
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by burhanmuhammad and here's what we found interesting.
Average Info
Notes Per Post
0
Likes Per Post
0
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
13 days
Number of Posts By Type
Text
17
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. is using 66 technologies for its website.
Text
Reflection- Working with OpenMRS and Volunteering

Working with OpenMRS, an HFOSS platform that provides medical record system in resource constraint environments and over 41 countries, during my senior year of college has been an amazing learning experience for me. I was able to grow professionally and personally from the challenges, I had while working on different projects ranging from being a lead team member of the Website Squad to fixing and reproducing bugs on the backend.
I had never heard about OpenMRS or anything about HFOSS platforms before my senior year. Therefore, the number one thing I am very happy to learn is how I can volunteer at any time in my life to HFOSS projects like OpenMRS and use my skills for social good and sustainability. Working with OpenMRS strengthened my values about empathy and having a sense of personal responsibility to take initiative. Especially in this virtual world when physically volunteering is hard, anyone can be a part of an HFOSS platform and volunteer from the comfort of their homes. Therefore, after working with OpenMRS, I feel prepared for a life of civic engagement, plan to be involved with the community, and move my way upwards as a leader in the OpenMRS community.
Overall, my leadership skills have greatly improved as I have had the privilege to learn from inspiring leaders in the OpenMRS community. Their abilities to take on new initiatives and keep improving OpenMRS motivate me to pursue more leadership opportunities at OpenMRS. Working with OpenMRS was very open-ended, I was not just a developer but also a product manager since my team took the initiative of building the new website for the OpenMRS from scratch as the old one hasn’t been updated in over a decade and is not user friendly. Working with the website team, we set different goals for us every week and made a project timeline, and currently, we will soon be launching our beta site and migrating from our old website to the new beta site. Working with different stakeholders during this project prepared me to be organized with timelines and be strategic in my decision-making as this project required paying attention to the details from getting the user interaction right to providing the right functionality.
Another valuable outcome of working with OpenMRS was being able to take ownership of my work and present it at weekly meetings, quarterly showcases, and OpenMRS annual conferences. This made me feel like a true product manager as I was talking with key stakeholders and getting different feedbacks to list the requirements and features of the website. Moreover, I have always been passionate about diversity, equity, and inclusion (DEI), and recently I had a productive discussion with Jennifer, the community manager of OpenMRS, of how we can make OpenMRS more inclusive. There might be an opportunity coming that we will make a separate small team that will work on DEI initiatives, and I could get to lead that team. For example, I have some interesting collaboration ideas like connecting OpenMRS with several coding camps that serve underrepresented groups. This could help the students get some real-life experience before they apply for workforce. I am super excited to work on these initiatives later this year.
Overall, my interactions with the OpenMRS community made me feel welcomed and included and I feel very happy that I chose OpenMRS. I have developed strong relationships with the community members, and I wish to continue working with them and even try to pursue more leadership roles in the future.
0 notes
Text
History of Facial Recognition

While in the old days facial recognition was considered an idea of science fiction, in the past decade we have seen significant advancements in this technology and these days we barely see any technology without facial recognition capabilities in it. From surveillance cameras to mobile phones, to personal laptops, facial recognition is widely used now. This technology has become a vital part in function of law enforcement agencies, Retailers, Airports, manufacturing industry, and more. Let’s see how this technology evolved over time and how it was discovered.
Woodrow Wilson Bledsoe is considered a father of facial recognition. In 1960s, Bledsoe developed a system that could organize face’s photos by hand using the RAND tablet. With the help of this table, the operator could calculate the coordinates of facial features such as the center of pupils, the inside corner of eyes, the outside corner of eyes, point of widows' peak, and so on. These metrics could then be stored in a data base, so that if a new photograph is entered in the database, the operator could get the most closely resembled photograph. These manual measurements were an important step in the discovery of facial recognition (Source).
In 1970s, Goldstein, Harmon, and Lesk used 21 facial markers like lip thickness, hair color, etc. to add increased accuracy to the manual facial recognition. At this point the biometrics still had to be manually computed. Then in 1988, Sirovich and Kirby used linear algebra to the problem of facial recognition. This was known as the Eigenface approach which shows that over 100 values are required to accurately code a face image. 1991 marked the beginning of automatic face recognition when Turk and Pentland advanced the Eigenface approach by demonstrating how to detect faces within images. Moreover, in the period 1993-2000s, The Defense Advanced Research Projects Agency (DARPA) and the National Institute of Standards and Technology initiated the Face Recognition Technology (FERET) program to encourage the commercial facial recognition market. This program created a database of facial images and tested 2413 still facial images representing 856 people. In 2006, Face Recognition Grand Challenge (FRGC) to evaluate modern face recognition algorithm available. The challenge result showed that these new algorithms were 10 times more accurate than those in 2002 and 100 times more accurate than those in 2010 (Source).
Clearly, there were a lot of events that led to the advancement of these algorithms. From 2010- present, Facebook has been using the facial recognition functionality to identify people, and more than 350 million photos are uploaded and tagged each day using this technology. Another major recent breakthrough was the inclusion of facial recognition technology in iPhone X in 2017. This made facial recognition technology accessible to million of people and in this tech savvy world the dependence on facial recognition technologies is increasing. Today, we see this technology in almost every popular phone and laptop (Source).
0 notes
Text
Privacy and Personal Data

The conversation on privacy and protection of personal data has gained tremendous attention in the last few years, and with time it is expected that users will take privacy into serious considering when purchasing merchandise, signing up for email lists, downloading apps, and more. Protection and fair use of personal data is becoming essential for any company to keep public trust to prevent heavy fines by violating any privacy laws (Source). This blog will talk about some of the companies that have been accused of violating their customers’ privacy.
Number 1 on our list is the video conferencing tool Zoom that gave personal data to third parties without user knowledge. The New York Times alleged Zoom to be engaged in undisclosed data mining during user conversations. When a person signed into a meeting, Zoom transmitted their data to a system that matched individuals with their LinkedIn profiles. Zoom promised to disable the subscription-based tool called LinkedIn Sales Navigator that resulted in this privacy breach. Click here to read more about this controversy.
Facebook has also been fined $5 billion for its role in Cambridge Analytica Data Harvesting. Cambridge Analytica used a third-party app to harvest data from a Facebook quiz for political purposes. This scandal was a clear example of the violation of consumer privacy violation. Read more here.
Also, in 2019, Government officials around the world were targeted by hackers through Facebook’s WhatsApp. An Israeli hacking tool developer allegedly built and sold a product that allowed the infiltration of WhatsApp’s servers due to an identified weakness. This problem caused at least 1,400 users to have their mobile phones hacked within approximately two weeks in April and May 2019 (Source).
Uber, the most common ride-sharing platform, around the world disclosed that hackers stole information of about 57million Uber riders around the world. This also includes the names and driver’s license numbers of around 600,000 drivers in the United States. According to Bloomsburg report, Uber paid the hacker around $100,000 to stay quiet about the privacy breach and delete the data. However, eventually, the news went public in November 2017. Uber had to spend over $158 million to cover up the data breach. Read more here.
The above examples make it clear that even the best companies like Google Facebook have led people’s data being exposed. Therefore, moving forward in this digital era, it is vital that we not just read all privacy and user agreements before signing up for a service or app but also restrict the type and number of permissions that installed apps have on devices. Moreover, it is important to review all current privacy settings for apps and sites at least monthly, and tweaking them as necessary.
0 notes
Text
History of Quantum Computing

A quantum computer uses the principles of quantum mechanics to do things that are fundamentally impossible for any computer that only uses classical physics. This blog will give an overview some key events that led to the development of the first quantum computer and what the future of quantum computers look like.
The buzz around quantum computing started in 1980 when Physicist Richard Feynman proposed a basic model for a quantum computer that would be capable of stimulating the evolution of quantum systems in an efficient way. He proposed the possibility to exponentially outpace classical computers. In 1965, Feynman was awarded the Nobel prize for his contributions in quantum electrodynamics and was involved in the development of the first atomic bomb. A few decades later, he started exploring the representation of binary numbers in relation to the quantum states of two-state quantum systems.
Then in 1985, David Deutsch, of Oxford University published a theoretical paper to explain the concept of quantum ‘gates’ that function similarly to the binary logic gates in a classic computer. However, it wasn’t until 1994, when a special algorithm known as the Shor’s Algorithm was introduced. Peter Shor, working for AT&T, developed an algorithm that allows quantum computers to efficiently factorize large integers exponentially quicker than the best classical algorithm on traditional machines. This algorithm implied that public key cryptography might be easily broken given a sufficiently large quantum computer. Shor’s algorithm was demonstrated at IMB in 2001, factoring 15 into 3 and 5 using a quantum computer with 7 qubits.
Then in 1996, Lov Grover, an Indian American scientist, developed a quantum database search algorithm that quadrupled the speed of many problems. Grover’s work was an important factor in preparing the way for the quantum computing revolution that is still ongoing today.
In 1988, the first working quantum computer was built using 2-qubit, and it could be loaded with data to solve quantum algorithms like Grover’s algorithm. Finally, in 2017, IBM introduced the first commercially usable computer.
IBM promises to achieve the milestone of building a 1000-qubit quantum computer by 2023. In its roadmap, IMB wants to build a quantum computer with over a million qubits and hopes to achieve this within the next decade. The picture below summarizes their roadmap of building a quantum computer and more details of IBM’s roadmap to IBM’s roadmap for building an open quantum software ecosystem can be found here.

0 notes
Text
History of Internet of Things

The Internet of Things (IOT) refers to the billions of devices that are now connected to the internet, all collecting and sharing data. Examples range from a smart bulb that you can control with a mobile app to anything that can be connected to internet is part of IOT. Considering how popular IOT is today, it is worthwhile to take a closer look into its origin and background evolution.
The internet of things (IOT) is relatively a new concept, and the term was introduced in 1999 by Kevin Ashton to promote Radio-frequency identification (RFID) technology, meaning the term is just 16 years old. During his work with Procter & Gamble as part of RFID supply chain in1999, Ashton used the term IOT. Ashton mentions "I could be wrong, but I'm fairly sure the phrase "Internet of Things" started life as the title of a presentation I made at Procter & Gamble (P&G) in 1999. Linking the new idea of RFID in P&G's supply chain to the then-red-hot topic of the Internet was more than just a good way to get executive attention. It summed up an important insight which is still often misunderstood " (Source). A visionary technologist, Ashton played an essential role in the IOT history by using IOT as the title of his presentation.
While IOT has been a newer concept, there have been machines communicating with one another since the 1800’s. Machines have provided direct communication since the development of telegraph in the 1830s. Then, the first radio voice transmission known as wireless telegraphy happened on June 3, 1900 which paved the way for further development of IOT.
The development of IOT took many decades. In 1962, the internet started as part of Defense Advanced Research Projects Agency and evolved into ARPANET in 1969. The ARPANET evolved into the modern internet after commercial service providers started supporting public use of ARPANET. Then, in 1993, the Department of Defense Global launched 24 fully operational satellites- Global Positioning Satellites (GPS). Then several commercial satellites started orbiting the earth. Today, these satellites provide most of the communication for IOT.
It’s interesting that today we have more connected device than people as summarized in the image below (Source). For a comprehensive timeline on the history and evolution of IOT, please click here.

0 notes
Text
History of Government Surveillance

Surveillance started way before even the telephone was invented. A stroke broker, D.C Williams, wiretapped corporate telephone lines and sold the information he overheard to stock traders in 1864. Until the 1920s, wiretapping was only used among private detectives and corporations and was not as popular. Then in 1928 supreme court allowed police to wiretap. It took several decades when in 1950 public started to question and raise concerns about wiretapping.
Things escalated fast when in 1978 congress passed the Foreign Intelligence Surveillance Act (FISA) which gave the government the power to spy on foreign entities to prevent terrorism, but this act paved the way for increased surveillance and spying on Americans. In 2008, FISA was amended in Section 702 according to which communication of all Americans could be spied on by FBI or NSA programs. These NSA programs store phone calls, emails, location information, and web searches belonging to millions of Americans and are one of the biggest spying programs to exist. Today, the official website of FISA describes its motives as “ The Court entertains applications made by the United States Government for approval of electronic surveillance, physical search, and certain other forms of investigative actions for foreign intelligence purposes”.
After 9/11 happened, the national affairs were in a state of panic, and this is when the USA PATRIOT Act was born. The Patriot Act increases the governments' surveillance powers in record searches, secret searches, intelligent searches, and trap and trace searches. More of these can be found here.
Then, the Five Eyes Collective was established between five major western countries, including the US, UK, Canada, New Zealand, and Australia, so that these nations could protect any incoming terrorist attacks by sharing intelligence information.
Today, the unconstitutional surveillance program at issue is called PRISM, under which the NSA, FBI, and CIA gather and search through Americans’ international emails, internet calls, and chats without obtaining a warrant. When Prism started in 2013, it included major tech companies like Google, Facebook, Apple, Skype, and it now includes even a larger set of companies. It is predicted that the surveillance programs are only expected to increase in the future, with data of millions of people easily accessed by the government. What do you think about the future of surveillance? Do you fear for your privacy rights to be violated even further?
0 notes
Text
History of Biometrics
The term biometrics is derived from the Greek words “bio” which means life and “metrics” which means to measure. It is fascinating that biometrics has been there for thousands of years. People have used numerous methods of identification through ages, and the automation of biometrics in recent years is based on ideas that were originally conceived even hundreds or thousands of years ago.
Evidence has been found that fingerprints were used in Clay tablets during business transactions in 500 BC by Babylonians. Moreover, Chinese merchants used children’s palms and footprints for identification in the fourteenth century. In early Egyptian history, traders were distinguished by their physical characteristics.
Then in 1800s, as crime rates started to increase with the industrial revolution, the law enforcement used the Bertillon system invented in France. This system was prone to error as it only recorded arm-length, height, and other body measurements on index cards. In the late 1800s fingerprinting became mainstream to help in the identification of criminals and to be used to be as signatures on legal contracts. Sir Edward Henry, an Inspector General of Police in Bengal, India, developed the first system of classifying fingerprints and this system is still being used today. This not only became the most popular method in criminal identification but also opened a new field of research for scientists to discover physiological characteristics to be used for identification.
With the widespread use of computers in the late 20th century, new possibilities for digital biometrics emerged. Although the idea to use the iris for identification purposes was suggested in the 1930s, the first iris recognition algorithm wasn’t patented until 1994 and became available commercially the next year.
Below is the timeline for biometrics history summarized for the 19th century. More details about the comprehensive timeline can be found here.


0 notes
Text
History of Autonomous Cars

The driverless dream began soon after automobiles were created. The 1920s marked one of the highest death rates due to car accidents that made creators of automobiles think about ways they could reduce road accidents. Therefore, the idea of a driverless and autonomous car is introduced to lessen traffic jams on busy roads, ensure safety, and, of course, make money.
The picture below shows a three-wheeled, radio-controlled trailer called Radio Air Service on an Ohio air force base in 1921. Though some people might not consider it autonomous, it was still the very first driverless car. The in 1925, inventor Francis Houdina drove a radio-controlled car through the streets of Manhattan with no one at the steering wheel. This radio-controlled car could start its engine, change gears, and honk the car’s horn to alert other drivers (Source).
In 1969, John McCarthy who is referred to as one of the founding fathers in the field of artificial intelligence hinted towards autonomous cars in his essay “Computer-Controlled Cars”. This essay paved a way for other researchers to think more about the subject of cars operated through technology. Then in 1990, Dean Pomerleau, a Ph.D. researcher at Carnegie Mellon wrote a thesis on how thesis how neural networks could enable steering control in cars in real-time by taking raw images from the road. Then, in 1995 Pomerleau took his autonomous minivan which traveled 2,797 miles coast-to-coast from Pittsburgh to San Diego.
Fast forward from the 1900s to 2000s, Google launched its project on self-driving cars in 2008, which today we know as Waymo. Today, Waymo remains one of the biggest leaders in the field of autonomous cars (read more here).
0 notes
Text
History of Google Image Search Function
We rarely think that the world of glamour and entertainment could inspire advancements in tech. However, singer, actress, and American Idol judge, Jennifer Lopez or “J Lo” is the reason why the Google image search function was created.
Lopez wore a green Versace dress which sent the internet into meltdown at the Grammys in 2000. The dress was a stunning fashion statement that not only wowed the paparazzi and the Grammy audience but also representatives from Google report that the iconic green Versace dress and the subsequent explosion of internet searches for J-Lo, was the inspiration for Google Images.
Eric Schmidt, executive chairman of Google, mentions in Project Syndicate that: "At the time, it was the most popular search query we had ever seen. But we had no surefire way of getting users exactly what they wanted: J.Lo wearing that dress." Schmidt further says that as a result of these massive searches "Google Image Search was born" (source).
To celebrate the anniversary of this iconic moment, Google partnered with the Italian fashion designer, Versace, to recreate the dress which J Lo wore in Milan Fashion Week. The show even incorporated a demonstration of Google’s voice-activated AI helper, Google Assistant (source).
Below is the image of the dress that made Google’s team realize they had to upgrade the search engine’s capabilities.

0 notes
Text
Diversity and Inclusion in Open-Source Projects
Diversity refers to empowering people by respecting and appreciating what makes them different, in terms of age, gender, ethnicity, religion, disability, sexual orientation, education, and national origin. Inclusion refers to making sure that people from different backgrounds feel welcome. Today, Diversity and Inclusion is a big issue in the Open-Source community because we are seeing less representation of people of color, women, and LGBTQ people. This blog will talk more in depth about diversity in open source projects.
GitHub surveyed more than 5500 open-source users and their demographic information revealed that 95% of the participants were male whereas only 3 percent female 1 % non-binary people participated. The results highlight the male dominance in open source community (Source). These numbers are far worse than the national statistics as the Bureau of Labor Statistics reveals that among all the professional programmers, 16% are from ethnic minorities, 22.6% are female, and 34% are from Black, Asian, and Latino backgrounds (Source.)
It’s believed that these representation imbalances in the opensource community could make the diversity in tech even worse. In a survey conducted by GitHub, half of the participants reported that open-source projects were a significant factor for them to land jobs. The debate is if people from marginalized areas cannot contribute to the open-source projects, they would find it even harder to get job offers. Therefore, having open source project contribution as a job requirement could harm a company’s diversity efforts.
In my case, as a first-generation college student and a person of color, I need to work the maximum available hours (18) in a week to cover my college expenses which makes it hard for people like myself to find time to volunteer for FOSS projects. Therefore, if companies and colleges require students to participate in FOSS as part of their class projects, this could increase FOSS participation and diversity. Moreover, a survey by Github reveals that many marginalized people in tech have experienced something negative in the open source community as summarized in the figure below. These negative experiences like stereotyping, rudeness, name calling further leads to lesser participation by marginalized people.Therefore, Open Source managers should make strict guidelines on the code of conduct to prevent any of these negative experiences. More articles and guidelines on how to increase diversity in open-source projects can be found here.
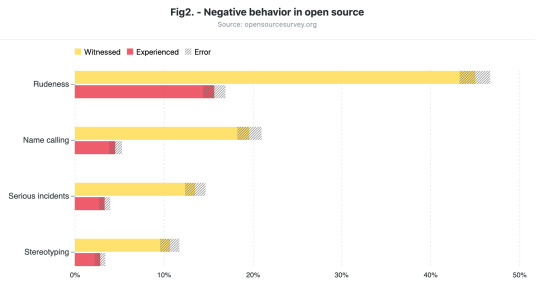
0 notes
Text
Open-Source vs Closed Source Software
With open-source software, the source code is publicly available for anyone to read or change. However, with closed source software (also known as proprietary software), the public is not given access to the source code, so they can’t see or modify it in any way.
Open-Source platforms are widely believed to be more reliable and secure than their closed source counterparts. The biggest advantage with open-source software if that you can verify yourself whether the code is secure, but with closed source software you must blindly trust the product. Moreover, with Open source, anyone can fix broken code while with closed source only vendor can fix it. This means that increased people are testing and fixing the code which makes open-source projects more secure. Moreover, OSS results in faster bug fixes, but with closed source software if a bug comes, you send a request and wait for the answer from the support team which makes the process slower (Source).
Some people debate that since anybody can view the code in an OSS, this gives hackers an advantage to look at code and exploit vulnerabilities. However, there have been cases when proprietary software has also been under attack. For example, in the pastMelissa Virus and ILoveYou Worm spread through Microsoft Word email attachments. which led Microsoft to completely shut down its inbound email system. Similarly, Wannacry is a global cyber-attack that happened in 2017. This was a ransomware crypto worm attack on computers with Windows operating system, and it did not let victims use their files on the hard disk until they paid a ransom in the cryptocurrency Bitcoin (Source).
Today, the vast majority of apps, games, and other popular software are closed source, so if you are like me and do not trust any closed source software, there are open-source alternatives available for these programs. For example, an open-source alternative to Microsoft Office is LibreOffice. Similarly, for Chrome, iTunes, and photoshop, we have Chromium, Rhythmbox, and GIMP as open-source alternatives, respectively. Other popular open-source examples include the Firefox web browser and WordPress blogging platform. To find out more alternatives click here. Moreover, the table below summarizes the popular alternatives.

0 notes
Text
Test Driven Development: Is it Worth it?

There’s a famous saying that all code is guilty unless proven innocent. This saying refers to Test-driven development (TDD) which is a development technique where you must first write a test that fails before you write new functional code. While this technique has become very popular over the last few years, many developers still believe that it’s not worth the effort. This blog will explore whether TDD is worth all the hype.
Why TDD? The simplest answer is that it is a good practice to achieve both good quality code and good test coverage. In summary, the three main rules that define mechanics of TDD include:
Write a test for the next bit of functionality you want to add.
Write the functional code until the test passes.
Refactor both new and old code to make it well structure.
In simple terms, test cases for each functionality are written and tested first and if the test fails then the new code is written to pass the test and make the code simple and bug-free. This earlier detection of ambiguities in requirements enables improved maintainability and changeability of codebases. Moreover, TDD gives better and self-documented software. It is believed that TDD leads to improved design qualities in the code and a higher degree of technical quality. Some developers also name TDD as Test-Driven Design because the basics of TDD involve using small tests to design systems and to instantly get value while building confidence in the system. One common misconception about TDD is that it is time-consuming and can cost more. While project build-outs take up to 30% longer with TDD, it reduces production bug density 40% — 80%. More bugs in the production could lead to increased maintenance costs. Therefore, it is better to have TDD even if you do ‘not have a budget or time for it because eventually, it could cost you more (Source ). However, TDD has some pitfalls which include too many tests at once for individuals or forgetting to run tests frequently. Test suites are hard to maintain and poor maintenance of test suits could result in long running time (Source). In summary, while there are some pitfalls including extra initial time and costs, it is a good investment of time and money because overall you get better code and save even more time and expense in the future.
Source for the image (here).
0 notes
Text
Testing Methods- Black/White/Grey
Software testing has different methods, and this blog will cover Black-Box Testing, White-Box Testing, and Grey-Box Testing. The diagram below summarizes their differences (source).
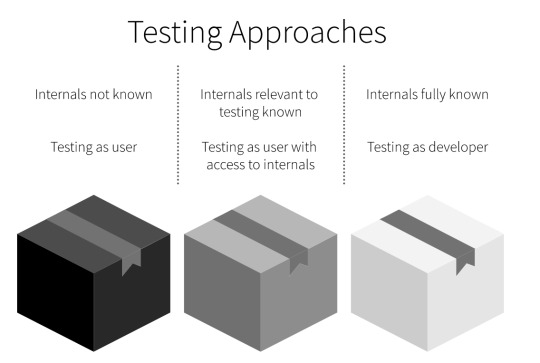
Black-Box testing, which is also known as closed-box testing, data-driven testing, or functional testing, is a technique of testing that requires no knowledge of the interior workings of the application. The tester is oblivious to the system architecture and the source code is not accessible. This means that many testers including from lower skill levels can test the application with no or little knowledge of implementation, programming language, or operating systems. This reduces the costs. Black-Box Testing is particularly useful when testing for large code sections as code access is not required. However, the test cases are difficult to design for this type of testing and only a limited number of test scenarios are performed.
In contrast with Black- Box Testing, in White Box Testing the tester has full knowledge of the internal workings of the application. White Box Testing is also known as clear-box testing, structural testing, or code-based testing. Because it requires testers to review the source code, it becomes easier to find out which type of data can help in testing the application effectively. However, this requires a more skilled level tester which increases costs. It also becomes hard to maintain white box testing because it is dependent on special tools like code analyzers and debugging tools.
Apart from Black-Box Testing and White-Box Testing, Grey-Box Testing is a combination of Black-box Testing and White Box Testing. The tester has limited knowledge of the internal working of the application. Just like Black-Box Testing, Grey Box testing is performed by end-users, also sometimes by testers and developers while White-Box Testing is normally performed by testers and developers. Just like Black-Box Testing being least time consuming and White-Box testing being the most time consuming, Grey-box Testing is partially time-consuming and exhaustive. Moreover, both Black-Box Testing and Grey-Box testing are not suitable for algorithm testing and only White-Box testing is suitable for algorithm testing. Read more about the difference and similarities between each of these three types of testing here.
0 notes
Text
Double Dispatch
Double dispatch is a technical term to describe the process of determining the method to invoke at runtime based both on receiver and argument types.The presence of Double Dispatch generally means that each type in a hierarchy has special handling code within another hierarchy of types. This approach to representing variant behavior leads to code that is less resilient to future changes as well as being more difficult to extend.
Languages like Java, Javascript, C++, Python support only Single Dispatch polymorphism which is the selection of the method to call based on one object. We can simulate the second level of polymorphism using Visitor pattern which makes it possible to define a new operation for classes of an object structure without changing the classes. More about techniques that developers can employ to use double dispatch can be found here.
Double Dispatch is often confused with overloading. The Difference between overloading and Multiple Dispatch is when the method to be called is decided at compile time then it is Overloading if the method is decided at runtime then it is multiple dispatch.
0 notes
Text
Foss Licensing
GPLv3, the third version of GNU General Public License (GPL) was a topic of intense debate and one of the most controversial developments ever in the free and open-source software (FOSS) communities.
While language changes to improve international use are relatively uncontroversial, other changes in the new version is hotly debated, including the section about patents, with its language to prevent a reoccurrence of the Microsoft-Novell deal signed in November 2007, and sections that restrict the use of the license with lockdown technologies. The GPLv3 contains an explicit patent license, so that people who license a program under the GPL license both copyrights as well as patents to the extent that this is necessary to use the code licensed by them. A comprehensive patent license is not thereby granted. Moreover, the new patent clause attempts to protect the user from the consequences of agreements between patent owners and licensees of the GPL that only benefit some of the licensees (corresponding to the Microsoft/Novell deal).
Some companies have created various kinds of devices that run GPLed software, and then rigged the hardware so that they can change the software that’s running, but you cannot. If a device can run arbitrary software, it’s a general-purpose computer, and its owner should control what it does. When a device thwarts you from doing that, we call that tivoization. GPLv3 stops tivoization by requiring the distributor to provide you with whatever information or data is necessary to install modified software on the device. Therefore, GPLv3 only stops people from taking away the rights that the license provides you. More details about incentives and objectives to tivoization can be found here.
Linus Torvalds, the leader of the Linux kernel project and one of the GPLv3's most vocal critics, did not support the VPLv3. He argued that GPL is a software license and thus it should not affect hardware. He not only believed that an anti-tivoization clause would restrict the freedom of product developers but also such a clause could make developers use property software instead of free software. He also argued that it would be better to let the free market decide about tivoization rather than trying to force a decision by non-market means.
0 notes
Text
Implementation Plan
The plan contains an overview of the system, a brief description of the major tasks involved in the implementation, the overall resources needed to support the implementation effort (such as hardware, software. facilities, materials, and personnel), and any site-specific implementation requirements. The plan is developed during the Design Phase and is updated during the Development Phase; the final version is provided in the Integration and Test Phase and is used for guidance during the Implementation Phase. The diagram below shows wherein a software development life cycle, the implementation phase fits (source).

In order to achieve deliverables of acceptance and meeting of objectives, the new system being built must be tested. Aligned with this, the end-users must be fully trained so the company will benefit from the new system. The activities that must be performed during the implementation phase include setting up the data, constructing software components, user/system documentation, training, and the best way to changeover. These activities are described below in more detail and links are provided for their respective sources.
Setting up the Data: The data conversion needs careful planning and can be divided into sections including what needs doing, when to do it, acquire conversion software, test new data against old, and perform the conversion.
Coding & Testing Phase. Includes implementation of the design specified in the design document into executable programming language code. The output of the coding phase is the source code for the software that acts as input to the testing and maintenance phase. The output of the testing phase is a test report containing errors that occurred while testing the application. This phase is complete when all the requirements have been met and when the result corresponds to the design.
Documentation: A system documentation is created during the system development phase. It includes things like source code, testing documentation, and API documentation (programmers' documentation or instructions). A user documentation needs to be created for end-users to explain how to interact with the system.
Training. Training is another important aspect to consider for a good implementation plan. The project team will train other employees who will then start working in the new system, and evaluate the changeover options
Installation / changeover. We must think about, method of installation, disruption to the organization, training, and familiarization, and evaluation. We can consider different methods of changeovers including direct changeover, parallel running, or gradually phased conversion.
Implementation Schedule. A Gantt chart can be used to keep track of strategic goals and manage the implementation schedule.
0 notes
Text
Version Control- Git Merge VS Rebase
Version control systems are a category of software tools that help a software team manage changes to source code over time. A huge number of software projects rely on Git for version control. One of the most talked-about topics in the Git community is understanding git merge and rebase. Therefore, this blog will compare Git merge with Git rebase.
Git merge is a command that allows you to merge branches from Git whereas Git rebase is a command that allows developers to integrate changes from one branch to another. They both integrate changes from one branch to another, but they do it in very different ways. The diagram below summarizes how git Merge and git Rebase integrate changes (Source).

From further research, I found both merge and rebase have their own pros and cons. Git rebase streamlines a complex history and cleans intermediate commits by making them a single commit, which can be helpful for the DevOps team. However, merge preserves entire history in chronological order, but it can clutter up Git logs and make it much more difficult to understand the flow of your project’s history. On the contrary, rebasing results in the linear project history, making it easier to use commands like git log, git bisect, and gitk. In summary, merge preserves history whereas rebase rewrites it.
When to use Merge or Rebase? Rebase should be used when working with small teams whereas merge should be used when working with large teams. It is advised that rebase should never be used on public branches. More about how and when to use git merge vs rebase can be found in this article from FreeCodeCamp.
0 notes