
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by georgebrown13 and here's what we found interesting.
Average Info
Notes Per Post
3
Likes Per Post
3
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
7 days
Number of Posts By Type
Text
8
Last Seen Tumblr Blogs





Fun Fact
US Tumblr user growth rate is estimated to slow down to 4.1%.
Text
Enterprise data migration made easy with Bryteflow
Data is at the heart of enterprise decision making. Today’s successful companies harness the power of business data to their advantage and generate insights to make high-impact decisions. Accurate and updated data helps businesses be more confident in planning, operating and executing decisions across functions. In the past, databases were flat and siloed, which meant slow and inconsistent data about objects, resources or users. Further, the data was arranged in a sparse format, making it time-consuming for teams to access and derive insights from. Today, a massive volume of data is stored inside data warehouses and data lakes in cloud servers.
As technology advanced, relationship-based databases came into existence, and they were used to collect, filter and organise information based on specific fields to generate custom analytics reports. With relational databases, the speed and accuracy increased many folds, and they quickly became the standard for creating, maintaining, managing and implementing database systems. Microsoft SQL server is one such cloud based relational database management system which offers end-to-end solutions for business data and applications. However, Amazon S3 is another popular cloud based storage system from Amazon Web Services (AWS) which provides 99.99% of downtime while ensuring high availability of data. If you are considering SQL server to S3 migration, then this article will guide you on how to go about executing this seamlessly.

Now before you go any further, it is important to understand what are some of the key features of Amazon S3 which make it a popular cloud database system. Firstly, the ease-of-use offered by Amazon S3 is unmatched, making it one of the simplest and intuitive systems to use. Secondly, Amazon S3 is highly secure, and very robust and stable, thanks to it being a part of the AWS stable. It also has SSL capabilities for added layers of security. This is why many enterprises are looking at backing up SQL server to S3 for gaining more flexibility and security control.
So, how to go about executing this transition? If you are ready to load your SQL server data to Amazon S3, then there are two ways of doing so. Method 1 is where you utilise Amazon AWS to extract, load and transform SQL server to S3, this method is both time consuming and complex, and requires knowledge of coding as well as dedicated resources. Method 2 is where you can automate the entire process of SQL server data to S3. This is where Bryteflow comes in.
Bryteflow is the easiest and fastest way to get your server data loaded into Amazon S3 with low to minimum impact on source. Bryteflow can automatically optimise replicated data in S3 making it analytics ready.
Try Bryteflow today and experience a real-time, fully automated server data replication tool.
0 notes
Text
Everything you need to know about Enterprise Big Data Integration
Businesses of varying size and scale around the world rely on the power of data and analytics to supercharge growth. In a rapidly evolving world, new challenges and competitors continue to emerge, and to remain on top of things is to rely on powerful data solutions. As the need for data-driven decision-making becomes stronger, fast-growing businesses must invest in agile, robust and scalable database management tools and solutions to stay ahead of the curve.
Over the past decade, many companies have started migrating their enterprise data from SAP to Bigquery in order to reduce on-premise maintenance costs and enjoy seamless, scalable, and secure data integration. Using BigQuery, Google’s cloud data warehouse solution, businesses are able to become more agile with an agile, always-on cloud solution.
So, what exactly is real-time analytics? Basically, real-time analytics is a process of applying techniques to derive insights for making better decisions faster. Real-time analytics means businesses can immediately access, process, and query data and guide their decisions. The rate of change of data is instantaneous, and data becomes old and obsolete faster than it used to before, and it loses its business value rapidly. With real-time data analytics companies can gather fresh, up-to-date insights.

Real-time data analytics is mission critical for businesses and it impacts the top as well as the bottom line of a company’s revenue and profitability. There are many reasons for this but the most important one is - software supports decision making and by getting access to real-time data management, businesses can make critical decisions at their desired pace.
This is where cloud databases and warehouse solutions like BigQuery offer the flexibility and technology needed to derive real-time insights from data. For organisations running on SAP data, integration with Google’s Bryteflow to make a hybrid approach can be powerful and flexible. Thankfully, now a bi-directional flow from SAP to Bigquery is now possible and officially supported by SAP. However, the process can be time taking and resource intensive, and it requires careful planning and robust data replication tools with technical know-how.
Thankfully, big data enterprises can now leverage the power of Bryteflow’s fully automated, no-coding environment for seamless and secure data migration from SAP to Bigquery in real-time. Bryteflow works easily with SAP HANA, ECC, S4/HANA, and SAP BW. With its robust, bulk loading capabilities, Bryteflow can ingest and replicate massive volumes of big data without constant monitoring or supervision. This frees up precious time and resources for your business during data replication scenarios.
If your business is ready to harness the flexibility and scalability of Google’s BigQuery cloud data warehouse, it’s time to experience the power of Bryteflow’s scalable, secure, and fully automated no-code solution. Get your free demo today!
1 note
·
View note
Text
How to Migrate Databases from Microsoft SQL Server to Amazon S3
In the modern data-driven business environment, organizations that have critical workloads running on an on-premises Microsoft SQL Server database are increasingly exploring avenues to migrate to the cloud due to its many inherent benefits. All the while, the same database engine (homogeneous migration) can be maintained with minimal to near-zero stoppage in work or downtime.
One way to get around this issue is to migrate databases from the Microsoft SQL Server to S3. To avoid downtime, this process is done using the SQL Server backup and restore method in collaboration with the Amazon Web Service Database Migration Service (AWS DMS). This method is very effective for migrating database code objects including views, storing procedures, and functions as a part of database migration.
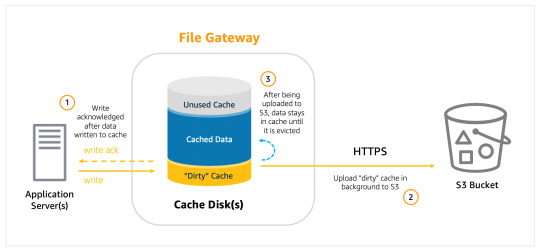
The solution of database migration from SQL Server to S3applies to all SQL Server databases regardless of size. Further, it can also be applied when there is a need to validate the target database during data replication from source to target, thereby saving time on data validation. The only limitation is that this solution may be used only when there are no restrictions on using SQL Server as a source for AWS DMS.
The critical issue here is why do organizations want to migrate databases from SQL Server to S3 (Amazon Simple Storage Service).It is primarily because S3 operates in the cloud and thereby provides unmatched data durability and scalabilityand unlimited storage capabilities. This is a big help for businesses as they do not have to invest in additional hardware and software to increase capacities whenever there is a sudden surge in demand for additional storage facilities.
Other cutting-edge features offered by Amazon S3 are data protection, access management, data replication, and cost affordability.S3 can go through billions of objects of Batch Operationsand the database replication process of SQL Server to S3 can be carried out both within and outside the region.
Several backup processes need to be completed before the database migration from SQL Server to S3can be taken up.
First, ensure that the AWS account used for migration has an IAM role and specific permissions have to be given for activities like write and delete access to the target S3 bucket. Next, be sure that the S3 bucket being used as the target and the DMS replication instance for migrating the data are in the same AWS region. Further, add a tagging access in the role so that objects that are written to the target bucket can be tagged via AWS CDC S3. Finally, DMS (dms.amazonaws.com) should be present in the IAM role as an additional entity.
It is also necessary to check whether the role assigned to the user for completing the migration task has the required permissions to do so.
0 notes
Text
Migrating Databases from Oracle to Amazon S3
Organizations today prefer to be on the cloud for the several benefits the cloud environment has to offer, one reason why migrating databases from Oracle to S3 is an attractive proposition. The Amazon Simple Storage Service (S3) offers unlimited storage service that is cost-effective and lies at the core of data lakes in AWS. For users of the Oracle database, a popular source for data lakes is the Amazon RDS (Relational Database Service).
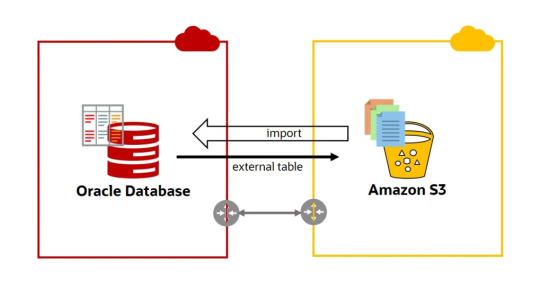
Migration from Oracle to S3 is possible only after certain aspects are essentially followed carefully. First, ensure that you have an account in the Amazon Web Service (AWS). Second, verify that an Amazon RDS for the Oracle database and an S3 bucket is in the same region where the AWS DMS (Database Migration Service) replication instance is created for migration.
After these are checked and before diving into the actual Oracle to S3 database migration the systems have to be readied for the process.
Prepare the source Amazon RDS for Oracle database replication.
Create an AWS Identity and Access Management (IAM) role to get access to the S3 bucket
Make a full load task as well as AWS DMS instance and endpoints
Finally, create a task that takes care of the Change Data Capture feature.
After these steps are put out of the way, the actual task of Oracle to S3 database migration can be initiated.
Database Migration from Oracle to S3
There are two ways that this database migration can be carried out.
The first method is by importing data, Oracle Data Pump, and Database Link where a link is established to the Oracle instance through the Oracle Data Pump and the Oracle DBMS_FILE_TRANSFER package. This can be done either with an Amazon RDS for an Oracle database instance or an Amazon EC2 instance. The Oracle data is exported to a dump file with the DBMS_DATAPUMP package during the migration activity and once completed, the file is copied to the Amazon RDS Oracle DB instance through a connected database link. The final stage is importing the data to S3 with the DBMS_DATAPUMP package.
The second method is importing data, Oracle Data Pump, and Amazon S3 bucket. The Oracle data in the source database is exported with the Oracle DBMS_DATAPUMP package and the file is dumped in an Amazon S3 bucket. This file is then downloaded to the DATA_PUMP_DIR directory in the RDS Oracle DB instance. In the final step, the dump file is imported and copied to the Amazon RDS Oracle DB instance with the DBMS_DATAPUMP package.
The goal of Oracle to S3is to ensure that the Oracle database is optimized on Amazon S3. This can be done either by running the EC2 compute instances and Elastic Block Store (EBS) storage on the Oracle in-premises databases or by migrating the on-premises Oracle database to Amazon RDS.
0 notes
Text
Why Should You Move Databases from Oracle to Snowflake
In the modern business environment, organizations are increasingly depending on database management systems to increase operational efficiencies and execute critical workloads. Hence, even though the traditional Oracle database has many advantages it has become essential to move databases from Oracle to Snowflake because of the many benefits that this cloud-based platform brings to the table.
Why should you move databases from Oracle to Snowflake?
There are several benefits of it.
Users get unmatched agility and elasticity from the Snowflake Cloud Data warehouse solution and they can scale up and down in data storage whenever needed, paying only for resources used.
Snowflake has the high computational ability and there is no drop in performance even when several concurrent users are simultaneously running intricate queries
Users can work with data in its native form – unstructured, semi-structured, or structured – a facility that is not available in Oracle. This is a critical reason for migrating databases from Oracle to Snowflake.
Snowflake offers automated and fully-managed services and users can quickly have their analytics and data processing projects up and running without any other drivers or applications.
Steps for database migration from Oracle to Snowflake
There are four steps for database migration from Oracle to Snowflake
Extracting data from the Oracle database: This is done with the SQL Plus query tool that is available out-of-the-box with the Oracle database server. The “Spool” command is used to execute this activity and the results are written in the file specified in the command until Spool is turned off. However, if data has to be extracted incrementally and only records that have changed after the last pull is to be selected, SQL has to be generated with proper pre-conditions.
Processing and formatting the data: The extracted data has to be processed and formatted during Oracle to Snowflake migration so that it matches the data structures acceptable to Snowflake. It supports major character sets including ISO-8859-1 to 9, Big5, EUC-KR, UTF-8, UTF-16, as well as all SQL constraints like UNIQUE, PRIMARY KEY, FOREIGN KEY, NOT NULL. This is a huge advantage during moving data.
Moving data to a cloud staging area: Before data can be loaded into Snowflake, it has to be temporarily located in a cloud staging area. For an internal staging option, the user and table will be automatically allotted that can be used to stage data to that user and table. A name can be allotted to it. In an external staging option, currently, Snowflake supports Amazon S3 or Microsoft Azure as staging locations.
Copying staged files to Snowflake: Copying the files from the staging area is the final step in database migration from Oracle to Snowflake. This is done with the “COPY INTO” command.
These are the steps that have to be taken for the seamless migration of databases to Snowflake from Oracle.
0 notes
Text
Why Should You Migrate Databases from Oracle to S3
The Simple Storage Service (S3) of Amazon Web Service (AWS) offers cutting-edge advantages to users. It provides unlimited storage service that is cost-effective and lies at the core of data lakes in AWS. For Oracle databases, the Amazon RDS (Relational Database Service) is also a popular source for data lakes.
There are certain preliminary procedures to migrate databases from Oracle to S3. The first is to have an account in AWS and second, ensure that an Amazon RDS for the Oracle database and an S3 bucket is in the same region where the AWS DMS (Database Migration Service) replication instance is created for migration.

Pre-tasks for Oracle to S3 database migration
Before starting the Oracle to S3 process certain preparatory steps have to be carried out. The first is to prepare the source Amazon RDS for Oracle database replication. Next, an AWS Identity and Access Management (IAM) role has to be created for getting access to the S3 bucket. Then, make a full load task as well as AWS DMS instance and endpoints, and finally, create an activity that takes care of Change Data Capture.
Once these are completed, the actual task of Oracle to S3database migration can be started.
Migrating databases from Oracle to S3
Data can be migrated from Oracle to S3 in two ways according to organizational needs.
Importing data, Oracle Data Pump, and Database Link: In this method, a link to the Oracle instance is established through the Oracle Data Pump along with the Oracle DBMS_FILE_TRANSFER package. An Amazon RDS for an Oracle database instance or an Amazon EC2 instance can be used for this purpose. During migration, the Oracle data is exported to a dump file with the DBMS_DATAPUMP package after which the file is copied to the Amazon RDS Oracle DB instance through a connected database link. Finally, the DBMS_DATAPUMP package imports the data to S3.
Importing Data, Oracle Data Pump, and Amazon S3 Bucket – Here, the Oracle DBMS_DATAPUMP package is used to export the Oracle database source data and this file is dumped in an Amazon S3 bucket. It is then downloaded to the DATA_PUMP_DIR directory in the RDS Oracle DB instance. In the final step, using the DBMS_DATAPUMP package, the data in the dump file is imported and copied to the Amazon RDS Oracle DB instance.
The objective of migrating databases from Oracle to S3 is to ensure that the Oracle database is optimized on Amazon S3. To do so, organizations can choose between two methods.
In the first, EC2 compute instances and Elastic Block Store (EBS) storage is run on the Oracle in-premises databases. The downside is that this method is complex since the entire servers and the storage infrastructure have to be replaced with that of Amazon Web Service. The second is to migrate the on-premises Oracle database to Amazon RDS.
0 notes
Text
The Structure of the SAP Data Lake and How is it Unique
A data lake is a storage repository for any form of data that can be accessed, examined, and analyzed for making critical data-based business decisions. In the current business environment, data is growing exponentially at petabyte levels, and managing databases is becoming more complex, mainly due to the number of sources like applications, various formats, IoT, and social media.
Data lakes, though, take these factors into account, and a technologically advanced one like SAP data lake helps organizations improve performance, lower costs, and gain more access and insights to data.

The SAP data lake is a relational data lake. That means the SAP IQ database is deployed in the cloud and provides processing capabilities at par with Azure or Amazon Web Service. The data lake also provides 10x compression of existing data, leading to great savings in storage costs.
The SAP data lakecan also store data in its native form – structured, semi-structured, and unstructured data - and the data lakecan be run either on the existing HANA Cloud instance or on an optimized new HANA Cloud instance. In both cases, extra storage space can be downloaded at any time. Other typical cloud-based data lake features that are available in the SAP data lake are increased data security, data encryption, audit logging, and tracking of data access.
The SAP Data Lake Architecture
TheSAP Data Lake architecture is in the form of a pyramid.
The top section holds data that is most critical for businesses and needs to be accessed frequently and sometimes immediately. It is also vital data, known as hot data, and is stored in memory. Hence, the cost of storing this data is very high.
At the middle of the pyramid is data that in the past would have been treated as cold storage but not now with the SAP HANA data and the SAP Data Lake. This data is not as frequently accessed as the top tier and hence storage costs are comparatively lower.
At the bottom of the pyramid is the raw data that is rarely used and would have been deleted in traditional databases to create additional space. However, it is retained in the SAP Data Lake as storage costs touch rock bottom, and organizations prefer to hold on to it. The trade-off here is the very slow rate of access
Summing up, it is seen that this cloud-based SAP data lake manages data through a reasonable life cycle, from critical and urgent data to cold and old data. This tiering in the form of a pyramid keeps costs down and it is possible to decide where to store the data based on how quickly and frequently it is to be accessed.
The SAP HANA Data Lake is based on the SAP IQ technology, is highly elastic, and works independently of HANA DB.
1 note
·
View note
Text
Why Migrate Database SQL Server to Amazon S3
Organizations today are constantly looking for ways to optimize the functioning of their database systems. And one of the methods open to users of the Microsoft SQL Server databases is to migrate to the cloud. In short, it means moving databases from SQL Server to S3 while using the same database engine for the source and the target (as in Homogeneous Migration) without stoppage or disruption of work.

It is now possible to use the SQL Server backup and restore method in conjunction with Amazon Web Service Database Migration Service (AWS DMS) to migrate databases from SQL Server to S3without any downtime or stoppage of work. Hence, it is also very easy to migrate database code objects including views and store procedures and functions as a part of database migration.
Database migration can be done from Microsoft SQL Server to S3regardless of the size of the database as it is available for the application during migration. Time taken for data validation while migrating database is also reduced as the validation goes on simultaneously on the target database while data is being loaded from the source database. However, this can be done only when there are no limitations on using SQL Server as a source for AWS DMS.
The critical reason why most organizations want to migrate databases from SQL Server to Amazon S3 (Simple Storage Service) is because of the unmatched data durability and scalability offered by S3. Being cloud-based, S3 offers unlimited storage capabilities and businesses can start new projects without investing in additional hardware and software. Additionally, users can scale up and down in data usage by paying only for the resources used.
Some of the other features that make migrating databases from Microsoft SQL Server to S3so attractive for businesses are data protection, access management, data replication, and cost affordability. Moreover, data replication can be done both within and outside the region since S3 can go through billions of objects of Batch Operations.
Before migrating database from SQL Server to S3, certain preconditions have to be fulfilled.
First, the S3 account that is used for the migration should have an IAM role, and permissions should be given for specific activities like write and delete access to the target S3 bucket. Next, the same AWS region should contain both the DMS replication instance for migrating the data and the S3 bucket being used as the targetTagging access must be assigned to the role to ensure that objects that are written to the target bucket can be tagged via AWS CDC S3. Also, it has to be ensured that DMS (dms.amazonaws.com) is present in the IAM role as an additional entity.
Finally, the role assigned to the user for completing the migration activity must have the required permission for it.
1 note
·
View note