#real-time Kafka dashboard
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. is using 66 technologies for its website.
Text
kafka management
LivestreamIQ – Kafka-hosted, web-based GUI that offers intelligent alerting and monitoring tools to reduce the risk of downtime, streamline troubleshooting, surface key metrics, and accelerate issue resolution. It helps offload monitoring costs related to storing historical data and is built on Confluent’s deep understanding of data in motion infrastructure. LiveStreamIQ empowers businesses to proactively manage their Kafka infrastructure, ensuring optimal performance, reliability, and security. It is a niche product for Kafka Environment Management that provides Intelligent Alerting, Unified Notification Gateway with a scalable architecture ensuring the Messaging system is up and running as per Business critical Needs.
Contac us at:
OUR ADDRESS
403, 4TH FLOOR, SAKET CALLIPOLIS, Rainbow Drive, Sarjapur Road, Varthurhobli East Taluk, Doddakannelli, Bengaluru Karnataka 560035
OUR CONTACTS
+91 97044 56015
#LiveStreamIQ#Kafka monitoring tool#real-time Kafka dashboard#Kafka alerting system#unified notifications Kafka#Kafka performance monitoring#Prodevans products#scalable Kafka solution#Kafka observability#streaming data monitoring
0 notes
Text
As I continue Kafka's character page thing (I needed a day or two of a break, life's been a bit tiring), I realized I messed up on my tags, as none of them actually contain the muse name. So, here's to ensuring none of them are too long with the names in! Man, it's obvious that I've been gone from a multimuse for far too long. So don't mind me.
On a different note, I've been seeing some opinions come out on the dashboard about the new Dain quest, and I wanted to give my two cents on it without spoiling anything, because I think it's needed. Now of course, keep in mind that I'm quite the lore junkie, but I actually was really quite fond of it, it definitely hit some strings with me, so I have to side with the word-y ones over on Reddit on this one. I got more answers than questions this time, they didn't sacrifice any lore nor did they overplay their hand, and I wanted to reach through my screen at HVY on numerous occasions through it. So it was a good balance. Now, I'd love to comment more, such as to explain why peopl's 'expected flaws' were actually strengths in my opinion instead, but I don't want to accidentally spoil anything. So it can wait.
Anyway, the real reason that I want to comment on this, is that I want to note that no one blames anyone else for being tired of a game that they've played for a very long time. But there's a clear difference between saying that sometimes, and reminding everyone with every single quest or new content that comes out, or even remind us in comparison with HVY's HSR or even WuWa. I get it. But stop comparing apples to oranges, and stop thinking that Genshin needs to employ new game marketing strategies to keep its player-base, because their numbers show that it doesn't need to do so. If you don't like the game anymore, then simply stop playing it. It's okay. You don't need to keep reminding us, you don't need to shit on it, you don't need to say 'Genshin would never' as if Genshin needs to do anything. Would it benefit from some quality of life changes? Absolutely. But guess where I'll still be despite it, and where I think many (not all, of course) people who are actively complaining will also be,
#i just wanted to make note. i've been so tired of this 'omg wuwa/hsr. GENSHIN WOULD NEVER'. it's not even me defending genshin.#it's me just sitting here going it's a (brand) new game. welcome to marketing strategies.#also me casually looking at half-completed clorinde tags. we're doing well.#[ out of character. ] don't bend or water it down. don't try to make it logical. rather: follow your most intense obsessions mercilessly.
10 notes
·
View notes
Text
How an E-commerce Brand Increased Conversions by 40% with AI-Powered Product Recommendations

An established e-commerce company specializing in fashion retail wanted to improve its product recommendation engine. Despite having a solid product catalog and a loyal user base, the brand struggled to convert casual browsers into buyers. By partnering with a provider of advanced AI development services, the company implemented a machine learning-based personalization system, resulting in a 40% increase in conversions within four months.
Client Background
Industry: E-commerce (Fashion Retail)
Target Market: B2C (millennials and Gen Z consumers)
Challenge: Low conversion rates despite high traffic
Project Goals
Increase product discovery and engagement.
Personalize the shopping experience across all customer touchpoints.
Use real-time data to dynamically adjust recommendations.
Measure ROI using clear A/B testing strategies.
The Problem: Why the Old Recommendation System Failed
Although the client invested heavily in marketing, their conversion rates stagnated at around 1.8%. Customers were browsing but not purchasing. Internal analysis revealed that their existing recommendation system relied on static, rule-based filters:
Customers were shown popular products, not personalized ones.
Search and recommendation results did not adapt to user behavior.
Relevance was low for returning users.
The lack of intelligent personalization left potential revenue on the table.
Why They Chose Custom AI Development Services
The client had tested third-party recommendation tools but faced limitations:
Rigid algorithms that couldn’t be retrained or tuned.
Inability to access raw model performance metrics.
No real-time behavioral integration.
They needed a solution built from the ground up:
One that could ingest real-time clickstream data.
Learn from user sessions.
Integrate with the existing tech stack without overhauling infrastructure.
The decision to hire a firm specializing in AI development services enabled them to get a custom-built engine tailored to their workflows and customer behavior.
The Solution: How the AI System Was Designed and Deployed
The solution involved three major components:
1. Behavioral Data Pipeline
Implemented trackers across product pages, category views, and cart behavior.
Data was processed in near real-time using Apache Kafka and stored in Amazon Redshift.
2. Machine Learning Model Development
Used a collaborative filtering and content-based filtering hybrid model.
Added session-based recommendations using RNN (Recurrent Neural Networks).
Tuned model using TensorFlow and PyTorch.
3. Personalization Algorithm Engine
Real-time engine built in Python.
Integrated with the frontend via REST APIs.
Delivered updated recommendations within 200ms response time.
The system was designed to:
Score product relevance for each user based on browsing patterns.
Consider contextual factors such as time of day, device type, and past purchase history.
Auto-adjust recommendations as users clicked, searched, or added items to cart.
Step-by-Step Implementation Timeline for the AI Recommendation System
Phase 1: Discovery & Data Mapping (Weeks 1-2)
Analyzed existing datasets.
Identified high-traffic product categories.
Mapped technical dependencies.
Phase 2: Model Building & Training (Weeks 3-6)
Trained initial ML models using historical customer data.
Validated predictions using accuracy and diversity metrics.
Phase 3: Integration & A/B Testing (Weeks 7-10)
Deployed engine to 50% of live traffic.
Ran A/B test against existing rule-based system
Phase 4: Optimization & Rollout (Weeks 11-16)
Tweaked models based on test results.
Rolled out to 100% of users.
Set up dashboards for continuous monitoring.
What Changed: Results and Measurable Business Impact of the AI System
Key Performance Improvements:
Conversion Rate: Increased from 1.8% to 2.5% (approx. 40% improvement).
Average Session Duration: Up by 18%.
Click-through Rate on Recommendations: Jumped from 4.2% to 7.9%.
Cart Abandonment: Reduced by 12%.
A/B Testing Findings:
Variant A (Old system): 1.8% conversion
Variant B (AI-powered): 2.5% conversion
Statistical significance achieved after 14 days
These results were made possible by aligning the AI recommendation engine to actual user behavior and real-time feedback.
Behind the Scenes: Technical Architecture That Powered the AI Engine
Data Sources:
User behavior logs (clicks, views, cart actions)
Product metadata (color, category, price, etc.)
User profiles and historical purchases
Tech Stack:
Data Processing: Apache Kafka, Amazon Redshift
ML Modeling: Python, TensorFlow, PyTorch
API Delivery: FastAPI
A/B Testing: Optimizely
Monitoring: Grafana, Prometheus
The modular setup allowed for scalability and easy updates as the catalog evolved.
Key Takeaways: What the Team Learned from Building the AI System
Rule-based recommendation systems are limited in scale and personalization.
A/B testing is critical in validating machine learning systems.
Real-time feedback loops significantly enhance AI effectiveness.
Transparent model evaluation metrics build internal trust among business teams.
Conclusion: How AI-Powered Personalization Transformed E-commerce ROI
The e-commerce brand saw a measurable business impact within a short time by leveraging custom AI development services. By moving from a rule-based to a dynamic AI-powered recommendation engine, they not only increased conversions but also improved user engagement across the board.
The case underlines the importance of:
Custom AI over off-the-shelf tools for personalization.
Investing in behavioral data infrastructure.
Building machine learning pipelines that are testable and interpretable.
For businesses looking to increase e-commerce ROI, AI-based product recommendations are not just a trend—they're a necessity.
0 notes
Text
Case Study: Reducing Food Waste Through Demand Prediction Algorithms
Food delivery platforms generate massive waste—restaurants prepare excess food for unpredictable demand, leading to 30-40% of prepared meals being discarded daily. We built a machine learning system that reduced partner restaurant food waste by 43% while improving order fulfillment rates, creating a win-win for business and sustainability.
The Problem: Predictable Waste in an Unpredictable Business
Our partner restaurants were caught in a brutal cycle:
Over-preparation: Fearing stockouts during peak hours, restaurants prepared 40% more food than needed
Under-preparation: Conservative estimates led to "sold out" items during high-demand periods
Inconsistent demand: Weather, events, and seasonality created unpredictable order patterns
Financial impact: Food waste represented 15-20% of restaurant costs, directly hitting profit margins
Initial data analysis revealed that restaurants were essentially gambling on demand, with no systematic approach to inventory planning.
Understanding the Data Landscape
Before building our prediction model, we analyzed 18 months of order data across 2,500 restaurants:
Temporal Patterns: Order volumes varied 300% between peak (Friday 7 PM) and off-peak (Tuesday 3 PM) periods.
Weather Impact: Rainy days increased comfort food orders by 45%, while sunny weekends boosted healthy options by 35%.
Event Correlation: Local events, holidays, and even sporting matches significantly influenced specific cuisine demand.
Menu Complexity: Restaurants with 100+ items had 60% higher waste rates than those with focused menus.
The Algorithm: Multi-Layer Prediction Engine
We developed a ensemble machine learning system combining multiple prediction models:
Layer 1: Time Series Forecasting
LSTM Neural Networks analyzed historical order patterns:
730-day lookback window for seasonal trends
Hour-by-hour demand prediction for each menu item
Confidence intervals to account for uncertainty
Auto-adjustment based on prediction accuracy
Layer 2: External Factor Integration
Gradient Boosting Models incorporated external variables:
Weather forecasts (temperature, precipitation, humidity)
Local events calendar (concerts, sports, festivals)
Economic indicators (payday cycles, holidays)
Competitor promotions and pricing
Layer 3: Real-Time Adjustment
Online Learning Algorithm adapted predictions throughout the day:
Live order velocity tracking
Social media sentiment analysis for trending cuisines
Real-time inventory updates from restaurant POS systems
Dynamic demand shifting between similar menu items
Technical Implementation
Data Pipeline: Apache Kafka streams processed 2M+ daily order events, feeding real-time features to our prediction models.
Feature Engineering: Created 200+ features including rolling averages, seasonal decomposition, and cross-restaurant demand correlations.
Model Training: Daily retraining on AWS SageMaker with automated hyperparameter tuning, achieving 85% prediction accuracy.
API Integration: RESTful APIs delivered predictions to restaurant dashboards with 99.5% uptime SLA.
Smart Recommendations System
Beyond predictions, we built an actionable recommendation engine:
Preparation Optimization: "Prepare 25 Margherita pizzas by 6 PM, with 80% confidence of selling 20-30 units"
Dynamic Menu Management: "Consider temporarily removing Pasta Carbonara—predicted low demand today"
Inventory Alerts: "Order more chicken—75% chance of stockout during dinner rush"
Pricing Strategies: "Increase dessert prices 10%—high demand predicted with low price sensitivity"
Pilot Program Results
We launched with 150 restaurants across 3 cities over 12 weeks:
Waste Reduction:
Food waste decreased 43% on average
Best performing restaurants achieved 60% waste reduction
Equivalent to 2,400 kg of food saved daily across pilot restaurants
Operational Efficiency:
"Sold out" incidents reduced by 67%
Order fulfillment rate improved from 89% to 96%
Kitchen preparation time optimized by 25%
Financial Impact:
Restaurant profit margins increased 12% on average
Food costs reduced by $2,300/month per restaurant
Customer satisfaction scores improved 18% (fewer disappointed customers)
Unexpected Insights
Weather isn't everything: While rain increases comfort food demand, the day of the week was actually a stronger predictor for most cuisines.
Cross-restaurant learning: Demand patterns from similar restaurants in different neighborhoods improved prediction accuracy by 15%.
Customer behavior loops: Reducing "sold out" items created positive feedback—customers ordered more frequently from reliable restaurants.
Seasonality depth: Beyond obvious patterns (ice cream in summer), we discovered micro-seasons tied to cultural events and social media trends.
Scaling Challenges and Solutions
Cold Start Problem: New restaurants lacked historical data, so we used similar restaurant profiles and gradually personalized predictions.
Data Quality: Inconsistent POS system integration required extensive data cleaning and validation pipelines.
Restaurant Adoption: Success required training restaurant managers to trust algorithmic recommendations over intuition—achieved through gradual rollout and success showcases.
Environmental and Business Impact
By year-end, our system prevented approximately 850 tons of food waste across partner restaurants—equivalent to:
3.4 million meals saved from landfills
2,100 tons of CO2 emissions prevented
$4.2 million in cost savings for restaurant partners
Key Learnings
Accuracy isn't everything: 85% prediction accuracy was sufficient—the key was providing confidence intervals so restaurants could make informed risk decisions.
External data is crucial: Weather and events data improved predictions more than complex deep learning architectures.
Adoption requires trust: The best algorithm fails without user buy-in. Clear explanations and gradual implementation built restaurant confidence.
The biggest insight? Sustainability and profitability aren't opposing forces—smart data application can drive both simultaneously.
0 notes
Text
Real-Time Data Streaming Solutions: Transforming Business Intelligence Through Continuous Data Processing
The Imperative for Real-Time Data Processing
The business landscape has fundamentally shifted toward real-time decision-making, driven by the need for immediate insights and rapid response capabilities. Organizations can no longer afford to wait hours or days for data processing, as competitive advantages increasingly depend on the ability to process and act on information within seconds. This transformation has made real-time big data ingestion a critical component of modern business intelligence architectures.

Real-time analytics enables organizations to predict device failures, detect fraudulent transactions, and deliver personalized customer experiences based on immediate data insights. The technology has evolved from a luxury feature to an essential capability that drives operational efficiency and business growth.
Streaming Technology Architecture
Modern streaming architectures rely on sophisticated publish-subscribe systems that decouple data producers from consumers, enabling scalable, fault-tolerant data processing. Apache Kafka serves as the foundation for many streaming implementations, providing a distributed event streaming platform that can handle high-throughput data feeds with minimal latency.
The architecture typically includes multiple layers: data ingestion, stream processing, storage, and consumption. Apache Flink and Apache Storm complement Kafka by providing stream processing capabilities that can handle complex event processing and real-time analytics. These frameworks support both event-time and processing-time semantics, ensuring accurate results even when data arrives out of order.
Stream processing engines organize data events into short batches and process them continuously as they arrive. This approach enables applications to receive results as continuous feeds rather than waiting for complete batch processing cycles. The engines can perform various operations on streaming data, including filtering, transformation, aggregation, and enrichment.
Business Intelligence Integration
Real-time streaming solutions have revolutionized business intelligence by enabling immediate insight generation and dashboard updates. Organizations can now monitor key performance indicators in real-time, allowing for proactive decision-making rather than reactive responses to historical data. This capability proves particularly valuable in scenarios such as fraud detection, where immediate action can prevent significant financial losses.
The integration of streaming data with traditional BI tools requires careful consideration of data formats and processing requirements. Modern solutions often incorporate specialized databases optimized for time-series data, such as InfluxDB and TimescaleDB, which can efficiently store and retrieve real-time data points.
Industry Applications and Use Cases
Financial services organizations have embraced real-time streaming for algorithmic trading, where microsecond-level latency can determine profitability. High-frequency trading systems process millions of market events per second, requiring sophisticated streaming architectures that can maintain consistent performance under extreme load conditions.
E-commerce platforms leverage real-time streaming to deliver personalized product recommendations and dynamic pricing based on current market conditions and customer behavior. These systems can process clickstream data, inventory updates, and customer interactions simultaneously to optimize the shopping experience.
Healthcare organizations utilize streaming solutions for patient monitoring systems that can detect critical changes in vital signs and alert medical staff immediately. The ability to process continuous data streams from medical devices enables proactive healthcare interventions that can save lives.
Performance Optimization for Streaming Systems
Optimizing streaming system performance requires addressing several technical challenges, including latency minimization, throughput maximization, and fault tolerance. In-memory processing techniques, such as those employed by Apache Spark Streaming, significantly reduce processing latency by eliminating disk I/O operations.
Backpressure mechanisms play a crucial role in maintaining system stability under varying load conditions. These systems allow downstream consumers to signal when they become overwhelmed, preventing cascade failures that could impact entire streaming pipelines.
Data partitioning strategies become critical for streaming systems, as they determine how data is distributed across processing nodes. Effective partitioning ensures that processing load is balanced while maintaining data locality for optimal performance.
Cloud-Native Streaming Solutions
Cloud platforms have democratized access to sophisticated streaming technologies through managed services that eliminate infrastructure complexity. Amazon Kinesis provides fully managed streaming capabilities with sub-second processing latency, making it accessible to organizations without specialized streaming expertise.
Google Cloud Dataflow offers unified batch and stream processing capabilities based on Apache Beam, enabling organizations to implement hybrid processing models that can handle both real-time and batch requirements. This flexibility proves valuable for organizations with diverse data processing needs.
Microsoft Azure Stream Analytics provides SQL-like query capabilities for real-time data processing, making streaming technology accessible to analysts and developers familiar with traditional database operations. This approach reduces the learning curve for implementing streaming solutions.
Data Quality in Streaming Environments
Maintaining data quality in streaming environments presents unique challenges due to the continuous nature of data flow and the need for immediate processing. Traditional batch-based quality checks must be redesigned for streaming scenarios, requiring real-time validation and error handling capabilities.
Stream processing frameworks now incorporate built-in data quality features, including schema validation, duplicate detection, and anomaly identification. These systems can quarantine problematic data while allowing clean data to continue processing, ensuring that quality issues don't disrupt entire pipelines.
Security and Compliance for Streaming Data
Streaming systems must address complex security requirements, particularly when handling sensitive data in real-time. Encryption in transit becomes more challenging in streaming environments due to the need to maintain low latency while ensuring data protection.
Access control mechanisms must be designed to handle high-velocity data streams while maintaining security standards. This often requires implementing fine-grained permissions that can be enforced at the stream level rather than traditional file-based access controls.
Future Trends in Streaming Technology
The convergence of artificial intelligence and streaming technology is creating new opportunities for intelligent data processing. Machine learning models can now be integrated directly into streaming pipelines, enabling real-time predictions and automated decision-making.
Edge computing integration is driving the development of distributed streaming architectures that can process data closer to its source. This trend is particularly relevant for IoT applications where bandwidth limitations and latency requirements make centralized processing impractical.
The success of real-time streaming implementations depends on careful architectural planning, appropriate technology selection, and comprehensive performance optimization. Organizations that successfully implement these solutions gain significant competitive advantages through improved operational efficiency, enhanced customer experiences, and more agile decision-making capabilities.
#RealTimeData#DataStreaming#BusinessIntelligence#DataAnalytics#machinelearning#DigitalTransformation#FraudDetection#aiapplications#artificialintelligence#aiinnovation
0 notes
Text
Unlocking Business Intelligence with Advanced Data Solutions 📊🤖

In a world where data is the new currency, businesses that fail to utilize it risk falling behind. From understanding customer behavior to predicting market trends, advanced data solutions are transforming how companies operate, innovate, and grow. By leveraging AI, ML, and big data technologies, organizations can now make faster, smarter, and more strategic decisions across industries.
At smartData Enterprises, we build and deploy intelligent data solutions that drive real business outcomes. Whether you’re a healthcare startup, logistics firm, fintech enterprise, or retail brand, our customized AI-powered platforms are designed to elevate your decision-making, efficiency, and competitive edge.
🧠 What Are Advanced Data Solutions?
Advanced data solutions combine technologies like artificial intelligence (AI), machine learning (ML), natural language processing (NLP), and big data analytics to extract deep insights from raw and structured data.
They include:
📊 Predictive & prescriptive analytics
🧠 Machine learning model development
🔍 Natural language processing (NLP)
📈 Business intelligence dashboards
🔄 Data warehousing & ETL pipelines
☁️ Cloud-based data lakes & real-time analytics
These solutions enable companies to go beyond basic reporting — allowing them to anticipate customer needs, streamline operations, and uncover hidden growth opportunities.
🚀 Why Advanced Data Solutions Are a Business Game-Changer
In the digital era, data isn’t just information — it’s a strategic asset. Advanced data solutions help businesses:
🔎 Detect patterns and trends in real time
💡 Make data-driven decisions faster
🧾 Reduce costs through automation and optimization
🎯 Personalize user experiences at scale
📈 Predict demand, risks, and behaviors
🛡️ Improve compliance, security, and data governance
Whether it’s fraud detection in finance or AI-assisted diagnostics in healthcare, the potential of smart data is limitless.
💼 smartData’s Capabilities in Advanced Data, AI & ML
With over two decades of experience in software and AI engineering, smartData has delivered hundreds of AI-powered applications and data science solutions to global clients.
Here’s how we help:
✅ AI & ML Model Development
Our experts build, train, and deploy machine learning models using Python, R, TensorFlow, PyTorch, and cloud-native ML services (AWS SageMaker, Azure ML, Google Vertex AI). We specialize in:
Classification, regression, clustering
Image, speech, and text recognition
Recommender systems
Demand forecasting and anomaly detection
✅ Data Engineering & ETL Pipelines
We create custom ETL (Extract, Transform, Load) pipelines and data warehouses to handle massive data volumes with:
Apache Spark, Kafka, and Hadoop
SQL/NoSQL databases
Azure Synapse, Snowflake, Redshift
This ensures clean, secure, and high-quality data for real-time analytics and AI models.
✅ NLP & Intelligent Automation
We integrate NLP and language models to automate:
Chatbots and virtual assistants
Text summarization and sentiment analysis
Email classification and ticket triaging
Medical records interpretation and auto-coding
✅ Business Intelligence & Dashboards
We build intuitive, customizable dashboards using Power BI, Tableau, and custom tools to help businesses:
Track KPIs in real-time
Visualize multi-source data
Drill down into actionable insights
🔒 Security, Scalability & Compliance
With growing regulatory oversight, smartData ensures that your data systems are:
🔐 End-to-end encrypted
⚖️ GDPR and HIPAA compliant
🧾 Auditable with detailed logs
🌐 Cloud-native for scalability and uptime
We follow best practices in data governance, model explainability, and ethical AI development.
🌍 Serving Global Industries with AI-Powered Data Solutions
Our advanced data platforms are actively used across industries:
🏥 Healthcare: AI for diagnostics, patient risk scoring, remote monitoring
🚚 Logistics: Predictive route optimization, fleet analytics
🏦 Finance: Risk assessment, fraud detection, portfolio analytics
🛒 Retail: Dynamic pricing, customer segmentation, demand forecasting
⚙️ Manufacturing: Predictive maintenance, quality assurance
Explore our custom healthcare AI solutions for more on health data use cases.
📈 Real Business Impact
Our clients have achieved:
🚀 40% reduction in manual decision-making time
💰 30% increase in revenue using demand forecasting tools
📉 25% operational cost savings with AI-led automation
📊 Enhanced visibility into cross-functional KPIs in real time
We don’t just build dashboards — we deliver end-to-end intelligence platforms that scale with your business.
🤝 Why Choose smartData?
25+ years in software and AI engineering
Global clients across healthcare, fintech, logistics & more
Full-stack data science, AI/ML, and cloud DevOps expertise
Agile teams, transparent process, and long-term support
With smartData, you don’t just get developers — you get a strategic technology partner.
📩 Ready to Turn Data Into Business Power?
If you're ready to harness AI and big data to elevate your business, smartData can help. Whether it's building a custom model, setting up an analytics dashboard, or deploying an AI-powered application — we’ve got the expertise to lead the way.
👉 Learn more: https://www.smartdatainc.com/advanced-data-ai-and-ml/
📞 Let’s connect and build your data-driven future.
#advanceddatasolutions #smartData #AIdevelopment #MLsolutions #bigdataanalytics #datadrivenbusiness #enterpriseAI #customdatasolutions #predictiveanalytics #datascience
0 notes
Text
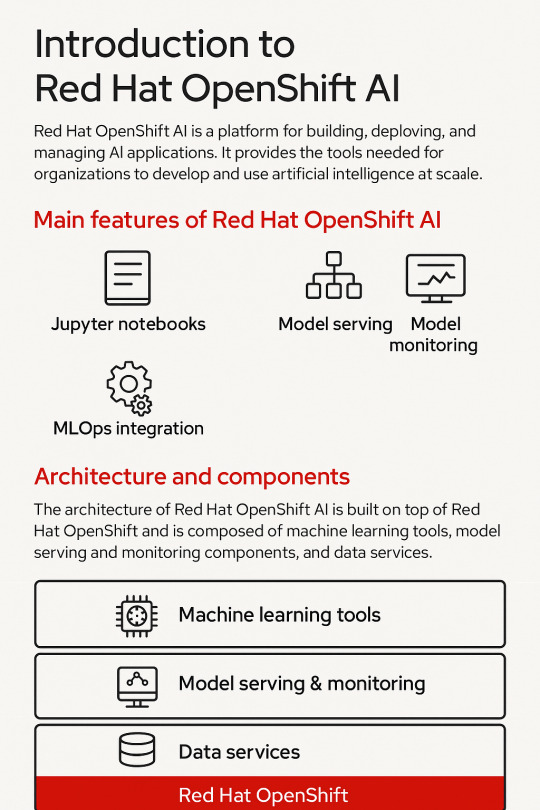
Introduction to Red Hat OpenShift AI: Features, Architecture & Components
In today’s data-driven world, organizations need a scalable, secure, and flexible platform to build, deploy, and manage artificial intelligence (AI) and machine learning (ML) models. Red Hat OpenShift AI is built precisely for that. It provides a consistent, Kubernetes-native platform for MLOps, integrating open-source tools, enterprise-grade support, and cloud-native flexibility.
Let’s break down the key features, architecture, and components that make OpenShift AI a powerful platform for AI innovation.
🔍 What is Red Hat OpenShift AI?
Red Hat OpenShift AI (formerly known as OpenShift Data Science) is a fully supported, enterprise-ready platform that brings together tools for data scientists, ML engineers, and DevOps teams. It enables rapid model development, training, and deployment on the Red Hat OpenShift Container Platform.
🚀 Key Features of OpenShift AI
1. Built for MLOps
OpenShift AI supports the entire ML lifecycle—from experimentation to deployment—within a consistent, containerized environment.
2. Integrated Jupyter Notebooks
Data scientists can use Jupyter notebooks pre-integrated into the platform, allowing quick experimentation with data and models.
3. Model Training and Serving
Use Kubernetes to scale model training jobs and deploy inference services using tools like KServe and Seldon Core.
4. Security and Governance
OpenShift AI integrates enterprise-grade security, role-based access controls (RBAC), and policy enforcement using OpenShift’s built-in features.
5. Support for Open Source Tools
Seamless integration with open-source frameworks like TensorFlow, PyTorch, Scikit-learn, and ONNX for maximum flexibility.
6. Hybrid and Multicloud Ready
You can run OpenShift AI on any OpenShift cluster—on-premise or across cloud providers like AWS, Azure, and GCP.
🧠 OpenShift AI Architecture Overview
Red Hat OpenShift AI builds upon OpenShift’s robust Kubernetes platform, adding specific components to support the AI/ML workflows. The architecture broadly consists of:
1. User Interface Layer
JupyterHub: Multi-user Jupyter notebook support.
Dashboard: UI for managing projects, models, and pipelines.
2. Model Development Layer
Notebooks: Containerized environments with GPU/CPU options.
Data Connectors: Access to S3, Ceph, or other object storage for datasets.
3. Training and Pipeline Layer
Open Data Hub and Kubeflow Pipelines: Automate ML workflows.
Ray, MPI, and Horovod: For distributed training jobs.
4. Inference Layer
KServe/Seldon: Model serving at scale with REST and gRPC endpoints.
Model Monitoring: Metrics and performance tracking for live models.
5. Storage and Resource Management
Ceph / OpenShift Data Foundation: Persistent storage for model artifacts and datasets.
GPU Scheduling and Node Management: Leverages OpenShift for optimized hardware utilization.
🧩 Core Components of OpenShift AI
ComponentDescriptionJupyterHubWeb-based development interface for notebooksKServe/SeldonInference serving engines with auto-scalingOpen Data HubML platform tools including Kafka, Spark, and moreKubeflow PipelinesWorkflow orchestration for training pipelinesModelMeshScalable, multi-model servingPrometheus + GrafanaMonitoring and dashboarding for models and infrastructureOpenShift PipelinesCI/CD for ML workflows using Tekton
🌎 Use Cases
Financial Services: Fraud detection using real-time ML models
Healthcare: Predictive diagnostics and patient risk models
Retail: Personalized recommendations powered by AI
Manufacturing: Predictive maintenance and quality control
🏁 Final Thoughts
Red Hat OpenShift AI brings together the best of Kubernetes, open-source innovation, and enterprise-level security to enable real-world AI at scale. Whether you’re building a simple classifier or deploying a complex deep learning pipeline, OpenShift AI provides a unified, scalable, and production-grade platform.
For more info, Kindly follow: Hawkstack Technologies
0 notes
Text
When Analytics Services Go Strategic: Solving Real Business Pain
Ever felt like your data is whispering insights that you just can’t hear? Most teams drown in dashboards, missing the golden trends hiding in plain sight.
With today’s rapid shifts—algorithm changes, economic uncertainties, evolving customer expectations—using analytics services strategically isn’t optional anymore—it’s essential. Yet too often, dashboards are loaded with vanity metrics that don’t move the needle.
In this post, you’ll discover how to transform your analytics services into a dynamic engine for growth—by aligning metrics with goals, unlocking real-time insight, embedding predictive intelligence, empowering teams, and building a culture that tracks ROI.
Align Analytics Services With What Actually Matters
A frequent challenge: endless dashboards full of data that doesn’t tell you what you need to know.
● Step 1: Map analytics services to strategic goals Define the handful of business outcomes leaders care about—revenue, retention, efficiency.
● Step 2: Pick 3–5 KPIs per function For example, Marketing: CAC, lead velocity, channel ROI. Finance: DSO, margin trends.
● Step 3: Build scorecards—not scatterplots Create clean views that compare current performance against targets.
Real-world example A SaaS company replaced drop-off rates with trial-to-paid conversion metrics and shortened their sales cycle by 15%.
Benefits Channels that support growth get visibility. Vanity metrics fall off your dashboard. Analytics services become growth tools, not noise.
Shift to Real-Time Pipelines: Speed = Competitive Edge
Late reports don’t help in a fast-moving world.
● Step 1: Audit ETL cadence Understand what updates daily vs hourly vs live-streaming.
● Step 2: Introduce micro-batches or event streams Use tools like Kafka or Airflow to refresh key reports every hour—or instantly for critical alerts.
● Step 3: Set automated alerts If inventory falls below threshold or conversion dips 10%, trigger notifications.
Example A retail brand spotted inventory issues within minutes, preventing a 20% drop in weekend sales.
Benefits Analytics services shift from retroactive reporting to proactive action—saving time, money, and trust.
Embed Predictive Intelligence Into Your Dashboards
Past performance is useful—predictive insight is transformational.
● Step 1: Find forecasting use cases Where do trends help decisions? Examples: customer churn, demand spikes, fraud threats.
● Step 2: Prototype lightweight models Start with linear regression or ARIMA forecasts embedded in BI dashboards.
● Step 3: Validate and iterate Compare predicted vs actual. Improve accuracy. Roll out to stakeholders.
Example A subscription company predicted churn a month ahead, allowing intervention that reduced attrition by 15%.
Benefits Analytics services evolve from answer-givers to question-forecasters—helping teams prioritize what matters next.
Democratize Insights With Self‑Service Analytics
When BI teams are overloaded, decisions slow.
● Step 1: Catalog common questions Sales wants deal-stage visibility. Support wants volume and handle time.
● Step 2: Build reusable dashboard templates Role-based, filterable, and with drill-down capability.
● Step 3: Run training and document processes Empower people with tooltips, templates, and 15-minute walk-throughs.
Example An HR team built its own turnover analysis, reducing BI dependencies by 40%.
Benefits Analytics services become accessible, timely, and integrated into everyday decision-making.
Prove ROI of Your Analytics Services
Budgets tighten—analytics leaders must show impact.
● Step 1: Track outcome metrics E.g., time saved, revenue uplift, error reduction.
● Step 2: Connect analytics to value “We saved 120 hours/week by automating lead reports.”
● Step 3: Share tangible wins Create before/after snapshots and circulate in stakeholder communications.
Example A/C pricing model optimization boosted Average Revenue per User 5%, justifying new analytics hires.
Benefits Analytics services earn a permanent seat at the table—and a growing budget.
Conclusion & What You Can Do Next
Analytics services can shift from dusty dashboards to strategic muscle—if you align, accelerate, empower, embed, and prove value.
Try this next week: Pick one area above—like real-time reporting or self-service dashboards. Launch with a small pilot, track impact, share results.
#AnalyticsServices#DataDrivenDecisions#BusinessAnalytics#DataStrategy#PredictiveAnalytics#DataTransformation#RealTimeAnalytics#BItools#DataOps#KPItracking#BusinessIntelligence#AnalyticsForGrowth#DataScienceStrategy#OperationalEfficiency#AnalyticsInnovation#InsightToAction#DataIsPower#SmartDashboards#ModernAnalytics#ScalableSolutions
0 notes
Text
Big Data Technologies: Hadoop, Spark, and Beyond

In this era where every click, transaction, or sensor emits a massive flux of information, the term "Big Data" has gone past being a mere buzzword and has become an inherent challenge and an enormous opportunity. These are datasets so enormous, so complex, and fast-growing that traditional data-processing applications cannot handle them. The huge ocean of information needs special tools; at the forefront of this big revolution being Big Data Technologies- Hadoop, Spark, and beyond.
One has to be familiar with these technologies if they are to make some modern-day sense of the digital world, whether they be an aspiring data professional or a business intent on extracting actionable insights out of their massive data stores.
What is Big Data and Why Do We Need Special Technologies?
Volume: Enormous amounts of data (terabytes, petabytes, exabytes).
Velocity: Data generated and processed at incredibly high speeds (e.g., real-time stock trades, IoT sensor data).
Variety: Data coming in diverse formats (structured, semi-structured, unstructured – text, images, videos, logs).
Traditional relational databases and processing tools were not built to handle this scale, speed, or diversity. They would crash, take too long, or simply fail to process such immense volumes. This led to the emergence of distributed computing frameworks designed specifically for Big Data.
Hadoop: The Pioneer of Big Data Processing
Apache Hadoop was an advanced technological tool in its time. It had completely changed the facets of data storage and processing on a large scale. It provides a framework for distributed storage and processing of datasets too large to be processed on a single machine.
· Key Components:
HDFS (Hadoop Distributed File System): It is a distributed file system, where the data is stored across multiple machines and hence are fault-tolerant and highly scalable.
MapReduce: A programming model for processing large data sets with a parallel, distributed algorithm on a cluster. It subdivides a large problem into smaller ones that can be solved independently in parallel.
What made it revolutionary was the fact that Hadoop enabled organizations to store and process data they previously could not, hence democratizing access to massive datasets.
Spark: The Speed Demon of Big Data Analytics
While MapReduce on Hadoop is a formidable force, disk-based processing sucks up time when it comes to iterative algorithms and real-time analytics. And so came Apache Spark: an entire generation ahead in terms of speed and versatility.
· Key Advantages over Hadoop MapReduce:
In-Memory Processing: Spark processes data in memory, which is from 10 to 100 times faster than MapReduce-based operations, primarily in iterative algorithms (Machine Learning is an excellent example here).
Versatility: Several libraries exist on top of Spark's core engine:
Spark SQL: Structured data processing using SQL
Spark Streaming: Real-time data processing.
MLlib: Machine Learning library.
GraphX: Graph processing.
What makes it important, actually: Spark is the tool of choice when it comes to real-time analytics, complex data transformations, and machine learning on Big Data.
And Beyond: Evolving Big Data Technologies
The Big Data ecosystem is growing by each passing day. While Hadoop and Spark are at the heart of the Big Data paradigm, many other technologies help in complementing and extending their capabilities:
NoSQL Databases: (e.g., MongoDB, Cassandra, HBase) – The databases were designed to handle massive volumes of unstructured or semi-structured data with high scale and high flexibility as compared to traditional relational databases.
Stream Processing Frameworks: (e.g., Apache Kafka, Apache Flink) – These are important for processing data as soon as it arrives (real-time), crucial for fraud-detection, IoT Analytics, and real-time dashboards.
Data Warehouses & Data Lakes: Cloud-native solutions (example, Amazon Redshift, Snowflake, Google BigQuery, Azure Synapse Analytics) for scalable, managed environments to store and analyze big volumes of data often with seamless integration to Spark.
Cloud Big Data Services: Major cloud providers running fully managed services of Big Data processing (e.g., AWS EMR, Google Dataproc, Azure HDInsight) reduce much of deployment and management overhead.
Data Governance & Security Tools: As data grows, the need to manage its quality, privacy, and security becomes paramount.
Career Opportunities in Big Data
Mastering Big Data technologies opens doors to highly sought-after roles such as:
Big Data Engineer
Data Architect
Data Scientist (often uses Spark/Hadoop for data preparation)
Business Intelligence Developer
Cloud Data Engineer
Many institutes now offer specialized Big Data courses in Ahmedabad that provide hands-on training in Hadoop, Spark, and related ecosystems, preparing you for these exciting careers.
The journey into Big Data technologies is a deep dive into the engine room of the modern digital economy. By understanding and mastering tools like Hadoop, Spark, and the array of complementary technologies, you're not just learning to code; you're learning to unlock the immense power of information, shaping the future of industries worldwide.
Contact us
Location: Bopal & Iskcon-Ambli in Ahmedabad, Gujarat
Call now on +91 9825618292
Visit Our Website: http://tccicomputercoaching.com/
0 notes
Text
Real Time Spark Project for Beginners: Hadoop, Spark, Docker
🚀 Building a Real-Time Data Pipeline for Server Monitoring Using Kafka, Spark, Hadoop, PostgreSQL & Django
In today’s data centers, various types of servers constantly generate vast volumes of real-time event data—each event representing the server’s status. To ensure stability and minimize downtime, monitoring teams need instant insights into this data to detect and resolve issues swiftly.
To meet this demand, a scalable and efficient real-time data pipeline architecture is essential. Here’s how we’re building it:
🧩 Tech Stack Overview: Apache Kafka acts as the real-time data ingestion layer, handling high-throughput event streams with minimal latency.
Apache Spark (Scala + PySpark), running on a Hadoop cluster (via Docker), performs large-scale, fault-tolerant data processing and analytics.
Hadoop enables distributed storage and computation, forming the backbone of our big data processing layer.
PostgreSQL stores the processed insights for long-term use and querying.
Django serves as the web framework, enabling dynamic dashboards and APIs.
Flexmonster powers data visualization, delivering real-time, interactive insights to monitoring teams.
🔍 Why This Stack? Scalability: Each tool is designed to handle massive data volumes.
Real-time processing: Kafka + Spark combo ensures minimal lag in generating insights.
Interactivity: Flexmonster with Django provides a user-friendly, interactive frontend.
Containerized: Docker simplifies deployment and management.
This architecture empowers data center teams to monitor server statuses live, quickly detect anomalies, and improve infrastructure reliability.
Stay tuned for detailed implementation guides and performance benchmarks!
0 notes
Text
Top Trends Shaping the Future of Data Engineering Consultancy
In today’s digital-first world, businesses are rapidly recognizing the need for structured and strategic data management. As a result, Data Engineering Consultancy is evolving at an unprecedented pace. From cloud-native architecture to AI-driven automation, the future of data engineering is being defined by innovation and agility. Here are the top trends shaping this transformation.

1. Cloud-First Data Architectures
Modern businesses are migrating their infrastructure to cloud platforms like AWS, Azure, and Google Cloud. Data engineering consultants are now focusing on building scalable, cloud-native data pipelines that offer better performance, security, and flexibility.
2. Real-Time Data Processing
The demand for real-time analytics is growing, especially in sectors like finance, retail, and logistics. Data Engineering Consultancy services are increasingly incorporating technologies like Apache Kafka, Flink, and Spark to support instant data processing and decision-making.
3. Advanced Data Planning
A strategic approach to Data Planning is becoming central to successful consultancy. Businesses want to go beyond reactive reporting—they seek proactive, long-term strategies for data governance, compliance, and scalability.
4. Automation and AI Integration
Automation tools and AI models are revolutionizing how data is processed, cleaned, and analyzed. Data engineers now use machine learning to optimize data quality checks, ETL processes, and anomaly detection.
5. Data Democratization
Consultants are focusing on creating accessible data systems, allowing non-technical users to engage with data through intuitive dashboards and self-service analytics.
In summary, the future of Data Engineering Consultancy lies in its ability to adapt to technological advancements while maintaining a strong foundation in Data Planning. By embracing these trends, businesses can unlock deeper insights, enhance operational efficiency, and stay ahead of the competition in the data-driven era. Get in touch with Kaliper.io today!
0 notes
Text
💬 Your Brand Has a Pulse. Are You Tracking It in Real Time?
You’ve seen it happen.
One negative tweet. A viral Reddit thread. A wave of frustrated reviews.
Suddenly, a brand built over years is scrambling to fix what could’ve been caught hours earlier.
👀 Enter: The Real-Time Brand Sentiment Dashboard
Not a vanity metric machine. Not a pretty chart for your next meeting.
A living, breathing radar that picks up customer emotions as they happen.
✔ Spot sudden spikes in anger ✔ Track joy, confusion, disappointment, not just “positivity” ✔ Fix product pain points before they go public ✔ Compare your sentiment score to competitors ✔ Turn raw feedback into smarter campaigns and product decisions
🧠 Built With:
Social & review data (Twitter, Reddit, G2, Google, TikTok…)
NLP & emotion analysis (because “not bad” isn’t the same as “great”)
Real-time pipelines (Kafka, Flink, or cloud tech)
Drill-down dashboards for PR, Product, CX, and Marketing
⚠️ What to Avoid
🚫 Over-alerting (you’ll ignore the noise) 🚫 Misreading sarcasm (hi, Twitter) 🚫 Relying only on charts (context matters)
💡 What to Do Instead
→ Monitor. → Understand. → Act fast. → Repeat.
Your brand deserves more than monthly reports and vague NPS scores. It deserves a dashboard that sees what customers feel, now.
📖 Read the full blog for the full blueprint → https://shorturl.at/OvQvP
#brandhealth#sentimentanalysis#sociallistening#realtimeanalytics#customerfeedback#digitalstrategy#42signals#marketingtools#prstrategy
0 notes
Text
Understanding Apache Kafka: The Backbone of Real-Time Data
visit the blog: https://velog.io/@tpointtechblog/Understanding-Apache-Kafka-The-Backbone-of-Real-Time-Data
Visit more blog:
https://themediumblog.com/read-blog/167042https://tpointtechblog.blogspot.com/2025/05/what-is-mysql-and-why-should-you-learn.htmlhttps://sites.google.com/view/learnjavaprogramminglanguage/home
https://dev.to/tpointtechblog/power-bi-for-beginners-complete-introduction-dashboard-creation-2khehttps://medium.com/@tpointtechblog/understanding-django-pythons-most-powerful-web-framework-2b969e7319f0
0 notes
Text
Empowering Businesses with Advanced Data Engineering Solutions in Toronto – C Data Insights
In a rapidly digitizing world, companies are swimming in data—but only a few truly know how to harness it. At C Data Insights, we bridge that gap by delivering top-tier data engineering solutions in Toronto designed to transform your raw data into actionable insights. From building robust data pipelines to enabling intelligent machine learning applications, we are your trusted partner in the Greater Toronto Area (GTA).
What Is Data Engineering and Why Is It Critical?
Data engineering involves the design, construction, and maintenance of scalable systems for collecting, storing, and analyzing data. In the modern business landscape, it forms the backbone of decision-making, automation, and strategic planning.
Without a solid data infrastructure, businesses struggle with:
Inconsistent or missing data
Delayed analytics reports
Poor data quality impacting AI/ML performance
Increased operational costs
That’s where our data engineering service in GTA helps. We create a seamless flow of clean, usable, and timely data—so you can focus on growth.
Key Features of Our Data Engineering Solutions
As a leading provider of data engineering solutions in Toronto, C Data Insights offers a full suite of services tailored to your business goals:
1. Data Pipeline Development
We build automated, resilient pipelines that efficiently extract, transform, and load (ETL) data from multiple sources—be it APIs, cloud platforms, or on-premise databases.
2. Cloud-Based Architecture
Need scalable infrastructure? We design data systems on AWS, Azure, and Google Cloud, ensuring flexibility, security, and real-time access.
3. Data Warehousing & Lakehouses
Store structured and unstructured data efficiently with modern data warehousing technologies like Snowflake, BigQuery, and Databricks.
4. Batch & Streaming Data Processing
Process large volumes of data in real-time or at scheduled intervals with tools like Apache Kafka, Spark, and Airflow.
Data Engineering and Machine Learning – A Powerful Duo
Data engineering lays the groundwork, and machine learning unlocks its full potential. Our solutions enable you to go beyond dashboards and reports by integrating data engineering and machine learning into your workflow.
We help you:
Build feature stores for ML models
Automate model training with clean data
Deploy models for real-time predictions
Monitor model accuracy and performance
Whether you want to optimize your marketing spend or forecast inventory needs, we ensure your data infrastructure supports accurate, AI-powered decisions.
Serving the Greater Toronto Area with Local Expertise
As a trusted data engineering service in GTA, we take pride in supporting businesses across:
Toronto
Mississauga
Brampton
Markham
Vaughan
Richmond Hill
Scarborough
Our local presence allows us to offer faster response times, better collaboration, and solutions tailored to local business dynamics.
Why Businesses Choose C Data Insights
✔ End-to-End Support: From strategy to execution, we’re with you every step of the way ✔ Industry Experience: Proven success across retail, healthcare, finance, and logistics ✔ Scalable Systems: Our solutions grow with your business needs ✔ Innovation-Focused: We use the latest tools and best practices to keep you ahead of the curve
Take Control of Your Data Today
Don’t let disorganized or inaccessible data hold your business back. Partner with C Data Insights to unlock the full potential of your data. Whether you need help with cloud migration, real-time analytics, or data engineering and machine learning, we’re here to guide you.
📍 Proudly offering data engineering solutions in Toronto and expert data engineering service in GTA.
📞 Contact us today for a free consultation 🌐 https://cdatainsights.com
C Data Insights – Engineering Data for Smart, Scalable, and Successful Businesses
#data engineering solutions in Toronto#data engineering and machine learning#data engineering service in Gta
0 notes
Text
How Modern Data Engineering Powers Scalable, Real-Time Decision-Making
In today's world, driven by technology, businesses have evolved further and do not want to analyze data from the past. Everything from e-commerce websites providing real-time suggestions to banks verifying transactions in under a second, everything is now done in a matter of seconds. Why has this change taken place? The modern age of data engineering involves software development, data architecture, and cloud infrastructure on a scalable level. It empowers organizations to convert massive, fast-moving data streams into real-time insights.
From Batch to Real-Time: A Shift in Data Mindset
Traditional data systems relied on batch processing, in which data was collected and analyzed after certain periods of time. This led to lagging behind in a fast-paced world, as insights would be outdated and accuracy would be questionable. Ultra-fast streaming technologies such as Apache Kafka, Apache Flink, and Spark Streaming now enable engineers to create pipelines that help ingest, clean, and deliver insights in an instant. This modern-day engineering technique shifts the paradigm of outdated processes and is crucial for fast-paced companies in logistics, e-commerce, relevancy, and fintech.
Building Resilient, Scalable Data Pipelines
Modern data engineering focuses on the construction of thoroughly monitored, fault-tolerant data pipelines. These pipelines are capable of scaling effortlessly to higher volumes of data and are built to accommodate schema changes, data anomalies, and unexpected traffic spikes. Cloud-native tools like AWS Glue and Google Cloud Dataflow with Snowflake Data Sharing enable data sharing and integration scaling without limits across platforms. These tools make it possible to create unified data flows that power dashboards, alerts, and machine learning models instantaneously.
Role of Data Engineering in Real-Time Analytics
Here is where these Data Engineering Services make a difference. At this point, companies providing these services possess considerable technical expertise and can assist an organization in designing modern data architectures in modern frameworks aligned with their business objectives. From establishing real-time ETL pipelines to infrastructure handling, these services guarantee that your data stack is efficient and flexible in terms of cost. Companies can now direct their attention to new ideas and creativity rather than the endless cycle of data management patterns.
Data Quality, Observability, and Trust
Real-time decision-making depends on the quality of the data that powers it. Modern data engineering integrates practices like data observability, automated anomaly detection, and lineage tracking. These ensure that data within the systems is clean and consistent and can be traced. With tools like Great Expectations, Monte Carlo, and dbt, engineers can set up proactive alerts and validations to mitigate issues that could affect economic outcomes. This trust in data quality enables timely, precise, and reliable decisions.
The Power of Cloud-Native Architecture
Modern data engineering encompasses AWS, Azure, and Google Cloud. They provide serverless processing, autoscaling, real-time analytics tools, and other services that reduce infrastructure expenditure. Cloud-native services allow companies to perform data processing, as well as querying, on exceptionally large datasets instantly. For example, with Lambda functions, data can be transformed. With BigQuery, it can be analyzed in real-time. This allows rapid innovation, swift implementation, and significant long-term cost savings.
Strategic Impact: Driving Business Growth
Real-time data systems are providing organizations with tangible benefits such as customer engagement, operational efficiency, risk mitigation, and faster innovation cycles. To achieve these objectives, many enterprises now opt for data strategy consulting, which aligns their data initiatives to the broader business objectives. These consulting firms enable organizations to define the right KPIs, select appropriate tools, and develop a long-term roadmap to achieve desired levels of data maturity. By this, organizations can now make smarter, faster, and more confident decisions.
Conclusion
Investing in modern data engineering is more than an upgrade of technology — it's a shift towards a strategic approach of enabling agility in business processes. With the adoption of scalable architectures, stream processing, and expert services, the true value of organizational data can be attained. This ensures that whether it is customer behavior tracking, operational optimization, or trend prediction, data engineering places you a step ahead of changes before they happen, instead of just reacting to changes.
1 note
·
View note
Text
How Azure Supports Big Data and Real-Time Data Processing

The explosion of digital data in recent years has pushed organizations to look for platforms that can handle massive datasets and real-time data streams efficiently. Microsoft Azure has emerged as a front-runner in this domain, offering robust services for big data analytics and real-time processing. Professionals looking to master this platform often pursue the Azure Data Engineering Certification, which helps them understand and implement data solutions that are both scalable and secure.
Azure not only offers storage and computing solutions but also integrates tools for ingestion, transformation, analytics, and visualization—making it a comprehensive platform for big data and real-time use cases.
Azure’s Approach to Big Data
Big data refers to extremely large datasets that cannot be processed using traditional data processing tools. Azure offers multiple services to manage, process, and analyze big data in a cost-effective and scalable manner.
1. Azure Data Lake Storage
Azure Data Lake Storage (ADLS) is designed specifically to handle massive amounts of structured and unstructured data. It supports high throughput and can manage petabytes of data efficiently. ADLS works seamlessly with analytics tools like Azure Synapse and Azure Databricks, making it a central storage hub for big data projects.
2. Azure Synapse Analytics
Azure Synapse combines big data and data warehousing capabilities into a single unified experience. It allows users to run complex SQL queries on large datasets and integrates with Apache Spark for more advanced analytics and machine learning workflows.
3. Azure Databricks
Built on Apache Spark, Azure Databricks provides a collaborative environment for data engineers and data scientists. It’s optimized for big data pipelines, allowing users to ingest, clean, and analyze data at scale.
Real-Time Data Processing on Azure
Real-time data processing allows businesses to make decisions instantly based on current data. Azure supports real-time analytics through a range of powerful services:
1. Azure Stream Analytics
This fully managed service processes real-time data streams from devices, sensors, applications, and social media. You can write SQL-like queries to analyze the data in real time and push results to dashboards or storage solutions.
2. Azure Event Hubs
Event Hubs can ingest millions of events per second, making it ideal for real-time analytics pipelines. It acts as a front-door for event streaming and integrates with Stream Analytics, Azure Functions, and Apache Kafka.
3. Azure IoT Hub
For businesses working with IoT devices, Azure IoT Hub enables the secure transmission and real-time analysis of data from edge devices to the cloud. It supports bi-directional communication and can trigger workflows based on event data.
Integration and Automation Tools
Azure ensures seamless integration between services for both batch and real-time processing. Tools like Azure Data Factory and Logic Apps help automate the flow of data across the platform.
Azure Data Factory: Ideal for building ETL (Extract, Transform, Load) pipelines. It moves data from sources like SQL, Blob Storage, or even on-prem systems into processing tools like Synapse or Databricks.
Logic Apps: Allows you to automate workflows across Azure services and third-party platforms. You can create triggers based on real-time events, reducing manual intervention.
Security and Compliance in Big Data Handling
Handling big data and real-time processing comes with its share of risks, especially concerning data privacy and compliance. Azure addresses this by providing:
Data encryption at rest and in transit
Role-based access control (RBAC)
Private endpoints and network security
Compliance with standards like GDPR, HIPAA, and ISO
These features ensure that organizations can maintain the integrity and confidentiality of their data, no matter the scale.
Career Opportunities in Azure Data Engineering
With Azure’s growing dominance in cloud computing and big data, the demand for skilled professionals is at an all-time high. Those holding an Azure Data Engineering Certification are well-positioned to take advantage of job roles such as:
Azure Data Engineer
Cloud Solutions Architect
Big Data Analyst
Real-Time Data Engineer
IoT Data Specialist
The certification equips individuals with knowledge of Azure services, big data tools, and data pipeline architecture—all essential for modern data roles.
Final Thoughts
Azure offers an end-to-end ecosystem for both big data analytics and real-time data processing. Whether it’s massive historical datasets or fast-moving event streams, Azure provides scalable, secure, and integrated tools to manage them all.
Pursuing an Azure Data Engineering Certification is a great step for anyone looking to work with cutting-edge cloud technologies in today’s data-driven world. By mastering Azure’s powerful toolset, professionals can design data solutions that are future-ready and impactful.
#Azure#BigData#RealTimeAnalytics#AzureDataEngineer#DataLake#StreamAnalytics#CloudComputing#AzureSynapse#IoTHub#Databricks#CloudZone#AzureCertification#DataPipeline#DataEngineering
0 notes