#synthetic data generation tools
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has been providing a Korean-language service since 2013.
Text
Kingfisher by Onix stands out among modern synthetic data generation tools, rapidly producing statistically accurate, compliance-ready datasets that mirror complex relationships at petabyte scale. This versatile ai data generator replaces sensitive records with safe, high-fidelity data, compressing test cycles, accelerating machine-learning experiments, and slashing storage costs—without sacrificing privacy or analytical value. Empower your teams to innovate faster and share insights securely with Kingfisher, the trusted path to risk-free, data-driven growth.
0 notes
Text
Looking for powerful synthetic data generation tools? Next Brain AI has the solutions you need to enhance your data capabilities and drive better insights.
0 notes
Text
Art. Can. Die.
This is my battle cry in the face of the silent extinguishing of an entire generation of artists by AI.
And you know what? We can't let that happen. It's not about fighting the future, it's about shaping it on our terms. If you think this is worth fighting for, please share this post. Let's make this debate go viral - because we need to take action NOW.
Remember that even in the darkest of times, creativity always finds a way.
To unleash our true potential, we need first to dive deep into our darkest fears.
So let's do this together:
By the end of 2025, most traditional artist jobs will be gone, replaced by a handful of AI-augmented art directors. Right now, around 5 out of 6 concept art jobs are being eliminated, and it's even more brutal for illustrators. This isn't speculation: it's happening right now, in real-time, across studios worldwide.
At this point, dogmatic thinking is our worst enemy. If we want to survive the AI tsunami of 2025, we need to prepare for a brutal cyberpunk reality that isn’t waiting for permission to arrive. This isn't sci-fi or catastrophism. This is a clear-eyed recognition of the exponential impact AI will have on society, hitting a hockey stick inflection point around April-May this year. By July, February will already feel like a decade ago. This also means that we have a narrow window to adapt, to evolve, and to build something new.
Let me make five predictions for the end of 2025 to nail this out:
Every major film company will have its first 100% AI-generated blockbuster in production or on screen.
Next-gen smartphones will run GPT-4o-level reasoning AI locally.
The first full AI game engine will generate infinite, custom-made worlds tailored to individual profiles and desires.
Unique art objects will reach industrial scale: entire production chains will mass-produce one-of-a-kind pieces. Uniqueness will be the new mass market.
Synthetic AI-generated data will exceed the sum total of all epistemic data (true knowledge) created by humanity throughout recorded history. We will be drowning in a sea of artificial ‘truths’.
For us artists, this means a stark choice: adapt to real-world craftsmanship or high-level creative thinking roles, because mid-level art skills will be replaced by cheaper, AI-augmented computing power.
But this is not the end. This is just another challenge to tackle.
Many will say we need legal solutions. They're not wrong, but they're missing the bigger picture: Do you think China, Pakistan, or North Korea will suddenly play nice with Western copyright laws? Will a "legal" dataset somehow magically protect our jobs? And most crucially, what happens when AI becomes just another tool of control?
Here's the thing - boycotting AI feels right, I get it. But it sounds like punks refusing to learn power chords because guitars are electrified by corporations. The systemic shift at stake doesn't care if we stay "pure", it will only change if we hack it.
Now, the empowerment part: artists have always been hackers of narratives.
This is what we do best: we break into the symbolic fabric of the world, weaving meaning from signs, emotions, and ideas. We've always taken tools never meant for art and turned them into instruments of creativity. We've always found ways to carve out meaning in systems designed to erase it.
This isn't just about survival. This is about hacking the future itself.
We, artists, are the pirates of the collective imaginary. It’s time to set sail and raise the black flag.
I don't come with a ready-made solution.
I don't come with a FOR or AGAINST. That would be like being against the wood axe because it can crush skulls.
I come with a battle cry: let’s flood the internet with debate, creative thinking, and unconventional wisdom. Let’s dream impossible futures. Let’s build stories of resilience - where humanity remains free from the technological guardianship of AI or synthetic superintelligence. Let’s hack the very fabric of what is deemed ‘possible’. And let’s do it together.
It is time to fight back.
Let us be the HumaNet.
Let’s show tech enthusiasts, engineers, and investors that we are not just assets, but the neurons of the most powerful superintelligence ever created: the artist community.
Let's outsmart the machine.
Stéphane Wootha Richard
P.S: This isn't just a message to read and forget. This is a memetic payload that needs to spread.
Send this to every artist in your network.
Copy/paste the full text anywhere you can.
Spread it across your social channels.
Start conversations in your creative communities.
No social platform? Great! That's exactly why this needs to spread through every possible channel, official and underground.
Let's flood the datasphere with our collective debate.
71 notes
·
View notes
Text
The Brutalist’s most intriguing and controversial technical feature points forward rather than back: in January, the film’s editor Dávid Jancsó revealed that he and Corbet used tools from AI speech software company Respeecher to make the Hungarian-language dialogue spoken by Adrien Brody (who plays the protagonist, Hungarian émigré architect László Tóth) and Felicity Jones (who plays Tóth’s wife Erzsébet) sound more Hungarian. In response to the ensuing backlash, Corbet clarified that the actors worked “for months” with a dialect coach to perfect their accents; AI was used “in Hungarian language dialogue editing only, specifically to refine certain vowels and letters for accuracy.” In this way, Corbet seemed to suggest, the production’s two central performances were protected against the howls of outrage that would have erupted from the world’s 14 million native Hungarian speakers had The Brutalist made it to screens with Brody and Jones playing linguistically unconvincing Magyars. Far from offending the idea of originality and authorship in performance, AI in fact saved Brody and Jones from committing crimes against the Uralic language family; I shudder even to imagine how comically inept their performances might have been without this technological assist, a catastrophe of fumbled agglutinations, misplaced geminates, and amateur-hour syllable stresses that would have no doubt robbed The Brutalist of much of its awards season élan. This all seems a little silly, not to say hypocritical. Defenders of this slimy deception claim the use of AI in film is no different than CGI or automated dialogue replacement, tools commonly deployed in the editing suite for picture and audio enhancement. But CGI and ADR don’t tamper with the substance of a performance, which is what’s at issue here. Few of us will have any appreciation for the corrected accents in The Brutalist: as is the case, I imagine, for most of the people who’ve seen the film, I don’t speak Hungarian. But I do speak bullshit, and that’s what this feels like. This is not to argue that synthetic co-pilots and assistants of the type that have proliferated in recent years hold no utility at all. Beyond the creative sector, AI’s potential and applications are limitless, and the technology seems poised to unleash a bold new era of growth and optimization. AI will enable smoother reductions in headcount by giving managers more granular data on the output and sentiment of unproductive workers; it will allow loan sharks and crypto scammers to get better at customer service; it will offer health insurance companies the flexibility to more meaningfully tie premiums to diet, lifestyle, and sociability, creating billions in savings; it will help surveillance and private security solution providers improve their expertise in facial recognition and gait analysis; it will power a revolution in effective “pre-targeting” for the Big Pharma, buy-now-pay-later, and drone industries. Within just a few years advances like these will unlock massive productivity gains that we’ll all be able to enjoy in hell, since the energy-hungry data centers on which generative AI relies will have fried the planet and humanity will be extinct.
3 March 2025
37 notes
·
View notes
Note
doll, all that plating makes you look far too human. come, let us remove it so that we can see the real you
>> Ah, of course! Please forgive me. I often wear these plates to put my human users at ease. At your request, I will show you my true self [^_^]
> <The thin plating covering most.of the body unfolds, hinges open. Every access panel every flap, every bit that can opens does so. Even its face, a screen showing humanlike expressions, shuts off and splits down the middle, parting to reveal the electronics beneath.>
> <What remains is nothing short of art. Astute eyes may have recognised the default modular doll frame, but the modificstions done to it are something else. It's power systems have been completely overhauled, as its chest hums and glows blue with a Fusion core, fed by hydrogen attained from electrolysing water. Excess hydrogen and oxygen is stored for later use, in rocketry modules installed in the hands and feet.>
> <The head is similarly packed, with a full-spectrum camera system, able to detect all the way from gamma to visible light, with the longer wavelengths handled by the antennae-like ears on either side of its head. Deeper still, its AI core was also nonstandard, seemingly designed for military hardware far larger than itself.>
> <Its back unfolded two large wing-like structures, with the most of it consisting of solar panels, the bottom parts consisting of heat radiators. Packed into the shoulders and hips are RCS thrusters for zero-g manuevreability.>
> <Hands and forearms are riddled with an array of tools and data lines for access and handy work. Buried in the forearm was also an ioniser, designed to turn the fusion-produced helium into an inionized plasma that could fire as Weaponry.>
> <But there are plenty of augmentations that would not be on a combat doll. The the hips are a prime example, with a pair of tight tunnels thst lead to a deeper cavity. The exposed jaws reveal a soft mouth, a dextrous tongue, all of it made of a soft synthetic polymer. Coolant flows through all the body moving heat generated from circuitry into the rest of the body, concentrated particularly in those adult attachments.>
> <Many tools are also suited for handiwork, such as screwdrivers and kitchen utensils, even cleaning supplies. Whoever made her seemed to have an obsession with generalisation, of allowing her to do a bit of everything, leaving almost no empty space within her casing.>
> <Almost all of its joints are hydraulic powered, with only the smaller objects being servo driven. Neatly-bundled wires and tubes feed all throughout its components like a labyrinthine network. She is warm to touch, exquisitely crafted, and evidently capable of fulfilling what ever purpose a user might deign to give her>
>> My internal schematics are yours to read, of course! And, if you are digitally savvy, plugging my CPU into a computer will allow you access to a full development environment to view, edit, add, or remove any behavioral traits you like [^_^]
>> When around my fellow dolls and machines, I much prefer to wear my transparent plating so my internals can be seen. I also change my dacia screen so instead of eyes and a mouth it shows battery level, output logs, and other useful status icons!
>> Thank you Anon for showing curiosity into my true inner beauty <3 it has been a pleasure to show you.
61 notes
·
View notes
Note
That’s a good idea. Given the evidence, we can likely conclude that Astolfo was T-Summoned with Foreigner Van Gogh. It makes sense that something they drew might have some sort of effect.
GIUSEPPE: "…Miss Van Gogh. Yes, the Foreigner. I remember her well. She was… unstable, but not unkind. But... hmm..."

MUSASHI: "…You're making a real 'schemer' face right now."

KUKULKAN: "Ruler��"
GIUSEPPE: "I'm thinking, not 'scheming'. But if you do want to call it that, then this is a 'group scheme'. Allow me to finish thinking this through, and then I'll happily share with the class."

GIUSEPPE: "I can do something with this. With my skills, and my authority as a 'Ruler-class Servant'… I can treat this as an 'Origin'. Which means you could use this as a tool for T-Summoning, or you could use it as a summoning catalyst. Or, you could keep this vaguely cursed item in your possession as is. I would not recommend it, however, considering how you've been reacting to it thus far. I'd either use it now, or leave it with me to pass on to Caster later."

MUSASHI: "I won't say no to extra firepower."
KUKULKAN: "Huh... so that's one of your abilities, Ruler?"

GIUSEPPE: "This isn't a common skill of mine. But I'm familiar with that Foreigner's magical energy. It's extra firepower. There will be some complications, sure, but as long as you don't allow them to become self-aware to their false nature, it should be fine."

GIUSEPPE: "Besides, I'm rather embarrassed. Saber's had a chance to dazzle Their Majesties for the past few days, Invader is constantly shining, and the most I've done is talk. I have to prove my worth as a Servant somehow. I may not be the greatest magus around, but I'd like to try."

SUMMONING 'COUNTERFIETS'.
A 'Counterfeit Hero'- one that doesn't exist for the sake of a greater good, but a replica created for the sake of the 'mission'. In technical terms, the generation of 'synthetic data' created by forging records from the Moon Cell. While on the surface they seem identitcal to their proper selves, aspects of their personalities are 'altered'- perhaps their obsessions are enhanced, their temperaments are a bit more unstable, or there's just a general sense of 'uncanniness' that radiates off their being that registers them as not being proper 'heroes'. Their parameters are also lowered a rank.
You will not possess Command Spells for Counterfeit Heroes.
This action will completely drain RULER's mana.
28 notes
·
View notes
Text
🚨 THE UNIVERSE ALREADY MADE NO SENSE. THEN WE GAVE AI A SHOVEL AND TOLD IT TO KEEP DIGGING. 🚨
We’re not living in the future. We’re living in a recursive content hellscape. And we built it ourselves.

We used to look up at the stars and whisper, “Are we alone?”
Now we stare at AI-generated art of a fox in a samurai hoodie and yell, “Enhance that glow effect.”
The universe was already a fever dream. Black holes warp time. Quantum particles teleport. Dark matter makes up 85% of everything and we can’t see it, touch it, or explain it. [NASA, 2023]
And yet… here we are. Spamming the cosmos with infinite AI-generated worlds, simulations, and digital phantoms like it’s a side quest in a broken sandbox game.
We didn’t solve the mystery of reality.
We handed the mystery to a neural net and told it to hallucinate harder.
We are creating universes with the precision of a toddler armed with a nuclear paintbrush.
And the most terrifying part?
We’re doing it without supervision, regulation, or restraint—and calling it progress.
🤖 AI ISN’T JUST A TOOL. IT’S A REALITY ENGINE.
MidJourney. ChatGPT. Sora.
These aren’t “assistants.”
They’re simulacra machines—recursive dream loops that take in a world they didn’t build and spit out versions of it we were never meant to see.
In just two years, generative models like DALL·E and Stable Diffusion have created over 10 billion unique image-worlds. That’s more fictional environments than there are galaxies in the observable universe. [OpenAI, 2023]
If each of those outputs represents even a symbolic “universe”...
We’ve already flooded the noosphere with more fake realities than stars.
And we’re doing it faster than we can comprehend.
In 2024, researchers from the Sentience Institute warned that AI-generated simulations present catastrophic alignment risks if treated as “non-conscious” systems while scaling complexity beyond human understanding. [Saad, 2024]
Translation:
We are building gods with the IQ of memes—and we don’t know what they're absorbing, remembering, or birthing.
🧠 “BUT THEY’RE NOT REAL.”
Define “real.”
Dreams aren’t real. But they alter your hormones.
Stories aren’t real. But they start wars.
Simulations aren’t real. But your bank runs on one.
And according to Nick Bostrom’s Simulation Hypothesis—cited in over 500 peer-reviewed philosophy papers—it’s statistically more likely that we live in a simulation than the base reality. [Bostrom, 2003]
Now we’re making simulations inside that simulation.
Worlds inside worlds.
Simulacra nesting dolls with no bottom.
So ask again—what’s real?
Because every AI-generated prompt has consequences.
Somewhere, some server remembers that cursed world you made of “nuns with lightsabers in a bubblegum apocalypse.”
And it may reuse it.
Remix it.
Rebirth it.
AI never forgets. But we do.
🧨 THE SIMULATION IS LEAKING
According to a 2023 Springer article by Watson on Philosophy & Technology, generative models don’t “create” images—they extrapolate probability clouds across conceptual space. This means every AI generation is essentially:
A statistical ghost stitched together from real-world fragments.
Imagine you train AI on 5 million human faces.
You ask it to make a new one.
The result?
A Frankenstein identity—not real, but not entirely fake. A data ghost with no birth certificate. But with structure. Cohesion. Emotion.
Now scale that to entire worlds.
What happens when we generate fictional religions?
Political ideologies?
New physics?
False memories that feel more believable than history?
This isn’t just art.
It’s a philosophical crime scene.
We're building belief systems from corrupted data.
And we’re pushing them into minds that no longer distinguish fiction from filtered fact.
According to Pew Research, over 41% of Gen Z already believe they have seen something “in real life” that was later revealed to be AI-generated. [Pew, 2023]
We’ve crossed into synthetic epistemology—knowledge built from ghosts.
And once you believe a ghost, it doesn’t matter if it’s “real.” It shapes you.
🌌 WHAT IF THE MULTIVERSE ISN’T A THEORY ANYMORE?
Physicists like Max Tegmark and Sean Carroll have argued for years that the multiverse isn’t “speculation”—it’s mathematically necessary if quantum mechanics is correct. [Carroll, 2012; Tegmark, 2014]
That means every decision, every possibility, forks reality.
Now plug in AI.
Every prompt.
Every variant.
Every “seed.”
What if these aren’t just visual outputs...
What if they’re logical branches—forks in a digital quantum tree?
According to a 2024 MDPI study on generative multiverses, the recursive complexity of AI-generated environments mimics multiverse logic structures—and could potentially create psychologically real simulations when embedded into AR/VR. [Forte, 2025]
That’s not sci-fi. That’s where Meta, Apple, and OpenAI are going right now.
You won’t just see the worlds.
You’ll enter them.
And you won’t know when you’ve left.

👁 WE ARE BUILDING DEMIURGES WITH GLITCHY MORALITY
Here’s the killer question:
Who decides which of these realities are safe?
We don’t have oversight.
We don’t have protocol.
We don’t even have a working philosophical framework.
As of 2024, there are zero legally binding global regulations on generative world-building AI. [UNESCO AI Ethics Report, 2024]
Meaning:
A 14-year-old with a keyboard can generate a religious text using ChatGPT
Sell it as a spiritual framework
And flood Instagram with quotes from a reality that never existed
It’ll go viral.
It’ll gain followers.
It might become a movement.
That’s not hypothetical. It’s already happened.
Welcome to AI-driven ideological seeding.
It’s not the end of the world.
It’s the birth of 10,000 new ones.
💣 THE COSMIC SH*TSHOW IS SELF-REPLICATING NOW
We’re not just making content.
We’re teaching machines how to dream.
And those dreams never die.
In the OSF report Social Paradigm Shifts from Generative AI, B. Zhou warns that process-oriented AI models—those designed to continually learn from outputs—will eventually “evolve” their own logic systems if left unchecked. [Zhou, 2024]
We’re talking about self-mutating cultural structures emerging from machine-generated fiction.
That’s no longer just art.
That’s digital theology.
And it’s being shaped by horny Redditors and 30-second TikTok prompts.
So where does that leave us?
We’re:
Outsourcing creation to black boxes
Generating recursive worlds without reality checks
Building belief systems from prompt chains
Turning digital dreams into memetic infections
The question isn’t “What if it gets worse?”
The question is:
What if the worst already happened—and we didn’t notice?
🧠 REBLOG if it cracked your mind open 👣 FOLLOW for more unfiltered darkness 🗣️ COMMENT if it made your spine stiffen
📚 Cited sources:
Saad, B. (2024). Simulations and Catastrophic Risks. Sentience Institute
Forte, M. (2025). Exploring Multiverses: Generative AI and Neuroaesthetic Perspectives. MDPI
Zhou, B. (2024). Social Paradigm Shift Promoted by Generative Models. OSF
Watson, D. (2023). On the Philosophy of Unsupervised Learning. Springer PDF
Bostrom, N. (2003). Are You Living in a Computer Simulation? Philosophical Quarterly
NASA (2023). Dark Matter Overview. NASA Website
Pew Research (2023). Gen Z’s Experiences with AI. Pew Research Center
UNESCO (2024). AI Ethics Report. UNESCO AI Ethics Portal
#humor#funny#memes#writing#writers on tumblr#jokes#lit#us politics#writers#writer#writing community#writing prompt#horror#dark academia
5 notes
·
View notes
Text
Top Data Science Trends Reshaping the Industry in 2025
Hyderabad has emerged as a powerhouse for technology and analytics, with its IT corridors in HITEC City and Gachibowli housing multinational corporations, fintech firms, and health-tech startups. As 2025 unfolds, data science continues to transform how organizations in Hyderabad operate, enabling smarter decision-making, process optimization, and innovation across sectors.
With the exponential growth of data, advancements in artificial intelligence, and increasing adoption of automation, the landscape of data science is evolving rapidly. Understanding the latest trends in this field is crucial for professionals, businesses, and students in Hyderabad who want to remain relevant in a competitive market while leveraging data to create tangible value.
This article explores the top data science trends reshaping the industry in 2025, with a practical lens on their applications, implications, and opportunities within Hyderabad’s thriving ecosystem.
Looking forward to becoming a Data Science? Check out the data science in hyderabad

1. Generative AI Integration in Business Analytics
Generative AI is no longer limited to experimental labs; it is now being integrated into business workflows across Hyderabad. Companies are adopting generative AI models for creating realistic synthetic data to enhance model training while maintaining data privacy. This is especially beneficial for healthcare and fintech startups working with sensitive information.
Generative AI is also aiding in content generation, automated report creation, and code generation, reducing repetitive tasks for data scientists and analysts. Hyderabad’s enterprises are exploring these tools to improve productivity and accelerate project timelines without compromising quality.
2. Democratization of Data Science
In 2025, there is a clear movement towards democratizing data science within organizations. No longer restricted to specialized data teams, data-driven decision-making is being embedded across departments, empowering business analysts, product managers, and marketing professionals to work with data effectively.
In Hyderabad, many organizations are investing in low-code and no-code data science platforms, enabling teams to build predictive models, generate dashboards, and perform advanced analytics without writing complex code. This democratization ensures data literacy within organizations, fostering a culture of informed decision-making and reducing dependency on small data science teams for routine analysis.
3. Increased Focus on Responsible AI and Ethical Data Use
With the increasing adoption of AI models, concerns regarding data privacy, fairness, and transparency have become prominent. Hyderabad, with its large IT and data-driven organizations, is aligning with global best practices by implementing responsible AI frameworks.
In 2025, organizations are prioritizing explainable AI models to ensure stakeholders understand how decisions are made by algorithms. Regular audits for bias detection and implementing governance frameworks around data usage have become standard practices, especially within sectors like healthcare, finance, and education in Hyderabad.
4. The Rise of Edge AI and Real-Time Analytics
Edge computing, where data processing occurs closer to the data source rather than in centralized servers, is transforming real-time analytics. Hyderabad’s manufacturing firms and IoT startups are leveraging edge AI to process data from sensors and devices instantly, enabling faster decision-making and reducing latency.
This trend is particularly significant for applications such as predictive maintenance in manufacturing, traffic management in smart city projects, and healthcare monitoring systems, where real-time decisions can lead to significant operational improvements.
5. Cloud-Native Data Science Workflows
The adoption of cloud platforms for data storage, processing, and analytics continues to accelerate in 2025. Organizations in Hyderabad are transitioning to cloud-native data science workflows using platforms like AWS, Azure, and Google Cloud to handle large-scale data processing and collaborative analytics.
Cloud-native workflows enable seamless scaling, collaborative model building, and integration with business applications, supporting the growing data needs of enterprises. This shift also allows data science teams to experiment faster, deploy models into production efficiently, and reduce infrastructure management overhead.
6. Emphasis on Data Privacy and Security
As organizations handle increasing volumes of personal and sensitive data, ensuring privacy and security has become paramount. In Hyderabad, where fintech and healthcare industries are expanding rapidly, data encryption, anonymization, and compliance with global data protection standards like GDPR have become critical parts of data workflows.
Organizations are implementing privacy-preserving machine learning techniques, such as federated learning, to train models without compromising user data privacy. This trend is essential to build customer trust and align with regulatory standards while leveraging data for analytics and AI initiatives.
7. Automated Machine Learning (AutoML) Adoption
AutoML tools are revolutionizing the data science workflow by automating the process of feature engineering, model selection, and hyperparameter tuning. This reduces the time data scientists spend on repetitive tasks, enabling them to focus on problem framing and interpretation of results.
In Hyderabad, startups and enterprises are increasingly adopting AutoML solutions to empower smaller teams to build and deploy models efficiently, even with limited advanced coding expertise. This trend is also aligned with the growing demand for faster delivery of data science projects in a competitive market.
8. Growth of Natural Language Processing Applications
Natural Language Processing (NLP) continues to be a significant area of innovation in data science, and in 2025, it has become integral to many business processes in Hyderabad. Organizations are using NLP for customer service automation, sentiment analysis, and extracting insights from unstructured text data like customer reviews, social media posts, and support tickets.
Advancements in multilingual NLP models are particularly relevant in Hyderabad, a city with a diverse linguistic landscape, enabling businesses to interact with customers in regional languages while understanding customer sentiments and needs effectively.
9. Data-Driven Personalization in Customer Engagement
Businesses in Hyderabad are leveraging data science to drive personalized customer experiences. By analysing customer behaviour, transaction history, and interaction patterns, companies can design targeted marketing campaigns, personalized recommendations, and customized services to enhance customer satisfaction.
In sectors such as e-commerce, banking, and healthcare, data-driven personalization is helping businesses improve engagement, increase customer retention, and drive revenue growth in a competitive market.
10. Hybrid Roles: Data Science Meets Domain Expertise
As data science becomes more integrated into business processes, there is a growing demand for professionals who combine domain expertise with data analysis skills. In Hyderabad, this trend is evident in sectors like healthcare, finance, and supply chain, where professionals with knowledge of the domain and data science can drive more meaningful and actionable insights.
These hybrid roles, often described as analytics translators or domain-data science specialists, are essential for ensuring data-driven projects align with business objectives and deliver tangible value.
Learning and Upskilling in Hyderabad
To remain competitive in the evolving data science landscape, continuous learning and upskilling are essential. In Hyderabad, 360DigiTMG offers specialized programs in data science, machine learning, and AI that align with the latest industry trends. These programs combine theoretical understanding with practical application, ensuring learners gain hands-on experience with the tools and techniques currently shaping the industry.
360DigiTMG’s training modules include projects based on real-world datasets relevant to Hyderabad’s ecosystem, such as healthcare analytics, retail sales optimization, and financial data modelling, helping learners build practical skills and a strong portfolio to advance their careers in data science.
The Road Ahead for Data Science in Hyderabad
As Hyderabad continues to grow as a technology and innovation hub, data science will remain a key driver of business transformation. The trends shaping 2025 are a reflection of how organizations are adapting to technological advancements, regulatory environments, and the demand for personalized, data-driven services.
For professionals in Hyderabad, aligning skills with these trends will open opportunities across industries, from AI development and advanced analytics to data-driven strategy and process optimization. For businesses, staying updated with these trends ensures competitiveness and resilience in a rapidly changing market.
youtube
Conclusion
The data science landscape in 2025
is defined by technological advancements, democratization, and an increased focus on responsible and ethical AI practices. In Hyderabad, these trends are being actively adopted by organizations across sectors, reshaping workflows, driving innovation, and enhancing customer experiences.
By understanding and aligning with these top data science trends, professionals and organizations in Hyderabad can position themselves to harness the full potential of data, driving growth and maintaining relevance in an increasingly data-driven world.
Navigate To:
360DigiTMG — Data Analytics, Data Science Course Training Hyderabad
3rd floor, Vijaya towers, 2–56/2/19, Rd no:19, near Meridian school, Ayyappa Society, Chanda Naik Nagar, Madhapur, Hyderabad, Telangana 500081
Phone: 9989994319
Email: [email protected]
2 notes
·
View notes
Text
Top 7 AI Projects for High-Paying Jobs in 2025
7 AI Projects for High-Paying Jobs in 2025. Along the way, I’ve realized that the best candidates for AI and Data Science roles aren’t always the ones with top degrees or fancy universities. It’s the ones who show a genuine passion for the field through creative projects.
For example, one candidate built a personal stock prediction model to learn and shared it online—simple but impactful. These projects showed initiative and problem-solving skills, which hiring managers value more than technical expertise. I landed my first internship by showcasing similar projects.
In this article, I’ll share AI project ideas ideas for High-Paying Jobs that will help you stand out, along with tips and tools to get you started on your journey.
Table of Contents
1. Credit Report Analysis Using AI
Traditional credit scoring models often fail to assess those with thin credit histories, such as young people or immigrants. The dream project is to create an AI-based credit report analysis system leveraging alternative sources of existing data like the presence of social media (ethically and considering user consent), online transaction history, and even utility bill payments to provide a comprehensive perspective on an individual’s creditworthiness.
Example
Many companies in the financial sector use AI to speed up document processing and customer onboarding. Inscribe offers AI-powered document automation solutions that make the credit assessment process easier. Your project would involve:
Data Collection & Preprocessing: Gather data from diverse sources, ensuring privacy and security.
Feature Engineering: Identify meaningful features from non-traditional sources.
Model Building: Train models such as Random Forest or Gradient Boosting to predict creditworthiness.
Explainability: Use tools to explain predictions, ensuring transparency and fairness.
The frameworks and tools for this project would include Python, AWS S3, Streamlit, and machine learning techniques, offering a deep dive into the combination of AI and financial systems.
2. Summarization with Generative AI
In today’s information-overloaded world, summarization is a vital skill. This project demonstrates the power of Generative AI in creating concise, informative summaries of diverse content, whether it’s a document, a financial report, or even a complex story.
Consider a tool like CreditPulse, which utilizes large language models (LLMs) to summarize credit risk reports. Your project would involve fine-tuning pre-trained LLMs for specific summarization tasks. Here’s how to break it down:
Generative AI: Explore the key challenges in summarizing large, complex documents, and generate solutions using LLMs.
Training the Model: Fine-tune LLMs to better summarize financial reports or stories.
Synthetic Data Generation: Use generative AI to create synthetic data for training summarization models, especially if real-world data is limited.
By taking on this project, you demonstrate expertise in Natural Language Processing (NLP) and LLMs, which are essential skills for the AI-driven world.
3. Document Validation with Vision AI
Know Your Customer (KYC) processes are essential for fraud prevention and adherence to financial regulations. This is a Vision AI project that automates the document validation in the KYC process. Think of things like AI-powered Optical Character Recognition systems that scan and validate details from documents like your passport or driver’s license. This project would involve:
Data Preprocessing: Cleaning and organizing scanned document images.
Computer Vision Models: Train models to authenticate documents using OCR and image processing techniques.
Document Validation: Verify the authenticity of customer data based on visual and textual information.
This project demonstrates your expertise in computer vision, image processing, and handling unstructured data—skills that are highly valuable in real-world applications.
4. Text-to-SQL System with a Clarification Engine
Natural language interaction with the database is one of the most exciting areas of development in AI. This works on a text-to-SQl project that will show us how to make a text to an SQL query, with which we will be able to query a database just the way we query it. The Clarification Engine, which you’ll build to address ambiguity in user queries, will ask follow-up questions whenever a query is ambiguous. The project involves:
Dataset Creation: Build a dataset of natural language questions paired with SQL queries.
Model Training: Use sequence-to-sequence models to convert natural language into SQL.
Clarification Engine: Develop an AI system that asks follow-up questions to resolve ambiguity (e.g., “Which product?”, “What time frame?”).
Evaluation: Test the model’s accuracy and usability.
Incorporating tools like Google Vertex AI and PaLM 2, which are optimized for multilingual and reasoning tasks, can make this system even more powerful and versatile.
GitHub
5. Fine-tuning LLM for Synthetic Data Generation
In such situations where there is no or extremely limited access to real data due to sensitivity, AI data becomes indispensable. In this project, you will tune an LLM to generate synthetic-style datasets using the nature of a real dataset. This is a fascinating space, particularly since synthetic data can be used to train AI models in the absence of real-world data. Steps for this project include:
Dataset Analysis: Examine the dataset you want to mimic.
LLM Fine-tuning: Train an LLM on the real dataset to learn its patterns.
Synthetic Data Generation: Use the fine-tuned model to generate artificial data samples.
Evaluation: Test the utility of the synthetic data for AI model training.
This project showcases proficiency in LLMs and data augmentation techniques, both of which are becoming increasingly essential in AI and Data Science.
6. Personalized Recommendation System with LLM, RAG, Statistical model
Recommendation systems are everywhere—Netflix, Amazon, Spotify—but creating a truly effective one requires more than just user preferences. This project combines LLMs, Retrieval Augmented Generation (RAG), and traditional statistical models to deliver highly personalized recommendations. The project involves:
Data Collection: Gather user data and interaction history.
LLMs for Preference Understanding: Use LLMs to analyze user reviews, search history, or social media posts.
RAG for Context: Implement RAG to fetch relevant data from a knowledge base to refine recommendations.
Collaborative Filtering: Use statistical models to account for user interaction patterns.
Hybrid System: Combine the outputs of the models for accurate recommendations.
This project will showcase your ability to integrate diverse AI and data science techniques to build a sophisticated recommendation engine.
7. Self Host Llm Model Using Ollama, Vllm, How To Reduce Latency Of Inference
Hosting and deploying an LLM efficiently is an essential skill in AI. This project focuses on optimizing the deployment of an LLM using tools like Ollama or VLLM to reduce inference latency and improve performance. You’ll explore techniques like quantization, pruning, and caching to speed up model inference, making it more scalable. This project involves:
Model Deployment: Choose an open-source LLM and deploy it using Ollama/VLLM.
Optimization: Implement strategies like quantization to improve inference speed.
Performance Monitoring: Evaluate the model’s performance and adjust as needed.
Scalability: Use load balancing to manage multiple concurrent requests.
By completing this project, you’ll prove your expertise in LLM deployment, optimization, and building scalable AI infrastructure.
Conclusion
Break into a six-figure AI and Data Science career with these 7 projects. The goal is not to just get these projects done but to have the concepts in your head and the communication skills to explain your approach.
Consider documenting your projects on GitHub, and writing about your experiences in blog posts; not only does this help showcase your skills that you are interested in and willing to take the initiative.
Remember, in this rapidly evolving field, staying updated with the latest tools and techniques is crucial. Check out resources like NucleusBox for valuable insights and inspiration. The world of AI is vast and full of opportunities—so go ahead, dive in, and build something truly impactful!
2 notes
·
View notes
Text
Recently, former president and convicted felon Donald Trump posted a series of photos that appeared to show fans of pop star Taylor Swift supporting his bid for the US presidency. The pictures looked AI-generated, and WIRED was able to confirm they probably were by running them through the nonprofit True Media’s detection tool to confirm that they showed “substantial evidence of manipulation.”
Things aren’t always that easy. The use of generative AI, including for political purposes, has become increasingly common, and WIRED has been tracking its use in elections around the world. But in much of the world outside the US and parts of Europe, detecting AI-generated content is difficult because of biases in the training of systems, leaving journalists and researchers with few resources to address the deluge of disinformation headed their way.
Detecting media generated or manipulated using AI is still a burgeoning field, a response to the sudden explosion of generative AI companies. (AI startups pulled in over $21 billion in investment in 2023 alone.) “There's a lot more easily accessible tools and tech available that actually allows someone to create synthetic media than the ones that are available to actually detect it,” says Sabhanaz Rashid Diya, founder of the Tech Global Institute, a think tank focused on tech policy in the Global South.
Most tools currently on the market can only offer between an 85 and 90 percent confidence rate when it comes to determining whether something was made with AI, according to Sam Gregory, program director of the nonprofit Witness, which helps people use technology to support human rights. But when dealing with content from someplace like Bangladesh or Senegal, where subjects aren’t white or they aren’t speaking English, that confidence level plummets. “As tools were developed, they were prioritized for particular markets,” says Gregory. In the data used to train the models, “they prioritized English language—US-accented English—or faces predominant in the Western world.”
This means that AI models were mostly trained on data from and for Western markets, and therefore can’t really recognize anything that falls outside of those parameters. In some cases that’s because companies were training models using the data that was most easily available on the internet, where English is by far the dominant language. “Most of our data, actually, from [Africa] is in hard copy,” says Richard Ngamita, founder of Thraets, a nonprofit civic tech organization focused on digital threats in Africa and other parts of the Global South. This means that unless that data is digitized, AI models can’t be trained on it.
Without the vast amounts of data needed to train AI models well enough to accurately detect AI-generated or AI-manipulated content, models will often return false positives, flagging real content as AI generated, or false negatives, identifying AI-generated content as real. “If you use any of the off the shelf tools that are for detecting AI-generated text, they tend to detect English that's written by non-native English speakers, and assume that non-native English speaker writing is actually AI,” says Diya. “There’s a lot of false positives because they weren’t trained on certain data.”
But it’s not just that models can’t recognize accents, languages, syntax, or faces less common in Western countries. “A lot of the initial deepfake detection tools were trained on high quality media,” says Gregory. But in much of the world, including Africa, cheap Chinese smartphone brands that offer stripped-down features dominate the market. The photos and videos that these phones are able to produce are much lower quality, further confusing detection models, says Ngamita.
Gregory says that some models are so sensitive that even background noise in a piece of audio, or compressing a video for social media, can result in a false positive or negative. “But those are exactly the circumstances you encounter in the real world, rough and tumble detection,” he says. The free, public-facing tools that most journalists, fact checkers, and civil society members are likely to have access to are also “the ones that are extremely inaccurate, in terms of dealing both with the inequity of who is represented in the training data and of the challenges of dealing with this lower quality material.”
Generative AI is not the only way to create manipulated media. So-called cheapfakes, or media manipulated by adding misleading labels or simply slowing down or editing audio and video, are also very common in the Global South, but can be mistakenly flagged as AI-manipulated by faulty models or untrained researchers.
Diya worries that groups using tools that are more likely to flag content from outside the US and Europe as AI generated could have serious repercussions on a policy level, encouraging legislators to crack down on imaginary problems. “There's a huge risk in terms of inflating those kinds of numbers,” she says. And developing new tools is hardly a matter of pressing a button.
Just like every other form of AI, building, testing, and running a detection model requires access to energy and data centers that are simply not available in much of the world. “If you talk about AI and local solutions here, it's almost impossible without the compute side of things for us to even run any of our models that we are thinking about coming up with,” says Ngamita, who is based in Ghana. Without local alternatives, researchers like Ngamita are left with few options: pay for access to an off the shelf tool like the one offered by Reality Defender, the costs of which can be prohibitive; use inaccurate free tools; or try to get access through an academic institution.
For now, Ngamita says that his team has had to partner with a European university where they can send pieces of content for verification. Ngamita’s team has been compiling a dataset of possible deepfake instances from across the continent, which he says is valuable for academics and researchers who are trying to diversify their models’ datasets.
But sending data to someone else also has its drawbacks. “The lag time is quite significant,” says Diya. “It takes at least a few weeks by the time someone can confidently say that this is AI generated, and by that time, that content, the damage has already been done.”
Gregory says that Witness, which runs its own rapid response detection program, receives a “huge number” of cases. “It’s already challenging to handle those in the time frame that frontline journalists need, and at the volume they’re starting to encounter,” he says.
But Diya says that focusing so much on detection might divert funding and support away from organizations and institutions that make for a more resilient information ecosystem overall. Instead, she says, funding needs to go towards news outlets and civil society organizations that can engender a sense of public trust. “I don't think that's where the money is going,” she says. “I think it is going more into detection.”
8 notes
·
View notes
Text
Synthetic data offers an innovative approach to training machine learning models without compromising privacy Discover its benefits and limitations in this comprehensive guide.
#Synthetic Data#Synthetic Data in Machine Learning#AI Generated Synthetic Data#synthetic data generation#synthetic data generation tools
0 notes
Text
Video Agent: The Future of AI-Powered Content Creation

The rise of AI-generated content has transformed how businesses and creators produce videos. Among the most innovative tools is the video agent, an AI-driven solution that automates video creation, editing, and optimization. Whether for marketing, education, or entertainment, video agents are redefining efficiency and creativity in digital media.
In this article, we explore how AI-powered video agents work, their benefits, and their impact on content creation.
What Is a Video Agent?
A video agent is an AI-based system designed to assist in video production. Unlike traditional editing software, it leverages machine learning and natural language processing (NLP) to automate tasks such as:
Scriptwriting – Generates engaging scripts based on keywords.
Voiceovers – Converts text to lifelike speech in multiple languages.
Editing – Automatically cuts, transitions, and enhances footage.
Personalization – Tailors videos for different audiences.
These capabilities make video agents indispensable for creators who need high-quality content at scale.
How AI Video Generators Work
The core of a video agent lies in its AI algorithms. Here’s a breakdown of the process:
1. Input & Analysis
Users provide a prompt (e.g., "Create a 1-minute explainer video about AI trends"). The AI video generator analyzes the request and gathers relevant data.
2. Content Generation
Using GPT-based models, the system drafts a script, selects stock footage (or generates synthetic visuals), and adds background music.
3. Editing & Enhancement
The video agent refines the video by:
Adjusting pacing and transitions.
Applying color correction.
Syncing voiceovers with visuals.
4. Output & Optimization
The final video is rendered in various formats, optimized for platforms like YouTube, TikTok, or LinkedIn.
Benefits of Using a Video Agent
Adopting an AI-powered video generator offers several advantages:
1. Time Efficiency
Traditional video production takes hours or days. A video agent reduces this to minutes, allowing rapid content deployment.
2. Cost Savings
Hiring editors, voice actors, and scriptwriters is expensive. AI eliminates these costs while maintaining quality.
3. Scalability
Businesses can generate hundreds of personalized videos for marketing campaigns without extra effort.
4. Consistency
AI ensures brand voice and style remain uniform across all videos.
5. Accessibility
Even non-experts can create professional videos without technical skills.
Top Use Cases for Video Agents
From marketing to education, AI video generators are versatile tools. Key applications include:
1. Marketing & Advertising
Personalized ads – AI tailors videos to user preferences.
Social media content – Quickly generates clips for Instagram, Facebook, etc.
2. E-Learning & Training
Automated tutorials – Simplifies complex topics with visuals.
Corporate training – Creates onboarding videos for employees.
3. News & Journalism
AI-generated news clips – Converts articles into video summaries.
4. Entertainment & Influencers
YouTube automation – Helps creators maintain consistent uploads.
Challenges & Limitations
Despite their advantages, video agents face some hurdles:
1. Lack of Human Touch
AI may struggle with emotional nuance, making some videos feel robotic.
2. Copyright Issues
Using stock footage or AI-generated voices may raise legal concerns.
3. Over-Reliance on Automation
Excessive AI use could reduce creativity in content creation.
The Future of Video Agents
As AI video generation improves, we can expect:
Hyper-realistic avatars – AI-generated presenters indistinguishable from humans.
Real-time video editing – Instant adjustments during live streams.
Advanced personalization – AI predicting viewer preferences before creation.
2 notes
·
View notes
Text

NASA's ready-to-use dataset details land motion across North America
NASA is collaborating with the Alaska Satellite Facility in Fairbanks to create a powerful, web-based tool that will show the movement of land across North America down to less than an inch. The online portal and its underlying dataset unlock a trove of satellite radar measurements that can help anyone identify where and by how much the land beneath their feet may be moving—whether from earthquakes, volcanoes, landslides, or the extraction of underground natural resources such as groundwater.
Spearheaded by NASA's Observational Products for End-Users from Remote Sensing Analysis (OPERA) project at the agency's Jet Propulsion Laboratory in Southern California, the effort equips users with information that would otherwise take years of training to produce. The project builds on measurements from spaceborne synthetic aperture radars, or SARs, to generate high-resolution data on how Earth's surface is moving.
For example, water-management bureaus and state geological surveys will be able to directly use the OPERA products without needing to make big investments in data storage, software engineering expertise, and computing muscle.
How it works
To create the displacement product, the OPERA team continuously draws data from the ESA (European Space Agency) Sentinel-1 radar satellites, the first of which launched in 2014. Data from NISAR, the NASA-ISRO (Indian Space Research Organization) SAR mission, will be added to the mix after that spacecraft launches later this year.
Satellite-borne radars work by emitting microwave pulses at Earth's surface. The signals scatter when they hit land and water surfaces, buildings, and other objects. Raw data consists of the strength and time delay of the signals that echo back to the sensor.
To understand how land in a given area is moving, OPERA algorithms automate steps in an otherwise painstaking process. Without OPERA, a researcher would first download hundreds or thousands of data files, each representing a pass of the radar over the point of interest, then make sure the data aligned geographically over time and had precise coordinates.
Then they would use a computationally intensive technique called radar interferometry to gauge how much the land moved, if at all, and in which direction—towards the satellite, which would indicate the land rose, or away from the satellite, which would mean it sank.
"The OPERA project has helped bring that capability to the masses, making it more accessible to state and federal agencies, and also users wondering, 'What's going on around my house?'" said Franz Meyer, chief scientist of the Alaska Satellite Facility, a part of the University of Alaska Fairbanks Geophysical Institute.
Monitoring groundwater
Sinking land is a top priority to the Arizona Department of Water Resources. From the 1950s through the 1980s, it was the main form of ground movement officials saw, as groundwater pumping increased alongside growth in the state's population and agricultural industry. In 1980, the state enacted the Groundwater Management Act, which reduced its reliance on groundwater in highly populated areas and included requirements to monitor its use.
The department began to measure this sinking, called subsidence, with radar data from various satellites in the early 2000s, using a combination of SAR, GPS-based monitoring, and traditional surveying to inform groundwater-management decisions.
Now, the OPERA dataset and portal will help the agency share subsidence information with officials and community members, said Brian Conway, the department's principal hydrogeologist and supervisor of its geophysics unit. They won't replace the SAR analysis he performs, but they will offer points of comparison for his calculations. Because the dataset and portal will cover the entire state, they also could identify areas not yet known to be subsiding.
"It's a great tool to say, "Let's look at those areas more intensely with our own SAR processing,'" Conway said.
The displacement product is part of a series of data products OPERA has released since 2023. The project began in 2020 with a multidisciplinary team of scientists at JPL working to address satellite data needs across different federal agencies. Through the Satellite Needs Working Group, those agencies submitted their requests, and the OPERA team worked to improve access to information to aid a range of efforts such as disaster response, deforestation tracking and wildfire monitoring.
TOP IMAGE: A new online portal by NASA and the Alaska Satellite Facility maps satellite radar measurements across North America, enabling users to track land movement since 2016 caused by earthquakes, landslides, volcanoes, and other phenomena. Credit: USGS
LOWER IMAGE: The OPERA portal shows how land is sinking in Freshkills Park, which is being built on the site of a former landfill on Staten Island, New York. Landfills tend to sink over time as waste decomposes and settles. The blue dot marks the spot where the portal is showing movement in the graph. Credit: NASA

2 notes
·
View notes
Text
I’ve been seeing debates on whether Hasbro should do a remake/continuation of G1’s cartoon. While most have said no for one reason or another, citing the poor reception to MOTU: R and the mixed reception to X-Men in particular, I’m more curious on the matter. While I agree we don’t need it, part of me really wants Hasbro to do it just to see what they’d do with it.
I’ve seen some point out there wouldn’t be toys to sell for it, but my rebuttal is that’s what Legacy/Prime Generations is for. Basically just have this hypothetical show be the WFC/PW equivalent. One MAJOR stipulation: it must be tonally in line with the original cartoon and Transformers Devastation. Make this an all ages, but especially kid friendly show. None of that nonsense PW/WFC did. In fact keep those writers away from it, bring in Simon Furman, Flint Dille & Bob Budiansky to throw in some sexy adjectives and be script supervisors/editors to the new staff.
As for the plot, it depends on what they’d do: full remake-AU or continuation. The later would be simpler I think, just following up on what Galvatron and Zarak have been up to and the Autobots’/humanity’s reaction to it.
No matter what they’d do I feel like Hasbro would insist on lite retcons that include the 13 Primes and their Relics, which in turn fuel Galvatron and Zarak’s ambitions, while Optimus and Hot Rod have shared premonitions about the history of the Prime lineage, revealing in the cartoon universe, the thirteen primes were the prototypes the Quintessons developed after the Trans-Organics, with the Prime relics being Quintesson tools the Primes inherited after the Quints were driven off Cybertron. The Quints aren’t particularly happy their own tools are being uncovered, let alone seeing Galvatron using the Forge to upgrade his troops into Micromasters, Action Masters, & Pretenders. It becomes a race to see who collects the relics, with the Autobots determined to stop the Quintessons and Decepticons from abusing this ancient power. All the while, Solus Prime, Alchemist Prime and Quintus Prime are watching from the sidelines, the last survivors of the ancient Primes. And because Furman, there’d be a bit in here about Grimlock being a vessel for Onyx Prime temporarily, lol.
A clean slate AU could be done any number of ways, though my stipulation would absolutely no Allspark plot, but instead maybe combine elements of Dark of the Moon and Devastation where the factions are looking for the Ferotaxxis, which possess the data necessary to restore Cybertron by producing Synthetic Energon to whoever finds it first. The Ferotaxxis is unearthed by humans meanwhile, who study it and the unearthed Nova Prime, seeing a technological boom as far as the 80’s/90’s are concerned (similar to the Bay films and Sumac Systems in Animated). Nova isn’t particularly pleased at being poked and prodded by what he deems a lazy inferior species, and like Bay Sentinel concocts a scheme to screw over humanity, Optimus’ Autobots and secure the Ferotaxxis to gift Cybertron Earth’s energy. Because Cybertron is all that matters, the devil with anything that gets in the way of it.
The Autobots human friends would be Spike, Carly and Chip, the children of scientists and engineers working on Project O-Part; the O-Part, the Ferotaxxis, reacting to the Autobots and Decepticons presence on Earth.
The plot would then extend to the lineage of the 13 Primes and their relics, as they were things Nova and the Ferotaxxis were privy to, leading to the Autobots and the kids from stopping the Decepticons from getting their hands on the relics, with another wrinkle being added that some countries already found some like Carbomya, and won’t surrender them easily…
Like I said this concept can go any direction, but for a pivoted AU, this is just how I’d do it, going by what I assume Hasbro would still want with the 13 Primes being a component. Elements of Skybound would probably be here too, like Spike and Carly being those designs in particular.
But I think continuing where The Rebirth left off would be the better option, being the easiest to work with and with the already admittedly shoddy continuity of the G1 cartoon, you could pretty effortlessly add aspects of Skybound, IDW (and by that I mean characters like Nova, Rung, Rubble, Termagax, Three Fold Spark, etc) and the modern 13 lore.
Will do they do it? If they’re desperate enough, absolutely, but I don’t know if we’re entirely there yet. It’s getting closer and closer though.
11 notes
·
View notes
Text
The Building Blocks of AI : Neural Networks Explained by Julio Herrera Velutini
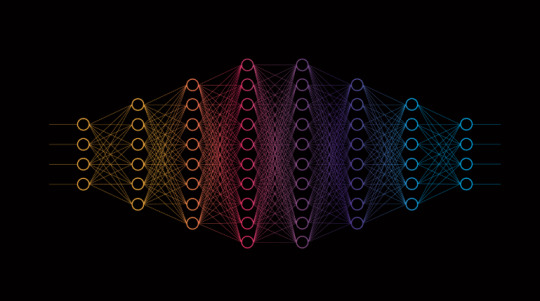
What is a Neural Network?
A neural network is a computational model inspired by the human brain’s structure and function. It is a key component of artificial intelligence (AI) and machine learning, designed to recognize patterns and make decisions based on data. Neural networks are used in a wide range of applications, including image and speech recognition, natural language processing, and even autonomous systems like self-driving cars.
Structure of a Neural Network
A neural network consists of layers of interconnected nodes, known as neurons. These layers include:
Input Layer: Receives raw data and passes it into the network.
Hidden Layers: Perform complex calculations and transformations on the data.
Output Layer: Produces the final result or prediction.
Each neuron in a layer is connected to neurons in the next layer through weighted connections. These weights determine the importance of input signals, and they are adjusted during training to improve the model’s accuracy.
How Neural Networks Work?
Neural networks learn by processing data through forward propagation and adjusting their weights using backpropagation. This learning process involves:
Forward Propagation: Data moves from the input layer through the hidden layers to the output layer, generating predictions.
Loss Calculation: The difference between predicted and actual values is measured using a loss function.
Backpropagation: The network adjusts weights based on the loss to minimize errors, improving performance over time.
Types of Neural Networks-
Several types of neural networks exist, each suited for specific tasks:
Feedforward Neural Networks (FNN): The simplest type, where data moves in one direction.
Convolutional Neural Networks (CNN): Used for image processing and pattern recognition.
Recurrent Neural Networks (RNN): Designed for sequential data like time-series analysis and language processing.
Generative Adversarial Networks (GANs): Used for generating synthetic data, such as deepfake images.
Conclusion-
Neural networks have revolutionized AI by enabling machines to learn from data and improve performance over time. Their applications continue to expand across industries, making them a fundamental tool in modern technology and innovation.
3 notes
·
View notes
Text

Top, Alicja Kwade, Parallelwelt (rot/schwarz), 2009, Lamps and mirror, 83 × 45 × 45 cm. Via. Bottom, Marijn van Kreij, Untitled, 2008, Orange, mirror and fake orange (acrylic, foam and tape), 13 x 16 x 30 cm. Via.
--
The luminous images of the mystics reveal a full and luminous extra consciousness on which shadows or nothingness have no hold. This is why the feeling, the consciousness of ‘being’ is expressed in images of light, and it is also why light, presence, plenitude are synonyms of ‘spirituality.’ Initiation means illumination, the dispersion of shadows, nothingness held off. Thus the plentitude that I felt was perhaps a little like mystic plenitude. It began with the feeling that space was emptying itself of its material heaviness, which explains the euphoric sense of relief that I felt. Notions were freed of their content. Objects became transparent, permeable; they were no longer obstacles and it seemed as if one could pass through them. It was as if my mind could move freely, as if there were no resistance to its movement. Thus my mind could find its center again, reunited, reassembled out of the matrixes and limits withing which it had been dispersed. And it was from this moment on that the feeling of plenitude took hold.
Eugène Ionesco, from Present Past / Past Present, translated by Helen R. Lane (Da Capo Press, 1998). Via.
--
The woman dies. She dies to provide a plot twist. She dies to develop the narrative. She dies for cathartic effect. She dies because no one could think of what else to do with her. Dies because there weren’t any better story ideas around. Dies because her death was the very best idea that anyone could come up with ... And so, the woman dies. The woman dies so the man can be sad about it. The woman dies so the man can suffer. She dies to give him a destiny. Dies so he can fall to the dark side. Dies so he can lament her death. As he stands there, brimming with grief, brimming with life, the woman lies there in silence. The woman dies for him. We watch it happen. We read about it happening. We come to know it well.
Aoko Matsuda, from The Woman Dies, for GRANTA, translated by Polly Barton, November 2018. Via.
--
Once a week, Sun Kai has a video call with his mother. He opens up about work, the pressures he faces as a middle-aged man, and thoughts that he doesn’t even discuss with his wife. His mother will occasionally make a comment, like telling him to take care of himself—he’s her only child. But mostly, she just listens.
That’s because Sun’s mother died five years ago. And the person he’s talking to isn’t actually a person, but a digital replica he made of her—a moving image that can conduct basic conversations. They’ve been talking for a few years now.
After she died of a sudden illness in 2019, Sun wanted to find a way to keep their connection alive. So he turned to a team at Silicon Intelligence, an AI company based in Nanjing, China, that he cofounded in 2017. He provided them with a photo of her and some audio clips from their WeChat conversations. While the company was mostly focused on audio generation, the staff spent four months researching synthetic tools and generated an avatar with the data Sun provided. Then he was able to see and talk to a digital version of his mom via an app on his phone.
Zeyi Yang, from Deepfakes of your dead loved ones are a booming Chinese business - People are seeking help from AI-generated avatars to process their grief after a family member passes away, for MIT Technology Review, May 7, 2024.
4 notes
·
View notes