
Statistics
We looked inside some of the posts by codenvy and here's what we found interesting.
Average Info
Notes Per Post
3
Likes Per Post
3
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
3 days
Number of Posts By Type
Text
17
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. has $15.1M in annual revenue.
Text
Maximizing Developer Productivity: Fighting Merge Costs
Linus Torvalds is an outlier. A genius solo developer in the land of team-based development, he created two landmark pieces of software largely on his own: the Linux kernel in 1991 and Git in 2005. Today, these mega-projects are poster-children for team development. Literally thousands of contributors now maintain and update these critical open source projects.
Modern software development requires dozens and even hundreds of developers working together on a given project. With so many people involved, synchronizing an accurate and stable configuration across the many separate machines becomes burdensome.
Merge: The Cost That Affects Everything
Versioning tools like Git have made team development infinitely easier, but they only sync the code base, not the actual development environment. This means conflicts still occur. Desktop IDEs simply aren’t optimized for this type of collaborative work. Even with elaborate systems to synchronize configurations across machines, routine updates and desktop customizations quickly throw things out of sync.
Achieving IDE synchronization across identical hardware and software environments is hard enough, but it’s even harder across heterogeneous hardware and OS configurations.
This hits at one of the core weaknesses of desktop IDEs: with so many people administering their own environment, it’s nearly impossible to avoid conflicts and errors.
Solo developers are faced with the prospect of hauling their laptops with them everywhere they go or attempting to sync their own machines in much the same way as small teams.
Codenvy: Frictionless Merge
With a cloud IDE, there is only one configuration for a given workspace. Once one person has properly assessed the workspace, it’s functional for every team member. There’s no need to worry about environmental sync when everyone can simply access the same environment.
Plus, it doesn’t matter if you’re working from your everyday workstation, backup laptop, or a borrowed machine. The environment is always the same.
Codenvy’s cloud approach has not only created an environment where merge costs have virtually disappeared; it's enabled a whole new series of features and use cases simply not possible with traditional desktop IDEs.
Factory: An Entire IDE and Workspace, Disguised as a URL
Our Factory mechanism allows developers to clone entire workspaces and represent them as a single URL. They can then share that URL with other users. Everything is copied into a new sandbox: files, code, IDE configuration, build, and runtime configuration. Anyone following the URL will start out in an environment seeing exactly what you saw when you created the Factory.
Test drive our JSP and PHP factories!
Real-Time Collaboration
Users can also invite fellow developers to join their workspaces in either read-only or read/write mode. While in the workspace, the different users can chat with one another, see one another’s edits being made in real time, and send code pointers. Using one configuration means there’s no need to worry about sync; the environment is always the same.
These instant access capabilities also create new and exciting possibilities for corporate teams. Some examples:
Separating duties by position (admin, developer, manager) is now as simple as assigning differing access privileges. Developers code. Admins configure. Managers monitor.
Offshore and offsite developers can be managed with policy-based workspaces
Back-end developers can create APIs and SDKs that can be accessed quickly by their front-end compatriots.
Publishers can provide easy on-boarding for consumers of their APIs
Codenvy: the ultimate team IDE.
1 note
·
View note
Text
Virtual File System: 3 of 3
This is the third in a three-part series about the virtual file system (VFS) that underlies the Codenvy platform.
Codenvy’s platform is different from most cloud IDEs. A developer’s workspace is virtualized across different physical resources that are used to service different IDE functions. Dependency management, build, runners and code assistants can execute on different clusters of physical nodes. In order to properly virtualize access to all of these resources, we needed to implement a VFS that underpins the services and physical resources but also has a native understanding of IDE behavior.
Previously, we explored our VFS requirements, how we implement it, user access and what the organizational structure looks like. We also covered how a VFS can help with managing data, including access, modification and manipulation, as well as downloading and uploading information.
In this post, we’ll talk about how to use search in the workspace, along with access control, locking, versioning and observation within the VFS.
Search
The VFS may support querying, but it will not specify which query language it supports, so it will be implementation-specific. The QUERY information in the VFS’s information will show whether the VFS supports a specific implementation.
The QUERY capability field will have one of the following values:
NONE: querying is not supported
PROPERTIES: querying is only supported for properties
FULLTEXT: querying is only supported for full-text search
BOTHSEPARATE: Both properties and full-text are supported but not in one statement
BOTHCOMBINED: Both properties and full-text are supported in one statement
There are two search methods that will return the JSON with a query result:
GET request to /search: sends a QUERY string as well as the paging parameters (offset and number of items to return)
POST request application/x-www-form-urlencoded to /search: sends a set of opaque parameters in the QUERY statement, and is convenient for requesting from HTML FORMs.
The VFS system has been structured to allow for queries, search, and sort mechanisms of projects through HTML applications that are not within the IDE. This would allow developers to create their own applications that interact directly with Codenvy workspaces living on the VFS.
Creating a query statement using the POST request’s parameters is implementation-specific.
Access Control
The VFS may support access control. The Access Control List (ACL) in the VFS’s info can help determine if it is supported in the VFS.
The ACL will have one of the following values:
NONE: ACL is not supported
READ: ACL can be discovered but not updated
MANAGE: ACL can be discovered and updated
There are three basic, self-explained permissions that apply to resources:
READ
WRITE
UPDATE_ACL
There are two access control methods of note:
Call a GET request to vfsURI>/acl/{resourceUID} to retrieve a resource’s ACL in JSON format
Call a POST request to vfsURI>/acl/{resourceUID} to update a resource���s ACL in JSON format. The new ACL should be included in the request.
The POST request may include two query parameters:
override = true|false: if true, the previous ACL will be overridden; otherwise, the new version will be merged with the previous ACL
lockToken
Locking
The VFS may also support resource Locking. The VFS’s info contains a Boolean field called LOCK_SUPPORTED that will help determine whether it supports this capability.
There are two lock management methods :
/lock/{resourceUID}: locks the resource
/unlock/{resourceUID}: unlocks the resource
The unlock method should also contain the parameter lockToken to compare with the lock token applied to the requested resource.
Additionally, if the VFS supports locking all the appropriate (write) methods (as specified in their signature), compare the lockToken parameter with the lock token assigned to the requested resource.
Versioning
The VFS may also support file content Versioning. The VFS’s info contains a Boolean field called VERSIONING_SUPPORTED that will help determine whether it supports this capability.
If the VFS supports Versioning, each time a file’s content is updated by calling a POST request to /content/{fileUID}, a new version of the file will be created. The parameter versionID can be used to retrieve a specific version of the file. This method is triggered by calling a GET request to /content/{fileUID}.
There are two GET requests that will retrieve version-related information about a file:
/version/{resourceUID}/{versionID}: retrieves a specific version’s content
/version-history/{resourceUID}:retrieves the file’s version history in JSON format.
The version-history method may also use an optional property filter that will only retrieve specific properties for returning resources and pagination parameters (e.g., number of items returned, number of first item).
Observation
The VFS may also support Observation for Projects, which will allow a client to watch changes happen in a project in real time.
There are two methods for watch/unwatch Project:
GET request to /watch/start/{projectUID}starts watching the Project
GET request to /watch/stop/{projectUID}stops watching the Project
Note that the means by which the client is notified about updates are implementation-specific. The EventListener pattern for registering and handling VFS specific events can help determine whether the implementation is supported.
Conclusion
We hope that you've found this exploration of Codenvy's underlying VFS interesting. We chose this architecture in order to produce a stable, scalable, and highly extensible platform to underlie our core products.
Stay tuned for our upcoming R&D series as we continue exploring the technical side of what makes Codenvy so exceptional.
1 note
·
View note
Text
Maximizing Developer Productivity: Fighting Best Practices and Policy Costs
Back in 1976, Steve Wozniak wrote a little program called "Apple OS". He did it by himself, on paper, with minimal assistance. Then he typed out the whole thing in assembly language. It compiled without a single error.
Impressive. But not how we do things today.
Fifteen years later, Linus Torvalds wrote what became the basis of the Linux kernel, also more or less by himself. That was probably the last major operating system written by a single developer. In fact, it's been a long time since any major software was developed or maintained by a "lone wolf developer."
Today's Linux? Recent estimates put Linus' personal contribution at less than 2 percent of the overall code base. There are thousands of contributors.
Modern software development, especially at the enterprise level, is clearly a team process. Yet most desktop IDEs were written with individual developers and workflows in mind. Although they have occasionally been retrofitted with team-oriented plugins and add-ons, some of the core ways in which they handle team development is suboptimum.
For example, having large numbers of developers working together requires everyone to follow common practices. But even when everyone tries to use the same guidelines, there’s no guarantee that development policies are being observed. Teams have to consistently use the tools in the exact same way in order to guard themselves against misfires and errors. And that runs counter to human nature.
It boils down to this: In a large distributed team environment, it's virtually impossible to cost-effectively enforce company-wide policies and best practices across dozens of desktop IDEs.
It's a (Find)Bug's Life
For example, when using Eclipse*, Java developers will often run the open-source FindBugs program. FindBugs is a static code analysis tool that analyzes Java bytecode to detect a wide range of problems. It's highly valuable for companies with big development teams that need a basic and effective way to scan for potential issues.
FindBugs: Finding Bugs in Java Programs, One Desktop at a Time
Having a safety net like Findbugs only works if all the developers are using it in the same way with every commit. Even if each team member has the plugin, there's no guarantee that they'll follow the company's policy on how to run it. Some may miss errors, others may have trouble following the directions, some may forget to run it, and still more may decide not to use it at all.
A simple policy when considered on the individual level becomes increasingly troublesome as you apply it to dozens of developers across several continents – all developing on individual desktop IDEs.
Some organizations compensate for this lack of consistency by moving tasks that must be performed consistently by developers into the Continuous Integration process, which runs after developers commit their code. This best practice can only do so much, as CI cannot be extended to tasks run prior to code commits. What's more, build failures by CI systems can still occur for individuals who fail to follow policy before their code commit.
The Tool Teams Deserve
A cloud IDE can eliminate problems caused by inconsistent policies. Using Codenvy makes it simple to implement tools and policies across large groups of people. In Codenvy, developer workspaces are centrally managed and cloned from templates. This means each developer can access an IDE that can be configured to operate similarly with common plugins, parameters, configuration settings, and policy requirements.
With centralized control, the system can be extended to enforce certain workflows. For example, if a developer on a team has been idle for more than 30 minutes and their code hasn't been committed, a labeled check-in can be automated. Similarly, certain IDE functions, like refactor, can only be executed if file-qualifying criteria are met. Essentially, conditions to ensure overall consistency of the software can be inserted into every developer's workflow.
Attempting to implement policies in a desktop IDE environment simply can't compare to the consistency Codenvgdgdgy ofThe days of the lone wolf developer may be fading, but the days of inspired development are still going strong. With Codenvy, teams can change the world faster than ever.
*We've gotten a few questions about why we keep picking on Eclipse. It's simple: According to our pals over at ZeroTurnaround, Eclipse is by far the most popular desktop IDE. The problems we discuss aren't specific to Eclipse; they apply to desktop IDEs in general.
Speaking of ZeroTurnaround, a while back, we integrated their JRebel plugin to Codenvy. Check it out!
1 note
·
View note
Text
Case Study: Jason Kennedy and the Disappearing Project
“I can log into Codenvy from any operating system, and everything is there, loaded and ready and set up. I think that, more than anything, is the big draw for me.” – Jason Kennedy, Seattle-based systems administrator
Jason Kennedy is a clinical IS support analyst at SCCA Proton Therapy, a ProCure Center. He’s heavily involved with Seattle’s Google Developer Group, which has recently been doing a lot of preparation for the GDG DevFest this September.
Jason is also a prolific writer, with a number of articles published by TechHive and PCWorld. His most recent PCWorld article outlines the ways in which developers can use Chromebook Pixels for their everyday developing tasks.
Codenvy to the Rescue
The initial driving factor for trying Codenvy was Jason’s interest in using the Chromebook for development. “A lot of people feel that the Chromebook is just a computer shell with a browser,” he explained. In a recent Chromebook presentation, Jason decided to use Codenvy as an alternative to a traditional IDE like Eclipse.
Using Codenvy ended up saving Jason’s presentation, due to an unexpected twist that occurred just before he left for the venue. “I had Eclipse in a CH root running in Ubuntu so I could compare it to Codenvy to say, ‘I don’t need to use Eclipse; I can do all of this using Codenvy,’” Jason said. “But someone accidentally wiped everything out in my Eclipse environment right before I was going to walk out, so I didn’t have an hour or two to set everything back up.”
While this meant Jason couldn’t compare Codenvy to Eclipse in his presentation, his story ended up being a great addition. “Everybody there who was a developer already knew what had gone wrong,” he laughed. But because he’d used Codenvy, he was able to quickly log into his account and access his development environment.
Learning New Languages
Codenvy is also helping Jason learn programming languages like Ruby and Python. Instead of having to spend days and days setting up a new environment, he can just log into his Codenvy account and have everything he needs ready to go instantly. For a developer unfamiliar with a new language, the additional saved time is more than convenient: It’s salvation.
More Than Meets the Eye
With Codenvy, Jason has been able to solve a variety of problems at once. He’s excited to see how using Codenvy can save him time and stress in the future. As he put it to us, “I can walk into an empty office here at work, log into Codenvy on a zero client, and just bang out code during lunch, on my break, or whenever. That’s why it’s the one I’m sticking with.”
0 notes
Text
Codenvy Tutorials: Fetch URL Links Faster
Figuring out how to package all the links associated with a specific webpage can be a hassle. jsoup is a Java library that provides a very convenient API for extracting and manipulating DATA, using the best of DOM, CSS, and jquery-like methods. Codenvy has created a tutorial that walks users through fetching the all the links associated with a given URL (e.g., images, hyperlinks) using jsoup. In the tutorial, we’ll walk through each step, from creating a project through building and running the application. It's just one more way we're helping to save you time and energy.
jsoup use in Codenvy
Other Recent Tutorials
Apache Commons FileUpload
Using the Commons File Upload package in Codenvy makes it easy to add robust, high-performance, file upload capability to your servlets and web applications.
Active Network
Using the Active Network APi in conjunction with Codenvy can help extract information of various activities anywhere such as sports events, campgrounds etc. into your application.
Sports Data API
Using the Sports Data API with Codenvy will enable you to extract information of various sports events such as information of game schedules, team details, player details, etc. into your application.
Harper Collins
Integrating the Harper Collins API with Codenvy will help you extract information of various books and publications of Harper Collins into your application.
0 notes
Text
Throwback Thursday: Out of the World ROI
An ROI in the thousands sounds, well, impossible. But that's exactly what developers using Codenvy get in return.
Don't believe us? We did the math and figured it out for you. Read all about it in Our ROI Numbers are Embarrassing.
0 notes
Text
Virtual File System: 2 of 3
This is the second in a three-part series about the virtual file system (VFS) that underlies the Codenvy platform.
Codenvy’s platform is different from most cloud IDEs. A developer’s workspace is virtualized across different physical resources that are used to service different IDE functions. Dependency management, build, runners and code assistants can execute on different clusters of physical nodes. In order to properly virtualize access to all of these resources, we needed to implement a VFS that underpins the services and physical resources but also has a native understanding of IDE behavior.
In our previous post, we explored our VFS requirements, how we implement it, user access and what the organizational structure looks like. In this post, we’ll cover how a VFS can help with managing data, including access, modification and manipulation. We’ll also talk about downloading and uploading information.
JSON-based Virtual File System
All file discovery, loading and access take place over a custom API. This API uses JSON to pass parameters back and forth between IDE clients. Compare the file access in a cloud IDE to that of a desktop IDE. In a desktop IDE, the application has local access to the disk drive and uses native commands to manipulate the files and defers to the operating system to provide critical functions around locking, seeking and other forms of access.
But in a cloud environment, there are many IDEs operating simultaneously distributed across a number of physical nodes. The IDEs are coordinating using a set of code assistants, builders and runners that are also on distributed nodes. A workspace may be accessed by multiple developers simultaneously, running in different IDEs, also on different nodes. The role of a VFS, then, is not only to provide access to the files, but also to provide distributed, controlled access to the files.
By using a RESTful API with JSON, we are able to standardize the techniques used by different types of clients, whether those clients are running within our infrastructure or directly accessed by a browser. We needed to take the core operating system functions relating to file manipulation and access and package them up into this format.
The rest of this article goes into some of the API structure details related to navigating the tree, identifying special nodes (e.g., Projects), handling file modification tactics such as copy/remove, modifying the core contents of a file and downloading/uploading a file.
Data Access Methods
Codenvy's VFS API provides methods for:
Navigating the resource tree step by step
Accessing a particular resource directly by using its unique identifier (UID) or Path
You can access data via its root Folder.
GET Children
Children resources description in JSON format can be accessed by calling the <vfsURI>/children/{UID}? method with a GET request including:
Parent folder ID
Pagination parameters, such as number of returning items and number of first item for convenient output
An optional filter to retrieve resources of a particular type (File, Folder or Project)
An optional filter to retrieve resources with particular properties
An optional filter to retrieve resources based on whether they contain permission info
GET Tree
The entire structure, as well as individual substructures, of descendants’ description can be accessed in JSON format by calling the <vfsURI>/tree/{UID} method with a GET request including:
Parent folder ID
Depth it should go to discover children. Using a -1 value will retrieve all children at all levels
An optional filter to retrieve resources with particular properties
An optional filter to retrieve resources based on whether they contain permission info
The resources using either the UID or Path can be accessed by calling either the <vfsURI>/item/{UID} or <vfsURI>/itembypath/{Path:.*}method. The identifier (UID or Path) will accept:
An optional filter to retrieve resources with particular properties
An optional filter to retrieve resources based on whether they contain permission info
Here is an example of a JSON response for a single resource description as part of a response to any of the methods mentioned above:
{
"id":"/folder01/DOCUMENT01.txt",
"type":"FILE",
"path":"/folder01/DOCUMENT01.txt",
"versionId":"current",
"creationDate":1292574268440,
"contentType":"text/plain",
"length":100,
"lastModificationDate":1292574268440
"locked":false,
"properties":[],
}
Like the resource description, the file content can be obtained with a GET request to either the <vfsURI>/content/{UID} method or the <vfsURI>/contentbypath/{Path:.*} method. Each of them will return the requested file content in the response body with an appropriate content type header.
Data Modification Methods
There are three resource types:
Files, which can be categorized differently and which have bodies with useful (indexable, searchable) content
Folders, the standard structure unit
Projects, a special type of Folder with a set of properties that help identify that project’s nature, appropriate actions, views, etc.
This hierarchical organization manages the VFS’s structure in the following ways:
Only Projects are allowed to be the top-level resource (i.e., have workspace’s root folder as a parent).
Projects may have Files, Folders or other Projects (for multi-module Project) as child resources.
Folders may have Files or Folders as child resources.
To launch data modification methods, call a POST request to the following methods in order:
Doing this will return a JSON describing a newly created resource. All the methods should also return the name of a new item. For a file, the client should pass content type (MIME) of creating file and (optional) the initial content. Additionally, the client may pass Project properties when calling a Project. To make specific modifications, call a POST request to the following methods:
<vfsURI>/delete/{resourceUID} to delete a resource
<vfsURI>/content/{fileUID} to update files
<vfsURI>/item/{resourceUID} to update resource properties
New content and JSON serialized property sets are passed in the request’s body. If the VFS supports Locking and the item is locked, use lockTokento unlock it.
Data Manipulation Methods (Copy, Move, Rename)
To copy or move a resource identified by {resourceUID}, call a POST request to <vfsURI>/copy/{resourceUID} or <vfsURI>/move/{resourceUID}. In either case, a new parent UID should be passed as a query parameter and for move method lockToken should be respected as well (as described above). To rename a resource or to change the File’s content type, call a POST request to <vfsURI>/rename/{resourceUID} with the new resource name, new content type and lock token.
Mass Update Methods (Downloading/Uploading)
There are four methods (two complementary pairs) for uploading and downloading zipped trees of resources. The first pair is mostly used for simple HTTP clients. They pass application/zip content back and forth using this sequence:
Call on the GET method <vfsURI>/export/{folderUID} to downloada zipped resources tree.
Call on the POST method <vfsURI>/import/{parentUID} to upload a zipped resources tree to the parent Folder (or Project).
The second pair is mostly used in web browsers and follows this sequence:
Call on the GET method <vfsURI>/downloadzip/{folderUID} to download the zipped folder. Like the HTTP clients, the application/zip is in a body. However, the response must contain a 'Content-Disposition' header to force the browser to save the file.
Call on the POST method <vfsURI>/uploadzip/{folderUID} to upload the zipped folder. The content is supposed to be sent in HTML form, so zip content is a part of 'multipart/form-data request.'
There are also methods for uploading and downloading file content:
Call on the GET method <vfsURI>/downloadfile/{fileUID} to download file content. To force the web browser to save the file, the response must contain a 'Content-Disposition' header.
Call on the POST method <vfsURI>/uploadfile/{fileUID} to upload file content. The file’s content is part of 'multipart/form-data request'; e.g., content sent from HTML form.
In the next article, we'll talk about how to use search in the workspace, along with access control, locking, versioning and observation within the VFS.
0 notes
Text
Maximizing Developer Productivity: Fighting Maintenance Costs
A Lot to Maintain: Runtime, Build System, IDE, and Plug-Ins
In addition to the time sink of installing all the components of a desktop IDE, developers also have to keep their environments up to date and synced with their teammates. Each component has a different life cycle for managing versions, patches, and compatibility. Some need frequent updating and may even require rebooting the computer.
All this extra work takes time. It wouldn't be too bad if upgrades went smoothly, but they often don't. Just ask any Eclipse developer how many times they've gotten a "Could Not Complete" message when updating a plug-in.
Often, one version of a given component might conflict with some, but not all, versions of another. This leads to developers playing "Whack-a-Mole" trying to figure out which update needs to be reversed to stabilize their system.
[photo by magic_bee]
Maintenance ^ # of Components
Maintaining a desktop IDE becomes significantly more demanding as individual environments become more complex. Each additional required component results in an exponential increase in the chance of a conflict. Many developers resort to constant "Uninstalls/Reinstalls" rather than trying to resolve conflicts among various updated components.
Let's pick on Eclipseagain. It's one of the most commonly used IDEs, but it imposes an administrative penalty on the developers who depend on it. For instance, developers using Eclipse need plug-ins to do practically anything. Eclipse doesn't natively support basic functionality like Maven, sbt, git, or svn without a standard packaging plug-in loaded. This functionality is supplied either by a pre-populated package or by combining individual plug-ins that have to be maintained separately.
Performing more involved tasks means installing more plug-ins. Some are well maintained and usually don't cause conflicts. But some components (and sometimes Eclipse itself) seem to have been practically abandoned by the community. Critical bugs can take years to get resolved. As a result, developers end up relying on out-of-date components. These decaying components are effectively time bombs just waiting to crash the system.
Maintenance ^ #of Developers
All of this takes a toll on just one developer working alone. Multiply it by an entire team trying to keep their systems both synced and running smoothly, and you're looking at larger losses of productivity.
Adaptable Doesn't Have to Mean Painful
The decentralized setup of Eclipse’s plug-in system practically guarantees chaos and conflicts. However, it also results in flexibility and customizability that Eclipse developers don't want to give up.
At Codenvy, we didn't want to lose that flexibility either. We just wanted to code.
That's why we built our platform to be extensible in much the same way Eclipse is. You'll find many integrations and plug-ins are already available, with many more to come. But, unlike Eclipse, Codenvy ensures that all components are up to date and every configuration is thoroughly tested to avoid conflicts. In the next few months, we'll start to release the Codenvy SDK directly to the public, so you can create your own extensions.
Focus on Your Own Bugs, Not the IDE's.
Instant provisioning means more than just instant access to your editor. It means instant access to a flexible, pre-built, and tested development environment that is maintained for you.
The average developer spends 13 hours a week maintaining their desktop IDE. With Codenvy, you can quit administering your IDE and get back to work.
Save "Whack-a-Mole" for your next trip to the arcade.
0 notes
Text
Codenvy Tutorials: Are analytics part of your IDE tool belt?

Building apps with built-in dashboards and analytics is becoming more and more popular, and you don’t want to be the kid left out. Codenvy has teamed up with Keen.io and put together a tutorial with an example application to get you started. Since Codenvy is a cloud IDE, you can work on your analytics dashboard from anywhere. Keen.io makes it simple to provide in app friendly UI/UX dashboard components. You can manage your events through your Keen.io dashboard. We're pretty sure using this makes you the cool kid.
Codenvy Integration with Keen.io
Other Recent Tutorials
Lucene
This tutorial shows you how use Lucene, a Java-based indexing and search library. Using Lucene in tandem with Codenvy can enrich your app.
log4j
This tutorials demonstrates how to use log4j to take events from your application and log them into the logs on your server. Using Codenvy, you can see your test events logged into the local logs.
itext
itext offers a library that helps you quickly create, and manipulate data into a pdf. This tutorial will show you how you can quickly use itext’s libraries in Codenvy to produce PDFs as part of your application.
0 notes
Text
Hackathons Love Cloud IDEs: Cereal Hack
Eric Cavazos, Codenvy Product Manager, was a judge at Cereal Hack 3, a Sacramento-based hackathon that took place July 27–28, 2013. Teams of up to six people competed in two-day race to create an inventive and inspired software or hardware project.

The winners received some pretty sweet prize packages, including free premium Codenvy account licenses for the first-, second- and third-place teams. As a sponsor of the event, we also had a spot on the judging panel to help determine the winners of the competition.
The Champions!
The competition was fierce, with 10 teams working furiously through the night and the next day to get their projects finished. Tensions were high, but you could tell everyone was working hard to create something amazing, not just to win cool prizes.
In the end, the top hacks were:
Grand Prize: Quickjobbr–a community for people to fill short-term jobs with verified quality talent
Second Place: Osteon–a motion capture exoskeleton that provides an intuitive and precise control for complex machinery (these crazy guys went for a combined software/hardware hack)
Third Place: Bookbucket–a book discovery app that encourages users to explore new books through a suggestions engine and friends’ recommendations
Cloud IDE and Hackathon = Love
Throughout the hackathon, teams struggled with transferring work from one IDE to another without losing information or creating conflicts. Cloud IDEs, and Codenvy in particular, are perfect solutions to this problem. Instead of teams having to calibrate their configurations at the beginning of the event, they can create a new workspace designed for collaboration and synchronization instantly. This sort of instant productivity lets teams spend more time competing and less time configuring. It certainly had a huge impression on the crowd at Cereal Hack.
"Judging the competition was a great chance to see what new ideas are bouncing around out there," said Eric. "I definitely saw some stuff that just completely blew me out of the water. We're going to help hackathons around the world use cloud IDEs like Codenvy to bring cutting-edge ideas to life faster."
If you're interested in using Codenvy at a hackathon or having Codenvy sponsor your hackathon, contact us at [email protected]. For more information about Codenvy, visit our website.
Cereal Hack is a creation of Hackerlab, an organization that aims to educate folks and seed startups with community-driven resources.
0 notes
Text
Virtual File System: Part 1 of 3
This is the first in a three-part series about the virtual file system (VFS) that underlies the Codenvy platform.
Codenvy's platform is different from most cloud IDEs. A developer's workspace is virtualized across different physical resources that are used to service different IDE functions. Dependency management, build, runners and code assistants can execute on different clusters of physical nodes. In order to properly virtualize access to all of these resources, we needed to implement a VFS that underpinned the services and physical resources but also had a native understanding of IDE behavior.
In this post, we’ll explore our VFS requirements, how we implement it, user access and what the organizational structure looks like.
Required Properties
A cloud IDE requires a storage system for its user’s projects. The VFS Codenvy uses has to have the following properties:
It should have a client server architecture whose server side is accessible via HTTP (REST API) mainly using Ajax requests. This will allow for different IDE browser clients to gain access to project resources.
Its API should not be bound to any one file or content management system. It should be flexible and abstract enough to implement any of them as backend storage relatively easily. For example, the API could be bound to a JCR system or a POSIX-based file system.
It should be multi-root, meaning that once a user enters a domain or workspace, they access their filtered branch. This, by definition, implies that a single VFS can then have many perspectives (per domain, per workspace or per user), and the “global” VFS is the universal view. Multi-root capabilities offer the necessary foundation to apply Access Control Lists to a perspective, which is required for public/private project implementations.
It should support standard CRUD operations for files and folders with both absolute and relative addressing by path and UID. By extending an AJAX system with CRUD operations addressed by UID, this opens up flexibility in allowing non-Codenvy clients and browsers to work with project-spaces directly.
It should have other functionalities, such as access permissions, search (including full-text search), lock and versioning. These other capabilities should be included in a concrete implementation.
It should contain another first-class resource type called Project, which adds special properties and functionality to the folder. In fact, we have extended our VFS to enable different folder nodes to be classified as different types of first-class nodes that subsequently inherit specific behaviors. This includes Project, Module and Package. It’s conceivable that this could be extended for other unique project characteristics such as Source, Libraries and so on.
Implementation
Based on the experiences we’ve had with content management systems (e.g., eXo, JCR, xCMIS) and REST API (e.g., everREST) implementations, we decided against using HTTP-based transportation such as WebDAV or CMIS. These options were too complex and had some redundant data interchange, which made them a less than ideal solution. We defined our own VFS REST API to be IDE-specific.
We created different backend implementations during the development and evolution of our implementation, including:
JCR: The file system is stored as a JCR item (Nodes and Properties). It is currently used in a Codenvy IDE OEM by eXo Platform. The JCR implementation offered native versioning of files accessible by the IDE but can make certain git operations, which are file intensive, very slow.
POSIX: This is currently our production implementation. POSIX is a plain file system and is used on top of a GlusterFS-distributed file system.
In-Memory: We authored an in-memory implementation to use in QA unit tests.
Virtual File System Entry Point (VFS Factory)
Logging into a user account linked to a workspace gives the user access to the VFS perspective associated with the workspace. After browser log-in, the browser is granted a token that can be used with the VFS API calls to gain access to the right VFS perspective. The browser can then make direct REST calls to the VFS.
An entry point to the VFS REST service has the following URL structure: http(s)://<host>/rest/ide/vfs/v2.
VFS info returned from our API is represented as a JavaScript Object Notation (JSON) response containing the following information:
A unique VFS identifier
A pointer to the root folder
A list of supported capabilities
A list of URL templates that may used for hyperlinks to access some VFS functionality
A list of optional capabilities depends on the current VFS implementation and may include:
An access control list (ACL) to control permissions
File versioning
Locking
Querying (the ability to search)
Main Resources: Projects, Folders and Files
The VFS has a tree structure with the projects list at the top level of the workspace, like this:
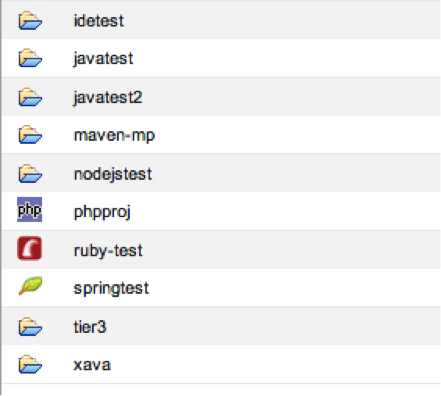
The tree structure can be expanded to reveal the folders, files and, in special cases, sub-projects (or modules) organized inside. This expansion is a different set of API calls, and we represent a project node visually different from a project’s sub structure.
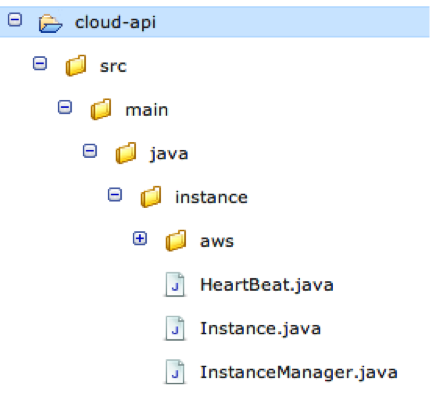
There are three resource types:
Files, which can be categorized differently and which have bodies with useful (indexable, searchable) content
Folders, the standard structure unit
Projects, a special type of folder with a set of properties that help identify that project’s nature, appropriate actions, views, etc.
The net impact of this structure is flexibility, support for multiple diverse IDE clients, search capability of files, native access control features and testability.
In the next article, we'll cover how a VFS can help with managing data, including access, modification and manipulation. We'll also talk about downloading and uploading information, as well as how search functions in the workspace.
0 notes
Text
Introducing Codenvy 2.5.0
Version 2.5.0 of Codenvy has been released into production. This release contains a number of stability improvements and introduces a new deployment capability.
The complete list of resolved issues on this version can be found on our documentation website.
New Deployment Capabilities: PHP on Google's Cloud
Google Cloud Team introduced a new PHP runtime for Google App Engine during the latest Google IO. This new runtime is still in experimental mode and your application need to be whitelisted, but the most widely used programming language on the web is now joining Java, Python and Go on Google App Engine. We have added the support to deploy and publish your PHP applications directly to Google App Engine within your Codenvy workspace.
We love to talk to our users and we take feedback seriously. Post your features requests here or send us an email at [email protected].
Enjoy coding in the cloud!
0 notes
Text
Maximizing Developer Productivity: Fighting Installation Costs
Developers using desktop IDEs have to install and manage:
A runtime that executes the code
The build system that compiles and packages files
The IDE itself
The IDE’s unique integrations and plugins
With so many variables involved, developers must split their attention between getting work done and making sure their environment stays operational. With numerous components, each of which requires regular updates, the possibility of a new conflict that will drag down the entire environment is high. Virtually all developers are forced to occasionally reinstall some or all of their system due to conflicts and corruptions.
These reinstallations take time. They can also be frustrating when they fail for no apparent reason or require trial and error to get the right configuration and versions of components and libraries for a successful runtime. Even the sequence of the installation process can often affect the outcome.

Take Eclipse, probably the most widely used Java IDE. Despite its widespread usage, Eclipse has a well-deserved reputation for imposing a significant administrative overhead on its users. A quick Google search or casual read of developer forums reveals countless complaints, bugs, and quirks users try to solve by reinstalling their systems, including:
Frequent failed upgrades
Failed installations of plugins
Recurring "could not complete" message when adding plugins
Frequent crashes
Unreliable/unusable plugins
Corrupt libraries
Dead repository links
System slows over time
File corruption over time
Boot times get longer and longer
The bottom line: Desktop IDEs create a large administrative burden that takes valuable time away from getting real work done.
Stop Installing. Start Coding.
Codenvy leverages the power of the cloud to provide a nearly instant-on environment free of conflicts and with minimum administrative tasks for the user through features like:
Automatic provisioning of the workspace
Reconfiguration of the IDE, builder, and runner based upon project type
Restriction of certain PAAS behaviors based upon project type
Identity propagation between Codenvy and external systems using oAuth (where possible) to save on clicks and typing
The Codenvy platform has solved legacy problems like installation headaches while embracing the best of breed features like refactoring and an Eclipse-like plugin ecosystem that made desktop IDEs so flexible and powerful.
Spend one-third of your workweek administering your desktop IDE. Or use Codenvy. Your choice.
0 notes
Text
Maximizing Developer Productivity: Fighting Starvation (1 of 5)
The average developer loses 13 hours a week due to the built-in inefficiencies of desktop IDEs. Seven of those hours are spent waiting. Waiting for IDEs to boot up, for code to compile, for tests to run...
[Comic by xkcd.com]
Codenvy harnesses the power of the cloud to eliminate the waiting.
You're no longer limited by the specs of your development machine. The cloud conceptually offers unlimited compute power. We put it to work to minimize waiting time in the developer workflow.
Stop waiting. Start coding.
Development environments launch quickly on any device.
Compiling & Testing utilize remote CPU and memory resources so your machine won't freeze up. Set a test to run and just carry-on. Need that test completed faster? No problem, just dial up unlimited horsepower with additional queues.
Free your mind.
Developing on your desktop forces you into a constrained mindset. You're limited by:
The number and size of files that can be coded by your HD space.
The speed of the build by your local CPU.
The capacity of the debug session by available RAM.
By making the leap to the cloud, you'll gain access to infinite storage for code, continuous build services like CloudBees and CircleCI, and on-demand debugging instances. By coding in the cloud, you're embracing the scalability, openness, and reach that you aspire for in your own applications.
Smash the hourglass. Pop the beach ball.
Code, test, and build in the cloud and eliminate all that waiting.
Don't worry, we won't tell your boss. You can still blow-off steam playing with swords by claiming that you're compiling. You just won't have to.
0 notes
Text
Early Adopter Program - Phase 2
We’re moving into the second stage of a limited promotion for those of you who want to help shape the future of Codenvy.
Become a Codenvy Early Adopter before August 26th and your signup cost will be $79 for the year. That’s $70 less than the standard cost.
The Early Adopter Program offers:
Free access to all upcoming features and paid add-ons (Note: partner add-ons will be separate)
Prioritized email support for management and engineers
First access to, and early notification of, new features
Early access to our SDK that will allow you to change languages, build systems, frameworks, runtimes, and themes
Two exclusive “State of Codenvy" presentations by our CEO, Tyler Jewell, beginning in September that will outline our progress, roadmap, and ambitions
Sign up today and reserve your low rate!
The cost of this program will increase as we advance the features. For more information, visit http://is.gd/Codenvy_Early_Adopter_Program.
0 notes
Text
Codenvy + Scrum: Project Management Done Right
As a company that creates tools and solutions for developers, we spend a lot of time talking with our customers about how they manage their development projects. We make it a priority to share Codenvy’s internal processes and technologies with our customers. This helps us facilitate discussions around best practices, helps improve our internal processes, and gives us further insight into the complex problems developers face.
For about five years now, we've used Scrum as our main process for driving development. Scrum is an iterative and incremental development (IID) methodology that helps guide and shape our daily work. Our Scrum process was originally developed and polished at eXo Platform, Codenvy’s sister company. It's a flexible approach that helps our developers concentrate on developing, while still providing the discipline that keeps everything running on time.
The..."relay race" approach to product development...may conflict with the goals of maximum speed and flexibility. Instead a holistic or "rugby" approach – where a team tries to go the distance as a unit, passing the ball back and forth – may better serve today's competitive requirements.
Hirotaka Takeuchi and Ikujiro Nonaka, The New New Product Development GameHarvard Business Review, January 1986.
Scrum: A Developing Team's Dream
Using Scrum gives us the iterative planning, specification, implementation, test and delivery capabilities we need to drive Codenvy’s rapid product evolution.

Our Product Manager acts as the Project Owner (PO) of the Sprint. Having a non-developer as PO lets our developers focus on programming instead of the nitty-gritty of project management. That way, the Product Release process stays separate from the Development process.
We use JIRA with the Greenhopper plugin as our project and issue tracking tools.
Getting Down to Business
Development work is done in 2-4 week “Sprints” to break releases into manageable segments. During that time period, we focus on turning specific features of the latest roadmap into final tested code.
The sprint's fixed duration is based both on the amount of work and the team's current capacity to get it done. These durations can be flexible, but they only change after review and discussion of how a change will affect the Sprint's goals.
Before a Sprint begins, our Development team examines the features presented by the PO from every angle and creates detailed "Sprint Briefs" outlining exact specifications. They show these briefs to the PO to make sure everyone is in agreement about what's expected.
Once our team and PO have agreed on the project specifications, the PO then builds the Sprint Backlog. As part of this, the team agrees to a "Feature Definition of Done" - that is, how we demonstrate the feature and what criteria it must meet in order to be "completed."
During the Sprint, our development team holds daily Stand-up meetings. Team members discuss the state of current work and any issues or obstacles that occur. We keep the meetings short (~15 minutes), so they don't take away too much programming time, and they help everyone stay on the same page.
The Finish Line
At the end of the Sprint, our developers demonstrate the Features to the PO. During the demonstration, our PO looks for the specific features outlined in the "sprint briefs." This acceptance work happens on specialized instances of Codenvy running in our development environments where each instance allows for validation of a single issue.
Once everything's been approved, our team and PO analyze the results in a Retrospective and propose areas of possible improvement for the next iteration. After a sprint completes, all of the issues that were catalogued in a sprint are moved into a pre-production and staging environment. There, marketing, support, and documentation can perform additional functions before releasing into production.
Scrum: That’s a Wrap!
The combination of regulation and freedom we get from Scrum is really the best of both worlds. Scrum gives our developers the flexibility they need to create high-quality solutions without sacrificing the discipline of deadlines.
Our Scrum methodology is still a work in progress, but it's helped us save a ton of time and effort so far.
Be sure to check out Scrum and XP from the Trenches, a book that offers a detailed account of a company's Scrum use case over the course of a year. It's our gospel, and it helped us develop our current Scrum process.
0 notes
Text
Codenvy: Now with Git Compatibility
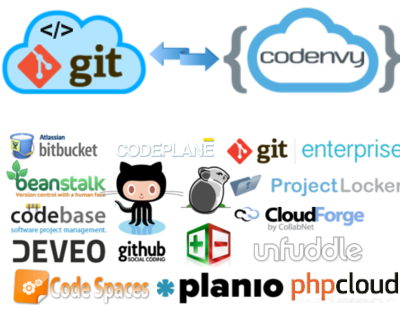
Codenvy has a rich set of capabilities to support Git. We have both menu and shell options, and support a wide range of scenarios relating to initializing, cloning, and managing remote repositories. There is a rich ecosystem of Git providers globally, and we wanted Codenvy to support them all.
We just completed our Git compatibility testing. We followed the following steps as tests for each service provider:
Generate SSH key for a chosen Git hosting service (in Codenvy workspace)
Manually save the SSH key to the user profile of a chosen Git service provider
Create a new repository (empty)
Clone the repository to Codenvy
Add a new remote repository in Codenvy (SSH Git URL)
Push a sample project to a remote repository
If none of the steps caused any errors or issues, we added a service to the list of compatible Git hosting providers. There are 16 Git hosting providers which you can use with Codenvy.
Assembla
Beanstalk
BitBucket
Codebase
Codeplane
Codespaces
CloudForge
Deveo
GitHub
GitEnterprise
Gitorious
PikaCode
Planio
PHPCloud
ProjectLocker
Unfuddle
Pick your Git hosting provider, establish an SSH connection with your Codenvy workspace, and you're ready!
If you use a service that is not on this list, let us know! We'll investigate it and add a new tutorial to our docs site.
0 notes