#web scraper chrome extension
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Total funding amounts to $125.3M.
Text
diy ao3 wrapped: how to get your data!
so i figured out how to do this last year, and spotify wrapped season got me thinking about it again. a couple people in discord asked how to do it so i figured i'd write up a little guide! i'm not quite done with mine for this year yet because i wanted to do some graphics, but this is the post i made last year, for reference!
this got long! i tried to go into as much detail as possible to make it as easy as possible, but i am a web developer, so if there's anything i didn't explain enough (or if you have any other questions) don't hesitate to send me an ask!!
references
i used two reddit posts as references for this:
basic instructions (explains the browser extension; code gets title, word count, and author)
expanded instructions (code gets title, word count, and author, as well as category, date posted, last visited, warnings, rating, fandom, relationship, summary, and completion status, and includes instructions for how to include tags and switch fandoms/relationships to multiple—i will include notes on that later)
both use the extension webscraper.io which is available for both firefox and chrome (and maybe others, but i only use firefox/chrome personally so i didn't check any others, sorry. firefox is better anyway)
scraping your basic/expanded data
first, install the webscraper plugin/extension.
once it's installed, press ctrl+shift+i on pc or cmd+option+i on mac to open your browser's dev tools and navigate to the Web Scraper tab

from there, click "Create New Site Map" > "Import Sitemap"

it will open a screen with a field to input json code and a field for name—you don't need to manually input the name, it will fill in automatically based on the json you paste in. if you want to change it after, changing one will change the other.
i've put the codes i used on pastebin here: basic // expanded

once you've pasted in your code, you will want to update the USERNAME (highlighted in yellow) to your ao3 username, and the LASTPAGE (highlighted in pink) to the last page you want to scrape. to find this, go to your history page on ao3, and click back until you find your first fic of 2024! make sure you go by the "last visited" date instead of the post date.

if you do want to change the id, you can update the value (highlighted in blue) and it will automatically update the sitemap name field, or vice versa. everything else can be left as is.
once you're done, click import, and it'll show you the sitemap. on the top bar, click the middle tab, "Sitemap [id of sitemap]" and choose Scrape. you'll see a couple of options—the defaults worked fine for me, but you can mess with them if you need to. as far as i understand it, it just sets how much time it takes to scrape each page so ao3 doesn't think it's getting attacked by a bot. now click "start scraping"!


once you've done that, it will pop up with a new window which will load your history. let it do its thing. it will start on the last page and work its way back to the first, so depending on how many pages you have, it could take a while. i have 134 pages and it took about 10-12 minutes to get through them all.
once the scrape is done, the new window will close and you should be back at your dev tools window. you can click on the "Sitemap [id of sitemap]" tab again and choose Export data.

i downloaded the data as .xlsx and uploaded to my google drive. and now you can close your dev tools window!
from here on out my instructions are for google sheets; i'm sure most of the queries and calculations will be similar in other programs, but i don't really know excel or numbers, sorry!
setting up your spreadsheet
once it's opened, the first thing i do is sort the "viewed" column A -> Z and get rid of the rows for any deleted works. they don't have any data so no need to keep them. next, i select the columns for "web-scraper-order" and "web-scraper-start-url" (highlighted in pink) and delete them; they're just default data added by the scraper and we don't need them, so it tidies it up a little.

this should leave you with category, posted, viewed, warning, rating, fandom, relationship, title, author, wordcount, and completion status if you used the expanded code. if there are any of these you don't want, you can go ahead and delete those columns also!
next, i add blank columns to the right of the data i want to focus on. this just makes it easier to do my counts later. in my case these will be rating, fandom, relationship, author, and completion status.
one additional thing you should do, is checking the "viewed" column. you'll notice that it looks like this:
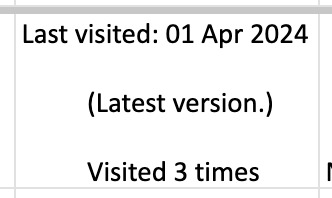
you can't really sort by this since it's text, not formatted as a date, so it'll go alphabetically by month rather than sorting by date. but, you'll want to be able to get rid of any entries that were viewed in 2023 (there could be none, but likely there are some because the scraper got everything on your last page even if it was viewed in 2023). what i did here was use the "find" dialog to search the "viewed" column for 2023, and deleted those rows manually.
ctrl/cmd+f, click the 3 dots for "more options". you want to choose "Specific range", then "C2:C#". replace C with the letter of your viewed column (remember i deleted a bunch, so yours may be different) and replace # with the number of the last row of your spreadsheet. then find 2023, select the rows containing it, right click > delete rows.
it isn't super necessary to do this, it will only add at most 19 fics to your count, but the option is there!

alright, with all that done, your sheet should look something like this:

exposing myself for having read stardew valley fic i guess
now for the fun part!!!
the math
yes, the math is the fun part.
scroll all the way down to the bottom of your sheet. i usually add 100 blank rows at the bottom just so i have some space to play with.
most of these will basically be the same query, just updating for the relevant column. i've put it in a pastebin here, but here's a screenshot so i can walk you through it:

you'll want to use lines 3-10, select the cell you want to put your data into, and paste the query into the formula bar (highlighted in green)

so, we're starting with rating, which is column E for me. if yours is a different letter you'll need to replace all the E's with the relevant letter.
what this does is it goes through the entire column, starting with row 2 (highlighted in yellow) and ending with your final row (highlighted in blue, you'll want to change this number to reflect how many rows you have). note that row 2 is your first actual data row, because of the header row.
it checks each row that has a value (line 5), groups by unique value (row 6), and arranges in descending order (row 7) by how many there are of each value (row 8). finally, row 10 determines how many rows of results you'll have; for rating, i put 5 because that's how many ratings there are, but you can increase the number of results (highlighted in pink) for other columns depending on how many you want. this is why i added the 100 extra rows!
next to make the actual number visible, go to the cell one column over. this is why we added the empty columns! next to your first result, add the second query from the pastebin:

your first and second cell numbers (highlighted in yellow and blue) should match the numbers from your query above, and the third number (highlighted in pink) should be the number of the cell with your first value. what this does is go through your column and count how many times the value occurs.
repeat this for the rest of the rows and you should end up with something like this! don't judge me and my reading habits please

now you can go ahead and repeat for the rest of your columns! as i mentioned above, you can increase the amount of result rows you get; i set it to 25 for fandom, relationship, and author, just because i was curious, and only two for completion status because it's either complete or not complete.
you should end up with something like this!

you may end up with some multiples (not sure why this happens, tagging issues maybe?) and up to you if you want to manually fix them! i just ended up doing a find and replace for the two that i didn't want and replaced with the correct tag.
now for the total wordcount! this one is pretty simple, it just adds together your entire column. first i selected the column (N for me) and went to Format > Number > 0 so it stripped commas etc. then at the bottom of the column, add the third query from the pastebin. as usual, your first number is the first data row, and the second is the last data row.

and just because i was curious, i wanted the average wordcount also, so in another cell i did this (fourth query from the pastebin), where the first number is the cell where your total is, and the second number is the total number of fics (total # of data rows minus 1 for the header row).

which gives me this:

tadaaaa!
getting multiple values
so, as i mentioned above, by default the scraper will only get the first value for relationships and fandoms. "but sarah," you may say, "what if i want an accurate breakdown of ALL the fandoms and relationships if there's multiples?"
here's the problem with that: if you want to be able to query and count them properly, each fandom or relationship needs to be its own row, which would skew all the other data. for me personally, it didn't bother me too much; i don't read a lot of crossovers, and typically if i'm reading a fic it's for the primary pairing, so i think the counts (for me) are pretty accurate. if you want to get multiples, i would suggest doing a secondary scrape to get those values separately.
if you want to edit the scrape to get multiples, navigate to one of your history pages (preferably one that has at least one work with multiple fandoms and/or relationships so you can preview) then hit ctrl+shift+i/cmd+option+i, open web scraper, and open your sitemap. expand the row and you should see all your values. find the one you want to edit and hit the "edit" button (highlighted in pink)

on the next screen, you should be good to just check the "Multiple" checkbox (highlighted in pink):

you can then hit "data preview" (highlighted in blue) to get a preview which should show you all the relationships on the page (which is why i said to find a page that has the multiples you are looking for, so you can confirm).

voila! now you can go back to the sitemap and scrape as before.
getting tag data
now, on the vein of multiples, i also wanted to get my most-read tags.
as i mentioned above, if you want to get ALL the tags, it'll skew the regular count data, so i did the tags in a completely separate query, which only grabs the viewed date and the tags. that code is here. you just want to repeat the scraping steps using that as a sitemap. save and open that spreadsheet.
the first thing you'll notice is that this one is a LOT bigger. for context i had 2649 fics in the first spreadsheet; the tags spreadsheet had 31,874 rows.
you can go ahead and repeat a couple of the same steps from before: remove the extra scraper data columns, and then we included the "viewed" column for the same reason as before, to remove any entries from 2023.
then you're just using the same basic query again!
replace the E with whatever your column letter is, and then change your limit to however many tags you want to see. i changed the limit to 50, again just for curiosity.
if you made it this far, congratulations! now that you have all that info, you can do whatever you want with it!
and again, if you have any questions please reach out!
55 notes
·
View notes
Note
784488414544297984 i never joined the archive server because i knew it would eventually turn to shit but as a data hoarder it irritates me how inefficient they're presumably being. anyway here's some tools that have helped me !! desktop only unfortunately
https://dht.chylex.com/ -> for discord server archival. this isn't immediately relevant to all this but i find it handy
https://github.com/mikf/gallery-dl -> a tool that runs in the background to download images/files from a site you input, automatically sorting it from oldest to newest. works slow but gets the job done. there are a lot of supported sites but for this specifically i use it for tumblr images, deviantart images, and deviantart journals
https://tumblthreeapp.github.io/TumblThree/ -> this one also downloads all images from a blog but not in order. i use it to download individual posts from a blog and as far as i know they're automatically sorted in order. if you fiddle with the settings you can download all posts as individual txt files, and then use the command prompt ren *.txt *.html to mass change the extension and them view those files in your browser with formatting
i also used the chrome extension GoFullPage - Full Page Screen Capture to take easy screenshots of things like the toyhouse while it was up, the au info pages, etc. doesn't work on really long pages but i've used it a lot
remember there is almost always an easier way to save things than just doing it by hand!! - <3, a web scraper
☝️☝️☝️
Very useful ask, please check it out!!
21 notes
·
View notes
Text
Mastering HIT Scraper For MTurk The Complete Guide

Amazon Mechanical Turk (MTurk) is a popular platform for earning extra income by completing micro-tasks, known as Human Intelligence Tasks (HITs). One of the most effective tools for maximizing your productivity and earnings on MTurk is HIT Scraper, part of the BZTurk extension. This comprehensive guide will walk you through everything you need to know about using HIT Scrapper for MTurk, including setting it up, using it strategically, and optimizing your workflow to earn more money in less time.
What is a HIT Scraper?
A tool designed to help MTurk workers (Turkers) find and accept HITs more efficiently. Unlike manually refreshing the HITs page and searching for tasks, HIT Scraper automatically scans for new HITs that match your criteria and accepts them for you. This automation saves time and increases your chances of grabbing high-paying tasks before they disappear.
Setting Up HIT Scrapper for MTurk
To get started with BZTurk, follow these steps:
1. Install the BZTurk Extension: HIT Scrapper is part of the BZTurk extension, a comprehensive toolset for MTurk workers. Install the extension from the Chrome Web Store or the Firefox Add-ons page.
2. Access MTurk HIT Catcher: Once the BZTurk extension is installed, click on the BZTurk icon in your browser’s toolbar. From the dropdown menu, select “HIT Scraper for MTurk.”
3. Configure Your Settings: Before you start scraping HITs, take some time to configure the settings. You can set the search interval (how often HIT Scraper checks for new HITs), the number of HITs to scrape simultaneously, and other preferences. The primary role of the Hit Scrapper is to find HITs. go to the settings and update them. Then, Start Hit Finder. Auto Hit Catcher will work in the background.
Using HIT Scraper Strategically
1. Set Up Watchers for High-Paying HITs: Use HIT Scraper to monitor specific requesters or types of HITs that you know pay well. By setting up watchers, HIT Scraper for mturk will prioritize these tasks, increasing your chances of catching them as soon as they become available.
2. Adjust Search Intervals: The default search interval might not always be optimal. Experiment with different intervals to find a balance between frequent searches and not overloading the system. Shorter intervals can help scrape HITs faster but may also increase the risk of getting rate-limited by MTurk.
3. Use Custom Watcher Groups: If you work on different types of HITs, create custom Watcher groups to organize your searches. For example, you can have one group for surveys, another for transcription tasks, and another for data entry. This organization helps you quickly switch focus based on the available tasks.
4. Monitor Your Queue: While HIT Scraper can automatically accept HITs, it’s essential to monitor your queue to ensure you’re not overwhelmed with more tasks than you can handle within the allotted time. Managing your queue helps maintain a steady workflow without risking expired HITs.
Optimizing Your Workflow
To maximize your earnings on MTurk using HIT Scrapper, follow these optimization tips:
1. Prioritize High-Paying HITs: Focus on scraping and completing HITs that offer higher pay rates. Use HIT Scraper to monitor these tasks and prioritize them over lower-paying ones.
2. Track Your Performance: Keep track of your accepted and completed HITs to analyze your performance. Use this data to adjust your strategies and identify which types of HITs are the most profitable for you.
3. Stay Updated on HIT Availability: Join MTurk forums, subreddits, and social media groups where Turkers share information about high-paying HITs and active requesters. Staying connected with the MTurk community helps you stay informed about new opportunities.
4. Take Breaks and Avoid Burnout: Working on MTurk can be intense, especially when using tools like HIT Scraper. Remember to take regular breaks to avoid burnout and maintain productivity.
Conclusion
HIT Scrapper, as part of the BZTurk extension, is a powerful tool that can help you increase your earnings on MTurk. By setting it up correctly and using it strategically, you can make the most of your time and earn more money in less time. So why wait? Start using HIT Scrapper today and see the difference it can make in your MTurk experience! Using the right tools and techniques is crucial for success on MTurk, and HIT Scraper, along with the BZTurk extension, can significantly enhance your efficiency and earnings. Whether you’re a seasoned Turker or just getting started, incorporating MTurk HIT Scraper into your workflow can help you achieve your financial goals faster and with less effort. Happy Turking!
0 notes
Text
Why Pay for an Amazon Scraper? Check Out a Free Web Scraper for Amazon!
To gain valuable insights, many companies and analysts rely on Amazon, a major e-commerce platform, for data. It’s crucial for businesses seeking to collect, store, and analyze large amounts of data. Amazon provides information on product prices, seller details, and market trends, essential for making informed decisions. As the e-commerce giant grows, sophisticated Amazon scrapers are needed to gather data effectively. However, Amazon has basic anti-scraping measures in place, necessitating cutting-edge scraping tools for comprehensive data extraction. AI-powered Amazon scrapers are in high demand due to their accuracy, flexibility, and scalability.
An Amazon scraper is a tool used to extract data from HTML, delivering it in a usable format. This digital bot is designed to collect data from Amazon efficiently, making it a valuable asset for businesses. With Amazon’s extensive product list, using scraper software is essential for data collection. Nearly 9 out of 10 consumers check prices on Amazon, highlighting the importance of pricing data. Amazon scraping tools enable the collection of price data for research, corporate purposes, or personal reference.
The process of scraping Amazon involves searching for the desired product, navigating to its detail page, and extracting relevant data like descriptions, prices, images, reviews, and seller information. Manual scraping is impractical due to Amazon’s vast product library. Outsourcing to companies like AIMLEAP for Amazon scraping services ensures accurate and efficient data extraction using AI-powered scrapers.
Data obtained from Amazon scrapers includes product specifications, prices, seller details, ASIN, sales rank, images, and reviews. This data is invaluable for evaluating competition, sentiment analysis, monitoring online reputation, and determining product rankings. Businesses can leverage this information for smart decision-making.
There are various free Amazon scraper tools available. They help extract Amazon data efficiently and can be used for both small and large-scale scraping. These tools bypass IP blocks, CAPTCHAs, and other obstacles, ensuring smooth data extraction. Some top free Amazon scrapers include:
ApiScrapy: Provides advanced scraping tools for large-scale data collection.
Data Miner: A Google Chrome extension for easy data extraction into CSV or Excel.
Web Scraper: An extension tool simplifying data extraction from complex sites.
Scraper Parsers: Extracts unstructured data in structured formats.
Amazon Scraper — Trial Version: Extracts prices, shipping, and product details.
Octoparse: Turns web pages into structured data sheets with a point-and-click interface.
ScrapeStorm: An AI-powered tool for visual scraping without programming.ParseHub: Collects data from any JavaScript or AJAX page.
The proportion of third-party sellers on Amazon has steadily risen, making it crucial for businesses to collect seller data. Automated scraping tools like Amazon scrapers streamline this process, providing accurate and authentic data. Businesses can collaborate with professionals like AIMLEAP to ensure high-quality data collection for informed decision-making.
0 notes
Text
How to Scrape Liquor Prices and Delivery Status From Total Wine and Store?

This tutorial is an educational resource to learn how to build a web scraping tool. It emphasizes understanding the code and its functionality rather than simply copying and pasting. It is important to note that websites may change over time, requiring adaptations to the code for continued functionality. The objective is to empower learners to customize and maintain their web scrapers as websites evolve.
We will utilize Python 3 and commonly used Python libraries to simplify the process. Additionally, we will leverage a potent and free liquor scraping tool called Selectorlib. This combination of tools will make our liquor product data scraping tasks more efficient and manageable.
List Of Data Fields

Name
Size
Price
Quantity
InStock – whether the liquor is in stock
Delivery Available: Whether the liquor is delivered
URL

Installing The Required Packages for Running Total
To Scrape liquor prices and delivery status from Total Wine and More store, we will follow these steps
To follow along with this web scraping tutorial, having Python 3 installed on your system is recommended. You can install Python 3 by following the instructions provided in the official Python documentation.
Once you have Python 3 installed, you must install two libraries: Python Requests and Selectorlib. Install these libraries using the pip3 command to scrape liquor prices and delivery data, which is the package installer for Python 3. Open your terminal or command prompt and run the following commands:
The Python Code

The Provided Code Performs The Following Actions:
Reads a list of URLs from a file called "urls.txt" containing the URLs of Total Wine and More product pages.
Utilizes a Selectorlib YAML file, "selectors.yml," to specify the data elements to scrape TotalWine.com product data.
Performs total wine product data collection by requesting the specified URLs and extracting the desired data using the Selectorlib library.
Stores the scraped data in a CSV spreadsheet named "data.csv."
Create The YAML File "Selectors.Yml"
We utilized a file called "selectors.yml" to specify the data elements we wanted to extract total wine product data. Create the file using a web scraping tool called Selectorlib.
Selectorlib is a powerful tool that simplifies selecting, highlighting up, and extracting data from web pages. With the Chrome Extension of Selectorlib Web Crawler, you can easily mark the data you need to collect and generate the corresponding CSS selectors or XPaths.
Selectorlib can make the data extraction process more visual and intuitive, allowing us to focus on the specific data elements we want to extract without manually writing complex CSS selectors.
To leverage Selectorlib, you can install the Chrome Extension of Selectorlib Web crawler and use it to mark and extract the desired data from web pages. The tool will then develop the imoportant CSS selectors or XPaths, which can be saved in a YAML file like "selectors.yml" and used in your Python code for efficient data extraction.


Functioning of Total Wine and More Scraper
To specify the URLs you want to scrape, create a text file named as "urls.txt" in the same directory as your Python script. Inside the "urls.txt" file, add the URLs you need to scrape liquor product data , each on a new line. For example:
Run the Total Wine data scraper with the following command:
Common Challenges And Limitations Of Self-Service Web Scraping Tools And Copied Internet Scripts
Unmaintained code and scripts pose significant pitfalls as they deteriorate over time and become incompatible with website changes. Regular maintenance and updates maintain the functionality and reliability of these code snippets. Websites undergo continuous updates and modifications, which can render existing code ineffective or even break it entirely. It is essential to prioritize regular maintenance to ensure long-term functionality and reliability, enabling the code to adapt to evolving website structures and maintain its intended purpose. By staying proactive and keeping code up-to-date, developers can mitigate issues and ensure the continued effectiveness of their scripts.
Here are some common issues that can arise when using unmaintained tools:
Changing CSS Selectors: If the website's structure changes, the CSS selectors are used to extract data, such as the "Price" selector in the selectors.yaml file may become outdated or ineffective. Regular updates are needed to adapt to these changes and ensure accurate data extraction.
Location Selection Complexity: Websites may require additional variables or methods to select the user's "local" store beyond relying solely on geolocated IP addresses. Please handle this complexity in the code to avoid difficulties retrieving location-specific data.
Addition or Modification of Data Points: Websites often introduce new data points or modify existing ones, which can impact the code's ability to extract the desired information. Without regular maintenance, the code may miss out on essential data or attempt to extract outdated information.
User Agent Blocking: Websites may block specific user agents to prevent automated scraping. If the code uses a blocked user agent, it may encounter restrictions or deny website access.
Access Pattern Blocking: Websites employ security measures to detect and block scraping activities based on access patterns. If the code follows a predictable scraping pattern, it can trigger these measures and face difficulties accessing the desired data.
IP Address Blocking: Websites may block specific IP addresses or entire IP ranges to prevent scraping activities. If the code's IP address or the IP addresses provided by the proxy provider are blocked, it can lead to restricted or denied access to the website.
Conclusion: Utilizing a full-service solution, you can delve deeper into data analysis and leverage it to monitor the prices and brands of your favorite wines. It allows for more comprehensive insights and enables you to make informed decisions based on accurate and up-to-date information.
At Product Data Scrape, we ensure that our Competitor Price Monitoring Services and Mobile App Data Scraping maintain the highest standards of business ethics and lead all operations. We have multiple offices around the world to fulfill our customers' requirements.
#WebScrapingLiquorPricesData#ScrapeTotalWineProductData#TotalWineDataScraper#ScrapeLiquorPricesData#ExtractTotalWineProductData#ScrapeLiquorDeliveryData#LiquorDataScraping
0 notes
Text
Exploring the Power of Web Scraping: Extracting "People Also Ask" Questions from Google Results

In this article, we'll look at how to use web scraping to extract useful information from Google search results. We'll specifically focus on obtaining the "People Also Ask" questions and save them to a Google Sheets document. Let's get started, but first, please show your support by liking the video and subscribing to the channel. Your encouragement fuels our desire to create informative content. Now, let us get down to work.
Prerequisites:
1Open a Google Sheets Document To begin, open a Google Sheets document in which we'll execute web scraping.
2Add the "Import from Web" Extension Go to the given
Link to the "Import from Web" addon. This plugin is essential for allowing web scraping capability in Google Sheets. Make sure you add this extension to your Google Sheets for easy connection.
Activating the Extension:
Once you've installed the extension, navigate to your Google Sheets document and select the "Extensions" option.
Locate and enable the "Import from Web" addon. This step gives you access to a myriad of web scraping features right within your Google Sheets.
Executing Web Scraping:
Define your keyword: In a specific cell, such as B1, put the keyword from which you wish to extract "People Also Ask" queries. For example, let's use the keyword "skincare".
Utilize the Import Functionality: In the
for SEO experts, digital marketers, and content developers. Google's "People Also Ask" feature is an often-overlooked yet extremely useful tool. In this tutorial, we'll look at the nuances of this tool and how it may be used to acquire key insights and drive content strategy. Let's get into the details.
Understanding of "People Also Ask":
Overview The "People Also Ask" feature in Google search results produces similar questions based on user queries.
Evolution: The function, which was first introduced in 2015, has expanded dramatically, now using machine learning to give relevant and contextually driven queries.
User Benefits "People Also Ask" improves the search experience by suggesting questions based on user intent, providing users with extra insights and leading content creators to relevant topics.
Exploring "People Also Ask"
In Action:
Accessing the Feature Do a Google search for your desired topic, such as "chocolate," then scroll down to the "People Also Ask" area.
Accordion-style Dropdowns Clicking on the accordion-style dropdowns shows a profusion of related questions, a veritable goldmine of content ideas.
Tailoring Content Look for questions that are relevant to your interests or industry niche, such as the history of cocoa or its health advantages.
Maximizing Insights with Web Scraping:
Introducing the "Scraper" Extension Use the "Scraper" Chrome extension, which is available in the Chrome Web Store, to extract and consolidate "People Also Ask" queries.
Simple Extraction Process: Right-click on a relevant question, choose "Scrape Similar," then change the XPath selection to collect all similar questions.
Scalability: A single query can return a multiplicity of
Related search results offer numerous chances for content creation and market insights.
Unlocking the Content Potential:
Content Ideation: Use scraped questions to find holes in existing content and create comprehensive content strategy.
Competitive Advantage By responding to user concerns completely, you can outperform competitors and increase brand visibility.
Strategic Implementation Create content that not only addresses individual questions but also reflects larger user intent and industry trends.
Use Web Scraping Tools for "People Also Ask" Questions
In the digital age, embracing technology is critical to staying ahead in SEO and content marketing. Web scraping tools are an effective way to extract relevant data from search engine results pages (SERPs) and obtain insight into user behavior and preferences. Here's how you can use these technologies to maximize their potential.
Conclusion:
By using web scraping, you may extract useful data directly from Google search results, providing you with actionable insights. Web scraping brings up a world of data-driven decision-making opportunities, whether you're undertaking market research, content creation, or SEO analysis. Stay tuned for future tutorials delving into additional web scraping features and advanced techniques. Until then, Happy scrapping, and may your data excursions be successful! Remember, the possibilities are limitless when you use the power of web scraping to extract valuable information from the enormous expanse of the internet. Happy scraping, and may your data excursions be both insightful and rewarding!
Incorporating Google's "People Also Ask" feature into your SEO and content strategy can unlock a wealth of opportunities for audience engagement and brand growth. By understanding user intent, leveraging web scraping tools, and crafting targeted content, you can position your brand as an authoritative voice in your industry. Embrace the power of "People Also Ask" and elevate your digital presence to new heights.
As you embark on your journey of content creation and SEO optimization, remember to harness the insights gleaned from "People Also Ask" to fuel your strategic initiatives and drive meaningful engagement with your audience. The possibilities are endless, and with the right approach, you can unlock boundless opportunities for success in the ever-evolving digital landscape.
0 notes
Text
Exploring the Power of Web Scraping: Extracting "People Also Ask" Questions from Google Results

In this article, we'll look at how to use web scraping to extract useful information from Google search results. We'll specifically focus on obtaining the "People Also Ask" questions and save them to a Google Sheets document. Let's get started, but first, please show your support by liking the video and subscribing to the channel. Your encouragement fuels our desire to create informative content. Now, let us get down to work.
Prerequisites:
1Open a Google Sheets Document To begin, open a Google Sheets document in which we'll execute web scraping.
2Add the "Import from Web" Extension Go to the given
Link to the "Import from Web" addon. This plugin is essential for allowing web scraping capability in Google Sheets. Make sure you add this extension to your Google Sheets for easy connection.
Activating the Extension:
Once you've installed the extension, navigate to your Google Sheets document and select the "Extensions" option.
Locate and enable the "Import from Web" addon. This step gives you access to a myriad of web scraping features right within your Google Sheets.
Executing Web Scraping:
Define your keyword: In a specific cell, such as B1, put the keyword from which you wish to extract "People Also Ask" queries. For example, let's use the keyword "skincare".
Utilize the Import Functionality: In the
for SEO experts, digital marketers, and content developers. Google's "People Also Ask" feature is an often-overlooked yet extremely useful tool. In this tutorial, we'll look at the nuances of this tool and how it may be used to acquire key insights and drive content strategy. Let's get into the details.
Understanding of "People Also Ask":
Overview The "People Also Ask" feature in Google search results produces similar questions based on user queries.
Evolution: The function, which was first introduced in 2015, has expanded dramatically, now using machine learning to give relevant and contextually driven queries.
User Benefits "People Also Ask" improves the search experience by suggesting questions based on user intent, providing users with extra insights and leading content creators to relevant topics.
Exploring "People Also Ask"
In Action:
Accessing the Feature Do a Google search for your desired topic, such as "chocolate," then scroll down to the "People Also Ask" area.
Accordion-style Dropdowns Clicking on the accordion-style dropdowns shows a profusion of related questions, a veritable goldmine of content ideas.
Tailoring Content Look for questions that are relevant to your interests or industry niche, such as the history of cocoa or its health advantages.
Maximizing Insights with Web Scraping:
Introducing the "Scraper" Extension Use the "Scraper" Chrome extension, which is available in the Chrome Web Store, to extract and consolidate "People Also Ask" queries.
Simple Extraction Process: Right-click on a relevant question, choose "Scrape Similar," then change the XPath selection to collect all similar questions.
Scalability: A single query can return a multiplicity of
Related search results offer numerous chances for content creation and market insights.
Unlocking the Content Potential:
Content Ideation: Use scraped questions to find holes in existing content and create comprehensive content strategy.
Competitive Advantage By responding to user concerns completely, you can outperform competitors and increase brand visibility.
Strategic Implementation Create content that not only addresses individual questions but also reflects larger user intent and industry trends.
Use Web Scraping Tools for "People Also Ask" Questions
In the digital age, embracing technology is critical to staying ahead in SEO and content marketing. Web scraping tools are an effective way to extract relevant data from search engine results pages (SERPs) and obtain insight into user behavior and preferences. Here's how you can use these technologies to maximize their potential.
Conclusion:
By using web scraping, you may extract useful data directly from Google search results, providing you with actionable insights. Web scraping brings up a world of data-driven decision-making opportunities, whether you're undertaking market research, content creation, or SEO analysis. Stay tuned for future tutorials delving into additional web scraping features and advanced techniques. Until then, Happy scrapping, and may your data excursions be successful! Remember, the possibilities are limitless when you use the power of web scraping to extract valuable information from the enormous expanse of the internet. Happy scraping, and may your data excursions be both insightful and rewarding!
Incorporating Google's "People Also Ask" feature into your SEO and content strategy can unlock a wealth of opportunities for audience engagement and brand growth. By understanding user intent, leveraging web scraping tools, and crafting targeted content, you can position your brand as an authoritative voice in your industry. Embrace the power of "People Also Ask" and elevate your digital presence to new heights.
As you embark on your journey of content creation and SEO optimization, remember to harness the insights gleaned from "People Also Ask" to fuel your strategic initiatives and drive meaningful engagement with your audience. The possibilities are endless, and with the right approach, you can unlock boundless opportunities for success in the ever-evolving digital landscape.
0 notes
Text
10 Must-Have AI Chrome Extensions for Data Scientists in 2024

Empowering data scientists with Top 10 AI Chrome Extensions
The field of data science demands a toolkit that evolves with the industry's advancements. As we enter 2024, the significance of AI Chrome extensions for data scientists cannot be overstated. This article discusses the top 10 extensions that enable data scientists to enhance productivity and streamline workflows.
Codeium:
Codeium, a versatile tool for programmers, streamlines code efficiency in over 20 languages. Through analysis and optimization, it significantly accelerates program execution, minimizing resource consumption. Whether you're a seasoned coder or a beginner, Codeium proves invaluable in enhancing code performance for quicker results and improved resource management.
EquatIO:
EquatIO transforms mathematical expression creation into a seamless digital experience. Whether typing, handwriting, or using voice dictation, it effortlessly translates thoughts into precise formulas. Compatible with Google Docs, Forms, Slides, Sheets, and Drawings, EquatIO fosters an engaging learning environment, offering advanced features like interactive quizzes and chemistry formula prediction.
Instant Data Scraper:
Instant Data Scraper is a powerful and free browser extension that uses AI for seamless data extraction from any website. No scripting needed; it analyzes HTML structures for relevant data, providing customization options for precision. Ideal for lead generation, SEO, and more, with secure data handling. No spyware, just efficient web scraping.
Challenge Hunt:
Challenge Hunt is your go-to app for staying updated on global programming competitions and hackathons. It covers coding challenges, hackathons, data science competitions, and hiring challenges. Set reminders for upcoming events and personalize your experience by selecting preferred online platforms. Never miss a coding opportunity with this all-in-one competition tracker.
CatalyzeX:
CatalyzeX is a browser extension that revolutionizes how researchers and developers access machine learning implementations. Seamlessly integrated into your web browser, it adds intuitive "[CODE] buttons" to research papers across Google, ArXiv, Scholar, Twitter, and Github. Instantly navigate to open source code, powered by the esteemed CatalyzeX.com repository, unlocking a world of cutting-edge machine learning advancements.
Sider:
Sider is a versatile text processing tool designed to streamline tasks in data science. Whether clarifying complex concepts, translating foreign text, summarizing articles, or rephrasing documents, Sider adapts seamlessly. Its versatility proves invaluable to students, writers, and professionals across academia, business, and technology.
Originality.AI:
Originality.AI is a vital data science tool addressing the challenge of discerning between human and AI-generated text. It accurately identifies authorship, distinguishing content created by humans from that generated by neural networks as AI advances in text creation.
Fireflies:
Fireflies, powered by GPT-4, is an invaluable assistant for data scientists. It excels in navigating and summarizing diverse content types like articles, YouTube videos, emails, and documents. In the era of information overload, Fireflies efficiently sorts and summarizes content from various sources, offering a vital solution for data professionals.
AIPRM:
AIPRM facilitates optimal use of Generative Pretrained Transformers by offering a diverse catalog of well-structured prompts designed for data scientists and IT professionals. With scenarios covering a range of use cases, users can customize GPT model responses to precise requirements, enhancing overall model effectiveness in diverse applications.
Code Squire.AI:
Code Squire.AI is a dedicated code assistant for data science, excelling in Pandas and supporting JupyterLab and Colab. It streamlines coding, reduces errors, and boosts efficiency in data science tasks.
0 notes
Text
How To Scrape Booking.Com Hotel Rental Data For Market Analysis
How To Scrape Booking.Com Hotel Rental Data For Market Analysis?
Hotel data scraping collects information and data related to hotels and their services from various sources, including hotel websites, online travel agencies (OTAs), and review platforms. amenities, customer reviews, and ratings. Hotel data scraping helps businesses and researchers gather insights into industry market trends to create competitive pricing strategies, optimize marketing efforts, and provide valuable information to consumers. Conducting such scraping activities in compliance with relevant legal regulations and website terms of service is essential.
About Booking.com
Booking.com is a prominent online travel agency and accommodation booking platform. It offers many lodging options worldwide, including hotels, vacation rentals, and more. Users can easily search for accommodations, read reviews, compare prices, and make reservations. With a user-friendly interface and a vast network of properties, Booking.com has become a popular choice for travelers seeking accommodations. The platform provides a convenient way to plan and book trips, and it's renowned for its extensive international reach and comprehensive travel services. Scrape Booking.com data to collect valuable information about accommodations, pricing, reviews, and availability, enabling data-driven decision-making, market analysis, and competitive insights for the travel and hospitality industry.
List of Data Fields
Hotel Name
Location
Pricing Information
Amenities
Room Types
Availability
Guest Reviews
Hotel Descriptions
Photos
Check-in and Check-Out Times
Contact Details
Steps to Scrape Hotel data from Booking.com
This article outlines the process of how to scrape hotel data from Booking.com. The primary objective is to collect data encompassing hotel prices, ratings, guest reviews, available amenities, and geographic locations. This data will serve as a valuable resource for uncovering customer behavior trends and patterns, including favored travel destinations, desired amenities, and booking trends for future analysis and decision-making. Web scrape hotel rental data by importing essential libraries for various tasks:
BeautifulSoup (bs4): This tool helps us extract data from HTML documents.
requests: It enables us to send HTTP requests and obtain responses.
To inspect HTML elements on a webpage, utilize your browser's integrated developer tools. In Google Chrome, follow these steps:
Launch Google Chrome and visit the webpage you wish to examine.
Right-click on the element you want to inspect and choose "Inspect." Alternatively, you can use the keyboard shortcut "Ctrl + Shift + I" (Windows/Linux) or "Cmd + Shift + I" (Mac) to open the Developer Tools panel.
Inside the Developer Tools panel, you'll find the HTML source code of the webpage. The element you right-clicked on will be in the Elements tab.
Navigate the HTML tree using the Elements tab to select any element for inspection. Selecting an element will highlight its corresponding HTML code in the panel, allowing you to view and modify its properties and attributes in the Styles and Computed tabs.
Browser developer tools simplify inspecting and analyzing a web page's HTML structure, which is valuable for web scraping endeavors.
The resulting soup object is a tool to traverse the HTML tree and extract data from the webpage using a hotel data scraper. From a list of hotels, we aim to obtain the following details:
Hotel name
Location
Price
Rating
Significance of Collecting Data from Hotel Rental Booking Platform
Competitive Intelligence: By scraping data, businesses can gain insights into the pricing, services, and offerings of competitors. This information allows them to adjust their strategies and stay competitive.
Price Comparison: Users can compare prices and deals across various booking platforms using hotel price data scraping services, helping them find the best and most affordable options.
Market Analysis: The data is helpful for market research and analysis. Businesses can identify market trends, popular destinations, and customer preferences, guiding their strategic decisions.
Customized Recommendations: Booking.com data scraping services can provide personalized recommendations to users based on their past preferences and the behavior of similar customers.
Improved User Experience: Accessing accurate and up-to-date information allows booking platforms to offer a seamless and user-friendly experience, reducing the chances of booking errors and enhancing customer satisfaction.
Optimized Inventory Management: For hotels and property owners, scraping data helps manage room availability, pricing, and offerings efficiently. It ensures that they are better prepared to meet customer demand.
Content Generation: Content providers can use scraped data to create valuable content, such as travel guides, reviews, and destination recommendations, catering to the needs and interests of travelers.
Data-Driven Decisions: Both businesses and travelers can make informed decisions by analyzing scraped data, whether related to booking accommodations, planning trips, or managing travel-related enterprises.
Scraping data from hotel rental booking platforms has significant implications for users, businesses, and the travel industry. It provides valuable insights and opportunities for better decision-making, enhanced user experiences, and staying competitive in a dynamic market.
Know More: https://www.iwebdatascraping.com/scrape-booking-com-hotel-rental-data.php
#ScrapeBookingComHotel RentalDat#Bookingcomdatascrapingservices#Bookingcomdatacollectionservices#Hotel datascraping#ScrapeBookingcomdata#ScrapeHoteldatafromBookingcom#hoteldatascraper#hotelpricedatascrapingservices
0 notes
Text
How To Use Bardeen AI | Automation, Benefits & More
You may have heard of Bardeen AI, a new and inventive no-code productivity platform that uses artificial intelligence to create workflows for you if you are looking for a way to automate repetitive and tedious tasks on the web।
However, what exactly is Bardeen AI, and how can it be used to increase creativity and efficiency?
We will answer these questions and more in this blog post, as well as show you how Bardeen AI can help you save money, time, and hassle.

Explain Bardeen AI.
Bardeen AI is a browser-based no-code productivity platform that uses artificial intelligence to empower your creativity, save time, and automate manual workflows।
By simply typing in your desired outcome, Barden AI lets you create workflows. Then, watch as the Magic Box creates the entire automation from scratch। Additionally, you have the ability to review and modify Bardeen AI created workflows for you।
Bardeen AI can do many things like scraping data, filling forms, sending emails, making reports, etc., which can be done with hundreds of web apps and websites। You can also set triggers so that your workflows run automatically when something happens on a schedule or in your apps। Bardeen AI काम करता है आपके ब्राउजर में स्थानीय रूप से।
Why Bardeen AI Is So Well-liked
Barden AI offers many advantages over conventional automation tools, which is why it is popular। Some of these advantages are:
● Simple to use: Bardeen AI can be used without the requirement for coding or other technical abilities. All you have to do is input your goals, and the Magic Box will take care of the rest. With a few clicks, you can easily modify or adjust any workflow that Bardeen AI generates for you.
● Quick and effective: There's no need to waste time copying and pasting data or navigating between tabs. Complex, multi-step procedures can be handled by Bardeen AI in a matter of minutes or seconds. Workflows can also be executed in the background while you attend to other chores.
● Imaginative and adaptable: You are not restricted to using pre-made forms or procedures. Bardeen AI is capable of developing unique processes for any situation or objective you may have in mind. To construct more varied and potent automations, you can also mix and match different workflows or technologies.
● Safe and discrete: You don't have to be concerned about data breaches or exposure. Your data never leaves your device because Bardeen AI operates locally in your browser. Also, you have control over who may modify or access your workflows.
How Bardeen AI Is Used
The steps below must be followed in order to employ Bardeen AI:
Create a free account by visiting the Bardeen.ai website.
Open Chrome and install the Bardeen AI extension.
Use your browser to access the Bardeen AI dashboard.
Select "Create Workflow" by clicking the button in the upper right corner.
Fill in the text box with your desired outcome. Take "Get answers for a YouTube video and save to Notion," for instance.
Await the workflow's generation from the Magic Box. On the right side, you can also observe the workflow's state and progress.
Examine and modify the workflow to suit your needs. By clicking on them, you can modify the workflow's inputs, outputs, actions, settings, and parameters.
Name and save your process.
To manually run your workflow, click the
What Qualities Does Bardeen AI Offer?
Bardeen AI is a robust and flexible no-code productivity platform with a plethora of capabilities. Among these characteristics are:
● Enchanted Box: The main component of Bardeen AI is the Magic Box, which leverages artificial intelligence to build workflows for you in accordance with your preferences or input. Workflows for a variety of operations, including data scraping, form filling, emailing, report generation, and more, can be created using the Magic Box.
● Scraper: With the help of the Scraper tool, you may import data directly into spreadsheets or other programs from any website or web application. Whether there are thousands of entries or only one, the scraper can handle any kind of data.
● Integrations: You may integrate Bardeen AI with hundreds of daily-use web apps and websites by using the Integrations function. The Integrations make it simple and effective for you to carry out tasks or exchange data between several apps or websites.
● Playbooks: You can utilize or customize hundreds of pre-built workflows for your own needs with the help of the Playbooks features. The Playbooks address a range of scenarios and use cases, including marketing, sales, hiring, research, and more.
● Community: Through the Community function, you may interact with other Bardeen AI users and professionals and receive assistance, suggestions, or ideas for new automations. You can find new playbooks or processes from other users and share your own with them through the Community.
Is It Free to Use Bardeen AI?
For as many as 100 workflow runs each month, Bardeen AI is free to use. If you require additional features or process runs, you can switch to a subscription plan. Before deciding to subscribe, you may also enjoy a 14-day free trial of any paid plan.
Read Also: How to Create Old School Anime With AI Powered Tools
In summary
Bardeen AI is a no-code productivity platform that runs in the browser and leverages artificial intelligence to automate tedious tasks, free up your time, and unleash your creativity.
With Bardeen AI, creating a workflow is as easy as entering in the desired result; the Magic Box will take care of creating the automation from scratch. Any workflow that Bardeen AI generates for you can also be reviewed and altered by you.
#ai tools#youtube#bardeenai#ai artwork#ai generated#artificial intelligence#ai art#ai#technology#machine learning
0 notes
Text
Effective Web Scraping Tools That Save Money
The internet stands as an unparalleled resource, brimming with invaluable data of immense authenticity. In today's digital age, data fuels the world, serving as the cornerstone of knowledge and power. With the exponential growth of the web scraping sector, driven by an escalating demand for data, organizations must harness this formidable resource to maintain a competitive edge.
To capitalize on the potential of data, businesses must first gather it. Fortunately, a plethora of pre-built web scraping tools streamline this process, enabling the automated extraction of bulk data in structured formats, sans the need for extensive coding.
Recent research by Bright Data and Vanson Bourne underscores the prevalence of data collection bots, with over half of financial services, technology, and IT companies in the UK and US deploying them. This trend is expected to surge in the coming years, as organizations increasingly rely on automated tasks to fuel their operations.
In virtually every sector, from eCommerce to banking, web scraping tools play a pivotal role in data collection, offering insights crucial for both personal and business endeavors. The exponential growth of data production, projected to surpass 180 zettabytes by 2025, underscores the indispensability of effective data extraction tools.
The COVID-19 pandemic further accelerated this growth, as remote work and increased reliance on digital platforms fueled a surge in data demand. To navigate this data-rich landscape, businesses must leverage advanced web scraping tools capable of efficiently collecting and structuring vast datasets.
These tools not only expedite data collection but also yield significant cost savings. By opting for pre-built scrapers, businesses eliminate the need for costly in-house development, accessing high-quality data extraction capabilities without hefty investments in technology and resources.
Here, we highlight three highly effective web scraping tools renowned for their affordability and functionality:
Apiscrapy: Apiscrapy stands out as a leading provider of advanced data extraction solutions, offering powerful tools that transform unstructured web data into well-organized datasets, all without the need for coding. With features such as real-time data delivery, database integration, and outcome-based pricing, Apiscrapy streamlines the data extraction process while minimizing costs.
Data-Miner.io: Ideal for novice users, Data-Miner.io is a user-friendly Google Chrome Extension designed for seamless data collection. From extracting search results to capturing contact information, this intuitive tool simplifies advanced data extraction tasks, delivering clean datasets in CSV or Excel formats.
Webscraper.io: Webscraper.io offers both a Chrome extension and a cloud-based extractor, catering to a diverse range of scraping needs. With its user-friendly interface and structured data collection capabilities, Webscraper.io simplifies data extraction from multiple web pages simultaneously, offering an affordable solution for businesses of all sizes.
Import.io: Import.io emerges as a versatile data extraction and transformation tool, offering businesses the ability to automate web scraping and transform unstructured online data into actionable insights. With customizable extractors, real-time data collection, and flexible pricing based on project size, Import.io is an invaluable asset for businesses seeking high-quality data at affordable rates.
In conclusion, web scraping tools serve as indispensable allies in the quest for data-driven decision-making. By leveraging these tools effectively, businesses can access vast repositories of valuable data, driving informed strategies and fostering growth in an increasingly data-centric world.
0 notes
Text
How to Scrape Liquor Prices and Delivery Status From Total Wine and Store?

This tutorial is an educational resource to learn how to build a web scraping tool. It emphasizes understanding the code and its functionality rather than simply copying and pasting. It is important to note that websites may change over time, requiring adaptations to the code for continued functionality. The objective is to empower learners to customize and maintain their web scrapers as websites evolve.
We will utilize Python 3 and commonly used Python libraries to simplify the process. Additionally, we will leverage a potent and free liquor scraping tool called Selectorlib. This combination of tools will make our liquor product data scraping tasks more efficient and manageable.
List Of Data Fields

Name
Size
Price
Quantity
InStock – whether the liquor is in stock
Delivery Available: Whether the liquor is delivered
URL

Installing The Required Packages for Running Total
To Scrape liquor prices and delivery status from Total Wine and More store, we will follow these steps
To follow along with this web scraping tutorial, having Python 3 installed on your system is recommended. You can install Python 3 by following the instructions provided in the official Python documentation.
Once you have Python 3 installed, you must install two libraries: Python Requests and Selectorlib. Install these libraries using the pip3 command to scrape liquor prices and delivery data, which is the package installer for Python 3. Open your terminal or command prompt and run the following commands:
The Python Code

The Provided Code Performs The Following Actions:
Reads a list of URLs from a file called "urls.txt" containing the URLs of Total Wine and More product pages.
Utilizes a Selectorlib YAML file, "selectors.yml," to specify the data elements to scrape TotalWine.com product data.
Performs total wine product data collection by requesting the specified URLs and extracting the desired data using the Selectorlib library.
Stores the scraped data in a CSV spreadsheet named "data.csv."
Create The YAML File "Selectors.Yml"
We utilized a file called "selectors.yml" to specify the data elements we wanted to extract total wine product data. Create the file using a web scraping tool called Selectorlib.
Selectorlib is a powerful tool that simplifies selecting, highlighting up, and extracting data from web pages. With the Chrome Extension of Selectorlib Web Crawler, you can easily mark the data you need to collect and generate the corresponding CSS selectors or XPaths.
Selectorlib can make the data extraction process more visual and intuitive, allowing us to focus on the specific data elements we want to extract without manually writing complex CSS selectors.
To leverage Selectorlib, you can install the Chrome Extension of Selectorlib Web crawler and use it to mark and extract the desired data from web pages. The tool will then develop the imoportant CSS selectors or XPaths, which can be saved in a YAML file like "selectors.yml" and used in your Python code for efficient data extraction.


Functioning of Total Wine and More Scraper
To specify the URLs you want to scrape, create a text file named as "urls.txt" in the same directory as your Python script. Inside the "urls.txt" file, add the URLs you need to scrape liquor product data , each on a new line. For example:
Run the Total Wine data scraper with the following command:
Common Challenges And Limitations Of Self-Service Web Scraping Tools And Copied Internet Scripts
Unmaintained code and scripts pose significant pitfalls as they deteriorate over time and become incompatible with website changes. Regular maintenance and updates maintain the functionality and reliability of these code snippets. Websites undergo continuous updates and modifications, which can render existing code ineffective or even break it entirely. It is essential to prioritize regular maintenance to ensure long-term functionality and reliability, enabling the code to adapt to evolving website structures and maintain its intended purpose. By staying proactive and keeping code up-to-date, developers can mitigate issues and ensure the continued effectiveness of their scripts.
Here are some common issues that can arise when using unmaintained tools:
Changing CSS Selectors: If the website's structure changes, the CSS selectors are used to extract data, such as the "Price" selector in the selectors.yaml file may become outdated or ineffective. Regular updates are needed to adapt to these changes and ensure accurate data extraction.
Location Selection Complexity: Websites may require additional variables or methods to select the user's "local" store beyond relying solely on geolocated IP addresses. Please handle this complexity in the code to avoid difficulties retrieving location-specific data.
Addition or Modification of Data Points: Websites often introduce new data points or modify existing ones, which can impact the code's ability to extract the desired information. Without regular maintenance, the code may miss out on essential data or attempt to extract outdated information.
User Agent Blocking: Websites may block specific user agents to prevent automated scraping. If the code uses a blocked user agent, it may encounter restrictions or deny website access.
Access Pattern Blocking: Websites employ security measures to detect and block scraping activities based on access patterns. If the code follows a predictable scraping pattern, it can trigger these measures and face difficulties accessing the desired data.
IP Address Blocking: Websites may block specific IP addresses or entire IP ranges to prevent scraping activities. If the code's IP address or the IP addresses provided by the proxy provider are blocked, it can lead to restricted or denied access to the website.
Conclusion: Utilizing a full-service solution, you can delve deeper into data analysis and leverage it to monitor the prices and brands of your favorite wines. It allows for more comprehensive insights and enables you to make informed decisions based on accurate and up-to-date information.
At Product Data Scrape, we ensure that our Competitor Price Monitoring Services and Mobile App Data Scraping maintain the highest standards of business ethics and lead all operations. We have multiple offices around the world to fulfill our customers' requirements.
#ScrapeLiquorPricesData#WebScrapingTotalWineData#TotalWineDataScraper#ExtractTotalWineProductData#TotalWineProductDataCollection#LiquorDataScrapingServices
0 notes
Text
How to Extract Products Data from H&M with Google Chrome

Data You Can Scrape From H&M
Product’s Name
Pricing
Total Reviews
Product’s Description
Product’s Details
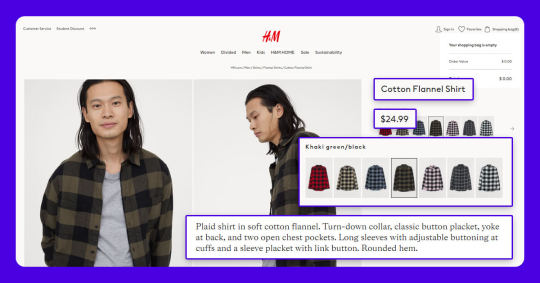
The screenshot provided below indicates various data fields, which we scrape at 3i Data Scraping:
Requests
Google’s Chrome Browser: You would require to download the Chrome browser and the extension requires the Chrome 49+ version.
Web Scraping for Chrome Extension: Web Scraper extension could be downloaded from Chrome’s Web Store. Once downloaded the extension, you would get a spider icon included in the browser’s toolbar.
Finding The URLs
H&M helps you to search products that you could screen depending on the parameters including product types, sizes, colors, etc. The web scraper assists you to scrape data from H&M as per the requirements. You could choose the filters for data you require and copy corresponding URLs. In Web Scraper toolbars, click on the Sitemap option, choose the option named “Edit metadata’ to paste the new URLs (as per the filter) as Start URL.
For comprehensive steps about how to extract H&M data, you may watch the video given here or continue to read:
Importing H&M Scraper
After you install the extension, you can right-click anyplace on the page and go to the ‘Inspect’ option as well as Developer Tool console would pop up. Just click on the ‘Web Scraper’ tab and go to the ‘Create new sitemap’ option as well as click on the ‘Import sitemap’ button. Now paste JSON underneath into Sitemap’s JSON box.
Running The Scraper
To start extracting, just go to the Sitemap option and click the ‘Scrape’ alternative from the drop-down menu. Another window of Chrome will come, permitting the extension for scrolling and collecting data. Whenever the extraction is completed, the browser will be closed automatically and sends the notice.
Downloading The Data
For downloading the extracted data in a CSV file format, which you could open with Google Sheets or MS Excel, go to the Sitemap’s drop-down menu > Export as CSV > Download Now.
Disclaimer: All the codes given in our tutorials are for illustration as well as learning objectives only. So, we are not liable for how they are used as well as assume no liabilities for any harmful usage of source codes. The presence of these codes on our website does not indicate that we inspire scraping or scraping the websites given in the codes as well as supplement the tutorial.
#data extraction#web scraping services#Extract data from H&M#H&M Data Scraping#Data Extractor#Web Scraping Services#Ecommerce data scraping services#Data Extractor from H&M
0 notes
Text

Web Scraper Tools For Marketing
With the accelerated pace of digital transformation, extracting data from numerous online sources has become remarkably essential. Today we have highly sophisticated page scraper tools, such as online data scraper tool, online screen scraper tool, or online web scraper tool free that allow us to effortlessly exfoliate information from the web, granting us access to a plethora of insights that aid in our decision making.
Among the various types of scrapeable data, Google Maps Data, Google Maps Directory, Google Maps Reviews, Google Play Reviews, Google search results, Trustpilot Reviews, Emails & Contacts, Amazon Products, Amazon Reviews, and Onlyfans Profiles are some popular choices.
Web scraping tools are becoming an essential element in today’s digital world, enabling businesses to tap into unstructured data on the web and transform it into structured, valuable information. For instance, you can use a free online URL Scraper tool to scrape website URLs and gain insight into your competitors’ tactics and strategies. Similarly, an email scraper can help you build a mailing list for your marketing initiatives, and an AI website scraper can help you crawl and extract complex data from websites in an efficient manner.
Scraping data using online scrape tools or online web scraper tools can have various applications. Amazon scraper can help you extract product details and reviews to conduct competitor analysis and market research. Google scraper can gather search data for SEO tracking, while LinkedIn scraper can facilitate recruitment process by collecting potential candidates’ data.
If you’re interested in exploring these tools, for more information, visit [here] (https://ad.page/micro ) to learn more about effective web scraping tools. Moreover, to get started with using these tools, register [here]( https://ad.page/app/register ).
Furthermore, you can use SERP scraping API or SERP scraper to routinely check your website’s ranking and performance. If you’re curious about how your site ranks on Google and other search engines, the Advanced SERP Checker is a handy tool that provides you with just that. You can find more about it [here](https://ad.page/serp).
Finally, the Onlyfans-scraper and Instagram scrapper are specific scraping tools popular in the influencer and entertainment industries for identifying potential collaborators, tracking engagement, or monitoring trends. And if you want a simple, accessible tool for your scraping projects, you may want to check free web scraper or free web scraper chrome extension to quickly extract web data directly from your browser.
These are a handful of the numerous tools that can Revolutionize the way we extract and analyse data online. In this digital era, understanding and harnessing the ability to web-scrape using these online scraper tools proves to be an essential skillset, opening doors to copious amounts of vital information that would otherwise be daunting to access. Whether it’s for market research, brand reputation monitoring, or collecting social media data, these tools offer solutions that cater to a wide range of needs.
To wrap up, the online environment is a gold mine of data waiting to be tapped into. With the right tools such as web scraper tool online, ai website scraper, email extractor and more, you can unlock immeasurable value from web data and use it to drive your business decisions and growth.
1 note
·
View note