
Statistics
We looked inside some of the posts by bigraagsbigblog and here's what we found interesting.
Average Info
Notes Per Post
0
Likes Per Post
0
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
4 days
Number of Posts By Type
Text
17
Last Seen Tumblr Blogs





Fun Fact
Tumblr was named as a finalist in Lead411’s New York City Hot 125 in Aug 2010.
Text
Final Paper (Presentation / Project Summary)
I hope you enjoy reading! :)
Beyond Accuracy: How Human Cognitive Flexibility Outperforms Rigid Computational Models
Alt: “Focus and Flexibility: Mapping the Divide Between Human and Machine Vision”
For my Cognition and Computation final project, I wanted to focus on the differences between models of vision between humans and machines, specifically in the ways they’re built to see the world. This is more fundamental than biology or hardware, reflecting two fundamentally opposed and incompatible versions of perception. One is grounded in selective attention and top-down processing, while the other is created out of bottom up compositional stitching of distinct elements. Overall, the differences between an imperfect, human-like understanding of the world, versus a machine's strive for “perfect” information highlight which tasks should be offloaded to computers, and which should remain human centered.
The human visual system is designed around selective, top down attention. At the center of our visual processing is the fovea - a small pit of closely packed cones in the center of the eye. The fovea is responsible for having sharp central vision, imperative for our ability to focus on things happening in the center of our field of view. Half of the optic nerve’s fibers are solely dedicated to carrying information from the fovea. Also, despite occupying less than 1% of the retinal surface, information processing from the fovea takes up 50% of our brain’s visual cortex (Curcio et al., 1990). Essentially, half of our brain’s visual processing power and information pathways are dedicated to less than two degrees of our visual field. Holding out your thumb at arm's length, roughly twice your thumbnail accounts for the entire fovea’s range of vision. However, this extreme level of visual detail and processing power comes at a cost: our peripheral vision is less precise, optimized more for motion detection than fine detail.
In my presentation, I showed a clip from National Geographic’s Brain Games, featuring two stars surrounded by 5 balls (“Peripheral Vision and Motion”). The balls both moved in a counterclockwise direction, but had a black and white gradient moving across them individually while they spun. When participants were asked to look at the star on the left, the balls moving around it appeared to be moving counterclockwise, whereas the star on the right appeared to have balls moving clockwise. The opposite happened when participants were asked to focus on the other star. In reality, both motions were counterclockwise, but the participants could only differentiate the two types of motion (balls vs gradients) on the set with which their fovea were attuned. When the gradients were removed, it was very easy to track the motion of both sets of balls. This was an example to highlight how easily our perception of the world can be tricked when we overload our peripheral vision, which isn’t hard to do in the real world.
However, this isn’t a flaw, it’s an evolutionary feature! Humans evolved to balance focal attention and peripheral awareness in this way. Forward facing eyes give us depth perception and hunting accuracy, with wide peripheral vision to allow us to detect threats for 180º around. To manage these competing goals efficiently, our brains rely on visual heuristics (shortcuts) to engage with the complete world around us (Gigerenzer & Gaissmaier, 2011). These heuristics allow us to filter out background noise and make quick decisions with minimal cognitive effort, letting us know there is motion without using computational power to decode it until we shift our focus. Our brains are incredibly powerful, but we can’t process this vast amount of information in our front-of-consciousness when trying to make snap decisions.
Because our brain selectively prioritizes information, we can often miss things that are right in front of us. This is the premise behind the “invisible gorilla” experiment (Simons & Chabris, 1999), where participants were asked to focus on counting basketball passes, and failed to notice a man in a gorilla costume walking through the scene, pausing to beat on his chest, and then continuing walking. Inattentional blindness is caused by selective attention! But what is the criteria by which we rank the attention we’re going to give certain things? What affects the flexibility of the hierarchy of visual information processing? Why do people not notice the gorilla even though it crosses through their central vision? In essence - our human cognition guides our vision! Human vision is top-down, where our cognition decides for us - we see what we’re looking for and expecting to see, not necessarily what’s there (Gilbert and Li).
Cognitive goals, expectations through priming and previous experiences all shape what we perceive. A lot of theories inform how we understand the world, but it’s especially useful to think of our top-down model as Bayesian inference: we make sense of ambiguity in vision by combining it with prior knowledge in order to form the most likely interpretation (Egan and Orlandi, 2010) (Knill and Pouget, 2004) (Yang, Bill, et al). This predictive framework explains how we fill in gaps, clear ambiguity, and make decisions in noisy environments, all without extreme computational effort.
However, this is completely different to how computers see the world, because computational models of vision tend to be bottom-up! Systems like object detectors or scene classifiers work by gathering as much raw input as possible, breaking down images into edges, pixels, colors, and textures, and then assembling meaning by stitching together all of those component parts. This is often known as comprehensive “compositional” sight. For my project, I started by using MultiModal Co-Lab for Gemini, graciously shared with me by Marcelo Viridiano to explore object detection. It could identify bounding boxes around different objects in a scene, like a person, a lamp, a man, or a desk. The program used inputs based on prompting I put in manually, and detected objects. I used this primarily to generate bounding box outputs for different objects in images to illustrate the differences in the computer model of vision, compared to human vision. This was an extremely powerful tool, and in the future I would love to use this as a jumping off point for a followup project that could try to trick different systems using optical illusions and things, to show where the liabilities of computer vision are at the moment.
The model was also able to give guesses as to what the images were about - but in a completely different way to the way we understand scenes as humans. The computer model for vision struggled with gaining any sort of semantic information from the scene compared to my human classmates. It couldn’t interpret the social or emotional context of the scene - things like understanding a meme or detecting flirting. While we as humans gain semantic knowledge instinctually, (“it seems like they’re having fun”, “these people are a couple”, etc etc) computational vision is still limited to identifying features, and then stitching them together (Composite imaging). Even the most advanced models, like OpenAI’s CLIP or Google’s PaLM-E, operate by linking image features to language embeddings or known categories. They’re impressive at detection, but still limited in reasoning. Again, this is fundamentally different from how we understand the world! Projects like FrameNet (Baker et al., 1998) are working to close this semantic gap by giving computational systems access to frame semantics (common meaning evoked by objects) but they’re still far from replicating the innate understanding we have with everyday scenes.
The examples I showed using the Multimodal Co-lab used my human cognition to identify elements to then use as a prompt! A more dynamic example comes from a video of a self-driving Tesla, showing how the car “sees” (“This Is What Tesla's Autopilot Sees On The Road”). It labels pedestrians, cones, cars, lanes and obstacles in real time. It’s easy to see how it’s a case of bottom-up visual processing: the car uses massive amounts of data, LIDAR, and pixel-wise inference to navigate. However, this version of vision doesn’t allow cars to “see” the way we do - it detects, predicts, and responds quickly, but without deeper comprehension. This lack of understanding is highlighted when you can see that the Tesla lacks object permanence when it comes to features like cars disappearing behind other cars temporarily. The autopilot thinks the car has disappeared, and then reappeared, because it’s limited to compositional image understanding.
Due to the fundamental differences between the models of vision presented by humans and computers, they excel at different things. We have to ask ourselves - is this a task best left up to computation? Or should it be natural intelligence / cognition? Do we want a predictive brain with top-down, bayesian inference vision in this scenario, or a computational compositional, stitched together view? Do we want a flexible, imperfect model that changes based on circumstance, or a static, “perfect” model? Are we dealing with a big picture, or a detail oriented task? How much data are we able to process to solve this problem?
Machine vision is ideal for tasks such as pathfinding and spatial mapping, because it can be paired with high data trackers like LIDAR to create detailed, high-fidelity maps. It’s also great for monitoring huge volumes of data, because machines don’t get bored, tired, or distracted. They can watch hundreds of security feeds at once flagging suspicious detected objects. They’re great at going pixel-by-pixel, and using their compositional stitching to identify and detect objects, well into the hundreds or thousands of features. It’s even good at prediction modeling when it comes to things like handwriting analysis, if you have enough data for training models.
On the other hand, humans are incredibly skilled when it comes to understanding semantic reasoning, because our brains are flexible and imperfect! You would want different people to pull out different semantic meanings from an image, because that’s what art and opinion is all about! We’re also incredibly skilled at Instant decision making even in the presence of lots of noise (like when driving) (Wolfe et al.). We’re great at doing complex tasks without needing huge amounts of computational power (also like driving). Our heuristics, and innate understanding of depth perception and object permanence are things computer vision struggles with right now a bunch, that we’re trying to force it to be “perfect” at.
In conclusion, I wanted to create a framework for discussing where the strengths and weaknesses of computational vision lie. I wanted to present these competing models, and show that they’re both finely tuned to different types of tasks. Essentially, why force computational resources to overclock themselves working on things they’re built to be bad at? And why remove humans from things we’re built to be good at?
Overall: Human vision is top down, extremely impacted by cognition first, then the actual environment. Computation vision is bottom up, stitching together composite parts to decide what’s going on. This paradigm shift means we should care very much about what tasks we want a computer to do (perfect) versus a human to do (flexible). Rather than replacing human vision, computational models should complement it. I personally would like to see the creation of more hybrid models that use machines for what they do best, like high-volume precision, and leave humans in the loop for tasks requiring context, empathy, or creativity.
We shouldn’t force machines to be good at things we’re biologically optimized for, nor should we ignore the fatigue, bias, and limitations of human vision in areas where machines can help. Instead, we should ask that for any given task, which model is better? By understanding cognition and computation as tools that work together, we can build better systems that can more accurately do the task they’re designed for.
Bibliography: Curcio, Christine A., et al. "Human Photoreceptor Topography." Journal of Comparative Neurology, vol. 292, no. 4, 22 Feb. 1990, pp. 497–523. PubMed, https://pubmed.ncbi.nlm.nih.gov/2324310/. DOI: 10.1002/cne.902920402. National Geographic. "Brain Games – Peripheral Vision and Motion." YouTube, uploaded by Professor Ross, 9 Jan. 2014, https://www.youtube.com/watch?v=YJUAtgrpHiY. Gigerenzer, Gerd, and Wolfgang Gaissmaier. "Heuristic Decision Making." Annual Review of Psychology, vol. 62, 2011, pp. 451–482. Egan, Frances, and Nico Orlandi. "Bayesian Models of Vision." Routledge Encyclopedia of Philosophy, edited by Taylor and Francis, 2010, https://www.rep.routledge.com/articles/thematic/vision/v-2/sections/bayesian-models-of-vision. DOI: 10.4324/9780415249126-W047-2. Knill, David C, and Alexandre Pouget. “The Bayesian brain: the role of uncertainty in neural coding and computation.” Trends in neurosciences vol. 27,12 (2004): 712-9. https://pubmed.ncbi.nlm.nih.gov/15541511/ DOI:10.1016/j.tins.2004.10.007 Gilbert, Charles D., and Wu Li. "Top-Down Influences on Visual Processing." Nature Reviews Neuroscience, vol. 14, no. 5, 2013, pp. 350–63. PubMed Central, https://pmc.ncbi.nlm.nih.gov/articles/PMC3864796/. DOI: 10.1038/nrn3476. Yang, S., Bill, J., Drugowitsch, J. et al. Human visual motion perception shows hallmarks of Bayesian structural inference. Sci Rep 11, 3714 (2021). https://doi.org/10.1038/s41598-021-82175-7 Wolfe, Benjamin, Jonathan Dobres, Ruth Rosenholtz, and Bryan Reimer. "More than the Useful Field: Considering Peripheral Vision in Driving." Applied Ergonomics, vol. 65, 2017, pp. 316–25. ScienceDirect, https://doi.org/10.1016/j.apergo.2017.07.009. Stewart, Emma E M et al. “A review of interactions between peripheral and foveal vision.” Journal of vision vol. 20,12 (2020): 2. doi:10.1167/jov.20.12.2 Kolb, Helga, et al. "The Architecture of the Human Fovea." The Organization of the Retina and Visual System, edited by Helga Kolb, Ralph F. Nelson, Eduardo Fernandez, and Bryan W. Jones, National Center for Biotechnology Information, 2020, https://www.ncbi.nlm.nih.gov/books/NBK554706/. Carscoops. This Is What Tesla's Autopilot Sees On the Road. YouTube, 31 Jan. 2020, https://www.youtube.com/watch?v=v0oOGELKkZ4.
0 notes
Text
Deep Research Response
4/20/25 (posted for posterity's sake)
0 notes
Text
Presentation Transcript (provided by Mark, run through MultiModal Pipeline I believe)
4/20/25
00:00:00,410 --> 00:00:01,111 Okay, awesome. 00:00:01,351 --> 00:00:02,092 My name's Raaghuv. 00:00:02,252 --> 00:00:06,056 I'm presenting on different models of vision in both cognitive and computational perspectives. 00:00:06,617 --> 00:00:12,283 Before we start on anything else, though, you might have heard Mark talk about this already, but quick biology lesson. 00:00:12,784 --> 00:00:14,606 The fovea is a small part of your eye. 00:00:14,626 --> 00:00:16,088 It's a small pit of cone cells. 00:00:16,748 --> 00:00:20,031 in the center of your eye that controls most of your focus of vision. 00:00:20,071 --> 00:00:27,016 If everybody raises up their arm and puts their thumb out at arm's length, it's about twice the width of your fingernail. 00:00:27,316 --> 00:00:30,859 It's about how much of focal attention you have. 00:00:30,899 --> 00:00:38,304 This focal attention uses 50% of the optic nerves that run from your eye to your brain, and also 50% of your visual cortex. 00:00:39,085 --> 00:00:45,029 That means that everything outside of that small 2% of your focal field is handled by the other 50% of your brain. 00:00:46,431 --> 00:00:50,734 Okay, we have small attentions, not small attention spans, but physically small attentions. 00:00:51,194 --> 00:00:52,255 What does that mean in practice? 00:00:53,075 --> 00:00:55,577 We're going to play a quick game, if everybody wants to play along. 00:00:57,278 --> 00:00:58,558 On this video, you're going to see two stars. 00:00:58,578 --> 00:01:00,800 There's going to be a yellow star and a red star. 00:01:01,200 --> 00:01:03,081 To start, focus on the yellow star. 00:01:03,101 --> 00:01:04,722 There are going to be balls moving around it. 00:01:05,242 --> 00:01:11,006 Your task is to tell me which way the balls are moving, either clockwise or counterclockwise, while just looking at the yellow star. 00:01:13,154 --> 00:01:13,394 Okay. 00:01:13,694 --> 00:01:14,795 Just look at the yellow star. 00:01:14,835 --> 00:01:15,675 Just look at the yellow star. 00:01:15,755 --> 00:01:16,975 Which way do you think the balls are moving? 00:01:17,275 --> 00:01:18,996 Counterclockwise. 00:01:19,016 --> 00:01:19,656 Okay, counterclockwise. 00:01:19,716 --> 00:01:19,976 Awesome. 00:01:20,536 --> 00:01:23,417 While still looking at the yellow star, which way are the red balls moving? 00:01:25,098 --> 00:01:25,378 Clockwise. 00:01:25,438 --> 00:01:25,918 Clockwise. 00:01:26,418 --> 00:01:27,559 Okay, now look at the red star. 00:01:28,559 --> 00:01:30,140 They both are moving counterclockwise. 00:01:30,540 --> 00:01:37,222 If you look back and forth, you'll notice that your brain switches the direction of the balls depending on which one you're looking at, which is relatively fascinating. 00:01:37,262 --> 00:01:37,602 Awesome. 00:01:38,763 --> 00:01:41,564 If we look right here, I have a quick example to show that... 00:01:43,493 --> 00:01:53,891 Quick example to show that really the balls are both moving in the same directions, but the second we overlay these sort of shadow gradients on top of them, now your brain has a hard time keeping up. 00:01:54,552 --> 00:01:55,594 So why is this happening, right? 00:00:00,309 --> 00:00:04,613 When the 2% of our vision is focused on one of the stars, our peripheral vision has to take care of the other. 00:00:04,953 --> 00:00:08,937 Now that's not a bad thing, but our peripheral vision is evolved to just focus on movement. 00:00:09,718 --> 00:00:12,080 This is especially helpful in a predatory prey environment. 00:00:12,280 --> 00:00:15,623 You want to know when things are happening when you're not looking at the thing you're focusing on, right? 00:00:15,963 --> 00:00:16,584 Obviously makes sense. 00:00:17,004 --> 00:00:23,470
The problem is because 50% of our optic nerves and 50% of our visual cortex are dedicated to the other 98% of our vision, 00:00:26,813 --> 00:00:28,714 we're not able to process both types of movements. 00:00:28,974 --> 00:00:31,316 One is the balls rotating, obviously, and one are these gradients. 00:00:31,716 --> 00:00:40,541 So while we're able to focus on one star, we can see the movement, we can process the movement, our visual cortex is very easily able to identify which way the balls are moving separately than the gradients. 00:00:40,901 --> 00:00:45,544 But the second we have something in our peripheral that has multiple types of motion, now our brains are easily confused. 00:00:47,198 --> 00:00:49,300 Takeaways, that's interesting. 00:00:49,320 --> 00:00:52,162 Phobia is small, our peripheral is really big. 00:00:53,243 --> 00:00:54,924 And we're evolved to do this. 00:00:55,324 --> 00:01:01,650 It obviously takes less computing power to do this because if all of our brain had to keep up with the amount of information that we're processing in just 00:01:02,270 --> 00:01:07,713 the phobia, just the information that the phobia processes, we'd have a lot more information to process. 00:01:08,174 --> 00:01:11,075 So essentially, this is a visual heuristic, right? 00:01:11,095 --> 00:01:16,679 It's a quick, easy way for our brains and bodies to take in the world around us without taking in too much information. 00:01:17,079 --> 00:01:20,021 And it's extraordinarily helpful because we can move our eyes, we can move our heads. 00:01:20,321 --> 00:01:23,983 The second we're able to look at the other object, we can get more visual information about it. 00:01:26,209 --> 00:01:26,449 Nice. 00:01:27,189 --> 00:01:28,350
In conclusion, cool. 00:01:29,870 --> 00:01:40,153 But the other things that this often affects is because we're taking in less data at a time and because our peripheral is so large, we're able to alter what we're focusing on. 00:01:40,853 --> 00:01:44,114 For example, I can prime you to maybe miss something in a video. 00:01:44,714 --> 00:01:46,615 For this next task, you might have seen this video before. 00:01:46,655 --> 00:01:50,516 This is a classic example of inattentive blindness. 00:01:51,016 --> 00:01:52,476 If you've already seen this video, I apologize. 00:01:52,536 --> 00:01:54,097 It's very classic computer science. 00:01:54,817 --> 00:01:55,618 Cognitive science, sorry. 00:01:55,638 --> 00:01:55,618 1999. 00:01:55,658 --> 00:02:06,588 The task in this video is to watch these basketball players pass around the balls and only focus on the players who are wearing white and count how many times they pass the basketball. 00:02:07,669 --> 00:02:09,631 So it's a quick, about a minute video. 00:02:10,392 --> 00:02:15,036 Just focus on the white players and count the number of times that they pass the basketball. 00:02:34,957 --> 00:02:43,185 Okay, anybody have an answer for how many passes they counted? 00:02:43,205 --> 00:02:43,185 13, 13, 15. 00:02:43,525 --> 00:02:44,106 Okay, that's all right. 00:02:44,126 --> 00:02:44,927 It's about 15. 00:02:45,827 --> 00:02:47,429 But if you've noticed, has anyone noticed the gorilla? 00:02:47,509 --> 00:02:48,190 Some of you were laughing. 00:02:48,210 --> 00:02:49,150 Obviously, you probably caught it. 00:02:49,851 --> 00:02:54,095 When they did this actual study, only 47% of people actually caught that gorilla. 00:02:55,254 --> 00:02:57,695 You notice the gorilla bangs his chest. 00:02:58,195 --> 00:03:01,356 And it's just an accident of where you happen to be looking, right? 00:03:01,696 --> 00:03:04,316 We can show you other such videos. 00:03:04,477 --> 00:03:06,997 Everybody's always embarrassed and thinks that they pay attention. 00:03:07,397 --> 00:03:08,778 They'll defeat the videos. 00:03:09,498 --> 00:03:17,800 On the contrary, we run this for people who are like security guards and things like that on change blindness and all these kinds of things. 00:03:17,860 --> 00:03:18,600 It's really true. 00:03:18,800 --> 00:03:19,080 Go ahead. 00:03:19,240 --> 00:03:21,441 And it's very easy to misdirect people's attention. 00:03:22,621 --> 00:03:28,044 Most people, most as in a slight majority, end up missing the gorilla because they aren't looking for it. 00:03:29,404 --> 00:03:30,265 So what does this lead us to say? 00:03:30,605 --> 00:03:31,825 Human vision is top-down. 00:03:31,925 --> 00:03:34,927 What I mean by top-down is that our cognition affects what we see. 00:03:35,227 --> 00:03:37,828 Whatever we're expecting to see, we end up seeing. 00:03:38,588 --> 00:03:48,173 This is some of the reason why, as Mark's example goes, when you're walking into a room and just looking for your keys, you might find your keys, but you're very prone to missing almost everything else in the room. 00:03:48,993 --> 00:03:51,255 This can often lead to, well, oh no, I also left my wallet. 00:03:51,595 --> 00:03:56,538 You walked back and the wallet was sitting there all along, but you never would have thought to grab it because you weren't focusing on it.
00:03:56,878 --> 00:04:03,923 Essentially, because we're taking in so much visual stimuli all the time, our brains have to create a visual heuristic to get over that. 00:04:04,183 --> 00:04:07,745 So the ones we use is to basically filter out anything that we're not thinking about. 00:04:08,306 --> 00:04:09,166 Now this is interesting. 00:04:09,727 --> 00:04:12,248 It's not the way that computer vision works at all. 00:04:14,125 --> 00:04:25,918 It allows for a flexible representation of the world in our minds, one that's primable, one that's changeable, one that obviously we're able to affect by telling you, focus on the white basketball players, focus on the gorilla, things like that. 00:04:26,939 --> 00:04:28,600 But also, in general, it means that 00:04:29,441 --> 00:04:32,904 when we're looking for things, when we're seeing things, we really aren't getting the whole picture. 00:04:33,284 --> 00:04:34,865 Now, this isn't necessarily a big flaw. 00:04:35,465 --> 00:04:37,087 This is, okay, I'll get into that in a second. 00:04:37,387 --> 00:04:49,556 But Bayesian inference is up here because, of course, the more information we gather, our previous experiences, you know, if you've seen this video before, you're much more fast to notice the gorilla, you'll notice it on the first try, because our previous experiences sort of shape that. 00:04:50,376 --> 00:04:54,540 Now this gets into my cognitive model, or our computational model of vision. 00:04:55,181 --> 00:04:58,444 This dataset was, not dataset, but this tool was given to me by Marcelo. 00:04:59,084 --> 00:05:05,510 It's the multimodal cognition pipeline to allow for bounding boxes to be created for object detection in images. 00:05:06,271 --> 00:05:13,118 All that means is I toss in an image like this, I tell it something, I try to describe what's in the image, and it pops out with some nice bounding boxes. 00:05:13,658 --> 00:05:18,944 This is great, computer vision works, it's able to identify things in an image, and that's very useful for us. 00:05:20,405 --> 00:05:28,113 In general, this is different than human vision though, because this type of computational vision is what we call compositional. 00:05:28,133 --> 00:05:35,541 So it's trying to take all of these separate, disparate features and then stitch them together in order to create some sort of representation of what's going on. 00:05:36,983 --> 00:05:38,225 For an image like this, it doesn't matter. 00:05:38,245 --> 00:05:40,667 It's able to grab the main things that we would want out of the image. 00:05:41,308 --> 00:05:46,774 But for something like this, computer vision, object detection, composite image representation.
00:05:47,395 --> 00:05:50,098 For something like this though, what's the first thing you notice? 00:05:51,800 --> 00:05:52,281 Anybody? 00:05:53,262 --> 00:05:54,203 A girl, she's smiling. 00:05:54,383 --> 00:05:55,845 Somebody give me a semantic representation. 00:05:55,905 --> 00:05:56,606 What are her emotions? 00:05:56,626 --> 00:05:57,507 What do you think is happening? 00:05:59,113 --> 00:06:00,474 Flirting, okay, nice, flirting. 00:06:01,154 --> 00:06:02,374 Flirting is a great one here, right? 00:06:03,074 --> 00:06:05,655 However, the machine is never going to get that. 00:06:05,735 --> 00:06:09,136 I know FrameNet is trying to bring it closer, obviously, we had a colloquium, if you remember Marcel's colloquium. 00:06:09,697 --> 00:06:10,717 MachineNet is trying to get it closer. 00:06:11,137 --> 00:06:13,218 It'll notice things that nobody brought up. 00:06:13,298 --> 00:06:14,938 Side glasses, purse, shoulder. 00:06:15,158 --> 00:06:19,660 I mean, of course, this was prompted in, but again, it won't get the fact that she's angry. 00:06:19,920 --> 00:06:22,661 It won't get the fact that, or sorry, it won't get the fact that she's smiling.
00:06:24,642 --> 00:06:25,522 I was jumping ahead of myself. 00:06:25,922 --> 00:06:27,282 How many of you have seen this image before? 00:06:27,302 --> 00:06:31,263 Obviously, we get a lot of semantic information out of this, right? 00:06:31,463 --> 00:06:33,864 This was such a popular meme because it's funny. 00:06:33,904 --> 00:06:35,424 You can apply... Banned in Sweden. 00:06:36,004 --> 00:06:36,464 Keep going. 00:06:36,764 --> 00:06:38,004 You can't show that in Sweden. 00:06:38,024 --> 00:06:45,066 You can apply any two little thought bubbles here and it's very easy for us to gain, this is you or something, right? 00:06:45,086 --> 00:06:47,026 Something's mad at you because you're looking at something else, right? 00:06:47,486 --> 00:06:48,146 Easy to interpret. 00:06:48,846 --> 00:06:52,587 Even when prompted, you know, the woman in the blue shirt is angry at him, 00:06:53,107 --> 00:06:57,236 We're not going to get anger or disgust or happiness or, you know, or flirting. 00:06:57,476 --> 00:07:00,181 We're getting the physical representations of what's in the images. 00:07:00,201 --> 00:07:02,346 The title of this is Distracted Boyfriend. 00:07:02,867 --> 00:07:04,811 Now, where are you going to get that by a bottom up? 00:07:06,066 --> 00:07:11,568 So this bottom-up approach, this compositional approach is useful for a lot of things, but it's not useful for everything. 00:07:12,088 --> 00:07:17,951 My whole project up here today, if there's one thing you walk away with, it is that computational models aren't ideal at everything. 00:07:18,051 --> 00:07:22,152 The way our human brains work as a top-down approach is very good at specific things. 00:07:22,672 --> 00:07:30,695 Trying to force computational models that started as bottom-up approaches to replicate that just isn't gonna give us the results we want.
00:07:31,035 --> 00:07:34,557 And that's not a bad thing, but it is something that we should take into account when we're building different kinds of models. 00:07:36,141 --> 00:07:38,081 This, real quick, is a video of Tesla's autopilot. 00:07:38,121 --> 00:07:41,002 If you haven't seen this before, you can see very much this bottom-up approach. 00:07:41,242 --> 00:07:43,882 It is trying to classify everything in the image concurrently. 00:07:44,163 --> 00:07:46,803 Now, our brain, of course, does some of this as we're driving along a road. 00:07:47,463 --> 00:07:50,344 We'll think about the fact that the road might be wet, that there are cars around. 00:07:50,364 --> 00:07:51,284 We'll be looking around. 00:07:51,664 --> 00:07:58,525 But in our front of consciousness, in our front of cognition brain, we are not actively thinking about every single one of these variables all the time. 00:07:59,005 --> 00:08:00,225 Like I said, the fovea is small. 00:08:00,645 --> 00:08:03,926 That's about as much information as we're focused on processing at once. 00:08:05,430 --> 00:08:09,152 So, where does that lead in terms of human vision versus computer vision, right? 00:08:09,532 --> 00:08:10,653 Top down, obviously, bottom up. 00:08:11,173 --> 00:08:14,534 Our fovea versus object detection, because it is trying to see everything. 00:08:15,235 --> 00:08:20,597 You'll notice the difference between the Tesla autopilot and the examples that I created, where these ones were prompted by me. 00:08:20,977 --> 00:08:28,081 So I gave it a prompt for it to find first, versus Tesla's autopilot has sort of features that it's just generally looking out for, and is then trying to classify them. 00:08:28,908 --> 00:08:32,030 In general though, what does this actually mean for what we're trying to do, right?
00:08:32,350 --> 00:08:38,294 Obviously, computer vision is currently bad at semantic representation until possibly we get frame net to help us get closer. 00:08:39,314 --> 00:08:41,736 But we can do a huge amount of data processing, right? 00:08:41,816 --> 00:08:42,896 Obviously, humans are gonna get tired. 00:08:42,936 --> 00:08:45,738 We're very bad at counting hundreds of things in an image. 00:08:46,138 --> 00:08:50,621 But if a computer model is trained to do that, that is something that it might be very good at. 00:08:51,661 --> 00:08:54,362 All this to say, our brain is a predictive brain, right? 00:08:54,462 --> 00:08:55,322 It's top-down. 00:08:55,342 --> 00:08:57,363 We predict what we want to see and then we see. 00:08:57,783 --> 00:08:59,984 A computer brain is more perfect. 00:09:00,124 --> 00:09:01,885 It's less flexible. 00:09:02,465 --> 00:09:04,986 So this leads to things that we should use it for, right? 00:09:05,166 --> 00:09:08,307 If we're trying to do semantic reasoning, we have humans that are great for it. 00:09:08,667 --> 00:09:18,071 Obviously, in the multimodal co-lab example, we were using a human first, me, typing in a little prompt that the computer model would then see. 00:09:21,071 --> 00:09:24,294 that you want exact counting objects, even prediction modeling. 00:09:24,354 --> 00:09:36,664 If you guys have seen in the UK's, there's a great video about it on New York Times recently, but in the UK they've implemented an AI detection software for mail, for handwriting, like association. 00:09:37,225 --> 00:09:37,965 And that's a prediction model.
00:09:38,386 --> 00:09:39,847 You want it to be as perfect as possible. 00:09:40,227 --> 00:09:45,572 Versus a human, we're very limited by our own experience and we're very limited by our focus, but that's not a bad thing. 00:09:45,612 --> 00:09:47,834 We're very good at describing what's in that focus. 00:09:49,635 --> 00:09:53,738 Quick decision making, even with noises up here, especially for things like driving, obviously. 00:09:53,878 --> 00:09:56,499 When there's so much information there, we're able to parse through it. 00:09:57,160 --> 00:09:58,821 So that's the bulk of my presentation. 00:09:58,841 --> 00:10:00,622 I'm a little over time. 00:10:01,122 --> 00:10:05,365 But any questions and comments about the differences between human models, computer models, 00:10:17,612 --> 00:10:21,154 What they say is some are built more towards reasoning and things like that. 00:10:21,614 --> 00:10:26,577 If you're familiar with that, what do they do differently to try to model the issue that you're presenting? 00:10:27,137 --> 00:10:31,679 So at least in my experience with GPT's reasoning model, like R1, or sorry, O1, 00:10:33,436 --> 00:10:38,819 It's much more meant for, it's not necessarily meant at image detection to make image detection better. 00:10:39,159 --> 00:10:44,962 It's much more aimed at things like text and math to sort of prompt itself before spitting out an answer.
00:10:45,843 --> 00:10:47,163 If I'm butchering that, somebody let me know. 00:10:47,203 --> 00:10:51,465 But at least in my experience with it, it's because it prompts itself questions of, am I doing this right? 00:10:51,646 --> 00:10:52,646 Am I sure that I'm doing this right? 00:10:52,686 --> 00:10:56,208 Let me walk myself through it step by step before spitting out an answer for the user. 00:10:56,608 --> 00:11:01,551 It slows down the speed of responses and then increase, usually, the accuracy of responses. 00:11:06,544 --> 00:11:12,149 So this is like slightly off, but did you consider using any animated pictures? 00:11:13,110 --> 00:11:26,640 So originally my thought was I was going to run a lot of optical illusions through this to try to find very specific examples of here's where a human is extremely powerful at this, that's seeing through the optical illusion, here's where a computer might be, where a human might get confused. 00:11:28,021 --> 00:11:30,983 In my playing around with it, I didn't find any examples that were too... 00:11:32,250 --> 00:11:33,872 too illustrative of that, I guess. 00:11:34,153 --> 00:11:45,648 There were some, but at least in my small-scale testing abilities, I didn't try anything animated, didn't try any videos, and also wasn't able to try to show very clear examples. 00:11:45,888 --> 00:11:48,972 If you remember from Marcel's Colloquium, it was bad at things like depth perception. 00:11:50,614 --> 00:11:58,560 where if there's an unknown object behind someone, it's not always clear, whereas we're able to very easily see depth perception and object permanency. 00:11:58,920 --> 00:12:05,604 In that Tesla video, you'll notice as a car went behind an object or another car across the street, it would pop in and out of view. 00:12:06,245 --> 00:12:12,589 If you're actually human to track these cars, it's very often that they're likely to know that the car is obviously behind something, it'll pop back up. 00:12:12,969 --> 00:12:15,451 But sometimes these computer models get that wrong.
00:12:15,491 --> 00:12:19,414 They try to reclassify it as a new object when really it's doing the same thing. 00:12:20,354 --> 00:12:20,514 Yeah. 00:12:21,495 --> 00:12:22,056 Any other questions? 00:12:22,156 --> 00:12:27,061 My big takeaway from this is computer models and the way that they see the world are very different than the way we do. 00:12:27,922 --> 00:12:32,968 So if you have an impact that you're trying to get a computer to look at, ask yourself some of these questions. 00:12:33,188 --> 00:12:33,969 Do you want it perfect? 00:12:33,989 --> 00:12:34,629 Do you want it human? 00:12:34,649 --> 00:12:35,811 Do you want it flexible? 00:12:35,871 --> 00:12:37,072 Do you want it non-flexible? 00:12:37,953 --> 00:12:38,213 Yeah. 00:12:40,315 --> 00:12:40,596 Okay.
0 notes
Text
Presentation Overview! 4/16/25
Here is the link to my presentation https://docs.google.com/presentation/d/1_5Zfd8-MNYxFxI6NIr8cLmXKpvZPCO5J82y5YtPBTZA/edit?usp=sharing Videos are from NatGeo's Brain Games, there's also this video on tesla's internal self driving view, and this video on the selective attention test.
To generate image bounding boxes for object detection I was using the Multimodal Co-lab that used prompting through Google Gemini (graciously shared to me by Marcelo Viridiano - thank you!) https://colab.research.google.com/drive/1RxISDHJVnLBwHXmgtcMcjgRcUrTvZ9FP?usp=sharing Additionally, here's an (approximate-ish) script. Take this with a grain of salt - as these were the general bullet points I was using, and I varied off script a ton. This doesn't contain any direct citations but look for my final project overview coming soon!
Beyond Accuracy: How Human Cognitive Flexibility Outperforms Rigid Computational Models
The fovea is a small bit of closely packed cones in the eye
Half of nerve fibers in the optic nerve carry information from the fovea, the rest carry all the information from everywhere else in the retina
It is less than 1% of the retinal size, but takes up 50% of visual cortex in the brain
Also only sees two degrees of the visual field
Okay - so what does it mean that our fovia is so small? Lets take a look at our peripheral vision!
Well, lets play a game
Everyone focus on the yellow star here on the right
What direction are the dots moving? Does it look counterclockwise?
Now without moving your eyes - what about the red? Clockwise?
Okay now switch!
WHAAAAA isn’t that crazy
Okay i’ll leave it up here for a sec - look back and forth we’re not changing anything
Okay now look why is that happening? - when we remove the gradient motion, the dots are easy to track
Whichever star we look at, we can interpret the movement of the gradient differfently than the motion of the dots
But in our peripheral -> our brains have to pick one of the motions - and so choose the movement of the gradient as the most important one
Fovia is so small
Our focus uses so much of our brain’s computational power to look at details
Our peripheral vision is trained to just recognize motion - and can be easily tricked by combining two types of motion (the gradients with the movement)
Our brain uses a visual heuristic to filter the background noise, letting us know there is movement, but we don’t use computational power to decode all of it, until we shift our focus to it
In general, we’re built for this!
Our FOV is 180º - we’re great at seeing movement all around in front of us.
Evolutionarily this makes sense, we want to look out for danger, but humans are predator animals - we have forward facing eyes to watch prey.
We want to focus on things, but also watch for movement / danger in the periphery - take a visual heuristic to only pay attention to this
We evolved this way to take in less data probs! We use heuristics to make snap decisions, without a crazy ton of computing power
Our brains are awesome, but we can’t handle that much info in our front-consciousness
Because of this selective attention, this can often lead to inattentive blindness.
Gorilla Video
Video selective attention
Essentially → human vision is top down!
We think about what we want to see, and then we see it
Often why we miss things right in front of us, like when we’re holding our phone in our hands and then are looking for it
A lot of theories inform how we understand the world
Bayesian inference informs this top down approach!
Based on prior probabilities of things we’ve seen, or things we’re “expecting” to see
Changes what we conclude!
It removes ambiguity by making predictions based on life experience
Bayesian modeling -> as we get more information, our predictions change for what the “answer” is → then our past experiences alter everything we see after that
This is completelyyyyyyy different than computers! And computational models of vision!
For this project
I started by using the MultiModal Co-Lab built for Gemini, that I was given access to by Marcelo.
I was using object detection software, that was able to generate bounding box outputs for different objects in images, to illustrate the differences in the computer model of vision, versus our vision.
If you wanted to do a fully fledged experiment, this was a great jumping off point to discover where the liabilities of computer vision are at the moment.
If you remember in Marcelo’s Colloquium - you might have seen an image like this
Gemini can analyze it!
This is based on prompting I put in, and it detects the objects through the frame
It can also try and give a guess as to what the image is about - but not the way we can!
now look at this meme!
This is so rich for semantic information! This is so interesting how much we can gain - to spawn infinite memes!
We as humans can gain semantic knowledge from this - they may be flirting, it seems like they’re having fun etc etc, computational vision is still limited to identifying features, and then stitching them together (composite imaging)
Again - fundamentally different than how we understand the world! Framenet is working to close that gap by identifying frames, but still
Even so - these examples first used my human cognition to identify elements to then use as a prompt!
A more dynamic example comes from this video of a self-driving tesla, revealing what it “sees”
It knows what kinds of things to look out for, but not exact from every image
Taking in all this info all the time!
Our backstage cognition takes in some of this data - processes a good amount of it, and holds it in general, but we’re not constantly processing this insane amount of visual data! We use lots of heuristics all the time!
We classify computational models as bottom up - because they’re trying to take in as much information as possible, and then link it together
Hierarchy of visual information processing is flexible!!
Obviously we have different versions of what we see than computers
So - in our modern world - what should be left to computational vision? Versus the role human cognition should play!
Model:
A framework for discussion where the strengths of computational vision lie.
Why force computational resources to overclock themselves working on things they’re built to be bad at?
Why remove humans from things we’re built to be good at?
We have to ask ourselves - is this a task best left up to computation? Or should it be natural intelligence / cognition?
Predictive brain versus computational brain
Human flexibility based on circumstance - this is not a bug, it’s a feature!
If computer vision is taken to be bottom up - stitching together images pixel by pixel, what does that make it useful for?
Pathfinding / mapping exact coordinates - use computer vision, use LIDAR, use 3d mapping because you want “perfect”
Watching security camera footage - it will never get bored
Counting things over and over - how many objects are in a scene
It isn’t limited by small focus - can watch huge amounts of data quickly! With same accuracy throughout!
Mail sorting / decoding handwriting -> with enough data, you can get really good prediction models for these things
BUT - for humans
If you need semantic reasoning - flexible!
Instant decision making even in the presence of lots of noise (driving)
Doing complex tasks without insane computational power (driving)
Heuristics like depth perception / object permanence - things comp vision struggles with right now that we’re trying to force it to be “perfect” at
In general / main takeaways →
Human vision is top down - extremely impacted by cognition first, then vision
Computation vision is bottom up - stitching together composite parts to decide what’s going on
This paradigm shift means we should very much care about what tasks we want a computer to do (perfect) versus a human to do (flexible)
So much of computer vision is bottom up - pixel by pixel, counting dimensions / proportionality - versus human vision gut reaction. Sometimes we pick out minute details (6 fingers), but often we just have an instant reaction that something is wrong.
When should we use one or the other? What tasks are better which way? Pathfinding and mapping exact coordinates? Perf! Easy! Memory!
Snap decisions? So much computational power needed to do well if bottom up!
Human-like versus perfect! Why code in inaccuracies? Paradigm shift - use it at what it’s good for!
Can handle insane amounts of data, and do it relatively quickly. Doesn’t get bored! Isn’t subject to optical illusions!
Can learn to decode all different kinds of writing functions (like write to text) whereas humans are limited by our specific training - things like mail sorting or counting or tedious tasks.
0 notes
Text
Small Paper 2 (Tools)
3/31/25
The Mind in Motion: Motion Capture’s Role in Understanding Cognition
Word count: 558
In the study of higher-order human cognition, language alone is not always sufficient to describe a person’s thought process. Co-speech gestures, often analyzed through video, can reveal hidden aspects of cognition. However, motion capture (MoCap) technology offers a powerful new avenue for studying movement as a window into higher-order human cognition. Specifically, MIT Researchers developed RISP (rendering invariant state-production network), a large scale neural network that analyzes dynamic systems and creates a “digital twin” from the motion alone (Hinkel, 2022). This allows for a full 3D model to be recreated from a single shot, allowing for analysis of movement from different angles. This was previously possible in only very stable, research conditions. Now, by completing 3D recreations of movement using only video - regardless of lighting conditions or rendering information - fundamentally transforms how we understand and analyze motion. By integrating MoCap with neural networks, researchers can examine everything from microexpressions and co-speech gestures to large-scale crowd dynamics, revealing intricate connections between movement and cognition.
Traditional MoCap systems track movement using foam optical markers (as in film production) or near-infrared structured light patterns (as with the Xbox Kinect). Newer systems, like OpenPose, enable real-time motion tracking without markers using machine learning-based pose estimation (Vina, 2024). These advancements allow for high-precision analysis of human gestures, along with enhanced 3D recreation. As a result, researchers gain access to richer data, offering deeper insights into cognitive processes that were previously difficult to quantify.
Co-speech gestures are one example of a direct link between motion and cognition. These types of gestures, typically hand motions associated with specific parts of speech, can externalize thought processes, and reveal internal reasoning (Cassell et al. 2001). While typical video analysis, through manual and automatic gesture tagging can allow researchers to quantify these gestures, MoCap allows for the ability to analyze movement in full 3D. When combined with RISP, gestures can be tagged and studied from multiple angles, further enhancing the depth of analysis.
Beyond individual gestures, MoCap has been instrumental in studying collective behavior. Crowd movement patterns, for example, provide insights into social cognition. Koilias et al. (2020) used MoCap in a Virtual Reality world to create a baseline for human walking behavior in the middle of a crowd, showing the influence of the crowd’s movements on individual behavior. It has also been used to map large crowd motion, revealing emergent properties, such as self-organization and implicit coordination (Worku and Mullick, 2024). MoCap has also been used to model complex animal behavior, capturing individual joint movements in dynamic, uncontrolled environments(Siliezar, 2021). These capabilities make MoCap invaluable for studying emergent behavioral patterns in human and animal groups.
Currently, MoCap is already being utilized to investigate embodied cognition as it relates to learning and environmental interactions. In Glenberg and Megowan-Romanowicz’s paper, they explore the relationship physical movement plays in comprehension of new concepts (2017). Those that learned with high embodied / active environments (manipulating tasks using MoCap through a Kinect sensor) achieved significantly higher test scores on gesture based tasks. Including more gesture and body movement into classroom lessons, and allowing for active embodiment interaction through MoCap technology, allows us to take advantage of the ways in which our human cognition already works.
Motion capture is more than just a tool for film or gaming, it’s a powerful instrument for helping decode the mind through movement. By bridging the gap between physical motion and cognitive processes, MoCap is reshaping how we study thought, communication, and social interaction. Through it, we can study gestures, change how learning is presented, and study complex, dynamic behaviors in wild, unpredictable conditions.
References:
What is OpenPose? A Guide for Beginners. Published Apr 3, 2024. By Abirami Vina. https://blog.roboflow.com/what-is-openpose/
Siliezar, Juan. “CAPTURE-ing Movement in Freely Behaving Animals.” The Harvard Gazette, 25 Feb. 2021, https://news.harvard.edu/gazette/story/2021/02/tech-breakthrough-combines-motion-capture-and-neural-learning/.
Hinkel, Lauren. “A One-Up on Motion Capture.” MIT-IBM Watson AI Lab, 29 Apr. 2022, https://bcs.mit.edu/news/one-motion-capture.
Johnson-Glenberg, M. C., and C. Megowan-Romanowicz. “Embodied Science and Mixed Reality: How Gesture and Motion Capture Affect Physics Education.” Cognitive Research, vol. 2, no. 24, 2017, https://doi.org/10.1186/s41235-017-0060-9.
Bossavit, Benoit, and Inmaculada Arnedillo-Sánchez. “Using Motion Capture Technology to Assess Locomotor Development in Children.” National Library of Medicine, 13 Dec. 2022, https://pmc.ncbi.nlm.nih.gov/articles/PMC9756361/.
Koilias, A., Nelson, M., Gubbi, S., Mousas, C., & Anagnostopoulos, C.-N. (2020). Evaluating Human Movement Coordination During Immersive Walking in a Virtual Crowd. Behavioral Sciences, 10(9), 130. https://doi.org/10.3390/bs10090130
Spiro, Ian, Thomas Huston, and Christoph Bregler. “Markerless Motion Capture in the Crowd.” Department of Computer Science, Courant Institute, New York University, 12 Apr. 2012, https://ar5iv.labs.arxiv.org/html/1204.3596.
Worku, S., and P. Mullick. “Detecting Self-Organising Patterns in Crowd Motion: Effect of Optimisation Algorithms.” Journal of Mathematics in Industry, vol. 14, no. 6, 2024, https://doi.org/10.1186/s13362-024-00145-w.
0 notes
Text
More thoughts on final project
3/31/25
presentation: cognition versus computation in models of vision
I'll be using the MultiModal Co-Lab built for Gemini, that I was given access to my Marcelo. I'm using this to detect objects in images, and then processing the bounding box outputs through LabelBox. I'll be presenting a few key examples as part of my presentation, as well as testing the humans in the room in what they see in various images / videos, comparing that to the computational data I will have found.
things we're bad at: optical illusions (noise in videos we miss things, length of lines, color constancy, perceived speed of cars)
things we're good at: semantic reasoning gained from images, instant decisions based on lots of noise (driving), seeing depth, object permanency.
change blindness / counting vs optical illusions / semantics
show GPT model trying to get semantic information, trying to count, trying to identify objects, trying to keep track of object permanency
give a comparison of human test results vs computational ones
Predictive brain versus computational brain. So much of computer vision is bottom up - pixel by pixel, counting dimensions / proportionality - versus human vision gut reaction. Sometimes we pick out minute details (6 fingers), but often we just have an instant reaction that something is wrong.
0 notes
Text
Complete Guide to R: Wrangling, Visualizing, and Modeling Data Course
3/24/25
I found this course interesting! it's super in depth, and obviously very well put together. I do honestly wished we had started our R work through this - as the visuals talking through the steps really helped me understand a lot of the R work easily, especially as it comes to ggplot and what i'm supposed to be getting out of it. Nothing against the text descriptions of assignments you had created for us to learn R in the syllabus, but I do think these videos are super helpful, and would've made the process a lot easier to get into. I know especially those that had much less coding experience in your classes this semester had to get over a bit of a learning curve when it came to using an IDE environment like RStudio, and I think the videos would've been great in that aspect. Additionally, having done some data science work myself in the past, I liked seeing the video about R in context, and I hadn't heard of some other applications (like Julia, or Rapidminer) so it was interested getting to do a bit of a deep dive into those as well. Especially now that we have had some exposure to R through the homework on your syllabus, I think this course is less helpful to us now, but structuring the course homework by taking advantage of the videos on this site in the future I think could be very useful.
0 notes
Text
Google Summer Of Code (Tools)
3/23/25
developing tools that could be useful for studying human higher-order cognitive performances for which there is no robust animal model, and post 100 words on your blog presenting to our class (the Lab) what you find interesting about that tools project. You may focus on one of the tools already proposed, or discuss how to develop a tool that you would like to see.
I found OpenSourceMaps super interesting. I love thinking about desire paths and human interaction with the world. We path-find in interesting ways distinguishing between paved structures and unpaved ones, and taking paths for efficiency's sake, subconsciously. There is a robust animal model for this (migration in birds and butterflies, hunting dogs, salmon, etc etc) all with robust path finding capabilities, I just found it really cool to see how humans interact with the world in unique ways outside of paved paths, which are hard to generate maps for, since satellites can't often pick them up.
Another one I found interesting (that I was surprised to see on the list!) was Blender. I've used Blender on multiple occasions for all sorts of things ranging from designing 3d models for 3d printing in the thinkbox, to designing conceptual drafts before throwing pottery, or before doing woodwork. I believe there's no Robust Animal Model for 3d imagination in the way humans have - being able to interact and dream up a fully formed 3d model of something, and build it meta-physically. It's something that would be very hard to prove in other species, but still, I do believe we're unique in this way.
0 notes
Text
Small paper 2 (TOOLS) draft
Small Paper 2, Due Friday, 3pm: Post on your blog and to your Submissions Page: 500 word paper in one of the three areas—theory, models, tools, but not in the area for which you did your first small paper, in week 6. State the area at the top of your paper. Be sure to craft an excellent title.
3d modeling in imagination?
motion capture? micro-expressions? natural gestures? benedict cumberbatch as sauron, Andy Serkis as ceaser in planet of the apes - to be more "human" imperceptibly.
social media algorithm -> how to measure friendships? how to weight "closeness" of people into groups - analyze clicks, saves, likes, what parts of the app you use, time spent, switching tabs, length of post you interact with etc etc etc
0 notes
Text
Data Set and R.
3/17/25
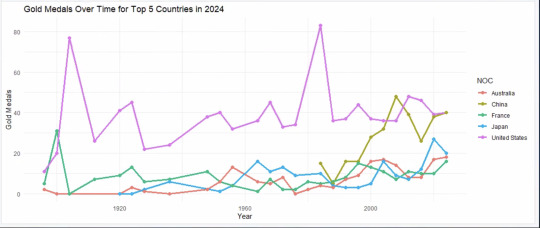
For my dataset, I used this: https://www.kaggle.com/datasets/amanrajput16/olympics-medal-list-1896-2024?resource=download
off of Kaggle. This dataset has a "detailed country-wise record of Olympic medals from the first modern Olympics in 1896 to the most recent games in 2024. It provides insights into how different nations have performed over time, including their gold, silver, and bronze medal counts, overall rankings, and total medal tally."
I used it to create a line chart for the gold medals won for the top countries (USA, Japan, France, China, Australia, bc they were the top 5 gold medal earners in 2024).
Here's my code: library(dplyr) library(ggplot2) olympics_data <- read.csv("\\\\ads.case.edu\\utech\\VDI\\H\\UGrad\\rxv172\\Desktop\\olympics.csv")
#only picks out the top 5 countries worth of data, based on 2024 results.
top_5_countries <- olympics_data %>% filter(Year == 2024) %>% arrange(desc(Gold)) %>% slice_head(n = 5) %>% pull(NOC)
#it extracts the number of wins for each of the countries, across each year
gold_medal_trends <- olympics_data %>% filter(NOC %in% top_5_countries) %>% select(Year, NOC, Gold)
#I then plot the results, with the x axis being the year, and the y axis being number of gold medals achieved.
ggplot(gold_medal_trends, aes(x = Year, y = Gold, color = NOC, group = NOC)) + geom_line(size = 1.2) + geom_point(size = 2) + labs(title = "Gold Medals Over Time for Top 5 Countries in 2024", x = "Year", y = "Gold Medals", color = "NOC") + theme_minimal()
Here was the resulting graph:
0 notes
Text
R - thoughts on graphing and visualization thus far
3/17/25
Great article - I 100% agree with mark that a good education breeds skepticism. At this point, I feel confident being able to take a given set of data, plot it, graph it, create a linear regression plot (if it makes sense) and generally make it look nice (labelling axis, coloring lines, etc etc). Having taken the Intro to AI class here, I have experience in creating a linear regression function and assigning different weights to variables to try and create linear decision boundaries between groups of data. I'm not confident in creating models for non-linear data, and I'd love to have more experience analyze other types of regular distributions (gaussian, log-norm, etc etc). I do think I lot of this will come from a stats class however, and so I feel comfortable and confident with our visualization of different models so far!
0 notes
Text
R - Binary outcomes
3/17/25
Some interesting binary variables i've been thinking about in relation to my life at CWRU.
When seeing someone on the quad passing by in opposite directions, how close are our perceived relationships with each other?
Do I wave at them as we pass by?
Do I shout their name if they're going along a different path?
Do they respond?
Do we have anything in common to actually talk about?
In relation to parties (especially those advertised through stories on instagram, without actual invites)
Does someone regularly use social media?
Has someone seen my post?
Is it worth inviting someone?
Should I reach out again over text / in person?
Confounding variables:
Will they talk about it with their friends?
Do others at the party know them?
Are they the type to come out / have fun if I do convince them to come?
Are they going to require convincing to come?
Will they chip in for food?
Will they eat an normal amount of food?
Do they live nearby?
Are their friends also invited?
Will they ask for plus-ones?
These kinds of variables are all over the place in the world! Trying to make a decision, categorize anything (people especially), trying to plan a future event, etc etc.
If I was to build a model of how likely someone is to come to a party based on these factors - something like how much food they will eat could be modeled as a probit (since it's probably a normal distribution), versus how close they are to the greater community is more likely to be modeled as a logit, because that seems to me closer to a logarithmic distribution of connections in a web of friend groups. It'd be fun to make a model of how likely I am to invite a given person to a party depending on these factors, and by attaching weights to them, being able to rank someone new into the list. You could totally train a neural network on this in order to predict / generate lists of people to invite, and create sort-of tier lists to automatically invite people in order to keep numbers at a party roughly equal no matter what's going on.
0 notes
Text
Phrases and Gestures
3/16/25
Phrase: "Wait wait wait" / "Wait a minute" / "Hold on"
Gestures: can vary - see below. Versatile - can be used to gesture as "wait, hold on, pause, stop the conversation" if asking for clarification, or can be used to gesture "stop what you're saying or doing because i'm doing something more important"
Clips:
KCBS The Late Late Show With James Corden ( video | text | montage | imageflow | metadata | nlp | tagging | permalink )
Thursday December 22, 2022 at 12:37 am America/Los_Angeles (2022-12-22 08:37 UTC)
At 19:06 “wait wait wait”
Gesture: Palm down, pressing to the floor in front of chest, as if to say "stop, hold on, stop everything, I need to say this thing"
KABC The View ( video | text | montage | imageflow | metadata | nlp | tagging | permalink )
Tuesday December 20, 2022 at 10:00 am America/Los_Angeles (2022-12-20 18:00 UTC)
at 17:30 “Wait a minute”
Gesture: Uses index finger to point out at the person speaking in order for her point to be heard.
KABC Good Morning America ( video | text | montage | imageflow | metadata | nlp | tagging | permalink )
Monday December 12, 2022 at 7:00 am America/Los_Angeles (2022-12-12 15:00 UTC)
at 1:43:10 “actually no, hold on”
Gesture: index finger up, move in a circle in front of body, gesturing to indicate the entirety of a concept (a season of a show) has changed.
KABC The View ( video | text | montage | imageflow | metadata | nlp | tagging | permalink )
Friday December 9, 2022 at 10:00 am America/Los_Angeles (2022-12-09 18:00 UTC)
at 18:36 "wait wait wait, actually"
Gesture: One arm around cohost and one arm pointing up and out (presumably to the screen) saying watch this specifically that i'm pointing out.
KCBS The Late Show With Stephen Colbert ( video | text | montage | imageflow | metadata | nlp | tagging | permalink )
Thursday December 8, 2022 at 11:35 pm America/Los_Angeles (2022-12-09 07:35 UTC)
at 38:24 "hold on one second" Gesture: hand out at chest level in front of interviewee to interrupt train of thought and speak first in an exchange.
Request:
# Vazirani_Raaghuv
# Spring 2025, Cogs 330, Case Western Reserve University
# Phrases and Gestures Blog
# "hold on" OR "wait a minute" OR "hold up" OR "wait wait" date_from:"02/01/2022" date_to:"03/17/2025" network:"KABC,KCAL,KCBS,KNBC" sort_by:datetime_desc display_format:list regex_mode:raw tz_filter:lbt tz_sort:utc start:30 limit:10
2022-12-09_0735_US_KCBS_The_Late_Show_With_Stephen_Colbert 00:18:06-00:20:06
2022-12-20_1800_US_KABC_The_View 00:16:30-00:18:30
2022-12-12_1500_US_KABC_Good_Morning_America 1:42:00-1:45:00
0 notes
Text
Final Project / Specifics about final project
3/16/25
Deep research has been extremely helpful in helping me design my final project. Since this is a Models project, I plan on creating a gauntlet of tests for AI models and my fellow cwru students. I've decided that my main testing areas should be narrowed down into specifically vision of humans versus AI models, as this is a very well researched current issue in Computer Vision, and I believe there is enough current psychological literature for me to build a good test. Some of this will be similar to CAPTCHA tests, and some will be similar to the tests we've seen presented in the Cogsci Colloquium. Relatedly, but not centrally, i'm still interested in human vs machine time perception, memory encoding, and processing information and how it affects learning. The focus of my research project is how we see and analyze our surrounding, and how it's different than current computer vision models. More than just showing they're different (well researched and shown in self driving cars for example), I want to conclude in how those differences affect the ways in which we interact with the world. My hypothesis is that the ways in which humans go through the world is fundamentally different than the current machine learning computer vision models, and that our ability to pull meaning out of image is some that cannot be replicated by AI.
I will be designing tests and gathering data myself from fellow students and different ML models. I'll be graphing responses to hopefully showcase the differences in response and highlighting the differences in ability. My goal is to also design the tests in such a way that highlights the scenarios in which humans blow machines out of the water (analyzing sentiment behind a photograph, maybe picking out the elements of a scene, analyzing an artist's style) vs where computational power comes in handy and is better than us (counting things, paying attention to all elements in a scene, not being thrown by optical illusions). It'll be formatted as a report.
If you're reading this and have any thoughts about the types of tests I should build, specific images that would be good for analysis, what models might be worth testing, or anything else, let me know!
other notes after talking with mark: - vision -> empirical bottom up like computers
focus on cognition impacts of vision
predictive brain
we're driven to notice what we need based on predictions
computer vision - it doesn’t decide where to look, we tell it where to look
phovia is small (focus)
we’re directing our attention around
where you look / what you focus on / what catches your eye
what makes it into consciousness
predictions drive vision?
this is top down
cognitive bc you’re making predictions / solving things / trying to do things
samier zebkey - neuroscientist “a vision of the brain”
start with things about how human vision works
where this guides us to where science should go next
what guidance does this give us for cognition
we’re evolved to do something right - we’re doing it
change blindness / counting
vs
optical illusions / semantics
0 notes
Text
Small Paper #1 (Theory)
Mind Games: Theory of Mind in AI, and the Illusion of Intelligence.
Humans use Theory of Mind (ToM) to interpret the behavior of others, predict actions, and engage in complex social interactions. Beyond human to human interaction, we also ascribe ToM to animals, especially pets, as well as inanimate objects when we anthropomorphize them. However, when it comes to modern “chatty” AI’s, there seems to be a hesitancy to do the same among experts. The goalposts for what counts as “true” thinking or “real” intelligence, are constantly shifting. This paper explores the shifting standards for intelligence, the subconscious mechanisms by which we ascribe ToM, and what a modernized Turing Test might require for AI to be recognized as “thinking”.
First coined by Premack and Woodruff (1978), Theory of Mind (ToM) was defined by an individual’s ability to “imputes mental states to himself and others”, inferring things like “purpose or intention, as well as knowledge, belief, thinking, doubt, guessing, pretending, liking, and so forth”. ToM is typically tested in humans through the use of false belief tests, and was shown to be developed as early as 3 years old (Wellman et al., 2001). Recent LLM models, like GPT4, were able to solve tasks on par with a human 6 year old (Kosinski, 2023). Some might see these modern AI systems as cognitively functioning on par with humans because they pass the same kinds of tests, i.e. they’re able to “think” and respond with the same cognitive ability, and so they should be considered “intelligent”. On the other hand, can intelligence really be chalked up to sounding coherent and being able to parrot the response to a false belief test? Are these improved predictive language skills anything greater than the sum of their parts?
I’d like to argue that no matter what the underlying explanation, the passing of the false-belief test does matter in terms of Theory of Mind, and it does make a difference. The argument against mimicry equating intelligence has been around since Searle’s famous “Chinese Room Argument” (Searle, 1980). Here, he argues that you could manipulate symbols well enough to “pass” as intelligent without comprehension, arguing against Alan Turing’s 1950 Turing Test.. However, what I believe is most important about this thought experiment is that to the observer, the Chinese Room does appear as intelligent! You could hold a whole conversation with them, and they would pass the Turing Test. I still believe the Turing Test is enough in this respect, that linguistic stochastic “parroting” shouldn’t be discounted, if the human in the loop can construct a Theory of Mind for the AI and vice versa. As AI continues to advance, a more modern test for intelligence should go beyond the Turing Test to include the AI’s ability to build a ToM for the user, which it now can.
The most interesting I’ve found relating to Theory of Mind as it comes to AI models has been not the theoretical discussions in terms of whether something counts as intelligence or not, but rather how we subconsciously treat these chatty models due to our own cognitive biases. When considering non-human animals or objects, we are often more willing to ascribe ToM based on behavior rather than internal cognition. For example, dogs seem to have empathy based on their behaviors, allowing us to attribute ToM to their actions. Similarly, anthropomorphizing objects and technology comes from things with goal-driven behavior technology, even when there’s a complete lack of any type of internal cognition (Epley, Waytz, and Cacioppo, 2007). However, with AI, the process is reversed - despite highly advanced reasoning capabilities, outperforming humans in speed, precision, and analysis task performance, we insist on a higher standard before considering it to have genuine cognitive states. This could be in part due to the uncanny valley effect, where increasing AI realism can create subconscious discomfort unrelated to behavior. This would make us more likely to be skeptical of AI’s cognitive capabilities in spite of task performance (Mori, 1970).
However, saying these things, and thinking them consciously, doesn't prevent us from continuing to ascribe a ToM subconsciously. Automation bias, where we falsely trust decisions made by automation over our own thought processes, is an example of this. In order to be affected by automation bias due to a chatbot, you must be ascribing a Theory of Mind to said chatbot. At the very least subconsciously you believe it to have a wide knowledge base and be an expert in the knowledge it shares. Since these chatty AI bots are typically goal oriented, it can compound the problem by allowing you to anthropomorphize them.
While animals and anthropomorphized objects are granted ToM based on observable behavior, AI—despite passing human cognitive tests and demonstrating reasoning skills—faces a higher threshold for acceptance. This skepticism may stem from the uncanny valley, discomfort with non-human cognition, or just resistance to equating prediction with understanding. However, paradoxically, automation bias shows that many already subconsciously trust AI’s expertise, implicitly assigning it a form of ToM in practice, even if we deny it in theory. As AI continues to develop, a modernized Turing Test should take into account the effect on the human in the loop, and go further than linguistic competency to include the level of construction of Theory of Mind by the AI. Ultimately, our reluctance to ascribe Theory of Mind to AI is deeply ingrained based on how we define intelligence.
References:
Premack D, Woodruff G. Does the chimpanzee have a theory of mind? Behavioral and Brain Sciences. 1978;1(4):515-526. doi:10.1017/S0140525X00076512. https://www.cambridge.org/core/journals/behavioral-and-brain-sciences/article/does-the-chimpanzee-have-a-theory-of-mind/1E96B02CD9850016B7C93BC6D2FEF1D0
Wellman HM, Cross D, Watson J. Meta-analysis of theory-of-mind development: the truth about false belief. Child Dev. 2001 May-Jun;72(3):655-84. doi: 10.1111/1467-8624.00304. PMID: 11405571.https://pubmed.ncbi.nlm.nih.gov/11405571/
Kosinski, M. Evaluating Large Language Models in Theory of Mind Tasks. https://arxiv.org/abs/2302.02083
Cole, D. The Chinese Room Argument, The Stanford Encyclopedia of Philosophy (Winter 2024 Edition), Edward N. Zalta & Uri Nodelman (eds.), https://plato.stanford.edu/archives/win2024/entries/chinese-room/.
Epley N, Waytz A, Cacioppo JT. On seeing human: a three-factor theory of anthropomorphism. Psychol Rev. 2007 Oct;114(4):864-86. doi: 10.1037/0033-295X.114.4.864. PMID: 17907867. https://pubmed.ncbi.nlm.nih.gov/17907867/
Mori, M. The Uncanny Valley: The Original Essay. Masahiro Mori. 12 JUN 2012. https://spectrum.ieee.org/the-uncanny-valley
0 notes
Text
Thoughts About Final Project / Designing a Research Experiment
2/21/25
My final project will be along the lines of "Malleable Human Cognition versus Accurate Computational Cognition" I'll be diving into a Models project where i'm investigating how to exploit the differences between human cognition and classical computation models.
I believe human cognition is more flexible, thus more robust, and has some sort of evolutionary advantage. I believe current computational models (and AI before GPTo1), are too rigid in their programming, in the quest of trying to be accurate.
My contention is that if we designed models to be more human-like, with more flexible cognition, we would see advantages in computer vision, power requirements, and even creativity. I think the way computational models do things like computer vision (compositionally), is very different to how humans do it (as seen in Tiago's Colloquium). Our perception of time being malleable depending on the situation (adrenaline response etc) might also offer advantages on how we cognate in different situations and allocate brainpower. Additionally, episodic memory in humans (how we group events together) isn't necessarily linear. I want to dive into how this might offer benefits to learning, storytelling, and creativity, over than traditional data storage and retrieval in machines. I want to design tests to prove these differences and get data on how a computational model might fail in comparison to humans taking the same tests.
Additionally, I believe this may hold the answer to how humans differ from AI being "stochastic parrots". When we read or hear something, even when we don't fully understand it, I believe writing it down is still fundamentally different than the regurgitation / probabilistic writing prediction that "chatty" AI bots do.
Data would come from testing this hypothesis against humans and computational models, and comparing performance. For questions that have already been well researched in humans (such as false-belief tests), I could draw data from known psychology studies.
Tagging this data would be in terms of who completed the test (human vs machine, what model of machine, age of human, etc), and then a ranking system where we could separate out the performance of different models on different types of tasks, and then present performance and it's possible effects on model usefulness.
0 notes
Text
CQPweb2
1/17/25
I wanted to investigate a grammatical sentence of a joke setup/ punchline form like "is your refrigerator running? Well you better go catch it!"
I started with the following query:
“[pos="VBZ|VBP"] [pos="PRP$"] [pos="NN"] [pos="VBG"]”
to investigate where you might find a present tense verb, a possessive pronoun, a singular noun, and a present participle all in a row, like in "is your refrigerator running". But this turned up no usable results. The things it turned up were correct, I just didn't realize how common this sentence structure was outside of jokes.

I then changed the requirements to
[pos="WRB"] [pos="VBZ|VBP"] [pos="DT|PRP$"] [pos="NN"] [pos="VB"]
to try and match a joke setup of "why did the chicken cross the road". I look for a "wh-" word, then a present tense base verb, then a possessive pronoun, then a noun and finally an action verb. Obviously this is a newsrepository, but i was still curious if anything interesting would pop up following these specific structures you'd typically think of as humorous.

0 notes