#browser based web scraper
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Mobile US users spent an average of 115.8 minutes on Tumblr app monthly.
Text
diy ao3 wrapped: how to get your data!
so i figured out how to do this last year, and spotify wrapped season got me thinking about it again. a couple people in discord asked how to do it so i figured i'd write up a little guide! i'm not quite done with mine for this year yet because i wanted to do some graphics, but this is the post i made last year, for reference!
this got long! i tried to go into as much detail as possible to make it as easy as possible, but i am a web developer, so if there's anything i didn't explain enough (or if you have any other questions) don't hesitate to send me an ask!!
references
i used two reddit posts as references for this:
basic instructions (explains the browser extension; code gets title, word count, and author)
expanded instructions (code gets title, word count, and author, as well as category, date posted, last visited, warnings, rating, fandom, relationship, summary, and completion status, and includes instructions for how to include tags and switch fandoms/relationships to multiple—i will include notes on that later)
both use the extension webscraper.io which is available for both firefox and chrome (and maybe others, but i only use firefox/chrome personally so i didn't check any others, sorry. firefox is better anyway)
scraping your basic/expanded data
first, install the webscraper plugin/extension.
once it's installed, press ctrl+shift+i on pc or cmd+option+i on mac to open your browser's dev tools and navigate to the Web Scraper tab

from there, click "Create New Site Map" > "Import Sitemap"

it will open a screen with a field to input json code and a field for name—you don't need to manually input the name, it will fill in automatically based on the json you paste in. if you want to change it after, changing one will change the other.
i've put the codes i used on pastebin here: basic // expanded

once you've pasted in your code, you will want to update the USERNAME (highlighted in yellow) to your ao3 username, and the LASTPAGE (highlighted in pink) to the last page you want to scrape. to find this, go to your history page on ao3, and click back until you find your first fic of 2024! make sure you go by the "last visited" date instead of the post date.

if you do want to change the id, you can update the value (highlighted in blue) and it will automatically update the sitemap name field, or vice versa. everything else can be left as is.
once you're done, click import, and it'll show you the sitemap. on the top bar, click the middle tab, "Sitemap [id of sitemap]" and choose Scrape. you'll see a couple of options—the defaults worked fine for me, but you can mess with them if you need to. as far as i understand it, it just sets how much time it takes to scrape each page so ao3 doesn't think it's getting attacked by a bot. now click "start scraping"!


once you've done that, it will pop up with a new window which will load your history. let it do its thing. it will start on the last page and work its way back to the first, so depending on how many pages you have, it could take a while. i have 134 pages and it took about 10-12 minutes to get through them all.
once the scrape is done, the new window will close and you should be back at your dev tools window. you can click on the "Sitemap [id of sitemap]" tab again and choose Export data.

i downloaded the data as .xlsx and uploaded to my google drive. and now you can close your dev tools window!
from here on out my instructions are for google sheets; i'm sure most of the queries and calculations will be similar in other programs, but i don't really know excel or numbers, sorry!
setting up your spreadsheet
once it's opened, the first thing i do is sort the "viewed" column A -> Z and get rid of the rows for any deleted works. they don't have any data so no need to keep them. next, i select the columns for "web-scraper-order" and "web-scraper-start-url" (highlighted in pink) and delete them; they're just default data added by the scraper and we don't need them, so it tidies it up a little.

this should leave you with category, posted, viewed, warning, rating, fandom, relationship, title, author, wordcount, and completion status if you used the expanded code. if there are any of these you don't want, you can go ahead and delete those columns also!
next, i add blank columns to the right of the data i want to focus on. this just makes it easier to do my counts later. in my case these will be rating, fandom, relationship, author, and completion status.
one additional thing you should do, is checking the "viewed" column. you'll notice that it looks like this:
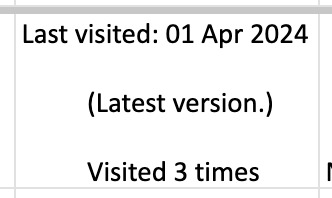
you can't really sort by this since it's text, not formatted as a date, so it'll go alphabetically by month rather than sorting by date. but, you'll want to be able to get rid of any entries that were viewed in 2023 (there could be none, but likely there are some because the scraper got everything on your last page even if it was viewed in 2023). what i did here was use the "find" dialog to search the "viewed" column for 2023, and deleted those rows manually.
ctrl/cmd+f, click the 3 dots for "more options". you want to choose "Specific range", then "C2:C#". replace C with the letter of your viewed column (remember i deleted a bunch, so yours may be different) and replace # with the number of the last row of your spreadsheet. then find 2023, select the rows containing it, right click > delete rows.
it isn't super necessary to do this, it will only add at most 19 fics to your count, but the option is there!

alright, with all that done, your sheet should look something like this:

exposing myself for having read stardew valley fic i guess
now for the fun part!!!
the math
yes, the math is the fun part.
scroll all the way down to the bottom of your sheet. i usually add 100 blank rows at the bottom just so i have some space to play with.
most of these will basically be the same query, just updating for the relevant column. i've put it in a pastebin here, but here's a screenshot so i can walk you through it:

you'll want to use lines 3-10, select the cell you want to put your data into, and paste the query into the formula bar (highlighted in green)

so, we're starting with rating, which is column E for me. if yours is a different letter you'll need to replace all the E's with the relevant letter.
what this does is it goes through the entire column, starting with row 2 (highlighted in yellow) and ending with your final row (highlighted in blue, you'll want to change this number to reflect how many rows you have). note that row 2 is your first actual data row, because of the header row.
it checks each row that has a value (line 5), groups by unique value (row 6), and arranges in descending order (row 7) by how many there are of each value (row 8). finally, row 10 determines how many rows of results you'll have; for rating, i put 5 because that's how many ratings there are, but you can increase the number of results (highlighted in pink) for other columns depending on how many you want. this is why i added the 100 extra rows!
next to make the actual number visible, go to the cell one column over. this is why we added the empty columns! next to your first result, add the second query from the pastebin:

your first and second cell numbers (highlighted in yellow and blue) should match the numbers from your query above, and the third number (highlighted in pink) should be the number of the cell with your first value. what this does is go through your column and count how many times the value occurs.
repeat this for the rest of the rows and you should end up with something like this! don't judge me and my reading habits please

now you can go ahead and repeat for the rest of your columns! as i mentioned above, you can increase the amount of result rows you get; i set it to 25 for fandom, relationship, and author, just because i was curious, and only two for completion status because it's either complete or not complete.
you should end up with something like this!

you may end up with some multiples (not sure why this happens, tagging issues maybe?) and up to you if you want to manually fix them! i just ended up doing a find and replace for the two that i didn't want and replaced with the correct tag.
now for the total wordcount! this one is pretty simple, it just adds together your entire column. first i selected the column (N for me) and went to Format > Number > 0 so it stripped commas etc. then at the bottom of the column, add the third query from the pastebin. as usual, your first number is the first data row, and the second is the last data row.

and just because i was curious, i wanted the average wordcount also, so in another cell i did this (fourth query from the pastebin), where the first number is the cell where your total is, and the second number is the total number of fics (total # of data rows minus 1 for the header row).

which gives me this:

tadaaaa!
getting multiple values
so, as i mentioned above, by default the scraper will only get the first value for relationships and fandoms. "but sarah," you may say, "what if i want an accurate breakdown of ALL the fandoms and relationships if there's multiples?"
here's the problem with that: if you want to be able to query and count them properly, each fandom or relationship needs to be its own row, which would skew all the other data. for me personally, it didn't bother me too much; i don't read a lot of crossovers, and typically if i'm reading a fic it's for the primary pairing, so i think the counts (for me) are pretty accurate. if you want to get multiples, i would suggest doing a secondary scrape to get those values separately.
if you want to edit the scrape to get multiples, navigate to one of your history pages (preferably one that has at least one work with multiple fandoms and/or relationships so you can preview) then hit ctrl+shift+i/cmd+option+i, open web scraper, and open your sitemap. expand the row and you should see all your values. find the one you want to edit and hit the "edit" button (highlighted in pink)

on the next screen, you should be good to just check the "Multiple" checkbox (highlighted in pink):

you can then hit "data preview" (highlighted in blue) to get a preview which should show you all the relationships on the page (which is why i said to find a page that has the multiples you are looking for, so you can confirm).

voila! now you can go back to the sitemap and scrape as before.
getting tag data
now, on the vein of multiples, i also wanted to get my most-read tags.
as i mentioned above, if you want to get ALL the tags, it'll skew the regular count data, so i did the tags in a completely separate query, which only grabs the viewed date and the tags. that code is here. you just want to repeat the scraping steps using that as a sitemap. save and open that spreadsheet.
the first thing you'll notice is that this one is a LOT bigger. for context i had 2649 fics in the first spreadsheet; the tags spreadsheet had 31,874 rows.
you can go ahead and repeat a couple of the same steps from before: remove the extra scraper data columns, and then we included the "viewed" column for the same reason as before, to remove any entries from 2023.
then you're just using the same basic query again!
replace the E with whatever your column letter is, and then change your limit to however many tags you want to see. i changed the limit to 50, again just for curiosity.
if you made it this far, congratulations! now that you have all that info, you can do whatever you want with it!
and again, if you have any questions please reach out!
55 notes
·
View notes
Text
"how do I keep my art from being scraped for AI from now on?"
if you post images online, there's no 100% guaranteed way to prevent this, and you can probably assume that there's no need to remove/edit existing content. you might contest this as a matter of data privacy and workers' rights, but you might also be looking for smaller, more immediate actions to take.
...so I made this list! I can't vouch for the effectiveness of all of these, but I wanted to compile as many options as possible so you can decide what's best for you.
Discouraging data scraping and "opting out"
robots.txt - This is a file placed in a website's home directory to "ask" web crawlers not to access certain parts of a site. If you have your own website, you can edit this yourself, or you can check which crawlers a site disallows by adding /robots.txt at the end of the URL. This article has instructions for blocking some bots that scrape data for AI.
HTML metadata - DeviantArt (i know) has proposed the "noai" and "noimageai" meta tags for opting images out of machine learning datasets, while Mojeek proposed "noml". To use all three, you'd put the following in your webpages' headers:
<meta name="robots" content="noai, noimageai, noml">
Have I Been Trained? - A tool by Spawning to search for images in the LAION-5B and LAION-400M datasets and opt your images and web domain out of future model training. Spawning claims that Stability AI and Hugging Face have agreed to respect these opt-outs. Try searching for usernames!
Kudurru - A tool by Spawning (currently a Wordpress plugin) in closed beta that purportedly blocks/redirects AI scrapers from your website. I don't know much about how this one works.
ai.txt - Similar to robots.txt. A new type of permissions file for AI training proposed by Spawning.
ArtShield Watermarker - Web-based tool to add Stable Diffusion's "invisible watermark" to images, which may cause an image to be recognized as AI-generated and excluded from data scraping and/or model training. Source available on GitHub. Doesn't seem to have updated/posted on social media since last year.
Image processing... things
these are popular now, but there seems to be some confusion regarding the goal of these tools; these aren't meant to "kill" AI art, and they won't affect existing models. they won't magically guarantee full protection, so you probably shouldn't loudly announce that you're using them to try to bait AI users into responding
Glaze - UChicago's tool to add "adversarial noise" to art to disrupt style mimicry. Devs recommend glazing pictures last. Runs on Windows and Mac (Nvidia GPU required)
WebGlaze - Free browser-based Glaze service for those who can't run Glaze locally. Request an invite by following their instructions.
Mist - Another adversarial noise tool, by Psyker Group. Runs on Windows and Linux (Nvidia GPU required) or on web with a Google Colab Notebook.
Nightshade - UChicago's tool to distort AI's recognition of features and "poison" datasets, with the goal of making it inconvenient to use images scraped without consent. The guide recommends that you do not disclose whether your art is nightshaded. Nightshade chooses a tag that's relevant to your image. You should use this word in the image's caption/alt text when you post the image online. This means the alt text will accurately describe what's in the image-- there is no reason to ever write false/mismatched alt text!!! Runs on Windows and Mac (Nvidia GPU required)
Sanative AI - Web-based "anti-AI watermark"-- maybe comparable to Glaze and Mist. I can't find much about this one except that they won a "Responsible AI Challenge" hosted by Mozilla last year.
Just Add A Regular Watermark - It doesn't take a lot of processing power to add a watermark, so why not? Try adding complexities like warping, changes in color/opacity, and blurring to make it more annoying for an AI (or human) to remove. You could even try testing your watermark against an AI watermark remover. (the privacy policy claims that they don't keep or otherwise use your images, but use your own judgment)
given that energy consumption was the focus of some AI art criticism, I'm not sure if the benefits of these GPU-intensive tools outweigh the cost, and I'd like to know more about that. in any case, I thought that people writing alt text/image descriptions more often would've been a neat side effect of Nightshade being used, so I hope to see more of that in the future, at least!
246 notes
·
View notes
Text
How Web Scraping TripAdvisor Reviews Data Boosts Your Business Growth

Are you one of the 94% of buyers who rely on online reviews to make the final decision? This means that most people today explore reviews before taking action, whether booking hotels, visiting a place, buying a book, or something else.
We understand the stress of booking the right place, especially when visiting somewhere new. Finding the balance between a perfect spot, services, and budget is challenging. Many of you consider TripAdvisor reviews a go-to solution for closely getting to know the place.
Here comes the accurate game-changing method—scrape TripAdvisor reviews data. But wait, is it legal and ethical? Yes, as long as you respect the website's terms of service, don't overload its servers, and use the data for personal or non-commercial purposes. What? How? Why?
Do not stress. We will help you understand why many hotel, restaurant, and attraction place owners invest in web scraping TripAdvisor reviews or other platform information. This powerful tool empowers you to understand your performance and competitors' strategies, enabling you to make informed business changes. What next?
Let's dive in and give you a complete tour of the process of web scraping TripAdvisor review data!
What Is Scraping TripAdvisor Reviews Data?
Extracting customer reviews and other relevant information from the TripAdvisor platform through different web scraping methods. This process works by accessing publicly available website data and storing it in a structured format to analyze or monitor.
Various methods and tools available in the market have unique features that allow you to extract TripAdvisor hotel review data hassle-free. Here are the different types of data you can scrape from a TripAdvisor review scraper:
Hotels
Ratings
Awards
Location
Pricing
Number of reviews
Review date
Reviewer's Name
Restaurants
Images
You may want other information per your business plan, which can be easily added to your requirements.
What Are The Ways To Scrape TripAdvisor Reviews Data?
TripAdvisor uses different web scraping methods to review data, depending on available resources and expertise. Let us look at them:
Scrape TripAdvisor Reviews Data Using Web Scraping API
An API helps to connect various programs to gather data without revealing the code used to execute the process. The scrape TripAdvisor Reviews is a standard JSON format that does not require technical knowledge, CAPTCHAs, or maintenance.
Now let us look at the complete process:
First, check if you need to install the software on your device or if it's browser-based and does not need anything. Then, download and install the desired software you will be using for restaurant, location, or hotel review scraping. The process is straightforward and user-friendly, ensuring your confidence in using these tools.
Now redirect to the web page you want to scrape data from and copy the URL to paste it into the program.
Make updates in the HTML output per your requirements and the information you want to scrape from TripAdvisor reviews.
Most tools start by extracting different HTML elements, especially the text. You can then select the categories that need to be extracted, such as Inner HTML, href attribute, class attribute, and more.
Export the data in SPSS, Graphpad, or XLSTAT format per your requirements for further analysis.
Scrape TripAdvisor Reviews Using Python
TripAdvisor review information is analyzed to understand the experience of hotels, locations, or restaurants. Now let us help you to scrape TripAdvisor reviews using Python:
Continue reading https://www.reviewgators.com/how-web-scraping-tripadvisor-reviews-data-boosts-your-business-growth.php
#review scraping#Scraping TripAdvisor Reviews#web scraping TripAdvisor reviews#TripAdvisor review scraper
2 notes
·
View notes
Text
Zillow Scraping Mastery: Advanced Techniques Revealed

In the ever-evolving landscape of data acquisition, Zillow stands tall as a treasure trove of valuable real estate information. From property prices to market trends, Zillow's extensive database holds a wealth of insights for investors, analysts, and researchers alike. However, accessing this data at scale requires more than just a basic understanding of web scraping techniques. It demands mastery of advanced methods tailored specifically for Zillow's unique structure and policies. In this comprehensive guide, we delve into the intricacies of Zillow scraping, unveiling advanced techniques to empower data enthusiasts in their quest for valuable insights.
Understanding the Zillow Scraper Landscape
Before diving into advanced techniques, it's crucial to grasp the landscape of zillow scraper. As a leading real estate marketplace, Zillow is equipped with robust anti-scraping measures to protect its data and ensure fair usage. These measures include rate limiting, CAPTCHA challenges, and dynamic page rendering, making traditional scraping approaches ineffective. To navigate this landscape successfully, aspiring scrapers must employ sophisticated strategies tailored to bypass these obstacles seamlessly.
Advanced Techniques Unveiled
User-Agent Rotation: One of the most effective ways to evade detection is by rotating User-Agent strings. Zillow's anti-scraping mechanisms often target commonly used User-Agent identifiers associated with popular scraping libraries. By rotating through a diverse pool of User-Agent strings mimicking legitimate browser traffic, scrapers can significantly reduce the risk of detection and maintain uninterrupted data access.
IP Rotation and Proxies: Zillow closely monitors IP addresses to identify and block suspicious scraping activities. To counter this, employing a robust proxy rotation system becomes indispensable. By routing requests through a pool of diverse IP addresses, scrapers can distribute traffic evenly and mitigate the risk of IP bans. Additionally, utilizing residential proxies offers the added advantage of mimicking genuine user behavior, further enhancing scraping stealth.
Session Persistence: Zillow employs session-based authentication to track user interactions and identify potential scrapers. Implementing session persistence techniques, such as maintaining persistent cookies and managing session tokens, allows scrapers to simulate continuous user engagement. By emulating authentic browsing patterns, scrapers can evade detection more effectively and ensure prolonged data access.
JavaScript Rendering: Zillow's dynamic web pages rely heavily on client-side JavaScript to render content dynamically. Traditional scraping approaches often fail to capture dynamically generated data, leading to incomplete or inaccurate results. Leveraging headless browser automation frameworks, such as Selenium or Puppeteer, enables scrapers to execute JavaScript code dynamically and extract fully rendered content accurately. This advanced technique ensures comprehensive data coverage across Zillow's dynamic pages, empowering scrapers with unparalleled insights.
Data Parsing and Extraction: Once data is retrieved from Zillow's servers, efficient parsing and extraction techniques are essential to transform raw HTML content into structured data formats. Utilizing robust parsing libraries, such as BeautifulSoup or Scrapy, facilitates seamless extraction of relevant information from complex web page structures. Advanced XPath or CSS selectors further streamline the extraction process, enabling scrapers to target specific elements with precision and extract valuable insights efficiently.
Ethical Considerations and Compliance
While advanced scraping techniques offer unparalleled access to valuable data, it's essential to uphold ethical standards and comply with Zillow's terms of service. Scrapers must exercise restraint and avoid overloading Zillow's servers with excessive requests, as this may disrupt service for genuine users and violate platform policies. Additionally, respecting robots.txt directives and adhering to rate limits demonstrates integrity and fosters a sustainable scraping ecosystem beneficial to all stakeholders.
Conclusion
In the realm of data acquisition, mastering advanced scraping techniques is paramount for unlocking the full potential of platforms like Zillow. By employing sophisticated strategies tailored to bypass anti-scraping measures seamlessly, data enthusiasts can harness the wealth of insights hidden within Zillow's vast repository of real estate data. However, it's imperative to approach scraping ethically and responsibly, ensuring compliance with platform policies and fostering a mutually beneficial scraping ecosystem. With these advanced techniques at their disposal, aspiring scrapers can embark on a journey of exploration and discovery, unraveling valuable insights to inform strategic decisions and drive innovation in the real estate industry.
2 notes
·
View notes
Text
Overcoming Bot Detection While Scraping Menu Data from UberEats, DoorDash, and Just Eat
Introduction
In industries where menu data collection is concerned, web scraping would serve very well for us: UberEats, DoorDash, and Just Eat are the some examples. However, websites use very elaborate bot detection methods to stop the automated collection of information. In overcoming these factors, advanced scraping techniques would apply with huge relevance: rotating IPs, headless browsing, CAPTCHA solving, and AI methodology.
This guide will discuss how to bypass bot detection during menu data scraping and all challenges with the best practices for seamless and ethical data extraction.
Understanding Bot Detection on Food Delivery Platforms
1. Common Bot Detection Techniques
Food delivery platforms use various methods to block automated scrapers:
IP Blocking – Detects repeated requests from the same IP and blocks access.
User-Agent Tracking – Identifies and blocks non-human browsing patterns.
CAPTCHA Challenges – Requires solving puzzles to verify human presence.
JavaScript Challenges – Uses scripts to detect bots attempting to load pages without interaction.
Behavioral Analysis – Tracks mouse movements, scrolling, and keystrokes to differentiate bots from humans.
2. Rate Limiting and Request Patterns
Platforms monitor the frequency of requests coming from a specific IP or user session. If a scraper makes too many requests within a short time frame, it triggers rate limiting, causing the scraper to receive 403 Forbidden or 429 Too Many Requests errors.
3. Device Fingerprinting
Many websites use sophisticated techniques to detect unique attributes of a browser and device. This includes screen resolution, installed plugins, and system fonts. If a scraper runs on a known bot signature, it gets flagged.
Techniques to Overcome Bot Detection
1. IP Rotation and Proxy Management
Using a pool of rotating IPs helps avoid detection and blocking.
Use residential proxies instead of data center IPs.
Rotate IPs with each request to simulate different users.
Leverage proxy providers like Bright Data, ScraperAPI, and Smartproxy.
Implement session-based IP switching to maintain persistence.
2. Mimic Human Browsing Behavior
To appear more human-like, scrapers should:
Introduce random time delays between requests.
Use headless browsers like Puppeteer or Playwright to simulate real interactions.
Scroll pages and click elements programmatically to mimic real user behavior.
Randomize mouse movements and keyboard inputs.
Avoid loading pages at robotic speeds; introduce a natural browsing flow.
3. Bypassing CAPTCHA Challenges
Implement automated CAPTCHA-solving services like 2Captcha, Anti-Captcha, or DeathByCaptcha.
Use machine learning models to recognize and solve simple CAPTCHAs.
Avoid triggering CAPTCHAs by limiting request frequency and mimicking human navigation.
Employ AI-based CAPTCHA solvers that use pattern recognition to bypass common challenges.
4. Handling JavaScript-Rendered Content
Use Selenium, Puppeteer, or Playwright to interact with JavaScript-heavy pages.
Extract data directly from network requests instead of parsing the rendered HTML.
Load pages dynamically to prevent detection through static scrapers.
Emulate browser interactions by executing JavaScript code as real users would.
Cache previously scraped data to minimize redundant requests.
5. API-Based Extraction (Where Possible)
Some food delivery platforms offer APIs to access menu data. If available:
Check the official API documentation for pricing and access conditions.
Use API keys responsibly and avoid exceeding rate limits.
Combine API-based and web scraping approaches for optimal efficiency.
6. Using AI for Advanced Scraping
Machine learning models can help scrapers adapt to evolving anti-bot measures by:
Detecting and avoiding honeypots designed to catch bots.
Using natural language processing (NLP) to extract and categorize menu data efficiently.
Predicting changes in website structure to maintain scraper functionality.
Best Practices for Ethical Web Scraping
While overcoming bot detection is necessary, ethical web scraping ensures compliance with legal and industry standards:
Respect Robots.txt – Follow site policies on data access.
Avoid Excessive Requests – Scrape efficiently to prevent server overload.
Use Data Responsibly – Extracted data should be used for legitimate business insights only.
Maintain Transparency – If possible, obtain permission before scraping sensitive data.
Ensure Data Accuracy – Validate extracted data to avoid misleading information.
Challenges and Solutions for Long-Term Scraping Success
1. Managing Dynamic Website Changes
Food delivery platforms frequently update their website structure. Strategies to mitigate this include:
Monitoring website changes with automated UI tests.
Using XPath selectors instead of fixed HTML elements.
Implementing fallback scraping techniques in case of site modifications.
2. Avoiding Account Bans and Detection
If scraping requires logging into an account, prevent bans by:
Using multiple accounts to distribute request loads.
Avoiding excessive logins from the same device or IP.
Randomizing browser fingerprints using tools like Multilogin.
3. Cost Considerations for Large-Scale Scraping
Maintaining an advanced scraping infrastructure can be expensive. Cost optimization strategies include:
Using serverless functions to run scrapers on demand.
Choosing affordable proxy providers that balance performance and cost.
Optimizing scraper efficiency to reduce unnecessary requests.
Future Trends in Web Scraping for Food Delivery Data
As web scraping evolves, new advancements are shaping how businesses collect menu data:
AI-Powered Scrapers – Machine learning models will adapt more efficiently to website changes.
Increased Use of APIs – Companies will increasingly rely on API access instead of web scraping.
Stronger Anti-Scraping Technologies – Platforms will develop more advanced security measures.
Ethical Scraping Frameworks – Legal guidelines and compliance measures will become more standardized.
Conclusion
Uber Eats, DoorDash, and Just Eat represent great challenges for menu data scraping, mainly due to their advanced bot detection systems. Nevertheless, if IP rotation, headless browsing, solutions to CAPTCHA, and JavaScript execution methodologies, augmented with AI tools, are applied, businesses can easily scrape valuable data without incurring the wrath of anti-scraping measures.
If you are an automated and reliable web scraper, CrawlXpert is the solution for you, which specializes in tools and services to extract menu data with efficiency while staying legally and ethically compliant. The right techniques, along with updates on recent trends in web scrapping, will keep the food delivery data collection effort successful long into the foreseeable future.
Know More : https://www.crawlxpert.com/blog/scraping-menu-data-from-ubereats-doordash-and-just-eat
#ScrapingMenuDatafromUberEats#ScrapingMenuDatafromDoorDash#ScrapingMenuDatafromJustEat#ScrapingforFoodDeliveryData
0 notes
Text
Extract API for Yemeksepeti Food Delivery Data

Extract API for Yemeksepeti Food Delivery Data for Real-Time Restaurant Intelligence
The results of this case study showcase how our scraping services provided the client with the ability to Extract API for Yemeksepeti Food Delivery Data to help build a large-scale food delivery intelligence platform in Turkey. The client was a global analytics company that required real-time structured data from hundreds of restaurants to analyze regional menu trends, pricing strategies, and consumer behavior. Our large, robust systems allowed us to deliver seamless access to all restaurant listings, customer ratings, delivery fees, and availability. Our Yemeksepeti Food Menu and Pricing Data Scraper were crucial in capturing item-level menu detail, promotional offers, and dynamic pricing to compare study orders across different cities. The client took advantage of scalable and reliable API access, using the extracted data to develop automated dashboards and forecasting tools to elevate their speed to insight and strategic decision-making. Our services played a significant role in enabling the client to convert their raw data into business intelligence in a highly competitive food delivery market.Download Now
The Client
The client, a leading food-tech analytics company across Europe and the Middle East, approached us to gather high-volume restaurant data from Yemeksepeti. They needed structured information on menus, reviews, pricing, and availability to power their analytics platform. After evaluating multiple providers, they selected us for our proven expertise in Web Scraping Yemeksepeti Food Items and Reviews Data, scalability, and fast turnaround. Our Yemeksepeti Food Data Scraping API Services offered a flexible solution tailored to their needs, enabling seamless integration with their internal systems. Additionally, our Real-Time Food Data Extraction capability from Yemeksepeti ensured they had the latest updates for time-sensitive reporting, helping them stay competitive in a fast-moving market.
Key Challenges
1. Scattered and Unstructured Data: The client struggled to gather consistent information across different cities and restaurant types, making Web Scraping Yemeksepeti Restaurant Listings Data manually time-consuming and inefficient.
2. Real-Time Monitoring Limitations: Their existing setup couldn't promptly track dynamic pricing, availability, or promotional changes, leading them to seek reliable Yemeksepeti Food Delivery App Data Scraping Services for continuous data updates.
3. Integration and Scalability Issues: The client lacked a scalable solution to feed large volumes of structured data into their analytics systems. This prompted the need for robust Yemeksepeti Food Delivery Scraping API Services to support automation and real-time data access.
Key Solutions
We provided tailored Food Delivery Data Scraping Services that captured structured data across thousands of Yemeksepeti restaurant listings, ensuring accuracy, consistency, and geographic relevance.
Our advanced Restaurant Menu Data Scraping collected complete details such as item names, prices, descriptions, and available add-ons, enabling the client to analyze competitive menu offerings across regions.
Through our scalable Food Delivery Scraping API Services , the client gained real-time access to continuously updated datasets, seamlessly integrated into their analytics platform, and supported timely decision-making across departments.
Methodologies Used
Geo-Segmented Crawling: We implemented region-specific crawlers to ensure accurate location-based insights, enhancing the performance of our Restaurant Data Intelligence Services.
Dynamic Page Rendering: Using headless browsers, we effectively captured content from JavaScript-heavy pages on Yemeksepeti, feeding high-quality inputs into our Food Delivery Intelligence Services.
Menu Structuring and Categorization: We built hierarchical models to map menu categories, combos, and add-ons, helping the client visualize offerings in their Food Price Dashboard .
Real-Time Monitoring Engine: Our system continuously tracked updates in menu items and pricing, ensuring the freshness of Food Delivery Datasets used for reporting and forecasting.
Data Validation and Cleanup Pipelines: We applied automated checks and normalization routines to remove duplicates and inconsistencies, delivering only reliable, usable data.
Advantages of Collecting Data Using Food Data Scrape
Real-Time Market Tracking: Access up-to-date data on restaurant menus, pricing, promotions, and availability across regions for timely business decisions.
Enhanced Competitive Intelligence: Gain deep insights into competitors' strategies, customer reviews, and menu structures to refine your offerings and stay ahead.
Scalable Data Collection: Easily scale data scraping operations across thousands of restaurants and multiple cities without compromising speed or accuracy.
Customizable Outputs: Receive structured data in your preferred format, tailored to your business needs, ready for analysis or integration.
Reduced Manual Effort: Automated workflows eliminate the need for manual data collection, saving time, reducing errors, and improving overall operational efficiency.
Client’s Testimonial
"Working with Food Data Scrape has been a game-changer for our analytics team. Their ability to deliver real-time, structured data from Yemeksepeti helped us build powerful dashboards and gain deep insights into food delivery trends. Their service's accuracy, scalability, and responsiveness exceeded our expectations."
— Emre Yıldız, Senior Data Analyst
Final Outcomes:
By the end of the project, the client successfully streamlined their data collection and transformed how they analyzed the food delivery landscape in Turkey. With real-time access to structured data through our services, they built a dynamic analytics platform featuring accurate restaurant listings, pricing trends, menu variations, and consumer preferences. Automated pipelines replaced manual processes, improving efficiency by over 70%. Their market research reports became more precise and timely, strengthening their value to stakeholders. Overall, our solution empowered the client to make smarter, faster decisions and solidified their position as a food delivery market intelligence leader.
Source>> https://www.fooddatascrape.com/extract-api-yemeksepeti-food-delivery-data.php
#ExtractAPIforYemeksepetiFoodDeliveryData#YemeksepetiFoodMenuandPricingDataScraper#WebScrapingYemeksepetiFoodItemsandReviewsData#YemeksepetiFoodDataScrapingAPIServices#RealTimeFoodDataExtractionfromYemeksepeti
0 notes
Text
Top Options To Scrape Hotel Data From Agoda Without Coding
Introduction
In today's competitive hospitality landscape, accessing comprehensive hotel information has become crucial for businesses, researchers, and travel enthusiasts. The ability to Scrape Hotel Data From Agoda opens doors to valuable insights about pricing trends, room availability, customer reviews, and market dynamics. However, many individuals and organizations hesitate to pursue data extraction due to concerns about technical complexity and programming requirements.
The good news is that modern technology has democratized data scraping, making it accessible to users without extensive coding knowledge. This comprehensive guide explores various methods and tools that enable efficient Agoda Hotel Data Extraction while maintaining simplicity and effectiveness for non-technical users.
Understanding the Value of Agoda Hotel Data
Agoda, one of Asia's leading online travel agencies, hosts millions of hotel listings worldwide. The platform contains a treasure trove of information that can benefit various stakeholders in the tourism industry. Market researchers can analyze pricing patterns through Hotel Price Scraping , business owners can monitor competitor rates, and travel agencies can enhance their service offerings through comprehensive data analysis.
The platform's extensive database includes room rates, availability calendars, guest reviews, hotel amenities, location details, and booking policies. Extracting this information systematically allows businesses to make informed decisions about pricing strategies, marketing campaigns, and customer service improvements.
Real-Time Hotel Data from Agoda provides market intelligence that helps businesses stay competitive. By monitoring price fluctuations across different seasons, locations, and property types, stakeholders can optimize their revenue management strategies and identify market opportunities.
No-Code Solutions for Hotel Data Extraction
No-Code Solutions for Hotel Data Extraction refer to user-friendly platforms and tools that enable hotel data scraping—like reviews, room availability, and pricing—without requiring programming skills. These solutions are ideal for marketers, analysts, and business users.
1. Browser-Based Scraping Tools
Modern web scraping has evolved beyond command-line interfaces and complex programming languages. Several browser-based tools now offer intuitive interfaces that allow users to extract data through simple point-and-click operations. These tools typically record user interactions with web pages and automate repetitive tasks.
Popular browser extensions like Web Scraper, Data Miner, and Octoparse provide user-friendly interfaces where users can select specific elements on Agoda's website and configure extraction parameters. These tools automatically handle the technical aspects of data collection while presenting results in accessible formats like CSV or Excel files.
1. Cloud-Based Scraping Platforms
Cloud-based scraping services represent another excellent option for non-technical users seeking Agoda Room Availability Scraping capabilities. These platforms offer pre-built templates specifically designed for popular websites like Agoda, eliminating the need for manual configuration.
Services like Apify, Scrapy Cloud, and ParseHub provide ready-to-use scraping solutions that can be customized through simple form interfaces. Users can specify search criteria, select data fields, and configure output formats without writing a single line of code.
Key advantages of cloud-based solutions include:
Scalability to handle large-scale data extraction projects
Automatic handling of website changes and anti-scraping measures
Built-in data cleaning and formatting capabilities
Integration with popular business intelligence tools
Reliable uptime and consistent performance
Desktop Applications for Advanced Data Extraction
Desktop scraping applications offer another viable path for users seeking to extract hotel information without programming knowledge. These software solutions provide comprehensive interfaces with drag-and-drop functionality, making data extraction as simple as building a flowchart.
Applications like FMiner, WebHarvy, and Visual Web Ripper offer sophisticated features wrapped in user-friendly interfaces. These tools can handle complex scraping scenarios, including dealing with JavaScript-heavy pages, managing login sessions, and handling dynamic content loading.
Desktop applications' advantage is their ability to provide more control over the scraping process while maintaining ease of use. Users can set up complex extraction workflows, implement data validation rules, and export results in multiple formats. These applications also include scheduling capabilities for automated Hotel Booking Data Scraping operations.
API-Based Solutions and Third-Party Services
Modern automation platforms like Zapier, Microsoft Power Automate, and IFTTT have expanded to include web scraping capabilities. These platforms allow users to create automated workflows to Extract Hotel Reviews From Agoda and integrate them directly into their existing business systems.
Companies specializing in travel data extraction often provide dedicated Agoda scraping services that can be accessed through simple web forms or API endpoints. Users can specify their requirements, such as location, date ranges, and property types, and receive Real-Time Hotel Data in return.
Benefits of API-based solutions include:
Immediate access to data without setup time
Professional-grade reliability and accuracy
Compliance with website terms of service
Regular updates to handle website changes
Customer support for troubleshooting
Automated Workflow Tools and Integrations
Modern automation platforms like Zapier, Microsoft Power Automate, and IFTTT have expanded to include web scraping capabilities. These platforms allow users to create automated workflows to Extract Hotel Reviews From Agoda and integrate them directly into their existing business systems.
These tools are particularly valuable for businesses that must incorporate hotel data into their operations. For example, a travel agency could set up an automated workflow that scrapes Agoda data daily and updates its internal pricing database, enabling dynamic pricing strategies based on Agoda Room Availability Scraping insights.
The workflow approach seamlessly integrates with popular business tools like Google Sheets, CRM systems, and email marketing platforms. This integration capability makes it easier to act on the extracted data immediately rather than manually processing exported files.
Data Quality and Validation Considerations
Ensure data quality when implementing any Hotel Data Intelligence strategy. Non-coding solutions often include built-in validation features that help maintain data accuracy and consistency. These features typically include duplicate detection, format validation, and completeness checks.
Users should establish data quality standards before beginning extraction projects. This includes defining acceptable ranges for numerical data, establishing consistent formatting for text fields, and implementing verification procedures for critical information like pricing and availability.
Regular monitoring of extracted data helps identify potential issues early in the process. Many no-code tools provide notification systems that alert users to unusual patterns or extraction failures, enabling quick resolution of data quality issues.
Legal and Ethical Considerations
Before implementing any data extraction strategy, users must understand the legal and ethical implications of web scraping. Agoda's terms of service, robots.txt file, and rate-limiting policies should be carefully reviewed to ensure compliance.
Responsible scraping practices include:
Respecting website rate limits and implementing appropriate delays
Using data only for legitimate business purposes
Avoiding excessive server load that could impact website performance
Implementing proper data security measures for extracted information
Regularly reviewing and updating scraping practices to maintain compliance
Advanced Features and Customization Options
Modern no-code scraping solutions offer sophisticated customization options that rival traditional programming approaches. These features enable users to handle complex scenarios like multi-page data extraction, conditional logic implementation, and dynamic content handling.
Advanced filtering capabilities allow users to extract only relevant information based on specific criteria such as price ranges, star ratings, or geographic locations. This targeted approach reduces data processing time and focuses analysis on the most valuable insights.
Many platforms also offer data transformation features that can clean, format, and structure extracted information according to business requirements. These capabilities eliminate additional data processing steps and provide ready-to-use datasets.
Monitoring and Maintenance Strategies
Successful Travel Industry Web Scraping requires ongoing monitoring and maintenance to ensure consistent performance. No-code solutions typically include dashboard interfaces that provide visibility into scraping performance, success rates, and data quality metrics.
Users should establish regular review processes to validate data accuracy and identify potential issues. This includes monitoring for website changes that might affect extraction accuracy, validating data completeness, and ensuring compliance with updated service terms.
Automated alerting systems can notify users of extraction failures, data quality issues, or significant changes in scraped information. These proactive notifications enable quick responses to potential problems and maintain data reliability.
Future Trends in No-Code Data Extraction
The landscape of no-code data extraction continues to evolve rapidly, with new tools and capabilities emerging regularly. Artificial intelligence and machine learning technologies are increasingly integrated into scraping platforms, enabling more intelligent data extraction and automatic application to website changes.
These technological advances make Hotel Booking Data Scraping more accessible and reliable for non-technical users. Future developments will likely include enhanced natural language processing capabilities, improved visual recognition for data element selection, and more sophisticated automation features.
How Travel Scrape Can Help You?
We provide comprehensive hotel data extraction services that eliminate the technical barriers typically associated with web scraping. Our platform is designed specifically for users who need reliable Real-Time Hotel Data without the complexity of coding or managing technical infrastructure.
Our services include:
Custom Agoda scraping solutions tailored to your specific business requirements and data needs.
Automated data collection schedules that ensure you always have access to the most current hotel information.
Advanced data filtering and cleaning processes that deliver high-quality, actionable insights.
Multiple export formats, including CSV, Excel, JSON, and direct database integration options.
Compliance management ensures all data extraction activities adhere to legal and ethical standards.
Scalable solutions that grow with your business needs, from small-scale projects to enterprise-level operations.
Integration capabilities with popular business intelligence tools and CRM systems.
Our platform handles the technical complexities of Hotel Price Scraping while providing clean, structured data that can be immediately used for analysis and decision-making.
Conclusion
The democratization of data extraction technology has made it possible for anyone to Scrape Hotel Data From Agoda without extensive programming knowledge. Users can access valuable hotel information that drives informed business decisions through browser extensions, cloud-based platforms, desktop applications, and API services.
As the Travel Industry Web Scraping landscape evolves, businesses embracing these accessible technologies will maintain competitive advantages through better market intelligence and data-driven decision-making.
Don't let technical barriers prevent you from accessing valuable market insights; Contact Travel Scrape now to learn more about our comprehensive Travel Aggregators data extraction services and take the first step toward data-driven success.
Read More :- https://www.travelscrape.com/scrape-agoda-hotel-data-no-coding.php
#ScrapeHotelDataFromAgoda#AgodaHotelDataExtraction#HotelPriceScraping#RealTimeHotelData#HotelDataIntelligence#TravelIndustryWebScraping#HotelBookingDataScraping#TravelAggregators
0 notes
Text
How to Use a Cricut to Make Shirts? (Full Guide)
Do you want to launch your first project but are still unsure about what to create? If so, let me tell you about one of the most popular and easiest crafts you can make: a personalized T-shirt!

Heat transfer vinyl enables crafters to personalize fabric projects by adding designs and text using heat and pressure. It’s a versatile material that is not limited to making T-shirts. You can create various DIY projects, such as wall hangings, hats, caps, tote bags, shoes, and numerous other items.
What You Need to Create a Shirt With Cricut
Make sure you have the following essentials before you start creating shirts with your machine:
Any Cricut Explore, Maker, or Joy machine
Cricut EasyPress 2
Weeding tool
T-shirt
EasyPress mat
Heat transfer vinyl
Scraper tool
Smart iron-on
StandardGrip cutting mat
How to Use a Cricut to Make Shirts: Easy Steps
If this is your first time crafting, follow these simple steps to make a shirt with your Cricut machine:
Step 1: Download Design Space
Go to a web browser and type design.cricut.com/setup
Now, enter your machine model in the search field.
Next, select the checkbox at the bottom left of the page.
After installation, open Cricut Design Space and Sign In. If you don’t have an account, click on Create Cricut ID and follow the instructions.
Step 2: Click on New Project
Once you have signed in successfully, open your Design Space.
Head over to the Cricut Design Space home page and click the New Project icon to start from scratch.
Then, it will take you directly to the canvas where you’ll design.

Step 3: Select the Text Menu
From the left-hand side of the navigation bar, you’ll see an option for “Text.”
After that, you have to click on the Text button.
Next, a text box will show up on your screen for you to enter text. Type whatever you want to get printed on your T-shirt.

Step 4: Design Your Text
At the top of the dropdown menu, select Font if you want to change the Font.
Get ready to choose your favorite text style from a list of hundreds of fonts.

Click on whichever you find the best.
Step 5: Curve Your Text
In the same dropdown menu at the top, you will find the Curve option. Click on it.
After clicking on the Curve option, a slider will show up on your display, allowing you to adjust the curve of your text by moving it left or right.

Step 6: Finalize Your Design
Once you’re satisfied with your design, click “Make It”.
Then, the Cricut Design Space will command your machine to cut.
You will be asked to choose between using a cutting mat and not using one.
Ensure you select “Mirror” on the cut screen when using iron-on and click Continue.
Step 7: Get Ready to Cut
Switch on your machine by pressing the power button.
Next, choose the base material type that best suits your material. I am selecting Smart Iron-On from the list. This step helps your machine determine the required pressure amount for cutting.
Place the HTV’s shiny, plastic sheet down on the mat. Smooth it out to remove any air bubbles or wrinkles.
Place the mat into your machine, positioning it under the rollers.
Press the up and down arrow buttons on your machine. It will pull up your mat, and it will be loaded successfully.
Finally, click on the Go or Start button to begin the cutting process.
Once cut, remove the excess vinyl using the weeding tool. Slowly lift a corner and pull it gently away from the transfer sheet.
Step 8: Transfer Your Design to T-shirt
Preheat your EasyPress. This will make your machine ready to transfer material to the shirt.
Ensure your shirt is clean and ready to receive the transfer design by using a lint roller to remove lint and debris from the shirt.
Place your shirt on the heat mat to ensure your safety.
Place your design on the shirt wherever you prefer, according to your personal preference.
Visit cricut.com/en/heatguide and select your machine from the available options.
Select your specific heat-transfer material and base material, then click the Apply button.
Follow the Cricut heat guide instructions and set your EasyPress to 315°F for 30 seconds if you’re using HTV.
Use light pressure and place your EasyPress on the design you’ve put on your T-shirt.
If your press is smaller than your design, divide your design into sections and heat it accordingly.
Peel off the backing sheet, and that’s it you’re done! Your design will stay intact on your T-shirt even after multiple washes!
Congratulations! Now that you’re no longer a beginner after learning how to use a Cricut to make shirts, your customized T-shirt is ready to wear and shine.
Final Thoughts
Remember, practice makes a man perfect, so don’t demotivate yourself if it doesn’t go as you want. Keep trying to strive for perfection. One last piece of advice I want to share with you is to always try to wash your T-shirt inside out so that it lasts a long time.
Have fun designing your projects, and share your thoughts with us!
Frequently Asked Questions (FAQs)
How Do I transfer a Cricut Image to a Shirt?
Follow the steps to learn if you want to transfer the image to a shirt:
On the left-hand side of the toolbar panel, click on the Image option if you want to use the image from the Cricut library.
If you want to personalize your T-shirt with your own image, slide down the toolbar, find the “Upload” option, and click on it.
Upload and resize your design. Ensure that the Mirror option is activated.
Finalize your design and cut it using the Cricut Design Space instructions.
Weed your T-shirt design and use the heat press machine to transfer the design.
Which Vinyl Is Best for Shirts?
HTV (Heat Transfer Vinyl) is often considered the best option for crafting T-shirts due to its versatility, ease of use, and durability. It allows for complex designs and is affordable for small orders. It also offers a wide range of special effects, textures, and finishes, making it ideal for personalized and high-end customization. However, you can use adhesive vinyl as a cheaper alternative.
Why Is My Cricut iron-on vinyl Not Sticking?
Iron-on transfers might not adhere properly due to several reasons:
Ensure the EasyPress or iron is set to the correct temperature for your specific vinyl and base material, as recommended in the Cricut Heat Guide.
Use firm, even pressure. Ironing boards and plastic surfaces can both hinder and facilitate proper adhesion.
Apply heat for the recommended duration, and consider reapplying heat to the material for an additional 10-15 seconds.
Ensure you’re using the correct peel type for your specific vinyl.
Source: How to Use a Cricut to Make Shirts
1 note
·
View note
Text
Boost Your Retail Strategy with Quick Commerce Data Scraping in 2025
Introduction
The retail landscape is evolving rapidly, with Quick Commerce (Q-Commerce) driving instant deliveries across groceries, FMCG, and essential products. Platforms like Blinkit, Instacart, Getir, Gorillas, Swiggy Instamart, and Zapp dominate the space, offering ultra-fast deliveries. However, for retailers to stay competitive, optimize pricing, and track inventory, real-time data insights are crucial.
Quick Commerce Data Scraping has become a game-changer in 2025, enabling retailers to extract, analyze, and act on live market data. Retail Scrape, a leader in AI-powered data extraction, helps businesses track pricing trends, stock levels, promotions, and competitor strategies.
Why Quick Commerce Data Scraping is Essential for Retailers?
Optimize Pricing Strategies – Track real-time competitor prices & adjust dynamically.
Monitor Inventory Trends – Avoid overstocking or stockouts with demand forecasting.
Analyze Promotions & Discounts – Identify top deals & seasonal price drops.
Understand Consumer Behavior – Extract insights from customer reviews & preferences.
Improve Supply Chain Management – Align logistics with real-time demand analysis.
How Quick Commerce Data Scraping Enhances Retail Strategies?
1. Real-Time Competitor Price Monitoring
2. Inventory Optimization & Demand Forecasting
3. Tracking Promotions & Discounts
4. AI-Driven Consumer Behavior Analysis
Challenges in Quick Commerce Scraping & How to Overcome Them
Frequent Website Structure Changes Use AI-driven scrapers that automatically adapt to dynamic HTML structures and website updates.
Anti-Scraping Technologies (CAPTCHAs, Bot Detection, IP Bans) Deploy rotating proxies, headless browsers, and CAPTCHA-solving techniques to bypass restrictions.
Real-Time Price & Stock Changes Implement real-time web scraping APIs to fetch updated pricing, discounts, and inventory availability.
Geo-Restricted Content & Location-Based Offers Use geo-targeted proxies and VPNs to access region-specific data and ensure accuracy.
High Request Volume Leading to Bans Optimize request intervals, use distributed scraping, and implement smart throttling to prevent getting blocked.
Unstructured Data & Parsing Complexities Utilize AI-based data parsing tools to convert raw HTML into structured formats like JSON, CSV, or databases.
Multiple Platforms with Different Data Formats Standardize data collection from apps, websites, and APIs into a unified format for seamless analysis.
Industries Benefiting from Quick Commerce Data Scraping
1. eCommerce & Online Retailers
2. FMCG & Grocery Brands
3. Market Research & Analytics Firms
4. Logistics & Supply Chain Companies
How Retail Scrape Can Help Businesses in 2025
Retail Scrape provides customized Quick Commerce Data Scraping Services to help businesses gain actionable insights. Our solutions include:
Automated Web & Mobile App Scraping for Q-Commerce Data.
Competitor Price & Inventory Tracking with AI-Powered Analysis.
Real-Time Data Extraction with API Integration.
Custom Dashboards for Data Visualization & Predictive Insights.
Conclusion
In 2025, Quick Commerce Data Scraping is an essential tool for retailers looking to optimize pricing, track inventory, and gain competitive intelligence. With platforms like Blinkit, Getir, Instacart, and Swiggy Instamart shaping the future of instant commerce, data-driven strategies are the key to success.
Retail Scrape’s AI-powered solutions help businesses extract, analyze, and leverage real-time pricing, stock, and consumer insights for maximum profitability.
Want to enhance your retail strategy with real-time Q-Commerce insights? Contact Retail Scrape today!
Read more >>https://www.retailscrape.com/fnac-data-scraping-retail-market-intelligence.php
officially published by https://www.retailscrape.com/.
#QuickCommerceDataScraping#RealTimeDataExtraction#AIPoweredDataExtraction#RealTimeCompetitorPriceMonitoring#MobileAppScraping#QCommerceData#QCommerceInsights#BlinkitDataScraping#RealTimeQCommerceInsights#RetailScrape#EcommerceAnalytics#InstantDeliveryData#OnDemandCommerceData#QuickCommerceTrends
0 notes
Text
Intuitive Powerful Visual Web Scraper - WebHarvy can automatically scrape Text, Images, URLs & Emails from websites, and save the scraped content in various formats. WebHarvy Web Scraper can be used to scrape data from www.yellowpages.com. Data fields such as name, address, phone number, website URL etc can be selected for extraction by just clicking on them! - Point and Click Interface WebHarvy is a visual web scraper. There is absolutely no need to write any scripts or code to scrape data. You will be using WebHarvy's in-built browser to navigate web pages. You can select the data to be scraped with mouse clicks. It is that easy ! - Scrape Data Patterns Automatic Pattern Detection WebHarvy automatically identifies patterns of data occurring in web pages. So if you need to scrape a list of items (name, address, email, price etc) from a web page, you need not do any additional configuration. If data repeats, WebHarvy will scrape it automatically. - Export scraped data Save to File or Database You can save the data extracted from web pages in a variety of formats. The current version of WebHarvy Web Scraper allows you to export the scraped data as an XML, CSV, JSON or TSV file. You can also export the scraped data to an SQL database. - Scrape data from multiple pages Scrape from Multiple Pages Often web pages display data such as product listings in multiple pages. WebHarvy can automatically crawl and extract data from multiple pages. Just point out the 'link to the next page' and WebHarvy Web Scraper will automatically scrape data from all pages. - Keyword based Scraping Keyword based Scraping Keyword based scraping allows you to capture data from search results pages for a list of input keywords. The configuration which you create will be automatically repeated for all given input keywords while mining data. Any number of input keywords can be specified. - Scrape via proxy server Proxy Servers To scrape anonymously and to prevent the web scraping software from being blocked by web servers, you have the option to access target websites via proxy servers. Either a single proxy server address or a list of proxy server addresses may be used. - Category Scraping Category Scraping WebHarvy Web Scraper allows you to scrape data from a list of links which leads to similar pages within a website. This allows you to scrape categories or subsections within websites using a single configuration. - Regular Expressions WebHarvy allows you to apply Regular Expressions (RegEx) on Text or HTML source of web pages and scrape the matching portion. This powerful technique offers you more flexibility while scraping data. - WebHarvy Support Technical Support Once you purchase WebHarvy Web Scraper you will receive free updates and free support from us for a period of 1 year from the date of purchase. Bug fixes are free for lifetime. WebHarvy 7.7.0238 Released on May 19, 2025 - Updated Browser WebHarvy’s internal browser has been upgraded to the latest available version of Chromium. This improves website compatibility and enhances the ability to bypass anti-scraping measures such as CAPTCHAs and Cloudflare protection. - Improved ‘Follow this link’ functionality Previously, the ‘Follow this link’ option could be disabled during configuration, requiring manual steps like capturing HTML, capturing more content, and applying a regular expression to enable it. This process is now handled automatically behind the scenes, making configuration much simpler for most websites. - Solved Excel File Export Issues We have resolved issues where exporting scraped data to an Excel file could result in a corrupted output on certain system environments. - Fixed Issue related to changing pagination type while editing configuration Previously, when selecting a different pagination method during configuration, both the old and new methods could get saved together in some cases. This issue has now been fixed. - General Security Updates All internal libraries have been updated to their latest versions to ensure improved security and stability. Sales Page:https://www.webharvy.com/ DOWNLOAD LINKS & INSTRUCTIONS: Sorry, You need to be logged in to see the content. Please Login or Register as VIP MEMBERS to access. Read the full article
0 notes
Text
Unlocking Sales Leads: How LinkedIn Data Extraction Tool Works with Sales Navigator Scraper – Powered by Data Reclaimer
In the digital era, sales success is no longer about cold calls and guesswork — it’s about smart data, targeted outreach, and precision prospecting. That’s where LinkedIn Sales Navigator and modern scraping tools like Sales Navigator Scraper come into play. Designed to enhance B2B lead generation, these tools extract actionable business intelligence directly from the world’s largest professional network. But how does a LinkedIn data extraction tool work? And what makes tools like those offered by Data Reclaimer a game-changer for sales professionals?
Let’s explore.
What Is LinkedIn Sales Navigator?
LinkedIn Sales Navigator is a premium tool provided by LinkedIn, tailored for sales teams and B2B marketers. It offers advanced search filters, lead recommendations, CRM integrations, and insights into buyer intent — all aimed at helping users connect with the right decision-makers.
However, manually collecting and organizing data from Sales Navigator can be time-consuming and inefficient. This is where data extraction tools or Sales Navigator scrapers come in, automating the process of pulling valuable data from LinkedIn profiles, company pages, and lead lists.
How LinkedIn Data Extraction Tools Work
When we ask "How LinkedIn Data Extraction Tool Works?", the answer lies in a combination of intelligent web scraping, automation frameworks, and ethical data handling practices.
1. User Authentication & Input
First, the user logs into their LinkedIn account — typically through Sales Navigator — and defines search parameters such as industry, location, job title, company size, or keywords.
2. Automated Crawling
Once parameters are set, the tool initiates an automated crawl through the search results. Using browser automation (often through headless browsers like Puppeteer or Selenium), it navigates LinkedIn just like a human would — scrolling, clicking, and viewing profiles.
3. Data Extraction
The scraper extracts public or semi-public information such as:
Full Name
Job Title
Company Name
Location
LinkedIn Profile URL
Contact info (if available)
Industry and seniority level
Connection level (1st, 2nd, 3rd)
4. Data Structuring
After extraction, the data is parsed and organized into a clean format — usually a CSV or JSON file — for easy import into CRMs like HubSpot, Salesforce, or marketing automation platforms.
5. Export and Integration
Finally, users can download the dataset or directly sync it to their sales stack, ready for outreach, segmentation, or analysis.
Why Use Sales Navigator Scraper by Data Reclaimer?
Data Reclaimer offers a cutting-edge Sales Navigator Scraper designed to be user-friendly, accurate, and compliant with best practices. Here’s why it stands out:
✅ High Accuracy & Speed
Unlike basic scrapers that miss key data points or get blocked, Data Reclaimer’s tool uses advanced logic to mimic human interaction, ensuring minimal detection and high-quality results.
✅ Custom Filters & Targeting
Pull data based on highly specific LinkedIn Sales Navigator filters such as seniority, department, activity, and more — allowing for razor-sharp targeting.
✅ Real-Time Data Updates
Stay ahead of outdated contact lists. The tool extracts real-time profile data, ensuring your leads are current and relevant.
✅ GDPR-Aware Extraction
Data Reclaimer ensures its scraping tools align with ethical and legal standards, including GDPR compliance by focusing only on publicly accessible data.
✅ Scalable for Agencies and Teams
Whether you're a solo marketer or part of a large agency, the Sales Navigator Scraper supports bulk extraction for large-scale lead generation.
Use Cases for LinkedIn Data Extraction Tools
From recruiters and B2B marketers to SDRs and startup founders, many professionals benefit from LinkedIn data scraping:
Lead Generation: Build targeted B2B lead lists quickly without manual searching.
Competitor Research: Analyze hiring trends, employee roles, or client networks.
Market Segmentation: Understand demographics within an industry or region.
Recruitment: Identify potential candidates based on roles and skills.
Corporate Intelligence: Map organizational charts and influencer hierarchies.
Ethical Considerations & Best Practices
Using a LinkedIn data extraction tool should always follow responsible use practices. Data Reclaimer advises:
Avoid scraping excessive data that may violate LinkedIn's terms of use.
Only extract information that is publicly available.
Use scraped data for B2B networking and not for spam or harassment.
Clearly disclose how data will be used when reaching out to prospects.
Respect for data privacy not only ensures compliance but also builds trust with your leads.
Tips for Maximizing Sales Navigator Scraper Efficiency
Refine Your Filters: The more specific your Sales Navigator search, the cleaner and more targeted your data output.
Use Proxy Rotation: To avoid IP blocks, consider rotating proxies or using a tool that automates this for you.
Limit Daily Requests: Over-scraping can trigger LinkedIn’s anti-bot systems. Stick to daily limits suggested by your scraper provider.
Enrich and Verify Data: Use email verification tools or enrichment platforms to validate and enhance extracted data.
Integrate with Your CRM: Automate lead nurturing by syncing extracted leads into your CRM system for immediate follow-up.
Conclusion: Sales Prospecting at Scale, the Smart Way
In today’s hyper-competitive B2B landscape, the ability to access high-quality, targeted leads can set you apart from the competition. Understanding how LinkedIn data extraction tools work, especially through powerful solutions like the Sales Navigator Scraper by Data Reclaimer, empowers sales teams to focus on closing deals instead of chasing contact information.
From startups to enterprise sales departments and B2B agencies, tools like these are not just about automation — they’re about intelligence, efficiency, and scalability.
1 note
·
View note
Text
Unlock the Full Potential of Web Data with ProxyVault’s Datacenter Proxy API
In the age of data-driven decision-making, having reliable, fast, and anonymous access to web resources is no longer optional—it's essential. ProxyVault delivers a cutting-edge solution through its premium residential, datacenter, and rotating proxies, equipped with full HTTP and SOCKS5 support. Whether you're a data scientist, SEO strategist, or enterprise-scale scraper, our platform empowers your projects with a secure and unlimited Proxy API designed for scalability, speed, and anonymity. In this article, we focus on one of the most critical assets in our suite: the datacenter proxy API.
What Is a Datacenter Proxy API and Why It Matters
A datacenter proxy API provides programmatic access to a vast pool of high-speed IP addresses hosted in data centers. Unlike residential proxies that rely on real-user IPs, datacenter proxies are not affiliated with Internet Service Providers (ISPs). This distinction makes them ideal for large-scale operations such as:
Web scraping at volume
Competitive pricing analysis
SEO keyword rank tracking
Traffic simulation and testing
Market intelligence gathering
With ProxyVault’s datacenter proxy API, you get lightning-fast response times, bulk IP rotation, and zero usage restrictions, enabling seamless automation and data extraction at any scale.
Ultra-Fast and Scalable Infrastructure
One of the hallmarks of ProxyVault’s platform is speed. Our datacenter proxy API leverages ultra-reliable servers hosted in high-bandwidth facilities worldwide. This ensures your requests experience minimal latency, even during high-volume data retrieval.
Dedicated infrastructure guarantees consistent uptime
Optimized routing minimizes request delays
Low ping times make real-time scraping and crawling more efficient
Whether you're pulling hundreds or millions of records, our system handles the load without breaking a sweat.
Unlimited Access with Full HTTP and SOCKS5 Support
Our proxy API supports both HTTP and SOCKS5 protocols, offering flexibility for various application environments. Whether you're managing browser-based scraping tools, automated crawlers, or internal dashboards, ProxyVault’s datacenter proxy API integrates seamlessly.
HTTP support is ideal for most standard scraping tools and analytics platforms
SOCKS5 enables deep integration for software requiring full network access, including P2P and FTP operations
This dual-protocol compatibility ensures that no matter your toolset or tech stack, ProxyVault works right out of the box.
Built for SEO, Web Scraping, and Data Mining
Modern businesses rely heavily on data for strategy and operations. ProxyVault’s datacenter proxy API is custom-built for the most demanding use cases:
SEO Ranking and SERP Monitoring
For marketers and SEO professionals, tracking keyword rankings across different locations is critical. Our proxies support geo-targeting, allowing you to simulate searches from specific countries or cities.
Track competitor rankings
Monitor ad placements
Analyze local search visibility
The proxy API ensures automated scripts can run 24/7 without IP bans or CAPTCHAs interfering.
Web Scraping at Scale
From eCommerce sites to travel platforms, web scraping provides invaluable insights. Our rotating datacenter proxies change IPs dynamically, reducing the risk of detection.
Scrape millions of pages without throttling
Bypass rate limits with intelligent IP rotation
Automate large-scale data pulls securely
Data Mining for Enterprise Intelligence
Enterprises use data mining for trend analysis, market research, and customer insights. Our infrastructure supports long sessions, persistent connections, and high concurrency, making ProxyVault a preferred choice for advanced data extraction pipelines.
Advanced Features with Complete Control
ProxyVault offers a powerful suite of controls through its datacenter proxy API, putting you in command of your operations:
Unlimited bandwidth and no request limits
Country and city-level filtering
Sticky sessions for consistent identity
Real-time usage statistics and monitoring
Secure authentication using API tokens or IP whitelisting
These features ensure that your scraping or data-gathering processes are as precise as they are powerful.
Privacy-First, Log-Free Architecture
We take user privacy seriously. ProxyVault operates on a strict no-logs policy, ensuring that your requests are never stored or monitored. All communications are encrypted, and our servers are secured using industry best practices.
Zero tracking of API requests
Anonymity by design
GDPR and CCPA-compliant
This gives you the confidence to deploy large-scale operations without compromising your company’s or clients' data.
Enterprise-Level Support and Reliability
We understand that mission-critical projects demand not just great tools but also reliable support. ProxyVault offers:
24/7 technical support
Dedicated account managers for enterprise clients
Custom SLAs and deployment options
Whether you need integration help or technical advice, our experts are always on hand to assist.
Why Choose ProxyVault for Your Datacenter Proxy API Needs
Choosing the right proxy provider can be the difference between success and failure in data operations. ProxyVault delivers:
High-speed datacenter IPs optimized for web scraping and automation
Fully customizable proxy API with extensive documentation
No limitations on bandwidth, concurrent threads, or request volume
Granular location targeting for more accurate insights
Proactive support and security-first infrastructure
We’ve designed our datacenter proxy API to be robust, reliable, and scalable—ready to meet the needs of modern businesses across all industries.
Get Started with ProxyVault Today
If you’re ready to take your data operations to the next level, ProxyVault offers the most reliable and scalable datacenter proxy API on the market. Whether you're scraping, monitoring, mining, or optimizing, our solution ensures your work is fast, anonymous, and unrestricted.
Start your free trial today and experience the performance that ProxyVault delivers to thousands of users around the globe.
1 note
·
View note
Text
Impact of AI on Web Scraping Practices

Introduction
Owing to advancements in artificial intelligence (AI), the history of web scraping is a story of evolution towards efficiency in recent times. With an increasing number of enterprises and researchers relying on data extraction in deriving insights and making decisions, AI-enabled web scraping methods have transformed some of the traditional techniques into newer methods that are more efficient, more scalable, and more resistant to anti-scraping measures.
This blog discusses the effects of AI on web scraping, how AI-powered automation is changing the web scraping industry, the challenges being faced, and, ultimately, the road ahead for web scraping with AI.
How AI is Transforming Web Scraping
1. Enhanced Data Extraction Efficiency
Standard methods of scraping websites and information are rule-based extraction and rely on the script that anybody has created for that particular site, and it is hard-coded for that site and set of extraction rules. But in the case of web scraping using AI, such complexities are avoided, wherein the adaptation of the script happens automatically with a change in the structure of the websites, thus ensuring the same data extraction without rewriting the script constantly.
2. AI-Powered Web Crawlers
Machine learning algorithms enable web crawlers to mimic human browsing behavior, reducing the risk of detection. These AI-driven crawlers can:
Identify patterns in website layouts.
Adapt to dynamic content.
Handle complex JavaScript-rendered pages with ease.
3. Natural Language Processing (NLP) for Data Structuring
NLP helps in:
Extracting meaningful insights from unstructured text.
Categorizing and classifying data based on context.
Understanding sentiment and contextual relevance in customer reviews and news articles.
4. Automated CAPTCHA Solving
Many websites use CAPTCHAs to block bots. AI models, especially deep learning-based Optical Character Recognition (OCR) techniques, help bypass these challenges by simulating human-like responses.
5. AI in Anti-Detection Mechanisms
AI-powered web scraping integrates:
User-agent rotation to simulate diverse browsing behaviors.
IP Rotation & Proxies to prevent blocking.
Headless Browsers & Human-Like Interaction for bypassing bot detection.
Applications of AI in Web Scraping
1. E-Commerce Price Monitoring
AI scrapers help businesses track competitors' pricing, stock availability, and discounts in real-time, enabling dynamic pricing strategies.
2. Financial & Market Intelligence
AI-powered web scraping extracts financial reports, news articles, and stock market data for predictive analytics and trend forecasting.
3. Lead Generation & Business Intelligence
Automating the collection of business contact details, customer feedback, and sales leads through AI-driven scraping solutions.
4. Social Media & Sentiment Analysis
Extracting social media conversations, hashtags, and sentiment trends to analyze brand reputation and customer perception.
5. Healthcare & Pharmaceutical Data Extraction
AI scrapers retrieve medical research, drug prices, and clinical trial data, aiding healthcare professionals in decision-making.
Challenges in AI-Based Web Scraping
1. Advanced Anti-Scraping Technologies
Websites employ sophisticated detection methods, including fingerprinting and behavioral analysis.
AI mitigates these by mimicking real user interactions.
2. Data Privacy & Legal Considerations
Compliance with data regulations like GDPR and CCPA is essential.
Ethical web scraping practices ensure responsible data usage.
3. High Computational Costs
AI-based web scrapers require GPU-intensive resources, leading to higher operational costs.
Optimization techniques, such as cloud-based scraping, help reduce costs.
Future Trends in AI for Web Scraping
1. AI-Driven Adaptive Scrapers
Scrapers that self-learn and adjust to new website structures without human intervention.
2. Integration with Machine Learning Pipelines
Combining AI scrapers with data analytics tools for real-time insights.
3. AI-Powered Data Anonymization
Protecting user privacy by automating data masking and filtering.
4. Blockchain-Based Data Validation
Ensuring authenticity and reliability of extracted data using blockchain verification.
Conclusion
The addition of AI to the web scrape has made it smarter, flexible, and scalable as far as data extraction is concerned. The use of AIs for web scraping will help organizations navigate through anti-bot mechanisms, dynamic changes in websites, and unstructured data processing. Indeed, in the future, web scraping with AI will only be enhanced and more advanced to contribute further innovations in sectors across industries.
For organizations willing to embrace the power of data extraction with AI, CrawlXpert brings you state-of-the-art solutions designed for the present-day web scraping task. Get working with CrawlXpert right now in order to gain from AI-enabled quality automated web scraping solutions!
Know More : https://www.crawlxpert.com/blog/ai-on-web-scraping-practices
0 notes
Text
Web Scraping 101: Everything You Need to Know in 2025

🕸️ What Is Web Scraping? An Introduction
Web scraping—also referred to as web data extraction—is the process of collecting structured information from websites using automated scripts or tools. Initially driven by simple scripts, it has now evolved into a core component of modern data strategies for competitive research, price monitoring, SEO, market intelligence, and more.
If you’re wondering “What is the introduction of web scraping?” — it’s this: the ability to turn unstructured web content into organized datasets businesses can use to make smarter, faster decisions.
💡 What Is Web Scraping Used For?
Businesses and developers alike use web scraping to:
Monitor competitors’ pricing and SEO rankings
Extract leads from directories or online marketplaces
Track product listings, reviews, and inventory
Aggregate news, blogs, and social content for trend analysis
Fuel AI models with large datasets from the open web
Whether it’s web scraping using Python, browser-based tools, or cloud APIs, the use cases are growing fast across marketing, research, and automation.
🔍 Examples of Web Scraping in Action
What is an example of web scraping?
A real estate firm scrapes listing data (price, location, features) from property websites to build a market dashboard.
An eCommerce brand scrapes competitor prices daily to adjust its own pricing in real time.
A SaaS company uses BeautifulSoup in Python to extract product reviews and social proof for sentiment analysis.
For many, web scraping is the first step in automating decision-making and building data pipelines for BI platforms.
⚖️ Is Web Scraping Legal?
Yes—if done ethically and responsibly. While scraping public data is legal in many jurisdictions, scraping private, gated, or copyrighted content can lead to violations.
To stay compliant:
Respect robots.txt rules
Avoid scraping personal or sensitive data
Prefer API access where possible
Follow website terms of service
If you’re wondering “Is web scraping legal?”—the answer lies in how you scrape and what you scrape.
🧠 Web Scraping with Python: Tools & Libraries
What is web scraping in Python? Python is the most popular language for scraping because of its ease of use and strong ecosystem.
Popular Python libraries for web scraping include:
BeautifulSoup – simple and effective for HTML parsing
Requests – handles HTTP requests
Selenium – ideal for dynamic JavaScript-heavy pages
Scrapy – robust framework for large-scale scraping projects
Puppeteer (via Node.js) – for advanced browser emulation
These tools are often used in tutorials like “Web scraping using Python BeautifulSoup” or “Python web scraping library for beginners.”
⚙️ DIY vs. Managed Web Scraping
You can choose between:
DIY scraping: Full control, requires dev resources
Managed scraping: Outsourced to experts, ideal for scale or non-technical teams
Use managed scraping services for large-scale needs, or build Python-based scrapers for targeted projects using frameworks and libraries mentioned above.
🚧 Challenges in Web Scraping (and How to Overcome Them)
Modern websites often include:
JavaScript rendering
CAPTCHA protection
Rate limiting and dynamic loading
To solve this:
Use rotating proxies
Implement headless browsers like Selenium
Leverage AI-powered scraping for content variation and structure detection
Deploy scrapers on cloud platforms using containers (e.g., Docker + AWS)
🔐 Ethical and Legal Best Practices
Scraping must balance business innovation with user privacy and legal integrity. Ethical scraping includes:
Minimal server load
Clear attribution
Honoring opt-out mechanisms
This ensures long-term scalability and compliance for enterprise-grade web scraping systems.
🔮 The Future of Web Scraping
As demand for real-time analytics and AI training data grows, scraping is becoming:
Smarter (AI-enhanced)
Faster (real-time extraction)
Scalable (cloud-native deployments)
From developers using BeautifulSoup or Scrapy, to businesses leveraging API-fed dashboards, web scraping is central to turning online information into strategic insights.
📘 Summary: Web Scraping 101 in 2025
Web scraping in 2025 is the automated collection of website data, widely used for SEO monitoring, price tracking, lead generation, and competitive research. It relies on powerful tools like BeautifulSoup, Selenium, and Scrapy, especially within Python environments. While scraping publicly available data is generally legal, it's crucial to follow website terms of service and ethical guidelines to avoid compliance issues. Despite challenges like dynamic content and anti-scraping defenses, the use of AI and cloud-based infrastructure is making web scraping smarter, faster, and more scalable than ever—transforming it into a cornerstone of modern data strategies.
🔗 Want to Build or Scale Your AI-Powered Scraping Strategy?
Whether you're exploring AI-driven tools, training models on web data, or integrating smart automation into your data workflows—AI is transforming how web scraping works at scale.
👉 Find AI Agencies specialized in intelligent web scraping on Catch Experts,
📲 Stay connected for the latest in AI, data automation, and scraping innovation:
💼 LinkedIn
🐦 Twitter
📸 Instagram
👍 Facebook
▶️ YouTube
#web scraping#what is web scraping#web scraping examples#AI-powered scraping#Python web scraping#web scraping tools#BeautifulSoup Python#web scraping using Python#ethical web scraping#web scraping 101#is web scraping legal#web scraping in 2025#web scraping libraries#data scraping for business#automated data extraction#AI and web scraping#cloud scraping solutions#scalable web scraping#managed scraping services#web scraping with AI
0 notes
Text
Unlocking Customer Insights: The Complete Guide to Scraping Blinkit Reviews Data

In today’s fast-paced digital economy, understanding your customer is everything. Blinkit, one of India’s top hyperlocal delivery apps, handles millions of grocery and essential deliveries daily. And behind every order lies a customer review full of insights. So, how can businesses tap into this goldmine of customer sentiment?
Simple: Web scraping Blinkit reviews data.
This guide explores how to systematically collect and analyze customer reviews using a Blinkit Reviews Scraper. From discovering market trends to improving products and customer service, you’ll see why review data is one of the smartest ways to sharpen your competitive edge.
Why Blinkit Reviews Matter
Formerly known as Grofers, Blinkit is a household name in rapid delivery. With thousands of SKUs and a large urban user base, Blinkit’s reviews offer:
Customer Sentiment: Understand real-time satisfaction levels, complaints, and delight factors.
Product Insights: Find out what users love or dislike about specific products.
Market Trends: Monitor new demands and seasonality from organic feedback.
Localized Preferences: Discover how customer experiences vary across cities and neighborhoods.
These reviews aren’t just opinions—they’re actionable data.
What is Web Scraping?
Web scraping is a method of automatically collecting data from websites. A Blinkit Reviews Scraper can extract structured insights like:
Star ratings
Review comments
Product references
Timestamps
This process is scalable, accurate, and faster than manual research. With tools like Datazivot’s Blinkit Reviews Data Extractor, businesses can turn raw text into meaningful trends in no time.
Powerful Use Cases for Blinkit Reviews Scraping
Let’s break down how you can use this data:
Product Development
Spot recurring issues (e.g., broken packaging, stale products)
Track positive mentions to replicate success across SKUs
Pricing Strategy
Use sentiment analysis to see if users feel products are worth their price
Competitor Benchmarking
Compare reviews of your products vs. competitor listings
Inventory Management
Predict demand spikes based on positive or trending reviews
Localized Campaigns
Customize your marketing based on what specific neighborhoods love most
Ethical and Legal Considerations
Before scraping:
Check Terms of Service: Always review Blinkit’s policies
Respect robots.txt: Only scrape data allowed by the website
Throttle Requests: Avoid being flagged or blocked
Use scraped data for internal insights, not redistribution. Ethical scraping builds trust and sustainability.
Technical Snapshot: Building a Blinkit Reviews Scraper
To effectively scrape Blinkit reviews, your tool should:
Handle JavaScript-heavy content
Navigate pagination
Extract structured data (ratings, comments, timestamps)
Simulate real-user behavior using headers/cookies
Store data in CSV, JSON, or databases
Popular tools:
BeautifulSoup + Requests (Python): Best for static content
Selenium/Puppeteer: Great for dynamic content
Scrapy: Excellent for scalable projects
Clean, Analyze, and Visualize the Data
Once scraped, clean the data:
Remove duplicates
Normalize text (e.g., lowercase, strip punctuation)
Translate reviews if multilingual
Then analyze:
Sentiment Scores (using NLTK or TextBlob)
Trend Graphs (using Pandas/Matplotlib)
Word Clouds (to visualize common issues or praise)
Real-World Applications
Here’s how brands are already using Blinkit review data:
Brand Reputation Monitoring: Real-time customer sentiment tracking
AI & ML Training: Feeding labeled review data into models
Campaign Optimization: Using reviews to fine-tune ad messaging
Customer Support Planning: Identify and fix issues before they escalate
Overcoming Scraping Challenges
Dynamic Pages: Use headless browsers like Puppeteer
IP Blocking: Rotate proxies and use user-agent headers
Captcha: Build fallback logic
Partnering with experts like Datazivot ensures you get clean, accurate, and compliant data.
Why Choose Datazivot?
We specialize in scalable and ethical web scraping solutions tailored to your goals. Whether you need one-time extraction or live data feeds, our Blinkit Reviews Data Scraper is designed for accuracy and speed.
Plug-and-play API solutions
Custom dashboards for insights
End-to-end support from data collection to visualization
Conclusion
Customer reviews are no longer just feedback—they’re data-driven blueprints for business growth. With Blinkit Reviews Data Scraping, you can unlock customer preferences, track trends, and outmaneuver the competition.
Start turning reviews into revenue.
🚀 Explore Datazivot's Blinkit Reviews Scraper and transform customer feedback into actionable insights.
Follow us on LinkedIn for more content on web scraping, data strategies, and eCommerce intelligence.
#startup#founder#branding#artists on tumblr#Web Scraping Blinkit Reviews Data#Blinkit Reviews Data Scraping#Scrape Blinkit Reviews Data#Blinkit Reviews Data Extractor#Blinkit Reviews Scraper
0 notes
Text
Data/Web Scraping
What is Data Scraping ?
Data scraping is the process of extracting information from websites or other digital sources. It also Knows as web scraping.
Benefits of Data Scraping
1. Competitive Intelligence
Stay ahead of competitors by tracking their prices, product launches, reviews, and marketing strategies.
2. Dynamic Pricing
Automatically update your prices based on market demand, competitor moves, or stock levels.
3. Market Research & Trend Discovery
Understand what’s trending across industries, platforms, and regions.
4. Lead Generation
Collect emails, names, and company data from directories, LinkedIn, and job boards.
5. Automation & Time Savings
Why hire a team to collect data manually when a scraper can do it 24/7.
Who used Data Scraper ?

Businesses, marketers,E-commerce, travel,Startups, analysts,Sales, recruiters, researchers, Investors, agents Etc
Top Data Scraping Browser Extensions
Web Scraper.io
Scraper
Instant Data Scraper
Data Miner
Table Capture
Top Data Scraping Tools
BeautifulSoup
Scrapy
Selenium
Playwright
Octoparse
Apify
ParseHub
Diffbot
Custom Scripts
Legal and Ethical Notes

Not all websites allow scraping. Some have terms of service that forbid it, and scraping too aggressively can get IPs blocked or lead to legal trouble
Apply For Data/Web Scraping : https://www.fiverr.com/s/99AR68a
1 note
·
View note