
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by blogsun and here's what we found interesting.
Average Info
Notes Per Post
4
Likes Per Post
2
Reblog Per Post
2
Reply Per Post
0
Time Between Posts
6 days
Number of Posts By Type
Text
13
Last Seen Tumblr Blogs





Fun Fact
The “We are the 99%” Tumblr blog became the slogan for the Occupy Wall Street movement.
Text
MC7019_Week12

This week's readings encourage me to think about how to become a competitive mass comm researcher. Nelson (2020) suggested computational grounded theory based on NLP with three steps. The first two-steps pattern detection & Hypothesis Refinement) are basically what quantitative researchers have already used when doing topic modelings or other NLP techniques. For example, like descriptive statistics, most researchers calculated word frequency tables or word clouds to figure out word distributions in their corpus. Based on the results, researchers decide how to clean the corpus. The second step is to conduct and review NLP modelings. Most researchers have reviewed the results from modelings to figure out the optimal parameter value (for example, the number of topics k in LDA). Researchers interpret their data to explain characteristics or patterns in corpus to examine RQ or Hypotheses. Nothing new.
The third step (pattern confirmation) is something new to me. Nelson (2020) suggested using machine learning to validate NLP modeling results. Although it looks nice, it is weird. For example, machine learning is a tool to classify and predict given data, parameters, and algorithms. In other words, if different training sets, parameters, and algorithms are used, validation results can be dramatically different. Instead, it is better to use human coders. For instance, human coders with enough training and acceptable inter-coder reliability about topics extracted by a topic modeling can hand-code a randomly selected subset of texts and then compare the results with topic modeling results.
Even though Nelson's study (2020) is not something new, it shows that recent qualitative researchers have programming knowledge with strong domain expertise. Many experts say that data scientists need three abilities: domain expertise, programming skills, and math. However, if you are not a developer, you do not need to spend too much time on math. Like Nelson (2020)'s saying, understanding various tools, algorithms, and programming is enough to conduct high-quality scientific research. If you have a middle-level programming language, it is a matter of time to apply up-to-date computational statistics to research. While developers would make more efficient and concise codings, the results would not differ from social scientists with middle-level programming and mass knowledge for social science.
After having middle-level programming skills, a competitive edge requires domain-specific knowledge. If you follow a graduate school curriculum in a social science field, you get to reach a certain standard of domain expertise. In addition, the entry barrier of social science fields is relatively low. Reading good textbooks and literature is not technically difficult because there are not many jargons and concepts that ordinary people cannot understand.
It is, however, impossible to yield and solve data scientific research questions and hypotheses without programming knowledge. Still, many social science programs do not include programming. In my case, I have developed programming skills from the traditional mass comm method class. Still, most methods classes teach social science statistics using SPSS. Most method instructors require students to analyze data, giving data and statistical assignment. When other classmates just did it with SPSS, I conduct the same analyses with R. When I saw the same R results from SPSS, I felt confident that I are doing right. If the results are different, I try to figure out the differences between SPSS and R. After the semesters, I have used R for my research projects with more complex and unstructured data. Not long before, I realized the strength of programming languages compared to other commercial statistical packages such as SPSS, SAS, and STATA. Programming language is more time-efficient and flexible to use data science tools. R or Python enables you to combine social scientific methods with text-mining, network analysis, and machine learning with little effort, which is impossible in commercial statistical packages. Many developers also present excellent packages for R or Python to get data from web.
In sum, it is important to resist the temptation to use SPSS with a graphical interface. Instead, spend more time with R and Python. Even though a high learning curve (3 - 6 months) is painful and boring, it is worth investing your valuable time. Before long, you will realize the convenience and strong power of R and Python over SPSS. While increasing domain expertise inside and outside classes, develop more specific programming skills one by one for your research questions and hypotheses. Personally, mass comm method classes do not have to cling to SPSS anymore for instructors' convenience. It will deteriorate students' competitiveness in job markets and research.
0 notes
Text
MC7019_Week11
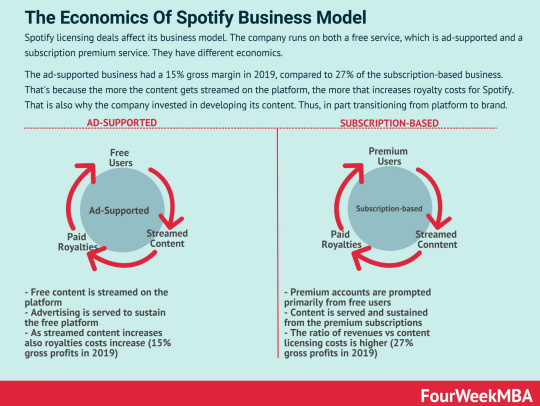
When I saw Spotify Teardown's book: Inside the Black Box of Streaming Music in the syllabus, I felt a little weird. Why does an emerging media class cover a music streaming service? I found the answer in the book. Spotify is transforming its identity toward a media company. The music company service relies on advertising and consumer data to make profits like Facebook and Twitter. It also provides not only music service but also other cultural goods such as television programs and books. As such, the book consistently argues that Spotify should be not considered a tech company but a media company that media laws should regulate. To support the arguments, the authors conducted multiple case studies and experiments.
For me, the biggest takeaway from this book is a methodology to figure out a platform algorithm. For example, the authors made fake accounts (bots) to figure out how Spotify recommends music based on different demographic variables embedded in each account. To investigate the effect of individual previous music selections on song recommendations, the authors had fake accounts play different songs systematically and compared the recommended results. Fake accounts are easy to make and run even though you have no programming knowledge. You can also analyze results even by content-analysis. But, the results would be valuable if you answer theoretically or practically important questions.
For example, Some people believe that a platform algorithm would discriminate people in housing, employment, financial services, and many other areas by socio-economic status (Gianfrancesco, Tamang, Yazdany, & Schmajuk, 2018; Sandvig, Hamilton, Karahalios, & Langbort, 2014). Regarding Spotify, the recommendation algorithm discriminates not famous singers, and its profit structure is winner-takes-all.
Another unique method is to use the network protocol analyzer, Wireshark (https://www.wireshark.org/), to investigate the final destinations of a user's click data on Spotify. You can learn how to use it within 10 minutes (https://www.youtube.com/watch?v=lb1Dw0elw0Q). They found that among 13 network traffic destinations, when you click a Spotify object, only one is related to Spotify services while twelve are not directly related to Spotify services such as coastal cable stations and data warehouses. Additional findings from the network protocol analyzer were that Spotify just rented music files from Google cloud service and used an open-source audio compression solution (i.e., Ogg Vorbis codec). In sum, the book said that Spotify is not a tech company as it has not enough original technologies for music streaming.
Also, the authors mention "the widening gap between political and public debates about the social responsibilities of digital media companies, such as Facebook and Google (pp. 5-6). However, the book does not give examples, evidence, and reasoning to support the argument. The book briefly requires digital media companies to open their data and algorithm to the public and researchers. In political communication, "the widening gap" is being studied under disagreement discounting (Butler & Dynes, 2016), failure to vote based on their constituents' preferences (Gilens and Page 2014), and ideological polarization relative to their voters (Bafumi and Herron 2010).
But, politicians' perceived social responsibility has not attracted enough attention even though politicians are key stakeholders to set CSR rules. Would politicians be more generous toward industries for national economic development? Or would they require companies to have a strict law-abiding spirit? Those would be interesting research questions.
0 notes
Text
MC7019_Week10
The book Instagram by Leaver, Highfield, and Abidin (2020) covers all the things about Instagram, from history to cultural impact, with concise writings. Because I only used Instagram for less than one month in 2010, I do not know much about Instagram in every aspect. But, I know Instagram has become daily necessities to communicate with others. This book helps fills the ten years gap to understand an Instagram phenomenon.
The big takeaway from this book is about chapter six (lifespans, p.174-190). Other things like influencers, political activism, and algorithm things are not much different from other social media books and literature. But, I never thought about content controllability for a baby and a deceased person. Instagram users record a person's entire life from birth to death. Before being delivered, parents upload ultrasounds images. Breasting, playing with a baby, all other things are also shared on Instagram. When someone passes away, people grieve and mourn on social media. The book presents the following question. Is it the right thing to upload contents without a baby and a deceased's? I think the question is timely and important question. As Instagram and other social media began at most 15 years ago, the problem is not much serious yet. But, it could be apparent.
For example, let's assume that you are a middle school student and some classmates bully you in school, saying you are very ugly. The villans would find your parents and baby pictures from your parent's Instagram and then share them with all other students with a comment that he initially looked stupid and ugly, and their parent appearance is also ugly. It will be very annoying and stressful. Even though your parents post those contents to share their happiness and harmonious family, the result could be quite disasters. As you post more contents on multiple platforms, it becomes much complex to manage shared content.
In addition, another big question is about how platforms and family members have to deal with the contents of a deceased person. After Molly Russell's suicide partly related to Instagram use, the family request access to the daughter to delete contents, but the platform denied it. However, after GDPR (General Data Protection Regulation), Instagram/Facebook allows family members to choose whether to delete a deceased family member's account or keep it a memorialized account. And the companies voluntarily develop a new system for a user to set legacy contact in case of death. Legacy contacts can delete and lock contents and write a pinned post for your profile and handle basic things. Even though social media gives more control and autonomy to a user after death, we have to think about it more. Is that enough? What should be done more for data privacy after death? Are there other problems that we did not anticipate before?
I guess that there will be an inheritance problem like copyright and royalty. For example, if a top influencer suddenly dies by a car accident without a will, and its contents are expected to attract many viewings and make profits in the future, is the account inherited property? Who has the heirship? What will happen that some family members want to delete a deceased influencer account while others do not?
Personally, I want to delete all the accounts and online content that I make after death. Thus, I minimize posting something online. Many Eastern people think that death means coming back to nothing. As a deceased person becomes dirt, leaving nothing, deleting all daily life contents would be the best choice for a social media user. But, my academic papers will persist as small bricks for human knowledge. What is your opinion?
0 notes
Text
MC7019_Week6

This week's subject is Emerging Media Psychology: Algorithms, Branding, Politics, and Sentiment. Among five papers, the interesting reading was Groshek and Koc-Michalska's study (2017). They categorized social media use patterns: active, passive, and incivil. Active users write a posting and participate in discussions, while passive users usually receive information through acquaintances and followers. Incivil users are defined as users who tend to post violent and aggressive content on social media.
According to the result, active users are more likely to support Democratic populists such as Bernie Sanders, while passive social media users and uncivil users are more likely to support Trump. This pattern of Trump-supporter social media users seems to correlate with their offline behaviors. Many Trump supporters before the 2016 presidential election did not publicly disclose their candidate preference. However, the shy voters led the election victory that any experts did not expect Also, the Capitol riot on January 6 seems to represent incivil Trump users' activities.
The fact that there are similar trends between online and offline activities in terms of candidate support presents the possibility of predicting election results. The increase in election forecasting accuracy needs a close examination of passive users as they usually do not leave postings on social media. Let's assume that we randomly sample 10,000 Twitter users. To classify a user's candidate preference, we have to investigate postings, following networks, and their engagement such as like and share.
If you periodically trace those users over time, their stance change can also be detected, reflecting public opinion trends. However, the dual screening study by McGregor et al. (2017) in week 8 showed a little contrast result. Their finding is that second screening leads to a decrease in political participation for those who do not favor Trump. Even though the data was also collected in the same presidential election season, the result is quite the opposite. To be specific, McGregor et al. (2017) showed that Democrats dual screening users are less likely to attend online political discussions and participation, both online and offline. Again, Groshek and Koc-Michalska's study (2017) found that Democratic users are more likely to participate in political discussions. Does it mean only Democrats doing dual screening were passive users while most Democrats were actively posted supporting content for their candidates? The answer remains to be seen.
In addition, this research counter-argued that social media is harmful to democracy due to filter-bubble. The result indicated no evidence that people are picky eater for political content on social media. Instead, social media use helps users be exposed to a diverse political opinion that they otherwise do not encounter.
One limitation of the study is that they discuss topics unrelated to their research questions. For example, they pointed out decreasing gatekeeping power of traditional news media and flourishing social media misinformation based on their research results even though their data did not support the argument.
0 notes
Text
MC7019_Week9

Because this book is not my research subject and I do not know much about black culture on social media, I could not understand a large portion of the book. I wrote some thoughts like below.
First, Do people really dismiss creativity by black as cleverness? Except for Facebook and Instagram, many anonymous users are on many social media platforms without disclosing their race. Whenever people read a posting, many people do not care about a poster's race. Without personal pictures or bio info on social media, it is hard to guess race. Instead, social media users focus on content themselves if a poster is an ordinary person. Content quality such as usefulness, timeliness, and entertaining factors are much important.
Second, Most Americans still respect a person based on individuals' morals, characteristics, and abilities. President Obama that I admire a lot is also respected as a successful former president and even re-elected while President Trump failed. On the internet, the thing is not so much different. Am I naive?
Third, Brock (2020) presented five categories for Black technocultural matrix: blackness, intersectionality, America, invention/style, modernity, and the future. He also said, "Black people must constantly confront context collapse in nearly every setting in Western racial ideology" (p. 230). My question is why black people try to be against context collapse? How about enjoying context collapse? The U.S., the immigrant country, is praised as cultural silos. The convergence of different cultures and ideas through immigrants has created excellent American culture that people in other countries admire. Of course, cultural diversity is important. But I hope that some races do not emphasize too much their original identity and cultures. There is old saying, too much is as bad as too little.
The author also argues that technological studies from social science undermine black people. For example, the book author said that many studies using surveys do not sample enough black people. But, the gold standard of the survey is a representative sample by random sampling from population. Many surveys try to generalize the results to the population. Thus, artificial sampling adjustment is not appropriate for most surveys. The criticism is not much persuasive. Among all American population (N = 328,239,523) in 2019, the proportion of black people is 13% (n = 44 millions) and that of white people 76.3%. The population composition ratio has been naturally reflected in many survey studies. Asians are more terrible in terms of sample size in a study. A few studies conducted in the U.S. context tend not to include Asian race value in their modeling. A race variable is usually black (or non-white) and white binary variable. FYI, the Asian population percentage in the U.S. is 5.9%, followed by American native Indian (1.3%).
In addition, the excessive discourse about black may cause backlash and reverse discrimination. Black-centered discrimination issues make other races such as Hispanics and Asians, marginalized in the U.S. society further. From the agenda-setting perspective, the focus on black people may ignore agenda about other races from media coverage, academic studies, and social media contents. From my personal experience, compared to other races, studies about black are prevalent in at least social science journals published in the U.S. Journalism and Mass Communication & Quarterly now call for "The Role of Social Media in the Black Lives Matter Movement." It is common in social science. As a result, black studies are broad and various compared to other races.
Lastly, all human beings should be equally treated regardless of race. In this sense, All Human Live Matters (AHLM) are worth getting attention along with BLM.
0 notes
Text
MC7019_Week8

Does second screening damage human cognition to process information as predicted by Nicholas Carr (2011)? Experiments by Kazakova and colleagues (2015) revealed that multitasking prevents people from processing information. That is a good reason why many instructors prohibit using digital devices during classes. The good news is that researchers have also found a good excuse to use a second screening. People use a second screening for seeking information and discussion (Zúñiga & the coworkers, 2015) even though the study context is political communication. Anyway, we can argue that digital device use should be allowed during classes because it helps us participate in class discussions actively and seek further information that the class does not cover.
Zúñiga and coworkers (2015) showed that second screening during news exposure encourages people to participate in political activities and discussions. The result was also supported in twenty countries Zúñiga and the coworkers (Zúñiga & Liu, 2017). Although those results are good evidence for the second screening effect on politics, there are some unclear points.
In a study which explains the second-screening effect among different countries, Zúñiga and Liu (2017) said, "One potential explanation may be that for the former set of countries, second screening becomes a more essential informational tool as they might not solely rely on a precarious, and less trustworthy, journalistic media. In contrast, in Germany, the United States, and the UK, the media journalistic market is more established, and freedom of the press might be preserved more diligently (p. 214)." However, according to Reuters institute digital news report 2019, 48% of Brazil's people trust most of their news, followed by Germany (47%), Turkey (46%), UK (40%), and US (32%). The media trust in UK and US is less than in Brazil and Turkey. Another statistic showed that media trust in China is 70% in 2020 (https://www.statista.com/statistics/685140/media-trust-china/). Another possible explanation would be a different media consumption habit and environment.
For example, In South Korea, watching 9 pm national news an enduring media consumption habit and social norm for a long time. A few eastern families usually gather around 9 pm to watch news together. In Eastern countries, at least in China and Korea, parents (mainly father) have a TV remote control while other family members have to follow the channel. Even though there is no personal motivation to watch news, family members gather in a living room. Thus, many people play a smartphone while wathcing news. When Korean people access the internet using a smart device, the first page they encounter is a portal website such as naver.com similar to Yahoo!. Such a portal mainly functions as news aggregators in Korea. A lot of political news from different sources is readily available. The habitual news consumption in a family may affect more intensive second-screening in some countries.
Also, many studies support the computer mediation model that links traditional news media consumption and political participation. However, media consumption behavior has been changed a lot. For example, a few people do not watch TV and newspapers recently. For them, there is no secnd screening. Their main news consumption device is smart devices. While watching news from social media or news aggregator services with a smartphone, they can easily seek other information and discuss the topics with others without second screening. Some questions come into my mind. Is there any difference between people who are using a second-screening with traditional media and only-online news audiences without a second-screening in terms of news content consumption in terms of the amount of political news consumption, news quality, and balanced news consumption? Do those differences result in different political activities? How about expanding a second-screening effect in class context? Is it detrimental for class activities? Should you not be allowed to use them in class?
0 notes
Text
MC7019_Week7

There is an old saying that artists were hungry. I don't even know the names of the most recent representative singers these days. Like me, without a strong interest in music, most ordinary people do not have enough time to enjoy each independent musicians (I even cannot recall any independent musician). It is not easy to find and listen to indie music in such an environment.
However, even though independent musicians cannot benefit much from social media, I believe that new media, especially YouTube, give many ordinary people unprecedented opportunities. Gamers, investors, cookers, or pundits are broadcasting their previously invisible contents in public space. Most content creators also had very limited audiences, like independent musicians, but some succeeded in getting more than 1 million followers.
For example, a six-year-old girl (https://www.youtube.com/channel/UCU2zNeYhf9pi_wSqFbYE96w/videos) makes more advertising profits than one of a Korean national broadcasting company (MBC) which consists of more than 1,700 elite employees. She just eats and plays at home or in a playground. That's it. Where people are crowded, money is also crowded. The place is now YouTube.
It is worth investigating how YouTube influencers gather such vast followers. Though content quality is also important, YouTube creators star cameo or guest in other content to be visible to others' followers. It is rare that traditional mass media several continuously cooperate on different channels. Network analysis for the joint-product of YouTube creators will give insight into which type of YouTube creators function as a bridge between other content and genres.
I strongly agree with Costa's finding (2018) that social media users make a different social sphere and keep each social group apart. Personally, I used multiple Facebook accounts. When I met a totally new friend network, I tend to make a new account. Because it is much easier to manage my face, and I have different stories to share with each group. For me, social media is not collapsed context but separated contexts.
However, many studies that I have read have assumed that one person has one account in one platform. Because of the assumption, many studies missed asking questions about different social spheres. Thus, a survey may produce aggregated results about each user's social media use and activities.
But, I do not know the motivation of making different social sphere on social media. Is it significantly related to cultural variables? For example, western people prefer keeping one account, and eastern people do not? But, I cannot guess from my personal experience because I have not asked my friends about how many accounts they have on Facebook.
Rieger and Klimmt (2019) teach me how to design research in a top-journal. Unlike many other studies that show just graphical visualization and statistics based on network property, this research examines eudaimonic contents on social media by using multiple methods such as network analysis, text-mining, content analysis, and experiment. An experimenter is recommended to make multiple-message design in each level of a factor to present generalizable results. For this, content-analysis can be conducted to identify various message types of interest for sampling (Slater, Peter, & Valkenburg, 2015). This standard procedure gives not only trustworthy evidence but also a high possibility to be published.

In terms of their research topics, meme, I also encounter several memes a day. However, personally, it is scarce to see eudaimonic content on any social media. Most memes are about humor, politics, and sensational content. If the researchers had used "use of eudaimonic memes online", not "use of memes online," their actual exposure to eudaimonic memes would be less than two on a 5-point Likert-type scale.
Though there are few real eudaimonic memes, it is a meaningful study by showing that eudaimonic memes positively influence emotion and behavior. As another research, a meme's effect with different framings on voters or consumers would be an interesting topic. For example, how would people respond to the Twitter meme that Elon Musk celebrates Dogecoin? Did it influence the recent huge drop of Tesla's stock price? Do those meme activities will negatively affect users' perception about his business and the qualification as CEO? Many interesting experiments are possible with mass comm theories.
0 notes
Text
MC7019_Week5
This week, I read six articles about social networks and social capital. They, in general, give me an interesting insight into social media research. However, there are some small limitations that I want to share.
Groshek and Tandoc (2017) said, "legacy news organizations, editors, and journalists are no longer situated as central gatekeepers in the contemporary multi-gated media environment." However, legacy journalists in nature were the least active in mentioning, retweeting, and following others. As official organizations, they tend to avoid unnecessary conflict and legal issues. Is that an indication of the declining role of legacy journalists in social media?
The research also needs to clarify the relation between gatekeeper and betweenness centrality based on mention network. They assumed that the higher betweenness centrality sores, the powerful a user are as gatekeepers. That is true. Betweenness centrality refers to "the degree to which actors who may not have a large number of direct links but are in a position between many other actors." (Freeman, 1979). Thus, this centrality explains the control of communication between users. However, this is correct when they analyze followers or following network. They made networks based on mention.
If somebody were mentioned the most and have the highest between centrality scores, does it mean he has a powerful gatekeeping role? Gatekeeping is defined as "controlling what should be presented to audiences and what should not." What if users mention the account not as an information source or gatekeepers but as sarcasm or critics? It may mean that the most mentioned account would be in the center of the issues without any gatekeeping role. However, as this article also does not analyze tweet contents, I do not know what the mentioned networks mean.
Compared to Groshek (2017), Shin et al (2017) did a content analysis in tweets about the 2012 US presidential election rumoring. Eight coders hand-coded 180,300 tweets for 11 months. So, I can understand the data attributes well. I think the results are much convincing. However, their network model only came from message senders, not considering receivers. We do not know whether a follower or ordinary users are polarized like the believer graph presented in Figure 1. The results should be limited to Twitter writers about political rumoring, not generalizing to other Twitter users.
Yang and the colleagues research (2018) assumes that many people have to participate RTBF debate. However, is it really necessary for ordinary citizens to pay attention to this issue? I think ordinary people do not need to be knowledgeable and participate in discussions about many issues. As representative democracy votes for major public officials on behalf of voters, ordinary people are enough to be exposed to various and logical viewpoints of an issue in order to evaluate which policy is better for the public good. The author mentioned, "there is much more of a plurality of opinions on Twitter than was ever possible in the traditional public sphere" (p. 1997). In addition, their participation in discussion is not prohibited on the platform. If Twitter functions as a discussion platform for elites and experts, that would be enough to become a public sphere.
Lu and Hampton (2017) showed that social media will increase social capital, controlling on- and offline social networks. As they mentioned 19 different activities on Facebook, its focus was profile status updating on social support. According to their research logic that I understand, profile status usually indicates emotional states. When other users see friends' feelings, they are more likely to support them (i.e., like and comment on profile status update). Thus, users can perceive who are usually attentive to their accounts and emotions. However, the results are not so much convincing to me. First, there is almost no difference in the results before/after controlling the four network variables (e.g., core network size, core has non-kin). The only difference is that private message does not support emotional support after controlling the network variables. In addition, the explanation power of four network variables is at least .02 in terms of R square. In other words, the four network variables only explain 2% of the model. Does those network variables really control on- and offline social network effect on social support?
0 notes
Text
MC7019_Week4
The book, are filter bubbles real?, is a useful resource for social media scientists to refer. Within the thin book, Bruns (2019) condensed the major research trend of filter bubble and echo chambers. He also touched on key limitations that should be overcome to progress scientific knowledge about the two popular concepts above a mere buzzword.
Clear conceptualization and operationalization are important to measure, share results, and replicate them by others. However, before reading this book, I also consider echo chambers and filter bubbles as an identical concept. Bruns (2017) suggested his definitions.
Echo chamber refers to "being when a group of participants choose to preferentially connect with each other, to the exclusion of outsiders" while filter bubble refers to being "when a group of participants, independent of the underlying network structures of their connections with others, choose to preferentially communicate with each other, to the exclusion of outsiders." Although they look quite the same, there is a key difference when you look at words by words.
First, echo chamber emphasizes network structures (e.g., followers), but filter bubble does not care much about network structure. Instead, filter bubble's main point is in networks of communication; to whom you communicate through social media (e.g., mention, reply, retweet). I am not sure whether the definition is what Pariser and Sustein intended to mean. But, if other scientists agree with this, there seem no flaws. And these definition makes me easy to conduct research in terms of methodologies. For example, if I analyze follower network structures, it is about echo chambers. If I analyze content-based networks based on mention, reply, and retweet, the research is about filter-bubble.
But, personally, other definition looks more persuasive and close to what ordinary people mean in their daily talks. Bakshy, Messing, and Adamic (2015) defined echo chambers as "in which individuals are exposed only to information from like-minded individuals" while "filter bubbles" was defined as "in which content is selected by algorithms according to a viewer's previous behaviors." How do we know which contents users were exposed to? How does social media algorithms work. Even algorithm developers themselves cannot clearly explain how it works because it continues to change over time. Thus, it is tough to measure filter bubble and echo chambers based on Bakshy and his colleagues' definition.
The book author also pointed out the importance of multi-platform studies for filter bubble and echo chamber to convince and generalize the results. He said that users exposed to information from like-minded users in A platform could consume diverse information from a B platform (context collapse). Besides, active users per issue may have different characteristics in many ways. However, it requires excessive effort to make such a paper. For example, let's consider a 3 x (platform: Twitter, Facebook, Instagram) x 3 (issues: climate change, immigration, flu vaccination) research. It is not 6 combinations, 9 combinations. Researchers also have to make a coding scheme for each issue to classify who are like-minded and not like-minded people. Except for the data accessibility issue, this kind of research is technically possible to me.
However, does it worth it? I guess that it takes at least one and a half years. At which point can I make a theoretical contribution to filter-bubble and echo chamber research? The important question is beyond whether or not filter bubble broadly exist. The key issue is how to minimize negative impact and maximize positive impact on democracy. However, you need to know the disease to cure. Which disease is in social media? Is it really filter bubble or echo chamber? I am not sure as the book author.
0 notes
Text
MC7019_Week3
The Internet Trap (Hindman, 2018) is an exciting and valuable book for me as one of mass communication researchers. The book mainly talked about how internet giant companies monopolize the internet revenue market with compounded audience. I agree with most of the arguments presented here, but I have some questions and thoughts after reading this book.
The author suggested that startups and small companies are hard to compete with big IT companies in the tilted playing field due to the technological gap. However, the continuing, rapid development in IT technology will allow startups to compete with current IT business leaders.
For example, there is now a little difference in web page loading speed between IT giants and small companies. However, what if internet speed becomes super fast anywhere five years later to load HTML-based webpages in less than .001 seconds and people thus cannot feel speed difference. If so, the speedy advantages would disappear. Likewise, many cloud service enables individuals to operate server farms and the usage fee decreases. I guess the technological barriers will not be so much as the author's expectation. "iPhones have over 100,000 times more processing power than the Apollo 11 computer ... million times more memory, and seven million times more storage" (https://www.macobserver.com/link/iphones-processing-apollo-11-computer/).
Some said Nintendo consoles could get us to the moon. That is why Eric Schmidt said, "somewhere in a garage [someone is] gunning for us. I know, because not long ago we were in that garage." The technological gap, I think, cannot be one of the critical factors to sustain the current internet market environment.
Recommendation systems based on machine learning also can be used at home with a small laptop. The SVD method widely used in top Netflix Prize award winners can be run within a few Python codes. The real gap is the amount of high-quality data set to train machine learning for recommendation systems. Data availability for personal recommendation system is limited to new competitors. Also, as many governments are overly concerned about data privacy, they are making very strict data policy laws. These privacy protection laws may be more likely to prevent emerging competitors from coming into the market than the current giants' business strategies and investment. Now, only a few companies like Google, Facebook, Apple, and Amazon can make a vicious cycle of attracting audiences from data and producing data from more audiences.
The book has a biased view about recommender systems for democracy. Most recommendations come from previous clicks to maximize clicks. The historical click was usually based on users' current political identification. A recommendation system would be one of the solutions to help people be exposed to important or opposite stance contents.
For example, if a recommendation algorithm successfully makes people exposed to news that is not politically-biased and important to common goods, it can strengthen our democracy. As users perceive the usefulness of high-quality news, more audience will likely use the platform in the long run. News trust is a robust variable to predict the sustainability of news media. For example, the New York Times is successfully becoming a majority-digital company as The paywall-driven subscription continues to grow. The success is not a click-based recommendation system, many news contents, and a bundling strategy. News trust is key to a successful transition.
Rather people in the print media age had no choice but to consume biased political information. When I was young, my father subscribed to conservative-partisan newspapers for more than 30 years. I often read it, and every news content seemed logical and persuasive to me. In those days, most Korean households subscribed to at least one newspaper and did not change their newspaper subscription for a long time. Korean broadcastings almost represent government stance. Thus, I rarely got an opposite point of view with one news channel. I think the US was not entirely different. But, things were changed after the internet. Technology has two-faces. How to use depends on humans.
0 notes
Text
MC7019_Week2
Digital Inequalities
Twenty-five years ago, when Bill Clinton and Al Gore coined the digital divide, concern was inaccessibility to digital devices across socioeconomic status. For example, the low-income likely did not have computers or internet access. As internet and smartphone penetration is prevalent globally, many expected that the digital divide naturally becomes weak. However, a new digital inequality problem arises regarding skill, motivation to use the internet, and types of activities performed (second or third level of digital divide).
Previous studies have found that systematic differences exist in digital skill and internet utilization across population. Younger and educated people are more likely to have competent skills and benefits from digital devices than older and less-educated people. Highly educated people are less likely to use social or entertainment purposes than low-educated people (Hoffmann, Lutz & Meckel, 2015). Gender is also an important variable to predict motivation for internet use. Women likely use the internet for social interaction and health/beauty information, while men use it for games and sexual content. In terms of race, minority teens tend to use smartphones for entertaining purposes while whites use them for information acquisition.
Unlike our general expectation, the digital divide gap is wide within youths called digital natives. Youths from higher-income families likely use smart devices to get information about finances, health, and education compared to lower-income families (Hassani, 2006).
Beyond socioeconomic variables, researchers try to find mediators such as IT education, attitude toward technology, online self-efficacy, and so on. Different content production types are also other academic interests such as social content, political content, and skilled content. Schradie (2011) insisted that "elite voices still dominate in the new digital commons." My opinion for digital inequality research is that correlational studies by survey are more than enough. Most studies use similar variables sets, such as sociodemographics, economic, cultural, and personal factors (see Appendix D in Scheerder, van Deursen, & van Dijk, 2017). Those studies found many significant variables to affect digital inequalities.
However, there are some questionable results: low predictive power and lack of causalities. The digital inequality studies of Hoffmann and his colleagues (2015) and Hargittai (2010) showed that the average R-square values are .35 and .20, respectively. The results indicate low-level model explanation power. Also, there are possibilities that internet use outcome significantly affects socioeconomic status. For example, white color workers who make money using computers are likely to get more income than blue color workers. However, many studies assumed the linear relation from sociodemographic to digital divide (e.g., skill and type of activities). White color workers make more income because they already have high digital skills and focus on productive activities with computers, which gives them more income and higher social status. In other words, there would be reinforcing and recurrent relations between independent variables and digital divide.
For example, Hargittai's study (2010) suggested that parental education is a significant variable for predicting children's internet skills and types of web uses. However, I guess that there are plausible alternative explanations. When parents have higher education, they are likely to have more household income, which subsequently affects their children's digital devices access and IT education. In other words, parental education is a dubious predictor. A one-shot survey study cannot examine the real causalities of the digital divide. A long-term panel survey would be one of the best methods to get strong evidence.
Lastly, digital devices do not have only negative impacts regarding equality issues. New technologies give safety assurance, job opportunities, and building social networks. Future research would conduct positive impacts of digital devices in terms of equality issues.
0 notes
Text
MC7019_Week1
Ellison and Boyd (2013) provide the definition of social network sites (SNSs) and why SNSs are a better definition term compared to others such as social networking, online social networks, or social networking sites. However, they do not mention the difference between social media and SNSs. They put SNSs under one of the genres of social media by saying that SNSs “is part of a category of tools referred to as "social media.” Personally, I encountered social media more in academic literature, and the definition is not much different from SNSs. According to Dictionary.com, it refers to “websites and other online means of communication that are used by large groups of people to share information and to develop social and professional contacts.” Thus, to justify why SNSs are one of the sub-categories under social media and the difference between them, it needs further explanation. The biggest differences between definition 1.0 (Boyd & Ellison, 2007) and definition 2.0 (Ellison & Boyd, 2013) are 1) shift from “web-based services” to “communication platform” and 2) interaction with user-generated contents. The new definition represents web 2.0 characteristics and users’ CMC practices. They believe that the previous definition of SNSs is not suited due to rapidly changing affordance and functionality in SNSs. However, they think researchers overlook this development. Me too, quick adoption to new affordance to new SNS features makes me insensitive to transitions. After reading it, I get to have an interest in what was motivation and affordance to attract me to SNSs, and what has been changed in the use of social media. In another article, Boyd (2015) emphasizes cultural meaning created by social media. She also explains what SNSs change not only in public but also in engineers. It would be interesting to do a survey or experiment with communication engineer samples about the perception of privacy issues, professional ethics, and their future imagination of SNSs. Researchers in mass communication usually study senders, receivers, and media. However, many ignored the engineering perspective. They are developing new features and services in social media: new media. Based on their motive, philosophy, and ethics, the development direction of SNSs can be expected. Of course, many SNSs are developing to attract more consumers and advertisers to make profits as a business. Except for the economic motive, other factors may contribute to solving “social dilemma” Schroeder (2018) criticized the current dominant paradigm of digital media study. He points out the importance of inputs.“ From my understanding, it includes visible content (e.g., news, social media postings) and invisible things (e.g., attention, interest, desire, involvement, engagement). Depending on the political system and media autonomous constraint, the input level is significantly different. Schroeder, however, suggested some extreme cases: the U.S., Sweden, China, and India. China is under one-communist party rule, and India is still a strong class-society called Caste. Even neighboring countries of China and India have quite different political systems. Many developed and developing countries have more similar political systems and the degree of autonomy of media institutions than the two big countries. Most of them have a western-style democratic system. Except for underdeveloped countries, not many countries share such a political system. China and India are outliers in terms of sample characteristics, which are usually removed during data-cleaning. If a unit of analysis is country and there is no weight on population numbers, it is acceptable to remove them from a sample. The problem is that China and India’s sum population is equivalent to 50% of the world population. The exclusion of the two countries from the analysis is to ignore half of the humans around the world. It would be a dilemma not to be easily solved. I agree with Schroeder’s stance that theory division between interpersonal and mass communication is becoming inapplicable as social media have both characteristics. What will be the future grand theory in mass communication?
2 notes
·
View notes
Text
MC7019_Week1
Ellison and Boyd (2013) provide the definition of social network sites (SNSs) and why SNSs are a better definition term compared to others such as social networking, online social networks, or social networking sites. However, they do not mention the difference between social media and SNSs. They put SNSs under one of the genres of social media by saying that SNSs "is part of a category of tools referred to as "social media." Personally, I encountered social media more in academic literature, and the definition is not much different from SNSs. According to Dictionary.com, it refers to "websites and other online means of communication that are used by large groups of people to share information and to develop social and professional contacts." Thus, to justify why SNSs are one of the sub-categories under social media and the difference between them, it needs further explanation. The biggest differences between definition 1.0 (Boyd & Ellison, 2007) and definition 2.0 (Ellison & Boyd, 2013) are 1) shift from "web-based services" to "communication platform" and 2) interaction with user-generated contents. The new definition represents web 2.0 characteristics and users' CMC practices. They believe that the previous definition of SNSs is not suited due to rapidly changing affordance and functionality in SNSs. However, they think researchers overlook this development. Me too, quick adoption to new affordance to new SNS features makes me insensitive to transitions. After reading it, I get to have an interest in what was motivation and affordance to attract me to SNSs, and what has been changed in the use of social media. In another article, Boyd (2015) emphasizes cultural meaning created by social media. She also explains what SNSs change not only in public but also in engineers. It would be interesting to do a survey or experiment with communication engineer samples about the perception of privacy issues, professional ethics, and their future imagination of SNSs. Researchers in mass communication usually study senders, receivers, and media. However, many ignored the engineering perspective. They are developing new features and services in social media: new media. Based on their motive, philosophy, and ethics, the development direction of SNSs can be expected. Of course, many SNSs are developing to attract more consumers and advertisers to make profits as a business. Except for the economic motive, other factors may contribute to solving "social dilemma" Schroeder (2018) criticized the current dominant paradigm of digital media study. He points out the importance of inputs." From my understanding, it includes visible content (e.g., news, social media postings) and invisible things (e.g., attention, interest, desire, involvement, engagement). Depending on the political system and media autonomous constraint, the input level is significantly different. Schroeder, however, suggested some extreme cases: the U.S., Sweden, China, and India. China is under one-communist party rule, and India is still a strong class-society called Caste. Even neighboring countries of China and India have quite different political systems. Many developed and developing countries have more similar political systems and the degree of autonomy of media institutions than the two big countries. Most of them have a western-style democratic system. Except for underdeveloped countries, not many countries share such a political system. China and India are outliers in terms of sample characteristics, which are usually removed during data-cleaning. If a unit of analysis is country and there is no weight on population numbers, it is acceptable to remove them from a sample. The problem is that China and India's sum population is equivalent to 50% of the world population. The exclusion of the two countries from the analysis is to ignore half of the humans around the world. It would be a dilemma not to be easily solved. I agree with Schroeder's stance that theory division between interpersonal and mass communication is becoming inapplicable as social media have both characteristics. What will be the future grand theory in mass communication?
2 notes
·
View notes