
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by surjithgaddam and here's what we found interesting.
Average Info
Notes Per Post
1
Likes Per Post
1
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
41 minutes
Number of Posts By Type
Text
2
Last Seen Tumblr Blogs





Fun Fact
Tumblr was acquired by Yahoo for $1.1B in 2013.
Text
Random Forest Analysis on Predicting Binary Response
Introduction
Random Forest is a versatile machine learning algorithm that excels in classification tasks. In this analysis, we applied a Random Forest model to predict the binary response variable ALCPROBS1 using a dataset containing multiple explanatory variables. Below, we present the methodology, results, and key insights derived from the analysis.
Methodology
1. Data Preparation
To prepare the dataset for modeling, the following steps were taken:
Target Variable and Features: The target variable, ALCPROBS1, was separated from the explanatory variables.
Handling Missing Data: Rows with missing values in the target variable or any explanatory variables were removed to ensure a clean dataset.
Data Splitting: The data was split into training and testing sets in a 70:30 ratio to evaluate model performance.

2. Training the Random Forest Model
A Random Forest classifier with 100 decision trees was trained on the training dataset. The random_state parameter ensured reproducibility.

3. Model Evaluation
The model was evaluated on the test dataset using the following metrics:
Accuracy
Confusion Matrix
Classification Report
Feature Importance

Results
Model Performance
Accuracy: The model achieved an accuracy of 80.77% on the test dataset.
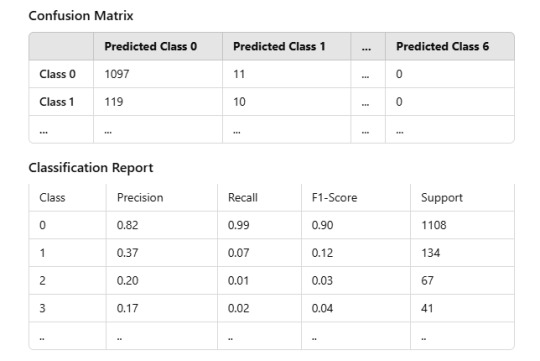
The model performed well for the majority class (0) but struggled with minority classes due to class imbalance.
Feature Importance
The top contributing features were:
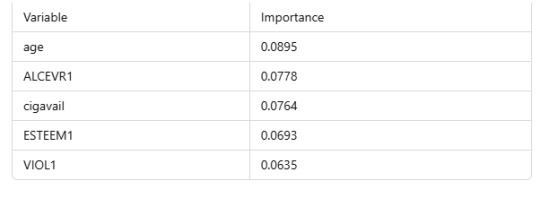
Interpretation
Handling Missing Data
Rows with missing values were removed, ensuring data integrity but potentially introducing bias. Future analyses should explore imputation techniques to retain more data.
Class Imbalance
The dataset had a significant imbalance in the target variable, with class 0 dominating. Techniques like oversampling, undersampling, or class-weight adjustments could help address this issue and improve performance for minority classes.
Key Predictors
age: Older individuals may show different patterns of alcohol-related issues.
ALCEVR1: History of alcohol use strongly correlates with alcohol-related problems.
cigavail: Access to cigarettes often links to risky behaviors, including alcohol use.
Limitations and Future Work
Class Imbalance: Future models should address class imbalance for improved generalization.
Feature Selection: Incorporating domain-specific features or interactions between variables may enhance accuracy.
Model Comparison: Comparing Random Forest with other models, such as Gradient Boosting or Support Vector Machines, could yield better insights.
Visualization: Visualizing feature importance and confusion matrix (e.g., heatmaps) can improve interpretability.
Conclusion
The Random Forest model demonstrated robust performance for the majority class but struggled with minority classes due to class imbalance. By addressing this issue and exploring additional predictors, future analyses can further enhance predictive accuracy and insights for alcohol-related problems.
0 notes
Text
Decision Tree
The dataset has 6,504 rows and 25 columns, including both categorical and numerical variables. Some columns contain missing values. For this analysis, we’ll use the column ALCPROBS1 as the binary target variable for classification, and the remaining columns (after preprocessing) as explanatory variables.
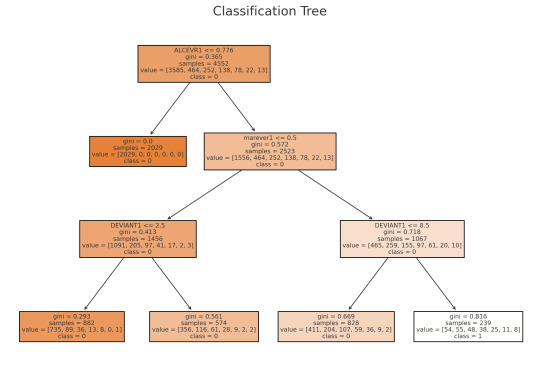
Classification Tree Analysis Results
Confusion Matrix:

Classification Report:
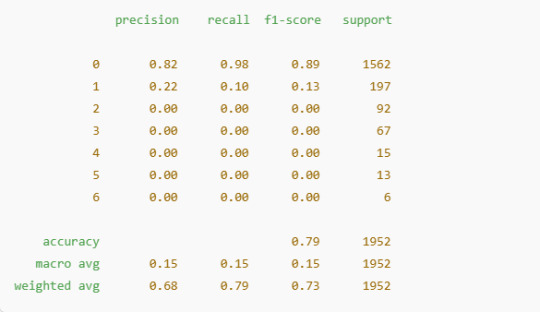
Class Imbalance: The model primarily predicts the majority class (0), as seen from the confusion matrix and weighted precision. This indicates a significant class imbalance in the dataset.
Performance: The overall accuracy is 79%, but precision and recall for minority classes are very low, highlighting a need for improved handling of class imbalance.
Tree Insights: The decision tree successfully captures key splits for predicting the majority class but fails to generalize for other classes.
1 note
·
View note