#pyspark training program
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has a low social media market share in South America.
Text
Navigating the Data Landscape: A Deep Dive into ScholarNest's Corporate Training

In the ever-evolving realm of data, mastering the intricacies of data engineering and PySpark is paramount for professionals seeking a competitive edge. ScholarNest's Corporate Training offers an immersive experience, providing a deep dive into the dynamic world of data engineering and PySpark.
Unlocking Data Engineering Excellence
Embark on a journey to become a proficient data engineer with ScholarNest's specialized courses. Our Data Engineering Certification program is meticulously crafted to equip you with the skills needed to design, build, and maintain scalable data systems. From understanding data architecture to implementing robust solutions, our curriculum covers the entire spectrum of data engineering.
Pioneering PySpark Proficiency
Navigate the complexities of data processing with PySpark, a powerful Apache Spark library. ScholarNest's PySpark course, hailed as one of the best online, caters to both beginners and advanced learners. Explore the full potential of PySpark through hands-on projects, gaining practical insights that can be applied directly in real-world scenarios.
Azure Databricks Mastery
As part of our commitment to offering the best, our courses delve into Azure Databricks learning. Azure Databricks, seamlessly integrated with Azure services, is a pivotal tool in the modern data landscape. ScholarNest ensures that you not only understand its functionalities but also leverage it effectively to solve complex data challenges.
Tailored for Corporate Success
ScholarNest's Corporate Training goes beyond generic courses. We tailor our programs to meet the specific needs of corporate environments, ensuring that the skills acquired align with industry demands. Whether you are aiming for data engineering excellence or mastering PySpark, our courses provide a roadmap for success.
Why Choose ScholarNest?
Best PySpark Course Online: Our PySpark courses are recognized for their quality and depth.
Expert Instructors: Learn from industry professionals with hands-on experience.
Comprehensive Curriculum: Covering everything from fundamentals to advanced techniques.
Real-world Application: Practical projects and case studies for hands-on experience.
Flexibility: Choose courses that suit your level, from beginner to advanced.
Navigate the data landscape with confidence through ScholarNest's Corporate Training. Enrol now to embark on a learning journey that not only enhances your skills but also propels your career forward in the rapidly evolving field of data engineering and PySpark.
#data engineering#pyspark#databricks#azure data engineer training#apache spark#databricks cloud#big data#dataanalytics#data engineer#pyspark course#databricks course training#pyspark training
3 notes
·
View notes
Text
Training Proposal: PySpark for Data Processing
Training Proposal: PySpark for Data Processing Introduction:This proposal outlines a 3-day PySpark training program designed for 10 participants. The course aims to equip data professionals with the skills to leverage Apache Spark using the Python API (PySpark) for efficient large-scale data processing[5]. Participants will gain hands-on experience with PySpark, covering fundamental concepts to…
0 notes
Text
Training Proposal: PySpark for Data Processing
Introduction:This proposal outlines a 3-day PySpark training program designed for 10 participants. The course aims to equip data professionals with the skills to leverage Apache Spark using the Python API (PySpark) for efficient large-scale data processing5. Participants will gain hands-on experience with PySpark, covering fundamental concepts to advanced techniques, enabling them to tackle…
0 notes
Text
BigQuery Studio From Google Cloud Accelerates AI operations

Google Cloud is well positioned to provide enterprises with a unified, intelligent, open, and secure data and AI cloud. Dataproc, Dataflow, BigQuery, BigLake, and Vertex AI are used by thousands of clients in many industries across the globe for data-to-AI operations. From data intake and preparation to analysis, exploration, and visualization to ML training and inference, it presents BigQuery Studio, a unified, collaborative workspace for Google Cloud’s data analytics suite that speeds up data to AI workflows. It enables data professionals to:
Utilize BigQuery’s built-in SQL, Python, Spark, or natural language capabilities to leverage code assets across Vertex AI and other products for specific workflows.
Improve cooperation by applying best practices for software development, like CI/CD, version history, and source control, to data assets.
Enforce security standards consistently and obtain governance insights within BigQuery by using data lineage, profiling, and quality.
The following features of BigQuery Studio assist you in finding, examining, and drawing conclusions from data in BigQuery:
Code completion, query validation, and byte processing estimation are all features of this powerful SQL editor.
Colab Enterprise-built embedded Python notebooks. Notebooks come with built-in support for BigQuery DataFrames and one-click Python development runtimes.
You can create stored Python procedures for Apache Spark using this PySpark editor.
Dataform-based asset management and version history for code assets, including notebooks and stored queries.
Gemini generative AI (Preview)-based assistive code creation in notebooks and the SQL editor.
Dataplex includes for data profiling, data quality checks, and data discovery.
The option to view work history by project or by user.
The capability of exporting stored query results for use in other programs and analyzing them by linking to other tools like Looker and Google Sheets.
Follow the guidelines under Enable BigQuery Studio for Asset Management to get started with BigQuery Studio. The following APIs are made possible by this process:
To use Python functions in your project, you must have access to the Compute Engine API.
Code assets, such as notebook files, must be stored via the Dataform API.
In order to run Colab Enterprise Python notebooks in BigQuery, the Vertex AI API is necessary.
Single interface for all data teams
Analytics experts must use various connectors for data intake, switch between coding languages, and transfer data assets between systems due to disparate technologies, which results in inconsistent experiences. The time-to-value of an organization’s data and AI initiatives is greatly impacted by this.
By providing an end-to-end analytics experience on a single, specially designed platform, BigQuery Studio tackles these issues. Data engineers, data analysts, and data scientists can complete end-to-end tasks like data ingestion, pipeline creation, and predictive analytics using the coding language of their choice with its integrated workspace, which consists of a notebook interface and SQL (powered by Colab Enterprise, which is in preview right now).
For instance, data scientists and other analytics users can now analyze and explore data at the petabyte scale using Python within BigQuery in the well-known Colab notebook environment. The notebook environment of BigQuery Studio facilitates data querying and transformation, autocompletion of datasets and columns, and browsing of datasets and schema. Additionally, Vertex AI offers access to the same Colab Enterprise notebook for machine learning operations including MLOps, deployment, and model training and customisation.
Additionally, BigQuery Studio offers a single pane of glass for working with structured, semi-structured, and unstructured data of all types across cloud environments like Google Cloud, AWS, and Azure by utilizing BigLake, which has built-in support for Apache Parquet, Delta Lake, and Apache Iceberg.
One of the top platforms for commerce, Shopify, has been investigating how BigQuery Studio may enhance its current BigQuery environment.
Maximize productivity and collaboration
By extending software development best practices like CI/CD, version history, and source control to analytics assets like SQL scripts, Python scripts, notebooks, and SQL pipelines, BigQuery Studio enhances cooperation among data practitioners. To ensure that their code is always up to date, users will also have the ability to safely link to their preferred external code repositories.
BigQuery Studio not only facilitates human collaborations but also offers an AI-powered collaborator for coding help and contextual discussion. BigQuery’s Duet AI can automatically recommend functions and code blocks for Python and SQL based on the context of each user and their data. The new chat interface eliminates the need for trial and error and document searching by allowing data practitioners to receive specialized real-time help on specific tasks using natural language.
Unified security and governance
By assisting users in comprehending data, recognizing quality concerns, and diagnosing difficulties, BigQuery Studio enables enterprises to extract reliable insights from reliable data. To assist guarantee that data is accurate, dependable, and of high quality, data practitioners can profile data, manage data lineage, and implement data-quality constraints. BigQuery Studio will reveal tailored metadata insights later this year, such as dataset summaries or suggestions for further investigation.
Additionally, by eliminating the need to copy, move, or exchange data outside of BigQuery for sophisticated workflows, BigQuery Studio enables administrators to consistently enforce security standards for data assets. Policies are enforced for fine-grained security with unified credential management across BigQuery and Vertex AI, eliminating the need to handle extra external connections or service accounts. For instance, Vertex AI’s core models for image, video, text, and language translations may now be used by data analysts for tasks like sentiment analysis and entity discovery over BigQuery data using straightforward SQL in BigQuery, eliminating the need to share data with outside services.
Read more on Govindhtech.com
#BigQueryStudio#BigLake#AIcloud#VertexAI#BigQueryDataFrames#generativeAI#ApacheSpark#MLOps#news#technews#technology#technologynews#technologytrends#govindhtech
0 notes
Text
Big Data vs. Traditional Data: Understanding the Differences and When to Use Python

In the evolving landscape of data science, understanding the nuances between big data and traditional data is crucial. Both play pivotal roles in analytics, but their characteristics, processing methods, and use cases differ significantly. Python, a powerful and versatile programming language, has become an indispensable tool for handling both types of data. This blog will explore the differences between big data and traditional data and explain when to use Python, emphasizing the importance of enrolling in a data science training program to master these skills.
What is Traditional Data?
Traditional data refers to structured data typically stored in relational databases and managed using SQL (Structured Query Language). This data is often transactional and includes records such as sales transactions, customer information, and inventory levels.
Characteristics of Traditional Data:
Structured Format: Traditional data is organized in a structured format, usually in rows and columns within relational databases.
Manageable Volume: The volume of traditional data is relatively small and manageable, often ranging from gigabytes to terabytes.
Fixed Schema: The schema, or structure, of traditional data is predefined and consistent, making it easy to query and analyze.
Use Cases of Traditional Data:
Transaction Processing: Traditional data is used for transaction processing in industries like finance and retail, where accurate and reliable records are essential.
Customer Relationship Management (CRM): Businesses use traditional data to manage customer relationships, track interactions, and analyze customer behavior.
Inventory Management: Traditional data is used to monitor and manage inventory levels, ensuring optimal stock levels and efficient supply chain operations.
What is Big Data?
Big data refers to extremely large and complex datasets that cannot be managed and processed using traditional database systems. It encompasses structured, unstructured, and semi-structured data from various sources, including social media, sensors, and log files.
Characteristics of Big Data:
Volume: Big data involves vast amounts of data, often measured in petabytes or exabytes.
Velocity: Big data is generated at high speed, requiring real-time or near-real-time processing.
Variety: Big data comes in diverse formats, including text, images, videos, and sensor data.
Veracity: Big data can be noisy and uncertain, requiring advanced techniques to ensure data quality and accuracy.
Use Cases of Big Data:
Predictive Analytics: Big data is used for predictive analytics in fields like healthcare, finance, and marketing, where it helps forecast trends and behaviors.
IoT (Internet of Things): Big data from IoT devices is used to monitor and analyze physical systems, such as smart cities, industrial machines, and connected vehicles.
Social Media Analysis: Big data from social media platforms is analyzed to understand user sentiments, trends, and behavior patterns.
Python: The Versatile Tool for Data Science
Python has emerged as the go-to programming language for data science due to its simplicity, versatility, and robust ecosystem of libraries and frameworks. Whether dealing with traditional data or big data, Python provides powerful tools and techniques to analyze and visualize data effectively.
Python for Traditional Data:
Pandas: The Pandas library in Python is ideal for handling traditional data. It offers data structures like DataFrames that facilitate easy manipulation, analysis, and visualization of structured data.
SQLAlchemy: Python's SQLAlchemy library provides a powerful toolkit for working with relational databases, allowing seamless integration with SQL databases for querying and data manipulation.
Python for Big Data:
PySpark: PySpark, the Python API for Apache Spark, is designed for big data processing. It enables distributed computing and parallel processing, making it suitable for handling large-scale datasets.
Dask: Dask is a flexible parallel computing library in Python that scales from single machines to large clusters, making it an excellent choice for big data analytics.
When to Use Python for Data Science
Understanding when to use Python for different types of data is crucial for effective data analysis and decision-making.
Traditional Data:
Business Analytics: Use Python for traditional data analytics in business scenarios, such as sales forecasting, customer segmentation, and financial analysis. Python's libraries, like Pandas and Matplotlib, offer comprehensive tools for these tasks.
Data Cleaning and Transformation: Python is highly effective for data cleaning and transformation, ensuring that traditional data is accurate, consistent, and ready for analysis.
Big Data:
Real-Time Analytics: When dealing with real-time data streams from IoT devices or social media platforms, Python's integration with big data frameworks like Apache Spark enables efficient processing and analysis.
Large-Scale Machine Learning: For large-scale machine learning projects, Python's compatibility with libraries like TensorFlow and PyTorch, combined with big data processing tools, makes it an ideal choice.
The Importance of Data Science Training Programs
To effectively navigate the complexities of both traditional data and big data, it is essential to acquire the right skills and knowledge. Data science training programs provide comprehensive education and hands-on experience in data science tools and techniques.
Comprehensive Curriculum: Data science training programs cover a wide range of topics, including data analysis, machine learning, big data processing, and data visualization, ensuring a well-rounded education.
Practical Experience: These programs emphasize practical learning through projects and case studies, allowing students to apply theoretical knowledge to real-world scenarios.
Expert Guidance: Experienced instructors and industry mentors offer valuable insights and support, helping students master the complexities of data science.
Career Opportunities: Graduates of data science training programs are in high demand across various industries, with opportunities to work on innovative projects and drive data-driven decision-making.
Conclusion
Understanding the differences between big data and traditional data is fundamental for any aspiring data scientist. While traditional data is structured, manageable, and used for transaction processing, big data is vast, varied, and requires advanced tools for real-time processing and analysis. Python, with its robust ecosystem of libraries and frameworks, is an indispensable tool for handling both types of data effectively.
Enrolling in a data science training program equips you with the skills and knowledge needed to navigate the complexities of data science. Whether you're working with traditional data or big data, mastering Python and other data science tools will enable you to extract valuable insights and drive innovation in your field. Start your journey today and unlock the potential of data science with a comprehensive training program.
#Big Data#Traditional Data#Data Science#Python Programming#Data Analysis#Machine Learning#Predictive Analytics#Data Science Training Program#SQL#Data Visualization#Business Analytics#Real-Time Analytics#IoT Data#Data Transformation
0 notes
Text

How to Prepare for a Data Engineering Bootcamp: Skills and Knowledge Primer
Preparing for a data engineering bootcamp involves strengthening foundational skills in programming, especially in Python or Java, and understanding basic database concepts. Familiarize yourself with SQL and NoSQL databases, practice data structure and algorithms, and explore introductory topics in big data technologies like Hadoop and Spark. Additionally, brushing up on statistics and data visualization can provide a well-rounded skill set, setting the stage for a successful bootcamp experience.
For more information visit: https://www.webagesolutions.com/courses/WA3020-data-engineering-bootcamp-training-using-python-and-pyspark
0 notes
Text
Hadoop Python

You are interested in information regarding Hadoop and Python. Hadoop is a widely used framework for storing and processing big data in a distributed environment across clusters of computers. At the same time, Python is a popular programming language known for its simplicity and versatility.
Integrating Python with Hadoop can be highly beneficial for handling big data tasks. Python can interact with the Hadoop ecosystem using libraries and frameworks like Pydoop, Hadoop Streaming, and Apache Spark with PySpark.
Pydoop: A Python interface to Hadoop allows you to write Hadoop MapReduce programs and interact with HDFS using pure Python.
Hadoop Streaming: A utility that comes with Hadoop and allows you to create and run MapReduce jobs with any executable or script as the mapper and the reducer.
Apache Spark and PySpark: While technically not a part of the Hadoop ecosystem, Apache Spark is often used in conjunction with Hadoop. PySpark is the Python API for Spark, allowing you to use Python to write Spark applications for big data processing.
Using Python with Hadoop is particularly advantageous due to Python’s simplicity and the extensive set of libraries available for data analysis, machine learning, and data visualization.
If you’re considering training or informing others about integrating Python with Hadoop, covering these tools and their practical applications is essential. This would ensure that the recipients of your information can effectively utilize Python in a Hadoop-based environment for big data tasks.
Hadoop Training Demo Day 1 Video:
youtube
You can find more information about Hadoop Training in this Hadoop Docs Link
Conclusion:
Unogeeks is the №1 IT Training Institute for Hadoop Training. Anyone Disagree? Please drop in a comment
You can check out our other latest blogs on Hadoop Training here — Hadoop Blogs
Please check out our Best In Class Hadoop Training Details here — Hadoop Training
S.W.ORG
— — — — — — — — — — — -
For Training inquiries:
Call/Whatsapp: +91 73960 33555
Mail us at: [email protected]
Our Website ➜ https://unogeeks.com
Follow us:
Instagram: https://www.instagram.com/unogeeks
Facebook: https://www.facebook.com/UnogeeksSoftwareTrainingInstitute
Twitter: https://twitter.com/unogeeks
#unogeeks #training #ittraining #unogeekstraining
0 notes
Text
Transform Your Team into Data Engineering Pros with ScholarNest Technologies

In the fast-evolving landscape of data engineering, the ability to transform your team into proficient professionals is a strategic imperative. ScholarNest Technologies stands at the forefront of this transformation, offering comprehensive programs that equip individuals with the skills and certifications necessary to excel in the dynamic field of data engineering. Let's delve into the world of data engineering excellence and understand how ScholarNest is shaping the data engineers of tomorrow.
Empowering Through Education: The Essence of Data Engineering
Data engineering is the backbone of current data-driven enterprises. It involves the collection, processing, and storage of data in a way that facilitates effective analysis and insights. ScholarNest Technologies recognizes the pivotal role data engineering plays in today's technological landscape and has curated a range of courses and certifications to empower individuals in mastering this discipline.
Comprehensive Courses and Certifications: ScholarNest's Commitment to Excellence
1. Data Engineering Courses: ScholarNest offers comprehensive data engineering courses designed to provide a deep understanding of the principles, tools, and technologies essential for effective data processing. These courses cover a spectrum of topics, including data modeling, ETL (Extract, Transform, Load) processes, and database management.
2. Pyspark Mastery: Pyspark, a powerful data processing library for Python, is a key component of modern data engineering. ScholarNest's Pyspark courses, including options for beginners and full courses, ensure participants acquire proficiency in leveraging this tool for scalable and efficient data processing.
3. Databricks Learning: Databricks, with its unified analytics platform, is integral to modern data engineering workflows. ScholarNest provides specialized courses on Databricks learning, enabling individuals to harness the full potential of this platform for advanced analytics and data science.
4. Azure Databricks Training: Recognizing the industry shift towards cloud-based solutions, ScholarNest offers courses focused on Azure Databricks. This training equips participants with the skills to leverage Databricks in the Azure cloud environment, ensuring they are well-versed in cutting-edge technologies.
From Novice to Expert: ScholarNest's Approach to Learning
Whether you're a novice looking to learn the fundamentals or an experienced professional seeking advanced certifications, ScholarNest caters to diverse learning needs. Courses such as "Learn Databricks from Scratch" and "Machine Learning with Pyspark" provide a structured pathway for individuals at different stages of their data engineering journey.
Hands-On Learning and Certification: ScholarNest places a strong emphasis on hands-on learning. Courses include practical exercises, real-world projects, and assessments to ensure that participants not only grasp theoretical concepts but also gain practical proficiency. Additionally, certifications such as the Databricks Data Engineer Certification validate the skills acquired during the training.
The ScholarNest Advantage: Shaping Data Engineering Professionals
ScholarNest Technologies goes beyond traditional education paradigms, offering a transformative learning experience that prepares individuals for the challenges and opportunities in the world of data engineering. By providing access to the best Pyspark and Databricks courses online, ScholarNest is committed to fostering a community of skilled data engineering professionals who will drive innovation and excellence in the ever-evolving data landscape. Join ScholarNest on the journey to unlock the full potential of your team in the realm of data engineering.
#big data#big data consulting#data engineering#data engineering course#data engineering certification#databricks data engineer certification#pyspark course#databricks courses online#best pyspark course online#best pyspark course#pyspark online course#databricks learning#data engineering courses in bangalore#data engineering courses in india#azure databricks learning#pyspark training course
1 note
·
View note
Text
Mastering PySpark: A Comprehensive Certification Course and Effective Training Methods
Are you eager to delve into the world of big data analytics and data processing? Look no further than PySpark, a powerful tool for efficiently handling large-scale data. In this article, we will explore the PySpark certification course and its training methods, providing you with the essential knowledge to master this transformative technology.
Understanding PySpark: Unveiling the Power of Big Data
PySpark is a Python library for Apache Spark, an open-source, distributed computing system designed for big data processing and analysis. It enables seamless integration with Python, allowing developers to leverage the vast capabilities of Spark using familiar Python programming paradigms. PySpark empowers data scientists and analysts to process vast amounts of data efficiently, making it an invaluable tool in today's data-driven landscape.
The PySpark Certification Course: A Pathway to Expertise
Enrolling in a PySpark certification course can be a game-changer for anyone looking to enhance their skills in big data analytics. These courses are meticulously designed to provide a comprehensive understanding of PySpark, covering its core concepts, advanced features, and practical applications. The curriculum typically includes:
Introduction to PySpark: Understanding the basics of PySpark, its architecture, and key components.
Data Processing with PySpark: Learning how to process and manipulate data using PySpark's powerful capabilities.
Machine Learning with PySpark: Exploring how PySpark facilitates machine learning tasks, allowing for predictive modeling and analysis.
Real-world Applications and Case Studies: Gaining hands-on experience through real-world projects and case studies.
Training Methods: Tailored for Success
The training methods employed in PySpark certification courses are designed to maximize learning and ensure participants grasp the concepts effectively. These methods include:
Interactive Lectures: Engaging lectures delivered by experienced instructors to explain complex concepts in an easily digestible manner.
Hands-on Labs and Projects: Practical exercises and projects to apply the learned knowledge in real-world scenarios, reinforcing understanding.
Collaborative Learning: Group discussions, teamwork, and peer interaction to foster a collaborative learning environment.
Regular Assessments: Periodic quizzes and assessments to evaluate progress and identify areas for improvement.
FAQs about PySpark Certification Course
1. What is PySpark?
PySpark is a Python library for Apache Spark, providing a seamless interface to integrate Python with the Spark framework for efficient big data processing.
2. Why should I opt for a PySpark certification course?
A PySpark certification course equips you with the skills needed to analyze large-scale data efficiently, making you highly valuable in the data analytics job market.
3. Are there any prerequisites for enrolling in a PySpark certification course?
While prior knowledge of Python can be beneficial, most PySpark certification courses start from the basics, making them accessible to beginners as well.
4. How long does a typical PySpark certification course last?
The duration of a PySpark certification course can vary, but it typically ranges from a few weeks to a few months, depending on the depth of the curriculum.
5. Can I access course materials and resources after completing the course?
Yes, many institutions provide access to course materials, resources, and alumni networks even after completing the course to support continued learning and networking.
6. Will I receive a certificate upon course completion?
Yes, upon successful completion of the PySpark certification course, you will be awarded a certificate, validating your proficiency in PySpark.
7. Is PySpark suitable for individuals without a background in data science?
Absolutely! PySpark courses are designed to accommodate individuals from diverse backgrounds, providing a structured learning path for beginners.
8. What career opportunities can a PySpark certification unlock?
A PySpark certification can open doors to various career opportunities, including data analyst, data engineer, machine learning engineer, and more, in industries dealing with big data.
In conclusion, mastering PySpark through a well-structured certification course can significantly enhance your career prospects in the ever-evolving field of big data analytics. Invest in your education, embrace the power of PySpark, and unlock a world of possibilities in the realm of data processing and analysis.

1 note
·
View note
Text
"The Fast and Furious: Exploring the Rapid Growth of Python in the Programming World"
The fastest growing and the most popular programming language in today’s programming world is Python. The word time, the word "Python" evoked images of a massive snake, but today, it's synonymous with a wildly popular programming language. According to the TIOBE Index, Python holds the prestigious position of being the fourth most popular programming language globally, and its meteoric rise shows no signs of slowing.

Python’s and Growing User Base:
Several factors contribute to Python's remarkable success. First and foremost is its widespread adoption in web development. Renowned companies such as Google, Facebook, Mozilla, Quora, and many others employ Python web frameworks, elevating its prominence in this domain. Another pivotal driver behind Python's rapid growth is its pivotal role in the realm of data science.
Another factor that takes Python to the next level programming language is its easy use in Data Science. Therefore, the language is steadily growing in demand in the last ten years. In 2018, it was found in a survey that the majority of developers are obtaining training for the language and started work as Python developers. Initially, Python was built to solve the code readability issues discovered in C and Java languages.
The Reason Behind the Popularity of Pythons:
●As per the record, the reason behind the demand for python is it is easy to use. The language is pretty simple and can be easily readable. The simplicity of the language makes Python a favorite programming language among developers. Moreover, Python is an efficient language.
●Today almost all the developers and big tech giants prefer Python for web development. Some famous web frameworks can be utilized for web development project requirements.
●Even high-level Python is being trained as coursework. So that student can get prepared for the upcoming pythons’ trends and achieve success in their careers.
Python's skyrocketing popularity and its path towards becoming the world's most popular programming language are indeed remarkable phenomena.
Several Key Factors Underpin This Incredible Rise:
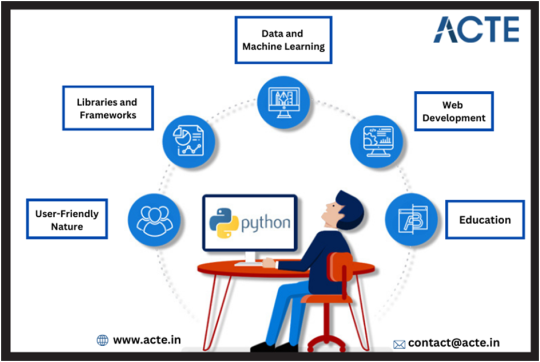
Python's User-Friendly Nature: Python stands out for its user-friendliness. Its simple, easily readable syntax appeals to both experienced developers and budding students. What's more, Python is highly efficient, allowing developers to accomplish more with fewer lines of code, making it a beloved choice.
A Supportive Python Community: Python has been around since 1990, providing ample time to foster a vibrant and supportive community. This strong support network empowers learners to expand their knowledge, contributing to Python's ever-increasing popularity. Abundant online resources, from official documentation to YouTube tutorials, make Python accessible to all.
Abundance of Libraries and Frameworks: Python's already widespread adoption has led to a wealth of libraries and frameworks developed by the community. These resources save developers time and effort, creating a virtuous cycle of popularity. Notable Python libraries include NumPy, SciPy, Django, BeautifulSoup, scikit-learn, and nltk.
Corporate Backing: Python's ascent is not solely a grassroots movement. Corporate support plays a significant role. Top companies like Google, Facebook, Mozilla, Amazon, and Quora have embraced Python for their products, with Google even offering guides and tutorials through its Python Class. This backing has been pivotal in Python's growth and success.
Python in Data and Machine Learning: Python plays a vital role in the hot trends of Big Data, Machine Learning, and Artificial Intelligence. It's widely used in research and development in these domains, and numerous Python tools like Scikit-Learn, Theano, and libraries such as Pandas and PySpark are instrumental.
Python in Web Development: Python's popularity extends to web development. It's an ideal choice for both learning and powering some of the world's most popular websites, including Spotify, Instagram, Pinterest, Mozilla, and Yelp. Python offers a range of web frameworks, from full-stack options like Django to microframeworks like Flask.
Python in Academics: The presence of Python in academic coursework is a testament to its significance. It's now a core requirement in many educational institutions, reflecting its crucial role in data science, machine learning, deep learning, and artificial intelligence. As more students learn Python, its future importance is assured.
Python's astonishing success is multifaceted and cannot be attributed to a single reason. Instead, it's the combined effect of the factors outlined above that paints a comprehensive picture of why Python has become such a pivotal and influential language in the world of programming.
If you're eager to improve your knowledge of Python, I strongly advise getting in touch with ACTE Technologies. They offer certification programs and the potential for job placements, ensuring a comprehensive learning experience. Their services are available both online and at physical locations. To commence your Python learning journey at ACTE Technologies, consider taking a methodical approach and explore the possibility of enrolling in one of their courses if it aligns with your interests.
0 notes
Text
The Power of Python in Data Science: Unleashing Insights and Opportunities
Introduction
In the realm of data science, Python has emerged as a powerhouse programming language, playing a pivotal role in unlocking insights, making data-driven decisions, and addressing complex business challenges. With its simplicity, versatility, and extensive libraries, Python is the go-to choice for data scientists worldwide. In this article, we'll explore how Python is used in data science and the role of specialized training, such as a Data Science with Python course, in harnessing its potential.
1. Data Collection and Extraction
Python's libraries and frameworks, such as Requests and BeautifulSoup, facilitate web scraping and data extraction. Data scientists can effortlessly collect data from websites, APIs, and databases, making it a crucial tool for acquiring diverse datasets.
Tip: Enrolling in a Data Science with Python course can provide hands-on experience in web scraping and data collection techniques.
2. Data Cleaning and Preprocessing
Data is rarely pristine, often requiring extensive cleaning and preprocessing. Python, with libraries like Pandas and NumPy, allows data scientists to efficiently handle missing values, outliers, and data transformation tasks.
Tip: Specialized courses cover data cleaning best practices and advanced techniques, enhancing your skills in data preprocessing.
3. Data Visualization
Python's Matplotlib, Seaborn, and Plotly libraries empower data scientists to create insightful visualizations that convey complex patterns and trends. Visualizations aid in data exploration, presentation, and storytelling.
Tip: A Data Science with Python course typically includes modules on data visualization, providing you with the skills to create compelling charts and graphs.
4. Machine Learning and Predictive Modeling
Python is synonymous with machine learning. Libraries like Scikit-Learn, TensorFlow, and Keras enable data scientists to build and deploy machine learning models for classification, regression, clustering, and more.
Tip: Specialized courses offer in-depth coverage of machine learning algorithms, model evaluation, and deployment strategies using Python.
5. Statistical Analysis
Python offers a wide range of statistical libraries, including SciPy and Statsmodels, that facilitate hypothesis testing, regression analysis, and advanced statistical techniques.
Tip: A Data Science with Python course typically includes modules on statistical analysis, providing you with a strong foundation in statistical methods.
6. Big Data and Distributed Computing
Python seamlessly integrates with big data frameworks like Apache Spark and Hadoop through libraries like PySpark. This enables data scientists to work with large-scale datasets and distributed computing.
Tip: Advanced courses in Data Science with Python cover big data processing and distributed computing concepts.
7. Deployment and Automation
Python's simplicity extends to deploying machine learning models and automating workflows. Frameworks like Flask and Django are commonly used for building web applications, while tools like Airflow automate data pipelines.
Tip: Specialized courses delve into deployment strategies and automation techniques using Python.
8. Natural Language Processing (NLP)
Python's NLTK and spaCy libraries make it a powerful choice for NLP tasks, including sentiment analysis, text classification, and language generation.
Tip: Courses often include modules on NLP, allowing you to explore text data and language processing techniques.
Conclusion
Python's prominence in data science is undeniable, offering a comprehensive ecosystem of tools and libraries that streamline every aspect of the data analysis pipeline. However, to become a proficient data scientist using Python, it's essential to invest in specialized training, such as a Data Science with Python course.
These courses provide hands-on experience, in-depth knowledge, and practical skills in using Python for data science. Whether you're a beginner looking to enter the field or an experienced data scientist seeking to expand your skillset, a Data Science with Python course can empower you to leverage Python's full potential, opening up a world of opportunities in the dynamic field of data science.
0 notes
Text
Data Engineering Bootcamp Training – Featuring Everything You Need to Accelerate Growth
If you want your team to master data engineering skills, you should explore the potential of data engineering bootcamp training focusing on Python and PySpark. That will provide your team with extensive knowledge and practical experience in data engineering. Here is a closer look at the details of how data engineering bootcamps can help your team grow.
Big Data Concepts and Systems Overview for Data Engineers
This foundational data engineering boot camp module offers a comprehensive understanding of big data concepts, systems, and architectures. The topics covered in this module include emerging technologies such as Apache Spark, distributed computing, and Hadoop Ecosystem components. The topics discussed in this module equip teams to manage complex data engineering challenges in real-world settings.
Translating Data into Operational and Business Insights
Unlike what most people assume, data engineering is a whole lot more than just processing data. It also involves extracting actionable insights to drive business decisions. Data engineering bootcamps course emphasize translating raw data into actionable and operational business insights. Learners are equipped with techniques to transform, aggregate, and analyze data so that they can deliver meaningful insights to stakeholders.
Data Processing Phases
Efficient data engineering requires a deep understanding of the data processing life cycle. With data engineering bootcamps, teams will be introduced to various phases of data processing, such as data storage, processing, ingestion, and visualization. Employees will also gain practical experience in designing and deploying data processing pathways using Python and PySpark. This translates into improved efficiency and reliability in data workflow.
Running Python Programs, Control Statements, and Data Collections
Python is one of the most popular programming languages and is widely used for data engineering purposes. For this reason, data engineering bootcamps offer an introduction to Python programming and cover basic concepts such as running Python programs, common data collections, and control statements. Additionally, teams learn how to create efficient and secure Python code to process and manipulate data efficiently.
Functions and Modules
Effective data engineering workflow demands creating modular and reusable code. Consequently, this module is necessary to understand data engineering work processes comprehensively. The module focuses on functions and modules in Python, enabling teams to transform logic into functions and manage code as a reusable module. The course introduces participants to optimal code organization, thereby improving productivity and sustainability in data engineering projects.
Data Visualization in Python
Clarity in data visualization is vital to communicating key insights and findings to stakeholders. This Data engineering bootcamp module on data visualization emphasizes techniques that utilize libraries such as Seaborn and Matplotlib in Python. During the course, teams learn how to design informative and visually striking charts, plots, and dashboards to communicate complex data relationships effectively.
Final word
To sum up, data engineering bootcamp training using Python and PySpark provides a gateway for teams to venture into the rapidly growing realm of data engineering. The training endows them with a solid foundation in big data concepts, practical experience in Python, and hands-on skills in data processing and visualization. Ensure that you choose an established course provider to enjoy the maximum benefits of data engineering courses.
For more information visit: https://www.webagesolutions.com/courses/WA3020-data-engineering-bootcamp-training-using-python-and-pyspark
0 notes
Text
PySpark is one of the famous Python APIs when it comes to Big Data or Data Analytics, which is an interface for Apache Spark in Python written using Python programming language. Our trainers are good at Hadoop Ecosystem, Apache Spark, Data Analytics, and Data Science. iconGen is a leading institute in the training industry to be part of the quickest developing Big Data communities, which makes us the best PySpark training in Velachery.
1 note
·
View note
Text
Mastering Big Data Tools: Scholarnest's Databricks Cloud Training

In the ever-evolving landscape of data engineering, mastering the right tools is paramount for professionals seeking to stay ahead. Scholarnest, a leading edtech platform, offers comprehensive Databricks Cloud training designed to empower individuals with the skills needed to navigate the complexities of big data. Let's explore how this training program, rich in keywords such as data engineering, Databricks, and PySpark, sets the stage for a transformative learning journey.
Diving into Data Engineering Mastery:
Data Engineering Course and Certification:
Scholarnest's Databricks Cloud training is structured as a comprehensive data engineering course. The curriculum is curated to cover the breadth and depth of data engineering concepts, ensuring participants gain a robust understanding of the field. Upon completion, learners receive a coveted data engineer certification, validating their expertise in handling big data challenges.
Databricks Data Engineer Certification:
The program places a special emphasis on Databricks, a leading big data analytics platform. Participants have the opportunity to earn the Databricks Data Engineer Certification, a recognition that holds substantial value in the industry. This certification signifies proficiency in leveraging Databricks for efficient data processing, analytics, and machine learning.
PySpark Excellence Unleashed:
Best PySpark Course Online:
A highlight of Scholarnest's offering is its distinction as the best PySpark course online. PySpark, the Python library for Apache Spark, is a pivotal tool in the data engineering arsenal. The course delves into PySpark's intricacies, enabling participants to harness its capabilities for data manipulation, analysis, and processing at scale.
PySpark Training Course:
The PySpark training course is thoughtfully crafted to cater to various skill levels, including beginners and those looking for a comprehensive, full-course experience. The hands-on nature of the training ensures that participants not only grasp theoretical concepts but also gain practical proficiency in PySpark.
Azure Databricks Learning for Real-World Applications:
Azure Databricks Learning:
Recognizing the industry's shift towards cloud-based solutions, Scholarnest's program includes Azure Databricks learning. This module equips participants with the skills to leverage Databricks in the Azure cloud environment, aligning their knowledge with contemporary data engineering practices.
Best Databricks Courses:
Scholarnest stands out for offering one of the best Databricks courses available. The curriculum is designed to cover the entire spectrum of Databricks functionalities, from data exploration and visualization to advanced analytics and machine learning.
Learning Beyond Limits:
Self-Paced Training and Certification:
The flexibility of self-paced training is a cornerstone of Scholarnest's approach. Participants can learn at their own speed, ensuring a thorough understanding of each concept before progressing. The self-paced model is complemented by comprehensive certification, validating the mastery of Databricks and related tools.
Machine Learning with PySpark:
Machine learning is seamlessly integrated into the program, providing participants with insights into leveraging PySpark for machine learning applications. This inclusion reflects the program's commitment to preparing professionals for the holistic demands of contemporary data engineering roles.
Conclusion:
Scholarnest's Databricks Cloud training transcends traditional learning models. By combining in-depth coverage of data engineering principles, hands-on PySpark training, and Azure Databricks learning, this program equips participants with the knowledge and skills needed to excel in the dynamic field of big data. As the industry continues to evolve, Scholarnest remains at the forefront, ensuring that professionals are not just keeping pace but leading the way in data engineering excellence.
#data engineering#data engineering course#data engineering certification#databricks data engineer certification#pyspark course#databricks courses online#best pyspark course online#best pyspark course#pyspark online course#databricks learning#data engineering courses in bangalore#data engineering courses in india#azure databricks learning#pyspark training course#big data
1 note
·
View note
Text
"Tech Giants' Choice: The Appeal of Python's Advantages"
Python is a general-purpose dynamic programming language that provides high-level readability and is interpreted. As Python is a dynamic programming language, it has some helpful advantages, so now we will learn about the Advantages of Python.
I gained expertise in Python programming through my training at ACTE Technologies. This learning experience was thorough and valuable. ACTE Technologies offered a well-structured Python course that enabled me to understand the basics of the language and advance to more advanced concepts.

The Main Advantages of Python Applications:
Simple and Easy to Learn Python is incredibly easy to learn and read because its syntax is similar to English. It's a powerful language that's also free and open source. You don't need to be highly skilled to start learning Python. It's a high-level language, meaning you can write code that's more human-readable, and Python takes care of converting it to a language the computer understands. Python helps catch errors early by interpreting the code.
Portable and Extensible
Python's portability and extensibility are significant advantages. It can run on various platforms, including Windows, Linux, Macintosh, and even gaming consoles that support Python. Python's extensibility allows you to integrate components from other programming languages like Java and .NET. Additionally, you can invoke libraries written in languages like C and C++.
3. Object-Oriented Programming
Python's support for object-oriented programming (OOP) is a valuable feature. It allows for concepts like polymorphism and inheritance, which make code more flexible and reusable. In Python, you can create shareable classes, enabling the reuse of code and providing a protective layer by abstracting knowledge. This makes it easier to develop prototypes quickly and write efficient and organized code, making Python a popular choice for many software development projects.
4.Artificial Intelligence
Artificial Intelligence (AI) involves creating computer programs that can mimic human intelligence and perform smart tasks using algorithms and programs. Python plays a significant role in AI development. It has libraries like scikit-learn, which simplify complex calculations with concise code. Additionally, popular AI libraries such as Keras and TensorFlow are seamlessly integrated with Python, enhancing its machine learning capabilities.
5. Computer Graphics
Python is a versatile programming language that serves developers well in various domains. It finds extensive use in both small and large-scale projects for creating Graphical User Interfaces (GUI) and developing desktop applications. Additionally, Python offers a dedicated game development framework, empowering developers to create interactive games and applications efficiently. Whether for GUI-based software or gaming projects, Python provides robust solutions to meet diverse development needs.

6. Testing Framework:
Python is well-suited for startups and product development. It offers integrated testing frameworks, like Pytest and Selenium, making it easier to conduct automated testing, detect and fix bugs, and streamline workflows.
7.Big Data:
Python is capable of handling large datasets and supports parallel computing. Libraries like Pydoop, Pandas, and PySpark enable data processing, analysis, and manipulation, making Python a valuable tool in the field of big data.
8. Scripting and Automation:
Python serves as an excellent scripting language. You can write scripts to automate tasks, such as web scraping, content posting, or any repetitive processes, making it a versatile choice for automation.
9. Data Science:
Python has become the preferred language for data scientists due to libraries like NumPy, Pandas, Matplotlib, and Seaborn. It excels in data analysis, visualization, and manipulation, helping researchers gain insights from vast datasets.
10.Popularity and High Salary:
Python's popularity has surged in recent years, and Python programmers often receive competitive salaries. Prominent tech companies like Google, YouTube, Instagram, Dropbox, and Facebook rely on Python for various purposes, contributing to its widespread use. Its ease of use and versatility make Python a top choice for both beginners and experienced programmers in various domains.
You can enroll in Python training at ACTE Technologies, where they offer comprehensive programs to help you become proficient in Python programming. These courses cover everything from the basics of Python to advanced topics like data science, machine learning, and web development. ACTE Technologies provides a structured and hands-on learning experience, allowing you to gain practical skills in Python for various purposes.
0 notes