#Clusterresource
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
130K people were victims of a chain letter scam that affected Tumblr in May 2011.
Text
What is Amazon EMR architecture? And Service Layers

Describe Amazon EMR architecture
The storage layer includes your cluster's numerous file systems. Examples of various storage options.
The Hadoop Distributed File System (HDFS) is scalable and distributed. HDFS keeps several copies of its data on cluster instances to prevent data loss if one instance dies. Shutting down a cluster recovers HDFS, or ephemeral storage. HDFS's capacity to cache interim findings benefits MapReduce and random input/output workloads.
Amazon EMR improves Hadoop with the EMR File System (EMRFS) to enable direct access to Amazon S3 data like HDFS. The file system in your cluster may be HDFS or Amazon S3. Most input and output data are stored on Amazon S3, while intermediate results are stored on HDFS.
A disc that is locally attached is called the local file system. Every Hadoop cluster Amazon EC2 instance includes an instance store, a specified block of disc storage. Amazon EC2 instances only store storage volume data during their lifespan.
Data processing jobs are scheduled and cluster resources are handled via the resource management layer. Amazon EMR defaults to centrally managing cluster resources for multiple data-processing frameworks using Apache Hadoop 2.0's YARN component. Not all Amazon EMR frameworks and apps use YARN for resource management. Amazon EMR has an agent on every node that connects, monitors cluster health, and manages YARN items.
Amazon EMR's built-in YARN job scheduling logic ensures that running tasks don't fail when Spot Instances' task nodes fail due to their frequent use. Amazon EMR limits application master process execution to core nodes. Controlling active jobs requires a continuous application master process.
YARN node labels are incorporated into Amazon EMR 5.19.0 and later. Previous editions used code patches. YARN capacity-scheduler and fair-scheduler use node labels by default, with yarn-site and capacity-scheduler configuration classes. Amazon EMR automatically labels core nodes and schedules application masters on them. This feature can be disabled or changed by manually altering yarn-site and capacity-scheduler configuration class settings or related XML files.
Data processing frameworks power data analysis and processing. Many frameworks use YARN or their own resource management systems. Streaming, in-memory, batch, interactive, and other processing frameworks exist. Use case determines framework. Application layer languages and interfaces that communicate with processed data are affected. Amazon EMR uses Spark and Hadoop MapReduce mostly.
Distributed computing employs open-source Hadoop MapReduce. You provide Map and Reduce functions, and it handles all the logic, making parallel distributed applications easier. Map converts data to intermediate results, which are key-value pairs. The Reduce function combines intermediate results and runs additional algorithms to produce the final output. Hive is one of numerous MapReduce frameworks that can automate Map and Reduce operations.
Apache Spark: Spark is a cluster infrastructure and programming language for big data. Spark stores datasets in memory and executes using directed acyclic networks instead of Hadoop MapReduce. EMRFS helps Spark on Amazon EMR users access S3 data. Interactive query and SparkSQL modules are supported.
Amazon EMR supports Hive, Pig, and Spark Streaming. The programs can build data warehouses, employ machine learning, create stream processing applications, and create processing workloads in higher-level languages. Amazon EMR allows open-source apps with their own cluster management instead of YARN.
Amazon EMR supports many libraries and languages for app connections. Streaming, Spark SQL, MLlib, and GraphX work with Spark, while MapReduce uses Java, Hive, or Pig.
#AmazonEMRarchitecture#EMRFileSystem#HadoopDistributedFileSystem#Localfilesystem#Clusterresource#HadoopMapReduce#Technology#technews#technologynews#NEWS#govindhtech
0 notes
Text
Unexpected errors when removing or adding node in SQL Server cluster
Case
After running SQL Server setup wizard to remove a node from a two-node SQL cluster, various cluster resources are removed and the SQL clustered instance remains in a failed state, even though the SQL Setup wizard had completed with exit code 0 (no errors). When trying to re-add the node, a series of errors occur, as described in this article. When trying to start the failed resources in the clustered SQL instance, the following error occurs (SQL error code 0x80071736):
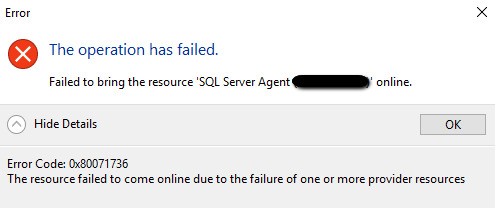
and/or the following error (SQL error code 0x8007139a), depending on whether the failed cluster resource has other failing dependency cluster resources or not.
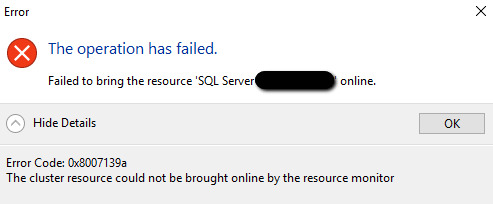
Also when trying to re-add the SQL node to the failed SQL instance, the client network access name is not shown (blank) and the following error occurs (SQL error code 0x84C00001):

Solution
Before you remove a node from the Windows Server operating system WFC cluster (evict node), it is important to first uninstall/remove any application-level clusters and other dependencies, for instance SQL Server clustered instances. In some cases however it appears that this can cause issues. In these cases, simply evicting the node from the WFC cluster is technically feasible and will not cause issues since the SQL clustered role basically relies on the WFC cluster information and keeps no separate configuration files, other than the registry. If the node which is being removed will be totally removed from the environment, then simply evicting the node can be justified. First investigate WFC cluster logs, SQL instance error logs, SQL server event logs and SQL Server setup logs. Check the cluster log on all cluster nodes, as per: https://blog.sqlauthority.com/2015/07/01/sql-server-steps-to-generate-windows-cluster-log/.

The SQL Server instance error log can be reviewed from inside the instance in SQL Server Management Studio. Each execution of Setup creates log files are created with a new timestamped log folder at %programfiles%Microsoft SQL Server100Setup BootstrapLog. The time-stamped log folder name format is YYYYMMDD_hhmmss. When Setup is run in an unattended mode, the logs are created at % temp%sqlsetup.log. All files in the logs folder are archived into the Log.cab file in their respective log folder. The SQL Server Setup logs should be investigated as per instructions at: https://docs.microsoft.com/en-us/previous-versions/sql/sql-server-2008-r2/ms143702(v=sql.105). Investigate all important cluster registry key groups: - Cluster - ComputerHKEY_LOCAL_MACHINECluster - Cluster Resources - ComputerHKEY_LOCAL_MACHINEClusterResources - Microsoft SQL Server - ComputerHKEY_LOCAL_MACHINESOFTWAREMicrosoftMicrosoft SQL Server I had same issue and checked again the cluster.log file, where I found following entries: r : Dependency expression for resource 'INSTANCENAME' is '()' 000022b0.00000958::2021/04/05-16:51:40.485 ERR SQL Server : Unable to open the SQL Server instance registry of 'Cluster' with error: 2. Please contact customer support 000022b0.00002fc0::2021/04/05-16:51:40.486 ERR SQL Server : GetRegKeyAccessMask: Could not get registry access mask for registry key SoftwareMicrosoftMicrosoft SQL ServerMSSQL15.INSTANCENAMECluster (status 2)). 000022b0.00002fc0::2021/04/05-16:51:40.486 ERR SQL Server : Worker Thread (1C8ECDE0): Failed to retrieve the SQL Server cluster registry key (last error = 2). 000022b0.00000958::2021/04/05-16:51:40.486 ERR SQL Server : SQL Cluster shared data upgrade failed with error 0 (worker retval = 2). Please contact customer support 000022b0.00000958::2021/04/05-16:51:40.486 ERR SQL Server : Failed to prepare environment for online. See previous message for detail. Please contact customer support 000022b0.00000958::2021/04/05-16:51:40.486 INFO SQL Server : SQL Server resource state is changed from 'ClusterResourceOnlinePending' to 'ClusterResourceFailed' 000022b0.00000958::2021/04/05-16:51:40.486 WARN Online for resource SQL Server (INSTANCENAME) failed. For some reason the SQL uninstall node setup had erroneously deleted some registry keys from path SoftwareMicrosoftMicrosoft SQL ServerMSSQL15.INSTANCENAMECluster. When i recreated them by using a healthy instance as reference, I was able to run the SQL Server repair wizard successfully. It appears that one good way to "reset" the registry key paths and values for a specific node of a WFC cluster is to evict the node from the WFC cluster and re-add it. This action needs to be performed with an administrator user which has all required permissions on the WFC cluster (file system, domain and registry) as well as permissions on the SQL cluster, if an SQL cluster is involved. You can try using the default domain admin user and then retest after refining the exact permissions needed. If there are still registry keys missing and you encounter akward behavior when running the SQL Server "Add node to existing cluster" wizard (i.e. SQL Server clustered instances not shown/populated by the SQL wizard), you should run ProcMon on the affected server at the time when the issue occurs and inspect which registry keys are being accessed. It is important to understand the registry path/key structure for all cluster related components in each WFC node. For this you should more sophisticated registry management tools, such as reg compare or the Nirsoft registry tool (for full registry snapshots or WinMerge for comparison of reg files). Run Powershell cmdlets to check available cluster resource types and cluster resource state: - Get-ClusterResource - Get-ClusterResourceType - Get-ClusterResourceGroup - Update-ClusterNetworkNameResource Check that all AD accounts (VNO, VCO) and permissions requirements have been met as per: https://docs.microsoft.com/en-us/previous-versions/windows/it-pro/windows-server-2008-R2-and-2008/cc731002(v=ws.10)?redirectedfrom=MSDN#BKMK_requirements. Also check that DNS forward and reverse resolution works consistently for all clustered instances from all WFC cluster nodes, as per: https://support.delphix.com/Delphix_Virtualization_Engine/MSSQL_Server/Resolving_Error_%22Failed_to_discover_cluster_address_for_cluster_environment%22_(KBA1594) Also check SPN status for all related computer objects and Windows services, as per: https://docs.microsoft.com/en-us/previous-versions/windows/it-pro/windows-server-2012-r2-and-2012/cc731241(v=ws.11). Check also that all WFC related network ports and protocols are allowed via the Windows Firewall in all WFC nodes, as per: https://docs.microsoft.com/en-us/troubleshoot/windows-server/networking/service-overview-and-network-port-requirements. Ensure also that the CLIUSR is present and enabled in all WFC nodes, as per https://docs.microsoft.com/en-gb/archive/blogs/askcore/so-what-exactly-is-the-cliusr-account. It is possible in some cases that a corruption occurs in the CLIUSR profile or more CLIUSR users are created and then deleted, which can lead to a corrupt configuration, as shown in the example below. If you encounter the below case, you will need to reboot the server in question and run Delfprof afterwards to cleanup the invalid user profiles.

Try a SQL Server node repair using SQL Server installation media (only on the passive node each time) as per the following article: https://www.mssqltips.com/sqlservertip/2592/fix-sql-server-agent-on-windows-failover-cluster/. When you repair an instance of SQL Server: - All missing or corrupt files are replaced. - All missing or corrupt registry keys are replaced. - All missing or invalid configuration values are set to default values. Before you continue, for SQL Server failover clusters, review the following important information: - Repair must be run on individual cluster nodes. - To repair a failover cluster node after a failed Prepare operation, use Remove node and then perform the Prepare step again. For more information, see Add or Remove Nodes in a SQL Server Failover Cluster (Setup). Possible and preferred cluster resource owners It is very important to check both the possible and preferred owner of each cluster resource at two levels: - Cluster role level Right click the SQL Server role, click Properties and check all relevant nodes in the General tab.

- Cluster role resource level (each role has many cluster resources underneath) Right click each of the cluster resources underneath the SQL role, click Properties and check all relevant nodes in the Advanced Policies tab.
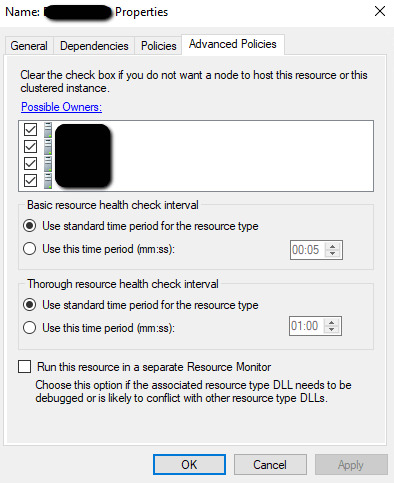
You need to ensure that the possible and preferred owners are consistent at both the cluster role level and the cluster role resource level for each subordinate resource. It appears that these settings can become inconsistent after removing a SQL Server node from the cluster by running the SQL Server wizard.
Sources
https://www.mssqltips.com/sqlservertip/2172/uninstalling-a-sql-server-clustered-instance/ https://www.mssqltips.com/sqlservertip/4231/how-to-remove-node-from-a-sql-server-failover-cluster/ https://docs.microsoft.com/en-us/previous-versions/sql/sql-server-2008-r2/ms191545(v=sql.105)?redirectedfrom=MSDN https://community.spiceworks.com/topic/1945302-sql-2014-add-node-fails https://serverfault.com/questions/1055297/cluster-network-name-blank-in-sql-cluster-node-configuration-setup-exit-with-e/1058129#1058129 https://support.delphix.com/Delphix_Virtualization_Engine/MSSQL_Server/Resolving_Error_%22Failed_to_discover_cluster_address_for_cluster_environment%22_(KBA1594) https://docs.microsoft.com/en-us/previous-versions/sql/sql-server-2008-r2/ms143702(v=sql.105) https://blog.sqlauthority.com/2016/04/13/sql-server-network-name-resource-fails-come-online-windows-server-2008-r2-failover-cluster/ https://joeydantoni.com/2012/06/29/recovering-from-a-deleted-cluster-resource/ https://docs.microsoft.com/en-us/troubleshoot/sql/failover-clusters/cluster-resource-goes-failed-state https://docs.microsoft.com/en-us/powershell/module/failoverclusters/update-clusternetworknameresource?view=windowsserver2019-ps https://docs.microsoft.com/en-us/troubleshoot/windows-server/networking/service-overview-and-network-port-requirements https://docs.microsoft.com/en-gb/archive/blogs/askcore/so-what-exactly-is-the-cliusr-account Read the full article
0 notes