
Leer hoe Google werkt en denkt, til jouw website, webwinkel of blog naar het volgende niveau en schrijf artikelen die ranken!
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by googleseocursus and here's what we found interesting.
Average Info
Notes Per Post
0
Likes Per Post
0
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
3 days
Number of Posts By Type
Text
17
Last Seen Tumblr Blogs





Fun Fact
Women make up for the other 50% of Tumblr’s audience.
Text
#seo#google#seo marketing#seo optimization#local seo#on page seo#marketing#off page seo#seotips#social media
0 notes
Text

Leer alles over de mensen zoeken ook functie van Google, en hoe jij er op in kunt spelen om jouw traffic een boost te geven!
#seo#google#seo marketing#seo optimization#off page seo#local seo#on page seo#marketing#seotips#social media
0 notes
Text

Ongeacht of het voor LinkedIn, Instagram of een ander digitaal platform is, de hedendaagse persoon heeft een profielfoto nodig.
Een professionele voor LinkedIn en dergelijke. Je kunt hiervoor een professionele fotograaf benaderen, maar met een beetje creativiteit en een ontspannen glimlach kun je ook zelf uitstekende resultaten behalen, zelfs met je smartphone!
Leer alles over het maken van een leuke profielfoto!
#social media#profile picture#google#seo optimization#marketing#seotips#off page seo#local seo#on page seo#seo marketing#seo
0 notes
Text

Lees alles over de whitepaper. Wat is het, en hoe maak je zelf een effectieve whitepaper.
#seo#google#seo marketing#seo optimization#off page seo#local seo#on page seo#marketing#social media#seotips#whitepaper
0 notes
Text

Lees over 8 Screaming Frog alternatieven om jouw SEO te optimaliseren!
#seo#google#seo marketing#seo optimization#seotips#local seo#marketing#on page seo#off page seo#social media
0 notes
Text

Wil jij alles leren over "boven de vouw" met betrekking tot webdesign en SEO?
Lees dan snel ons artikel om er alles over te leren!
#seo#google#seo marketing#seo optimization#seotips#marketing#on page seo#local seo#social media#off page seo
0 notes
Text
Bekijk het laatste nieuws op ons WordPress platform!
#seo#google#seo marketing#seo optimization#on page seo#social media#off page seo#marketing#local seo#seotips
0 notes
Text
Wat is LinkedIn?

Wat is LinkedIn? In dit artikel beantwoorden wij deze vraag, en geven we jou tal van tips om jouw LinkedIn profiel te optimaliseren!
#seo#google#seo marketing#seo optimization#off page seo#seotips#local seo#on page seo#marketing#social media#linkedin
0 notes
Text
Technical SEO
Technical SEO is essential, not an option! Technical SEO remains the crucial foundation for any successful strategy.
Here’s why technical SEO is more important than ever.
Read in Dutch: Technische SEO
SEO has changed more in the past decade than any other marketing channel.
Through a series of algorithmic developments, SEO has remained the cornerstone of a successful digital strategy — after all, 51% of online traffic arrives at websites through organic search.
SEO has become mainstream. Yet we must recognize that SEO requires new skills and approaches to be successful in an increasingly competitive world.
With more than 5,000 devices integrated with Google Assistant and the rise of voice searches, the focal points of searches have decentralized.
The SERP as we knew it is a thing of the past; search is now dynamic, visual and everywhere. This has a significant impact on organizations, as SEO is a collaborative discipline that requires the synthesis of multiple specialties to achieve optimal results.
Central to all of this is technical SEO, which is still the foundation of any successful strategy.
Roughly speaking, technical SEO can be divided into the following topics:
Site content
Ensure that content can be crawled and indexed by all major search engines, particularly by using log file analysis to interpret their access patterns and structured data to enable efficient access to content elements.
Structure
Create a site hierarchy and URL structure that allows both search engines and users to find the most relevant content. This should also facilitate the flow of internal link equity through the site.
Conversion
Identify and resolve any blockages that prevent users from navigating the site.
Performance
An important development is the evolution from technical SEO to performance-based specialization.
This has always been true, but marketers of all types have realized that technical SEO is much more than just “housekeeping.”
Getting the above three areas in order will lead to better site performance through search and other channels.
Site, search engine & content optimization
The term “search engine optimization” may no longer be adequate, as we expand our scope to include content marketing, conversion optimization and user experience.
Our work now includes:
Optimizing the site for users.
Ensure accessibility of content to all major search engines and social networks.
Create content that appeals to the right audience across multiple marketing channels.
Technical SEO more important than ever
SEO has evolved into a part of something bigger, requiring the application of technical skills in a different way.
It has evolved into a more versatile and nuanced digital channel that has transcended the traditional “Search Engine Optimization” category.
The basics of organic search remain firmly in place, with a well-deserved emphasis on technical SEO driving performance on web, mobile and devices.
SEO specialists are often at the forefront of technological innovations, and this does not seem to be changing in a world of voice-activated search, digital assistants and Progressive Web Apps.
New approaches are required to maximize these opportunities. This begins with defining exactly what SEO means and extends to the ways we lead collaboration within our organizations.
The level of technical knowledge required is back to what it used to be.
However, where and how you apply that knowledge is critical to technical success. Focus your skills on optimizing:
Your website
Mobile and desktop devices
Mobile apps
Voice search
Virtual reality
Different search engines (not just Google anymore — think Amazon, for example)
Your URL structure
The URL structure of a website should be clear, and legible to the user. This is because the URL is there not only for search engines such as Google, but also as an indication to the user so they can see where they are at a glance.
The usefulness of keywords in a URL
Apart from a small potential impact on ranking, there are clear benefits to site visitors when keywords are included in a URL.
Keywords in the URL can help users understand what a page is about. Even though these keywords may not always appear in the SERPs, they do become visible when linked as a bare URL.
Example of a bare URL: https://voorbeeld.com/infographics/blog-schrijven
When in doubt, optimize for the user, because Google always recommends making pages useful to users.
This often corresponds to the kind of Web pages that Google likes to place high in search results.
Best practice for URL structure
There are some best practice rules you can apply to your URL structure. This will ensure that search engines can better index your pages, but also ensure that people understand the URL.
Your URLs always in lowercase
Most servers have no problems with URLs with mixed uppercase and lowercase letters. Still, it’s a good idea to standardize how your URLs look.
URLs are usually written in lowercase “like-this-dot-com,” as opposed to mixed capital letters “Like-This-Dot-Com” or completely capitalized “IF-This-Dot-COM.”
Do this, too, because that’s what users expect and it’s easier to read than everything in capital letters.
Standardizing your URLs helps prevent linking errors inside and outside the site.
Use hyphens
Always use hyphens (-) and no underscores (_), because underscores are not visible when the URL is published as a bare link.
Here is an example of how underlining in links is a bad practice:
Without underlining:
The same URL but with underlining:
This means that users cannot accurately see the URL.
Use accurate keywords in category URLs
Using a less relevant keyword as the category name is a common mistake that comes from choosing the keyword with the most traffic.
Sometimes the keyword with the highest traffic is not necessarily what the pages in the category are about. Choose category names that really describe what the pages inside are about.
When in doubt, choose the words that are most relevant to users looking for the content or products listed in those categories.
Avoid unnecessary words in the URL
Sometimes a CMS adds the word /category/ to the URL structure.
This is an undesirable URL structure. There is no justification for a URL structure that looks like /category/infographics/.
It should just be /infographics/.
Similarly, if a better word than “blog” exists to tell users what to expect from a section on your site, use that instead.
Words lead users to the content they are looking for.
Use them appropriately. Future-proof Your URLs Just because there’s a date in the article title doesn’t mean it belongs in the URL.
If you plan to make a “Top xxx for 20xx” type of post, it is generally better to use the same URL year after year.
So instead of:
example.com/infographics/blog-writing-2023
Try removing the year and just use:
example.com/infographics/blog-writing
The advantage of updating the content and title annually, while keeping the same URL, is that all links that went to the previous year’s content are preserved.
The trailing slash
A trailing slash is this symbol: /.
The Worldwide Web Consortium (W3C) — the group responsible for Web standards — recommends as a best practice that the trailing slash should be used to denote a “container URI” for indicating parent/child relationships.
(A URI is used to identify resources in the same way as a URL, except that those resources may not be on the Web.)
A parent/child relationship is when a category contains multiple web pages. The category “container” is the parent and the web pages it contains are the child documents that fall within the category.
For example:
Could be another page then:
Mueller’s 2017 tweet confirmed an official Google blog post from 2010 (To Slash or Not to Slash) that made similar statements.
However, even in that 2010 blog post, Google largely left it up to publishers to decide how to use trailing slashes. But Google’s adherence to a general trailing slash convention reflects that position.
How does Google process its URLs?
Here is an example of how Google encodes URLs.
This URL ends with .html and is clearly a web page:
This URL ending with a trailing slash is a category page:
And this is the container for the month and year 2020:
The above examples conform to the standard recommendation to use trailing slashes at the end for a category directory and not to use it at the end of the URL when it is a web page.
SEO-friendly URLs
The subject of SEO-friendly URLs is more extensive than one might suspect, with many nuances.
Although Google is showing URLs less and less frequently in its SERPs, popular search engines such as Bing and DuckDuckGo still do.
URLs are a good way to show a potential site visitor what a page is about.
Proper use of URLs can improve click-through rates wherever the links are shared.
And shorter URLs are more user-friendly and easier to share.
Web pages that are easy to share help users make the pages popular.
Don’t underestimate the power of popularity for ranking purposes because search engines show, in part, what users expect to see.
The URL is a modest and somewhat overlooked part of the SEO equation, but it can contribute a lot to getting your pages to rank well.
XML sitemaps for SEO
In simple terms, an XML sitemap is a list of URLs of your website.
It acts as a road map to tell search engines what content is available and how to access it.
In the example above, a search engine will find all nine pages in a sitemap with one visit to the XML sitemap file.
On the website, it has to jump through five internal links to find page 9.
This ability of an XML sitemap to aid crawlers in faster indexing is especially important for websites that:
Have thousands of pages and/or deep website architecture.
Add new pages regularly.
Often change the content of existing pages.
Suffer from weak internal linking and orphan pages.
Not having a strong external link profile.
In the example above, a search engine will find all nine pages in a sitemap with just one visit to the XML sitemap file.
On the website, the search engine must navigate through six internal links to find page 9. This ability of an XML sitemap to help search engines with faster indexing is particularly important for Web sites that:
Have thousands of pages and/or a complex website architecture.
Add new pages regularly.
Often change the content of existing pages.
Experiencing problems with weak internal links and orphan pages.
Not having a strong external link profile.
Never forget to indicate your Sitemap in the Google Search Console and other platforms such as Bing webmaster.
Different types of sitemaps
There are several types of sitemaps. Let’s look at the ones you really need. XML Sitemap Index
XML sitemaps have a few limitations:
A maximum of 50,000 URLs.
An uncompressed file size limit of 50MB.
Sitemaps can be compressed with gzip (the file would be called something like sitemap.xml.gz) to save bandwidth from your server. But once unzipped, the sitemap should not exceed either limit.
If you exceed any of these limits, you will need to distribute your URLs across multiple XML sitemaps.
These sitemaps can then be combined into a single XML sitemap index file, often called sitemap-index.xml. Basically a sitemap for sitemaps.
For exceptionally large websites that want a more detailed approach, you can also create multiple sitemap index files. For example:
sitemap-index-articles.xml
sitemap-index-products.xml
sitemap-index-categories.xml
Note that you cannot nest sitemap index files together.
In order for search engines to easily find all your sitemap files at once, you want:
Submit your sitemap index(es) to Google Search Console and Bing Webmaster Tools.
Specify your sitemap index URL(s) in your robots.txt file. This will point search engines directly to your sitemap as you invite them to crawl your site.
Sitemap for images
Image sitemaps are designed to improve indexing of image content.
However, in modern SEO, images are embedded in page content, so they are crawled along with the page URL.
Additionally, it is a good practice to use JSON-LD schema.org/ImageObject markup to highlight image properties to search engines, as this provides more attributes than an XML image sitemap.
Therefore, an XML image sitemap is unnecessary for most Web sites. Including an image sitemap would only waste crawl budget.
The exception is if images drive your business, such as a stock photo website or an e-commerce site that extracts product page views from Google Image searches.
Know that images do not have to be on the same domain as your Web site to be submitted in a sitemap. You can use a CDN as long as it is verified in Search Console.
Sitemap for video
As with images, if videos are crucial to your business, submit an XML video sitemap. If not, a video sitemap is unnecessary.
Save your crawl budget for the page where the video is embedded, and make sure you mark all videos with JSON-LD as a schema.org/VideoObject. This will help search engines effectively search and index your video content.
Sitemap for Google news
Only sites registered with Google News should use this sitemap.
If you are registered, add articles published in the last two days, up to a limit of 1,000 URLs per sitemap, and update with fresh articles as soon as they are published.
Contrary to some online advice, Google News sitemaps do not support image URLs.
Dynamic sitemaps
Dynamic XML sitemaps are automatically updated by your server to reflect relevant website changes as soon as they occur.
To create a dynamic XML sitemap:
Ask your developer to code a custom script, be sure to provide clear specifications
Use a dynamic sitemap generator tool
Install a plugin for your CMS, for example, the Yoast SEO plugin for WordPress or the XML sitemap generator for Google.
Checklist for best practice Sitemaps
Invest time to:
Include Hreflang tags in XML sitemaps
The tags and to be used
Compress sitemap files with gzip
To use a sitemap index file
Image, video and Google News sitemaps to be used only if dexation furthers your KPIs
Generate XML sitemaps dynamically
Taking care to include URLs in only one sitemap
Sitemap index URLs to be listed in robots.txt
Sitemap index submission to both Google Search Console and Bing Webmaster Tools
Include only SEO-relevant pages in XML sitemaps
Fix all errors and warnings
Analyze trends and types of valid pages
Calculate indexing rates of submitted pages
Address causes of exclusion for submitted pages
Robot tags and robots.txt
Before we go into the basics of what meta robots tags and robots.txt files are, it is important to know that there is no side that is better than the other for use in SEO.
Robots.txt files give crawlers instructions about the entire site. While meta robots tags go deeper into the details of a specific page.
There is no right or wrong answer. It is a personal preference based on your experience.
What is Robots.txt?
A robots.txt file gives crawlers instructions on what they should or should not search. It is part of the robots exclusion protocol (REP).
Googlebot is an example of such a crawler. Google uses Googlebot to search websites and gather information about that site to understand how the site should be ranked in Google’s search results.
You can find the robots.txt file of any website by adding /robots.txt to the web address, such as:
example.com/robots.txt
User-agent: *
Disallow: /
Allow: /infographics/
Disallow: /archives/
The asterisk * after user-agent indicates that the robots.txt file is intended for all bots visiting the site.
The slash / after “Disallow” instructs the robot not to visit any page on the site (this is for illustration purposes only).
In the robots.txt file structure, you will find commands such as “allow” and “disallow,” which specifically indicate which directories or files are allowed to be scanned by search engines or not.
These instructions are essential for determining which parts of a Web site are accessible to search engine crawlers and which parts should remain private or hidden.
This is a crucial aspect for Web site administrators to effectively manage and optimize their site structure and content for search engines.
The crawl budget
Another reason why robots.txt is important has to do with Google’s so-called “crawl budget.
Google explained that every website has a certain crawl budget, meaning there is a limit to how much and how often their crawlers visit and index a website.
By effectively using robots.txt, webmasters can ensure that Google’s crawlers spend their time and resources indexing the most important pages, rather than wasting time on less relevant or duplicate content.
Google indicates:
Googlebot is designed to be a good citizen of the web. Crawling is its main priority, while making sure it doesn’t degrade the experience of users visiting the site. We call this the “crawl rate limit,” which limits the maximum fetching rate for a given site.
Simply put, this represents the number of simultaneous parallel connections Googlebot may use to crawl the site, as well as the time it has to wait between fetches.
If you have a large Web site with low-quality pages that you don’t want Google to index, you can instruct Google to “Reject” these pages in your robots.txt file.
This makes more of your crawl budget available for crawling the high-quality pages you want Google to position you well for.
By being selective in which pages are indexed, you can optimize your site’s effectiveness in search results.
So what is a Robots.txt like?
Using a robots.txt file is crucial to SEO success. However, improper use can cause confusion as to why your Web site is not ranking well. Search engines crawl and index your site based on the instructions in your robots.txt file. Some common guidelines in robots.txt are:
User-agent: * — Gives all spiders the rules for crawling your site. The asterisk represents all spiders.
User-agent: Googlebot — Specifies instructions only for Google’s spider.
Disallow: / — Instructs all crawlers not to crawl your entire site.
Disallow: — Gives all crawlers permission to crawl your entire site.
Disallow: /staging/ — Tells all crawlers to ignore your staging site.
Disallow: /ebooks/*.pdf — Prevents crawlers from crawling PDF files, which can cause duplicate content problems.
User-agent: Googlebot Disallow: /images/ — Specifies that only Googlebot should disallow all images on your site.
- A wildcard representing any string of characters.
$ — Used to indicate the end of a URL.
What do you have to hide?
The robots.txt file is often used to keep certain directories, categories or pages out of search results. You do this with the “disallow” directive. Here are some common pages I hide with a robots.txt file:
Pages with duplicate content (often printer-friendly versions)
Pagination pages
Dynamic product and service pages
Account pages
Administrator pages
Shopping carts
Chat features
Thank you pages
Meta robots
Meta-robots tags, also known as meta-robots guidelines, are HTML code snippets that give search engine crawlers instructions on how to crawl and index pages on your Web site.
These tags are added to the <head> section of a web page. For example:
<meta name=”robots” content=”noindex” />
Meta-robots tags consist of two parts. The first part of the tag, ‘name=’, identifies the user agent, such as “Googlebot.” The second part, “content=,” specifies what you want the bots to do.
Different types
Meta-robots tags have two types:
Meta-robots tag
These tags are often used by SEO marketers. They allow you to give specific instructions to user agents (such as Googlebot) about which parts of a website should be crawled. An example is:
<meta name=”googlebot” content=”noindex,nofollow”>
This tag instructs Googlebot not to index the page and not to follow backlinks, so the page does not appear in the SERPs.
For example, such a tag could be used for a thank you page.
X-robots tag
This tag provides the same functionality as the meta-robots tags, but within the headers of an HTTP response. It provides more functionality than the meta-robots tags, but requires access to .php, .htaccess or server files.
For example, you would use this tag if you want to block an image or video without blocking the entire page.
The various parameters
The meta-robots tag provides several guidelines that you can use in your code, but it is first important to understand these guidelines and their functions. Here is an explanation of the most important meta-robots tag guidelines:
all — Default setting with no restrictions on indexing and content.
index — Allows search engines to index this page in their search results. This is the default setting.
noindex — Removes the page from the search index and search results.
follow — Allows search engines to follow internal and external backlinks on the page.
nofollow — Does not allow search engines to track internal and external backlinks.
none — Same as noindex and nofollow.
noarchive — Does not show a ‘Saved copy’ link in the SERPs.
nosnippet — Does not show a detailed description of this page in the SERPs.
notranslate — Does not provide translation of this page in the SERPs.
noimageindex — Does not index the images on the page.
unavailable_after: [RFC-850 date/time] — Does not show this page in the SERPs after the specified date/time.
max-snippet — Sets a maximum number of characters for the meta description.
max-video-preview — Determines the number of seconds for a video preview.
max-image-preview — Sets the maximum size for an image preview.
404 and soft 404 notifications
Google Search Console warns publishers about two types of 404 errors: the standard 404 and the so-called “soft 404. Although they both carry the code 404, they differ significantly.
Therefore, it is crucial to understand the distinction between these errors in order to solve them effectively.
HTTP status codes
When a Web page is opened by a browser, it returns a status code indicating whether the request was successful, and if not, why not.
These responses are given by what are known as HTTP response codes, but officially they are called HTTP status codes.
A server provides five categories of response codes; this article deals specifically with one response, the 404 status code for “page not found.
Why do 404 status codes happen?
All codes within the range of 4xx responses mean that the request could not be fulfilled because the page was not found. The official definition reads:
4xx (Client error): The request contains bad syntax or cannot be fulfilled.
The 404 response leaves in the middle whether the Web page might return. Examples of why the ‘404 Page Not Found’ error message occurs:
If someone accidentally deletes a web page, the server responds with the 404 page not found.
If someone links to a nonexistent Web page, the server replies that the page was not found (404).
The official documentation is clear on the ambiguity of whether a page is temporarily or permanently gone:
“The 404 (Not Found) status code indicates that the originating server has not found a current representation for the target resource or is unwilling to reveal that one exists.
A 404 status code does not indicate whether this lack of representation is temporary or permanent…”
What is a soft 404?
A soft 404 error is not an official status code. The server does not send a soft 404 response to a browser because no soft 404 status code exists.
Soft 404 describes a situation where the server presents a Web page and responds with a 200 OK status code, indicating success, while the Web page or content is actually missing.
This can be confusing because the server seems to indicate that everything is fine, while the desired content is not available. This can lead to problems with user experience and SEO because it appears that the page exists when in reality it does not.
Reasons for a soft 404
There are four common reasons for a soft 404:
A missing web page where the server sends a 200 OK status. This occurs when a page is missing, but the server configuration redirects the missing page to the home page or a custom URL.
Missing or “thin” content. If content is completely missing or very limited (also known as thin content), the server responds with a 200 status code. Search engines classify this as soft 404s.
The missing page is redirected to the home page. Some redirect a missing page to the home page to avoid 404 error messages even though the home page was not requested.
Missing page redirects to a custom web page. Sometimes missing pages redirect to a specially designed web page that gives a 200 status code, resulting in Google classifying it as soft 404s.
Soft 404 errors due to errors in code
Sometimes a page is not really missing, but certain problems, such as programming errors, cause Google to classify the page as missing. Soft 404s are important to investigate because they can indicate broken code. Common programming problems are:
A missing file or component that should place content on a Web page.
Database errors.
Missing JavaScript.
Empty search results pages.
404 errors have two main causes:
An error in the link sends users to a non-existent page.
A link to a page that once existed but suddenly disappeared.
Link errors
When a 404 error is caused by a link failure, you need to fix the broken links. The challenging part of this task is finding all the broken links on a site.
This can be particularly troublesome for large, complex Web sites with thousands or even millions of pages.
In such cases, crawler tools are very useful. There are many website crawling software options available: free tools such as Xenu and Greenflare, or paid software such as Screaming Frog, DeepCrawl, Botify, Sitebulb and OnCrawl.
Several of these programs offer free trial versions or free versions with limited features.
Of course, you can also use your favorite SEO tool such as SEMrush, Ahrefs or Ubersuggest and perform a technical SEO scan of your website.
What if a page no longer exists?
If a page no longer exists, you have two options:
Restore the page if it was accidentally deleted.
Create a 301 redirect to the most related page if the removal was intentional.
First, you need to locate all link errors on the site. As with locating all link errors for a large-scale website, you can use crawler tools for this.
However, crawler tools cannot find orphan pages: pages that are not linked anywhere from navigation links or from any of the pages.
Orphan pages may exist if they were once part of the website, but after a website redesign, the link to this old page disappears, while external links from other websites may still lead to it.
To check whether such pages exist on your site, you can use several tools.
How do you solve 404 problems?
Crawling tools don’t detect soft 404 because it’s not a 404 error. But you can use them to find something else.
Here are some things to watch out for:
Thin Content: Some crawlers report pages with little content and a sortable word count. Start with pages with the fewest words to assess whether the page has thin content.
Duplicate Content: Some crawlers are sophisticated enough to determine what percentage of the page is template content. There are also specific tools for finding internal duplicate content, such as SiteLiner. If the main content is almost the same as many other pages, you should examine these pages and determine why duplicate content exists on your site.
In addition to crawlers, you can also use Google Search Console and search under crawl errors for pages listed as soft 404s.
Crawling an entire site to find problems that cause soft 404s allows you to locate and fix problems before Google detects them.
After detecting these soft 404 problems, you need to correct them.
Often the solutions seem obvious. This can include simple things like expanding pages with thin content or replacing duplicate content with new and unique content.
During this process, here are a few points to consider:
Merge pages
Sometimes thin content is caused by being too specific with the page theme, leaving you with little to say.
Merging multiple thin pages into one page may be more appropriate if the topics are related. This not only solves problems with thin content, but can also solve problems with duplicate content.
Find technical issues causing duplicate content
Even with a simple web crawler like Xenu (which only looks at URLs, comment tags and title tags and not content), you can still find duplicate content problems by looking at URLs.
Why use HTTPS?
HTTP websites have long been a fixture on the Internet.
Nowadays, HTTPS, the newer variant, is on the rise. But what exactly is the difference?
HTTP stands for HyperText Transfer Protocol and is used to receive information from the Web. It was originally developed to secure and authorize transactions on the Web. In simple terms, it displays information to the Internet user.
However, without a secure connection, any network between the source host and the target host can alter the information received by the target host.
This is where HTTPS comes in. HTTPS, which stands for HyperText Transfer Protocol Secure, uses SSL (Secure Sockets Layer) for a more secure way of transporting data. This ensures a secure connection, which is a win for everyone.
The benefit of HTTPS
Let’s take a look at the benefits of using HTTPS. Improved Search Results
Google has not confirmed that HTTPS is a ranking factor, but does prefer sites that use HTTPS.
Research showed that HTTPS has a positive impact on visibility in the SERPs.
Better User Experience
Browsers such as Firefox and Chrome indicate whether a Web site is safe. Studies show that 84% of users would stop a purchase on an unsafe site. A secure browsing experience increases retention.
Protect your Users’ Information
With HTTPS, you protect your users’ data. A data breach like Marriott’s or Facebook’s can be prevented by maintaining HTTPS status with SSL/TLS certificate.
Get the lock icon
77% of visitors worry about misuse of their data online. The lock icon builds trust and credibility.
HTTPS is Necessary for AMP
Mobile optimization and the use of AMP require a secure site with SSL.
More effective PPC campaigns
HTTPS helps reduce bad ad practices and increase conversions. Google Ads began automatically redirecting HTTP search ads to HTTPS in 2018 and warned advertisers to stop using HTTP address for landing pages.
Corrected data in Google Analytics
Optimize page speed
Page speed is a crucial factor in digital marketing today. It has a significant impact on:
How long visitors stay on your site.
How many of them become paying customers.
How much you pay per click in paid searches.
Where you rank in organic search results.
Unfortunately, many websites perform poorly in terms of page speed, which has a direct negative impact on their revenue.
There are countless tasks that digital marketers can spend their days on, and there is never enough time to do them all. As a result, some tasks get pushed to the background.
Optimizing page speed is one of those tasks that is often put off. This is understandable because many people do not fully understand the importance of this often overlooked factor, thus failing to see the value of investing time and money to improve it by just a few seconds.
What may seem like an insignificant amount of time to some marketers, including those who focus solely on search engine optimization, has proven to be significant, according to data from both industry giants and our own analytics.
Switch to a good hosting provider
In our efforts to reduce costs, especially given the cumulative costs of everyday tools such as Raven, SEMrush, Moz and more, it sometimes seems like we are carrying an extra financial burden.
Many opt for affordable, shared web hosting that houses numerous sites, like a compact car full of circus clowns. Unfortunately, this comes at the expense of performance.
Your site may be accessible, as with most hosts, but slow load times can discourage visitors and keep them from making purchases.
Some may not see this problem, but for visitors, every second counts.
For users, a Web site visit is purposeful, whether for information or a purchase. Any delay can negatively affect their experience, causing them to leave the site without taking action.
How much difference can it make?
Amazon research found that even an unremarkable delay of 100 milliseconds resulted in a 1% drop in sales. A similar trend was observed at Walmart.
So this almost imperceptible time margin has a significant impact. Consider how much greater the impact is with an even longer load time.
A fast website is not only good for your sales, it also improves your search engine rankings and lowers your advertising costs.
In short, a slow website can be detrimental in competition. So choose a web host that offers speed at a reasonable price, such as those for WordPress websites.
By researching and testing yourself, you can choose a web host that satisfies both your audience and search engines.
Reduce the number of HTTP calls
Each separate file type required to display and run a Web page, such as HTML, CSS, JavaScript, images and fonts, requires a separate HTTP request. The more requests, the slower the page loads.
The problem is often in the structure of the website: many themes load multiple CSS and JavaScript files. Some, such as jQuery or FontAwesome, are even loaded from a remote server, which significantly increases loading time.
This is exacerbated by additional CSS and JavaScript files added by plugins. The result is soon a good number of HTTP requests just for CSS and JavaScript files.
Add in the individual requests for each image on a page, and the number of requests adds up quickly.
To reduce this, you can do the following:
Combine JavaScript files into a single file.
Merge CSS files into one file.
Limit or eliminate plugins that load their own JavaScript and/or CSS files.
Use sprites for commonly used images.
Whenever possible, use a font such as HeroIcons instead of image files, because then only one file needs to be loaded.
Activate compression
By enabling GZIP compression, you can significantly reduce the download time of your HTML, CSS and JavaScript files. This is because these files are downloaded as smaller, compressed files and then decompressed in the user’s browser.
Don’t worry, your visitors don’t have to do anything extra for this. All modern browsers support GZIP and process it automatically with all HTTP requests. This leads to faster loading times of your web pages, without requiring extra effort from your visitors.
Enable browser caching
By enabling browser caching, elements of a Web page are stored in your visitors’ browsers.
When they revisit your site or visit another page, their browser can load the page without having to send a new HTTP request to the server for the cached elements.
Once the first page is loaded and its elements stored in the user’s cache, only new elements need to be downloaded on subsequent pages.
This can significantly reduce the number of files that need to be downloaded during a typical browser session, leading to faster load times and a better user experience.
Minimize resources
Minimizing your CSS and JavaScript files by removing unnecessary white space and comments reduces file size and thus download time.
Fortunately, you don’t have to perform this process manually, as there are several online tools available that can convert a file into a smaller, minimized version.
There are also several WordPress plugins that replace the links in the head of your website for your regular CSS and JavaScript files with a minimized version, without modifying your original files. Some popular caching plugins are:
W3 Total Cache
WP Super Cache
WP Rocket
It may take some effort to get the settings right because minimization can often break CSS and JavaScript. Therefore, test your Web site thoroughly after you minimize everything.
Prioritize content above the fold
Your Web site can appear to load faster if it is programmed to prioritize content above the fold, or content visible before a visitor scrolls down.
This means making sure that elements that appear above the fold are also near the beginning of the HTML code so that the browser can download and display them first.
Optimize media files
With the use of mobile devices with high-quality cameras and convenient content management systems such as WordPress, many people load up photos immediately without realizing that they are often at least four times larger than necessary.
This slows down your website considerably, especially for mobile users.
Optimizing media files on your website can greatly improve your page speed and is relatively easy, so a good investment of time. Optimizing Images
Choose the ideal format: JPG is perfect for photographic images, while GIF or PNG are better for images with large areas in a single color. Use 8-bit PNG for images without transparent background and 24-bit for images with transparent background. Even better, but use the latest format webp.
Scale images. If an image on your website displays 800 pixels wide, it makes no sense to use an image 1600 pixels wide.
Compress imagesIn addition to being a top image editing program, Adobe Photoshop also offers excellent image compression capabilities starting at a few dollars per month. You can also use free WordPress plugins such as EWWW Image Optimizer, Smush and TinyJPG, which automatically compress uploaded images.
However, this doesn’t get you there yet. To really optimize media on your website, you need to provide images that are sized to fit the screen, rather than simply resizing them.
There are two ways to do this, depending on how an image is implemented:
Images within your website’s HTML can be provided with src set, allowing the browser to select, download and display the appropriate image based on the screen size of the device a visitor is using.
Images placed via CSS, usually as background images, can be served using media queries to select the appropriate image based on the screen size of the device a visitor is using.
Optimize video
Choose the best format. MP4 is usually the best choice because it provides the smallest file size.
Offer the optimal size (dimensions) tailored to the screen size of visitors.
Remove the audio track if the video is used as a design element in the background.
Compress the video file. I often use Adobe Premiere or even better Adobe Media Encoder, but Camtasia is also a good option.
Shorten the video length.
Consider uploading videos to YouTube or Vimeo instead of hosting them locally, and use their iframe embed code.
Using Caching and CDNs
Caching allows your Web server to store a static copy of your Web pages so that they can be delivered more quickly to a visitor’s browser.
A CDN (Content Delivery Network) allows these copies to be distributed across servers worldwide. This allows a visitor’s browser to download pages from the server closest to their location. This greatly improves the speed of your page.
Some popular CDNs are:
Cloudflare
Bunny
Kinsta
Microsoft Azure
Google Cloud
Amazon AWS
Avoid duplicate content
In the world of SEO and website architecture, eliminating duplicate content is often one of the biggest challenges.
Many content management systems and developers build sites that are fine for displaying content, but do not work optimally from an SEO perspective.
This often leads to problems with duplicate content, which the SEO must solve. There are two types of duplicate content, both problematic:
On-site duplicate content
the same content is on two or more unique URLs of your site. This is usually manageable by the site administrator and web development team.
Off-site duplicate content
when two or more websites publish the exact same content. This often cannot be controlled directly, but requires cooperation with third parties and owners of the websites in question.
Why is duplicate content a problem?
The problem of duplicate content is best explained by first explaining why unique content is good.
Unique content is one of the best ways to stand out from other websites. When the content on your website is unique, you stand out.
With duplicate content, whether it’s content you use to describe your products or services or content published on other sites, you lose the benefit of uniqueness.
In the case of duplicate content on your own site, individual pages lose their uniqueness.
Consider the illustration below. If A represents content that is duplicated on two pages, and B through Q pages that link to that content, then the duplication causes the link value to be split.
Now imagine that pages B-Q all link to just one page A. Instead of splitting the value of each link, all the value would go to a single URL, increasing the chances of that content scoring in search results.
Whether onsite or offsite, all duplicate content competes with itself. Each version might attract attention and links, but none will receive the full value it would receive if it were the sole and unique version.
However, when valuable and unique content is found at no more than one URL on the Web, that URL has the best chance of being found because it is the sole collector of authority signals for that content.
Now that we understand this, let’s look at the problems and solutions for duplicate content.
Off-site duplicate content
Duplicate content from external sources can be classified into three main categories:
Third-party content published on your own site. This is often in the form of standard product descriptions provided by the manufacturer.
Your own content published on third-party sites with your permission. This usually takes the form of article distribution or sometimes reverse article distribution.
Content that has been copied from your site and published elsewhere without your approval. This is the domain of content scrapers and thieves.
Each of these situations requires a specific approach. For the first and second, it is important to guard the uniqueness of your own content, while for the third, you need to take action against unauthorized duplication.
Content scrapers and thieves
Content scrapers, or content scrapers, are a major source of duplicate content on the Web. They use automated tools to copy content from other Web sites and publish it on their own sites.
These sites often try to generate traffic to get revenue from ads. An effective approach against these practices is limited. You can file a copyright infringement report with search engines such as Google, but this can be time-consuming.
Another strategy is to use absolute links in your content that point to your own site. Those who copy your content will often leave these links intact, allowing visitors to be directed back to your site.
Adding a canonical tag to the original page can also help. When scrapers copy this tag, it signals to Google that you are the original source. This is a good practice regardless of whether you are dealing with scrapers.
Republishing content
Several years ago, it was popular among SEO experts to republish their content on “ezine” websites as a link-building strategy. However, as Google became stricter on content quality and link schemes, this practice declined.
Nevertheless, republishing content with the right focus can be an effective marketing strategy. It is important to realize that many publishers want unique rights to this content to prevent multiple versions of it from diminishing its value on the Web.
Although Google is getting better at assigning rights to the original content creator, republishing can still lead to a small problem of duplicate content, especially if there are two versions that both generate links.
Still, the impact will be limited if the number of duplicate versions remains manageable. Usually the first published version is seen as the canonical version, so publishers often get more value out of the content than the author republishing it on his own site.
On-site duplicate content
Technically, Google treats all duplicate content the same, meaning that internal duplicate content is treated the same as external duplicate content.
However, internal duplication is less excusable because you actually have control over it. It often stems from poor site architecture or development.
A strong site architecture is essential for a strong website. If developers do not follow best practices for search engine friendliness, it can lead to self-competition and loss of ranking opportunities for your content.
Some argue that proper architecture is not necessary because Google “will figure it out.” But this reliance on Google carries risks.
Indeed, Google can sometimes consider duplicates as one, but there is no guarantee that this always happens. So it is better to take action yourself and not rely completely on Google’s algorithms.
Poor website architecture
A common problem in Web site architecture is how pages are accessed in the browser. By default, almost all pages on your site may open with a slightly different URL. If not addressed, these URLs lead to the same page with the same content.
For example, for the home page alone, there are four different access paths:
http://voorbeeld.com
http://www.voorbeeld.com
https://voorbeeld.com
https://www.voorbeeld.com
For internal pages, additional variations arise by adding or omitting a slash at the end of the URL, such as:
http://voorbeeld.com/pagina
http://voorbeeld.com/pagina/
http://www.voorbeeld.com/pagina
http://www.voorbeeld.com/pagina/
Etc.
This means up to eight alternate URLs for each page!
While Google should in principle understand that all of these URLs should be treated as one, the question remains as to which URL is preferable.
The solution with 301 redirects and consistent internal links
Besides the canonical tag, which I discussed earlier, the solution here is to make sure that all alternate versions of URLs redirect to the canonical URL.
This is not just a problem for the home page. The same issue applies to every URL on your site. Therefore, redirects should be implemented globally.
Make sure that every redirect leads to the canonical version. For example, if the canonical URL is https://www.voorbeeld.com, every redirect should point to it. A common mistake is to create additional redirect steps that can look like this:
example.com > https://voorbeeld.com > https://www.voorbeeld.com
example.com > www.voorbeeld.com > https://www.voorbeeld.com
Instead, referrals should be direct:
http://voorbeeld.com > https://www.voorbeeld.com/
http://www.voorbeeld.com > https://www.voorbeeld.com/
https://voorbeeld.com > https://www.voorbeeld.com/
https://www.voorbeeld.com > https://www.voorbeeld.com/
http://voorbeeld.com/ > https://www.voorbeeld.com/
http://www.voorbeeld.com/ > https://www.voorbeeld.com/
https://voorbeeld.com/ > https://www.voorbeeld.com/
By reducing the number of redirect steps, you speed up page loading, reduce server bandwidth and reduce the chance of errors during the process.
Finally, make sure that all internal links on the site point to the canonical version. Although the redirect should resolve duplicate content, redirects can fail due to server- or implementation-side issues.
If that happens, even temporarily, linking internally to only the canonical pages can help prevent a sudden increase in duplicate content problems.
URL parameters and query strings
URL parameters are used to fetch new content from the server, usually based on certain filters or choices.
Take for example the URL example.com/infograhics/. Below are two alternate URLs for the same page:
example.com/infograhics/?type=seo
example.com/infograhics/?sort=age&display=12
These filters can result in multiple unique URLs, depending on the order in which the filters are applied:
example.com/infograhics/?type=seo&sort=age
example.com/infograhics/?type=seo&sort=name
example.com/infograhics/?type=seo&sort=name&sub=onpage
As you can see, these parameters can generate a large number of URLs, most of which do not contain unique content.
Of the parameters listed, “type” is probably the only one for which you would want to write specific content. The other parameters usually do not add unique content.
Parameters for filters
Strategically planning your navigation and URL structure is essential to avoid duplicate content problems.
This process includes understanding the difference between a legitimate landing page and one that allows visitors to filter results.
For example, landing pages (and canonical) URLs should look like this:
example.com/infographics/on-page-seo/
example.com/infographics/off-page-seo/
example.com/infographics/social-media/
And the URLs for filtered results could look like this:
example.com/infographics/on-page-seo/?sort=age&sub=social-media
example.com/infographics/on-page-seo/?sort=age
With correctly constructed URLs, you can do two things:
Add the appropriate canonical tag (everything before the “?” in the URL).
In Google Search Console, specify that Google should ignore all such parameters.
Pagination
Pagination on Web sites is a versatile phenomenon, used in various contexts such as displaying products on category pages, article archives, gallery slideshows and forum discussions.
For SEO professionals, dealing with pagination is not a question of “if,” but “when. As websites grow, content is often spread across multiple pages to improve user experience (UX).
Our job is to help search engines crawl and understand the relationship between these URLs so they can index the most relevant page.
How pagination can be detrimental
You may have heard that pagination is bad for SEO. However, this is usually due to an incorrect approach to pagination, and not the pagination itself.
Let’s look at the supposed disadvantages of pagination and how to overcome the SEO problems it can cause.
Pagination creates thin content
This is correct if you divide an article or photo gallery across multiple pages (to increase ad revenue by increasing page views), leaving each page with too little content.
However, this is incorrect if you put the user’s desires to easily consume your content above revenue from banner ads or artificially inflated page views. Place a user-friendly amount of content on each page.
Pagination uses crawl budget
This is correct if you allow Google to crawl through pagination pages. There are cases where you would want to use this crawl budget.
For example, for Googlebot to navigate through paginated URLs to reach deeper content pages.
Often incorrect when you set the pagination parameter settings in Google Search Console to “Do not crawl” or use a disallow in robots.txt, in cases where you want to save your crawl budget for more important pages.
SEO best practice for pagination
For efficient crawl of paginated pages by search engines, your website should contain anchor texts with href attributes to these paginated URLs.
Make sure your site uses <a href=”you-paginated-url-here”> for internal links to paginated pages. Do not load paginated anchor texts or href attributes via JavaScript.
Also indicate the relationship between component URLs in a paginated sequence with rel=”next” and rel=”prev” attributes.
Complete the rel=”next” / “prev” with a self-referring rel=”canonical” link.
So /category?page=4 should point rel=”canonical” to /category?page=4.
This is appropriate because pagination changes the page content and thus is the main copy of that page.
If the URL contains additional parameters, include them in the rel=”prev” / “next” links, but not in the rel=”canonical.”
For example:
<link rel=”next” href=”https://www.voorbeeld.com/categorie?page=2&order=nieuwste" />
<link rel=”canonical” href=”https://www.voorbeeld.com/categorie?page=2" />
This will indicate a clear relationship between the pages and avoid the potential for duplicate content.
Change meta data on the pages
John Mueller noted, “We don’t treat pagination any differently. We see them as normal pages.”
This means that pagination pages will not be recognized by Google as a series of pages merged into one piece of content, as they previously advised. Each paginated page can compete with the main page for ranking.
To encourage Google to return the main page in the SERPs and avoid warnings for “duplicate meta descriptions” or “duplicate title tags” in Google Search Console, you can make a simple change to your code.
For example, customize the title and meta description of each pagination page to make them unique and avoid duplication. This can help highlight the relevance of each individual page and increase the likelihood of higher rankings.
Do not show in sitemap
Although paginated URLs are technically indexable, they are not a priority for SEO and thus not something on which you should spend crawl budget. Therefore, they don’t belong in your XML sitemap.
By leaving them out of that, you focus search engines’ attention more on your main pages, which can improve your site’s overall SEO performance.
Think of paginated pages as secondary elements that support the user experience but do not necessarily contribute to the core of your search engine optimization strategy.
A ‘show all’ page
The “View All” page was conceived to aggregate all component page content on one URL, with all paginated pages pointing to the “View All” page via a rel=”canonical” to consolidate rank signal.
The idea was that if your paginated series has an alternative “View All” version that provides a better user experience, search engines will favor this page for inclusion in search results rather than a relevant segment page of the pagination chain.
This begs the question: why have paginated pages at all?
Simply put, if you can offer your content on a single URL with a good user experience, there is no need for pagination or an “View All” version.
If that can’t be done, say for a category page with thousands of products, then it would be ridiculously large and too slow to load, and pagination is the better option.
A “View All” version would not provide a good user experience in such a case. Using both rel=”next” / “prev” and a “View All” version does not give clear direction to search engines and will lead to confused crawlers. So don’t do it.
Noindex pagination pages
A classic method to solve pagination problems was to use a robots noindex tag, to prevent paginated content from being indexed by search engines.
However, relying solely on the noindex tag for pagination management results in any rank signals from component pages being ignored.
A bigger problem with this method is that a prolonged noindex on a page can eventually lead Google to not follow the links on that page (nofollow).
This may cause content linked from the paginated pages to be removed from the index.
Infinite scrolling or more loading
A more modern approach to pagination management includes:
Infinite Scroll: This involves pre-fetching content and adding it directly to the user’s current page as they scroll down.
‘Load More’ Button: Where content is loaded after clicking a ‘view more’ button.
These methods are popular with users, but less so with Googlebot. Googlebot does not mimic behaviors such as scrolling to the bottom of a page or clicking to load more. Without modifications, search engines cannot search your content effectively.
To be SEO-friendly, convert your infinite scroll or “load more” page to an equivalent paginated series based on searchable anchor links with href attributes that are accessible even with JavaScript disabled.
Use JavaScript to adapt the URL in the address bar to the corresponding paginated page when the user scrolls or clicks.
In addition, implement a pushState for any user action that resembles a click or turning a page. This can be seen in a demo created by John Mueller.
Essentially, you’re still applying the recommended SEO best practices, but adding additional functionality for the user experience
Pagination crawling blocking
Some SEO professionals recommend avoiding the issue of pagination management altogether by simply blocking Google from crawling paginated URLs.
Use one of these methods to discourage search engines from crawling paginated URLs:
The messy way: Add “nofollow” to all links pointing to paginated pages.
The clean way: Use a “robots.txt disallow.
The way without a developer: Set the pagination page parameter to “Paginates” and for Google to crawl “No URLs” in Google Search Console.
By using either of these methods, you prevent search engines from recognizing the ranking signals of paginated pages, and limit the internal link equity from paginated pages to the destination content pages.
At the same time, you hinder Google’s ability to discover your destination content pages.
The obvious benefit is that you save on the crawl budget.
There is no clear right or wrong approach here. You have to determine what the priority is for your Web site.
Schedule markup
Schema Markup, found at Schema.org, is a form of microdata that once added to a Web page, creates an enriched description, known as a “rich snippet,” that is visible in search results.
Major search engines such as Google, Yahoo, Bing and Yandex began collaborating in 2011 to create Schema.org.
Schema markup is particularly important in the age of search algorithms such as Hummingbird and RankBrain. How a search engine interprets the context of a query determines the quality of the search result.
Schema can provide context to an otherwise unclear Web page, increasing the relevance and clarity of information for search engines.
What can you use schedule for?
There is no evidence that microdata directly affects organic search rankings.
Nevertheless, rich snippets make Web pages appear more prominently in the SERPs, which has been shown to improve click-through rates.
Few things in SEO today can quickly make a difference. Schema markup can, however.
What is Schedule used for?
Companies and organizations
Events
People
Products
Recipes
Reviews
Videos
Listed above are some of the most popular uses of schema. But if your Web site contains any kind of data, chances are it can be associated with an “item scope,” “item type,” and “item prop.
These terms refer to the structure of schema markup, which helps define and specify data on your Web site, allowing search engines to better understand and index that data.
Using microdata
Adding schema to your Web pages with Microdata is a process of labeling HTML elements with tags that are readable by search engines. Microdata is an excellent starting point for beginners because of its ease of use.
Suppose you have a store that sells courseware. In your source code, you could have something like this:
<div> <h1>Google SEO course</h1> <h2>The best SEO course in the Netherlands</h2> </div>
You start by determining the ‘item type’ of your content. Then you label specific properties of the item, such as the name of the company, with ‘itemprop’.
In this way, you highlight relevant parts of your Web page to make it clear to search engines what your content is about.
<div itemscope itemtype=”http://schema.org/LocalBusiness"> <h1 itemprop=”name”>Google SEO course</h1> <h2>The best SEO course in the Netherlands</h2> </div>
This method helps improve visibility in search results by providing structured data.
For a complete list of item types and further specifications, visit Schema.org.
You can also use JSON-LD. JSON-LD is a user-friendly format for linked data. It is easy for people to understand and edit.
Based on the successful JSON format, JSON-LD provides a way to make JSON data work at the Web level. This format is well suited for programming environments, REST Web services and unstructured databases such as Apache CouchDB and MongoDB.
JSON-LD combines the simplicity of JSON with additional functionality to allow data to collaborate and exchange more efficiently on the Web.
Below is an example of a JSON-LD code snippet that can be placed within the <head> tags of your HTML page.
<script type=”application/ld+json”> { “@context”: “http://schema.org", “@type”: “Store”, “name”: “Google SEO course”, “description”: “The best Google SEO course in the Netherlands”, “address”: { “@type”: “PostalAddress”, “streetAddress”: “Belt Mill 22”, “addressLocality”: “Papendrecht”, “addressRegion”: “South Holland” }, “telephone”: “+31 (0) 6 12 34 56 78”, “openingHours”: [ “Mo-Sa 09:00–172:00”, ], “url”: “http://googleseocursus.nl" } </script>
Tools to do an SEO audit
There are a wide variety of tools that can help you conduct an SEO audit. Below is a short list of popular tools that can help you.
Screaming Frog
SEMrush
Ahrefs
Moz
Ubersuggest
Copyscape
Google Tag Manager
Google Analytics
Google Search Console
Bing Webmaster Tools
GTMetrix
Pingdom
PageSpeed Tool
#local seo#seo#google#seotips#marketing#off page seo#seo optimization#seo marketing#on page seo#social media
0 notes
Text

User Generated Content is van cruciaal belang voor elke website of webwinkel die wilt groeien.
In ons artikel over UGC lees je precies wat het is, en hoe je exact kunt inspelen op UGC.
#seo#google#seo marketing#seo optimization#ugc#marketing#on page seo#local seo#seotips#social media#off page seo
0 notes
Text
Hoger in Google komen met zoekmachine optimalisatie
0 notes
Text
Getting started with SEO for Bing in 2023
Be found better in Bing thanks to SEO optimization with the Bing webmaster tools. In this article, we give you tips on how to get found better in this search engine.
SEO optimization for Bing is slightly different from Google. In this article I will show you how you can make your website rank higher in Bing thanks to search engine optimization.
Determine your priority: Google or Bing
Before you get started optimizing for Bing, it is wise to think carefully about the search engine you want to optimize for.
One reason to optimize for Bing could be that if you are already in the top positions in Google, you want to implement the same for Bing. Another reason is, that your target audience uses Bing more than Google.
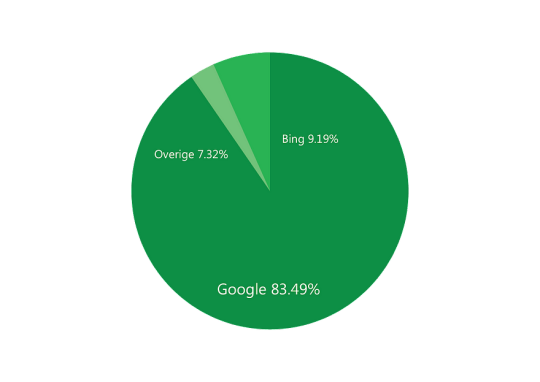
Microsoft Bing VS Google
According to the most recent July 2023 data, over 83.49% of all searches worldwide are done at Google. Bing accounts for a 9.19% share worldwide.
So this means, on average, with Google you have a much better chance of being visible within the search results. Other search engines have less than 1% of the world’s searches and so are actually negligible.
The different search engines
In anno 2023, there are several search engines. The most popular search engines are:
Google
Bing
Yahoo
Baidu
Baido is a Chinese search engine that focuses mainly on the Chinese market. Baido accounts for about 1.2% of all searches worldwide.
Yahoo is familiar to almost everyone, of course, especially if you are a little older. Chances are then you grew up with it. In addition to these search engines, you also have DuckDuckGo, Yandex and AOL Search.
Bing and statistics
Regarding the demographics of users and their ages, there is a difference between Bing and Google. Let’s take a look at the statistics.
Demographics
Bing is mainly widely used in other countries. Let’s look at exactly which countries use the Bing search engine:
China: 36.17%
The united states: 26.25%
Japan: 3.71%
Germany: 3.18%
France: 3.10%
Other countries: 27.58%
Ages
Bing is primarily used by people between the ages of 25 and 34:
18–24 years old: 24%
25–34 years old: 29%
35–44 years old: 19%
45–54 years old: 13%
55–64 years old: 9%
65+ years old: 6%
Google is primarily used by people between the ages of 25 and 34:
18–24 years old: 16.6%
25–34 years old: 21.1%
35–44 years old: 19.2%
45–54 years old: 18.1%
55–64 years old: 13.9%
65+ years old: 11.2%
Difference between education and income
There is a clear difference in demographic characteristics between Bing and Google users, based on factors such as income, education level and residence.
Bing users tend to be older, with higher income and education levels, and more likely to live in rural and suburban areas.
In contrast, Google users tend to be younger and more tech-savvy, but have lower income and education levels on average.
For website owners, these differences are essential. In fact, each platform requires a unique approach in marketing strategies to be effective.
To get a better understanding of which search engines your visitors are using, it is recommended to employ tools such as Google Analytics.
Using Google Analytics to determine provenance
With Google Analytics, it is possible to quickly determine the origin. So this way you can see exactly whether a visitor arrived at your website via Google or via Bing.
In addition to tracking where a user comes from, there are numerous other traffic sources you can analyze with Analytics.
Want to see in Google Analytics how many people come to your website via Google, Bing or another search engine? Then go to “Traffic acquisition” through the menu.
Next, click the blue “plus icon” next to the “Session default channel group” under the chart on the left. Next, add “Traffic source” and then “Session source.”
You will now see that, provided people arrived at your website through other search engines, they too will be listed.
It is important to ensure that the data you collect is reliable. This requires accurate configuration of your Google Analytics account. Furthermore, it is crucial that the tracking code is properly implemented on every page of your website.
It is also important that your Bing and Google ad campaigns are correctly labeled with UTM codes. By doing this, you can accurately track where your website traffic is coming from and identify which campaigns are most effective.
Optimizing for Bing
Now, of course, the big question is, “So how do I optimize for Bing?” Let’s look at the most important things to optimize for Bing.
Technical SEO for Bing
Uses HTTPS: Using HTTPS is a necessity. It shows your website that it is secure, which creates trust with the user. So make sure you have a valid SSL certificate.
Think mobile first: Having a mobile-friendly website is extremely important, regardless of which search engine you go for. It ensures that your users have an optimal experience.
Optimize images: Make sure you optimize images. You can use tools like TinyJPG for compression, while techniques like image source set ensure that the best images load on any device.
Verify your website with Bing: Registering your website with Bing Webmaster tools gives you access to various insights, and can also give you an overview of any problems.
Create an XML sitemap: Having a sitemap is crucial if you want Bing (or any search engine), to crawl your website properly. Don’t forget to submit the sitemap to Bing.
Add schema markup: Add schema markup where possible. This helps Bing better understand your pages. It also makes it easier for Bing to display rich snippets in search results.
Improve loading speed: Remove unused CSS and javascript, minify files and ensure proper caching and possibly a CDN to provide the fastest possible website for your visitors.
Accessibility: Make sure your website is accessible to everyone. So write good alt tags and title tags so that it is readable even by people with disabilities or screen readers.
Avoid duplicate content: Make sure you don’t have duplicate content. You can prevent this by using canonicals, for example.
Resolve errors and warnings: Bing Webmaster Tools will display errors and warnings when found. Always try to resolve these as best you can.
Writing quality content
Now that you have your technical SEO in order, it’s time to write quality articles. Bing prefers comprehensive and in-depth articles. Of course, the articles must be unique and contain the right keywords naturally.
Let’s see how we can approach this:
Do a keyword research: Use your favorite program such as SEMrush or Ubersuggest to do a keyword research. Then naturally incorporate these keywords into your title, description, headers and text.
Write a catchy title and meta description: Writing a catchy and quality title and meta description is very important. After all, this is the first thing a visitor sees when searching in a search engine. So make sure you have a catchy title and description, and try to include a short CTA such as “Read more soon.”
Write quality content: Write high-quality content that matches the visitor’s intent, and answers the visitor’s question as well and quickly as possible. So make sure your content is useful, informative and relevant. Also consider using Bottom Line Up Front (BLUF), to give your visitor a good answer as quickly as possible.
Use headers: Divide your article into headers. Headers make it easy for your visitor to scan the content, but it also provides clarity. Incorporate relevant keywords into headers.
Optimize title and alt tags: Provide well-descriptive title and alt tags. Incorporate keywords naturally into these texts and use about 7 to 10 words.
Add internal links: Adding internal links ensures that you provide your visitor with extra (relevant) information, but also ensures that search engines like Bing can crawl your website better. Make sure internal links are always relevant and really add extra information for the user.
Add sources: If possible, you can add external sources. This helps answer your visitor’s question. Also, search engines will see this and appreciate it when you mention relevant sources. Think of a Wikipedia for example.
Write comprehensive articles: Bing prefers comprehensive and in-depth articles in which you answer the visitor’s question as best you can. These types of articles answer the user’s question as best as possible and all at once.
Make use of media: Include photo and video relevant to the topic. No one wants to read a long slice of text. So break up the text with photo and video to enrich your content.
Think about readability: Always try to write for the target audience you want to reach. Use a clear writing style, create short sentences and paragraphs, and make sure the words are not too difficult.
Link building for Bing
Bing values backlinks more than Google does. Especially the December 2022 SpamBrain update has brought many changes to Google.
As always, it is important that you get quality backlinks that came about naturally. So buying backlinks or simply submitting your website everywhere is not recommended.

Build backlinks: Bing values backlinks from other high-quality websites. Think website with high traffic, high domain authority and low spam score.
Quality over quantity: Get quality and relevant backlinks. One good backlink is worth more than five bad ones. So a bakery linking to a clothing store is not a good backlink.
Use quality anchors: Make sure you get backlinks with the right anchor tags. A “read more” anchor doesn’t say much, but a “Do your own link building” anchor is much more valuable. So incorporate important keywords into the anchors.
Capitalize on social media: Take advantage of social media to generate free backlinks and traffic. You can also answer people’s questions on platforms such as Quora or Reddit. This will showcase your expertise, and people (and search engines) will be more likely to come to your website.
Write guest blogs: Writing guest blogs is a great way to get free quality backlinks to your website. However, it is important that you write guest blogs on websites from the same industry. So an SEO specialist does not have to write a blog on a lifestyle blog.
Create infographics: These visual representations combine attractive design with useful information and are ideal for sharing on social networks. By using infographics, you can not only attract more visitors to your website, but also create valuable backlinks.
Leverage PR: By employing effective PR strategies, you can increase the visibility of your website. This approach not only attracts more visitors, but can also help grow the number of backlinks to your site.
Collaborate with influencers: Collaborating with relevant influencers in your industry can be effective in driving more visitors to your site and gaining backlinks. Make sure you choose the right influencers that align with your industry for maximum impact.
To measure is to know
“Measuring is knowing” is an essential principle in SEO, SEA and marketing. Precise measurements are the basis for effective strategies.
By continuously measuring, you gain insight into what works and what doesn’t. This allows you to adjust and optimize strategies.
That way, you will continue to make progress and ensure that your marketing efforts produce maximum results.
Read more on our Dutch blog: Google SEO cursus
0 notes
Text
Heb jij ze al gelezen?
Hebben jullie onze meest populaire blog artikelen al gelezen met betrekking tot SEO en marketing?
WordPress SEO optimaliseren: Een complete uitleg van A tot Z
Van 0 naar 10.000 volgers per maand
Blogpagina’s optimaliseren voor SEO
Productpagina’s optimaliseren voor SEO
Een natuurlijk backlinkprofiel opbouwen
Wat is technische SEO en wat komt er bij kijken?
De skyscraper techniek voor gratis backlinks
Geld verdienen met je blog
Facebook SEO: vergroot je vindbaarheid en traffic
De AVG wet in het kort
Boost je online zichtbaarheid met Pinterest SEO
Tiktok SEO: Boost je zichtbaarheid
Concurrentiegerichte SEO: Versla je concurrent met deze stappen
Waarom een Google bedrijfsprofiel een must is
Vergeet ook niet meteen om onze populaire infographics te downloaden, ze zijn helemaal gratis!






#seo#google#seo marketing#seo optimization#local seo#marketing#on page seo#seotips#off page seo#social media
0 notes