#invokeai
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The average Tumblr user visits about 67 pages every month.
Text

Dark Theme 4
#darktheme#wod#world_of_darkness#invokeai#darkart#darkfantasy#photoshop#vampire#vampiregirl#vampirethemasquerade#worldofdarkness#vampirebloodlines
5 notes
·
View notes
Text

Fat Albert Einstein.
2 notes
·
View notes
Text
InvokeAI prompt and library UI/UX concepts
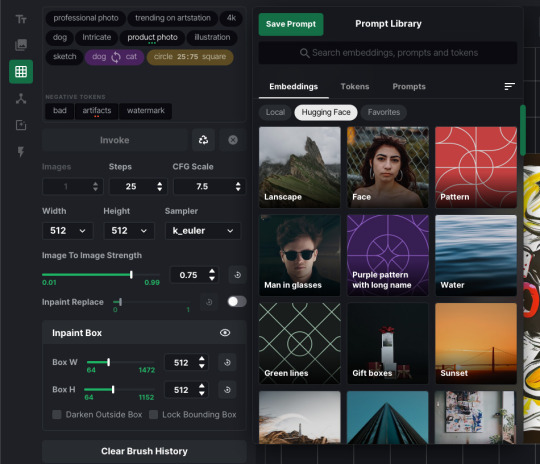
As part of my work on InvokeAI in 2022-2023, I prepared a lot of ideas and mockups demonstrating how the interface should work.
Main concept:
- Tags instead of tokens. That means they would be more interactive, separate blocks, but we would keep compatibility with the text interface and ability to switch between them. - Keeping all the existing features and displaying them in the UI, including weights, blend, swap.Plan the ability to control them with a click rather than keyboard input. - Don't divide fields into positive and negative prompts, it's better to separate tags by colour or form. - Autocomplete tokens as you type. - Suggest tokens, depending on the context. Not sure exactly how to implement it yet. But at least we know what user has entered before, and could suggest frequently used tokens, for example. - Presets: saving and loading prompts. - Libraries: tokens and TI. Like on that screenshot, but without a separate field for them, because in my opinion it's part of the prompt. Search, display suggestions with pictures, add a few by click. Design sources https://www.dropbox.com/sh/hwetq9hcnftswk2/AACopwF3GBkCApUn3nS99iY4a?dl=0
Prompt UI ideas:
Different styles Make the positive tags rounded and the negative tags square.

Input Entering a word the usual way, a word or group of words turns into a tag after entering a comma or enter. Two clicks on the centre of the tag, on the word inside — edit.

When focus in the input field, a block appears at the right with a selection of concepts and a search. On a separate tab in the same block, token and string management — save, load, search, select. When you change the focus from the input field this block disappears. The context menu (right button click) contains tag types and operations with them like with any objects in any editors. Copy, paste, cut, delete, and so on. This is necessary for some cases and to duplicate features and make them more accessible.

When hovering over a tag, the tag block enlarges — so it's easier to hit it and we solve the problem of changing very short words and typos. At the same time, the text or token, the word inside the tag, remains in its place, it should not move. Only the size of the form around the tag changes. A great solution is the dock response in macos, it is magnetised to the cursor. Change token type (weight, blend, swap) By left-clicking on the tag, cyclically. This changes the tag visually, for example, I want to assign to each type of tag a different color, or rather a gradient, to distinguish them from other tags without additions. Change is also accessible through the context menu.

Change the weight By clicking on the right and left side of the tag. The side is highlighted and turns into a + or - button. When you change the weight, the tag has an indicator below — dots. I’m not sure there is a need for more than 3 (+++ or - - -). Also, if a user uses our text syntax, we can turn it into a tag of some type.


Swap tokens / objects Tag with two words, between which there is an icon like refresh. Each word is edited separately, mechanics as described above. You write one word, a tag is created, the focus goes to the part of the swap for the other word. Or write two words with unused character between them (like & or %). Swap with hover:

Blend Tag with two words, each of which has a weight indicator for blending. The mechanics are as described above. Selecting multiple tags Possible via shift or ctrl, then selecting a type via the context menu. For example, to change the weight of a group of tags or change them to negative tags.

Moving and merging tags: drag one tag on another and merge them to swap or blend. Drag to any part of the field and leave it there.

Option to automatically arrange the tags. This refers to grouping negative tags after positive ones. It would be convenient, but not necessary. Suggestions while typing Some tokens in the separate block below the cursor (can be disabled, optional).

Suggestions include tokens suggestions when the user doesn't know what to type in, but we know the context of the prompt. Also, if the user doesn't know how to start, has no ideas at all, we can set the “Random prompt” for example. Autocomplete tokens while typing Add the token’s part at the right side of a cursor, add it as a token with enter:

Concepts & tokens library
Tokens library consists of four types: - Single token — a keyword, tag - Style concept — several tokens for some style, which can be added to any prompt - Prompt — complete prompt to save it outside an image and to share - Embedding — TI trained
- There are local and remote (Hugging Face) embeddings. Local embeds can be marked as favourites (if HF remote embed is marked, it downloads to the local storage).
Prompts presets
“Save prompt” button is always there. If no token is selected, it saves a full prompt. If one token is selected, it saves the token. If multiple tokens are selected, it saves style.

Tokens organised into categories — folders or just virtual categories in some local file. Favourites — all frequently used tokens. Tokens are sorted A–Z. Main categories are: - Subject — landscape, portrait, still life, some objects, people, animals, etc. - Setting — location & context: cityscape, rural, interior, studio… - Style — art styles, such as surrealism, dada, installation, futurism and so - Artist — artists names - Medium — what and how the object is drawn or made of. Drawing, photo, ceramics, steel, oil painting, wood, etc. - Composition — arrangement of the elements, abstracts like symmetry, balance, emphasis (if they work at all). - Camera & Light — available camera models, films, focal lengths, lighting names and other photographic terms. - Emotion — happy, sad, horror, smart, beautiful…
Prompts
Prompts are organised in “folders” created by a user. “Previously used” prompts — those that the user has in the log file. Some of the prompts already have pictures (previously generated), maybe we can show them, too.

NOTE: All this work was done for InvokeAI project in 2023. Original document is here. You can use it for free and reach me if you want to develop something. Read the full article
0 notes
Text

Birthday card for a friend and a Thank You card for attendees of a recent equestrian event. Done with a combination of things - Krita, Rebelle, Affinity Photo, and a few different SDXL models using Invoke. Still figuring out workflows to get ideas on to paper.
0 notes






Note
so like I know this is a ridiculously complicated and difficult thing to pull off so I obviously can't expect you to just give me a full tutorial or something, but do you think you could give me some pointers on how to get started training my own ai?
The software you should research is called KohyaSS, and the best kind of model to practice training on is a LoRA. Basically an add-on to a base model that adds a new style or concepts.
I haven't trained anything new in a few months, so my recommendations are most likely very outdated. I heard that OneTrainer is a more user friendly alternative to Kohya, but I haven't tried it myself.
Just one thing before you start training though, make sure you understand basic AI techniques before trying to jump into making your own model. Checkpoints, denoising, seeds, controlnets, LoRA, IP adapters, upscaling etc. InvokeAI is a good interface to practice with and their tutorials are good. Free to run too.
18 notes
·
View notes
Note
hello! anon looking for advice on ethical AI gen. i've got a pretty decent comp setup (nvidia on my laptop and i thiiiink my desktop?) and i'm fairly ok tech-wise, so i'd love to set up something local. :) any guides or advice would be very appreciated- thank you for your time!
Hi!!!!
First off, welcome aboard! It's always a lot of fun to have more interested and creative-minded folks playing with these toys! I love the super-specific-fetish-porn that dominates the genAI scene, don't get me wrong, but it's always nice to see people interested in exploring these tools in other ways too!! (Not to say you shouldn't make super specific fetish porn; goodness knows about a third of my generations are!)
Now, I did a little write up about how to get yourself started locally here:
I'm a big believer in the InvokeAI interface, in part because it's easy to set up and update, and in part because I find the in-painting to be the most precise and comfortable.
However, the reality is, Automatic1111 is the "standard choice" in terms of interfaces for local generation, and most tutorials will assume either that you use it, or that you are familiar enough with your own UI to be able to "translate" the guide.
Invoke is very much a "second line" option, behind A1111 and ComfyUI, but it's the one I am most familiar with as it had robust Linux support the soonest, and I'm a horrible little linux gremlin.
Now, you specify that you're doing alright techwise, so I'm going to get a little technical about specs.
Most of the tech demands for image generation come down to the amount of memory in your video card. I have an 8GB memory video card, which means I can run up through about Stable Diffusion 2.1, but not something more extreme like Flux.
More VRAM means more models you can run at all. More power means those models run faster.
It's generally claimed that you need 6GB of VRAM to get going, but there are Stable Diffusion 1 models that will run on 4GB, because that's what I was running 2 years ago when this tech dropped and it worked Okay Enough.
Your Laptop may have a video card with that kind of ram, especially if it's a gaming laptop, but most people use desktops to run genAI for a reason haha. It's a lot cheaper to get that kind of memory and power in a desktop format.
If you don't have enough VRAM, though, don't worry. You can generate using your processor and regular RAM too! It will, however, be much MUCH slower. Currently, my videocard generations take about 1 second per "step" for a 1024x768, and I usually run at around 25 steps. Processor generations take me a whopping 40 times that long, so a single image takes around 15 minutes.
What I'm getting at here is, if you can run on your video card, you really really want to run on your video card.
If your desktop can run generations but your laptop can't, you may also want to look into setting up remote access to your desktop via your laptop, so you can generate on the desktop but interface on the laptop on the go!
Generally, people set this up as a "headless" system, where the desktop is not generating graphics for the OS at all. This will maximize the power available for image generation. However, I have never set up a headless windows terminal, and I have literally no idea how, so I can't really point you in the right direction there, beyond telling you the keyword to search is "headless windows terminal."
3 notes
·
View notes
Text

Ancient Steel, Neon Soul
Tools used:
Checkpoint: Jib Mix Realistic XL-v16.0 Aphrodite EclecticEuphoria Universal SD3_k4 Jib Mix Flux v8-AccentuEight
web-ui: stable-diffusion-webui (AUTOMATIC1111) stable-diffusion-webui-forge ComfyUI InvokeAI
Other: Photoshop
#artistsontumblr#digitalart#fantasyart#cyberpunk#warriorwoman#illustration#art#scifiart#steampunk#characterdesign#epicfantasy#swordfighter#tattooedwarrior#futuristicvibes#neoncity#dystopianworld#heroicfantasy#darkandgritty#painting#digitalillustration#cyberfantasy#sci-fantasy#womenwithswords#adventurer#conceptart#fantasyworlds#digitalarts#femalecharacter#aestheticart#urbanfantasy
3 notes
·
View notes
Text



TESFEST2023 - Day 6 - Blood
For the Blood theme, I would like to share an idea that has been incubating for a while. It may make it into Mage Apprentice along the theme of Blood Magic, or it may end up its own mod. Or maybe it will end up in the bin of intriguing ideas that didn't become reality. We will see.
The story of the Blood Sisters would revolve around fleshing out the Forsworn culture, back story, and answer questions such as 'where does their affinity with Hagraven come from?', 'how did Briarhearts come about?' or 'where are the children?'.
Most importantly, it would give the player a chance to join the Forsworn, experience their culture and discover their image of blood thirsty savages is nothing more than propaganda from the Empire.
[Images generated with Stable Diffusion and InvokeAI. These are placeholders until I create the NPCs in-game]
More details after the break if you don't mind spoilers for the story.
The Blood Sisters would be three powerful holy women, each leading a different tribe of Forsworns (I saw something about multiple Forsworn tribes once but I can't find that web article again).
The Blood Elder is an old woman with white hair, as close to a Hagraven as possible without becoming one. She rules the southern side of the Reach, centered on Bards Deep Summit.
The Blood Mother is a pregnant middle age woman with white hair, who rules the Deepwood Redoubt enclave.
The Blood Maiden is a young woman with white hair, barely out of her teens. She rules most of the Reach and centered on Karthspire.
--
Crushed between the Nords on side and the Empire on the other, the Forworns were facing extinction - of their people and of their culture.
Their true leader, Enid, a young holy woman with white hair, barely out of her teens, took desperate measures to ensure the survival of her people.
Tapping into an ancient blood magic ritual, she split herself into three versions of herself at a different age.
The Maiden would be perpetually young - idealist, fierce and fearless. She would lead her people in merciless attacks against the enemies of her people.
The Mother would look perpetually pregnant, as she would carry in her womb the souls of all of their children placed there for safekeeping.
The Elder would be perpetually wise and would come up with powerful alliances with Hagravens, Flame Atronach and other creatures. She would instruct her people in dark rituals (Briarhearts).
One thing Enid did not anticipate is that her three self would not agree to a common strategy and would split the Forsworns into three tribes.
The role of the player would be to meet each one separately, discover they are one and the same, and reunite them into a joint council.
And Madanach in all this? The King in rags would be actually a puppet. A diversion to distract their enemies (and it worked, since they jailed him for it).
--
Culturally, I would model the Forswon after Celtic influences, like what the Picts were to the Roman Empire. That would make sense given their relationships to Bretons.
I still have a lot of research to do before fleshing this story out but it feels right so far, and it could evolve into the missing 'join the Forsworn' quest I have been looking for.
4 notes
·
View notes
Text
CVE-2024-12029 – InvokeAI Deserialization of Untrusted Data vulnerability
http://i.securitythinkingcap.com/TLz7q8
0 notes
Text

Dark Theme
#darktheme#wod#world_of_darkness#invokeai#darkart#darkfantasy#photoshop#vampire#vampiregirl#vampirethemasquerade#worldofdarkness#vampirebloodlines
2 notes
·
View notes
Text

Einstein = MotorCycle²
0 notes
Text
I trained a neural network on my drawings

Warning: this article is a bit outdated. Download the model here: https://huggingface.co/netsvetaev/netsvetaev-free. It’s great for seamless patterns, abstract drawings, and watercolor-styled images. How to use it and train a neural network on your own pictures?

How to use .ckpt model
You download the .ckpt file, put it in your models folder. Then it all depends on what fork you're using. In InvokeAI, which I use, the models are added by usual loading invoke.py and executing !import_model command in console.
How to train neural network on your images if you don't have nvidia 4090?
Google has a wonderful service called Colab: Google gives you free server for about an hour. That's enough to build a model from 15-30-50 images. First go here and get acquainted with colab (but don't touch anything): https://colab.research.google.com/github/ShivamShrirao/diffusers/blob/main/examples/dreambooth/DreamBooth_Stable_Diffusion.ipynb All that is required from you, except for clicking through each code window and uploading pictures, is a hugging face token.
Huggingface Token & Settings
Register at huggingface.co, and then create a token in the settings: https://huggingface.co/settings/tokens
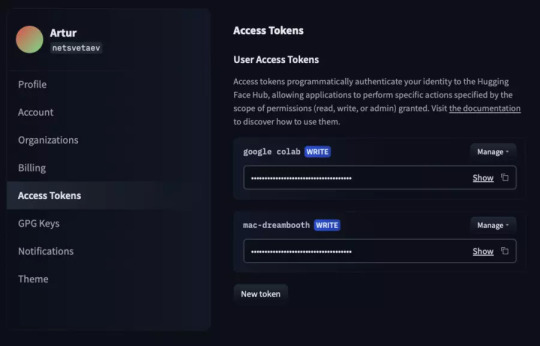
Insert the token here:
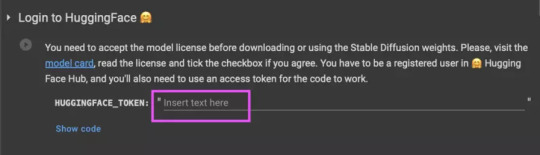
Check the box to save the model to google drive and name a folder, if you want (it will be created automatically)
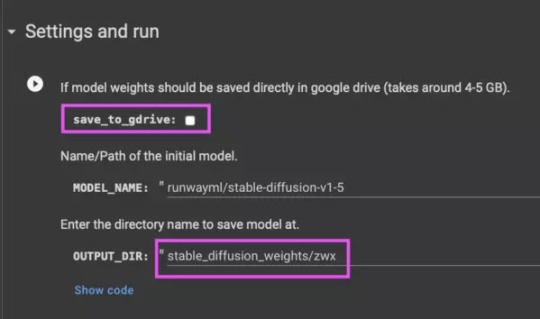
Next, specify how we will call your style or object
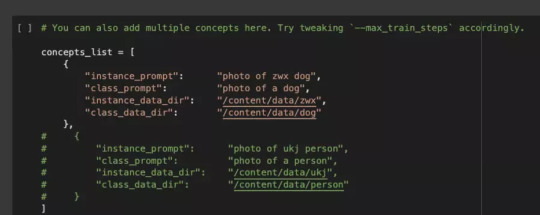
This is not so important, but you need to remember this token to invoke your object. Then upload the pictures:
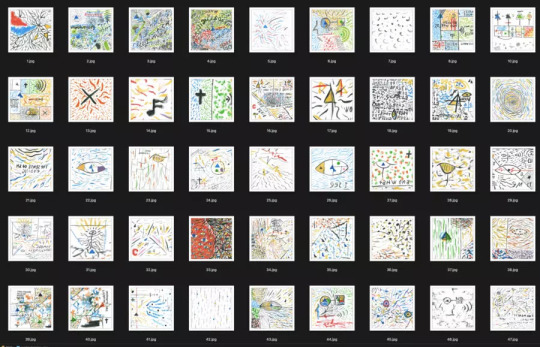
Dataset
You need to use the size of 512x512 pixels, and it is better to prepare them in advance. It's up to you to decide what to cut, but I recommend to cut it so that the composition and significant objects were preserved. You can also make several separate zoomed in and cropped pictures.
Depending on the number of images, you can change the number of training steps. A reasonable number is 100 steps * number of pictures. For 8 images (at least 8 is enough, btw) — 800 steps is enough. Too many steps is also bad: the generation will become too contrast and you will get artifacts on images (overtrained model).
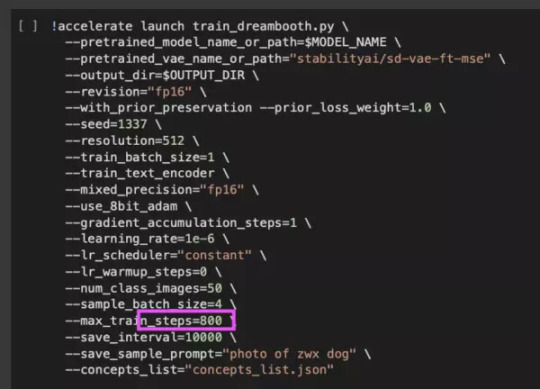
Next, simply start each block in the colab with the Play button in the top left corner and wait for the completion of each code. When you get to the section shown above and start it, you will see the learning process. It will take about 10 minutes to prepare + another 15-30 minutes, depending on the number of pictures and steps.
Test your ai model
After training you can test the model on test generation and convert it to .ckpt format:
Now you have the file on your Google disk: download it and add it to your favorite fork. Additionally you can delete unnecessary files and finish the process.
Other examples:


About me
My name is Artur Netsvetaev, I am a product manager, entrepreneur and UI/UX designer. I help with the development of the InvokeAI interface and have been using it myself since the beginning of this project. First published: https://habr.com/ru/articles/699002/ Read the full article
0 notes
Text
Automatic1111 vs InvokeAI In 2025
I’ve used both pretty extensively, and like both of them for different things. Invoke great in/outpainting interface iteration workflow is superior – that is, if you hit Invoke multiple times without accepting a generation; with auto, every time you hit generate it resets the image viewer infinite undo is great masking is better, since you can zoom in via the interface; in auto, I have to…
0 notes

Note
Hi, do you know of any good up-to-date guides on getting stable diffusion/inpainting installed and working on a pc? I don't even know what that would *look* like. Your results look so cool and I really want to play with these toys but it keeps being way more complicated than I expect. It's been remarkably difficult to find a guide that's up to date, not overwhelming, and doesn't have "go join this discord server" as one of the steps. (and gosh github seems incredibly unapproachable if you're not already intimately familiar with github >< )
The UI I use for running Stable Diffusion is Invoke AI. The instruction in it's repo is basically all you'll need to install and use it. Just make sure your rig meets the technical requirements. https://github.com/invoke-ai/InvokeAI Github is something you'll need to suffer through, unfortunately, but it gets better the longer you stew in it. Invoke goes with SD already in it, you won't need to install it separately. I do inpainting through it's Unified Canvas feature. The tutorial I watched to learn it is this: https://www.youtube.com/watch?v=aU0jGZpDIVc The difference in my workflow is that I use the default inpainting model that goes with Invoke.

You can grab something fancier off of civit.ai if you feel like it. For learning how to train your own models you'll need to read this: https://github.com/bmaltais/kohya_ss Don't try messing with it before you get acquainted with Invoke and prompting in general, because this is the definition of overwhelming.
Hope this'll be a good jumping off point for you, I wish you luck. And patience, you'll need a lot of that.
34 notes
·
View notes