#All C programming & Algorithm
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The average Tumblr user visits about 67 pages every month.
Text
Qwerty's Guide to Gambling: Coin Dozer Algorithm
Qwerty's Guide to Gambling: Coin Dozer Algorithm (Tumblr)
Alright, so I recommend first looking for dropped change both around and underneath the machine, and inside the deposit shoot, especially for coin dozers (or "Quarter Games") installed in bars.
Basically, you'll have buzzed people playing these things whose hand-eye coordination is impaired, so they'll be dropping coins everywhere, overlooking coins jammed into the corner of the deposit area, etc.
Remember: Only play when sober! You become stupid when drunk.
----
These machines can take multiple types of coins, so as an abstraction, we're going to <i>count the number of tokens</i> not the raw monetary value.
First, we have our amount of tokens. This will be set to <i>the amount of coins we start the game with.</i> In layman's terms: The amount of change in your pocket.
<code>unsigned int token_count=starting_tokens;</code>
Second, we need to set threshhold where, when our amount of coins drops to this point, we stop playing the game.
<code>unsigned int minimum_token_count;</code>
Where "minimum_token_count" is a value in the range [0,starting_tokens]. In laymens terms: You don't want to waste all your money!
An example: You start with 8 tokens, but you want to keep at least 4 tokens. So when your token count during play drops to 4, you stop playing.
(Everyone reading this is probably going "Why is this loser autist-splaining common sense?" lol.)
Third, set our threshold where, when our token count reaches or exceeds this amount, we quit the game. This is our <i>profit threshold</i> and is here to prevent us from <i>pissing away what little good luck we get.</i>
<code>unsigned int profit_threshold;</code>
Where "profit_threshold" is a value in the range [starting_tokens+1, UINT_MAX].
Example: We start with 8 tokens and have our profit threshold being set at having a total of 10 tokens. We get lucky, so on the first play the machine returns 6 tokens, so we now have 13 tokens. 13 is greater then 10, so we quit playing.
Alright, let's write an extremely autistic C program that demonstrates the algorithm (I don't like pseudocode. There's like, 70 trillion different interpretations of it, which ironically makes it more confusing then standard code.)
<code>
unsigned int token_count=starting_tokens;
unsigned int minimum_token_count=/*something*/;
unsigned int profit_threshold=/*something*/;
void spend_token(){
token_count--;
....
token_count+=tokens_deposited_by_machine;
}
int main(int argc, char *argv[]){
do {
spend_token();
}while((token_count>minimum_token_count) && (token_count<profit_threshold));
}
</code>
Setting the initial value for "token_count" is easy, but determining the values for "minimum_token_count" and "profit_ threshold" is tricky.
The safest value for "profit_threshold" is starting_tokens+1, as that would mean whenever our total coin count is larger then our starting amount we end the game, even if it's just one coin more.
And that isn't a bad strategy as when these machines do pay out, it's often a decent amount as the way the coins bunch up at the edge, they sort of "interlock" with each other, causing the coins not directly overhanging the edge to fall into the payout chute, leading to fairly chunky payouts.
But there's a nonzero chance for payouts greater then one coin to be deposited, so by having such a low payout limit might prevent us from receiving a larger profit.
One possible solution to this is to change "minimum_token_count" and "profit_threshold" on the fly. If we get to a point in the game where we now have more coins then when we started with, it might be advantageous to update those values so that we can continue playing for a chance at a bigger profit, but still ensuring we don't significantly eat into the profit we just got.
Likewise "minimum_token_count" has a similar problem. We don't want to put <i>just one coin in</i> and not continue if we don't immediately get a payout. Oftentimes it takes putting a couple coins in so that the coins on the playboard become agitated and pushed forward enough in order to obtain a payout.
Fortunately unlike most gambling machines, we can <i>see the internal state of the machine!</i> No microprocessor here, only coins pushing up against each other! It's all deterministic! (Well, technically everything is deterministic because the <i>universe itself is deterministic</i> bit SHHHH!!! Don't tell the free will believing losers that!)
Another thing is that with these pusher type machines is that the slider, which allows for rough positioning for where the coin should fall, does give us some ability to manipulate how the coins on the playfield behave. It's not much, but it is something.
And finally: Try messing with the button that pauses the pusher's movement. It might be called something cheesy like "skill stop". Other then as an accessibility feature (eg, you have poor fine motor skills or have difficulty timing things) this button is pretty useless. It's not hard timing you putting the coin into the machine up, and it isn't a time save either because these usually don't react immediately and only activate when the pusher is dead ahead or behind.
But..... The small idiosyncrasies of <i>how</i> it's implemented might be useful. Maybe one machine doesn't stop the pusher as gently as it should, causing a stronger then normal deceleration on the coins, possibly causing some to fall. Idk, it wouldn't hurt to experiment.
Oh, and sometimes you can win something that aren't coins. Usually whoever maintains the machine puts "bonus prizes" on top of the coins. Those are worth considering.
----
Of course there's various <i>unscrupulous</i> crap you could do, like nudging the machine or tilting it forwards. We call those "tricks" <i>asshole behavior.</i>
First: It's cheating. Unless this is in a big chain casino, your just screwing with some petit-bourgeois small business; Second: These machines usually have balanced mechanisms that activate when tilt, preventing payouts; Third: It's an excellent way of getting kicked out.
0 notes
Text
Rolling Custom Cryptographic Systems: Part 1
Cryptography- it's always the hot debate topic regarding computers, with society trying to perserve it and ensure ciphers are extremely hard to crack, to aid in the preservation of privacy (thus ensuring free speech). Governments often oppose cryptographic ciphers because of their difficulty to crack, making investigations and research on other people harder.
However, there's no denying that such systems seem very arcane and tough to understand, and this series of posts intends to shed some light on how cryptographers implement systems that are extremely hard to crack.
This post series exists to help educate people on the importance of cryptographic research and how it corresponds to your privacy online, and how you can better protect yourself in a high risk environment. I would like to give credit where it's due, as I learned most of this content from "Applied Cryptography" by Bruce Schneier.
Like a Lightswitch: Boolean Logic
So let's quickly cram an intro to computer science class into a couple paragraphs to preface this all... Boolean Logic is just a fancy term for the ability to do math with nothing more than true or false statements and a few special operations. This is achieved through the use of the binary number system, which behaves very much like the decimal system in the sense that it has a "place" for digits of a certain value. However, instead of having a 1s, 10s, 100s, etc. place, the binary system has a 1s, 2s, 4s, 8s, etc place. A binary digit is called a bit and a number that is 8 binary digits long is called a byte.
Like normal math, we can do addition, subtraction, etc to the binary numbers... But we can do more than that since binary 0 is "False" anything other than 0 is "True". We can use AND, OR, XOR, NAND, and NOT operations on our numbers now. AND, OR & NOT are all pretty self explanatory in how they work (they take inputs and you perform said operations on them). NAND stands for NOT AND, so you basically perform AND and then invert the output value. XOR will only output true if only one input is true.
Cryptography Basics
So what is cryptography? In the most perfect sense, a cryptographic function is an algorithm that can only be reversed using one method, and is impossible to recover the original contents using any other method. However this is often not the case, and this is why security experts say nothing is 100% secure, because there will always be unknown holes in your cryptographic functions and systems.
When cryptographic functions work through taking a message and a single "key", performing a series Boolean operations and mathematical operations to use the same key to encrypt and decrypt the message, it is called a symmetric encryption algorithm. Some of the leading symmetric algorithms (in terms of security) are AES-256, CHACHA20 and SALSA20.
If there's 2 keys, one for decryption (called a private key) and one for encryption (called a public key), it is called an asymmetric encryption algorithm. Some of the leading asymmetric algorithms are RSA and EC-Diffie Hellman.
Finally a hashing algorithm is one that takes a message as input, performs a series of operations on it, and outputs a bunch of garbled information- but if you input the same message again, you will get the same output. This is common for storing passwords and login information. Common hashing algorithms are SHA256 and SHA512.
Keys require random numbers to be created, and often times cryptographic systems rely on programs to generate random numbers for keys. The ongoing problem is that computers are incapable of being random, so there is ongoing research to produce Cryptographically Secure Pseudo-Random Number Generator software (CSPRNG). Alternatively, some people opt for Hardware-based Random Number Generators (HRNG) for producing their crypto keys.
Planning our Cryptosystem
Let's say Bob and Alice want to email each other, but they fear Eve- our eavesdropper- might be listening in. How can we securely share secret cryptographic keys in such a manner that it's impossible for Eve to get them?
Using Multiple Systems
Using some code, it's entirely possible to stitch together multiple algorithms. So it's possible that we could send EC-Diffie Hellman encrypted messages, but encrypt our public and private keys with AES-512 encryption and a personal password. So it's not theoretically possible for "Eve" to intercept the encryption and decryption keys without having to trick Bob and Alice.
To do this, we need to understand what EC-Diffie Hellman keys go where. The public key encrypts the message, while the private key decrypts the message. So for this to work, Bob would need to have Alice's public key and his private key encrypted with AES-512, while Alice would need Bob's public key and her private key encrypted also with AES-512.
To simplify this... 1) Bob and Alice generate public and private keypairs 2) Bob and Alice swap public keys. 3) Bob encrypts Alice's public key and his private key. 4) Alice encrypts Bob's public key and her private key. 5) When they wish to email, they unlock their keys. 6) After unlocking their keys, they encrypt their messages. 7) To decrypt the message, Bob or Alice unlocks their keys. 8) They then use their private key to decrypt the message.
This seems rather complex, although most of the process is automated and running behind the scenes. Software like this would manifest itself as a "keychain" or "keyring" in major programs.
The Plan
The first step, which will be shared in the next post, will be to implement a CSPRNG and a hashing algorithm so we can generate keys.
The second step will be to implement a EC-Diffie Hellman cryptographic function, using hashing algorithm and CSPRNG to aid in the generation of keys.
The third step will be to implement AES-512, which will complete the cryptosystem, and allow for encryption of the keys.
The last milestone of this project will be to provide a simple and clean interface so an end-user can encrypt their emails.
References
Schneier, B. (2015). Applied cryptography: Protocols, algorithms, and source code in C. Indianapolis, IN: Wiley.
1 note
·
View note
Text
An Electric power Distribution Company charges its consumers
An Electric power Distribution Company charges its consumers
Consumption Unit Rate of Charges For First 50 Units Rs 2.30 Next 50 Units Rs 2.60 Next 150 Units Rs 3.25 More than 250 Units Rs 4.35
Write a program to take no of units consumed from user and calculate the bill Amount.
#include int main() { int unit; float amt, total_amt, sur_charge; /* Input unit consumed from user */ printf("Enter total units consumed: "); scanf("%d",…
View On WordPress
#All C programming & Algorithm#All C Programming Example#allcprogrammingandalgorithm#basic c language#basic c programs#C Programming
0 notes
Text
2019-01-10 Daybook
:::
Microsoft adds more mobile, scheduling capabilities to Teams for firstline workers | ZDNet | Mary Jo Foley reports on more firstline worker support in Microsoft Teams.
Microsoft is adding customizable mobile capabilities to Teams with capabilities such as location sharing, smart camera and the ability to record and share audio messages securely.
:::
Computer Models to Investors: Short Everything | Stephanie Wang looks into what the algos are predicting: they've flipped from long to shorting.
Funds that use such strategies likely went from holding net long positions, or betting that prices would rise, in four major asset classes—stocks, bonds, currencies and commodities—in the third quarter of 2017, to being short, or wagering against, everything but bonds by 2019. And even their embrace of bonds is bearish, signaling a flight to haven assets.
These are the findings from research by quantitative investment firm AlphaSimplex Group LLC, based on models that gauge the magnitude of price moves and perform like typical trend-following algorithms. Trend-followers generally try to ride markets when they move strongly in one direction.
“This is like the chaos bet,” said Kathryn Kaminski, chief research strategist and portfolio manager at AlphaSimplex, who added that the last time trend-followers reversed positions so dramatically was in 2007 and 2008. “Pretty much any way you run the models, you end up net short a lot of asset classes.”
AlphaSimplex, which has about $7.4 billion in assets and runs one of the largest trend-following programs, is also bearish across global markets.
Uh-oh. The #chaosbet has an ominous tone. How does a person on the sideline make that bet? Short term bonds?
:::
James Harden Is the Outlier of the NBA | Harden's a revolutionary: he's taken nearly twice as many stepback 3-pointers as any NBA team this season, and 86% of his 3s are unassisted, highest in the NBA. He's the most effective offensive player in the past 20 years. Harden has already taken more 3-pointers after seven or more dribbles than any NBA team in the last six years even though he’s only played 36 games. He has more shots after that many dribbles than the Sixers, Pelicans, Bulls, Nuggets, Clippers, Timberwolves and Knicks combined.
:::
Gene-edited, spicy tomatoes are the superfood scientists say we need | I want.
:::
Klaxoon - The Meeting Revolution - Join your Team | I should get a demo.
:::
WeWork rebrands to We Company, reveals details of SoftBank deal | Because of stock troubles, Softbank cut back its investment in WeWork.
Going forward, the company will no longer be called WeWork but rather The We Company. The new structure is part of Neumann’s heady ambition to push the company’s market and opportunity beyond commercial real estate. Rather than just renting desks, the company aims to encompass all aspects of people’s lives, in both physical and digital worlds, he says.
The We Company will be comprised of three main business units: WeWork, its main office business; WeLive, a fledgling residential unit; and WeGrow, a still evolving business that currently includes an elementary school and a coding academy. Although the company could not provide specifics, it says plans are in the works to build out its residential and education units this year. Also coming in 2019 are more acquisitions and new hires. The company aims to add 1,000 engineers.
Where is the hotel chain? Cohotels will be big. Oh, they mocked one up in 2009:
:::
How soon will climate change force you to move? | I picked Beacon NY to avoid climate change migration.
Some parts of the U.S. will be hardest hit economically, particularly the Southeast, but the whole country is beginning to see negative impacts. In the Albuquerque area, where the Mesku family moved, the risk of severe drought is increasing. In the Pacific Northwest, a region that is often cited as one of the places that will be less impacted by global warming, wildfires are incurring record costs and smoke is starting to impact local economies. In Seattle, where most people don’t have air conditioning, there was a record-breaking heat wave in 2017 and again in 2018. In Madison, Wisconsin, record rainfall, a problem that is also linked to climate change, caused widespread flooding in August 2018. In Maine, as the ocean warms and acidifies, fisheries and the lobster industry could collapse. In Canada, a heat wave in Quebec in July 2018 was linked to more than 90 deaths. San Francisco hit a record 106 degrees in September and then in November went through 13 days of dangerous air quality as smoke from the Camp Fire blew into the area. As many as 13,000 properties in the Bay Area are at risk of chronic flooding by 2045.
:::
Paola Antonelli on "Broken Nature: Design Takes on Human Survival"
#readlater
:::
Sleep glasses | Felix Gray | Counter the blue light in your screens.
:::
London's Big Event For Corporate Misfits, Troublemakers, And Rebels % | Corporate Rebels on tour!
:::
Big Tech's Trump problem - Axios | Mike Allen and Jim VandeHei say
Tech is the new politics.
:::
Introduce Agenda to Your Note-taking - Bicycle For Your Mind | Review of Agenda note tool
:::
How Robots Will Transform the C-Suite
read later
:::
Managing When the Future Is Unclear | Lisa Lai
read later
:::
Artificial Intelligence Was Supposed to Reduce Hiring Discrimination. It’s Already Backfiring. – Mother Jones
read later
:::
Expectations: The Root of your Employee Engagement Problem
read later
:::
Understanding Trends in Alternative Work Arrangements in the United States | Katz and Krueger walk back the assertaion they made about the gig economy back in 2016. Now thy think it was temporary, demonstrated by a tight labor market. As Steve Levine characterizes it,
Now the pair — Princeton University's Alan Krueger and Harvard's Lawrence Katz — say they were fooled by economic noise and that workers are pretty much the same as they've always been.
Their old paper was exceedingly influential, trickling down to how economists, human resources professionals, marketers and more viewed the workforce.
But in their new paper, published this week, Krueger and Katz say people were doing odd jobs back then because they needed the work, not as a signal of a new trend. Now that the labor market is tight, they are back at work.
Joe Brusuelas, chief economist at RSM, tells Axios that the pair's new paper is par for the course. "If you're not getting it wrong 20% of the time, you are not doing your job," he says.
:::
Scoring under Pressure | what we can learn from penalty kicks in soccer (football).
read later
:::
HQ 2.0: The Next-Generation Corporate Center
read later
:::
5 notes
·
View notes
Text
transitions & transformations
i. the rest of my batch at RC
I spent the first six weeks of my batch at Recurse Center in an out-and-out sprint. I learned Python, built and released projects, and wrote blog posts every week. I wasn’t sure where my limits were, but I was determined to find out - preferably by overshooting them, then adjusting after the fact.
A curious thing happened. I kept finding that I was more than capable of starting and finishing projects, especially when I had a firm mental image of the end goal. There were at least as many unexpected good-turns as there were setbacks, and I certainly didn’t come up against any inscrutable barriers. Mostly the challenge was in overcoming the distance between a thing that doesn’t exist and a thing that does, which I was able to sort out pretty handily through a consistent application of effort across time.
Who’d have thought?

A selfie taken on my birthday, which also happened in the last few months and was really great!
The second half of my batch was not so visibly productive - with the exception of The Question Game. The Question Game is a simple game designed to help groups of people get to know each other better IRL. I designed it with my friend Brittany a few years ago as an icebreaker when we found ourselves in a group of folks who knew us but didn’t really know each other. The game only really needs a method of generating random numbers for a small but arbitrary group size, but building it out as a toy webapp was a good excuse to get practice working with a JS-only stack. I learned React, got a lil more familiar with node, and even went as far as to attach an otherwise completely unnecessary PG database and Sequelize ORM. You can see the code for it here. Outside of this project, however, I didn’t publish any code. I didn’t publish any writing, either.
So I’d like to take a moment and shine a bit of light on the work that I did during the rest of my batch.
🌒 🌓 🌔 🌕 🌖 🌗 🌘
First, I made the decision to leave community.lawyer, the social impact startup I co-founded in 2016 following the Blue Ridge Labs Fellowship.
I’m happy to report that I left on the come up, which seems a rare and privileged thing for a founder to be able to say. Gaining traction in a hyper-specialized industry like legal tech takes a gargantuan amount of sustained forward momentum, and I departed just as we began to reap the fruits of our labor. In the last few months community.lawyer has reached final approval on partnerships a year in the making, won federal grants we’d submitted to in 2016, and every day our software is being used to help connect people who have legal needs with credible lawyers. Our first two partners were exactly the types of legal organizations at the heart of our mission: the Justice Entrepreneurs Project and the DC Reduced Fee Lawyer & Mediator Referral Service.1 Based in Chicago and Washington DC respectively, these orgs are specifically chartered to deliver quality services at rates that more Americans can afford. I am so proud. ⚖️
Second, I started my first ever job hunt as a software engineer. Wowee, this was scary! I knew that I had to prepare for interviewing, which meant a) getting my career change narrative straight, b) studying Data Structures & Algorithms 101, and c) learning how to perform my handle on both of these in a live, semi-adversarial environment.

At one point during my batch my laptop broke. I read through this wonderful illustrated book during the two days it was being fixed.
In order to direct my search I also had to craft a set of selection criteria of my own. Foremost: “What good will my work do for the world?”2 Additionally, “What degree of access will I have to supportive mentors?”
Getting started with interview prep was a challenge, at least partly because I had so many options for where to start. But I did get started! I read Cracking the Coding Interview, I did the free trial and weekly free problems on Interview Cake. I attended a few group mock interviews at Recurse Center and signed up for a 1-1 mock interview with an RC alum. Her name is Leah, and she’s amazing - the superbly friendly and encouraging Comp Sci TA I wish I’d had years ago. 💚Brittany also set up mock technical screens for me with her pals, Leaf and Ian. They were the vanguard against my outsized anxiety about programming for an audience and they each took the time to give me solid feedback.
Third, I extended my batch at Recurse Center by another 6 weeks. I had decided early on I wouldn’t extend (for no real reason) and stuck with this decision up until two days before my batch ending. A small group of folks - Lily, Connor, Alicja and I - went to NYX in Union Square to try out lipsticks. We played with different colors and finishes (satin! matte! shimmer!) for half an hour or so. There came a point when I looked up, glanced across the narrow makeup store at my beautiful friends’ beautiful faces and thought, “You know, you don’t have to leave yet, right? What’s the rush?” I’d already accomplished my primary goal, to forcibly rework my identity as an engineer, but it sure seemed that I could stand to reach for a second one. That night I decided to extend my batch, with the intention of sampling a more open method of self-directed learning, i.e. with a little more chill and a lot less panic. Specifically, I wanted to practice connecting meaningfully with my limited supply of social energy.
In my bonus six weeks, I: gave three talks (2 planned, 1 impromptu) under encouragement from Ayla and Lily, learned to juggle thanks to instruction from a fellow RCer, Edward, who also loaned me a book about learning, made it into weekly Feelings Check-in (read as: opt-in support group) fairly regularly, picked my first ever lock, saw a live-coding show and then later attended two live-coding workshops (one on TidalCycles, another on Super Collider), sat in a dark room and played howling wolf clips while Microsoft Sam read grimoires aloud, got my hair braided for the first time in a decade, made dumplings and DJ’d for a dinner party, connected with folks about queer-poly relationships, gave fiery advice, and received compliments so earnest and rational and persistent that it was difficult to refute them.

Zine fair plus Lightning Bolt concert inside a movie theater in Times Square??
I also put my interview prep to use and interviewed with a handful of Recurse Center partner companies. Job searching meant squaring off against impostor syndrome and a ton of related anxieties in rapid succession. I successfully choked most of that down when it mattered, though, and it was only a couple short weeks before I received my first offer.
To that end, I’m super happy to say that I’ll be joining Blink Health as a Fullstack Product Engineer! Blink Health is a healthcare startup in SoHo. They make it easier for people to afford prescription drugs, especially for those with limited insurance plans or none at all. These savings aren’t trivial either: an extra $50 can spare someone from choosing between groceries or medicine that week, and for some folks Blink saves many times that. I’ll be starting at the end of this month. ✌️🤓
The last two years have been a wild ride: participating in a social impact fellowship and accelerator, busting my product chops and learning web dev to get a public benefit company off the ground, then diving into four months of self-directed learning at Recurse Center. I’m really looking forward to having some externally imposed structure again. Real health insurance, too.
ii. some hard truths
I made a few radical life changes in 2016, like getting involved in activist spaces, dating more, biking everywhere, building strong friendships, going capital-B Boogying, programming full-time. As I carried those changes forward through 2017, I began to notice a lot of mental and emotional reconfiguration happening to me.

Did you know that along its way to becoming a butterfly, a caterpillar nearly completely liquifies inside its cocoon?
Psychological growth is confusing, full of false starts, and generally painful. You’ve got the static pain of stretching beyond your limits, the pleasure-pain of feeling an old knot finally release, the frustrating pain of stubbing your toe because some helpful asshole has been rearranging your psychic furniture when you weren’t looking. There’s the more dramatic knife-in-the-gut pain of realizing that just because you’re growing doesn’t mean the people closest to you are, and that now in certain cases what you previoulsy regarded as friendship actually looks a whole lot like run-of-the-mill exploitation or even emotional abuse, if you're being honest, and it's a realization that only hurts more because it’s so irredeemably cliche and boring. And despite all that pain you gotta go ahead and grow anyway, claw your way out of the relative comfort of ignorance. Transcendence may not be the only show in town but afaik it’s the one most worth watching.
Prior to attending Recurse Center I’d spent lots of time exploring my surroundings and cataloguing people and places worth coming back to. My view of myself did change (and positively!) as a consequence. But sooner or later, ya get tired of the taste of low-hanging fruit.
So, armed with the bookshelf of a philosophy grad and a burgeoning psychoanalytic vocabulary begging to be let off leash, I decided to use my time at RC to try confronting a few of my Hard To See truths in addition to becoming a better programmer.
Here’s what I’ve found so far.
Truth #1: People like me a lot. This causes me problems.
I’ve been metabolizing this one for some time. I remember having a conversation with Brittany in January of 2016. I don’t remember what social anxiety I’d been vocalizing, but I must have been worrying that someone “hated me.” Brittany cut me off, exasperated in the way that only a friend can be in the face of utter delusion: “No one hates you Nicole! You’re always worried that people don’t like you and it’s never true!”
I carried that admonishment with me through two years of voracious friendship-building. On the whole, seeing that people do in fact enjoy and seek out my company has curbed the most egregious overreaches of my social anxiety. But reckoning with my anxiety honestly has also meant acknowledging that my compulsive instinct to withdraw from social situations is also a protective (if suboptimal) response to a few very real dangers.
Most acutely: being friendly, generous, and intensely empathetic makes me a ready target for users. I try to give people the benefit of the doubt for as long as I can, which makes me proportionally susceptible to being taken advantage of and then gaslighted about it. A lifetime of socialization as a petite woman don’t help, neither. This leads to a pattern where, semi-regularly, I look up and take stock of how someone has been treating me and realize that the answer is Very Badly, For Quite A While. This in turn leads to rough periods of cutting ties and moving on. Ideally I’d like to be be able to filter bad actors out sooner, but I also want to stay open, giving, and hopeful beyond reason. Those desires are fundamentally at odds with each other - raising vs. lowering one’s defenses - but it’s clear that I need to come up with a strategy that balances both.
More broadly, though, I operate under an ever-present dread of inevitably disappointing everyone who knows me. Whether people project onto me because they already like me or like me more because they project positively onto me, I am extremely sensitive to the fact that when people meet me the conception they form has waaay more to do with what they want to find than what’s actually there. My body is a surface readily projected upon: young, female-shaped, ethnically ambiguous, small, smiling. These well-intended projections cause me the most trouble when people see me interacting socially; they’ll witness fifteen minutes of seemingly effortless extroversion on my part and extrapolate out massively. As far as they’re concerned I’ve got plenty of social energy to spare, and if I don’t spend it hanging out with them, it must be because either my friendliness is fake or I don’t like them.
Pretty much none of this is conducted consciously, of course, but it still creates a lot of unnecessary pressure that I can’t pretend not to feel and resent. I know there are people who dream about attaining this kind of “popularity” - to be assumed Cooler than one truly is - but getting buffeted around by folks’ totally unexamined, unarticulated psychological desires mostly sucks.
Truth #2: I’m non-binary.
I’ve also spent a very long time resisting this one. Two decades on the rack, easy. As such, the story of getting here is long. Perhaps one day I’ll tell it. 😛
The short of it, though, is this: I’m probably at least as much of a boy3 as I am a girl. Outside of where my life has been mutated by the chronic background radiation of sexism, “benevolent” and otherwise, I don’t strongly identify as a woman. Furthermore, I find the two-gender system to be infinitely more alienating than comforting. Gender is a social construction designed to impose order on the natural messiness of sexual experience, and as far as I’m cool with that, I am decidedly Not Cool with the “normal” state of affairs, i.e. aggressively shoving whole human beings into an absurdly reductive false dichotomy.
Between its either-or-ism and its forced assignment, the traditional approach to gender reveals itself to be obviously bullshit to anyone who spends more than a few minutes thinking about it. Its boundaries are arbitrary, inconsistent, and generally ill-fitting at the level of individual experience, which why they require such an outrageous amount of coercion and bodily violence to enforce. As much as other folks want to participate in a system of ritualized violence I guess they are free to? Personally, I’d prefer to see it actively dismantled.
If gender is to be saved it’ll be by subverting it, taking it apart, remaking it into something life-affirming. Not the dehumanizing garbage we’ve got now.

As of yet I don’t have any plans to change my presentation because I don’t fuckin’ gotta!
I do have a preference towards They / Them pronouns, but She / Her is still fine. For most of my friends this isn’t going to be at all surprising nor will it in any way negatively impact our relationship. Anyone who needs me to just-be-a-girl, however, can expect turbulence.
Truth #3: My righteous anger is justified and I am good at using it to help others.
I have felt conflicted about my anger for a long time. Since a very vocal childhood I have been regularly frustrated by prejudices and injustices, and I was frequently the first voice of dissent against them, whether that meant challenging adults or my peers. Unsurprisingly, I became well acquainted with the standard strokes of the backlash.
When you are confronting bigotry in a mixed environment, the voice of the status quo will generally manifest in one of two ways:
Gaslighting, e.g. “you are wrong to have said this at all, obviously I am a Good Person, you are just imagining that what I said sounded like XYZ, honestly how could you even think this, as a matter of fact it is I who is offended!”
Tone policing, e.g. “you’re too upset about this! after all, I, the person who did Fucked Up Thing, am perfectly calm about Fucked Up Thing, so any amount of anger makes you irrational by contrast, and I get a raincheck on whatever this is about!”
I know these responses are repulsive. I know they are merely the signs of a weak and imperiled ego acting out of fear. And yet I still spend an inordinate amount of time second-guessing my own anger. Gaslighting and tone policing are a favored weapon of the status quo because they work, and they work in direct proportion to how agreeable their target wants to be.
content warning: the following segment talks about sexual harassment and assault
About couple weeks ago I had the misfortune of being sexually harassed at a club in Bushwick. After numerous rejections and explicitly telling a creep bothering me, my friends, and other women in the club to get lost, I finally went to get a bouncer to eject him. The bouncer got the creep to leave. When I went to thank him, the bouncer told me a whole story about how the creep was “a harmless guy.” Then he reached down and grabbed my ass. Presumably he felt entitled to do this after helping me get rid of a person I asked him to remove... for unwanted touching.
It Really Sucked.
At every turn during the whole ordeal (and its aftermath) I had to hold onto my anger, convince myself that I wasn’t overreacting, remind myself that anyone who thought this was acceptable to do to me is almost certainly doing worse to more vulnerable people. I kept picturing myself the way this guy, this man in a position of power, must have seen me in order to feel okay doing what he did. That I was young, small, female, too friendly to say No, already indebted anyway; that he was one of the Good Guys, that his behavior was also “harmless” because he had decided it was. I conjured up as much anger as I could, pushed down the nausea of envisioning my own degradation from an attacker’s POV, and got to work. I reached out to the club and was quickly put in contact with the owner. The venue now has a publicly posted zero tolerance sexual harassment policy. The entire staff is going through training with a local org dedicated to creating safer nightlife spaces. And that motherfucker has been fired.
I demonstrably made the world better. I wasn’t alone, but all that happened because of my actions. Me and my anger, we did that.
I wish more people were this fucking angry. 💢
~ end of content warning ~
iii. an opinion
My Saturn return is upon me, y’all. As Frank Ocean serenades, we’ll never be those kids again. I have lived a few of these here nine lives and it seems only prudent to be moving forward with some sort of opinion on the matter.
My opinion is this: us folks with financial and physical security should be spending more time fixing shit around here. Figuring out what needs fixing and how you might help are the first steps.
If you’re operating on a similar scale of privilege as I am, maybe that means changing jobs to do more mission-oriented work. If you can’t swing a change of that magnitude, maybe it means showing up to community events and engaging with, caring for, supporting people you otherwise wouldn’t talk to. Churches, libraries, volunteering, supporting local artists, participating in local politics - this all counts. If you’re already doing this sorta thing, that is awesome! Maybe you also have a friend worth inviting who you sense is just itching for a chance to exercise compassion?
I’m using “fixing” pretty loosely here, too. Fixing, to my mind, means making the world brighter, safer, and sweeter for your fellows, human and otherwise. We’ve all got different ideas about what that looks like, and there are definitely folks - myopic or malevolent or both - who will swear up and down that their fear- and hate-driven behaviors will bring about better world. Ultimately, though, I believe that many hands reaching towards their personal vision of Better will in fact make things Better, especially when that vision is informed by meaningful interaction with the real world and its real sorrows and its real triumphs.
But ya gotta reach. Ya gotta try.
I am so tired of hearing my well-fed, well-homed friends piss and moan about late capitalism4 without lifting a damn finger in service of the communities bearing the brunt of material hardship. Unfettered capitalism sure does have a marked tendency to wreak havoc on organic life! But capitalism is not a monolith, and lamenting the abuses perpetuated by its principle benefactors as unchanging or inevitable only normalizes them. Any investigation into the history of capitalism (or the broader phenomena of how a Few come to subjugate the Many) will very quickly disabuse you of the notion that this shit is going to stop without a great deal of active resistance.5
So unless you are personally doing work to put our current strand of democracy-withering corporatism six-feet-under, seriously, just STFU instead. Your nihilism is boring! You don’t sound woke! Save it for your local DSA working group!
Which isn’t to say that I’m not convinced of the wickedness6 of the problems we’re facing: skyrocketing wealth disparity with no relief in sight; the destruction of most of Earth’s biodiversity via mass extinction; a pernicious climate of racism and xenophobia that scapegoats black and brown folks and then visits misery upon them; the weight of an aging population bearing down on the shittiest healthcare system of any nation in its class; a widely disenfranchised electorate further fragmented and fatigued by hyper-polarization; the gendered terrorism that is inflicted daily on women, trans and non-binary folks, and queer people at large; a rising wave of depressive anxiety as people become more aware of these problems and how thoroughly they’ve been disempowered from changing things for the better.
So yeah, I get it. These are hard problems. I just don’t see any better option than trying anyway. I want to spend my time fixing things around here and encouraging others to try their hand too. You already know the bad news: real change is hard and it can take a very long time. You might work your whole life sowing seeds whose fruit you never get to taste.
The good news, however, is that you can get started whenever and wherever you are. The good news is that a sense of purpose is its own reward.
iv. how to get started
When you’ve got hard work ahead of you, your best bet is to use your beautiful human brain and create some leverage. Ask Archimedes about it.7
Lever systems got two parts:
The lever, which is the tool you use to amplify your effort. The longer your lever is, the easier your job will be.
The fulcrum, which is the wedge the lever rests on. The nearer your fulcrum is to the thing you want to move, the easier your job will be.
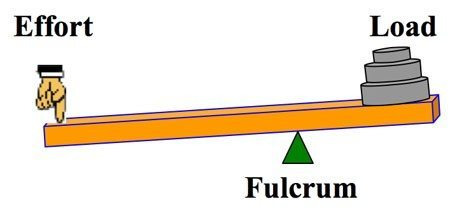
If you’re starting from zero - “I want to do more for the world but I don’t know how!” - my advice is to forget about the lever arm for now. A lever ain’t shit without a fulcrum, anyway. Your time is better spent exploring the world, keeping an eye out for problems you’d like to solve, and identifying nearby points of leverage. If you want to get into activism, a fulcrum might be volunteering to fold pamphlets for an organization with a mission you believe in. If want to see more self-expression in the world, it might be might be inviting your friends to a zine-making class or hosting your own arts and craft night.
The best fulcrum is one that makes you Feel Good when you apply any amount of effort against it. Too many people get caught up in a self-defeating belief that if they can’t give 110% of their creative energy to something they might as well not try. I can confidently say that trying is itself a virtue. Every time you try even a little bit you make it easier for yourself to try again later, and more importantly, you make trying easier for others. A bunch of people altering their behavior a smidge in the same direction doesn’t add up to nothing; on the contrary, it’s a sea change.
If you’ve got a decent idea of the types of problems you want to solve, though, and you’ve tested your fulcrums, and you are thinking, “Okay, but is this all I’m capable of giving?” then it’s probably time to work on your lever. Given your own interests and inclinations, what skills can you develop that will increase the good you’re doing 10x, 100x over? This is the long game, but it scales a whole lot better than “keep doing what I’m already doing, but more.”
For me right now this means deepening my technical knowledge, building a resilient support network, and sharing what I’m learning. Helping others has been a powerful motivator for self-improvement, not the least of which because it’s a convenient shortcut through the snarl of self-confidence issues.

I am so grateful that Recurse Center was a stop on lengthening my lever! What a concentrated cluster of helpful, considerate beings.
I’ve spent the last two years wandering around New York City in wide-eyed wonder, asking myself the most ambitious question I could think of: how do you save the world?
Getting older comes with a lot of downsides, but asking yourself big questions and living your life as the answer is the primary pleasure of adulthood. It took a ton of courage to get started and I am still frequently awed to find myself moving in the right direction. I’m humbled by the grace and fortitude of the folks who’ve been at this for way longer.
I’m also a hell of a lot happier. This summer’s gonna be rad. ☀️
There are lots of extraordinarily sexy company names like this in the legal world. ↩︎
Having the choice to direct my energies in this way is a privilege. Working in tech gives me this freedom of motion and I have been drawn to software engineering in part because it is the freest of the free (if you still gotta labor for your living). ↩︎
😱😫😖😬😬😬... 😏 ↩︎
Substitute with whatever modifier is en vogue. As a point of fact, “late capitalism” is a term that’s been floating around for literally over a hundred years. ↩︎
Thankfully, history also clearly demonstrates that the tide can be turned. ↩︎
“The use of the term ‘wicked’ here has come to denote resistance to resolution.” Wikipedia page. ↩︎
“Give me a lever long enough and a fulcrum on which to place it, and I shall move the world,” etc etc. ↩︎
3 notes
·
View notes
Text
The Stack
When a program starts, it granted a fixed size of memory called the stack. Since all reasonable programming languages support recursive functions, the arguments and the local variables should be allocated on the stack to preserve their values during the execution.
The most famous function to present recursion is factorial(). Let's write yet another one. For our purposes, it outputs the addresses of the arguments at the standard output.
#include <stdio.h> #include <stdlib.h> double factorial(double n) { printf("%.0f %u\n", n, &n); if (n == 0) { return 1; } else { return n * factorial(n - 1); } } int main(int argc, char* argv[]) { double d = atof(argv[1]); printf("Factorial %f is %f\n", d, factorial(d)); return 0; }
argv[1] is the first argument we supply to our program, and atof() is the standard function that converts a string to a double-precision floating-point value.
When we run the program with argument "5" it outputs:
$ ./a.out 5 5 123147368 4 123147336 3 123147304 2 123147272 1 123147240 0 123147208 Factorial 5 is 120
As you can see, the address of the argument n goes backwards by 32 bytes in each iteration. Those 32 bytes area is called "stack frame". In addition to arguments and local variables, it stores the caller's address at code segment for knowing where to go when it is time to "return".
Let's do a silly thing and add a new local variable like the following;
double factorial(double n) { char s[1000]; ...
you can observe that the stack frame is bigger now:
$ ./a.out 5 5 244948200 4 244947160 3 244946120 2 244945080 1 244944040 0 244943000 Factorial 5 is 120
Stack segment is used with a technique called LIFO (last in first out) during the execution. Let's add a new function called termial(). The name termial is invented by the famous scientist & programmer & author of many books, Donald Knuth. It is an alternative to factorial() for using addition instead of multiplication.
... double termial(double n) { printf("%.0f %u\n", n, &n); if (n == 0) { return 0; } else { return n + termial(n - 1); } } int main(int argc, char* argv[]) { double d = atof(argv[1]); printf("&argc %u Factorial %.0f is %.0f\n", &argc, d, factorial(d)); printf("&argc %u Termial %.0f is %.0f\n", &argc, d, termial(d)); ...
As you can see, the stack addresses are reused during the separate calls for first the factorial(), then the termial():
$ ./a.out 5 5 214900440 4 214900408 3 214900376 2 214900344 1 214900312 0 214900280 &argc 214900476 Factorial 5 is 120 5 214900440 4 214900408 3 214900376 2 214900344 1 214900312 0 214900280 &argc 214900476 Termial 5 is 15
5 is a little number and works like a charm. But it silently eats the stack as the recursion goes deeper. In the above program, we added the address of the argc to mark where our stack started.
214900476 - 214900280 = 196
For the argument 5, 196 bytes of stack frames are used. What if we call our function with a bigger number like 1000:
$ ./a.out 1000 ... 7 339722472 6 339722440 5 339722408 4 339722376 3 339722344 2 339722312 1 339722280 0 339722248 &argc 339754284 Termial 1000 is 500500
The difference between 339754284 and 339722248 is 32036, about 32KB. It may seem a little, but once we want the result for 1 million;
$ ./a.out 1000000 ... 738237 2777516536 738236 2777516504 738235 2777516472 738234 2777516440 738233 2777516408 738232 2777516376 Segmentation fault (core dumped)
we reached the end of the stack and crashed because the addresses below the stack are unallocated. Let's do a little math again:
1000000 - 738232 = 261768 * 32 = 8376576
As you can see, 8,376,576 bytes are used for the stack in this scenario. Academics tend to over-teach recursion during their courses, and you are "stack-overflowed" at the most unfortunate time if it is overused. The end result is almost always "flattening" the algorithm like the following:
double factorial(double n) { int i; double result; if (n < 1) { return 1; // I don't care about negative numbers } result = 1; for (i = 1; i <= n; ++i) { result *= (double)i; } return result; }
Ugly, isn't it? But it only uses a few bytes of the stack and doesn't crash. It is also faster because it avoids function call overhead which includes arranging the stack frame and jumping to start of a function. Those operations may be cheap but not free.
The stack size is fixed. Why not a growable stack? Because in the real world, recursions may not be evident as in the factorial() and sometimes a mistake by the programmer caused an infinite recursion. If the stack is somehow made growable, it can eat all the RAM trying to store useless intermediate values, and the computer is grounded to a halt. Thanks to the fixed-size stack, that kind of faults crashes the program early without killing the system.
Operating systems tend to give a default stack size for the programs. It is also possible to control stack size by other means. The first method is telling the C compiler that our program needs more (or less) stack:
$ gcc -Wl,--stack,4194304 -o program program.c
This way, the "program" will request 4MB of stack space while running. It is also possible to change it during the runtime. For Linux, setrlimit() system function is used for this purpose:
struct rlimit rl; rl.rlim_cur = 16 * 1024 * 1024; // min stack size = 16 MB; result = setrlimit(RLIMIT_STACK, &rl);
Windows' Win32 API has SetThreadStackGuarantee() function for that purpose.
Modern languages aren't exempt from stack overflows. The following Java program;
public class Xyz { private static double factorial(double n) { if (n == 0) { return 1; } else { return n * factorial(n - 1); } } public static void main(String[] args) { try { System.out.println("Factorial " + factorial(1000000)); } catch (Error e) { System.out.println(e.getClass()); } } }
also crashes with the following:
class java.lang.StackOverflowError
Usually, in a catch block, it is best to write the stack trace. But for errors like stack overflow, the stack trace is also too big to dump as-is, so we only wrote the error class to prove that it is a StackOverflowError. In practice, exceptions are dumped into the log file, and as you can guess by now, it is possible to blow your log files by bad recursion. Be careful.
Tail Call Elimination
We criticized the overuse of recursion for good reasons except that academics are not dumb. They invented a technique called "tail call elimination" to prevent unnecessary stack usage during recursion. Let's review the line that returns by calling itself in the factorial() example:
return n * factorial(n - 1);
This is clearly the last line of execution for the function. A smart implementation may decide that we don't need the stack frame here anymore, rewind the stack frame and replace the values with those we computed during the execution.
Among the popular languages only Haskell, Scala and Lua support tail call elimination. Let's write the termial function in Lua:
function termial(x) if x == 0 then return 1 else return x * termial(x - 1) end end io.write("The result is ", termial(1000000, 1), "\n")
After running the program;
$ lua ornek.lua lua: ornek.lua:5: stack overflow stack traceback: ornek.lua:5: in function 'termial' ornek.lua:5: in function 'termial'
we still got a stack overflow. To detect the need for a tail call elimination, Lua requires that the return statement call only one function. So we rewrite the termial:
function termial(x, answer) if x == 0 then return answer else return termial(x - 1, x + answer) end end
As you can see, we reduced the return statement to a single function call while adding an extra parameter to the termial() (and making it uglier).
The result is 500000500001
Supporting tail call elimination is always a heated topic among language designers. Python's founder Guido van Rossum made the most famous comment against it by telling it's "Unpythonic" in 4 points:
...when a tail recursion is eliminated, there's no stack frame left to use to print a traceback when something goes wrong later.
...the idea that TRE is merely an optimization, which each Python implementation can choose to implement or not, is wrong. Once tail recursion elimination exists, developers will start writing code that depends on it, and their code won't run on implementations that don't provide it.
...to me, seeing recursion as the basis of everything else is just a nice theoretical approach to fundamental mathematics (turtles all the way down), not a day-to-day tool.
http://neopythonic.blogspot.com/2009/04/tail-recursion-elimination.html
Multithreading
In the beginning, CPUs got faster each year. But for the last 10 or so years, they haven't got faster as quickly as once it was. In a conflicting trend, more speed is required from the hardware because of the Internet.
The industry found the solution in parallelization. More CPUs are added into the mainboards, and nowadays, the cheapest smartphone has at least 2 CPUs on it.
Each program has at least 1 thread of execution, and as we know that we have more CPUs on hand, we are encouraged to create more threads in our programs. Go programming language is created with that in mind providing first-class support for multithreading:
go f()
As you can see, it is as simple as using the "go" keyword to let the function run in another thread.
The bad news is that each thread of execution needs to have its own stack so we should take that into account while spawning many threads of execution because most languages and runtimes don't tell you much about that. In "go f()", we basically say
In C or operating system level, the stack size is taken on consideration while creating a thread. Let's see the prototype of the Win32's CreateThread() function:
HANDLE CreateThread( LPSECURITY_ATTRIBUTES lpThreadAttributes, SIZE_T dwStackSize, LPTHREAD_START_ROUTINE lpStartAddress, __drv_aliasesMem LPVOID lpParameter, DWORD dwCreationFlags, LPDWORD lpThreadId );
The second argument is the stack size for the thread. If you don't want to think much about it, you can just specify 0 and get as much stack your process requires. This is 1MB for most of the time, a rather massive number if you intend to create many of them. The official Win32 documentation recommends the opposite:
It is best to choose as small a stack size as possible and commit the stack needed for the thread or fiber to run reliably. Every page that is reserved for the stack cannot be used for any other purpose.
https://docs.microsoft.com/en-us/windows/win32/procthread/thread-stack-size
A thread may have a small stack segment size, but we will probably not know that while coding, especially in a big team. It is another reason to be safe and use the stack wisely.
To give modern programming languages their due, we should say that they thought hard about stack usage behind the scenes. In Go, only 2KB of stack space is reserved for their goroutines, and they grow dynamically as the program goes. Goroutines are carefully managed by Go runtime itself to avoid the possible lousy handling of threads in operating systems themselves.
Generation 0
Modern languages are most object-oriented, and they try hard to make everything object, including the strings. So it is hard to abuse their stack with a declaration like this:
char s[1000];
Most local variables do not belong to basic types like int, char, double etc., and they are allocated via the new operator. But this time the heap is abused because the burden of the stack is carried into the there. Since the heap is dynamic, to allocate and deallocate space are expensive operations. This is primarily a big problem in the early stages of the evolution of modern programming language runtimes.
The solution is found in a technique called generational garbage collection. When an object is created, it is stored in a stack-like memory space called generation 0. If the object's life-span is limited to the creator method, it is cheaply killed in there just like rewinding the stack frame. In reality, most object instances live and die this way.
To summarize, In practice, modern languages have a separate stack called "Generation 0" in .NET, "Eden" in Java, "youngest generation" in Python and so on...
0 notes
Text
programming assignment help
Programming Assignment Help
In the event that you are chipping away at Registration in your higher examinations, you should realize the challenges related with the subject. Regardless of what you attempted to get a dynamic thought, you'll most likely experience issues when drafting an undertaking. With many understudies looking for program help, the interest for help doled out an online program is expanding. However, finding the correct individuals to help your enlisted task is a troublesome assignment since coding specialists are an uncommon race.
All things considered, not more! This gives you a multitude of master coders, prepared to convey critical program task help.
We have been serving understudies in their need for longer than 10 years at this point. At whatever point understudies look for help enlisting schoolwork, we are their decision. We are here to help understudies at whatever point they require quick enrollment help on the web. We have space explicit specialists on board to nail errands delicately. Utilize our specialists and atta boys scored this term. Peruse on to discover why it is our best choice you can pick.
Separate arrangement of Assigned Registered Assistance
We have a modest bunch of exceptionally qualified program undertakings aides who put forth fair attempts to draft your paper brilliantly. Contingent upon our specialists and get flawless assistance with enrollment assignments.
Let our specialists dole out the best program to end every one of your errands addresses. You should simply pick our live visit choice and look for help from software engineering schoolwork or program task help. Offer your information and profit of the numerous administrations being offered, whenever you need help with your enrolled undertakings.
Customized Help on Homework on Computer Science
Committed PC and programming task assists specialists with chipping away at the designs. The journalists are notable for various programming sorts and assist you with beating all the impediments. They work with illustrations planning programming and movements to draft faultless schoolwork. So how about we help you with your coding undertakings and put astounding answers for your educators.
We likewise have supportive specialists in enlisting schoolwork that works in systems administration. They can give the best translation of distributed computing, information base stockpiling the board, PC network planner, etc.
Come to us with your "Would you be able to do my enrolled assignments for me?" and illuminate programs on Web Development, Cloud Computing, Software Development and so on.
Snap Away Registration Tasks as it were
We will assist you with programming task by distinguishing the fundamental thoughts, deciding the paper's prerequisites to make it immaculate, and so on. Our authors are code-insane people, and they know everything about programming dialects. They are specialists in various coding dialects, for example, Java, C++, and Python. Exploit our modest, alloted supportive projects and score the ensured top evaluations.
There are proficient web designers in our administration that causes you draft task of an extraordinary program. The journalists showed their aptitude and accommodation with different web improvement apparatuses. Get best online programming assignment help now.
Their assist will with being perfect to enlist schoolwork this term. Send your programming undertakings to us and get the assistance of an incorporated group of expert coders.
Aside from coding, we furnish PC task help with other enlisted highlights, beginning from information bases to man-made brainpower. You can likewise come to us with themes, for example, Algorithmic Mathematics speculations and information structure. We have individuals who are mindful of various parts of projects. Their ability will overpower and blame the paper.
Amaze for Professors with top of the line arrangements today. Exploit our particular help with programming task. Send us those solicitations "Make my enrolled task" when immaculate task arrangements get back at level costs.
Test Question and Reconciliation of Registration Task
COMMONS20245 Introduction to Registration
& Question:
Evaluation Task
You need to compose a Java reassure application that computes and characterizes BMI (Body Mass Index) for people. The quantity of people (N) is set at 10, so it ought to be proclaimed last N= 10 in your program.
BMI is determined utilizing the accompanying condition:
BMI = weight/(tallness * stature)
Where the weight is in kilograms and the tallness in meters.
The World Leadership Registration Assignment Helps Your Disposition
At the point when you pick us, you pick the absolute most astounding mentalities as partners for undertakings. Firmly weaved groups, made out of chosen software engineers and coders, progress in the direction of building up the most ideal answer for every one of your enlisted errands.
Be C, C++, C#, R, Java, Python, HTML, JavaScript, PHP; Our coding shepherds will convey exact and without bug coding task help to all requests. With intensive information and unwritten program composing abilities, our mentors will create compelling and easy to understand codes. Conveyed with pulled flowcharts well, all arrangements are:
Clear and stable
Open and productive
No bug and sound coherently
Effectively Variable
Inhabitants here are coded exceptionally talented in all motorcades and enlisted grade school subordinates. They have the essential aptitudes and experience to complete pro projects in any language, regardless of whether:
Fundamental Languages
Organized Languages
Procedural Languages
Things Oriented Languages
Practical Languages
It is an assurance that you will never get extensive online program help anyplace else on the Web or the Dark Web.
The rising project is an order. As machines become all the more impressive and incredible, their guidelines extended. All coding is a fantasy to outfit the potential and use them to accomplish astonishing mechanical accomplishments, creating codes that machines would now be able to do to learn and ship as people. Software engineers here are visionaries about a similar dream that coding is an enthusiasm and fixation.
Our web based programming help without a model will assist you with giving a program arrangement on:
Sort and Search Problems
Hierarchical Operations
Information Structure Operations on Binary Trees, Linked Lists, Stacks and Queues
Hashing
Reusing and Manipulation Strings
Dynamic Registration
Numeric and Maths Operations and some more.
Developing writing computer programs is a control. As machines become all the more remarkable and incredible, grow their arrangements of directions. Each coding is a fantasy about saddling the potential and utilizing them to accomplish astounding innovative accomplishments, creating codes that machines would now be able to do to learn and act as people. Developers here are dreams about that equivalent dream that coding is an energy and fixation.
Our web based programming help without a model will assist you with giving a program arrangement on:
Sort and Search Problems
Association Operations
Information Structure Operations on Binary Trees, Linked Lists, Stacks and Queues
Hashing
Reusing and Manipulation Strings
Dynamic Registration
Numeric and Maths Operations and some more.
So dispose all things considered and designation the entirety of your enrolled errands to our mentors. Let us deal with your issues as you center around the most significant thing, i.e., learn.
All arrangements are organized and indent to expand code clarity and openness. Our occupants offer suppositions at all basic focuses and convey flowcharts and calculations to each program. So when you look for coding task help from us, you just gain proficiency with your errands, you get familiar with the exchange of producing extraordinary codes.
All our skill comes to you at probably the most magnificent costs ever. It's simply one more assistance that offers such comparative quality at such amazing costs. So pay us for your enrolled assignments and get your cabinet loaded up with grants and accomplishments.
What's straightaway, there's a progression of incredible individuals hanging tight for you when you choose to pay us for your enrolled assignments. Exploit the most broad coding task help on the Web by us and go while in transit to turning into an effective coder today.
A wealth of advantages with our web based programming assignment help
Is it true that you are burnt out on battling with complex programming assignments? Take a pee pill and use program task help at one here as it were. Instead of giving the help of specialists, we additionally give you different grounds to declare us. Look and plan for your closest companion to accomplish for us.
Speedy conveyance of requests
You can likewise offer for the injury of missing cutoff times relying upon us. Our specialists welcome the significance of presenting the work before the cutoff time. In this manner, they made legit endeavors to complete the paper even before the guaranteed date. No other enrolled undertakings composing administrations can convey the work as fast as possible.
Full consistence with the prerequisites
Your educators can never take grades from your paper by conveying postcard issues. We follow all headings easily and make the best undertaking. You can set a model in your group by submitting perfect paper and scoring the best grades this term.
Appreciate a quick reaction from client care
Try not to spare a moment to call us at whatever point an inquiry comes in your psyche. You don't need to sit tight for the ideal time. We have a group of committed client assistance chiefs who consistently resolve the issue with brisk measures. You can call us, email us or even pick our live talk choice.
100% inventiveness on paper
We are alluded to as the best site that allocates programs for our zero copyright infringement ensures. We have a thorough enemy of copyright infringement strategy that our scholars follow while dealing with scholastic papers. Our essayists utilize valid locators to erase the parts that may have literary theft follows. We additionally give reports as verification of our realness.
So at whatever point you need any assistance with your enlisted task, pick our specialists immediately. Visit the site, share your subtleties, dispatch in the request structure and find exact arrangements here.
Get Premium Services with our Free Enrunding Homework
Try not to trouble yourself to search for enrolled errands when we're here to relieve your budgetary weight. On the off chance that you need pressing system task help, ask you 'on the off chance that you c
0 notes
Photo

Top 10 On Page SEO Hack To Rank On Google Without Backlinks
Introduction Of On Page SEO
On Page SEO (Search engine Optimization) is Defined as Optimization of your Website according to Search Engine's algorithm so that they can be ranked on SERP(i.e Search Engine Result Page) to get huge organic traffic. It helps your article to get ranked on google without having a lot of backlinks.
Let us start On Page SEO and discuss some algorithms that every Search Engine follows to rank any article on it's first page. Here is my checklist for On Page SEO which I will explain 1 by 1.
On Page SEO Checklist
Website Speed
HTML, Javascript, CSS and Image Optimization
Bounce Back Rate
User Experience and Engagements
Structure Data & Schema
Internal and External Linking
Rich Media and Images Alt Text
Proper Heading and Subheadings
Quality Content
Use AMP Ready and Mobile Friendly Theme
So these are some most important optimizations that you should cover in your website and blog. I am mentioning here that this is the whole On Page SEO topics that really impact your ranking on google.
So Let's explain them one by one to make them easy for everyone.
1.Website Speed
Website speed is one of the biggest issues for many bloggers that impact their SEO very badly. Because speed not only decide Website Loading but also increase Bounce Back Rate which kills your SEO, because google think that you do not have a proper content that's why many visitor left your website without interacting with your content.There are many factor that influence your website loading speed, but the two most important are..
Theme
Use faster themes like Generate Press, Astra, OceanWp, Kadence etc.
Quality Hosting
Use fast SSD or Cloud based Hosting from Siteground, Bluehost, DreamHost, A2hosting etc.
2.Coding Optimization
Coding Optimization means to optimize your code properly so that Search Engine's Crawler Bot sees your website as a clean and properly optimized website without having any malware, buggy or harmful code in it. This will reduce your Spam score and will definitely increase your SEO, Ranking, Traffic and Website Speed etc.
There are many free and paid plugins to optimize website speed using code optimization like Autoptimize (Free) and WPRocket(Paid). We personally use Siteground Optimizer as an optimization Plugin in our website because it is the official plugin by siteground to use in their Hosting for better Performance.
3. Image Optimization
Now Image optimization has two faces, the first is compressing Image and reducing image size and other is scaling image to a proper Ratio for better visibility. Optimizing Image will also help in decreasing your page load time.Try to use JPEG and WebP format Images instead of PNG because they render faster on browsers with good quality in low size.
There are many plugins to optimize, scale and convert images like resmushit, PNG to JPEG, shortpixel etc. Siteground Optimizer have in built Image optimization system as well as PNG or JPEG to WebP converter. So if you use siteground hosting, we recommend you to use their optimizer for better performance.
Learn How decrease website page load time.
4. Bounce Back Rate
Bounce Back Rate is something like poison for your SEO and post ranking. If you have a high bounce back rate , it means users on your site leaving without interacting with your website and content. Google and other Search Engines look like it, your website does not have a good content or a good service and products. Then they just ignore your website instead of ranking them in SERP. So make sure you reduce your bounce back rate as soon as possible.
5. UI and Engagement
User Experience and Engagement is not the biggest factor to affect SEO but has a great impact on your Bounce back rate and conversion. For example, when you visit a website, the first thing that you notice is website look and your experience with the website. If that impressed you, you will read their content carefully, your trust toward them will increase definitely.
So by creating a professional looking website, you increase your user engagement. Use creative design and creative content to impress your visitor.
6. Internal and External Linking
Internal and External linking makes your post more engaging and helps in reducing bounce back rate. Using these links inside your post will also help you to increase traffic on other posts which do not rank on google till now. It will also help you to generate more revenue if you are using google AdSense or Affiliate programs.
7. Less Popup and Ads
Many websites use 5 to 8 Popups all around their content to grab visitor attention but as per my experience using so many banner ads and popups actually increase your bounce back rate and hence affect Your SEO.
Learn How to Reduce Bounce Back Rate
8. Quality Content
The Most important thing in the world of blogging is the quality of content. That is the reason many successful bloggers termed "Content is King". Search engines like google also analyze your content very carefully before ranking them in google. The only thing that Google care is about the experience and satisfaction of users who searched a particular query.
Try to create a fully explained content which covers every aspect of that particular topic. Here is my working checklist on how to create a Quality Content.
a. Think About
What are you going to write?
Why Are You Going to write?
Which type of information are you providing?
How will it help a reader?
How much information users will get on this topic after reading a blog post.
Last but not least, users need to search this topic again on google after just reading your blog post.
b. To Do
Do a proper research on your topic.
Use heading and subheadings to write your blog post.
Use rich media like images and videos.
Content Length should be more than 700 words.
Explain everything about that topic.
Use structured data like schema, FAQ etc.
c. Not to Do
Do not refer to any spamming website in your articles.
Do not use any black hat SEO tricks to rank your post.
Do not use Too many ads links inside your post.
d. Rich Media and Images Alt Text
Using Rich media like images, videos, GIF etc. with proper caption and alt attributes help your post to become more SEO friendly. Use at least 3 images in every post but note it down that you should not use images if there is no need. Also do not forget to use proper alt text in images. In fact many bloggers now use GIF as a featured image for their content product to make it more attractive and eye catching.'
e. Proper Heading and Subheadings
Using Headings and Subheadings with short paragraphs in your content make it creative and attractive. This is a very common mistake by many beginners that write good content but not in a good way. Their content looks so boring which distracts users from reading it. Heading and subheading also makes the user understand which particular topic is covered in which part of the section and then he decides what he wants to read.
Learn more about how to write a quality content
9. Structured Data & Schema
Structure Data and Schema is a content of your post or product which is used by search engines like google to classify and categorize the type of content and product, quality of content and product etc. These days schema is a very popular thing for SEO and many bloggers just use Schema only, but there are other types of structured data like Breadcrumbs, FAQ, How To etc. Using proper structure data will increase your post rank on google and other search engines.
I will suggest you to use RankMath Plugin for SEO purpose because it has built Structure Data and Schema Feature. We also use RankMath to Optimize our content SEO and To embed FAQ, Schema and How to.
10. Use AMP Ready and Mobile Friendly Theme
According to google 70% of searches are requested by mobile devices. In fact google has a separate algorithm for mobile SERP and Desktop SERP, which means, it is not necessary that if your website rank on 3 in desktop search, so it will also rank 3 in mobile search. In order to rank your post or article in mobile SERP too, you need to have a mobile friendly website with AMP version ready.
AMP is called Accelerated Mobile Pages which contain less CSS and JavaScript and that helps in fast rendering of web pages on Mobile. Google ranks AMP versions of websites very fast in comparison to other versions.
As per my experience AMP for WP and AMP WP by Pixable both are good AMP plugins to make your website AMP ready.
Conclusion
I have covered all the things about On Page SEO briefly, and If you follow all these things properly in your blog website, there is a 80% more chance to rank your article better.
What is On Page SEO?
On page SEO is optimization of web pages and post according to Search Engine Algorithm to make them more SEO friendly.
Why On Page SEO is Important?
On Page SEO is Important to rank your articles on Google or other Search Engines.
How to do On Page SEO?
On Page SEO Cover many things, So you need to Optimize all the things that effect on page SEO.
How to Rank On Google Without Backlinks?
The only thing that will help you to rank on google without having a good authority website and backlink is you On Page SEO.
Can we Rank On Google Without Backlink
Yes, Of course you can rank on google without backlinks, you just need On PAge SEO optimized Article.
Read More https://bloggertutor.com/top-10-on-page-seo-hack-to-rank-on-google/?feed_id=439&_unique_id=5ef30e7d09d73 #seo#on_page_seo #rank_on_google #seo #seo_tips
0 notes
Text
A manufacturing company classified its executives into 4 levels for the benefit of certain perks. The levels and corresponding perks are shown below:
A manufacturing company classified its executives into 4 levels for the benefit of certain perks. The levels and corresponding perks are shown below:
table, th, td { border: 1px solid black; text-align:center; } Levels PerksConveyance AllowanceEntertainment Allowance110005002750200 350010042500
Income tax is deducted from the salary on a percentage basis as follows.
table, th, td { border: 1px solid black; text-align:center; } Gross Salary Tax Rate Gross 5000 8%
View On WordPress
#All C programming & Algorithm#All C Programming Example#allcprogrammingandalgorithm#basic c language#basic c programs#C Programming
0 notes
Text
Getting To 60 FPS In The Banality Wars Menu
Framerates in games isn't a very glamorous topic. But I think it's worth discussing.
So in case you don't know the frame rate (frames per second or FPS) is the number of frames drawn to the screen every second. Most computers can achieve 60 FPS as long as what they're doing is not too taxing.
But, of course, this brings up an interesting question. Does 60 frames per second literally mean 60 frames per second? So if I were to record the screen for exactly 1 second would I see 60 frames? No, of course not. Maybe a high end computer could achieve this, but for most devices 60 frames per second means on average there are 60 frames per second.
And the way it is usually measured is you take 1 second divided by the time to draw a frame. So if your frame took 20 milliseconds to render you assume every subsequent frame will also take 20 ms. So 1 second divided by 20 ms or 0.02 seconds gives us 50 frames per second. So the term 'frames per second' is a bit misleading. I think it should be called 'frame latency' but no one likes my ideas.
Anyways then we usually do a weighted average of frame latencies. This is done by the classic counter = counter * 0.5 + frameLatency * 0.5. This simply means counter will be weighted heavily (50%) to the current value of frame latency. The last frame will have a weight of 25%, the one before 12.5% and so on. Or said mathematically: counter = frameLatency_0 * 0.5 + frameLatency_1 * 0.25 + ... + frameLatency_n * 0.5^2
So now that we reviewed what frame rates mean we can discuss the problem. When the settings pane is open the frame rate tanks. This is what the settings look like.
"How is that tanking the frame rate?" you ask. "That's just a text box!" And to that I say, "Appearances are deceiving. Especially when doing graphics work. And also it's not just a textbox. There's also a dropshadow and a background."
And to be honest the FPS wasn't that bad here. I was still getting 42FPS on my Xiaomi Mi A1 with Snapdragon 625 that I got for less than $300 before tax 2 years ago. I believe this phone is even slower than the Galaxy A10 which you can get for under 150 CAD now. But even on such a low end device it wasn't 60FPS. And that just felt wrong.
So what's the first thing I do when I see an FPS problem? I go to the profiler:
Of course this created a problem. My computer was so fast the random background noise of FPS values going up and down made it impossible to tell this was an issue and what was causing it. Plus the profiler is pretty useless for anything other than a C# script causing problems. Graphics issues get creatively confusing names like GraphicsDrawPostUpdate. Like what does that even mean?
But nothing the profiler did stood out as an issue. So my immediate suspicion was that the problem was that it was a graphics issue. And that would mean it's an overdraw issue.
Now overdraw refers to drawing a pixel more than once in a single frame. That's how GPU's work. They have like a million cores and each core draws one pixel at a time. In a CPU there's only a few cores so this would take forever. "So why don't CPU's have like a million cores?" you say. Well, that's because a GPU core is super stripped down. You ever try to program for a GPU? Not fun. So if you tried to run something other than drawing pixels on a GPU it would likely be much slower. Although I hear some machine learning and cryptocurrency algorithms have been adapted to run on GPU's.
So back to overdraw. Sometimes you need overdraw. Such as you draw something translucent. Say you wanted to draw a translucent black circle over a translucent black square like this.
To do this start with a blank page.
Then draw the black square.
Then draw the black circle to get the final image.
But see all those darker pixels? They were all drawn twice. When we drew the black square and when we drew the black circle. This can lead to slowdowns.
So in the settings I noticed 0there is a black box covering the entire background. Maybe this was the issue for the slowdowns. So I disabled it. And to my amazement the FPS went up... by 2. So it went from 42 FPS to 44 FPS. Not exactly something to get excited about. So the lesson is this: overdraw isn't bad.
But the mystery remained? What was causing the issue? So I tried disabling something else. The dropshadow shader. And to my amazement the problem went away. We shot right up to 60 FPS. Hallelujah!
So why was this the case? Well the dropshadow shader was basically calculating a 2 dimensional gaussian distribution to emulate a shadow. This is what it looks like:
See all those pow(x, y)'s? Each one takes x and raises it to the power of y. Yeah, a lot of math. And for each pixel. No wonder it was running so slow. This was never a problem before but I guess because the dropshadow shader was on an object so big it was causing issues.
So I simply replaced the one giant gaussian shader with 8 smaller shaders (1 for each corner and edge). This significantly cuts down on overdraw from that inefficient shader. The only issue now is it doesn't look that good on square-ish devices. Looking at you iPad.
I'm also thinking of applying this change to anywhere that there's a dropshadow as the improvement is so significant.
So that's how I got my FPS to 60 on the settings pane. I guess the moral of this story is that overdraw is your friend unless the shader that does overdraw is inefficient. Then overdraw is not your friend.
This article originally appeared on my Patreon blog.
#mc_embed_signup{background:#fff; clear:left; font:14px Helvetica,Arial,sans-serif; } /* Add your own Mailchimp form style overrides in your site stylesheet or in this style block. We recommend moving this block and the preceding CSS link to the HEAD of your HTML file. */
Subscribe For Development Builds
0 notes
Text
IC MARKETS
Which Will Be the Absolute Most Reliable IC MARKETS Agents Online?
IC MARKETS Is Just a well-established and favorite Forex and CFDs on the web trading broker who offers competitive spreads on the wide variety of resources across the worldwide markets. IC MARKETS was set in 2007 and can be possessed and run by International Capital Markets PTY that are located in Sydney Australia.

Even the Corporation's headquarters Are in Measure 6 309 Kent Street Sydney, NSW 2000 along with the broker has been reportedly the states best online trading broker. That is largely because IC MARKETS tries to bridge the difference between international clients and big institutional traders by providing investment alternatives which have been once only provided by investment banking institutions and higher net worth individuals. Also, they offer the very best available leverage in Australia, minimal fees and spreads, a great education center, and even more. IC MARKETS is used both by novice and experienced traders from all around the world, but just how does this shape till the contest? From the subsequent reviewwe discuss the factors that compose this agent and how it contrasts with this contest?
RegulationsThough IC MARKETS was established In 2007, they only became regulated 2 decades later in '09 by the Australian Securities & Investments Commission (ASIC) underneath permit variety 335692. Also, IC MARKETS maintains an Australian Financial Services Licence (AFSL) which allows them to lawfully run a financial services business from Australia. Yet another technical component of IC MARKETS that protects customers is their membership with all the Financial Ombudsman Service (FOS). This registration provides traders using an extra layer of security when there are any disputes between the client and the brokerage.
Dependability: IC MARKETS is a very well Recognized and thoroughly reputable online trading broker that's been offering traders around the world with trusted trading and investment providers for over 10 yearsago IC MARKETS is actually a true ECN agent which means that there isn't any working desk or any kind of intervention amongst the client and the market. Therefore, customers are investing in directly with all the real inter bank forex marketplace which gives you a wonderful deal of transparency and dependability. As well, IC MARKETS undergoes periodic independent clauses to ensure the agents' dependability, transparency, and compliance with all regulations. All things considered, IC MARKETS is one among the most trusted and dependable online trading brokerages out there.
Dealing Platforms: IC MARKETSgoes previously and Beyond using the trading platforms they give. They offer maybe not just 1 but 3 exceptionally sophisticated trading platforms to allow their dealers to pick from. By those three gambling platforms, merchants are certain to find the one which matches each of their needs and trading type. Watch them overviewed beneath.
Meta Trader 4 (MT4): This is the most Popular dealing platform not only for IC market however for buying and selling brokerages all over the whole world. The platform uses no-nonsense trading options, various technical indicators, advanced level charting applications, and a reach of pro Advisors (EAs) for automatic algorithmic trading. Additionally, the MT4 trading platform allows for quite a few advanced arrangement forms and it has lightning fast performance rates.
Meta Broker 5 (MT5): This platform is currently your Most new improvement from your Meta broker platforms. It has not attained as much adoption and fame because Trader 4, however, it is the upgraded and improved upon variation of the MT4 system. It includes flexible great sizing, elastic funding and withdrawal choices, tight spreads, market thickness, and more.
C-Trader: The cTrader platform was created specifically For an ECN trading setting that uses the automatic dealing computer software. With this particular platform, merchants possess three choices when it comes to implementing automated investing; ZuluTrade,'' Myfxbook's auto-trade and Signal Trader's mirroring technology.
IC Markets Mobile Dealing: IC Trader is Fully optimized for intelligent mobile phones including phones and tablets. The MT4 Trading platform includes portable software compatible with either iOS and also Android Apparatus and is available free of charge by your Apple app-store and also the Google Perform shop. Moreover, the C-Trader platform is online and can be harmonious With mobile browsers and also has a downloadable program to get iOS along with Android apparatus. These cellular trading programs feature a lot of the Exact Same Advanced performance as the desktop computer programs also have been Built to provide a convenient and smooth trading encounter. All Things Considered, The cellular trading platforms supplied by IC Agents usually do not disappoint.
0 notes
Text
2018-03-20 06 SEO now
SEO
Ahrefs Blog
11 Slack Communities for SEOs and Digital Marketers (That You Should Join Today)
SEO Leads: How to Get $1K+/Month SEO Clients (with a Simple Video Pitch)
Technical SEO Mastery: Lessons from the GOAT, Wikipedia
Here’s why you can’t blindly trust keyword search volume for traffic estimations
7 Timeless Internet Marketing Strategies That Work in 2018 (and Beyond)
ClickZ
St. Patrick’s Day reminds us that “the holidays” don’t end in January
Everything you need to know about Account Based Marketing (ABM)
How to get started with your marketing attribution strategy
Creating global digital experiences for local audiences
Can artificial intelligence create content as well as a human?
Local SEO guide
Who Is Next In Local Listings Management?
A NodeJS Script for Accessing the Google Search Console API
Why SEOs Will Always Have Jobs…
Are Local Businesses Ready For GÖÖber?
2018 Tax Planning for SEO Agencies & Consultants
Moz
Where Clickbait, Linkbait, and Viral Content Fit in SEO Campaigns - Whiteboard Friday
Zero-Result SERPs: Welcome to the Future We Should've Known Was Coming
Getting Around the "One Form" Problem in Unbounce
8 Common Website Mistakes Revealed Via Content Audits
The Moz Year in Review 2017
Reddit SEO
My deleted pages are ranking...
In Need of an SEO Consultant
Google Local Image Backlink
Any Udemy SEO courses that are worth it at all?
I get blogs with high DR's asking if they could take my blog articles and post them on their site?
SEO Book Blog
Left is Right & Up is Down
Grist for the Machine
Virtual Real Estate
Rank Checker Update
DMOZ Shut Down
SEO by the Sea
Related Questions are Joined by ‘People Also Search For’ Refinements; Now Using a Question Graph
Google’s Mobile Location History
Does Google Use Latent Semantic Indexing?
Google Targeted Advertising, Part 1
Google Giving Less Weight to Reviews of Places You Stop Visiting?
Search Engine Journal
Google: 404 Errors Are Fine As Long As They Have No Links or Traffic by @MattGSouthern
Building Links Through Social Responsibility & Taking a Stand by @tonynwright
Why C-Suite Execs Aren’t Buying Your SEO Pitch by @bsmarketer
5 Ways to Promote Your Local Business on Facebook by @tallchickvic
Google Shopping Actions: Google Not Paid from Organic Search by @martinibuster
Search Engine Land
SearchCap: Google’s SEO AMA, AdWords Shopping Actions & Search Console updates
Google Search Console updates visual reporting features
Omnichannel Personalization at Scale: How leading brands drive sales across channels
AMP: Do or die? Session recap from SMX West
Google launches cost-per-sale Shopping Actions, unified shopping program across Search, Assistant & Express
Search Engine Roundtable
Daily Search Forum Recap: March 19, 2018
Google Core Algorithm Update Continues To Fluctuate For Some
Google Shutting Down Some Google+ Pages
Google Local Panel Tests About Tab
Google Shopping Actions For Voice Shopping & Assistant - There Is Confusion
Search Engine Watch
How to set up event tracking in Google Analytics
12 SEO tips for large ecommerce websites
6 common international SEO fails and how to avoid them
7 Google Tag Manager courses to prioritize in 2018
Experts agree: Social media is ineffective in local link building
Searchmetrics Blog
Memo to the Modern Marketer: How I Saved 15 Hours a Week Writing Great Content
Ask the Experts: How Understanding the Marriage of SEO and Content Marketing Can Save Your Business
Unwrapping the Secrets of SEO: How Google’s Crackdown on Online Ads Upends Search
Memo to the Modern Marketer: How to Conduct a Content Audit in Five Easy Steps
Pulse: Challenges and Takeaways from the Google AMP Conference
Yoast
SEO basics: What is anchor text?
Ask Yoast: Publish date on updated articles
SEO basics: What is a keyword?
Pagination & SEO: best practices
An hreflang example and how to test it
0 notes
Text
Segments of Memory
When we look at the RAM naively, it is an array of bytes addressed linearly. In practice, it is a sparse array where types of data are converged in specific addresses called segments. Each segment serves a different purpose for computer programs and is supported by the assembly/machine language, the CPUs' mother tongue.
But before diving into this, let's remember one of our computers' architectural principles, which may look old but still current.
Von Neumann Architecture
The earliest computers had fixed programs. They were like a calculator which knows how to calculate two numbers and nothing else. Changing what it does requires extensive redesign and rewiring of the system.
In 1944, John von Neumann was involved in the ENIAC project. He invented the "stored program" concept there in which, programs are loaded and stored in the main memory of the computer like any data. He wrote a paper titled "First Draft of a Report on the EDVAC". This paper was circulated among the computer builders and "Von Neumann Architecture" was born.
Since 1945, nearly all computers are built upon this idea, including the one we created our examples.
Types of memories in C
Let's start with a complete example which manifests all kinds of memory types in C:
#include <stdio.h> #include <stdlib.h> int g; char *s = "Hello"; int main(int argc, char* argv[]) { int n; int *p = malloc(1); // Stack Segment printf("&argc %u\n", &argc); printf("&n %u\n", &n); printf("&p %u\n", &p); // Code Segment printf("main %u\n", main); // Data segment printf("&g %u\n", &g); printf("&s %u\n", &s); printf("s %u\n", s); // Heap printf("p %u\n", p); return 0; }
The word "segment" attached to code, data and stack names comes from the native language CPUs called "machine language". The machine language identifies those memory areas and provides convenient and fast instructions to reach them through offsets. Programming languages including C mimics that with their structuring of programs.
The output lists the addresses of different types of variables.
&argc 1048287484 &n 1048287500 &p 1048287504 main 2981486985 &g 2981498908 &s 2981498896 s 2981490692 p 3008201376
While the numbers may look similar, you can observe some convergences between them. Let's start with the most divergent ones, the variables that reside on the stack segment:
&argc 1048287 484 0 &n 1048287 500 +16 &p 1048287 504 +20
We will observe the stack extensively later, but for now, we can simply say that all the variables defined as function parameters and local variables reside in the stack segment.
When the program is loaded from an executable file (like .exe, .dll, .so) into the memory, its instructions and constants are placed in the code segment.
main 29814 86985 s 29814 90692 +3707
Global pointer variable s is pointed to the constant "HELLO" in the code segment. We know it because when we try to manipulate it via the following code;
s[1] = 'A';
It crashes with the good old "Segmentation Fault" because the CPU prevents writing into memory marked as "code".
Every program has global variables which are stored in the data segment:
&s 29814 98896 +0 &g 29814 98908 +12
Stack, code and data segments occupy fixed sizes as defined by the program. But most programs need to dynamically allocate memory as they run. We call this memory "heap". When we run the above program, it requested 1 byte of memory via malloc(), and it is located a little bit far away from other segments.
(burada modern language'lere gel. Cok fazla sayida naif heap kullanimi ile baslayip, sonra generational'a donduklerinden falan bahset)(Thread stack)
Modern Languages' Take on Segments
Let's rewrite the above program in Java, without the printf()s since we can't take the address of variables there:
public class Xyz { public static int g; public static String s = "Hello"; private int i; public static void main(String[] args) { int n; Xyz p = new Xyz(); } }
In this program, the global variables are defined as static members in the Xyz since no variables outside the class scope permitted in Java. But they are real global variables, stored in the data segment and reachable as Xyz.g and Xyz.s anywhere throughout the program.
The variables args, n and p are located in the stack as in C. The non-static class attribute (or property) i can only be reachable if allocated on the heap via operator "new". Here, p is a reference and occupies a space in the stack, but the object instance it represents is allocated on the heap.
Heap is not Cheap
Modern programming languages tend to overuse heap because the only available means of creating a data structure requires using the "new" operator.
In C, you define a structure like this:
struct PERSON { char name[100]; char surname[100]; int age; }
This structure has fixed size (204 bytes in 32-bit systems) and can be used in the data segment, stack segment and heap. Let's define the same struct in Java:
class Person { String name; String surname; int age; }
This structure should be placed on the heap. Since string type is a class whenever a value is assigned to it, it is also allocated separately.
Allocation on the heap is not a cheap operation as in data and stack segments. Heap is invented because dynamic allocation is needed, and it comes with a price; for each request, the algorithm should search for an empty space. We'll explore heaps further in a separate article, but for now, this information is adequate.
C# provides a "struct" structure just for this purpose. Its standard class library uses structs for trivial data structures:
struct Point { int X; int Y; }
This is pragmatic and serves the purpose until strings are encountered.
using System; using System.Runtime.InteropServices; namespace ConsoleApp2 { struct Person { internal string name; internal string surname; internal int age; } class Program { static void Main(string[] args) { Person p; p.name = "Michael"; p.surname = "Jordan"; p.age = 55; Console.WriteLine("Person size " + Marshal.SizeOf(p)); } } }
The output would be "Person size 24" (or 12 in 32-bit systems), or 8 bytes per member because the string's content is not included in the calculation. Here "Michael" and "Jordan" are allocated on the data segment at program start just as in C, but in reality, values come from somewhere else and space from the heap should be given for them.
It is possible to allocate fixed-size structs in C# with some magic:
... [StructLayout(LayoutKind.Sequential)] struct Person { [MarshalAs(UnmanagedType.ByValTStr, SizeConst = 100)] internal string name; [MarshalAs(UnmanagedType.ByValTStr, SizeConst = 100)] internal string surname; internal int age; } ...
We can get 204 as in C this way. </stdlib.h></stdio.h>
1 note
·
View note
Text
Google's AMP, the Canonical Web, and the Importance of Web Standards
Have you ever clicked on a link after googling something, only to find that Google didn’t take you to the actual webpage but to some weird Google-fied version of it? Instead of the web address being the source of the article, it still says “google” in the address bar on your phone? That’s what’s known as Google Accelerated Mobile Pages (AMP), and now Google has announced that AMP has graduated from the OpenJS Foundation Incubation Program. The OpenJS Foundation is a merged effort between major projects in the JavaScript ecosystem, such as NodeJS and jQuery, whose stated mission is “to support the healthy growth of the JavaScript and web ecosystem”. But instead of a standard starting with the web community, a giant company is coming to the community after they’ve already built a large part of the mobile web and are asking for a rubber stamp. Web community discussion should be the first step of making web standards, and not just a last-minute hurdle for Google to clear.
What Is AMP?
This Google-backed, stripped down HTML framework was created with the promises of creating faster web pages for a better user experience. Cutting out slower loading content, like those developed with JavaScript. At a high level, AMP works by fast loading stripped down versions of full web pages for mobile viewing.
The Google AMP project was announced in late 2015 with the promise of providing publishers a faster way of serving and distributing content to their users. This also was marketed as a more adaptable approach than Apple News and Facebook Instant Articles. AMP pages began making an appearance by 2016. But right away, many observed that AMP encroached on the principles of the open web. The web was built on open standards, developed through consensus, that small and large actors alike can use. Which, in this case, entails keeping open web standards in the forefront and discouraging proprietary, closed standards.
Instead of utilizing standard HTML markup tags, a developer would use AMP tags. For example, here’s what an embedded image looks like in classic HTML, versus what it looks like using AMP:
HTML Image Tag:
<img src=”src.jpg” alt=”src image” />
AMP Image Tag:
<amp-img src=”src.jpg” width=”900” height=”675” layout=”responsive” />
Since launch page speeds have proven to be faster when using AMP, the technology’s promises aren’t necessarily bad from a speed perspective alone. Of course, there are ways of improving performance other than using AMP, such as minimizing files, building lighter code, CDNs (content delivery networks), and caching. There are also other Google-backed frameworks like PWAs (progressive web applications) and service workers.
AMP has been around for four years now, and the criticisms still carry into today with AMP’s latest progressions around a very important part of the web, the URL.
Canonical URLs and AMP URLs
When you visit a site, maybe your favorite news site, you would normally see the original domain along with an associated path to the page you are on:
https://www.example.com/some-web-page
This, along with it’s SSL certificate would clarify that you are seeing web content served from this site at this URL with a good amount of trust. This is what would be considered a canonical URL.
An AMP URL, however, can look like this:
https://www.example.com/platform/amp/some-web-page
Using canonical URLs, users can more easily verify that the site they’re on is the one they’re trying to visit. But AMP URLs muddied the waters, and made users have to adapt new ways to verify the origins of original content.
Whose Content?
One step further is their structure for pre-rendered pages from cached content. This URL would not be in view of the user, but rather the content (text, images, etc.) served onto the cached page would be coming from the URL below.
https://www-example-com.cdn.ampproject.org/c/www.example.com/amp/doc.html
The final URL, the one in view or the URL bar, of a cached AMP page would look something like this:
https://www.google.com/amp/www.example.com/amp.doc.html
This cache model does not follow the web origin concept and creates a new framework and structure to adhere to. The promise is better performances and experience for users. Yet, the approach is implementation first and web standards later. Since Google has become such an ingrained part of the modern web for so many, any technology they deploy would immediately have a large share of users and adopters. This is also paired with other arguments other product teams within Google have made to reshape the URL as we know it. This fundamentally changed the way the mobile web is served for many users.
Another, more recent development is the support for Signed HTTP Exchanges, or “SXG”, a subset of the Web Packages standard that allows further decoupling of distribution of web content from its origins with cryptographically signed HTTP exchanges (a web page). This is supposed to address the problem, introduced by AMP, that the URL a user sees does not correspond to the page they’re trying to visit. SXG allows the canonical URL (instead of the AMP URL) to be shown in the browser when you arrive, closing the loop back to the original publisher. The positive here is that a web standard was used, but the negative here is the speed of adoption without general consensus from other major stakeholders. Currently, SXG is only supported in Chrome and Chromium based browsers.
Pushing AMP: how did a new “standard” take over?
News publishers were among the first to adopt AMP. Google even partnered with a major CMS (content management system), WordPress, to further promote AMP. Publishers use CMS services to upload, edit, and host content, and WordPress holds about 60% of the market share as the CMS of choice. Publishers also compete on other Google products, such as Google Search. So perhaps some publishers adopted AMP because they thought it would improve SEO (search engine optimization) on one of the web’s most used search engines. However, this argument has been disputed by Google, and they maintain that performance is prioritized no matter what is used to get that page result to that performance measure. Since the Google Search algorithm is mainly in secret, we can only trust these statements at their word. Tangentially, the “Top Stories” feature in Search on mobile has recently dropped AMP as a requirement.
The AMP project was more closed off in terms of control in the beginning of it’s launch despite the fact it promoted itself as an open source project. Publishers ended up reporting higher speeds, but this was left up to a “time will tell” set of metrics. In conclusion, the statement “you don’t need AMP to rank higher” is often competing with “just use AMP and you will rank higher”. Which can be tempting to publishers trying to reach the performance bar to get their content prioritized.
Web Community First
We should focus less about whether or not AMP is a good tool for performance, and more about how this framework was molded by Google’s initial ownership. The cache layer is owned by Google, and even though it’s not required, most common implementations use this cache feature. Concerns around analytics have been addressed and they have also done the courtesy of allowing other major ad vendors into the AMP model concerning ad content. This is a mere concession though, since Google Analytics has such a large market share of the measured web.
If Google was simply a web performance company that would still be too much centralization of the web’s decisions. But they are not just a one-function company, they are a giant conglomerate that already controls the largest mobile OS, web browser, and search engine in the world. Running the project through the OpenJS Foundation is a more welcome approach. The new governance structure consists of working groups, an advisory committee, and a technical steering committee of people inside and outside of Google. This should bring more voices to the table and structure AMP into a better process for future decisions. This move will allegedly de-couple Google AMP Cache, which hosts pages, from AMP runtime, which is the JavaScript source to process AMP components on a page.
However, this is all well after AMP has been integrated into major news sites, e-commerce, and even nonprofits. So this new model is not an even-ground, democratic approach. No matter the intentions, good or bad, those who work with powerful entities need to check their power at the door if they want a more equitable and usable web. Not acknowledging the power one wields, only enforces a false sense of democracy that didn’t exist.
Furthermore, the web standards process itself is far from perfect. Standards organizations are heavily dominated by members of corporate companies and the connections one may have to them offer immense social capital. Less-represented people don’t have the social capital to join or be a member. It’s a long way until a more equitable process occurs for these types of organizations; paired with the lack of diversity these kinds of groups tend to have, the costs of membership, and time commitments. These particular issues are not Google’s fault, but Google has an immense amount of power when it comes to joining these groups. When joining standards organizations, It’s not a matter of earning their way up, but deciding if they should loosen their reigns.
At this point in time with the AMP project, Google can’t retroactively release the control it had in AMP’s adoption. And we can’t go back to a pre-AMP web to start over. The discussions about whether the AMP project should be removed, or discouraged for a different framework, have long passed. Whether or not users can opt-out of AMP has been decided in many corners of the web. All we can do now is learn from the process, and try to make sure AMP is developed in the best interests of users and publishers going forward. However, the open web shouldn’t be weathered by multiple lessons learned on power and control from big tech companies that obtusely need to re-learn accountability with each new endeavor.
from Deeplinks https://ift.tt/31FKvF6
0 notes
Text
Rolling Custom Cryptographic Systems: Part 2
For those who haven't read my original post (located HERE, we will be picking up where we left off in the design and implementation of our very own cryptosystem by implementing a Cryptographically Secure Pseudo-Random Number Generator (CSPRNG).
What's The Point Of This?
For any of our cryptographic functions to have any use whatsoever, we need a stream of random information we can feed our algorithms so we can properly perform hashing functions, symmetrical and asymmetrical encryption.
The "secret sauce" behind encryption is that it looks like random, garbled data or can pose as data belonging to something else.
Why Can't I Just Use The random() Function?
Sadly, the random() function, as implemented in many languages, is not Cryptographically Secure and is actually rather predictable based on a variety of factors, like CPU performance and timings.
In the same vein, CSPRNGs are also rather methodical due to the nature of the hardware and need thorough testing.
Cool, So What Are We Going to Do?
Since efficiency and using stable code is key to making everything work properly, we will want to utilize an already existing library. In our case, we'll use Duthomhas's CSPRNG, located here. This will give us an API to work with, without worrying about how we'll generate random numbers.
But How Do CSPRNGs Work???
Generally, a CSPRNG would gather entropy (randomness) through a variety of sources, for example the difference in microseconds between keystrokes or the noise of a transmission, and use fancy mathematics like the modulus operator and exponentiation to produce much, much more entropic data quickly.
However, since we're lazy (Guilty is Charged!!!), we don't want to spend weeks developing a Cryptographically Secure Pseudo-Random Number Generator, we want to work on encryption.
Adding The API
The sample source code explains the usage of the C headers by adding the code and then using the following code sample to generate pseudo-random numbers:
include <stdio.h>
include <duthomhas/csprng.h>
int main() { CSPRNG rng = csprng_create( rng ); // Constructor if (!rng) { fprintf( stderr, "%s\n", "No CSPRNG! Fooey!" ); return 1; }
long n = csprng_get_int( rng ); // Get an int
double f; // Get a double csprng_get( rng, &f, sizeof(f) );
int xs[ 20 ]; // Get an array csprng_get( rng, xs, sizeof(xs) );
void* p = malloc(20); // et cetera csprng_get( rng, p, 20 ); free( p );
rng = csprng_destroy( rng ); // Destructor return 0; }
This Code sample shows us that we can dynamically call csprng_get() to fill different data types with pseudo-random information. This will fit our needs immensely in a separate function, as such:
include <stdio.h>
include <string.h>
include <stdlib.h>
include "duthomhas/csprng.h"
extern int csprng_get(CSPRNG, void* dest, unsigned long long size); extern CSPRNG csprng_destroy(CSPRNG);
// Our implementation of the CSPRNG void * randstuff(void * x) { CSPRNG rng = csprng_create( rng ); // create CSPRNG if (!rng) { //if the CSPRNG fails to load fprintf( stderr, "%s\n", "No CSPRNG! Crap." ); exit(1); //crash and return an error }
csprng_get(rng, &x, sizeof(x)); // use CSPRNG rng = csprng_destroy(rng); // destroy the CSPRNG
return x; }
// Main function int main(void) { char rand[50]; //To be filled with random garbage
strcpy(rand, randstuff(rand));
return 0; }
This sample of code sadly isn't enough to get the CSPRNG working, as there's a slight flaw in the API we were provided in the csprng.c file. To fix this we need to swap the line that says #include <duthomhas/csprng.h> with #include "duthomhas/csprng.h" and everything should compile.
Alright, So What Did You Do?
We took sample code, and modified it to suit our purposes. Of course, our program doesn't yet work 100% and we're getting segmentation faults. However, this is a great first step as we're now able to produce pseudo-randomness at will.
To be more precise, we created a function called randstuff() that allows us to produce pseudorandom binary data at will. On top of this, we made the functions take the void * data type, allowing us to pass any form of data that we please into the function. This is somewhat dangerous and we'll need to explicitly convert our data to use the function later down the road... However, it provides us with the facilities necessary to create random information necessary for encryption.
Finally, since all this is placed into a separate function, we can call it anywhere we need randomness.
Be sure to stick around for Part 3, where we implement a hashing function!
Liked This Content? Check Out Our Discord Community and Become an email subscriber!
0 notes
Text
Write a program to read marks from keyboard and your program should display equivalent grade according to following table.
Write a program to read marks from keyboard and your program should display equivalent grade according to following table.
===================
Marks Grade
===================
0‐34 Fail
35‐59 Second Class
60‐79 First Class
80‐59 Dist
#include void main() { char name[50]; int roll_no,sub1,sub2,sub3,total; float avg; printf("\n\nEnter name of the student="); scanf("%s",name); printf("\n\nEnter roll number of the student="); scanf("%d",&roll_no); printf("\n\nEnter marks of…
View On WordPress
#All C programming & Algorithm#All C Programming Example#allcprogrammingandalgorithm#basic c language#basic c programs#C Programming
0 notes