
Auf diesem Blog erklären wir Dir die physiologischen und anatomischen Grundlagen der Sprachübertragung. 10 Themen werden hier übersichtlich zusammenfassend dargestellt, sodass Studierende, Schüler*Innen und auch alle anderen Interessierten sich schnell und verständlich Wissen aneignen können. Jedes Thema bezieht sich auf die Folien der Vorträge aus dem Kurs PAGSR WiSe 22/23 TU Berlin. Der Blog wurde von den Studierenden der TU Berlin Studiengang „Kultur und Technik“ mit Schwerpunkt Sprache und Kommunikation Hoai Thuong Ngo und Asbjørn Barfod erstellt. Wir wünschen viel Spaß beim Lesen!
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by pagsr2023 and here's what we found interesting.
Average Info
Notes Per Post
1
Likes Per Post
1
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
2 hours
Number of Posts By Type
Text
11
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. is using 66 technologies for its website.
Text
Videobericht - Phonetiklabor ZAS
Im Zuge des PAGSR Seminars wurde eine Gruppe von Studierenden ausgesandt, um dem Leibniz - Zentrum Allgemeine Sprachwissenschaft (ZAS) einen Besuch abzustatten. In dem Zentrum wird sich intensiv mit den Themenbereichen Phonetik, Akustik und Technik auseinander gesetzt. Klickt auf den folgenden Link, um zu schauen was die Studierenden dort für spannende Eindrücken gesammelt haben. An dieser Stelle vielen Dank an die Gruppe für das Aufzeichnen ihres Ausflugs und dem Erstellen dieser schönen Reportage!
Link zu dem Video: https://drive.google.com/file/d/13aLItV9ZSllwZZAzlWA-EZ0DAVzLsPCF/view
Dokumentation von: Lea Teichmann, Katharina Rieker, Kaya Schweigert, Berkant Tezel, Toby Klug
0 notes
Text
Thema 1 Respiration und Atmung
ANATOMIE DER ATMUNG
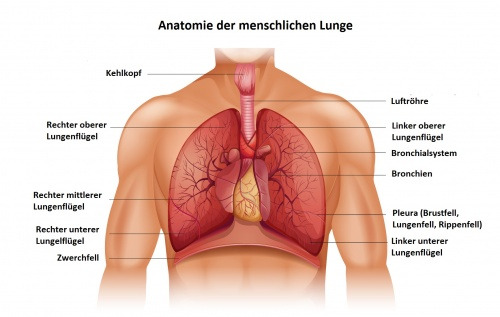
Im Volksmund heißt es, das Atmen sei das, was uns am Leben hält. Natürlich bedarf es weitaus mehr, jedoch wird unserer Lunge damit lebensnotwendiger Sauerstoff zugeführt.
Die Atemwege lassen sich in zwei Teile gliedern. Die oberen Atemwege beginnen in der Nase, Nasennebenhöhlen, Mund und Rachen. Im unteren Bereich folgen Kehlkopf, Luftröhre und Bronchien. Die Luftröhre (lat. Trachea) ist mit einer Schleimhaut und kleinen Flimmerhärchen ausgestattet. In diesem Bereich wird die Atemluft gereinigt, erwärmt und befeuchtet. Sobald diese über die Bronchien in den Lungenbläschen in der Lunge angelangt ist, wird der Sauerstoff über die Blutbahn im ganzen Körper verteilt. Unterhalb der Lunge befindet sich das Zwerchfell, das auch unabdingbar ist für Atmung.
Aufbau der Lunge
Die Lunge liegt im Brustkorb (lat. Thorax) gut geschützt und umhüllt von den Rippen. Auf der rechten und linken Seite befinden sich zwei identische Lungenflügel, die mit der Luftröhre durch jeweils eine Hauptbronchie verbunden sind. Diese verzweigen sich in den Lungenflügeln in immer dünnere Bronchien, deren Enden mit Lungenbläschen (Alveolen) bestückt sind.
Atmung
Beim Einatmen strömt die Luft durch die oberen Atemwege und die Lunge. Dabei weiten sich Brustkorb und Lunge. Die Veränderung des Lungenvolumens und des Luftdrucks innerhalb der Lunge entsteht bei der Ausdehnung (Einatmen) und der Verengung (Ausatmen) des Brustraums. Im Ruhezustand beträgt das Lungenvolumen ca. 4 Liter, bei sehr starkem Einatmen bis zu 7 Liter und bei kräftigem Ausatmen wird es bis auf 2 Liter zusammengepresst. Unterhalb der Lunge befindet sich das Zwerchfell, das mit den Zwischenrippen- und Bauchmuskeln für die Atembewegungen zuständig ist. Sie sorgen nämlich für die Druckdifferenz, welche die Lunge nicht von selbst initiieren kann. Die Atempumpe steuert die Bewegung in der Lunge, und damit die Ventilation, bestehend aus zwei Systemen: der Brustwand und dem Lungensystem.
In der Lunge geht die äußere Atmung vonstatten. Hier findet ein Gasaustausch statt. Sauerstoff wird in das Blut aufgenommen und durch das Ausatmen wird Kohlenstoffdioxid aus dem Blut freigesetzt. Daraufhin folgt die innere Atmung, welche auch als Zellatmung bezeichnet wird, da sie sich im Inneren der Zellen abspielt. Hierbei transportiert das Blut den Sauerstoff von der Lunge zu den Zellen. Innerhalb der Mitochondrien wird mittels Sauerstoff Glucose sukzessiv zu Kohlenstoffdioxid und Wasser abgebaut und die darin gespeicherte Energie biochemisch freigesetzt.
Im Durchschnitt atmet man 12-20 mal in der Minute. 40 Prozent davon macht das Einatmen aus, 60 Prozent die Ausatmung. Beim Sprechen wird allerdings viel mehr Einatmung benötigt, da der Zeitraum bis zum nächsten Atemzug durch das Reden verlängert wird. Die Töne, die wir fürs Sprechen brauchen, werden durch einströmende und ausströmende Luft erzeugt.
Inspiration und Expiration
Als Inspiration bezeichnet man den aktiven Vorgang des Einatmens bei dem Luft in die Lunge gelangt. Bei der Inspiration sind Zwerchfell (Diaphragma), Zwischenrippenmuskeln (Musculi Intercostales) und ein Teil der inneren Zwischenrippenmuskulatur, die zwischen den Rippenknorpeln verläuft, aktiv und angespannt. Das Lungenvolumen vergrößert sich und kann Atemluft aufnehmen.
Als Expiration bezeichnet man den passiven Teil des Atemzyklus, bei dem die Luft Lunge und Atemwege verlässt. Bei Entspannung der Brustmuskulatur und Zwerchfell, lassen elastische Rückstellkräfte von Lunge und Brustkorb das Lungenvolumen schrumpfen und bewegen somit die Luft wieder nach außen.
Quellen
Atemmuskulatur, abgerufen am 01.02.2023, von https://de.wikipedia.org/wiki/Atemmuskulatur
Chapter 2 Respiratory Anatomy ,Perkins,
Innere und Äußere Atmung, abgerufen am 01.02.2023 von https://studyflix.de/biologie/innere-und-ausere-atmung-5025
Referat und Folien von Katalinka Malitzki
0 notes
Text
Thema 2 Phonation und Stimmgebung
PHYSIOLOGIE DES KEHLKOPFS
Der Kehlkopf (Larynx) ist ein knorpelig-muskuläres Verschlusssystem, das sich in der mittleren Halsregion zwischen Rachen (Pharynx) und Luftröhre (Trachea) befindet. Die Kehlkopfknorpel sind untereinander sowie mit Rachen und Zungenbein durch verschiedene elastische Bänder und Muskeln miteinander verbunden und dadurch in der Lage sich zu bewegen. Extrinsische Larynxmuskeln (Außenmuskulatur) steuern die gänzliche und vertikale Kehlkopfbewegung. Intrinsische Larynxmuskeln (Innenmuskulatur) sind zuständig für die Steuerung der Abduktion, Adduktion und Spannung der Stimmlippen.
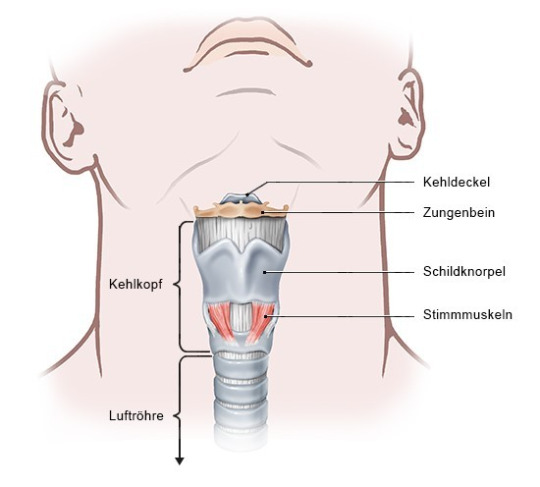
Er besteht aus den folgenden vier Knorpelteilen:
Schildknorpel (Cartilago thyreoidea) = äußerer Vorsprung (“Adamsapfel” bei männlichen Personen) und umschließt einen großen Teil des Kehlkopfknorpels
Ringknorpel (Cartilago cricoidea) = ringartiger Kreis mit Siegelteil auf der Rückseite
Kehldeckelknorpel (Cartilago epiglottica) = blattförmige elastische Knorpelplatte, die während des Schluckakts auf den Eingang der Luftröhre gedrückt wird und diesen verschließt
Stellknorpel (Cartilagines arytaenoideae) = Stimmlippen (M.cricothyroideus) befinden sich am vorderen Teil des Stellknorpels, der Raum dazwischen wird als Stimmritze (Glottis) bezeichnet, Adduktion (aneinander angenähert) der Stimmlippen in verschiedene phonatorische Positionen, Abduktion (voneinander entfernen) der Stimmlippen für stimmlose Laute oder Atmung.
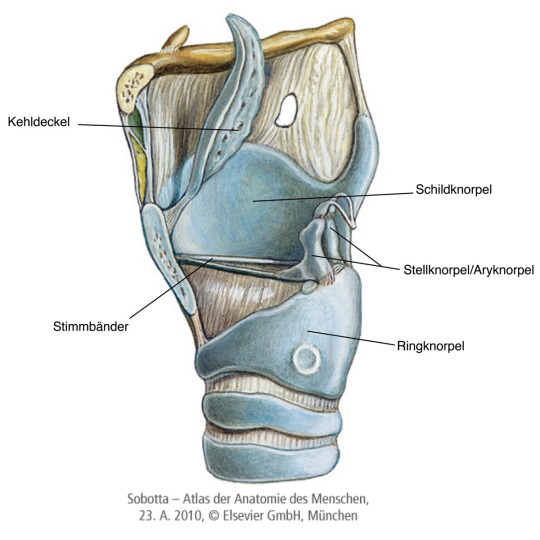
Funktionen des Kehlkopfs:
Reguliert die Belüftung der Lunge und dient der Atmung. Während des Einatmens ist der Kehldeckel (Epiglottis) geöffnet und die Stimmlippen und Stellknorpel liegen in voller Länge auseinander, sodass die Atemluft ungehindert in die Luftröhre strömen kann.
Um zu verhindern, dass Nahrungsbestandteile, Flüssigkeiten oder andere Fremdkörper in die Luftröhre und Lunge gelangen und nur ausschließlich in der Speiseröhre (Ösophagus) landen, klappt der am oberen Ende des Kehlkopfes befestigte Kehldeckel (Epiglottis) während des Schluckens herunter und verschließt die Öffnung zur Luftröhre.
Der Kehlkopf trägt als Tonerzeuger einen wesentlichen Teil zur Stimmbildung bei. Etwa in der Mitte des Kehlkopfes befinden sich die Stimmlippen. Betrachtet man den Kehlkopf von oben, ähneln die in Querfalten gelegte Schleimhaut der Stimmlippen einem Vorhang. Diese sind während des Einatmens geöffnet und beim Ausatmen gespannt. Die dabei aus der Lunge strömende Luft drückt gegen die geschlossenen Stimmlippen (subglottischer Druck) bis diese auseinander gehen, passiert die Glottis und versetzt die Stimmlippen in Schwingungen, die im Zusammenspiel mit den Bewegungen von Zunge und Mund unterschiedliche Klänge und Geräusche in variierenden Lautstärken fabrizieren und schlussendlich als Gesprochenes oder Gesang wahrgenommen wird. Damit der Phonationsvorgang gelingt, muss währenddessen die Atemregulation gleich bleiben sowie der Schluckreflex unterdrückt bleiben.
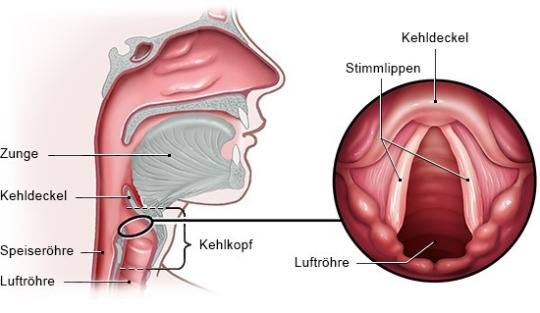
Phonation und Perzeption:
Wahrgenommene Tonhöhe: Je kürzer die Stimmlippen sind, desto schneller schwingen sie (wie bei z.B. Säuglingen oder Kindern) Je schneller die Stimmlippen schwingen, desto höher ist der Ton.
Wahrgenommene Lautstärke: Je höher der subglottale Druck (Volumen und Strömungsgeschwindigkeit der austretenden Luft), desto lauter die Stimme.
Wahrgenommene Stimmqualität: Die Qualität ändert sich mit zunehmendem Alter und variiert je nach Phonationsart, die z.B. wie folgt aussehen können:
Behauchte Stimme = Stimmlippen sind mäßig gespannt und nie vollständig geschlossen
Raue Stimme = Sehr starke Stimmlippenspannung
Heisere Stimme = Zusammenwirken von den Merkmalen der behauchten und rauen Stimme
Quellen:
Wie funktioniert der Kehlkopf, (01.12.2021.) abgerufen am 10.02.2023, von: https://www.gesundheitsinformation.de/wie-funktioniert-der-kehlkopf.html
Aufbau und Funktion des Kehlkopfs, (06.02.2020), abgerufen am 8.02.2023, von: https://www.apotheken.de/krankheiten/hintergrundwissen/4217-aufbau-und-funktion-des-kehlkopfs
Kehlkopf (Larynx): Lage, Form und Kehlkopfknorpel, (2014), abgerufen am 12.02.2023, von:https://www.thieme-connect.de/products/ebooks/lookinside/10.1055/b-0034-88222
Kehlkopfmuskeln, (18.01.2023), abgerufen am 01.02.2023, von:https://flexikon.doccheck.com/de/Kehlkopfmuskeln
Jaeger, (2012), abgerufen am 07.02.2023, von:https://www.phonetik.uni-muenchen.de/~jaeger/index-Dateien/Transkription/Transkription_II_SoSe12/Sitzung%207/Handout_Sitzung%207_Trans_II_SoSe12_Jaeger.pdf
Phonation und Stimmqualität, (25.5.2021), abgerufen am 10.02.2023 von:https://www.coli.uni-saarland.de/courses/einf_phon_phon/2021_SS/slides/phonation.pdf
Referat und Folien von Maria Pavlova und Lisanne von Friedling
0 notes
Text
Thema 3 Artikulation und Resonanzräume
ANATOMIE UND PHYSIOLOGIE
Artikulation ist die Bildung von Lauten und Wörtern der menschlichen Sprache und entsteht durch eine Modifikation des Luftstroms. Man kann sich die Sprachschall-Erzeugung als ein Quelle-Filter-System vorstellen. Die Quelle erzeugt ein Schallsignal, das in dem Vokaltrakt gefiltert und zur Sprache modifiziert wird. Die Quelle befindet sich im Bereich des Vokaltrakts. Dem folgenden Abbild kann man die essenziellen Bestandteile der Artikulation entnehmen:
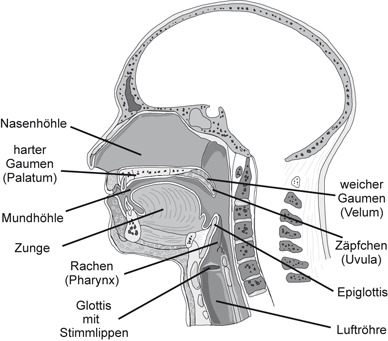
Der Vokaltrakt/Artikulationstrakt/Sprechakt ist der Teil vom Sprechapparat, der oberhalb des Kehlkopfes liegt. Von der Stimmritze im Kehlkopf bis zu den Lippen und der Nase verlaufen die Hohlräume. Man unterteilt diese Hohlräume wiederum in Rachen-, Nasen- und Mundhöhle. Der Vokaltrakt kann mit Hilfe der Lippen und Zunge verengt und geschlossen werden.
Ähnlich wie die Hohlräume wird auch der Rachen (Pharynx) in drei Teile, bestehend aus Nasopharynx, Oropharynx und Laryngopharynx unterteilt. Er verläuft von der Schädelbasis bis hin zur Speise- Luftröhre und ist ca. 12 - 15 cm lang.
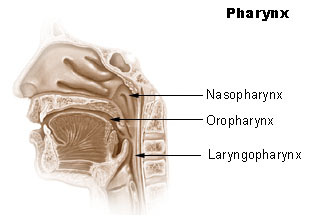
Der Nasenraum (Nasopharynx) ist ein Teil vom Atemtrakt und sorgt für die Trennung der Atem- und Speisewege. Hier liegt auch das menschliche Geruchsorgan. Im Sprechapparat gibt der Nasenraum der Stimme Resonanzraum und wird für nasale Konsonanten und nasale Vokalen benutzt. Um Schall zu erzeugen, ist subglottaler Druck notwendig. Subglottaler Druck wird durch eine Trennung vom Nasenraum und Mundraum erzeugt. Frikative und Affrikate entstehen, wenn der Artikulationsort verengert wird. Die andere Möglichkeit für die Erzeugung von Konsonanten ist Burst.

Primäre Determinanten von Vokalen und Konsonanten.
1.Stimmhaft oder Stimmlos
2.Art der Artikulation
3.Vertikaler Ort der Artikulation
4.Horizontaler Ort der Artikulation
Connected Speech = Wenn wir reden, werden nicht alle Buchstaben immer gleich ausgesprochen. Beim Hören verstehen wir, was gesagt wird, indem wir jedes Wort in erkennbare Segmente teilen.
Koartikulation = Menschen sprechen mit 6-7 Silben bzw. 10-14 Lauten pro Sekunde. Koartikulation bezeichnet die Überlappung verschiedener Laute.
Im Mundraum (Oropharynx) befinden sich einige der wichtigen Artikulationsorganen: die Zunge, die Lippen, die Zähne, der Gaumen, das Gaumensegel und das Gaumenzäpfchen. Die Zunge kann besonders gut das Volumen von Mund und Rachenraum variieren, sie koordiniert den Sprechakt, sie hilft uns beim Saugen, Schlucken und beim Schmecken.
Der Rachenraum (Laryngopharynx) erstreckt sich von Zungenbasis und -bein abwärts bis zur Kehlkopf- und Speiseröhrenöffnung. In diesem Abschnitt befindet sich die Rachenmuskulatur. Sie dient dem Verschließen des Kehlkopfes, schiebt Nahrung in die Speiseröhre und nimmt bei dem Schluckakt eine wichtige Funktion ein.
Die Gesichtsmuskeln zählen auch zu den relevanten Teilen vom Sprechapparat. Den vorderen Bereich der Muskeln bildet die Stelle an Lippen und Schneidezähnen. Am hinteren Gaumenbogen befindet sich die hintere Grenze der Mundhöhle. Die Gesichtsmuskulatur wird in drei Bereiche aufgeteilt:
Buccinator (Wangenmuskel) ist ein mimischer Muskel, der uns beim Ausdrücken von bestimmten Aktivitäten hilft wie z.B. dem Weinen, Lachen, Pfeifen und Pusten.
Orbicularis Oris (Mundringmuskel) ist ein Schließmuskel, der zu den Lippen gehört. Er gehört zu den mimischen Muskeln und spielt außerdem eine Rolle beim Aussprechen, z.B. beim Bilden von Vokalen wie o und u.
Musculus Risorius (Lachmuskel) ein weiterer mimischer Gesichtsmuskel. Auch wenn dieser vergleichsweise relativ klein und schwach ist, sorgt er dafür, dass wir damit eine der stärksten Gesten ausüben können: Lachen!
Quellen
Vokaltrakt, (2000), abgerufen am 02.02.2023, von: https://www.researchgate.net/figure/Abbildung-14-Vokaltrakt-Mathelitsch-Friedrich-2000-23_fig4_353530427
Referat und Folien von Viktoria Titova und Maria Zaragoza
0 notes
Text
Thema 4 Indirekte Erfassung von Bewegung
ELEKTROGLOTTOGRAPHIE
Die Elektroglottographie (ELG) ist ein Verfahren, bei dem die Aktivität des Kehlkopfs beim Sprechen beobachtet wird. Aus den Darstellungen des Vibrationszyklus der Stimmlippen lassen sich wertvolle Informationen über den linguistischen Gebrauch der Stimme gewinnen. 1950 wurde die Elektroglottographie entwickelt, erstmalig angewendet und in den darauffolgenden Jahrzehnten immer wieder weiterentwickelt und optimiert.
Wie funktioniert es?
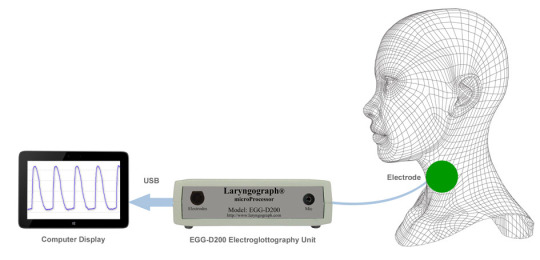
Bei diesem nicht-invasiven Verfahren werden Oberflächenelektroden über den beiden Flügeln des Schildknorpels angebracht. Zwischen den Elektroden wird die Wechselstromwiderstand der Stimmlippen gemessen. Das Ergebnis ist ein “Lx-Laryngographisches” Signal, das die horizontale Öffnungs- und Schließbewegung der Stimmlippen anzeigt. Je schneller sich das Lx-Signal ändert, desto größer ist die Lx-Geschindigkeit.
Wenn die Glottis geschlossen ist, kommen positive Werte, wenn er offen ist kommt negative Werte. In der Schließungsphase schließt sich nur ein kleiner Teil der Stimmlippen. Vorne bleiben die Stimmlippen ständig offen. In der Öffnungsphase, bleibt der hintere Teil geschlossen.
Es wird vor allem im Bereich der Medizin Phonetik benutzt. In der Medizin für Kehlkopf-Stimmlippen-Diagnostik/Behandlung. In der Phonetik werden die Stimmlippenaktivität während der Artikulation von Sprachlauten analysiert. Basierend darauf können Stimmlosigkeit und Stimmhaftigkeit verdeutlicht werden. In der Sprachtechnologie dient das Verfahren der Segmentierung von Sprachsignalen.
STIMMKLANG
Stimmhöhe und Tiefe
Mit der Veränderung der Intonation lassen sich bestimmte Stimmungen zum Ausdruck bringen, z.B. Erstaunen oder Höflichkeit. Solche Veränderungen bedeuten jedoch teils eine besondere Anspannung im Kehlkopfbereich. Im Normalfall greift man daher beim Sprechen auf die Indifferenzlage zurück. Hierbei handelt es sich um die mittlere Sprechstimmlage eines Menschen, die individuell veranlagt ist und am schonendsten auf die Stimmbänder wirkt.

Verschiedenen Stimmhöhen werden bestimmte Eigenschaften zugeschrieben. Ähnlich verhält es sich bei der Lautstärke. Sehr laute oder sehr leise Stimmen, die der jeweiligen Gesprächssituation entsprechend sind, werden eher negativ aufgefasst und beurteilt. Grundsätzlich aber wird kräftigen Stimmen Dominanz und Vitalität zugesprochen.
Die Tonhöhe wird generell bestimmten Geschlechterrollen zugeschrieben. Eine Theorie besagt, dass Frauen unbewusst eine “Kleine-Mädchen” Stimme benutzen, um eine untergeordnete Rolle einzunehmen. Eine sehr hohe Stimmlage kann auch dazu führen, dass die Person jünger eingeschätzt wird. Bei männlichen Personen wird eher vom Gegenteil ausgegangen, denn tiefe Männerstimmen werden als angenehm und souverän empfunden.
Eine Abbildung vom Ablauf und Entstehung der Stimmgebung:
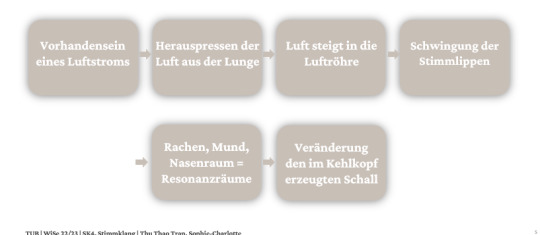
Die Stimmgebung ist die Erzeugung von Lauten und geschieht durch Schwingungen der Stimmlippen. Mit Glottis bezeichnet man den Raum zwischen den Stimmlippen und den Stellknorpeln (Auch Stimmritze genannt). Die Veränderung der Stimmritze ist eine wichtige Voraussetzung für die Stimmbildung.
Durch diese Schwingungen der Stimmlippen entstehen Druckunterschiede, die sich als Schallwellen fortpflanzen und vom Gehör aufgenommen werden. Die Durchschnittswerte für die Häufigkeit des Schließens der Stimmlippen während des Sprechens sind beim Mann 120 und bei der Frau 220 mal in der Sekunde.
Eine Übersicht möglicher Stimmgebungen und deren Wirkung:
Die neutrale Stimmgebung
Schwingungen erstrecken sich über die gesamte Länge der Stimmritze
Adduktion: Der Stimmritze wird geschlossen
Mediale Spannung: Der Stellknorpel wird gedreht
Längsspannung der Stimmlippen durch aktive und passive Längsspannung.
Die Tonhöhe kann unter anderem durch eine aktive Spannung der Stimmlippen und den Atemdruck verändert werden, auch von der Länge der Stimmlippen abhängig.
Die knarrende Stimme
Entspannte und dicke Stimmlippen, geringe Schwingungshäufigkeit
Grad des Knarrens und zeitliche Verteilung ist unterschiedlich
Vermittelt ein Gefühl von Ruhe und Gelassenheit
Häufigste Abweichung von der neutralen Stimmgebung
Die behauchte Stimme
Sprechapparat und Kehlkopfmuskulatur weitgehend entspannt
Ganzer Luftdruck ist einbezogen beim Schallgebungsprozess, schwankt jedoch häufig und ist schwächer als bei der neutralen Stimmgebung
Kann in entsprechenden Situationen Intimität und romantische Stimmungen hervorrufen, vor allem bei Frauen wird diese Art der Stimmgebung positiv gewertet
Die Flüsterstimme
Flüsterdreieck = viel Luft entweicht mit rascher Pressung durch Glottis mit totalem Verschluss der Stimmlippen, nur im unteren der Teil der Glottis eine dreieckförmige Öffnung durch zusätzliche Auswärtsdrehung der Stellknorpel
Dadurch herrscht erhöhte Muskelanspannung
Auf paralinguistischer Ebene: Flüstern wird situationsgemäß als Ausdruck von Heimlichkeit oder Vertraulichkeit wahrgenommen
Falsett
“Falsche Stimme” wird eher im Bereich des Singens oder Schauspiels angewendet und ist eher untypisch in der normalen Kommunikation
Relativ hoher Ton aufgrund geringer Schwingung
Wird häufig von Männern genutzt zur Nachahmung der weiblichen Sprechstimme
Die raue Stimme
Starkes Gegeneinanderziehen der Stimmlippen, unregelmäßige Schwingungen
Paralinguistisch als Wut und Ärger verstanden, wird mit Anspannung assoziiert
bei längerem Gebrauch kann sie zu Schädigungen der Stimmbänder führen bzw. sind die Stimmbänder krankheitsbedingt angegriffen und die Stimme wird rau
Quellen
Referat und Folien von Luca Toni
Referat und Folien von Thu Thao Tran, Sophie Giannakoulopoulos und Yaren Yalcinkaya
0 notes
Text
Thema 5 Direkte Erfassung von Form
BILDGEBENDE VERFAHREN X-RAX, CT UND MRT
Röntgenstrahlung wurde 1895 von dem deutschen Physiker Wilhelm Conrad Röntgen entdeckt. Bei dem Verfahren der Radiographie erfolgt die Erzeugung der Strahlen mittels Röntgenröhren. Die Ergebnisse werden analog auf Röntgenfilm oder auf einer Röntgenspeicherrolle festgehalten.
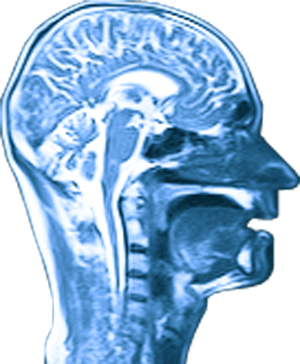
Bei Computertomographie geschieht die Erzeugung von Röntgenstrahlungen aus vielen Richtungen. Hierbei findet die Bildentwicklung auf digitaler Ebene statt. Die Abbildung wird mittels eines Computers zu einer digitale Aufnahme umgewandelt. Dies ermöglicht uns das Bild in 3D zu sehen.
1890 wurde das Verfahren der Cineradiographie entwickelt, das sich seit 1940 etabliert hat. Durch das Zusammenstellen von Aufnahmen mehrerer Bilder, im 20. Jahrhundert wurde auch noch der Ton inkludiert, konnten ganze Filme mit bewegenden Objekten fabriziert werden.
In der Medizin ist Bildgebende Verfahren eine apparative Untersuchungsmethode. Ein Bild wird gemacht, bestehend aus entweder 2 oder 3D.
Docvacim und X-Articulators sind Datenbanke und ein Programme zur Untersuchung der Artikulation. EMA ist für den Untersuchungsbereich Lippen bis harter Gaumen, mit MRI kann der Vokaltrakt geometrisch abgebildet werden und mit Cineradiographie ist es möglich der gesamter Vokaltrakt zu untersuchen.
Mit X-Articulators wird der ganzen Mandibel getrackt; die Weichteile (Lippen, Larynx und Epiglottis) und die Zunge.
Die Vorteile beim X-Articulators sind unter anderem: Abbildung des gesamten Vokaltraktes, dass die harten und weichen Teile beide sichtbar sind, eine große Datenmenge ist vorhanden und es ist möglich, diese Software weiterzuentwickeln. Es ist natürlich ein großer Nachteil, dass die Versuchsperson den Strahlen ausgesetzt ist. Außerdem kostet das Verfahren sehr viel Energie und Geld.
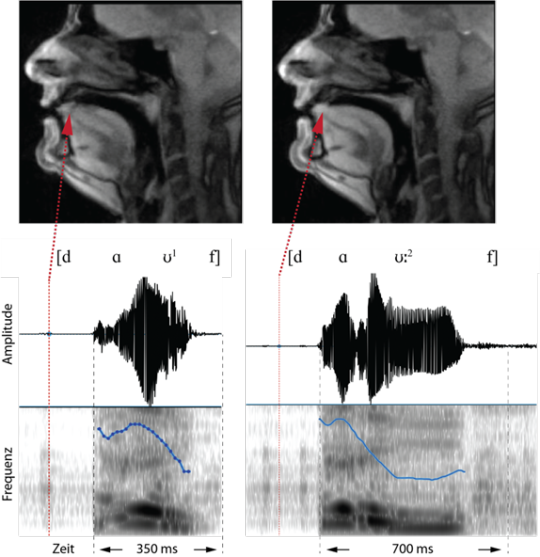
MRT
Magnetresonanztomographie arbeitet mit Magnetfeldern und Radiowellen und nicht mit Röntgenstrahlen. Das bedeutet keine Strahlung für der/die Patient*in.
Im Körper ist ein minimales Magnetfeld, das von den drehenden Atomkernen im Körper kommt. Das MRT-Gerät benutzt auch ein Magnetfeld und die magnetische Wasserstoffkernen im Magnetfeld im Körper verändern sich und dabei senden sie spezielle Signale aus, die während der Untersuchung gemessen werden, und daraus entstehen am Ende Bilder auf einem Schirm.
Die Vorteile beim MRT Verfahren sind, dass es eben überhaupt nicht gefährlich ist wegen Strahlung, dass eine 3D-Darstellung möglich ist und dass ein hoher Weichteilkontrast möglich ist. Die Kosten und die geringe Auflösung sind eher von Nachteil.
Quellen
Elektroglottographie, Wikipedia, abgerufen am 26.01.2023, von: https://de.wikipedia.org/wiki/Elektroglottographie#Funktion_und_Anwendung
Seeing speech, (2018), abgerufen am 14.02.2023, von: https://www.seeingspeech.ac.uk/
Kernspintomographie/Magnetresonanztomographie, (o.D.), abgerufen am 08.02.2023, von: https://www.die-radiologie.de/kernspintomographie
Echtzeit MRT in der Phonetik: Einblicke in Details der Artikulation, (01.02.2022) abgerufen am 12.02.2023 von: https://www.sprachspuren.de/mrt/
Referat und Folien von Sophie Hoppe
Referat und Folien von Julian Kistler
0 notes
Text
Thema 6 Direkte Erfassung von Bewegung
POINT - TRACKING - VERFAHREN "EMA" & "MOTION CAPTURING"
Beim Point-tracking Verfahren werden Artikulatoren Punkte zugeteilt, es erfolgt ein Tracken dieser Punkte. Dabei werden verschiedene Spannungsgebiete und artikulatorische Bewegungsabläufe gemessen. Spezielle Systeme, die die Messqualität im Vokaltrakt erhöhen, kommen hier zum Einsatz. Anwendungsbereiche davon sind z.B. die Kieferorthopädische Diagnostik, Phonetik, Sprachtherapie oder Linguistik.
EMA (Elektromagnetische Artikulographie)
Das Verfahren arbeitet nach dem Prinzip der elektromagnetischen Induktion. Es trackt die Bewegung der Artikulatoren, indem es die Bewegungsverlauf der Empfängerspulen durch Magnetfelder misst. Sendespulen erzeugen ein inhomogenes Magnetfeld. Bewegungen werden gemessen und graphisch dargestellt. Das System besteht aus Transmittergehäuse und Sensoren, Kopfhalterung, Transmitter- und Empfängerelektronik und Präzisionsgeräte für das Kalibrieren der Magnetfelder und die Befestigung der Sensoren der Artikulatoren.
Vorteilhaft an EMA ist der Aspekt, dass es sich hierbei um ein non-invasives Verfahren handelt, und es nicht die Sprechbewegungen beeinflusst, während man die artikulatorischen Bewegungen im Vokaltrakt misst. Außerdem kann es den sichtbaren und nicht sichtbaren Artikulatoren abbilden. Die Nachteile sind unter anderem, dass es keine vollständige Erfassung der Zunge gibt und nur Messwerte einzelner Punkt im Vokaltrakt gewonnen werden können, sowie die Erforderlichkeit einer Kooperationsbereitschaft des Probanden.

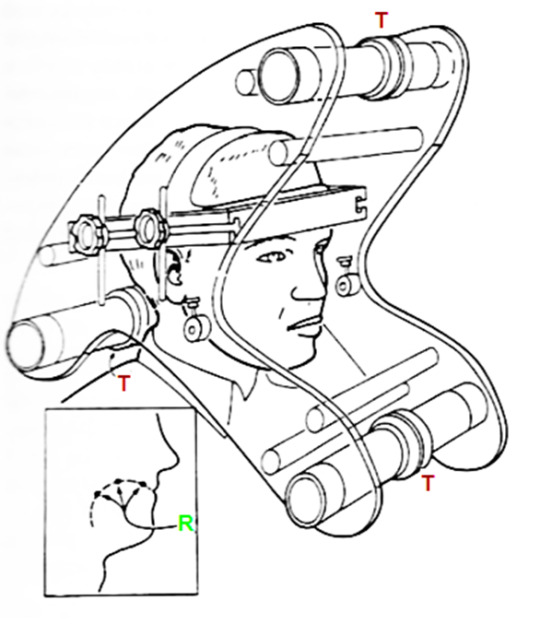
Perkells Articulometer
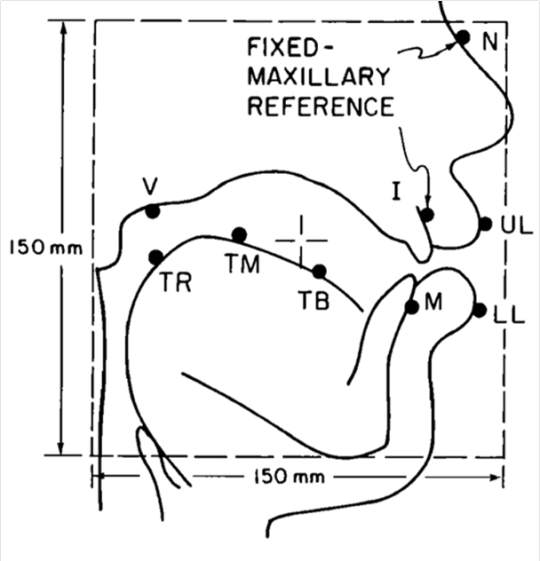
Es ist ein Gestell und wird auf den Kopf des*der Sprecher*in gesetzt. Auf dem Nasenrücken und den Schneidezähnen werden Fixpunkte installiert. Drei Transmitter-Spulen (T) erschaffen jeweils ein magnetisches Wechselfeld, drei überlappende Felder stellen sicher, dass die genaue Lokalisation der Receiver Spulen (R) erfolgt. Die neun Punkte auf der zweiten Abbildung markieren mögliche Messpunkte (Unterkiefer, Lippen, Zunge, Gaumen)
MOTION CAPTURING
Motion Capturing bedeutet wortwörtlich übersetzt “Bewegung” (Motion) und “Einfangen/Erfassen” (Capturing)
Bei diesem Verfahren werden mit Hilfe von Spezialkameras Ortswechsel in Echtzeit aufgenommen. Performer*Innen tragen einen Anzug mit Sensoren, aus deren Analyse dreidimensionale Bewegungsaufzeichnung gewonnen werden.
Es gibt verschiedene Arten von Sensorsystemen, das gängigste darunter ist das “Optische System”. Hierbei geschieht das Erfassen entweder mit aktiven Markern (Leuchtdioden auf Körper des Performers, werden direkt von Kamera erfasst) oder passiven Markern (Marker werden erst durch Infrarotpulse der Kamera reflektiert und erleuchtet). Es wird hauptsächlich in Animationen für Computerspiele und Filmen benutzt. Die Bewegungsaktivitäten eines virtuellen oder fiktiven Charakters können dadurch komplex und real dargestellt werden. In anderen Bereichen wie Biomedizin, Ingenieurwesen und Militär wird das Motion Capturing Verfahren genutzt.

Auch in der Sprachwissenschaft werden folgende sogenannte Point-Tracking-Verfahren benutzt zur Messung des Artikukationstrakt:
EMMA (Electromagnetic Midsagittal Articulometer) misst einzelne Punkte der artikulatorische Bewegungsabläufe beim Schlucken und Sprechen, zeichnet Lippen-, Zungen- und Kieferbewegungen auf, die Datenerhebung nur in der Mitte des Artikulationstrakt statt
Beim X-Ray Microbeam handelt es sich um die Verwendung von Röntgenstrahlen. Dass die Proband*Innen den Strahlen ausgesetzt sind, ist kein vorteilhafter Aspekt.
Optotrak Messmaschine weist durch die dreidimensionale Punktverfolgung eine hohe Effektivität auf. Jedoch kann diese Gerätschaft nicht direkt im Mund- und Rachenraum genutzt werden.
Alle Point-Tracking Verfahren zeigen wie Artikulation und Sprachrhythmus organisiert werden, weisen auf welche Unterschiede, Gemeinsamkeiten oder Korrelationen es zwischen Sprecher*Innen, Sprachen und Sprachfehlern bestehen und dienen der Sprachanalyse.
Quellen
Motion Capture, (o.D), abgerufen am 03.02.2023, von: https://ar-tracking.com/en/product-program/motion-capture
Referat und Folien von Susi-Roberta Sieg
Referat und Folien von Marc Krause
0 notes
Text
Thema 7 komplexe physiologische Messungen
ELEKTROMYOGRAFIE
Die Elektromyografie (EMG) ist eine biomechanische Methode zur Messung und Beurteilung der Muskelaktivität. Die Muskelfaser - Aktionsströme werden ermittelt und in Form eines Elektromyogramm graphisch dargestellt. Im neurologischen Diagnostik- Kontext wird diese Untersuchung primär durchgeführt, um festzustellen, ob eine muskuläre (Myopathie) oder nervliche (Neuropathie) Krankheit vorliegt.
In der Sprachproduktionsforschung wird mit Hilfe des EMG-Verfahrens ermittelt, welche Muskeln in welcher Intensität und Zeitabfolge mitwirken während des Artikulationsprozesses (u.a. Lippen-, Zungen- und Gaumenmuskulatur).
Elektrische Muskelaktivität
Um einen Muskel zu bewegen, leitet das Gehirn einen elektrischen Impuls über einen Nerv bis zur neuromuskulären Platte, der Schnittstelle zwischen einer Muskelzelle und einem motorischen Nerv. Dieser Impuls löst die Ausschüttung von Botenstoffen aus, die dafür sorgen, dass Ionenkanäle in der Muskelfasermembran geöffnet werden und es entsteht dort ein Ionenfluss. Dieser führt wiederum zu einer elektrischen Spannung, auch Muskelaktionspotential genannt, die sich über die gesamte Muskelzelle ausbreitet und Muskelzuckungen auslöst. Beim EMG werden diese Potentiale erfasst und ausgewertet.
Es gibt zwei unterschiedliche Verfahrensarten, um die Messung durchzuführen: Nadel- und Oberflächen-EMG.
Nadel - EMG
Hierbei wird eine feine, konzentrische Nadelelektrode durch die Haut in den Muskel gestochen. Die elektrische Muskelaktivität wird im Ruhezustand sowie in Bewegung gemessen (auch Muskelaktionspotential genannt), sodass aus den Ergebnissen Rückschlüsse über den Zustand des Muskels gezogen werden können. Je nach bestimmten Nadeltypen können auch besonders kleine oder tiefer liegende Muskelfasern akkurat gemessen werden.
Oberflächen - EMG
Hier werden Oberflächenelektroden auf die Haut geklebt, die die elektrische Muskelaktivität (Muskelsummenpotential) ableiten. Man kann vorteilhafterweise bei diesem nicht-invasiven Verfahren größere Muskelbereiche untersuchen und hat währenddessen mehr Bewegungsspielraum. Allerdings sind Messergebnisse längst nicht präzise, zumal hier nicht die Aktivität einer einzelnen Muskelfaser festgestellt werden kann. Daher wird dies bei diagnostischen Untersuchungen zur Feststellung von Krankheiten nicht angewendet.
In der Sprachforschung wird EMG benutzt, um der Kontraktion zu untersuchen: Hiermit kann man herausfinden wann die Kontraktion startet und stoppt, wie stark sie ist und wie lange es dauert.
Quellen:
Elektromyografie, (21.10.2021.) abgerufen am 25.01.2023, von:https://www.netdoktor.de/diagnostik/elektromyografie/
Elektromygraphen (EMG-Geräte) und evozierte potentiale (EP), (2002) abgerufen am 28.01.2023, von:https://link.springer.com/chapter/10.1007/978-3-662-12453-6_10#:~:text=Daher%20ist%20auch%20der%20Begriff,hier%20ist%20die%20Nadelmyographie%20unumg%C3%A4nglich.
Elektromygraphie, (o.D.), abgerufen am 03.03.2023, von: https://gesundpedia.de/Elektromyographie_(EMG)
Muskelfunktionsdiagnostik, (o.D.), abgerufen am 01.03.2023., von:https://suedstadt-orthopaeden.de/muskelfunktionsdiagnostik-emg-analyse/
Referat und Folien von Hannah Friedländer
0 notes
Text
Thema 8 Stimm- und Sprechwirkung
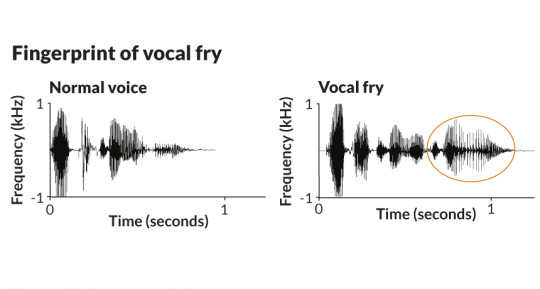
VOKAL FRY / KNARRSTIMME
Vocal Fry oder auch Knarrstimme genannt, entsteht durch eine geringe Längsspannung, Verengung (Laryngalisierung) und daraus resultierende unregelmäßige Schwingung von kurzen und dicken Stimmlippen. Starke Adduktion und mediale Kompression ermöglichen nur die Schwingung im vorderen Bereich der Stimmlippen mit plötzlicher Schließung und andauernden Schließungsphasen. Der knorpelige Teil der Glottis ist fest geschlossen, während ein Teil der muskulösen Glottis offen ist und mit geringer Amplitude vibriert.
Vocal Fry kann in manchen Fällen stimmschädigend sein. Es wird in sprachlichen Interaktionen verwendet, u.a. um Absatz- und Satzgrenzen zu markieren. Jedoch kann die Knarrstimme auch schlechter verstanden oder gehört werden. Die tiefere Tonlage des Vocal Frys und abweichende Grundfrequenz kann als weniger natürlich oder vertrauenswürdig wahrgenommen werden von dem gegenüber, vor allem bei weiblichen Sprecherinnen (18-46 Hz). Diese Abweichung von der modalen Intonation führt teilweise zu von Vorurteilen behafteten Annahmen wie fehlender Bildung, Kompetenz oder Attraktivität und kann daher z.B. auf dem Arbeitsmarkt zum Nachteil sein für Sprecher*Innen mit Knarrstimme. Dessen ungeachtet kann eine tiefe Stimme auch positiv mit Autorität und Dominanz assoziiert werden.
STIMME UND PERSÖNLICHKEIT
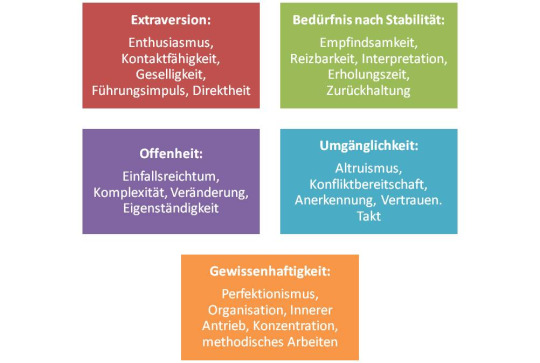
Per allgemeiner Definition sind die Stimme Ausdrucksmittel unseres menschlichen Wesens und die Persönlichkeit die Verkörperung unserer selbst. Seit der Antike wurden durch aufgestellte Theorien über die Persönlichkeit wie die “Humoraltheorie”, der später daraus abgeleiteten “Vier - Temperamenten Typologie” von Hans J. Eysenck und verschiedener Persönlichkeitstests (z.B. Big Five oder Myers Briggs Test) Menschen und ihre Persönlichkeit kategorisiert.
("Big Five" Modell, Test dazu auf www.test123.com)
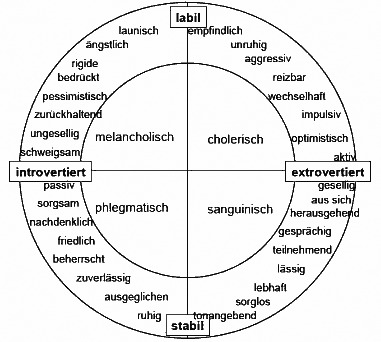
("Vier - Temperamenten - Typologie" nach Hans J. Eysenck)
Persönlichkeitsbeurteilung
Anhand eines stimmlichen Parameters kann man Stimmen und deren Perzeption festmachen. In der Regel werden charakteristische stimmliche Abweichungen von der Norm der jeweiligen Zuhörer- und Sprechergemeinschaft negativ aufgefasst und bewertet. Stimmen werden mit Persönlichkeitsmerkmalen verbunden, sodass wir aus der Stimme des*der Sprecher*in ´eine Persönlichkeit und unsere eigene visuelle Vorstellung ableiten.
Es wird beurteilt nach:
Grundfrequenz f0 und Pitch
Lautstärke und Intensität
Vocal Fry/Laryngalisierung
Behauchung
Rauheit
Intonation
Eine durchschnittliche Stimmhöhe wird als natürlich und angenehm wahrgenommen.
Tiefe Stimmen bei Männern wirken kompetent, offen, durchsetzungsfähig und mutig.
Eine deutliche Intonation wird assoziiert mit Qualitäten wie Kompetenz, Selbstbewusstsein und Temperament. Spricht man nämlich in monotoner Stimmlage ohne variierende Tonhöhen, wird es als langweilig und einschläfernd empfunden.
Zu kleine Resonanzräume und geringe Lautstärke werden als Verschlossenheit oder Schüchternheit aufgefasst. Wenn da noch ein großer Teil an Flüster- und Rauschanteilen mitwirkt, wird dieser Eindruck umso mehr verstärkt.
Eine Knarrstimme gepaart mit Rauheit kann ein Zeichen von Wut oder Aggressivität sein.
Nasale Stimmen können in der Wahrnehmung als Arroganz empfunden werden.
Quellen:
Vocal Fry, (2014) abgerufen am 25.01.2023., von: https://www.sciencenews.org/article/vocal-fry
Audite Vocem, (o.D), abgerufen am 29.01.2023, von: https://www.coli.uni-saarland.de/groups/BM/phonetics/audite_vocem_22/audite_stimm.html
Mein Selbstversuch: Das Big-Five Persönlichkeitsmodell, (04.05.2012.) abgerufen am 12.02.2023, von: https://www.svenja-hofert.de/fuehrungundorganisation/mein-selbstversuch-das-big-5-personlichkeitsmodell/
Gesamtsysteme, (o.D.) abgerufen am 10.03.2023, von: http://www.verhaltenswissenschaft.de/Psychologie/Personlichkeit/Gesamtsysteme/gesamtsysteme.htm
Referat und Folien von Cosima Johne, Constanze Schacht und Hanna Finkmann.
Referat und Folien von Carolin Kühn
0 notes
Text
Thema 9 Stimme und Emotion
AKUSTISCHE MUSTER DES EMOTIONSAUSDRUCKS
Emotionale Zustände werden anhand der Stimme beurteilt. Die Stimme ist das primäre Instrument für den Emotionsausdruck, aufgrund ihrer kommunikativen Funktionen und physiologischen Grundlagen.
Affektausbrüche definieren sich durch einzelne oder wiederholte Lauten, die geprägt sind von einer auffallend intensiven Emotion. Verschiedene Reize können in einem meist beschränkten Zeitraum die Emotionen eines Menschen und somit seinen Zustand beeinflussen. Im wissenschaftlichen Rahmen wurden die Emotionen Ekel, Überraschung, Scham, Interesse, Freude, Angst, Traurigkeit und Wut in Zusammenhang mit der Stimme untersucht. Am besten wurden Traurigkeit und Wut erkannt, am zweitbesten Angst und Freude, Ekel wurde am schlechtesten erkannt. Die Grundfrequenz F0 hat den stärksten Einfluss auf die Beurteilung der Emotionen anhand der Stimme. In der Liste mit "unverzichtbaren" Parametern “The Genva Minimalistic Acoustic Parameter Set” (GeMAPS) finden sich die wichtigsten Merkmale von vokalen Schallwellen:
Grundfrequenz
Amplitude
Spektrum
Zeitbezogene Parameter
Laut dem TEEP-Modell (Tripartite Emotion Expression and Perception) haben emotionale Zustände eine immens starken Einfluss auf den Körper und können die Muskelspannung und Atmung verändern. In dem Fall spricht man von dem Push - Effekt: Emotionale Prozesse -> Physiologische Veränderung -> Voraussehbarer Änderung des Mechanismus Sprachproduktion
Beim Einsatz von elektroakustischer/ digitaler Geräte und/ oder menschlicher Stimme werden phonatorisch-artikulatorische Merkmale der vokalen Emotionsdarstellung gemessen.
Mit Hinblick auf Kultur- und Sprachunterschiede wurde in kulturell übergreifenden Studien festgestellt, dass die Eigenschaften von Sprache in Bezug auf emotionale Qualität variieren. Es lässt sich damit erklären, dass die Grundfrequenz und Sprechgeschwindigkeit von Sprecher*innen in verschiedenen Kulturen unterschiedlich verwendet werden.
Messungen und Studien basierend auf folgendem Parameter:
F0, Hochfrequente Energie, Artikulationsgeschwindigkeit, Variabilität von F0,
F0-Bereich:
• F0: Grundfrequenz
• Hochfrequente Energie
• Artikulationsgeschwindigkeit
• Variabilität von F0
• F0-Bereich: Frequenzbereich
Es kann zu Missverständnisse führen, wenn im Übertragungsprozess Fehler entstehen, z.B. beim Telefonat wird ein Großteil der höherfrequenten Informationen im Sprachsignal eliminiert. Es gibt natürlich großen Kultur und Sprachunterschiede, und was für Emotionen mit welche Sprachmerkmalen verbunden sind, allerdings scheint der stimmliche Ausdruck in einigen Emotionszuständen universell zu sein.
ERGEBNISSE DER PERZEPTIONSTESTS
Im alltäglichen Leben existiert kein universales Verständnis und Wahrnehmung von Gefühlen, Stimmungen und Emotionen, da diese von Mensch zu Mensch subjektiv erlebt werden. Auch in sprachlicher Hinsicht gibt es jeweils eine Bandbreite an Wörtern, die für unterschiedliche Gefühlsausdrücke stehen, jedoch mit derselben Emotion assoziiert werden.
In einer Studie soll das Wissen über den Ausdruck von Emotionen in Stimme und Sprechweise in Erfahrung gebracht und erweitert werden.

Die Versuchspersonen wurden in zehn Gruppen, einzeln am PC aufgeteilt. Innerhalb von 30 Minuten wurden über Kopfhörer in jeweils unterschiedlichen Reihenfolgen Sätze abgespielt. Die Proband*Innen hatten während dessen die Aufgabe, den emotionalen Gehalt und die Realitätsnähe der Sätze anhand vorgegebener Antworten zu beurteilen.
Die Antworten bestanden aus den Grundemotionen: Freude, Langeweile, Trauer, Ärger, Ekel
Sie mussten angeben, ob die Emotionen in den abgespielten Sätzen authentisch und überzeugend waren.
Ergebnis: Alle Emotionen wurden mit 80% erkannt. Mit Blick darauf, dass die Sätze unter unnatürlichen Umstände gesprochen und aufgenommen wurden, wurden die intendierten Emotionen von den Hörer*Innen erfasst und zu 60% als überzeugend deklariert, jedoch als unnatürlich empfunden.
Ärger wurde am besten erkannt, wahrscheinlich weil dieser leichter zu produzieren und zu erkennen ist. Denn evolutiv ist die Fähigkeit, Aggressionen auszudrücken und schnell zu erkennen von großer Wichtigkeit.
Trauer war am schwierigsten zu erkennen. Anscheinend fanden Schauspieler*innen es schwer, Trauer darzustellen.
Was auch Interessant war, war dass emotionale Äußerungen von männlichen Sprechern signifikant schlechter erkannt als die weibliche Sprecher*in waren.
Stärke der Emotionen
Ein anderen Test wurde durchgeführt um die Stärke der Emotionen herauszufinden.

Die verschiedenen Tests haben gezeigt, dass Emotionen schwer zu erfassen sind, weil es für jeden Mensch individuell ist, und dass Grundemotionen mit hoher Erregung leichter zu erkennen sind.

EMOTIONSERKENNUNG
Speech Emotion Recognition ist ein Prozess der Vorhersage menschlicher Emotionen basierend auf Sprachsignalen. Ziel in der Forschung ist die Optimierung maschineller Intelligenz, damit diese nicht nur menschliche Emotionen erkennt, sondern auch emotionale Verhaltensweise künstlich erzeugen kann.
“Big Six” Emotionskategorie nach Ekman

Nach dem US - Psychologen Ekman existieren sechs Grundemotionen, die weltweit vertreten sind und fast deckungsgleich zum Ausdruck gebracht werden. Unabhängig von Kultur, Sprache und Erziehung können Menschen diese Basisemotionen voneinander ablesen und zuordnen. Vom wissenschaftlichen Standpunkt aus erfolgt die universal verständliche Kommunikation unserer Grundemotionen primär non-verbal und aus evolutionären Gründen. Anhand bestimmter Merkmale können diese Gefühle festgemacht werden.
Datenkorpus: Die Herstellung einen Datenkorpus um Emotionen zu untersuchen gestaltet sich als schwierig, aufgrund der Knappheit an natürlichen Sprachdaten von verschiedenen Emotionen und der subjektiven Wahrnehmung dieser. Daher werden z.B. Äußerungen von Schauspieler*Innen verwendet und ausgewertet, bei denen die Texte und damit verbundenen Emotionen klar festgehalten sind (Berlin Database of Emotional Spech “EMO-DB”)
SER Funktionsweise
Nach der Segmentierung (Zerlegung) einer Audio werden ihre Merkmale extrahiert und ausgewertet. Diese werden im letzten Schritt klassifiziert und es erfolgt das Zuordnen der passenden Emotionen.
Die Forschung beschäftigt sich weiterhin konstant mit der Herausarbeitung idealer Audiomerkmale (wie z.B. Tonhöhe, Mel - Frequency - Cepstral - Koeffizienten, Signalenergie). Die LVA (Layered-Voice-Analysis) Technologie, 1997 von Amir Liberman entwickelt, kann Muster und Anomalien im Sprachfluss, verschiedene Emotions- und Stresszustände erkennen.Angesichts dieser Erkenntnisse kann ein erhöhtes Verständnis vom mentalen Zustand eines Subjekts aufgebracht werden.
Das SER - Verfahren findet seinen Nutzen in den Bereichen der Versicherungen, HR Recruiting, Call Center, Security oder Kreditvergabe.
Quellen
Six basic emotions, (o.D.), abgerufen am 13.02.2023, von: https://www.researchgate.net/figure/Six-basic-emotions-Source-https-managementmaniacom-en-six-basic-emotions_fig2_312160510
Ekman’s six basic emotions and Plutchiks wheel of emotions, (o.D.) abgerufen am 13.03.2023., von: https://www.researchgate.net/figure/Ekmans-six-basic-emotions-and-Plutchiks-wheel-of-emotions-the-middle-circle-contains-8_fig1_346179935
freepik, (o.D), abgerufen am 08.03.2023., von: https://de.freepik.com/vektoren-kostenlos/winzige-wissenschaftler-identifizieren-die-emotionen-von-frauen-anhand-von-stimme-und-gesicht-emotionserkennung-erkennung-emotionaler-zustaende-konzept-der-emo-sensortechnologie_11669264.htm
Referat und Folien von Christin Woest
Referat und Folien von Laura Klinger
0 notes
Text
Thema 10 Sprachsynthese
SMART SPEAKERS

Ein Smart Speaker ist ein technisches Gerät mit integriertem Lautsprecher und Mikrofon, das mit einer Sprachassistent Software ausgestattet und mit dem Internet verbunden ist.
Nutzer*Innen können mit Hilfe von Sprachsteuerung und Spracherkennung drahtlos auf diverse Funktionen zugreifen, die sowohl im Dienste der Unterhaltung als auch von pragmatischer und organisatorischer Natur sind. Die Sprachbefehle des Nutzers werden aufgezeichnet und von der Spracherkennung ausgewertet, die einen Teilbereich der sogenannten “Künstlichen Intelligenz" abdeckt. Mit Hilfe von Algorithmen und stetigem maschinellen Lernen, ist sie u.a in der Lage die menschliche Sprache zu identifizieren und sie in maschinenlesbarer Form zu transkribieren.
Wurde ein Sprachbefehl erkannt, wird dieser von einer cloudbasierten Sprachverarbeitungs- und KI-Engine interpretiert und ausgeführt. Der Sprachassistent generiert nach Erhalt des Sprachbefehls eine Antwort in Textform.
Das Text-To-Speech-System, auch ein Teilbereich der Künstlichen Intelligenz, gleicht die Wörter aus der Textantwort mit gespeicherten Ausspracheregeln und fabriziert daraus eine Reihe von Phonemen. Mit Hilfe einer Datenbank von bereits aufgenommener gesprochener Sprache wird die Aussprache abgeglichen, sodass aus ausgewählten, entsprechend akkuraten Audiosignale eine künstliche Sprachaufnahme zu der Textantwort entsteht.
Inzwischen nutzen ca. 41% des deutschen Haushalts im Alltag Smart Speakers. Smart-Home Steuerung, Musikwiedergabe oder Sprechende Suchmaschine, alle diese Funktionen können kleine Aufgaben übernehmen und dem Nutzer Abhilfe schaffen.
Auch am Arbeitsplatz wird davon Gebrauch gemacht. Nutzer*Innen werden von technischen Geräte an zukünftige Termine und anstehende Aufgaben erinner. Raumreservierungen im Büro oder das Notieren relevanter Anmerkungen/Notizen können auch von Smart Speakers übernommen werden. Momentan finden sich die meisten Speaker eher im privaten Bereich eines “Smart Homes” wieder. Das Interesse und die Nachfrage ist da, insbesondere nach smarter Sprachsteuerung in weiteren Haushaltsgeräten.
SPRECHERKENNUNG

Unter Spracherkennung versteht man das Erkennen einer Person anhand ihrer Stimme. Die Individualität einer Stimme setzt zusammen aus:
Anatomische Merkmale: Größe des Kehlkopfes, Länge und Dicke der Stimmbänder,
Größe und Form der Zähne und Nasennebenhöhlen, Zusammenwirken von Kehlkopfquelle und Vokaltraktfilter
Soziodemografische Merkmale: bei von klein auf gesprochener Muttersprache ist die Aussprache regional geprägt und innerhalb der Norm der jeweiligen Sprechergemeinschaft, neu/später erlernte Sprache kann durch noch abweichende, andere Intonation bestimmter Wörter auffallen, an das Umfeld angepasste Aussprache wie Jugendsprache oder das Mischen verschiedener Sprache (Anglizismen, Multilingualität)
Abweichende Verhaltensweise der Stimme: aufgrund anatomischer Unregelmäßigkeiten oder Krankheit (z.B. Demenz, Parkinson, MS),
Sprachfehler (z.B. Stottern, Lispeln, Nuscheln)
Forensische Phonetik
Forensische Phonetik ist die Wissenschaft der Produktion, Transmission und Rezeption von Schallsignalen im gerichtlichen Kontext, die vor Gericht als Beweismittel dienen, um die soziale und regionale Herkunft der Täter*innen zu ermitteln.
Forensische Phonetiker*Innen untersuchen verschiedene Aufnahmen, um diese mit der Stimme der Tatverdächtigen zu vergleichen. Durch Gegenüberstellung verschiedener sprachlicher Aufnahmen erfolgt die Verdächtigenidentifizierung.
Arten der Spracherkennung:
Naive Sprecherkennung: Die Naive Spracherkennung ist eine unversierte und nicht-wissenschaftliche Spracherkennung, die z.B. am Telefon erfolgt oder von ungeschulten Zeugen getätigter Identitätszuweisung durch Stimmen.
Technische Sprecherverifizierung: z.B. bei automatischen Authentifizierungsprozessen, bei dem der Computer die Stimme mit einer Vorlage vergleicht
Technische Sprechidentifikation: Bei der Hörmethode wird eine Stimme mit mehreren Vorlagen abgeglichen und Phonetiker*Innen analysieren akribisch die Aufnahme, die von guter bis sehr schlechter Qualität und Länge sein können (z.B. im Falle von Beweismittel von Verbrechen)
Mittels der Akustikmethode werden mit Transkriptionen die stärksten Stimmenvariationen unter mehreren Sprecher*Innen ermittelt und daraus rhetorische und linguistische Informationen extrahiert.
Quellen
Smart Speaker, Wikipedia, (o.D.) abgerufen am 10.02.2023., von: https://de.wikipedia.org/wiki/Smart_Speaker
Forensische Phonetik, (o.D.) abgerufen am 04.03.2023., von: https://www.uni-marburg.de/de/fb09/igs/arbeitsgruppen/phonetik/forschung/forensische-phonetik
Sprechen statt Tippen, (o.D.) abgerufen am 02.03.2023., von: https://www.it-production.com/hardware-und-infrastruktur/sprechen-statt-tippen/
What is a smart speaker?, (11.10.2019) abgerufen am 24.01.2023, von: https://www.aarp.org/home-family/personal-technology/info-2019/smart-speaker-uses.html
Referat und Folien von Adelina Kurzrock
Referat und Folien von Jonas Claußner
1 note
·
View note