
Just like a movie but Python instead of an octopus and no one gets eaten by a shark
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by mypythonteacher and here's what we found interesting.
Average Info
Notes Per Post
1
Likes Per Post
1
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
3 days
Number of Posts By Type
Text
17
Last Seen Tumblr Blogs





Fun Fact
Tumblr was acquired by Yahoo for $1.1B in 2013.
Text
More Pandas
To print out a particular number of decimal places:
bw_rate = before_washing.deaths.sum() / before_washing.births.sum() * 100
aw_rate = after_washing.deaths.sum() / after_washing.births.sum() * 100
print(f'Average death rate before 1847 was {bw_rate:.4}%')
print(f'Average death rate AFTER 1847 was {aw_rate:.3}%')
To test for a condition and add a column of data (using NumPy):
df_monthly['washing_hands'] = np.where(df_monthly.date < handwashing_start, 'No', 'Yes')
0 notes
Text
Ever more Pandas
To filter based on two terms: international_releases = data.loc[(data.USD_Domestic_Gross == 0) &(data.USD_Worldwide_Gross != 0)]
OR
international_releases = data.query('USD_Domestic_Gross == 0 and USD_Worldwide_Gross != 0')
print(f'Number of international releases: {len(international_releases)}')
international_releases.tail()
To drop certain rows:
data_clean = data.drop(future_releases.index)
0 notes
Text
NumPy
The crown jewel of NumPy is the ndarray. The ndarray is a homogeneous n-dimensional array object. What does that mean? 🤨
A Python List or a Pandas DataFrame can contain a mix of strings, numbers, or objects (i.e., a mix of different types). Homogenous means all the data have to have the same data type, for example all floating-point numbers.
And n-dimensional means that we can work with everything from a single column (1-dimensional) to the matrix (2-dimensional) to a bunch of matrices stacked on top of each other (n-dimensional).
To import NumPy: import numpy as np
To make a 1-D Array (Vector): my_array = np.array([1.1, 9.2, 8.1, 4.7])
To get the shape (rows, columns): my_array.shape
To access a particular value by the index: my_array[2]
To get how many dimensions there are: my_array.ndim
To make a 2D Array (matrix):
array_2d = np.array([[1, 2, 3, 9],
[5, 6, 7, 8]])
To get the shape (columns, rows): array_2d.shape
To get a particular 1D vector: mystery_array[2, 1, :]
Use .arange()to createa a vector a with values ranging from 10 to 29: a = np.arange(10, 30)
The last 3 values in the array: a[-3:]
An interval between two values: a[3:6]
All the values except the first 12: a[12:]
Every second value; a[::2]
To reverse an array: f = np.flip(a) OR a[::-1]
To get the indices of the non-zero elements in an array: nz_indices = np.nonzero(b)
To generate a random 3x3x3 array:
from numpy.random import random
z = random((3,3,3))
z
or use the full path to call it.
z = np.random.random((3,3,3)) # without an import statement
print(z.shape)
z
or
random_array = np.random.rand(3, 3, 3)
print(random_array)
To create a vector of size 9 from 0 to 100 with values evenly spaced: x = np.linspace(0,100, num=9)
To create an array called noise and display it as an image:
noise = np.random.random((128,128,3))
print(noise.shape)
plt.imshow(noise)

To display a random picture of a raccoon:
img = misc.face()
plt.imshow(img)
1 note
·
View note
Text
Even More Pandas
To count the number of different categories in a column: ratings = df_apps_clean.Content_Rating.value_counts()
Using Plotly:
import plotly.express as px
fig = px.pie(labels=ratings.index,
values=ratings.values,
title="Content Rating",
names=ratings.index,
)
fig.update_traces(textposition='outside', textinfo='percent+label')
fig.show()
To get rid of commas in numerical values and convert to floats:
df_apps_clean.Installs = df_apps_clean.Installs.astype(str).str.replace(',', "")
df_apps_clean.Installs = pd.to_numeric(df_apps_clean.Installs)
To see the types of each of the columns: df.info()
0 notes
Text
More Pandas
To get a bunch of analytical data: df.describe()
To sample 5 different rows: df_apps.sample(5)
To delete a column; df_apps.drop("Android_Ver", axis=1, inplace=True)
To see how many NaN values are in a particular column: df_apps['Rating'].isna().sum()
to create a list of rows that have NaN in a particular column:
nan_rows = df_apps[df_apps.Rating.isna()]
To print just duplicated rows: duplicated_rows = df_apps_clean[df_apps_clean.duplicated()]
To display just the rows with Instagram:
df_apps_clean[df_apps_clean.App == "Instagram"]
To delete duplicate rows:
df_apps_clean = df_apps_clean.drop_duplicates()
(but alone it will leave rows with only slight differences in a column=)
To delete duplicate rows based on criteria:
df_apps_clean = df_apps_clean.drop_duplicates(subset=["App", "Type", "Price"])
(specifies what needs to be the same to consider them a duplicate)
0 notes
Text
Pandas
To import Pandas; import pandas as pd
To create a dataframe from a csv: fd = pd.read_csv("title.csv")
To see the first 5 rows of a dataframe: df.head()
To get the number of rows and columns: df.shape
To get the names of the columns: df.columns
To see NaN (not a number) values (where True = NaN): df.isna()
To see the last 5 rows of a dataframe: df.tail()
To create a clean dataframe without rows with NaN: clean_df = df.dropna()
To access a particular column by name: clean_df['Starting Median Salary']
To find the highest value in a column: clean_df['Starting Median Salary'].max()
To get the row number or index of that value: clean_df['Starting Median Salary'].idxmax()
To get the value from another column at that index: clean_df['Undergraduate Major'].loc[43] OR clean_df['Undergraduate Major'][43]
To get the entire row at a given index: clean_df.loc[43]
To get the difference between two columns:
clean_df['Mid-Career 90th Percentile Salary'] - clean_df['Mid-Career 10th Percentile Salary'] OR
clean_df['Mid-Career 90th Percentile Salary'].subtract(clean_df['Mid-Career 10th Percentile Salary'])
To insert this as a new column;
spread_col = clean_df['Mid-Career 90th Percentile Salary'] - clean_df['Mid-Career 10th Percentile Salary']
clean_df.insert(1, 'Spread', spread_col)
clean_df.head()
To create a new table sorted by a column: low_risk = clean_df.sort_values('Spread')
To only display two columns: low_risk[['Undergraduate Major', 'Spread']].head()
To see how many of each type you have:
clean_df.groupby('Group').sum()
To count how many you have by of each category: clean_df.groupby('Group').count()
To round to two decimal places:
pd.options.display.float_format = '{:,.2f}'.format
To get the averages for each category:
clean_df.groupby('Group').mean()
To rename columns:
df = pd.read_csv('QueryResults.csv', names=['DATE', 'TAG', 'POSTS'], header=0)
To get the sum of entries:
df.groupby("TAG").sum()
To count how many entries there are:
df.groupby("TAG").count()
To select an individual cell:
df['DATE'][1]
or df.DATE[1]
To inspect the datatype:
type(df["DATE"][1])
To convert a string into a datetime:
df.DATE = pd.to_datetime(df.DATE)
To pivot a dataframe:
reshaped_df = df.pivot(index='DATE', columns='TAG', values='POSTS')
To replace NaN with zeros:
reshaped_df.fillna(0, inplace=True) or
reshaped_df = reshaped_df.fillna(0)
To check there aren't any NaN values left:
reshaped_df.isna().values.any()
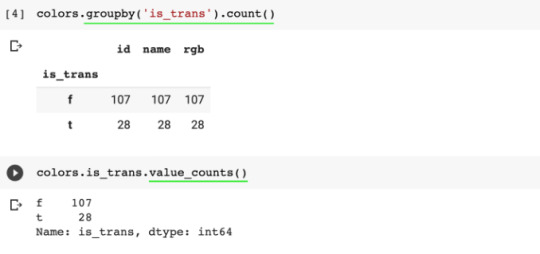
To count how many of each type there is:
colors.groupby("is_trans").count() or
colors.is_trans.value_counts()
To find all the entries with a certain value (to filter by a condition):
sets[sets['year'] == 1949]
To aggregate data:
themes_by_year = sets.groupby('year').agg({'theme_id': pd.Series.nunique})
Note, the .agg() method takes a dictionary as an argument. In this dictionary, we specify which operation we'd like to apply to each column. In our case, we just want to calculate the number of unique entries in the theme_id column by using our old friend, the .nunique() method.
To rename columns:
themes_by_year.rename(columns = {'theme_id': 'nr_themes'}, inplace= True)
To plot:
plt.plot(themes_by_year.index[:-2], themes_by_year.nr_themes[:-2])
To plot two lines with two axis:
ax1 = plt.gca() # get current axes
ax2 = ax1.twinx() #allows them to share the same x-axis
ax1.plot(themes_by_year.index[:-2], themes_by_year.nr_themes[:-2])
ax2.plot(sets_by_year.index[:-2], sets_by_year.set_num[:-2])
ax1.set_xlabel("Year")
ax1.set_ylabel("Number of Sets", color="green")
ax2.set_ylabel("Number of Themes", color="blue")
To get the average number of parts per year:
parts_per_set = sets.groupby('year').agg({'num_parts': pd.Series.mean})
To change daily data to monthly data:
df_btc_monthly.head()
0 notes
Text
CMD and Git
Using Git Locally
To make a directory: mkdir Story
To create a txt file: type nul > chapter1.txt
To open a file: chapter1.txt
To initialise a Git repository: git init
To see hidden files: dir /ah
To get Git status: git status
To add something to Git: git add chapter1.txt
To commit with a message: git commit -m "Complete Chapter 1"
To see the Git log: git log
To add multiple files at once: git add .
Git add only puts it in a staging area before committing.
To see what files have been modified since the last commit: git status
To see differences between the current and last commit: git diff chapter3.txt
To roll back to the last commit: git checkout chapter2.txt
Putting things on GitHub from CMD
To create a remote repository: git remote add origin https://github.com/AlexisElizabeth/Story.git
This tells the local git rep that a remote git rep is somewhere on the internet. Origin is the name of the remote and you can theoretically call it anything. Origin is the convention though.
To push the local repository on to the remote repository:
git branch -M main
git push -u origin main
0 notes
Text
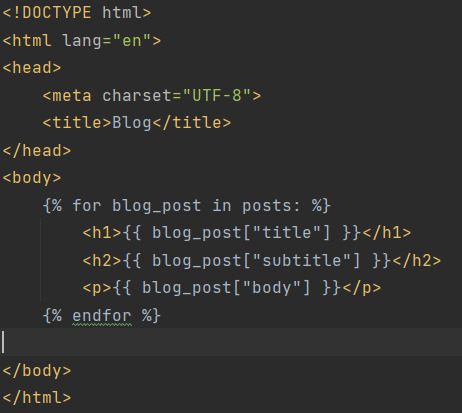
Jinja
Jinja is a web template engine for the Python programming language. It lets you run Python in HTML docs.



0 notes
Text
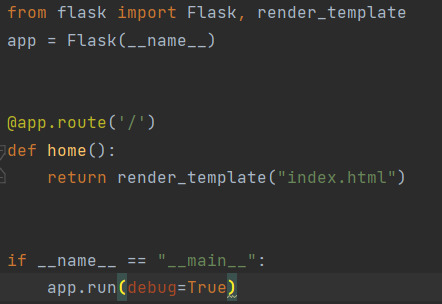
React
You can add pictures and HTML to a project using React by making a folder called "static" and putting photos and CSS stylesheets in there, and making a folder called "templates" for HTML.
In developer tools in Chrome you can edit things by typing into the console: document.body.contentEditable=true
Then you can edit the body in the developer tools, save it all and put it back in your project.
0 notes
Text
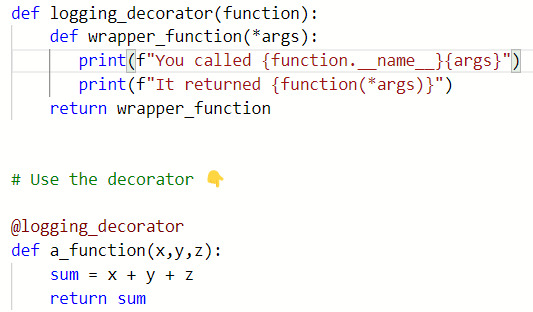
Flask 2
To have different paths do different things:
@app.route('/bye') def bye(): return 'Bye'
To use part of the path as variables:
@app.route('/username/<name>/<int:number>') def greet(name, number): return f"Hello {name} you are {number} years old"
To run debug:
if __name__ == "__main__": app.run(debug=True)


0 notes
Text
Flask
In the terminal window:
set FLASK_APP=main.py $env:FLASK_APP = "main.py" flask run
The command line or the shell
Kernel - operating system
Shell - the user interface used to interact with the Kernal
GUI shells - using windows to find files
Command Line Interface - an alternative way of interfacing with the kernel
Why use the command line?
Greater control. To exert more power over your tools. On a day-to-day basis, being a command-line user makes things easier and faster.
chdir/dir - print working directory
dir - lists all the files and folders in the current working directory
cd - change directory (tab will fill in the rest of the file name if you type part)
cd... - go up one level
mkdir - make a directory(folder)
type nul > filename.txt to create a file
del filename.txt to delete a file
rmdir - remove (delete) directory
Pycharm has an emulator terminal. All they've done is bundled the command prompt into Pycharm. You can do everything in the terminal in Pycharm including running the flask server, etc.
Search for command prompt cheatsheet for more instructions
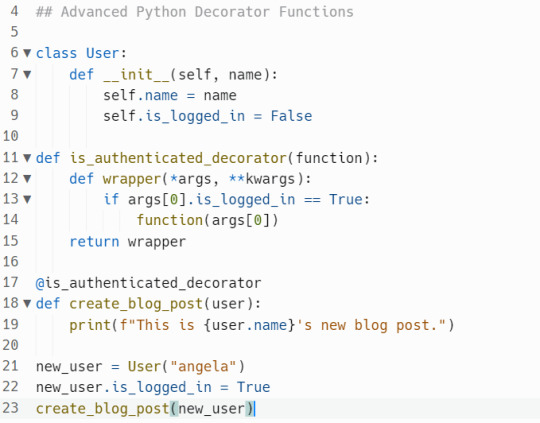
Python Decorators
Functions are first-class objects and can be passed around as arguments e.g. int/string/float etc.
def calculate(calc_function, n1, n2):
return calc_function(n1, n2)
result = calculate(add, 2, 3)
Functions can be nested in other functions
def outer_function():
print("i'm outer")
def nested_function():
print("I'm inner")
nested_function()
outer_function()
Functions can be returned from other functions
def outer_function():
print("i'm outer")
def nested_function():
print("I'm inner")
return nested_function
inner_function = outer_function() (will run outer)
inner_function()
Decorator Functions
A decorator function is a function that wraps another function and gives it some additional functionality.
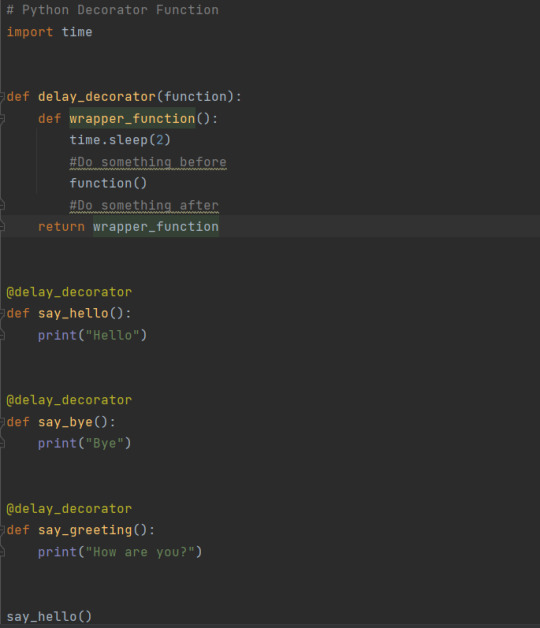
@delay_decorator - syntactic sugar
OR
decorated_function = delay_decorator(say_greeting)
decorated_function()
0 notes
Text
Selenium
To get Selenium running:
from selenium import webdriver from selenium.webdriver.chrome.service import Service
url2 = "https://www.python.org/"
chrome_driver_path = "C:\Development\chromedriver.exe" driver_service = Service(executable_path=chrome_driver_path) driver = webdriver.Chrome(service=driver_service)
driver.get(url2)
To find an element by name:
search_bar = driver.find_element(By.NAME, value="q")
To find an element by ID:
price = driver.find_element(By.ID, value="mbc-price-1")
The element is an object. To print it:
print(price.text)
You can access other attributes of the object. To get the placeholder in a search bar:
print(search_bar.get_attribute("placeholder"))
To get the tag name:
print(search_bar.tag_name)
To get the size of an image:
logo = driver.find_element(By.CLASS_NAME, value="python-logo") print(logo.size)
To get something when you have a class and a tag (so this is an a href text inside a div class):
documentation_link = driver.find_element(By.CSS_SELECTOR, value=".documentation-widget a") print(documentation_link.text)
If all else fails, use Xpath, which locates something using a path structure. You can copy the Xpath from "inspect":
bug_link = driver.find_element(By.XPATH, value='//*[@id="site-map"]/div[2]/div/ul/li[3]/a') print(bug_link.text)
To find the Xpath of any part of the website:
To put text into a search bar:
search = driver.find_element(By.NAME, value="search") search.send_keys("Fart")
To click enter:
from selenium.webdriver.common.keys import Keys
search.send_keys(Keys.ENTER)
0 notes
Text
Web Scraping and Beautiful Soup
from bs4 import BeautifulSoup
with open("website.html", encoding="utf8") as file: contents = file.read()
To print first p tag:
soup = BeautifulSoup(contents, "html.parser") print(soup.p)
To make the HTML indented:
soup.prettify()
To print all a tags:
print(soup.find_all(name="a"))
To print text of all anchor tags:
all_anchor_tags = soup.find_all(name="a")
for tag in all_anchor_tags: print(tag.getText())
To get content of all links:
for tag in all_anchor_tags: print(tag.get("href"))
To get one h1 tag in particular:
heading = soup.find(name="h1", id="name") print(heading)
To get a heading with a class not an ID:
section_heading =soup.find(name="h3", class_="heading")
To get a certain attribute:
(section_heading.get("class")
To find one item:
company_url = soup.select_one(selector="p a") print(company_url)
To find an item by ID:
name = soup.select_one(selector="#name") print(name)
To get a list of everything in class Heading:
headings = soup.select(".heading") print(headings)
0 notes
Text
Advanced Authentication and POST/PUT/DELETE Requests
HTTP Requests
Get: requests.get() - request is made to get data from external
Post: requests.post() - we give an external system a piece of data
Put: requests.put() - update a piece of data in an external service, like Google sheets
Delete: requests.delete() - delete data in external service, like Tweet, etc.
In anything but .get() you call them json and not params
response = requests.post(url=pixela_endpoint, json=user_params)
To print response text: print(response.text)
To send a secure request by putting the token in the header: response = requests.post(url=graph_endpoint, json=graph_config, headers=headers)
To format datetime as a string: today.strftime("%Y%m%d")
To set the day: today = datetime(year=2022, month=10 , day=29)
0 notes
Text
API Keys, Authentication, Environment Variables and Sending SMS
API endpoints: the URL
API parameters: passing in different inputs to get back different data
Now, APIs that use authentication. Some data costs money and you have to pay if you're running an application that needs data.
Environment Variables are to avoid updating the main code or to hide things like API keys. Environment variables allow us to store items separately from the codebase.
TO SET ENVIRONMENT VARIABLES
or dir env: seems to work
To store a local environment variable: set OWM_API_KEY=20e2530194e965234aaedf3f73a0a04f
Then to put in code: api_key = os.environ.get("OWM_API_KEY")
0 notes
Text
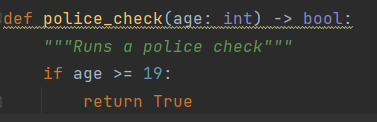
Data Types: Type Hints
To assign a data type to a variable without assigning a value:
age: int
You can also do this in a function:
def police_check(age: int):
That way you don't enter the wrong data type into a function.
You can also specify the data type of output:
def police_check(age: int) -> bool:
This helps your IDE identify potential bugs
0 notes
Text
API Practice
HTML Escape / Unescape
Escapes or unescapes an HTML file removing traces of offending characters that could be wrongfully interpreted as markup.
import html
then new_text = html.unescape(text)
To make the UI it's own class:
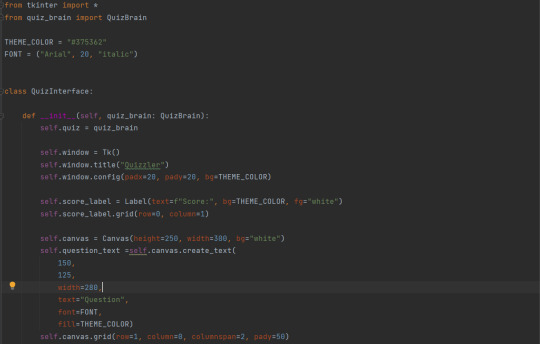
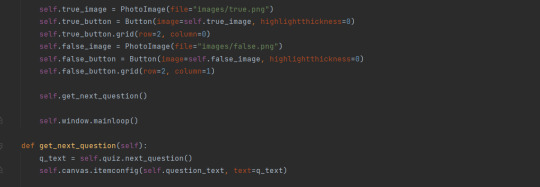
Note that you can pass in the quiz, and also, how you assign the type of the quiz
0 notes