
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by datavan and here's what we found interesting.
Average Info
Notes Per Post
1
Likes Per Post
1
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
21 days
Number of Posts By Type
Text
2
Last Seen Tumblr Blogs





Fun Fact
Women make up for the other 50% of Tumblr’s audience.
Text
Cassandra Demo
In this second blog post, I am going to show everyone how to create your very own 3 node Cassandra cluster. You will have to have some items set up beforehand. The first item that will need to be created are three different virtual machines, each with a working operation system. In this exercise, I have created three different VM using the VMware Work Station; each with a working Linux Ubuntu OS. (Why Linux Ubuntu? No real reason, I just like that OS. Beware that for different OS, there will be different commands that I might not cover).
The second item that will need to be set up is a two-parter. Both the Java Development Kit and the Python Software Development Kit need to be functional in each VM, for Cassandra to be able to execute properly. In this exercise, I have installed the most current stable version the JDK available. The only thing I will mention, in case anyone is following along with the blog, do remember to include the following line of code in your .bashrc user profile file:
#$ export PATH=$PATH:~/Documents/jdk1.8.0_202/bin
It is the only way Cassandra will recognize that the JDK is running on your OS.
As for the Python SDK, that is a whole another animal all together. The following commands (2 commands) need to be entered on command line, within the Python directory:
#$ ./configure --prefix=/usr/local
#$ make
Once this is done, the source code for Python itself has been compiled. You will also need to download PIP, which lets you manage libraries, directories and drivers for Python. Now with the way Python works, you can have several versions of Python present on the same OS. You need to make sure the version you are working with is Python 2.7 (Documentation does say that it supports 3.6, 3.7 and 3.8). The last item you will download for the SDK is the Cassandra-driver, which lets the python interpreter talk to the ./cqlsh program (more on that later).
#$ pip install cassandra-driver.
Why both Java and Python? Cause nothing in programming in ever truly easy. Java is what your Cassandra node uses to execute its programming, because Cassandra itself was written in Java. Now, the CQL Shell or cqlsh for short is the command line shell use to interact with your Cassandra nodes. Python is the native protocol driver for this shell. There is indication when I read the cqlsh documentation, that other languages can be used for talking to the cqlsh; but for the purposes of this blog I will be using Python. I did not go into further research about that particular topic.
The last item you need to research before we can further and start the set up of our Cassandra nodes, is probably the most complicated one of them all. You need to find out the IP address for each of the VM. A simple ip addr, will do the trick. The three ip address for my VM are the following:
Cassandra Node 1 – 192.168.8.135
Cassandra Node 2 – 192.168.8.136
Cassandra Node 3 – 192.168.8.137
Once, the VMs are setup (each with a working OS, JDK, SDK and the IP address are recorded) Cassandra can finally be downloaded. I am working with the latest stable version of Cassandra 3.11.10. Once unzip, the configuration file cassandra.yaml is the only thing that needs to be modified and/or touched.
Just a quick intro before we move on. YAML (or YAML Ain’t Markup Language) is a human-readable data-serialization language, commonly used for configuration files where data is being sorted or transmitted. I just wanted to make sure everyone knows that bit of information; there is a lot more to YAML.
With that out of the way, we are going to start setting up our first Cassandra Node, or cass1. There are several things that can to be configured, but there are only two decision that have to be made in this YAML file (When looking from the perspective of this test cluster, in industry a lot more settings would be considered). The first decision is naming the cluster; for the cluster to work, all of the cluster nodes must have a shared name between them. Its how they first recognize themselves within the cluster ring. In my case, I used the cluster name ‘INTP – 362’.

Cluster Name
It is important that you make the name simple and easy to reproduce. My first test cluster had a more complicated name in the intent to be funny, and two of my nodes would not “gossip” to one another (more on gossiping later). And I used copy and paste, which sometimes does not work.
Once the cluster name is decided on. The next decision are the seed nodes and non-seed nodes. A seed node serves two functions:
When a new node joins the cluster, it will learn about the topology of the cluster or ring by contacting a seed node.
They are also what assist other nodes in gossip convergence.
A seed node is still not a single point of failure; if a seed node “dies”, a cluster can survive without. I choose cass1 and cass2 to be my seed nodes. It is industry standard to at least have 3 seed nodes per cluster; the typical small sized cluster is around 5 nodes. Since, I only have 3 nodes, I decide to just do 2 seed nodes to demonstrate what they do. To set up the seed nodes, the IP address for each of the selected nodes are to be place, in between the double quotes; separate by commas but with no spaces in between (see image below).
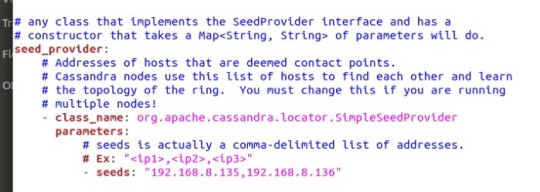
Seed Nodes
With the seeds nodes and the cluster name taken care of, the basic decision-making process to get this cluster running is done. I do want to point out that there are many other settings and configurations that can be made through this YAML file. Everything from how many concurrent read or write can be done at a time, which ports each node will use to communicate thought TCP/UDP (Ports 7000, 9042), what is a cache size for different types of operations; so many different settings I am not getting into because really there is no time. But I will speak about to two particular settings that gave a lot of problems for several days. Those are Listen Address and RPC Address.
Just to expand out knowledge base, RPC is a framework or set of tools that allow programmer to call a piece of code in a remote process. Again, there is a lot more to this framework; but that is the bare minimum just to understand why this address is important.
As a default, Listen Address and RPC Address come with the value ‘Localhost’; which should work since they do use the localhost to work. They even suggest just leaving it blank, since that will activate:
InetAddress.getLocalHost()
A protocol that will find the local IP address of the machine and retrieve for use. Except its not reliable, it even mentioned in the configuration file that it might not work. The documentation for both Cassandra and the YAML configuration file does not, to my knowledge, ever mention how to deal with this. Why do I mention this? Because in this case, the nodes will not actually wake up (at least in my experience). The actual best thing to do, is to actually use the IP Address number itself. My lesson learned here is that sometimes hardcoding an important value is necessary.
What is going on in the background is that the nodes can’t gossip. What is gossip? It’s the protocol that Cassandra uses to communicate between nodes. It’s a peer-to-peer system, that periodically exchanges state information about themselves and about other nodes in the ring. Basically, Cassandra nodes are just gossiping all the time, about how they are doing.
The gossiping protocol is very similar to the TCP three-way handshake; so much so that in the Cassandra server start up process, it is called a handshake. In the image below, you can the different Cassandra nodes handshaking each other.
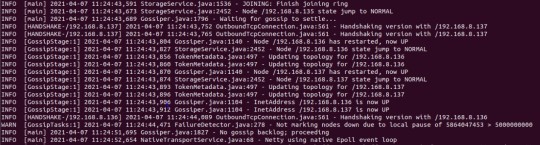
Handshake
I think that is enough for now about the YAML configuration file; there is a lot more to it, entire Wikipedia pages just dedicated to explaining each one of the different settings. We are moving to yet another program that needs to be install for Cassandra to run. Why didn’t I mention this one before? Because its not mentioned anywhere (Note: I am not bitter about this).
iptables is this cool linux utility that lets you block or allow traffic, it’s a neat firewall. Cassandra needs it install and running to be able to gossip to other nodes. In iptables, there are policy chains, which are:
Input - this is for incoming connections.
Forward - incoming connections not being delivered locally, think a router.
Output - this is for outgoing connections.
Now, I only had so much time to actually research iptables and all its useful commands. Due to time constraints I concentrated on understanding the command I needed to run my Cassandra nodes. The command is:
#$ sudo iptables -A INPUT -p tcp -s 192.168.8.135 -m multiport --dports 7000,9042 -m state --state NEW,ESTABLISHED -j ACCEPT
A – Type of policy
p – Type of connection the protocol uses
s – Is the IP address to listen for
m multiport – is when there are multiple ports
dport – The ports to listen for
m state – The state of the connection (The only states I know of are NEW and ESTABLISHED)
j – Is the command for the response policy (Accept, Drop or Reject)
This command must be done on each node, with the other nodes IP address (so the command must be entered twice in each node). Finally, Cassandra will be run. There is an order to these things. Seed nodes must be woken up first before non-seed nodes, it is the only caveat to waking up Cassandra nodes to start gossiping.
To confirm that the nodes are running and gossiping, Cassandra comes with application called nodetool. The application will take different commands, the only one we care about at the moment is the status command.

Nodetool program
The UN means Up and Normal, which is really the piece of information we care about. This means each node on the rack is running. Since we have confirmed all the Cassandra nodes are up and running. The CQL shell program can be started. In the bin directory, the following commands needs to be typed:
#$ ./cqlsh 192.168.8.135
The IP address at the end of the command must be the IP address of the node you want to access. As you can see from the image below, I am still in Cassandra node 1. But I am able to access another Cassandra node though its IP address.

Accessing different nodes
With the CQL shell running, we can finally explore the CQL language. It is very similar to SQL, super similar. It is basically the same thing (at least syntax-wise it does not behave the same way), with some key exception. All the relational part of SQL is non-existent in CQL. That means no JOINS, no FOREIGN KEYS, none of that stuff. But the following commands, are all permissible (and again Syntax is the same, but the behavior of the command might be different):
Alter
Create
Delete
Insert
Select
Update
Where
There are more commands, I am just showcasing the classic ones. Let’s start with the creation of a KEYSPACE (Database in the SQL world). The command is the following:
#$ CREATE KEYSPACE test WITH replication = {‘class’:’SimpleStrategy’, ‘replication_factor’ : 3};
Finally, replication at work. There are two replication classes. The SimpleStrategy class, which will assign the same replication factor to the entire cluster. This is used for evaluation purposes, single data center test (Like what I am doing in this blog), and development environments. In industry they use the second class, called ‘NetworkTopologyStrategy’. This strategy is for assigning the replication factor to each data center in a comma separated list, giving you more flexibility and control. The Data center names must match the snitches data center name. In a real data center, there are snitch nodes; in basic terms the snitch determines which data centers and racks nodes belong to. The snitch allows network topology to be discovered, thus making routing more efficient.
A note about replication factor for both strategies, the number does not have match the number of nodes present in your cluster. It is not a requirement for the command to run. There can be a KEYSPACE with a replication factor of 2, in a 5 nodes cluster. It is documented that it is recommended that your replication factor does not exceed the number of nodes present in your cluster (But again this will not cause any immediate problems). The following command is not recommended, with my current cluster set up:
#$ CREATE KEYSPACE test WITH replication = {‘class’:’SimpleStrategy’, ‘replication_factor’ : 4};
But it is permissible. Why? The idea of scaling. I could start setting up KEYSPACEs with replication factor of 4 in my cluster right now, and add a new node (cass4) in the future.
Now that we have our KEYSPACE set up. We can now proceed to create a table and inserting some data.
#$ CREATE TABLE student (name text PRIMARY KEY, id int, age int);
#$ INSERT INTO student(name,id,age) VALUES (‘alex’,105,32);
With everything set up correctly, we can see the replication happening. I used cass1 to insert my data. And the KEYSPACE, TABLE and data was replicated into the other nodes.
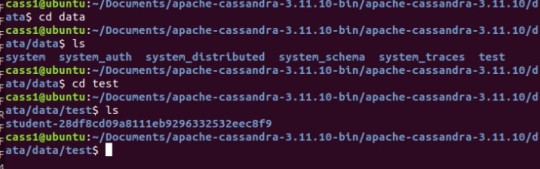
Cassandra Node 1 – test data
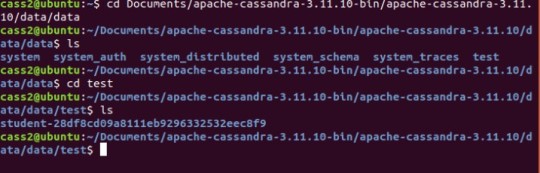
Cassandra Node 2 – test data
Cassandra Node 3 – test data
As observed in all three different nodes, the student table is present.
The last cool thing I am going to show you, is how UPDATEs are a bit different in CQL vs SQL. In SQL an UPDATE command is both a read and a write; and this is important to note, because it first reads the tablespace and if the WHERE clause is not present the UPDATE will not happen. In CQL, the UPDATE command is only a write. This means that if the WHERE clause of an UPDATE command is based on a primary key (see example below), the UPDATE will happen as an INSERT if the row does not exist. I will showcase this in action, in the demo video.
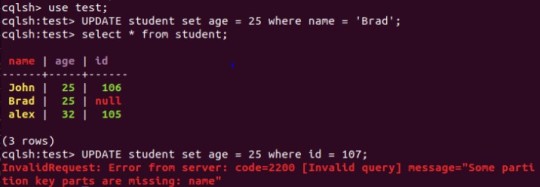
UPDATE command in CQL
I hope this blog brought to light some of the lessons I learned while trying to navigate my way through Cassandra. Lessons like the value of documentation, but that ultimately there might be vital information missing; further research into some unexpected places might be need; and even some trial and error might be a possible avenue. I also hope I help shed some light on the world of NOSQL, and the cool application (cool to me at least) that is Cassandra.
Thank you so much for reading my blog
Here is the Demo Video.
youtube
0 notes
Text
Blog Post 1
It holds true that for most of 19th and 20th century, in the business world, there were two resources that influence most, if not all of decision and moves being made. These two resources were time and money. With enough of both of these resources, any business (with a healthy amount of hard work) could, and would succeed. In the 21st century, the business world has started to really concentrate on a third resource (previously important, but not so much as the former two). This third resource is of course Information, which is really starting to define who has power and influence; and who doesn’t; mainly based on the capacity of storage, processing speed, accessibility and reliability of the information they handle.
Information is really dictating a lot of market trends, because the main idea is that, the more a business knows, the better it can predict. And they can predict a lot, well anything (to a certain degree of course, but the accuracy is sort of scary and surprising). A strong proven practice are personalized ads on the internet; like the ads one can see on the sidebar when you are messing around Facebook and not doing homework, or whatever. The only real bottleneck with all of this, is how do you create what is called “relevant information”. Well, that is actually kind of easy, all you need is data, lots and lots of data, like massive amounts of data and an analyst (read: my dream job).
Now getting data might be relatively easy; every nowadays is outputting data in some way, shape or form (just need to know what or where to look for). The true challenge here is how to organize and store said data, to be used later to create the previously mentioned “relevant information”. Why is it challenging? Well, its because not all data is same; and this has nothing to do with its important, all data is important (until it isn’t), its more about its digital attributes and composition.
What do I mean by, not all data is same? The data produced from different unique sources is going to look very different, and that makes storage a challenge. Data could be different documents in various formats, an array of numbers, several different pictures, even a collection of keystrokes are considered value data to some individuals. So, storing all this different type of data types can be difficult, if a corporation is interested in one than one of these data types. Relational style databases did pretty well at the beginning.
But a relational style database, or SQL databases, can only go so far when tackling this problem because of the ridged way everything is structured, and by its nature the defined structure isn’t really mutable (like it is, but really its every costly time wise to do so, and you might end up just creating a new database). Non-relational style database, also called NoSQL (Not Only SQL) databases are in a way much more flexible in the way the store data.
But we aren’t talking about a few tables, second challenge of SQL databases, they aren’t really scalable, corporation handle data on a much large scale; an estimate by priceonomis is 7.5 septillions (that’s 21 zeros) gigabytes of data. Oh, and this is what they generate in a day, granted I will say that only about half of this data is usable but still, that a whole lot of data!
Before we jump more into NoSQL, lets compare for a bit the two different styles of database.
https://youtu.be/LA5gY-LH63E
https://youtu.be/mqV-zYQhavc
Getting back on topic, that being NoSQL, which offers corporation the way to actually manage all this data. I am going to focus on one particular NoSQL database, Cassandra (created in 2008 by Apache). Why Cassandra? There are others such as MongoDB and Couchbase (very popular in the industry right now) but Cassandra offers two distinct advantages (in my opinion):
1. Cassandra has its on language, CQL, or Cassandra query language; which is very close to SQL, they aren’t really close enough to be siblings more like cousins. It is very easy for someone that has SQL knowledge to pick up CQL. Because of the way data is organized in a non-structured way, there is no support in CQL for things like “JOIN”, “GROUP BY”, or “FOREIGN KEY”. A great thing is that CQL can actual actually handle object data. This is probably due to the fact that Cassandra was written in Java.
2. The asynchronous masterless replication that Cassandra employs. The basic concept (its not super complex but it ain’t a cake walk either) is through this style of replication, this database model offers a high availability or accessibility to data with no single point of failure. This is due to data clusters.
https://youtu.be/zk00Bu8s4p0
Before we tackle replication together (because its what I really want to showcase), we need to cover a few concepts, just to make sure we are all on the same page.
Database Clusters
this is an industry standard practice for corporation and business that handle data in large quantities (so basically every corporation really). The idea is that there are two or more servers or nodes running together, servicing the same data sets, in both read and write requests. Why do this? Why have two very expensive pieces of equipment ($1000 to $2500 on the enterprise level) doing the same thing? Redundancy. Meaning that all nodes have the same data, this ensures that backups, restoration and data accessibility is almost a guarantee. The multiple servers also help with load balancing and scaling, because there are more nodes, more users can access the same data across the different nodes. And because of the larger network of nodes within the database, a lot of process can be automated. There can be one node just dedicate to being a coordinator/manager node (this is not a master node in anyway), which would run specific scripts and subprograms for the entire network.
Database Replication
ok, ok, there idea is simple its just copying data from one node to another in a database cluster. And you are right, but the process behind it is what truly impressive (at least to me). By the way a database that has replication added to it, is called a distributed database management system or DDBMS. So, database replication will track any changes, additions, or deletions made to any data point, will perform the same operation on the same data point in all other locations. There are several different replication techniques and models (will be explored in future posts). The key of database replication is the set up of them, several steps must be properly followed and understood for the overall set up to work. Replication is not the same as backing up data, because the replicated data is still within the network, connected to the original data; while backing up data is usually stored offsite.
Single Point of Failure
In the business world, having the lights on and getting/keeping everything running is a great concern, because it affects the bottom line. But let’s be realistic, something is going to fail at some point (its inevitable). And one of the goals of a database (based on the CAP theorem) is availability, so having a point of failure within a database system is not something most companies are looking for. This is solved by using database clusters, and replication, since they create a failsafe through redundancy. And it does it on several levels, between the load balancing, the multiple servers, and the multiple levels of access to data.
https://youtu.be/l0IQDSdVcs4
1 note
·
View note