#KubeFed
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
1,644 Tumblr posts in 1 second.
Text
TikTok parent company creates KubeAdmiral for Kubernetes

While Kubernetes is still the de-facto standard in container orchestration, a lot of people who work on it would agree that it is in fact quite hard and in need of a lot of polishing. Read More. https://www.sify.com/cloud/tiktok-parent-company-creates-kubeadmiral-for-kubernetes/
#KubeAdmiral#TikTok#Kubernetes#Container#PublicCloud#PrivateCloud#KubeFed#ByteDance#Cluster#ContainerOrchestration
0 notes
Text
The Need for Multicluster Management in Modern IT Environments
As businesses continue to scale their cloud infrastructure, the need for multicluster management has become increasingly vital. Whether running Kubernetes workloads across multiple on-premises, hybrid, or cloud environments, managing multiple clusters efficiently is essential for ensuring high availability, security, and streamlined operations.
What is Multicluster Management?
Multicluster management refers to the ability to oversee, configure, and maintain multiple Kubernetes clusters from a single control plane. This approach simplifies operations, enhances security, and provides better visibility across distributed environments.
Why Multicluster Management Matters
High Availability & Resilience – Running workloads across multiple clusters prevents single points of failure, ensuring that applications remain available even if one cluster experiences an issue.
Scalability – As businesses expand, adding new clusters across different regions and cloud providers helps improve performance and reduces latency.
Security & Compliance – Managing multiple clusters allows organizations to segment workloads, enforce policies, and apply consistent security controls across different environments.
Cost Optimization – Distributing workloads across clusters enables efficient resource utilization and cost control by leveraging cloud-native scaling capabilities.
Challenges of Multicluster Management
Despite its advantages, managing multiple clusters introduces complexity. Some of the key challenges include:
Cluster Sprawl: Managing a growing number of clusters can lead to operational overhead if not properly organized.
Consistency & Policy Enforcement: Ensuring that all clusters adhere to security and governance policies can be difficult without centralized control.
Networking & Service Discovery: Cross-cluster communication and service discovery require specialized configurations to maintain seamless connectivity.
Monitoring & Observability: Collecting and analyzing logs, metrics, and events from multiple clusters require robust observability tools.
Tools for Effective Multicluster Management
Several tools and platforms help organizations streamline multicluster management, including:
Red Hat Advanced Cluster Management for Kubernetes (RHACM) – Provides centralized management, governance, and application lifecycle management for multiple clusters.
Rancher – A popular open-source tool that simplifies cluster provisioning, monitoring, and security policy enforcement.
Google Anthos – A hybrid and multicloud platform that provides a consistent Kubernetes experience across cloud providers and on-premises data centers.
Kubernetes Federation (KubeFed) – An open-source project that enables the synchronization and management of resources across clusters.
Best Practices for Multicluster Management
To successfully implement multicluster management, organizations should follow these best practices:
Define a Clear Strategy – Determine the purpose of each cluster (e.g., production, staging, testing) and establish a standardized approach to managing them.
Implement Centralized Governance – Use policy-based controls to enforce security and compliance standards across all clusters.
Automate Deployments – Utilize CI/CD pipelines and GitOps practices to automate application deployments and configuration management.
Enhance Observability – Leverage monitoring and logging tools to gain real-time insights into cluster health and performance.
Optimize Network Connectivity – Configure service mesh solutions like Istio or Linkerd for secure and efficient cross-cluster communication.
Conclusion
Multicluster management is becoming an essential component of modern cloud-native architectures. By adopting the right strategies, tools, and best practices, organizations can enhance scalability, improve resilience, and ensure security across multiple Kubernetes environments. As multicloud and hybrid IT infrastructures continue to evolve, efficient multicluster management will play a critical role in driving operational efficiency and innovation.
For organizations looking to implement multicluster management solutions, leveraging platforms like Red Hat Advanced Cluster Management (RHACM) can provide a streamlined and comprehensive approach. Interested in learning more? Contact us at HawkStack Technologies for expert guidance on Kubernetes and cloud-native solutions!
For more details www.hawkstack.com
0 notes
Photo

For anyone interested in exploring multi-cluster apps for Kubernetes, Rags Srinivas has a good starter use case with the Cassandra Operator (K8ssandra) using KubeFed.
0 notes
Text
Sometimes you do need Kubernetes! But how should you decide?

At RisingStack, we help companies to adopt cloud-native technologies, or if they have already done so, to get the most mileage out of them.
Recently, I've been invited to Google DevFest to deliver a presentation on our experiences working with Kubernetes.
Below I talk about an online learning and streaming platform where the decision to use Kubernetes has been contested both internally and externally since the beginning of its development.
The application and its underlying infrastructure were designed to meet the needs of the regulations of several countries:
The app should be able to run on-premises, so students’ data could never leave a given country. Also, the app had to be available as a SaaS product as well.
It can be deployed as a single-tenant system where a business customer only hosts one instance serving a handful of users, but some schools could have hundreds of users.
Or it can be deployed as a multi-tenant system where the client is e.g. a government and needs to serve thousands of schools and millions of users.
The application itself was developed by multiple, geographically scattered teams, thus a Microservices architecture was justified, but both the distributed system and the underlying infrastructure seemed to be an overkill when we considered the fact that during the product's initial entry, most of its customers needed small instances.
Was Kubernetes suited for the job, or was it an overkill? Did our client really need Kubernetes?
Let’s figure it out.
(Feel free to check out the video presentation, or the extended article version below!)
youtube
Let's talk a bit about Kubernetes itself!
Kubernetes is an open-source container orchestration engine that has a vast ecosystem. If you run into any kind of problem, there's probably a library somewhere on the internet that already solves it.
But Kubernetes also has a daunting learning curve, and initially, it's pretty complex to manage. Cloud ops / infrastructure engineering is a complex and big topic in and of itself.
Kubernetes does not really mask away the complexity from you, but plunges you into deep water as it merely gives you a unified control plane to handle all those moving parts that you need to care about in the cloud.
So, if you're just starting out right now, then it's better to start with small things and not with the whole package straight away! First, deploy a VM in the cloud. Use some PaaS or FaaS solutions to play around with one of your apps. It will help you gradually build up the knowledge you need on the journey.
So you want to decide if Kubernetes is for you.
First and foremost, Kubernetes is for you if you work with containers! (It kinda speaks for itself for a container orchestration system). But you should also have more than one service or instance.

Kubernetes makes sense when you have a huge microservice architecture, or you have dedicated instances per tenant having a lot of tenants as well.
Also, your services should be stateless, and your state should be stored in databases outside of the cluster. Another selling point of Kubernetes is the fine gradient control over the network.
And, maybe the most common argument for using Kubernetes is that it provides easy scalability.
Okay, and now let's take a look at the flip side of it.
Kubernetes is not for you if you don't need scalability!
If your services rely heavily on disks, then you should think twice if you want to move to Kubernetes or not. Basically, one disk can only be attached to a single node, so all the services need to reside on that one node. Therefore you lose node auto-scaling, which is one of the biggest selling points of Kubernetes.
For similar reasons, you probably shouldn't use k8s if you don't host your infrastructure in the public cloud. When you run your app on-premises, you need to buy the hardware beforehand and you cannot just conjure machines out of thin air. So basically, you also lose node auto-scaling, unless you're willing to go hybrid cloud and bleed over some of your excess load by spinning up some machines in the public cloud.

If you have a monolithic application that serves all your customers and you need some scaling here and there, then cloud service providers can handle it for you with autoscaling groups.
There is really no need to bring in Kubernetes for that.
Let's see our Kubernetes case-study!
Maybe it's a little bit more tangible if we talk about an actual use case, where we had to go through the decision making process.
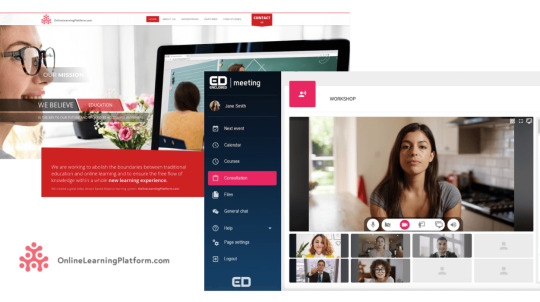
Online Learning Platform is an application that you could imagine as if you took your classroom and moved it to the internet.
You can have conference calls. You can share files as handouts, you can have a whiteboard, and you can track the progress of your students.
This project started during the first wave of the lockdowns around March, so one thing that we needed to keep in mind is that time to market was essential.
In other words: we had to do everything very, very quickly!
This product targets mostly schools around Europe, but it is now used by corporations as well.
So, we're talking about millions of users from the point we go to the market.
The product needed to run on-premise, because one of the main targets were governments.
Initially, we were provided with a proposed infrastructure where each school would have its own VM, and all the services and all the databases would reside in those VMs.
Handling that many virtual machines, properly handling rollouts to those, and monitoring all of them sounded like a nightmare to begin with. Especially if we consider the fact that we only had a couple of weeks to go live.
After studying the requirements and the proposal, it was time to call the client to..
Discuss the proposed infrastructure.
So the conversation was something like this:
"Hi guys, we would prefer to go with Kubernetes because to handle stuff at that scale, we would need a unified control plane that Kubernetes gives us."
"Yeah, sure, go for it."
And we were happy, but we still had a couple of questions:
"Could we, by any chance, host it on the public cloud?"
"Well, no, unfortunately. We are negotiating with European local governments and they tend to be squeamish about sending their data to the US. "
Okay, anyways, we can figure something out...
"But do the services need filesystem access?"
"Yes, they do."
Okay, crap! But we still needed to talk to the developers so all was not lost.
Let's call the developers!
It turned out that what we were dealing with was an usual microservice-based architecture, which consisted of a lot of services talking over HTTP and messaging queues.
Each service had its own database, and most of them stored some files in Minio.
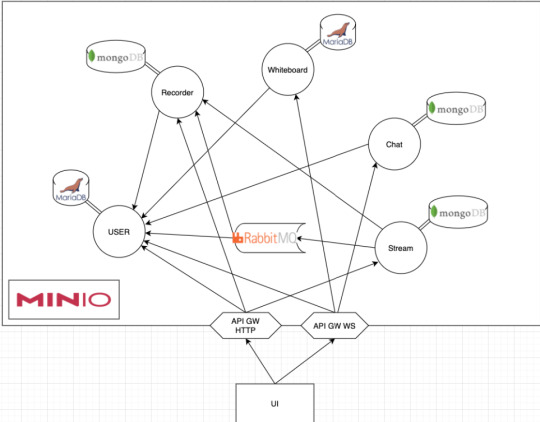
In case you don't know it, Minio is an object storage system that implements the S3 API.
Now that we knew the fine-grained architectural layout, we gathered a few more questions:
"Okay guys, can we move all the files to Minio?"
"Yeah, sure, easy peasy."
So, we were happy again, but there was still another problem, so we had to call the hosting providers:
"Hi guys, do you provide hosted Kubernetes?"
"Oh well, at this scale, we can manage to do that!"
So, we were happy again, but..
Just to make sure, we wanted to run the numbers!
Our target was to be able to run 60 000 schools on the platform in the beginning, so we had to see if our plans lined up with our limitations!
We shouldn't have more than 150 000 total pods!
10 (pod/tenant) times 6000 tenants is 60 000 Pods. We're good!
We shouldn't have more than 300 000 total containers!
It's one container per pod, so we're still good.
We shouldn't have more than 100 pods per node and no more than 5 000 nodes.
Well, what we have is 60 000 pods over 100 pod per node. That's already 6 000 nodes, and that's just the initial rollout, so we're already over our 5 000 nodes limit.

Okay, well... Crap!
But, is there a solution to this?
Sure, it's federation!
We could federate our Kubernetes clusters..
..and overcome these limitations.
We have worked with federated systems before, so Kubernetes surely provides something for that, riiight? Well yeah, it does... kind of.
It's the stable Federation v1 API, which is sadly deprecated.
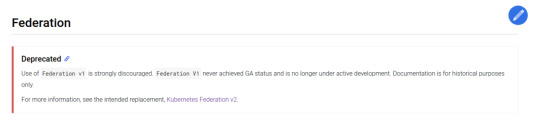
Then we saw that Kubernetes Federation v2 is on the way!
It was still in alpha at the time when we were dealing with this issue, but the GitHub page said it was rapidly moving towards beta release. By taking a look at the releases page we realized that it had been overdue by half a year by then.
Since we only had a short period of time to pull this off, we really didn't want to live that much on the edge.
So what could we do? We could federate by hand! But what does that mean?
In other words: what could have been gained by using KubeFed?
Having a lot of services would have meant that we needed a federated Prometheus and Logging (be it Graylog or ELK) anyway. So the two remaining aspects of the system were rollout / tenant generation, and manual intervention.
Manual intervention is tricky. To make it easy, you need a unified control plane where you can eyeball and modify anything. We could have built a custom one that gathers all information from the clusters and proxies all requests to each of them. However, that would have meant a lot of work, which we just did not have the time for. And even if we had the time to do it, we would have needed to conduct a cost/benefit analysis on it.
The main factor in the decision if you need a unified control plane for everything is scale, or in other words, the number of different control planes to handle.
The original approach would have meant 6000 different planes. That’s just way too much to handle for a small team. But if we could bring it down to 20 or so, that could be bearable. In that case, all we need is an easy mind map that leads from services to their underlying clusters. The actual route would be something like:
Service -> Tenant (K8s Namespace) -> Cluster.
The Service -> Namespace mapping is provided by Kubernetes, so we needed to figure out the Namespace -> Cluster mapping.
This mapping is also necessary to reduce the cognitive overhead and time of digging around when an outage may happen, so it needs to be easy to remember, while having to provide a more or less uniform distribution of tenants across Clusters. The most straightforward way seemed to be to base it on Geography. I’m the most familiar with Poland’s and Hungary’s Geography, so let’s take them as an example.
Poland comprises 16 voivodeships, while Hungary comprises 19 counties as main administrative divisions. Each country’s capital stands out in population, so they have enough schools to get a cluster on their own. Thus it only makes sense to create clusters for each division plus the capital. That gives us 17 or 20 clusters.
So if we get back to our original 60 000 pods, and 100 pod / tenant limitation, we can see that 2 clusters are enough to host them all, but that leaves us no room for either scaling or later expansions. If we spread them across 17 clusters - in the case of Poland for example - that means we have around 3.500 pods / cluster and 350 nodes, which is still manageable.
This could be done in a similar fashion for any European country, but still needs some architecting when setting up the actual infrastructure. And when KubeFed becomes available (and somewhat battle tested) we can easily join these clusters into one single federated cluster.
Great, we have solved the problem of control planes for manual intervention. The only thing left was handling rollouts..
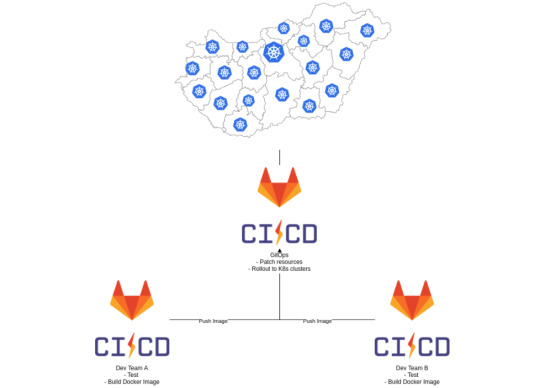
As I mentioned before, several developer teams had been working on the services themselves, and each of them already had their own Gitlab repos and CIs. They already built their own Docker images, so we simply needed a place to gather them all, and roll them out to Kubernetes. So we created a GitOps repo where we stored the helm charts and set up a GitLab CI to build the actual releases, then deploy them.
From here on, it takes a simple loop over the clusters to update the services when necessary.
The other thing we needed to solve was tenant generation.
It was easy as well, because we just needed to create a CLI tool which could be set up by providing the school's name, and its county or state.
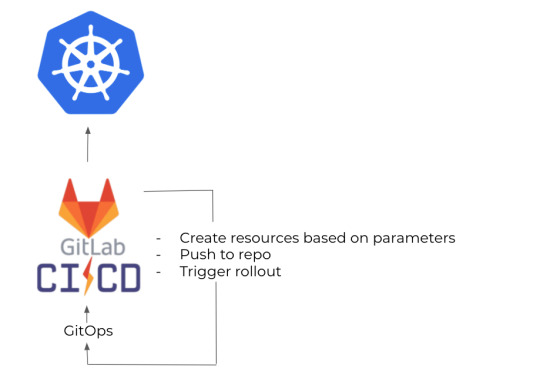
That's going to designate its target cluster, and then push it to our Gitops repo, and that basically triggers the same rollout as new versions.
We were almost good to go, but there was still one problem: on-premises.
Although our hosting providers turned into some kind of public cloud (or something we can think of as public clouds), we were also targeting companies who want to educate their employees.
Huge corporations - like a Bank - are just as squeamish about sending their data out to the public internet as governments, if not more..
So we needed to figure out a way to host this on servers within vaults completely separated from the public internet.
In this case, we had two main modes of operation.
One is when a company just wanted a boxed product and they didn't really care about scaling it.
And the other one was where they expected it to be scaled, but they were prepared to handle this.
In the second case, it was kind of a bring your own database scenario, so you could set up the system in a way that we were going to connect to your database.
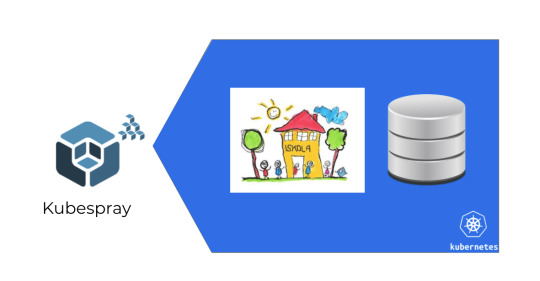
And in the other case, what we could do is to package everything — including databases — in one VM, in one Kubernetes cluster. But! I just wrote above that you probably shouldn't use disks and shouldn't have databases within your cluster, right?
However, in that case, we already had a working infrastructure.
Kubernetes provided us with infrastructure as code already, so it only made sense to use that as a packaging tool as well, and use Kubespray to just spray it to our target servers.
It wasn't a problem to have disks and DBs within our cluster because the target were companies that didn't want to scale it anyway.
So it's not about scaling. It is mostly about packaging!
Previously I told you, that you probably don't want to do this on-premises, and this is still right! If that's your main target, then you probably shouldn't go with Kubernetes.
However, as our main target was somewhat of a public cloud, it wouldn't have made sense to just recreate the whole thing - basically create a new product in a sense - for these kinds of servers.
So as it is kind of a spin-off, it made sense here as well as a packaging solution.
Basically, I've just given you a bullet point list to help you determine whether Kubernetes is for you or not, and then I just tore it apart and threw it into a basket.
And the reason for this is - as I also mentioned:
Cloud ops is difficult!
There aren't really one-size-fits-all solutions, so basing your decision on checklists you see on the internet is definitely not a good idea.
We've seen that a lot of times where companies adopt Kubernetes because it seems to fit, but when they actually start working with it, it turns out to be an overkill.
If you want to save yourself about a year or two of headache, it's a lot better to first ask an expert, and just spend a couple of hours or days going through your use cases, discussing those and save yourself that year of headache.
In case you're thinking about adopting Kubernetes, or getting the most out of it, don't hesitate to reach out to us at [email protected], or by using the contact form below!
Sometimes you do need Kubernetes! But how should you decide? published first on https://koresolpage.tumblr.com/
0 notes
Text
A Kubefed tutorial to synchronise k8s clusters!
New Post has been published on https://www.unternehmensmeldungen.com/a-kubefed-tutorial-to-synchronise-k8s-clusters/
A Kubefed tutorial to synchronise k8s clusters!
itnext.io - For now they have to take a shuttle to travel from one planet to another in order to synchronise their deployments. This takes too much time and the crew is exhausted. Fortunately, helped by some for…Mehr zu Kubernetes Services, Kubernetes Training und Rancher dedicated as a Service l...
Ganzen Artikel zu A Kubefed tutorial to synchronise k8s clusters! lesen auf https://www.unternehmensmeldungen.com/a-kubefed-tutorial-to-synchronise-k8s-clusters/ Mehr Wirtschaftsnachrichten und Unternehmensmeldungen unter https://www.unternehmensmeldungen.com
0 notes
Text
A Kubefed tutorial to synchronise k8s clusters!
New Post has been published on https://finanznachrichten.online/a-kubefed-tutorial-to-synchronise-k8s-clusters/
A Kubefed tutorial to synchronise k8s clusters!
itnext.io - For now they have to take a shuttle to travel from one planet to another in order to synchronise their deployments. This takes too much time and the crew is exhausted. Fortunately, helped by some for…Mehr zu Kubernetes Services, Kubernetes Training und Rancher dedicated as a Service l...
Ganzen Artikel zu A Kubefed tutorial to synchronise k8s clusters! lesen auf https://finanznachrichten.online/a-kubefed-tutorial-to-synchronise-k8s-clusters/
0 notes
Text
A Kubefed tutorial to synchronise k8s clusters!
New Post has been published on https://www.adhocmitteilung.de/a-kubefed-tutorial-to-synchronise-k8s-clusters/
A Kubefed tutorial to synchronise k8s clusters!
itnext.io - For now they have to take a shuttle to travel from one planet to another in order to synchronise their deployments. This takes too much time and the crew is exhausted. Fortunately, helped by some for…Mehr zu Kubernetes Services, Kubernetes Training und Rancher dedicated as a Service l...
Ganzen Artikel zu A Kubefed tutorial to synchronise k8s clusters! lesen auf https://www.adhocmitteilung.de/a-kubefed-tutorial-to-synchronise-k8s-clusters/
0 notes
Text
使用KubeFATE在Kubernetes上部署聯邦學習集群
FATE(Federated AI Technology Enabler)是聯邦機器學習技術的一個框架,其旨在提供安全的計算框架來支持聯邦 AI 生態。在本專題,我們將介紹如何基於FATE架構從0到1部署聯邦學習集群,本文是該系列的第四篇文章,旨在解決在Kubernetes部署運維FATE的問題。
背景及KubeFATE架構
在之前的文章中,我們介紹瞭如何使用KubeFATE部署一個基於Docker Compose的FATE聯邦學習集群,以便於快速嘗試體驗聯邦學習。但隨著聯邦學習的正式投入使用,訓練集、模型都會逐漸變大。在生產環境裡,我們會遇到以下問題:
1、FATE集群如何適應企業組織內部各種安全、合規要求,以及網絡、安全域等IT環境;…
from 使用KubeFATE在Kubernetes上部署聯邦學習集群 via KKNEWS
0 notes
Text
5 Kubernetes trends to watch in 2020
It’s been a busy year for Kubernetes, marked most recently by the release of version 1.17, the fourth (and last) release of 2019. Many signs indicate that adoption is growing – that might be putting it mildly – and few omens suggest this will change soon.
Organizations continue to increase their usage of containerized software, fueling Kubernetes’ growth.
“As more and more organizations continue to expand on their usage of containerized software, Kubernetes will increasingly become the de facto deployment and orchestration target moving forward,” says Josh Komoroske, senior DevOps engineer at StackRox.
Indeed, some of the same or similar catalysts of Kubernetes interest to this point – containerization among them – are poised to continue in 2020. The shift to microservices architecture for certain applications is another example.
“2020 will see some acceleration by organizations for transformation to a microservices-based architecture based on containers, from a service-oriented architecture (SOA),” says Raghu Kishore Vempati, director for technology, research, and innovation at Altran. “The adoption of Kubernetes as an orchestration platform will hence see a significant rise.”
Rising adoption is really just table stakes in terms of Kubernetes issues that IT leaders and practitioners should keep tabs on in 2020. Let’s dig into five other probable trends in the year ahead.
Key Kubernetes trends
1. Expect a rising tide of “Kubernetes-native” software
In many organizations, the first step toward Kubernetes adoption to date might be best described as Oh, we can use Kubernetes for this! That means, for example, that a team running a growing number of containers in production might quickly see the need for orchestration to manage it all.
More organizations will develop software specifically with Kubernetes in mind.
Komoroske expects another adoption trend to grow in the near future: We can build this for Kubernetes! It’s the software equivalent of a cart-and-horse situation: Instead of having an after-the-fact revelation that Kubernetes would be a good fit for managing a particular service, more organizations will develop software specifically with Kubernetes in mind.
“I expect…not only containerized software that happens to be deployable in Kubernetes, but also software that is aware of and able to provide unique value when deployed in Kubernetes,” Komoroske says.
The roots of this trend are already growing, evident in the emerging ecosystem around Kubernetes. As Red Hat VP and CTO Chris Wright has noted, “Just as Linux emerged as the focal point for open source development in the 2000s, Kubernetes is emerging as a focal point for building technologies and solutions (with Linux underpinning Kubernetes, of course.)”
As a subset of this trend, Komoroske anticipates the growth of software branded as “Kubernetes-first” (or Kubernetes-native). There’s a marketplace reason, of course: Kubernetes is a hot topic, and the name alone attracts attention. But there’s substance underneath that, and Komoroske sees some specific areas where new solutions are likely to spring up.
“Software that is released and branded as ‘Kubernetes-first’ will be increasingly common, possibly manifesting as custom resources definitions or Kubernetes Operators,” Komoroske says.
On that topic, if you need a crash course in Operators, or need to help others understand them, check out our article: How to explain Kubernetes Operators in plain English.
2. Will Federation (finally) arrive?
Vempati notes that there has been interest in better Federation capabilities in Kubernetes for a little while now; from his vantage point, the ensuing development efforts in the community appear to be getting closer to paying off.
“While many features of Kubernetes have acquired maturity, Federation has undergone two different cycles of development,” Vempati says. “While v1 of Kubernetes Federation never achieved GA, v2 (KubeFed) is currently in Alpha. In 2020, the Kubernetes Federation feature will most likely reach Beta and possibly GA as well.”
You can access the KubeFed Github here. It’s also helpful to understand the “why” behind KubeFed: It’s potentially significant for running Kubernetes in multi-cloud and hybrid cloud environments. Here’s more of Vempati’s perspective on the issue:
“Federation helps coordinate multiple Kubernetes clusters using configuration from a single set of APIs in a hosting cluster,” Vempati says. “This feature is extremely useful for multi-cloud and distributed solutions.”
3. Security will continue to be a high-profile focus
As the footprint of just about any system or platform increases, so does the target on its back.
As the footprint of just about any system or platform increases, so does the target on its back. It’s like a nefarious version supply and demand; the greater the supply of Kubernetes clusters running in production, the greater “demand” there will be among bad actors trying to find security holes.
“As the adoption of Kubernetes and deployment of container-based applications in production accelerate to much higher volumes than we’ve seen to date, we can expect more security incidents to occur,” says Rani Osnat, VP of strategy at Aqua Security. “Most of those will be caused by the knowledge gap around what constitutes secure configuration, and lack of proper security tooling.”
It’s not that Kubernetes has inherent security issues, per se. In fact, there’s a visible commitment to security in the community. It simply comes with some new considerations and strategies for managing risks. According to Osnat, bad actors are getting better at spotting vulnerabilities.
“Our team has seen that it currently takes only one hour for attackers to recognize an unprotected cluster running in the public cloud and attempt to breach it,” Osnat says. “The most common attack vector is cryptocurrency mining, but wherever that’s possible, other types of attacks such as data exfiltration are possible.”
Osnat says it’s incumbent on IT teams to properly harden their environments: “Implement runtime protection to monitor for indicators of compromise and prevent them from escalating,” Osnat advises as one tactic.[Source]-https://enterprisersproject.com/article/2020/1/kubernetes-trends-watch-2020
Basic & Advanced Kubernetes Certification using cloud computing, AWS, Docker etc. in Mumbai. Advanced Containers Domain is used for 25 hours Kubernetes Training.
1 note
·
View note
Text
पिक नुकसानीचे पंचनामे करा ; शेतकऱ्यांचे एक तास रास्तारोको आंदोलन
पिक नुकसानीचे पंचनामे करा ; शेतकऱ्यांचे एक तास रास्तारोको आंदोलन
केज तालुक्यातील कुंभेफळ येथे पिके पावसाअभावी वाळून गेल्यामुळे शेतकरी मेटाकुटीस आला आहे. तसेच येथील परिसरातील पंधरा गावच्या शेतकऱ्यांनी पिकांचे पंचनामे करून हेक्टरी एक लाख रुपये मदत देण्यात यावी याबरोबरच अशा विविध मागण्यांसाठी सोमवारी सकाळी १० वाजेच्या सुमारास राष्ट्रीय महामार्गावर रास्तारोको आंदोलन केले.
यामध्य�� करपलेल्या पिकांचे पंचनामे करून हेक्टरी १ लाख रुपये मदत द्यावी, खरीप हंगाम 2017,…
View On WordPress
0 notes
Text
Cluster Federation in Kubernetes 1.5
Editor’s note: this post is part of a series of in-depth articles on what's new in Kubernetes 1.5 In the latest Kubernetes 1.5 release, you’ll notice that support for Cluster Federation is maturing. That functionality was introduced in Kubernetes 1.3, and the 1.5 release includes a number of new features, including an easier setup experience and a step closer to supporting all Kubernetes API objects. A new command line tool called ‘kubefed’ was introduced to make getting started with Cluster Federation much simpler. Also, alpha level support was added for Federated DaemonSets, Deployments and ConfigMaps. In summary:
DaemonSets are Kubernetes deployment rules that guarantee that a given pod is always present at every node, as new nodes are added to the cluster (more info).
Deployments describe the desired state of Replica Sets (more info).
ConfigMaps are variables applied to Replica Sets (which greatly improves image reusability as their parameters can be externalized - more info).
Federated DaemonSets, Federated Deployments, Federated ConfigMaps take the qualities of the base concepts to the next level. For instance, Federated DaemonSets guarantee that a pod is deployed on every node of the newly added cluster. But what actually is “federation”? Let’s explain it by what needs it satisfies. Imagine a service that operates globally. Naturally, all its users expect to get the same quality of service, whether they are located in Asia, Europe, or the US. What this means is that the service must respond equally fast to requests at each location. This sounds simple, but there’s lots of logic involved behind the scenes. This is what Kubernetes Cluster Federation aims to do. How does it work? One of the Kubernetes clusters must become a master by running a Federation Control Plane. In practice, this is a controller that monitors the health of other clusters, and provides a single entry point for administration. The entry point behaves like a typical Kubernetes cluster. It allows creating Replica Sets, Deployments, Services, but the federated control plane passes the resources to underlying clusters. This means that if we request the federation control plane to create a Replica Set with 1,000 replicas, it will spread the request across all underlying clusters. If we have 5 clusters, then by default each will get its share of 200 replicas. This on its own is a powerful mechanism. But there’s more. It’s also possible to create a Federated Ingress. Effectively, this is a global application-layer load balancer. Thanks to an understanding of the application layer, it allows load balancing to be “smarter” -- for instance, by taking into account the geographical location of clients and servers, and routing the traffic between them in an optimal way. In summary, with Kubernetes Cluster Federation, we can facilitate administration of all the clusters (single access point), but also optimize global content delivery around the globe. In the following sections, we will show how it works. Creating a Federation Plane In this exercise, we will federate a few clusters. For convenience, all commands have been grouped into 6 scripts available here:
0-settings.sh
1-create.sh
2-getcredentials.sh
3-initfed.sh
4-joinfed.sh
5-destroy.sh
First we need to define several variables (0-settings.sh)
$ cat 0-settings.sh && . 0-settings.sh
# this project create 3 clusters in 3 zones. FED_HOST_CLUSTER points to the one, which will be used to deploy federation control plane
export FED_HOST_CLUSTER=us-east1-b
# Google Cloud project name
export FED_PROJECT=<YOUR PROJECT e.g. company-project>
# DNS suffix for this federation. Federated Service DNS names are published with this suffix. This must be a real domain name that you control and is programmable by one of the DNS providers (Google Cloud DNS or AWS Route53)
export FED_DNS_ZONE=<YOUR DNS SUFFIX e.g. example.com>
And get kubectl and kubefed binaries. (for installation instructions refer to guides here and here). Now the setup is ready to create a few Google Container Engine (GKE) clusters with gcloud container clusters create (1-create.sh). In this case one is in US, one in Europe and one in Asia.
$ cat 1-create.sh && . 1-create.sh
gcloud container clusters create gce-us-east1-b --project=${FED_PROJECT} --zone=us-east1-b --scopes cloud-platform,storage-ro,logging-write,monitoring-write,service-control,service-management,http://ift.tt/1w5YE3G
gcloud container clusters create gce-europe-west1-b --project=${FED_PROJECT} --zone=europe-west1-b --scopes cloud-platform,storage-ro,logging-write,monitoring-write,service-control,service-management,http://ift.tt/1w5YE3G
gcloud container clusters create gce-asia-east1-a --project=${FED_PROJECT} --zone=asia-east1-a --scopes cloud-platform,storage-ro,logging-write,monitoring-write,service-control,service-management,http://ift.tt/1w5YE3G
The next step is fetching kubectl configuration with gcloud -q container clusters get-credentials (2-getcredentials.sh). The configurations will be used to indicate the current context for kubectl commands.
$ cat 2-getcredentials.sh && . 2-getcredentials.sh
gcloud -q container clusters get-credentials gce-us-east1-b --zone=us-east1-b --project=${FED_PROJECT}
gcloud -q container clusters get-credentials gce-europe-west1-b --zone=europe-west1-b --project=${FED_PROJECT}
gcloud -q container clusters get-credentials gce-asia-east1-a --zone=asia-east1-a --project=${FED_PROJECT}
Let’s verify the setup:
$ kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
*
gke_container-solutions_europe-west1-b_gce-europe-west1-b
gke_container-solutions_europe-west1-b_gce-europe-west1-b
gke_container-solutions_europe-west1-b_gce-europe-west1-b
gke_container-solutions_us-east1-b_gce-us-east1-b
gke_container-solutions_us-east1-b_gce-us-east1-b
gke_container-solutions_us-east1-b_gce-us-east1-b
gke_container-solutions_asia-east1-a_gce-asia-east1-a
gke_container-solutions_asia-east1-a_gce-asia-east1-a
gke_container-solutions_asia-east1-a_gce-asia-east1-a
We have 3 clusters. One, indicated by the FED_HOST_CLUSTER environment variable, will be used to run the federation plane. For this, we will use the kubefed init federation command (3-initfed.sh).
$ cat 3-initfed.sh && . 3-initfed.sh
kubefed init federation --host-cluster-context=gke_${FED_PROJECT}_${FED_HOST_CLUSTER}_gce-${FED_HOST_CLUSTER} --dns-zone-name=${FED_DNS_ZONE}
You will notice that after executing the above command, a new kubectl context has appeared:
$ kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
...
federation
federation
The federation context will become our administration entry point. Now it’s time to join clusters (4-joinfed.sh):
$ cat 4-joinfed.sh && . 4-joinfed.sh
kubefed --context=federation join cluster-europe-west1-b --cluster-context=gke_${FED_PROJECT}_europe-west1-b_gce-europe-west1-b --host-cluster-context=gke_${FED_PROJECT}_${FED_HOST_CLUSTER}_gce-${FED_HOST_CLUSTER}
kubefed --context=federation join cluster-asia-east1-a --cluster-context=gke_${FED_PROJECT}_asia-east1-a_gce-asia-east1-a --host-cluster-context=gke_${FED_PROJECT}_${FED_HOST_CLUSTER}_gce-${FED_HOST_CLUSTER}
kubefed --context=federation join cluster-us-east1-b --cluster-context=gke_${FED_PROJECT}_us-east1-b_gce-us-east1-b --host-cluster-context=gke_${FED_PROJECT}_${FED_HOST_CLUSTER}_gce-${FED_HOST_CLUSTER}
Note that cluster gce-us-east1-b is used here to run the federation control plane and also to work as a worker cluster. This circular dependency helps to use resources more efficiently and it can be verified by using the kubectl --context=federation get clusters command:
$ kubectl --context=federation get clusters
NAME STATUS AGE
cluster-asia-east1-a Ready 7s
cluster-europe-west1-b Ready 10s
cluster-us-east1-b Ready 10s
We are good to go.
Using Federation To Run An Application In our repository you will find instructions on how to build a docker image with a web service that displays the container’s hostname and the Google Cloud Platform (GCP) zone.
An example output might look like this:
{"hostname":"k8shserver-6we2u","zone":"europe-west1-b"}
Now we will deploy the Replica Set (k8shserver.yaml):
$ kubectl --context=federation create -f rs/k8shserver
And a Federated Service (k8shserver.yaml):
$ kubectl --context=federation create -f service/k8shserver
As you can see, the two commands refer to the “federation” context, i.e. to the federation control plane. After a few minutes, you will realize that underlying clusters run the Replica Set and the Service.
Creating The Ingress After the Service is ready, we can create Ingress - the global load balancer. The command is like this:
kubectl --context=federation create -f ingress/k8shserver.yaml
The contents of the file point to the service we created in the previous step:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: k8shserver
spec:
backend:
serviceName: k8shserver
servicePort: 80
After a few minutes, we should get a global IP address:
$ kubectl --context=federation get ingress
NAME HOSTS ADDRESS PORTS AGE
k8shserver * 130.211.40.125 80 20m
Effectively, the response of:
$ curl 130.211.40.125
depends on the location of client. Something like this would be expected in the US:
{"hostname":"k8shserver-w56n4","zone":"us-east1-b"}
Whereas in Europe, we might have:
{"hostname":"k8shserver-z31p1","zone":"eu-west1-b"}
Please refer to this issue for additional details on how everything we've described works.
Demo
youtube
Summary
Cluster Federation is actively being worked on and is still not fully General Available. Some APIs are in beta and others are in alpha. Some features are missing, for instance cross-cloud load balancing is not supported (federated ingress currently only works on Google Cloud Platform as it depends on GCP HTTP(S) Load Balancing).
Nevertheless, as the functionality matures, it will become an enabler for all companies that aim at global markets, but currently cannot afford sophisticated administration techniques as used by the likes of Netflix or Amazon. That’s why we closely watch the technology, hoping that it soon fulfills its promise.
PS. When done, remember to destroy your clusters:
$ . 5-destroy.sh
--Lukasz Guminski, Software Engineer at Container Solutions. Allan Naim, Product Manager, Google
0 notes
Text
使用KubeFATE快速部署聯邦學習實驗開發環境(二)
在前面的文章中,我們介紹過如何使用KubeFATE來部署一個單節點的FATE聯邦學習集群。在真實的應用場景中,聯邦學習往往需要多個參與方聯合起來一起完成任務。基於此,本文將講述如何通過KubeFATE和Docker-Compose來部署兩個參與方的FATE集群,並在集群上運行一些簡單的測試以驗證其功能的完整性。
FATE集群的組網方式
聯邦學習的訓練任務需要多方參與,如圖1所示,每一個party node都是一方,並且每個party node都有各自的一套FATE集群。而party node和party node之間的發現方式有兩種。分別是點對點和星型。默認情況下,使用KubeFATE部署的多方集群會通過點對點的方式組網,但KubeFATE也可以單獨部署Exchange服務以支持星型組網。
部署兩方訓練的集群
使用KubeFATE和Docker-Compose部署兩方訓練的集群
KubeFATE的使用分成兩部分,第一部分是生成FATE集群的啟動文件(docker-compose.yaml),第二個部分是通過docker-compose的方式去啟動FATE集群。從邏輯上可將進行這兩部分工作的機器分別稱為部署機和目標機器。…
from 使用KubeFATE快速部署聯邦學習實驗開發環境(二) via KKNEWS
0 notes
Text
使用KubeFATE快速部署聯邦學習實驗開發環境(一)
FATE(Federated AI Technology Enabler)是一個聯邦學習框架,能有效幫助多個機構在滿足用戶隱私保護、數據安全和政府法規的要求下,進行數據使用和建模。但由於其係統的分佈式特性,導致使用存在一定門檻。鑑於此,VMware聯合微眾銀行一起開發了KubeFATE項目,致力於降低FATE的使用門檻和系統運維成本。本文將首先分析FATE的整體架構,幫助讀者理解各部件的作用;然後將展示如何從一台Linux機器開始,通過KubeFATE一步一步來搭建聯邦學習的實驗環境。
FATE整體架構
一個正常工作的FATE集群裡麵包含了若干組件,其中有些負責任務調度、有些負責存儲,各個組件各司其職,聯合起來一起完成任務。一個FATE集群所包含的組件如下圖所示。
各個服務的功能描述如下:
FATE Flow:該服務分為Client和Server兩部分,其中Client部分由用戶使用,用於向FATE集群提交聯邦學習任務;FATE Flow
… from 使用KubeFATE快速部署聯邦學習實驗開發環境(一) via KKNEWS
0 notes
Text
FATE发布1.3版本,首次增加联邦推荐算法
抗疫战场上的好消息不断传来,关于“数据免疫力”的话题也不断升温。如同人体需要提升自身免疫能力以抵抗人际接触中的潜在病毒威胁,企业和个人用户数据如何提高“免疫能力”,在越来越广泛的行业应用与合作中提升自身数据安全和防御能力?
近来,联邦学习进入行业视野。联邦学习在符合数据安全和政策法规的前提下,帮助各行各业实现多方协作训练AI。FATE(Federated AI Technology Enabler)作为联邦学习首个工业级开源框架,实现了同态加密和多方计算(MPC)的安全计算协议,支持联邦学习架构,内置机器学习算法的联邦学习实现。
近日,FATE发布了2020年的第一个版本更新FATE v1.3。在这一版本中,FATE首次增加联邦推荐算法模块FederatedRec,该模块包含6大推荐场景中常用的算法,包括5种纵向联邦算法和1种横向联邦算法,可用于解决联邦学习场景下的推荐问题,比如评分预测,物品排序等。
此外,该团队与VMware中国研发开放创新中心云原生实验室的团队联合发布的KubeFATE也在这一版本中迎来更新,整体进行了重构,并引入了对最新版本的FATE-Serving支持,使得用户可以进行在线推理。最后,针对FederatedML等多个模块,新版本也进行了更新及优化。…
from FATE发布1.3版本,首次增加联邦推荐算法 via KKNEWS
0 notes
Text
5 Kubernetes trends to watch in 2020
It’s been a busy year for Kubernetes, marked most recently by the release of version 1.17, the fourth (and last) release of 2019. Many signs indicate that adoption is growing – that might be putting it mildly – and few omens suggest this will change soon.
Organizations continue to increase their usage of containerized software, fueling Kubernetes’ growth.
“As more and more organizations continue to expand on their usage of containerized software, Kubernetes will increasingly become the de facto deployment and orchestration target moving forward,” says Josh Komoroske, senior DevOps engineer at StackRox.
Indeed, some of the same or similar catalysts of Kubernetes interest to this point – containerization among them – are poised to continue in 2020. The shift to microservices architecture for certain applications is another example.
“2020 will see some acceleration by organizations for transformation to a microservices-based architecture based on containers, from a service-oriented architecture (SOA),” says Raghu Kishore Vempati, director for technology, research, and innovation at Altran. “The adoption of Kubernetes as an orchestration platform will hence see a significant rise.”
Rising adoption is really just table stakes in terms of Kubernetes issues that IT leaders and practitioners should keep tabs on in 2020. Let’s dig into five other probable trends in the year ahead.
Key Kubernetes trends
1. Expect a rising tide of “Kubernetes-native” software
In many organizations, the first step toward Kubernetes adoption to date might be best described as Oh, we can use Kubernetes for this! That means, for example, that a team running a growing number of containers in production might quickly see the need for orchestration to manage it all.
Komoroske expects another adoption trend to grow in the near future: We can build this for Kubernetes! It’s the software equivalent of a cart-and-horse situation: Instead of having an after-the-fact revelation that Kubernetes would be a good fit for managing a particular service, more organizations will develop software specifically with Kubernetes in mind.
“I expect…not only containerized software that happens to be deployable in Kubernetes, but also software that is aware of and able to provide unique value when deployed in Kubernetes,” Komoroske says.
The roots of this trend are already growing, evident in the emerging ecosystem around Kubernetes. As Red Hat VP and CTO Chris Wright has noted, “Just as Linux emerged as the focal point for open source development in the 2000s, Kubernetes is emerging as a focal point for building technologies and solutions (with Linux underpinning Kubernetes, of course.)”
As a subset of this trend, Komoroske anticipates the growth of software branded as “Kubernetes-first” (or Kubernetes-native). There’s a marketplace reason, of course: Kubernetes is a hot topic, and the name alone attracts attention. But there’s substance underneath that, and Komoroske sees some specific areas where new solutions are likely to spring up.
“Software that is released and branded as ‘Kubernetes-first’ will be increasingly common, possibly manifesting as custom resources definitions or Kubernetes Operators,” Komoroske says.
On that topic, if you need a crash course in Operators, or need to help others understand them, check out our article: How to explain Kubernetes Operators in plain English.
2. Will Federation (finally) arrive?
Vempati notes that there has been interest in better Federation capabilities in Kubernetes for a little while now; from his vantage point, the ensuing development efforts in the community appear to be getting closer to paying off.
“While many features of Kubernetes have acquired maturity, Federation has undergone two different cycles of development,” Vempati says. “While v1 of Kubernetes Federation never achieved GA, v2 (KubeFed) is currently in Alpha. In 2020, the Kubernetes Federation feature will most likely reach Beta and possibly GA as well.”
You can access the KubeFed Github here. It’s also helpful to understand the “why” behind KubeFed: It’s potentially significant for running Kubernetes in multi-cloud and hybrid cloud environments. Here’s more of Vempati’s perspective on the issue:
“Federation helps coordinate multiple Kubernetes clusters using configuration from a single set of APIs in a hosting cluster,” Vempati says. “This feature is extremely useful for multi-cloud and distributed solutions.”
3. Security will continue to be a high-profile focus
As the footprint of just about any system or platform increases, so does the target on its back. It’s like a nefarious version supply and demand; the greater the supply of Kubernetes clusters running in production, the greater “demand” there will be among bad actors trying to find security holes.
“As the adoption of Kubernetes and deployment of container-based applications in production accelerate to much higher volumes than we’ve seen to date, we can expect more security incidents to occur,” says Rani Osnat, VP of strategy at Aqua Security. “Most of those will be caused by the knowledge gap around what constitutes secure configuration, and lack of proper security tooling.”
It’s not that Kubernetes has inherent security issues, per se. In fact, there’s a visible commitment to security in the community. It simply comes with some new considerations and strategies for managing risks. According to Osnat, bad actors are getting better at spotting vulnerabilities.[Source]-https://enterprisersproject.com/article/2020/1/kubernetes-trends-watch-2020
Basic & Advanced Kubernetes Certification using cloud computing, AWS, Docker etc. in Mumbai. Advanced Containers Domain is used for 25 hours Kubernetes Training.
0 notes