#DataDuplicates
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 16.74 million mobile monthly users in the US.
Text

#ExcelAnalysis#DataAnalysis#Spreadsheet#DataProcessing#ExcelSheets#DataManagement#OrderNumber#ResponsiblePerson#DataValidation#DataDuplicates#RecurringOrders#ExecutiveOrders#UniqueOrders#DataIdentification#CommentSection#ExcelTasks#DataProcessingTasks
0 notes
Text
جلوگیری از Data Duplication یا تکرار داده چه اهمیتی دارد؟
Data Duplication چیست؟ تکرار دادهها (Data Duplication) یکی از مشکلات رایج در مدیریت اطلاعات است که میتواند منجر به کاهش کارایی دیتابیس، افزایش هزینه ذخیرهسازی، پیچیدگی در پشتیبانگیری و حتی ایجاد خطای تحلیلی شود. در این مقاله قصد داریم بهصورت جامع به موضوع تکرار دادهها بپردازیم و راهکارهای جلوگیری از آن را بررسی کنیم.
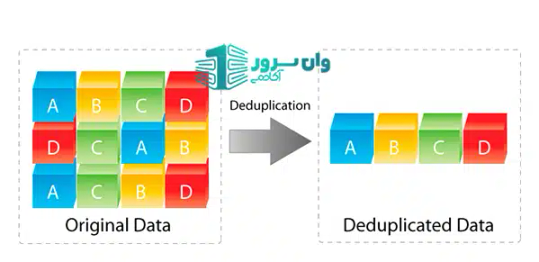
Data Duplication چیست؟
Data Duplication به معنای وجود چند نسخه یکسان از داده در یک یا چند محل مختلف از سیستمهای ذخیرهسازی است. این موضوع ممکن است در سطح فایلها، رکوردهای دیتابیس یا حتی بکاپها رخ دهد. مثلاً وقتی یک رکورد مشتری چند بار در دیتابیس ثبت شود، بدون اینکه تفاوتی بین آنها وجود داشته باشد.
چرا تکرار داده مشکلزاست؟
- کاهش کارایی دیتابیس: جستجو در دیتابیسی که دارای اطلاعات تکراری است، زمانبرتر میشود و باعث فشار بیشتر به منابع سیستم میگردد. - افزایش هزینه ذخیرهسازی: نگهداری اطلاعات تکراری فضای بیشتری اشغال میکند، بهویژه در دیتاسنترها و سرورهای هاستینگ. - ریسک تحلیل اشتباه: در تحلیل دادهها، رکوردهای تکراری باعث انحراف نتایج میشوند. - پشتیبانگیری پیچیدهتر: بکاپگیری از اطلاعات تکراری باعث افزایش حجم نسخه پشتیبان و زمان بکاپ میشود. - کاهش کیفیت اطلاعات (Data Quality): یکی از مهمترین عوامل افت کیفیت دادهها، تکرار بدون هدف آنهاست.
کاهش هزینه ذخیرهسازی
انواع Data Duplication
- Exact Duplicate: دادهها دقیقاً یکسان هستند. - Partial Duplicate: اطلاعات مشابه هستند ولی ممکن است در جزئیات تفاوتهایی وجود داشته باشد. - Unintentional Duplicate: بهصورت تصادفی در سیستم ذخیره شدهاند. - Intentional Duplicate: عمداً برای مقاصد خاص ایجاد شدهاند، مثلاً در سیستمهای بکاپ.
دلایل رایج تکرار داده
- عدم تعریف کلید اصلی مناسب (Primary Key) - خطای انسانی در ورود داده - عدم استانداردسازی اطلاعات ورودی - نبود سیاستهای کنترل کیفیت اطلاعات - وارد کردن اطلاعات از م��ابع مختلف بدون پاکسازی (Data Cleaning)
راهکارهای جلوگیری از تکرار داده
- استفاده از کلیدهای یکتا (Unique Keys) در دیتابیس - اجرای الگوریتمهای Deduplication در سطح فایل یا رکورد - پاکسازی دادهها قبل از واردسازی (Data Cleaning) - استفاده از نرمافزارهای Data Integration با قابلیت کنترل تکرار - آموزش نیروی انسانی برای ورود دقیق اطلاعات
ارتباط Data Duplication با سرویسهای هاستینگ
در سیستمهای هاستینگ، بهویژه وقتی پای دیتابیسها و بکاپهای متعدد در میان است، Data Duplication میتواند بهشدت هزینهزا باشد. تکرار فایلهای یکسان در هاست اشتراکی یا اختصاصی باعث کاهش فضای مفید و افزایش زمان پشتیبانگیری میشود. همچنین بر عملکرد کلی سرور نیز تأثیر منفی دارد.
راهکار وان سرور برای جلوگیری از تکرار دادهها
وان سرور با ارائه سرویسهای حرفهای هاست لینوکس، بکاپگیری خودکار، و سیستم مانیتورینگ فایلها، به شما کمک میکند تا با کمترین حجم ذخیرهسازی، بیشترین بهرهوری را از منابع داشته باشید. در سرورهای ما از تکنولوژی Deduplication برای جلوگیری از تکرار فایلها استفاده میشود. همچنین دیتابیسهای MySQL بهصورت خودکار بررسی میشوند تا رکوردهای تکراری شناسایی و حذف شوند.
جمعبندی
Data Duplication چیست؟ یکی از چالشهای مهم در مدیریت سیستمهای اطلاعاتی و هاستینگ است. با شناسایی دلایل و اجرای راهکارهای درست، میتوان از هزینههای اضافی و خطاهای اطلاعاتی جلوگیری کرد. پس بهتر است همین حالا سیستمهای خود را از نظر تکرار داده بررسی کنید. Read the full article
#DataDuplication#MySQL#Reducestoragecost#storage#تکراردادهها#دیتابیسهایMySQL#کاهشهزینهذخیرهسازی#کیفیتدادهها
0 notes
Text
#BackUp#LinuxFileReplication#LinuxFileDuplication#HybridCloudEnvironments#ArtificialIntellingence#MachineLearning#EnhancedSecurity#DataReplication#DataDuplication#DataIntegrity#AIIntegration
0 notes
Photo

10 Tips to Avoid Costly Data Entry Disasters
To avoid data entry disasters, businesses can work with reliable data entry companies that provide services of trained and experienced data entry operators. https://www.managedoutsource.com/infographics/10-tips-to-avoid-costly-data-entry-disasters/
0 notes
Text
Data Cleaning using Pandas
Data Cleaning using Pandas: Fixing the bad values in your dataset is called data cleaning.
Fixing the bad values in your dataset is called data cleaning. Before proceeding you must read the introduction to pandas library. These bad values can be: Empty cellsWrong DataDuplicates data cleaning by removing Empty cells Some cells may be empty in our dataset so removing those cells is very important for accurate results. Following are two ways to handle empty cells: Removing…
View On WordPress
0 notes