
Dette er stedet hvor Arkivverket tester ut nye ideer. Vi tar gjerne imot tilbakemeldinger.
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by arkivverketbeta and here's what we found interesting.
Average Info
Notes Per Post
4
Likes Per Post
2
Reblog Per Post
2
Reply Per Post
0
Time Between Posts
4 months
Number of Posts By Type
Text
17
Last Seen Tumblr Blogs





Fun Fact
Tumblr has a 66 index score for customer satisfaction in the US.
Text
Agentic RAG: Neste steg i KI-chat for innholdet i digitalarkivet
I forrige artikkel fortalte vi om hvordan vi har testet ut en KI-basert chatløsning med RAG (Retrieval Augmented Generation) i bunnen. Denne løsningen ga oss nyttige erfaringer med å kombinere generativ kunstig intelligens med vårt eget arkivmateriale og veiledninger, hjelpetekster og annet støttemateriale. Erfaringene har vist at RAG er et godt utgangspunkt, men at vi raskt støter på utfordringer når vi prøver å dekke flere behov enn tradisjonelle søk eller enkle KI-svar kan håndtere. "agentic RAG"
Vi har tatt et steg videre ved å prøve ut en "agentic RAG", som er en utvidelse av den tradisjonelle RAG-tilnærmingen. Mens man i en vanlig RAG-løsning hovedsakelig henter frem informasjon og svarer direkte på brukerens spørsmål ut fra dette, opptrer en agentic RAG mer som en selvstendig “agent” som dynamisk justerer sine egne arbeidsprosesser. Den kan for eksempel validere svar, foreslå mer presise spørsmål, og endre søkestrategier når resultatene ikke er gode nok. Fremover ønsker vi å implementere enda mer autonomi i valg av funksjoner og strategier ut fra et satt mål i løsningen, men dette er en reell start.
Hva er en agent og hva er agentic RAG?
Enkelt forklart kan man si at en agent er et system som observerer et miljø/en situasjon/noen parametre, den har også fått satt et mål. Basert på observasjonene utfører den handlinger for å oppnå dette målet. Agenten vurderer effekten av sine handlinger, justerer strategien og fortsetter mot målet.
En agentic RAG er i bunn og grunn en agentisk tilnærming til informasjonsinnhentings-oppgaver basert på en agent-arkitektur. I en tradisjonell RAG har man en ganske statisk prosess for å hente frem og presentere informasjon. En agentic RAG innebærer at KI-en kan ta beslutninger på egenhånd om hvordan den skal løse informasjonsinnhentingen. I stedet for å ha fast definerte trinn for «chunking», innhenting og generering, kan en agentisk RAG dynamisk justere søkeparametere, revidere spørsmål, foreslå nye strategier, bruke ulike “verktøy” (f.eks. API-kall eller funksjoner) og avgjøre når nok kontekst er innhentet til å svare på en tilfredsstillende måte.
Det er nettopp derfor det snakkes mye om agentisk RAG for tiden. Vi og mange andre har prøvd å løse RAG ved hjelp av statiske regler for oppdeling av tekstbiter og søk med ulik grad av kompleksitet, og da oppdager man raskt at virkeligheten er mer rotete. Dataene er ikke alltid som man har sett for seg, og spørsmålene kan være vage eller flertydige. Da trenger man et system som kan operere mer fleksibelt, mer utforskende og mer problemløsende.
Hvorfor trenger vi dette?
Arkivkunnskap kan være kompleks, og brukere vet ikke alltid hvilke ord de skal søke på eller hvor de bør starte. Her gjør agentisk funksjonalitet en stor forskjell:
Forbedre spørsmål: Agentic RAG kan omskrive og bearbeide brukerens spørsmål for å gjøre dem tydligere og mer presise.
Kombinere søkestrategier: Systemet bruker semantiske og hybride søk som finner meningsinnhold, ikke bare eksakte ord. Hva som egner seg, kan den avgjøre på egenhånd. Den kan justere parametere som similarity, og tilpasse taktikken basert på resultatene.
Dynamisk tilpasning: Hvis svarene er mangelfulle, foreslår løsningen nye spørsmål, prøver alternative søkeord eller utvider søket – alt uten at brukeren må vite hvordan.
Kvalitetssikring: Løsningen validerer svarene og foreslår presiseringer om nødvendig, slik at brukeren får mest mulig pålitelig informasjon.
Hvordan fungerer løsningen i praksis?
Når en bruker stiller et spørsmål, tar systemet først tak i spørsmålet, forbedrer det eller gjør andre tilpasninger og benytter deretter semantiske og hybride søk for å hente frem relevant informasjon fra arkivene. Denne informasjonen struktureres slik at KI-modellen kan formulere et svar med lenker til kilder Alt dette skjer uten at brukeren trenger å vite nøyaktig hvordan ting fungerer, systemet tar hånd om prosessen og jobber aktivt i kulissene for å levere best mulig svar, i stedet for bare å presentere det første og beste treffet.
Agentiske egenskaper
Målbasert tilnærming: Systemet har et klart mål: å besvare brukerens spørsmål med størst mulig nøyaktighet. Dette er tydelig i hvordan det validerer svar og bruker fallback-strategier for å forbedre resultatene når de ikke er tilstrekkelige.
Adaptiv respons: Ved lite treff, tilpasser løsningen arbeidsflyten ved å benytte alternative strategier som omskriving, utvidede spørringer eller oppfølgingsspørsmål. Altså en viss grad av dynamisk beslutningstaking.
Systemet integrerer ulike teknologier og verktøy (LLM, Elasticsearch, hybrid søk) og velger passende metoder basert på behov, så den har fleksibilitet i hvordan det løser oppgaver.
Integrert logikk: Agenten fungerer som en koordinator som setter sammen, validerer og justerer informasjon fra ulike kilder.
Dynamisk kontekststyring: Systemet kan ta hensyn til tidligere samtaler og tilpasser neste steg etter dette.
Fallback-optimalisering: Med flere iterasjoner og alternative strategier øker sannsynligheten for at brukeren får et tilfredsstillende svar.
Proof of concept og veien videre

Denne løsningen er på et utprøvingsstadium og ligger ikke ute i en beta-utgave. Det er mange muligheter for utvidelser, og selve grunnstrukturen må forbedres. Den viktigste utvidelsen vil være å sørge for at løsningen har enda mer autonomi i valg av funksjoner og strategier, for eksempel ved å gi LLM-en en beskrivelse av målet og tilgjengelige verktøy, og la den selv bestemme hvilke handlinger som er nødvendig for å oppnå målet. Dette ville bringe det nærmere en løsning med reell "agency." Dette er vi i gang med. Fremtidige andre utvidelser kan for eksempel omfatte (med ulik grad av kompleksitet):
Forbedret validering og resonnering
Dynamisk søketilpasning: Juster parametere som temperatur, "similarity” og vekting automatisk.
Oppgave-oppdeling: Løsningen bryter opp komplekse spørsmål i deloppgaver og løser dem trinnvis. For eksempel, for spørsmålet «Forklar forholdet mellom A og B», kan agenten først hente info om A, deretter B, og så sette sammen informasjonen selvstendig.
Forbedrede feedback-sløyfer: Brukerfeedback: La brukere gi tilbakemelding, slik at løsningen kan justere hvordan den oppfører seg over tid.
Kontekstrevisjon: La brukeren revidere tidligere innlegg i samtalen, slik at konteksten blir oppdatert dynamisk.
Integrasjon med kunnskapsgrafer og andre data: Bygge opp en enkel kunnskapsgraf: Følger entiteter, relasjoner og temaer på tvers av samtaler, og foreslå relevante, sammenkoblede opplysninger. Under dette ligger også integrasjon med arkivdata og arkivkunnskap. Ved at for eksempel systemet tilpasser hvilke arkiv den skal bruke basert på spørsmålet.
Oppsummert vil vi si at agentic RAG er en naturlig videreutvikling fra RAG. Ved å gi løsningen evnen til å ta egne avgjørelser, velge verktøy, og tilpasse strategien underveis, blir den i stand til å hente frem og formidle arkivkunnskap på en mer dynamisk og pålitelig måte.
Ta gjerne kontakt med oss på [email protected] hvis du har tilbakemeldinger, eller er nysgjerrig på arbeidet vårt med KI, søk eller digitalarkivet generelt.
0 notes
Text
Test av KI-basert chat i Digitalarkivet
For et par år siden ble ChatGPT offentlig tilgjengelig, og det vi fikk prøve virket nesten litt… magisk? Plutselig var det mulig å kommunisere med en datamaskin med naturlig språk, og få fornuftige svar, til og med på norsk! Brukergrensesnittet minnet mye om chat-botene vi er vant med fra mange tjenester på nettet, men med KI-genererte svare føltes det nesten som at man kommuniserte med et menneske: Du kunne stille oppfølgingsspørsmål, eller be om enklere forklaringer, eller mer detaljer.
Kanskje en slik type KI-chat kunne være en være en fin måte å utforske og forstå arkivinnhold på, som et alternativ til tradisjonelt søk eller å få hjelp av en saksbehandler hos Arkivverket? Mange kan oppleve at arkivene kan være vanskelig å finne frem i, samtidig som arkivene inneholder mye materiale som er viktig eller interessant for store deler av befolkningen.
Men så var det med fornuftige svar, da. Helt fra starten var det åpenbart at ChatGPT og tilsvarende løsninger kunne komme med svar som var helt feil, med samme skråsikkerhet som riktige svar. Vi sier gjerne at den hallusinerer når den svarer feil. Dette er et stort problem med denne teknologien – du må egentlig dobbeltsjekke alle svar du får – og det sier også litt om måten slike KI-modeller utvikles på.
Bak KI-chatene ligger en stor språkmodell (LLM, eller Large Language Model). Disse lages (eller «trenes») ved å analysere store mengder tekst, i praksis store deler av internett. Disse modellene beregner (eller «predikerer») hva det neste ordet i svaret skal være. Det ødelegger kanskje litt av den magiske følelsen, men ChatGPT og tilsvarende løsninger er i bunn og grunn bare anvendt statistikk. Og hvis du spør om ting som er dårlig representert i treningsdataene så blir det statistisk grunnlag for å predikere ordene dårligere og du kan få oppdiktede svar. Det er også verdt å tenke på at KI-modellene ikke forholder seg til virkeligheten direkte, kun til tekster som beskriver virkeligheten. KI-modellen vet altså ikke selv om det den svarer er galt eller riktig.
Ofte inkluderer treningsdataene svært mye av tilgjengelig informasjon, men likevel vil fakta, meninger, tjenester og produkter som er viktige for f.eks. Digitalarkivet og arkiv-domenet ikke være en del av det modellen «vet». Det kan være fordi det er informasjon som er privat eller skjult, fordi den ikke anses som viktig nok til å inkludere eller fordi den er for ny. Hvis vi brukte f.eks. ChatGPT for å finne informasjon i Digitalarkivet vil den sjelden kunne gi riktige svar, samtidig som at det er en fare for at svarene den gir faktisk høres fornuftige ut.
Tillit til arkivene er svært viktig. Man må kunne stole på at det man finner er riktig, og at man finner det man trenger, og da passer det dårlig med løsninger som kan dikte opp opplysninger. Det er vanskelig å hindre hallusinasjoner i en AI-modell, men «Retrieval Augmented Generation» - eller RAG - er en måte å komme rundt problemet på.
RAG vil helt enkelt si at systemet kan basere svar på andre kilder enn de som modellen er trent på, slik at kunnskapshullene i modellen tettes. Det blir omtrent som å gi KI-modellen jukselapper. Det er fortsatt KI-modellen som skriver svarene, men den har altså tilgang til ekstra informasjon som den kan basere svarene på. RAG skjer i to trinn:
1. Hente informasjon Basert på informasjon i ulike databaser, kunnskapssamlinger, ontologier, dokumenter og bøker så lager man en samling over små kunnskapsbiter i form av "embeddings". Embeddings er et format som gjør at vi maskinelt kan finne likheter i betydning (semantisk) mellom f.eks ulike tekstsnutter. Når vi da får inn et spørsmål fra brukeren og gjør denne om til en embeddings kan vi gjøre et semantisk søk og finne de tekstbitene som er likest i betydning til det brukeren spør om.
2. Generere svar Brukerens spørsmål og de relevante bitene som har blitt funnet sendes som en pakke til en generativ KI-modell, som GPT, Claude, Mistral eller LlaMA, som laget et svar basert pakken den har fått. På denne måte kan vi sikre at KI-en har fått opplysningene den trenger for å gi et godt svar. Noe som er viktig i valg av modell er at den er god til å ta instruksjoner fra oss. I pakken vi sender legger vi nemlig til en hel masse beskjeder til modellen om hva den skal gjøre og ikke gjøre. Her finnes det et stort spenn av forskningsbaserte teknikker for å gi disse beskjedene på best mulig måte.

Denne teknologien har Arkivverket testet ut i en proof of concept (poc). Det er enkelt å sette opp en grunnleggende RAG-løsning, men for å få testet ut om RAG faktisk kan løse våre hypoteser om behov og utfordringer så har vi gått videre og laget en mer avansert og modulær RAG-arkitektur. Her har vi tatt i bruk ulike teknikker og algoritmer basert på forskning og det som rører seg i rag-verdenen på hvert av de ulike stegene i prosessen for å sørge for et mest mulig pålitelig og utfyllende svar til brukeren basert på våre data.
Poc-en består av to løsninger, som til sammen har latt oss teste ut RAG på flere typer innhold:
Den ene løsningen inneholder materiale om arkivkunnskap, som veiledninger og hjelpetekster. Dette kan være svært nyttig for brukere som har dårlig kjennskap til arkivene og som ikke helt vet hvordan de skal komme i gang med å finne informasjon.
Den andre inneholder to vidt forskjellige typer digitalisert arkivmateriale, henholdsvis arkiver fra Alexander Kielland-ulykken og dagbøker fra reindriftsforvaltningen.
En fordel med RAG er at det er relativt enkelt og billig å innarbeide mer informasjon, da dette skjer ved å oppdatere søket. Uten RAG ville vi vært nødt til å trene nye versjoner av selve KI-modellen for å oppdatere den med ny informasjon, noe som er langt mer ressurskrevende.
Det er et viktig poeng at løsning skal kjøre på våre egne systemer, heller enn at vi kobler oss på eksterne tjenester. Det er viktig at vi både har kontroll på teknologien vi bruker og på datagrunnlaget som legges inn i systemet. Det å kunne velge en modell som fungerer godt på norsk er viktig, og vi bør kunne bytte ut AI-modeller hvis det f. eks. dukker opp en ny som fungerer bedre til vårt bruk. Vi bør også ha mulighet til å velge teknologi ut ifra økonomiske faktorer.
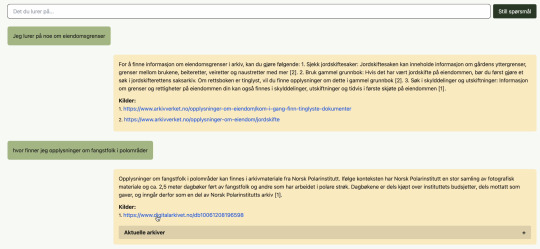
Poc-en inkluderer også et chatte-grensesnitt, som du selv kan teste ut ved å klikke på lenkene nederst i artikkelen. I menyen til venstre kan du justere flere aspekter ved hvordan spørsmålene blir behandlet og hva slags svar du får, så her er det bare å leke seg!
Det er to momenter til som er verdt å legge merke til, som begge er viktige for å skape tillit til resultatene:
I tillegg til at løsningen svarer på spørsmål, gir den også en lenke til originalkildene slik at brukeren kan få bekreftet svaret eller bla videre i originalkilden hvis hen ønsker å utforske innholdet mer.
Løsningen forklarer at den ikke kan svare hvis brukeren spør om noe som den ikke har informasjon om, i stedet for å hallusinere frem feil svar.
_ _ _
Poc-en har vist oss at en chatteløsning med RAG i bunnen har mange fordeler:
Brukeren får beskjed hvis systemet ikke vet svaret, heller enn at løsningen dikter opp et svar.
Brukeren kan benytte naturlig språk, og skrivefeil eller dårlige formuleringer blir ofte forstått
Systemet vil forstår betydningen av det brukeren spør om og kan derfor gi svar som kan være nyttige for brukeren selv om det ikke samsvarer i språk. Den kan også gi svar ut fra informasjon som er relatert til brukerens spørsmål i større grad en f.eks et leksikalt søk.
Brukeren kan ha en dialog med systemet, og for eksempel stille oppfølgingsspørsmål eller be om presiseringer.
Brukeren får lenker til originalkildene slik at det lett å verifisere svarene hen får.
Vi ser også noen utfordringer ved en slik løsning:
En slik avansert RAG-arkitektur er avansert og ressurskrevende å lage. Det kan tenkes at det finnes andre løsninger som gir noen av de samme gevinstene.
Svarene man får er basert på arkivmateriale som kan inneholde utrykk og holdninger som er foreldede eller støtene. Slik utrykk og holdninger kan dermed også finne veien inn svarene som chatboten gir. Brukere er nok forberedt på at eldre materiale inneholder språk som vi ikke vil brukt i dag, men det kan virke støtende eller underlig hvis slikt språk benyttes i en nyskrevet tekst. Det finnes teknikker for å minimere dette problemet som vi kan ta i bruk, men man vil neppe klare å eliminere det helt.
Og selv om RAG reduserer faren for oppdiktede svar betraktelig så er det ikke helt en vanntett metode. Den generative modellen som skal formulere svaret kan fortsatt klare å hallusinere innhold som ikke var med i informasjonsbitene som svaret skal baseres på. (https://arstechnica.com/ai/2024/06/can-a-technology-called-rag-keep-ai-models-from-making-stuff-up)
_ _ _
Vi har et godt grunnlag som kan peke ut noen retninger for videre utforsking, og vi er spente på hva vi kan lære av dere som prøver løsningen. Veien videre har ikke blitt avgjort, men selv om vi har laget en omfattende og grundig poc så er det mye arbeid igjen for å få en ferdig løsning. Hensikten med en poc er å finne ut om man er inne på noe, om konseptet er teknisk mulig å realisere. Det langt unna et ferdig produkt, noe som betyr at det kan forekomme små og store feil. Merk også at datagrunnlaget som benyttes ikke nødvendigvis er oppdatert, og at f. eks. veiledningene man søker i kan inneholde feil.
Et kjent problem er at selv om kildehenvisningen blir riktig, så kan den en sjelden gang f. eks. starte nummereringen på 2 eller hoppe over 3. Årsaken er at det søket er mer optimistisk enn språkmodellen-en og derfor finner flere mulige kilder til svar enn det språkmodellen faktisk finner svar i. Dermed kan listen over kilder ha litt underlig nummerering.
Her er lenker til de to løsningene, så du selv kan teste dem:
Veiledninger og arkiv-kunnskap: https://rag.beta.arkivverket.no
Alexander Kielland-ulykken og dagbøker fra reindriftsforvaltningen: https://rag-transcriptions.beta.arkivverket.no
Ta gjerne kontakt med oss på [email protected] hvis du har tilbakemeldinger, eller er nysgjerrig på arbeidet vårt med KI, søk eller digitalarkivet generelt.
0 notes
Text
Bruk av klyngeanalyse for å utforske store datasett
Så, du har fått ansvaret for klessalget på årets loppemarked, og du ser utover de 50 sekkene med klær som har blitt levert inn. Sikkert mange T-skjorter og olabukser, men det kan også være alt fra hullete sokker til ballkjoler i sekkene. Det er nesten umulig å få oversikt, men likevel skal du forsøke å stille ut alt på en ryddig måte, slik at det er lett å finne frem i den overfylte gymsalen.
Dette er et ganske godt bilde på utfordringen Arkivverket står overfor når vi skal hente ut og strukturere informasjon fra ukjente datasett.
Et helt konkret eksempel: Vi er i gang med å bruke maskinlæring for å hente ut informasjon fra gamle sesjonsskjemaer. Disse har kun vært tilgjengelig på papir, men vi ønsker å kunne hente ut opplysninger fra skjemaene slik at de kan brukes digitalt. Foreløpig har vi skannet 1,4 millioner skjemaer, men dette arbeidet pågår fortsatt.
For å hente ut opplysningene fra de skannede skjemaene, trenger vi å vite hvor på skjemaet de ulike opplysningene – navn, fødselsdato, helseopplysninger o.l. – står. Hvis alle skjemaene hadde vært like kunne, vi laget én kunstig intelligens-modell som hentet ut de ulike opplysningene ut ifra posisjon på skjemaet. Men det ble raskt klart at sesjonsskjemaene kunne ha ganske forskjellig oppsett. Hvor mange varianter av skjemaene finnes? Hvilke varianter er vanlige? Finnes det helt irrelevante dokumenter i samlingen, som ikke har noe å gjøre med sesjon? Er noen skjemaer skannet opp ned? Det ville være en uoverkommelig oppgave å få oversikt over dette ved å gå manuelt gjennom alle skjemaene, og det er her klyngeanalyse kommer inn i bildet.

Klyngeanalyse – på engelsk «clustering» – er en teknikk innen maskinlæring som brukes til å finne grupper av objekter som er like hverandre (i vårt tilfelle sesjonsskjemaer) i et datasett. Dette kan brukes til å identifisere mønstre og sammenhenger i dataene. Klyngeanalyse kan brukes i mange forskjellige sammenhenger, for eksempel innen markedsføring, medisin og finans.
For å forstå hvordan klyngeanalyse fungerer, kan vi gå tilbake til loppemarked-eksempelet: Vi ønsker å sortere klærne etter f.eks. farge og størrelse. Vi kan gjøre dette ved å se på egenskapene (features) til hvert klesplagg (farge og størrelse) og gruppere dem sammen basert på disse egenskapene. På samme måte kan klyngeanalyse brukes til å gruppere objekter i et datasett basert på deres egenskaper.
For å utføre klyngeanalyse trenger vi først et datasett med objekter og deres egenskaper. Deretter bruker vi en algoritme til å finne grupper av objekter som er like hverandre. Algoritmen kan variere avhengig av hvilken type klyngeanalyse som utføres.
En vanlig type klyngeanalyse er k-means-klynging. Denne algoritmen deler objektene inn i k antall grupper basert på vektorer for objektene, generert fra egenskapene deres. Algoritmen starter med å velge k antall tilfeldige sentroider (midtpunkter) i datasettet. Deretter beregner den avstanden mellom hvert objekt og hver sentroid, og plasserer hvert objekt i den gruppen som har den nærmeste sentroiden. Deretter beregner algoritmen gjennomsnittet av alle objektene i hver gruppe, og bruker dette som den nye sentroiden for gruppen. Prosessen gjentas til sentroidene ikke lenger endrer seg.

Etter å ha kjørt en slik klyngeanalyse, har vi et ganske godt bilde av datasettet, men det er ikke alltid algoritmen finner fornuftige egenskaper ved objektene. For eksempel kan samme skjematype bli plassert i to ulike klynger fordi de de har forskjellig farge. Men det er tross alt enklere å gå gjennom et lite sett med klynger for å sjekke om de er fornuftige, enn å gå gjennom en million objekter.
Når klyngeanalysen er gjort kan vi bruke klyngene som grunnlag for å definere klasser og deretter trene en klassifiseringsalgoritme som kan gruppere nye skjemaer i disse klassene. Når disse operasjonene er gjort, har vi et mye bedre bilde av hva slags jobb vi står overfor. Vi vet hvor mange skjemaer som finnes, hva slags skjemaer som det kan lønne seg å fokusere på og hvilke man kan vente med – eller til og med ignorere. Dette er et viktig grunnlag for neste trinn, arbeidet med å hente ut informasjon slik at den blir digitalt tilgjengelig.
Dersom du ønsker å ta kontakt utover bloggen, kan du også sende en epost til [email protected]
0 notes
Text
Håndskriftsgjenkjenning og variasjonen i håndskrift
Kikk her for en liten innføring i automatisk håndskriftgjenkjenning.
I forrige innlegg viste vi at utfordringene i håndskriftsgjenkjenning begynner allerede når vi skal finne teksten på hver enkelt side. Nå skal vi ta for oss det neste steget i prosessen med å transkribere et dokument, nemlig selve tekstgjenkjenningen.
Akkurat som mennesker må også maskiner trene for å bli gode til å lese håndskrift. Jo mer håndskrift vi leser, og jo mer variert den er, jo flinkere blir både vi og maskiner til å lese nye håndskrifter vi aldri har sett før. De fleste mennesker i dag trenger ikke å lære seg å lese spesielt mange håndskrifter for å klare seg i hverdagen. Kanskje holder det å kunne lese sin egen, eventuelt også håndskriften til de man bor med. Verktøyene vi bruker for å lese av arkivmaterialet i Arkivverket, derimot, må kunne lese enormt mange håndskrifter - og det er en umulig oppgave å skulle lære dem alle spesifikt. I og med at arkivene går tilbake til 1100-tallet, er det mye forskjellig som rører seg i de ulike kildene. Dette setter høye krav til programvaren vi bruker, og innebærer at vi må trene den til å forstå det vi vil den skal lese og transkribere for oss.

I bunn og grunn finnes det minst like mange håndskrifter som det finnes skribenter. Antagelig kan vi si at det finnes flere, siden håndskriften til én og samme person kan endre seg i løpet av et liv. Vi vet ikke hvor mange ulike skribenter som har bidratt til å skrive de milliardene med dokumentsider som ligger i magasinet, men vi kan trygt si at arkivene våre representerer et bredt spekter av håndskrifter.
Håndskriftene i én og samme tidsperiode kan ha flere likhetstrekk, og jo lenger bak i tid vi går, jo mer annerledes blir stilen fra moderne håndskrift. Det er dermed mulig å se tendenser for de ulike håndskriftene i arkivmaterialet vårt, fordelt utover århundrene. Håndskriften fra 1950 skiller seg for eksempel radikalt fra håndskriften i 1820, som stort sett var gotisk. Gotisk og antikva – den skriften vi bruker i dag – ble også ofte brukt sammen. I perioder var det slik at skribentene hadde to forskjellige måter å skrive på: brevskrift og bokskrift. Bokskriften var mer formell, og ble for eksempel brukt i produksjonen av publiserte bøker. Brevskriften var mer uformell, og ble som navnet tilsier brukt i private brev og andre mindre offisielle situasjoner. I diplomer, altså brev, fra middelalderen, kan man gjerne se begge skrifttyper bli brukt i ett og samme dokument.

Navnene Christian Stochflet og Niels Randulf (linje to og fire) i antikva, mens resten er gotisk.
Fra starten av 1900-tallet og bakover er arkivene stort sett skrevet på dansk. Dette gir oss muligheten til å bruke danske håndskriftsgjenkjenningsmodeller på vårt materiale. For ikke bare er selve skriftspråket mer eller mindre det samme i Norge og Danmark i denne perioden, men skribentene er gjerne utdannet på samme sted og har jobbet med mange av de samme typene dokumenter. Det er derfor mange likheter i håndskrift og dokumentlayout i de to landene. Arbeidet med håndskriftsgjenkjenning blir betydelig enklere om man kan benytte seg av slike eksisterende modeller og treningsdata, siden det tar mye ressurser å lage det selv.
Et eksempel på dette er at vi nå bruker en stor dansk modell Rigsarkivet i Danmark har trent på tusenvis av sider med sitt eget materialet, på en branntakstprotokoll fra Trondheim fra 1766 i vårt arkiv. Vi har brukt verktøyet Transkribus til dette, som vi har matet med bildene fra Digitalarkivet. Deretter har vi brukt modellen på bildene, som både har segmentert og transkribert teksten. Den maskinelle transkripsjonen var så god at vi kunne lagt den ut på Digitalarkivet for søk, men vi har valgt å korrigere alle sidene først, slik at transkripsjonene blir helt riktige.
Så lenge modellene er trent på dansk-norske dokumenter fra omtrent samme tidsperiode, vil språket være relativt likt på tvers av materialet. Hvis vi derimot trener modeller som strekker seg over flere århundrer, vil ikke bare håndskriften endre seg, men også skriftspråket. Det trengs mer treningsdata for å trene en modell som skal kunne håndtere så stor variasjon. Dette gjør det utfordrende å trene én stor modell som skal kunne transkribere materiale fra alle århundrer, sammenlignet med en modell som kun skal håndtere ett århundre. Det meste Arkivverket har av materiale, er enten på dansk-norsk, moderne norsk eller ulike samiske språk, og det aller eldste i arkivet er enten på latin eller norrønt. Disse ulike språkene ville trengt sine egne modeller, slik vi jobber i dag.
De fleste modeller Arkivverket bruker og trener selv, er altså enspråklige og basert på ett århundre. De er trent på flere skribenter, men ikke mer enn ett språk. Likevel er noen århundrer vanskeligere enn andre. Jo lenger bak i tid vi går, jo færre blir rettskrivningsreglene. Det fantes i liten grad normering av dansk skriftspråk før midten av 1700-tallet, og på 1600-tallet ville den gjengse skribent mer eller mindre skrive ord slik han eller hun følte for. I og j ble ofte brukt inkonsekvent, og det samme med u, v og w. “hodet” kunne skrives huedet og hvedet, og “den” kunne likeså godt bli skrevet den som thenndt i ett og samme dokument. Etter hvert som standardiseringen i skrift blir vanligere, blir det også enklere å lage gode modeller, siden ordene skrives på mer konsekvente måter.
Det er også slik at selv om to kilder er på samme språk og er fra samme tidsperiode, kan de ha ulike vokabular. Dette gjør at modeller kun trent på rettsmateriale ikke nødvendigvis kan brukes for å transkribere eiendomsmateriale. Vi har dermed behov for modeller som er spesialiserte på litt ulike domener.
For å oppsummere kan vi si at Arkivverket hele tiden jobber for å trene og bruke modeller som gir mest for pengene. Modellene bør kunne brukes på så mye materiale som mulig, og innhold som er så viktig som mulig for brukerne. Vi må med andre ord hele tiden tenke på hva som kjennetegner de ulike kildene vi er interesserte i å transkribere, og hva som skal til for å oppnå resultatet vi er ute etter – nemlig historiske kilder som blir enklere å finne frem til og finne frem i.
Har du spørsmål om arbeidet vårt med håndskriftsgjenkjenning? Send oss en e-post på [email protected].
0 notes
Text
Håndskriftgjenkjenning og layout
Kikk her for en liten innføring i automatisk håndskriftgjenkjenning.
Alle har vel opplevd at håndskrift kan være vanskelig å forstå, så det er kanskje ikke så overraskende at det kan være utfordrende å benytte teknologi til å forstå håndskrevne dokumenter. Det som kanskje ikke er like intuitivt, er at det også er knyttet utfordringer til layout og sideoppsett i denne prosessen. Vi mennesker forstår stort sett ganske greit hvordan teksten «flyter» på en side, selv når kolonner, tabeller, overskrifter, løpende tekst og illustrasjoner blir brukt om hverandre, men dette er langt fra selvfølgelig for et dataprogram.
Før teksten kan transkriberes, må vi ha en modell som gjenkjenner layouten på sidene, slik at programmet kan «se» hvor på siden teksten står, og forstå hva som er riktig rekkefølge på teksten. Hvis programmet for eksempel ikke forstår at det er to kolonner på siden, vil den lese vannrett bortover på tvers av kolonnene, istedenfor for å lese den første kolonnen før den andre.
Arkivverket har et vidt spekter av dokumenter i sine magasiner, og sideoppsett varerier både over tid og fra kilde til kilde. Skadede middelaldermanuskripter, kirkebøker med tabelloppsett og rettsdokumenter med løpende tekst illustrerer noe av bredden. Men også innen en enkel kilde kan det være store variasjoner. Alle eksemplene under er hentet fra branntakster, som inneholder taksering og beskrivelse av hus i forbindelse med brannforsikring. Vi har erfart at det finnes noen hovedtyper av layout i materialet vårt:
Løpende tekst
Løpende, homogen tekst er noe av det enkleste å jobbe med, og det finnes gode og brukervennlige verktøy som effektivt kan kjenne igjen tekstlinjene på siden med god presisjon. Men når den løpende teksten deles opp i kolonner, eller hvis det skannede bildet dekker to sider, er arbeidet komplisert nok til at vi av og til må trene en egen modell, eller eventuelt rette opp resultatene manuelt etterpå.

Tabeller
Tabeller - med og uten kantstreker - er mer komplisert, og krever at vi trener en modell som gjenkjenner tabelloppsettet. Dokumenter med ulike oppsett kan bety at vi må trene flere modeller, eller at vi må utvide den eksisterende modellen med mer treningsdata. Tabeller inneholder også gjerne strukturerte data - for eksempel vil en kolonne med overskriften «Navn» inneholde nettopp navn. Det er ofte hensiktsmessig å hente ut slike data: Når vi for eksempel vet at en kolonne er navn, kan vi bruke det som utgangspunkt for å lage et navneregister. Dermed er det nyttig hvis modellene også klarer å klassifisere innholdet i tabellen.

Skjemaer
Skjemaer inneholder også ofte strukturert informasjon som det er ønskelig å hente ut, men de har gjerne et mindre strengt oppsett enn tabeller. For tabeller kan vi trene opp modeller som kjenner igjen kolonner og rader, men for skjemaer trenger vi en modell som forstår hvor på siden ulike opplysninger står.

Blandet layout
Det er heller ikke uvanlig at ulike typer layout blandes, slik at en side kan bestå av løpende tekst, tabeller, lister, overskrifter og regnestykker (som rent visuelt kan minne om små tabeller uten kantstreker). Hvis en kilde inneholder noen enkeltsider med blandet layout som skiller seg markant fra resten, kan det koste mer enn det smaker å trene modellen for disse sidene. Det er kanskje da like greit å transkribere disse sidene manuelt. Og hvis alle eller mange av sidene i en kilde har forskjellige kombinasjoner av layoutelementer, kan det være at vi rett og slett bør nedprioritere kilden til fordel for enklere materiale.

Rot
I tillegg til disse eksemplene finner vi også sider som rett og slett er rotete: skribling i margen eller mellom linjene, overstrykinger, tekst på skrå, tegninger eller underskriftsområder med navn plassert rundt omkring. Noen ganger mangler deler av siden, eller den kan være klusset til med for eksempel blekkflekker. Igjen er det nok lurt å vurdere kost-nytte ved å trene modeller som skal ta høyde for slike problemer.

* * *
Vi har nevnt hvordan vi kan jobbe med ulike layout-utfordringer, men det er noen overordnede momenter som er viktige:
Det finnes ikke én teknologi som løser alle problemer. Arkivverket har et eget KI-team som kan lage eller sette sammen teknologi som kan løse mer kompliserte saker.
Ikke alle problemer må løses nå. Den teknologiske utviklingen går fort, så hvis en kilde ikke er spesielt viktig, er det kanskje like greit å vente med nettopp denne kilden til teknologien har blitt mer moden.
Begge punktene peker i en viktig retning: Det er viktig å jobbe smidig og utforskende med disse utfordringene. Får vi til det vi ønsker raskt nok? Eller bør vi forsøke en annen metode, eller kanskje til og med avbryte og ta fatt på en annen kilde?
Når vi har trent modeller som klarer å gjenkjenne layouten, kommer neste fase, hvor den faktiske skriftgjenkjenningen gjøres. Mer om det i neste artikkel!
Har du spørsmål om arbeidet vårt med håndskriftsgjenkjenning? Send oss en e-post på [email protected].
0 notes
Text
Håndskriftsgjenkjenning i praksis
Håndskriftsgjenkjenning – eller handwritten text recognition (HTR) på engelsk – er det å benytte maskinlæring til automatisk transkribering av håndskrevne dokumenter. Arkivverket har omtrent 600 millioner håndskrevne sider i sine magasiner, og håndskriftsgjenkjenning er et viktig verktøy for å gjøre disse dokumentene søkbare og lesbare på Digitalarkivet. Håndskriftsgjenkjenning og andre maskinlæringsteknikker er derfor viktige satsingsområder for Arkivverket.
Her skal vi kort forklare hvordan denne arbeidsprosessen fungerer.
Før det er mulig å automatisk transkribere dokumentene i arkivet, må de skannes. Dette er en enorm jobb i seg selv, men Arkivverket har allerede skannet og publisert 25 millioner bilder som inneholder håndskrift.
Men så er det bare å sette i gang? Ikke helt: Maskinlæring av avhengig av relevante “modeller” for å fungere. En slik maskinlæringsmodell er et program som har lært seg å finne mønstre i ulike typer data. Vi trener modeller ved å gi dem eksempler som er representative for materialet som modellene skal "forstå”. Dette kalles “treningsdata”. (Hvis du er nysgjerrig på maskinlæring, modeller og trening, kan du se denne filmsnutten på YouTube: https://youtu.be/aircAruvnKk) I vårt tilfelle er treningsdata skannede dokumenter pluss “fasit” i form av transkripsjoner og informasjon om hvor teksten befinner seg – mer om det senere.
Det må være et visst samsvar mellom det modellen er trent på og det den skal brukes til, og i utgangspunktet må vi lage disse modellene selv. Heldigvis finnes det flere offentlig tilgjengelige modeller og treningsdata som vi kan benytte. De kan for eksempel være trent på dansk arkivmateriale- som ligner vårt eget. Men hvis det er for store forskjeller i layout, håndskrift eller vokabular, vil ikke modellen gi godt nok resultat. Hva «for store forskjeller» faktisk innebærer, er avhengig av mengde av og variasjon i treningsdata som modellen er bygget på. Dette kan bety at vi må «krydre» modellen med våre egne treningsdata, eller lage helt nye modeller som passer til materialet vi skal bruke håndskriftsgjenkjenningen på.
I praksis foregår håndskriftsgjenkjenning i to trinn, som trenger hver sin modell.
Først må layout og oppsett på siden analyseres: For at selve skriftgjenkjenningen skal fungere, må modellen vite hvor på siden teksten er, og hva som er riktig rekkefølge på teksten. Med løpende tekst er dette ganske greit, men mange dokumenter inneholder tabeller, skjemaer, kolonner, figurer eller en blanding av disse. Layoutanalyse – eller «segmentering», som det ofte kalles – bruker egne modeller som trenger egne treningsdata. Disse kan vi lage ved å fortelle modellen hvor alle linjene med tekst befinner seg.
Når layouten er analysert, kan vi begynne med selve tekstgjenkjenningen og transkripsjonen. Disse modellene kan også være litt hårsåre: Har vi kun trent modellen på håndskriften til én person, vil den antagelig fungere dårlig på en annen persons håndskrift. Vi blir likevel litt hjulpet på vei av at det har vært systematiske endringer i skriftform over tid. Vi kan derfor trene modeller som fungerer ganske godt på skrift fra for eksempel 1700-tallet. Imidlertid er det slik at desto større variasjon modellen skal håndtere, desto mer treningsdata trenger den. Skal vi bruke en modell trent på 1700-tallsskrift for å transkribere 1800-tallsskrift, må vi antagelig lager mer treningsdata eller bruke en annen modell.
Hva som er et «godt nok» resultat av håndskriftsgjenkjenningen, er også interessant. Maskinlæring er en statistisk metode som aldri vil gi helt korrekt resultat. Likevel er en transkripsjon som inneholder noen feil bedre enn ingen transkripsjon i mange brukssituasjoner. For eksempel kan selv en transkripsjon med ganske mange feil være nyttig som grunnlag for søk. Og en transkripsjon med noen feil være til god hjelp for å forstå vanskelig håndskrift i et skannet dokument.
Har du spørsmål om arbeidet vårt med håndskriftsgjenkjenning? Send oss en e-post på [email protected].
0 notes
Text
Første kilde transkribert med HTR tilgjengelig
Arbeidet med håndskriftsgjenkjenning (HTR) på Arkivverket nådde nylig en viktig milepæl. Endelig er det mulig å søke i maskinelt transkribert håndskrift på Digitalarkivet! Du kan nå søke i kilden “Sunnhordland sorenskrivar: Storskifteprotokoll Etne m.fl., 1883-1891", helt uten å kunne lese håndskriften i den skannede originalen. Det vil etter hvert bli publisert flere slike HTR-leste kilder.
Transkripsjonene av “Sunnhordland sorenskrivar” er publisert i en søkeportal på Digitalarkivet som heter Fritekstsøket. Denne søkeinngangen til Arkivverkets materiale ble sluppet i 2022, og var i utgangspunktet laget for å gjøre OCR-leste dokumenter søkbare. OCR, eller optical character recognition, er en metode som er laget for å maskinelt transkribere trykkskrift. Transkripsjonene som OCR og HTR produserer, er like nok til at Fritekstsøket kan brukes til å vise begge deler.
Transkripsjoner laget med OCR og HTR inneholder ikke bare lesbar tekst, men også et sett med koordinater. Koordinatene sier noe om hvor på bildet teksten står, og dette muliggjør en annerledes type visning av bilde og tekst på Digitalarkivet. Teksten du søker på, kan nå markeres på selve bildet, og dette kan gjøre det enda enklere å navigere større mengder materiale.
Du kan lese et utdrag fra den HTR-leste kilden “Sunnhordland sorenskrivar” med lenken under. Trykk på “Vis dokumenter” for å se den spesialtilpassede visningen for HTR- og OCR-leste dokumenter. Noen av sidene er korrigert av mennesker, men de fleste sidene er kun generert av maskinen. Det vil derfor være flere feil i transkripsjonen. Merk også at Fritekstsøket er i utvikling, og at det derfor kan komme endringer fortløpende.
https://fritekstsok.digitalarkivet.no/?periodFrom=1874&periodTo=1886&s=%22Af%20Fj%C3%A6lbergs%20Thinglag%22
Har du spørsmål om arbeidet vårt med håndskriftsgjenkjenning? Send oss en e-post på [email protected].
0 notes
Text
HTR: automatisk transkripsjon av håndskrevne dokumenter
Arkivverket har ca. 600 millioner håndskrevne sider i sine magasiner, og ca. 25 millioner av dem har så langt blitt skannet og lagt ut på digitalarkivet.no. For at håndskrevne dokumentene skal bli både søkbare og lettere å lese, må de konverteres til digital tekst. Tradisjonelt har arbeidet med å transkribere håndtekst blitt gjort manuelt, men med så store mengder materiale ville det vært en helt uoverkommelig oppgave å få transkribert alle dokumentene for hånd. Derfor satser Arkivverket på å benytte HTR til denne oppgaven.
HTR står for handwritten text recognition, og innebærer at man benytter maskinlæring for å konvertere håndskrevne dokumenter til digital tekst. Maskinlæring er form for kunstig intelligens (KI). Helt kort kan man si at vi trener opp et dataprogram til å «forstå» håndskreven tekst, slik at den kan gjøres om til digital tekst. Maskinskrevet tekst, som Arkivverket også har store mengder av, kan også transkriberes med HTR.
Det er ikke nytt at Arkivverket jobber med maskinlæring og håndskriftgjenkjenning: Vi har et eget KI-team, og i tillegg har vi gjort systematisk testing av blant annet HTR-løsningen Transkribus.
Teknologi er viktig i arbeidet med HTR, men det er ikke mindre viktig med kunnskap om historie, kilder, arkiv og selvsagt skrift: Arbeidet er i høy grad avhengig av kompetanse og innsats fra mange ulike deler av Arkivverket. Derfor ansatte Arkivverket to skriftkoordinatorer våren 2022. Målet er at dette skal gi arbeidet fart og retning, og bidra til at vi beveger oss fra tester og eksperimenter til standardiserte arbeidsflyter med større volum. Trykket skrift blir allerede tilgjengeliggjort i stor skala ved hjelp av OCR, og hvis vi får til noe av det samme for håndskrift vil det bidra til bedre tilgang til arkivene, mer effektiv bruk av ressurser og bredere datagrunnlag for forskning.
Arkivverket er ikke alene om å jobbe med slike problemstillinger. Det er et godt samarbeid mellom nordiske arkivinstitusjoner, og vi samarbeider også med andre aktører i Norge. Vi planlegger å skrive mer om hva vi jobber med her, men send gjerne en e-post til [email protected] hvis du synes dette høres interessant ut!
0 notes
Text
ARKIVVERKET BRUKER MASKINLÆRING
Vår satsing på maskinlæring i Arkivverket har for lengst gått over fra prøving og feiling til å utvikle faktiske nyttetjenester. Så det er på tide med en oppdatering av bloggen vår.
Sist snakket vi om sladding av personnummer i grunnboksblader fra Digitalarkivet. Vi har lyst til å formidle at dette nå har gått fra test til produksjon. Det er vår første automatiserte tjeneste basert på maskinlæring. Den har nå vært i drift i et par måneder, og resultatene så langt er vellykkede.
Søk – og deretter bestillingen – er som tidligere:

Personnummeret er de 5 siste siffer i fødselsnummer. Datatilsynet regner ikke fødselsnumme som en sensitiv personopplysning (ref. beskrivelse hos Datatilsynet). Likevel ønsker vi ikke at dette skal komme på avveie, så vi gjorde en vurdering av personvernkonsekvenser – DPIA – i forbindelse med slike bestillinger
Flere metoder ble vurdert, der vi endte opp med å anbefale – og utvikle – denne prosedyren:

Det betyr at bestilling av grunnboksblad nå kan gjennomføres automatisk, og dermed mye raskere enn tidligere. Denne rutinen ble valgt etter en kost/nytte/risiko-vurdering (se nedenfor).
Typisk for bruk av maskinlæring er at når den erstatter manuelt arbeid, vil det ofte – som her – være arbeid som er både monotont og kjedelig.
Etter bestilling får man en epost som ser slik ut etter sladding:

En side fra et bestilt dokument ser slik ut:

Selve programvaren er som vanlig utviklet ved å lage modeller basert på store treningssett med tilsvarende bilder av grunnboksblader.
Den maskinelle rutinen består av to steg.
Identifiser nøyaktig hvor i et bilde (koordinater) personnummer står (dette er det vanskelige)
Bruk deretter programvare for å endre disse områder (polygoner) slik at de blir svarte (dette er det enkle – her kan man velge mellom flere standardløsninger)
Dokumentene hadde til dels dårlig kvalitet. Vanlig OCR-tolkning klarte bare ca. 75 % av tekstene i et bilde. Vi måtte derfor utvide verktøykassa.
Vi har blant annet brukt følgende programvare:
OpenCV for forbehandling (forbedre dokument kvalitet ved justering, binarisering osv.).
tesseract-ocr for dokumenttolking. Tesseract kunne tolke ca. 90 % av alle tekster som står i et dokument (etter forbehandling). Tesseract- resultatene samles i - - -
Pandas DataFrame-format. I hver rad inkluderes et tolket ord og det knyttes koordinater til «bounding box». Ord med koordinater som overlapper med koordinater fra treningsdata, ble definert som fasit/target (personnummer).
Scikit-Learn-verktøy ble tatt i bruk for å organisere trenings-/test-data og evaluere resultatene.
XGBoost ble tatt i bruk for å definere og trene modellen over treningsdataene.
Alt dette krever mye maskinressurser. Vi har implementert trening over GPU (i motsetning til CPU) for å øke treningshastighet. Det skal vi komme tilbake til i et senere innlegg.
Modellen leverer ca. 89 % av riktige personnummer som står i «tolket» informasjon. Det betyr at for hele arbeidsflyten er presisjon ca. 80 % (90 % * 89 % = 80 % - ref. Tesseracts presisjon over.).
Ingen intelligens – kunstig eller menneskelig – er ufeilbarlig. Så det vil i denne løsningen dessverre forekomme feil – i den forstand at sladdingen mangler eller er upresis.
Vi har imidlertid laget rutiner for tilbakemelding fra brukerne dersom de oppdager feil. Feil kan være både «falske negative» (for lite sladdet) eller «falske positive (for mye sladdet)
Tilbakemeldingene gjør oss i stand til å forbedre modellene ytterligere – og dermed øke kvaliteten. Vi tror det bare er et tidsspørsmål før maskinell presisjon her overstiger den menneskelige.
Dersom du ønsker å ta kontakt utover bloggen, kan du også sende en epost til [email protected] gjenstår det bare å glede seg til videre forbedring av vår intelligens utover høsten. Vi har fått hjelp av noen flittige studenter til å teste en alternativ hypotese (Kan personnummer gjenkjennes med metoder som brukes til å gjenkjenne trafikkskilt?), noe som ser ut til å ha gitt enda bedre resultater. Følg med for videre innlegg!

1 note
·
View note
Text
Prinsipper for Digitalarkivet
Som en del av utviklingsarbeidet i Digitalarkivet har det blitt beskrevet et overordnet sett med prinsipper. Prinsippene gjelder i første omgang arbeidet med Digitalarkivet, men representerer samtidig en måte å tenke på som står sentralt i alt utviklingsarbeid i Arkivverket.
Hensikten med prinsippene er å bidra til samordning av utviklingsarbeidet internt i Arkivverket, slik at viktige valg henger sammen på tvers av teamene, og at valgene som fattes er konsekvente og i tråd med blant annet politiske føringer. Vi tror dette også vil gi forutsigbarhet i utviklingsarbeidet for interessenter, og bidra til at det skal være lettere å tilpasse seg og bruke Digitalarkivet
Prinsippene er ikke en erstatning for regelverk og strategier. Krav i regelverket og føringer fra forskjellige strategier gjentas i liten grad i prinsippene. Disse må teamene i Arkivverket forholde seg til uavhengig av prinsippene.
Prinsippene er som følger:
- Brukernes behov står i sentrum
- Arkiv er lett tilgjengelig for berettiget gjenbruk og viderebruk
- Tilliten til informasjonen opprettholdes
- Personvern er innebygget
- Informasjonssikkerhet er basert på bevisst forhold til interne og eksterne aktører og konkrete behov for informasjonsutveksling
- Arkivverket skal forholde seg aktivt til andre aktører som tilbyr tjenester innen bevaring og tilgjengeliggjøring av arkiv
- Tjenester er i kontinuerlig endring
- Digitale løsninger skal utvikles uten å begrenses av analoge konsepter
- Samarbeid med kommunesektoren
Les mer om det enkelte prinsipp i dette dokumentet.
Det er en rekke juridiske forhold disse prinsippene ikke adresserer. Arkivverket er oppmerksom på noen slike utfordringer og vil jobbe videre med dem.
Selv om prinsippene ikke gjelder andre enn Arkivverket, tror vi likevel de kan være nyttig å være kjent med for Arkivverkets interessenter.
Send gjerne en epost til Kristin Jacobsen ([email protected]) om dere har kommentarer eller spørsmål til prinsippene.
1 note
·
View note
Text
Arkivverket tester maskinlæring
Utrolig nok har det gått et år siden Arkivverket begynte sin store satsing på Maskinlæring. Tida har gått fort, men resultatene har kommet enda fortere. Hjemmekontor ingen hindring. Vi satser nå enda hardere for 2021, og styrker staben med ytterligere nyansettelser.
I dette innlegget fokuserer vi på forbedring av bildebehandling og resultater fra OCR og HTR – gjenkjenning av håndskrift.
De siste månedene har vi arbeidet mye med gammelt materiale – gammel håndskrift og gammel maskinskrift med tvilsom kvalitet. Felles for disse er at vi har en skannet versjon der vi må prøve å få ut en meningsfylt tekst. Håndskrift er den største utfordringen, men det som er skrevet på skrivemaskin før ca. 1980 (og rettetasten - - ) kan også være vanskelig (blåpapir, papirkvalitet, skitt - -).
Tolking av skannede dokumenter
Tolking av disse dokumenter kan deles i 3 trinn:
1: Klassifisere dokumenter på grunn av skjema eller dokument typer 2: Dele klassifisert dokumenter «intelligent» inn i bokser eller objekter, med antagelse om hvilken informasjon som finnes hvor 3: Tolke skriften i disse boksene.
Det siste kan igjen deles i 2:
3A: Basere seg på å forstå «tegn for tegn». 3B: Basere seg på en tolkning av hele innholdet, basert på sannsynlige eller ofte forekommende varianter (typisk: koblet mot et sett av navn).
Begge deler krever en trent modell for å gi gode resultater. Som et eksempel kan vi se på et «hovedregisterkort» fra en folketelling.

Her kan man i cellen «Etternavn» enten gjenkjenne tegnene G-u-l-b-r-a-n-d-s-e-n hver for seg, hjulpet av mønstre fra kjente navn, eller man kan gjenkjenne hele navnet «Gulbrandsen» ut fra en begrenset liste av navn. Eller aller helst – man kan kombinere to metoder og vekte resultatene for å oppnå enda bedre presisjon. Folkeregisteret
Vi har nå kommet ganske langt med tolking av disse folkeregisterkortene. Resultatet vil etter hvert bli en søkbar tjeneste på Digitalarkivet. (Her tillater vi oss å tipse om søk i folketellingen for 1920 - som nylig er sluppet på Digitalarkivet.)
Dette er et pågående arbeid som i 2021 vil gi resultater i form av nye søke-tjenester på Digitalarkivet.
Noen gamle registerkort byr på problemer – slik som dette:

Fjerning av støy
Kortet over illustrerer at det i mange tilfeller er vanskelig å tolke selve layout-en i bildet, slik som over.
I tillegg vil vi ofte ha problemer med «støy» (linjer, flekker, skribling - - ). Og det vil ikke bare være et problem for håndskrift, det vil også ofte gjelde eldre maskinskrift.
I mange tilfeller kan vi kompensere støy i bildet med preprosessering – det vil si å forbehandle skannede bilder før de sendes til «tolking».
Her har vi hatt stor glede av programpakkene OpenCV for å forbedre bilder, og P2PaLa for layout analyse.. Hvis vi kan tydeliggjøre skriften ved blant annet å øke kontrast og fjerne støy vil tegn-tolkingen ofte bli mye bedre.
Her kan de spesielt interessert lese seg opp på metoder som
Contrast-limited adaptive histogram equalization
Non-local means denoising
Singular value decomposition
Image binarization
Det siste har med hell brukt i kombinasjon med OCR-programvaren Tesseract.
Som et eksempel kan man i det dynamiske bildet under se forandring fra et «råbilde» - via fjerning av støy og økt kontrast - til ferdig tolket tekst. Dokumentet er fra arkivet over norske flyktninger i Sverige under annen verdenskrig. Siden disse dokumentene fortsatt ikke er 100 år gamle må vi her sladde deler av innholdet.

Om valg av «fri» programvare
All programvare vi har nevnt hittil er basert på fri bruk og åpen kildekode. For å tolke innhold – spesielt i håndskrevet tekst – har vi imidlertid delvis brukt programpakken Transkribus. Foruten gjenkjenning av skrift er Transkribus ganske god på å identifisere «bokser» med innhold. I tillegg har den også et godt brukergrensesnitt for manuell trening og klassifikasjon. Mengder av korrekt tolket innhold gir gode maskinlærings-modeller.
Transkribus baserer seg på en lisens-modell. Men deler av programpakken kan etter hvert erstattes av fri programvare. Her har vi testet mye med programvaren PyLaia, og for enkelte dokumentkategorier oppnådd svært gode resultater. Analyse av alternativer vil fortsette neste år. ______________________________________________________________
Stor takk til våre kompetente medarbeidere Eivind og Javad som utvikler metoder og modeller, samtidig som de formidler kunnskap slik at selv de(n) som skriver denne spalten forstår. ______________________________________________________________
Avslutningsvis
Vi var i forrige innlegg innom Turingtesten, og ny programvare nærmer seg stadig «Bestått». Så til slutt tar vi med en liten dialog fra en av de mer intelligente datamaskiner vi har snakket med (fra https://aidungeon.io).
Siden vi nå tar juleferie, vil vi jo da gjerne vite hvilket forhold den kunstige intelligensen har til jula:

______________________________________________________________
Så herved ønskes en god jul fra Team Maskinlæring i Arkivverket.

Dersom du ønsker å ta kontakt utover bloggen, kan du også sende en epost til [email protected]. ____________________________________________________________
0 notes
Text
Høring om europeisk referansearkitektur for arkiv
E-ark er et EU-prosjekt som inngår i arbeidet med å realisere CEF eArchiving. Formålet med CEF eArchving er å utvikle spesifikasjoner, programvare, veiledning og kunnskap som kan understøtte arkivskapere, bevaringsinstitusjoner og leverandører i deres arbeid med langtidsbevaring og tilgjengeliggjøring av arkiv. Arkivverket deltar i arbeidet sammen en rekke andre europeiske nasjonalarkiv og leverandører av programvare for arkiv.
En viktig del av arbeidet i E-ARK er å utvikle en referansearkitektur for arkiv. Denne referansearkitekturen består blant annet av prinsipper, overordnede beskrivelser av forretningsprosesser, aktører mv. Hensikten med referansearkitekturen er å beskrive en sammenheng mellom de ulike leveransene fra E-ARK og gi føringer for hvordan de best brukes, samt å gi et overordnet rammeverk for å skape felles forståelse og grunnlag for samarbeid. Arkivverket har hatt en sentral rolle i dette arbeidet.
Nå er en tidlig versjon av deler av referansearkitekturen ute på en høring. Alle som er interessert er velkommen til å gi sine tilbakemeldinger. Det som er ute for kommentering er utkast til prinsipper og utkast til motivasjonselementer. I følgebrevet er det mer informasjon om høringen og arbeidet med referansearkitekturen.
Dersom du har kommentarer eller spørsmål, meld tilbake til Øivind Langeland hos Arkivverket, senest innen midten av september 2020 ([email protected])
0 notes
Text
ARKIVVERKET TESTER MASKINLÆRING
Det er en stund siden vi oppdaterte oss på denne siden, men det jobbes jevnt og trutt. Hjemmekontor ingen hindring. Fokus har endret seg litt fra "grunnforsking" til hvordan vi kan få konkret nytteverdi. Det betyr både å effektivisere interne arbeidsprosesser og etter hvert øke kvalitet og brukervennlighet på Digitalarkivet. Vi har også laget en liten demo.
Før vi går videre til vår beskrivelse av vår demo har vi lyst til å nevne et nytt prosjekt:
Gammel grunnbok – og sladding av personnummer:

(Klikk to ganger på bildet for å forstørre, Escape for å komme tilbake).
Av personverngrunner kan vi ikke vise personnummer når brukere vil ha innsyn i grunnboksblader. Alle forespørsler må derfor gjennom en manuell sladde-prosess hos Arkivverket før vi kan sende dokumentene til brukerne. Team ML (Maskinlæring) analyserer om det er mulig med automatisk identifikasjon og sladding av personnummer. Rutiner som utvikles her kan forhåpentligvis generaliseres og brukes til annen anonymisering eller fjerning av sensitive data. I tillegg vil vi kunne fremheve andre sentrale data, slik som gårds- og bruksnummer.
Men det vi har mest lyst til å snakke om er at vi har laget en liten demo.
Vi skrev sist om hvordan man kunne bruke et programmeringsgrensesnitt (API) inn mot modellene som er bygget via maskinlæring. Og vi nevnte NER/Named Entity Recognition ("Deteksjon av begreper"). Nå har vi kombinert disse og testet på 5 protokoller fra gamle regjeringsforhandlinger. I Digitalarkivet er de organisert slik:

De kan nås direkte slik:
https://media.digitalarkivet.no/view/39780/1
https://media.digitalarkivet.no/view/39781/1
https://media.digitalarkivet.no/view/39782/1
https://media.digitalarkivet.no/view/39783/1
https://media.digitalarkivet.no/view/39784/1
- eller man kan gjøre et søk på kilde i Digitalarkivet:

Underliggende sider kan også nås direkte, eksempelvis slik for side 8 i arkiv 3970 fra 1981: https://media.digitalarkivet.no/view/39780/8.
NB:
1: Man må ha bruker og være innlogget på Digitalarkivet - og 2: For å se hva vår relativt kunstige intelligens har funnet ut må man først klikke på ikonet øverst til høyre

for å aktivisere side-menyen (dersom den ikke allerede er aktiv), og deretter klikke på øyet i menyen:

Da vil man for URLen over se dette i høyre ramme:

I den grad vi kan knytte organisasjoner og institusjoner til et sted vil det komme opp et lite ikon -

- som man kan klikke på og få opp plasseringen på kart, slik (https://media.digitalarkivet.no/view/39780/2):

Kartløsningen her bruker Open Street Map (https://www.openstreetmap.org/) bak kulissene.
Det vil ta en stund å kjøre hele Digitalarkivet gjennom disse analysene (flere måneder ren maskintid), men vi bygger på etter hvert i prioritert dokument-rekkefølge. Samtidig vil modellene bak kontinuerlig utvides og forbedres. I mellomtiden håper vi mange tester funksjonaliteten. Vi setter pris på alle tilbakemeldinger og forslag til forbedringer.
Arkitekturen bak tjenesten (eksterne kall via programgrensesnitt) er vist i vårt forrige innlegg.
Vi er helt klar over at det er en stund til våre rutiner består Turing testen (https://no.wikipedia.org/wiki/Turingtest), men det er nok heller ikke nødvendig for at brukere skal synes dette er nyttig.
Dersom du ønsker å ta kontakt utover bloggen, kan du også sende en epost til [email protected].
God sommer fra Arkivverket.

0 notes
Text
Arkivverket tester maskinlæring
Modellene vi har etablert og testet er nå «pakket inn» i et programgrensesnitt slik at det kan kalles fra andre steder og systemer. Dette avslutter fase 1 i vår maskinlærings pilot. Erfaringene er gode, og Arkivverket styrker derfor nå vår satsing innen kunstig intelligens. Vi kommer tilbake med mer informasjon etter hvert.
Siden sist har vi:
1: finjustert våre modeller. 2: modularisert og forberedt kode for produksjon. 3: utredet modeller for å pakke kode og funksjonalitet inn i «containere» (Kubernetes/Docker). 4: etablert et API (programgrensesnitt) der man kan selektere funksjonalitet.
Etablering av en modell «på tvers»
I fjor etablerte vi en del modeller basert på treningssett fra utvalgte arkiver av samme type. Og vi testet modellene på arkiver som «lignet». Naturlig nok ga dette gode resultater. Vi har nå gått videre og etablert en felles modell basert på treningssett fra flere kategorier av arkiver. Da går – naturlig nok – presisjonen ned, men til gjengjeld vil modellene kunne gi resultater for et bredere sett av dokumenter. Resultatene er lovende så langt, og det vil bli arbeidet mer med dette.
Kobling mot «autoritetsregistre»
Her tror vi det er mye å hente ved å kombinere maskinlæring med kvalitetssikring via eksterne registre (Skatteetaten, Stedsregistre, Navneregistre, Brønnøysund). Vi har gjort en test mot Kartverkets liste av stedsnavn. Der har vi lært at kobling mot andre datasett er både mulig og kan gi økt kvalitet. Det er likevel ikke helt rett frem. For stedsnavn er det for eksempel slik at mange steder har samme navn. Så valg av hvilket som er relevant må «vektes», og optimalt vurderes ut fra kontekst.
Forbedret deteksjon av begreper («Entities»)
Vi gjorde tidligere en del eksperimenter med spaCy for å dra ut begreper som sted, navn, organisasjon, dato - - . Dette var imidlertid ikke helt vellykket.
Vi bruker nå modellen XLM-RoBERTa, som er mer språkuavhengig og gir et mye bedre resultat når det gjelder å identifisere og isolere denne type begreper. Det man finner kan illustreres slik:

API og forberedelse av «container»
De modellene som er bygget, og den programvaren som er utviklet er nå «pakket» inn og lagt bak et programgrensesnitt (API). Det kan nås utenfra og tilbys som en tjeneste – på sikt også til eksterne. Skjematisk ser det slik ut:

Noen kommentarer:
- Digitalarkivet vil bli en bruker av dette API-et. Dokumenter vil bli sendt inn, og ut kommer informasjon om elementer i dokumentet, hva de er og hvor i dokumentet disse finnes. - Et mulig bruksområde vil være sladding av sensitiv informasjon. - Informasjon som mottas fra API-et, kan lagres og gjenbrukes. - Arkivverket vil i økende grad publisere bildemateriale basert på informasjonsstandarden IIIF.
API-et er slik designet at man kan velge én eller flere prediksjoner (avsender, mottaker, tittel, klasse, unntatt offentlighet - -). API-et grener så ut og prosesserer forespørslene i parallell.
Maskinlæringsmiljøet er også forberedt for «container»-teknologi, som i prinsippet kan kjøres hvor som helst. Kjøring i «skyen» vil også være en mulighet så lenge sikkerheten er ivaretatt.
«Innpakningen» kan dermed se omtrent slik ut:

Vår satsing på maskinlæring går nå over i en ny fase, for dette er bare begynnelsen. Vi kan referere til Moores lov, som sier at datamaskiner dobles i kapasitet ca. annet hvert år. For maskinlæring ser det ut til at denne tidsperioden ligger nærmere 3 måneder.
Så her ligger det mange muligheter som vi foreløpig bare aner konturene av.
Dersom du ønsker å ta kontakt utover bloggen, kan du også sende en epost til [email protected].
0 notes
Text
Nye veiledere for dokumentasjon av arkivsystemer
Arkivverket jobber med å tilby bedre veiledning for offentlige organer på arkivverket.no. Vi har flere nye veiledere under utvikling. Vi er opptatt av å brukerteste dem underveis i prosessen for å finne ut om de er nyttige, forståelige og fungerer som de skal.
Vi er i direkte kontakt med både IKA-er og kommuner som gir oss tilbakemeldinger og innspill fra et brukerperspektiv. Vi fokuserer på målgruppe og nytte, språk og forklaringer, eksempler og innhold, struktur og navigering. Frem til fredag 21. februar tar vi imot tilbakemeldinger om disse to veilederne: • Veileder for systemoversikt med beskrivelser • Veileder for dokumentasjonskrav for fullelektroniske arkivsystemer Målet er at de skal gjøre det enklere å dokumentere fullelektroniske arkivsystemer og andre elektroniske systemer som kan inneholde arkiv. Ønsker du å komme med innspill? Send en e-post til [email protected].
0 notes
Text
ARKIVVERKET TESTER MASKINLÆRING
Vår pilot for maskinlæring nærmer seg avslutning. Resultatene har vært mer lovende enn de vi faktisk hadde forventet.
Siden sist har vi:
1: Testet modellene på flere datasett 2: Prøvd å identifisere flere metadata – som for eksempel saksbehandler 3: Gjort ytterligere presisjonsmålinger 4: Prøvd å auto-klassifisere dokumenter unntatt offentlighet
Vi kan illustrere punkt 3 med resultater fra et skole-uttrekk der vi har trent modellen til å identifisere hovedkategorier av dokumenter:

Et par ting er verdt å merke seg:
Med en slik modell vil man kunne ordne ukategoriserte dokumenter inn i et sett av kategorier. Som resultatene viser er modellen ikke perfekt, men alternativet er ofte å ikke ha kategorier på dokumentene i det hele tatt
Modellene er «domeneavhengige». «Prediksjonene» vil være en av kategoriene den har blitt trent på, i dette tilfellet «skoler». For andre domener vi prediksjonene ikke ha noen verdi. Man bør derfor ha én modell per domene.
For spesielt interesserte kan vi også kommentere på «precision», «recall» og «f1-score»:
Det er liten vits i å «forutsi» noe for bare 10% av materialet
Men det er også liten vits i å forutsi noe for 90% av materialet, dersom mesteparten av gjetningene er feil
Flere detaljer om dette kan leses i Wikipedia artikkelen om “F1 Score”
En annen undersøkelse vi har gjort er om vi automatisk kan identifisere ut fra teksten om dokumenter er unntatt offentlighet. For en av de dokumentsamlinger vi testet ble resultatet slik:

Her hadde vi «fasiten» i form av manuell klassifisering slik at vi kunne måle presisjon. En interessant observasjon var at vår AI-programvare oppdaget en del feil – dokumenter som skulle vært unntatt offentlighet, men som manuelt var klassifisert som offentlige.
Vi har også så smått begynt å se på bildebehandling for å identifisere dokumenter og dokumenttyper. En utfordring her kan være at man mottar scannede arkiver der dokumenter ligger hulter til bulter inne i en stor og uoversiktlig fil. Dette vil ofte være normen når man skal digitalisere store volumer med begrensede ressurser.
Over nyttår vil vi etablere et rammeverk for en «produksjonsløype». Den kan brukes som ledd i en kjede for å etablere utvidet kunnskap om den informasjon vi mottar. Men aktivitetsnivå dempes nok litt i uke 52. Så mer om dette i januar.
I mellomtiden – God u-kunstig jul fra oss.

Dersom du ønsker å ta kontakt utover bloggen, kan du også sende en mail til [email protected].
2 notes
·
View notes
Text
Arkivverket viser film om maskinlæring
Vi har lyst til å informere om at Arkivverket viser en film om maskinlæring på Sognsvann (Sognsveien 221, 0863 Oslo) mandag 25. november kl. 15.00. Den vises i vårt auditorium – Wergelandssalen. Her er alle velkomne.
Filmen er «Data Science Pioneers» - som har fått gode omtaler. «With humor and humanity, Data Science Pioneers presents a fireside chat-style documentary about the passionate data scientists driving us towards technological revolution.” (fra IMDb).
Man kan lese om filmen og se en trailer på https://www.datascience.movie/.
Filmen varer i litt over en time.
Hvis man har spørsmål - ta kontakt via epost [email protected].
0 notes