
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by mshai002 and here's what we found interesting.
Average Info
Notes Per Post
0
Likes Per Post
0
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
13 days
Number of Posts By Type
Text
17
Last Seen Tumblr Blogs





Fun Fact
Tumblr’s website traffic is steadily declining.
Text
Final optimisation of the piece in real-life
I had bought a super bright LED lamp on a desperate sale online. It was quite perfect, I realised soon after. It could work for a modest-scope optimisation. I looked around my space and the living room. I found two speakers of my housemate’s that could do the job for audio effect. However, no place to present the work in the best way possible. I always wanted to make a confrontational piece. I tried last year but was not allowed to play on the speakers, hence the headphones then.


This is in the living room I later realised was taken, limiting me to my room.

I prefer it now that I moved around the furniture a bit. I made a plan.
I moved the sofa away and pulled the table forward from the wall and visualised this. However, I checked my little speaker in my room and it was actually perfect too. Now that this piece was not in the gallery space, the speakers could match the rest of the minimalist aesthetic. The following is the making-of of the final piece.




I placed the speaker under the top table. It was loud enough.
0 notes
Text
code Finalized check
The way the code works is by learning a limited amount of real faces and the terms that caused their real trauma and checking if the audience’s faces’ contours match the learned faces. The prediction happens even if they are unlike any from the database. This is the human ambivalence in the machine. It tells you whom you look like and what they faced.
However, this was perplexing during the making because I could not be sure whether the code was actually even working. And because there is a limited dataset and this computer can only work on minimal projects efficiently, I could not bet on its non-ambivalence, let’s say. So I created the dataset including my experience with my face taken by the camera of the computer. Since the computer sees faces from its camera, taking my photos from it should give me the accurate result. It should, after learning my face, detect my face perfectly. And it did.

0 notes
Text
Finalis(/z)ing the concept of the work. Realising that it raises more questions than answers. The concept is thus extended
Transcomputerism or transrobotica (?) is now evidently clear to be an interesting propostion that I am touching upon. How does abuse and shame, conveyed usually with some sense of ambivalence, be imparted to a robot? And what does it mean for us and our ideas of prejudice and abuse?
Prejudice through the eyes of a robot is, as can be seen in the project, relentless and monotone. It says what it has learned without perceiving its subject’s humanity. This apathy is rather at a rudimentary level, a level we humans define in evolutionary terms as a savage. So is the robot a savage? If we consider this, then that would mean we are including a robot into sphere of existence.
Would we eventually include robots into our lives as potentially ‘equal’ citizens? Is this notion even just absurd? Ultimately, whether the abuse comes from a human or a machine, it stings.
My housemates that who experienced my machine abuse, were uncomfortable. One friend, not a housemate, who learned about the piece said she felt a connection with the person that was abused. It was an interesting proposition I hadn’t conceived before. Being shamed loudly by a machine based on a database of similar specific experiences, not only affects the audience in a negative way but also gives them a perception. Allows them to put themselves in the abused’s shoes. Although I thought about the impact on people, I did not imagine a machine with its robotic neutral voice to be taken much seriously.
It thus raises questions about human connection, and also about how a machine can impact someone like that. The machine plays the catalyst in this community building. The work created in collaboration with real people. I think this may be the key to the connection. I always wanted to do something with the community. I did it last year where participants shared their experiences of trauma.
0 notes
Text
Feedback from friends and Prof. Tanaka; Transcomputerism (?)
When coming close to finishing my piece, I began to worry about concepts. I had, by this point, decided that I was going to make the database reflect societal aspects of public shaming so that the speech read out the expletive at the person who looks similar to those in the database. As explained already, the haar cascade assesses the contours of the face and any given person’s face is recognized depending on similarity. And my face was recognized as similar to one from the database. Although I hadn’t actually checked if it even would recognize my face had it been in the data trained on, I had moved on. Now, the question arose about what kind of data should I use and to what end. Initially it had been the data associated with race, with each race labled by their respective expletive. This was in a way to make my specific experience of racial public shaming into something more evocative and therefore universal.
Professor Atau Tanaka expressed his keenness about this idea. And encouraged me to play around the voices to see what the possibilities were technically. After trying, I had another meeting where we discussed the peculiarity of the neutral tone of the computational voice that of something like Siri from the iPhone. By exploring societal shame through data and seeing faces of strangers through the code, which only knows to recognize faces based on the shamed ones, questions arise about the trans-humanist aspect. Trans-humanism is defined as the enhancement of humans using tech. These are things I discussed with my friends over the phone for some feedback.
https://www.extremetech.com/extreme/192385-an-interview-with-zoltan-istvan-leader-of-the-transhumanist-party-and-2016-presidential-contender/3

Perhaps the piece also enhances the computer’s human capacity. The fact that the dataset is limited to six images for each label, due to lack of super-computing resources and large data, itself appreciates the limitations faced by humans more generally. When we recognize someone or something we are essentially recalling what was similar from our past; from our respective datasets. Therefore the utterly human quality of ambivalence is imparted to the machine. This fact of ambivalence of a computational model raises further questions about the possibilities of the ways in which automation can evolve.
The evolution resembles that of a child’s. However, Jung contends that as babies we carry imprints of visions from our DNA. Apart from this point the rest seems analogous. So I have begun to wonder about not the trans-humanism but rather trans-computerism (?).
0 notes
Text
Implementing speech, and timer on a thread
Here I will explore my research into turning text into speech from my deep learned predicting model. ‘pyttsx3′, it is called. It, after downloading, and maybe running, it initializes and starts the ‘engine’. And this engine initializes the drivers, which will load the speech from the main drivers ‘module’. My application would basically, I think, run and stop events. The good thing about it is that it seems very straightforward to implement in the code. And what is most appealing is that it has a sort of in-built start and stop. Because of this, I thought that I didn’t need to run an if loop with the timer.
I faced two days of failure installing and trying to run the library. However, once in, I was able to start playing with the various options. There weren’t too many.
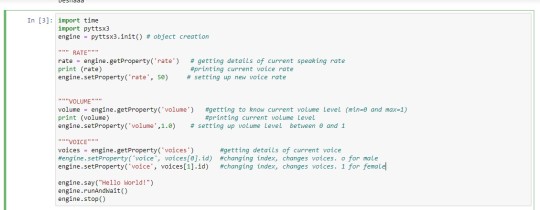
As can be seen, there is the rate: speed, volume, voice: 2 male and 2 female. The voices are standard neutral computer voices. When I was trying to get it to say different things, I began to appreciate its ‘computer voice’. And then I implemented it within my faces.py’s loop in which the cam is turned on and the confidence is greater than 45%. But the loop simply loops and even though it was working(!), it wasn’t adequate. The voice just kept reading out the labels continuously as the code was functioning within that loop.
Now I needed to use the timer. This unexpected realisation jolted me to frantically research about it. After a couple of days, I found it in conjunction with what is called ‘thread’. Dr. Grow (April) explained how via this I can run more than one thing at a time. The relevance is in its relation with the cam, of course, and the speech.
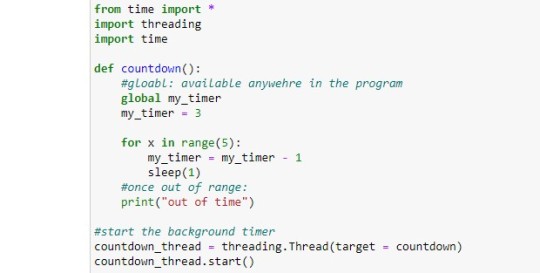
As can be seen above, I get time and thread. I define a function of the timer and run it on the thread.
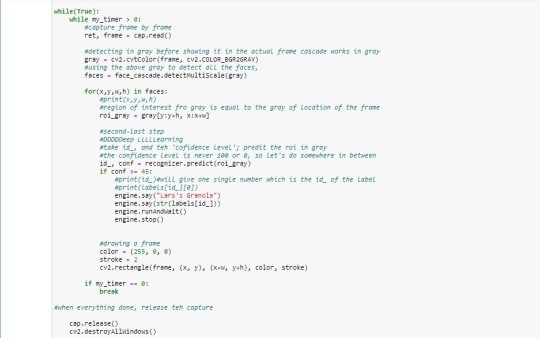
After I begin the cam loop, I also start one of the timer. And the whole region of interest and the prediction, along with the speech goes within it. To decide the time, I checked to see how long it takes for the prediction. And the no. is less than 5 secs. In this period, the prediction happens without even opening the cam window fully.
April helped me perfect the indentation by pointing out that the last bit--cap.release() and cv2.destroyAllWindows()--was still within the cam loop, which will execute it separately and not when the timer would run out. So by adjusting the indent, including it within the timer loop, after the code breaks once the prediction is done, the window closes.
0 notes
Text
making core code
Faces.py
In the first part of my code, I am setting up the video capture using cv2 (numpy import is for the next step, converting images into numbers). And then while it is running, I convert the frame, which ‘reads’, into grayscale. This is because, as could be seen in my previous blog about haar cascades, to detect (before ‘recognizing’), the in-built cascade classifier depends on the grayscale. The faces get turned into pixels, which will be in shades from black to white, and numbered and recorded, against which are checked new faces for detection. And to use the haar cascade I copy-pasted the file from the cv2′s libraries into the project file.
This code’s guidances was, apart from stackoverflow and other youtube videos, predominantly from ‘codingforentrepreneurs’ git page on openCV: https://github.com/codingforentrepreneurs/OpenCV-Python-Series
https://medium.com/swlh/gender-classifier-with-tensorflow-164b62a3557e
https://docs.opencv.org/2.4/modules/contrib/doc/facerec/tutorial/facerec_gender_classification.html
I set up the detect function using the grey version and then draw a frame around the face detected. Below can be seen the output, is the measurements and the position of the face on cam.
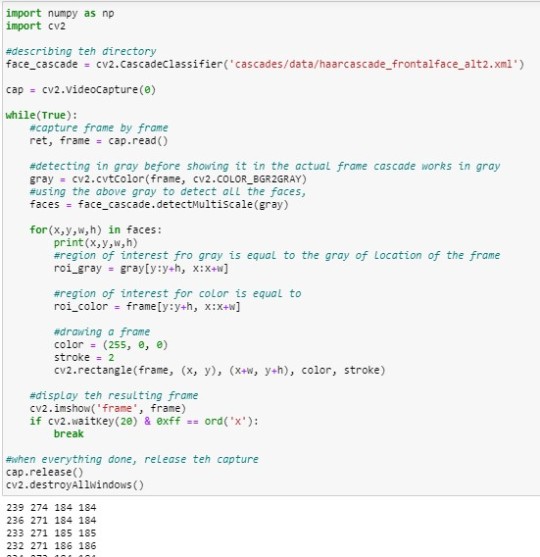
FacesTrain.py
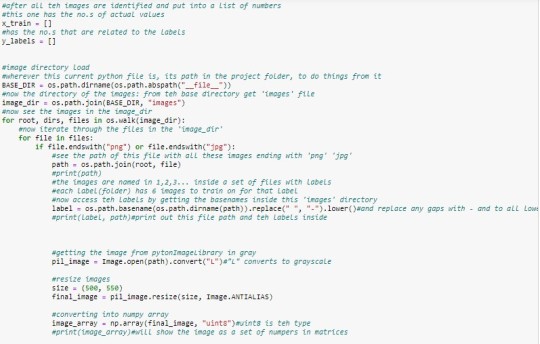
In this new file, we will load the images and train on them. The first step is to set up the ‘os.walk’. We import os and then ‘walk through’ our directory and look through images. This took me some time to figure out. The BASE_DIR is basically the base directory where all these files are. And then the image_dir will get the images’ directory from within it. Walking through the images, we see if they are jpg or png and add them from our recognised ‘root’ and ‘file’ into ‘path’. We also, as a precaution get rid of all spaces with hyphens in the names: Mehroz Shaikh will become Mehroz-Shaikh. After lots of complicated trials, I was able to grasp the os.path concept, though still not that confidently. But it works. We create an empty dictionary via y_labels and x_train, similar to what we did in data mining. The labels are the ultimate class in the y-axis, and the other one is everything else. We train on all of it. Before training, we need to turn the images into numbers using ‘pillow’ as PIL. From PIL’s Image, we will convert the images grey before converting into NumPy's arrays.
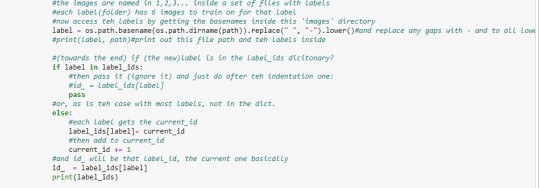
Now we have images as numbers from the above. And then, we do the same face detection we did for faces.py. We need to learn the faces that are in grayscale as well in the dataset. We, like in faces.py, will set up the region of interest and ‘append’ them to x_train. Then we need to create ids in with the labels with number values associated with it. We create a dictionary of label_ids, along with a ‘current_id’ to integrate it into the code and add values. This is in the form of the conditionals, whereby we add the labels that are not in the dictionary to it. The x_train takes the region of interest and the y_labels takes the id_s. Then we will save the labels so that we can use it in faces.py. For this we will use a library called ‘pickle’. We open labels through pickle as ‘f’, and store the label_ids into this file for prediction.
Now we will implement the recognizer from openCV that is in-built: LBPHFaceRecognizer. Once we set it up, at the bottom of the code we simply ask it train: recognizer.train(x_train, np.array(y_labels)), and save as a .yml file. This is exactly what I learned in Data Mining module. Now the training file is ready and when run, trains and saves in the yml file, which we will use in the faces.py file.
This trained model needs to be used in the faces.py file by bringing in the LBPHFaceReacognizer here too, but we also set it up to .read(). We will now implement the predicting in the code after the grey region of interest (roi) was set up before. We set the prediction on id and conf (for confidence). When we run and test, we will set a threshold of somewhere between 0 to 100. We set it to >=45. If the confidence is more than that then predict (and print) the corresponding id_. However, the id_ is just a number and not the name, so we will now use this id and get its name using ‘pickle’. After importing pickle, we will do what we did--open, but not write but read so ‘rb’, and then instead of dumping the label_ids and f, for file, we will load the f. We will add this to a og_labels={}, which we will quickly adjust the order of so that the name is first and put this version into n empty dictionary called labels={}. Now when we test the prediction, we search the id_s in this labels. We also resize the images for slight adjustment in the training code.
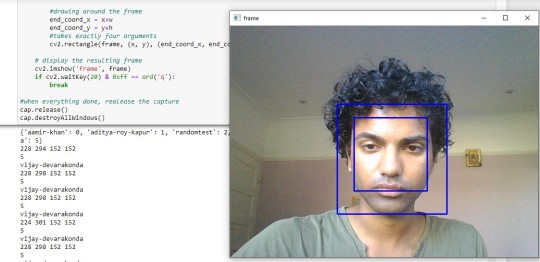
0 notes
Text
After feedback from Dr. Grow and friends
Speech from text is from ‘pyttsx3′ in python. Now that I have my core code working with various images in the data set and the training model learning them to detect new faces in the camera. I discussed the idea of using shout effect instead of applying text to the screen with my tutor, Dr. Grow. She helped me realise that the shout is much more effective than the simple text. The point being that it is loud and unexpected, and therefore punchier. We discussed for a long while the problematics of how my idea has evolved.
I had planned something initially and that eventually turned into a vision that instinctively arose. As expressed in previous blogs, that piece will be percieved by the audience facing the big lights and hearing an expletive shouted out from the speakers hidden behind the lights. When I first was discussing this in the classroom, Jin, a classmate and friend, said that the piece is heavily evocative of shaming. She expressed how this is something that resonates with her experience as a diaspora. I did not pay much heed to this as I was trying to make sense of it linearly leading from my prior research I had done so far. So I decided that the work would be about gender classifications, only because it seemed a natural evolution from my previous idea. However, after presenting my and talking about my plan with my friend, who is an academic in anthropology, I realised what I was thinking instinctively. She said that the work makes complete sense as a piece about shame and honour. I picked it up from her: ‘shame and honour’. It is true in fact, I had been bullied all my life for being gay, abused physically and verbally. And after coming here was confronted belligerently my a haggard white man who called me a ‘paki homosexual’ multiple times in a bus, loud enough for everyone to hear. I thought I had forgotten about it but seems like it was lurking in my brain.
So considering what Jin and my other friend made me realize about the shaming aspect of my piece, I have decided to explore it conceptually and technically. Conceptually, I image that whoever is in front of the camera will be checked against a set of faces that corresponds to their race, and based on that the code would shout out a corresponding expletive. Of course with Dr. Grow pointing out that it just becomes a racist machine, I also understand that I do not need to put anyone else through the traumatic abuse. Perhaps I should further personalize the plan by making it be so only those who look similar to me get the expletive. Otherwise not. And similarly, technically, the piece would necessarily have to have the shout effect, although not on loud speakers as would be the case had the pandemic not shut the institution down.
So now I am exploring how to implement this shouting. Dr. Grow guided me to this text to speech function that can be applied. And this is what I am exploring now.
0 notes
Text
Classification
I can classify either live or not. I want it live. Wekinator supplemented my understanding of Data Mining algorithms which are key for this final project, however, on its own it turned out pretty useless. I cannot do my project on the software. I need to code, so that I can manipulate the dataset as well as how they are classified. After scouring the internet for useful tutorials on classification code, I got closer and closer classification of Gender. The thing is, this is too complex for my level of learning, and plus, I can’t do everything. I need to do something specific that can be done and be graspable by me in order to be able to problematise it.
In the process I decided to land gender classification for my code. There are different softwares that can be used for this, one of which is the Tensorflow one. The process broadly requires input of data: images of men and women, training the code on it and then outputting. Haar cascade is very big in face detection. I believe it can be done on openCV with a live webcam. A way to do this would be to scrape the internet for faces and classify them and then a much larger dataset to train a much faster neural network model which will enhance the live performance.
The first thing we need is the camera input stream. This is the basic starting point. The input image needs to be turned into greyscale for the following steps where we will have to implement Haar cascade model. The greyscaled CV2 image input is in the form of numbers which allows us to directly manipulate the image itself or extract information from it.
Haar Cascade is a kind of machine learning, however, it does not use neural networks. It is trained on several pos+ and neg- images and then used to detect objects. It simplifies the process by identifying simple features in the grayscale images.

In the above image we can see how it is done. The box with the black and white sections is a kernel, which is a square matrix that specifies weights of various pixels in an image. This process in the image is called ‘convolution.’ The pipeline is basically like all systems: input image -> Kernel Convolution -> output image. The feature below the black and white box is obtained by removing the pixels under the white rectangle from the total no. of pixels under the black rectangle. For a face detecting algorithm, Haar cascade identifies more than 200 features out of 160,000+ for 95% accuracy.
The identified features are compared with previously checked models. When a match is recognised it is marked as face. And in openCV Haar cascade for face recognition. Once there is an image, most of the image might not be the face itself. So we need to just check if a window is face or not face. If it is not, then discard the whole image and ignore it next time, and just focus on the face regions. Not all features will be checked, just one at a time, which makes it easy to discard the irrelevant ones.
I found that Python comes with Haar cascade models built-in. In the two most relevant tutorial I found which taught me all this, they use Haar-cascade’s frontal face default cascade. I am now looking into a tutorial that just sets up the video stream in grayscale and looks at some image samples minimally ‘recognise’ faces.
0 notes
Text
Wekinator’s nearest-neighbours algorithm (and Data Mining)
I looked at Decision trees last time in Wekinators and Data Mining. They both now explore K-Nearest Neighbour algorithm. For nearest neighbours, the entire training data is stored. Basically, if a data point is to be classified, this model checks who is it close to. And based on the K no. of closest data points, the classification of it is decided. For this a distance has to be measured, within which the data points that fall are assessed for the prediction of the data point in question.
There are three main steps in this: Distance measurement, check the neighbours, and make the decision. The distance is measured using two common formulae: Euclidean and Manhattan distance. Once this distance checking function is built in code, we need to first measure the distance between each point in the dataset against the new incoming data points. Once these distances are calculated we must ‘sort’ them and select the optimal no. of K. For the prediction, the most similar neighbours are to be collected from the training set. For the classification the most represented, or common classification among the no. of K selected points is designated. However, among the nearest points there can be irrelevant points who also get the same degree of classification. Our Data Mining teacher suggested we change the weight of the points based on their relevance by doing 1/distance before and then adding up the total weight. Then pick the most frequent one. All this online the decision tree is not binary but regression-based. The degree is measured to very decimal levels. We scale the data here: x-mean of column/standard deviation. The standard deviation measure of the ‘spread’ of the data. The larger the spread the greater the value. It’s good if the data is large, however, smaller one is problematic.

For a smaller dataset, we need to make the data complex by using a method called: Cross-Validation, whereby the data is split in, for example, ten sets, and the first 9 sets are used for training and the last one for testing. This process is repeated 9 more times as we do the same 9 against 1 for each set. And then average all accuracies to get the final accuracy.
0 notes
Text
Further reflection
Way earlier I wanted to expose to extreme the audiences to what represented by data classification on a big screen whereby everyone could be confronted with their stereotypes and be abused by it in public. Another provocative piece fro them to confront themselves and see data classification out in the open. What will this picture entail? who will they see themselves...
I got confused and lost trying to make sense of intersectionality of groups of varying people. I need to focus on the initial core of my practice to provoke thought. They won’t have a fun time wit it. They won’t want to deal with it. Data sets of refined meanings won’t go far. What we need to see is what can be done. We need to liberate ourselves from it all.
In my now refined new plan the sensor sees people with flash lights on them and they will stand in front of the abusive lights discomforted. The camera near the Big lights will capture and ‘classify them.’
Bringing them face to face with their classifications, facing themselves. I cannot be trying to teach something to someone. No messaging. Like Paglen said that is not what an artist has to do, that is theory. But confrontation with reality. If we don't even confront the realities who will we be able to think about them however we could.
I cannot be reacting. We are all reacting to something in our practice though no matter what.
I need datasets for classifications. When someone stands there we see what the world tells is we are. More exaggeration. Less imagination.
In terms of carricature we can see each other in the worst way possible.
0 notes
Text
Wekinator
I was recommended by a number of people to look into wekinator machine learning. I learned a lot which actually helped me grasp my Data Mining module better. Machine learning pipeline was explained in a simple way as follows: the structure of machine learning is made up of three main linear aspects; the first being (1) Input, whereby a sensor of some sort (game controller, webcam...) receives information, which gets transferred to a (2) processor decision-making process, where the process basically figures out what to do with the info that just came in. Once it decides what to do, the decision is transferred to (3) the output, where it basically ends up doing something in the end (an animation or a sound...).
The second step’s processor is basically the core and, in my case, the most relevant topic in the subject. This step entails what is called ‘supervised learning,’ which, unlike un-supervised learning, is supervised by the person who assigns certain samples to train it on. These samples are called training sets. This training set is what the model learns from. And each sample is basically a simple combination of the first two steps: the first-step and the last-step: input and output. The process of learning and creating an algorithm is a three-step process: training set, algorithm learning, and model creation. The process of using a learning algorithm to build models is called ‘induction,’ or ‘learning a model,’ or ‘building a model.’ However, a classifier is not the same as a model. Models define the classifiers, and not every classifier is defined by a model.
How Wekinator and my Data Mining module worked together in my understanding of the basics of machine learning: While learning an algorithm there needs to be a pattern recognition based on the training set. The pattern is then used to ultimately classify the end decision. What action or output should be selected for this particular output. Classification is the most salient feature in my project.

For classifications, the computer recognises a certain number of categories, or classes. These categories are independent and are the last column in the table. There are multiple ways of classifying data. Common ones that I learned are Decision Trees and Nearest Neighbours algorithms. A decision tree is diagramed below on paper. The tree starts with a root node from which follow certain attribute test, which are the columns headings apart from the first and last one as the former is just ID and the last one is the classification itself. After the root node, when an test condition is checked, there are multiple answers, however, we prefer just two to simplify the process. And after each test we check the answer for which we apply a further test or, if it is suitable to get the classification, one is applied. The classification is not necessarily binary, there can be more than two classifications, which is termed ‘multi class classification problem.’ For classifications, not every attribute test is conducive to classifiability. Optimal combination of attributes that best discriminates instances from different classes is key.
As already mentioned the process of learning an algorithm from the training set is called induction, and the same way the output is called deduction. And induction and deduction steps need to be independent of each other. The deduction has to be evaluated for its accuracy by no. correct predictions/total no. of predictions. The error rate has to be measured--what it got wrong: no. of predictions/total no. of predictions. A learning algorithm has to attain the highest accuracy and the lowest error rate. The selection of the attribute test is crucial and has to be done based on which attribute leads to what was just mentioned optimally. A known measure here is the purity check. How ‘pure’ is it? The higher the purity the lower the error rate. Purity is measured by the following algorithms: Entropy, Gini and Classification Error. However, the purest does not mean the best because the attribute error would be 0, that would mean simply checking the ID and seeing the result, there is nothing for it to go against but the classification itself. So is the first ID this classification or not, basically. We thus need one that can be elaborated, descriptive.

Decision Trees as can be seen at the bottom in this image, is fast but is exponentially large, getting bigger and bigger with the conditions as each decision boundary involves only a single attribute.
There is one major problem here: model overfitting. Even if a model fits perfectly well on the given training set, it will not be generalisable as it learns it all too well and adapts to that set permanently and rigidly. A reason for this is that the training set may be too small and thus not generalisable. Another problem is that the training set may be too complex due to which it become too unique and the tree becomes too specific, niche. Therefore, the resulting tree will not provide a good estimate of how well the tree will perform with unseen attributes.
Wekinator had a lot of limitations, worked on limited ports, and once at a time.I understand from discussing it my friends that it was just there to introduce the concept of machine learning. There is no coding involved, if you want to measure a distance, just press the button basically. It helped understand how general algorithms learn from data; how to choose one over another. Working with small datasets created by the users themselves, we get a perspective of the human process behind creating real-world machine learning systems.
0 notes
Text
New Plan
I have created a new plan or the ideal final installation.
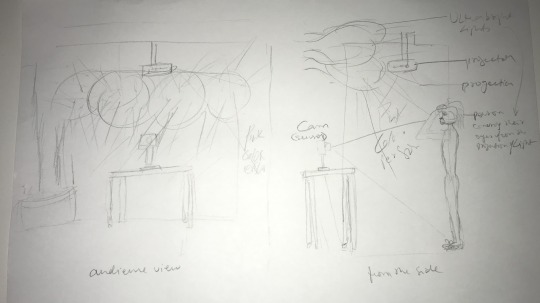
I this image above we see two perspectives, one will be the participating audience member facing the work and on the right, we see from the side how the work might appear. In the same spot decided for in the last plan, I will set up super bright lights as if the person is being confronted in the secret intelligence camps as shown in the movies. The bright lights will force the participant to hide their face from it. However, behind the lights sit a webcam or other sort of camera, which will be trying hard to detect the person’s face, and as soon it detects the face, it will classify it. The classification, which I am hoping would be crass enough to make everyone uncomfortable, will be projected on the wall on the right. After thinking more about it, I realized that sound is most confrontational as sight can be hidden. A loud sound will be unavoidable. The classification will be read out loud through speakers placed next to the table.
The people I have spoken to about this idea said that it sounds like open shaming and would be possibly excruciating for the person facing it. I understand how badly it will provoke people, however, that is the point. I am so much more comfortable with this idea than the last one.
0 notes
Text
Further research following the plan
In the plan posted previously, I wanted to work on creating software that reverses the hierarchy implied in wordNet and ImageNet by redefining the terms in their dictionaries with the help of intersectionally the most subordinated groups of people here. However, after much reflection and further research, I have come to realize the utterly uncreative and reactionary mode of thinking of mine. My work, as elaborated in previous blogs, has always been provocative and even disturbing to some. And the clean monochrome aesthetics I found delivered the punch best.

In this plan above, I find nothing inspiring. I thought that I needed to use my research in the model, but I have come to despise it much. I want to create a work that is bigger and more provocative and confrontational as I did before. I have now gravitated towards it through my research itself.
I learned more about wordNet. To be honest, the dictionary is nothing remarkable in itself. The fact that it was real people in California and New Jersey in the US is not devious. They were just trying to create a dictionary that would be helpful to researchers. They did not plan to be discriminatory. They were only carrying out research on their own among themselves. The main person behind ImageNet, the most prominent offshoot of wordnet, was, in fact, led by an East Asian woman, Fei Fei Li. The software is innocent in its making. I feel the need to emphasize this point as it gets convoluted by the critics, which includes myself.
There is, in fact, nothing artificial about AI, it is created by humans for humans. The people who labeled images for ImageNet were from more than 167 countries, according to Fei Fei; it was not the perception of a few white men in the US. The prejudices span the globe. I am not for a second becoming complacent about this. I could create a reactionary piece that aims to turn the hierarchy implicit in ImageNet. However, I do not feel it does much. I still am concerned about the general public’s complacency. I do not think that using my artwork, I need to send a clear message to anyone. This is not an essay or a feel-good piece for school kids.
ImageNet’s aim was to provide a massive dictionary for machine vision to learn from and use it in making machine learning software. Fei Fei is aware of the social repercussions of blind practices in computing. She literally said that we need to recognize that “machine values are human values!” I already said that I cannot be doing machine learning for good as that is not the purpose of art. I want to take this opportunity to do what I really want to do. I want to affect the viewer profoundly by conjuring up all the ways I imagine the dynamics of machine scrutiny works by taking it far and forcing the viewer to react humanly, the way we all do with the information we do not want to face. We hide, we ignore, we deflect. I want to focus on human nature via machine learning’s classifications.
0 notes
Text
Planning
Data can be seen as points of knowledge that we all have. How we see things is based on past experiences from which we pick up points against which we assess all that comes along. Those points can be seen as data points. The world, in many western countries, is built on a hierarchy of the white-hetero-patriarchy. How would the reverse of it look? Trevor Paglen’s Barbican’s Curve installation featured images of each category like Investor, Pizza, Apple, and so on, from a specific data set, called ImageNet, which was created by professors at Stanford University and Princeton University in the US. These professors created categories using a dictionary called WordNet created at Princeton University and used the definitions there to illustrate what was thought represented the categories.

Figure 1: Trevor Paglen's Curve installation at the Barbican
My project will look at what if intersectionally subordinated groups of people—with subordination by the intersection of racism, classism, ableism, (skin-) colorism, agism…— created the categories instead of middle- and upper-class white-hetero-patriarchal people. (White in terms of traditional structures built by white men.) what if the conception of these subordinated groups defined what shaped the world?
Final product research and plan
I looked extensively into most of Trevor Paglen’s work, elaborated in this blog earlier. His work is in the form of mostly eerie photography of the arcane intelligence outposts of the US. He tracks the places through thousands of censored documents released by his Govt. and finds the locations where they carry out their covert operations; alternatively, through satellite data, the location of other covert operations where the US is the dominant power, like the UK.

Figure 2: NSA GCHQ, Surveillance Base, Cornwall, UK, 2015 by Trevor Paglen
In the above image, we see one of Paglen’s spectacular images of a US surveillance base in the UK.

Figure 3: untitled, Reaper Drone, 2010 by Trevor Paglen
In figure 3, is another work that looks at surveillance drones, but again the image itself does not exclaim what it is about, an evocative photograph that conceptually is based on drones. Paglen’s is one way to present the work visually that I want to make. It can be coded and conceptually presented in a way that is entirely arcane to the viewer. However, I looked at other artists who work with data in their work too.

Figure 4: In The Shadow of Giants, 2013 by Nathalie Miebach
In Figure 4 above, we have the work of Nathalie Miebach. In her work, she uses weather data’s interactions to form sculptures. The sculptures are made out of basket material, but she does not design them; they are dictated by her weather data itself, giving it its bizarre abstract form. So it is more a scientific rendition than purely artistic.
I also found interesting the work of Hal Abelson, who printed out code on sheets of Fax paper as can be seen in figure 5.

Figure 5: Turtle Geometry, 1969 by Hal Abelson
The works explored above were my most favorite of all the works I looked at, including the ‘non-tech’ art explored further in this blog earlier. Using elements of all the above artworks, I can produce something more pertinent to my idea. My work in previous years has been very straightforward, inspired by the instructionists. However, after speaking to audience members, I am not sure how memorable it was. I realize that I need to have a more enhanced experience to make sure of memorability as I do aim to have a lasting effect on my audience. I am thus planning to have a kind of installation that explores all the above forms of presentation. I will look into photography of the intersectional groups, or the data they produce. I will also print out their data sets as something the audience can interact with within the space. I will most likely have a computer in which the audience can also explore the data digitally. I will have sound as well to give a new sensorial experience.

Figure 6: Untitled, work from Year 2, Mehroz Shaikh
In figure 6 is my previous year’s work, where I explored experiential installation. The audience could wear headphones and hear the voices of Goldsmiths Anti-Racist Action’s Occupation’s women’s frustration with racism, sexism, and ableism at the institution. I will have a table again, which I also had in my year one final piece. A table immediately invites a person to come sit down and see what is presented. The minimalism is similar to Halson’s printed work. I will play the voices of the intersectional groups aloud in the space which will read out their definitions of categories they defined. I will also print out the ideas that are explored by these groups of people, which will mainly be their redefinition of the concepts explored by the white-hetero-patriarchal men in the US. Print, Sound and then a computer screen that will allow them to explore the data on their own. I believe through the visual, tangible, and audible experience, they will remember the definitions that the people in question proposition better.
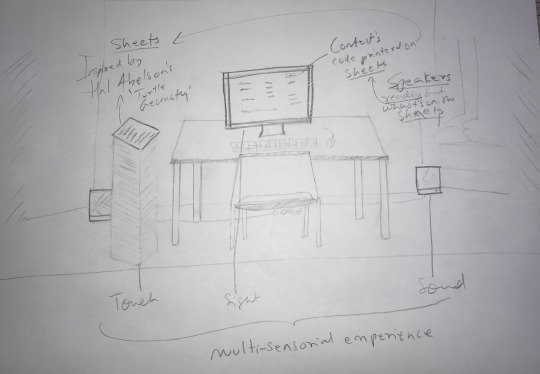
Figure 7: Sketch of the potential work’s core aspects
Knowledge, skills, and techniques needed
The existing knowledge I have is the concept of intersectionality and the groups of people of interest. The task is to collect data from them and then render them in data sets. For rendering in data sets, I will have to learn the use of python in machine learning and data science, a course I am now taking as my other module of study. I will need to learn how to convert the definitions I get from the intersectional groups of people into numbers that can be computed for predictive output. The predictive output is important, however, the classification is key, which comes before. The former is a potential output, whereas the latter is fundamental to the basic prototype of this piece. I am already learning classifications in data mining, and through my research and talking to various coders I found an online tool called Wekinator, which is a real-time software to convert the classifications into meaningful forms, which is exactly what I will be doing. I am also learning the fundamentals of data sets in machine learning via a Goldsmiths online course called: Machine Learning for Artists and Musicians.
Basic prototype
The basic prototype will have a data set collected from the intersectional groups of people in python. It will be rendered via an interface that people can use, a list of categories that are defined and to be used in various machine learning programs. The data could be visualized in a number of ways, however, my presentation will be minimalistic and straightforward as has always been. The interface will be rendered with p5.js live on the web.
Figure 8 Potential appearance of the categories found
The basic prototype in terms of code on the computer from figure 7 will look similar to the image above, listing the categories of terms that will predict images based on what the code has learned from my data sets, though I am going to explore towards the end what I can do more with the visual aspect.
Timeline & Milestones
I will divide the timeline into three phases. Since the knowledge I need for the course relies on learning how to apply my existing knowledge in data mining and machine learning:
- The first week from now, I will focus on what can be classified from a data set and what kind of data I need and how I will collect it and from whom. - In the second week, I will start implementing the knowledge of data processing and its application in practice from my Data Mining course with some sample data I will create on my own. - In the third week, I will finalize the kinds of data I will need for this project, the various categories, and how to get them. I will also start approaching various intersectional identity people to participate in my data collection. I will also computationally implement my sample data algorithmically through machine learning once classifiable. - In the fourth week, I will continue to collect data, as it will not happen in a week, by finding more people and getting them to help me out. I will now be able to not only classify data sets but also start to apply machine learning models on it via Wekinator. - In the fifth week, I will continue to collect data and modeling machine learning algorithms on it. - In the sixth week, I will continue to collect data and continue to implement classification on them with more models that I will learn and experiment with. - In the seventh week, I will continue to collect data and not only implement classification but also start algorithmically applying models on them for various purposes. - In the eighth week, I will finalize the collected data and classify all of it, making sure it is running well and then begin to create an interface for the visualization of this data which I will also learn at the machine learning course. I will also see what can be done about the audio as a form of output through it. - In the ninth week, I will assess all the interface and data sets with the teachers and be ready to go off and do the final embellishments over the next month. Depending on the application, the timeframe may vary for the tasks planned at this point
0 notes
Text
Trevor Paglen (Huge Inspiration)
After, in the class, we saw Rita’s gallery visit, which was at the Barbican showing Trevor’s work: From ‘Apple’ to ‘Anomaly,’ I realized that this was my guy. I decided to go to his show next week at the barbican. There were only two pieces, it turned out. I went through the whole show in less than 10 minutes. I knew that his work with data and classifications is what I was interested in. He wasn’t just an artist interested in data sciences, he also had a deep aesthetic sense. The lighting, and the framing, of the ‘this is not an apple' piece, which then leads to the next one, a series of over 20,000 images starting from an apple (Trevor describes as a "nouny noun") and ending at the anomaly (he describes this as entirely subjective).
I decided that I needed to learn all about him. I bought two of his books, one, a small one on his Barbican show, and the other, a larger one about his oeuvre with multiple interviews and essays and most of his work. The following are from the 19 page long notes I took from reading the books. They led me to an idea which I will reveal in the end.
My initial idea before getting on with Trevor was to maybe create an entirely new social media platform free of all the suspicious usage of users’ data that the current option we have engaged in. In Rita’s presentation in class, her description of the apple piece in the show struck me. She said that AI sees an apple as an apple, whereas, as humans, we can see it as ‘this is not an apple’...
Trevor, in the first interview, said that he didn’t think ‘timeless truths’ exists (Trevor Paglen, Phaidon, p.12). According to him, every artist has to decide what they are mainly interested in and process accordingly, not because they are compelled by an external (institutional, for example) force.
He is an in-depth researcher with a Ph.D. in Geography, masters, and a bachelor's in Fine Art. I love this aspect of his work. Many artists like Michel Hoellebueq (French Author) proudly disdain research as something that is for inferior artists, which I find quite outdated and outright wrong. The reason for this is explained quite well by Paglen (p.13). The artist shows their audience how to see things differently, and Trevor says, seeing things around us difficult. “Everyday life is sculpted and modulated by forces that are usually quite invisible to us....” This is why research is vital; to understand how the structures around us are working and transforming in their speed. And by engaging through an understanding of the functionalities and scopes, we can see possibilities. This is precisely what I wrote in one of my previous blogs. The audiences are too scared of tech, and so cannot imagine an alternative, and I wanted to change that. However, before inspiring the viewer to believe alternative ideas, the artist herself needs to be able to see her subject to its core. Trevor says that “when I talk about learning How to see the moment we live in, I mean developing new metaphors in new vocabularies that can help us orient our perception and make sense of the world around us” (p.32). Research allows “you to think far more complexly about a subject than you can without that language.”

NSA GHCQ Surveillance Base, Cornwall, UK, 2015
My initial idea about making a functional alternative social media did not do it for me. I felt a lack of imagination in the concept. It felt reactionary at best. Trevor articulates for me what I was lacking (p.29). He says that art should not be about a strategy to accomplish this or that. “I don’t think that art does linear arguments very well at all. For example, in a lot of the visual work, I have done... I am trying to take familiar images... and suggest that they mean something different from what you think they mean.” He says that art can inspire but not relay a message, which is accomplished via writing. He says that art and literature can go hand-in-hand to drive a message home, but the art on its own “is just different.”
Investigative rigor:
I have always appreciated art that was a result of in-depth knowledge that is critically engaging, not superficial impressions. An impression is the first instinct, and relying on first instinct is extremely dangerous as it is informed by deep-set bias we’re brought up with. His work Terminal Air (2007) showcased the (US) government’s covert anti-terror operations, which flew suspected people away to far off locations like Guantanamo Bay.
As already blogged about, I work for the Uni student-run independent newspaper The Leopard. This year I became the News Editor, which means that I have to not only work on my pieces but also guide and edit others’. Paglen’s work has a lot to do with investigations. He does in-depth research into how top-secret things by the government--of the US- such as the missions carried out to kidnap and torture suspects from the country taken far off to places like Guantanamo Bay (p. 72). He said that he was “drawn to the patches--mysterious to those unfamiliar with their acronyms and iconography...” He learned the grammar of the way things are done through is research, and that is how he figured out more about the secret world (p.65). This interest transpired in his work Torture Taxi, for which he had to go through “raw documents culled from aviation records, corporate records of front companies, various declassified reports, and documents obtained from lawyers representing prisoners at Guantanamo Bay... the interlocking webs of front companies, fake identities, drop boxes, airfields, law offices, flight records, and numerous other pieces of seemingly banal information that constituted the rendition program’s basic infrastructure” (p.70). He went through all the leading companies and every single person, fake and possibly real, mentioned in the documents. He verified a list of places where actual hidden work happened and photographed them (p.72). The photographs were shot from afar zooming in. The images make one feel exactly like they look, confused by the banality and the fact of the reality behind the banality. They are quite dark. In his Barbican book, Sarah Cook writes that he is interested in seeing what invisibility looks like (Barbican, p.8).

Torture Taxi, 2013
In other words works, he shot videos of secret locations that are blatantly out in the open using a drone (p.77). He also mapped out the flight connections of various suspects being flown around a few select spots from the US. This exposure of highly salient yet openly being done things that are supposed to be hidden makes really resonate with my work in journalism. I am always trying to figure out what is going on. But over time, I’ve come to realize that there are multiple truths in any situation, various parties with numerous reasons. And I became tired of negativity. As seen in my previous blog posts, I was quite cynical and provocative with the audience. I would like to do something more balanced this year, as I am also trying with the articles I write and edit. Looking at his work can make one feel more optimistic about what can change because they know what has been happening right around them. They can talk about it, they can participate in it, they can engage with it.
Apart from political investigative matters, he’s done in-depth research on outer space use to the world too. That is political also, as it has to do with the US’s space work as a state. He has looked into how the satellites that are ‘secret’ roam the space looking everywhere along with satellites from India and China. He says that “even though they aren’t supposed to be officially there, these spacecraft have to obey the same laws of physics that everything else in the known universe has to obey” (p.128). This is important here because it reiterates the idea that what is out there that people see are arcane and mysterious is actually something they deal directly with, too, in a very tangible way. They follow the same physics as everything we know. I was writing about this before, wanting to make the arcane algorithms accessible to the people. The same philosophy as that of the founders of Git, open-source...
He then talks about how photography, his medium of much of his work. Photography was initially used for the same purposes as he uses it for. To research and capture the mysterious. The difficult parts being captured in photos were vital for the American military to find those spots which could be used for their operations. Muybridge, one of the great photographers in the US, was also working for the US military to photograph. “ Yosemite’s granite cliffs and forested valleys ” among other landscapes. Watkins, another famous photographer in the US, photographed for mining interests. Paglen points out that Muybridge was carrying a camera instead of a gun but doing the same thing: conquest for annihilation (p.130). This shows that his awareness of his own medium is critical. The photographers used their skill at uncovering mysterious places for the annihilation of those spaces. In a similar vein, through his photographs of the hidden secret operations’ locations of the US army, he is aiming for the annihilation of them.
His work is overall, highly aware of specificity. He focuses on particular aspects of a specific country. He doesn’t ever make grand universal statements as a lot of Western cultural producers do. He recognizes the smallness of his American scope. He expresses this by talking about an exercise in which you take “out all the pieces of music and languages that are familiar to you, then play the unfamiliar ones over a slideshow of the images. The “it’s a small” (p.132). He recognizes that there is so much his education in the US that has not exposed him to learn. And only someone sho dedicated to research would make such a statement about ignorance and hence the need to learn more deeply.
Machine eyes:
In thinking about what the future holds in terms of the consequences we will reap as a result of our current ‘progress,’ Trevor suggests a “kind of speculative ethical relationship...” (p.29). The progress of AI, the space debris, the consequences of anthropocentric plunder of the natural resources... Paglen also addresses the speed of information that we are dealing with daily. There is no information but doesn’t necessarily lead to thinking and knowledge creation. Sight is being detached from knowledge. This knowledgeless data consumption is precisely how AI works (p.101). Through artistic means, Paglen wants people to think expansively and imaginatively. And this coming to do with trying to speculate an ethical relationship with the future as we need, he applied ethics to our consumption as an idea materially in space (pp.135). Not thinking about the future results in cuts made in education budgets and climate catastrophe planning (p.135). He found that all the countries venturing into space were leaving behind a residue that will last for more than 100 million years. The most recent controversy was about India’s successful mission of targeting and destroying satellites in space from the ground. Imagining a future where someone will go there millions of years later and encounter that residue, he decided to create The Last Picture. The images he took and curated together were placed together in launched into space with a satellite rocket that was being launched by an agency in a city in the US (p.136). The images, he said, would be something like what cave paintings are to us today.

The Last Picture, 2012
The issue with how a machine ‘sees’ is that it sees everything precisely as it is. Trevor’s piece, Shark, Liner Classifier (2017), is a photograph of sharks that the computer is fed to see. The AI machine spewed out the image of Shark, which “looks. indistinct and abstract to human eyes, it is a Precise representation of the computer vision system” (p.33). Speaking about Machine Eyes, 2014, he says that the point mentioned before about looking without seeing, sight, and knowledge being disconnected. That is basically what machines do. Run through data, compare them, and technically parse out whatever is possible in those very reduced technical ways. This is what AI is. Sarah Cook writes that the role of the human is missing in all this (Barbican, p.13). And that is what needs to be scrutinized. I wonder if the machine, after all, is as smart as we think we are or make it?

From ‘apple’ to ‘anomaly,’ 2019
In the Barbican book, Paglen explains how his work was dealing with AI. AI systems are developed by a few technology companies. And those companies, in the west, have a very limited worldview. Their perception of what means what is the basis for the ‘training set.’ This set contains classifications of representations. His work here is looking at a data set called ImageNet, which was created by professors at Stanford and Princeton. ImageNet took a gameset from WordNet, in which the collection of “words and concepts and scraped the internet for images that they thought would illustrate them...” then labeled those images. This set was created between 2009 and 2011 and wasn’t updated since. This means that the data set created by a couple of people in the US with a very limited worldview at a specific time was used. The collections were literally frozen in time and a particular place in terms of meaning. Paglen wonders how we could be shaping the softwares based on such data. He says that the creation of this data is entirely unethical (Barbican, p.41) because of its specificity. I think that the problem here is that the training set’s vision is very narrow and frozen in a specific time and place. So its claim to universality representing all humans everywhere is not valid. Pardo, Paglen’s interviewer, says that the basis is “outmoded” with subjectivities that are relationally subjective.
Paglen finally says: If we’re already looking at public training sets that have bad politics built into them, one can only imagine what is going on behind closed doors.
This sparked an idea in my head. What if we see what things will be like if the data set was created by people with good politics?
0 notes
Text
Gallery visits
I went to see four of the shows suggested by our teacher, Atau Takana. The one at Vinyl factory, I simply couldn’t find. The show at Matt’s was closed for the day and White Cube was not even open. The two shows I got to see were Whitechapel’s Anna Maria Maiolino, Brazilian artist, and the Tate’s Nam June Paik, Korean artist. The two are quite different in their scope but very similar in many ways I thought.
Maiolino’s super tactile work engaged with natural materials such as clay that were created to resemble left over moulds and human excrement among other things. Apart from this, there were works on paper that explored surfaces beneath. On the other hand, Paik’s work was mainly in the video and audio medium. The two, considering the medium of their work, can be seen as completely opposite, but I found quite a few works of Paik that were just as tactile but in a different way. The tactility was in the audio and visual sense.
Therefore, one was physically tactile in a classical way, whereas the other was non-physically tactile in a more modern way.
The first following series of images are from Anna Maria Mailino’s work. The work in the show was made over six decades. exploring themes that had much to do with everyday life, matter, materiality and more.

The piece in the above image was made out of clay created using moulds. The clay’s form resembles food, snakes, and human/animal excrement. Compared to other works made using clay this piece stood out. This one had a polish, it was stuck to a vertical square plate of the same background and was arranged harmoniously. The pattern of the six plates is broken by the plate in the second row that stands outside of it. This asymmetry to me is evocative of a community or a group with one--or more--members who break out, who don’t belong as symmetrically with the others. As a mother, and being in Brazil during crackdowns on freedoms, this piece I find to be her powerful yet kind and accepting expression of difference. Also the snakes or food or excrements or whatever else the moulded clay resembles, are converging in various directions, with or without an aim. The shapes are cut off here and there, but not everywhere. Each plate considered as a single entity and following the elaboration of individual difference, speaks of the differences within each entity. Lack of solid direction and fragmentation.

This above work is literally a mould used to create other works of the artist. Mailino is unearthing the neglected inside of mould, a mould that shaped finished, polished work like the one before this one. As already mentioned the insides are important to the artist. This mould is not just a mould in its presentation, it is the insides of an independent thing in itself, with its own complexities. It is the creator of other work and before that, of after as in this piece, it is a work in itself. This could make one think of the Mother, the creator, ‘the wife,’ kingmaker... It is also the child, the created, the husband, the king/queen. The lack of polish given to works that are created out of it leaves the creator used up and with things left over from the thing created. In that sense this work creates and doesn’t empty out but keeps a bit of what it creates. It doesn’t lose, it gains.

This piece is a work on paper, or rather translucent papers. There two translucent sheets with ink drawings, placed one above the other. The drawings are very similar. But upon closer look one can see that they are not the same. The sheet in the background resembles the one above but quite differently. The sheet beneath seems to have more complete figures, while the sheet above has less complete figures, left off here and there. It’s like a print, whereby around the final stages of the inks drying up, the figures begin to be thinner and lighter and some parts disappearing. So the sheet on top is the light print of the one under it.
The alignment is curious too. The top one is slightly amiss to showcase the one under. First glance shows the one under as the shadow of the one one above. I believe that may be the point. But the shadow is an incomplete reflection of the real thing. It is just a dark mass with no texturally physical shape, or contour or colour. But here, the shadow is the complete image of the drawing on top. This is such an exciting piece of work, not like much I've seen before.

This work as mentioned before is focused on the inside. the inner complexity. The edgy, geometric, sophisticated outside when cut has a slightly surprising inside. There are lines, but why? Just like the mould piece, this one begs to differ with the outer layers as the final work. The inner is complex, raw and accidental but it is the basis of the outer layer. By turning the inside out, in such a clinical manner as above the outer layer is tarnished. But the tarnishing done by such force is the objective I feel.
The following works are from Nam June Paik’s Tate show. He was, according to Tate, one of the leading figures in bridging technology and art. His work is in video, sculpture, broadcasting, performance and more. The following are mainly video, audio works rendered sculpturally.

The piece above bridges the person who sits on the chair to themselves via recording and projection. Instead of themselves I should say their outer selves, considering the work of Maiolino. And more specifically than the outer self, the top of the person’s. This side is recorded by the camera above and is projected onto the screen placed underneath the bottom of the person sitting. The screen is reflected on the glass of the chair’s seat. This is work is closer to human engagement conceptually physically than a work showcased outside the person like Maiolino’s work. The cycle of recording and showcasing to the person’s backside is quite funny. Connecting the head to the backside is subversive and denotes idiocy of the person using technology. But at the same time it conveys that technology as a medium is more engaging of the person physically directly conceptually than other work. There is a sensorial experience as well as conceptual.

The piece above is in correlation with the one below. The above one is quiet and the one below is boisterous. The former to do with meditation, concentration, peace, the latter to do with noise and anxiety. The two works showcased in sequence as here explore two polarised uses of tech. It can sooth as well as cause anxiety. It can enrich as well as depress.

The two shows quite different from each other from artist from two different continents were altogether very exciting. However, I don’t know how much they’ve inspired me for my own work yet. As blogged about before, my taste is usually more to do with the content than the presentation of the content, although that matters. I have to now ask myself am I afraid of messing up visually. I guess I am. The non-Black-and-White world is colourful, it is the grey area of endless possibilities.
I thought of my work as possibly conceptual but I have to see if there is scope for anything more. At the moment I am lost.
0 notes
Text
Understanding Data Breaches (originally published on the 30th of Oct on a different blog now deleted )
In what follows, I trace the actions of a ‘data science company’ and discuss through academic work from datasociety.com how the data is used and for what purposes. This is basically the case study I’ve researched this past week. I will end with some of my ruminations over what I’ve learned.
One of the biggest scandals in data recently was the Cambridge Analytica one. The company was founded by Alexander Nix of SCL group with a team that included Cristopher Wylie, who exposed most of what the company did with data (nyt.com, guardian.com). The offices were set up in Cambridge by the SCL group with its employees based out of London to lure Steve Bannon of Breitbart News in the U.S. for his grand plans (guardian.com). The vintage of Cambridge was crucial as it allowed them to present themselves as academic and ideas-based. Although they had nothing to do with the University of Cambridge, they acted as if they were.
The plan was to collect data of the citizens of the U.S. to get them to vote for the party Steve Bannon wanted to win, the Republican Party, represented by the eventual winner Donald Trump. For investment in this scheme, they brought in a hedge fund billionaire, who wanted the same thing to happen in the elections.
‘Cambridge Analytica’ approached Aleksandr Kogan from the university, who worked in psychological research. Through his research, he created an app for them to use on Facebook. The app was called: ‘thisisyourlife’ (cam.co.uk). Facebook users from different parts of the U.S. were invited to participate in the app, which was presented as a personality test that paid money for collecting their data for academic purposes. Over 270,000 users across the country participated (pix11.com). And at that time, Facebook’s feature allowed apps such as this one to pull data from the friends of the users (cbsnews.com). By exploiting this feature, through 270,000 users, they were able to collect data of over 50 million people in the country (guardian.com).
Cambridge Analytica though the app’s terms basically had the consent for the perusal of its users’ data, but Not of the millions of friends of those users. Facebook, by calculating how many friends the users of the app had, gave the number of 87 million (pix11.com). The data that was compromised included public profiles, page likes, birthdays, and locations (npr.com).
The company also had a team of ‘creatives,’ including designers, artists, composers… who then created a wide range of content and ‘injected’ that into websites, blogs…, wherever the now analyzed profiles were most susceptible to false information online, according to Christopher Wylie, the whistleblower (guardian.com).
The point here was, as succinctly put by Wylie in his Guardian interview, to change the society by first breaking it up. Fragmenting it by spreading ‘fake news,’ which included Disinformation, Publicity, and Propaganda, PR, Public Diplomacy, Public Affairs, Information Operations, and Agitprop… Disinformation: intentional lies to mislead. Publicity and Propaganda: spreading to a large group of people persuasive information through advertising. PR, Public Diplomacy, or Public Affairs: systemic operations that contain a messy mix of facts and interpretations. Information Operations: a military term that referred to the strategic use of technological means and psychological resources to disrupt the opponent’s information capacities and protect allies by using fake grassroots accounts, bots, PR as well, and more. Agitprop: whereby the propaganda campaigns are designed to prompt the audiences to take action. All these terms are from the report, Lexicon of Lies: Terms for problematic information by datasociety.net.
The fake news spread by Cambridge Analytica and other organizations across the world aim not only to foster support for something but also to spread Uncertainty or Derail debate. This kind of uncertainty leads to a growing distrust in the media (datasociety.net); it also destabilizes and disrupts the communities online. This sort of desirability naturally is expected to lead to people either disengaging or supporting a candidate who can stand tall and face and tackle ‘Fake News,’ such as Donald Trump.
This is an excellent example of what I was discussing last week about how data companies and social media companies callously use regular people. Reading this in the news without having a computation understanding is dating to the readers. I would like to demystify and expose the accessibility of all this so they can engage better and be able to have more meaningful debates over this. This will then enable many of the people to come forward with viable solutions and challenge the monopolies that are disrupting their peace so disturbingly.
I have looked into the skills Aleksandr Kogan had apart from his deep specialization in psychology. The computational skills include Node.js, Python, R, Javascript, SQL, and some more. I will further research next week, which of his skills were relevant in creating the app: ‘thisisyourlife.’
0 notes