
Statistics
We looked inside some of the posts by technocinema and here's what we found interesting.
Average Info
Notes Per Post
5
Likes Per Post
4
Reblog Per Post
1
Reply Per Post
0
Time Between Posts
7 months
Number of Posts By Type
Text
17
Last Seen Tumblr Blogs





Fun Fact
When “GIF” was named word of the year in 2012, Oxford Dictionaries U.S.A. credited Tumblr for pushing the word.
Text
To Create or Promote

A colleague with whom I co-taught at USC for many years always said that you can either do your best creative work or you can successfully promote the things you make, but you can't do both at the same time. As harsh as this truth is, I have found it to be functionally correct, but with some recently realized nuances. My colleague, of course, had risen to a place in his professional and creative life where he had others to help with promoting his work, leaving him with unfettered time to work on his ideas. Although this is far from true for me at this particular juncture, I have found myself engaged in a surprisingly generative cycle of creative practice and self-promotion that has been sustaining in unexpected ways.

This week, alone, I have two different films -- one a feature length video essay and the other an experimental short, dome film -- appearing in festivals in the US and Canada (Interrobang in Des Moines and Fivars in Ontario). In addition, I just received notification that the short has been accepted by a festival in Portland and the feature will screen at the Hammer Museum in the fall in conjunction with Filmforum's 50th anniversary celebration!

All of this coincides with the work I have been doing with Todd Furmanski to create an immersive/interactive version of the Machine Visions project, which is now entering an exciting phase of near-completion in anticipation of the IDFA DocLab deadline in less than two weeks. To be clear: entering these projects in festivals has been an unrelenting bummer, punctuated by occasional moments of gratification, including the recent notification that Reality Frictions received the Best Found Footage award from Interrobang! I don't know whether it helps or doesn't help that both of the projects I have completed in the past year resist easy classification on the film festival circuit.

The challenges of exhibiting video essays -- especially at feature length -- was the focus of my presentation and roundtable organized with Allison de Fren at the SCMS conference in Chicago last spring, and included my UCLA colleague and documentary-essayist Kristy Guevara-Flanagan and Czech festival curators/archivists Veronika Hanakova and Jiri Anger. Based on the surprisingly strong and enthusiastic turnout for this panel, which was scheduled in the earliest time slot of the first day of the conference, it's clear that video essayists are hungry for a broadened range of screening options. The consensus in discussion with video essay geeks at SCMS was that the film festival circuit is every bit as opaque and pitiless as academic publishing and for many of us, the stakes are just as high.
What has surprised me more is the reception accorded to the dome version of Machine Visions: Mojave (equirectangular trailer above), which has been accepted to show in more of the festivals to which I have submitted it than not. Partly, this speaks to the relatively small number of festivals that are equipped with dome projection facilities -- usually a planetarium with which the festival has partnered -- and possibly the fact that dome films remain a relatively niche format for enthusiasts of immersive media. Coming out of the pandemic, when VR exhibition became unreasonably difficult, I have been experimenting with different formats for 360 display, and dome projection, thus far, has turned out to be among the most gratifying, preserving many of the pleasures of VR-style immersion without the complications of hardware.

Although we intend to ultimately create both VR and AR versions of Machine Visions: Mojave, at this point, dome projection is proving to be the best format for a time-based experience, while large-screen, interactive installation -- such as the playtest (above) using UCLA's virtual production facility, a 30' wide LED wall, which was brighter and more spectacular than any projection environment I have tried -- offers an extremely satisfying overall experience. Based on an initial round of playtesting, much of our preparation for the IDFA submission has focused on playability, including the incorporation of a joystick for more intuitive navigation and some strategic constraints to prevent users from, for example, exceeding the boundaries of the playable environment and never finding their way back.

How does all of this relate to the opening anecdote about the seeming disjunction between creation and promotion? Much of what is required for promoting these projects is to articulate core concepts and their relation to the technology used to create them. Rather than thinking of these as two separate -- to say nothing of exclusive -- operations, I am finding them to be at least mutually informing. Synthesizing and articulating the concepts driving each stage of the project, which is required for festival submissions and program descriptions, also supports the creative process as we plow through an otherwise overwhelming array of design options for each successive iteration.
0 notes
Text
On Seeing with Mechanical Eyes
Being as I have described this blog as "an experiment in researching in public," the whole point is to reflect on works-in-progress before they are really ready for public consumption. Of course, this goes against my desire for control and precision, but I've found the informal writing space of the blog to serve as an effective testing ground for ideas that remain incompletely baked even though they have been in the oven for a while.

In fact, I have recently begun pushing proposals for this project out into the world under a variety of names and formats. These range from a full-scale art-book proposal that failed to get traction at the one press and with the one editor who I could imagine publishing it, to a UCLA Arts grant, where the same set of ideas were warmly embraced, providing the resources needed for the initial stages of my investigation. I also recently submitted a proposal for an article-length version of the project to a journal claiming to welcome arts-based research. This process of working in simultaneous and divergent directions is new for me in some ways, but in other ways very familiar. As with my writing process for Technologies of Vision, which coincided with completing the video essay Screening Surveillance and the Scalar article Chaos and Control, I welcome the ability to bounce back and forth between text-writing, media-curating and video-editing, driven not by any particular formal imperative but by the critical needs of any given thread of argument.
On a practical level, I am left now with multiple titles for various iterations of the project. Ask the Joshua Tree: Modeling Futures of the Mojave Desert Ecosystem was the title funded by UCLA to create a gallery-based digital artwork incorporating multiple media technologies, from photogrammetry-based 3D models embedded in a procedurally generated virtual environment to dome projections of aerial 360 video and virtual camera perspectives captured inside a game engine. I continue to be fascinated by the potential of mirroring these two types of images: a 360 video camera suspended from a drone uniquely simulates the omniscient perspective of a virtual camera in a computer-generated 3D environment. What happens when we blur the lines between these two?

The aerial 360 video system also echoes Michael Snow’s analogue-mechanical film apparatus (above) created for La Région Centrale / The Central Region (1971), which propelled a 16mm camera through a series of pre-programmed patterns of movement to capture images of the Canadian wilderness from every possible angle. The abstraction of Snow's landscape derives from the variable speeds with which the machine's counterbalanced, robotic arms sweep the camera through nested arcs of motion, defined by a 'score' of geometric increments - a pre-digital machine for the movement of parts. Snow's resulting film, some 3 hours long, is an exercise in endurance, with images that range from languorous pans across a featureless sky or barren landscape to rapid, acrobatic orchestrations of texture, color, light and space. Snow may have drawn inspiration from Stan VanDerBeek's hemispherical Movie Drome projection environment (below), which was created around the same time, but the film was never intended for immersive, or even multi-channel projection. Instead, Snow (and others) confined their Structuralist experiments with camera movement (and other properties of the film apparatus) to a conventional, rectangular frame.

What makes the "vision machine" created for La Région Centrale uniquely relevant to this project is its prescient articulation of a visual field composed of “coordinated spaces." Snow's camera apparatus anticipates the affordances of reframed 360 video as well as the experience of lived spaces as instrumented volumes where each point in space is defined by mathematical coordinates. Although I have written about this from an abstract, theoretical perspective in the past, it is quite another matter to test my hypotheses that the ways of seeing that are facilitated by such an apparatus - Snow's stated goal was to capture images in "every direction and on every plane of a sphere" - represents a compelling bridge between this proto-computational technology of vision from the 1970s and the digitally coordinated spaces of today.

My hope is that something beyond the pleasures of the digital analogue will become apparent when these two are juxtaposed, interchanged, superimposed, interlaced, etc. A promising initial experiment with reframed aerial 360 video resulted in a sequence incorporating both the "tiny planet" and "rabbit hole" effects of Insta360 Studio. The image above was created by pivoting the angle of view of two different reframings of the same landscape to be diametrically opposed along the Z-axis, then compositing them together to create a contiguous landscape that simultaneously appears to be rotating radially outward while the center of the frame billows and revolves gently in the opposite direction. But how to return a 2D visual effect that was extracted from the unique properties of a 360 image back to spherical form?
I am hopeful about the capacity of tools for content aware image expansion to extend the field of this disorienting and already unreal-looking landscape, coupled with plane-to-sphere projection to solve for the geometry of the reframed image when reinserted in 360 degree image space. In fact, part of the conceptual origin of this project derives from my early observation that the organic irregularity of the Joshua Tree proved uniquely confounding to algorithms for image recognition and synthesis.

In my initial experiments using Stable Diffusion (above), synthetic Joshua Trees took on a variety of unexpectedly baroque forms, including physically impossible features such as loop-shaped branches. Because Joshua trees have inconsistent (environmentally influenced) patterns of growth resulting in no ideal or "typical" form, they are both unusually forgiving of the "mistakes" to which generative AI remains prone, and simultaneously resistant to achieving any sort of definitive or "correct" outcome. Of course, my own project remains indifferent to the AI industry's drive toward photorealism, instead focusing on reciprocal dynamics of human and machine vision, such that errors and anomalies are more useful than plausible reproductions.

This brings us to concerns that are central to the elements of this project clustered under the title The Act of Seeing with Mechanical Eyes. The title pays homage to another film from 1971: Stan Brakhage's The Act of Seeing with One's Own Eyes. Brakhage's title purports to be the literal translation of the term "autopsy," and it puts forward a theory of seeing antithetical to that of La Région Centrale. Shot in a Pittsburgh morgue where bodies are being subjected to procedures of forensic pathology prior to burial/cremation, the film has uncharacteristic hints of documentary evidence-gathering, while still preserving much of Brakhage's signature style: fuzzy, jerky images captured with a handheld camera that constantly reminds us of the physical presence of the filmmaker; lingering close-ups and disjointed editing that obsessively return to the most explicit of the autopsy procedures, etc. In other words, Brakhage offers an extended meditation on the most graphic and grisly - fleshy, oozing, decaying - elements of human corporeality -- an embodied counterpoint to the mechanization of human vision proposed by Snow in his own time, and by machine learning and image synthesis today.
Close to the heart of both Joshua Tree projects is my desire to mobilize the environmental context of the Mojave Desert - need I say that it, and Joshua Trees in particular, face severe threats from climate change? - as a metaphor to demonstrate the potentials of decentering the human perspective in the discourse of generative AI. A video essay that I'm working on tackles this issue from a different angle, historicizing representations of Artificial Intelligence as seen on film and TV, but the message resonates across both undertakings. The oppositions that continue to dominate discussions of AI - human/machine; organic/artificial; real/fake, etc. - ironically reproduce the kind of binary logic that is more commonly used to argue for the superiority of human thinking (creativity, intuition, originality, etc.) over the rote mechanics of computation. My formal commitment to the Joshua Tree projects is to propose not an equivalency between human and computer vision, but a kind of measured coexistence that may allow reasoned discourse to take place. At the very least, the abstract pleasures we derive from synthetic imaging should be weighed against the calculable environmental damage that attend these technologies at every point along the supply chain.

As much as a critical intervention in environmental discourse about AI and the Mojave, The Act of Seeing with Mechanical Eyes is itself an experiment with the limits, potentials, and parameters of visuality. Our eyes, like our bodies, increasingly function as extensions of computational machines, not the other way around. Cameras are no longer primarily used for capturing reflected light, but as instruments for generating a data field translatable into multiple, potential visual forms. Using a combination of human vision (lenses) and machine vision (GenAI), my goal is to displace the anthropocentric perspective in favor of hybrid and even contradictory ways of seeing. I would ultimately like to use this combination of imaging systems to imagine new possibilities for the co-evolution of Joshua trees and humans - perhaps not on the same scale as the obligate mutualism of the Yucca Moth and Joshua Tree - but at least a shared desire for generational survival as we face the age of the Anthropocene together.
0 notes
Text
Reflections on Flux Festival 2024

Photo credit: Sarah M. Golonka
Of course I'm biased, but not in a bad way. Having witnessed the hundreds of hours of curating and organizing that Holly and her collaborators – the old team from RES Magazine and RESFest – put into this amazing four-day festival, I knew it would be unlike any of the other public events I have been to that are struggling to come to terms with the impact and potentials of generative AI. It also makes sense that FluxFest extends the logic of the RESFest in terms of capturing a moment, however fleeting and transient it may be – this I regard as a feature, not a bug, by the way – in the unfolding evolution of digital culture. This is where the genius of Flux lies. Industry-sponsored AI events and those promoted by organizations that want to be recognized as a source of investment advice are all inextricably cathected with the self-serving logic of venture capital, which thrives on being right about what's cool, what's next, and who to watch and listen to.

Photo credit: Sarah M. Golonka
Flux, as the name suggests, embraces the indeterminacy of any given moment, with its fickle basis in technologies, each of which promises to be the next big thing, and instead looks for cultural resonances and significance; a curated experience that is agnostic about form and largely indifferent to newness and coolness even when it is capturing things that are new and cool. As such, it is also appropriate that the event unfolded over a series of days at venues scattered around the city -- from UCLA's Hammer Museum to the School of Cinematic Arts at USC, to the Audrey Irmas Pavilion (AIP) somewhere in between.

Photo credit: Sarah M. Golonka
Although I managed to make it to all four events, the highlight was definitely the day-long series of performances, screenings, talks and installations at the AIP, where close to a thousand people converged - the event's sponsorship by USC and Holly's research unit AIMS (AI for Media and Storytelling) skewed the demographic toward students, but well-mixed with Flux loyalists and a sizable number who either remembered or were old enough to remember the RES days of the early 2000s.

Although my plan had been to help with documenting the event in 360 video, I instead found myself assisting with the VR installations on the second floor, where multiple exhibits were set up for attendees to experience projects ranging from the VR version of Carlos López Estrada's “For Mexico, For All Time,” which accompanied the 2024 UFC championships at The Las Vegas Sphere, to Scott Fisher's Mobile and Environmental Media Lab's (MEML) collaboration with Pau Garcia of Domestic Data Streamers, which used a variety of image synthesis technologies to recreate memories conjured by visitors to the installation.

Dubbed "Synthetic Memories" and working in near-realtime, a team of USC students from Fisher's lab created 180-degree memory spaces and Gaussian splat-based 3D environments, all of which were experienced in a head-mounted display. My own childhood memory of being menaced by a possum from the treehouse in my grandparents' backyard yielded two equally striking image spaces. Unfortunately, the generative AI system never quite captured the threat posed by the possum as I experienced it. The creature that was supposed to be snarling up at me in the printed souvenir of the experience (below) looks more like a friendly, overfed otter, but this image will nonetheless probably one day entirely replace my biological memories of the situation.

Of course, the environments created with both the Gaussian splat and gen AI software uncritically naturalize arbitrary conventions for the aesthetics of memory: soft-focus, muted color palette, fuzzy borders, etc., all of which are rooted in a cinematic vocabulary that is more semiotic convention than anything organically related to remembering. But for now, these experiments are making lemonade out of the indistinct yet still compellingly dimensionalized aesthetics of the environments created by Fisher's team.

After having my own memory space conjured by this apparatus, I had not expected to spend the next 9 hours informally staffing López Estrada's adjacent VR installation, but I made the mistake of admitting that I knew how to set up and operate a Quest 3 headset. Although I haven't taught my VR class at UCLA for over a year and was a little out of practice troubleshooting the Quests, there was something uniquely rewarding about spending the day within a few yards of Scott Fisher, some 40 years after his team at NASA Ames developed the first functional headmounted display in the mid-1980s. The way I see it, if Scott Fisher – one of VR's true visionaries and pioneers – is willing spend 9 hours ushering dozens of visitors through a VR exhibit, who am I to sneak out to take in the rest of the Flux events?

Photo credit: Sarah M. Golonka That said, some of the more memorable elements of the festival, for me were Kevin Peter He's live cinema performance with Jake Oleson, which was preceded by a how-to workshop at USC's IMAX theater, exposing some of the secrets of his live, VJ-style navigation of procedurally generated, landscapes populated with infernal, humanoid specters.

Another perverse highlight was Jan Zuiderveld's self-serve Coffee Machine installed in the lobby outside the VR exhibits, which served up AI-generated insults to users along with a pretty decent cup of espresso. Although it was admittedly a relief for everyone that the festival came to such a successful conclusion, I won't be surprised if the legacy of the RESFest lives on in the form of a traveling, international version of the Flux Festival. Whatever its afterlife may be, the 2024 Flux Festival has set a bar that seems unlikely to soon be surpassed by the bright-eyed evangelists and doomsaying haters who dominate much of the current landscape of generative AI.
0 notes
Text
Reality Frictions world tour continues

It all started with a single invitation from Jason Mittell to visit Middlebury College to screen Reality Frictions and visit two of his classes. Since Mittell and Middlebury have been at the center of the video essay world for the past decade, I correctly assumed that one would be a class on "Videographic Criticism." What I didn't see coming was Jason's other class, titled "Faking Reality," which resonated even more strongly with the conceptual concerns of Reality Frictions. In fact, my own film came together as the result of a class at UCLA titled "Reality Fictions," coupled, of course, with my own class on "Videographic Scholarship." The trip to Middlebury coincided with the beginning of Fall colors, which made for an incredibly beautiful drive up from Boston and the reception from both students and Middlebury faculty including InTransition co-founder Christian Keathley was correspondingly warm and congenial.

Although it goes against my most reclusive instincts, knowing that I would be in New England motivated me to reach out to old colleagues and friends at Dartmouth and MIT's Open Doc Lab to pitch the idea of additional screenings. Amazingly, these connections paid off in ways I never expected, beginning with a generous invitation from Mark Williams and Daniel Chamberlain for a screening at Dartmouth on my way back to Boston. In the course of working out logistics, Mark put me in touch with a colleague at Shanghai Film Academy with whom he has been developing a collaboration in connection with the ongoing Media Ecology Project. The Shanghai connection was doubly fortuitous -- in addition to inviting me to screen the film, I was asked to deliver a keynote address at an Artificial Intelligence conference at Shanghai University taking place the same weekend.

Although generative AI was only one of the inspirations for Reality Frictions, I have been developing some ideas about the current generation of image synthesis technologies going back to my research on machine learning for Technologies of Vision. The Pujiang Innovation forum's focus on "Entering the Era of AI-generated Art" turned out to be the perfect venue to consolidate and share these initial thoughts, especially regarding the need to historicize the current wave of imaging technologies and aesthetics.

Another riff in the talk emphasized the reciprocal relationships between both human/machine vision and analogue/algorithmic imaging, all of which are resulting in some striking and enigmatic modes of recombination. It was sometimes hard to know how these ideas -- and images! -- were received by the audience, which was clearly focused more on industrial applications and engineering challenges, but the panel discussion afterwards suggested that the perspectives I brought from an art and design context provided a useful counterpart to the conversation.

Another complicating factor was the fact that the primary language of the conference was Mandarin, which necessitated some impressive feats of simultaneous translation enacted by a heroic team of human translators. For all of the hand-wringing about the prospect of lost jobs in the media industries due to AI, my real sympathies lie with the women tasked with the two-way art of live, simultaneous translation. If I had to bet on anyone's job being gone because of AI this time next year, it's theirs.

My next stop after the conference and screening at Shanghai Film Academy was NYU Shanghai, where the excellent Anna Greenspan arranged for a screening of Reality Frictions under the auspices of the Center of AI and Culture she co-directs there. Audiences at both Shangahi universities were remarkably receptive and enthusiastic -- in some cases even more insistent on pursuing the philosophical implications of my deliberately false bifurcation of reality and non-reality than their American college student counterparts.

For the return flight to Los Angeles, I left Shanghai in the afternoon and arrived a couple of hours earlier the same day, making it the longest and most agonizing election day I've ever experienced in more ways than one. Along with generative AI, the other motivating factor behind the film's investigation of the porous boundaries between truth and lie, of course, was the election that was decided a few hours after my return to the U.S. Even with an election outcome that suggests otherwise, I stand by the film's assertion that viewers have greater capacity for distinguishing truth from lie than we sometimes give them credit for. Of course, this reading emerged from within the deep blue bubble of southern California and a day-to-day engagement with media-making as a semiotic exercise. Although I didn't plan it this way, the next stop for Reality Frictions turned out to be in a state that lies at the other end of the ideological spectrum.

The University of Nebraska Lincoln -- thanks to the collaboration of Wendy Katz and Jesse Fleming -- generously hosted both me and Holly for a screening and talk on AI and Creativity, creating an unusual bridge between the Art History and Emerging Media Arts (EMA) programs via the university's Hixson-Lied Visiting Artist series. The reception to both events was again warm and engaged and we got a chance to glimpse both the remarkable profusion of public art on the campus thanks to Wendy's walking tours and some genuinely groundbreaking and inspiring work in mindful design emerging from Jesse's work in the EMA.

The final stop on this leg of pre-holiday screenings took place just a few days after we got back from Nebraska, this time via Zoom. Although it was not possible to arrange a screening at the Open Doc Lab as I passed through Cambridge, the screener I forwarded to them wound up in the hands of Cinematographer/Documentarian extraordinaire Kirsten Johnson, who invited me to screen the film during an upcoming residency at the University of Missouri's School of Journalism, which turned out to be followed by one of the most dynamic Q/A sessions I've had. Although it is still early in this film's life cycle, I am both encouraged by the positivity of the in-person screenings and discouraged by the majority of festival responses. Video essays, as a form, do not fit easily into the pre-existing categories offered by most film festivals. When such categories do exist -- and they are mostly in Europe -- they are almost always limited to a maximum of 20-30 minutes. And while there is something extremely gratifying about touring with a film like this, it is unsustainable in every sense of the word. To close out this thread, I will note one other piece of good news that arrived -- a panel that I organized with Allison de Fren was accepted by SCMS. We will be joined for the upcoming conference in Chicago by my UCLA colleague Kristy Guevara-Flanagan, who has also been touring with her recently completed short film As Long As We Can, and Czech scholar-curator-archivist-editors Jiří Anger and Veronika Hanáková for a roundtable discussion titled "Beyond Electronic Publication: Expanding Venues for Videographic Scholarship." See you in Chicago!
0 notes
Text
Reality Frictions awarded by Madrid Film Festival and Impact Docs awards!

I am extremely happy to report that my feature documentary/video essay, Reality Frictions, has won awards from both the Madrid International Film Festival (where it had its world premiere) and the US-based Impact Docs awards! Huge thanks go to sound designer/mixer, Eric Marin, whose 5.1 mix completely transformed the audio experience of the film for theatrical exhibition.

I'm also grateful to festival programmers at Madrid for making a place for this film, which is more than twice as long as what I would recommend for a video essay (though it's also less than half as long as Thom Andersen's Los Angeles Plays Itself, which it's hard to believe is now more than 20 years old and still seems completely current). Reality Frictions doesn't fit neatly into any of the typical festival boxes. It's too personal and essayistic to meet most criteria for "documentary," and too long and nowhere near weird enough to be programmed as "experimental." I'm still diligently sending it to an array of festivals around the world that claim to be open to non-traditional forms and we'll see how that goes. In the mean time, the world premiere made for a perfect excuse to explore the amazing art and culture of Madrid!

0 notes
Text
Reality Frictions explores the boundaries between fact and fiction

Although I have been researching this topic and gathering materials on and off for several years, the project went into high gear about a year ago when I posted a call to the scholars and makers associated with the Visible Evidence documentary film community, requesting examples of "documentary intrusions" -- roughly defined as moments when elements from the real world (archival images, real people, inimitable performance, irreversible death, etc.) intrude on fictional or quasi-fictional story worlds.

The response was overwhelming -- in just a few days, I received some 85 suggestions and enthusiastic expressions of support. This community immediately recognized the phenomenon and reinforced many of the examples I had already gathered, while also directing me to dozens more, such as the bizarre and troubling inclusion of Bruce Lee's funeral as a plot device in his final film, Game of Death (1978). For practical reasons, I decided to limit the scope of the project to Hollywood films and their immediate siblings in streaming media & television, but the international community of Visible Evidence noted the erosion or complication of fact/fiction binaries in many non-US contexts as well -- definitely enough for a sequel or parallel project in the future.
As the editing progressed, I quickly realized that the real challenge lay in curating and clarifying the throughline of the project without becoming overwhelmed or distracted by the many possible variations on the fact/fiction theme. The conceptual core of the project was always inspired by Vivian Sobchack's concept of "documentary consciousness," described in her book Carnal Thoughts (2000). Sobchack's inspiration, in turn, derived from a scene in Jean Renoir's film The Rules of the Game (1939) depicting the undeniable, physical deaths of more than a dozen animals as part of the film's critique of the elitism and narcissism of France's pre-war bourgeoisie. Sobchack returned to this scene in two separate chapters of the book for meditations on the ethics and impact of these animal deaths for filmmakers and viewers alike, relating them to both semiotic and phenomenological theories of viewership.

On the advice of filmmakers and scholars who viewed early cuts of the film, nearly all academic jargon has been chiseled out of the narration, leaving what I hope is a more watchable and engaging visual essay that embraces the pleasures and paradoxes found at the intersection of reality and fiction. Additional feedback convinced me to stop trying to make my own VO sound like Encke King, my former classmate who supplies the gravelly, world-weary narration for Thom Andersen's Los Angeles Plays Itself (2003). I've done my best to talk more like myself here, but there's no denying Thom's influence on this project -- both as a former mentor at CalArts and for the strategies of counter-viewing modeled in LAPI. Going back even farther, I would note that it was my work as one of the researchers for Thom's earlier film (made with Noel Burch), Red Hollywood (1996), that got me started thinking about the role of copyright in historiography and the ethical imperative for scholars and media makers to assert fair use rights rather than allowing copyright owners to define what histories may be told with images. This singular insight guided much of my work for the past two decades, realized principally in my ongoing administration of the public media archive Critical Commons (which celebrates its 15th anniversary this month!) as an online resource for the transformative sharing of copyrighted media.

This project also bridges the gap between my first two books, Technologies of History: Visual Media and the Eccentricity of the Past (2011) and Technologies of Vision: The War Between Data and Images (2017). The historiographical focus of this project emerged as an unplanned but retrospectively inescapable artifact of engaging questions of authenticity and artifice, and it afforded the pleasures of revisiting some of my favorite examples, such as Cheryl Dunye's Watermelon Woman (1996) and Alex Cox's Walker (1987), both exemplary for their historiographical eccentricity. An additional, important element of context is the recent emergence and proliferation of generative AI for image synthesis. Technologies of Vision addressed some of the precursors to the current generation of synthetic imaging, which has only accelerated the arms-race between data and images, but recent developments in the field have sharpened the need for improved literacy about the way these systems work -- as well as the kind of agency it is reasonable to attribute to them.

Reality Frictions also aims to intervene in the anxious discourse that has emerged in response to image synthesis, especially among documentarians who feel confidence in photographic and videographic representation slipping away, and journalists besieged by knee-jerk charges of fake news. While I totally understand and am sympathetic to these concerns, challenges to truth-telling in journalism and documentary film hardly began with digital imaging, let alone generative AI. It is axiomatic to this project that viewers have long negotiated the boundaries between images and reality. The skills we have developed at recognizing or confirming the truth or artifice found in all kind of media remain useful when considering synthetic images. Admittedly, we are in a moment of transition and rapid emergence in generative AI, but I stand by this project's call to look to the past for patterns of disruption and resolution when it comes to technologies of vision and the always tenuous truth claim of non-fiction media.

Although the format of this project evolved more or less organically, starting with a personal narrative rooted in childhood revelations about the world improbably drawn from TV of the 1970s, the final structure approaches a comprehensive taxonomy of the ways reality manages to intrude on fictional worlds. Of course the volume and diversity of these instances makes it necessary to select and distill exemplary moments and patterns, all of which provides what I regard as this project's main source of pleasure. One unexpected tangent turned out to be the different ways that side-by-side comparisons trigger uncanny fascination at the boundary between the real and the nearly real. Hopefully without belaboring the point, I aim to parse these strategies from the pleasures of uncanny resemblance to what I view as superficial and mendacious attempts to bolster a flimsy truth claim simply by casting (and costuming, etc.) actors to "look like" the people they are supposed to portray.

Other intersections of fact and fiction are less overt, requiring extra-textual knowledge or the decoding of clues that transform the apparent meaning of a scene. Ultimately, I prefer it when filmmakers respect viewers' ability to deploy existing critical faculties and infer their own meanings. Part of the goal of this project is to heighten viewers' attentiveness to the ways reality purports to be represented on screen; to dissolve overly simplistic binaries, and to suggest the need for skepticism, especially when dramatic flourishes or uplifting endings seem designed to trigger readymade responses. While stories of resilient individuals and obstacles that are overcome conform to Hollywood's obsession with emotional closure and narrative resolution, we should be mindful of the events and people who are excluded by the presumptions underlying these structures.

A realization that develops over the course of the video is that the films with the most consistently complex and deliberate structures for engaging the problematics of representing reality on film come from filmmakers who directly engage systems of power and privilege, especially related to race. From Ava DuVernay's re-writing of Martin Luther King's speeches in Selma (2014), to Ryan Coogler and Spike Lee's inclusions of documentary footage in Fruitvale Station (2013), Malcolm X (1992), and BlacKkKlansman (2018), the stakes are raised for history films with direct implications for continuing injustice in the present. For these makers -- as for the cause of racial justice or the critique of structural power writ large -- the significance of recognizing continuities between the real world and the cinematic one is clear. This is not to argue for a straightforward correspondence between cinema and reality; on the contrary, in the examples noted here, we witness the most complex and controlled entanglements of both past and present; reality and fiction.

In the end, I view Reality Frictions as offering a critical lens on a cinematic and televisual phenomenon that is more common and more complex than one might initially expect. Do I wish the final film were less than an hour long? Yes, and I have no doubt this will dissuade some prospective viewers from investing the time, but once you start heading down this path, there's no turning back and my sincere hope is that I will have made it worth your while.
0 notes
Text
Pedagogies of Resistance: Reflections on the UC Academic Workers Strike

Please don’t misunderstand: I was far from the most active member of the faculty in my department or university throughout the recent UC System strike and I do not presume to speak from a position of any particular authority about it. Others -- especially among our junior faculty -- were much more involved, showing up at picket lines on a daily basis, actively organizing and strategizing with faculty from other campuses, taking food to strikers, canceling or moving classes to the picket lines, holding teach-ins, withholding grades, informing colleagues about issues and encouraging greater involvement and understanding from all. Those who were fully present for the duration of this strike earned my greatest respect many times over. I share these observations as an extension of my high regard for the real work done by the students and faculty around me and the tangible risks that many of them -- nearly all of whom had much more to lose than I -- were willing to take. Nonetheless, here is what I learned:
• Collective action opens doors and builds bridges. The neoliberal university allows and encourages silos and barriers to persist between units and individuals who might otherwise find shared interests and common cause. Each time I attended strike support actions, I met people and had conversations that might never have happened otherwise. I now feel more connected to a network of faculty that spans multiple fields across my university and, to a certain extent, the UC system as a whole. I hope this awareness continues long past the resolution of this particular strike and contributes to the erosion of institutional divisions.
• The privilege of tenure is real and it needs to be exercised, but contradictions remain. I have long been ambivalent about the tenure system and the caste hierarchy it imposes on our profession -- and I have rarely witnessed the historical justification that tenure enables individuals to speak truth to power. Ironically, in my immediate circles, those who were most willing to put themselves on the line most consistently and most visibly in support of strikers were precisely those without the protection of tenure or senior faculty standing. It made sense to me at the time that it was incumbent on people in my position to step in whenever possible, speaking for those in more vulnerable positions and offering a barrier against any possible negative responses. However, more than once in recent months I have had to question this impulse to speak in place of my junior and even mid-career colleagues. When "speaking for" colleagues who are, let's say, junior faculty women of color, how is that not a form of silencing? Does capitulating to the perceived need to offer "protection" to more vulnerable colleagues reinforce a dynamic in which the potential for retribution is expected or even normalized? Shouldn't the goal instead be to honestly confront institutional power dynamics and work toward a commitment to open exchange without fear of reprisal?
• For most of those involved in the strike, it was their first exposure to collective action of this kind. My evidence for this is anecdotal, but I believe it's true. At the first rally I attended, a speaker asked through a megaphone for a show of hands from those going on strike for the first time. Hands shot up from nearly every student worker. This fact alone made me hope for a positive result -- not only because I believe the union's advocacy for student workers is justified, but because of the potential represented by some 48,000 graduate students taking this experience with them into their professional futures. Unlike many trade-based unions in which members maintain a longterm commitment to a single field, the graduate workers leading this strike will inevitably land in many different types of positions across a multitude of professional fields within a matter of years. Taking with them a successful experience of collective self-advocacy, coupled with practical knowledge of strategy and implementation, could bring a much needed ripple effect and invigoration of union activity in multiple spheres.
• This was also almost certainly the first experience with a strike for most of the students who were directly impacted. While I care deeply about the well-being of our graduate teaching assistants and researchers, I also feel a responsibility to the 300,000+ UC undergraduates whose college education was disrupted to a greater or lesser extent by the strike. As much as I hope to seed the world with thousands of former graduate workers who have gained experience and wisdom about striking, I also want ten times their number of future college graduates to carry a positive disposition toward collective action into the future they are inheriting. As we have seen with absolute clarity in recent years, we cannot rely on top-down solutions to climate change. With planetary extinction hanging in the balance, collective action against the industries that profit from destroying the planet is the only hope future generations have for preserving a habitable world. For generations too readily susceptible to cynicism, I hope that witnessing the accomplishments of this strike (which were substantive, even if they fell short of the goals that were hoped for by many) will encourage them to organize against forces resistant to climate justice and other seemingly intractable issues including extremes of economic disparity and institutions entrenched in capitalism, patriarchy and white supremacy.
• Strikes are pedagogical; academic strikes even more so. Looking beyond the immediate circumstances of the strike, which included a set of familiar elements: demands, accusations, misinformation, inflammatory rhetoric, conciliatory rhetoric, official statements, backchannel communications, rumors, confusion, clarifications, etc., I was struck by the frequency and effectiveness with which much of the activity of strikers and those responding to it took a pedagogical form. Teach-ins organized by graduate student strikers are an obvious example, but reports of classes being moved to the picket lines and student research or creative projects pivoting to directly address the issues of the strike or the history of labor organizing (etc.) offer similar cases in point. In preparing for a Winter term without TAs, faculty creatively reimagined teaching strategies and course content not only to accommodate the lack of support, but to make sure students knew how and why their education was being compromised. Those who withheld grades informed students of the reasons for the disruption and encouraged dialogue and understanding. The strike and its responses thus became coextensive with the university's core activities of teaching and learning and demonstrated the mutability of these skills across multiple domains. All of this leads to a final observation:
• Maybe there is hope for the renewal of higher education. On my bad days, I see little difference between the most corrupt, violent and destructive forces in American culture and our increasingly neoliberal institutions of higher education. Worse, the elitism of these institutions seems clearly aligned with all of the factors currently hastening our destruction: concentrations of wealth, social divisions, institutional authoritarianism, neoliberal subjectivity. These institutions -- universities -- may be compromised by and complicit with much that I oppose ideologically, but they continue to afford me the ability to teach, write, speak and create work that is as expressive of my own values as I make it. Not all of the workers who led or participated in this strike will end up as educators, but some will -- and as I look ahead to the final days of my own career sometime in the current decade, I'm encouraged by the thought that my place may be taken by those who initiated, participated in, or learned from this action.

0 notes
Text
Failures in Photogrammetry

I had the chance to try out my home made photogrammetry calibration system in Joshua Tree last week. With temperatures in triple digits throughout the day, the only reasonable time for this type of activity is early in the morning when the Mojave is also at its most beautiful and wildlife are at their most active. I was surrounded by quail and lizards (no snakes) while setting up and plumbing/leveling the posts a little before dawn and a coyote loped by a few yards away, seemingly indifferent to my presence.
I have long suspected that photogrammetry would supply the key to my practical investigation of the conjunction of data and images following on the theoretical and historical research I did on this subject for Technologies of Vision. Although I have done small-scale experiments in the past with a hardware-based system (Occipital Structure Sensor) that captured infrared depth information to an iPad along with photographic textures, the Joshua Tree environment was orders of magnitude larger and more complex. In addition, my intended processing platform is the entirely software-based Metashape by Agisoft (previously PhotoScan), which generates all depth information from the photographs themselves.
Note: if you have somehow stumbled on this post and are hoping to learn the correct way to use Metashape, please look elsewhere. The internet is full of people -- many of whom don’t really know what they’re doing -- offering authoritative advice on how to use this particular piece of software and I don’t want to add myself to the list. While it’s true that my eventual goal is to gain proficiency with various photogrammetry workflows, I’m currently deriving at least equal pleasure from my near total inability to execute any part of this process as intended. Even the measuring sticks in the above image are of my own conception and may not serve any useful purpose whatsoever.

I captured this segment of landscape three separate times, all using a DJI Mavic 2 Pro, but the drone was only in flight for one of the three capture sessions, partly because of unpredictable winds, but also because of not wanting to be reported on by the neighbors. The Joshua Tree Highlands area has declared itself a no-fly zone out of respect for the wildlife, so when I did put the drone up, I flew a grid pattern that was low and slow, capturing video rather than still images to maximize efficiency. As a side note, Metashape is able to import video directly, from which it extracts individual frames like the one above, but something went wrong at the photo alignment stage, and these images -- which should have generated my most comprehensive spatial mapping -- instead produced a faux-landscape that was more exquisitely distorted than any of the other processes I tried.

The thumbnail array below comes from one of my terrestrial capture sessions, the first of which, in my exuberance, consisted of well over 500 images. When this image set took 30+ hours to generate a dense point cloud, I re-photographed the entire area at what I hoped would be a more reasonable total of around 70 images. Even when not in flight, the Mavic generates metadata for each image, including GPS coordinates and information about elevation, camera angle, focal length, etc. Metashape uses this data to help spatialize the images in a 3D environment, creating a visual effect that bears a distinct resemblance to the Field-Works series created -- I have no doubt through a much more laborious process -- by the Japanese media artist Masaki Fujihata beginning in the early 2000s.


When I wrote about Masaki’s work for TechnoVision, I offered Field-Works (above) as a good object that celebrated the gaps and imperfections in spatialized image systems, in contrast with the totalizing impulse and literal aspiration to world-domination represented by Google Earth. With this practice-based research, then -- my own “Field-Works” -- I remain equally driven by the desire to succeed at capturing a photorealistic landscape, with dimensional data accurate enough to inform an architectural plan, and a secret hope -- even an expectation -- that the result will instead turn out to be an interesting failure -- more like Clement Valla’s dazzling collection Postcards from Google Earth (below), where algorithmically generated photographic textures ooze and stretch in a failed attempt to conceal irregularities in the landscape.

In fact, my first experiment with transforming drone images into dimensional data resulted in just such an outcome. This scene from the back yard (where proximity to LAX also dictates a no-fly zone) grew increasingly interesting with each stage of distortion from image to point cloud to mesh to textured model. The drone never went higher than about 12 feet on two circular passes of about 10 images each and the model was deliberately selected to confound the software. The mesh platform of the wagon, covered with leaves that changed position when blown by the rotors of the Mavic confused the software enough to yield a kind of molten surface reminiscent of Valla, an effect that I have not been able to reproduce since.


This first attempt was created using a free, open source Mac-compatible program called Regard 3D. Although I now have access to PCs with decent graphics processing capability through the VR lab at UCLA, I preferred to stay in the Mac environment to avoid multiple trips across town. In fact, the majority of this post was written while one photogrammetry program or another was rendering models, meshes or depth maps in the background. Although the results from Regard 3D were more than gratifying, I went ahead and purchased an educational license for Metashape and then immediately upgraded to the Pro version when I realized all the features that were withheld from the standard version. Metashape has the advantage of robust documentation -- going back to its days as PhotoScan -- and in-application help features as well as a very active community forum that seems relatively welcoming to people who don’t know what they’re doing.

For my second backyard test, I chose slightly more conventional (solid) surfaces and included some reference markers -- 8′ measuring sticks and Agisoft Ground Control Points (GCPs -- seen in lower right and left corners of the image above) to see if these would help with calibration for the mapping in Joshua Tree. Metashape handled the process effortlessly, resulting in a near-photorealistic 3D model. The measuring sticks allowed me to confirm the scale and size of objects in the final model, but the GCPs could not have functioned as intended because I didn’t manually enter their GPS coordinates. Instead, the software seems to have relied on GPS data from the Mavic and I’m not sure my handheld GPS unit would have been any more accurate at locating the GCPs anyway. In fact, when I got to Joshua Tree, although I dutifully printed out and took a bunch of GCP markers like the one below with me, I forgot to use them and didn’t miss having them when reconstructing the landscape.

Although images like this, which are designed to be read by non-human eyes, have been in public circulation for decades -- QR codes, bar codes, etc. -- they continue to fascinate me as fulcrum-objects located at the intersection of data and images. When Metashape “sees” these patterns in an imported image, it ties them to a system of spatial coordinates used to verify the lat/long data captured by the drone. When used correctly, the visual/human register takes precedence over the data systems of machines and satellites. Although unintentional, my failure to use the GCPs may have been a gesture of unconscious resistance to these systems’ fetishization of Cartesian precision.

After 36 hours of processing my initial set of 570 images (mapped by location above on the left), Metashape produced a “dense point cloud” (right) representing all vertices where the software identified the same visual feature in more than one image. Although the area I intended to map was only about 5000 square feet, the software found vertices extending in all directions -- literally for miles -- across the Joshua basin. A bounding box (below) is used to exclude outlying vertices from the point cloud and to define a limited volume for the next stages of modeling.

The point cloud can also be viewed using the color information associated with each vertex point (below). This begins to resemble a low-resolution photographic representation of the landscape, which also reveals the areas (resembling patches of snow on the ground) where image-data is missing. Likewise, although the bounding box has removed most outlying information from the distant hillsides, many vertices have still been incorrectly mapped, appearing as sparse clouds against the white background. Metashape has the ability to scan and remove these artifacts automatically by calculating the confidence with which each vertex has been rendered, but they can also be deleted manually. Still not fully trusting the software, I removed the majority of these orphan points by hand, which also allowed me to exclude areas of the model that I knew would not be needed even though they might have a high confidence value. Under other circumstances, of course, I am totally opposed to “cleaning” data to minimize artifacts and imperfections, but the 30+ hours of processing required to render the initial cloud had left me scarred and impatient.

The next step is to create a wireframe mesh that defines the surfaces of the model, transforming the point cloud into a dimensional web of triangles. With tens of millions of potential vertices to incorporate, the software may be set to limit the mesh to a maximum number of triangular faces, which in turn, determines the final precision of the model.

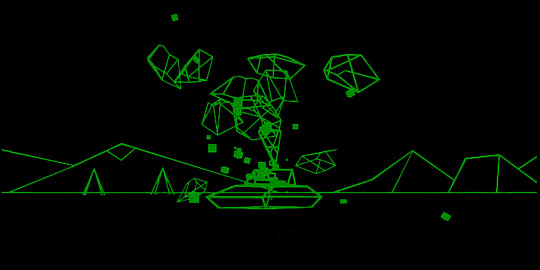
At this point, the model can be rotated in space and a strong sense of the overall contours of the landscape is readily apparent. The aesthetics of the wireframe are also exquisite in their own right -- admittedly perhaps as a result of my fascination with the economical graphic environment of the early 80s Atari game Battlezone (below) -- and there is always a part of me that wants to export and use the wireframe as-is. In fact, I assume this is possible -- though I haven’t yet tried it -- and I look forward to figuring out how to create 3D flythroughs and/or navigable environments with these landscapes rendered as an untextured mesh.

The final stage in creating the model is for Metashape to generate textures based on the original photographs that are mapped onto the mesh surfaces. At this stage, gaps in the point cloud are filled in algorithmically, eliminating the snow effect on the ground. By limiting the size of the model and deleting as many artifacts as possible, the final texturing was relatively quick, even at high resolution, and the resulting model is exportable in a variety of 3D formats.

Metashape also offers the ability to generate digital elevation maps (DEMs), which register relative heights of the landscape signified by color or shape. I’m reasonably certain that the DEM image below is the result of some egregious error, but it remains among my favorite outputs of this exercise.

The final image included here is the single frame used by the photogrammetry software for texture mapping. Although it gives the appearance at first glance of being an aerial photograph of a strangely featureless landscape, this file is actually an indexed palette of all the color and texture combinations present on all surfaces of the 3D model. If photogrammetry constitutes the key technology operating in the interstices between data and images, these files are arguably the most liminal of all its components. Neither mimetic nor computational, they provide visual information (“pixel-data”) that is necessary to the perceptual phenomenon of photorealism, while denying the pleasures of recognition. In a literal sense, this single image contains every color and texture that may be seen in the 3D model, rendered here as an abstraction fully legible only to the eyes of the machine.

0 notes
Text
Live-VR Corridor wins award for Best Mixed Reality at New Media Film Festival!

My installation “Live-VR Corridor (after Bruce Nauman)” made its world debut at the 9th New Media Film Festival in Los Angeles where it received the festival’s award for Best Mixed Reality!
“The overall result is an unsettling self-conscious experience of doubling and displacement.” - Ted Mann on Bruce Nauman’s Live-Taped Video Corridor (1970)
Although its multiple histories are easily forgotten or ignored, the current generation of Virtual Reality art belongs to a tradition that includes experiments with perception and embodiment in film, video and installation art. Recalling parts of this history, Steve Anderson’s Live-VR Corridor consists of a ½ scale replica of Bruce Nauman’s Live-Taped Video Corridor (1970), one of the earliest works of video installation art. Live-VR Corridor is both a mixed reality homage to Nauman and a highly pleasurable, self-reflexive work of art in its own right. Just as the rise of amateur video in the 1970s spawned multiple experiments with liveness, surveillance and self-representation, today’s consumer VR offers a unique visual format that reactivates the pleasures and problematics found in looking, seeing and being seen. Nauman’s original Live-Taped Video Corridor consisted of two closed-circuit video monitors positioned at the end of a narrow 30’ corridor. The lower monitor featured a pre-recorded videotape of the empty corridor, while the upper monitor showed a live video feed from a camera positioned above the corridor entrance. As viewers walked toward the monitors, they saw themselves from behind on the top monitor and a persistently empty corridor on the bottom monitor. The closer a viewer got to the monitor, the smaller their image became, frustrating their desire to see themselves, while the empty corridor on the bottom suggested that they had become invisible or dislocated in time.

When wearing the headmounted display (HMD), Live-VR Corridor viewers perceive a digital model that precisely duplicates the physical corridor they are in. Like Nauman’s original, the top monitor displays an image of viewers that shrinks procedurally as they approach it, frustrating their desire to see what they look like wearing the HMD. Unlike Nauman’s project, the bottom image displays a live feed from the forward-facing camera built in to the HMD. Thus, viewers who hold their hands in front of their face will see them on the monitor at the end of the corridor. As viewers move forward, their hands and other body parts grow more useful for orienting themselves spatially, but to do this, viewers must give up a traditional sense of embodied presence, shifting their viewing perspective to the monitor at the end of the corridor.

As the project unfolds, a voice queries the viewer’s sense of space, vision and embodiment. The project rewards slowness and contemplation, tracking the viewer’s gaze to reward exploration and curiosity by procedurally transforming the surfaces of the corridor in unexpected ways. An impatient viewer who rushes to see their image in the monitor will find that it shrinks to just a few pixels in size, while a calm viewer who takes time to experience the textures and sounds of the corridor can coax the scaled image to grow back to full-size, revealing what they look like wearing the HMD. Even at full size, the mirror image in the monitor continues to disorient the viewer by multiplying, reversing and displacing the viewpoint of the images in physical and virtual space.

Although perceptually complex, Live-VR Corridor is technologically simple, using two analogue surveillance cameras and 15” reference monitors for the images that appear in the physical corridor. The 15’ long walls are lightweight theatrical flats made with ¼” plywood that may be assembled or disassembled in a matter of hours. Two soft lights provide basic illumination. The physical corridor’s virtual double was created in Unity for display using an off-the-shelf HTC Vive system with two position trackers mounted at opposite ends of the corridor. The top (virtual) monitor shows a webcam video feed that is dynamically scaled in response to a viewer’s movements down the corridor. The bottom (virtual) monitor shows a direct video feed from the camera built in to the Vive headset, which captures analogue video images displayed on the monitors in physical space. No controllers or special calibrations are needed. The total footprint for the installation is 16’ x 2’. Average user experience is 3:00 minutes.
Watch video at: https://vimeo.com/230192895 Password: Anderson
Download 2-page description of Live-VR Corridor.
Access Technical Specifications document.
0 notes
Text
Mapping “VR”
In the course of completing my chapter on the transformation of space through data (Data/Space), I've been frustrated by the imprecision with which contemporary use of the term "VR" serves to flatten distinctions among a diverse range of media practices. This suggests to me that the primary utility of the term “Virtual Reality” now lies, as it always has, in the realm of marketing and promotion.
Among the biggest changes I see between the first generation of VR that emerged in the 1980s and 90s and what we are seeing today is that “virtual reality” in the mid-2010s has lost some of its emphasis on the idea of “telepresence,” that is, the perception of occupying a space other than where a person’s physical body is located. This concept was important enough for artist-engineers Scott Fisher and Brenda Laurel to name their startup company “Telepresence Research” in 1989 and it is still occasionally acknowledged as a desirable aspect of virtual experience (see, for example, Survios’ “Six Elements of Active VR”). Below is the diagram created by Fisher’s lab to describe the aspirations of its “Virtual Interface Environment” for NASA in 1985.
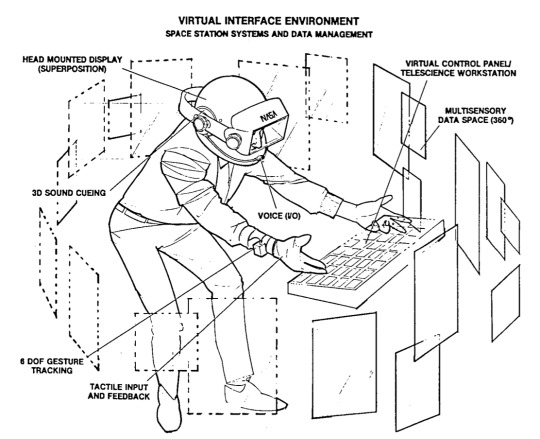
Note that, unlike the vast majority of today’s “VR” systems, Fisher’s VIEW system did not compromise on the technical complexity required for the true experience of telepresence. For example, the operator is not required to occupy a fixed position in space, nor is s/he constrained to a single form of user input. Interface takes place via combinations of voice, gesture and tactile input with dimensional sound, stereoscopic vision and haptic feedback in response; the operator’s body is tracked and located in space and, in anticipation of multi-user applications, representable as a customizable 3D avatar.
Fisher notably resisted using the term “virtual reality” in favor of the location-specific phrase “virtual environment.” Although this term offered the benefit of greater precision, it apparently held less marketing appeal than “VR,” which is appropriately attributed to the consummate entrepreneur and relentless self-promoter Jaron Lanier. In a 1989 article titled “Virtual Environments,” Fisher eschews “VR” entirely and only brushes against it in his final sentence in order to undermine its use in a singular, monolithic form, “The possibilities of virtual realities, it appears, are as limitless as the possibilities of reality.”
In retrospect, we might speculate how the first generation hype cycle for VR might have unfolded differently if the transformation proposed by the technology had been the sensation of remote presence within a digitally generated environment (as Fisher framed it) rather than the virtualization of reality itself. Arguably, it was the idea that technology – like the psychedelic drugs of the 1960s counterculture described by Fred Turner – could be used to transform reality that contributed to the ultimate public disillusionment with the real world capabilities of first-generation VR. The surprising thing is how quickly and unself-consciously the hyperbolic discourse of VR promoters in the 2010s has been willing to embrace the repetition of this history.
For now, those who would like to think seriously about the cluster of media platforms and technologies currently gathered under the VR marketing umbrella would be well served by at least noting the very significant differences between, say, spherical, live action video viewed from a single position with a fixed time base, as compared with an entirely procedurally-generated 3D game environment with body tracking and an indefinite time base. If not for the fact that both systems require viewers to strap a display apparatus to their face, we would never otherwise consider equivocating among such divergent media forms.
Below (and somewhat more legibly here) is my first attempt to more precisely parse the various forms that I see emerging, evolving and blending within this space. Like all such schematics, this image is incomplete and idiosyncratic. Given the transient nature of these technologies and their (mis)uses, it would be a sisyphean task to try to get it right for more than an instant. For now, I would welcome any thoughts, corrections, additions or clarifications via the “Ask Questions/Make Suggestions” link in this research blog’s navigation bar.
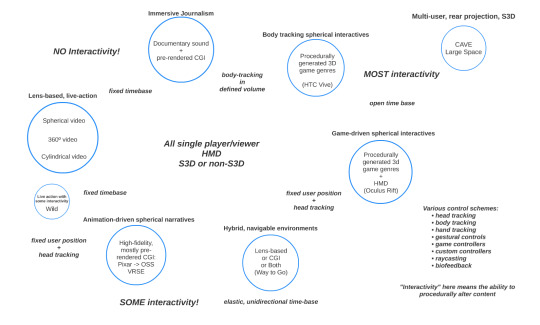
Finally, in the course of framing this book project as a kind of “history of the present,” I have been struck repeatedly by the simultaneous, intense desire to claim a history for VR (albeit one that blithely skips over the 1980s-90s) that is rooted in previous moments of technological emergence. For example, the felt sense of presence associated with virtual reality is routinely compared with the image of viewers running screaming from the theater upon seeing Lumiere’s “Arrival of a Train at La Ciotat” long after cinema history abandoned this origin myth as naive, ahistorical fantasy. Another talk I attended recently about the state of the art in “VR” content production also included alarming revisions of the history of both cinema and television, claiming that “film did not come of age until the 1970s” and “television did not mature until the 2000s.” The point, which could have been perfectly well-taken without such wildly uninformed comparisons, was simply that content producers are still figuring out what kind of stories or experiences can most effectively motivate viewers to willingly strap a display apparatus onto their face. With no disrespect intended toward Martin Cooper, when thinking about these questions from a historical perspective, a juxtaposition like the one below may help to recalibrate some of the industry’s current, ahistorical hyperbole.

5 notes
·
View notes
Text
Lidar and its discontents
I just discovered the work of UK design firm ScanLAB thanks to Geoff Manaugh's article on driverless cars in last week’s New York Times. Having tracked down ScanLAB’s website, I was additionally gratified to discover their 2014 project Noise: Error in the Void. Flushed with excitement, I swung the computer around to show Holly. "Oh, yeah,” she said, “didn't you know about ScanLAB?" It’s not that our research is in any way competitive. Her book is about the future of cinema and mine is about work that blurs the boundaries between images and data. But, really, if everyone but me knew about ScanLAB before today, someone really should have said something.

Having received permission from my editor to change the book’s title to Technologies of Vision: The War Between Data and Images, I dashed off an image request to ScanLAB, asking to include an image in the book. While most of the writing about Lidar and other technologies for capturing volumetric data focuses on faithful reproduction of the physical world, Manaugh’s article was refreshingly open to the kind of alternative, artistic uses pursued by ScanLAB - albeit in parallel with utilitarian pursuits such as the development of driverless cars. The NY Times article even included an example of the visual artifacts that occur when data capturing systems get “confused” by their surroundings. The final image in the London Scenes slideshow includes an image of a bus that has been misrecognized as part of the city’s architecture. The caption explains, “Trapped in traffic, the mobile scanner inadvertently recorded a London double-decker bus as a continuous mega-structure, while stretching the urban world around it like taffy.”
This seemingly circumstantial aberration actually continues ScanLAB’s longtime interest in work that acknowledges - even celebrates - uncapturable or unrenderable spaces; that finds value and beauty the in gaps, glitches and fissures where the representational capacities of data and image come into conflict. Their project Noise: Error in the Void was entirely devoted to highlighting the artifacts resulting from a scanning project in Berlin. Outlying data resulting from reflections, clouds or human figures is ordinarily “cleaned” before being incorporated into a 3D model. But in Noise, such “unclean” data is the whole point. An image of the Berlin Oberbaum Bridge, captured late in 2013, for example, radiates a psychedelic aura of reflections, echoes and overmodulations. ScanLAB describes the process of capturing these images:
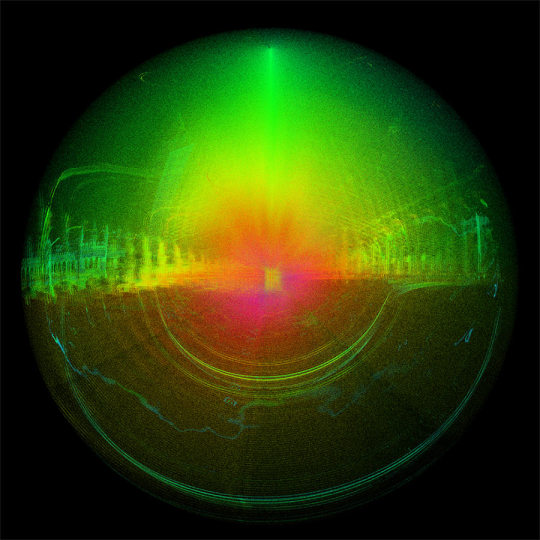
The scan sees more than is possible for it to see. The noise is draped in the colours of the sky. The clouds are scanned, even though out of range. Everything is flat; broken only by runway markings. Traces of dog walkers spike up into the cloud. The ground falls away to the foreground in ripples. The horizon line is muddy with the tones of the ground and the texture of the sky. The center is thick with points, too dense to see through. Underground only the strongest noise remains.
Part of what interests me is attempts to explain the ways that data systems are - and are not - able to “see” or reproduce the world. When talking about machine vision, metaphors of human perception and consciousness abound. I have previously written about the ubiquity of references to the subconscious when describing Google’s Deep Dream software in terms of hallucination or psychosis, but a similar sentiment concludes Manaugh’s discussion of driverless cars, elevating the stakes of the discussion from a commercial experiment by ultra-privileged tech companies and those who can afford next-generation consumer products, to the vastly more provocative realm of posthumanism and artificial intelligence:
ScanLAB’s project suggests that humans are not the only things now sensing and experiencing the modern landscape — that something else is here, with an altogether different, and fundamentally inhuman, perspective on the built environment … As we peer into the algorithmic dreams of these vehicles, we are perhaps also being given the first glimpse of what’s to come when they awake.
I’m still not convinced that metaphors of (sub)consciousness and optics hold the key to theorizing the current generation of technologies of vision that are most provocatively troubling the received boundaries between data and image. However, I find in this work by ScanLAB and others, which deliberately refuses to accept the priority of convergence and synthesis as the preferred (to say nothing of ‘natural’) relationship between data and image, the most productive vector for investigation. ScanLAB, if you’re out there, please let me include an image in the book!
0 notes
Text
Machine vision in recurse
Since 2012, I’ve been fascinated with Google’s Unsupervised Learning project, which was originally (and more evocatively) titled “Google Brain.” From Google’s description the project:
Most of the world's data is in the form of media (images, sounds/music, and videos) -- media that work directly with the human perceptual senses of vision and hearing. To organize and index these media, we give our machines corresponding perception capabilities: we let our computers look at the images and video, and listen to the soundtracks and music, and build descriptions of their perceptions.
An image related to the project was circulated widely, purporting to have been entirely generated by Google’s unsupervised learning system. Most often distributed as a diptych, the image pair showed distinct outlines of a human face and a cat face oriented to face the camera/viewer (a third image of a human torso was also released but did not circulate as widely).

Google described these as examples of the “perceptions” generated by Google’s “brain” after it was exposed to a data set of 10 million random, untagged images. The system’s “learning” is dubbed “unsupervised” because the computers were not told what to look for within the image set. This is what set Google Brain apart from other machine vision algorithms in which computers “look for” images that match a particular combination of graphical features. The “finding” of this experiment was that computers, when provided with no information or guidance, will, all on their own, identify human faces and cats as the most prominent image phenotypes in the collection (and by extension, the internet at large).
It’s worth noting that this research was unveiled just a year after Google engineer James Zern revealed that only about 30% of the billions of hours of videos on YouTube accounted for approximately 99% of views on the site. In other words, 70% of the videos that are uploaded to YouTube are seen by almost no one. This would mean that the company’s ostensible revenue model of targeted advertising is of limited value to the majority of its content, while 70% of the vast and expensive architecture of YouTube is devoted to media that return no appreciable ad revenue to the company. The only way to monetize a media collection of this type on a scale that makes it worthwhile to a company like Google is by figuring out a way to translate images into data.
With this goal in mind, the raw materials represented by YouTube’s billions of hours of video represents an invaluable resource for the emerging - and potentially vastly lucrative - field of machine vision. The human and cat images released by Google were received and circulated as objects of wonder and bemusement, without any signs of the criticism or skepticism for which internet communities are ordinarily known. One might speculate that these images were meant to serve a palliative function, reassuring the public that, whatever it is that Google might be doing with those billions of hours of valueless video provided to them freely by the public, it’s all just as trivial and unthreatening as a cute kitten video or a casual self portrait.
This is where the plot thickens. The point of training computers to make sense of vast, undifferentiated image collections is surely to enhance Google’s ability to use large-scale data analytics to understand, shape and predict human behavior, particularly with regard to broad patterns of consumption. While Google closely guards this aspect of its business, in June 2015, Google Research publicized a process that it called “inceptionism” releasing a collection of provocative images emerging from the company’s “neural net” of image recognition software. Google also released an open source version of the software on the developer repository GitHub along with detailed descriptions of process on the Google Research blog.

The vast majority of public discourse surrounding these images fell into one of two camps: drug-induced psychedelia or visualization of the subconscious through dreams or hallucinations. Google itself encouraged the latter model by dubbing the system “Deep Dream” and invoking Christopher Nolan’s 2010 film Inception, about the narrative traversal of conscious and unconscious states through collective, lucid dreaming. A unique and easily recognizable visual aesthetic rapidly emerged, combining elements of the natural world and geometric or architectural shapes. Comparisons with psychoanalysis-inspired surrealist art and drug-induced literature abounded, overwhelming alternate readings that might challenge the uncritical conjunction of human and artificial intelligence.

A proliferation of online Deep Dream conversion engines invited human viewers to experiment with a variety of enigmatic parameters (spirit, neuron, Valyrian) that shape the resulting images. While early services offered to perform deep dream conversions with no control over image recognition parameters for a few dollars per image, it took only a few months for greatly improved “free” (ad supported) services such as the Deep Dream Generator to emerge, allowing free, unlimited, user-customizable conversions.
The ready availability of a user-friendly version of the software begs the question: what would happen if the deep dream algorithm were used to “interpret” an image generated by the software used to develop it? One conceivable outcome of this reversal might be to reveal evidence of the "perception” process by which the human and cat images were originally derived - perhaps similar to the way language translation systems are tested by converting a sentence from one language to another and then reversing the process to see if the original sentence is reproduced.

Obviously, this didn’t happen. The custom recognition parameters of the Deep Dream software alone are sufficient to preclude a one-to-one conversion, but I found this experiment to be nonetheless revealing. Both human and animal visages became more animalistic; except for the eyes, the primate face in particular became more simian than human, while the fuzzy, undifferentiated halo surrounding both heads acquired a reptilian aura. In the end, this experiment in algorithmic recursion offers little more than amusement or distraction, which may well be the point of Google’s well-publicized gesture in making the software freely available. While these images invite comparisons with dark recesses of the unconscious, one might more productively wonder about the everyday systems and values that are thereby shielded from critique.
0 notes
Text
New Media, Old Media Out!

Very happy to announce publication of the latest edition of New Media, Old Media: A History and Theory Reader, edited by Wendy Chun and Anna Watkins Fisher. This new and expanded volume is about 3/4 new material, including my essay “Reflections on the Virtual Window Interactive,” about Anne Friedberg’s online companion to her book The Virtual Window. Available from Routledge or Amazon.
0 notes
Text
Bad Object 2.0 live in G|A|M|E !

The much-anticipated issue #4 of G|A|M|E The Italian Journal of Game studies just launched, devoted to the topic "Re-framing video games in the light of cinema." It includes my Scalar project "Bad Object 2.0: Games and Gamers." Quoting from dozens of clips from North American film and TV, the basic contours of this project’s argument are simple. From its origins in the 1970s through the end of the 1980s, Hollywood’s vision of games was remarkably accepting; narratives were largely balanced in terms of gender, and the youth culture emerging around games was portrayed with relative dignity. During this time, the games industry was still establishing its foothold in the homes of North America and making its way into the leisure time of families. In spite of stunning profits in the earliest days of the 1980s, the industry suffered a massive collapse in 1983, followed by a rebound of home consoles in the 1990s that placed it in more direct competition with the film and television industries. By the 2000s, console games were thoroughly integrated into American homes, posing for the first time a viable threat to the hegemony of the film and television industries for domestic entertainment. Throughout this period of ascendance, cinematic tropes of gaming grew more critical, with gamers increasingly associated with a range of antisocial behaviors, especially violence, addiction and repressed sexuality. Ultimately, the project argues that depictions of games on film and television include both a dominant discourse of pejoration and notable exceptions that allow for complex, alternate readings.
0 notes
Text
Technologies of Cinema live on Review the Future!

My interview with Ted Kupper and Jon Perry (former USC students made good) just went live on their excellent podcasting site Review the Future. In this wide-ranging and productively digressive discussion, we talk about everything from Hollywood’s depiction of videogames and gamers to the incorporation of decommissioned IBM air defense systems into the visual vocabulary of technology narratives on film and TV.
0 notes
Text
Critical Digital Humanities at UC Riverside

I had the opportunity to demo all three platforms that currently subtend the digital components of Technologies of Cinema (Scalar, Critical Commons, Difference Analyzer) as part of Jim Tobias’ Critical Digital Humanities series at UC Riverside last week. The event was led by UCLA’s Miriam Posner, under the suggestive title “Analytical Technics for (Post-) Humanists: The Case of the Missing Instruments.” While Miriam presented a range of new and emerging tools for conducting digital humanities research, along with a call for research tools that don’t yet exist, my own presentation was shamelessly self-promotional, focusing on tools not for research but for ideation, assemblage and (electronic) publishing. As always, the Difference Analyzer (which is still in pre-beta) stole the show, sparking insightful questions and interest even beyond the immediate context of media studies. Chandler, if you’re reading this, stop reading and get back to coding!
0 notes
Text
Technologies of Cinema at Poetics & Politics documentary symposium

I’m very pleased to be presenting Technologies of Cinema at UC Santa Cruz this weekend on a panel titled “Repertoires of Archives” along with co-panelists Matt Soar and Martin Lucas. Poetics & Politics is just in its second year, following a debut at Aalto University in Helsinki in 2013, but this year’s event, organized by UCSC’s Irene Gustafson and UCLA’s Aparna Sharma, is genuinely international in scope and seems nicely balanced in its attention to theory and practice.
0 notes