
Delivering courses for Big Data analytics, Hadoop clustering on Cloudera, HortonWorks distributions in Russia, Moscow
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by bigdataschool-moscow and here's what we found interesting.
Average Info
Notes Per Post
0
Likes Per Post
0
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
21 days
Number of Posts By Type
Text
4
Link
13
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 16.74 million mobile monthly users in the US.
Text
Типы данных и движки в ClickHouse: Фундамент для производительности. Урок 2

Приветствуем вас во второй части нашего курса по основам ClickHouse (далее CH)! В первой статье мы разобрались, что такое ClickHouse, почему он так хорош для аналитики и как запустить его локально или в облаке. Теперь пришло время углубиться в две ключевые концепции, которые определяют, как CH хранит и обрабатывает ваши данные: типы данных ClickHouse и движки таблиц (Table Engines). Понимание этих концепций критически важно для создания производительных решений. Неправильный выбор может привести к не оптимальной производительности и избыточному потреблению ресурсов, поэтому давайте разберем все по порядку. Типы Данных ClickHouse: Точность и Эффективность Хранения CH, как и любая СУБД, требует, чтобы вы указывали тип данных для каждого столбца. Однако CH предлагает множество специализированных типов данных, которые позволяют достичь высокой эффективности хранения и обработки. Выбор правильного типа данных может значительно повлиять на размер вашей базы и скорость запросов. Числовые типы данных используемые в ClickHouse ClickHouse предоставляет широкий спектр числовых типов, что позволяет выбрать оптимальный для памяти диапазон значений. Целые числа: Это типы от Int8/UInt8 до Int256/UInt256. Правило простое: всегда выбирайте наименьший тип, который может вместить ваши значения. Например, для возраста человека идеально подойдет UInt8. Числа с плавающей точкой: Float32 и Float64 используются для вычислений, где требуется высокая точность. Десятичные числа (Decimal): Типы Decimal32, Decimal64 и другие незаменимы там, где потеря точности недопустима, например, при работе с денежными суммами. Строковые типы Обработка строк часто бывает ресурсоемкой, и CH предлагает несколько вариантов для оптимизации. String: Строка произвольной длины, самый универсальный тип. FixedString(N): Строка фиксированной длины. Идеальна для данных вроде хэшей или кодов стран. LowCardinality(String): Это "секретное оружие" для оптимизации. Используется для столбцов с небольшим количеством уникальных значений. ClickHouse создает словарь уникальных значений и для каждой строки хранит лишь короткий числовой индекс. Это драматически улучшает сжатие и ускоряет фильтрацию и группировку.

Дата и время Date: Хранит только дату. DateTime: Хранит дату и время с точностью до секунды. DateTime64(precision): Хранит дату и время с точностью до милли-, микро- или наносекунд. Важная рекомендация: всегда храните временные метки в UTC, чтобы избежать проблем с часовыми поясами. Прочие важные типы Boolean: Хранится как UInt8 (0 или 1). UUID: Для хранения универсальных уникальных идентификаторов. IPv4, IPv6: Специализированные и эффектив��ые типы для IP-адресов. Array(T): Массив значений одного типа. Nullable(T): Оборачивает любой тип, позволяя ему хранить значение NULL. Используйте его только при необходимости. Практический пример: Выбор типов данных для ClickHouse таблиц Давайте пересмотрим таблицу access_logs из первой статьи и посмотрим, как типы данных влияют на нее: CREATE TABLE access_logs ( timestamp DateTime64(3), -- Точность до миллисекунд для детального анализа событий event_type LowCardinality(String),-- Ограниченное число уникальных типов событий -> эффективно user_id UInt64, -- Большое количество пользователей, ID всегда положительный ip_address IPv4, -- Оптимизировано для хранения IP-адресов url String, -- Произвольная длина, высокая кардинальность -> String duration_ms UInt32, -- Продолжительность всегда положительная, до нескольких миллиардов миллисекунд is_mobile Nullable(UInt8) -- Добавим новое поле: может быть NULL, если неизвестно ) ENGINE = MergeTree() ORDER BY (timestamp, user_id); Правильный выбор типов данных ClickHouse — это первое, что нужно сделать для обеспечения производительности и экономии ресурсов. Движки Таблиц (Table Engines): Сердце Хранения Данных Движок таблицы (Table Engine) определяет, как данные хранятся, читаются, записываются, индексируются и реплицируются. Это одна из самых мощных и отличительных особенностей CH . Выбор движка критически важен, так как он определяет производительность, надежность и функциональность вашей таблицы. CH предлагает множество движков, но для аналитических задач наиболее важными являются движки семейства MergeTree. Они оптимизированы для сценариев OLAP (Online Analytical Processing) и обеспечивают высокую производительность на больших объемах данных. Семейство движков MergeTree: ваш рабочий инструмент Движки MergeTree спроектированы для хранения огромных объемов данных и обеспечивают молниеносное выполнение аналитических запросов. Ключевые особенности MergeTree: Колоночное хранение: Как мы уже обсуждали, данные хранятся по столбцам. Партиционирование (Partitioning): Данные могут быть разбиты на логические части (партиции) по заданному критерию (часто по дате или месяцу). Это позволяет ClickHouse читать только те данные, которые релевантны запросу, и эффективно удалять старые данные. Сортировка (Ordering): Данные внутри каждой партиции отсортированы по указанному ключу сортировки (ORDER BY). Это ускоряет фильтрацию и агрегацию. Индексирование (Indexing): Поверх отсортированных данных создается разреженный индекс (primary index), который позволяет быстро находить блоки данных. Слияние (Merging): Данные записываются в небольшие, отсортированные части (data parts). В фоновом режиме ClickHouse периодически объединяет эти части в более крупные, что оптимизирует хранение и производительность.
Синтаксис базового движка MergeTree: CREATE TABLE my_table ( col1 DataType, col2 DataType, -- ... ) ENGINE = MergeTree() PARTITION BY expression -- (Опционально) Выражение для партиционирования ORDER BY (col1, col2) -- Ключ сортировки (ОБЯЗАТЕЛЕН для MergeTree) PRIMARY KEY (col1) -- (Опционально) Выборка подмножества из ORDER BY для первичного индекса TTL expression -- (Опционально) Время жизни данных SETTINGS setting = value -- (Опционально) Дополнительные настройки PARTITION BY: Определяет, как данные будут разбиты на партиции. Чаще всего используется по дате или части даты (toYYYYMM(timestamp)). Это наиболее важная оптимизация для работы с большими временными рядами. При запросах по диапазону дат CH будет читать только нужные партиции, игнорируя остальные. ORDER BY: Определяет, как данные отсортированы внутри каждой партиции. Это ваш основной индекс. Запросы с WHERE или GROUP BY по столбцам из ORDER BY будут выполняться быстрее. PRIMARY KEY: В отличие от традиционных СУБД, PRIMARY KEY в CH не гарантирует уникальность. Он просто определяет, какие столбцы используются для построения разреженного первичного индекса. Если не указан, по умолчанию используется ORDER BY. Вариации MergeTree Помимо базового MergeTree, существуют специализированные движки, наследующие его функциональность и добавляющие специфическое поведение: ReplacingMergeTree: Назначение: Обработка дубликатов. При слиянии частей данных, если есть строки с одинаковым значением ключа сортировки (ORDER BY), ReplacingMergeTree оставляет только одну (последнюю по времени вставки или указанному столбцу-версии). Пример: Для таблицы пользователей, где нужно хранить только актуальную информацию о каждом пользователе. ENGINE = ReplacingMergeTree() - ver_column опционален и указывает на столбец, по которому определяется "самая свежая" запись. SummingMergeTree: Назначение: Агрегация данных "на лету" при слиянии частей. Все числовые столбцы (кроме тех, что в ORDER BY) суммируются, если строки имеют одинаковое значение ключа сортировки. Пример: Для агрегации метрик (просмотры, клики, суммы транзакций) по измерениям (дата, кампания, пользователь). Значительно уменьшает объем хранимых данных. ENGINE = SummingMergeTree() - опционально можно указать, какие столбцы суммировать. Если не указаны, суммируются все числовые. AggregatingMergeTree: Назначение: Хранение предварительно агрегированных данных. Используется совместно с агрегатными функциями ClickHouse engine, которые возвращают промежуточные состояния (AggregateFunction). Пример: Если вам нужно часто считать uniqCombined или quantiles по большому объему данных, вы можете предварительно агрегировать их. Это более продвинутый движок, требующий понимания работы с AggregateFunction. CollapsingMergeTree: Назначение: Удаление "парных" строк (например, событие "вход" и "выход") или хранение только последнего состояния записи, используя специальный столбец Sign. Пример: Отслеживание сессий или состояний сущностей, где важно фиксировать изменения и убирать промежуточные состояния. GraphiteMergeTree: Назначение: Оптимизирован для хранения данных временных рядов, подобных метрикам Graphite. Replicated*MergeTree: (Например, ReplicatedMergeTree, ReplicatedReplacingMergeTree и т.д.) Назначение: Обеспечивает репликацию данных между серверами в кластере, используя Apache ZooKeeper (или ClickHouse Keeper) для координации. Это ваш выбор для production-систем, где нужна отказоустойчивость. Практический Пример: Использование ClickHouse MergeTree engine с Партиционированием Вернемся к нашей таблице access_logs. Добавим партиционирование по месяцу, что очень распространено для временных рядов. Удалим старую таблицу (если она существует): DROP TABLE IF EXISTS my_first_db.access_logs; -- Создадим новую таблицу с партиционированием CREATE TABLE my_first_db.access_logs ( timestamp DateTime64(3), event_type LowCardinality(String), user_id UInt64, ip_address IPv4, url String, duration_ms UInt32 ) ENGINE = MergeTree() PARTITION BY toYYYYMM(timestamp) -- Партиционируем по году и месяцу из поля timestamp ORDER BY (timestamp, user_id); Здесь toYYYYMM(timestamp) извлекает год и месяц из временной метки (например, 202406 для июня 2024 года). ClickHouse автоматически создаст отдельные директории для каждой партиции на диске. Вставим данные (включая данные за разные месяцы): INSERT INTO my_first_db.access_logs (timestamp, event_type, user_id, ip_address, url, duration_ms) VALUES ('2024-05-15 10:00:00.123', 'page_view', 100, '192.168.1.1', '/old_home', 150), ('2024-05-15 10:00:01.456', 'click', 100, '192.168.1.1', '/old_button_a', 20), ('2024-06-19 10:00:00.123', 'page_view', 101, '192.168.1.1', '/home', 150), ('2024-06-19 10:00:01.456', 'click', 101, '192.168.1.1', '/button_a', 20), ('2024-06-19 10:00:02.789', 'page_view', 102, '10.0.0.5', '/products', 300), ('2024-06-20 10:00:03.000', 'page_view', 101, '192.168.1.1', '/contact', 100), ('2024-06-20 10:00:04.111', 'click', 102, '10.0.0.5', '/product_details', 50), ('2024-07-01 08:00:05.222', 'page_view', 103, '172.16.0.10', '/home', 200), ('2024-07-01 08:01:05.222', 'page_view', 104, '172.16.0.11', '/home', 250); Проверим партиции (только для локальной инсталляции или через системные таблицы). В clickhouse-client вы можете посмотреть, какие партиции создались:

Вы видите отдельные партиции для 202405, 202406 и 202407. Выполним запрос с фильтрацией по партиции. Когда вы запрашиваете данные за конкретный месяц, CH будет читать только соответствующую партицию:

Этот запрос будет очень быстрым, так как CH сразу поймет, что ему нужно работать только с партицией 202406. Другие категории движков (краткий обзор) Хотя MergeTree – ваш основной инструмент для аналитики, стоит знать о других категориях движков: Лог-движки (Log, TinyLog, StripeLog): Простые движки для небольших объемов данных, которые записываются последовательно и не изменяются. Не поддерживают ORDER BY, PARTITION BY. Когда использовать: Для временных таблиц, небольших логов, для быстрой отладки, где не требуется сложная аналитика. Движки для внешних систем (Kafka, MySQL, PostgreSQL, ODBC, JDBC, S3, URL, File): Позволяют ClickHouse напрямую работать с данными из внешних источников, не импортируя их. Когда использовать: Для чтения данных из стриминговых платформ ( Kafka), PostgreSQL, S3 и других источников (более подробно посмотрим на них в Уроке 7 посвященном интеграции) Специальные движки (Dictionary, Distributed, Buffer): Dictionary: Для работы со словарями (маппингами), которые загружаются в оперативную память для быстрого сопоставления. Distributed: Не хранит данные сам по себе, а позволяет выполнять распределенные запросы по нескольким серверам CH. Buffer: Для временного буферизации данных перед их записью в другой движок (обычно MergeTree). Практическое Задание для Самостоятельного Изучения Чтобы закрепить материал, предлагаю следующее упражнение. Выполните его в вашей локальной инсталляции Docker или в ClickHouse Cloud. - Создайте новую базу данных с именем my_app_data. - Создайте таблицу user_profiles в этой базе данных с использованием ReplacingMergeTree (чтобы гарантировать уникальность профилей по user_id при наличии дубликатов). Включите следующие столбцы: user_id (UInt64) username (String) email (String) registration_date (Date) last_login_timestamp (DateTime) is_premium (UInt8 или Nullable(UInt8)) region (LowCardinality(String)) version (UInt64) - используйте его как столбец версии для ReplacingMergeTree. Определите ORDER BY для этой таблицы по user_id и registration_date. Вставьте несколько записей в user_profiles, включая: Несколько уникальных пользователей. Несколько записей для одного и того же user_id, но с разными version и last_login_timestamp, чтобы увидеть, как ReplacingMergeTree работает. Убедитесь, что последняя запись для пользователя имеет наибольший version. Проверьте данные с помощью SELECT * FROM user_profiles. Попробуйте вставить еще одну запись для существующего пользователя с более высоким version и измененными данными (например, новый email). Снова проверьте данные и убедитесь, что ReplacingMergeTree оставил только самую свежую версию записи для этого пользователя (возможно, вам придется подождать несколько секунд, пока произойдет слияние, или принудительно выполнить его с помощью OPTIMIZE TABLE user_profiles FINAL; — не используйте OPTIMIZE в продакшене без понимания его работы). Это упражнение поможет вам на практике понять, как работают типы данных и движки MergeTree. Заключение Типы данных и движки таблиц — это не просто теоретические концепции в CH; это фундаментальные строительные блоки, которые напрямую влияют на производительность, стоимость хранения и эффективность ваших аналитических решений. Правильный выбор и понимание их работы позволят вам раскрыть весь потенциал СУБД ClickHouse. В следующей статье ( Урок 3) мы углубимся в выполнение запросов: рассмотрим базовые DML операции (вставка, выборка) и продвинутые SQL-функции, которые помогут вам извлекать максимум информации из ваших данных. Использованные референсы и материалы Официальная документация ClickHouse по типам данных и движкам таблиц. Документация Apache Kafka и Apache ZooKeeper. SQL-блокнот к Уроку 1 бесплатного курса доступен в нашем репозитории на GitHub Read the full article
0 notes
Text
Что такое ClickHouse: Полный гид по колоночной СУБД для сверхбыстрой аналитики. Урок 1.

Если вы работаете с большими данными, то не можете пройти мимо ClickHouse — мощной колоночной СУБД, которая меняет правила игры в аналитике. 📊 Знаете ли вы, что именно колоночное хранение данных позволяет ClickHouse обрабатывать миллиарды записей с невероятной скоростью? Представьте: для расчёта среднего возраста пользователей ClickHouse читает только нужный столбец, экономя ресурсы и время! ⏱️ Хотите попробовать? Начните с легкой установки через Docker или арендуйте облачный сервис ClickHouse Cloud – быстро, удобно и без лишних сложностей. В статье мы подробно расскажем о том, как подключиться, создавать таблицы и запускать первые запросы. Сделайте шаг в будущее аналитики уже сегодня! 🚀 #ClickHouse #DataAnalytics #BigData #CloudComputing #TechInnovation Read the full article
0 notes
Text
Large Language Model

Large Language Models, LLM (Большие языковые модели) – это класс моделей искусственного интеллекта (ИИ),1 обученных на огромных объемах текстовых (а иногда и других типов) данных для понимания, генерации и манипулирования человеческим языком. Эти модели способны выполнять широкий спектр задач, связанных с обработкой естественного языка (NLP), и лежат в основе многих современных технологий, от чат-ботов до сложных систем анализа данных. Как работают LLM? В основе большинства современных Больших Языковых Моделей (LLM) лежит архитектура трансформер (Transformer), впервые представленная в статье Google Brain "Attention Is All You Need". Ключевые аспекты их работы: Ней��онные сети: Large Language Models являются глубокими нейронными сетями, состоящими из множества слоев. Архитектура трансформера использует механизм внимания (attention mechanism), который позволяет модели взвешивать важность различных частей входного текста при обработке информации. Это помогает улавливать контекст и связи между словами, даже если они находятся далеко друг от друга в предложении. Обучение на данных: LLM обучаются на гигантских наборах текстовых данных, которые могут включать книги, статьи, веб-сайты, код и многое другое (подробнее о масштабах данных можно найти в публикациях OpenAI или Google AI). Этот процесс называется самообучением (self-supervised learning), где модель учится предсказывать следующее слово в последовательности или заполнять пропущенные части текста. Этапы обучения: Предварительное обучение (Pre-training): На этом этапе модель обучается на общих текстовых данных для получения фундаментальных языковых знаний. Дообучение (Fine-tuning): После предварительного обучения модель может быть дообучена на более специфичных наборах данных для решения конкретных задач (например, ответы на вопросы, перевод, написание кода) или для придания ей определенного стиля общения. Ключевые возможности Large Language Models Современные LLM демонстрируют впечатляющие способности: Генерация текста: Создание связных и осмысленных текстов на заданную тему, от коротких сообщений до полноценных статей и даже художественных произведений. Понимание и анализ текста: Извлечение смысла, определение тональности, классификация текстов, выявление сущностей. Перевод: Машинный перевод между различными языками с высоким качеством. Суммаризация: Автоматическое создание кратких выжимок из длинных документов. Ответы на вопросы (Q&A): Поиск и предоставление ответов на основе доступной информации. Написание кода: Генерация, отладка и объяснение программного кода на различных языках программирования. Диалоговые системы: Ведение сложных и контекстно-зависимых диалогов (основа для чат-ботов и виртуальных ассистентов). Области применения Large Language Models находят применение во множестве сфер: Поисковые системы: Улучшение понимания запросов и релевантности результатов. Виртуальные ассистенты и чат-боты: (например, Google Assistant, Amazon Alexa, ChatGPT) для поддержки клиентов, образования, развлечений. Создание контента: Помощь в написании статей, маркетинговых материалов, сценариев. Разработка программного обеспечения: Автоматизация написания кода, поиск ошибок, генерация документации. Образование: Персонализированные обучающие программы, проверка заданий, помощь в изучении языков. Здравоохранение: Анализ медицинских записей, помощь в диагностике (требует особой осторожности и верификации). Научные исследования: Обработка и анализ больших объемов научных публикаций.

Проблемы и ограничения Несмотря на значительные успехи, большие языковые модели(LLM) имеют ряд ограничений и вызывают определенные опасения: "Галлюцинации" и неточности: Модели могут генерировать правдоподобную, но фактически неверную или бессмысленную информацию. Проверка фактов остается критически важной. Предвзятость (Bias): LLM обучаются на данных, созданных людьми, и могут наследовать существующие в этих данных социальные и культурные предвзятости. Организации, такие как AI Ethics Lab, исследуют эти проблемы. Высокие вычислительные затраты: Обучение крупных LLM требует значительных вычислительных ресурсов и энергии. Отсутствие истинного понимания и сознания: Модели оперируют статистическими закономерностями в данных, но не обладают реальным пониманием мира или самосознанием. Этические вопросы: Возможность злоупотребления для создания дезинформации, дипфейков, а также вопросы влияния на рынок труда. Вопросы ответственного ИИ активно обсуждаются. Будущее Large Language Models Развитие больших языковых моделей продолжается стремительными темпами. Ожидается: Улучшение мультимодальности: Способность обрабатывать и генерировать не только текст, но и изображения, аудио, видео (например, как в модели Google Gemini). Повышение точности и снижение "галлюцинаций." Более эффективные методы обучения: Снижение вычислительных затрат и объемов данных, необходимых для обучения. Улучшение способностей к рассуждению и планированию. Более широкая и глубокая интеграция в различные аспекты повседневной жизни и профессиональной деятельности. В данной статье были использованы следующие материалы: arXiv.org cтатья по архитектуре "Attention Is All You Need" Официальные блоги и публикации исследовательских лабораторий ИИ: Google AI Blog / DeepMind Blog: (ai.google/blog/, deepmind.google/blog/) Публикуют новости о разработках, включая Gemini, LaMDA, PaLM и др. OpenAI Blog: (openai.com/blog/) Информация о моделях GPT, DALL-E и исследованиях в области ИИ. Meta AI Blog: (ai.meta.com/blog/) Публикации об исследованиях и моделях, таких как Llama. Read the full article
0 notes
Text
MergeTree
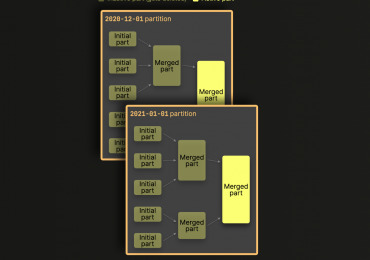
MergeTree – это семейство движков таблиц в ClickHouse, разработанное для хранения данных, отсортированных по первичному ключу. Эти движки обеспечивают высокую производительность для широкого спектра аналитических запросов, поддерживая быструю вставку данных и их последующую фоновую обработку (слияние кусков данных). Семейство MergeTree является основой для большинства высоконагруженных задач в ClickHouse. Основные функциональные возможности Движки семейства MergeTree предоставляют мощный набор функций для эффективной работы с большими объемами данных: Хранение данных, отсортированных по первичному ключу: Данные физически упорядочиваются на диске согласно выражению ORDER BY (первичный ключ). Это позволяет очень быстро выполнять запросы с фильтрацией по этому ключу или диапазону его значений. Партиционирование: Данные можно разбивать на отдельные части (партиции) по заданному критерию, обычно по месяцам или дням (PARTITION BY). Это ускоряет запросы, затрагивающие только определенные партиции, и упрощает управление данными (например, удаление старых партиций). Разреженный первичный индекс: ClickHouse не индексирует каждую строку, а только блоки данных (гранулы). Это экономит место и позволяет быстро находить нужные блоки данных для чтения. Размер гранулы задается настройкой index_granularity. Поддержка репликации и дедупликации (для ReplicatedMergeTree): ReplicatedMergeTree обеспечивает отказоустойчивость путем хранения копий данных на разных серверах и гарантирует консистентность данных между репликами. Также он позволяет выполнять дедупликацию вставляемых блоков данных. Манипуляции с данными: Поддерживаются операции ALTER для изменения структуры таблицы, удаления и обновления данных (хотя последние являются тяжеловесными операциями и реализуются через фоновые мутации). TTL (Time To Live): Возможность автоматически удалять устаревшие данные на уровне строк или целых партиций. Под��ержка семплирования данных: Позволяет выполнять запросы на выборке данных для получения приблизительных результатов значительно быстрее. Плюсы и минусы Плюсы: Высочайшая производительность запросов: Особенно для аналитических запросов с агрегациями и фильтрацией по диапазонам благодаря сортировке и разреженному индексу. Эффективное сжатие данных: За счет сортировки однотипные данные располагаются рядом, что улучшает коэффициенты сжатия. Горизонтальная масштабируемость: Легко масштабируется путем добавления новых серверов (особенно с ReplicatedMergeTree). ️ Надежность: ReplicatedMergeTree обеспечивает отказоустойчивость. Быстрая вставка данных: Данные пишутся на диск быстрыми пачками (batches - part). Минусы: Медленные обновления и удаления: Операции UPDATE и DELETE являются асинхронными и ресурсоемкими, так как требуют перезаписи целых кусков данных (parts). MergeTree не предназначен для OLTP-нагрузок, с частыми точечными изменениями. Сложность выбора первичного ключа: От правильного выбора ORDER BY сильно зависит производительность. Неэффективен для запросов с фильтрацией по столбцам, не входящим в первичный ключ (без использования вторичных индексов). Особенности реализации и использования Данные в таблицах MergeTree хранятся в виде кусков (parts). Каждый кусок отсортирован по первичному ключу. При вставке новых данных создаются новые небольшие куски. ClickHouse периодически в фоновом режиме сливает (merges) эти куски в более крупные, поддерживая оптимальную структуру данных и эффективность. Ключевые аспекты при создании таблицы: ENGINE = MergeTree(): Базовый движок. ORDER BY (expression): Определяет первичный ключ и порядок сортировки. Это самый важный параметр для производительности. PARTITION BY (expression): (Опционально) Определяет, как данные будут разбиты на партиции. Часто используется дата (например, toYYYYMM(EventDate)). SETTINGS index_granularity = 8192: Определяет количество строк в одной грануле индекса. Значение по умолчанию обычно подходит для большинства сценариев. Пример создания таблицы: CREATE TABLE visits ( CounterID UInt32, EventDate Date, UserID UInt64, VisitID String, URL String, Income Float64 ) ENGINE = MergeTree() PARTITION BY toYYYYMM(EventDate) ORDER BY (CounterID, EventDate, intHash64(UserID)) SETTINGS index_granularity = 8192; В этом примере данные партиционируются по месяцам, а первичный ключ состоит из CounterID, EventDate и хеша UserID. Best Practices Тщательно выбирайте первичный ключ (ORDER BY): Включайте столбцы, которые чаще всего используются в WHERE клаузах для фильтрации диапазонов. Не делайте ключ слишком широким (много столбцов), это может замедлить вставку и слияния. Порядок столбцов в ORDER BY имеет значение. Используйте партиционирование разумно: Наиболее частый ключ партиционирования – дата (месяц, день). Избегайте слишком гранулярного партиционирования (например, по секундам), это приведет к большому количеству кусков. Оптимизируйте index_granularity: Стандартное значение (8192) хорошо подходит для большинства случаев. Уменьшение может улучшить скорость чтения для очень выборочных запросов, но увеличит размер индекса. Избегайте частых мелких вставок: Старайтесь вставлять данные большими пачками (сотни тысяч или миллионы строк за раз), чтобы уменьшить количество создаваемых мелких кусков. Мониторьте процесс слияния кусков: Слишком много кусков может замедлить запросы. Настройте параметры слияния при необходимости. Используйте ReplicatedMergeTree для production-сред: Это обеспечит отказоустойчивость. Для удаления и обновления данных используйте мутации (ALTER TABLE ... DELETE/UPDATE) с осторожностью: Помните, что это фоновые тяжеловесные операции. Иллюстрация структуры кусков MergeTree :

Troubleshooting и Тюнинг Распространенные проблемы: Медленные запросы: Проверьте, используется ли первичный ключ в фильтрах. Проанализируйте EXPLAIN запроса. Слишком много кусков (parts) в таблице. Проверьте system.parts. Слишком долгие слияния (merges): Большое количество мелких кусков. Недостаточно ресурсов сервера (CPU, I/O). Ошибка Too many parts: Увеличьте max_parts_in_total или оптимизируйте вставку/слияния. Тюнинг: Параметры слияния: max_bytes_to_merge_at_max_space_in_pool: Максимальный общий размер кусков для слияния при максимальной доступности дискового пространства. max_parts_to_merge_at_once: Максимальное количество кусков, объединяемых в одном слиянии. Настройки находятся в конфигурационном файле ClickHouse (обычно config.xml или в профилях пользователей). Настройки таблицы: merge_with_ttl_timeout: Частота проверки и выполнения TTL-слияний. Системные настройки: background_pool_size: Количество потоков для фоновых операций (включая слияния). max_concurrent_queries: Ограничение одновременных запросов. Пример проверки количества кусков: SELECT database, table, count() AS parts_count, sum(rows) AS total_rows, formatReadableSize(sum(data_uncompressed_bytes)) AS uncompressed_size, formatReadableSize(sum(data_compressed_bytes)) AS compressed_size FROM system.parts WHERE active AND database = 'your_database' AND table = 'your_table' GROUP BY database, table; Источники для дальнейшего изучения: Официальная документация ClickHouse - MergeTree: https://clickhouse.com/docs/ru/engines/table-engines/mergetree-family/mergetree/ Официальная документация ClickHouse - ReplicatedMergeTree: https://clickhouse.com/docs/ru/engines/table-engines/mergetree-family/replication/ Блог Altinity - ClickHouse MergeTree: (Ищите статьи по "Altinity ClickHouse MergeTree" - Altinity часто публикует глубокие технические материалы по ClickHouse) Пример: https://altinity.com/blog/tag/mergetree/ Статьи на Хабре по ClickHouse: (Поиск "ClickHouse MergeTree Хабр" выдаст множество статей от русскоязычного сообщества). Пример хорошей обзорной статьи или разбора конкретных кейсов. Блог Sematext - ClickHouse Monitoring & Performance: (Ищите "Sematext ClickHouse MergeTree" - они часто пишут о мониторинге и оптимизации). Пример: https://sematext.com/blog/clickhouse-monitoring-tools/ (хотя это общая статья, часто затрагиваются аспекты MergeTree). И конечно мы приглашаем Вас на наш курс "CLICH: Построение DWH на ClickHouse" где на практике вы научитесь конфигурировать и использовать кластер ClickHouse в качестве OLAP платформы для аналитики больших данных. Read the full article
0 notes
Link
0 notes
Link
0 notes
Link
0 notes
Link
0 notes
Link
0 notes
Link
0 notes
Link
0 notes
Link
#BigData#DataLake#DeltaLake#DWH#ETL#PySpark#Python#Security#Spark#SQL#архитектура#безопасность#Большиеданные#обработкаданных
0 notes
Link
0 notes
Link
0 notes