#validation failed for archived log
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Premium Tumblr themes are available from anywhere between $9 to $49.
Text
[EXPERIMENT #0000]
Title: The World Demands Paper Trails of Lunacy
Author: Il Dottore, Inventor of Problems No One Dared to Imagine
[Introduction]
In the pursuit of knowledge, one must not merely seek answers, but provoke questions so peculiar they haunt the dreams of lesser minds.
Why concern oneself with simple truths when it is far more enlightening to wonder: “can I make someone confess to a crime they didn’t commit simply by exposing them to progressively larger vegetables?”
This log is the official public archive for my lesser experiments — bizarre hypotheses, fleeting whims and half-baked theories. Not worthy of grand ceremonies, nor approved by the Fatui, of course. But still, oddly illuminating.
Many will dismiss these pages as absurd. Some, dangerously foolish. A rare few — those deluded enough to seek meaning in the bubbling nonsense — may glimpse the twisted spark of genius.
To those few: Beware. You have already been marked.
[Purpose]
These logs document experiments conducted for reasons including, but not limited to:
Passing the time between catastrophes
Exploring bizarre questions, no matter how ridiculous
Satisfying personal curiosities
General amusement
Science, allegedly
All outcome are accurate. Subjects were technically willing, or at least, too slow to refuse. Assistants received warnings regarding possible side effects: unexplained weeping, prolonged eye contact with inanimate objects, and spontaneous existential crisis.
Some even signed consent forms — mostly out of fear.
[What is regarded as a valid hypothesis?]
Anything. Especially ones unburdened by logic, ones that make people slowly turn and walk away while whispering, “Are they allowed to do that?”.
A sound hypothesis does not require dignity, coherence, or adherence to the criteria set by ‘traditional scientific institutions’. It does not need to be precise, measurable, or even fully thought through. A passing question muttered at 03:00 hours is more useful to me than a decade of academic drivel.
Consider, for example:
What happens if I whisper compliments to a person every day for a month, then suddenly stop?
Do lemon’s possess opinions, and if so, are they rude?
Does the average person feel more or less guilt when interrogated by a sock puppet with a badge?
If I yell at a banana every day at the same time, will it ripen out of spite?
If I dramatically declare “You’ve failed the lettuce test” and walk away, how many people will panic despite knowing nothing about said test?
Do oranges experience existential dread when peeled in complete silence?
The above are not experiments I have performed. They are possibilities. Suggestions. Threats, perhaps.
[Submissions]
Here lies the collection point for all curious experimental proposals, no matter how nonsensical, twisted, or outright absurd.
Each will be inspected, dissected, and possibly distorted beyond recognition. Results are never guaranteed.
You may leave your proposals openly as public notes, where others can witness your lapse in judgement.
Or, for those of you too ashamed to be publicly associated with your proposal, you may make a contribution privately using my trusted [submit your inquiries] button.
Should a particular proposal pique my interest (or my madness), it will be tested and documented. If the results are truly disastrous, the blame will fall squarely on the originator.
Welcome to my laboratory,
Where nonsense reigns and the strange becomes routine.
I eagerly anticipate the delightful disorder your hypotheses shall unleash upon my humble domain of discovery.
Yours in scientific mischief,
~ Il Dottore
#il dottore#genshin impact#dottore#genshin rp#fatui#harbinger#the doctor#in character#genshin#zandik#literate rp#genshin impact rp#roleplay#writing#writeblr
10 notes
·
View notes
Text
Reliable Microsoft 365 Migration Software for Large-Scale Enterprise Deployments
Enterprise-level Microsoft 365 migrations demand more than just mailbox transfers. The complexity increases with scale, data volume, legacy dependencies, compliance mandates, and tight downtime windows. Without a reliable migration solution, organizations risk email interruptions, data loss, and productivity setbacks. Choosing the right software is critical to ensure a smooth and secure transition.

Enterprise Migration Challenges That Demand Robust Solutions
Large-scale deployments typically involve thousands of mailboxes and terabytes of data. Migrating this data is not just about speed. It’s about integrity, continuity, and control. Enterprises often face issues such as throttling by Microsoft servers, broken mailbox permissions, calendar inconsistencies, and bandwidth limitations during migration windows.
Handling multiple domains, public folders, archive mailboxes, and hybrid configurations further complicates the process. Standard migration tools fail to handle these requirements efficiently. A purpose-built migration platform is essential for structured execution.
Features That Define Reliable Microsoft 365 Migration Software
A reliable enterprise migration solution must address the full lifecycle of the migration. It should support planning, execution, monitoring, and validation. It should also provide flexibility in terms of migration types and scenarios.
Support for tenant-to-tenant migration, Exchange to Microsoft 365, and PST import is a baseline. But what truly defines enterprise-grade software is its ability to handle granular mailbox filtering, role-based access control, auto-mapping, and impersonation-based migration.
Bandwidth throttling by Microsoft 365 is another concern. The right software must manage these limitations intelligently. It should use multithreaded connections and automatic retry mechanisms to maintain performance without violating Microsoft’s service boundaries.
Audit trails and reporting are equally important. Enterprises require a complete overview of what data moved, what failed, and what requires attention. Detailed logs and reports ensure transparency and make post-migration validation easier.
EdbMails: A Purpose-Built Tool for Enterprise Migrations
EdbMails Microsoft 365 Migration Software is built to address the challenges of enterprise deployments. It simplifies complex migration scenarios by providing automated features that reduce manual intervention. The software handles large user volumes efficiently without compromising speed or accuracy.
It supports tenant-to-tenant migrations with automatic mailbox mapping. This eliminates the need for extensive scripting or manual assignment. Its impersonation mode ensures that all mailbox items including contacts, calendar entries, notes, and permissions are transferred without requiring individual user credentials.
EdbMails also includes advanced filtering options. You can choose to migrate only specific date ranges, folders, or item types. This level of control helps in managing data volume and compliance boundaries.
Its incremental migration feature ensures that only new or changed items are migrated during subsequent syncs. This reduces server load and prevents duplicate content. Built-in throttling management ensures optimal data transfer rates even during peak usage times.
The software generates real-time progress dashboards and post-migration reports. These reports help IT administrators validate the outcome and identify any gaps immediately. The logs also serve as compliance evidence during audits.
Deployment and Usability at Scale
One of the key factors in enterprise environments is usability. EdbMails offers a clean, GUI-based interface that minimizes the learning curve. Admins can initiate and manage large-scale batch migrations from a centralized dashboard. There’s no need for extensive PowerShell scripting or third-party integration.
It supports secure modern authentication, including OAuth 2.0, ensuring that enterprise security policies remain intact. The software does not store any login credentials and operates under the secure authorization flow.
Another benefit is the ability to pause and resume migrations. In case of planned maintenance or network downtime, the migration process can be continued from where it left off. This reduces the risk of data loss and eliminates the need to restart from scratch.
Final Thoughts
Large-scale Office 365 migration require a solution that can handle complexity with accuracy and consistency. EdbMails stands out by offering an enterprise-ready platform that simplifies the migration journey. It reduces risks, accelerates deployment timelines, and ensures a seamless transition to the cloud.
For IT teams managing enterprise workloads, reliability is non-negotiable. EdbMails delivers that reliability with the technical depth and automation required for large-scale success.
0 notes
Text
Telegram Bot for TG Account MarketPlace – For Sale
Looking for an automated solution to buy and sell Telegram accounts? Introducing a fully functional Telegram bot designed for businesses and individuals managing large volumes of accounts.
Bot Features:
1. Account Purchasing:
• Three account categories:
• Good — accounts without 2FA or spam blocks.
• Medium — accounts with spam blocks.
• Random — a mix of accounts, primarily with 2FA.
• Flexible export options:
• tdata, session, auth key.
• Displays only available categories:
• If a category is empty, it is marked as unavailable, ensuring a smooth user experience.
2. Account Selling:
• Upload archives containing Telethon/Pyrogram sessions.
• Automated checks:
• Validity of accounts.
• Presence of spam blocks.
• Presence of 2FA.
• Categorization:
• goodAccounts — valid accounts.
• spamAccounts — accounts with spam blocks.
• passwordAccounts — accounts with 2FA.
• Provides detailed statistics and freezes the user’s balance for 24 hours after verification.
3. Referral System:
• A built-in referral system rewards users with a percentage of all future sales made by their referred users.
• Encourages users to invite more people and boosts overall bot activity.
4. Automated and Manual Balance Replenishment:
• Integrated with Cryptomus payment system for automated balance top-ups:
• Secure and fast cryptocurrency payments.
• Users receive immediate balance updates upon successful transactions.
• Manual balance management via admin panel remains available:
• Users can contact admins directly to top up their balances.
5. JSON File Support:
• Extracts data (including 2FA passwords) from JSON files in the uploaded archive.
• JSON files are provided to buyers along with the purchased accounts.
6. Proxy Management:
• Supports bulk uploading of proxies.
• Automatically switches to the next proxy if the current one fails.
• Notifies the administrator of non-working proxies.
7. Balance and Hold System:
• After selling accounts, balances are frozen for 24 hours.
• Allows users to top up their balance using Cryptomus or through manual admin approval.
8. Admin Panel:
• Comprehensive statistics:
• Available accounts by category.
• Sold accounts.
• Full action logs.
• Management tools:
• Adjust prices for account categories.
• Add or deduct user balances.
• Manage proxies.
Interface:
1. Simple and Intuitive Menu:
• Main Menu:
• Account purchasing.
• Account selling.
• User Profile:
• Displays ID, balance, purchase history, and referral earnings.
• Convenient category selection with real-time availability updates.
2. Admin Panel:
• Full control over the bot:
• Configure pricing.
• Manage user balances.
• View logs and statistics.
• Monitor Cryptomus payments for seamless automation.
Why Choose This Bot?
• Fully automated account management process.
• Built-in referral system for user growth and passive income.
• Supports all popular formats: tdata, session, auth key.
• Integrated with Cryptomus for automated cryptocurrency payments.
• Easy-to-use interface for both users and admins.
• Comprehensive control from account verification to buying and selling.
#telethon #telegram #json #session #tdata #authkey #whatsapp #wa #6stage #6key #hash #signup #autoregister #python #registration #phoenixsoft #firebase #safetynet #api
???? Price: 1500$ ( source code ) or 500$ ( rent 1 year )
???? For inquiries, contact on Telegram: @phoenixsoftceo
0 notes
Text
Telegram Bot for TG Account MarketPlace – For Sale
Looking for an automated solution to buy and sell Telegram accounts? Introducing a fully functional Telegram bot designed for businesses and individuals managing large volumes of accounts.
Bot Features:
1. Account Purchasing:
• Three account categories:
• Good — accounts without 2FA or spam blocks.
• Medium — accounts with spam blocks.
• Random — a mix of accounts, primarily with 2FA.
• Flexible export options:
• tdata, session, auth key.
• Displays only available categories:
• If a category is empty, it is marked as unavailable, ensuring a smooth user experience.
2. Account Selling:
• Upload archives containing Telethon/Pyrogram sessions.
• Automated checks:
• Validity of accounts.
• Presence of spam blocks.
• Presence of 2FA.
• Categorization:
• goodAccounts — valid accounts.
• spamAccounts — accounts with spam blocks.
• passwordAccounts — accounts with 2FA.
• Provides detailed statistics and freezes the user’s balance for 24 hours after verification.
3. Referral System:
• A built-in referral system rewards users with a percentage of all future sales made by their referred users.
• Encourages users to invite more people and boosts overall bot activity.
4. Automated and Manual Balance Replenishment:
• Integrated with Cryptomus payment system for automated balance top-ups:
• Secure and fast cryptocurrency payments.
• Users receive immediate balance updates upon successful transactions.
• Manual balance management via admin panel remains available:
• Users can contact admins directly to top up their balances.
5. JSON File Support:
• Extracts data (including 2FA passwords) from JSON files in the uploaded archive.
• JSON files are provided to buyers along with the purchased accounts.
6. Proxy Management:
• Supports bulk uploading of proxies.
• Automatically switches to the next proxy if the current one fails.
• Notifies the administrator of non-working proxies.
7. Balance and Hold System:
• After selling accounts, balances are frozen for 24 hours.
• Allows users to top up their balance using Cryptomus or through manual admin approval.
8. Admin Panel:
• Comprehensive statistics:
• Available accounts by category.
• Sold accounts.
• Full action logs.
• Management tools:
• Adjust prices for account categories.
• Add or deduct user balances.
• Manage proxies.
Interface:
1. Simple and Intuitive Menu:
• Main Menu:
• Account purchasing.
• Account selling.
• User Profile:
• Displays ID, balance, purchase history, and referral earnings.
• Convenient category selection with real-time availability updates.
2. Admin Panel:
• Full control over the bot:
• Configure pricing.
• Manage user balances.
• View logs and statistics.
• Monitor Cryptomus payments for seamless automation.
Why Choose This Bot?
• Fully automated account management process.
• Built-in referral system for user growth and passive income.
• Supports all popular formats: tdata, session, auth key.
• Integrated with Cryptomus for automated cryptocurrency payments.
• Easy-to-use interface for both users and admins.
• Comprehensive control from account verification to buying and selling.
#telethon #telegram #json #session #tdata #authkey #whatsapp #wa #6stage #6key #hash #signup #autoregister #python #registration #phoenixsoft #firebase #safetynet #api
???? Price: 1500$ ( source code ) or 500$ ( rent 1 year )
???? For inquiries, contact on Telegram: @phoenixsoftceo
0 notes
Text
Crosscheck archive in rman
Crosscheck Archivelog all Validation failed for archived log #oracle #oracledba #oracledba #database #ocptechnology #rman
Crosscheck Archivelog all Validation failed for archived log In this article, we are going to learn how to perform crosscheck for archives in the oracle database step by step. Validation failed for archived solution. validation failed Sometimes we face the error validation failed message during rman backup. Actually, we face the error because someone deletes or moved the archives from their…

View On WordPress
#crosscheck archivelog all#crosscheck archivelog all delete#crosscheck archivelog all hangs#crosscheck archivelog all validate#delete expired archivelog all#delete noprompt expired archivelog all#rman crosscheck and delete expired commands#rman crosscheck backup command#validate and crosscheck in rman#validation failed for archived log
0 notes
Photo

Why Tumblr Chooses Censorship
It’s a strange day to jump online and suddenly hear about a major policy change on Tumblr from a few people I talk too. Words like “Total Bullshit”, “End of Tumblr”, “Burning Garbage Heap” and so on tossed among them to describe the policy change. Curious enough I logged on began reading over all the purposed changes and I admit I am a bit disheartened. Usually when a digital institution like AOL, Yahoo, Napster, or MySpace falls it because they didn't evolve and became stagnant in what they were providing the internet. I can’t think of a time where a site willfully regressed its own freedom of speech on a broad scale and basically swallowed a poison capsule that destroys their user base (perhaps deservingly so) but here we are.
That point aside, I am trying to have insight and hindsight to understand how/why they were pushed to this reckless conclusion (I will be leaving foresight out because I think Tumblr lacks foresight, the exodus from Tumblr will dramatically change the culture of this site likely for the worse). Tumblr like any social media medium is struggling in the current age of the internet; Bots, Far Right Extremists, Fake News, Illegal Porn, Data Theft, and so on. Many companies are walking this fine line between trying to combat these problems while preserving freedom of speech.
I struggle to find my own footing on this topic because I believe that society with LESS censorship historically does better. You look to countries in the past that repressed sexuality, individual thought, and so on; those countries were often the ones to invite the rise of repressive groups doing atrocious acts in history. While on the other hand because of this open and free social media platform we all see the echoing of those same repressive groups (who are also on Twitter, Facebook, Reddit, and Youtube) and to simply say/do nothing about their posts will inevitably allow them to rise still. This is where I struggle as I believe in that concept of a free society but I do feel that removing fake new stories is essential for the health of democracy.
I imagine the reason why sexual images are the target is that Tumblr makes things so easy to post. It's not hard to imagine pictures of minors getting liked or reposted from one blog or another happening. The problem is many of those pictures will circulate for a long period of time not being flagged as underage and there is good chance that every user has knowingly or unknowingly looked at an image like this on the web. I explore the porn side of Tumblr and have once or twice encountered a Tumblr full of these images at which point I couldn't close that tab fast enough and get the hell out of dodge. So Tumblrs solution of handling this problem instead of playing whack a mole with these underage accounts? Ban all adult content.
I can understand this motivation being a foolproof way of making sure there is no underage porn because there will be no porn. I imagine the result will be very effective, so effective that the various members of the community be they straight, bi, or gay who had their own private collection of legal adult material on Tumblr will stop visiting the site. A slow-moving exodus of users from Tumblr this site to perhaps a new blogging alternative that isn't so restrictive. I don’t suspect Tumblr will be closing its doors the week after the policy kick in (though they will see a HUGE decline in traffic) but even the PG accounts will likely move on because a sizeable user base shifted away and people want to be where the party is at. And much as I love Tumblr, it will not be here (sadly).
PC Culture VS Censorship Culture
One thing I noticed on the various posts is some people attempting to blame this policy change on the PC Culture. I am not sure I believe that as a valid argument. While I don't get along with PC Culture all the time (part of my free society is believing that humor is apart of it and PC Culture doesn't always like humor), I do think PC Culture has a broad/accepting view of orientation and sexuality. Just important is people having the right to explore those thoughts and feelings of their own free will. Tumblr has been one of those sites allowing emerging gay men and women to find others like them but also explore their sexuality with images/gifs/videos. What Tumblr might have not noticed is that the site itself is kind of a cultivation of the best images from the web, sure you can find some pretty hard porn on occasion but of all the adult sites on the web, Tumblr provides an almost artistic lense to the images that come thru the site.
Censorship can come from various political/social/religious groups but this sort of censorship against the human body, sex, and sexuality, in general, comes from a very conservative mindset. People who don’t wish to see nudity in any form on any medium; people who think a woman's nipple is lewd, that breastfeeding publically is disgusting, and that anything remotely sexual is a sin. And by the nature of Tumblrs policy change their beliefs align themselves alarmingly close to these individuals.
There is a thin veneer of progressive views on the site that remains where they say they are ok with this and that like gender orientation surgery but its just that a veneer. Once a person has transitioned anything that is shared of their new body (nudity or sex wise) beyond the initial transition falls into the realm of ‘smut’ by Tumblrs policies. I imagine the perception they are trying to sell us is “Hey we are still the same progressive safe haven for LGTBQ community! Stay with us!” but secretly thinking “Everything you enjoy in the bedroom is horrible and we fucking hate you.”
Perhaps I am being hyperbolic in that statement but damn if it doesn't feel like a vast policy of censorship on the human body. And whenever this happens (historically) it always comes from hyper-conservatives.
A General Attack On Expression and Orientation
I touched on this topic a little bit above but I feel it's worth stating again that Tumblr might be losing its safe-haven status for gender expression and sexual orientation. When scrolling through Tumblr you will likely see those new expressions of genders that is beyond that of ‘traditional’ male and female definitions. And while I don’t have any attraction to some of these new expressions, I understood why they are there and don’t get upset if/when the cross my feed. Like two men having sex my mind thinks “Not for me but I am sure that will make someones day”. I view sex (in all its forms) as natural, I don’t have to be into it for me to be ok with it (if that makes sense). It’s visual participation if that image you see isn't a turn on for you and does nothing for you, simply move on.
Tumblr’s policy doesn't seem to care about this concept of visual participation and while it is taking away my straight/lesbian porn I enjoy. It is also sweeping up all these new forms of expression and orientation in the process.
I am not sure what else to say... I am a straight male and I try to have a deep empathy for other people when I can. I feel this argument can be better structured but I also come from a position where I don’t know all the details. I add this to the post because Tumblr seemed to go out of their way to suggest that they would protect this community but from a long view that doesn't seem to be the case.
A Lessons To Be Learned
I am not going to say fuck Tumblr. I don’t want to see them fail. I liked what this space was about and what it provided. I prefer they reconsider changing the guidelines and consider a different course of action but I also understand why they want to do this. It’s “The Easy Way” to do things. If they ban all porn then it simplifies managing underage nudity and allows the site to have less criticism drawn to it.
I do, however, think this broad censorship approach will ultimately hurt the site and the community though. People will leave, alternative websites will arise and Tumblr will eventually become no more. I am not going to tell anyone to boycott or delete their accounts. I plan to collect my writing and images, backup my favorite adult gifs (might need to buy a hard drive) and settle into this new reality. I know I will personally be visiting the site less as I used to look at porn here at some of the better cultivated Tumblr archives. That lack of traffic by me and all the other users will hurt the company. I hope they understand eventually I won't show up at all and over time, eventually, no one else will either. Maybe the site will survive and change into something else but right now under these conservative policies of censorship, Tumblr won't last.
Sad Regards, Michael California
Update: Posted this originally with a woman in a shower with large censorship bars over the naughty bits. Flagged despite the fact she was more covered than most Sports Illustrated models. I know I just wrote above I am not advocating leaving the site... but after all this and the fact that Tumblr Support finally responded to a far-right Tumblr blogger photoshopping/doctoring a PM conversation we had before posting it to his blog. I feel as though Tumblr A) hates sex and sexuality B) not only enables but protects racism and harassment on this website. I think it’s time to move on.
#Tumblr#Tumblr Suppor#Staff#Policy Change#Tumblr Policy#RIP Tumblr#Censorship#Tumblr Ban#Tumblr Purge#Community Guidlines#Tumblr Community Guidlines
246 notes
·
View notes
Text
Adobe Flash Player Asking For Password Mac
Install the Adobe AIR Runtime. Steps to follow on Windows: 1. Go to C: Program Files (x86) Common Files Adobe AIR Versions 1.0. While holding the “Ctrl” key, select the Adobe AIR Application Installer.exe -> Right click on it -> Run as Administrator. Do not take your finger off the “ctrl” key until you see the window open up. A new malware by the name of Snake enters your Mac by asking you to install Adobe Flash Player. If your Mac asks to install Adobe Flash Player, it can possibly be a Malware. Malware for MacOS is dubbed as 'Snake' By. This virus asks for the administrator’s password. It’s normal because the original flash player by Adobe also. When version 10.3.181.14 of Adobe Flash Player was released it installed the Flash Player Settings Manager in Control Panel. Local Storage Settings can be managed through this console. There are three options Allow, Ask before using local storage and Block. Noooo it at one point caused 83% of mac crashes back on Mavericks DON'T INSTALL IT, anyway flash is going out of fashion and less people develop for it (I had to convert all my web-apps to HTML5 because the lack of interest in flash). Flash Player is alerting you that information might be shared between two sites and is asking if you want to allow or deny such access. In the question shown above, (site1) represents the name of the person or company who created the application that is trying to access another site, represented by (site2). There's yet another flaw in the Adobe Flash Player browser plugin that needs to be urgently patched. The good news is that Google Chrome, Microsoft Internet Explorer 10 and 11, and Microsoft Edge.
Enable Flash player in the TOR browser bundle on Mac (Macbook Pro or Macbook Air): You need to follow these steps, sometimes things get updated but the way is same, so you may need to exert some brain energy while doing the steps mentioned below, I can’t spoon feed you but I can guide you to achieve your purpose, if you still get confused then ask me in the comments. But if your only sole purpose is to play videos on the tor, then this method is safe and you can play your videos behind a college, work or office proxy. Browser for mac adobe flash player ipad.
This technote addresses the installation issue of Adobe AIR applications after 30th Oct 2017 that is signed with SHA1 certificate. It is applicable to both Windows and Mac.
Issue
When you install your AIR application, the installation fails with the below error. The error dialog is a generic installation failure message that could occur for various reasons. One of them is due to signature validation failure.
Who should use this solution?
If your developed AIR application fails to install after 30th Oct 2017.
Issue confirmation
Follow the steps below to verify if the signature validation failure is the cause of the installation failure:
Open the application installation logs. The location of the log files for different platforms is mentioned in the article: https://helpx.adobe.com/air/kb/logging-air-2-desktop-application.html
If the installation log contains the error: “Package signature validation failed”, it indicates that the application is signed with SHA1 certificate.
Set your system date to a date prior to 30th Oct 2017, and try to install the application again. Successful installation confirms that your application is impacted by the signature validation issue.
Solution
You will have to re-sign your Adobe AIR application. Follow the steps below to re-sign your application:
Rename your Adobe AIR application by changing its extension from .air to .zip. In case you don’t see the extension in the filename, enable the filename extension before renaming the application.
Extract the .zip file renamed in Step 1.
Go to the extracted folder and perform the following modifications (in the order specified):
Move xml present inside META-INFAIR folder to the root of the extracted folder.
Delete “META-INF” folder.
Delete “mimetype” file located in the root of the extracted folder.
Download the latest AIR SDK for your platform from http://www.adobe.com/devnet/air/air-sdk-download.html.
Locate the AIR SDK archive file downloaded in Step 4 and extract the AIR SDK Compiler (if on Windows) or mount the AIR SDK Compiler dmg (if on Mac).
Open the command prompt and change the current working directory to the root directory of the extracted AIR application directory.
Use the command below to re-package the AIR application with a new certificate:
<AIR_SDK_compiler_path>binadt -package -storetype pkcs12 -keystore <app_signing_certficate_path> myApp.air application.xml .
Command line parameters:
AIR_SDK_compiler_path – Location of AIR SDK compiler extracted or mounted in Step 5.
app_signing_certficate_path – Fully qualified path of your application signing certificate. Make sure you are using SHA256 certificate.
myApp.air – Name of the application to be packaged.
application.xml – The file that was moved in Step 3.A
When prompted, enter the password of your application signing certificate.
Note: Do not ignore the . (dot) at the end of the packaging command above. It is used to package all the resources present in your existing application. For more details on packaging AIR applications, refer https://help.adobe.com/en_US/air/build/WS901d38e593cd1bac1e63e3d128cdca935b-8000.html.
Workaround
AIR applications with the above-mentioned issue can be installed using two methods.
Using keyboard shortcuts:
Install the Adobe AIR Runtime
Steps to follow on Windows:
1. Go to C:Program Files (x86)Common FilesAdobe AIRVersions1.0 Adobe flash player free download.
Is adobe flash player dangerous for mac. Snake has to be welcomed into your operating system by you. There isn't someone shooting corrupted files through your ethernet cable directly into your software.
Adobe Flash Player Asking For Password Mac
2. While holding the “Ctrl” key, select the Adobe AIR Application Installer.exe -> Right click on it -> Run as Administrator. Do not take your finger off the “ctrl” key until you see the window open up.
3. Select and open the AIR application to be installed.
Steps to follow on Mac:
1. Go to /Applications/Utilities
2. While holding the “command” key, double click on the Adobe AIR Application Installer. Do not take your finger off the “command” key until you see the window open up.
3. Select and open the AIR application to be installed.
The Adobe AIR Application should be installed successfully.
Using the new -ignoreExpiredCertificateTimestamp directive while launching AIR Application installer using Command Prompt/Terminal
Install the Adobe AIR Runtime
Steps to follow on Windows:
1. Open a command prompt as Administrator.
2. Run the following command:
“C:Program Files (x86)Common FilesAdobe AIRVersions1.0Adobe AIR Application Installer.exe” – ignoreExpiredCertificateTimestamp
3. Window opens up.
4. Select and open the AIR application to be installed.
Steps to follow on Mac:
1. Open Terminal.
2. Run the following command:
/Applications/Utilities/Adobe AIR Application Installer.app/Contents/MacOS/Adobe AIR Application Installer/ -ignoreExpiredCertificateTimestamp
3. Window opens up.
4. Select the AIR application to be installed.
Adobe AIR Applications gets installed successfully.
Lesson 14: Should I Still Use Adobe Flash Player?
Adobe Flash Player Asking For Password
/en/internetsafety/driving-safely-with-mobile-devices/content/
Should I still use Adobe Flash Player?
Whenever you use the Internet, your browser uses small applications called plug-ins to display certain types of content. For example, the Adobe Flash Player plug-in can be used to play videos, games, and other interactive content. Although Flash Player has long been one of the most well-known plug-ins, it has become much less popular in recent years.
There are a few reasons for this decline in popularity. Because Flash Player is a relatively old plug-in, it has become increasingly vulnerable to online threats like viruses and hackers. Most web browsers have even started disabling Flash Player content by default for security reasons.
Also, because Flash Player was designed for desktop computers, it's not very good at displaying content on mobile devices, including smartphones and tablets. Some mobile browsers, including Safari for iOS, can't even use Flash Player.

Should I stop using it?
Although you don't need to completely stop using Flash Player, you should use caution. Most browsers have an Ask to Activate or Ask First setting for Flash, which we recommend using. This keeps Flash disabled most of the time, but it gives you the option to temporarily enable it when you're on a site that you know and trust.
Keeping Flash Player up to date
Because older versions of Flash are vulnerable to online threats, you'll want to make sure you're always using the most recent version. If you're not running the most recent version, you might see an error message instead of your content.
However, we don't recommend updating the plug-in directly from a warning message like this. Some misleading advertisements are cleverly disguised as warning messages, but they won't actually take you to an update page. That's why it's best to download the update directly from the Adobe website.
It's also worth pointing out that some browsers update all of your plug-ins automatically, including Flash Player. If you're using a browser like Internet Explorer, you'll probably need to update your plug-ins manually.
Adobe flash player 10 1 download free download - Adobe Flash Player, Macromedia Flash Player Uninstaller, and many more programs. Best Video Software for the Mac. Download free Adobe Flash Player software for your Windows, Mac OS, and Unix-based devices to enjoy stunning audio/video playback, and exciting gameplay. Mar 22, 2015 Re: Can't install Flash player on Mac 10.10.1 Lexilix Mar 22, 2015 7:37 PM ( in response to martinaio ) Had the same problem (stalling at 25% or 30%). Adobe flash player for mac 10.10.1. Flash is the standard for engaging PC experiences – 99% of PCs worldwide have Flash Player installed and 85% of the top 100 websites use Flash. Approximately 75% of online videos are viewed and 70% of web games are delivered using Adobe Flash technology.
How to update Adobe Flash player:
Navigate to https://get.adobe.com/flashplayer/ in your web browser.
Locate and select the Download or Install button. Flash Player may also try to install additional software, so be sure to deselect any offers like this before downloading. In the image below, we've deselected the McAfee Security Scan Plus option.
Locate and double-click the installation file (it will usually be in your Downloads folder). Note that you'll need to close your web browser before you can install the plug-in.
Follow the instructions that appear. Flash Player will be updated to the most recent version.
In many cases, your browser will open automatically to a new page to confirm the installation. This means the plug-in is ready to use whenever you need it.
0 notes
Text
It is gone... Jill stood in silence with that conclusion in her mind, but she wasn’t willing to believe her own thoughts and lower her weapon as she still aim at the doors. The last attempt the creature had done to break through had been a minute, two or three ago. To Jill it felt like an eternity so she had lost sense of time. They are gone... She breathe out and felt her shoulders relax, her stance drop and the sense of relief wash over her like a warm wave. Jill was safe for now. Safe and alone.
I’m so sorry... The survivor’s guilt weigh heavy on Jill’s mind as she pull out the magazine to see how much ammo she had. [Randomized outcome] Five bullets... That pistol and ammo was the final gift from Brad Vickers, a gift she rob from their unconsciouss body, as they now lay ravished on the courtyard at the mercy of the creature that had done it to them. Nearly did it to me. Jill wish to go out and help them, attempt to drag them indoors to safety, but she knew that it would only have her share their fate. There is nothing I can do anymore. Reason ease her guilt for now. Jill turn around to see the Goddess looking down at her, watching her and judging her lacking efforts.. Don’t look at me.
The statue was something that Jill had liked until the mansion incident. From that day forward she had felt uneasy in the main hall of the police station as it remind her of the Spencer estate and her imagination had the Goddess statue turn into a presence that haunt her when she was in their field of view. The statue remind her of other of its kind back at the mansion. Jill stare back up at the Goddess with anxiety, the smile it had turn into a gleeful smirk in her mind. You hoped I would have been caught so you could watch it happen... To her they were treacherous Goddess, one with desire to see her fail and be used for their pleasure. Jill wouldn’t have herself taken on their altar under their lustful gaze.
However, Jill didn’t have much to defend herself with. She need ammo, weapons and other equipment to survive. S.T.A.R.S. office might still have something useful left in there and the weapon storage and the locker room in the basement should have what she need. The police station was a good place to restock and prepare for what would wait her outside. When she would leave the building it would happen either through the front doors on foot or driving out of the underground parking lot.. If I’m lucky. A car would cover a lot more distance too.
She move past the statue and saw how the stairs to upstairs were blocked off at the other end of the main hall and the emergency ladder hadn’t been pushed down from the upper floor. Jill would have to go through either the west or the east wing of the building to reach the stairways there if she was going up. Circling behind the statue Jill came to the information desk she had called from the Bar Jack. There was no note on where the receptionist had went or regarding what happened in the station. All there was were the file binders unrelated to the outbreak, typewriter and written instructions by the phone on how to answer and instruct the civilians to come to the police station... Maybe they abandon the hall. The building was large and the police could have fall back to the second floor to have easier time defending it or go as far as attempt mass evacuation through the underground garage. Maybe the remaining police force is spread thin and the main hall was left unguarded. Jill could only guess what had happened.
She boot up the desk computer to find answers, but it only brought her to login screen that demand either a password or an user card to be verified by the scanner next to the computer. With her S.T.A.R.S. card Jill would be able to log in, but she had to return it after her suspension. Her card could still be valid. Could be either in the archives or the store room. The computer had access to the security cameras around the station. Jill sigh and shook her head, maybe the operations room would be a better bet to find information which parts of the station the police still had control over and where the civilians are waiting for the evacuation even if the plans there might already be outdated.
Maybe I sho- “AHh?” Her ecstatic shock echo through the hall. Jill lean against the desk as she felt the weight inside her stomach shift slightly. She move her hand to feel how the bulge had grown. The eggs had shift around as they fought over space. It create a constant pressure and weight in her lower abdomen. The unnatural bulge on her stomach was still hard to notice, but it was felt the moment one rest their hand on it. [The eggs have grown, -1 to survival skill] The eggs would soon hatch.. Oh god. The time was running out. Jill had to move.
[Vote for what Jill should do]
0 notes
Text
Amazon DynamoDB now supports audit logging and monitoring using AWS CloudTrail
Amazon DynamoDB is a fully managed, multi-Region, multi-master database that delivers reliable performance at any scale. Because of the flexible DynamoDB data model, enterprise-ready features, and industry-leading service level agreement, customers are increasingly moving sensitive workloads to DynamoDB. Regulated industries (e.g., education, media, finance, and healthcare) may require detailed information about data access activity to help implement security controls and meet industry requirements, including compliance, auditing, and governance of their AWS accounts. Previously, you could use AWS CloudTrail to log control plane activity on your DynamoDB tables and glean information such as who created or deleted a table and when a table was changed. You can now enable data plane activity logging for fine-grained monitoring of all DynamoDB item activity within a table by using CloudTrail. If you’re a database administrator or security professional, you can use this information as part of an audit, to help address compliance requirements, and to monitor which AWS Identity and Access Management (IAM) users, roles, and permissions are being used to access table data. CloudTrail records DynamoDB data events and publishes the log files to an Amazon Simple Storage Service (Amazon S3) bucket. Each event carries information, such as who performed an action and when, which resources were impacted, and many other details. Events are combined in JSON format and saved in CloudTrail log files. With these files, you can track and understand when, for example, an IAM user accessed sensitive information stored in a DynamoDB table. In this post, we show how to create a new trail on the CloudTrail console and enable data event logging for a DynamoDB table. You can use this trail to monitor, alarm, and archive item-level activity on a table. Solution overview This walkthrough provides a step-by-step example of how to create a DynamoDB table, create a CloudTrail trail, enable data events for DynamoDB, create a DynamoDB item, and then review the CloudTrail event. The post assumes that you’re working with an IAM role that can access DynamoDB, CloudTrail, and Amazon S3. If you don’t have an IAM role to access these resources, it’s recommended that you work with your AWS account administrator. The AWS usage in this post alone falls within the Free Tier, but if you consume resources beyond the walkthrough, you could incur associated costs. It’s recommended that you remove resources after the walkthrough. Creating a DynamoDB table To log DynamoDB data events in CloudTrail, you first need a DynamoDB table. For the purposes of this blog post, we create a basic table to follow along with this post. On the DynamoDB console, in the navigation pane, choose Dashboard. Choose Create table. For Table name, enter DynamoDB-CloudTrail. For Partition key, enter pk. Leave Sort key Select Default settings. Choose Create to create the table. Now that you have created the DynamoDB table, you can create and configure the CloudTrail trail to log the data events on the table. Creating a trail Before you enable data event logging in CloudTrail so that you can monitor item-level activity on the DynamoDB table, you must first create a new CloudTrail trail. For a detailed explanation about trail attributes, see Creating a Trail. On the CloudTrail console, choose Create a trail. Choose Trails in the navigation pane. Choose Create trail. For Trail name, enter DynamoDB-DataEvents-Trail. For Storage location, select Create new S3 bucket. For Trail log bucket and folder, enter an S3 bucket name. The console suggests a new bucket name, which must be unique across all existing bucket names in Amazon S3. You also can choose to make your own unique bucket name. Log file SSE-KMS encryption is an additional setting that, if required by your security controls, requires you to use either a new or existing AWS Key Management Service (AWS KMS) customer managed CMK. The remaining configurations are optional enhancements. 9. Choose Next. You’re redirected to the Choose log events page of the Create trail wizard. Enabling CloudTrail data event logging To enable CloudTrail data event logging for items in your DynamoDB table, complete the following steps: On the Choose log events page, choose Data events. Deselect Management events. Select Data events. DynamoDB data event logging is enabled on a per-table basis in CloudTrail and is disabled by default. This resource-specific configuration allows for data events to be logged on sensitive tables for security and compliance requirements or audit purposes. For Data event source, choose DynamoDB. The default option is to log data events for all DynamoDB tables, but you can deselect the Read and Write check boxes to select individual tables in the subsequent section. Choose Browse to choose the DynamoDB table that you created initially. Choose Next. On the Review and create page, review the configuration and choose Create trail. Now that you have a new trail, you can create and delete an item in the DynamoDB table. On the details page for DynamoDB table you created, choose Create item. Enter the data to insert as a table item. For simplicity, you can disable View DynamoDB JSON and enter values to correspond with the item pk, as shown in the following screenshot. Choose Create item. You can see the new item you created in the Items preview section. You also can delete this item by selecting the item and choosing Delete item(s) from the Actions menu. Understanding and using data event records Creating and deleting items creates data event records in the newly created trail, which you can view in CloudTrail. The following code example shows a CloudTrail record of a DeleteItem action, which is the action you performed in the previous step: { "eventVersion": "1.06", "userIdentity": { "type": "AssumedRole", "principalId": ":", "arn": "arn:aws:sts:: :assumed-role//", "accountId": "", "accessKeyId": "", "sessionContext": { "sessionIssuer": { "type": "Role", "principalId": "", "arn": "arn:aws:iam:: :role/", "accountId": ", "userName": "" }, "attributes": { "creationDate": "2020-10-01T20:00:25Z", "mfaAuthenticated": "false" } } }, "eventTime": "2020-10-20T15:00:25Z ", "eventSource": "dynamodb.amazonaws.com", "eventName": "DeleteItem", "awsRegion": "us-east-1", "sourceIPAddress": "", "userAgent": "console.amazonaws.com", "requestParameters": { "tableName": "", "key": { "key": "" }, "returnValue": "NONE", "returnConsumedCapacity": "NONE" }, "responseElements": null, "requestID": "", "eventID": "", "readOnly": false, "resources": [ { "accountId": "", "type": "AWS::DynamoDB::Table", "ARN": "arn:aws:dynamodb:us-east-1::table/" } ], "eventType": "AwsApiCall", "apiVersion": "2012-08-10", "managementEvent": false, "recipientAccountId": "", } The preceding CloudTrail record is for a single request to DynamoDB, and it details the user and data request information. The record includes a detailed attribution of the principal and the assumed role sessionContext that sent the request, as well as the sourceIPAddress and userAgent (in this case, the console), and whether the user was mfaAuthenticated (not in this case). In addition to the user identity, each record contains detailed information about the data event on DynamoDB. These details include requestParameters, tableName, key, eventName, and more. If a request fails, the error code also is logged. The record combines user and activity, which makes monitoring, alarming, and archiving possible for security and compliance requirements. This record’s user and data event attribution is the information your security team needs to identify a bad actor and build an authoritative reference of compromised activity. Security teams across industries, including finance, healthcare, education, and social media, use these attribution systems not only as detective and preventive controls (identifying and blocking access), but also as a corrective control (impact analysis). Given the potentially high volume of requests per second on a DynamoDB table, it’s important that you consider how you use your data event logs. If your logs are for audit purposes, you should keep the logs active all the time and apply appropriate data lifecycle policies to the data in the S3 bucket. However, if you need the data event logs only for specific activities, such as user access audits, user behavior validation, or troubleshooting, you can enable and disable data event logging situationally in CloudTrail. For robust monitoring and alerting, you also can integrate data events with Amazon CloudWatch Logs. To enhance your analysis of DynamoDB service activity and identify changes in activities for an AWS account, you can query AWS CloudTrail logs using Amazon Athena. For example, you can use queries to identify trends and further isolate activity by attributes, such as source IP address or user. Cleaning up After you create a DynamoDB table and CloudTrail trail, enable data events, create a DynamoDB item, and review the result in CloudTrail, you should remove any resources that you created in this process. Resources that remain active can incur associated costs. Conclusion In this post, we showed how you can use CloudTrail to enable data plane event logging on DynamoDB tables so you can extract invaluable insights to help meet your organization’s security practices for compliance and auditing purposes. To learn more about DynamoDB data plane event logging, see Logging DynamoDB Operations by Using AWS CloudTrail. Additional charges apply for data events. For more information, see AWS CloudTrail pricing. About the Authors Mazen Ali is a Senior Technical Product Manager on the Amazon DynamoDB team. https://aws.amazon.com/blogs/database/amazon-dynamodb-now-supports-audit-logging-and-monitoring-using-aws-cloudtrail/
0 notes
Text
Version 426
youtube
windows
zip
exe
macOS
app
linux
tar.gz
I had a great week. I mostly fixed and cleaned things.
downloaders from the future
It seems gelbooru changed their markup recently, and our default downloader stopped pulling tags, at least for some. A user helpfully created an update--which is rolled into today's release if you missed it--but unfortunately users who were running older clients ran into an unusual versioning bug. The updated downloader would only work correctly on above v422 or so, leading older clients to get a variety of annoying errors about 'md5', 'hex' or 'additional_info' when either booting or trying to inspect the broken object.
I have fixed the problem here. Anyone who recently imported a 'downloader from the future' should have it fixed today. Furthermore, the various ways you import downloaders now try to check against versions your current client can support, and if they are too advanced, you now get a nice non-spammy popup message and the too-complex objects are discarded from the import. If the advanced object is buried deeper inside the downloader, it may not be able to discard neatly yet, and you will just get a 'soft' popup message about it, but I hope to tighten this up in future.
This version checking is also applied more softly across the whole program. It is less likely that one of your internal objects will be from the 'future', but the client will now make a popup if this is so. Please let me know if you get a whole bunch of these. With luck, this is ultimately a rare problem and I can toughen up this error and actually stop clients from running if their objects ever turn invalid.
I also fixed up error recovery in the downloader system UI and multi-column lists across the program. When some borked object enters them, they now try to show an appropriate 'cannot render' style text, rather than raising an error.
the rest
I also updated the gelbooru pools downloader. Some users get different pool 'gallery' markup from the site, we are not sure why, but it should be fixed now.
Last week's network object breakup went well overall. There was one unfortunate but harmless error popup that could appear on client shutdown, typically when certain websites had downloads start in the last five minutes of the program, which I have fixed.
Also fixed is the new fast tag search sometimes dropping subtag results. If you noticed that 'samus aran' was not appearing in results, even though 'character:samus aran' existed and could appear in a 'character:anything' query, this is now fixed. Thank you to the users who reported on this and helped me figure it out. A new maintenance routine will run on update to fill in any gaps that may have appeared for you. It shouldn't take more than a minute, even if you sync with the PTR.
I added a new 'profile' mode to the help->debug menu, 'callto profile mode'. This one tracks mostly UI-level jobs that work in the background. If I have been talking to you recently about heavy downloaders or similar making the UI juddery, please give it a go and send me the profile logs as usual. Also, profiles in general should be less spammy with the popups.
The 'bandwidth used this session' section of the main window's status bar is now more accurate. In certain cases, after a delay, it could report bandwidth used in a session in the hours or days before boot, but now it is exclusive to this session. The difference here is usually not noticeable, but if you restarted a client after pausing all network traffic and then left it open for three hours, it could be confusing!
full list
misc:
thanks to help from Codexx at 8chan.moe, the old 8kun board is completely migrated and archived at 8chan.moe /hydrus/. going forward I will be maintaining a Hydrus Network General there on /t/ for merged release posts, Q&A, and Bug Reports. the plan is that whenever it fills up, it will be moved to the /hydrus/ archive. the links across the program and help are updated, please let me know if I missed any. Endchan /hydrus/ remains as a bunker
fixed a bug where subtag entries in the new tag fast search cache were being deleted for all namespaces when a single namespaced version was went to count 0. it meant some autocomplete results were not appearing, often after some sibling changes. a new 'repopulate' job has been added to the database regenerate menu to fix this efficiently if something like it happens again. this routine will be run on update to fix all users, it shouldn't take long (issue #785)
fixed a bug where the new network objects would throw an error on save when a 'dirty' object was quickly deleted. I think this was typically sessions that only have ephemeral session cookies being created in the final five minutes of the program and then being cleared during program exit
when an archive/delete filter finishes, it now fires off all its changes in one go. previously they would go in ~64-file chunks over the next few hundred milliseconds. this will add a small amount of 'refresh lag', delaying page refreshes etc..., on bigger filter jobs for some clients, but it will guarantee that if you hit F5 real quick after finishing filtering on a processing page with non-random sort, you won't see the same files again at the top, only for them to be swiftly archived/deleted as you watch. trash file performance is much better these days, let me know how this goes for you if you do megafilters
the tag import options whitelist now checks subtags of parsed tags. if you add 'samus aran' to the whitelist, but the site delivers 'character:samus aran', this now passes the whitelist
thanks to a user's submission, the gelbooru 0.2.5 post parser is updated and should get tags again, for those users who stopped getting them last week--however, I never experienced this myself, so please let me know if you still have trouble. there could be something more complicated going on here
updated the gelbooru 0.2.x gallery parser to handle an alternate form of gelbooru pools--we did not figure out why different users are being given different markup, it wasn't as simple as being logged in or not, but there is a difference for some. this parser is folded in on update, so the gelb pool downloader should be fixed for users who had trouble with it
also updated the gelbooru pool gallery url class to infer next page url, as in the alternate form the next page is difficult to parse
the 'clear all closed pages' command under the 'undo' menu now asks for yes/no confirmation
added a 'callto' profile mode, which will be very useful in diagnosing GPU lag in future. the 'callto' jobs are little off-main-thread things like image rendering and async panel preparation. should help us figure out where big download pages etc... are eating up CPU
the different profile modes in the debug menu now all show popup messages, but only when their job exceeds the particular profile's interesting time, usually 3-20ms. this should reduce spam
the 'this session' bandwidth tracker on the status bar is now a special tracker that only includes data from boot. previously, it was using the 'global' tracker, which after certain time intervals (four minutes, three hours, three days), will compress bandwidth history into larger time windows to save space. if one of these windows covered time before the client started, it could spookily report a little bandwidth used on a client started with network traffic paused
bandwidth data usage in times shorter than the last ten seconds (which are smoothed out to avoid bumps) now also get the 'don't get bandwidth from the future on motherboards that had a briefly crazy system clock' fix from last week
fixed some disengaged database tuning that was leading to worse cancel times on certain jobs
updated a whole bunch of the help so section headings are links with nice #fragment/anchor ids, making it easy to link other users to a particular section. I will continue this work, and future help will follow this new format
fixed some bad character encodings in the changelog document, siblings help, and tagging schema help. these should now be utf-8 valid
.
object load improvements:
the client now detects serialisable (saveable) objects that were generated in a future version format your client does not yet support. this mostly affects downloader objects like parsers, where you might import an object a user in a much newer version of the client made. for instance, this week some users imported a fixed gelbooru parser in an older client, which was then saved and double-updated later on, and that caused other problems down the line. downloader imports deal with this situation cleanly, but otherwise it mostly makes a popup notifying you of the problem and asking to contact me. there are about 170 places in the program where objects are deserialised and I am not ready to make this a fullblown error until I know more about people's IRL situations. let's hope this is not widespread. if you run into this, please let me know!
if you were running an older client and manually imported the updated gelbooru parser that was going around, and then you got errors about 'md5', hex' or 'additional_info' something, it _should_ be automatically fixed on update. you should be able to update from previous to ~422, see it in network->downloader components->manage parsers, and it should just work. many users will have the entry overwritten anyway in the above gelb update I am rolling in. if any of this does still give you trouble, please delete and re-import the affected object(s)
importing one of these future-versioned serialised objects using the import/export buttons on a multi-column list, either clipboard, json, or png, will cleanly discard future objects with a non-spammy notification
the Lain drag-and-drop easy downloader import does the same
the parser 'show what this can parse in nice text' routine now fails gracefully
multi-column lists now handle a situation where either the display or sort data for a row cannot be generated. a single error popup per list will be generated so as not to spam, bad sorts will be put at the top, and 'unable to render' will occupy all display cells
.
network server stuff
fixed being able to delete an account type in the server admin menu
the way accounts are checked for permissions serverside now works how the client api does it, unified into a neater system that checks before the job starts
did some misc server code cleanup, and clientside, prepped for restoring account modification and future improvements
next week
I started on the network updates this week. I will be cleaning more server code and reworking my ancient unit tests, and getting some older admin commands that were 'temporarily' turned off working again. I'll also continue reformatting the help to make sure all the headers have #fragment links, to help external linking to specific sections.
0 notes
Text
2020: Typhoons batter PH amid health crisis
#PHnews: 2020: Typhoons batter PH amid health crisis
MANILA – While the Philippines is trying to recover from the economic recession brought about by the coronavirus disease 2019 (Covid-19) pandemic, three strong typhoons hit hard parts of the country in the last quarter of 2020, causing billions of agricultural and infrastructure damages, not to mention the lives lost.
Typhoons Rolly, Ulysses, and Vicky claimed lives, damaged crops, destroyed homes and infrastructures, and flooded communities and provinces especially in the Bicol Region and Cagayan Valley. The death count from Ulysses, considered to be the deadliest that hit the country this year, climbed to over 100 and left more than PHP20 billion in damage.
Hard-hit areas include Cagayan Valley, Central Luzon, Calabarzon, Bicol, Cordillera Administrative Region (CAR) and the National Capital Region (NCR).
The typhoons left many provinces underwater for weeks.
The National Disaster Risk Reduction and Management Council (NDRRMC) said the terrain in said areas has been saturated. pushing the risk of massive flooding incidents to become higher.
President Rodrigo Duterte immediately formed the Build Back Better Task Force to oversee rehabilitation efforts of these typhoon-hit areas.
The task force also targets to streamline and expedite post-disaster efforts in a sustained and integrated manner.
Department of Environment and Natural Resources (DENR) Secretary Roy Cimatu and Department of Public Works and Highways (DPWH) Secretary Mark Villar were assigned to lead the task force.
Under the recommendation of the NDRRMC, Duterte placed the entire Luzon island under a state of calamity to hasten the relief and rehabilitation efforts.
To help mitigate future calamities, the government said environmental plans will be in place to help cushion their effects.
The DENR was tasked by Duterte to strengthen its forest protection programs and look into illegal logging and mining problems which are reported to have caused the flooding in Cagayan province.
They were also instructed to investigate the connection between the landslides and the illegal mining activities in the Cagayan Valley.
Cagayan River dredging
Meanwhile, the DENR recently inked a memorandum of agreement (MOA) with two dredging operators valid for two years for free.
In February, Cimatu issued DENR Administrative Order (DAO) 2020-07 rationalizing dredging activities in heavily silted river channels in the country to help restore their natural state and water flow and reduce flooding.
The order will also ensure the protection and proper management of the disposition of sand.
For the Cagayan River, the approved River Dredging Plan covers 30.8 kilometers of the river dredging zone.
The MOA states that the DENR shall conduct a survey of non-metallic and metallic resources in the River Dredging Zone to determine valuable materials.
To avoid future flooding in Cagayan, DENR said the Magapit River will be widened to avoid bottlenecks and cause severe flooding in communities.
Cimatu said dredging is necessary for the heavily silted Cagayan River, the longest and the largest by discharge volume of water in the country, to prevent a repeat of the massive flooding in the provinces of Cagayan and Isabela during successive typhoons last month.
Aside from dredging, he added that they will strictly enforce a 20-meter easement rule along both sides of the river.
DENR, Cimatu said, will also look at illegal logging activities especially in Sierra Madre, Cordillera, and Caraballo mountain.
Greening, tree planting
Aside from dredging, the DENR will also be conducting widespread tree planting activities.
In Cagayan River, Cimatu said they will be planting bamboos 20-meter wide from the river banks.
The DENR also said there are about 200 million trees ready to be planted once the project has been finalized together with concerned local government units (LGUs) and the private sector.
Meanwhile, the DENR said it is on track to surpass its reforestation target for 2020.
The latest data from DENR shows about 45,000 hectares out of the 47,166 hectares 2020 target or 95 percent of denuded and open forestland have been planted with 35.6 million seedlings.
Cimatu said he is confident that they will be able to hit their 2020 target under the government's reforestation initiative Enhanced National Greening Program (ENGP).
Stop illegal logging
Cimatu said illegal loggers must be stopped even before they are able to cut trees by shifting their efforts from reactive to preventive.
He said the massive flooding that occurred in the Cagayan Valley region, Rizal province, and Marikina City during the onslaught of Ulysses should serve as a “wake-up call”.
Cimatu said confiscated undocumented forest products are not trophies but rather a “manifestation of their failure” as DENR enforcement officers because this means the agency failed to prevent these trees from being illegally cut.
Cimatu also created four special composite teams that would prevent anti-illegal logging operations in Cagayan Valley, the Bicol Region, and the Upper Marikina River Basin Protected Landscape.
He said identifying and penalizing the financiers and operators of illegal loggers is the key to curb unauthorized activities.
Cimatu earlier said the DENR would not scale down its efforts in enforcing forestry laws, pandemic or not.
Probe quarry operations
The four composite teams formed by the DENR will also investigate quarry operations in the province of Rizal following the massive flooding that affected some of its towns and the nearby Marikina City.
The teams will focus on the quarry operations within the Marikina River Basin equipped with aerial mapping drones.
The residents in the area blame the illegal quarrying for the destructive floods that left them submerged with floods.
To date, the Mines and Geosciences Bureau (MGB) in Calabarzon earlier issued a temporary suspension of at least 11 quarry and crushing plant operators within the river basin that drains toward the Marikina River. (PNA)
***
References:
* Philippine News Agency. "2020: Typhoons batter PH amid health crisis." Philippine News Agency. https://www.pna.gov.ph/articles/1125950 (accessed December 30, 2020 at 11:28PM UTC+14).
* Philippine News Agency. "2020: Typhoons batter PH amid health crisis." Archive Today. https://archive.ph/?run=1&url=https://www.pna.gov.ph/articles/1125950 (archived).
0 notes
Text
Your Web-Site Is Not Secure Anymore
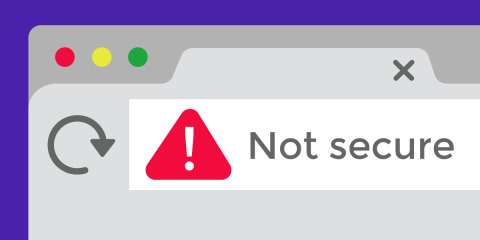
Cyber-Invasion is a growing menace for every business, whether it’s stealing private data, taking control of your digital system, or shutting down your Web-Site. The Cyber-Criminals can seriously impact any business, at any time. VBK Technologies have been running analysis since its existence on different possible Cyber-Invading techniques and hence has been proven a record in securing Web-Based-Applications. As a company, we always desire to improve our service and deliver the best result to our customers. Hence, our development team works every-day to save our customers from every kind of Cyber-Invasion. To the amazement, VBK Technologies has not only stood up for their customers in the past but now it has been providing ground-breaking research for all their customers with special deliverables given services from VBK Technologies. But there is a side, which VBK Technologies has chosen to opt for the betterment of the web world, and it’s White Ethical Cyber-Invasion which makes its way through the corporate business world and provides in-depth security services for an overall web security protection to their valued customers. Apart from that, we have maintained a wise standard, when it comes to Infection Hunting and hence proven excellence for its quality and Security Excellence. Our team has taken the responsibility to represent our company and earned much gratitude. Whether it is on spreading information security concerns, attending a conference related to Cyber-security, educating industries regarding recent Cyber-Threats and how to deal with those strikes. This has vastly resulted in extreme awareness among various business owners and they have to take matters seriously or else it can bring great losses for their business. Cyber-Criminals can infiltrate your security in so many ways; however, in this article, we have mentioned some of the techniques Employed in most popular Cyber-Invasions.
Remote Code Execution Cyber-Invasion
A Remote Code Execution Cyber-Invasion is a result of either server-side or client-side security weaknesses. The libraries, frameworks, remote directories on a server that haven’t been monitored and other programing modules that run on the basis of authenticated Client access can be extremely vulnerable components and the Web-Applications that Employs these components are always invaded by things like scripts, virus, and small command lines that extract information. By failing to provide an identity token, Cyber-Criminal could invoke any web service with full permission.
Cross Web-Site Request Forgery Cyber-Invasion
A Cross Web-Site Request Forgery Cyber-Invasion happens when a Client is logged into a session (or account) and a Cyber-CriminalsEmploys this opportunity to send them a forged HTTP request to collect their cookie information. In most cases, the cookie remains valid as long as the Client or the Cyber-Criminal stay logged into the account. This is why Web-Siteasks you to log out of your account when you’re finished — it will expire the session immediately. In some cases, The Cyber-Criminals can generate requests to the application, once the Client’s browser session is compromised and the worst part is that the application won’t be able to differentiate between a valid Client and a Cyber-Criminal. In this case, the Cyber-Criminals creates a request that will transfer money from a Client’s account and then embeds this strike in an image request or iframe stored on various Web-Sites under the Cyber-Criminal’s control.
Packet Editing
Packet editing Cyber-Invasions are silent infiltration. Cyber-Criminalsstrike in the midst of data being exchanged, but both the Client and Web-Site administrators do not know that the Cyber-Invasion is occurring.
When a Client makes a request to the web server processes the request and responds back to the Client. For example, if a Client executes Web-Based-Applications, then the webserver will send a response so that the Client can process the data they requested. However, while the web server sends the response, a Cyber-Criminal can edit the response and access unauthorized rights to that data. This is called Man in the Middle Cyber-Invasion or Packet editing.
Cyber-Invasion By Injections
Injection infiltration occurs when there are flaws in your SQL Data-Archives, SQL libraries, or even the operating system itself. When your company employees unknowingly open some credible files with hidden commands or injections, then in doing so they allow Cyber-Criminals to successfully gain unauthorized access to private data such as credit card numbers, social security numbers or other private financial information.
The Cyber-Criminal modifies the ‘id’ parameter in their browser to send: ‘ or ‘1’=’1. This changes the meaning of the query to return all the records from the accounts Data-Archives to the Cyber-Criminal, instead of only the intended customers.
Broken Authentication And Session Management Cyber-Invasions
Cyber-Invasion is a growing menace for every business, whether it’s stealing private data, taking control of your digital system, or shutting down your Web-Site. The Cyber-Criminals can seriously impact any business, at any time. VBK Technologies have been running analysis since its existence on different possible Cyber-Invading techniques and hence has been proven a record in securing Web-Based-Applications. As a company, we always desire to improve our service and deliver the best result to our customers. Hence, our development team works every-day to save our customers from every kind of Cyber-Invasion. To the amazement, VBK Technologies has not only stood up for their customers in the past but now it has been providing ground-breaking research for all their customers with special deliverables given services from VBK Technologies. But there is a side, which VBK Technologies has chosen to opt for the betterment of the web world, and it’s White Ethical Cyber-Invasion which makes its way through the corporate business world and provides in-depth security services for an overall web security protection to their valued customers. Apart from that, we have maintained a wise standard, when it comes to Infection Hunting and hence proven excellence for its quality and Security Excellence. Our team has taken the responsibility to represent our company and earned much gratitude. Whether it is on spreading information security concerns, attending a conference related to Cyber-security, educating industries regarding recent Cyber-Threats and how to deal with those strikes. This has vastly resulted in extreme awareness among various business owners and they have to take matters seriously or else it can bring great losses for their business. Cyber-Criminals can infiltrate your security in so many ways; however, in this article, we have mentioned some of the techniques Employed in most popular Cyber-Invasions.
Click-Jacking Cyber-Invasions
Click-Jacking also called a UI Redress Cyber-Invasions, is when Cyber-Criminal Employs multiple opaque layers to trick a Client into clicking the top layer without them knowing.Thus the Cyber-Criminal is “hijacking” clicks that are not meant for the actual page, but for a page where the Cyber-Criminal wants you to be. For instance, by employing a safely crafted combination of iframes, text boxes, and stylesheets, leads a Client to assume that they are typing in the login credentials for their bank account, but they are actually typing into an invisible frame controlled by the Cyber-Criminal.
DDoS Cyber-Invasions
DDoS, or Distributed Denial of Services, is where a server or a machine’s services are made unavailable to its Clients and when the system is offline, the Cyber-Criminal proceeds to either compromise the entire Web-Site or a specific function of a Web-Site to their own advantage. It’s kind of like having your car stolen when you really required it. The normal goal of a DDoS Cyber-Invasion is to completely take down or temporarily interrupt successfully running system. The most common example of a DDoS Cyber-Invasions could be sending tons of URL requests to a Web-Site or a webpage in a very small amount of time. This may result in bottlenecking at the server-side because the CPU just ran out of resources. Denial-of-service Cyber-Invasions are considered violations of the Internet practice policy issued by the Internet Architecture Board and it also violates the acceptable internet practice policies of virtually all Internet service providers.
Cross Website Scripting Cyber-Invasions
Cross Web-Site Scripting, which is also described as an XSS Cyber-Invasion, occurs when an application, URL receives a requestor file packet. The infected packet or request then travels to the web browser window and bypasses the validation process. Once an XSS script is triggered, its deceptive property makes Clients believe that the compromised page of a specific Web-Site is legitimate. For Instance, if www.abcdxyzple.com/gfdhxccd.html has XSS script in it, the Client might see a popup window asking for their credit card info and other sensitive info. As a result, the Client’s session ID will be sent to the Cyber-Criminal’s Web-Site, allowing the Cyber-Criminals to hijack the Client’s current session. That means the Cyber-Criminals has access to the Web-Site admin credentials and can take complete control over it.
Symlinking–An Insider’s Cyber-Invasions
A Symlink is basically a special file that “points to” a hard link on a mounted file system. A Symlinking Cyber-Invasion occurs when Cyber-Criminal positions the Symlink in such a way that the Client or applications that access the endpoint think they’re accessing the right file when they’re really not.
If the endpoint file is output, the consequence of the Symlink Cyber-Invasions is that it could be modified instead of the file at the intended location. Alteration made in the endpoint file could include overwriting, corrupting, changing permissions or even appending. In different variations of a Symlinking Cyber-Invasion, a Cyber-Criminal may be able to control the changes to a file, grant them advanced access, insert false information, expose sensitive information or corrupt and manipulate application files.
DNS Cache Poisoning
DNS Cache Poisoning also described as DNS Spoofing, involves old cache data that you might think you no longer have on your digital-system. The Cyber-Criminal can identify the liabilities in the domain name system, which allows them to exploit those liabilities and divert traffic from legit servers to a fake WebSite or Server. This form of Cyber-Invasion can spread and replicate itself from one DNS server to another DNS, “poisoning” everything in its path. Once the DNS server finds the appropriate IP address, data transfer can begin between the client and Web-Site’s server. The given below visualization will display how this process will take place at a larger scale. Once the DNS server locates domain-to-IP translation, then it has to cache subsequent requests for the domain. As a result, the DNS lookup will happen much faster. However, this is where DNS spoofing can act as a great trouble creator, as a false DNS lookup can be injected into the DNS server’s cache. This can result in an alteration of the visitors’ destination.
Since DNS servers cache the DNS translation for faster, more efficient browsing, Cyber-Criminals can take advantage of this to perform DNS spoofing. If a Cyber-Criminal is able to inject a forged DNS entry into the DNS server, all clients will now be using that forged DNS entry until the cache expires. The moment the cache expires, the DNS entry has to return to the normal state, as again the DNS server has to go through the complete DNS lookup. However, if the DNS server’s Programs still hasn’t been updated, then the Cyber-Criminal can replicate this error and continue funneling visitors to their Web-Site.DNS cache poisoning can also sometimes be quite complex to spot. If the Infected Web-Site is very similar to the Web-Site it is trying to impersonate, some clients’ may not even notice the difference. Additionally, if the Cyber-Criminal is using DNS cache poisoning to compromise one company’s DNS records in order to have access to their emails for example, then this may also be extremely complex to detect.
Social Engineering Cyber-Invasions
A social engineering strike is not technically a Cyber-Invasion. However, you can become of a larger scam or a Cyber-Invasion, if you share your information out of good faith. By sharing information such as credit card numbers, social security numbers, and banking credentials. You allow those scammers to exploit that information and they can use your information for any illegal activities. People pretending to call you from Microsoft can take control of your systems and once they do take the control of your system, then all your personals information including your browsing information and credentials are at risk of being comprised. As matter of fact, they have no intention to fix any of your issues, but instead, they only require one-time access of your computer to plant their infected files and enjoy the unlimited access to all the information saved in your system or other activities your perform. If they succeed in planting infected files in your computer then it is highly possible that they can monitor each and every activity you do on that system, those infected files can save all your credentials and browsing activity to transmit that information to those scammers.
Web Server Security And Server Security
Various high-profile cyber-Invasion have proven that web security remains the most critical issue to any business that conducts its operations online. Due to the sensitive information they usually host, the web servers are one of the most targeted public faces of an organization. Securing a web server is as important as securing the Web-Site or Web-Based-Applications itself and the network around it. If you have a secure Web-Based-Applications and an insecure web server, or vice versa, it still puts your business at a huge peril. Only by strengthening the venerable point, one can ensure the optimum security of their company’s server. However, securing a web server can be an extremely complex task to do and a frustrating one too, as one might have to take the help of the trained professional. In addition to that one might have to spend multiple hours of coding and research, an overdose of caffeine to save them from working all night without headaches and data infiltration in the future. Irrelevant of what web server programs and operating system you are running, and out of the box configuration is usually insecure. It extremely important, that you take the necessary steps to increase web-server security.
Remote Access
Nowadays it is neither logical nor practical when the admin has to login to the local webserver. If remote access is required, one must make sure that the remote connection is secured properly, by using tunneling and encryption protocols. Using security tokens and other single sign-on equipment and programs is a very good security practice. It is extremely important that one must restrict the remote access to a specific number of IP’s and only to authorized accounts. It is also very essential that one should avoid operating their digital-systems, on public networks to access corporate servers remotely. Accessing private and confidential servers using places like public wireless networks or internet cafes can result in a huge breach in your security in the future.
Deserted Accounts
Deserted default Client accounts created during an operating system install should be disabled. There is also a long list of programs that were installed when Client accounts were created on the operating system. Such accounts should also be checked properly and change of permissions is highly required. The built-in administrator account should be renamed and it should not be abandoned, same for the root Client on a Linux / Unix installation. Every administrator accessing the webserver should have his own Client account, with the correct privileges required. It is also a good security practice not to share each other’s Client accounts.
Remove All Deserted Modules, Application, Extensions And Unnecessary Services
Mostly when it comes to installation of Apache, then it is most likely that the installation will have a number of pre-defined modules enabled, which are not at all required in a typical web server scenario, until and unless they are specifically required. Turn off such modules to prevent targeted Cyber-Invasion against such modules. The same thing goes with the Microsoft-Web Server; As in this installation, the IIS is configured to serve an immense amount of application types. The list of application extensions should only contain a list of extensions the Web-Site or Web-Based-Applications will be using. Every application extension should also be restricted to employ specific HTTP verbs only, where possible. Only Employ security tools provided with web server programs. Recently Microsoft has launched various tools to assist the system admin to successfully secure IIS web server installation process. The Apache also has a module known as Mod_Security, however, configuring such tools is extremity time consuming and very tedious process and they do have to add an extra bit of security and peace of mind, especially when it comes to custom Web-Based-Applications. The default installation of the operating system and configurations is not that secure. In other words in a default installation, many services related to network are installed which are not actually useful for web server configuration. This includes services such as RAS, print server service and remote registry services. The more services running on an operating system, the more ports will be left open, thus leaving more open doors for infected Clients to exploit. I highly recommend that one should turn off all the unimportant service, so they don’t start automatically every time you reboot the server. In addition to that turning off unnecessary services will also provide an extra boost to your server performance by reducing the excess load on your server’s hardware.
Employ Web-Liability Scanners
Scanners are handy tools that help you automate and ease the process of securing a web server and Web-Based-Applications. Now a day various Web-Liability Scanners also come equipped with a port scanner, which when enabled will port scan the web server hosting the Web-Based-Applications being scanned. Similar to a network security scanner, In the future, we might also have a number of advanced security checks against the open ports and network services running on your web server. In addition to that these Web-Liability Scanners ensure Web-Site and web server security by checking for SQL Injection, Cross Web-Site scripting, web server configuration problems, and other vulnerabilities. It checks password strength on authentication pages and automatically audits shopping carts, forms, dynamic Web 2.0 content, and other Web-Based-Applications. As the scan is completed, the programs produce detailed reports that pinpoint where vulnerabilities exist.
Monitor And Audit The Server
It is extremely important that you store every log that are present in a Web-Server in a segregated area. Archives like Web-Site access logs, network services logs, Data-Archives server logs, and operating system logs should be actively monitored and frequently inspected and should not avoid any strange log entries. Log files tend to give all the information about an attempt of a Cyber-Invasion, and even a successful strike, but most of the time these are ignored. If one witnesses any strange activity from the logs, then they should address or escalate that matter immediately, so the issue can be further investigated.
Install All Security Patches On Time
If someone assumes that by employing fully patched programs they have fully secured their server then they are living in huge illusion, as having fully patched programs does not mean that their server is fully secure. It is also extremely essential for one to maintain the latest version of their operating system, latest security patches and any other programs running on that operating system. Up until this day, Cyber-Invasion incidents still occur because Cyber-Criminals took advantage and exploited unpatched servers and programs.
Permissions and Privileges
Network and file sharing permission plays a significant role in overall Web-Server security, as if a web server engine is compromised via network service programs, the infected Client can operate the account on which the network service is running to carry out tasks, such as execute specific files. Hence, it is extremely essential for one to always assign the least privileges required for a network service to operate. It is also very important to assign minimum privileges to the anonymous Client who requires access to the Web-Site, Web-Based-Applications files and also backend data and Data-Archives.
Separate Development / Testing / Production Environment
Since it is easier and faster for a developer to develop a newer version of Web-Based-Applications on a production server, it is quite common that development and testing of Web-Based-Applications are done directly on the production servers itself. It is a common occurrence on the internet to find newer versions of a specific Web-Site, or some content which should not be available to the public in directories such as /test/, /new/ or other similar subdirectories.
Because the Web-Based-Applications were tended to various vulnerabilities in their early stages of development and they use to lack in a number of input validation and sometimes failed greatly in providing satisfactory results. Such applications could easily be discovered and exploited by an infected Client, by using free available tools on the internet.
To ease more the development and testing of Web-Based-Applications, developers tend to develop specific internal applications that give them privileged access to the Web-Based-Applications, Data-Archives and other web server resources, which a normal anonymous Client would not have. Such Web-Base Application lacks various types of restrictions and they are just test applications only operated by developers. Once the developers complete their testing and development process, on a production server, then it is extremely easy to discover these applications employing infected Clients. This might help the Cyber-Criminals to compromise or exploit sensitive information to gain control over the production server.
Ideally, development and testing of Web-Based-Applications should always be done on servers isolated from the internet, and should never involve or connect to real-life data-archives.
Web-Based-Applications Content And Server-Side Scripting
The Web-Based-Applications or Web-Site files and scripts should always be on a separate partition or drive other than that of the operating system, logs, and any other system files. During our year of encounters with the case files related to various activities of these Cyber-Criminals, we have learnt one thing that by gaining access to the webroot directory, the invaders can easily exploit other liabilities and then they can further access on various other sensitive information such as operating system and other system files and the data of the whole disc. From there onwards, the infected Clients have access to execute any operating system command, resulting in complete control of the webserver.
Stay Informed
Nowadays, information and tips on the programs and operating system being exercised can be found freely on the internet. It is highly recommended for one to stay aware and they should keep researching the latest Cyber-Invasions and the techniques used to carry out the invasion and by reading these security-related newsletters, forums, magazines and another type of community. You will have a chance to come up with better security measures.
#cybersecurity#technology#web development#web design#security#Webmaster#technologies#webdesign#Secure#web developing company#web developers#blog
0 notes
Text
Moving from KDP to IngramSpark
During August and September of 2018, Createspace officially merged with Amazon’s Kindle Direct Publishing (KDP), and the usage of the previous interface, rules, and pricing were no longer valid. The migration process was a bit of a learning curve for many people and caused some indie authors and publishers to steer away from Amazon’s services altogether. Each person has their reasons as to why they want to move away from Amazon’s KDP, this blog post is not to discuss the why. So where do you go and how do you do it? There are other print on demand services out there such as Lulu, Blurb, and IngramSpark. In this post, we’re going to look at moving from KDP to IngramSpark.
Why IngramSpark?
Competitive pricing and customization. Some of the other print on demand services offer excellent products as well. I have used Blurb before and like it. However, they don’t have the same customizations or price point per book as IngramSpark has.
Yes, Amazon’s KDP is still cheaper, but this post isn’t about convincing you why you should move from Amazon’s KDP. We’re going to assume you already made your choice why, for whatever the reason may be. This post is about how to do it.
From the time I migrated my first book over to IngramSpark – which was January 2019 – there was very little information online. The process I took was trial and error, a couple of months of determination, and some costly mistakes. I hope the information here helps you avoid some headaches during your migration!
Step One: Do you own your ISBN?
Okay, so we’re ready to migrate our book from KDP to IngramSpark. The first question to ask yourself is: do you own your ISBN? Or did Amazon provide one for you? If you own your ISBN, then great, you can migrate the same version of the book over to IngramSpark. If you don’t own your ISBN (Amazon provided one for you), you cannot migrate this edition of your book. This is a critical step. The process below is intended if you own your ISBN and need to make the migration over to IngramSpark.
Find out more about getting your own ISBN on selfpublishing.com.
Why Transfer an ISBN Vs Making a New One?
The benefit of keeping your ISBN vs just making a new one is you keep the edition of your book. All sales, stores, libraries, and archives reference the ISBN to know what book is what. When you get a new ISBN, you are creating a new version of your book, and it needs to be resubmitted to book stores like Indigo, sites like Goodreads, etc. Basically, you are publishing a new book.
Step Two: Creating an IngramSpark account
This should be a no-brainer but make sure you create an account on their website. Follow their steps which are very similar to Amazon’s KDP. There are a few different choices on terminology, but that is all.
Do not begin re-creating your title in IngramSpark yet. Doing so, your re-created title on Ingramspark will be replaced with the latest-live Amazon version if you migrate the same ISBN version. Read the steps below to see if you need to create the title or not.
Using a New ISBN
For those that do not own their own ISBN, you need to obtain a new one. This process is more straightforward than transferring an ISBN you own. In Canada, they are free through the Government’s website. If you’re in the USA, IngramSpark does let you buy an ISBN through Bowker. Once you obtain a new ISBN, you can follow the steps of creating a new novel on IngramSpark’s website, order a proof, and publish.
Step Three: Migrating Your Existing ISBN
Remember, with Amazon, once your book is published, it can never officially be removed from Amazon. Even if you unpublish it, the book still appears on search results and your author page. It’s up to you if you want to continue having your book available on Amazon for people to buy or if you want to unpublish it completely. The steps below are the same.
Log onto KDP and edit the paperback you wish to migrate.
Go to Paperback Rights & Pricing
Uncheck “Expanded Distribution”
Both KDP and IngramSpark have a distribution with the same resellers and leaving this checked on creates a conflict between the two distributors. Be sure to uncheck it, so the book is only on the Amazon marketplace.
Contact Amazon by going to their help, under Book Details and ISBN. Choose either E-mail or Phone, whichever you prefer.
For email, be very specific what you want to do. For the subject: Migrating my ISBN 000-0-0000000-0-0 over to IngramSpark For the message include this sentence: Please release my ISBN 000-0-0000000-0-0 to allow IngramSpark to migrate the book. Amazon’s support prefers exact instructions. I failed to mention IngramSpark the first time, and they denied releasing my ISBN. Be polite and respectful too. It gets you a lot further than demanding.
Step Four: Inform IngramSpark
After you have finished the initiation process with KDP, inform IngramSpark through their Live Chat which ISBN and title of your book you are migrating. Inform them that you want to distribute through IngramSpark and have already requested for KDP to release the ISBN.
Ingram will send you a transfer form for you to fill out and send back to them. Once this is complete, the process can take about 30 days for the migration to be finished.
Step Five: Review
Now, you wait 30 days. You will get an email when the migration is complete which can take less time. If it does, be sure to order a proof copy of your book and review all settings and metadata to ensure it is correct.
IngramSpark copies the last live published version of your book from Amazon KDP. Ordering a proof is a good indicator to ensure that you are printing the right file. Unlike KDP, there is a charge for updating the file. To avoid future charges, be sure that your proof is correct before hitting publish.
Summary
Moving from KDP to IngramSpark is a lengthy, technical, process. Be patient and professional during the process, and it will go as smoothly as it can. Again, for whatever the reason is for you to move from Amazon’s KDP, I hope this guide offers some clear direction on the process. When I went through the process, most information I could find was out of date and inaccurate.
If you have some of your own experiences with migrating from KDP or have questions, please share in the comments.
0 notes
Text
MySQL Backup and Recovery Best Practices
In this blog, we will review all the backup and restore strategies for MySQL, the cornerstones of any application. There are a few options, depending on your topology, MySQL versions, etc. And based on that, there are some questions we need to ask ourselves to make sure we make the right choices. How many backups we need to keep safe, or what’s the best retention policy for us? This means the number of backups to safeguard, whether local or remote (external fileserver, cloud). The retention policy can be daily, weekly, or monthly, depending on the free space available. What is the Recovery Time Objective? The Recovery Time Objective (RTO) refers to the amount of time that may pass during a disruption before it exceeds the maximum allowable threshold specified in the Business Continuity Plan. The key question related to RTO is, “How quickly must the data on this system be restored?” What is the Recovery Point Objective? The Recovery Point Objective (RPO) is the duration of time and service level within which a business process must be stored after a disaster in order to avoid unacceptable consequences associated with a break in continuity. The key question related to RPO is, “How much data can we lose?” Different Types of Backups There are two backup types: physical and logical. Physical (Percona XtraBackup, RDS/LVM Snapshots, MySQL Enterprise Backup), and also you can use cp or rsync command lines to copy the datadir as long as mysql is down/stopped. Logical (mysqldump, mydumper, mysqlpump, mysql shell only for mysql 8) Also is recommended to take a copy of binlog files, why? Well, this will help us to recover until the last transaction. Why are backups needed? Backups are needed in case of multiple problems: Host Failure: We can get multiple problems from disks stalled or broken disks. Also from cloud services, our DB instance can be broken and it’s non-accessible. Corrupted Data: This can happen on a power outage, MySQL wasn’t able to write correctly and close the file, sometimes when MySQL starts again it cannot start due to corrupted data and the crash recovery process cannot fix it. Inconsistent Data: When a human mistake, delete/update erroneous data over the primary or replica node. DataCenter Failure: power outage or internet provider issues. Legislation/Regulation: provide consistent business value and customer satisfaction. Now let me explain those different types of backups mentioned above, but before I continue, it’s important to configure a new and dedicated replica node for backups purposes, due to the high CPU load to avoid any issue on any other replica node (AKA backup server). Logical Backup This is a dump from logical database structure (CREATE DATABASE, CREATE TABLE statements) and content (INSERT statements). This is recommended to be used against smaller amounts of data. The disadvantage of this method is slower (backup and restore) if you compare it with physical backups. Using mydumper you can backup and restore a single database or a single table if it’s needed, and this is useful to copy some data to a different environment to run tests. Also, mydumper can take a consistent (as long as all the tables are InnoDB engine) backup and provides accurate master and slave log positions. The output is larger than for physical backup, particularly when saved in text format, but it can be compressed on the fly depending on the software you are using. Mydumper can compress and mysqldump needs to add a pipe to redirect the output to gzip, for example. Logical backups are used to address data corruption or the need to restore a subset of tables. Physical (Raw) Backup In short, this consists of exact copies of database directories and files. This can be a copy for all or a part from MySQL datadir directory. This kind of backup is most used to restore or create a new replica node easily and quickly and is used to address host failure. It’s recommended to restore using the same MySQL version. I recommend using Percona XtraBackup because it can include any related files such as configuration files like cnf config files. Snapshot Backups Some file system implementations enable “snapshots” to be taken. These provide logical copies of the file system at a given point in time, without requiring a physical copy of the entire file system. MySQL itself does not provide the capability for taking file system snapshots but it is available using third-party solutions such as LVM or ZFS. The disadvantage is that sometimes physical backups do not compress much, because data is usually in a binary format and sometimes the table is already compressed. Binary Log Backups Binlog backups specifically address RPO. Binary log files contain records of each SQL query executed that made changes. From MySQL 5.6 on, you can use mysqlbinlog to stream binary logs from a remote server. You can combine binlog backups with Percona XtraBackup or mydumper backup to allow restoration up to the end of the most-recently-backed-up binary log. Incremental / Differential Backups An incremental backup is a backup of everything that has changed since the last backup (a binary log backup is a special case of an incremental backup). This is a very good option if the dataset size is huge, as you can take a full backup at the beginning of the week and run incremental backups per day. Also, the backup size is smaller than the full backup. The main risks associated with incremental backups are: – A single corrupt incremental backup may invalidate all the others – Incremental backups typically negatively affect the RTO For a differential backup, it copies the differences from your last backup, and the advantage is that a lot of data does not change from one backup to the next, so the result can be significantly smaller backups. This saves disk space. Percona XtraBackup supports both incremental and differential backups. Offsite Storage It’s highly recommended to copy all the backup methods to another place, like the cloud or an external file server, so in case of host failure or data center failure, you have another copy. Not all the backup files need to be uploaded to the cloud, sometimes the time you need to spend in the download is bigger than the time consumed in the recovery process. A good approach is to keep 1-7 days locally on the backup server in case a fast recovery is needed, and this depends on your business regulations. Encryption Backups have sensitive data, so it’s highly recommended to encrypt, especially for offsite storage. This adds more time when you need to restore a backup but it keeps your data safe. GPG is a good option to encrypt backups, and if you use this option or some other alternative, don’t forget to get a copy of the keys/passphrase. If you lose it, your backups will be useless. Restore Testing Depending on your business, it’s highly recommended to test your backups at least once per month. This action validates your backups are not corrupted and it provides critical metrics on recovery time. This process should be automated to get the full backup, restore it, and finally configure this server as a replica from the current primary or another replica. This is good as well to validate that the replication process has no errors. Many customers are using this methodology to refresh their QA/STG environment to have fresh data from production backups. In addition to the above, it is recommended to create a manual or automated restore documentation process to keep all the steps together, so in case of disaster, you can follow it without wasting time. Retention Requirements Last but not least, it is very important to keep multiple copies of different backup types. Our best recommendation is: One or two physical backups locally on the backup server (as long as space allows it). Seven daily and four weekly logical backups locally on the backup server. 30 days of binlog backups locally on the backup server. For offsite backups (like S3, Google Cloud, etc.), keep monthly backups for one year or more. For local backups, keep in mind you will need a minimum of 2.5 times the current dataset size as free disk space to save/meet these retention policies. Don’t forget to encrypt all the backup types! Legal or regulatory requirements may also dictate how long data must be archived. Percona Can Help Percona can help you choose, implement, and optimize the most appropriate MySQL backup and recovery solution for your MySQL ecosystem. If your current solution unexpectedly fails, we can facilitate your recovery with onsite, remote, or emergency consulting services. We can also help you take steps to prevent another occurrence. Every situation is unique and we will work with you to create the most effective solution for your business. Contact Us https://www.percona.com/blog/2021/01/12/mysql-backup-and-recovery-best-practices/
0 notes
Text
Polyaxon v0.4.3: stable — Improved dashboard, setup, and documentation

Mourad
Apr 4
Today, we are pleased to announce the v0.4.3 release, a stable version with improved functionalities and documentation.
This release also marks the anniversary of several clusters running non-stop for over year, the adoption of the platform by several Fortune 500 companies, and millions of experiments scheduled and tracked by Polyaxon since the initial release (based on the anonymous opt-in metrics reporting).
Polyaxon is now moving towards semantic versioning, and will provide versioned documentation and migrations notes from one version to another starting from the next release v0.5. We are also moving to a bi-weekly release cycle
Polyaxon Dashboard
Polyaxon is an open source, self-hosted, platform for model management and machine learning (ML) and deep learning(DL) workload orchestration on Kubernetes.
Install or upgrade Polyaxon.
Developing Polyaxon as an open source, and having a product used by thousands of machine learning and deep learning practitioners every week, means we receive a constant stream of feedback; in particular one recurrent request: “Improving functionality X would help me more than adding new features.”
That’s why this release focuses on productivity and stability improvements that every Polyaxon user (machine learning practitioners and DevOps engineers) can benefit from.
Effort to bring more CLI functionalities to the dashboard
Better Ingress support and documentation
Better SSL documentation
Support of Custom Cluster DNS
Improved Helm chart
Better deployment config validation
More functionalities in the dashboard
When we started Polyaxon, the dashboard was just a nice thing to have to complement and give a visual aspect of the operations created by the CLI. Throughout the last couple of months we have been adding more functionalities and features to the dashboard, to enable users to bookmark, archive, restore, delete, and filter for jobs and experiments.
The adoption of the dashboard has increased, and we noticed that most users look for functionalities in the dashboard before checking the reference documentation for the CLI.
In this last release, we made a lot of changes to the dashboard to enable users to do more and most of the important actions without the need to use our CLI:
Reenabling the possibility to create projects from dashboard
Adding the possibility to create experiments, experiment groups, jobs, builds from dashboard
Starting & Stopping notebooks from the dashboard
Starting & Stopping tensorboards from the dashboard for experiments, groups, selections, and projects
Restarting experiments
Tables with search enabled to quickly check the history of created and running notebooks and tensorboards
Better handling of errors, loading indicators, and several UX improvements
Adding default searches to the tables to enable users to quickly filter based on some statuses
Quick shortcuts to go directly to integrations, references, and other documentation sections.
You should expect more features and improvements in the next couple of months, in particular:
Possibility to create/sync templates to use for starting experiments and jobs
Simpler search and filtering with UI components to help you create queries in an intuitive way
Better visualization
Better artifacts tagging and management
Better insights and metrics for your jobs and experiments per project and cluster wide
Move the cluster wide dynamic configuration from EE to CE to easily set and update deployment options
Improved Ingress support and documentation


Polyaxon and NGINX ingress documentation
Prior to v0.4.3, Polyaxon Helm Chart included an NGINX Ingress controller, that made our ingress resource useless to many companies. Although we provided a way to modify the annotations it was not clear what to change, which made several large team opt-out of using our ingress and create their own.
In this version Polyaxon Helm Chart does not include an Ingress controller anymore, and has generic ingress resource that can be used with any Ingress Controller. We made a reference documentation for NGINX, and we will update with more documentation on how to use other stable and most used ingress controllers in the future.
Better Support of Custom Cluster DNS
Everyday, several users try to deploy Polyaxon on custom Kubernetes clusters, and often times with a Custom Cluster DNS. Polyaxon deployments fail on these custom clusters sometimes. We suggested for users who reached out to us to use KubeDNS, but several others just move on without having the chance to try our platform.
We now have documentation how to configure Polyaxon to work with any DNS backend or Custom Cluster DNS, making the platform compatible with most Kubernetes installations.
Better SSL documentation
The recommended way to serve Polyaxon HTTPS is by using an ingress with TLS enabled, the new ingress resource gives complete control over how to deploy the ingress controller. However, some users decide to deploy Polyaxon with a NodePort service type exposed on the internet, and we are also in the process of releasing a public version of Polyaxon Tracking on docker, docker-compose, and other container services, so we added documentation reference on how to setup SSL for Polyaxon API using self-signed certificates or browser trusted certificates.
Improved Helm chart
We made several improvement to Polyaxon Helm Chart to make it readable and removed several pluggable components. Namely we removed the NFS-Provisioner from the chart and we made it as an external repo to give users the possibility to use it, as an option, to provision MultiReadWrite volumes for hosting their data, outputs/artifacts, and logs.
Better deployment config Validation
Polyaxon deploy is now in “stable beta” and can be used to validate your config deployment files as well as other necessary dependencies before installing or upgrading Polyaxon.
We will be adding a new documentation section to outline how to do some advanced stuff like, specifying the version and deployment type, to not upgrade Polyaxon to a newer version by mistake for example.
Other improvements and bug fixes
We fixed several issues and regressions, one notable regression was related to authenticating native docker builder to pull private DockerHub images, we also published new documentation for private DockerHub images in addition to the generic docker registries’ documentation.


Polyaxon and dockerhub documentation
We fixed the issue with browser caching requiring users to hard reload their page after an upgrade, and several other small UX issues.
We also update the documentation and the chart to set the “eventMonitors” service as a singleton.
Conclusion
Polyaxon is now stable and production ready, although it was already used in production mode at several companies, and it’s powering thousands of researchers and machine learning practitioners every week.
We are very thankful to all companies, teams, and research institutions who used our platform and provided feedback to improve it.
Next release, we will be pushing more automation, we will release a public Beta of the Machine Learning CI tool and Polyflow an events/actions based framework.
Polyaxon will keep improving and providing the simplest machine learning layer on Kubernetes. We hope that these updates will improve your workflows and increase your productivity, and again, thank you for your continued support.
DataTau published first on DataTau
0 notes
Text
Winrar 5.0

Xyraclius.com memberitahu pengunjung tentang topik seperti Crack PES 2013, Download Apps on Computer dan Free Zip File Download. Ikuti ribuan pengunjung yang puas yang mendapatkan Download Zip Files, Download Software Forex dan Download Free Computer Games.
Winrar 5.01
Winrar 5.0 64 Bit
Winrar 5.0
Winrar 5.0 For Mac
Winrar Installation

Pick a software title..to downgrade to the version you love!
WinRAR 4.01 Change Log

Added support for file sizes stored in binary format in TAR archives.
Some TAR archives use the binary size format instead of octal for files larger than 8 GB.
Spectrum speed test ohio. Bugs fixed:
WinRAR is a powerful archiver extractor tool, and can open all popular file formats. RAR and WinRAR are Windows 10 (TM) compatible; available in over 50 languages and in both 32-bit and 64-bit; compatible with several operating systems (OS), and it is the only compression software that can work with Unicode. WinRAR is a powerful archive manager. It can backup your data and reduce the size of email attachments, open and unpack RAR, ZIP and other files downloaded from Internet, create new archives in RAR and ZIP file format.
'Repair' command failed to properly reconstruct structure of RAR archives, which contained at least one file with packed size exceeding 4 GB.
This bug did not affect the recovery record based repair. It happened only if recovery record was not found and WinRAR performed reconstruction of archive structure;
even if 'Do not extract paths' option in 'Advanced' part of extraction dialog was set as the default, WinRAR still unpacked file paths if called from Explorer context menu;
after entering a wrong password for encrypted ZIP archive, sometimes WinRAR ignored subsequent attempts to enter a valid password;
'Wizard' command did not allow to create self-extracting and multivolume archives, when compressing a single folder or a file without extension;
'Import settings from file' command did not restore multiline comments in WinRAR compression profiles;
when converting RAR volumes having name1.name2.part#.rar name format, 'Convert archives' command erroneously removed '.name2' name part. So resulting archive had name1.rar file name instead of expected name1.name2.rar;
RAR could crash when creating a new archive with -agNNN switch if archive number in generated name was 110 or larger;
WinRAR failed to display non-English file names in 7-Zip archives properly if they used a non-default code page. It was the display only problem, such names were unpacked correctly.
WinRAR 4.01 Screenshots
WinRAR 4 Builds
WinRAR Comments
Please enable JavaScript to view the comments powered by Disqus.blog comments powered by Disqus
6677
Here we describe basic data structures of archive format introduced in RAR 5.0. If you need information about algorithms or more detailed information on data structures, please use UnRAR source code.
Contents
Winrar 5.01
Data types
General archive structure
Archive blocks
Main archive header
File header and service header
Service headers
Data types
vint
Winrar 5.0 64 Bit
Variable length integer. Can include one or more bytes, where lower 7 bits of every byte contain integer data and highest bit in every byte is the continuation flag. If highest bit is 0, this is the last byte in sequence. So first byte contains 7 least significant bits of integer and continuation flag. Second byte, if present, contains next 7 bits and so on.
Currently RAR format uses vint to store up to 64 bit integers, resulting in 10 bytes maximum. This value may be increased in the future if necessary for some reason.
Sometimes RAR needs to pre-allocate space for vint before knowing its exact value. In such situation it can allocate more space than really necessary and then fill several leading bytes with 0x80 hexadecimal, which means 0 with continuation flag set.
byte, uint16, uint32, uint64
Burp scanner free. Byte, 16-, 32-, 64- bit unsigned integer in little endian format.
Winrar 5.0
Variable length data
Winrar 5.0 For Mac
We use ellipsis .. to denote variable length data areas.
Hexadecimal values
We use 0x prefix to define hexadecimal values, such as 0xf000
Winrar Installation
0 notes