
This guide is inspired by the book by Jon Erickson "Hacking: The Art of Exploitation".
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by abeginnersguidtohacking and here's what we found interesting.
Average Info
Notes Per Post
24
Likes Per Post
3
Reblog Per Post
19
Reply Per Post
2
Time Between Posts
2 days
Number of Posts By Type
Text
15
Last Seen Tumblr Blogs





Fun Fact
Premium Tumblr themes are available from anywhere between $9 to $49.
Text
I was asked why the command 'uname' returns 'Darwin' and noticed I hadn’t addressed this in the post. Darwin is the 'flavor’ of Unix that my Mac uses. The uname command can also be used to show other information about your computer:

Experimenting with Shell commands
A look at Chapter 0x330
Before we can even begin exploiting a machine, we may need to do some experimentation to learn about a machine. We can often do this through playing around with the BASH shell and Perl since they are common on most machines. We’re going to be looking at some Perl examples in this post. Perl is actually a bit of an odd programming language, and is more of a combination of both Perl 5 and Perl 6 which are both developed independently of each other. For our sake we can just think of it as a high level interpreter language with shell script abilities that we can use to execute instructions. Like this:

$ perl -e ‘<command>’ tells perl to execute the command in between the single quotes. We can also pass functions and Perl will give us the outputs in return, in these next two examples I pass the shell command uname (which returns the username), then the output for the command is replaced with the command between the parentheses.

This is useful in Perl as it allows us to do command substitution to quickly generate overflow buffers. We can test this technique on the last program auth_overflow.c with buffers of precise lengths.

So, in previous posts we’ve seen how we can use buffer overflow to overwrite the return address, but in most cases, we wont actually know where the return address is. Next post we’re going to try to use some of these shell experimentation techniques to find and successfully overwrite the return address.
3 notes
·
View notes
Text
Format String Vulnerabilities
Continuing with 0x350
Last post we saw that when format strings are used incorrectly, they can access lower parts of the stack. We also learnt about a format parameter %n that writes to memory. This post, were going to be looking into how we can exploit poor format strings to gain infomation about a victims system. I would definalty recomd reading my past posts on injection floors and using BASH as we are going to be using some of these techniques in this post.
Have a look at these three similar ways of printing out the classic “Hello, world!” string. Which one would you most likely use?

Like most people, you probably use the first method, and if you’re particularly irresponsible, maybe the third. You may already be able to see the vulnerabilities in methods 1 and 3, in fact even my compiler gives me a warning:

You’ll also notice that the program still runs perfectly fine in these normal conditions, so whats the problem? Well things start to become problematic when the string contains a format parameter, which is the case for most strings. In this case, the format parameter should evaluate and access the corresponding argument in the function. When there is no corresponding argument however, as we saw in the last post, the string will just go to the next value on the stack.
The hex representation parameter
Lets quickly talk about another interesting format parameter, %x, that prints the hexadecimal value of an unsigned int. We can use it in a few different ways however, as shown below:

This is going to give us a few different outputs, for the example belowe were I gave the program the number 6441, we get four outputs.
Also, remember that 6441 = 1*16^3 + 9*16^2 + 2*16^1 + 9*16^0
%x prints the value in hex
%0x pads the number with 0s, however in this case has no effect
%8x displays the value with width 8 and pads with spaces
%08x does the same as above but pads with 0s
for more on this, I’d recommend using the manual ($ man printf) or reading up on different format parameters here

This actually becomes useful for hackers as it gives us a way to examine the stack, lets take a look at some vulnerable code below:
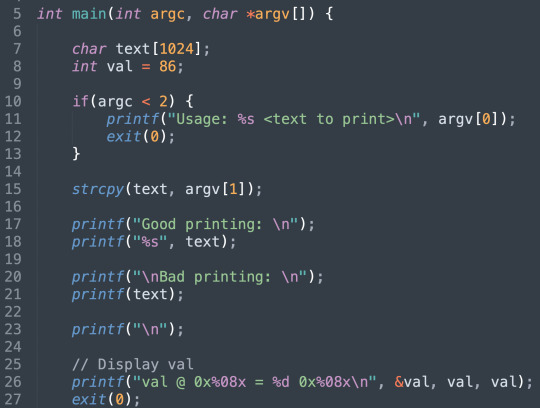
You’ll notice that the developer has used some bad format (and the compile displays a warning when we compile) strings on line 20, because of this, we can use some bash commands to examine the stack:

Apologies for the large screen shot, but take note of the command highlighted in blue,
$ ./format $(perl -e 'print "%08x."x40')
This command uses perl to print %08x 40 times. In other words, the perl command is trying the string “%08x” for us, not printing in the same sense that our C program prints and displaces in ther terminal emulator. As you can see, the first method of, or the ‘Good printing’, just prints out our input, which is 40 lots of %08x, which doesn't tell us anything. This is exactly what the program should do. In the second method however, the printf function will look for a corresponding arguments when it sees the percent sign, since there is none it just goes to the next location on the stack, and then prints it out for us as a 8 digit hex value. The developers poor formatting string has allowed us to inject the print statement is our own code.
1 note
·
View note
Text
Format Strings
A look at chapter 0x350
Format strings are another exploit that hackers can use to elevate privileges. Like most exploits we’ve looked at so far, format string exploits also depend on a developer or programmer making a mistake, luckily for us, we know this is incredibly common. Format string vulnerabilities however are easier to spot than memory management vulnerabilities and as such are not as common any more.
Format strings get used extensively in functions like printf(), essentially all they do is pass information to a function. This is done with format parameters, such as %d or %c, which get matched with different arguments. For every parameter there must also be a matching argument passed to the function. E.g:
printf(”my name is %s, and I am %d years old.”, name, age);
where name is a pointer to a string and age is a decimal integer. There is another slightly less used format parameter, %n, which behaves in an interesting way compared to our regular format strings.
Normal format parameters read data and then display it, however, %n does the opposite. %n writes the number of bytes that have been written by the function to the address in the corresponding function argument. To demonstration this, what do you think the following code’s output would be?

Lets deconstruct this,
Initialize an integer a, but don't assign it, then create a string which contains “hello”
%s links to hello, which is printed out, as well as ‘: ‘
%n links to the address of a, so the program counts how many bytes have been printed so far, which is 7 since each char printed is one byte. So the integer 7 is now stored in a.
%*s will now print a ‘lots of’ ““. Meaning ““ gets printed 7 times.
The code then prints out a just for good measure
Lets have a look:

This is a neat example because it also shows why %n is useful, we can align our strings neatly. But we now have a format string writing to memory, which immediately sounds some warning bells.
When we call any function in C, for example
printf(”%d, %d, %d\n”, a, b, c);
the arguments get pushed onto the stack in reverse order, (go read my blog post on the stack). So for the example above, our stack will look a bit like this:
address of format string
Value of a
Value of b
Value of c
Bottom of stack
So what do you think is going to happen if we pass three format parameters designated by the percent sign, but then only two corresponding arguments?
printf(”%d, %d, %d\n”, a, b);
The function wont have any troubles printing out the values of a and b (which are integers in this case), but when it gets to the third %d, the printf function will just go to the next value on the stack (which in this case, is the value c, which we can see from the stack above). Not a huge mistake in this example, but this reveals an interesting property about format strings.
1 note
·
View note
Text
Overflow into other segments
A look at Chapter 0x340
Buffer overflow isn’t excluded to the stack. In fact overflow can occur in the the heap, and the BSS. If we have a vulnerable variable, all following variables are now also compromised and vulnerable to buffer overflow attacks and the programs control flow can be altered. However when we attack to perform buffer overflow attacks on segments outside the stack, the control flow can be quite limited and it can be a far bit harder to exploit these types of control points.
Heap-Based Overflow
Lets take a look at a simple program that shows the address of a data file and a buffer:

Ever machine will store these variables at a different location, so for our sake lets assume our last two print statements return our two address;
Address of buffer = 0x804a008
between datafile and buffer = 0x804a07
Notice the distance between these two location is 104 bytes
As the first buffer is null terminated, we shouldn’t be able to put more than 104 bytes of data into this variable without overflow. When we do copy in 104 bytes into the buffer, the null terminate is overflowed into the datafile, which cannot be opened as a file. We can however, overwrite the datafile with something actually useful. Lets use some Perl and our BASH commands from one of my earlier posts:
$ ./notetaker $(perl -e 'print "A"x104 . "testfile"')
If you have GDB, it’s worth looking at these programs with the debugger as we can see a huge amount of information about exactly what the program does.
When we run this, we will most likely run into errors, this is because we have overflowed the datafile with the testfile. Naturally the program will now try to write to the testfile but this will cause problems when we try to use free() as errors in the heap header will be detected leading to the programs execution. This is because of the control points within the heap architecture itself, just like the stack. Heap memory management functions are in place to prevent such unlinking attacks which makes heap based overflow quite hard. However, we can still try and trick a program into doing what we want before free() is called and avoid using heap header information all together.
1 note
·
View note
Text
CTF - Resources
Capture the Flag events tend to focus on the following areas
vulnerability discovery
exploit creation
toolkit creation
operational trade craft
But you don't necessarily need to be an expert at all of these areas since most competitions are completed by teams. On top of that, in the work force we will likely be working in teams as well. Hence knowing everything isn’t necessary, it is important to be good at a few of these aspects and preferable very good at one or 2. That said, to be an active member of a team we have to have a decent level of understanding in all these areas as team work often requires us to give aid to other aspects of a project. Here are a bunch of resources that I’m going to be going over tonight and in the future to prepare for CTF events.
Trail of Bits
Short YouTube Intro about CTFs
CBT Guide
1 note
·
View note
Text
Sec Soc Capture the Flag - team JazzJumperGate
Taking a step away from The Art of Exploitation since tomorrow I will be competing a capture the flag style hacking completion. These events are known to be a fantastic way to increase you technical hacking and exploitation abilities and are pretty much a race to crack the system. Myself along with three other classmates from the Friday lab group will be representing our MaDdog tutor in the hopes of getting Jazz his jumper. Hence our team name: JazzJumperGate

So in light of this, and given the relevance this competition has on this series, I’ll be preparing for tomorrow and blogging about what I find.
3 notes
·
View notes
Text
Experimenting with Shell commands
A look at Chapter 0x330
Before we can even begin exploiting a machine, we may need to do some experimentation to learn about a machine. We can often do this through playing around with the BASH shell and Perl since they are common on most machines. We’re going to be looking at some Perl examples in this post. Perl is actually a bit of an odd programming language, and is more of a combination of both Perl 5 and Perl 6 which are both developed independently of each other. For our sake we can just think of it as a high level interpreter language with shell script abilities that we can use to execute instructions. Like this:
$ perl -e ‘<command>’ tells perl to execute the command in between the single quotes. We can also pass functions and Perl will give us the outputs in return, in these next two examples I pass the shell command uname (which returns the username), then the output for the command is replaced with the command between the parentheses.
This is useful in Perl as it allows us to do command substitution to quickly generate overflow buffers. We can test this technique on the last program auth_overflow.c with buffers of precise lengths.
So, in previous posts we’ve seen how we can use buffer overflow to overwrite the return address, but in most cases, we wont actually know where the return address is. Next post we’re going to try to use some of these shell experimentation techniques to find and successfully overwrite the return address.
3 notes
·
View notes
Text
While we’re on the topic of experimentation to figure out information about a system that we are attempting to attack, I thought I might add to this post.
In SQL injections, the first thing we have to do is work out exactly what type of SQL is being used by the website. There are different types of database management systems that may be in use, such as
mySQL
PostgreSQL
SQL Server
SQLite
Since all these different variants have slightly different syntax, all we have to do is pass an instruction that is limited to one specific variation. An example of this is the mySQL function SLEEP(), and the SQL Server function, WAITFOR DELAY. Both these functions do essentially the same thing, but with different syntax, meaning if we are able to successfully get the system to execute one of these commands, we will know which system we are dealing with.
OWASP Vulnerabilities - Injection flaws
Pretty much all website have some kind of user input, some kind of communication, think of a search bar for example. Of course when you type something into a search bar, the search engine treats whatever you’ve just typed as a string of characters, and then probably goes searching through its data base to match it up with items. If instead of typing in a regular search item into the search bar you instead pass actual code instructions or scripts, surly the search engine will again just treat it as a string. The search engine SHOULD look for items in its database and treat the (seemly odd looking) input as just a string, but unfortunately, there are often ways of getting a computer to treat the user string as control / instructions.
This type of problem is when there is a failure to separate control and data. An example of this being old pay phones, that used to send a tone at a precise frequency once someone had paid to use the phone. However, people quickly figured out that you could simply play the exact tone and be able to use the phone for free. This was the case because there was no separation between the control (the frequency tone) and data (the users voice).
So, essentially, injections involve an attacker ‘injecting’ malicious code into a user input stream and causing the programs execution stream to change. These types of flaws can be used for a range of different attacks: - Using an SQL injection to modify values in the database. This can result in series compromise of sensitive data - Installing malware - Executing malicious code through server scripting code like PHP or ASP - Escalating privileges to root permissions through exploiting shell injection vulnerabilities. - using cross site scripting to attack users with HTML / script injection
preventative measures: - Use APIs that are secure from input characters - Use a static type stream to enforce language operation - Server side whitelisting, essentially limiting the number valid inputs from users. Can be down with Java script although this is less secure - Escape dangerous characters with input encoding - Prevent HTML / XSS attacks against site visitors through output encoding - Modular shell disassociation from kernel
1 note
·
View note
Text
Intro to Buffer overflow
A look at Chapter 0x320
Buffer overflow is an incredibly common computer exploit that exists due to the way computers store memory. Most internet worms use this exploit and comes from the fact that although C is a high level language, but places the responsibility of data management on the programmer. Since there is no safe guard to ensure that all of the content of a variable will fit into its allocated memory location.
The simplicity of C does aid in creating efficient programs and add control, but also leads to more memory leaks and buffer overflow vulnerabilities. Take a look now at the example bellow,we have a very simple function meant to return 1 if the password string is correct, and 0 otherwise.

Then, calling this function inside main() as so:

When we compile and run in normal conditions we get an expected output:

But have a think about how we might be able to use buffer overflow exploits to trick the function into returning 1...

It might be apparent as to why this is happening straight away. You’ll notice that strcpy(), unlike strlcpy(), doesn’t take in a length of the string that it is attempting to copy, meaning it will just continue to copy the entire string into the specified memory location until it is done. In this particular case, strcpy(), copys ‘A’ into our string password_buffer, but only the first 16 characters, after that, the function continues to overwrite flag and therefore changing the return value of the function. This is likely going to be some large number.
The second flaw in this program is our if statement, the condition of our if statement will be met with any nonzero return value. All of which results in grating access to a password that our program defiantly should not have.
2 notes
·
View notes
Text
A post from my other blog about buffer overflow and memory errors, but relevant to this series. See if you can spot the vulnerabilities in each of the examples. Buffer overflow post coming soon
Vulnerabilities - C code
Humans don’t think like computers do, which is probably a good thing in most cases, except when we are trying to get computers to do stuff. Because humans and machines think in such vastly different ways we have to spend huge amounts of time learning how to write code and even then the best of us make huge mistakes all over the place. So let’s have a look at some classic examples:
Can you see what’s wrong with this?

The main issue is that our variable ‘max’ is an unsigned short, while our variable ‘length’ is simply a just a short, and therefore by default, a signed short.
The problem with this is that a large number in the form of an unsigned short could be 11111111 (which is 255 in decimal), but, in the form of a signed int, the first binary digit is used to store the sign. So 11111111 would actually be treated as -127, and since -127 is not greater than max (line 9), that test case would fail.
Check out line 27 of this code…

Despite the bad if statements that are have left out the curly brackets, the big problem comes from sizeof(buffer)
Notice that the sizeof function will actually return the size of the pointer ‘buffer’ not the actual string *buffer. This will always be either 4 or 8 depending on the OS.
Last one Hint - it’s a problem with passing the wrong type again

Again, bad if statement, but otherwise we can see that in our if statement we are comparing two different data types. This time a short and a long.
Errors are hard to find
This exercise, along with many others has shown the difficulties in debugging and finding errors. Even in something with less than 10 lines of code, it can take some time to spot the issue, yet this is what humans need to be able to do. Computers are not at the level where they can enter debug themselves, they only do what they have been told to do, so we must be very clear with what we tell them to do. Humans may easily understand that the length of a string, shouldn’t be a negative value, it just doesn’t make sense, but computers don’t operate in the same realm and hence these errors proliferate modern code.
1 note
·
View note
Text
The Stack and Stack Frame
This may seem like a somewhat off topic post, but I think it’s important I detail what the stack and the stack frame are as we are going to be needing to understand these concepts going forward. For more, I’d recommend reading up about stacks here. Essentially, the stack is a collection of data. It’s called the stack since it has two primary functions, push and pop, where push is placing an item on top of the stack and pop is taking an item off the top of the stack. Exactly like a normal stack of paper might work. To remember this primary fundamental concept of the stack we use the acronym LIFO for Last In - First Out.

Whenever we want to save data, say when we run a program, where are going to have to place that data somewhere. To do this we have to first establish our stack frame. Here’s an example of a program I wrote in MIPS assembly language. In the MIPS architecture, when we call a program a stack frame isn’t automatically established for us, so we have to do it ourselves, hence why I think this serve as a good example of how the stack works.

There is a bit of syntax to understand, but the concepts are quite simple. In line 35, the instruction addi simple adds the -4 to value stored in the second register $sp, the result of this instruction is then stored in the first register, which is again $sp. The register $sp itself is the Stack Pointer, which always contains a memory address of the top of the stack.
Then, in the next line (36), the instruction sw stands for ‘save word’, where word is a data type and the instruction after that (37), la which stands for ‘load address’. These two instructions establish the frame pointer, stored in register $fp, which essentially points to the start of our stack frame. Then we use addi again to move the stack pointer and then use sw to save the return address into the register $ra.
Once we have established our frame the rest is just saving some registers that we will use during the execution of our program. We use addi to repeatedly move the stack frame down and then use sw to save our registers, starting with register $s0 and continuing until we have enough, in this case, $s5.
After the end of our program, well want to free these registers since they aren’t needed any more. Also, since we are thinking like security engineers, I’m sure you can see why we wouldn’t want to just leave all the data from our program lying around in random memory. To do this we have to ‘tear down the stack frame’ like so:

You’ll notice here that we are adding 4, not subtracting, as we are releasing reach register in the reverse order that we pushed them onto the stack. It can be confusing that the stack ‘goes down’ (of course this is abstrack memory, so there is no such thing as up or down) so here is a little representation of the stack that I think might help:
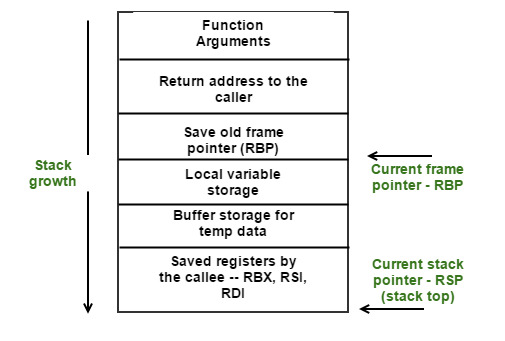
Before my next post, think about how the stack frame is set up and how we might be able to exploit that fact.
1 note
·
View note
Text
Deniability: The forgotten hacker ingredient
As an attacker, it's always important to cover your tracks through Tor or other anti-detection methods. However, if you’re the only one using Tor on your IP, its gonna be pretty hard to deny that you are the attacker. This is why deniability is super important and an aspect of every succesful attack.
This creates a conundrum, deniability vervus anti-detetion? In many cases, increasing your anti-detection methods will worsen your deniability, this is becuase most ‘law abiding’ citizens don’t need/know/want to use advanced privacy methods.

An incredibly intereesting example of this was given to us during one of my classes for Security Engineering:
If we imagine the hard drive as just a book with all our data on it, we can think of the operating system as just a bot that reads that book for us. Most operating systems have a bunch of security measures to prevent someone getting in and reading all our data. This is great and will probably prevent your friends from loging in and making Facebook status on your behalf, but if you’ve been stealing, distributing and selling millions of credit card details and major government bodies are invovled, your OS security probably wont be that great. But! Not only that, but they wont even both cracking your OS, theyll just take your computer and read the hard drive (remeber its just a book) directily with their own equipment.
But it’s ok, becuase there are methods of Hardware-based encryption. For example, disk encryption hardware essentially encrypes the entire book that is your hard drive, so when it is read by the NSA or whoever, they wont be able to make any sense of it. However, now you’ve lost some of your deniability. And on top of that the police will most likley ‘ask’ you to decrype the hardrive for them, and if you refuse, you’ve lost even more of your deniability.
If you don’t like the idea of a police state, or you value your privacy, or you’re a hacker yourself and want to increase your own deniability, then you should probably encourage everyone to use methods like Full Disk Encription (FDE). If everyone used it, then the police wouldn’t really have a point when they aurgue that you must be a criminal since you’re using FDE.
3 notes
·
View notes
Text
Human error and how we exploit it
The reason hackers are able to do what they do is that a programmer somewhere made a small error, often an off-by-one or the use of improper Unicode. Always something small and insignificant, that is hard to spot while writing code. However, all humans have similarities and hence we all make similar types of mistakes. If every single mistake in code was entirely unique, it would be significantly harder to exploit as these mistakes would be harder to find.

An awful lot of these mistakes are to do with memory corruption. These are bad mistakes to make as they allow attacks to access parts of the memory that they otherwise were not meant to. From this attackers are able to access nearby variables (depending on their location in the stack) or even the return address of a function. We’ll be taking a further look at specific exploits involving memory soon.
The attacker always aims to obtain control of the targets execution flow which is often done by inserting and running malicious code in corrupted memory. In normal conditions this will likely cause the program to crash however if the attack is successful in controlling the environment of the program then they may be able to get it to do what they want. These kinds of attacks are called the execution of arbitrary code.
Next well be looking at Buffer Overflows, a super interesting exploit and probably one that you've encountered accidentally while programming yourself. I look forward to seeing you then!
1 note
·
View note
Text
Exploitation - 0x300
Computers are totally logical machines, they do exactly what they are told and nothing more or less. We all know that essentially computers only understand two signals, on or off, and we have to string countless on and off signals together to be able to get any meaning out of computers. However, computer programs are all built by humans, which are not perfectly rational agents, to say the least.
As a hacker, it's our goal is to get a system to do something that we want it to do, even if the system has deliberately been designed to not allow us to do so. To do this we must exploit flaws in the logic of the systems we are attacking, these flaws have been put there by humans (accidentally) as setting up perfect security systems is incredibly difficult.
An extreme example of the “slave to logic” model of computers is from the film iRobot, where the robots are told to protect all human life, and as such, they resort to locking up all humans and preventing them from leaving their homes, as that is the safest way for humans to live. Of course, we will be looking into more common and somewhat more realistic expectations.
A good example of a common logic flaw is the off-by-one error, otherwise known as the fencepost error. Essentially, if need to fence off a ten meter stretch of land, and want your fence posts separated by one meter, how many fence posts do you need? If you thought 10, then you just made a fencepost, take an extra second to think about it, since you need one fence post at the start of the 10 meters, having one more fence post each meter will mean you'll still have the final meter unfenced.
These kinds of errors go unnoticed a lot for two main reasons, its often very difficult to test every single possible outcome of a program and a lot of testing is only done in normal conditions of the program. As hackers, we need to think outside the box as we are going to have to breach system by using abnormal conditions to get computers to do what we want them to do.
As testing, or lack thereof is a major aspect for why these exploitative flaws go overlook, often the best time for an attack is immediately after the release of certain software. Every time a program becomes more complex, more flaws are added to a system.
Exploitations are a result of computers doing exactly what they are told “To the letter of the law” and as both defenders and attackers we need to make sure that we understand the way computer programs carry out commands in order to get them to do exactly what we want. This means we must make what we say mean exactly what we intend.
1 note
·
View note
Text
So you wanna be a hacker?
I am a computer science student at the University of New South Wales, and on this blog, I’m going to be doing my best to give some basic tutorials on how to hack computer systems. I am doing this to better understand the mind of the attacker so that as a security engineer I am able to build more secure systems. I am going to be learning from Jon Erickson’s book “Hacking: The Art of Exploitation” and passing on what I have learnt to my readers. I would defiantly recommend acquiring a copy of the book yourself if this is something you are interested in. So with that, let's get hacking!

1 note
·
View note