
MODELADO DE BASE DE DATOS, MODELAMIENTO CONCEPTUAL, SISTEMA MANEJADOR DE BASE DE DATOS, ETC.
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by databasemodeling and here's what we found interesting.
Average Info
Notes Per Post
2
Likes Per Post
2
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
3 days
Number of Posts By Type
Text
4
Last Seen Tumblr Blogs





Fun Fact
Celebrities use Tumblr as well.
Text
INTRODUCCIÓN A NUEVAS TECNOLOGÍAS
BASES DE DATOS ORIENTADAS POR OBJETO.

Una base de datos es una colección de datos que puede constituirse de forma que sus contenidos puedan permitirse el encapsular, tramitarse y renovarse sencillamente, elementos de datos, sus características, atributos y el código que opera sobre ellos en elementos complejos llamados objetos. Las bases de datos están constituidas por objetos, que pueden ser de muy diversos tipos, y sobre los cuales se encuentran definidas unas operaciones donde interactúan y se integran con las de un lenguaje de programación orientado a objetos, es decir, que los componentes de la base de datos son objetos de los lenguajes de programación además que este tipo de base de datos están diseñadas para trabajar con lenguajes orientados a objetos también manipulan datos complejos de forma rápida y segura.
Las bases de datos orientadas a objetos se crearon para tratar de satisfacer las necesidades de estas nuevas aplicaciones. La orientación a objetos ofrece flexibilidad para manejar algunos de estos requisitos y no está limitada por los tipos de datos y los lenguajes de consulta de los sistemas de bases de datos tradicionales.
Los objetos estructurados se agrupan en clases. Las clases utilizadas en un determinado lenguaje de programación orientado a objetos son las mismas clases que serán utilizadas en una base de datos; de tal manera, que no es necesaria una transformación del modelo de objetos para ser utilizado. De forma contraria, el modelo relacional requiere abstraerse lo suficiente como para adaptar los objetos del mundo real a tablas. Los conjuntos de las clases se estructuran en subclases y superclases, los valores de los datos también son objetos.
Muchas organizaciones que actualmente usan tecnología orientada a objetos también desean los beneficios de los sistemas de gestión de base de datos orientados a objetos. En otras palabras, se desea la migración de bases de datos y aplicaciones de bases de datos relacionales a orientadas a objetos. La migración a la tecnología de objetos consiste de la ingeniería reversa de los programas de aplicación y la migración de la base de datos. El objetivo de la migración de la base de datos es tener un esquema equivalente y la base de datos disponibles. Esto desde luego puede ser logrado por medio de la transformación manual del código de los programas lo cual resulta demasiado complicado. Para esto existen tres enfoques que hacen uso de la tecnología de objetos para bases de datos relacionales.
Una base de datos orientada a objetos es una base de datos donde los elementos son objetos. Estos pueden ser bases de datos multimedia (videos, imágenes y sonidos), donde la herencia nos permita una mejor representación de la información, estas bases de datos tienen una identidad de ser un Todo, y no solo una parte de una gran base, por ejemplo, una base de secuencias de ADN.
El objetivo de una base de datos orientada a objetos son los mismos que los de las bases de datos tradicionales, pero con la ventaja de representar las modelos de datos con un marco mucho más eficiente, manteniendo la integridad y relación entre ellos.
Primera y Segunda Generación de BDOO

La primera generación de Sistemas Gestores de Bases de Datos Orientadas a Objetos (SGBDOO) data de 1986 cuando la compañia Graphael lanza G-Base, en 1987 Servio Corp introdujo GemStone, luego en 1988 Ontologic lanza su sistema VBase y la empresa Simbolics lanza Statice. Todos ellos con la finalidad de apoyar lenguajes persistentes como los usados para la inteligencia artificial.
La segunda generación se caracterizó por emplear una arquitectura cliente-servidor, y puede considerarse a partir del lanzamiento de Ontos en 1989, así como de Objet Design, Objectivity y de Versant Objet Technology,
Una tercera generación fue marcada por la salida al mercado de Itasca en 1990, que es una versión comercial de Orion, otros ejemplos son O2 de la compañia Altair así como Zeitgeist creado por Texas Instruments. De igual manera lo que marcó la tercera generación fue que ya se manejaban lenguajes de definición y manipulación de datos orientados a objetos (DDL/DML).
OMG Y CORBA EXPERIENCIAS, PROMESAS, REALIDAD Y FUTURO. ESTÁNDARES.

El OMG es un consorcio internacional sin ánimo de lucro establecido en 1989. Su objetivo es, ayudar a reducir la complejidad, disminuir los costes y acelerar la introducción de nuevas aplicaciones software, promoviendo la teoría y la práctica de la tecnología de objetos en los sistemas distribuidos.
Originalmente estaba formada por 13 compañías, pero los miembros del OMG han crecido progresivamente y en la actualidad es el consorcio de software más grande del mundo, compuesto por más de 760 vendedores, programadores y usuarios. De hecho, todas las grandes compañías de software interesadas en el desarrollo orientado a objetos distribuidos son miembros del OMG.
El OMG alcanza sus objetivos promoviendo la adopción de especificaciones de interfaz y de protocolo, que permiten la interoperabilidad y portabilidad de las aplicaciones orientadas a objetos distribuidos. En este consorcio no se producen guías de cómo implementar o producir software, sólo especificaciones.
Los miembros del OMG contribuyen tecnológicamente y con ideas en respuesta a RFI (Request For Information) y RFP (Request For Proposals), emitidas por el OMG. El OMG no establece estándares en la industria, se formó para promover mediante el consenso de sus participantes, la adopción de estándares de facto por parte de los vendedores. El estándar a ser adoptado, debe existir como una implementación; es decir, sólo se aprueba un estándar si alguien lo ha implementado y se comprueba su correcto funcionamiento.
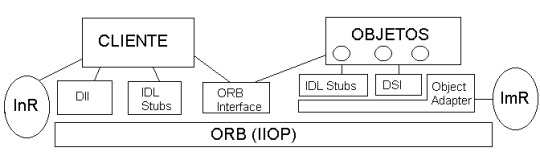
El Object Management Group o OMG es un consorcio formado en 1989 dedicado al cuidado y el establecimiento de diversos estándares de tecnologías orientadas a objetos, tales como UML, XMI, CORBA y BPMN. Es una organización sin fines de lucro que promueve el uso de tecnología orientada a objetos mediante guías y especificaciones. El grupo está formado por diversas compañías y organizaciones con distintos privilegios dentro de la misma.
Common Object Request Broker Architecture (CORBA)

Es un estándar definido por Object Management Group (OMG) que permite que diversos componentes de software escritos en múltiples lenguajes de programación y que corren en diferentes computadoras, puedan trabajar juntos; es decir, facilita el desarrollo de aplicaciones distribuidas en entornos heterogéneos.
CORBA es una tecnología que oculta la programación a bajo nivel de aplicaciones distribuidas, de tal forma que el programador no se tiene que ocupar de tratar con sockets, flujos de datos, paquetes, sesiones etc. CORBA oculta todos estos detalles de bajo nivel. No obstante, CORBA también brinda al programador una tecnología orientada objetos, las funciones y los datos se agrupan en objetos, estos objetos pueden estar en diferentes máquinas, pero el programador accederá a ellos a través de funciones normales dentro de su programa.
Introducción
CORBA fue el primer producto propuesto por OMG. Su objetivo es ayudar a reducir la complejidad, disminuir los costes y acelerar la introducción de nuevas aplicaciones informáticas, promoviendo la teoría y la práctica de la tecnología de objetos en los sistemas distribuidos.
Es una tecnología que oculta la programación a bajo nivel de aplicaciones distribuidas. No obstante, también brinda al programador una tecnología orientada objetos; las funciones y los datos se agrupan en objetos y estos objetos pueden estar en diferentes máquinas, pero el programador accederá a ellos a través de funciones normales dentro de su programa.
CORBA es más que una especificación multiplataforma, también define servicios habitualmente necesarios como seguridad y transacciones. Y así este no es un sistema operativo en sí, en realidad es un middleware.
Historia
Su primera versión se lanzó en 1991.
En 1995 aparece CORBA 2, con nuevas normas que permiten: que puedan cooperar implementaciones de diferentes fabricantes, que pueda ser implementado sobre cualquier nivel de transporte y que pueda funcionar en Internet sobre TCP/IP, creando un protocolo: IIOP (Internet IOP).
CORBA 3 se muestra en 2002, como intento de plantar cara a Microsoft y su modelo de programación de objetos distribuidos DCOM. Entre otras cosas, se introdujo el CORBA Component Model (CCM), con el que se pasó de un modelo de objetos distribuidos (EJB, restringido a Java) a un modelo distribuido orientado a componentes.
Características
Entre las principales características de CORBA nos encontramos con:
Independencia en el lenguaje de programación y sistema operativo: CORBA fue diseñado para liberar a los ingenieros de las limitaciones en cuanto al diseño del software. Actualmente soporta Ada, C, C++, C++11, Lisp, Ruby, Smalltalk, Java, COBOL, PL/I y Python.
Posibilidad de interacción entre diferentes tecnologías: uno de los principales beneficios de la utilización de CORBA es la posibilidad de normalizar las interfaces entre las diversas tecnologías y poder así combinarlas.
Transparencia de distribución: ni cliente ni servidor necesitan saber si la aplicación está distribuida o centralizada, pues el sistema se ocupa de todo eso.
Transparencia de localización: el cliente no necesita saber dónde ejecuta el servicio y el servicio no necesita saber dónde ejecuta el cliente.
Integración de software existente: se amortiza la inversión previa reutilizando el software con el que se trabaja, incluso con sistemas heredados.
Activación de objetos: los objetos remotos no tienen por qué estar en memoria permanentemente, y se hace de manera invisible para el cliente.
Otras como: el fuerte tipado de datos, la alta capacidad de configuración, libertad de elección los detalles de transferencia de datos, o la compresión de los datos.
BASE DE DATOS DEDUCTIVAS

Sistema de bases de datos que tenga la capacidad de definir reglas con las cuales deducir o inferir información adicional a partir de los hechos almacenados en las bases de datos se llama Sistema de Bases de Datos Deductivas. Puesto que parte de los fundamentos teóricos de algunos sistemas de ésta especie es la lógica matemática, a menudo se les denomina Bases de Datos Lógicas. Una base de datos deductiva es, en esencia, un programa lógico; mapeo de relaciones base hacia hechos, y reglas que son usadas para definir nuevas relaciones en términos de las relaciones base y el procesamiento de consultas.
Los sistemas Bases de Datos Deductivas intentan modificar el hecho de que los datos requeridos residan en la memoria principal (por lo que la gestión de almacenamiento secundario no viene al caso) de modo que un SGBD se amplíe para manejar datos que residen en almacenamiento secundario.
En un sistema de Bases de Datos Deductivas por lo regular se usa un lenguaje declarativo para especificar reglas. Con lenguaje declarativo se quiere decir un lenguaje que define lo que un programa desea lograr, en vez de especificar los detalles de cómo lograrlo. Una máquina de inferencia (o mecanismo de deducción) dentro del sistema puede deducir hechos nuevos a partir de la base de datos interpretando dichas reglas. El modelo empleado en las Bases de Datos Deductivas está íntimamente relacionado con el modelo de datos relacional, y sobre todo con el formalismo del cálculo relacional.
También está relacionado con el campo de la programación lógica y el lenguaje Prolog. Los trabajos sobre Bases de Datos Deductivas basados en lógica han utilizado Prolog como punto de partida. Con un subconjunto de Prolog llamado Datalog se definen reglas declarativamente junto con un conjunto de relaciones existentes que se tratan como literales en el lenguaje. Aunque la estructura gramatical se parece a la de Prolog, su semántica operativa (esto es, la forma como debe ejecutarse un programa en Datalog) queda abierta.
Una Base de Datos Deductiva utiliza dos tipos de especificaciones: hechos y reglas. Los hechos se especifican de manera similar a como se especifican las relaciones, excepto que no es necesario incluir los nombres de los atributos. Recordemos que una tupla en una relación describe algún hecho del mundo real cuyo significado queda determinado en parte por los nombres de los atributos. En una Base de Datos Deductiva, el significado del valor del atributo en una tupla queda determinado exclusivamente por su posición dentro de la tupla.
Las reglas se parecen un poco a las vistas relacionales. Especifican relaciones virtuales que no están almacenadas realmente, pero que se pueden formar a partir de los hechos aplicando mecanismos de inferencia basados en las especificaciones de las reglas. La principal diferencia entre las reglas y las vistas es que en las primeras puede haber recursión y por tanto pueden producir vistas que no es posible definir en términos de las vistas relacionales estándar.
Las BDD buscan derivar nuevos conocimientos a partir de datos existentes proporcionando interrelaciones del mundo real en forma de reglas. Utilizan mecanismos internos para la evaluación y la optimización.
NECESIDAD DE LA INFERENCIA EN LAS APLICACIONES
La inferencia en las aplicaciones nacen con el afán de ofrecer una respuesta a las necesidades planteadas por los usuarios y por las aplicaciones avanzadas, en donde se necesitan herramientas semánticamente más ricas que las provistas por las Bases de Datos Relacionales, aparecen recientes aplicaciones de los sistemas de bases de datos que consiste en ofrecer recursos para definir Reglas Deductivas y Activas que permitan deducir, inferir u obtener información nueva a partir de los datos almacenados o sucesos condicionados.
La finalidad de estas aplicaciones es incorporar a las Bases de Datos Relacionales los beneficios de la inferencia lógica como instrumento para la formalización integrada de los aspectos estáticos y dinámicos del modelado relacional de la Base de Datos en las aplicaciones.
QUE ES DATALOG PURO.

Datalog es una consulta de las reglas del lenguaje y de bases de datos deductivas que sintácticamente es un subconjunto de Prolog . Sus orígenes se remontan al inicio dela programación lógica, pero llegó a ser prominente como un área separada en torno a 1977, cuando Hervé Gallaire y Minker Jack organizó un taller sobre la lógica y las bases de datos. David Maier se le atribuye haber acuñado el término de datalog.
FACILIDAD DE LA NEGACIÓN ESTRATIFICADA DEL MODELAJE CONCEPTUAL AL DISEÑO DE BASE DE DATOS DEDUCTIVAS
Contar con negación estratificada permite la capacidad de modelado natural de objetos del mundo real, encapsulando su estructura y comportamiento, que proporcionan los modelos orientados a objetos; la capacidad de derivación de nuevos conocimiento a partir de datos existentes, suministrando vínculos del mundo real en forma de reglas, que proporcionan los modelos de datos deductivos; y, además, la capacidad de almacenamiento persistente que proporcionan los sistemas administradores de bases de datos.
BASES DE DATOS ACTIVAS COMO PROVEEDORAS DE MECANISMOS DE APOYO A: REGLAS DE INTEGRIDAD, MANTENIMIENTO DE DATOS DERIVADOS, "TRIGGERS", ALERTAS, CONTROL DE VERSIONES.
El paradigma de bases de datos activas planteado por Morgenstern en 1983, describe la noción de una base de datos activa, como una metáfora de su comportamiento, el cual se concentra” en la dinámica de la interacción con los usuarios unido a la “inteligencia” de la base de datos. Una base de datos activa, son aquellas bases de datos capaz de detectar situaciones de interés y de actuar en consecuencia. El mecanismo que se utiliza se parece a las reglas de producción utilizadas en el área de inteligencia artificial.
Representación de una Base de Datos Activa.
El poder especificar reglas con una serie de acciones que se ejecutan automáticamente cuando se producen ciertos eventos, es una de las mejoras de los sistemas de gestión de bases de datos que se consideran de gran importancia desde hace algún tiempo. Mediante estas reglas se puede hacer respetar reglas de integridad, generar datos derivados, controlar la seguridad o implementar reglas de negocio. De hecho, la mayoría de los sistemas relacionales comerciales disponen de disparadores (triggers). Se han realizado mucha investigación sobre lo que debería ser un modelo general de bases de datos activas desde que empezaron a aparecer los primeros disparadores. El modelo que se viene utilizando para especificar bases de datos activas es el modelo evento–condición–acción (ECA).
Dentro de este modelo las reglas que se utilizan para especificar situaciones con sus acciones, se les llaman reglas del tipo (ECA) o reglas que siguen el paradigma de (ECA).
El formato genérico de estas reglas es:
ON Event
IF Condition
THEN Action
El evento (o eventos) que dispara la regla: Pueden ser operaciones de consulta o actualización que se aplican explícitamente sobre la base de datos. También pueden ser eventos temporales (por ejemplo, que sea una determinada hora del día) u otro tipo de eventos externos (definidos por el usuario).
La condición: Determina si la acción de la regla se debe ejecutar. Una vez que ocurre el evento disparador, se puede evaluar una condición (es opcional). Si no se especifica condición, la acción se ejecutaría cuando suceda el evento. Si se especifica condición, la acción se ejecutaría sólo si la condición es evaluada en verdadero.
La acción a realizar: Puede ser una transacción sobre la base de datos o un programa externo que se ejecutaría automáticamente.
Casi todos los sistemas relacionales incorporan reglas activas simples denominadas disparadores (triggers), que están basados en el modelo ECA:
Los eventos son sentencias SQL de manejo de datos (INSERT, DELETE, UPDATE).
La condición (que es opcional) es un predicado booleano expresado en SQL.
La acción es una secuencia de sentencias SQL, que pueden estar inmersas en un lenguaje de programación integrado en el producto que se esté utilizando (por ejemplo, PL/SQL en Oracle).
El modelo ECA se comporta de un modo simple e intuitivo: cuando ocurre el evento, si la condición es verdadera, entonces se ejecuta la acción. Se dice que el disparador es activado por el evento, es considerado durante la verificación de su condición y es ejecutado si la condición es cierta. Sin embargo, hay diferencias importantes en el modo en que cada sistema define la activación, consideración y ejecución de disparadores.
Los disparadores relacionales tienen dos niveles de granularidad: a nivel de fila y a nivel de sentencia. En el primer caso, la activación tiene lugar para cada tupla involucrada en la operación y se dice que el sistema tiene un comportamiento orientado a tuplas. En el segundo caso, la activación tiene lugar sólo una vez para cada sentencia SQL, refiriéndose a todas las tuplas invocadas por la sentencia, con un comportamiento orientado a conjuntos. Además, los disparadores tienen funcionalidad inmediata o diferida. La evaluación de los disparadores inmediatos normalmente sucede inmediatamente después del evento que lo activa (opción después), aunque también puede precederlo (opción antes) o ser evaluados en lugar de la ejecución del evento (opción en lugar de). La evaluación diferida de los disparadores tiene lugar al finalizar la transacción en donde se han activado (tras la sentencia COMMIT).
Un disparador puede activar otro disparador. Esto ocurre cuando la acción de un disparador es también el evento de otro disparador. En este caso, se dice que los disparadores se activan en cascada.
El lenguaje de reglas de este tipo debe tener componentes para especificar eventos, especificar condiciones y especificar acciones. Adicionalmente a la especificación de las reglas es importante conocer cómo es la semántica de la ejecución de estas. En particular, existen tres aspectos relevantes en la forma en cómo se ejecutan las reglas, que describen el dinamismo de una base de datos.
Granularidad del procesamiento de las reglas.
Es importante saber si una regla se dispara una vez por cada tupla “tocada” o una sola vez por todas las tuplas “tocadas”.
Anidamiento de reglas y terminación.
Otro aspecto importante es si se puede especificar una sola regla por evento o más de una. En el caso en el que se permita más de una regla por evento, en cuál orden se ejecutan esas reglas y cuándo se termina la ejecución.
Concurrencia con las transacciones.
Finalmente, es necesario determinar si las reglas se van a ejecutar como parte de la transacción donde se disparen o si se van a ejecutar como transacciones aparte. Esto es fundamental por la propiedad de atomicidad que se debe garantizar para las transacciones de una base de datos.
De este modo, al encontrarse las reglas definidas como parte del esquema de la base de datos, se comparten por todos los usuarios, en lugar de estar replicadas en todos los programas de aplicación. Cualquier cambio sobre el comportamiento reactivo se puede llevar a cabo cambiando solamente las reglas activas, sin necesidad de modificar las aplicaciones. Además, mediante los sistemas de bases de datos activas se hace posible integrar distintos subsistemas (control de accesos, gestión de vistas, etc.) y se extiende el ámbito de aplicación de la tecnología de bases de datos a otro tipo de aplicaciones.
Características de las reglas activas
Además de las características que poseen los disparadores que incorporan los sistemas relacionales, algunos sistemas más avanzados y algunos prototipos de bases de datos activas ofrecen algunas características que incrementan la expresividad de las reglas activas:
Respecto a los eventos, estos pueden ser temporales o definidos por el usuario. Los eventos temporales permiten utilizar expresiones dependientes del tiempo, como, por ejemplo: cada viernes por la tarde, a las 17:30 del 29/06/2002. Los eventos definidos por el usuario son eventos a los que el usuario da un nombre y que son activados por los programas de usuario. Por ejemplo, se podría definir el evento de usuario ¨ nivel_alto_azufre ¨ y que una aplicación lo activara; esto activaría la regla que reacciona al evento.
La activación de los disparadores puede que no dependa de un solo evento, sino que dependa de un conjunto de eventos relacionados en una expresión booleana que puede ser una simple disyunción o una combinación más compleja que refleje la precedencia entre eventos y la conjunción de eventos.
La consideración y/o ejecución de reglas se puede retrasar. En este caso, la consideración y/o la ejecución tienen lugar durante transacciones distintas, que pueden ser completamente independientes o pueden estar coordinadas con la transacción en la que se ha verificado el evento.
Los conflictos entre reglas que se activan por el mismo evento se pueden resolver mediante prioridades explícitas, definidas directamente por el usuario cuando se crea la regla. Se pueden expresar como una ordenación parcial (utilizando relaciones de precedencia entre reglas), o como una ordenación total (utilizando prioridades numéricas). Las prioridades explícitas sustituyen a los mecanismos de prioridades implícitos que poseen los sistemas.
Las reglas se pueden organizar en conjuntos y cada conjunto se puede habilitar y deshabilitar independientemente.
Propiedades de las reglas activas.
No es difícil diseñar reglas activas de modo individual, una vez se han identificado claramente el evento, la condición y la acción. Sin embargo, entender el comportamiento colectivo de las reglas activas es más complejo ya que su interacción suele ser sutil. Por este motivo, el problema principal en el diseño de las bases de datos activas está en entender el comportamiento de conjuntos complejos de reglas. Las propiedades principales de estas reglas son terminación, confluencia e idéntico comportamiento observable.
Un conjunto de reglas garantiza la terminación cuando, para cada transacción que puede activar la ejecución de reglas, esta ejecución produce un estado final en un número finito de pasos.
Un conjunto de reglas garantiza la confluencia cuando, para cada transacción que puede activar la ejecución de reglas, la ejecución termina produciendo un estado final único que no depende del orden de ejecución de las reglas.
Un conjunto de reglas garantiza un comportamiento observable idéntico cuando, para cada transacción que puede activar la ejecución de reglas, esta ejecución es concluyente y todas las acciones visibles llevas a cabo por la regla son idénticas y producidas en el mismo orden.
Estas propiedades no tienen la misma importancia. Concretamente, la terminación es una propiedad esencial; se debe evitar la situación en que las transacciones, activadas por el usuario, causan ejecuciones infinitas por la activación recursiva de reglas. Por otra parte, la confluencia y el idéntico comportamiento observable no son esenciales.
El proceso del análisis de reglas permite la verificación de si las propiedades deseadas se cumplen en un conjunto de reglas. Una herramienta esencial para verificar la terminación es el grafo de activación, que representa interacciones entre reglas. El grafo se crea incluyendo un nodo para cada regla y un arco de la regla R1 a la regla R2 cuando la acción de R1 contiene una sentencia del lenguaje de manejo de datos que es también uno de los eventos de R2. Una condición necesaria para la no terminación es la presencia de ciclos en el grafo de activación: sólo en este caso podemos tener una secuencia infinita de ejecución de reglas.
Los sistemas que tienen muchas reglas activas suelen ser cíclicos. Sin embargo, sólo unos pocos ciclos son los que provocan situaciones críticas. De hecho, el que un grafo sea cíclico es condición necesaria pero no suficiente para la no terminación.
Uno de los problemas que ha limitado el uso extensivo de reglas activas, a pesar de su potencial para simplificar el desarrollo de bases de datos y de aplicaciones, es el hecho de que no hay técnicas fáciles de usar para diseñar, escribir y verificar reglas. Por ejemplo, es bastante difícil verificar que un conjunto de reglas es consistente, es decir, que no se contradice. También es difícil garantizar la terminación de un conjunto de reglas bajo cualquier circunstancia. Para que las reglas activas alcancen todo su potencial, es necesario desarrollar herramientas para diseñar, depurar y monitorizar reglas activas que puedan ayudar a los usuarios en el diseño y depuración de sus reglas.
Aplicaciones de las Base de Datos activas
Las aplicaciones del paradigma de base de datos activas son muy variadas. Una primera clasificación de las aplicaciones lo establece el uso de las reglas para labores internas del DBMS, o sea, reglas generadas por el sistema, no visibles a los usuarios, o para labores externas, las cuales son especificadas por el usuario y permiten realizar labores específicas dependientes del dominio del problema. Algunos ejemplos de las actividades que se pueden realizar en estas aplicaciones se muestran a continuación.
Internas: Soportar las características clásicas del manejo o administración de las bases de datos. Ejemplos de estas aplicaciones son:
Control de integridad. (Restricciones implícitas y explícitas.)
Mantenimiento de vistas y datos derivados, los cuales pueden existir virtualmente o ser materializados.
Administración de copias de los datos (duplicación).
Seguridad. Recuperación ante fallas.
Existen otras aplicaciones internas potenciales, pues hasta el momento no han sido explotadas por los DBMS, entre ellas se encuentran: mantenimiento de versiones, administración de la seguridad, “tracking” de eventos.
Externas: Estas aplicaciones contienen conocimiento de la aplicación, expresándola en forma de reglas, a las cuales comúnmente se les llama reglas del negocio.
Con respecto al control de integridad las restricciones que se pueden establecer con las reglas activas son:
Restricciones estáticas: Se evalúan sobre un estado de la base de datos, un ejemplo de estas son las restricciones de dominio.
Restricciones dinámicas: Se evalúan sobre la transición de un estado a otro, por ejemplo: el sueldo de un empleado sólo puede aumentar.
Independientemente de si las restricciones son estáticas o dinámicas, dependiendo de quién las especifica, se pueden dividir en:
Restricciones “built-in”: Son restricciones fijas y especificadas con cláusulas del lenguaje de Definición de Datos (DDL), por ejemplo: referential integrity (foreign keys, REFERENCES) y claves primarias (PRIMARY KEY).
Restricciones genéricas: Son restricciones especificadas por el usuario, por ejemplo con la definición de CONSTRAINTS; algunos ejemplos de estos son: NOT NULL, UNIQUE y CHECK.
Ventajas.
Mayor productividad.
Mejor mantenimiento.
Reutilización de código.
Reducción del tráfico de mensajes.
Posibilidad de optimización semántica.
Facilitar el acceso a la Base de Datos a usuarios finales.
Desventajas.
Escritura de programas que consulten periódicamente el estatus de la Base de Datos.
Incorporación de código en cada uno de los programas que actualizan la Base de Datos.
Encontrar criterios de interpretación para las reglas activas.
Los Triggers o Disparadores
youtube
Son objetos que se asocian con tablas y se almacenan en la base de datos. Su nombre se deriva por el comportamiento que presentan en su funcionamiento, ya que se ejecutan cuando sucede algún evento sobre las tablas a las que se encuentra asociado. Los eventos que hacen que se ejecute un trigger son las operaciones de inserción (INSERT), borrado (DELETE) o actualización (UPDATE), ya que modifican los datos de una tabla.
La utilidad principal de un trigger es mejorar la administración de la base de datos, ya que no requieren que un usuario los ejecute. Por lo tanto, son empleados para implementar las REGLAS DE NEGOCIO (tipo especial de integridad) de una base de datos. Una Regla de Negocio es cualquier restricción, requerimiento, necesidad o actividad especial que debe ser verificada al momento de intentar agregar, borrar o actualizar la información de una base de datos. Un trigger puede prevenir errores en los datos, modificar valores de una vista, sincronizar tablas, entre otros.
Desafíos y líneas de investigación en los SGBDA
Aunque, como ya se ha señalado, las bases de datos activas empiezan a considerarse maduras, todavía existen múltiples aspectos de investigación en este campo, como, por ejemplo: Mecanismos de verificación de condición; se debe diseñar mecanismos para las reglas que sean lo suficientemente eficientes como para permitir un procesamiento rápido de transacciones. Integración de la verificación de la condición de la regla y su ejecución con el proceso de transacciones. Mecanismos para bloqueo de reglas. Optimización de las reglas. Mejora del poder expresivo de las reglas. En la actualidad existen todavía pocas aplicaciones reales sobre SGBD activos, y ello se debe en gran parte a la falta de herramientas que soporten estas características en el proceso de desarrollo, tal y como se señala en WIDOM (1994).
Ejemplo 1 (Triggers)
Un sencillo ejemplo (para SQL Server) sería crear un Trigger para insertar un pedido de algún producto cuando la cantidad de éste, en nuestro almacén, sea inferior a un valor dado.
CREATE TRIGGER TR_ARTICULO ON ARTICULOS AFTER UPDATE AS BEGIN INSERT INTO HCO_ARTICULO (IDARTICULO, STOCK, FECHA) SELECT ID_ARTICULO, STOCK, GETDATE() FROM INSERTED END INSERT INTO ARTICULOS VALUES (1, 'MEMORIA', 12, '12/03/2014') SELECT * FROM ARTICULOS UPDATE ARTICULOS SET STOCK = STOCK - 20 WHERE ID_ARTICULO = 1 SELECT * FROM HCO_ARTICULO
Ejemplo 2 (Triggers)
Dada una tabla con información sobre «expedientes», vamos a crear un Trigger que controle las modificaciones del «estado del expediente» de la siguiente manera:
Anotará en el campo «stateChangedDate» la fecha/hora en la que se produjo un cambio de estado. A modo de histórico, insertará un registro en tabla «expStatusHistory» con información sobre los cambios de estado de cada expediente.
-- -------------------------------------------------------------------- -- Creamos una base de datos si no existiese. -- --------------------------------------------------------------------
IF NOT EXISTS (SELECT * from sys.databases where name = 'db_test') BEGIN CREATE DATABASE db_test; END
-- Establecemos la base de datos predeterminada USE db_test;
-- -------------------------------------------------------------------- -- Creamos una tabla si no existiese. -- Representa los datos de expedientes -- --------------------------------------------------------------------
IF NOT EXISTS (SELECT * FROM sys.sysobjects WHERE name='expedientes' AND xtype='U') BEGIN CREATE TABLE expedientes ( code VARCHAR(15) NOT NULL, state VARCHAR(20) DEFAULT 'INICIO', stateChangedDate DATETIME, PRIMARY KEY (code) ); END;
-- Insertamos algunos expedientes de ejemplo DELETE FROM expedientes WHERE code IN ('exp1','exp2', 'exp3'); INSERT INTO expedientes (code) VALUES ('exp1'); INSERT INTO expedientes (code) VALUES ('exp2'); INSERT INTO expedientes (code) VALUES ('exp3');
-- Si no existe la tabla de cambios de esstado la creamos IF NOT EXISTS (SELECT * FROM sys.sysobjects WHERE name='expStatusHistory' AND xtype='U') BEGIN CREATE TABLE expStatusHistory ( id INT IDENTITY, code VARCHAR(15) NOT NULL, state VARCHAR(20) NOT NULL, date DATETIME DEFAULT GetDate(), PRIMARY KEY (id) ); END;
-- Borramos el Trigger si existise IF OBJECT_ID ('StatusChangeDateTrigger', 'TR') IS NOT NULL BEGIN DROP TRIGGER StatusChangeDateTrigger; END;
GO -- Necesario
-- Cremamos un Trigger sobre la tabla expedientes CREATE TRIGGER StatusChangeDateTrigger ON expedientes AFTER UPDATE AS -- ¿Ha cambiado el estado? IF UPDATE(state) BEGIN -- Actualizamos el campo stateChangedDate a la fecha/hora actual UPDATE expedientes SET stateChangedDate=GetDate() WHERE code=(SELECT code FROM inserted);
-- A modo de auditoría, añadimos un registro en la tabla expStatusHistory INSERT INTO expStatusHistory (code, state) (SELECT code, state FROM deleted WHERE code=deleted.code); -- La tabla deleted contiene información sobre los valores ANTIGUOS mientras que la tabla inserted contiene los NUEVOS valores. -- Ambas tablas son virtuales y tienen la misma estructura que la tabla a la que se asocia el Trigger. END;
Ejemplo 3 (Triggers)
Implementar un Trigger que permita mostrar un mensaje cada vez que se inserte o actualice un registro en la tabla pasajero.
CREATE TRIGGER trmensaje_pasajero
ON pasajero
FOR INSERT, UPDATE
AS
PRINT 'Pasajero actualizado correctamente'
go
update pasajero set nombre='Jcarlos'
where num_documento='47715777'
0 notes
Text
IMPLEMENTACIÓN DE BASE DE DATOS AVANZADAS
OBJETO-RELACIONAL

El término Base de Datos Objeto Relacional (BDOR) se usa para describir una base de datos que ha evolucionado desde el modelo relacional hacia otra más amplia que incorpora conceptos del paradigma orientado a objetos. Por tanto, un Sistema de Gestión Objeto-Relacional (SGBDOR) contiene ambas tecnologías: relacional y de objetos.
Una idea básica de las BDOR es que el usuario pueda crear sus propios tipos de datos, para ser utilizados en aquella tecnología que permita la implementación de tipos de datos predefinidos. Además, las BDOR permiten crear métodos para esos tipos de datos. Con ello, este tipo de SGBD hace posible la creación de funciones miembro usando tipos de datos definidos por el usuario, lo que proporciona flexibilidad y seguridad.
Los SGBDOR permiten importantes mejoras en muchos aspectos con respecto a las BDR tradicionales. Estos sistemas gestionan tipos de datos complejos con un esfuerzo mínimo y albergan parte de la aplicación en el servidor de base de datos. Permiten almacenar datos complejos de una aplicación dentro de la BDOR sin necesidad de forzar los tipos de datos tradicionales. Son compatibles en sentido ascendente con las bases de datos relacionales tradicionales, tan familiares a multitud de usuarios. Es decir, se pueden pasar las aplicaciones sobre bases de datos relacionales al nuevo modelo sin tener que rescribirlas. Adicionalmente, se pueden ir adaptando las aplicaciones y bases de datos para que utilicen las funciones orientadas a objetos.
BD ACTIVAS

Bases de datos activas. En muchas aplicaciones, la base de datos debe evolucionar independientemente de la intervención del usuario como respuesta a un suceso o una determinada situación. En los sistemas de gestión de bases de datos tradicionales (pasivas), la evolución de la base de datos se programa en el código de las aplicaciones, mientras que en los sistemas de gestión de bases de datos activas esta evolución es autónoma y se define en el esquema de la base de datos.
Un sistema de bases de datos activas es un sistema de gestión de bases de datos (SGBD) que contiene un subsistema que permite la definición y la gestión de reglas de producción (reglas activas). Las reglas siguen el modelo evento–condición–acción (modelo ECA): cada regla reacciona ante un determinado evento, evalúa una condición y, si esta es cierta, ejecuta una acción. La ejecución de las reglas tiene lugar bajo el control de un subsistema autónomo, denominado motor de reglas, que se encarga de detectar los eventos que van sucediendo y de planificar las reglas para que se ejecuten. En el modelo ECA una regla tiene tres componentes:
El evento (o eventos) que dispara la regla. Estos eventos pueden ser operaciones de consulta o actualización que se aplican explícitamente sobre la base de datos. También pueden ser eventos temporales (por ejemplo, que sea una determinada hora del día) u otro tipo de eventos externos (definidos por el usuario).
La condición que determina si la acción de la regla se debe ejecutar. Una vez ocurre el evento disparador, se puede evaluar una condición (es opcional). Si no se especifica condición, la acción se ejecutará cuando suceda el evento. Si se especifica condición, la acción se ejecutará sólo si la condición se evalúa a verdadero.
La acción a realizar puede ser una transacción sobre la base de datos o un programa externo que se ejecutar automáticamente.
Casi todos los sistemas relacionales incorporan reglas activas simples denominadas disparadores (triggers), que están basados en el modelo ECA:
Los eventos son sentencias SQL de manejo de datos (INSERT, DELETE, UPDATE).
La condición (que es opcional) es un predicado booleano expresado en SQL.
La acción es una secuencia de sentencias SQL, que pueden estar inmersas en un lenguaje de programación integrado en el producto que se esté utilizando (por ejemplo, PL/SQL en Oracle).
El modelo ECA se comporta de un modo simple e intuitivo: cuando ocurre el evento, si la condición es verdadera, entonces se ejecuta la acción. Se dice que el disparador es activado por el evento, es considerado durante la verificación de su condición y es ejecutado si la condición es cierta. Sin embargo, hay diferencias importantes en el modo en que cada sistema define la activación, consideración y ejecución de disparadores. Los disparadores relacionales tienen dos niveles de granularidad: a nivel de fila y a nivel de sentencia. En el primer caso, la activación tiene lugar para cada tupla involucrada en la operación y se dice que el sistema tiene un comportamiento orientado a tuplas. En el segundo caso, la activación tiene lugar sólo una vez para cada sentencia SQL, refiriéndose a todas las tuplas invocadas por la sentencia, con un comportamiento orientado a conjuntos. Además, los disparadores tienen funcionalidad inmediata o diferida. La evaluación de los disparadores inmediatos normalmente sucede inmediatamente después de levento que lo activa (opción después), aunque también puede precederlo (opción antes) o ser evaluados en lugar de la ejecución del evento (opción en lugar de). La evaluación diferida de los disparadores tiene lugar al finalizar la transacción en donde se han activado (tras la sentencia COMMIT). Un disparador puede activar otro disparador. Esto ocurre cuando la acción de un disparador es también el evento de otro disparador. En este caso, se dice que los disparadores se activan en cascada.
BD DEDUCTIVAS

El verbo «deducir» hace referencia a la capacidad de extraer conclusiones a partir de cierta información, reglas o principios generales. Y este es básicamente el funcionamiento de las bases de datos deductivas.
Una base de datos deductiva consiste en un sistema de almacenamiento que, a través de ciertas reglas definidas, es capaz de utilizar la información contenida en la base de datos para deducir información adicional.
Este tipo de bases de datos se fundamenta en materias como la lógica matemática y el cálculo relacional, por ello también se las suele denominar como bases de datos lógicas. Su objetivo es definir nuevas relaciones para el procesamiento de consultas a través de la información presente en la propia base de datos.
Para ello, las bases de datos deductivas utilizan un lenguaje declarativo (normalmente Prolog). Este lenguaje tiene la particularidad de definir reglas que marcan lo que el programa, en este caso la base de datos, desea conseguir. Esto lo diferencia de los lenguajes usados habitualmente en otras bases de datos como el SQL, que definen el cómo conseguirlo.
En definitiva, las bases de datos activas y deductivas son capaces de deducir nuevos hechos a partir de la información presente en la data base, teniendo en cuenta determinadas reglas definidas de antemano por su lenguaje.
Las principales características de las bases de datos deductivas son las siguientes:
Utilizan el lenguaje DataLog, un lenguaje declarativo.
Permiten hacer consultas a través de reglas lógicas, deduciendo nueva información por medio de los datos presentes en la database.
Son capaces de soportar conjuntos y objetos de gran complejidad.
Al contrario que en otras bases de datos, no existen relaciones entre entidades, sino predicados. También se basan en hechos en lugar de tulpas.
Pueden establecer negaciones por estratos.
En cualquier caso, la característica fundamental de esta base de datos es que ha de ser modelada a través de reglas lógicas, las cuáles le permiten deducir información a partir de los datos ya almacenados.
ORIENTADO A OBJETO DINÁMICO

Se relacionan aspectos relacionados con las secuencias posibles de eventos (vidas posibles) en el diagrama de interacción entre estados (uno por clase) y la interacción entre objetos en el Diagrama de Interacción entre objetos (uno para la aplicación).
Con este, se pueden obtener directamente las precondiciones que deben cumplirse para que ocurra un cambio de estado. Estas precondiciones quedan reflejadas, en la descripción de las transiciones, como la unión del evento que ocurre y las condiciones que deben evaluarse para provocar el cambio. Las restricciones que tienen los estados se deben cumplir para que En la condición hay que especificar las tablas involucradas y se puede usar NOT, EXIST, funciones de agregación, AND, OR, IN, BETWEEN. <atributo>=<condición> 173 el objeto se mantenga en ese estado, por lo tanto, lo contrario de una restricción tiene que ser una condición de alguna de las transiciones de salida que se deriven de ese estado.
DISPARADORES

Un disparador define una acción que la base de datos debe llevar a cabo cuando se produce algún suceso relacionado con la misma. Los disparadores (triggers) pueden utilizarse para completar la integridad referencial, también para imponer reglas de negocio complejas o para auditar cambios en los datos. El código contenido en un disparador, denominado cuerpo del disparador, está formado por bloques PL/SQL. La ejecución de disparadores es transparente al usuario.
Existen varios tipos de disparadores, dependiendo del tipo de transacción de disparo y el nivel en el que se ejecuta el disparador (trigger):
Disparadores de nivel de fila: se ejecutan una vez para cada fila afectada por una instrucción DML. Los disparadores de nivel de fila se crean utilizando la cláusula for each row en el comando créate trigger.
Disparadores de nivel de instrucción: se ejecutan una vez para cada intrucción DML. Por ejemplo, si una única intrucción INSERT inserta 500 filas en una tabla un disparador de nivel de instrucción para dicha tabla sólo se ejecutará una vez. Los disparadores de nivel de instrucción son el tipo predeterminado que se crea con el comando create trigger.
Disparadores Before y After: puesto que los disparadores son ejecutados por sucesos, puede establecerse que se produzcan inmediatamente antes (before) o después (after) de dichos sucesos.
Disparadores Instead Of: puede utilizar INSTEAD OF para indicar a Oracle lo que tiene que hacer en lugar de realizar las acciones que invoca el disparador. Por ejemplo, podría usar un disparadorINSTEAD OF en una vista para gestionar las inserciones en una tabla o para actualizar múltiples tablas que son parte de una vista.
Disparadores de esquema: puede crear disparadores sobre operaciones en el nivel de esquema tales como create table, alter table, drop table, audit, rename, truncate y revoke. Puede incluso crear disparadores para impedir que los usuarios eliminen sus propias tablas. En su mayor parte, los disparadores de nivel de esquema proporcionan dos capacidades: impedir operaciones DDL y proporcionar una seguridad adicional que controle las operaciones DDL cuando éstar se producen.
Disparadores en nivel de base de datos: puede crear disparadores que se activen al producirse sucesos de la base de datos, incluyendo errores, inicios de sesión, conexiones y desconexiones. Puede utilizar este tipo de disparador para automatizar el mantenimiento de la base de datos o las acciones de auditoría.
LAS NUEVAS GENERACIONES DE SISTEMAS DE BASES DE DATOS ORIENTACIÓN POR OBJETOS DECLARATIVIDAD Y DEDUCCIÓN

Las bases de datos se utilizan normalmente para guardar una variedad de información dependiendo del dominio de la aplicación elegida. Los datos necesitan a menudo ser periódicamente actualizados en cuanto a la información con la que cuenta (valores), como de los cambios en el dominio de la aplicación
Declaratividad y deducción en base de datos orientados a objetos
Las bases de datos declarativas son sumamente intuitivas para el usuario y le permite abstraerse de los problemas de programación inherentes a otros métodos. Este modelo suele usarse para bases de conocimiento que no son más que base de datos con mecanismos de consulta en los que el trabajo de extracción de información a partir de los datos recae en realidad sobre el ordenador en lugar de sobre el usuario. Entre las bases de datos declarativas podemos citar fundamentalmente dos las deductivas y las funcionales. Ambas extienden paradigmas o métodos de programación a las bases de datos de manera que ambos programa y base de datos puedas cooperar más eficientemente en la resolución del problema.
Una base de datos deductiva puede ser considerada también como integrada por un conjunto de tablas. Sin embargo, nuestro punto de vista varía esencialmente. A veces es necesario ver una misma cosa desde distintos puntos de vista, ya que ello ayuda a compararlo con distintas cosas que ya conocemos y permite adoptar soluciones que de otra forma serian difíciles de comprender.
LA INTEROPERABILIDAD COMO RESPUESTA A LA DIVERSIDAD DE SISTEMAS DE BASES DE DATOS EXISTENTES.
youtube
INTERACCIÓN CON LA MODELACIÓN IMPACTO
Los modelos de datos definen con claridad cómo se modela la estructura lógica de una base de datos. Estos, son entidades necesarias para introducir la abstracción en un DBMS (Data Base Management System), entendiendo por abstracción al proceso de aislar un elemento de su contexto o del resto de elementos que lo pueden acompañar. Un modelo de base de datos incluye, además, las relaciones y limitaciones que determinan cómo se pueden almacenar los datos y acceder a ellos.
Actualmente, vivimos en la era de la tecnología y los datos, ya que estos tienen infinidad de usos: económicos, sociales, etc… y se han convertido en foco de mayor estudio e inversión. Pero desde ya hace décadas que se establecieron modelos para su almacenamiento y gestión, aparecieron los primeros modelos. Los datos han adoptado una importancia de grandes dimensiones en la actualidad, más si cabe, de ahí la relevancia de los modelos de base de datos. Siempre han tenido un papel clave en la informática, en la empresa y en muchos sectores, ya que la recopilación y gestión de los datos son fundamentales para que las empresas o instituciones mantengan su orden y sus relaciones. Por todo esto, es muy importante establecer efectivos modelos de gestión de base de datos y un correcto mantenimiento y mejora.
METODOLOGÍAS EXISTENTES DE DISEÑO DE BASES DE DATOS

En general no existe una metodología consagrada o dedicada exclusivamente, sin embargo, ciertas etapas son distinguibles:
Diseño Conceptual: cuyo objetivo es obtener una buena representación de los recursos de información de la empresa, con independencia de usuarios o aplicaciones en particular y fuera de consideraciones de eficiencia del computador.
Un modelo conceptual de datos identifica las relaciones de más alto nivel entre las diferentes entidades.
Las características del modelo conceptual de datos incluyen:
Incluye las entidades importantes y las relaciones entre ellas.
No se especifica ningún atributo.
No se especifica ninguna clave principal.

Diseño Lógico: cuyo objetivo es transformar el esquema conceptual obtenido en la etapa anterior, adaptándolo al modelo de datos en el que se apoya el SGBD que se va a utilizar (modelo relacional).
Un modelo de datos lógicos describe los datos con el mayor detalle posible, independientemente de cómo se implementarán físicamente en la base de datos.
Las características de un modelo de datos lógicos incluyen:
Incluye todas las entidades y relaciones entre ellos.
Todos los atributos para cada entidad están especificados.
La clave principal para cada entidad está especificada.
Se especifican las claves externas (claves que identifican la relación entre diferentes entidades).
La normalización ocurre en este nivel.
Los pasos para diseñar el modelo de datos lógicos son los siguientes:
Especifique claves primarias para todas las entidades.
Encuentra las relaciones entre diferentes entidades.
Encuentra todos los atributos para cada entidad.
Resuelva las relaciones de muchos a muchos.
Normalización.

Diseño Físico: cuyo objetivo es conseguir una instrumentación lo más eficiente posible del esquema lógico.
El modelo de datos físicos representa cómo se construirá el modelo en la base de datos.
Un modelo de base de datos física muestra todas las estructuras de tabla, incluidos el nombre de columna, el tipo de datos de columna, las restricciones de columna, la clave principal, la clave externa y las relaciones entre las tablas.
Las características de un modelo de datos físicos incluyen:
Especificación de todas las tablas y columnas.
Las claves externas se usan para identificar relaciones entre tablas.
La des normalización puede ocurrir según los requisitos del usuario.
Las consideraciones físicas pueden hacer que el modelo de datos físicos sea bastante diferente del modelo de datos lógicos.
El modelo de datos físicos será diferente para diferentes Sistemas de Gestión de Base de datos. Por ejemplo, el tipo de datos para una columna puede ser diferente entre MySQL y SQL Server.
Los pasos básicos para el diseño del modelo de datos físicos son los siguientes:
Convertir entidades en tablas.
Convertir relaciones en claves externas.
Convertir atributos en columnas.
Modificar el modelo de datos físicos en función de las restricciones / requisitos físicos.

Modelo Entidad Relación y sus Extensiones
Modelo Entidad Relación. Un diagrama o modelo entidad-relación (a veces denominado por sus siglas E-R ("Entity relationship") o "DER" (Diagrama de Entidad Relación), es el modelo más utilizado para el diseño conceptual de bases de datos. Fue introducido por Peter Chen en 1976.
Entidades débiles
El concepto de entidad débi no es tratado con suficiente claridad por diferentes autores; en general hay un consenso en considerarla como una entidad que tiene dependencia de existencia de otra, ya sea porque sus atributos internos no son suficientes para identificarla o bien porque no lo son dentro del dominio de aplicación. La llave primaria de un conjunto de entidades débiles se forma mediante la llave primaria del conjunto de entidades fuertes, de cuya existencia depende el conjunto de entidades débiles, y el discriminante del conjunto de entidades débiles.
El conjunto de entidades que identifica un conjunto de entidades débiles se llama "Propietario" (Owner) del conjunto de entidades débiles.
Especialización
Un conjunto de entidades puede incluir subgrupos de entidades que se diferencian de alguna forma de las otras entidades del conjunto. Por ejemplo, un subconjunto de entidades en un conjunto de entidades puede tener atributos que no son compartidos por todas las demás entidades. El proceso de designación de subgrupos dentro de un conjunto de entidades es la especialización. Un conjunto de entidades se puede especializar mediante más de una característica distintiva.
Generalización
En el modelo ER es posible establecer jerarquías de generalización entre los conjuntos de entidades. Un conjunto de entidades (E) es una generalización de un grupo de conjuntos de entidades E1, E2, …, En sí, cada elemento de los conjuntos de entidades (E1, E2, …, En) es también un elemento del conjunto de entidades E.
La representación gráfica en el DER, se realiza como se muestra en la figura. La flecha va hacia el conjunto de entidades generalizado. En el sentido contrario se habla de de especialización.
Propiedad de cubrimiento
Cubrimiento total o parcial: el cubrimiento de una generalización es total (t) si cada elemento del conjunto de entidades genérico es transformado en al menos un elemento de los conjuntos de entidades de nivel más bajo o específicos; es parcial (p) si existe algún elemento del conjunto de entidades genérico que no es transformado a algún elemento de los conjuntos de entidades específicos.
Cubrimiento exclusivo o solapado: el cubrimiento de una generalización es exclusivo (e) si cada elemento del conjunto de entidades genérico es transformado a lo sumo a un elemento de los conjuntos de entidades específicos; es solapado (s) si existe algún elemento del conjunto de entidades genérico que es transformado a elementos de dos o más conjuntos de entidades diferentes.
Los siguientes ejemplos, ilustran las formas en que son combinados los distintos cubrimientos de la generalización.
El cubrimiento de la generalización: Persona de los conjuntos de entidades Masculino y Femenino es total y exclusivo (t, e).
El cubrimiento de la generalización: Persona de los conjuntos de entidades Masculino y Empleado es parcial y solapado (p, s).
El cubrimiento de la generalización: Vehículo de los conjuntos de entidades Bicicleta y Auto es parcial y exclusivo (p, e).
El cubrimiento de la generalización: Deportista de los conjuntos de entidades Futbolista y Tenista en una escuela que requiere que cada alumno participe al menos en uno de estos deportes es total y solapada (t, s).
Agregaciones
Una limitación del modelo ER básico es que no facilita expresar interrelaciones entre interrelaciones. Una interrelación y los conjuntos de entidades que relaciona, pueden ser manejados como un conjunto de entidades en un nivel de abstracción mayor, lo que posibilita que se pueda asociar con otros conjuntos de entidades. Este mecanismo es conocido como "Estructura de Agregación o Agregación de Conjuntos de Entidades", y permite representar la interrelación Part_Of. La agregación se representa en el DER como un rectángulo englobando a la interrelación que la conforma.
Clase membresía de una interrelación o función en la interrelación
Esta extensión permite especificar si la aparición de una ocurrencia de un tipo de entidad en una interrelación, es obligatoria u opcional. Es obligatoria si en la interrelación al menos una ocurrencia del tipo de entidad tiene que darse en la interrelación, en caso contrario es opcional. Nótese que la opcionalidad puede representarse mediante la especificación de la cardinalidad mínima como cero.
Ejemplo:Aquí se introduce la semántica de que un empleado puede o no trabajar en uno o varios proyectos, o sea, habrá entidades del tipo de entidad empleado que no participan en la interrelación. Nótese que la interrelación obligatoria u opcional también puede ser expresada a través de las cardinalidades mínimas y máximas.
Interrelaciones de grado mayor que 2
Interrelación ternaria: Las interrelaciones pueden envolver más de dos entidades. Aquellas que envuelven tres, no son inusuales. Como un ejemplo consideremos la base de datos en la figura de abajo, la cual es para guardar información sobre compañías, los productos que estos producen y los países a las cuales estos exportan esos productos.
El conjunto de países a los cuales un producto es exportado, varía de producto a producto y también de compañía a compañía. La interrelación VENTAS es ternaria, es decir, esta envuelve tres entidades. La funcionalidad de la interrelación ternaria VENTAS es representada en la figura como “muchos a muchos a muchos” (N-M-P). Esto refleja los hechos siguientes sobre la interrelación:
Para un par dado (compañía, producto) existen por lo general muchos países a los cuales ese producto se vende. Para un par dado (país, producto) existen varias compañías que exportan ese producto a ese país. Para un par dado (compañía, país) existirán muchos productos exportados por esa compañía a ese país.
Object ModelingG Technique
Las técnicas de modelado de objetos son una metodología de análisis, diseño e implementación orientada a objetos que se enfoca en crear un modelo de objetos del mundo real y luego utilizar este modelo para desarrollar software orientado a objetos. técnica de modelado de objetos, OMT fue desarrollada por James Rambaugh. Hoy en día, OMT es una de las técnicas de desarrollo orientado a objetos más populares. Lo utilizan principalmente los desarrolladores de sistemas y software para respaldar el desarrollo del ciclo de vida completo mientras se dirigen a implementaciones orientadas a objetos.
OMT ha demostrado ser fácil de entender, dibujar y usar. Tiene mucho éxito en muchos dominios de aplicación: telecomunicaciones, transporte, compiladores, etc. La popular técnica de modelado de objetos se utiliza en muchos problemas del mundo real. El paradigma orientado a objetos que utiliza OMT abarca todo el ciclo de desarrollo, por lo que no es necesario transformar un tipo de modelo en otro.
La metodología OMT cubre el ciclo de vida completo del desarrollo de software. La metodología tiene la siguiente fase.
Análisis- El análisis es la primera fase de la metodología OMT. El objetivo de la fase de análisis es construir un modelo de la situación del mundo real para mostrar sus importantes propiedades y dominio. Esta fase se ocupa de la preparación de modelos precisos y correctos del mundo real. La fase de análisis comienza con la definición de un enunciado del problema que incluye un conjunto de objetivos. Este enunciado del problema se expande luego en tres modelos; un modelo de objeto, un modelo dinámico y un modelo funcional. El modelo de objetos muestra la estructura de datos estáticos o el esqueleto del sistema del mundo real y divide toda la aplicación en objetos. En otras palabras, este modelo representa los artefactos del sistema. El modelo dinámico representa la interacción entre los artefactos diseñados anteriormente representados como eventos, estados y transiciones. El modelo funcional representa los métodos del sistema desde la perspectiva del flujo de datos. La fase de análisis genera diagramas de modelos de objetos, diagramas de estado, diagramas de flujo de eventos y diagramas de flujo de datos.
Diseño del sistema: la fase de diseño del sistema viene después de la fase de análisis. La fase de diseño del sistema determina la arquitectura general del sistema utilizando subsistemas, tareas concurrentes y almacenamiento de datos. Durante el diseño del sistema, se diseña la estructura de alto nivel del sistema. Las decisiones que se toman durante el diseño del sistema son:
El sistema se organiza en subsistemas que luego se asignan a procesos y tareas, teniendo en cuenta la concurrencia y la colaboración.
El almacenamiento de datos persistente se establece junto con una estrategia para administrar información compartida o global.
Las situaciones límite se verifican para ayudar a orientar las prioridades de compensación.
Diseño de objetos: la fase de diseño de objetos se produce una vez finalizada la fase de diseño del sistema. Aquí se desarrolla el plan de implementación. El diseño de objetos se ocupa de clasificar completamente las clases, asociaciones, atributos y operaciones existentes y restantes necesarios para implementar una solución al problema. En diseño de objetos:
Las operaciones y las estructuras de datos están completamente definidas junto con los objetos internos necesarios para la implementación.
Se determinan las asociaciones de nivel de clase.
Se comprueban cuestiones de herencia, agregación, asociación y valores predeterminados.
Implementación: el proceso de implementación del OMT es una cuestión de traducir el diseño en construcciones de un lenguaje de programación. Es importante tener buenas prácticas de ingeniería de software para que la fase de diseño se traduzca sin problemas a la fase de implementación. Por lo tanto, al seleccionar el lenguaje de programación, se deben tener en cuenta todas las construcciones para seguir los puntos notables.
Para aumentar la flexibilidad.
Para hacer enmiendas fácilmente.
Para la trazabilidad del diseño.
Para aumentar la eficiencia.
Bases de datos espaciales y de imágenes
Una base de datos espacial (spatial database) es un sistema administrador de bases de datos que maneja datos existentes en un espacio o datos espaciales. En este tipo de bases de datos es imprescindible establecer un cuadro de referencia (un SRE, Sistema de Referencia Espacial) para definir la localización y relación entre objetos, ya que los datos tratados en este tipo de bases de datos tienen un valor relativo, no es un valor absoluto. Los sistemas de referencia espacial pueden ser de dos tipos: georreferenciados (aquellos que se establecen sobre la superficie terrestre. Son los que normalmente se utilizan, ya que es un dominio manipulable, perceptible y que sirve de referencia) y no georreferenciados (son sistemas que tienen valor físico, pero que pueden ser útiles en determinadas situaciones).
La construcción de una base de datos geográfica implica un proceso de abstracción para pasar de la complejidad del mundo real a una representación simplificada que pueda ser procesada por el lenguaje de las computadoras actuales. Este proceso de abstracción tiene diversos niveles y normalmente comienza con la concepción de la estructura de la base de datos, generalmente en capas; en esta fase, y dependiendo de la utilidad que se vaya a dar a la información a compilar, se seleccionan las capas temáticas a incluir.
La estructuración de la información espacial procedente del mundo real en capas conlleva cierto nivel de dificultad. En primer lugar, la necesidad de abstracción que requieren los computadores implica trabajar con primitivas básicas de dibujo, de tal forma que toda la complejidad de la realidad ha de ser reducida a puntos, líneas o polígonos.
En segundo lugar, existen relaciones espaciales entre los objetos geográficos que el sistema no puede obviar; la topología, que en realidad es el método matemático-lógico usado para definir las relaciones espaciales entre los objetos geográficos puede llegar a ser muy compleja, ya que son muchos los elementos que interaccionan sobre cada aspecto de la realidad.
Un modelo de datos geográfico es una abstracción del mundo real que emplea un conjunto de objetos dato, para soportar el despliegue de mapas, consultas, edición y análisis. Los datos geográficos, presentan la información en representaciones subjetivas a través de mapas y símbolos, que representan la geografía como formas geométricas, redes, superficies, ubicaciones e imágenes, a los cuales se les asignan sus respectivos atributos que los definen y describen.
0 notes
Text
DISEÑO AVANZADO DE BASES DE DATOS
PARADIGMAS DE BASES DE DATOS.

Un modelo de base de datos es un tipo de modelo de datos que determina la estructura lógica de una base de datos y de manera fundamental determina el modo de almacenar, organizar y manipular los datos.
Ejemplos de modelos de base de datos:
Modelo jerárquico
Modelo en red
Modelo relacional
Modelo entidad-relación
Modelo entidad–relación extendido
Base de datos orientada a objetos
Modelo documental
Modelo entidad–atributo–valor
Modelo en estrella
Los modelos físicos de datos incluyen:
Índice invertido
Fichero plano
Otros modelos lógicos pueden ser:
Modelo asociativo
Modelo multidimensional
Modelo multivalor
Modelo semántico
Base de datos XML
Grafo etiquetado
Triplestore
ESTRATEGIAS DE DISEÑO
Orientado a Objeto Conceptual
El primer paso en el diseño de una base de datos es la producción del esquema conceptual. Normalmente, se construyen varios esquemas conceptuales, cada uno para representar las distintas visiones que los usuarios tienen de la información. Cada una de estas visiones suelen corresponder a las diferentes áreas funcionales de la empresa como, por ejemplo, producción, ventas, recursos humanos, etc.
Estas visiones de la información, denominadas vistas, se pueden identificar de varias formas. Una opción consiste en examinar los diagramas de flujo de datos, que se pueden haber producido previamente, para identificar cada una de las áreas funcionales. La otra opción consiste en entrevistar a los usuarios, examinar los procedimientos, los informes y los formularios, y también observar el funcionamiento de la empresa.
A los esquemas conceptuales correspondientes a cada vista de usuario se les denomina esquemas conceptuales locales. Cada uno de estos esquemas se compone de entidades, relaciones, atributos, dominios de atributos e identificadores. El esquema conceptual también tendrá una documentación, que se irá produciendo durante su desarrollo.
Las tareas a realizar en el diseño conceptual son las siguientes:
Identificar las entidades.
Identificar las relaciones.
Identificar los atributos y asociarlos a entidades y relaciones.
Determinar los dominios de los atributos.
Determinar los identificadores.
Determinar las jerarquías de generalización (si las hay).
Dibujar el diagrama entidad-relación.
Revisar el esquema conceptual local con el usuario.
Objeto Relacional
El término Base de Datos Objeto Relacional (BDOR) se usa para describir una base de datos que ha evolucionado desde el modelo relacional hacia otra más amplia que incorpora conceptos del paradigma orientado a objetos. Por tanto, un Sistema de Gestión Objeto-Relacional (SGBDOR) contiene ambas tecnologías: relacional y de objetos. Una idea básica de las BDOR es que el usuario pueda crear sus propios tipos de datos, para ser utilizados en aquella tecnología que permita la implementación de tipos de datos predefinidos. Además, las BDOR permiten crear métodos para esos tipos de datos. Con ello, este tipo de SGBD hace posible la creación de funciones miembro usando tipos de datos definidos por el usuario, lo que proporciona flexibilidad y seguridad.
Los SGBDOR permiten importantes mejoras en muchos aspectos con respecto a las BDR tradicionales. Estos sistemas gestionan tipos de datos complejos con un esfuerzo mínimo y albergan parte de la aplicación en el servidor de base de datos. Permiten almacenar datos complejos de una aplicación dentro de la BDOR sin necesidad de forzar los tipos de datos tradicionales. Son compatibles en sentido ascendente con las bases de datos relacionales tradicionales, tan familiares a multitud de usuarios. Es decir, se pueden pasar las aplicaciones sobre bases de datos relacionales al nuevo modelo sin tener que rescribirlas. Adicionalmente, se pueden ir adaptando las aplicaciones y bases de datos para que utilicen las funciones orientadas a objetos.
Las tareas a realizar en el diseño relacional son las siguientes:
Convertir los esquemas conceptuales locales en esquemas lógicos locales.
Derivar un conjunto de relaciones (tablas) para cada esquema lógico local.
Validar cada esquema mediante la normalización.
Validar cada esquema frente a las transacciones del usuario.
Dibujar el diagrama entidad – relación.
Definir las restricciones de integridad.
Revisar cada esquema lógico local con el usuario correspondiente.
Mezclar los esquemas lógicos locales en un esquema lógico global.
Validar el esquema lógico global.
Estudiar el crecimiento futuro.
Dibujar el diagrama entidad/relación final.
Revisar el esquema lógico global con los usuarios.
ESQUEMA CONCEPTUAL
Entidad Relación
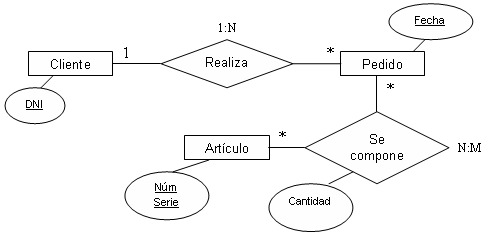
Cabe destacar que, para todo proceso de modelado, siempre hay que tener en claro los conceptos, estos nos brindan conocimiento necesario y además fundamentan nuestro modelo al momento de presentarlo a terceros. Formalmente, los diagramas ER son un lenguaje gráfico para describir conceptos. Informalmente, son simples dibujos o gráficos que describen información que trata un sistema de información y el software que lo automatiza.
Entidades
Las entidades son el fundamento del modelo entidad relación. Podemos adoptar como definición de entidad cualquier cosa o parte del mundo que es distinguible del resto. Por ejemplo, en un sistema bancario, las personas y las cuentas bancarias se podrían interpretar como entidades. Las entidades pueden representar entes concretos, como una persona o un avión, o abstractas, como por ejemplo un préstamo o una reserva. Se representan por medio de un rectángulo y pueden ser de tipo: maestras, transaccionales, históricas y temporales.
Atributos
Se representan mediante un círculo o elipse etiquetado mediante un nombre en su interior. Cuando un atributo es identificativo de la entidad se suele subrayar dicha etiqueta.
Por motivos de legibilidad, los atributos suelen no aparecer representados en el diagrama entidad-relación, sino descritos textualmente en otros documentos adjuntos.
Relación
Describe cierta dependencia entre entidades o permite la asociación de las mismas. Por ejemplo:
Si tenemos dos entidades, CLIENTE y HABITACIÓN, podemos entender la relación entre ambas al tomar un caso concreto (ocurrencia) de cada una de ellas. Entonces, podríamos tener la ocurrencia Habitación 502, de la entidad HABITACIÓN y la ocurrencia Henry Johnson McFly Bogard, de la entidad CLIENTE, entre las que es posible relacionar que la habitación 502 se encuentra ocupada por el huésped de nombre Henry Johnson McFly Bogard.
Entidad Relación Extendido
Los diagramas Entidad-Relación no cumplen su propósito con eficacia debido a que tienen limitaciones semánticas. Por ese motivo se suelen utilizar los diagramas Entidad-Relación extendidos (EER) que incorporan algunos elementos más al lenguaje:
Entidades fuertes y débiles
Cuando una entidad participa en una relación puede adquirir un papel fuerte o débil. Una entidad débil es aquella que no puede existir sin participar en la relación; es decir, aquella que no puede ser unívocamente identificada solamente por sus atributos.
Una entidad fuerte (también conocida como entidad regular) es aquella que sí puede ser identificada unívocamente. En los casos en que se requiera, se puede dar que una entidad fuerte "preste" algunos de sus atributos a una entidad débil para que esta última se pueda identificar.
Las entidades débiles se representan mediante un doble rectángulo; es decir, un rectángulo con doble línea.
Se puede hablar de la existencia de dos tipos de dependencias en las entidades débiles:
Dependencia por existencia: Las ocurrencias de la entidad débil pueden identificarse mediante un atributo identificador clave sin necesidad de identificar la entidad fuerte relacionada.
Dependencia por identidad: La entidad débil no puede ser identificada sin la entidad fuerte relacionada. (Ejemplo: si tenemos una entidad LIBRO y otra relacionada EDICIÓN, para identificar una edición necesitamos conocer el identificador del libro).
Cardinalidad de las relaciones
Cardinalidad es el número de entidades con la cual otra entidad puede asociar mediante una relación binaria; la cardinalidad puede ser: Uno a uno, uno a muchos o muchos a uno y muchos a muchos. El tipo de cardinalidad se representa mediante una etiqueta en el exterior de la relación, respectivamente: "1:1", "1:N" y "N:M", aunque la notación depende del lenguaje utilizado, la que más se usa actualmente es el unificado. Otra forma de expresar la cardinalidad es situando un símbolo cerca de la línea que conecta una entidad con una relación:
"0" si cada instancia de la entidad no está obligada a participar en la relación.
"1" si toda instancia de la entidad está obligada a participar en la relación y, además, solamente participa una vez.
"N" , "M", ó "*" si cada instancia de la entidad no está obligada a participar en la relación y puede hacerlo cualquier número de veces.
(también se puede representar como N:M) Ejemplos de relaciones que expresan cardinalidad:
Un policía (entidad) tiene (relación) un arma (entidad) siempre y cuando no realice funciones de oficina, pudiendo entonces tenerla o no asignada. Es una relación 0:1.
Cada esposo (entidad) está casado (relación) con una única esposa (entidad) y viceversa. Es una relación 1:1.
Una factura (entidad) se emite (relación) a una persona (entidad) y solo una, pero una persona puede tener varias facturas emitidas a su nombre. Todas las facturas se emiten a nombre de alguien. Es una relación N:1.
Un cliente (entidad) puede comprar (relación) varios servicios (entidad) y un servicio puede ser comprado por varios clientes distintos. Es una relación N:M.
Atributos en relaciones
Las relaciones también pueden tener atributos asociados. Se representan igual que los atributos de las entidades. Un ejemplo típico son las relaciones de tipo "histórico" donde debe constar una fecha o una hora. Por ejemplo, supongamos que es necesario hacer constar la fecha de emisión de una factura a un cliente, y que es posible emitir duplicados de la factura (con distinta fecha). En tal caso, el atributo "Fecha de emisión" de la factura debería colocarse en la relación "se emite".
Herencia
La herencia es un intento de adaptación de estos diagramas al paradigma orientado a objetos. La herencia es un tipo de relación entre una entidad "padre" y una entidad "hijo". La entidad "hijo" hereda todos los atributos y relaciones de la entidad "padre". Por tanto, no necesitan ser representadas dos veces en el diagrama. La relación de herencia se representa mediante un triángulo invertido interconectado por líneas a las entidades. La entidad conectada por la parte superior del triángulo es la entidad "padre". Solamente puede existir una entidad "padre" (herencia simple). Las entidades "hijo" se conectan por la parte inferior del triángulo.
Agregación
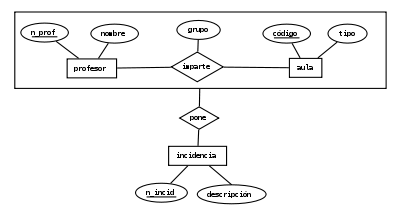
Es un tipo de relación dinámica, donde el tiempo de vida de una o más entidades de bajo nivel que están incluidas en una entidad de alto nivel es independiente a la entidad que la incluye (entidad de alto nivel). Es una abstracción a través de la cual las relaciones se tratan como entidades de un nivel más alto. Se utiliza para expresar relaciones entre relaciones o entre entidades y relaciones. Se representa englobando la relación abstraída y las entidades que participan en ella en un rectángulo. En la figura se muestra un ejemplo de agregación en el que se representa la situación en la que un profesor, cuando está impartiendo una clase, puede poner una incidencia ocurrida a lo largo de ésta (se fue la luz, falta la configuración de un determinado software, etc.).
Orientado a Objeto Conceptual
El modelo de base de datos orientada a objetos agrupa la información en paquetes relacionados entre sí: los datos de cada registro se combinan en un solo objeto, con todos sus atributos. De esta manera, toda la información está disponible en el objeto, ya que sus datos quedan agrupados en lugar de distribuidos en diferentes tablas. En los objetos no solo pueden guardarse los atributos, sino también los métodos, lo que refleja la afinidad de estas bases de datos con los lenguajes de programación orientados a objetos: al igual que en estos, cada objeto presenta un conjunto de acciones que pueden llevarse a cabo.
Los objetos se dividen a su vez en clases. Más concretamente, un objeto es una unidad concreta de una clase abstracta, lo que crea una jerarquía de clases y subclases. Dentro de esta estructura, las subclases adoptan las propiedades de las clases superordinadas y las complementan con sus propios atributos. Al mismo tiempo, los objetos de una clase también pueden relacionarse con otras clases, lo que rompe la jerarquía estricta y permite formar redes. Los objetos simples también pueden combinarse para crear objetos más complejos.
Para gestionar los diversos objetos, el SGBD orientado a objetos correspondiente asigna automáticamente un código de identificación único a cada registro, que permite recuperar los objetos una vez que se han guardado.
Ejemplo: en el contexto de una base de datos orientada a objetos, podemos guardar una bicicleta como objeto, con todos sus atributos y métodos: es roja, se puede conducir, tiene sillín, etc. Este objeto forma parte de la clase “bicicletas”, en la que, por ejemplo, también podría incluirse una bicicleta azul y otra verde. A su vez, la clase “bicicletas” es una subcategoría de “vehículos”, que también incluye la clase “coches”. Por otra parte, el objeto también está relacionado con la clase “actividades de ocio”. Si accedemos a este objeto a través de su código de identificación único, dispondremos directamente de todos sus métodos y atributos.
Objeto Relacional Conceptual
El modelo relacional ha sido suficiente para las aplicaciones tradicionales comerciales o de negocios, estas aplicaciones se caracterizan por manejar datos muy simples en grandes volúmenes. Datos simples generalmente se refieren a datos alfanuméricos que, con bastante precisión y facilidad, pueden ser representados en un computador. Estas aplicaciones han evolucionado en cuanto a sus necesidades de manipulación, y de almacenamiento y análisis de datos históricos en lo que se ha denominado “data warehouses” y “OLAP (on-line analytical processing)”.
Supongamos una aplicación donde se quieren llevar las historias médicas de los pacientes de una clínica o de un centro integral de medicina. Si se quieren almacenar datos alfanuméricos de los pacientes, como, por ejemplo, sus datos personales, lista de las alergias que sufre, historia familiar de enfermedades, tratamientos quirúrgicos recibidos, y resultados de ex ‘amenes de sangre, el modelo ER-E es suficiente, y el esquema conceptual se puede implementar eficientemente en un manejador que siga el modelo relacional. Sin embargo, si la historia médica incluye también: imágenes de resonancia magnética de la rodilla del paciente, video de alguna operación, fotos de algún ´órgano o de los cromosomas encontrados como resultado de una amniocentesis, con anotaciones de los médicos, los modelos ER-E y OMT dejan de ser suficientemente expresivos, y el modelo relacional es completamente inconveniente, pues no tiene estructura ni operaciones apropiadas para manejar esos datos.
Existen muchas aplicaciones con necesidades similares a la aplicación medica descrita anteriormente, por ejemplo, las de CAD/CAM, los sistemas de información geográficos, las bases de datos multimedia, entre otras.
Una primera aproximación a este problema fue la de extender el modelo relacional (en teoría) para dar cabida a estos nuevos datos y sus necesidades de manipulación, lo cual dio lugar a las bases de datos extensibles, que planteaban modelos con extensiones al relacional para albergar otros tipos de datos y sus operaciones. Una de las primeras implementaciones de estas ideas fue el manejador Postgres (Stonebraker 1987), el cual todavía existe, con el nuevo nombre de PostgresSQL y es uno de los productos de software libre más robustos en el área de base de datos.
En paralelo, estaban los investigadores del área de orientación por objetos definiendo las bases de datos orientadas por objeto, pues el paradigma de OO es naturalmente extensible, y con ello se podían representar esos datos e incluir sus operaciones encapsuladas en la misma noción de objeto. De estos esfuerzos nacieron varias generaciones de software para manejar bases de datos orientadas por objeto, conocidos como OODBMS.
Otra corriente de pensamiento, propuso liberar al modelo relacional de la restricción de que los dominios de los atributos fuesen atómicos, con lo cual las relaciones no tenían que estar en 1NF (primera forma normal) y se llamaron “non-first normal form relations” o NFNF o NF 2. Llevando esta noción hasta el extremo, se podía definir una tabla con atributos cuyos valores pudieran ser tablas completas. Por ejemplo, se puede definir una tabla DEPARTAMENTO con cinco atributos: código-D, nombre-D, jefe-D, Empleados y Proyectos, donde el atributo Empleados toma como valores, tablas con dos atributos nombre y dirección del empleado, y el atributo Proyectos es otra tabla, con atributos nombreProyecto y presupuesto.
Orientado a Objeto Dinámico
Son bases de datos donde la información almacenada se modifica con el tiempo, permitiendo operaciones como actualización, borrado y edición de datos, además de las operaciones fundamentales de consulta. Un ejemplo, puede ser la base de datos utilizada en un sistema de información de un supermercado.
Base de Datos Activas
youtube
El concepto de Bases de Datos Activas (SGBDA) se define en la capacidad del motor de manejar eventos al momento en que los datos sufren cambios como modificación, eliminación o actualización, es decir, cuando se producen ciertas condiciones ejecuta de forma automática ciertas acciones, además el motor de BD debe ser capaz de monitorizar y reaccionar ante eventos de manera oportuna y eficiente.
Estas características de reaccionar ante condiciones son definidas en el esquema de base de datos, de manera que, se elimina la responsabilidad de la aplicación que hace uso de la misma a gestionar tales eventos; la manera más común de definirlos en el esquema es a través de “triggers”, característica esta que maneja la gran mayoría de los motores de BD más conocidos en el mercado. Mediante los triggers se define el evento a recoger, y, mediante el propio lenguaje del motor escogido, se escriben las acciones a tomar. Mediante estas reglas se puede hacer respetar reglas de integridad, generar datos derivados, controlar la seguridad o implementar reglas de negocio.
Las Bases de Datos Activas manejan la vigilancia de condiciones (con disparadores y alertas). Un SGBD activo vigila continuamente el estado de la Base de datos y reacciona espontáneamente cuando ocurren sucesos predefinidos. Desde el punto de vista funcional, un Sistema de Gestión de Bases de Datos Activas vigila condiciones disparadas por sucesos que representan acciones de bases de datos.
La característica que se viene utilizando para especificar bases de datos activas es el modelo evento–condición–acción, por ejemplo:
Tras la modificación de la tabla persona, se chequea su fecha de nacimiento y se procede a actualizar el campo edad, de todos los registros. Por supuesto esta definición descrita en lenguaje fácilmente entendible para nosotros humanos, debe traducirse al lenguaje de programación del motor, haciendo uso de los triggers para disparar la acción tras el evento modificación.
SGBDA VENTAJAS Y DESVENTAJAS:
VENTAJAS
Mayor productividad.
Mejor mantenimiento.
Reutilización de código.
Reducción del tráfico de mensajes.
Posibilidad de optimización semántica.
Facilitar el acceso a la Base de datos a usuarios finales.
DESVENTAJAS
Escritura de programas que consulten periódicamente el estatus de la Base de Datos.
Incorporación de código en cada uno de los programas que actualizan la Base de datos.
Encontrar criterios de interpretación para las reglas activas.
Las aplicaciones del paradigma de base de datos activas son muy variadas. Una primera clasificación de las aplicaciones lo establece el uso de las reglas para labores internas del DBMS, o sea, reglas generadas por el sistema, no visibles a los usuarios, o para labores externas, las cuales son especificadas por el usuario y permiten realizar labores específicas dependientes del dominio del problema.
EJEMPLO BASE DE DATOS RELACIONADA POR SUS CAMPOS CLAVE
Una Escuela desea tener una base de datos, que almacene los datos principales de un alumno, la carrera que estudia, las materias que cursa y los profesores que le imparten clase. De igual manera se desea llevar un registro de las materias que imparte cada profesor.

2 notes
·
View notes
Text
MODELADO DE BASE DE DATOS
¿QUÉ ES EL MODELADO DE BASE DE DATOS?

Un modelo de base de datos (Data Información Estructurada) es un tipo de modelo de datos que determina la estructura lógica de una base de datos y de manera fundamental determina el modo de almacenar, organizar y manipular los datos.
Entre los modelos lógicos comunes para bases de datos se encuentran:
MODELO JERÁRQUICO

Un modelo de datos jerárquico es un modelo de datos en el cual los datos son organizados en una estructura parecida a un árbol. La estructura permite a la información que se repite y usa relaciones (padre/Hijo): cada padre puede tener muchos hijos, pero cada hijo sólo tiene un padre. Todos los atributos de un registro específico son catalogados bajo un tipo de entidad.
En una base de datos, un tipo de entidad es el equivalente de una tabla; cada registro individual es representado como una fila y un atributo como una columna. Los tipos de entidad son relacionados el uno con el otro usando 1: Trazar un mapa de n, también conocido como relación de uno a varios. El ejemplo más aprobado de base de datos jerárquica modela es un IMS diseñado por la IBM.
MODELO EN RED
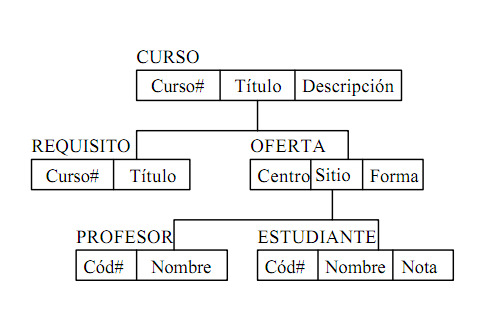
Una base de datos de red es una base de datos conformada por una colección o set de registros, los cuales están conectados entre sí por medio de enlaces en una red. El registro es similar al de una entidad como las empleadas en el modelo relacional.
Un registro es una colección o conjunto de campos (atributos), donde cada uno de ellos contiene solamente un único valor almacenado.
El enlace es exclusivamente la asociación entre dos registros, así que podemos verla como una relación estrictamente binaria.
Una estructura de base de datos de red, llamada algunas veces estructura de plex, abarca más que la estructura de árbol: un nodo hijo en la estructura red puede tener más de un nodo padre. En otras palabras, la restricción de que en un árbol jerárquico cada hijo puede tener sólo un padre, se hace menos severa.
Así, la estructura de árbol se puede considerar como un caso especial de la estructura de red.
MODELO RELACIONAL

El modelo relacional, para el modelado y la gestión de bases de datos, es un modelo de datos basado en la lógica de predicados y en la teoría de conjuntos.
La idea fundamental es el uso de relaciones. Estas relaciones podrían considerarse en forma lógica como conjuntos de datos llamados tuplas. Pese a que esta es la teoría de las bases de datos elacionales creadas por Codd, la mayoría de las veces se conceptualiza de una manera más fácil de imaginar, pensando en cada relación como si fuese una tabla que está compuesta por registros (cada fila de la tabla sería un registro o "tupla") y columnas (también llamadas "campos").
Es el modelo más utilizado en la actualidad para modelar problemas reales y administrar datos dinámicamente.
MODELO ENTIDAD–RELACIÓN
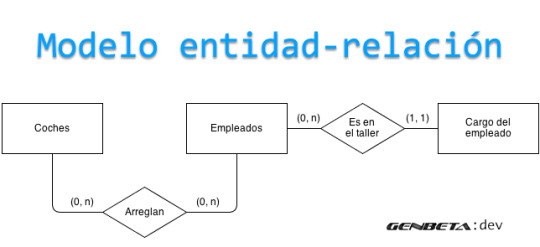
Un modelo entidad-relación o diagrama entidad-relación (a veces denominado por sus siglas en inglés, E-R Entity relationship; en español DER: "Diagrama de Entidad-Relación") es una herramienta para el modelado de datos que permite representar las entidades relevantes de un sistema de información, así como sus interrelaciones y propiedades.
¿QUÉ ES EL MODELO?
Un modelo es un conjunto de herramientas conceptuales para describir datos, sus relaciones, su significado y sus restricciones de consistencia.
¿QUÉ ES EL MODELAMIENTO CONCEPTUAL?
Un modelo conceptual es un lenguaje que se utiliza para describir esquemas conceptuales. El objetivo del diseño conceptual es describir el contenido de información de la base de datos y no las estructuras de almacenamiento que se necesitarán para manejar esta formación.
UBICACIÓN DEL MODELO CONCEPTUAL EN EL CONTEXTO DEL PROCESO DE DISEÑO DE BASES DE DATOS.

El modelado conceptual permite describir, de un modo totalmente independiente de la implementación, los datos que el usuario quiere recoger en el sistema. Dependiendo de la cantidad de información que se desee representar, tendremos aplicaciones más o menos orientadas a los datos. Así, por ejemplo, la gestión de una biblioteca es una aplicación pura de Bases de Datos (en adelante BD) ya que prácticamente toda la funcionalidad del sistema se centra en el mantenimiento de los datos (introducir un libro, prestar un libro, etc.). Existen, sin embargo, otras aplicaciones, como por ejemplo un sistema de control de navegación aérea, en las que los datos son algo secundario. Podemos decir que, en general, los datos son el núcleo de todo SI orientado a la gestión.
El desarrollo estructurado de software, a diferencia de lo que ocurre en el desarrollo orientado a objetos, mantiene una clara separación entre los datos y las funciones del sistema. Por ello, es necesario disponer, en cada una de las etapas del proceso de desarrollo, de técnicas específicas para la especificación de los datos, que serán diferentes de las técnicas orientadas a la especificación de las funciones o procesos. El modelado conceptual es una actividad que se realiza en la etapa de análisis, paralelamente al modelado de procesos o funciones. Su objetivo, como ya hemos dicho, es captar toda la información del mundo real que se desea representar en el mundo informático. En este proceso es importante abstraer los detalles sin importancia y representar tan sólo aquella información que sea relevante.
En este punto no nos interesa el cómo ni donde se va a implementar el sistema. De hecho, dependiendo del tipo de sistema (más o menos orientado a los datos), del volumen de información, de los requisitos de eficiencia, etc. se podrán utilizar distintos mecanismos de persistencia de los datos: Sistemas de Bases de Datos, Sistemas de Ficheros, etc. De estos aspectos nos ocuparemos en la etapa de diseño (ver la unidad dedicada a diseño estructurado de datos). En esta etapa interesa recoger la máxima cantidad de información posible, por lo necesitamos una técnica que cumpla los siguientes requisitos:
Ser independiente de los modelos o lenguajes de implementación
Tener una capacidad semántica alta
Ser lo más cercana posible al usuario
Aunque existen diversas técnicas, utilizaremos el modelo E/R porque además de cumplir los requisitos anteriores es la técnica de modelado conceptual universalmente aceptada para el desarrollo estructurado.
¿QUÉ ES UN SISTEMA MANEJADOR DE BASE DE DATOS?

Un sistema manejador de bases de datos (SGBD, por sus siglas en inglés) o DataBase Management System (DBMS) es una colección de software muy específico, orientado al manejo de base de datos, cuya función es servir de interfaz entre la base de datos, el usuario y las distintas aplicaciones utilizadas.
Como su propio nombre indica, el objetivo de los sistemas manejadores de base de datos es precisamente el de manejar un conjunto de datos para convertirlos en información relevante para la organización, ya sea a nivel operativo o estratégico.
Lo hace mediante una serie de rutinas de software que permiten su uso de una manera segura, sencilla y ordenada. Se trata, en suma, de un conjunto de programas que realizan tareas de forma interrelacionada para facilitar la construcción y manipulación de bases de datos, adoptando la forma de interfaz entre éstas, las aplicaciones y los mismos usuarios.
Su uso permite realizar un mejor control a los administradores de sistemas y, por otro lado, también obtener mejores resultados a la hora de realizar consultas que ayuden a la gestión empresarial mediante la generación de la tan perseguida ventaja competitiva.
¿QUÉ SON LAS TABLAS?
Tabla en las bases de datos, se refiere al tipo de modelado de datos donde se guardan los datos recogidos por un programa. Su estructura general se asemeja a la vista general de un programa de tablas.
¿QUÉ SON LOS CAMPOS?
En informática, un campo es un espacio de almacenamiento para un dato en particular.
En las bases de datos, un campo es la mínima unidad de información a la que se puede acceder; un campo o un conjunto de ellos forman un registro, donde pueden existir campos en blanco, siendo este un error del sistema operativo. Aquel campo que posee un dato único para una repetición de entidad, puede servir para la búsqueda de una entidad específica.
Tipos de campos informáticos.
Alfanumérico: contiene cifras numéricas y caracteres alfabéticos.
Numérico: existen de varios tipos principalmente como enteros y reales.
Auto incrementable: son campos numéricos enteros que incrementan en una unidad su valor para cada registro incorporado. Su utilidad resulta más que evidente: servir de identificador registro.
Booleano: admite dos valores, «verdadero» ó «falso».
Fechas: almacenan fechas facilitando posteriormente su explotación. Almacenar fechas de esta forma posibilita ordenar los registros por fechas o calcular los días entre una fecha y otra.
Memo: son campos alfanuméricos de longitud ilimitada. Presentan el inconveniente de no poder ser indexados.
En las hojas de cálculo los campos son llamados "celdas".
¿QUÉ SON LOS REGISTROS?
En informática, o concretamente en el contexto de una base de datos relacional, un registro (también llamado fila o tupla) representa un objeto único de datos implícitamente estructurados en una tabla. En términos simples, una tabla de una base de datos puede imaginarse formada de filas y columnas (campos o atributos). Cada fila de una tabla representa un conjunto de datos relacionados, y todas las filas de la misma tabla tienen la misma estructura. No puede haber un registro duplicado, los datos deben ser diferentes en al menos uno de los campos.
Un registro es un conjunto de campos que contienen los datos que pertenecen a una misma entidad. Se le asigna automáticamente un número consecutivo (número de registro) que en ocasiones es usado como índice, aunque lo normal y práctico es asignarle a cada registro un campo clave para su búsqueda.
ABSTRACCIONES COMÚNMENTE USADAS EN EL MODELAJE CONCEPTUAL.
La abstracción es un proceso mental que se aplica al seleccionar algunas características y propiedades de un conjunto de objetos y excluir otras no pertinentes.
El concepto de una bicicleta puede verse como un proceso de abstracción, en el que se han excluido los detalles de su estructura.
Podemos destacar tres niveles principales según la visión y la función que realice el usuario sobre la base de datos:
Nivel físico: El nivel más bajo de abstracción describe como se almacenan realmente los datos. En el nivel físico se describen en detalle las estructuras de datos complejas de bajo nivel.
Nivel conceptual: Que es el siguiente nivel más alto de abstracción, se describe cuáles son los datos reales que están almacenados en la base de datos y qué relaciones existen entre los datos.
Nivel lógico: El siguiente nivel más alto de abstracción describe que datos se almacenan en la base de datos y que relaciones existen entre esos datos. La base de datos completa se describe así en términos de un número pequeño de estructuras relativamente simples en el nivel físico, los usuarios del nivel lógico no necesitan preocuparse de esta complejidad. Los administradores de base de datos, que deben decidir la información que se mantiene en la base de datos, usan el nivel lógico de abstracción.
ABSTRACCIONES Y REQUERIMIENTOS DE DATOS.
Independencia de implementación: No modelar representación de datos, organización interna, entre otros.
Abstracción: Tomar solo aspectos principales (cosas que no cambien)
Formalidad: Sintaxis no ambigua, Rico en semántica
Constructibilidad: Debe facilitar la comunicación analista usuario
Fácil de analizar: Para detectar ambigüedad, inconsistencia, completitud
Trazabilidad: Habilidad para seguir los elementos del modelo
Ejecutabilidad: Poder animar el modelo, para comparar con la realidad
Minimalidad: No redundancia de conceptos (cada cosa expresada de una forma)
DISEÑO DE BASES DE DATOS
Proceso de Diseño
El proceso de diseño consta de los pasos siguientes:
Determinar la finalidad de la base de datos.
Buscar y organizar la información necesaria: Reúna todos los tipos de información que desee registrar en la base de datos, como los nombres de productos o los números de pedidos.
Dividir la información en tablas: Divida los elementos de información en entidades o temas principales, como Productos o Pedidos. Cada tema pasará a ser una tabla.
Convertir los elementos de información en columnas: Decida qué información desea almacenar en cada tabla. Cada elemento se convertirá en un campo y se mostrará como una columna en la tabla.
Por ejemplo, una tabla Empleados podría incluir campos como Apellido y Fecha de contratación.
Especificar claves principales: Elija la clave principal de cada tabla. La clave principal es una columna que se utiliza para identificar inequívocamente cada fila, como Id. de producto o Código de cliente.
Definir relaciones entre las tablas: Examine cada tabla y decida cómo se relacionan los datos de una tabla con las demás tablas. Agregue campos a las tablas o cree nuevas tablas para clarificar las según sea necesario.
Ajustar el diseño: Analice el diseño para detectar errores. Cree las tablas y agregue algunos registros con datos de ejemplo. Compruebe si puede obtener los resultados previstos de las tablas. Realice los ajustes necesarios en el diseño.
Aplicar las reglas de normalización: Aplique reglas de normalización de los datos para comprobar si las tablas están estructuradas correctamente. Realice los ajustes necesarios en las tablas.
youtube
0 notes