#pyspark online classes
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
130K people were victims of a chain letter scam that affected Tumblr in May 2011.
Text
How to Read and Write Data in PySpark
The Python application programming interface known as PySpark serves as the front end for Apache Spark execution of big data operations. The most crucial skill required for PySpark work involves accessing and writing data from sources which include CSV, JSON and Parquet files.
In this blog, you’ll learn how to:
Initialize a Spark session
Read data from various formats
Write data to different formats
See expected outputs for each operation
Let’s dive in step-by-step.
Getting Started
Before reading or writing, start by initializing a SparkSession.
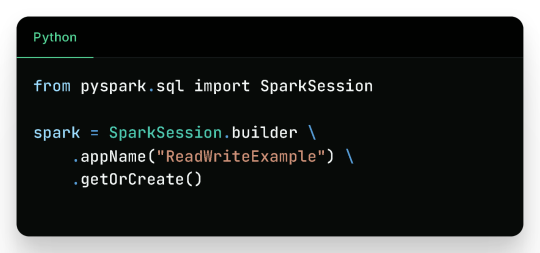
Reading Data in PySpark
1. Reading CSV Files
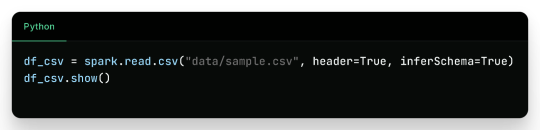
Sample CSV Data (sample.csv):

Output:

2. Reading JSON Files
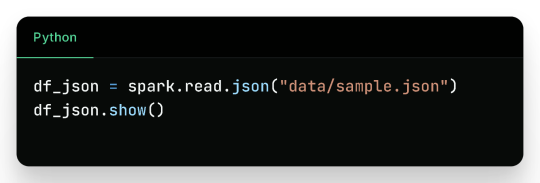
Sample JSON (sample.json):

Output:

3. Reading Parquet Files
Parquet is optimized for performance and often used in big data pipelines.

Assuming the parquet file has similar content:
Output:
4. Reading from a Database (JDBC)

Sample Table employees in MySQL:

Output:

Writing Data in PySpark
1. Writing to CSV
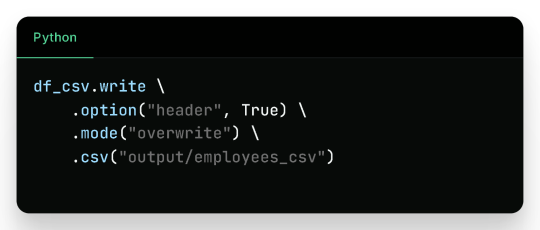
Output Files (folder output/employees_csv/):

Sample content:

2. Writing to JSON

Sample JSON output (employees_json/part-*.json):
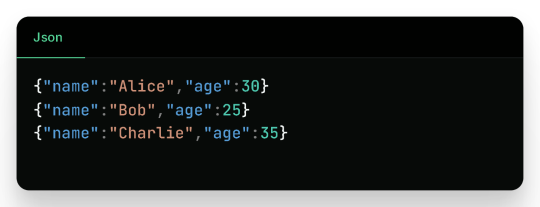
3. Writing to Parquet
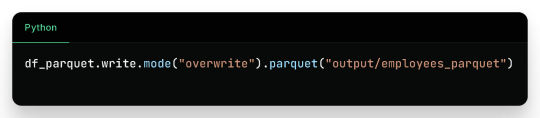
Output:
Binary Parquet files saved inside output/employees_parquet/
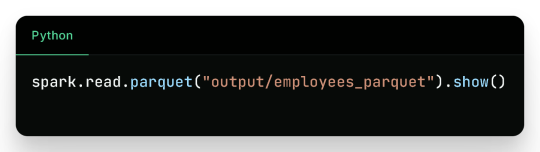
You can verify the contents by reading it again:
4. Writing to a Database
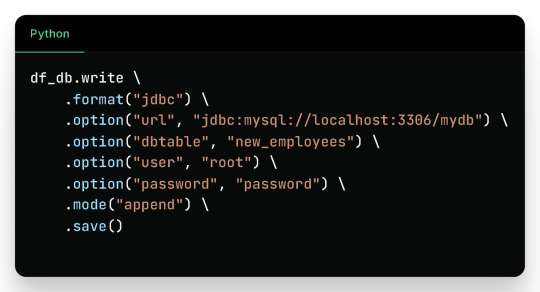
Check the new_employees table in your database — it should now include all the records.
Write Modes in PySpark
Mode
Description
overwrite
Overwrites existing data
append
Appends to existing data
ignore
Ignores if the output already exists
error
(default) Fails if data exists
Real-Life Use Case
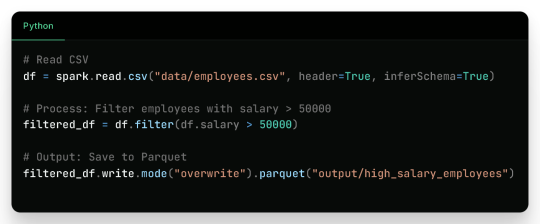
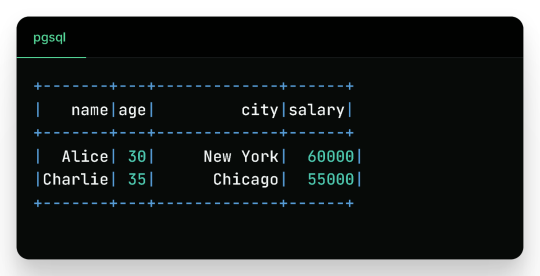
Filtered Output:
Wrap-Up
Reading and writing data in PySpark is efficient, scalable, and easy once you understand the syntax and options. This blog covered:
Reading from CSV, JSON, Parquet, and JDBC
Writing to CSV, JSON, Parquet, and back to Databases
Example outputs for every format
Best practices for production use
Keep experimenting and building real-world data pipelines — and you’ll be a PySpark pro in no time!
🚀Enroll Now: https://www.accentfuture.com/enquiry-form/
📞Call Us: +91-9640001789
📧Email Us: [email protected]
🌍Visit Us: AccentFuture
#apache pyspark training#best pyspark course#best pyspark training#pyspark course online#pyspark online classes#pyspark training#pyspark training online
0 notes