
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by mysticpandakid and here's what we found interesting.
Average Info
Notes Per Post
2
Likes Per Post
2
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
3 days
Number of Posts By Type
Text
17
Last Seen Tumblr Blogs





Fun Fact
Tumblr was attacked by a cross-site scripting worm deployed by the Internet troll group GNAA on Dec 3, 2012.
Text

Real-time Insights with Azure Synapse – Unlock Data Power
Break down data silos and transform scattered information into actionable insights with Azure Synapse. Collect data from multiple sources, process it seamlessly, and present real-time analytics using Power BI. At AccentFuture, we help you master these skills to drive smarter, data-driven decisions.
#Azure Synapse#Real-time insights with Azure Synapse#Azure Synapse training#Azure Synapse analytics#Data silos and integration#Real-time data analysis#Power BI with Azure Synapse#Azure data integration#Data transformation with Azure Synapse#Azure Synapse course online#Learn Azure Synapse#Best Azure Synapse training#Azure Synapse online training#Cloud data analytics#Real-time business insights
1 note
·
View note
Text

Improve operational efficiency, sustainability, and customer satisfaction with predictive insights. 👉 Full Article: Read Blog | Learn: Accentfuture Training
1 note
·
View note
Text

Databricks vs BigQuery vs Snowflake – A Quick Comparison
Choosing the right data platform can transform your analytics strategy. ✅ Databricks – Best for big data processing, AI, and multi-language support. ✅ Google BigQuery – Ideal for serverless, lightning-fast SQL analytics. ✅ Snowflake – Perfect for cross-cloud compatibility and secure data sharing.
At AccentFuture, we provide expert Databricks training to help you master modern data engineering and analytics. Learn how to work efficiently across different platforms and boost your career in the cloud data space.
0 notes
Text

Financial Analytics Ecosystem – Turning Data into Actionable Insights
At AccentFuture, we help you navigate the complete financial analytics ecosystem from big data processing and machine learning to advanced analytics enabling organizations to extract powerful, actionable insights. Our training equips you to master every layer, transforming raw data into strategic decisions that drive business growth.
#FinancialAnalytics#BigData#MachineLearning#AdvancedAnalytics#ActionableInsights#AccentFuture#DataDrivenDecisions
0 notes
Text
Delta Sharing & Data Collaboration: Empowering the Future of Open Data at Scale
In today's fast-moving data ecosystem, collaboration isn't a luxury it's a necessity. As enterprises generate more data than ever before, the ability to seamlessly share, consume, and collaborate on data across teams, platforms, and organizations has become a key competitive advantage. This is where Delta Sharing, the first open protocol for secure data sharing, steps in to redefine how organizations exchange insights without sacrificing control or performance.
At AccentFuture, we believe that understanding Delta Sharing is not just valuable it's essential for modern data engineers and analysts navigating the Lakehouse architecture era.

🌐 What is Delta Sharing?
Delta Sharing is an open-source protocol developed by Databricks that enables secure, real-time data sharing across different platforms and tools, without requiring recipients to be on the same infrastructure or cloud provider. Unlike traditional data APIs, Delta Sharing lets you share live data directly from your Delta Lake tables, making it ideal for collaboration across:
Departments within the same company
Vendors, partners, or clients
Public datasets and communities
Because it is open and cloud-agnostic, it avoids vendor lock-in and fosters a truly collaborative, ecosystem-driven approach to data.
⚙️ How Delta Sharing Works
At a high level, Delta Sharing enables data providers to publish Delta tables via a sharing server or REST API. Authorized recipients can access the data using familiar tools like Python, Pandas, Apache Spark, Power BI, or even third-party platforms—without copying or duplicating the dataset.
Here’s why it’s a game-changer:
✅ Live Access: Consumers always see up-to-date data.
🔐 Fine-grained Security: Row-level and column-level access controls.
🚀 Performance: Built on the fast and optimized Delta Lake storage engine.
🌍 Cross-platform Support: Recipients don’t need Databricks accounts.
🤝 Real-World Collaboration Use Cases
Delta Sharing supports numerous enterprise and data science use cases where collaboration is critical:
Marketing & Sales Teams Share campaign insights or lead data across global regions securely and instantly.
Healthcare & Research Collaborate on sensitive patient or genomic datasets with strict access controls.
Public Datasets Enable transparency and open innovation by publishing live data with controlled access.
Supplier Networks Manufacturers can provide real-time inventory data to suppliers without building complex APIs.
📈 Benefits for Data Engineers and Analysts
For data professionals and students enrolled in AccentFuture’s Azure Databricks and Data Engineering courses, mastering Delta Sharing unlocks a host of advantages:
Learn real-world architectures involving Delta Lake, Unity Catalog, and Delta Sharing
Improve collaboration in multi-team projects across clouds and data stacks
Understand data governance and access control in shared environments
Enhance employability by learning modern, open data-sharing standards
In essence, Delta Sharing bridges the gap between data producers and consumers—whether within a single enterprise or across global partners.
🎓 Why Learn Delta Sharing with AccentFuture?
AccentFuture delivers industry-aligned training on Delta Lake, Databricks, and advanced data engineering practices. Our modules are crafted by experts who understand the demands of real-world projects.
With us, you get:
🔧 Hands-on labs using Delta Sharing, Apache Spark, and Unity Catalog
🧠 Real-time use cases on data versioning, collaboration, and governance
🎯 Mock interviews and certification prep for Databricks certifications
💼 Career support for roles like Data Engineer, Analytics Consultant, and Cloud Data Specialist
By enrolling in our Databricks Training programs, you gain both technical depth and collaborative skills that companies are looking for.
Related Articles :-
Ignore PySpark, Regret Later: Databricks Skill That Pays Off
Databricks Interview Questions for Data Engineers
VACUUM in Databricks: Cleaning or Killing Your Data?
Stream-Stream Joins with Watermarks in Databricks Using Apache Spark
Real-World Use Cases of Snowflake in Retail, Finance, and Healthcare
💡 Ready to Make Every Compute Count?
📓 Enroll now: https://www.accentfuture.com/enquiry-form/
📧 Email: [email protected]
📞 Call: +91–9640001789
🌐 Visit: www.accentfuture.com
0 notes
Text
Lakehouse Architecture Best Practices: A Unified Data Future with AccentFuture
In the evolving landscape of data engineering, Lakehouse Architecture is emerging as a powerful paradigm that combines the best of data lakes and data warehouses. As businesses demand faster insights and real-time analytics across massive datasets, the Lakehouse model has become indispensable. At AccentFuture, our advanced courses empower learners with real-world skills in modern data architectures like the Lakehouse preparing them for the data-driven jobs of tomorrow.
What is Lakehouse Architecture?
Lakehouse Architecture is a modern data platform that merges the low-cost, scalable storage of a data lake with the structured data management and performance features of a data warehouse. It enables support for data science, machine learning, and BI workloads all within a single platform.
With engines like Apache Spark and platforms like Databricks, the Lakehouse allows for seamless unification of batch and streaming data, structured and unstructured formats, and analytics and ML workflows.

Top Best Practices for Implementing a Lakehouse Architecture
1. Start with a Clear Data Governance Strategy
Before jumping into implementation, define clear data governance policies. This includes data access control, lineage tracking, and auditability. Utilize tools like Unity Catalog in Databricks or Apache Ranger to set up granular access control across different data personas—engineers, analysts, scientists, and business users.
Tip from AccentFuture: We guide our learners on implementing end-to-end governance using real-world case studies and tools integrated with Spark and Azure.
2. Use Open Data Formats (Delta Lake, Apache Iceberg, Hudi)
Always build your Lakehouse on open table formats like Delta Lake, Apache Iceberg, or Apache Hudi. These formats support ACID transactions, schema evolution, time travel, and fast reads/writes—making your data lake reliable for production workloads.
Delta Lake, for example, enables versioning and rollback of data, making it perfect for enterprise-grade data processing.
3. Optimize Storage with Partitioning and Compaction
Efficient storage design is critical for performance. Apply best practices like:
Partitioning data based on high-cardinality columns (e.g., date, region).
Z-Ordering or clustering to optimize read performance.
Compaction to merge small files into larger ones to reduce I/O overhead.
At AccentFuture, our Databricks & PySpark Training includes labs that teach how to optimize partitioning strategies with Delta Lake.
4. Implement a Medallion Architecture (Bronze, Silver, Gold Layers)
Adopt the Medallion Architecture to organize your data pipeline efficiently:
Bronze Layer: Raw ingested data (logs, streams, JSON, CSV, etc.)
Silver Layer: Cleaned, structured data (joins, filtering, type casting).
Gold Layer: Business-level aggregates and KPIs for reporting and dashboards.
This tiered approach helps isolate data quality issues, simplifies debugging, and enhances performance for end-users.
5. Use Data Lineage and Metadata Tracking
Visibility is key. Implement metadata tracking tools like:
Data Catalogs (Unity Catalog, AWS Glue Data Catalog)
Lineage Tracking tools (OpenLineage, Amundsen)
These tools help teams understand where data came from, how it was transformed, and who accessed it—ensuring transparency and reproducibility.
6. Embrace Automation with CI/CD Pipelines
Use CI/CD pipelines (GitHub Actions, Azure DevOps, or Databricks Repos) to automate:
Data ingestion workflows
ETL pipeline deployments
Testing and validation
Automation reduces manual errors, enhances collaboration, and ensures version control across teams.
AccentFuture’s project-based training introduces learners to modern CI/CD practices for data engineering workflows.
7. Integrate Real-Time and Batch Processing
Lakehouse supports both streaming and batch data processing. Tools like Apache Spark Structured Streaming and Apache Kafka can be integrated for real-time data ingestion. Use triggers and watermarking to handle late-arriving data efficiently.
8. Monitor, Audit, and Optimize Continuously
A Lakehouse is never “complete.” Continuously monitor:
Query performance (using Databricks Query Profile or Spark UI)
Storage usage and costs
Data pipeline failures and SLAs
Audit data access and transformations to ensure compliance with internal and external regulations.

Why Learn Lakehouse Architecture at AccentFuture?
At AccentFuture, we don’t just teach theory we bring real-world Lakehouse use cases into the classroom. Our Databricks + PySpark online courses are crafted by industry experts, covering everything from Delta Lake to real-time pipelines using Kafka and Airflow.
What You Get:
✅ Hands-on Projects ✅ Industry Interview Preparation ✅ Lifetime Access to Materials ✅ Certification Aligned with Market Demand ✅ Access to Mentorship & Career Support
Conclusion
Lakehouse Architecture is not just a trend—it’s the future of data engineering. By combining reliability, scalability, and flexibility in one unified platform, it empowers organizations to extract deeper insights from their data. Implementing best practices is key to harnessing its full potential.
Whether you're a budding data engineer, a seasoned analyst, or a business professional looking to upskill, AccentFuture’s Lakehouse-focused curriculum will help you lead the charge in the next wave of data innovation.
Ready to transform your data skills? 📚 Enroll in our Lakehouse & PySpark Training today at www.accentfuture.com
Related Articles :-
Databricks Certified Data Engineer Professional Exam
Ignore PySpark, Regret Later: Databricks Skill That Pays Off
Databricks Interview Questions for Data Engineers
Stream-Stream Joins with Watermarks in Databricks Using Apache Spark
💡 Ready to Make Every Compute Count?
📓 Enroll now: https://www.accentfuture.com/enquiry-form/
📧 Email: [email protected]
📞 Call: +91–9640001789
🌐 Visit: www.accentfuture.com
0 notes
Text

Discover how combining Apache Spark, Power BI, and Tableau on Databricks enhances big data analytics and real-time insights. This powerful trio empowers organizations to process large-scale data, visualize patterns instantly, and make informed business decisions.
🚀 What You'll Learn:
How Apache Spark powers large-scale data processing
Real-time visualization with Tableau
Data-driven insights using Power BI
Seamless integration using Databricks
🎓 Learn Databricks from experts: 🔗 AccentFuture Databricks Training Course 📝 Read full blog here: 🔗 Databricks + Power BI + Tableau Integration Explained
💡 Start building your data career with the right tools and insights!
#Databricks#ApacheSpark#PowerBI#Tableau#DataVisualization#BigData#DataEngineering#AccentFuture#DataAnalytics#MachineLearning#LinkedInLearning#FlipboardTech#Scoopit#DataCommunity#TechTraining#RealTimeInsights#BItools
0 notes
Text

Empowering Data Enthusiasts: The Continuous Growth Cycle
This visual illustrates the Cycle of Data Enthusiast Empowerment—starting with learning Databricks and progressing through community engagement, project contributions, skill enhancement, reputation building, and staying ahead in the data landscape. At AccentFuture, we foster this growth cycle through expert-led courses, hands-on training, and active community support—empowering learners to thrive in the dynamic world of data.
#databricks training#databricks training course#pyspark training#databricks online training#learn databricks
0 notes
Text

Looking to accelerate your career in data engineering? Our latest blog dives deep into expert strategies for mastering Databricks—focusing purely on data engineering, not data science!
✅ Build real-time & batch data pipelines ✅ Work with Apache Spark & Delta Lake ✅ Automate workflows with Airflow & Databricks Jobs ✅ Learn performance tuning, CI/CD, and cloud integrations
Start your journey with AccentFuture’s expert-led Databricks Online Training and get hands-on with tools used by top data teams.
📖 Read the full article now and take your engineering skills to the next level! 👉 www.accentfuture.com
#Databricks#DataEngineering#ApacheSpark#DeltaLake#BigData#ETL#DatabricksTraining#AccentFuture#CareerGrowth
0 notes
Text

0 notes
Text

Unlock the full potential of your data systems with the Databricks & Generative AI Cycle! From training data engineers and building efficient pipelines to applying generative AI for intelligent automation—this continuous cycle ensures scalable, optimized, and AI-ready data workflows. Start your journey with AccentFuture and empower your team to lead in the AI-driven data era. 💡🚀 #Databricks #GenerativeAI #DataEngineering #AccentFuture #AIpipeline #LearnDatabricks
0 notes
Text

Master Databricks efficiency with our Databricks Runtime & Compute Optimization program at AccentFuture. This best Databricks online course covers tuning runtimes, cluster management, and scaling techniques. Whether you're starting a Databricks course or enhancing skills through Databricks online course training, this hands-on Databricks online course is tailored for real-world impact. With expert-led Databricks online training and a project-based Databricks training course, you'll confidently learn Databricks to optimize performance and costs. Perfect for engineers, analysts, and data scientists looking to elevate their workflows.
#databricks training#databricks training course#best databricks online course#databricks course#databricks online course#databricks online course training#databricks online training#learn databricks
0 notes
Text
#Databricks Training#Databricks Course#Databricks Online Training#Delta Lake VACUUM#Time Travel in Delta Lake#Optimize Delta Table Storage
0 notes
Text

Master the Feature Engineering Cycle with our Databricks online training. At Accentfuture, our Databricks training course helps you handle real-world data tasks. Join now to learn Databricks through expert-led Databricks training.
0 notes
Text

Explore the Databricks vs. BigQuery comparison with AccentFuture! Understand architecture, performance, and use cases to make the right choice. Perfect for those in Databricks online training or looking to learn Databricks through expert-led Databricks training courses.
0 notes
Text
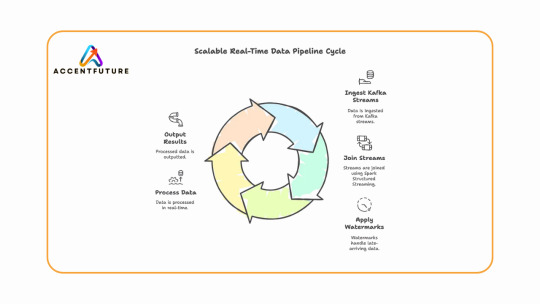
Learn how to build real-time data pipelines using Databricks Stream-Stream Join with Apache Spark Structured Streaming. At AccentFuture, master streaming with Kafka, watermarks, and hands-on projects through expert Databricks online training.
#Databricks Stream-Stream Join#Structured Streaming in Databricks#Watermarking in Apache Spark#Apache Spark Structured Streaming#Databricks Kafka Streaming#Stream Joins in Apache Spark#Real-Time Data Pipeline with Spark#Databricks Streaming Example
0 notes