that a BA should be aware of how clients are utilizing the framework.
Do they clearly see the benefits envisaged in the business case?
In essence, Business Analysts are the navigators, responsible for reaching the end destination, which implies a satisfying resolution of a business problem.
The BA must always be aware of what the end-game is, how to get there and should be competent enough of handling course adjustments as they occur.
Wrapping Up...
Witnessing how quickly economic conditions and business needs are changing. You need to prepare yourselves and create a proper plan to stay relevant in this rat race.
Finding success as a business analyst requires proper planning and commitment to your career. Without planning for your future, you will end up feeling lost on your way. No one can accurately predict how the job market will look like - a few years, or even months for that matter. So it would be in your best interest to prepare yourself by enrolling in business analyst training programs, to acquire the in-demand skills that can help you break into this exciting and prosperous domain.
EngineerBabu boasts a talented bunch of business analysts working to ensure that our customers receive the best quality deliverables. So, if you are looking to expand your horizons and explore this lucrative domain, consider forwarding us your resume.
In case you are looking for a tech partner to make your product dreams a reality, call us for a free consultation. We have a host of award-winning products in our portfolio.
Also, tell us how you felt about this article in the comments below. If there's anything that you would like for us to know, you can talk to us.
Recommended readings for you-
How to Hire Dedicated PHP Developer at EngineerBabu?
Best Way To Hire Node.js Developer
How to build a Fintech App, like BankOpen?
How we Developed a Grocery Delivery App with 1,00,000+ Downloads!
An EduTech App for Indian Students to Crack Entrance Exams
0 notes
Text
Cybercrimes and Computer Security Systems
Cybercrimes and Computer Security Systems Q.1 Based on research identify and assess the fraud that occurred in the organization as well as the impacts on corporation investors and creditors. Computer security systems are the measures put in place by organization to ensure maximum security of data from accidental or deliberate threats which might cause unauthorized modification, disclosure or destruction of data and the protection of information systems from the degradation or non- availability of services On the other hand, cybercrimes are the illegal or crimes that have been made possible by computers and include the network intrusion and the dissemination of computer viruses as well as the computer based variation of existing crimes such as identity thefts, bullying and terrorism. The point of vulnerability in computer crime are the servers and the communication channels which are used by fraudsters to illegally obtain organization information pertaining their assets, cash and other investments. The fraud which occurred at Prime bank included the following; Action fraud, hacking and cyber vandalism Investment fraud- it is the deception relating to investment that affects and organization and it includes illegal insider trading, prime bank investment schemes and fraudulent manipulation of the stock market. Credit/debit card fraud or theft – It is the act or fraud that involves an authorized individual taking other peoples credit or debit card information for the purpose of charging purchases to the account or removing funds from it. Fraudsters gather this personal information by using stolen cards or hacking client’s mailbox. Business fraud – This is where some few members of the organization plot a scheme to defraud the organization in respect to its financial resources or assets. They achieve this by manipulating figures on accounting books or organization database. Many banks are faced by the challenge to combat this type of fraud because its increasingly experienced. Communication fraud – It is the fraudulent act or process in which information is exchanged using different forms of media e.g. theft of wireless or tapping and sniffing of internet communication channels. Virus attack fraud/malicious code fraud – This is where fraudsters use computer programs which has ability to replicate and spread to other files such as micro viruses, script viruses and bad applets that may be downloaded onto client and activated merely by surfing to a website of an organization. Impacts of fraud to both investors and creditors Fraud has a substantial impact on any person or organization that has a financial interest in the success of the organization and hence there is need to mitigate and prevent frauds in organizations. Creditors will not be willing to supply raw materials to such firm because they will be uncertain if they will be paid when their debt accrue. Some of them will even caution other creditors to ensure they don’t attempt partnering with such organization hence in the long run the company name and reputations will be ruined. Investors on the other hand will not associate themselves with organization marred by fraud hence most of them will not invest or partner with fraud firms. Those with shares in such institution will sell them quickly to avoid more losses. Q.2 How financial forensic investigation could have detected fraud in Prime Bank They did so by maintaining an effective audit function in the bank to aid in detecting any malpractice done by the employees or other internal stakeholders. Alternatively they could have also used a tip from a loyal employee to detect occupational fraud. Accounting intelligence might have been used to detect fraud by critically analyzing the bank transaction in respect to balances, withdrawals and payments. The risk factors encountered or considered was the possibility of being provided with inaccurate information as well as being bribed by internal managers so as to portray the positive side of the company rather than the schemes, fraud and losses experienced by the bank. Most the elements of fraud are easily identifiable and feasible in organizations but managers usually fail to take necessary actions to report the fraud. These elements include the massive losses of funds unaccounted by managers, consistent losses on annual reports, large debt owed to creditors and suppliers and many complaints from clients claiming loss of money in their bank accounts. All this elements are useful to forensic accountants because it helps them get an overview of possible business functions that might have been associated with fraud. Q .3 Economic losses experienced in Prime bank limited The economic consequences of false disclosure on the product markets due to fraud elicited inefficient prices and quantities of stock due to management desire to avoid detection. Due to losses incurred the company interest rates increased making many customers and investors shy away from borrowing for capital investments due to high lending rate hence resulted to huge economic loss because most projects stalled due to lack of funds to facilitate their progress. Computer fraud cause massive loss of financial resources hence the bank was running in negative income. This situation denied the government tax which could have been used in developing public utilities, social amenities and infrastructure which increases the country’s economy. It also resulted into loss of employment for many staff due to institution inability to pay and maintain them which had a big impact on economy because the consumption rate of those individuals would drop due to less disposable outcome. The plan or action to be taken to prevent economic loss due to fraud Economic loss has adverse effects on the demand and supply of basic commodities which essentially affects circulation and the prices of goods and services in the economy hence there is need for organization to ensure proper measures are put in place to mitigate and prevent computer fraud and cybercrimes. The actions or plans to be taken include the following; Ensuring total protection of internet communications through use of encryption Uses of firewalls to protect networks – Firewalls are Software application that acts as a filter between a company’s private network and the Internet .Firewall methods include: Packet filters and Loading... application gateways. There is need to protect all institution servers as well as organization database from fraudsters through use of passwords and codes Securing all channels of communication (SSL, S-HTTP and VPNs ) Creating security organizations which will be in charge of all computer security matters and to keep management aware of security issues, administer access controls, authentification procedures and authorization policies as well as performing computer security audit Comparing and contrasting accidental fraudsters and predators Accidental fraudsters are usually first time offenders and their reason why they commit fraud is because of non-sharable problems that can only be solved with money. On the other hand predators are fraudsters who commit more fraud by targeting organizations to commit crime. Their schemes are harder to detect because they are usually better organized. Examples of accidental fraudsters include the following; Natural hazards like floor or fire which can wreck the entire system in an organization Human errors which consist of unexpected things which human beings does or unintended effects of technology Failure of utilities Equipment failure Examples of predators are; Illegal access to organization management information system Sabotage and Espionage Both accidental and predators fraudsters have one thing in common and that is; They try to gain unauthorized access to computers systems, disrupting, defacing or destroying a company’s websites and systems with the aim of accessing confidential information or stealing cash. The fraud which occurred in Prime bank was accidental because it involved some few individuals who wanted to make more cash and accumulate vast wealth in a day. The fraud was initiated by their personal desires to be richer as well as to be seen with a lot of assets. Q5. How teamwork and leadership are effective tools for financial forensic investigation Teamwork is a situation where two or more employees interact with each other, sharing common belief as well as working towards the same objectives. By working as a team, synergy and integration is enhanced through sharing of information across teams which is useful in forensic investigation. Teamwork is effective tool for financial forensic investigation because; It increases the results and maintain the best performance of the team in providing useful information With teamwork, better ideas to prevent and identify fraud are generated and implemented There is more fun and motivation which compel team members to provide useful accounting information for forensic purposes Less time is taken to complete a project or task On the other hand leadership is the art of influencing others to direct their will, abilities and effort towards the achievement of the leader’s goal .Therefore in organizations, leadership is influencing individuals and group’s effort towards the achievement optimum achievement of organizations objectives of forensic investigation. It acts a tool for financial forensic investigation because leadership is interested in effectiveness and focuses on people hence has greater ability to detect fraud in organizations. An effective leader focuses on people aspect of management and therefore is able to provide all the information relating to the activities of their staff which can aid in fraud identification. REFERENCES Gerety, Mason and Kenneth Lehn, 1997, The causes and consequences of accounting fraud, Managerial and Decision Economics, 18, 587-599 Sadka, Gil, 2006, An Extension to The Economic Consequences of Accounting Fraud in Product Markets: Cournot Competition, Unpublished Manuscript, Columbia University. Kranacher, M.-J., Riley Jr., R. A., & Wells, J. T. (2011). Forensic Accounting and Fraud Examination. Hoboken: John Wiley & Sons, Inc. Graham Curtis, 1998, Business Information Systems, System Security and Design, University Of East London Kenneth C. Laudon, Carol Guercio Traver, 2004 Second Edition, Commerce Security and Encryption Read the full article
0 notes
Text
CS189 Introduction To Machine Learning HW6 Solved
Submit your predictions for the test sets to Kaggle as early as possible. Include your Kaggle scores in your write-up (see below). The Kaggle competition for this assignment can be found at https://www.kaggle.com/t/b500e3c2fb904ed9a5699234d3469894 Submit a PDF of your homework, with an appendix listing all your code, to the Gradescope assignment entitled “Homework 6 Write-Up”. In addition, please include, as your solutions to each coding problem, the specific subset of code relevant to that part of the problem. You may typeset your homework in LaTeX or Word (submit PDF format, not .doc/.docx format) or submit neatly handwritten and scanned solutions. Please start each question on a new page. If there are graphs, include those graphs in the correct sections. Do not put them in an appendix. We need each solution to be self-contained on pages of its own. In your write-up, please state with whom you worked on the homework. In your write-up, please copy the following statement and sign your signature next to it. (Mac Preview and FoxIt PDF Reader, among others, have tools to let you sign a PDF file.) We want to make it extra clear so that no one inadvertently cheats. “I certify that all solutions are entirely in my own words and that I have not looked at another student’s solutions. I have given credit to all external sources I consulted.” Submit all the code needed to reproduce your results to the Gradescope assignment entitled “Homework 6 Code”. Yes, you must submit your code twice: in your PDF write-up following the directions as described above so the readers can easily read it, and once in compilable/interpretable form so the readers can easily run it. Do NOT include any data files we provided. Please include a short file named README listing your name, student ID, and instructions on how to reproduce your results. Please take care that your code doesn’t take up inordinate amounts of time or memory. If your code cannot be executed, your solution cannot be verified. In this assignment, you will develop neural network models with MDS189. Many toy datasets in machine learning (and computer vision) serve as excellent tools to help you develop intuitions about methods, but they cannot be directly used in real-world problems. MDS189 could be. Under the guidance of a strength coach here at UC Berkeley, we modeled the movements in MDS189 after the real-world Functional Movement Screen (FMS). The FMS has 7 different daily movements, and each is scored according to a specific 0-3 rubric. Many fitness and health-care professionals, such as personal trainers and physical therapists, use the FMS as a diagnostic assessment of their clients and athletes. For example, there is a large body of research that suggests that athletes whose cumulative FMS score falls below 14 have a higher risk of injury. In general, the FMS can be used to assess functional limitations and asymmetries. More recent research has begun investigating the relationship between FMS scores and fall risk in the elderly population. In modeling MDS189 after the real-world Functional Movement Screen, we hope the insight you gain from the experience of collecting data, training models, evaluating performance, etc. will be meaningful. A large part of this assignment makes use of MDS189. Thank you to those who agreed to let us use your data in MDS189! Collectively, you have enabled everyone to enjoy the hard-earned reward of data collection. Download MDS189 immediately. At 3GB+ of data, MDS189 is rather large, and it will require a while to download. You can access MDS189 through this Google form. When you gain access to MDS189, you are required to agree that you will not share MDS189 with anyone else. Everyone must fill out this form, and sign the agreement. If you use MDS189 without signing the agreement, you (and whomever shared the data with you) will receive an automatic zero on all the problems on this homework relating to MDS189. The dataset structure for MDS189 is described in mds189format.txt, which you will be able to find in the Google drive folder.
1 Data Visualization
When you begin to work with a new dataset, one of the first things you should do is spend some time visualizing the data. For images, you must look at the pixels to help guide your intuitions while developing models. Pietro Perona, a computer vision professor at Caltech, has said that when you begin working with a new dataset, “you should spend two days just looking at the data.” We do not recommend you spend quite that much time looking at MDS189; the point is that the value of quality time spent visualizing a new dataset cannot be overstated. We provide several visualization tools in mds189visualize.ipynb that will enable you to view montages of: key frames, other videos frames, ground truth keypoints (i.e., what you labeled in LabelBox), automatically detected keypoints from OpenPose, and bounding boxes based on keypoint detections. Note: Your responses to the questions in this problem should be at most two sentences. To get a sense of the per-subject labeling quality, follow the Part 1: Same subject instructions in the cell titled Key Frame visualizations. For your write-up, you do not need to include any images from your visualizations. You do need to include answers to the following questions (these can be general statements, you are not required to reference specific subject ids): What do you observe about the quality of key frame annotations? Pay attention to whether the key frames reflect the movement labeled. What do you observe about the quality of keypoint annotations? Pay attention to things like: keypoint location and keypoint colors, which should give a quick indication of whether a labeled keypoint corresponds to the correct body joint. To quickly get a sense of the overall variety of data, follow the Part 2: Random subject instructions in the cell titled Key Frame visualizations. Again, for your write-up, you do not need to include any images from your visualizations. Include an answer to the following question: What do you observe about the variety of data? Pay attention to things like differences in key frame pose, appearance, lighting, frame aspect ratio, etc. We ran the per-frame keypoint detector OpenPose on your videos to estimate the pose in your video frames. Based on these keypoints, we also estimated the bounding box coordinates for a rectangle enclosing the detected subject. Follow the Part 3: same subject instructions in the cell titled Video Frame visualizations. Again, for your write-up, you do not need to include any images from your visualizations. You do need to include answers to the following question: What do you observe about the quality of bounding box and OpenPose keypoint annotations? Pay attention to things like annotation location, keypoint colors, number of people detected, etc. Based on the third visualization, where you are asked to look at all video frames for on movement, what do you observe about the sampling rate of the video frames? Does it appear to reasonably capture the movement? For the key frames, we can take advantage of the knowledge that the poses should be similar to the labeled poses in heatherlckwd’s key frames. Using Procrustes analysis, we aligned each key frame pose with the corresponding key frame pose from heatherlckwd. Compare the plot of the raw Neck keypoints with the plot of the (normalized) aligned Neck keypoints. What do you observe? Note: We introduce the aligned poses because we offer them as a debugging tool to help you develop neural network code in problem 2. Your reported results cannot use the aligned poses as training data.
2 Modular Fully-Connected Neural Networks
First, we will establish some notation for this problem. We define hi+1 = σ(zi) = σ(Wihi + bi). In this equation, Wi is an ni+1×ni matrix that maps the input hi of dimension ni to a vector of dimension ni+1, where ni+1 is the size of layer i + 1. The vector bi is the bias vector added after the matrix multiplication, and σ is the nonlinear function applied element-wise to the result of the matrix multiplication and addition. zi = Wihi +bi is a shorthand for the intermediate result within layer i before applying the activation function σ. Each layer is computed sequentially where the output of one layer is used as the input to the next. To compute the derivatives with respect to the weights Wi and the biases bi of each layer, we use the chain rule starting with the output of the network and propagate backwards through the layers, which is where the backprop algorithm gets its name. In this problem, we will implement fully-connected networks with a modular approach. This means different layer types are implemented individually, which can then be combined into models with different architectures. This enables code re-use, quick implementation of new networks and easy modification of existing networks.
2.1 Layer Implementations
Each layer’s implementation will have two defining functions: forward This function has as input the output hi from the previous layer, and any relevant parameters, such as the weights Wi and bias bi. It returns an output hi+1 and a cache object that stores intermediate values needed to compute gradients in the backward pass. def forward(h, w): """ example forward function skeleton code with h: inputs, w: weights""" # Do computations... z = # Some intermediate output # Do more computations... out = # the output cache = (h, w, z, out) # Values needed for gradient computation return out, cache backward This function has input: upstream derivatives and the cache object. It returns the local gradients with respect to the inputs and weights. def backward(dout, cache): """ example backward function skeleton code with dout: derivative of loss with respect to outputs and ,→ cache from the forward pass """ # Unpack cache h, w, z, out = cache # Use values in cache, along with dout to compute derivatives dh = # Derivative of loss with respect to a dw = # Derivative of loss with respect to w return dh, dw Your layer implementations should go into the provided layers.py script. The code is clearly marked with TODO statements indicating what to implement and where. When implementing a new layer, it is important to manually verify correctness of the forward and backward passes. Typically, the gradients in the backward pass are checked against numerical gradients. We provide a test script startercode.ipynb for you to use to check each of layer implementations, which handles the gradient checking. Please see the comments of the code for how to appropriately use this script. In your write-up, provide the following for each layer you’ve implemented. Listings of (the relevant parts of) your code. Written justification/derivation for the derivatives in your backward pass for all the layers that you implement. The output of running numerical gradient checking. Answers to any inline questions. 2.1.1 Fully-Connected (fc) Layer In layers.py, you are to implement the forward and backward functions for the fully-connected layer. The fully-connected layer performs an affine transformation of the input: fc(h) = Wa + b. Write your fc layer for a general input h that contains a mini-batch of B examples, each of which is of shape (d1,··· ,dk). 2.1.2 Activation Functions In layers.py, implement the forward and backward passes for the ReLU activation function 0 γ < 0 σReLU(γ) = γ otherwise Note that the activation function is applied element-wise to a vector input. There are many other activation functions besides ReLU, and each activation function has its advantages and disadvantages. One issue commonly seen with activation functions is vanishing gradients, i.e., getting zero (or close to zero) gradient flow during backpropagation. Which of activation functions (among: linear, ReLU, tanh, sigmoid) experience this problem? Why? What types of one-dimensional inputs would lead to this behavior? 2.1.3 Softmax Loss In subsequent parts of this problem, we will train a network to classify the movements in MDS189. Therefore, we will need the softmax loss, which is comprised of the softmax activation followed by the crossentropy loss. It is a minor technicality, but worth noting that the softmax is just the squashing function that enables us to apply the cross-entropy loss. Nevertheless, it is a commonly used shorthand to refer to this as the softmax loss. The softmax function has the desirable property that it outputs a probability distribution. For this reason, many classification neural networks use the softmax. Technically, the softmax activation takes in C input numbers and outputs C scores which represents the probabilities for the sample being in each of the possible C classes. Formally, suppose s1 ··· sC are the C input scores; the outputs of the softmax activations are esi ti = PCk=1 esk for i ∈ . The cross-entropy loss is E = −logtc, where c is the correct label for the current example. Since the loss is the last layer within a neural network, and the backward pass of the layer is immediately calculated after the foward pass, layers.py merges the two steps with a single function called softmaxloss. You have to be careful when you implement this loss, otherwise you will run into issues with numerical stability. Let m = maxCi=1 si be the max of the si. Then E = −logtc = log PCesc sk = log PCesc−emsk−m = −(sc − m) + logXkC=1 esk−m. e k=1 k=1 We recommend using the rightmost expression to avoid numerical problems. Finish the softmax loss in layers.py.
2.2 Two-layer Network
Now, you will use the layers you have written to implement a two-layer network (also referred to as a one hidden layer network) that classifies movement type based on keypoint annotations. The input features are pre-processed keypoint annotations of an image, and the output are one of 8 possible movement types: deadbug, hamstrings, inline, lunge, stretch, pushup, reach, or squat. You should implement the following network architecture: input - fc layer - ReLU activation - fc layer - softmax loss. Implement the class FullyConnectedNet in fcnet.py. Note that this class supports multi-layer networks, not just two-layer networks. You will need this functionality in the next part. In order to train your model, you need two other components, listed below. The data loader, which is responsible for loading batches of data that will be fed to your model during training. Data pre-processing should be handled by the data loader. The solver, which encapsulates all the logic necessary for training models. You don’t need to worry about those, since they are already implemented for you. See startercode.ipynb for an example. For your part, you will need to instantiate a model of your two-layer network, load your training and validation data, and use a Solver instance to train your model. Explore different hyperparameters including the learning rate, learning rate decay, batch size, the hidden layer size, and the weight scale initialization for the parameters. Report the results of your exploration, including what parameters you explored and which set of parameters gave the best validation accuracy. Debugging note: The default data loader returns raw poses, i.e., the ones that you labeled in LabelBox. As a debugging tool only, you can replace this with the heatherlckwd-aligned, normalized poses. It’s easier and faster to get better performance with the aligned poses. Use this for debugging only! You can use this feature by setting debug = True in the starter code. All of your reported results must use the un-aligned, raw poses for training data.
2.3 Multi-layer Network
Now you will implement a fully-connected network with an arbitrary number of hidden layers. Use the same code as before and try different number of layers (1 hidden layer to 4 hidden layers) as well as different number of hidden units. Include in your write-up what kinds of models you have tried, their hyperparameters, and their training and validation accuracies. Report which architecture works best.
3 Convolution and Backprop Revisited
In this problem, we will explore how image masking can help us create useful high-level features that we can use instead of raw pixel values. We will walk through how discrete 2D convolution works and how we can use the backprop algorithm to compute derivatives through this operation. To start, let’s consider convolution in one dimension. Convolution can be viewed as a function that takes a signal I and a mask G, and the discrete convolution at point t of the signal with the mask is ∞ X (I ∗ G) = IG k=−∞ If the mask G is nonzero in only a finite range, then the summation can be reduced to just the range in which the mask is nonzero, which makes computing a convolution on a computer possible. Figure 1: Figure showing an example of one convolution. As an example, we can use convolution to compute a derivative approximation with finite differences. The derivative approximation of the signal is I0 ≈ (I − I)/2. Design a mask G such that (I ∗ G) = I0. Convolution in two dimensions is similar to the one-dimensional case except that we have an additional dimension to sum over. If we have some image I and some mask G, then the convolution at the point (x,y) is ∞ ∞ X X (I ∗ G) = IG m=−∞ n=−∞ or equivalently, ∞ ∞ X X (I ∗ G) = GI, m=−∞ n=−∞ because convolution is commutative. In an implementation, we’ll have an image I that has three color channels Ir, Ig, Ib each of size W × H where W is the image width and H is the height. Each color channel represents the intensity of red, green, and blue for each pixel in the image. We also have a mask G with finite support. The mask also has three color channels, Gr,Gg,Gb, and we represent these as a w × h matrix where w and h are the width and height of the mask. (Note that usually w W and h H.) The output (I ∗ G) at point (x,y) is w−1 h−1 XX X (I ∗ G) = Ic · Gc a=0 b=0 c∈{r,g,b} In this case, the size of the output will be (1 + W − w) × (1 + H − h), and we evaluate the convolution only within the image I. (For this problem we will not concern ourselves with how to compute the convolution along the boundary of the image.) To reduce the dimension of the output, we can do a strided convolution in which we shift the convolutional mask by s positions instead of a single position, along the image. The resulting output will have size b1 + (W − w)/sc × b1 + (H − h)/sc. Write pseudocode to compute the convolution of an image I with a set of masks G and a stride of s. Hint: to save yourself from writing low-level loops, you may use the operator ∗ for element-wise Figure 2: Figure showing an example of one maxpooling. multiplication of two matrices (which is not the same as matrix multiplication) and invent other notation when convenient for simple operations like summing all the elements in the matrix. Masks can be used to identify different types of features in an image such as edges or corners. Design a mask G that outputs a large value for vertically oriented edges in image I. By “edge,” we mean a vertical line where a black rectangle borders a white rectangle. (We are not talking about a black line with white on both sides.) Although handcrafted masks can produce edge detectors and other useful features, we can also learn masks (sometimes better ones) as part of the backpropagation algorithm. These masks are often highly specific to the problem that we are solving. Learning these masks is a lot like learning weights in standard backpropagation, but because the same mask (with the same weights) is used in many different places, the chain rule is applied a little differently and we need to adjust the backpropagation algorithm accordingly. In short, during backpropagation each weight w in the mask has a partial derivative ∂∂wL that receives contributions from every patch of image where w is applied. Let L be the loss function or cost function our neural network is trying to minimize. Given the input image I, the convolution mask G, the convolution output R = I∗G, and the partial derivative of the error with respect to each scalar in the output, ∂R∂, write an expression for the partial derivative of the loss with respect to a mask weight, ∂G∂c, where c ∈ {r,g,b}. Also write an expression for the derivative of ∂L ∂Ic. Sometimes, the output of a convolution can be large, and we might want to reduce the dimensions of the result. A common method to reduce the dimension of an image is called max pooling. This method works similar to convolution in that we have a mask that moves around the image, but instead of multiplying the mask with a subsection of the image, we take the maximum value in the subimage. Max pooling can also be thought of as downsampling the image but keeping the largest activations for each channel from the original input. To reduce the dimension of the output, we can do a strided max pooling in which we shift the max pooling mask by s positions instead of a single position, along the input. Given a mask size of w × h, and a stride s, the output will be b1 + (W − w)/sc × b1 + (H − h)/sc for an input image of size W × H. Let the output of a max pooling operation be an array R. Write a simple expression for element R of the output. Explain how we can use the backprop algorithm to compute derivates through the max pooling operation. (A plain English answer will suffice; equations are optional.)
4 Convolutional Neural Networks (CNNs)
In this problem we will revisit the problem of classifying movements based on the key frames. The fullyconnected networks we have worked with in the previous problem have served as a good testbed for experimentation because they are very computationally efficient. However, in practice state-of-the-art methods on image data use convolutional networks. It is beyond the scope of this class to implement an efficient forward and backward pass for convolutional layers. Therefore, it is at this point that we will leave behind your beautiful code base from problem 1 in favor of developing code for this problem in the popular deep learning framework PyTorch. PyTorch executes dynamic computational graphs over Tensor objects that behave similarly to numpy ndarray. It comes with a powerful automatic differentiation engine that removes the need for manual backpropagation. You should install PyTorch and take a look at the basic tutorial here: https://pytorch.org/ tutorials/beginner/deep_learning_60min_blitz.html. The installation instructions can be found at https://pytorch.org/ under ‘Quick Start Locally’. You will be able to specify your operating system and package manager (e.g., pip or conda). Debugging notes One of the most important debugging tools when training a new network architecture is to train the network first on a small set of data, and verify that you can overfit to that data. This could be as small as a single image, and should not be more than a batch size of data. You should see your training loss decrease steadily. If your training loss starts to increase rapidly (or even steadily), you likely need to decrease your learning rate. If your training loss hasn’t started noticeably decreasing within one epoch, your model isn’t learning anything. In which case, it may be time to either: a) change your model, or b) increase your learning rate. It can be helpful to save a log file for each model that contains the training loss for each N steps, and the validation loss for each M >> N This way, you can plot the loss curve vs number of iterations, and compare the loss curves between models. It can help speed up the comparison between model performances. Do not delete a model architecture you have tried from the code. Often, you want the flexibility to run any model that you have experimented with at any time without a re-coding effort. Keep track of the model architectures you run, save each model’s weights, and record the evaluation scores for each model. For example, you could record this information in a spreadsheet with structure: model architecture info (could be as simple as the name of the model used in the code), accuracy for each of the 8 classes, average accuracy across all 8 classes, and location of the model weights. These networks take time to train. Please start early! Cloud credits. Training on a CPU is much slower than training on a GPU. We don’t want you to be limited by this. You have a few options for training on a GPU: Google has generously provided $50 in cloud credits for each student in our class. This is exclusively for students in CS 189/289A. Please do not share this link outside of this class. We were only given enough cloud credits for each student in the class to get one $50 credit. Please be reasonable. Google Cloud gives first-time users $300 in free credits, which anyone can access at https:// google.com/ (least user-friendly) Amazon Web Services gives first-time users $100 in free credits, which anyone can access at https://aws.amazon.com/education/awseducate/ (most user-friendly) Google Colab, which interfaces with Google drive, operates similarly to Jupyter notebook, and offers free GPU use for anyone at https://colab.research.google.com/ Google Colab also offers some nice tools for visualizing training progress (see debugging note 3 above). Implement a CNN that classifies movements based on a single key frame as input. We provide skeleton code in problem4, which contains the fully implemented data loader (mds189.py) and the solver (in train.py). For your part, you are to write the model, the loss, and modify the evaluation. There are many TODO and NOTE statements in problem4/train.py to help guide you. Experiment with a few different model architectures, and report your findings. For your best CNN model, plot the training and validation loss curves as a function of number of steps. Draw the architecture for your best CNN model. How do the number of parameters compare between your best CNN and a comparable architecture in which you replace all convolutional layers with fullyconnected layers? Train a movement classification CNN with your best model architecture from part (a) that now takes as input a random video frame, instead of a key frame. Note: there are many more random frames than there are key frames, so you are unlikely to need as many epochs as before. Compare your (best) key frame and (comparable architecture) random frame CNN performances by showing their per-movement accuracy in a two-row table. Include their overall accuracies in the table. When evaluating models, it is important to understand your misclassifications and error modes. For your random image and key frame CNNs, plot the confusion matrices. What do you observe? For either CNN, visualize your model’s errors, i.e., look at the images and/or videos where the network misclassifies the input. What do you observe about your model’s errors? Be sure to clearly state which model you chose to explore. For the Kaggle competition, you will evaluate your best CNN trained for the task of movement classification based on a random video frame as input. In part (d), we did not ask you to tune your CNN in any way for the video frame classifier. For your Kaggle submission, you are welcome to make any improvements to your CNN. The test set of images is located in the testkaggleframes directory in the dataset Google drive folder. For you to see the format of the Kaggle submission, we provide the sample file kagglesubmissionformat.csv, where the predictedlabels should be replaced with your model’s prediction for the movement, e.g., reach, squat, inline, lunge, hamstrings, stretch, deadbug, or pushup. Read the full article
0 notes
Text
The answer to life, the universe, and everything
A team led by Andrew Sutherland of MIT and Andrew Booker of Bristol University has solved the final piece of a famous 65-year old math puzzle with an answer for the most elusive number of all: 42.
The number 42 is especially significant to fans of science fiction novelist Douglas Adams’ “The Hitchhiker’s Guide to the Galaxy,” because that number is the answer given by a supercomputer to “the Ultimate Question of Life, the Universe, and Everything.”
Booker also wanted to know the answer to 42. That is, are there three cubes whose sum is 42?
This sum of three cubes puzzle, first set in 1954 at the University of Cambridge and known as the Diophantine Equation x3+y3+z3=k, challenged mathematicians to find solutions for numbers 1-100. With smaller numbers, this type of equation is easier to solve: for example, 29 could be written as 33 + 13 + 13, while 32 is unsolvable. All were eventually solved, or proved unsolvable, using various techniques and supercomputers, except for two numbers: 33 and 42.
Booker devised an ingenious algorithm and spent weeks on his university’s supercomputer when he recently came up with a solution for 33. But when he turned to solve for 42, Booker found that the computing needed was an order of magnitude higher and might be beyond his supercomputer’s capability. Booker says he received many offers of help to find the answer, but instead he turned to his friend Andrew “Drew” Sutherland, a principal research scientist in the Department of Mathematics. “He’s a world’s expert at this sort of thing,” Booker says.
Sutherland, whose specialty includes massively parallel computations, broke the record in 2017 for the largest Compute Engine cluster, with 580,000 cores on Preemptible Virtual Machines, the largest known high-performance computing cluster to run in the public cloud.
Like other computational number theorists who work in arithmetic geometry, he was aware of the “sum of three cubes” problem. And the two had worked together before, helping to build the L-functions and Modular Forms Database (LMFDB), an online atlas of mathematical objects related to what is known as the Langlands Program. “I was thrilled when Andy asked me to join him on this project,” says Sutherland.
Booker and Sutherland discussed the algorithmic strategy to be used in the search for a solution to 42. As Booker found with his solution to 33, they knew they didn’t have to resort to trying all of the possibilities for x, y, and z.
“There is a single integer parameter, d, that determines a relatively small set of possibilities for x, y, and z such that the absolute value of z is below a chosen search bound B,” says Sutherland. “One then enumerates values for d and checks each of the possible x, y, z associated to d. In the attempt to crack 33, the search bound B was 1016, but this B turned out to be too small to crack 42; we instead used B = 1017 (1017 is 100 million billion).
Otherwise, the main difference between the search for 33 and the search for 42 would be the size of the search and the computer platform used. Thanks to a generous offer from UK-based Charity Engine, Booker and Sutherland were able to tap into the computing power from over 400,000 volunteers’ home PCs, all around the world, each of which was assigned a range of values for d. The computation on each PC runs in the background so the owner can still use their PC for other tasks.
Sutherland is also a fan of Douglas Adams, so the project was irresistible.
The method of using Charity Engine is similar to part of the plot surrounding the number 42 in the “Hitchhiker” novel: After Deep Thought’s answer of 42 proves unsatisfying to the scientists, who don’t know the question it is meant to answer, the supercomputer decides to compute the Ultimate Question by building a supercomputer powered by Earth … in other words, employing a worldwide massively parallel computation platform.
“This is another reason I really liked running this computation on Charity Engine — we actually did use a planetary-scale computer to settle a longstanding open question whose answer is 42.”
They ran a number of computations at a lower capacity to test both their code and the Charity Engine network. They then used a number of optimizations and adaptations to make the code better suited for a massively distributed computation, compared to a computation run on a single supercomputer, says Sutherland.
Why couldn’t Bristol’s supercomputer solve this problem?
“Well, any computer *can* solve the problem, provided you are willing to wait long enough, but with roughly half a million PCs working on the problem in parallel (each with multiple cores), we were able to complete the computation much more quickly than we could have using the Bristol machine (or any of the machines here at MIT),” says Sutherland.
Using the Charity Engine network is also more energy-efficient. “For the most part, we are using computational resources that would otherwise go to waste,” says Sutherland. “When you’re sitting at your computer reading an email or working on a spreadsheet, you are using only a tiny fraction of the CPU resource available, and the Charity Engine application, which is based on the Berkeley Open Infrastructure for Network Computing (BOINC), takes advantage of this. As a result, the carbon footprint of this computation — related to the electricity our computations caused the PCs in the network to use above and beyond what they would have used, in any case — is lower than it would have been if we had used a supercomputer.”
Sutherland and Booker ran the computations over several months, but the final successful run was completed in just a few weeks. When the email from Charity Engine arrived, it provided the first solution to x3+y3+z3=42:
42 = (-80538738812075974)^3 + 80435758145817515^3 + 12602123297335631^3
“When I heard the news, it was definitely a fist-pump moment,” says Sutherland. “With these large-scale computations you pour a lot of time and energy into optimizing the implementation, tweaking the parameters, and then testing and retesting the code over weeks and months, never really knowing if all the effort is going to pay off, so it is extremely satisfying when it does.”
Booker and Sutherland say there are 10 more numbers, from 101-1000, left to be solved, with the next number being 114.
But both are more interested in a simpler but computationally more challenging puzzle: whether there are more answers for the sum of three cubes for 3.
“There are four very easy solutions that were known to the mathematician Louis J. Mordell, who famously wrote in 1953, ‘I do not know anything about the integer solutions of x3 + y3 + z3 = 3 beyond the existence of the four triples (1, 1, 1), (4, 4, -5), (4, -5, 4), (-5, 4, 4); and it must be very difficult indeed to find out anything about any other solutions.’ This quote motivated a lot of the interest in the sum of three cubes problem, and the case k=3 in particular. While it is conjectured that there should be infinitely many solutions, despite more than 65 years of searching we know only the easy solutions that were already known to Mordell. It would be very exciting to find another solution for k=3.”
The answer to life, the universe, and everything syndicated from https://osmowaterfilters.blogspot.com/
0 notes