#chrome web scraper multiple pages
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
BuzzFeed published a report claiming that Tumblr was utilized as a distribution channel for Russian agents to influence American voting habits during the 2016 presidential election in Feb 2018.
Text
diy ao3 wrapped: how to get your data!
so i figured out how to do this last year, and spotify wrapped season got me thinking about it again. a couple people in discord asked how to do it so i figured i'd write up a little guide! i'm not quite done with mine for this year yet because i wanted to do some graphics, but this is the post i made last year, for reference!
this got long! i tried to go into as much detail as possible to make it as easy as possible, but i am a web developer, so if there's anything i didn't explain enough (or if you have any other questions) don't hesitate to send me an ask!!
references
i used two reddit posts as references for this:
basic instructions (explains the browser extension; code gets title, word count, and author)
expanded instructions (code gets title, word count, and author, as well as category, date posted, last visited, warnings, rating, fandom, relationship, summary, and completion status, and includes instructions for how to include tags and switch fandoms/relationships to multiple—i will include notes on that later)
both use the extension webscraper.io which is available for both firefox and chrome (and maybe others, but i only use firefox/chrome personally so i didn't check any others, sorry. firefox is better anyway)
scraping your basic/expanded data
first, install the webscraper plugin/extension.
once it's installed, press ctrl+shift+i on pc or cmd+option+i on mac to open your browser's dev tools and navigate to the Web Scraper tab

from there, click "Create New Site Map" > "Import Sitemap"

it will open a screen with a field to input json code and a field for name—you don't need to manually input the name, it will fill in automatically based on the json you paste in. if you want to change it after, changing one will change the other.
i've put the codes i used on pastebin here: basic // expanded

once you've pasted in your code, you will want to update the USERNAME (highlighted in yellow) to your ao3 username, and the LASTPAGE (highlighted in pink) to the last page you want to scrape. to find this, go to your history page on ao3, and click back until you find your first fic of 2024! make sure you go by the "last visited" date instead of the post date.

if you do want to change the id, you can update the value (highlighted in blue) and it will automatically update the sitemap name field, or vice versa. everything else can be left as is.
once you're done, click import, and it'll show you the sitemap. on the top bar, click the middle tab, "Sitemap [id of sitemap]" and choose Scrape. you'll see a couple of options—the defaults worked fine for me, but you can mess with them if you need to. as far as i understand it, it just sets how much time it takes to scrape each page so ao3 doesn't think it's getting attacked by a bot. now click "start scraping"!


once you've done that, it will pop up with a new window which will load your history. let it do its thing. it will start on the last page and work its way back to the first, so depending on how many pages you have, it could take a while. i have 134 pages and it took about 10-12 minutes to get through them all.
once the scrape is done, the new window will close and you should be back at your dev tools window. you can click on the "Sitemap [id of sitemap]" tab again and choose Export data.

i downloaded the data as .xlsx and uploaded to my google drive. and now you can close your dev tools window!
from here on out my instructions are for google sheets; i'm sure most of the queries and calculations will be similar in other programs, but i don't really know excel or numbers, sorry!
setting up your spreadsheet
once it's opened, the first thing i do is sort the "viewed" column A -> Z and get rid of the rows for any deleted works. they don't have any data so no need to keep them. next, i select the columns for "web-scraper-order" and "web-scraper-start-url" (highlighted in pink) and delete them; they're just default data added by the scraper and we don't need them, so it tidies it up a little.

this should leave you with category, posted, viewed, warning, rating, fandom, relationship, title, author, wordcount, and completion status if you used the expanded code. if there are any of these you don't want, you can go ahead and delete those columns also!
next, i add blank columns to the right of the data i want to focus on. this just makes it easier to do my counts later. in my case these will be rating, fandom, relationship, author, and completion status.
one additional thing you should do, is checking the "viewed" column. you'll notice that it looks like this:
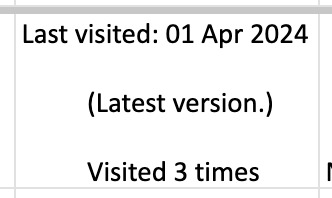
you can't really sort by this since it's text, not formatted as a date, so it'll go alphabetically by month rather than sorting by date. but, you'll want to be able to get rid of any entries that were viewed in 2023 (there could be none, but likely there are some because the scraper got everything on your last page even if it was viewed in 2023). what i did here was use the "find" dialog to search the "viewed" column for 2023, and deleted those rows manually.
ctrl/cmd+f, click the 3 dots for "more options". you want to choose "Specific range", then "C2:C#". replace C with the letter of your viewed column (remember i deleted a bunch, so yours may be different) and replace # with the number of the last row of your spreadsheet. then find 2023, select the rows containing it, right click > delete rows.
it isn't super necessary to do this, it will only add at most 19 fics to your count, but the option is there!

alright, with all that done, your sheet should look something like this:

exposing myself for having read stardew valley fic i guess
now for the fun part!!!
the math
yes, the math is the fun part.
scroll all the way down to the bottom of your sheet. i usually add 100 blank rows at the bottom just so i have some space to play with.
most of these will basically be the same query, just updating for the relevant column. i've put it in a pastebin here, but here's a screenshot so i can walk you through it:

you'll want to use lines 3-10, select the cell you want to put your data into, and paste the query into the formula bar (highlighted in green)

so, we're starting with rating, which is column E for me. if yours is a different letter you'll need to replace all the E's with the relevant letter.
what this does is it goes through the entire column, starting with row 2 (highlighted in yellow) and ending with your final row (highlighted in blue, you'll want to change this number to reflect how many rows you have). note that row 2 is your first actual data row, because of the header row.
it checks each row that has a value (line 5), groups by unique value (row 6), and arranges in descending order (row 7) by how many there are of each value (row 8). finally, row 10 determines how many rows of results you'll have; for rating, i put 5 because that's how many ratings there are, but you can increase the number of results (highlighted in pink) for other columns depending on how many you want. this is why i added the 100 extra rows!
next to make the actual number visible, go to the cell one column over. this is why we added the empty columns! next to your first result, add the second query from the pastebin:

your first and second cell numbers (highlighted in yellow and blue) should match the numbers from your query above, and the third number (highlighted in pink) should be the number of the cell with your first value. what this does is go through your column and count how many times the value occurs.
repeat this for the rest of the rows and you should end up with something like this! don't judge me and my reading habits please

now you can go ahead and repeat for the rest of your columns! as i mentioned above, you can increase the amount of result rows you get; i set it to 25 for fandom, relationship, and author, just because i was curious, and only two for completion status because it's either complete or not complete.
you should end up with something like this!

you may end up with some multiples (not sure why this happens, tagging issues maybe?) and up to you if you want to manually fix them! i just ended up doing a find and replace for the two that i didn't want and replaced with the correct tag.
now for the total wordcount! this one is pretty simple, it just adds together your entire column. first i selected the column (N for me) and went to Format > Number > 0 so it stripped commas etc. then at the bottom of the column, add the third query from the pastebin. as usual, your first number is the first data row, and the second is the last data row.

and just because i was curious, i wanted the average wordcount also, so in another cell i did this (fourth query from the pastebin), where the first number is the cell where your total is, and the second number is the total number of fics (total # of data rows minus 1 for the header row).

which gives me this:

tadaaaa!
getting multiple values
so, as i mentioned above, by default the scraper will only get the first value for relationships and fandoms. "but sarah," you may say, "what if i want an accurate breakdown of ALL the fandoms and relationships if there's multiples?"
here's the problem with that: if you want to be able to query and count them properly, each fandom or relationship needs to be its own row, which would skew all the other data. for me personally, it didn't bother me too much; i don't read a lot of crossovers, and typically if i'm reading a fic it's for the primary pairing, so i think the counts (for me) are pretty accurate. if you want to get multiples, i would suggest doing a secondary scrape to get those values separately.
if you want to edit the scrape to get multiples, navigate to one of your history pages (preferably one that has at least one work with multiple fandoms and/or relationships so you can preview) then hit ctrl+shift+i/cmd+option+i, open web scraper, and open your sitemap. expand the row and you should see all your values. find the one you want to edit and hit the "edit" button (highlighted in pink)

on the next screen, you should be good to just check the "Multiple" checkbox (highlighted in pink):

you can then hit "data preview" (highlighted in blue) to get a preview which should show you all the relationships on the page (which is why i said to find a page that has the multiples you are looking for, so you can confirm).

voila! now you can go back to the sitemap and scrape as before.
getting tag data
now, on the vein of multiples, i also wanted to get my most-read tags.
as i mentioned above, if you want to get ALL the tags, it'll skew the regular count data, so i did the tags in a completely separate query, which only grabs the viewed date and the tags. that code is here. you just want to repeat the scraping steps using that as a sitemap. save and open that spreadsheet.
the first thing you'll notice is that this one is a LOT bigger. for context i had 2649 fics in the first spreadsheet; the tags spreadsheet had 31,874 rows.
you can go ahead and repeat a couple of the same steps from before: remove the extra scraper data columns, and then we included the "viewed" column for the same reason as before, to remove any entries from 2023.
then you're just using the same basic query again!
replace the E with whatever your column letter is, and then change your limit to however many tags you want to see. i changed the limit to 50, again just for curiosity.
if you made it this far, congratulations! now that you have all that info, you can do whatever you want with it!
and again, if you have any questions please reach out!
55 notes
·
View notes
Text
Effective Web Scraping Tools That Save Money
The internet stands as an unparalleled resource, brimming with invaluable data of immense authenticity. In today's digital age, data fuels the world, serving as the cornerstone of knowledge and power. With the exponential growth of the web scraping sector, driven by an escalating demand for data, organizations must harness this formidable resource to maintain a competitive edge.
To capitalize on the potential of data, businesses must first gather it. Fortunately, a plethora of pre-built web scraping tools streamline this process, enabling the automated extraction of bulk data in structured formats, sans the need for extensive coding.
Recent research by Bright Data and Vanson Bourne underscores the prevalence of data collection bots, with over half of financial services, technology, and IT companies in the UK and US deploying them. This trend is expected to surge in the coming years, as organizations increasingly rely on automated tasks to fuel their operations.
In virtually every sector, from eCommerce to banking, web scraping tools play a pivotal role in data collection, offering insights crucial for both personal and business endeavors. The exponential growth of data production, projected to surpass 180 zettabytes by 2025, underscores the indispensability of effective data extraction tools.
The COVID-19 pandemic further accelerated this growth, as remote work and increased reliance on digital platforms fueled a surge in data demand. To navigate this data-rich landscape, businesses must leverage advanced web scraping tools capable of efficiently collecting and structuring vast datasets.
These tools not only expedite data collection but also yield significant cost savings. By opting for pre-built scrapers, businesses eliminate the need for costly in-house development, accessing high-quality data extraction capabilities without hefty investments in technology and resources.
Here, we highlight three highly effective web scraping tools renowned for their affordability and functionality:
Apiscrapy: Apiscrapy stands out as a leading provider of advanced data extraction solutions, offering powerful tools that transform unstructured web data into well-organized datasets, all without the need for coding. With features such as real-time data delivery, database integration, and outcome-based pricing, Apiscrapy streamlines the data extraction process while minimizing costs.
Data-Miner.io: Ideal for novice users, Data-Miner.io is a user-friendly Google Chrome Extension designed for seamless data collection. From extracting search results to capturing contact information, this intuitive tool simplifies advanced data extraction tasks, delivering clean datasets in CSV or Excel formats.
Webscraper.io: Webscraper.io offers both a Chrome extension and a cloud-based extractor, catering to a diverse range of scraping needs. With its user-friendly interface and structured data collection capabilities, Webscraper.io simplifies data extraction from multiple web pages simultaneously, offering an affordable solution for businesses of all sizes.
Import.io: Import.io emerges as a versatile data extraction and transformation tool, offering businesses the ability to automate web scraping and transform unstructured online data into actionable insights. With customizable extractors, real-time data collection, and flexible pricing based on project size, Import.io is an invaluable asset for businesses seeking high-quality data at affordable rates.
In conclusion, web scraping tools serve as indispensable allies in the quest for data-driven decision-making. By leveraging these tools effectively, businesses can access vast repositories of valuable data, driving informed strategies and fostering growth in an increasingly data-centric world.
0 notes
Text
Exploring the Power of Web Scraping: Extracting "People Also Ask" Questions from Google Results

In this article, we'll look at how to use web scraping to extract useful information from Google search results. We'll specifically focus on obtaining the "People Also Ask" questions and save them to a Google Sheets document. Let's get started, but first, please show your support by liking the video and subscribing to the channel. Your encouragement fuels our desire to create informative content. Now, let us get down to work.
Prerequisites:
1Open a Google Sheets Document To begin, open a Google Sheets document in which we'll execute web scraping.
2Add the "Import from Web" Extension Go to the given
Link to the "Import from Web" addon. This plugin is essential for allowing web scraping capability in Google Sheets. Make sure you add this extension to your Google Sheets for easy connection.
Activating the Extension:
Once you've installed the extension, navigate to your Google Sheets document and select the "Extensions" option.
Locate and enable the "Import from Web" addon. This step gives you access to a myriad of web scraping features right within your Google Sheets.
Executing Web Scraping:
Define your keyword: In a specific cell, such as B1, put the keyword from which you wish to extract "People Also Ask" queries. For example, let's use the keyword "skincare".
Utilize the Import Functionality: In the
for SEO experts, digital marketers, and content developers. Google's "People Also Ask" feature is an often-overlooked yet extremely useful tool. In this tutorial, we'll look at the nuances of this tool and how it may be used to acquire key insights and drive content strategy. Let's get into the details.
Understanding of "People Also Ask":
Overview The "People Also Ask" feature in Google search results produces similar questions based on user queries.
Evolution: The function, which was first introduced in 2015, has expanded dramatically, now using machine learning to give relevant and contextually driven queries.
User Benefits "People Also Ask" improves the search experience by suggesting questions based on user intent, providing users with extra insights and leading content creators to relevant topics.
Exploring "People Also Ask"
In Action:
Accessing the Feature Do a Google search for your desired topic, such as "chocolate," then scroll down to the "People Also Ask" area.
Accordion-style Dropdowns Clicking on the accordion-style dropdowns shows a profusion of related questions, a veritable goldmine of content ideas.
Tailoring Content Look for questions that are relevant to your interests or industry niche, such as the history of cocoa or its health advantages.
Maximizing Insights with Web Scraping:
Introducing the "Scraper" Extension Use the "Scraper" Chrome extension, which is available in the Chrome Web Store, to extract and consolidate "People Also Ask" queries.
Simple Extraction Process: Right-click on a relevant question, choose "Scrape Similar," then change the XPath selection to collect all similar questions.
Scalability: A single query can return a multiplicity of
Related search results offer numerous chances for content creation and market insights.
Unlocking the Content Potential:
Content Ideation: Use scraped questions to find holes in existing content and create comprehensive content strategy.
Competitive Advantage By responding to user concerns completely, you can outperform competitors and increase brand visibility.
Strategic Implementation Create content that not only addresses individual questions but also reflects larger user intent and industry trends.
Use Web Scraping Tools for "People Also Ask" Questions
In the digital age, embracing technology is critical to staying ahead in SEO and content marketing. Web scraping tools are an effective way to extract relevant data from search engine results pages (SERPs) and obtain insight into user behavior and preferences. Here's how you can use these technologies to maximize their potential.
Conclusion:
By using web scraping, you may extract useful data directly from Google search results, providing you with actionable insights. Web scraping brings up a world of data-driven decision-making opportunities, whether you're undertaking market research, content creation, or SEO analysis. Stay tuned for future tutorials delving into additional web scraping features and advanced techniques. Until then, Happy scrapping, and may your data excursions be successful! Remember, the possibilities are limitless when you use the power of web scraping to extract valuable information from the enormous expanse of the internet. Happy scraping, and may your data excursions be both insightful and rewarding!
Incorporating Google's "People Also Ask" feature into your SEO and content strategy can unlock a wealth of opportunities for audience engagement and brand growth. By understanding user intent, leveraging web scraping tools, and crafting targeted content, you can position your brand as an authoritative voice in your industry. Embrace the power of "People Also Ask" and elevate your digital presence to new heights.
As you embark on your journey of content creation and SEO optimization, remember to harness the insights gleaned from "People Also Ask" to fuel your strategic initiatives and drive meaningful engagement with your audience. The possibilities are endless, and with the right approach, you can unlock boundless opportunities for success in the ever-evolving digital landscape.
0 notes
Text
Exploring the Power of Web Scraping: Extracting "People Also Ask" Questions from Google Results

In this article, we'll look at how to use web scraping to extract useful information from Google search results. We'll specifically focus on obtaining the "People Also Ask" questions and save them to a Google Sheets document. Let's get started, but first, please show your support by liking the video and subscribing to the channel. Your encouragement fuels our desire to create informative content. Now, let us get down to work.
Prerequisites:
1Open a Google Sheets Document To begin, open a Google Sheets document in which we'll execute web scraping.
2Add the "Import from Web" Extension Go to the given
Link to the "Import from Web" addon. This plugin is essential for allowing web scraping capability in Google Sheets. Make sure you add this extension to your Google Sheets for easy connection.
Activating the Extension:
Once you've installed the extension, navigate to your Google Sheets document and select the "Extensions" option.
Locate and enable the "Import from Web" addon. This step gives you access to a myriad of web scraping features right within your Google Sheets.
Executing Web Scraping:
Define your keyword: In a specific cell, such as B1, put the keyword from which you wish to extract "People Also Ask" queries. For example, let's use the keyword "skincare".
Utilize the Import Functionality: In the
for SEO experts, digital marketers, and content developers. Google's "People Also Ask" feature is an often-overlooked yet extremely useful tool. In this tutorial, we'll look at the nuances of this tool and how it may be used to acquire key insights and drive content strategy. Let's get into the details.
Understanding of "People Also Ask":
Overview The "People Also Ask" feature in Google search results produces similar questions based on user queries.
Evolution: The function, which was first introduced in 2015, has expanded dramatically, now using machine learning to give relevant and contextually driven queries.
User Benefits "People Also Ask" improves the search experience by suggesting questions based on user intent, providing users with extra insights and leading content creators to relevant topics.
Exploring "People Also Ask"
In Action:
Accessing the Feature Do a Google search for your desired topic, such as "chocolate," then scroll down to the "People Also Ask" area.
Accordion-style Dropdowns Clicking on the accordion-style dropdowns shows a profusion of related questions, a veritable goldmine of content ideas.
Tailoring Content Look for questions that are relevant to your interests or industry niche, such as the history of cocoa or its health advantages.
Maximizing Insights with Web Scraping:
Introducing the "Scraper" Extension Use the "Scraper" Chrome extension, which is available in the Chrome Web Store, to extract and consolidate "People Also Ask" queries.
Simple Extraction Process: Right-click on a relevant question, choose "Scrape Similar," then change the XPath selection to collect all similar questions.
Scalability: A single query can return a multiplicity of
Related search results offer numerous chances for content creation and market insights.
Unlocking the Content Potential:
Content Ideation: Use scraped questions to find holes in existing content and create comprehensive content strategy.
Competitive Advantage By responding to user concerns completely, you can outperform competitors and increase brand visibility.
Strategic Implementation Create content that not only addresses individual questions but also reflects larger user intent and industry trends.
Use Web Scraping Tools for "People Also Ask" Questions
In the digital age, embracing technology is critical to staying ahead in SEO and content marketing. Web scraping tools are an effective way to extract relevant data from search engine results pages (SERPs) and obtain insight into user behavior and preferences. Here's how you can use these technologies to maximize their potential.
Conclusion:
By using web scraping, you may extract useful data directly from Google search results, providing you with actionable insights. Web scraping brings up a world of data-driven decision-making opportunities, whether you're undertaking market research, content creation, or SEO analysis. Stay tuned for future tutorials delving into additional web scraping features and advanced techniques. Until then, Happy scrapping, and may your data excursions be successful! Remember, the possibilities are limitless when you use the power of web scraping to extract valuable information from the enormous expanse of the internet. Happy scraping, and may your data excursions be both insightful and rewarding!
Incorporating Google's "People Also Ask" feature into your SEO and content strategy can unlock a wealth of opportunities for audience engagement and brand growth. By understanding user intent, leveraging web scraping tools, and crafting targeted content, you can position your brand as an authoritative voice in your industry. Embrace the power of "People Also Ask" and elevate your digital presence to new heights.
As you embark on your journey of content creation and SEO optimization, remember to harness the insights gleaned from "People Also Ask" to fuel your strategic initiatives and drive meaningful engagement with your audience. The possibilities are endless, and with the right approach, you can unlock boundless opportunities for success in the ever-evolving digital landscape.
0 notes
Text
LinkedIn Job Scraping Tool
Do you know any tool that enables scraping of LinkedIn accounts
LinkedIn is a powerful platform for professionals to showcase their skills, connect with potential employers, and build networks. However, when it comes to collecting data and extracting information from LinkedIn accounts at scale, one tool that stands out is Octoparse. This web scraping tool allows users to automate the process of scraping data from LinkedIn profiles quickly and efficiently.
Octoparse offers a range of features that make it an ideal choice for anyone looking to scrape LinkedIn accounts. With its easy-to-use interface, users can navigate through the platform effortlessly, creating web scraping tasks without any coding knowledge required. The tool also supports multiple browsers, enabling users to scrape LinkedIn profiles using various web browsers such as Chrome or Firefox.
Apart from Octoparse's user-friendly interface and compatibility with different browsers, another standout feature is its ability to handle dynamic websites. Many LinkedIn profiles have dynamic content that loads as the user scrolls down or interacts with the page. This can be a challenge for traditional scrapers but not for Octoparse. It automatically detects these dynamic elements and adjusts accordingly, ensuring accurate extraction of data from even the most complex LinkedIn profiles.
In conclusion, if you need a reliable tool for scraping LinkedIn accounts efficiently and effectively, give Octoparse a try. Its intuitive interface, browser compatibility, and ability to handle dynamic websites set it apart from other options in the market.
Overview of the importance of LinkedIn scraping
LinkedIn scraping refers to the process of extracting data from LinkedIn profiles and pages using a specialized tool. It has become increasingly important for businesses and professionals alike. With over 700 million users, LinkedIn provides a wealth of valuable information that can be utilized for various purposes such as lead generation, market research, competitor analysis, recruitment, and networking.
One of the key reasons why LinkedIn scraping tools is important is because it allows businesses to gather valuable insights about their target audience. By analyzing user profiles and collecting data on job titles, industries, skills, and connections, companies can gain a better understanding of their potential customers' needs and preferences. This information can then be used to tailor marketing strategies or develop new products and services that cater specifically to these requirements.
Moreover, LinkedIn scraping can also help professionals in their career development efforts. By automating the process of gathering contacts and connections from relevant industry influencers or thought leaders, individuals can expand their network significantly faster than traditional methods. Additionally, by examining patterns in job descriptions or skill sets required for certain roles within an industry or company, professionals can identify areas for improvement in their own skill set or even uncover hidden job opportunities.
What is LinkedIn scraping: Explanation and definition
LinkedIn scraping refers to the process of extracting data from LinkedIn profiles or pages using automated software or tools. This technique allows users to gather relevant information such as job titles, companies, and contact details for networking or marketing purposes. A LinkedIn scraping tool enables users to navigate through the vast database of professionals on the platform and retrieve valuable insights that would normally take hours of manual searching.
Although some might argue that LinkedIn scraping violates the platform's terms of service, many businesses and recruiters view it as an efficient way to source talent or generate leads. By automating the process, it saves time and effort compared to manually visiting individual profiles. However, with increased concerns about privacy and data protection, it is important for practitioners of LinkedIn scraping to be mindful of ethical considerations and regulations surrounding data usage. Additionally, as technology evolves, so do the methods employed in these tools; advanced algorithms are now capable of offering more accurate search results by identifying patterns within user behavior and preferences.
Tools for scraping LinkedIn accounts: Popular options
One popular option for scraping LinkedIn accounts is LinkedIn Job Scraping Tool. This tool allows users to extract job listings and relevant data from LinkedIn, such as company names, job titles, and locations. It offers a variety of features including the ability to search by keyword, location, industry, or company name. With this tool, users can save time by automating the process of finding and organizing job opportunities from LinkedIn.
Another widely used tool for scraping LinkedIn accounts is Dux-Soup. This Chrome extension enables users to automate their lead generation activities on LinkedIn. It allows you to visit profiles in bulk, endorse skills automatically, send personalized messages to connections or prospects, and

even export data like job titles or industries into CSV files for further analysis. These capabilities make it an invaluable tool for professionals looking to expand their network or generate leads through LinkedIn.
Overall, these popular tools for scraping LinkedIn accounts are essential resources for anyone looking to streamline their job search efforts or enhance their lead generation activities on the platform. With the ability to extract relevant data efficiently and automate various tasks on LinkedIn, they offer valuable insights and help users maximize their productivity in leveraging this powerful professional networking platform.
Benefits of using a LinkedIn scraping tool
LinkedIn is arguably the most powerful platform for professional networking and job hunting. However, manually extracting data from LinkedIn profiles can be a tedious and time-consuming task. This is where a LinkedIn scraping tool comes in handy. By using such a tool, users can automate the process of extracting valuable data from multiple LinkedIn profiles quickly and efficiently.
One of the key benefits of using a LinkedIn scraping tool is saving time. Instead of spending hours manually gathering information, users can simply input their search criteria into the tool and let it do the work for them. This not only frees up precious time but also allows users to focus on more meaningful tasks, such as connecting with potential clients or building relationships with industry influencers.
Moreover, a LinkedIn scraping tool provides users with access to a vast amount of data that would otherwise be inaccessible or difficult to obtain. From contact details and job titles to educational backgrounds and work experience, this tool can extract comprehensive profiles that offer valuable insights about potential business partners or candidates for job openings.
Tips for successful LinkedIn scraping
Web scraping on LinkedIn can be an incredibly powerful tool for businesses and individuals alike. However, to ensure successful scraping and avoid any ethical or legal issues, there are a few tips to keep in mind. Firstly, make sure you have a clear understanding of LinkedIn's terms of service and adhere to them strictly. Respect their guidelines regarding data usage and access limitations.
Secondly, consider using reliable web scraping tools that offer anti-blocking measures. LinkedIn has implemented several countermeasures to prevent scraping activity, such as CAPTCHA tests and IP blocking. Using robust scraping software that can handle these challenges will improve your chances of success.
Finally, it is crucial to rotate your proxies when scraping LinkedIn profiles. This helps distribute the workload across different IP addresses and reduces the risk of getting blocked by the platform. Additionally, setting up proper rate limits between requests will make your activity appear more natural.
Conclusion: Final thoughts on the topic
In conclusion, the use of a LinkedIn data extractor has undoubtedly revolutionized the way we gather information and make strategic decisions in today's fast-paced digital world. This invaluable tool allows us to access a vast amount of professional data with just a few clicks, providing us with valuable insights into potential business opportunities and collaborations.
One of the most remarkable aspects of using a LinkedIn data extractor is its ability to streamline and automate the process of collecting crucial information. Gone are the days of manual searching and painstakingly compiling spreadsheets. With this tool, we can now save valuable time and resources by effortlessly extracting relevant data such as contact details, job titles, or industry preferences. This newfound efficiency allows businesses to focus on what truly matters: making meaningful connections and driving growth.
However, it is vital to remember that while LinkedIn data extractors offer unparalleled convenience, they should always be used ethically and responsibly. Respecting privacy policies and obtaining proper consent when using extracted data is critical for maintaining trust within professional networks. Additionally, staying up-to-date with any changes in regulations regarding data usage ensures compliance while mitigating potential legal risks.
#best web scraping tools#data extraction#web scraping services#data extraction service#data extraction from image#web scraping solution
0 notes
Text
0 notes
Text
How To Extract Booking.Com Data For Hotels?
This tutorial blog will tell you how to extract booking.com data for hotels with Selectorlib as well as Python. You may also use to scrape hotels data from Booking.com.

How to Extract Booking.com?
Search Booking.com for the Hotels data with conditions like Locations, Room Type, Check In-Check out Date, Total People, etc.
Copy the Search Result URL as well as pass that to the hotel scraper.
With the scraper, we would download the URL with Python Requests.
After that, we will parse the HTML with Selectorlib Template for scraping fields like Location, Name, Room Types, etc.
Then the scraper will save data into the CSV file.
The hotel scraper will scrape the following data. You can add additional fields also:

Hotel’s Name
Location
Room Type
Pricing
Pricing For (eg: 2 Adults, 1 Night)
Overall Ratings
Bed Type
Total Reviews
Rating Tile
Links
Installing the Packages Required to Run a Booking Data Scraper
We would require these Packages of Python 3
Python Requests to do requests as well as downloading HTML content through Search Result pages from Booking.com.
SelectorLib Python suites to extract data with YAML files that we have made from webpages, which we download.
Make installation using pip3
pip3 install requests selectorlib
The Code
It’s time to make a project folder named booking-hotel-scraper. In this folder, add one Python file named scrape.py
After that, paste the code given here in scrape.py
from selectorlib import Extractor import requests from time import sleep import csv # Create an Extractor by reading from the YAML file e = Extractor.from_yaml_file('booking.yml') def scrape(url): headers = { 'Connection': 'keep-alive', 'Pragma': 'no-cache', 'Cache-Control': 'no-cache', 'DNT': '1', 'Upgrade-Insecure-Requests': '1', # You may want to change the user agent if you get blocked 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.113 Safari/537.36', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9', 'Referer': 'https://www.booking.com/index.en-gb.html', 'Accept-Language': 'en-GB,en-US;q=0.9,en;q=0.8', } # Download the page using requests print("Downloading %s"%url) r = requests.get(url, headers=headers) # Pass the HTML of the page and create return e.extract(r.text,base_url=url) with open("urls.txt",'r') as urllist, open('data.csv','w') as outfile: fieldnames = [ "name", "location", "price", "price_for", "room_type", "beds", "rating", "rating_title", "number_of_ratings", "url" ] writer = csv.DictWriter(outfile, fieldnames=fieldnames,quoting=csv.QUOTE_ALL) writer.writeheader() for url in urllist.readlines(): data = scrape(url) if data: for h in data['hotels']: writer.writerow(h) # sleep(5)
This code will:
Open the file named urls.txt as well as download HTML content given for every link in that.
Parse this HTML with Selectorlib Template named booking.yml
Then save the output file in the CSV file named data.csv
It’s time to make a file called urls.txt as well as paste the search result URLs in it. Then we need to create a Selectorlib Template.
Make Selectorlib Template for Scraping Hotels Data from Booking.com Searching Results
You may notice that within a code given above, which we used the file named booking.yml. The file makes this code so short and easy. The magic after making this file is the Web Scraping tool called Selectorlib.
Selectorlib makes selecting, marking, as well as extracting data from the webpages visually easy. A Selectorlib Web Scraping Chrome Extension allows you to mark data, which you want to scrape, and makes CSS Selectors required for extracting the data. After that, preview how the data could look like.
In case, you require data that we have given above, you should not use Selectorlib. As we have already done it for you as well as produced an easy “template”, which you may use. Although, if you need to add new fields, you may use Selectorlib for adding those fields into a template.
Let’s see how we have moticed the data fields we needed to extract with Chrome Extension of Selectorlib.
When you have made the template, just click on ‘Highlight’ button to highlight and preview all selectors. In the end, just click on ‘Export’ option and download YAML file, which is a booking.yml file.
Let’s see how the template – booking.yml will look like:
hotels: css: div.sr_item multiple: true type: Text children: name: css: span.sr-hotel__name type: Text location: css: a.bui-link type: Text price: css: div.bui-price-display__value type: Text price_for: css: div.bui-price-display__label type: Text room_type: css: strong type: Text beds: css: div.c-beds-configuration type: Text rating: css: div.bui-review-score__badge type: Text rating_title: css: div.bui-review-score__title type: Text number_of_ratings: css: div.bui-review-score__text type: Text url: css: a.hotel_name_link type: Link
Run a Web Scraper
For running the web scraper, from a project folder,
Try to search Booking.com to see your Hotels requirements
Copy as well as add search results URLs into urls.txt
Then Run the script python3 scrape.py
Find data from the data.csv file
Let’s take a sample data from the search results pages.
Contact Web Screen Scraping if you want to Extract Booking.com Data for Hotels!
1 note
·
View note
Text
Top 5 Web Scraping Tools in 2021
Web scraping, also known as Web harvesting, Web data extraction, is the process of obtaining and analyzing data from a website. After that, for various purposes, the extracted data is saved in a local database. Web crawling can be performed manually or automatically through the software. There is no doubt that automated processes are more cost-effective than manual processes. Because there is a large amount of digital information online, companies equipped with these tools can collect more data at a lower cost than they did not collect, and gain a competitive advantage in the long run.
Web scraping benefits businesses > HOW!
Modern companies build the best data. Although the Internet is actually the largest database in the world, the Internet is full of unstructured data, which organizations cannot use directly. Web scraping can help overcome this hurdle and turn the site into structured data, which in many cases is of great value. The benefits of sales and marketing of a specific type of web scraping are contact scraping, which can collect business contact information from websites. This helps to attract more sales leads, close more deals, and improve marketing. By using a web scraper to monitor job commission updates, recruiters can find ideal candidates with very specific searches. By monitoring job board updates with a web scrape, recruiters are able to find their ideal candidates with very specific searches. Financial analysts use web scraping to collect data about global stock markets, financial markets, transactions, commodities, and economic indicators to make better decisions. E-commerce / travel sites get product prices and availability from competitors and use the extracted data to maintain a competitive advantage. Get data from social media and review sites (Facebook, Twitter, Yelp, etc.). Monitor the impact of your brand and take your brand reputation / customer review department to a new level. It's also a great tool for data scientists and journalists. An automatic web scraping can collect millions of data points in your database in just a few minutes. This data can be used to support the data model and academic research. Moreover, if you are a journalist, you can collect rich data online to practice data-driven journalism.
Web scraping tools List.....
In many cases, you can use a web crawler to extract website data for your own use. You can use browser tools to extract data from the website you are browsing in a semi-automatic way, or you can use free API/paid services to automate the crawling process. If you are technically proficient, you can even use programming languages like Python to develop your own web dredging applications.
No matter what your goal is, there are some tools that suit your needs. This is our curated list of top web crawlers.
Scraper site API
License: FREE
Website: https://www.scrapersite.com/
Scraper site enables you to create scalable web detectors. It can handle proxy, browser, and verification code on your behalf, so you can get data from any webpage with a simple API call.
The location of the scraper is easy to integrate. Just send your GET request along with the API key and URL to their API endpoint and they'll return the HTML.
Scraper site is an extension for Chrome that is used to extract data from web pages. You can make a site map, and how and where the content should be taken. Then you can export the captured data to CSV.
Web Scraping Function List:
Checking in multiple pages
Dental data stored in local storage
Multiple data selection types
Extract data from dynamic pages (JavaScript + AJAX)
Browse the captured data
Export the captured data to CSV
Importing and exporting websites
It depends on Chrome browser only
The Chrome extension is completely free to use
Highlights: sitemap, e-commerce website, mobile page.
Beautiful soup
License: Free Site: https://www.crummy.com/software/BeautifulSoup/ Beautiful Soup is a popular Python language library designed for web scraping. Features list: • Some simple ways to navigate, search and modify the analysis tree • Document encodings are handled automatically • Provide different analysis strategies Highlights: Completely free, highly customizable, and developer-friendly.
dexi.io
License: Commercial, starting at $ 119 a month.
Site: https://dexi.io/
Dexi provides leading web dredging software for enterprises. Their solutions include web scraping, interaction, monitoring, and processing software to provide fast data insights that lead to better decisions and better business performance.
Features list:
• Scraping the web on a large scale Intelligent data mining • Real-time data points
Import.io
License: Commercial starts at $ 299 per month. Site: https://www.import.io/ Import.io provides a comprehensive web data integration solution that makes it fast, easy and affordable to increase the strategic value of your web data. It also has a professional service team who can help clients maximize the solution value. Features list: Pointing and clicking training • Interactive workflow • Scheduled abrasion • Machine learning proposal • Works with login • Generates website screen shots • Notifications upon completion • URL generator Highlights: Point and Click, Machine Learning, URL Builder, Interactive Workflow.
Scrapinghub
License: Commercial version, starting at $299 per month. Website: https://scrapinghub.com/ Scraping hub is the main creator and administrator of Scrapy, which is the most popular web scraping framework written in Python. They can also provide data services on demand in the following situations: product and price information, alternative financial data, competition and market research, sales and market research, news and content monitoring, and retail and distribution monitoring. functions list: • Scrapy Cloud crawling, standardized as Scrapy Cloud •Robot countermeasures and other challenges Focus: Scalable crawling cloud.
Highlights: scalable scraping cloud.
Summary The web is a huge repository of data. Firms involved in web dredging prefer to maintain a competitive advantage. Although the main objective of the aforementioned web dredging tools / services is to achieve the goal of converting a website into data, they differ in terms of functionality, price, ease of use, etc. We hope you can find the one that best suits your needs. Happy scraping!
2 notes
·
View notes
Text
Yahoo Groups - Scraping in Chrome
What is scraping? It’s where you use a bot to cruse the internet for you and collect data into a spreadsheet. Bots can work a lot faster than you and don’t get tired or distracted so if you’ve got a lot of data to collect scraping makes your life easier.
Now it’s the end of 2019 and you’ve got a yahoo group full of old Fanfic Files that you’d like to download before it’s gone forever. Sure you can download everything by hand or use a custom script to scrape it perfectly into folders quickly but lets be honest, you ain’t got time for that shit - mentally or physically. Your best bet is using a free scraping tool and leave it going while you’re at work so you can come home to 1,000s of ancient fandom fics. Sure this inelegant solution will perform so slowly you’ll wonder if it’s a geriatric, overweight snail powered by farts but f*ck it, at least you won’t have to sit at the computer clicking on every single htm and txt file in your yahoo group right?
Here are some helpful steps below the break.

Step One:
Create a folder for your downloads. With Chrome’s settings you can then switch your download folder to this new folder.
Trust me, you don’t want your thousands of historical fic mixing in with all the other porn crap in your downloads folder. The scraping won’t be maintaining subfolder file structure so you’ll have all your group’s files in one heap of a mess. Possibly half of them helpfully named ‘Chapter_One.htm’ The less sorting you have to do later the better.
Step Two:
Install a browser extension scraper. In this case we’re using Chrome’s Web Scraper:
Once installed you can access it on any webpage by opening Chrome’s developer tools using F12 and selecting ‘Web Scraper’ from the tool’s menu bar. Note: You’ll want to dock the developer tools window to the bottom of the screen using the buttons I’ve highlighted below. vvv
If you want more details on how to use Web Scraper, click on the blue web symbol that will appear to the right of your address bar in Chrome. You’ll find tutorials and documentation. I didn’t read any of it. Why any of you are listening to me is a mystery. But if you’re happy with the blind leading the blind, jump to our next step.
Step Three:
Now we can import your Sitemap for scraping. Start by navigating in Chrome to the yahoo groups file page. Something like, https://groups.yahoo.com/neo/groups/awesomefanfic/files
Open the Web Scraper in developer tools (F12) for this page, if you haven’t already, and click “create new sitemap”>“Import Sitemap”
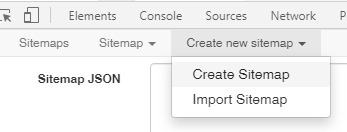
Then paste the following code into the "Sitemap JSON” field:
{"_id":"testscrape1","startUrl":["YOUR FILES"],"selectors":[{"id":"folderName","type":"SelectorLink","parentSelectors":["_root"],"selector":".yg-list-title a","multiple":true,"delay":0},{"id":"subfolder","type":"SelectorLink","parentSelectors":["folderName"],"selector":".yg-list-title a","multiple":true,"delay":0},{"id":"subfiles","type":"SelectorLink","parentSelectors":["subfiles"],"selector":".yg-list-title a","multiple":true,"delay":0},{"id":"Files","type":"SelectorText","parentSelectors":["folderName"],"selector":".yg-list-title a","multiple":true,"regex":"","delay":0},{"id":"subFiles","type":"SelectorLink","parentSelectors":["subfolder"],"selector":".yg-list-title a","multiple":true,"delay":0},{"id":"SubFileNames","type":"SelectorText","parentSelectors":["subfolder"],"selector":".yg-list-title a","multiple":true,"regex":"","delay":0},{"id":"dummy","type":"SelectorText","parentSelectors":["subFiles"],"selector":".yg-list-title a","multiple":true,"regex":"","delay":0}]}
You’ll going to need to change where it says “YOUR FILES” to your yahoo group’s files page. Copy it from the address bar. It will look something like: "startUrl": ["https://groups.yahoo.com/neo/groups/awesomefanfic/files"]
You may want to rename your Sitemap in the second field. Otherwise it will be named “testscrape1″
Once you’ve made your changes, hit the import button and you’re ready to start scraping.
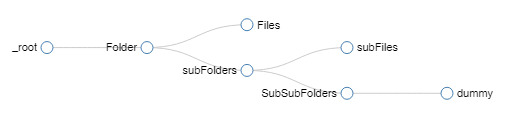
Note: This imported JSON code provides a Sitemap structure designed to download all the documents up to a level two subfolder and place them all into that download folder. It will also create a spreadsheet record of each file’s location.
Step Four:
Now we Scrape.
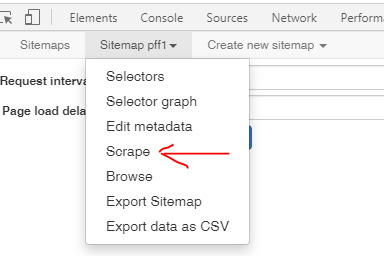
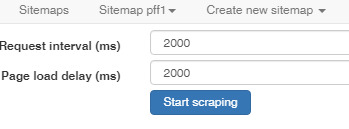
Once it starts scraping it will open a new window and slowly (SOOO SLOWLY) start downloading your old files. Note: Do NOT close Web Scraper window while it is running a scrape or you will have to start again from beginning. Again, it will not be downloading folders so all the files will be dumped in one big heap. Luckily the spreadsheet it creates showing where every file came from, will help.

Step Five:
Once you’ve walked the dog, gone to work, eaten a feast for the elder gods, and danced with your coven at midnight the scraping should be about done (results dependent on number of grizzled files to download). The Web Scraper window should close on it’s own. You’re tomb-of-ancient-knowledge will be ready in the location you specified in step one. It’s possible the Scrape missed some hoary files because yahoo was refusing to open a folder or the file was in a deeper subfolder than level two (the bot checking for subfolders is why this scrape is so slow so I didn’t go deeper). For best results you will need to review the scraped file data and compare it to what you downloaded. Use “Export data as CSV” and then use your new spreadsheet to rebuild your file structure and check for any missing files. NOTHING listed in the “dummy” column will be downloaded. You will have download everything in that column (and deeper) manually.
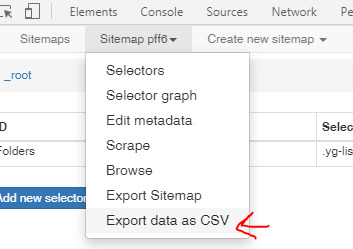
With luck, only a handful of files will need to be downloaded manually after your review. Treasure your prize and if you’re a mod of the group, help save the files for the gen z fic readers by sharing your hoard on Hugo-award-winning AO3.
Bonus (Expert Mode):
Using the spreadsheet and batch file scripts you can recreate your file structure quickly and move the files into the new folders. A few changes will turn your list of urls into folder locations on your PC and bam! You’ve got a everything organized again! A few things to watch for: 1. You will have to remove spaces and special characters from folder names. 2. File names should be in double quotes in your batch file or have all spaces removed. 3. Files with the same name from different folders (Like chapter1.htm) should probably be done manually before running the batch to move the rest.
-------------------------------
Thank you for reading.
Don’t like my jokes or my solution? Feel free to call me out and post better solutions here. Hope this helps!
10 notes
·
View notes
Text
Data Scraper Software- What Makes It More Valuable ?
Data Scrapper is an advanced tool that can help you to extract data from different sources. It will search all the data on a website and then store it in a database or text file. This data scraper software has many features that enables you to extract data with ease.
How to get data from a website ?
To get data from a website, you should use a Website Scraping Software. It is the most efficient way of extracting content from websites.
Web crawlers are software tools that automatically navigate the World Wide Web and retrieve information from it. For example, when you search for something on Google, it uses its own web crawler to find relevant results for your query and serve them up for you.
When you want to scrape data from a webpage manually (without using any software), here’s what needs to be done:
You need to find the HTML code of the website’s page that contains the data you want to extract. There are a few different ways of doing this, but one of the most popular methods is by using Chrome DevTools. It enables you to view and edit any page on the internet from within your browser window.
Once you find the HTML code of the page, you need to extract all its content. This can be done by searching for tags that appear on each row of data and copying their contents into a separate document.
What is Data Scraper Software?
Data Scraper software is a type of software that helps you in extracting data from websites, databases and spreadsheets. It can also be used for scraping data from PDF files.
The primary reason people use Data Scraper Software is because it saves them time and effort. By using this software, you will be able to extract large amounts of data from multiple sources at the same time with ease.
Scraper software can be used for different purposes, such as for data mining, data processing and analysis. If you run a business and need to extract information from multiple sources, then this software will help you do so quickly and efficiently.

Data Scraper Software Makes it More Valuable?
Data Scraper Software is a powerful tool for web scraping. It allows you to extract data from websites, mine data from websites and even extract data from social media.
Data extraction is the process of locating, extracting, transforming and loading (ETL) structured or unstructured data into a central repository. This is often a database that can be queried or analyzed using business intelligence tools. The type of content that can be extracted using this software includes text, tables, links and images among others.
Conclusion
Data scraper software is a type of software that helps us to get data from different websites. It can also be used for extracting data from PDF files and Excel spreadsheets.
Data scraper is very useful in many ways like getting contact details, mailing list or product inventory from online stores etc. You just need to enter the URL of the website where you want to extract data from then click on "Start Scraping" button, that's it!
Source By - http://bit.ly/3Js99Pg
0 notes
Text
Octoparse vs parsehub

OCTOPARSE VS PARSEHUB HOW TO
OCTOPARSE VS PARSEHUB HOW TO
Learn how to use a web scraper to extract data from the web. The only downside to this web scraper tool extension is that it doesn’t have many automation features built-in. The tool lets you export the extracted data to a CSV file. The plugin can also handle pages with JavaScript and Ajax, which makes it all the more powerful. It can crawl multiple pages simultaneously and even have dynamic data extraction capabilities. It lets you set up a sitemap (plan) on how a website should be navigated and what data should be extracted. Web scraper is a great alternative to Outwit hub, which is available for Google Chrome, that can be used to acquire data without coding. As it is free of cost, it makes for a great option if you need to crawl some data from the web quickly. You can refer to our guide on using Outwit hub to get started with extracting data using the web scraping tool. Extracting data from sites using Outwit hub doesn’t demand programming skills. Out of the box, it has data points recognition features that can make your web crawling and scraping job easier. Once installed and activated, it gives scraping capabilities to your browser. Outwit hub is a Firefox extension that can be easily downloaded from the Firefox add-ons store. Here are some of the best data acquisition software, also called web scraping software, available in the market right now. You can acquire data without coding with these web scraper tools. DIY webscraping tools are much easier to use in comparison to programming your own data extraction setup. If you need data from a few websites of your choice for quick research or project, these web scraping tools are more than enough. DIY software belongs to the former category. Some are meant for hobbyists, and some are suitable for enterprises. Today, the best software web scraping tools can acquire data from websites of your preference with ease and prompt. Tools vs Hosted Services 7 Best Web Scraping Tools Without CodingĮver since the world wide web started growing in terms of data size and quality, businesses and data enthusiasts have been looking for methods to extract web data smoothly.
0 notes
Text
Building A Web Scraper

Create A Web Scraper
Web Scraper Google Chrome
Web Scraper Lite
Web Scraper allows you to build Site Maps from different types of selectors. This system makes it possible to tailor data extraction to different site structures. Export data in CSV, XLSX and JSON formats. Build scrapers, scrape sites and export data in CSV format directly from your browser. Use Web Scraper Cloud to export data in CSV, XLSX. It also has a number of built-in extensions for tasks like cookie handling, user-agent spoofing, restricting crawl depth, and others, as well as an API for easily building your own additions. For an introduction to Scrapy, check out the online documentation or one of their many community resources, including an IRC channel, Subreddit, and a. This question is related to link building method i am doing seo for web development company and website has more than 2lac backlinks, majority of backlinks come from social bookmarking, article and press release submission. In this recent penguin 2.0 update, i lost my ranking on majority of keywords. Advanced tactics 1. Customizing web query. Once you create a Web Query, you can customize it to suit your needs. To access Web query properties, right-click on a cell in the query results and choose Edit Query.; When the Web page you’re querying appears, click on the Options button in the upper-right corner of the window to open the dialog box shown in screenshot given below.
What Are Web Scrapers And Benefits Of Using Them?

A Web Scraper is a data scraping tool that quite literally scrapes or collects data off from websites. Microsoft office for mac catalina. It is the process of extracting information and data from a website, transforming the information on a web-page into a structured format for further analysis. Web Scraper is a term for various methods used to extract and collect information from thousands of websites across the Internet. Generally, you can get rid of copy-pasting work by using the data scrapers. Those who use web scraping tools may be looking to collect certain data to sell to other users or to use for promotional purposes on a website. Web Data Scrapers also called Web data extractors, screen scrapers, or Web harvesters. one of the great things about the online web data scrapers is that they give us the ability to not only identify useful and relevant information but allow us to store that information for later use.
Create A Web Scraper
How To Build Your Own Custom Scraper Without Any Skill And Programming Knowledge?
Modern post boxes uk. Sep 02, 2016 This question is related to link building method i am doing seo for web development company and website has more than 2lac backlinks, majority of backlinks come from social bookmarking, article and press release submission. In this recent penguin 2.0 update, i lost my ranking on majority of keywords.
Web Scraper Google Chrome
If you want to build your own scraper for any website and want to do this without coding then you are lucky you found this article. Making your own web scraper or web crawler is surprisingly easy with the help of this data miner. It can also be surprisingly useful. Now, it is possible to make multiple websites scrapers with a single click of a button with Any Site Scraper and you don’t need any programming for this. Any Site Scraper is the best scraper available on the internet to scrape any website or to build a scraper for multiple websites. Now you don’t need to buy multiple web data extractors to collect data from different websites. If you want to build Yellow Pages Data Extractor, Yelp Data Scraper, Facebook data scraper, Ali Baba web scraper, Olx Scraper, and many web scrapers like these websites then it is all possible with AnySite Scraper. Over, If you want to build your own database from a variety of websites or you want to build your own custom scraper then Online Web Scraper is the best option for you.
Build a Large Database Easily With Any site Scraper
In this modern age of technology, All businesses' success depends on big data and the Businesses that don’t rely on data have a meager chance of success in a data-driven world. One of the best sources of data is the data available publicly online on social media sites and business directories websites and to get this data you have to employ the technique called Web Data Scraping or Data Scraping. Building and maintaining a large number of web scrapers is a very a complex project that like any major project requires planning, personnel, tools, budget, and skills.
Web scraping with django python. Web Scraping using Django and Selenium # django # selenium # webscraping. Muhd Rahiman Feb 25 ・13 min read. This is a mini side project to tinker around with Django and Selenium by web scraping FSKTM course timetable from MAYA UM as part of my self-learning prior to FYP. Automated web scraping with Python and Celery is available here. Making a web scraping application with Python, Celery, and Django here. Django web-scraping. Improve this question. Follow asked Apr 7 '19 at 6:14. User9615577 user9615577. Add a comment 2 Answers Active Oldest Votes. An XHR GET request is sent to the url via requests library. The response object html is. If your using django, set up a form with a text input field for the url on your html page. On submission this url will appear in the POST variables if you've set it up correctly.
Jul 10, 2019 The Switch itself (just the handheld screen) includes a slot for a microSD Card and a USB Type-C Connector. The Nintendo Switch Dock includes two USB 2.0 Ports and a TV Output LED in the front. The 'Switch tax' also applies to many games that had been previously released on other platforms ported later to the Switch, where the Switch game price reflects the original price of the game when it was first released rather than its current price. It is estimated that the cost of Switch games is an average of 10% over other formats. Get the detailed specs for the Nintendo Switch console, the Joy-Con controllers, and more. Switch specs. The S5200-ON is a complete family of switches:12-port, 24-port, and 48-port 25GbE/100GbE ToR switches, 96-port 25GbE/100GbE Middle of Row (MoR)/End of Row (EoR) switch, and a 32-port 100GbE Multi-Rate Spine/Leaf switch. From the compact half-rack width S5212F-ON providing an ideal form factor. Switch resistance is referred to the resistance introduced by the switch into the circuit irrespective of its contact state. The resistance will be extremely high (ideally infinite) when the switch is open and a finite very low value (ideally zero) when the switch is closed. 2: Graph Showing Typical Switch Resistance Pattern.
Web Scraper Lite
You will most likely be hiring a few developers who know-how to build scale-able scrapers and setting up some servers and related infrastructure to run these scrapers without interruption and integrating the data you extract into your business process. You can use full-service professionals such as Anysite Scraper to do all this for you or if you feel brave enough, you can tackle this yourself.
Apr 15, 2021 Currently, you cannot stream Disney Plus on Switch, however, there is a piece of good news for Nintendo Switch users. It seems that Disney lately announced that Disney Plus streaming service will be accessible on Nintendo’s handheld console. The news originates from a presentation slide revealing the new streaming service available on consoles. Disney plus on switch. Mar 15, 2021 Though mentioned earlier, Disney Plus is available on few gaming consoles. Unfortunately, it is not available on Nintendo Switch as of now. Chances are there to bring it in on the future updates as Nintendo Switch is getting popular day by day. Despite the own store by Nintendo switch, it has only a few apps present. No, there is no Disney Plus app on the Nintendo Switch. If you want to stream movies or shows on your Switch, you can instead download the Hulu or YouTube apps. Visit Business Insider's homepage. Nov 30, 2020 Disney Plus is not available on the handheld console. The Switch only offers YouTube and Hulu as of now, not even Netflix. This tells us that the Nintendo Switch is indeed capable of hosting a.
0 notes
Text
Hunting for Data: a Few Words on Data Scraping

No matter how intelligent and sophisticated your technology is, what you ultimately need for Big Data Analysis is data. Lots of data. Versatile and coming from many sources in different formats. In many cases, your data will come in a machine-readable format ready for processing — data from sensors is an example. Such formats and protocols for automated data transfer are rigidly structured, well-documented and easily parsed. But what if you need to analyze information meant for humans? What if all you have are numerous websites?
This is the place where data scraping, or web scraping steps in: the process of importing information from a website into a spreadsheet or local file saved on your computer. In contrast to regular parsing, data scraping processes output intended for display to an end-user, rather than as input to another program, usually neither documented nor structured. To successfully process such data, data scraping often involves ignoring binary data, such as images and multimedia, display formatting, redundant labels, superfluous commentary, and other information which is doomed irrelevant.
Applications of Data Scraping
When we start thinking about data scraping the first and irritating application that comes to mind is email harvesting — uncovering people’s email addresses to sell them on to spammers or scammers. In some jurisdictions, it is even made illegal to use automated means like data scraping to harvest email addresses with commercial intent.
Nevertheless, data scraping applications are numerous and it may be useful in every industry or business:

Applications of Data Scraping
Data Scraping Tools
The basic — and easiest — way to data scrape is to use dynamic web queries in Microsoft Excel, or install the Chrome Data Scraper plugin. However, for more sophisticated data scraping, you need other tools.
Here we share some of the top data scraping tools:
1. Scraper API
Scraper API is a tool for developers building web scrapers. It handles proxies, browsers, and CAPTCHAs so developers can get the raw HTML from any website with a simple API call.
Pros:
It manages its own and impressive internal pool of proxies from a dozen proxy providers, and has smart routing logic that routes requests through different subnets and automatically throttles requests in order to avoid IP bans and CAPTCHAs, so you don’t need to think about proxies.
Drawback:
Pricing starts from $29 per month.
2.Cheerio
Cherio is the most popular tool for NodeJS developers who want a straightforward way to parse HTML.
Pros:
Cheerio offers an API similar to jQuery, so developers familiar with jQuery will have no difficulties with it.
It offers many helpful methods to extract text, html, classes, ids, and more.
Drawback:
Cheerio (and ajax requests) is not effective in fetching dynamic content generated by javascript websites.
3.Scrapy
Scrapy is the most powerful library for Python. Among its features is HTML parsing with CSS selectors, XPath or regular expressions or any combination of the above. It has an integrated data processing pipeline and provides monitoring and extensive logging out of the box. There’s also a paid service to launch Scrapy spiders in the cloud.
Pros:
Scrapy has multiple helpful features and highly customizable settings.
It is easy to extend.
Drawback:
In the free version, you still have to manage proxies, CAPTCHAs and JS rendering by yourself.
Documentation can be confusing.
4.Beautiful Soup
Sometimes Scrapy is an overkill for simple HTML parsing. In such cases, Beautiful Soup is a good choice. It is intended for Python developers who want an easy interface to parse HTML. Like Cheerio for NodeJS developers, Beautiful Soup is one of the most popular HTML parsers for Python.
Pros:
It is easy to use even for inexperienced developers;
It is ex tremely well documented, with many tutorials on using it to scrape various website in both Python 2 and Python 3.
Drawback:
Beautiful Soup does not support web crawling with only HTML parser included.
The performance of the built-in html.parser is rather poor, though it can be solved by integration of Beautiful Soup with the lxml library.
5.ParseHub
Parsehub is a powerful tool for building web scrapers without coding, so it can be used by analysts, journalists, academicians and everyone interested. It has many features such as automatic IP rotation, allowing scraping behind login walls, going through dropdowns and tabs, getting data from tables and maps, and more.
Pros:
It is extremely easy to use: you click on the data and it is exported in JSON or Excel format.
It has a generous free tier, that allows users to scrape up to 200 pages of data in just 40 minutes.
Drawback:
Of course, it is not the best option for developers as it requires additional steps to import its output and does not provide the usual flexibility.

Bonus:Diffbot
Diffbot is different from most web scraping tools, since it uses computer vision instead of html parsing to identify relevant information on a page. In this way, even if the HTML structure of a page changes, your web scrapers will not break as long as the page looks the same visually.
Pros:
Thanks to its relying on computer vision, it is best suited for long running mission critical web scraping jobs.
Drawback:
For non-trivial websites and transformations you will have to add custom rules and manual code.
Like all other aspects of Data Science, data scraping evolves fast, adding machine learning to recognize inputs which only humans have traditionally been able to interpret — like images or videos. Coupled with text-based data scraping it will turn the world of data collection upside down.
Meaning that whether or not you intend to use data scraping in your work, it’s high time to educate yourself on the subject, as it is likely to go to the foreground in the next few years.
0 notes
Text
Top 30 Tools That Every Programmer Should Have


This is list of few essential tools from my coding workflow. I think these tools should be part of every programmer’s toolkit. Whether you are writing simple “Hello World” program or a complex web application, these tools make your coding easier and increase productivity. Devdocs.io – API documentation for all popular programming languages and framework. It also includes instant search and works offline too. 2. Glitch.com – you can create your own web apps in the browser. import GitHub repos, use any NPM package or build on any popular frameworks and directly deploy to firebase. 3. Bundlephobia.com – you can quickly find the import cost of any package in the NPM registry. 4. Babeljs.com/repl – write code in modern JavaScript and BebelJS will transform your code into JavaScript that is compatible with older browsers. 5. Codeplay.com – you can quickly build frontend responsive layouts with frameworks like Bootstrap, Materialize CSS and SemanticUI. 6. Httpie.org – it is a command-line tool that is very useful for making HTTP requests to web servers and RESTful APIs. It is as powerful as CURL and Wget but simpler. 7. Regexr.com – a vey good tool for testing your regular expressions in the browser. 8. Jex.im/regulex – write any regular expression into the editor and you will get a visual representation of how the pieces work. 9. Buildregex.com – with this tool you can construct regular expressions visually. 10. Explainshell.com – Type any Unix command get a visual explanation of each flag and argument in the command. 11. Tldr.ostera.io – Unix man pages are long and complex. This site offers you practical examples for all popular Unix command without you having to dive into the man pages. 12. Mockaroo.com – it quickly generate dummy test data in the browser in CSV, JSON, SQL and other formats. 13. Jsdelivr.com – it serve any GitHub file or WordPress plugin through a CDN. It Combine multiple files in a single URL. You can add “min” to any JS or CSS file to get a minified version. 14. Carbon.now.sh – you can create beautiful screenshots of your source code. 15. Waketime.com – know exactly how long you spend coding with detailed metrics per file and even language. Also see : Why You Should Learn Dart Programming Language. 16. astexplorer.net – paste JavaScript code into editor and generate the abstract Syntax Tree that will help you understand how the JavaScript Parser works. 17. Hyper.is – it is alternative to the command line terminal and also iTerm. Use with the “Oh my Zsh” shell and it will add superpower to your terminal. 18. Curlbuilder.com – you can make your own CURL requests in the browser. 19. Htaccess.madewithlove.be – easily test the direct and rewrite rules in the .htaccesss file of your Apache server. 20. Trackjs.com – it monitors error in your JavaScript based web projects and get instant email notifications when a new error is detected. 21. Ngrok.com – start a local server, fire up ngrok and ppoint to the port where the locahost is running and get public URL of your tunnel. 22. Codeshare.io – it is an online code editor for pair programming or you can use it for teaching code to students remotely. 23. Webhooks.site – it inspect the payloads and debug HTTP webhooks in the browser. All HTTP reuests are logged in real-time. 24. Surge.sh – easiest way to deploy web pages and other static content from the command line. It supports custom domain and SSL. 25. Visbug – you must have this add-on for web development that brings useful web design tool right in your browser. 26. Puppeteerssandbox.com – the puppeteer is a Node.js framework for automating Google Chrome. Use sandbox to quickly test all your scripts in the browser. 27. Prettier.io/playground – you can beautify your JavaScript and TypeScript code using this tool. 28. Json.parser.online.fr – this is the only JSON parser you will ever need to analyse and beautify your complex JSON strings. 29. Katacoda.com – it is a training platform for software developers where anyone can create their own dedicated and interactive training environment. 30. Codesandbox.io – it is a full-featured online IDE where you can create web apps in all languages including vanilla JavaScript, React, TypeScript, Angular and ue. 31. Apify.com – you can write your own web scraper using JavaScript and schedule your scrapers to run at specific time intervals automatically. 32. Insomnia.rest – it is a desktop based REST client that lets you create HTTP requests and view response details all in easy to use interface. You Will Also Like : 30 Most Useful Websites On The Internet. Read the full article
0 notes
Text
Easy Google Search Result API with Zenserp (Sponsored)
No matter how much experience I gain in this industry, one task I continue to fail at is building an accurate, flexible, and maintainable scraper for site search. As soon as sites change their HTML structure, my scrape is borked. When looking to build my own search results page, I looked around and the best solution I found was Zenserp. Zenserp, created by Saas Industries, is an easy to use, logical SERP API for getting customizable Google search results!
Quick Hits
Rolling your own SERP is verify difficult and impossible to maintain (think proxy networks and CAPTCHAs) — trust Zenserp to do it for you
API payloads are logical and easy to use
Get multiple data types: organic, paid, local, maps, and more
Zenserp does not store or sell your query requests
Very strong infrastructure – no QPS limit!
Provides a method for bulk data retrieval to consolidate API requests
Free to start!
Let’s have a look at using Zenserp’s API!
Using zenserp
After signing up for a free Zenserp account, you can start making requests. zenserp even has a nice question builder that allows you to export search code in cURL, Python, PHP, or Node.js:
Note: the API key used here was rotated and will no longer work
Note the available options: the search phrase, location requesting from, which Google domain you prefer, and language. Additional options include whether you want a text or image search, the number of results, and which page of results (page 1, page 2, etc.) you’d like. Super customizable!
Let’s have a look at the resulting payload:
{ "query": { "q": "david walsh blog", "hl": "en", "gl": "US", "location": "United States", "search_engine": "google.com", "apikey": "MY_API_KEY", "url": "https://google.com/search?q=david+walsh+blog&uule=w+CAIQICINVW5pdGVkIFN0YXRlcw&hl=en&gl=US&sourceid=chrome&ie=UTF-8" }, "organic": [ { "position": 1, "title": "David Walsh Blog - JavaScript Consultant", "url": "https://davidwalsh.name/", "destination": "https://davidwalsh.name", "description": "A blog featuring tutorials about JavaScript, HTML5, AJAX, PHP, CSS, WordPress, and everything else development.", "isAmp": false, "sitelinks": [ { "title": "About David Walsh", "description": "David Walsh. My name is David Walsh. I'm a 33-year old web ...", "url": "https://davidwalsh.name/about-david-walsh" }, { "title": "7 Essential JavaScript Functions", "description": "Seven JavaScript functions that every developer should keep ...", "url": "https://davidwalsh.name/essential-javascript-functions" }, { "title": "JavaScript", "description": "The webpack JavaScript utility has taken over the modern ...", "url": "https://davidwalsh.name/tutorials/javascript" }, { "title": "Incredible Demos", "description": "Chris Coyier's Favorite CodePen Demos IV. Did you know you ...", "url": "https://davidwalsh.name/tutorials/demos" }, { "title": "Recent Tutorials", "description": "A blog featuring tutorials about JavaScript, HTML5, AJAX, PHP ...", "url": "https://davidwalsh.name/page/2" }, { "title": "I Don't Hate Arrow Functions", "description": "While arrow functions clearly have a ubiquitous community ...", "url": "https://davidwalsh.name/i-dont-hate-arrow-functions" } ] }, { "position": 2, "title": "David Walsh Blog - Home | Facebook", "url": "https://www.facebook.com/davidwalshblog/", "destination": "https://www.facebook.com › davidwalshblog", "description": "David Walsh Blog, Madison. 7996 likes · 23 talking about this. David Walsh's blog about HTML5, JavaScript (MooTools, jQuery, Dojo), CSS, PHP, AJAX,...", "isAmp": false }, { "position": 3, "title": "David Walsh Blog - Facebook", "url": "https://d.facebook.com/davidwalshblog/?__tn__=%2As-R", "destination": "https://d.facebook.com › davidwalshblog", "description": "David Walsh Blog, Madison, WI. 8005 likes · 7 talking about this. David Walsh's blog about HTML5, JavaScript (MooTools, jQuery, Dojo), CSS, PHP, AJAX,...", "isAmp": false }, // ... ], "number_of_results": 32600000 }
Since I wanted organic results, the organic property provides an interesting array of results which match when I do a manual query of david walsh blog. Notice the amount of detail in the first result, especially sitelinks, which represents the sub-links you see within a manual search on Google — wow!
If there are paid search results, those will be in the payload as well. Let’s look up bitcoin:
{ "query": { "q": "bitcoin", "hl": "en", "gl": "US", "location": "United States", "search_engine": "google.com", "apikey": "API_KEY", "url": "https://google.com/search?q=bitcoin&uule=w+CAIQICINVW5pdGVkIFN0YXRlcw&hl=en&gl=US&sourceid=chrome&ie=UTF-8" }, "paid": [ { "paidPosition": "top", "title": "Buy & Sell Bitcoin | #1 in Crypto Security & Safety | coinbase.com", "trackingUrl": "https://google.com/aclk?sa=l&ai=DChcSEwjDssyHo9HkAhUahtUKHXNyAlUYABAAGgJ3cw&sig=AOD64_1Gml8jrX5PSNhnHex8ZD2ErH6vIg&q&ved=2ahUKEwjXq8aHo9HkAhXSZVAKHXrWAUoQ0Qx6BAgVEAE&adurl", "destinationUrl": "https://www.coinbase.com/signup", "breadcrumbs": [], "visurl": "www.coinbase.com/", "description": "Coinbase is the Safest, Most Secure Place to Buy and Sell Bitcoin, Ethereum, and More. We’re Obsessed with Security So You Don’t Have to Be. Buy, Sell, and Trade Crypto Safely. iOS & Android App. Secure Storage. Over 20M+ Users. Most Trusted." }, { "paidPosition": "top", "title": "Buy Bitcoin In 90 Seconds | Get Started For Free", "trackingUrl": "https://google.com/aclk?sa=l&ai=DChcSEwjDssyHo9HkAhUahtUKHXNyAlUYABABGgJ3cw&sig=AOD64_0a5ShbhklcaLMdUNRMqxNkiDtDSw&q&ved=2ahUKEwjXq8aHo9HkAhXSZVAKHXrWAUoQ0Qx6BAgWEAE&adurl", "destinationUrl": "https://gemini.com/", "breadcrumbs": [ { "url": "https://exchange.gemini.com/register", "text": "Buy Bitcoin Instantly" }, { "url": "https://gemini.com/", "text": "\"Best Crypto Exchange\"" }, { "url": "https://gemini.com/security/", "text": "Industry-Best Security" } ], "visurl": "www.gemini.com/", "description": "Gemini Makes Buying Bitcoin Simple, Safe & Secure. Open A Free Account Today & Start Experiencing The Future of Money! Trade In Minutes. Superior Security. Most Trusted. Free Sign Up. Services: Buy & Sell Bitcoin, Price Charts, Price Alerts, Secure Custody." } ], "organic": [ { "position": 1, "isCarousel": true, "isVertical": false, "news": [ { "title": "China's PBC Is Warming Up To Digital Currencies -- Good News For ...Forbes9 hours ago", "url": "https://www.forbes.com/sites/panosmourdoukoutas/2019/09/14/chinas-pbc-is-warming-up-to-digital-currencies-good-news-for-bitcoin-eth-xrp-and-ltc/" }, { "title": "Bitcoin Price Indicator May Signal Next Leg HigherCoinDesk12 hours ago", "url": "https://www.coindesk.com/bitcoin-price-indicator-may-signal-next-leg-higher" }, { "title": "Ethereum Network Demand Surges; Will ETH’s Price Follow?NewsBTC3 mins ago", "url": "https://www.newsbtc.com/2019/09/14/ethereum-network-demand-surges-will-eths-price-follow/" } ] }, // ... ], "number_of_results": 513000000 }
Notice the paid key which provides results usually seen at the top of searches for which were paid for by each vendor.
The above queries are the simplest but only the tip of the iceberg; here are a few other valuable search options:
device – mobile or desktop results
tbm – image search (isch) or maps (lcl)
timeframe – h, d, w, etc. for search results based on time units
There are loads of other customizations available to see in the Zenserp documentation.
Google Trends
Zenserp also provides a /trends API endpoint to query Google Trends:
curl https://app.zenserp.com/api/v1/trends \ -F "keyword[]=bitcoin" \ -F "keyword[]=ethereum" \ -F "apikey=YOUR-API-KEY"
Notice that you can provide multiple keywords using the array syntax!
Use Cases
The obvious use case for Zenserp is creating my own custom search page but SERPs are so much more useful than that — you could brainstorm any variety of use cases:
Monitoring your (or the competition’s) search placement for an important keyword
Tracking popular trends
Analyzing searches your users are making via your own search forms using SERP in the background
Downloading images that match a given term
Tracking a given business type’s density in a given area using Maps search
….too many to list!
As much as I love trusting my own scraping talents, it’s so much easier to trust Zenserp. I save time in maintenance and get the advantage of their easy to use API and its wealth of options. The more I learn about topics in this industry, the more I’ve learned to delegate difficult tasks to experts. Zenserp is the my expert in Google search results APIs.
The post Easy Google Search Result API with Zenserp (Sponsored) appeared first on David Walsh Blog.
Easy Google Search Result API with Zenserp (Sponsored) published first on https://deskbysnafu.tumblr.com/
0 notes
Text
The Essential Tools for Programmers
This is a list of essential tools and services from my coding workflow that I think should be part of every web programmer’s toolkit. Whether you a building a simple “Hello World” app or a complex web application, these tools should make your coding easier and increase productivity.
The Web Developer’s Toolkit
1. devdocs.io — API documentation for all popular programming languages and frameworks. Includes instant search and works offline too.
2. glitch.com — create your own web apps in the browser, import GitHub repos, use any NPM package or build on any popular frameworks and directly deploy to Firebase.
3. bundlephobia.com — quickly find the import cost (download size) of any package in the NPM registry. Or upload your package.json file to scan all dependencies in your project.
4. babeljs.io/repl — Write your code in modern JavaScript and let Babel transform your code into JavaScript that is compatible with even older browsers.
5. codeply.com — quickly build frontend responsive layouts with frameworks like Bootstrap, Materialize CSS and SemanticUI.
6. httpie.org — a command-line tool that is useful for making HTTP requests to web servers and RESTful APIs. Almost as powerful as CURL and Wget but simpler.
7. regexr.com — A good tool for testing your regular expressions in the browser.
8. jex.im/regulex — Write any regular expression into the editor and get a visual representation of how the pieces work.
9. buildregex.com — Construct regular expressions visually.
Also see: The Most Useful Websites on the Internet
10. explainshell.com — Type any Unix command and get a visual explanation of each flag and argument in the command.
11. tldr.ostera.io — Unix man pages are long and complex. This site offers practical examples for all popular Unix command without you having to dive into the man pages.
12. mockaroo.com — quickly generate dummy test data in the browser in CSV, JSON, SQL and other export formats.
13. jsdelivr.com — Serve any GitHub file or WordPress plugin through a CDN. Combine multiple files in a single URL, add “.min” to any JS/CSS file to get a minified version automatically. Also see unpkg.com.
14. carbon.now.sh — create beautiful screenshots of your source code. Offers syntax highlighting for all popular languages.
15. wakatime.com — know exactly how long you spend coding with detailed metrics per file and even language. Integrates with VS Code, Sublime text, and all popular code editors.
16. astexplorer.net — paste your JavaScript code into the editor and generate the Abstract Syntax Tree that will help you understand how the JavaScript parser works.
17. hyper.is — A better alternative to the command line terminal and also iTerm. Use with the Oh My Zsh shell and add superpowers to your terminal.
18. curlbuilder.com — make your own CURL requests in the browser.
19. htaccess.madewithlove.be — easily test the redirect and rewrite rules in the .htaccess file of your Apache server. See useful .htaccess snippets.
Also see: The Best Places to Download HTML Templates
20. trackjs.com — monitor errors in your JavaScript based web projects and get instant email notifications when a new error is detected.
21. ngrok.com — Start a local web server, fire up ngrok, point to the port where the localhost is running and get a public URL of your tunnel.
22. codeshare.io — An online code editor for pair programming, live interviews with video conferences or for teaching code to students remotely.
23. webhooks.site — Easily inspect the payloads and debug HTTP webhooks in the browser. All HTTP requests are logged in real-time. Another good alternative is RequestBin.
24. surge.sh — the easiest way to deploy web pages and other static content from the command line. Supports custom domains and SSL. Also see Zeit Now.
25. visbug — A must-have add-on for web developers that brings useful web design tools right in your browser. Available for Google Chrome and Firefox.
26. puppeteersandbox.com — Puppeteer is a Node.js framework for automating Google Chrome. Use the sandbox to quickly test your scripts in the browser. Also see try-puppeteer.com.
27. prettier.io/playground — Beautify your JavaScript and TypeScript code using Prettier, the favorite code formatter of programmers.
28. json.parser.online.fr — The only JSON parser you’ll ever need to analyze and beautify your complex JSON strings.
29. scrimba.com — Create your own programming screencasts in the browser or watch other developers code.code.
30. katacoda.com — A training platform for software developers where anyone can create their own dedicated and interactive training environments.
31. codesandbox.io — A full-featured online IDE where you can create web applications in all popular languages including vanilla JavaScript, React, TypeScript, Vue and Angular. Also see StackBlitz.com and Repl.it.
32. apify.com — Write your own web scrapers using JavaScript and schedule your scrapers to run at specific intervals automatically.
33. vim-adventures.com — The Vim text editor is hugely popular among programmers. The site will help you master the various key commands through a game.
34. insomnia.rest — A desktop based REST client that lets you create HTTP requests and view response details all in a easy-to-use interface. Advanced users may consider Postman.
Also see: The Most Awesome Teachers for Learning Web Development
The post The Essential Tools for Programmers appeared first on Digital Inspiration.
via Digital Inspiration Technology Blog https://ift.tt/2Em4psx
0 notes