
I'm here to share all I know and learn about Solana and Python! You can support me by following me and liking my posts.
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by brandonmillman and here's what we found interesting.
Average Info
Notes Per Post
56
Likes Per Post
1
Reblog Per Post
55
Reply Per Post
0
Time Between Posts
2 minutes
Number of Posts By Type
Text
5
Last Seen Tumblr Blogs





Fun Fact
US Tumblr user growth rate is estimated to slow down to 4.1%.
Text
3 Top Cryptocurrencies Trending on Solana with 100X Potential
The Solana-based coins that are trending on DEXTools show that the market is trying to gain traction under the influence of outside forces. This post will look at three of the most popular cryptocurrency coins right now on the Solana ecosystem that have been making waves on DEXTool.
The graphic displays high gain percentages and scores for both new and old tokens. This implies that a substantial amount of money is being invested in these projects by investors. These assets are also extremely reasonably priced, enabling investors to acquire as much of them as they can. The durability of these assets and the profits they offer investors will be the main factors to be taken into account. We shall thus investigate a few popular tokens that show promise for financial gains for investors.

Top Cryptocurrencies That Are Trending on Solana
Meanwhile, 2023 was a noteworthy year for Solana’s SOL token. The project’s aggressive price appreciation was driven by a number of causes, surpassing those of several other prominent digital currencies. According to CoinMarketCap data, the cryptocurrency — which is the original digital asset of the Solana network — soared to a yearly high of around $125 around Christmas. By now, the altcoin had increased over 1,100% since the start of the year. Furthermore, according to CoinMarketCap data, it has recently attracted a lot of interest.
Jupiter (JUP)
A governance token called JUP is linked to the Jupiter platform and allows community members to actively take part in decision-making. The platform is adding more DeFi product features, such as Perpetuals Trading, Limit Order, DCA/TWAP, and Bridge Comparator.
Jupiter debuted GMX-style perpetual futures lately, after first concentrating on token swaps. In the future, it also intends to launch a decentralised stablecoin.
Jupiter also wants to give tokens to as many people in its community as possible. The concept uses military-grade encryption to protect user data privacy and security while democratising blockchain accessibility.
Because of Jupiter’s superior encryption powers, safe dApps can be created on both public and private networks. This is consistent with its goal of ensuring that blockchain technology is both secure and widely available.
Furthermore, Jupiter merits being included to the watchlist due to its community governance and dedication to security and privacy. Jupiter is a really attractive choice for people who want to learn more about the changing blockchain scene.

The price of Jupiter increased by 126% in the last year. It did better than Bitcoin and Ethereum as well as 79% of the top 100 crypto assets. At present, the attitude around price projection for Jupiter is neutral, and the Fear & Greed Index shows a level of 63 (Greed).
However, 2021 was Jupiter’s best year ever, with a staggering price gain of 1,770.22%. Jupiter typically has its highest performance in Q1, averaging a gain of 4,541.87%. It struggles, meanwhile, in Q2, with an average loss of -56.06%.
While you’re here, consider joining our Telegram Channel where you can find FREE reliable crypto signals!
2. GUAC, or guacamole
The Solana blockchain powers Guacamole Token’s operations. In the realm of decentralised finance (DeFi), it gives precedence to security and decentralisation in encrypted peer-to-peer transactions.
In order to safeguard and authenticate transactions and guarantee the highest level of security, the project integrates digital identity with a sophisticated encryption technique. Its goal is to offer a decentralised, dependable, and safe platform for online transactions. These goals include things like sophisticated encryption and digital identity.
In addition, GUAC tokens can be traded on both decentralised and centralised cryptocurrency exchanges. The most widely used exchange for guacamole trades and purchases is CoinEx. The most active trading pair is GUAC/USDT, with $6,017.36 worth of trades in the past day. But there are other well-liked choices, such Bitget and Orca.

In terms of GUAC’s price history, it reached its highest point of $0.00001401 on August 2, 2022. On the other hand, on May 10, 2023, it reached its lowest known price of $0.061524.
The lowest price, however, fell to $0.061524 (cycle low) after reaching its all-time high and then increased to $0.061578 (cycle high). As of right now, there is a bearish price prediction attitude for avocado, and the Fear & Greed Index shows that greed is at level 63.
While you’re here, consider joining our Telegram Channel where you can find FREE reliable crypto signals!
3. CSTR, or CoreStarter
On Solana, CoreStarter is a cross-chain fundraising platform with high-yield staking and an NFT marketplace. Its goal is to promote genuine decentralisation and assist small investors.
But CoreStarter wants to encourage smaller investors, in contrast to typical launchpads that favour larger ones. Through the use of a reverse algorithm paradigm, it provides them with higher APY. Long-term investors and low token holders alike benefit from an even playing field created by this creative strategy that rewards loyalty.
Furthermore, CoreStarter is unique in that it can be integrated with blockchains such as Binance, Ethereum, Matic, and Cardano. With the help of this functionality, entrepreneurs can raise money using a decentralised financial system. They also gain from integrated stake payouts made possible by CoreStarter DAO.
Only the best businesses and entrepreneurs are highlighted on CoreStarter’s platform thanks to a strict project selection procedure. In order to maintain its standards, the platform also prioritises authenticity and high-quality programming.
Token owners can also take part in different IDOs and stake their CSTR tokens for high APY. Additionally, they can vote on proposals to have a role in project decisions.
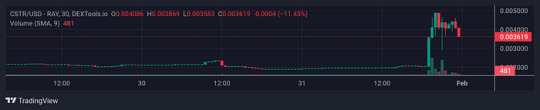
The current price of CoreStarter is $0.002999. The cryptocurrency has a $268,291 24-hour trading volume and a $21,358 market capitalization. This suggests a 0.00% market domination.
In addition, CSTR’s price increased by 53.92% over the previous day. On November 17, 2021, it reached an all-time high of $0.706935, which was its highest recorded price. On November 4, 2023, the project’s price dropped to an all-time low of $0.001104. In the meantime.
The highest price that CSTR has hit from its lowest point is $0.006701. As of this now, the Fear & Greed Index is reading 63 (Greed), while the CoreStarter price prediction emotion is neutral. Trading above the 200-day simple moving average, CoreStarter has a circulating supply of 7.12 million CSTR, out of a maximum supply of 100.00 million CSTR.
It also has excellent liquidity according to its market capitalization. The year 2023 was the best for CoreStarter, with a price gain of 11.51% from $0.002901 to $0.003235.
0 notes
Text
Two Cryptocurrencies to Invest in 2024: Investing in These Altcoins is Like Buying Ethereum Under $10 and Solana Under $0.9

I have realized that many cryptocurrency investors, including myself, are greedy. We always desire more, like Oliver Twist. We often wish we had invested in cryptocurrency earlier when Bitcoin was under $100, ETH under $5, and SOL under a dollar.
However, the real problem is not about investing early in crypto projects, because even those who invested in Bitcoin early without understanding its fundamentals sold their assets before it reached $10.
The real issue is investing in crypto projects without conviction. This alone has caused many to sell their crypto assets before they gained mainstream adoption.
If you don’t believe me, ask those who invested in Bitcoin when it was under $100. How many of them still hold their BTC to this day? If you’re in this category, please share your story in the comment section so that we can learn from it.
You see, finding the next 100x crypto isn’t a big deal, but can you hold on when things are not going your way? As an investor, the temptation to sell your cryptocurrency assets when prices fluctuate is something you must deal with.
For example, if you had bought Solana (SOL) in 2020 for less than $0.92, would you have imagined it reaching above $250 in 2021? Probably not. So, whether you missed the opportunity to invest early in crypto or are just starting today, you need conviction to set long-term goals.
All Hope Is Not Lost
Thankfully, there are new narratives and emerging blockchain technologies that have disrupted the crypto market in recent months. Investing in these projects can compensate for your late arrival in the cryptocurrency market.
Since narratives drive the crypto market, we will follow the smart money concept to invest in two projects supported by whales, institutional investors, and crypto influencers.
However, I will not encourage you to sell your car, mortgage your house, take a loan, or invest your rent fees in these crypto projects. I do not support such financial recklessness.
You must understand that investing in new cryptocurrency projects is always risky, and the chances of losing your capital are high. So, only invest the amount you’re willing to gamble with so you don’t suffer from depression if your investment goes underwater. Now the question is…
What are the 100x Crypto Projects to Invest in 2024?

Recently, two cryptocurrency projects that haven’t experienced the cryptocurrency bull market caught my attention, and if you know what that means, you will add this article to your watchlist.
For example, Solana, Avalanche, Fantom, and Polkadot had their first bull run in 2021, and they delivered incredible gains to early investors. They outperformed Chainlink, Litecoin, Ethereum, Bitcoin Cash, and other old-generation tokens in terms of their return on investments (ROIs)
So, if you are still holding the 2017 and 2021 tokens like my grandma, and hoping to make 5–10x returns from them, good luck.
You might earn some profits from those old tokens, but investing in Sei Network, Manta Network, and other newer projects could yield higher returns. These new projects could offer over 100x returns on your investment if you follow the right strategy.
How to Find and Invest in Emerging Crypto Gems

To increase your chances of success investing in emerging crypto gems, you need to consider the following criteria:
Get in early
Invest in projects that haven’t experienced a bull market
Have conviction
Stick with the plan
Focus on social media hype and influencers promoting new projects
Keep the process simple.
By following these steps, you can stay ahead of the curve and make insane profits. But when the market becomes saturated, you can take profits from these new projects and put them into Stablecoins, BTC, ETH, SOL, and other top crypto that make up your long-term portfolio.
Two Examples of Emerging Crypto Gems: Sei Network and Manta Network
Now that you know the criteria for finding and investing in emerging crypto gems, let me introduce you to two projects that have huge potential in this bull run: Sei Network and Manta Network.
These two projects are shaping how the blockchain industry should function and challenging developers on LI and L2 blockchains to think deeply because of the innovative ideas they brought on board. First, let’s start with Sei Network.
Sei Network: The Fastest and Cheapest Blockchain for Trading

Most people ask what is Sei Network, and how we can make a potential 100x return investing in this project.
Sei is the first sector-specific Layer 1 blockchain, specialized for trading to give exchanges an unfair advantage. It enables mass adoption of digital assets by building the fastest Layer 1 blockchain, designed to scale with the industry to enhance speed, improve security, and be user-friendly.
Is Buying Sei Tokens a Good Investment
Yes, I believe that investing in SEI tokens is a good investment, although not without risk. As with any cryptocurrency investment, there is no guarantee of profits, and you should always do your own research and only invest what you can afford to lose.
Fundamentally, the SEI token has a lot of upsides potential, since it is the native currency of Sei Network, and it is used for various purposes, such as:
Paying for transaction fees on the network
Staking to secure the network and earn rewards
Participating in governance and decision-making
Accessing exclusive services and features on the network.
The Sei Network has also attracted some reputable and influential players in the crypto space, such as:
Binance Labs
Coinbase Ventures
Pantera Capital
Alameda Research, and
Multicoin Capital.
These smart investors and virtual capitals (VCs) are allocating funds to this hidden gem, which means they probably know something we don’t know. Therefore, I have added SEI to my crypto watchlist, and I suggest you do the same before it becomes too mainstream and expensive.
Manta Network: The Privacy Layer for Web3 Applications

Manta Network is a modular ecosystem for web3 applications that offers a privacy layer for decentralized finance (DeFi). One of its components is Manta Pacific, which is a Layer 2 (L2) deployment that leverages Celestia, a modular data availability layer.
With Manta Network, users can build and deploy any Solidity-based decentralized applications and leverage its technology stack to deliver faster transaction speeds and lower gas costs than a Layer 1 (L1) blockchain.
Fundamental Analysis

If this project follows the price-discovery pattern of Solana, it could reach a 50% market cap of what Solana achieved in the 2021 bull market (over $43 billion). That would translate to over 50x returns, putting the average price of MANTA at $170.
If it reaches a $77 billion market cap, which is not impossible in the crypto space, we could see the average price of MANTA above $300. So, you can see that we are still early on this project and its potential is huge. See the screenshot above.
But someone may argue by saying, I don’t see MANTA reaching such high figures. Well, I need you to remember that LINK and LTC, which are older and more established tokens, once had the billion-dollar market cap status when Solana and Avalanche were struggling under a $500 million cap in 2020.
However, before the peak of the 2021 bull market, both Solana and Avalanche surpassed LINK and LTC in terms of market cap and performance.
So, overtaking is allowed in the cryptocurrency market, and investors move funds to new and exciting projects with high potential rewards. Hence, we should follow their strategies for investing in Sei Network and Manta Network to maximize profits in this bull run.
Comparing SEI’s Market Cap to ETH in 2017

In 2017, Ethereum had a market cap of $2 billion, with an average price of $10. Similarly, the Sei network currently has a market cap of less than $2 billion, at an average price of $0.65. Imagine the potential if this project reaches a $50 billion market cap before the end of this bull market. However, such gains require conviction in this project.
Sei is often touted as the “Solana killer,” and we can capitalize on this narrative. This isn’t about which blockchain has superior technology or use cases; it’s purely speculative. The goal is to identify the hidden gem altcoin that will yield the most significant gains in this bull run, and I am following the money trail.
Advantages of Investing in New Crypto Projects
Consider this: if you had invested $1000 in Litecoin in November 2021 and sold at its peak in May for $400, you could have turned $1,000 into $10,000.
Similarly, if you had invested $1000 in hot narrative tokens like Solana in November 2020 and sold at its peak for $250 in November 2021, you could have turned $1,000 into over $100,000.
This shows the profitability of investing in new tokens with a strong narrative and industry backing. Remember, crypto influencers promoted Solana in 2021, thereby attracting retail and institutional funds into the Solana ecosystem. Now, these same influencers and many more are touting SEI and MANTA as the hot narratives for 2024.
When Is the Best Time to Invest In SEI and MANTA?

Examining the SEI-USD pair above, the market structure is bearish. I would recommend waiting for a pullback towards the EMA-100 on the daily timeframe (around $0.458), which could act as a support level before purchasing this token.
However, it could drop further if the selling pressure is high, or reverse from its current price if there’s bullish news in the market. So, invest carefully. Personally, I will rely on the information on my chart until I observe a bullish reversal in the market.
When Is the Best Time to Buy MANTA tokens?

The MANTA-USD pair has limited data on the daily timeframe, so I will analyze the chart on the 4-hour and 1-hour timeframes. On both timeframes, the MANTA-USD pair is bearish and currently trading below the EMA 20. This market structure doesn’t look appealing, so I would wait for more data before investing in this project.
I would advise you to monitor the chart and wait for a pullback before heavily investing in these new projects. However, if you’re not concerned about technical analysis, you can invest in them using the DCA method.
You can either invest bi-weekly, monthly, or whenever you have resources, to accumulate more tokens. I hope this strategy proves successful for you and leads to financial freedom by the end of this bull market.
Final Thoughts
I have done my best to provide both fundamental and technical reasons why SEI and MANTA could be the game changes in this bull run. Now, the choice is yours to make. You can go all in on these projects or invest using the dollar-cost averaging method.
0 notes
Text
6 python libraries to make beautiful maps
At some point any Data Scientist faces the need to analyze or model geo spatial data, and it can’t be done without the crucial visual part. As I’m a huge map-lover, I’m glad to share with you these 6 great libraries for making informative and stylish maps. Some of the libraries I shared here are more suitable for static visualizations, others for interactive ones, so the range of problems they can tackle is wide.
1. Cartopy
Cartopy is a powerful well-known library perfect for plotting static maps with scalar or polygon data. It provides many built-in layers for land, water and administrative borders. It’s really easy-to-use and has an intuitive set of commands.
As an example, let’s try to visualize MODIS data.If you want to follow along, you can find the code here.
To install the package, you can use regular expression with pip:!pip install cartopy
Now let’s load the data:import numpy as np import matplotlib.pyplot as plt
lats = np.load('lats.npy') lons = np.load('lons.npy') data = np.load('data.npy')
After this we can plot the data right away:proj = ccrs.PlateCarree() #let's set the map's projection
fig, ax = plt.subplots(subplot_kw=dict(projection=proj), figsize=(10, 20))#now we need to create a figure with the pre-set projection and a size
ax.set_extent([-160, -105, 40 ,70], crs=ccrs.PlateCarree())#let's limit the coordinates to have only the region of MODIS product
plt.contourf(lons, lats, data, transform=ccrs.PlateCarree(), cmap = 'summer') #let's add a countor of the data using matplotlib '''Adding nice cartopy features''' ax.add_feature(cfeature.BORDERS, edgecolor='black', linewidth=1) ax.add_feature(cfeature.LAKES, alpha=0.5) ax.add_feature(cfeature.LAND) ax.add_feature(cfeature.COASTLINE, edgecolor='black', linewidth=1) ax.add_feature(cartopy.feature.RIVERS, edgecolor='blue', linewidth=0.5) states_provinces = cfeature.NaturalEarthFeature( category='cultural', name='admin_1_states_provinces', scale='10m', facecolor='none') ax.add_feature(states_provinces, edgecolor='black', zorder=10, linestyle = '-', linewidth=0.5)
ax.gridlines(draw_labels=True)#formating the grid
As you can judge from the result, cartopy provides a great abundance of ways to customize your map, as you can manually set colors, linewidth, density and other parameters of your layers. Additionally, the code itself is really intuitive and easy to understand.
Cartopy is one of the tools I regularly use in my work, and I hope that you’ll find it extremely helpful as well!
2. Folium
Now let’s add the world’s countries. To do that I’ll use the defualt geopandas dataframe:import geopandas as gpd df = gpd.read_file(gpd.datasets.get_path('naturalearth_lowres'))
map = folium.Map(zoom_start=4, tiles="Cartodb Positron") gdf_json = df.to_json()
3. Plotly
Plotly is another famous library known for its beautiful interactive charts. Among many features, it has several functions to plot maps, such as px.choropleth, px.choropleth_mapbox, px.scatter_mapbox, px.scatter_geo and some others. You can find more details here.
As a demonstration let’s plot the same geo pandas dataset, but this time visualizing gdp_md_est variable. It can be done very easily within the following lines:import plotly.express as px
4. ipyleaflet
The fourth library I want to show you is ipyleaflet.It’s another great JS-based library for interactive mapping. One of my favorite things about this package is the amount of tiles it has. So let’s start with the basic one:from ipyleaflet import Map
You can play around with other options, there are literally dozens of them!
Now let’s plot some real world data. One of the most impressive features of the library I found is Velocity visualization. For this purpose, we can use NCEP(WMC) forecast data, which has 1° resolution. The dataset is acquired for 2016–04–30 06:00 and was provided in the docs of the ipyleaflet library. To read it we will use xarray, which is perfect to read netCDF4 files.from ipyleaflet.velocity import Velocity import xarray as xr import os import requests
if not os.path.exists('wind-global.nc'): url = 'https://github.com/benbovy/xvelmap/raw/master/notebooks/wind-global.nc' r = requests.get(url) wind_data = r.content with open('wind-global.nc', 'wb') as f: f.write(wind_data)
m = Map(center=(45, 2), zoom=4, interpolation='nearest', basemap=basemaps.CartoDB.DarkMatter)
ds = xr.open_dataset('wind-global.nc')
wind = Velocity(data=ds, zonal_speed='u_wind', meridional_speed='v_wind', latitude_dimension='lat', longitude_dimension='lon', velocity_scale=0.01, max_velocity=20) m.add(wind)
As you can see the output is not simply an interactive map, it’s an animated one. So it definitely enhances data representativeness and makes your data speak!
5. geemap
Geemap is a package for interactive mapping integrated with Google Earth Engine. So obviously it’s really convenient when your’re working with python ee library, which is python GEE package.
As a demonstration, let’s collect land cover data from Dynamic World product for an island in the Northern Europe:import ee
radius = 1250 point=ee.Geometry.Point([19.9, 60.2]) roi = point.buffer(radius) #setting a circle around the point of interest
DW = ee.ImageCollection("GOOGLE/DYNAMICWORLD/V1")\ .filterDate(start = '2022-07-08', end='2022-08-30')\ .filterBounds(roi) #getting the data DW_list = DW.toList(DW.size()) #converting the data to GEE List
Now we can do the plotting:m = geemap.Map(center=[60.2, 19.9], zoom=14)
I’d say that geemap is a really great tool to work with GEE. It has tons of different function, which can solve a solid range of tasks. The main and only disadvantage is it’s not super user-friendly. You need to know ee library syntaxis and have a general understanding of how GEE works before using geemap.
6. ridgemap
This library is the last and truly my favorite one, since it allows to make truly unique plots, which are pieces of art.
Before plotting, let’s install two libs:!pip install ridge_map mplcyberpunk
Now let’s create a map:import matplotlib.pyplot as plt from ridge_map import FontManager, RidgeMap import ridge_map as rm import mplcyberpunk import matplotlib.font_manager as fm
plt.style.use("cyberpunk") plt.rcParams["figure.figsize"] = (16,9)
fm = FontManager('https://github.com/google/fonts/blob/main/ofl/arbutusslab/ArbutusSlab-Regular.ttf?raw=true')
r = RidgeMap(bbox=(-15, 32, 45,90), font=fm.prop) #creating a map
values =r.get_elevation_data(num_lines=200) #getting elevation data values = r.preprocess(values=values, #setting hypoparameters water_ntile=70, vertical_ratio=40, lake_flatness=3)
From my point of view, this is awesome! You can check out the library, find a plenty of other visualizations and post your own:)
Hopefully you’ll find these libraries helpful and worth including in your toolbox.
0 notes
Text
Stock Market Sentiment Prediction with OpenAI and Python
In today’s stock market, staying informed about news and events is crucial for making strategic decisions. Recognizing the impact of sentiment on market trends is essential to adjust strategies accordingly. The process begins with accessing vast amounts of market news available through various sources. Foremost among these are the requirements for data quality (such as the number of sources, data update rate, etc.) and ease of use.
Although the data is available online and easily accessible, one of the most convenient methods for our needs is to use an API endpoint to integrate market data and news directly into our code. There is a variety of financial data providers that offer API connections; they vary in the data packages, support approach, and quality of data they provide.
In this article, we are going to use the Stock Market and Financial News API provided by one of the Market Data providers named EODHD, which, in my opinion, boasts a great balance of quality and price. The API provides an endpoint for extracting insights from financial news, facilitating easy analysis of market sentiment. With its ease of use, users can query and retrieve news articles, enabling a dynamic assessment of the market’s positive or negative tones.
By showcasing the capabilities of the API, I aim to demonstrate its seamless integration into sentiment analysis, enabling us to make informed decisions based on prevailing market sentiments. In the fast-paced environment of the stock market, having access to such a resource ensures a more adaptive and strategic approach to investing.
Without further ado, let’s dive into the article.
Importing Packages
Let’s start with importing the required packages into our Python environment. We’ll be using three packages in this article which are pandas for working with dataframes, eodhd for extracting data, and langchain for building the LLM model. Apart from these, we will also be using other secondary packages like config and re. Import all the necessary packages using the following code:!pip install openai !pip install langchain !pip install eodhd !pip install config
import re import requests import pandas as pd import config as cfg from eodhd import APIClient from langchain.chains import LLMChain from langchain.prompts import PromptTemplate from langchain.chat_models import ChatOpenAI
Before importing, make sure to install the packages using the command line. Now that we have all the required packages imported into our Python environment, we can proceed to the next step which is activating the API key.
API Key Activation
It is essential to register the EODHD API key with the package in order to use its functions. If you don’t have an EODHD API key, firstly, head over to their website, then, finish the registration process to create an EODHD account, and finally, navigate to the ‘Settings’ page where you can find your secret EODHD API key. It is important to ensure that this secret API key is not revealed to anyone. You can activate the API key by following this code:api_key = '<YOUR API KEY>' api = APIClient(api_key)
The code is pretty simple. In the first line, we are storing the secret EODHD API key into api_key, and then in the second line, we are using the APIClient class provided by the eodhd package to activate the API key and stored the response in the client variable.
Note that you need to replace <YOUR API KEY> with your secret EODHD API key. Apart from directly storing the API key with text, there are other ways for better security such as utilizing environmental variables, and so on.
Extracting the Data
We are going to use the Stock Market and Financial News API by accessing the Python library provided by EODHD as follows:resp = api.financial_news(s = "AAPL.US", from_date = '2024-01-01', to_date = '2024-01-30', limit = 100) df = pd.DataFrame(resp) # converting the json output into datframe df.tail()
Let me explain the parameters in the API:
s: String. REQUIRED if parameter ‘t’ is not set. The ticker code to get news for.
t: String. REQUIRED if parameter ‘s’ is not set. The tag to get news on a given topic. you can find the provided topic list on this page: https://eodhd.com/financial-apis/stock-market-financial-news-api/
api_token: String. REQUIRED. Your api_token to access the API. You will get it after registration.
from and to: the format is ‘YYYY-MM-DD’. If you need data from Mar 1, 2021, to Mar 10, 2021, you should use from=2021–03–01 and to=2021–03–10.
limit: Number. OPTIONAL. The number of results should be returned with the query. Default value: 50, minimum value: 1, maximum value: 1000.
offset: Number. OPTIONAL. The offset of the data. Default value: 0, minimum value: 0. For example, to get 100 symbols starting from 200 you should use limit=100 and offset=200.
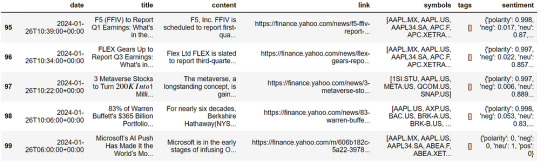
The output data has the following fields:
date: The date and time of the article are in ISO 8601 format.
title: The title of the article.
content: The full body of the article.
link: The link to the source.
symbols: The array of ticker symbols is mentioned in the article.
Cleaning the Data
Now this data is unclean and contains lots of line breaks and different commands. So we are going to clean them:#funtion to clean the textual data def clean_text(text): cleaned_text = re.sub(r'\s+', ' ', text) return cleaned_text.strip()
# Apply the replacement function to the entire column df['content'] = df['content'].apply(clean_text)
Now we have applied it to all the data and we can move forward with our chatbot.
LLM
Now we will use Langchain to form an LLM chain with the OpenAI model.llm = ChatOpenAI(model = "gpt-3.5-turbo", openai_api_key = 'YOUR OPENAI API KEY', temperature = 0)
NOTE: You should replace YOUR OPENAI API KEYwith your own OpenAI API key for the smooth functioning of the code without any errors.
This code snippet initializes the Language Model (LM) by instantiating GPT-2.5-turbo with a temperature of 0. The choice of temperature 0 ensures determinism in our model, preventing it from getting sidetracked and maintaining a focused and consistent generation.
Now, we are going to use different techniques to make it precise for our downstream task i.e. Sentiment analysis. There are lots of different ways to do it:
1) Prompt Engineering:
Prompt engineering is a growing field that involves designing and optimizing prompts to maximize the performance of large language models like GPT. As these models advance, the way we prompt them becomes increasingly important. Recent research shows that well-crafted prompts can significantly improve reliability and enable models to tackle more complex tasks than previously believed.
Following are some prompt engineering techniques that are commonly used:
Zero-shot prompting: This method enables large language models (LLMs) to handle new tasks even without prior examples or understanding of the task. It operates through a technique called ‘prompting,’ where you simply give the LLM a natural language description of the desired task.
Few-shot prompting: While large-language models demonstrate remarkable zero-shot capabilities, they still fall short on more complex tasks when using the zero-shot setting. Few-shot prompting can be used as a technique to enable in-context learning where we provide demonstrations in the prompt to steer the model to better performance. The demonstrations serve as conditioning for subsequent examples where we would like the model to generate a response.
Chain of Thought Prompting: Chain of thought prompting is a helpful technique for AI systems to simplify complex tasks by breaking them down into manageable steps. Instead of tackling a challenging problem in one go, this method promotes explaining the reasoning process by breaking the solution into a series of smaller, incremental steps. It begins by clearly defining the end goal and then considers the logical prerequisites and sub-tasks required to reach that goal.
2) Fine-tuning
Fine-tuning is a useful process that lets users tailor pre-trained language models (LLMs) for specific tasks. By fine-tuning a model on a small dataset containing task-specific data, you can enhance its performance for that particular task while keeping its overall language understanding intact.
The two main Fine-tuning Methods are as follows:
Full instruction fine-tuning: Full instruction fine-tuning is a technique used to adapt Large Language Models (LLMs) to specific tasks. The process involves adjusting all parameters of the LLM using task-specific data. This adaptation allows the model to perform more effectively on specific tasks, potentially leading to improved performance. The need for full instruction fine-tuning arises because even the most powerful pre-trained LLM might not always meet specific needs right out of the box. For instance, an application might require a unique structure or style, or the pre-trained LLM might lack knowledge about specific documents crucial to the application. Furthermore, certain domains, industries, and even particular enterprises often have unique terminologies, concepts, and structures not prominently represented in the general pretraining data. Therefore, full instruction fine-tuning is a valuable method for tailoring LLMs to more specific use cases.
Parameter-efficient fine-tuning: Parameter-efficient fine-tuning (PEFT) is a technique used to adapt large pre-trained models to various downstream applications without fine-tuning all of a model’s parameters. This is because fine-tuning all parameters can be prohibitively costly. Instead, PEFT methods only fine-tune a small number of (extra) model parameters. This significantly decreases computational and storage costs while yielding performance comparable to a fully fine-tuned model. PEFT addresses issues such as the infeasibility of full fine-tuning on consumer hardware and the high cost of storing and deploying fine-tuned models independently for each downstream task. It also overcomes the problem of catastrophic forgetting, a behavior observed during the full fine-tuning of Large Language Models (LLMs).
In this instance, we will leverage prompt engineering techniques, utilizing the Langchain template functionality, to construct an optimized prompt for conducting sentiment analysis in the stock market. The objective is to create a prompt that not only provides sentiment Analysis but also offers explanations for the model’s inferences.template = """ Identify the sentiment towards the Apple(AAPL) stocks from the news article , where the sentiment score should be from -10 to +10 where -10 being the most negative and +10 being the most positve , and 0 being neutral
Also give the proper explanation for your answers and how would it effect the prices of different stocks
Article : {statement} """
#forming prompt using Langchain PromptTemplate functionality prompt = PromptTemplate(template = template, input_variables = ["statement"]) llm_chain = LLMChain(prompt = prompt, llm = llm)
Now that we’ve established the LLM chain, let me give you an example of its inference.
Running the LLM chain :print(llm_chain.run(df['content'][13]))

Analysis
Now to to analyze the market condition of AAPL (Apple) stocks let’s analyze 100 articles and draw some conclusions.
So, first, we have to make sure we don’t cross the token limit of our model, which is 4097 for me. So we will filter out articles with a number of tokes < 3500:#A function to count the number of tokens def count_tokens(text): tokens = text.split() return len(tokens)
Counting tokes for all the rows in a dataframe:# Applying the tokenization function to the DataFrame column df['TokenCount'] = df['content'].apply(count_tokens)
Filtering the data frame according to TokenCount:# Define a token count threshold (for example, keep rows with more than 2 tokens) token_count_threshold = 3500
# Create a new DataFrame by filtering based on the token count new_df = df[df['TokenCount'] < token_count_threshold]
# Drop the 'TokenCount' column from the new DataFrame if you don't need it new_df = new_df.drop('TokenCount', axis = 1)
# Resetting the index new_df = new_df.reset_index(drop = True)
Now, this time I would change my prompt template so that I would get a concise output:template_2 = """ Identify the sentiment towards the Apple(AAPL) stocks of the news article from -10 to +10 where -10 being the most negative and +10 being the most positve , and 0 being neutral
GIVE ANSWER IN ONLY ONE WORD AND THAT SHOULD BE THE SCORE
Article : {statement} """
#forming prompt using Langchain PromptTemplate functionality prompt_2 = PromptTemplate(template = template_2, input_variables = ["statement"])
Let’s form the new LLM chain:llm_chain_2 = LLMChain(prompt = prompt_2, llm = llm)

Great, we are now able to get a concise output. Now, we are going to create a for-loop to iterate through the data and get the sentiment of each news:x = [] for i in range(0,new_df.shape[0]): x.append(llm_chain_2.run(new_df['content'][i]))
Visualization
Now let’s form some pie charts to see the market sentiment of AAPL stocks:import matplotlib.pyplot as plt
dt = pd.DataFrame(x) #Converting into Dataframe column_name = 0 # this is my column name you should change it according to your data value_counts = dt[column_name].value_counts()
# Plotting the pie chart plt.pie(value_counts, labels = value_counts.index, autopct = '%1.1f%%', startangle = 140) plt.title(f'Pie Chart') plt.axis('equal') # Equal aspect ratio ensures that the pie is drawn as a circle.

The pie chart indicates that a significant number of articles were neutral. However, to ensure accuracy, we should filter our data and focus on analyzing only the non-neutral information.
Removing neutral values:value_to_remove = '0' # Remove all rows where the specified value occurs in the column dt_new = dt[dt[0] != value_to_remove]
Visualizing the new data:value_counts = dt_new[column_name].value_counts()
# Plotting the pie chart plt.pie(value_counts, labels = value_counts.index, autopct = '%1.1f%%', startangle = 140) plt.title(f'Pie Chart') plt.axis('equal') # Equal aspect ratio ensures that the pie is drawn as a circle.

Observing the trends, the combination of +5 and +7 contributes to nearly 40% of the data. Factoring in additional values like +10, +8, and +3, the cumulative percentage of positive articles rises to 52.5%. This pattern indicates a prevailing optimistic sentiment, implying a favorable perception of Apple Inc. in recent articles. The positive outlook identified may have potential implications for shaping overall sentiments regarding Apple’s market performance.
Conclusion
In our study, we employed the Stock Market Financial News API provided by EODHD to collect stock market news articles and utilized OpenAI’s sentiment analysis model to assess the sentiments conveyed in these articles.
To ensure seamless compatibility between our data and the OpenAI model, LangChain, a language processing tool, was utilized. To refine the inputs for the OpenAI model and improve the accuracy of our sentiment analysis, we implemented prompt engineering techniques. We conducted sentiment analysis on 100 articles to gauge the current market sentiment surrounding APPL stocks.
This holistic methodology enabled us to extract meaningful insights into market trends based on the sentiments expressed in the news. With that being said, you’ve reached the end of the article. Hope you learned something new and useful today. Thank you very much for your time.
0 notes
Text
Create Openbook Market ID - Raydium Market ID 0.23 SOL
What is an Openbook Market ID?
Raydium.io, one of the most popular DeFi platforms on the Solana network, requires you to create an "Openbook Market ID" to list and trade your token project on the platform. OpenBook is a decentralized and open-source tool of the Serum V3 program on Solana. Creating an Openbook Market ID is mandatory to list on DeFi platforms such as Raydium.io.
0.23 Creating a Market ID in exchange for SOL
The cost of creating a Market ID on Raydium.io is usually around "3 SOL". However, through Openbookgui.com, one of the platforms that supports Openbookv2, you can create a 100% compatible market ID for only 0.23 SOL. With this method, you can create a market ID that is fully compatible with Serum V3 liquidity. You can access the Openbookgui.com website via the following link https://www.openbookgui.com/
Note: On platforms like Dexlab, it is strongly discouraged to try to reduce the fee by changing the "Length" values. This is the wrong approach and can lead to errors in Serum V3 liquidity. As a result of these errors, users may encounter frequent errors in trading, which will seriously damage your project's reputation. I have made the video below for you to better understand all the steps and to see how easy the process is.
Steps to Create Openbook Market ID
First, go to https://www.openbookgui.com/ and connect your Phantom wallet (Openbook v2 is only supported by Phantom and requires a non-mobile device).
Base Mint: In this field you need to enter your token contract address.
Quote Mint: You do not need to change this field, but you can use USDC or USDT if you wish.
USDC Address: EPjFWdd5AufqSSqeM2qN1xzybapC8G4wEGGkZwyTDt1v
USDT Address: Es9vMFrzaCERmJfrF4H2FYD4KCoNkY11McCe8BenwNYB
Min. Order Size: This is set to "1" by default, but you can customize it if you want by referring to the table below.
Price Tick: This is set to "4" by default, but you can customize it.
You can use the examples below to customize your Tickers settings.
Review all your settings and make sure you have enough (0.23 SOL) in your account, then click the "Create" button to complete the process. Market ID creation takes approximately 15 seconds.
In my next article with more information about Raydium.io liquidity, I will try to explain the topic with simpler explanations and examples. Goodbye for now and good luck!
Openbook-v2: https://github.com/openbook-dex/openbook-v2/blob/master/idl/openbook_v2.json
56 notes
·
View notes