
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by codingbrewery-blog and here's what we found interesting.
Average Info
Notes Per Post
1
Likes Per Post
1
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
8 days
Number of Posts By Type
Text
9
Last Seen Tumblr Blogs





Fun Fact
70% of Tumblr users say the Dashboard is their favorite place to spend time online.
Text
Clean Code Concepts: Be SOLID: Open Closed Principle

In this series, we would focus on some of the language-agnostic parts which can be used to improve your ability to write cleaner code in any language. So let’s dive right into the SOLID concepts of object-oriented design. S.O.L.I.D is an acronym for the first five object-oriented design(OOD) principles by Robert C. Martin. It stands for: S – Single-responsibility principle O – Open-closed principle L – Liskov substitution principle I – Interface segregation principle D – Dependency Inversion Principle Read more about it here Read the full article
0 notes
Text
Data Preprocessing and Cleaning: Part 1: Column Normalization

Before applying any dimensionality reduction technique sometimes it is important to preprocess the data. There are several ways which we can use for preprocessing data. In this post, we will explore one of the common ways to do data preprocessing which is column normalization (or feature scaling). Read more about it here Read the full article
0 notes
Text
Data Preprocessing and Cleaning: Part 1: Column Normalization

Before applying any dimensionality reduction technique sometimes it is important to preprocess the data. There are several ways which we can use for preprocessing data. In this post, we will explore one of the common ways to do data preprocessing which is column normalization (or feature scaling). Read more about it here Read the full article
0 notes
Text
Clean Code Concepts: Be SOLID: Single Responsibility Principle

Writing clean code is more of an art rather than a science. So What really makes code cleaner?. In this series called Clean Code Concepts, we investigate some of the ways to write code in a clean way. There are several aspects to write cleaner code, some are language agnostic others are language dependent. In this series, we would focus on some of the language-agnostic parts which can be used to improve your ability to write cleaner code in any language. So let's dive right into it. S.O.L.I.D is an acronym for the first five object-oriented design(OOD) principles by Robert C. Martin. It stands for: S - Single-responsibility principle O - Open-closed principle L - Liskov substitution principle I - Interface segregation principle D - Dependency Inversion Principle In this blog post, we would focus exclusively on Single-responsibility principle along with examples in Java and python. What is it? Single Responsibility Principle states that "A class should have one and only one reason to change." The question here is what begets change in software applications. It will be most probably due to the addition of new features(unless you are refactoring legacy code). How to think of SRP The best way to think about it is to think of each class as an API. What does this class(or API) is intended to do? If we have to make modifications to a class/service, for different reasons, it means the abstraction is incorrect, and that the class has too many responsibilities. We want to avoid creating classes that try to "Do it All" Refactoring Code to SRP If you need to refactor some code and you want to check for SRP, you try to see if we can find methods that are mutually exclusive. In that case, we may want them to be part of separate classes. In other words, if we have 2 reasons to change for a class, we have to split the functionality into two classes. Implementation Suppose we need to create an Employee Management Software for an application. Below are the requirements Save and remove employees Print employee reports in XML and CSV Let's say we create a class with a UML like this: Employee id: long name: String dept: String working: Boolean saveEmployee() removeEmployee() printXMLReport() printCSVReport() What is wrong with this approach The class is trying to do too much. It is saving to DB , preparing reports. Let’s say, nurses, doctors, etc inherit from the employee class. Now it will become a nightmare for programmers if every different employee object wants to handle the class in their own way. A single indentation change would require us to make code changes in a lot of places. Secondly, all the operations seem to be an operation that should be performed on an employee rather than the employee should perform these operations. Therefore these methods do not belong to employee class. What if the database implementation changes. Now we need to modify the code in the employee class and all classes that inherit it. Database interaction should be done by a separate class If the format of XML or CSV changes?. That would again lead to the same problem where an indentation change might lead to change in lots of places. Also, see do you see two mutually exclusive features here. The report formatting part of employee and data class of employee. Let's try to implement classes which follow SRP. Suppose we have
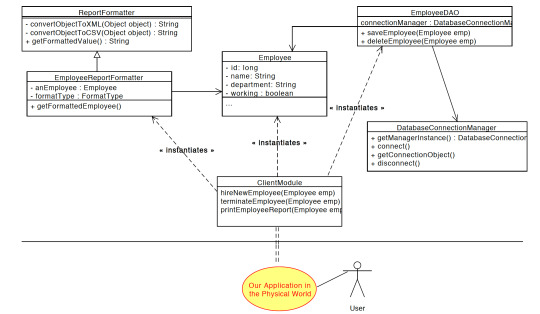
Few things to note here are The employee class is a POJO(plain old java object) or a data class. The EmployeeDAO(DAO stands for Data Access Object) is responsible for all operations for operations (saving and deleting employees) on employees to the database. The DAO class has a dependency relationship with the employee class. Also, The DAO class has an aggregation association relation with the DatabaseConnectionManager. DAO object “has a” connection manager object. Both the connection manager and DAO object have their own object lifetimes. The EmployeeReportFormatter class has an aggregation dependency on the employee class. EmployeeReportFormatter has an Employee object. The solid arrow represents inheritance. So Reportformater is the parent class where we implement all the formatting. The EmployeeReportFormatter simply inherits the ReportFormatter and all methods from it. Here is the implementation in Java. Here is a similar implementation in Python3. Read the full article
0 notes
Text
Maths 101 : Part 7: Estimating Confidence Intervals
In statistics, a confidence interval (CI) is a type of interval estimate which we compute using the statistics of the observed data. The interval has an associated confidence level that, loosely speaking, quantifies the level of confidence that the value of the parameter lies in the interval. Let's say we have a population of data which contain weights of all students in a class. In this population, we can pick a random variable which is a sample(randomly selected) of n=10 students {x1,x2,...x10}. Now if we find the mean of the sample and compare it to mean of the population. We will see that the mean of the sample is very similar to mean of the population(not equal to(It may or may not be equal), but similar to). µ(sample) ≅ µ(population) In fact, as we increase the number of students in the sample (n), we see the mean of the sample becomes closer to mean of the population. Point Estimate vs Interval estimate

The question of confidence intervals (or interval estimates) comes in when we don't know the real mean value of the population and all we know is the mean of the sample. Here we can say with some degree of certainty/confidence/higher probability that the mean of the population is within a particular range. Example Let's say for our sample of n = 10 students, our mean of the sample is µ = 160 lbs and the standard deviation is σ=10 lbs. Now since we know that the distribution is Gaussian for weights of students in a general population, we can say The mean of the population lies between lbs with 95.4% probability. This estimation is called point estimate and the range is called confidence interval.

Methods of finding confidence intervals Case 1: if we know the standard deviation of the population. If σ(population) is known, we can say that if we have taken n samples, In that case, we can say,

Here if we want to have a confidence level of 95%, we will take the value of Z as 2. Case 2: If we don't know the standard deviation of the population Confidence interval using bootstrapping Let's say we want to find the 95% confidence interval for the median. So when we find the sample of size n: S: {x1,x2,x3...xn} n=10 From this we will take a sample of size m: {x11,x12,...x1m} such that m m1 {x31,x32,...x3m} -->m2 : : : {xk1,xk2,...xkm} --> mk So now we have a set of k medians {m1,m2...mk} Lets say k=1000. After that, we sort these samples and then we can say our confidence interval lies between m25 and m975. A similar calculation is made for calculating the variance, mean and standard deviation. This method is called non-parametric technique since it doesn't make any assumptions about the data. https://gist.github.com/deepanshululla/da7c5738b56d72714340d34db68d9e4b Read the full article
0 notes
Text
Maths 101 : Part 7: Estimating Confidence Intervals
In statistics, a confidence interval (CI) is a type of interval estimate which we compute using the statistics of the observed data. The interval has an associated confidence level that, loosely speaking, quantifies the level of confidence that the value of the parameter lies in the interval. Let's say we have a population of data which contain weights of all students in a class. In this population, we can pick a random variable which is a sample(randomly selected) of n=10 students {x1,x2,...x10}. Now if we find the mean of the sample and compare it to mean of the population. We will see that the mean of the sample is very similar to mean of the population(not equal to(It may or may not be equal), but similar to). µ(sample) ≅ µ(population) In fact, as we increase the number of students in the sample (n), we see the mean of the sample becomes closer to mean of the population. Point Estimate vs Interval estimate

The question of confidence intervals (or interval estimates) comes in when we don't know the real mean value of the population and all we know is the mean of the sample. Here we can say with some degree of certainty/confidence/higher probability that the mean of the population is within a particular range. Example Let's say for our sample of n = 10 students, our mean of the sample is µ = 160 lbs and the standard deviation is σ=10 lbs. Now since we know that the distribution is Gaussian for weights of students in a general population, we can say The mean of the population lies between lbs with 95.4% probability. This estimation is called point estimate and the range is called confidence interval.

Methods of finding confidence intervals Case 1: if we know the standard deviation of the population. If σ(population) is known, we can say that if we have taken n samples, In that case, we can say,

Here if we want to have a confidence level of 95%, we will take the value of Z as 2. Case 2: If we don't know the standard deviation of the population Confidence interval using bootstrapping Let's say we want to find the 95% confidence interval for the median. So when we find the sample of size n: S: {x1,x2,x3...xn} n=10 From this we will take a sample of size m: {x11,x12,...x1m} such that m m1 {x31,x32,...x3m} -->m2 : : : {xk1,xk2,...xkm} --> mk So now we have a set of k medians {m1,m2...mk} Lets say k=1000. After that, we sort these samples and then we can say our confidence interval lies between m25 and m975. A similar calculation is made for calculating the variance, mean and standard deviation. This method is called non-parametric technique since it doesn't make any assumptions about the data. https://gist.github.com/deepanshululla/da7c5738b56d72714340d34db68d9e4b Read the full article
0 notes
Text
Maths 101 : Part 6: Measuring relationship between two Random Variables
Suppose you have taken the data for heights and weights of students in class and you want to figure out the correlation between heights and weights of students. The relation between these two parameters is defined mathematically by one of the 3 ways 1) Covariance 2) Pearson Correlation Coefficient 3) Spearman's rank correlation coefficient Each of these metrics has its own pros and cons so let's dive deeper into them. Covariance Covariance is a measure of the joint variability of two random variables. If the greater values of one variable mainly correspond with the greater values of the other variable, and the same holds for the lesser values, (i.e., the variables tend to show similar behavior), the covariance is positive. In the opposite case, when the greater values of one variable mainly correspond to the lesser values of the other, (i.e., the variables tend to show the opposite behavior), the covariance is negative. The sign of the covariance, therefore, shows the tendency in the linear relationship between the variables

In case we want to the covariance of a variable with respect to itself, it is always zero. A simple way to understand covariance is by using this graph as an example

In this we can see stock market returns increase as economic growth increases and vice versa, hence we can say these two are positively correlated. Further gasoline prices and world oil production decrease as the other increase and we can say they are negatively correlated. The reason why monotonically increasing seems to have positive covariance is because for any point they will be either above mean or below mean and hence make overall covariance +tive. Note 1) The magnitude of covariance has nothing to do with the amount of overlap. Let's say something has a covariance of 5 doesn't mean anything. In fact, even if we change the units of heights and weights from cms to feet, lbs to kgs the covariance for the same dataset will change. What if we standardize the datasets before applying covariance, that becomes correlation and that can tell how much the data is correlated. 2) However, if there are outliers in the dataset, we may have a situation where covariance is -time for monotonically increasing relation. Pearson correlation coefficient The Pearson correlation coefficient (PCC), also referred to as Pearson's r, the Pearson product-moment correlation coefficient (PPMCC) or the bivariate correlation, is a measure of the linear correlation between two variables X and Y. Owing to the Cauchy–Schwarz inequality it has a value between +1 and −1, where 1 is the total positive linear correlation, 0 is no linear correlation, and −1 is the total negative linear correlation


ρ =1 when there is a positive and perfect correlation. A naive example of this would be the height of a group of individuals in cms and inches. 0 Read the full article
0 notes
Text
Maths 101 : Part 6: Measuring relationship between two Random Variables
Suppose you have taken the data for heights and weights of students in class and you want to figure out the correlation between heights and weights of students. The relation between these two parameters is defined mathematically by one of the 3 ways 1) Covariance 2) Pearson Correlation Coefficient 3) Spearman's rank correlation coefficient Each of these metrics has its own pros and cons so let's dive deeper into them. Covariance Covariance is a measure of the joint variability of two random variables. If the greater values of one variable mainly correspond with the greater values of the other variable, and the same holds for the lesser values, (i.e., the variables tend to show similar behavior), the covariance is positive. In the opposite case, when the greater values of one variable mainly correspond to the lesser values of the other, (i.e., the variables tend to show the opposite behavior), the covariance is negative. The sign of the covariance, therefore, shows the tendency in the linear relationship between the variables

In case we want to the covariance of a variable with respect to itself, it is always zero. A simple way to understand covariance is by using this graph as an example

In this we can see stock market returns increase as economic growth increases and vice versa, hence we can say these two are positively correlated. Further gasoline prices and world oil production decrease as the other increase and we can say they are negatively correlated. The reason why monotonically increasing seems to have positive covariance is because for any point they will be either above mean or below mean and hence make overall covariance +tive. Note 1) The magnitude of covariance has nothing to do with the amount of overlap. Let's say something has a covariance of 5 doesn't mean anything. In fact, even if we change the units of heights and weights from cms to feet, lbs to kgs the covariance for the same dataset will change. What if we standardize the datasets before applying covariance, that becomes correlation and that can tell how much the data is correlated. 2) However, if there are outliers in the dataset, we may have a situation where covariance is -time for monotonically increasing relation. Pearson correlation coefficient The Pearson correlation coefficient (PCC), also referred to as Pearson's r, the Pearson product-moment correlation coefficient (PPMCC) or the bivariate correlation, is a measure of the linear correlation between two variables X and Y. Owing to the Cauchy–Schwarz inequality it has a value between +1 and −1, where 1 is the total positive linear correlation, 0 is no linear correlation, and −1 is the total negative linear correlation


ρ =1 when there is a positive and perfect correlation. A naive example of this would be the height of a group of individuals in cms and inches. 0 Read the full article
0 notes
Text
Multithreading in Java

Runnable A Runnable is basically a type of class (Runnable is an Interface) that can be put into a thread, describing what the thread is supposed to do. This interface is designed to provide a common protocol for objects that wish to execute code while they are active. For example, Runnable is implemented by class Thread. Being active simply means that a thread has been started and has not yet been stopped. In addition, Runnable provides the means for a class to be active while not subclassing Thread. A class that implements Runnable can run without subclassing Thread by instantiating a Thread instance and passing itself in as the target. In most cases, the Runnable interface should be used if you are only planning to override the run() method and no other Thread methods. This is important because classes should not be subclassed unless the programmer intends on modifying or enhancing the fundamental behavior of the class. The Runnable Interface requires of the class to implement the method run() like so: public class MyRunnableTask implements Runnable { public void run() { // do stuff here } } Either you can implement Runnable or extend the thread class both spin up a new thread. It is preffered to use Runnable though since Java doens't support multiple inheritance so classes inhertied by thread class can't inherit anything else and it is basically an overkill to provide all functions that a thread provides to a new sub class that doesn't need it Join Join tells main thread to wait for all the threads to complete their execution. Volatile The volatile keyword is used when two threads need to access a common section of memory i.e. RAM. The usage is usually all instance variables are stored in CPU core cache since it is closer to CPU core. However if two threads on two seperate cores need to maintain state then we use volatile keyword to make store the variable store in RAM which is accessible by both cores. There is a performance hit and causes instruction reordering while using the volatile keyword Thread.start() vs Thread.run() The way to create a new thread is by calling the start method and when we directly call the run() method it doesn't create a new thread. It just invokes it with the current thread. Thread.run() does not spawn a new thread whereas Thread.start() does, i.e Thread.run actually runs on the same thread as that of the caller whereas Thread.start() creates a new thread on which the task is run. Interrupts (Thread.interrupt()) Thread.interrupt() sets the interrupted status/flag of the target thread. Then code running in that target thread MAY poll the interrupted status and handle it appropriately. Some methods that block such as Object.wait() may consume the interrupted status immediately and throw an appropriate exception (usually InterruptedException) Interruption in Java is not pre-emptive. Put another way both threads have to cooperate in order to process the interrupt properly. If the target thread does not poll the interrupted status the interrupt is effectively ignored. Polling occurs via the Thread.interrupted() method which returns the current thread's interrupted status AND clears that interrupt flag. Usually the thread might then do something such as throw InterruptedException. What is interrupt ? An interrupt is an indication to a thread that it should stop what it is doing and do something else. It's up to the programmer to decide exactly how a thread responds to an interrupt, but it is very common for the thread to terminate. How is it implemented ? The interrupt mechanism is implemented using an internal flag known as the interrupt status. Invoking Thread.interrupt sets this flag. When a thread checks for an interrupt by invoking the static method Thread.interrupted, interrupt status is cleared. The non-static Thread.isInterrupted(), which is used by one thread to query the interrupt status of another, does not change the interrupt status flag. Joins / Thread.Join() java.lang.Thread class provides the join() method which allows one thread to wait until another thread completes its execution. If t is a Thread object whose thread is currently executing, then t.join(); it causes the current thread to pause its execution until thread it join completes its execution. If there are multiple threads calling the join() methods that means overloading on join allows the programmer to specify a waiting period. However, as with sleep, join is dependent on the OS for timing, so you should not assume that join will wait exactly as long as you specify. There are three overloaded join functions. join(): It will put the current thread on wait until the thread on which it is called is dead. If thread is interrupted then it will throw InterruptedException. public final void join() join(long millis) It will put the current thread on wait until the thread on which it is called is dead or wait for specified time (milliseconds). public final synchronized void join(long millis) join(long millis, int nanos) It will put the current thread on wait until the thread on which it is called is dead or wait for specified time (milliseconds + nanos). public final synchronized void join(long millis, int nanos) Read the full article
1 note
·
View note