#stdin
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Users from the US are the majority of Tumblr visitors.
Text

again
#kelp the silly#drew this yesterrday bc i dont want to start with this stdin stuff . . . its like. . intriguing but also i have No idea how to start this#today i really failed at getting groceries and im frustrated#ivan shitson the killer of grass !!!#redisigning his ass 20 times a day
23 notes
·
View notes
Text
Also: you're likely to run the program from within a shell in the terminal application, in which case:
The shell process itself ~captures*** the output of the program (i.e. the 'blah' it sent to its stdout), and tells the terminal to display that*
The terminal process then figures**** how that translates into a fresh arrangement of pixels on screen, and makes it happen**
Ok another question: C and so on compile to assembly. When I type printf('blah blah blah'); that sends the relevant text to the console. But how does it do that? Isn't it the OS that handles like, the console and shit? How would you write that function in assembly?
#* certainly someone in the process should decode the string of bytes into like utf-8 but iunno who does that#terminal probably?#might depend though#** I think in principle a process can directly write to “video memory” which the video card immediately-ish displays?#but probably there're a couple more abstraction layers there#e.g. the terminal might tell the window manager that it has new things to show and its the latter that talks to video hardware#-#also someone ought to handle the initial launch of the program#load it into memory; do the launching syscall; define where its stdin/out '''are'''; do the launching syscall#proobably the shell also does that but i don't actually know#*** is about that#**** I'm guessing terminal asks _something_ for fonts but fuck if i know what#abusing computers for fun and profit#banter
27 notes
·
View notes
Text
programming language where instead of return-value semantics all functions are stdin-stdout based (but with streams that can have arbitrary typing maybe?)
22 notes
·
View notes
Text
I didn't quite get all my tentpole goals for my programming language project done this weekend, but I got much closer than I originally expected! I'm hoping to have transpilation to C ready by the end of my week to show my friend. I did start setting up program entrypoints in uv, though, and there's something emotionally magical about typing into the stdin of a process, and have it spit out a processed version of your input. Like... oh my god! That's my lexer, and my parser! They work! This is a thing I can play with now! This process is also forcing me to confront some things earlier than I expected, like the way the built-in Error type works. In the earlier prototype this was basically just an enum of a couple options, and no further detail. But needing to represent errors as a C type has pushed me to actually make them structures with multiple fields:
Format string (TODO: printf format rather than Python format), in the final version this will usually be a pointer to a static piece of memory.
Format args.
Parent error (allows for printing a whole traceback).
I wouldn't say I'm thrilled by how much I'm currently having to use PyObject* as a gross hack in my structures right now, but it helps my code play nice with the Python garbage collection infrastructure, and should make it possible to incrementally migrate to a C implementation later.
3 notes
·
View notes
Text
list of things external to the Linux or GNU projects that you have to learn to some extent to get a comfortable multimedia desktop and programming environment for a project of significant size: X11, Wayland, Gtk, Qt, Terminal Emulators, Pipewire, PulseAudio, XDG Protocols (Open, Desktop portals, Desktop entries), NetworkManager/iwd/wpa_supplicant, GRUB, Systemd, Cmake, Wine, Clang, a decent text editor (meaning: not vi or nano). all of these have completely different configuration standards and interfaces
list of things you need external to the 9front distribution of plan 9 to get a comfortable multimedia desktop and programming environment for a project of significant size: netsurf if you really need a browser with css support? rio themes are still contained in a patch and not installed by default but they're on the contrib 9p share and really easy to get. you can get an ext4 filesystem server on contrib too, to get files to and from a unix without booting a second machine. video playback is possible with treason, on contrib. all of it is spoken to with launch flags, file descriptors (stdin/out), pipes, and filesystem reads and writes
2 notes
·
View notes
Text
A bit of actual Assembly knowledge for once. Let's cover some basic operations.
In C, to print something, you say:
printf("Hello, World!");
One argument. Very simple. Very understandable.
But it's not so easy in Assembly, is it?
Here's what the same looks like in Assembly, assuming you've properly declared a string called msg, and you're using Linux syntax (Assembly is formatted different between operating systems. I recommend Linux because it makes the most sense for developers).
mov rax, 1
mov rdi, 1
lea rsi, [msg]
mov rdx, 14
syscall
What's going on here?
Well, there are four parts to a simple print statement in Assembly. Each are put into place by registers in your CPU. rax, for example, is one of these registers.
We use mov to move values into the register. Notice that the syntax is: opcode destination, source
- rax holds the number for your function. In this case, 1 is used for print. (Full list of function numbers here)
- rdi holds the first argument in your function (arg0), which is 1 for standard output (stdout). For comparison, 0 is standard input (stdin)
- rsi (arg1) holds the actual text from the string. We use lea (load effective address) instead of mov, because if we used mov, we would get the memory address (location) of msg rather than the value of msg.
- rdx (arg2) holds the number of characters you want to print. There are 13 chars in our string msg: (Hello, World!). Thus, we allocate 14 characters, so we may also include a null character which says where to end the string.
- syscall basically just tells the computer to activate the function you have set up. Without it, you're just moving arbitrary values for no reason.
I know I know, it's a lot. But there is value in learning this language. Assembly runs way faster and uses much less space than higher level languages like C.
In my own experience, hello world code comes out to be about 15 kilobytes in C, but only about 200 bytes in Assembly. You read that right. Bytes. Without a kilo, mega or giga.
2 notes
·
View notes
Text
Code Blog, Project 001 Understanding Unicode
Day 02
Mostly I was setting up my environment today.
I got a very simple c program running on one of my servers when I realized I would need a better way to step through my code.
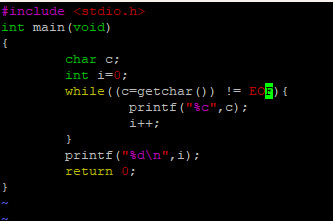
The code compiles and runs but more advanced debugging it could be a challenge.

Brainstorming:
I could get better at using tmux and find a command line debugger.
I could develop my C code in Visual Studio as a C++ project, upload the final files to my server and then figure out any incompatibilities.
I could Google for a C language IDE that can run on Windows.
Today's Path Forward:
I’m going to explore the third option today and see how things go.
I’m trying out a program called CLion

I got CLion installed, activated the free trial and got it to SSH into my server.
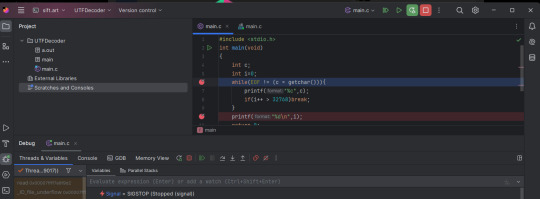
The current problem I'm stuck on is that I can't get it to read from standard in. I don't know if this feature exists in CLion.
I tried dumping the source file as a text sample into stdin. I did it as a Program argument. This probably isn't the way CLion expects things. When I ran the debugger the code doesn't seem to be reading anything.
Another issue I'm thinking of is that the debugging features seem to be just a GUI for GDB.
I will probably have to get good with GDB anyway. I may be better off just using a tmux terminal with GDB in one of the panes. I'm not sure which solution (tmux or CLion) to explore.
I may work on this some more today. I'll see where I'm at tomorrow.
11 notes
·
View notes
Note
#include <stdint.h>
#include <stdio.h>
#ifdef _WIN32
#iinclude <io.h>
#include <fcntl.h>
#define main() M();
int main(){setmode(fi leno(stdin),O_BINARY);return M();}int M() #endif int main() {uint32_t h[20]={0}, i=0,x=~i/15,f=x*x-x,a=f^x, b=f^x*9,c=~a,d=~b;int64_t z=0, g=0,l=566548,p=585873,o=882346,e ,m=64336,k,n;for(;d=h[c=h[b=h[a=h[i= 0]+=a,1]+=b,2]+=c,3]+=d,f;){for(n=64 ;n==8?h[h[5]=g,4]=g>>32,f=z>=0:n;)h[4+ --n/4]=x=(z<0?0:(z=getchar())>=0?g+=8,z: 128)<<24|x>>8;;for(e=0,k=~e<<40;(x=i/16) <4;a=d,d=c,c=b,b+=x<<n|x>>(32-n))n=((e*m +k*p)>>21)+e*l+k*o,k=(((k*m-e*p)>>21)+k* l-e*o)>>20,e=n>>20,n=(i|12)*152%543%82 %4+i%4*43/8+4,x=a+((x>2?~d|b:x>1?b^d :x?(b^c)&d:(c^d)&~b)^c)+h[19-((x*7/2 &5)-~(x*5&6)*i++)%16]+(e>>40^e>> 8);}for(;i<33;putchar(i++<32?a +=a>9?'a'-10:'0':'\n'))a=h [i/8]>>(i%8*4^4)&15; return 0;}
🥵
2 notes
·
View notes
Text
I'm like if a girl was Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'girl' is not de
5 notes
·
View notes
Text
histdir
So I've started a stupid-simple shell/REPL history mechanism that's more friendly to Syncthing-style cloud sync than a history file (like basically every shell and REPL do now) or a SQLite database (which is probably appropriate, and it's what Atuin does while almost single-handedly dragging CLI history UX into the 21st century):
You have a history directory.
Every history entry gets its own file.
The file name of a history entry is a hash of that history entry.
The contents of a history entry file is the history entry itself.
So that's the simple core concept around which I'm building the rest. If you just want a searchable, syncable record of everything you ever executed, well there you go. This was the smallest MVP, and I implemented that last night - a little shell script to actually create the histdir entries (entry either passed as an argument or read on stdin if there's no entry argument), and some Elisp code in my Emacs to replace Eshell's built-in history file save and load. Naturally my loaded history stopped remembering order of commands reliably, as expected, which would've been a deal-breaker problem in the long term. But the fact that it instantly plugged into Syncthing with no issues was downright blissful.
(I hate to throw shade on Atuin... Atuin is the best project in the space, I recommend checking it out, and it significantly inspired the featureset and UX of my current setup. But it's important for understanding the design choices of histdir: Atuin has multiple issues related to syncing - histdir will never have any sync issues. And that's part of what made it so blissful. I added the folder to Syncthing - no separate account, no separate keys, nothing I must never lose. In most ways, Atuin's design choice of a SQLite database is just better. That's real, proper engineering. Serious software developers all know that this is exactly the kind of thing where a database is better than a bunch of files. But one benefit you get from this file-oriented granularity is that if you just design the naming scheme right, history entries never collide/conflict in the same file. So we get robust sync, even with concurrent use, on multiple devices - basically for free, or at least amortized with the setup effort for whatever solution you're using to sync your other files (none of which could handle updates from two different devices to a single SQLite database). Deleting a history entry in histdir is an "rm"/"unlink" - in Atuin it's a whole clever engineering puzzle.)
So onto preserving order. In principle, the modification time of these files is enough for ordering: the OS already records when they were last written to, so if you sort on that, you preserve history order. I was initially going to go with this, but: it's moderately inconvenient in some programming languages, it can only handle a 1-to-1 mapping (one last-modified timestamp) even though many uses of history might prefer an n-to-1 (an entry for every time the command was called), and it requires worrying about questions like "does {sync,copy,restore-from-backup,this-programmatic-manipulation-I-quickly-scripted} preserve the timestamp correctly?"
So tonight I did what any self-respecting drank-too-much-UNIX-philosophy-coolaid developer would do: more files. In particular:
Each call of a history entry gets its own file.
The file name of a call is a timestamp.
The contents of a call file is the hash of the history entry file.
The hash is mainly serving the purpose of being a deterministic, realistically-will-never-collide-with-another-history-entry (literally other causes of collision like hackers getting into your box and overwriting your memory are certain and inevitable by comparison) identifier - in a proper database, this would just be the primary key of a table, or some internal pointer.
The timestamp files allow a simple lexical sort, which is a default provided by most languages, most libraries, and built in by default in almost everything that lists/iterates a directory. That's what I do in my latest Elisp code in my Emacs: directory-files does a lexical sort by default - it's not pretty from an algorithmic efficiency standpoint, but it makes the simplest implementation super simple. Of course, you could get reasonably more efficient if you really wanted to.
I went with the hash as contents, rather than using hardlinks or symlinks, because of programmatic introspection simplicity and portability. I'm not entirely sure if the programmatic introspection benefits are actually worth anything in practice. The biggest portability case against symlinks/hardlinks/etc is Windows (technically can do symlinks, but it's a privileged operation unless you go fiddle with OS settings), Android (can't do hardlinks at all, and symlinks can't exist in shared storage), and if you ever want to have your histdir on something like a USB stick or whatever.
Depending on the size of the hash, given that the typical lengths of history entries might be rather short, it might be better for deduplication and storage to just drop the hash files entirely, and leave only the timestamp files. But it's not necessarily so clear-cut.
Sure, the average shell command is probably shorter by a wide margin than a good hash. The stuff I type into something like a Node or Python REPL will trend a little longer than the shell commands. But now what about, say, URLs? That's also history, it's not even that different conceptually from shell/REPL history, and I haven't yet ruled out it making sense for me to reuse histdir for that.
And moreover, conceptually they achieve different goals. The entry files are things that have been in your history (and that you've decided to keep). They're more of a toolbox or repertoire - when you do a fuzzy search on history to re-run a command, duplicates just get in the way. Meanwhile, call files are a "here's what I did", more of a log than a toolbox.
And obviously this whole histdir thing is very expandable - you could have other files containing metadata. Some metadata might be the kind of thing we'd want to associate with a command run (exit status, error output, relevant state like working directory or environment variables, and so on), but other stuff might make more sense for commands themselves (for example: this command is only useful/valid on [list of hosts], so don't use it in auto-complete and fuzzy search anywhere else).
So... I think it makes sense to have history entries and calls to those entries "normalized" into their own separate files like that. But it might be overkill in practice, and the value might not materialize in practice, so that's more in the TBD I guess.
So that's where I'm at now. A very expandable template, but for now I've just replicated basic shell/REPL history, in an a very high-overhead way. A big win is great history sync almost for free, without a lot of the technical downsides or complexity (and with a little effort to set up inotify/etc watches on a histdir, I can have newly sync'ed entries go directly into my running shells/REPLs... I mean, within Emacs at least, where that kind of across-the-board malleability is accessible with a reasonably low amount of effort). Another big win is that in principle, it should be really easy to build on existing stuff in almost any language to do anything I might want to do. And the biggest win is that I can now compose those other wins with every REPL I use, so long as I can either wrap that REPL a little bit (that's how I'll start, with Emacs' comint mode), or patch the common libraries like readline to do histdir, or just write some code to translate between a traditional history file and my histdir approach.
At every step of the way, I've optimized first and foremost for easiest-to-implement and most-accessible-to-work-with decision. So far I don't regret it, and I think it'll help a lot with iteratively trying different things, and with all sorts of integration and composition that I haven't even thought of yet. But I'll undoubtedly start seeing problems as my histdirs grow - it's just a question of how soon and how bad, and if it'll be tractable to fix without totally abandoning the approach. But it's also possible that we're just at the point where personal computers and phones are powerful enough, and OS and FS optimizations are advanced enough, that the overhead will never be perceptible to me for as long as I live - after all, its history for an interface with a live human.
So... happy so far. It seems promising. Tentatively speaking, I have a better daily-driver shell history UX than I've ever had, because I now have great reliable and fast history sync across my devices, without regressions to my shell history UX (and that's saying something, since I was already very happy with zsh's vi mode, and then I was even more happy with Eshell+Eat+Consult+Evil), but I've only just implemented it and given it basic testing. And I remain very optimistic that I could trivially layer this onto basically any other REPL with minimal effort thanks to Emacs' comint mode.
3 notes
·
View notes
Text
Yeah, I did
I fried this Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: fried_rice_joke() takes exactly three arguments (2 given)
You're telling me a french fried this
Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: fried_rice_joke() takes exactly three arguments (2 given)
16K notes
·
View notes
Text
CS211 Spring 2020 Programming Assignment III Defusing a Binary Bomb
Introduction The nefarious Dr. Evil has planted a slew of “binary bombs” on our class machines. A binary bomb is a program that consists of a sequence of phases. Each phase expects you to type a particular string on stdin. If you type the correct string, then the phase is defused and the bomb proceeds to the next phase. Otherwise, the bomb explodes by printing “BOOM!!!” and then terminating. The…
0 notes
Text
CSCI 247 Project 2 Defusing binary bomb Solved
The nefarious Dr. Evil has planted a slew of “binary bombs” on our class machines. A binary bomb is a program that consists of a sequence of phases. Each phase expects you to type a particular string on stdin. If you type the correct string, then the phase is defused and the bomb proceeds to the next phase. Otherwise, the bomb explodes by printing “BOOM!!!” and then terminating. The bomb is…
0 notes
Text
CS 332/532 – 1G- Systems Programming
Lab 10 Solved Objectives Review Linux I/O Streams Discuss sharing between parent and child processes Review copying file descriptors – dup2() system call Linux I/O Streams Before we discuss I/O redirection, let us review how I/O is handled in Linux systems. Each process in a Linux environment has three different file descriptors available when a process is created: standard input (stdin – 0),…
0 notes