
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by senura96universe-blog and here's what we found interesting.
Average Info
Notes Per Post
1
Likes Per Post
1
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
5 days
Number of Posts By Type
Text
4
Last Seen Tumblr Blogs





Fun Fact
BuzzFeed published a report claiming that Tumblr was utilized as a distribution channel for Russian agents to influence American voting habits during the 2016 presidential election in Feb 2018.
Text
Distributed Systems and Distributed Computing
There are several definitions for to clarify the terms of distributed systems and the distributed computing.
Distributed System is a collection of independent computers that are connected with an interconnection network or otherwise we can say a Distributed System is consists of a collection of autonomous computers connected through a network and distribution middle ware which enables computers to co-ordinate their activities and to share the resources of a system.
Because of that users are preceive the system as a single ,integrated computing facility.
If we talk about the Distributed computing , we can say that Distributed computing a method of computer processing in which different parts of a computer program are run on two or more computers, that are communicating with each other over a network.
Distributed computing has some of characteristics such as -
1) It allows to successes usually give the finder credit. 2)Distributed Computing projects that contains -
i) hunting prime number ii)analyze the DNA codes.
Standalone Systems And The Distributed Systems
There are some important systems that we need to learn about the systems such as 1)Standalone Systems
2) Distributed Systems
<Standalone Systems>

In technically says that a Standalone System is a binary and can be launched directly.Standalone Systems do not run on the streams run time environment
Standalone Systems can generate a standalone application by providing the T - option at the compile time.All Operators will be fused into a single partition.
Single Processing Element also called as PE , will be generated for this partition. Standalone executable is also generated with the name standable in the output/bin directory.
There are couple of advantages of Standalone Systems such as -
1)Damage Control 2)Simplicity
3) More-convienient
4) Do not affect for other users.
Distributed Systems

We already talk about something little bit about the Distributed Systems at the beginning of the article.Lets discuss something more about that.
Distributed Systems are applications that can be submitted to the streams run time environment for execution.
The operators in a Distributed application can be fused into more than one PE(Processing Element) can be distributed in the multiple hosts.
To run the distributed application on a streams instance,you need to promote compiler generated ADL to Streamstool commands.
Advantages Of the Distributed Systems -
1) Scalability 2)Redundancy
Elements Of The Distributed Systems

There are several elements of related to introducing elements of the distributed systems .They are -
1) Processing Components 2)Data Networks
3) Data Stores
4) Configuration of Above Elements
Lets talk about each elements briefly.
Processing Components -
Processing Components are initially divided into five sub categories.They are - 1)Accessing pages and components
2) Link to related pages. 3)Open New Window 4)Save Pages
5)Work with dialog boxes.
i) Accessing pages and components -
components typically consists of several related pages within the same window.Some Pages contain only one page.The significant pages contain required fields come in the order.
As the finish with one page , users can select the folder of another page to open it.leafing through several pages of a single form.
There are some basic steps that used to access to a page.They are - 1)Select The content reference from the menu hierachy.
2)On the search page , enter search criteria to identify the row of data that you want to retrieve from the database.
ii) Link to related pages. -
When you click a component link, the new transaction contains the same component links, which enable you to return to the original transaction. The component or page in which you are working appears in black text and is not underlined.
Some applications may identify these related links in another way. For example, you might see the phrase Go to: along with the related links at the bottom of a page. You might also see a drop-down list box with the word …More, which contains additional related transaction links.
iii) Open New Window -
The New Window link in the page bar opens a new browser window or child window that displays a search page for the current component. From this window, you can view or enter new data.
You can open as many child windows as needed by clicking the New Window link. Do not select select File, then select New, then select Window from the browser menu.
Doing so copies the current HTML from the parent window instead of opening a new PeopleSoft-maintained window session.
iv) Saving Pages -
After modifying the data on a page, you must click the Save button to commit your changes to the database. When you click the Save button, a processing sign spins in the upper right corner of the page. When processing is complete, the Saved icon appears.
If you attempt to leave the page without saving—by clicking another content reference from the menu hierarchy or by clicking a different toolbar button, such as Next in List,—a save warning appears.
Click OK to return to the page to save your changes. Click Cancel to exit the page without saving.
v) Working with the dialog boxes -
For each dialog boxes ,there are some unique characteristics .Those characteristics are -
1) They are modal, meaning that they hover on top of a primary page, which is grayed out. 2)You can drag and relocate them using the title bar.
3)They display informational text. 4)They display at least one button.
Services Of The Distributed Systems

There are multiple services which provide by the Distributed Systems.With all those services , one or more protocols have been involved to make it better.
The services are as follows -
1) Mail Services (SMTP,POPS,IMAP)
2) Files transferring and sharing (FTP)

3) Remote Logging(telnet)

4) Games and Multimedia(RTP,SIP)

5) Web (Http)

<Web Applications and Client-Server Applications>
Web Based Applications are basically divided into the main two sections such as - 1)Web Applications
2) Client-Server Applications
Web Applications are known as browser-based applications are software that runs inside on your web browser.
The Examples for the web applications are - 1)Google Docs -

2) Google Sheets

3) Office Online

4) Office 365

5) Web-Ex

6) Go to Meeting

Client-Server Applications are pieces of software that runs on a client computer and makes requests to remote server.
There are some examples for client-server applications such as - 1)SSH

2) ShadowShocks

3) Skype

Characteristics Of Web applications and The Client-Server Applications
There are unique characteristics to identify each category.The characteristics of the web applications are -
1)cloud-hosted and scalable 2)Cross Platform
3)Modular and loosley coupled 4)Easily Tested with automated tests
5) Traditional and SPA behaviors supported. 6)Simple development and deployment
If we talk about the characteristics of the client-server applications ,we can simply divide into client side and the server side seperately.
So the client side characteristics are -

1) It's the first active
2) Sends requests to the server
3) Expects and receives the responses from the server.
Server side characteristics are -

1) Initially passive(waiting for a query)
2)It's listening and the ready to respond to requests sent by clients 3)When a requests comes,he treats it and send a response.
Different architectures of Distributed Systems
There are several architectures of Distributed systems that contribute to maintain distributed systems more efficiently.
The most well known web architectures are - 1)Client -Server Architecture
2)3-tier architecture
Client-server architecture is one of most well known architecture used in technology.In this architecture there should be two sides .They are -
1) Server Side 2)Client Side
This architecture is depending on the both sides.If one side has some issues it can't be exist.

There are multiple characteristics to be discussed.So lets talk each about them.
1) Combination of a client or front-end portion that interacts with the user, and a server or back-end portion that interacts with the shared resource.
The client process contains solution-specific logic and provides the interface between the user and the rest of the application system.
The server process acts as a software engine that manages shared resources such as databases, printers, modems, or high powered processors.
2) The front-end task and back-end task have fundamentally different requirements for computing resources such as processor speeds, memory, disk speeds and capacities, and input/output devices.
3) The environment is typically heterogeneous and multi-vendor. The hardware platform and operating system of client and server are not usually the same.
Client and server processes communicate through a well-defined set of standard application program interfaces (API’s) and RPC’s.
4) An important characteristic of client-server systems is scalability. They can be scaled horizontally or vertically. Horizontal scaling means adding or removing client workstations with only a slight performance impact.
Vertical scaling means migrating to a larger and faster server machine or multi servers
As well as the Client-Server Architecture ,there is an another architecture called '3 tier architecture' 3 -tier architecture gives more benefits.It allows a developer the opportunity to extend,
modularize, and be able to configure their application
The 3-tier architecture shortens time to market and reduces the cost to integrate new features into software as a service (SaaS), Cloud, and on-premise applications.

According To The Techopedia ,The 3 tier architecture is (a definition)-
“3-tier architecture is a client-server architecture in which the functional process logic, data access, computer data storage and user interface are developed and maintained as independent modules on separate platforms.”
a tier simply means a layer.So according to this architecture there are 3 layers considered with the architecture.Those layers are -
1) Presentation Layer 2)Application Layer 3)Data Layer
Lets give some short description about those layers .
1) Presentation Layer -
sends content to browsers in the form of HTML/JS/CSS. This might leverage frameworks like React, Angular, Ember, Aurora, etc
2) Application Layer -
uses an application server and processes the business logic for the application. This might be written in C#, Java, C++, Python, Ruby, etc
3) Data Layer -
is a database management system that provides access to application data. This could be MSSQL, MySQL, Oracle, or PostgreSQL, Mongo, etc.
These are the main benefits of the 3 tier architecture.
1) It gives you the ability to update the technology stack of one tier, without impacting other areas of the application.
2) It allows for different development teams to each work on their own areas of expertise.
Today’s developers are more likely to have deep competency in one area, like coding the front end of an application, instead of working on the full stack.
3) You are able to scale the application up and out. A separate back-end tier, for example, allows you to deploy to a variety of databases instead of being locked into one particular technology. It also allows you to scale up by adding multiple web servers.
4) It adds reliability and more independence of the underlying servers or services.
5) It provides an ease of maintenance of the code base, managing presentation code and business logic separately, so that a change to business logic, for example, does not impact the presentation layer.
Micro-service Architecture and Monolithic Architecture Comparisons.

There are multiple advantages and also disadvantages in micro-service architecture and the monolithic architecture.
<Advantages Of the Micro-service Architecture >-

1) It tackles the problem of complexity by decomposing application into a set of manageable services which are much faster to develop, and much easier to understand and maintain.
2) It enables each service to be developed independently by a team that is focused on that service.
3) It reduces barrier of adopting new technologies since the developers are free to choose whatever technologies make sense for their service and not bounded to the choices made at the start of the project.
4) Microservice architecture enables each service to be scaled independently.
Disadvantages Of Micro-service Architecture
1) Microservices architecture adding a complexity to the project just by the fact that a microservices application is a distributed systems.
You need to choose and implement an inter-process communication mechanism based on either messaging or RPC and write code to handle partial failure and take into account other fallacies of distributed computing.
2) Testing a Micro-Services application is also much more complex then in case of monolithic web application. For a similar test for a service you would need to launch that service and any services that it depends upon (or at least configure stubs for those services).
<Advantages Of Monolithic Architecture>-

Advantages Of Monolithic Architecture
1) Simple to develop.
2) Simple to test. For example you can implement end-to-end testing by simply launching the application and testing the UI with Selenium.
3) Simple to deploy. You just have to copy the packaged application to a server.
4) Simple to scale horizontally by running multiple copies behind a load balancer.
Disadvantages Of Monolithic Architecture
1) This simple approach has a limitation in size and complexity.
2) Application is too large and complex to fully understand and made changes fast and correctly.
3) The size of the application can slow down the start-up time.
4) You must redeploy the entire application on each update.
5) Impact of a change is usually not very well understood which leads to do extensive manual testing.
6) Continuous deployment is difficult.
7) Monolithic applications can also be difficult to scale when different modules have conflicting resource requirements.
<MVC Architecture>

MVC Architecture also known as the Model , View and Controller Architecture. Lets discuss about the main elements of this architectures.Those elements are -
1) Model 2)View 3)Controller
Model is the central component of the pattern.It is the application dynamic data structure,independent of the user interface.Directly manages the data,logic and rules of the application.
View is so any representation of information such as a chart, diagram or table
Controller is Accepts input and converts it to commands for the model or view.
MVC architecture is highly used in web applications.There are multiple goals in the MVC architecture .They are -
1) Simultaneous Development
2) code reuse.
There are multiple advantages and disadvantages that can gain from the MVC Architecture. The advantages are -
1)Simultaneous Development 2)High - cohesion
3)Low coupling 4)Ease of modification
5)Multi views for a model.
The Disadvantages are - 1)code navigability
2)Multi - artifact consistency 3)Pronounced Learning curve.
Comparison Of The RMI and RPC

RPC is C based, and as such it has structured programming semantics, on the other side, RMI is a Java based technology and it's object oriented.
With RPC you can just call remote functions exported into a server, in RMI you can have references to remote objects and invoke their methods, and also pass and return more remote object references that can be distributed among many JVM instances, so it's much more powerful.
RMI stands out when the need to develop something more complex than a pure client-server architecture arises.
It's very easy to spread out objects over a network enabling all the clients to communicate without having to stablish individual connections explicitly.
<XML And Json>


There are some pros and cons of the xml and Json .Here They are
Json -
Pros -
1) Simple syntax, which results in less "markup" overhead compared to XML
2) Easy to use with JavaScript as the markup is a subset of JS object literal notation and has the same basic data types as JavaScript.
3) JSON schema for description and datatype and structure validation
4) JsonPath for extracting information in deeply nested structures
Cons -
1) Simple syntax, only a handful of different data types are supported
2) No support for comments.
XML
Pros -
1) Generalized markup; it is possible to create "dialects" for any kind of purpose
2) XML Schema for datatype, structure validation. Makes it also possible to create new datatypes
3) XSLT for transformation into different output formats
4) XPath/XQuery for extracting information in deeply nested structures
5) built in support for namespaces
Cons -
1)Relatively wordy compared to JSON (results in more data for the same amount of information).
0 notes
Text
Industry Practices Tools 2 Importance of maintaining the code quality It is seen that good quality software and code is not as easy as pie. It requires consistent efforts and sheer focus of the software development team to meet the quality goals. This is an essential thing for the software project. The developers are often seen side-stepping the quality standards when they are required to complete their tasks in a short span of time. A coding standard makes sure that all the developers working on the project are following certain specified guidelines. The code can be easily understood and a proper consistency is maintained. Consistency has a positive impact on the quality of the program and one should maintain it while coding. Also, it should be taken care that the guidelines are homogeneously followed across different levels of the system and they do not contradict each other. The finished program code should look like that it has been written by a single developer, in a single session Why coding standards are needed? 1. Security concerns Software becomes vulnerable to attacks if it is inconsistent, contains bugs and errors in logic. Most of the aforementioned problems arise due to the faulty programming code that might have resulted from poor coding practices. 2. Issues related to site performance Poor coding has an adverse effect on the performance of the site. The performance issues comprise of a multitude of things like when the user is interacting with the site, server response issues, reusability & flow of the code, etc. When the coding standards are implemented, these problems can be easily overcome giving you a secure site with minimum or no performance issues. • Enhanced Efficiency: It is often seen that the software developers spend a larger part of their time in solving those issues that could have been prevented. Implementing the coding standards would help the team to detect the problems early or even prevent them completely. This will increase the efficiency throughout the software process. • Easy to maintain If the coding standards are followed, the code is consistent and can be easily maintained. This is because anyone can understand it and can modify it at any point in time. • Bug rectification It becomes really easy to locate and correct bugs in the software if the source code is written in a consistent manner. Different aspects to measure quality of code ode quality can have a major impact on software quality, on the productivity of software teams, and their ability to collaborate. But how can you measure code quality, to determine if your code is worth its salt? . You can use any of these metrics to evaluate your current quality level, and understand if it’s getting any better. • Cyclomatic complexity—the more complex a codebase is, the greater the risk of errors slipping through to production which break the software because extremely complex code is difficult to test. Cyclomatic complexity is the number of linearly independent paths through a program's source code, and it is tied closely to reliability. • Regular Code Reviews. According to a recent survey, software professionals rank code reviews as the number one way to improve programming. These reviews enable developers to collaborate and share knowledge with each other, which improves their work. Furthermore, reviews ensure that code adheres to established standards. • Functional Testing. Functional testing is important because it encourages developers to focus on software functionality from the outset, reducing extraneous code. The aim of software development is to write an application that delivers exactly what users need. • Clear Requirements. Most software development projects begin with a requirements document, or story cards in agile development. A project with clear, feasible requirements is much more likely to achieve high quality than ambiguous, poorly specified requirements. Tools to maintain code quality Code Review is nothing but testing the Source Code. Generally, it is used to find out the bugs at early stages of the development of software. With this code review, the quality of the software gets improved and the bugs/errors in the program code decrease. The Code Review Tools automates the review process which in turn minimizes the reviewing task of the code. There are two ways of performing reviews namely Formal Inspections and Walkthroughs. #1) Collaborator Collaborator is the most comprehensive peer code review tool, built for teams working on projects where code quality is critical. • See code changes, identify defects, and make comments on specific lines. Set review rules and automatic notifications to ensure that reviews are completed on time. • Custom review templates are unique to Collaborator. Set custom fields, checklists, and participant groups to tailor peer reviews to your team’s ideal workflow. • Easily integrate with 11 different SCMs, as well as IDEs like Eclipse & Visual Studio • Build custom review reports to drive process improvement and make auditing easy. • Conduct peer document reviews in the same tool so that teams can easily align on requirements, design changes, and compliance burdens. 2) Review Assistant Review Assistant is a code review tool. This code review plug-in helps you to create review requests and respond to them without leaving Visual Studio. Review Assistant supports TFS, Subversion, Git, Mercurial, and Perforce. Simple setup: up and running in 5 minutes. Key features: • Flexible code reviews • Discussions in code • Iterative review with defect fixing • Team Foundation Server integration • Flexible email notifications • Rich integration features • Reporting and Statistics • Drop-in Replacement for Visual Studio Code Review Feature and much more #3) Codebrag • Codebrag is a simple, light-weight, free and open source code review tool which makes the review entertaining and structured. • Codebrag is used to solve issues like non-blocking code review, inline comments & likes, smart email notifications etc. • With Codebrag one can focus on workflow to find out and eliminate issues along with joint learning and teamwork. • Codebrag helps in delivering enhanced software using its agile code review. • License for Codebrag open source is maintained by AGPL. #4) Gerrit • Gerrit is a free web-based code review tool used by the software developers to review their code on a web-browser and reject or approve the changes. • Gerrit can be integrated with Git which is a distributed Version Control System. • Gerrit provides repository management for Git. • Using Gerrit, project members can use rationalized code review process and also the extremely configurable hierarchy. • Gerrit is also used in discussing a few detailed segments of the code and enhancing the right changes to be made. Need for dependency management tool in software development A Dependency is an external standalone program module (library) that can be as small as a single file or as large as a collection of files and folders organized into packages that performs a specific task. For example, backup-mongodb is a dependency for a blog application that uses it for remotely backing up its database and sending it to an email address. In other words, the blog application is dependent on the package for doing backups of its database. Dependency managers are software modules that coordinate the integration of external libraries or packages into larger application stack. Dependency managers use configuration files like composer.json, package.json, build.gradle or pom.xml to determine: 1. What dependency to get 2. What version of the dependency in particular and 3. Which repository to get them from. Comparing different package management tools . DPKG – Debian Package Management System Dpkg is a base package management system for the Debian Linux family, it is used to install, remove, store and provide information about .deb packages. It is a low-level tool and there are front-end tools that help users to obtain packages from remote repositories and/or handle complex package relations and these include: APT (Advanced Packaging Tool) It is a very popular, free, powerful and more so, useful command line package management system that is a front end for dpkg package management system. Users of Debian or its derivatives such as Ubuntu and Linux Mint should be familiar with this package management tool. 2. RPM (Red Hat Package Manager) This is the Linux Standard Base packing format and a base package management system created by RedHat. Being the underlying system, there several front-end package management tools that you can use with it and but we shall only look at the best and that is: DNF – Dandified Yum It is also a package manager for the RPM-based distributions, introduced in Fedora 18 and it is the next generation of version of YUM. Build Tools Build tools are programs that automate the creation of executable applications from source code(eg. .apk for android app). Building incorporates compiling,linking and packaging the code into a usable or executable form. Basically build automation is the act of scripting or automating a wide variety of tasks that software developers do in their day-to-day activities like: 1. Downloading dependencies. 2. Compiling source code into binary code. 3. Packaging that binary code. 4. Running tests. 5. Deployment to production systems. In small projects, developers will often manually invoke the build process. This is not practical for larger projects, where it is very hard to keep track of what needs to be built, in what sequence and what dependencies there are in the building process. Using an automation tool allows the build process to be more consistent. Build Automation tools Build automation tools are part of the software development lifecycle where source code is compiled into machine code by a build script. Once the code is completed it is integrated into a shared environment. There it interacts with other software components built by other developers. Before the code is integrated steps are taken to ensure the new code does not negatively impact other developers’ work within the development team. Typically build automation is completed with a scripting language that enables the developer to link modules and processes within the compilation process. This scripting encompasses several tasks including documentation, testing, compilation, and distribution of the binary software code. Build automation is a crucial step in moving towards a continuous delivery model and is an important part of DevOps, or best practices to establish a more agile relationship between Development and IT Operations. Different Build Tools 1. Scala oriented Build Tool (SBT): SBT, an acronym that stands for Scala oriented build tool is a build tool that is meant for Scala, Java and many more programming languages as such. Not like the other sets of build tools, SBT is specifically targeted to work towards Scala and Java Projects. Adding to the points that are discussed already, SBT provides a special interactive mode making Scala builds significantly faster using the same JVM as against the traditional batch operation where a number of build tasks are executed in a sequence. SBT is perfectly capable of compiling Scala code, packaging archive artifacts, executing tests and also to support many other build operations. Following are some of the advantages of using SBT, let us now take a look at each and every one of them: Features: • SBT can be effortlessly used if it is a smaller and a simpler project. • Commonly identified being used with Scala open source projects. • Provides an awesome integration if you are using IntelliJ IDEA IDE for your development. • Most of the tasks that you will need (as like compile, test, run, doc, publish-local and the console) operations/tasks are usage ready with SBT. • It is also pointed by few as a feature that dependencies can be open source repositories that are grabbed directly from GitHub. 2. CMake: CMake is cross-platform free and open-source software that helps in managing build processes of a software using its compiler-independent method. CMake also provides its support for directory hierarchies and also to applications that do depend on multiple libraries. CMake always works in conjunction with additional build environments as like the Xcode (from Apple) and Visual Studio (from Microsoft). The only pre-requisite for CMake will be a C++ compiler on its build system as such. Following are some of the advantages of using CMake, let us now take a look at each and every one of them: Features: • Enables cross-platform discovery of the available system libraries. • Provides automatic discovery and configuration for the tool-chain. • Ease in use than its predecessor (Make). • Ease in the compilation of your own files into a shared library in a platform agnostic way. • CMake does more than what Make is capable of doing and can perform more complex tasks. 3. Terraform: Terraform is a software tool that is designed to safely and efficiently build, combine and to launch infrastructure. It is a tool that is dedicated to building, changing and also to version infrastructure. It can manage the existing and the most popular service providers alongside the in-house solutions as well with utmost ease. The configuration files describe how and in what way Terraform should run the required applications in the datacenter. Terraform provides and generates an execution plan that puts in the better description the way to reach the desired state. Executes this documented way and to build the described infrastructure. Terraform has the ability to identify the changes made to the configuration and creates the incremental execution plans that can be further applied. Terraform has the ability to manage and include low-level components such as the compute instances, storage, networking, high-level components such as DNS entries, SaaS features etc. Having discussed all about these features, let us now take a look at the benefits or advantages that Terraform has to offer to individuals or organization who choose to use this offering for their own need. Following are some of the advantages of using Terraform, let us now take a look at each and every one of them: Features: • JSON is not a coding language as it is very evident that most of the lines are just braces, brackets from the CFTs that we look at. Terraform has a custom HCL for creating templates to ease the document and also comment your code. • User data scripts can be written in separate files exactly as you would write them on the server locally. 4. Bower: The tool Bower is a known package management system that works solely for the client-side programming on the internet, which depends on Node.js and npm. Bower is said to work with GIT and GitHub repositories. Bower is said to offer a generic and an un-opinionated solution to the problem of front-end package management, which exposing the necessary package dependency model via an API. This API can further be consumed by a more opinionated build stack. Bower runs over GIT and is package-agnostic. Following are some of the advantages of using Bower, let us now take a look at each and every one of them: Features: • There is no need to specifically and manually download the required dependencies. • There is a possibility to optionally install the packages that are part of the scaffolding based on user prompts. • No need to commit any missing dependencies to your version control. • Declare your dependencies in bower.json so that the dependencies are declaratively managed. • There is no need for us to segregate between various builds. Build Life Cycle example Maven is based around the central concept of a build lifecycle. What this means is that the process for building and distributing a particular artifact (project) is clearly defined. For the person building a project, this means that it is only necessary to learn a small set of commands to build any Maven project, and the POM will ensure they get the results they desired. There are three built-in build lifecycles: default, clean and site. The default lifecycle handles your project deployment, the clean lifecycle handles project cleaning, while the site lifecycle handles the creation of your project's site documentation. A Build Lifecycle is Made Up of Phases Each of these build lifecycles is defined by a different list of build phases, wherein a build phase represents a stage in the lifecycle. For example, the default lifecycle comprises of the following phases (for a complete list of the lifecycle phases, refer to the Lifecycle Reference): validate - validate the project is correct and all necessary information is available compile - compile the source code of the project test - test the compiled source code using a suitable unit testing framework. These tests should not require the code be packaged or deployed package - take the compiled code and package it in its distributable format, such as a JAR. verify - run any checks on results of integration tests to ensure quality criteria are met install - install the package into the local repository, for use as a dependency in other projects locally deploy - done in the build environment, copies the final package to the remote repository for sharing with other developers and projects. These lifecycle phases (plus the other lifecycle phases not shown here) are executed sequentially to complete the default lifecycle. Given the lifecycle phases above, this means that when the default lifecycle is used, Maven will first validate the project, then will try to compile the sources, run those against the tests, package the binaries (e.g. jar), run integration tests against that package, verify the integration tests, install the verified package to the local repository, then deploy the installed package to a remote repository What is Maven? Apache Maven is a build automation tool for Java projects. Think of Ant, or Make, but much more powerful and easier to use. If you've ever had to deal with building a Java project with dependencies or special build requirements then you've probably gone through the frustrations that Maven aims to eliminate. Maven has been an open source project under Apache since 2003, starting at Sonatype before that. Given its strong backing and immense popularity, Maven is very stable and feature-rich, providing numerous plugins that can do anything from generate PDF versions of your project's documentation to generating a list of recent changes from your SCM. And all it takes to add this functionality is a small amount of extra XML or an extra command line parameter. Maven’s Conventions over Configurations Convention over Configuration Maven uses Convention over Configuration, which means developers are not required to create build process themselves. Developers do not have to mention each and every configuration detail. Maven provides sensible default behavior for projects. When a Maven project is created, Maven creates default project structure. Developer is only required to place files accordingly and he/she need not to define any configuration in pom.xml. As an example, following table shows the default values for project source code files, resource files and other configurations. Assuming, ${basedir} denotes the project location − Item Default source code ${basedir}/src/main/java Resources ${basedir}/src/main/resources Tests ${basedir}/src/test Complied byte code ${basedir}/target distributable JAR ${basedir}/target/classes In order to build the project, Maven provides developers with options to mention life-cycle goals and project dependencies (that rely on Maven plugin capabilities and on its default conventions). Much of the project management and build related tasks are maintained by Maven plugins. Developers can build any given Maven project without the need to understand how the individual plugins work. We will discuss Maven Plugins in detail in the later chapters. Have a lot of dependencies? No problem. Maven connects to remote repositories (or you can set up your own local repos) and automatically downloads all of the dependencies needed to build your project. Maven Phase A Maven phase represents a stage in the Maven build lifecycle. Each phase is responsible for a specific task. Here are some of the most important phases in the default build lifecycle: • validate: check if all information necessary for the build is available • compile: compile the source code • test-compile: compile the test source code • test: run unit tests • package: package compiled source code into the distributable format (jar, war, …) • integration-test: process and deploy the package if needed to run integration tests • install: install the package to a local repository • deploy: copy the package to the remote repository Phases are executed in a specific order. This means that if we run a specific phase using the command: Maven Build Lifecycle The Maven build follows a specific life cycle to deploy and distribute the target project. There are three built-in life cycles: • default: the main life cycle as it’s responsible for project deployment • clean: to clean the project and remove all files generated by the previous build • site: to create the project’s site documentation Each life cycle consists of a sequence of phases. The default build life cycle consists of 23 phases as it’s the main build lifecycle. On the other hand, clean life cycle consists of 3 phases, while the site lifecycle is made up of 4 phases. Maven Goal Each phase is a sequence of goals, and each goal is responsible for a specific task. When we run a phase – all goals bound to this phase are executed in order. Here are some of the phases and default goals bound to them: • compiler:compile – the compile goal from the compiler plugin is bound to the compile phase • compiler:testCompile is bound to the test-compile phase • surefire:test is bound to test phase • install:install is bound to install phase • jar:jar and war:war is bound to package phase We can list all goals bound to a specific phase and their plugins using the command: 1 mvn help:describe -Dcmd=PHASENAME For example, to list all goals bound to the compile phase, we can run: 1 mvn help:describe -Dcmd=compile And get the sample output: 1 2 compile' is a phase corresponding to this plugin: org.apache.maven.plugins:maven-compiler-plugin:3.1:compile Maven Build Profile A Build profile is a set of configuration values, which can be used to set or override default values of Maven build. Using a build profile, you can customize build for different environments such as Production v/s Development environments. Profiles are specified in pom.xml file using its activeProfiles/profiles elements and are triggered in variety of ways. Profiles modify the POM at build time, and are used to give parameters different target environments (for example, the path of the database server in the development, testing, and production environments). Types of Build Profile Build profiles are majorly of three types. Type Where it is defined Per Project Defined in the project POM file, pom.xml Per User Defined in Maven settings xml file (%USER_HOME%/.m2/settings.xml) Global Defined in Maven global settings xml file (%M2_HOME%/conf/settings.xml) Dependency Management in Maven In Maven, dependency is another archive—JAR, ZIP, and so on—which your current project needs in order to compile, build, test, and/or to run. The dependencies are gathered in the pom.xml file, inside of a <dependencies> tag. When you run a build or execute a maven goal, these dependencies are resolved, and are then loaded from the local repository. If they are not present there, then Maven will download them from a remote repository and store them in the local repository. You are allowed to manually install the dependencies as well. <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> <scope>test</scope> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-core</artifactId> <version>4.3.5.RELEASE</version> </dependency> </dependencies> If pom.xml points to many artifacts of the same groupId, you should use properties in order to factorize the code for easy maintenance.
0 notes
Text
Industry Practices and Tools
Version Control System
Version Control System is a system that records changes to a file or set of files over time so that you can recall specific versions later. As an example web designers want to keep every version of an image or layout, a VCS is very helpful for them to accomplish this requirement. VCS is helpful to minimize disruption of team members , compare the source code with previous version to fix existing bugs and restore to previous version. With version control system every team member is able to work with any file at any time. Later the modification can merge into a common version.

Different Models of Version Control Systems
Local Version Control System
Earliest version control system model. Cannot be used to collaborative software development. Every file is in a local computer. This approach is very simple. This type is error prone which means the chance of writing wrong code is very high
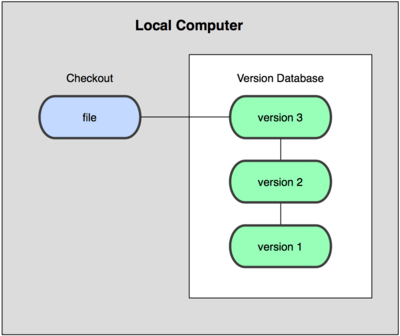
Centralized Version Control System
This approach can be used for collaborative software development. Every one in the team has a certain degree of what others do. Administrators have grained control over who can do what. In this approach all the changes are tracked under the centralized server. If the server dies , all will be vanished.so there is a single point of failure.

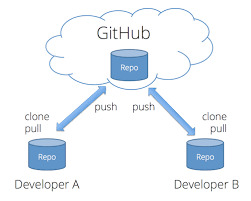
Distributed Version Control System
In this approach there is no single point of failure. Client computers can fully mirror the repository. If server dies can copy back from client computer. Also admins don’t have any grained control over who can do what. But different group of people can communicate in different ways simultaneously within the same project. Every client computer clone is consider as a full backup of data.

Git and GitHub
Git is a distributed version control system designed to handle everything from small to very large projects with speed and efficiency .Also git supports to the distributed non linear workflows and data integrity.

GitHub is a code hosting platform for collaboration and version control. GitHub is one of the implementation of Git.
GitHub essentials are:
Repositories
Branches
Commits
Pull Requests
Git (the version control software GitHub is built on)
Commit – Action of storing the new snapshot of project’s state in the VCS history.
Push - Pushing refers to sending your committed changes to a remote repository, such as a repository hosted on GitHub. For instance, if you change something locally, you'd want to then push those changes so that others may access them
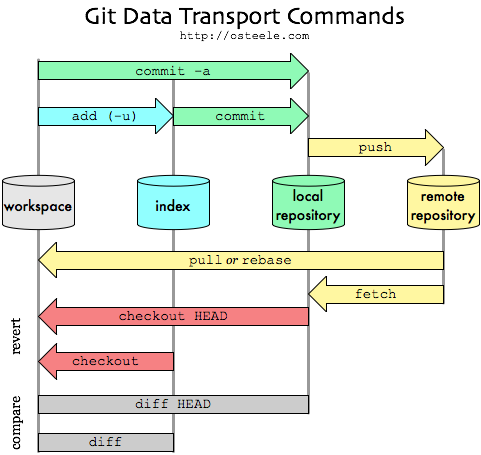
Uses of staging area and git directory
Uses of staging area-
· staging helps you split up one large change into multiple commits
· staging helps in reviewing changes
· staging helps when a merge has conflicts
· staging helps you keep extra local files hanging around
· staging helps you sneak in small changes
Collaboration of workflow
A Git Workflow is a recipe or recommendation for how to use Git to accomplish work in a consistent and productive manner. Git workflows encourage users to leverage Git effectively and consistently
every team has its own workflow based on the type of project, company size, team preferences, and many other things. The bigger the team, the harder it is to keep everything under control: problems with conflicts become more common, release dates need to be postponed, priorities keep getting changed on the fly, etc. etc. There are many types of Git workflow
Basic Git Workflow
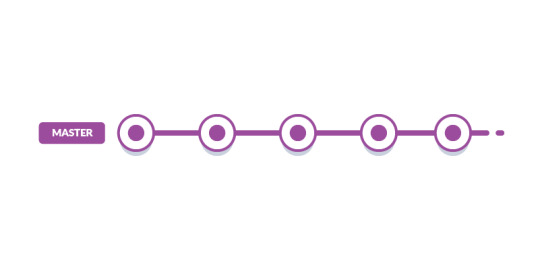
The most popular workflow among Git developers and the entry stage of every project.The idea is simple: there is one central repository. Each developer clones the repo, works locally on the code, makes a commit with changes, and push it to the central repository for other developers to pull and use in their work.
CDN
Content Delivery Networks (CDN) accounts for large share of delivering content across websites users and networks across the globe. The content found in the websites of today contain a variety of formats such as text, scripts, documents, images, software, media files, live streaming media and on-demand streaming media and so on. In order to deliver such diverse content to users across the globe efficiently, CDNs are deployed in datacenters. CDNs accelerate website performance and provide a numerous benefits for users and also for the network infrastructure
· Faster content load / response time in delivering content to end users.
· Availability and scalability, because CDNs can be integrated with cloud models
· Redundancy in content, thus minimizing errors and there is no need for additional expensive hardware
· Enhanced user experience with CDNs as they can handle peak time loads
· Data integrity and privacy concerns are addressed
Difference between CDN and web hosting services
Web Hosting is used to host your website on a server and let users access it over the internet. A content delivery network is about speeding up the access/delivery of your website’s assets to those users.
Traditional web hosting would deliver 100% of your content to the user. If they are located across the world, the user still must wait for the data to be retrieved from where your web server is located. A CDN takes a majority of your static and dynamic content and serves it from across the globe, decreasing download times. Most times, the closer the CDN server is to the web visitor, the faster assets will load for them.
Web Hosting normally refers to one server. A content delivery network refers to a global network of edge servers which distributes your content from a multi-host environment
Free and Commercial CDNS
Free CDN -.Cloudflare , Incapsula , Photon by Jetpack , Swarmify
Requirements for virtualization

When people talk about virtualization, they’re usually referring to server virtualization, which means partitioning one physical server into several virtual servers, or machines. Each virtual machine can interact independently with other devices, applications, data and users as though it were a separate physical resource.
Different virtual machines can run different operating systems and multiple applications while sharing the resources of a single physical computer. And, because each virtual machine is isolated from other virtualized machines, if one crashes, it doesn’t affect the others.
There are many types of virtualizations
· Network virtualization splits available bandwidth in a network into independent channels that can be assigned to specific servers or devices.
· Application virtualization separates applications from the hardware and the operating system, putting them in a container that can be relocated without disrupting other systems.
· Desktop virtualization enables a centralized server to deliver and manage individualized desktops remotely. This gives users a full client experience, but lets IT staff provision, manage, upgrade and patch them virtually, instead of physically.
Hypervisor
A hypervisor is a process that separates a computer’s operating system and applications from the underlying physical hardware. Usually done as software although embedded hypervisors can be created for things like mobile devices.
The hypervisor drives the concept of virtualization by allowing the physical host machine to operate multiple virtual machines as guests to help maximize the effective use of computing resources such as memory, network bandwidth and CPU cycles.
Difference between virtualization and emulation
· With virtualization, the virtual machine uses hardware directly, although there is an overarching scheduler. As such, no emulation is taking place, but this limits what can be run inside virtual machines to operating systems that could otherwise run atop the underlying hardware. That said, this method provides the best overall performance of the two solutions.
· With emulation, since an entire machine can be created as a virtual construct, there are a wider variety of opportunities, but with the aforementioned emulation penalty. But, emulation makes it possible to, for example, run programs designed for a completely different architecture on an x86 PC. This approach is common, for example, when it comes to running old games designed for obsolete platforms on todays modern systems. Because everything is emulated in software, there is a performance hit in this method, although todays massively powered processors often cover for this.
Difference between VMs and dockers
VMs
Heavyweight
Limited performance
Each VM runs in its own OS
Hardware-level virtualization
Startup time in minutes
Allocates required memory
Fully isolated and hence more secure
Containers
Lightweight
Native performance
All containers share the host OS
OS virtualization
Startup time in milliseconds
Requires less memory space
Process-level isolation, possibly less secure
fffffffffff
fffffffffffffff
fffffffff
0 notes
Text
Introduction to Frameworks
Programming Paradigms
A programming paradigm is a style or way of programming .Paradigms can be classified according to their characteristics and features. There are some common paradigms like structured , non-structured , functional , object oriented etc. Programming paradigms can be also termed as an approach to solve some problem or do some tasks using some programming languages.
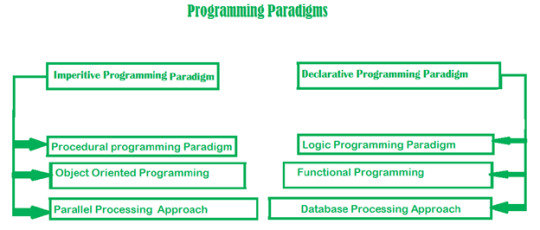
Declarative and Imperative Paradigms
Both declarative and imperative paradigms are programming paradigms. But there is a difference between 2 paradigms
Declarative Paradigm- Express the logic of computation without expressing its control flow. With declarative programming we write the code that describes what we want but no need to explain the flow of execution step by step. This helps to minimize side – effects. Lisp , R are some well known languages for declarative approach. Many markup languages such as HTML, MXML, XAML, XSLT... are often declarative.
var results = collection.Where( num => num % 2 != 0);
In this example the implementation details have not been specified. One benefit of declarative programming is that it allows the compiler to make decisions that might result in better code than what you might make by hand.
· Imperative Paradigm - Use a sequence of code to explain flow of execution. When we use imperative approach the global state of system is changed. Since the state of the system is changed there are side – effects . The declarative programs can be dually viewed as programming commands or mathematical assertions.
eg:
var numbersOneThroughTen = new List<int> { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
//With imperative programming, we'd step through this, and decide what we want:
var evenNumbers = new List<int>();
foreach (var number in numbersOneThroughTen)
{ if (number % 2 == 0)
{
evenNumbers.Add(number);
}
}
//The following code uses declarative programming to accomplish the same thing.
// Here, we're saying "Give us everything where it's odd"
var evenNumbers = numbersOneThroughTen.Select(number => number % 2 == 0);
Difference Between Procedural and Functional Programming
Procedural and functional programming are programming paradigms. But there are differences between 2 paradigms.
Functional Programming is a style of building the structure and elements of computer programs that treats computation as the evaluation of mathematical functions and avoids changing-state and mutable data
Procedural Programming is derived from structured programming, based upon the concept of the procedure call. Procedures, also known as routines, subroutines, or functions (not to be confused with mathematical functions, but similar to those used in functional programming . simply contain a series of computational steps to be carried out.
· Functional Programming origins from Lambda calculus which has no side – effects but procedural programming has side effects cause to change the global state of system.
· Functional programming use declarative approach while the procedural programming uses imperative approach
· Functional programming focuses on expressions and the procedural programming focuses on statements.
· Functional programming is used to academia and procedural programming is used for commercial software development
Lambda expressions and Lambda calculus in functional programming
Lambda calculus is a framework to study computations with functions. In other hand Lambda Calculus is conceptually the simplest programming language in the world. 3 simple rules are used
1.All you have are functions , They are all anonymous
2.A function should take only ONE argument
3.A function should return a value
Two keywords ‘λ’ and ‘.’. And you can model any problem
Lamdba calculus includes three different types of expressions
1. E :: = x(variables)
2. | E1 E2(function application)
3. | λx.E(function creation)
“No side – effects “ and “Referential Transparency” in Functional Programming
No side – effects – In functional programming ,output only depends on the input. Execution of a function does not affect to the global state of a system .Also global state of a system does not affect to the result of a function
Referential Transparency -v The expression “ Referential Transparency” is used in different domains. In mathematics referential transparency is the property of expressions that can be replaced by other expressions having the same value without changing the result in anyway
X = 2 + (3 *4)
After applying referential transparency
X = 2 + 12
In functional programming referential transparency is used for programs with the meaning of “replace equals with equals”.
eg:-
int globalValue = 0;
int rq(int x) { globalValue++;
return x + globalValue; }
int rt(int x) { return x + 1; }
Key Features of Object Oriented Programming
Object oriented programming is a programming paradigm based on the concept of “objects” which may contain data , in the form of fields. Since OOP is a structured programming paradigm there are many advantages and key features like inheritance polymorphism , abstraction etc. Java , C++ , C# are well – known OOP languages.
Class is a abstract definition of data type . further more class can be defined as an entity that determines how an object will behave and what the object will contain. In other words, it is a blueprint or a set of instruction to build a specific type of object. A class includes properties and methods.
Object is a specific instance of a class. Objects have states and behaviours .
Eg:- Person p = new Person(“ Drake”);
The concept of a data class makes it possible to define subclasses of data objects that share some or all of the main class characteristics. Called inheritence, this property of OOP forces a more thorough data analysis, reduces development time, and ensures more accurate coding.
The concept of data classes allows a programmer to create any new data type that is not already defined in the language itself
Encapsulation describes the idea of bundling data and methods that work on that data within one unit, e.g., a class in Java.
Abstraction is a process that show only “relevant” data and “hide” unnecessary details of an object from the user

How the event – driven programing is different from other paradigms?
Event – driven programming focuses on events(user events , schedulers , timers , hardware interrupts) that are triggered outside the system and mostly related to systems with GUI elements where the users can interact with GUI elements

An internal event loop(main loop ) is used to identify user events and the necessary handlers. But in other programming paradigms no changes are entertained. Event driven programming has a procedure which is dependent on occurrence of events while the other programming paradigms have modular approach. Event driven programming is bit complex to understand in logic. But most of the other programming paradigms are easy to understand.
Compiled , Markup and Scripting Languages
Programming languages can be classified according to the way they are processed and executed. Programming languages are used to control the behavior of a machine(computer).
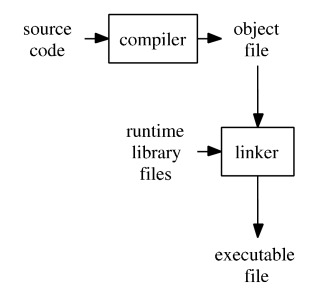
Compiled Languages
A source code is compiled to a executable code. Source code is reduced to a set of machine-specific instructions before being saved as an executable file. Purpose of the compilation process is converting a source code from human-readable format into machine code. The benefits of using a compiler to compile code is that it generally runs faster than interpreted code as it doesn't need to work it out on the fly as the application is running. The compiled program has also been checked for errors whilst it is being compiled. This will enable you to fix all coding errors before getting a fully running program.
Scripting Languages
A source code is directly executed .There is no compilation process for scripting languages. The code is saved in the same format that you entered. In general, it is considered that interpreted code will run more slowly than compiled code because it has to actively perform the step of turning the code into something the machine can handle on the fly as opposed to compiled code which can just run. Interpreted code is always available for reading and it can be easily changed to work the way you want it to. With compiled code, you need to find where the code is kept, change it, compile it and redeploy the program.

Markup Language
A markup language is used to control the presentation of data and not to considered as a programming language. There is no compilation or interpretation process .The tools(web browser) that can understand the markup language can render the output. A markup language is used to describe the data and the formatting in a textual format. There is a general rule, that a markup language will not describe a process or an algorithm (like programming language does) but is just pure data.

Role of Virtual Machine
A virtual machine (VM) is an operating system (OS) or application environment that is installed on software, which imitates dedicated hardware. The end user has the same experience on a virtual machine as they would have on dedicated hardware.
Specialized software, called a hypervisor, emulates the PC client or server's CPU, memory, hard disk, network and other hardware resources completely, enabling virtual machines to share the resources
The use of virtual machines also comes with several important management considerations, many of which can be addressed through general systems administration best practices and tools that are designed to manage VMs
Several vendors offer virtual machine software, but two main vendors dominate in the marketplace: VMware and Microsoft
How the JS is executed?
An execution context is an abstract concept of an environment where the Javascript code is evaluated and executed. Whenever any code is run in JavaScript, it’s run inside an execution context.
Types of execution context
o Global Execution Context
This is the default or base execution context. The code that is not inside any function is in the global execution context. It performs two things: it creates a global object which is a window object (in the case of browsers) and sets the value of this to equal to the global object. There can only be one global execution context in a program.
o Function Execution Context
Every time a function is invoked, a brand new execution context is created for that function. Each function has its own execution context, but it’s created when the function is invoked or called. There can be any number of function execution contexts. Whenever a new execution context is created, it goes through a series of steps in a defined order
o Eval Function Execution Context
Every time a function is invoked, a brand new execution context is created for that function. Each function has its own execution context, but it’s created when the function is invoked or called. There can be any number of function execution contexts. Whenever a new execution context is created, it goes through a series of steps in a defined order.
o Execution Context Stack
Execution context stack is a stack data structure to store all the execution stacks created while executing the JS code. Global execution context is present by default in execution context stack and it is at the bottom of the stack. While executing global execution context code, if JS engines finds a function call, it creates functional execution context of that function and pushes that function execution context on top of execution context stack.
Web browsers can interpret the JavaScript code. In every web browser there is a javascript interpreter to parse and execute JavaScript code.
How the HTML is rendered?
HTML is a markup language. Web browser can be used to render the output of a markup language.
The primary function of a web browser is to request resources from the web and display them inside of a browser window. Typically a browser will request HTML, CSS, JavaScript and image content from a server and interpret them based on web standards and specifications(The way the browser interprets and displays HTML files is specified in the HTML and CSS specifications. These specifications are maintained by the W3C (World Wide Web Consortium) organization, which is the standards organization for the web). They follow standards because it allows websites to behave the same way across all browsers, and creates less work and fewer headaches for web developers.
Main components of a browser: the user interface , browser engine , rendering engine , networking , UI backend , javascript interpreter.
CASE tools for different software systems
IOT systems
1. Arduino -Arduino is an open-source prototyping platform based on easy-to-use hardware and software
2. Eclipse IOT Project - Eclipse is sponsoring several different projects surrounding IoT. They include application frameworks and services; open source implementations of IoT protocols and tools for working with Lua, which Eclipse is promoting as an ideal IoT programming language
3. Kinoma - Kinoma, a Marvell Semiconductor hardware prototyping platform encompasses three different open source projects
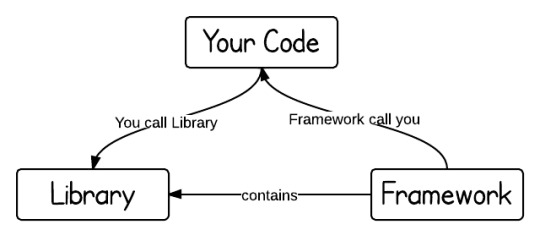
Difference between Frameworks ,Library , Plugin
The key difference between a library and a framework is "Inversion of Control". When you call a method from a library, you are in control. But with a framework, the control is inverted: the framework calls you.
A library is just a collection of class definitions. The reason behind is simply code reuse, i.e. get the code that has already been written by other developers. The classes and methods normally define specific operations in a domain specific area. For example, there are some libraries of mathematics which can let developer just call the function without redo the implementation of how an algorithm works.
Plugin: Is a collection of few methods used to perform particular task.
A Plugin extends the capabilities of a larger application
f
1 note
·
View note