#Mulesoft JSON data
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In Q3 of 2020, 31% of US users access the Tumblr app daily.
Text
Mulesoft json
Exploring MuleSoft's Enhanced JSON Integration Capabilities
MuleSoft continues to evolve its integration platform, bringing in new features and enhancements that cater to modern integration needs. The latest version of MuleSoft introduces advanced JSON integration capabilities, making it easier and more efficient to work with JSON data. Here's a closer look at what the new version offers and how it can benefit your integration projects.
Enhanced JSON Processing
The latest version of MuleSoft offers significant improvements in JSON processing. This includes faster parsing and serialization of JSON data, reducing latency and improving overall performance. Whether you're dealing with large payloads or high-throughput scenarios, MuleSoft's optimized JSON handling ensures your integrations run smoothly.
JSON Schema Validation
MuleSoft now includes built-in support for JSON Schema validation. This feature allows developers to define JSON schemas that specify the structure and constraints of JSON data. By validating incoming and outgoing JSON messages against these schemas, you can ensure data integrity and catch errors early in the integration process. This is particularly useful for APIs and microservices where data consistency is critical.
Simplified DataWeave Transformations
DataWeave, MuleSoft's powerful data transformation language, has been enhanced to provide even more intuitive and efficient handling of JSON data. With the new version, you can take advantage of:
Enhanced Syntax: Simplified and more readable syntax for common JSON transformations, making it easier to write and maintain transformation scripts.
Improved Functions: A richer set of built-in functions for manipulating JSON data, reducing the need for custom code.
Performance Improvements: Optimizations that enhance the performance of DataWeave scripts, particularly when dealing with complex JSON transformations.
JSON Path Expressions
MuleSoft's new version introduces support for JSON Path expressions, allowing developers to query and manipulate JSON data more effectively. JSON Path is akin to XPath for XML, providing a powerful way to navigate and extract specific elements from JSON documents. This feature is particularly useful for handling deeply nested JSON structures, making it easier to work with complex data.
Seamless Integration with Anypoint Platform
The enhanced JSON capabilities are seamlessly integrated with MuleSoft's Anypoint Platform, ensuring a consistent and efficient experience across the entire integration lifecycle. From design and development to deployment and monitoring, you can leverage these new features to build robust and scalable integrations.
Anypoint Studio: Use the graphical design environment to easily create and test JSON transformations and validations.
Anypoint Exchange: Access and share reusable JSON schemas, templates, and connectors, speeding up your development process.
CloudHub: Deploy your integrations to the cloud with confidence, knowing that MuleSoft's enhanced JSON capabilities will ensure optimal performance and reliability.
Real-World Use Cases
The new JSON integration features in MuleSoft can be applied to a wide range of real-world scenarios:
API Development: Ensure your APIs handle JSON data efficiently, with robust validation and transformation capabilities.
Microservices Architecture: Facilitate communication between microservices using lightweight and efficient JSON messaging.
Data Integration: Integrate data from various sources, transforming and validating JSON payloads to maintain data consistency and quality.
Conclusion
MuleSoft's latest version brings powerful new JSON integration features that enhance performance, simplify development, and ensure data integrity. Whether you're building APIs, integrating microservices, or handling complex data transformations, these enhancements provide the tools you need to succeed. Embrace the new capabilities of MuleSoft and take your integration projects to the next level.
Would you like to highlight specific MuleMasters training courses that cover these new JSON capabilities in MuleSoft more information
#mulesoft training#mulesoft course#mulesoft#software#Mulesoft json#Mulesoft esb#Mulesoft JSON data#Mulesoft integration
0 notes
Text
How Mulesoft Enhances Data Connectivity Across Platforms?
Today, data engineering and integration projects require skilled data transformation to harmonize diverse data formats and structures. This complex process includes tasks such as mapping specific fields, reshaping JSON payloads, and managing intricate nested data. In this context, DataWeave serves as the Swiss Army knife in the MuleSoft ecosystem. It is a robust and versatile transformation language that enables you to manipulate data within your MuleSoft integrations.
This blog compares DataWeave with Python, examining how DataWeave is essential for solving data transformation challenges. It aims to equip MuleSoft developers with the tools to streamline complex data manipulation and enhance integration workflows.
Read our full blog on Mulesoft - https://bit.ly/3yyivFI

0 notes
Text
MuleSoft GCP

Integrating MuleSoft with Google Cloud Platform (GCP) enables leveraging a wide range of cloud services provided by Google, such as computing, storage, databases, machine learning, and more, within Mule applications. This integration can enhance your MuleSoft applications with powerful cloud capabilities, scalability, and flexibility offered by GCP, supporting various use cases from data processing and analysis to leveraging AI and machine learning services.
Key Use Cases for MuleSoft and GCP Integration
Cloud Storage: Integrate with Google Cloud Storage for storing and retrieving any data at any time. This is useful for applications that manage large amounts of unstructured data like images, videos, or backups.
Pub/Sub for Event-Driven Architecture: Use Google Cloud Pub/Sub for messaging and event-driven services integration, enabling the decoupling of services for scalability and reliability.
BigQuery for Big Data: Leverage Google BigQuery for analytics and data warehousing capabilities, allowing Mule applications to perform interactive analysis of large datasets.
Cloud Functions and Cloud Run: Invoke Google Cloud Functions or Cloud Run services for serverless computing, allowing you to run containerized applications in a fully managed environment.
AI and Machine Learning: Integrate with Google Cloud AI and Machine Learning services to add intelligence to your applications, enabling features like image analysis, natural language processing, and predictive analytics.
Strategies for Integrating MuleSoft with GCP
GCP Connectors and Extensions:
Check Anypoint Exchange for any available connectors or extensions for GCP services. These connectors can simplify integration by providing pre-built operations and authentication mechanisms.
Custom Integration via APIs:
For GCP services without a dedicated MuleSoft connector, use the HTTP Connector in Anypoint Studio to call GCP’s RESTful APIs. This method requires handling authentication, usually via OAuth 2.0, and crafting API requests according to the GCP service’s API documentation.
Service Account Authentication:
Use GCP service accounts for authenticating from your Mule application to GCP services. Service accounts provide credentials for applications to authenticate against GCP APIs securely.
Store the service account key file securely and use it to generate access tokens for API calls.
Cloud Pub/Sub Integration:
To integrate with Cloud Pub/Sub, use the Pub/Sub API to publish and subscribe to messages. This can facilitate event-driven architecture patterns in your Mule applications.
Cloud Storage Integration:
Use the Google Cloud Storage JSON API to upload, download, and manage objects in buckets. Ensure your Mule application handles the authentication and authorization flow to interact with Cloud Storage.
Error Handling and Logging:
Implement robust error handling and logging mechanisms, especially for handling API rate limits, quotas, and retries for transient errors.
Best Practices
Securely Manage Credentials: Use MuleSoft’s secure configuration properties to store GCP credentials securely. Avoid hardcoding credentials in your application code.
Optimize API Usage: Be mindful of GCP’s API quotas and limits. Implement efficient API calls and caching where appropriate to reduce load and costs.
Monitor Integration Health: Utilize Anypoint Monitoring and Google Cloud’s monitoring tools to keep track of the health, performance, and usage metrics of your integrations.
Review GCP’s Best Practices: Familiarize yourself with best practices for security, architecture, and operations recommended by Google Cloud to ensure your integration is scalable, secure, and cost-effective.
Demo Day 1 Video:
youtube
You can find more information about Mulesoft in this Mulesoft Docs Link
Conclusion:
Unogeeks is the №1 Training Institute for Mulesoft Training. Anyone Disagree? Please drop in a comment
You can check out our other latest blogs on Mulesoft Training here — Mulesoft Blogs
You can check out our Best in Class Mulesoft Training details here — Mulesoft Training
Follow & Connect with us:
— — — — — — — — — — — -
For Training inquiries:
Call/Whatsapp: +91 73960 33555
Mail us at: [email protected]
Our Website ➜ https://unogeeks.com
Follow us:
Instagram: https://www.instagram.com/unogeeks
Facebook: https://www.facebook.com/UnogeeksSoftwareTrainingInstitute
Twitter: https://twitter.com/unogeeks
#MULESOFT #MULESOFTTARINING #UNOGEEKS #UNOGEEKS TRAINING
0 notes
Text
Snowflake interview questions and answers

Snowflake provides cloud-based data warehousing that enables advanced solutions for organizational storage, handling, and analysis. Its unique characteristics include high speed, ease of use, and versatility making it stand out from other conventional offerings. Reporting and data warehousing are integral parts of any organization’s IT infrastructure.
To take on these tasks, Snowflake leverages the functionality of an innovative SQL query engine with a flexible architecture natively established for the cloud. This approach enables users to easily customize and start creating ready-to-query tables with little or no administration costs.
Snowflake Architecture:
Q: Can you explain the architecture of Snowflake?
A: Snowflake has a three-tier architecture: Compute, Storage, and Cloud Services. Compute handles query processing, Storage manages data storage, and Cloud Services coordinate and manage activities across the system.
2. Q: How does Snowflake handle scaling?
A: Snowflake can easily scale up or down by adding or removing virtual warehouses. Each warehouse consists of clusters of compute resources that can be adjusted based on the workload
SQL and Querying:
Q: What is the difference between a database and a schema in Snowflake?
A: In Snowflake, a database is a container for schemas, and a schema is a container for database objects. A database can contain multiple schemas, and each schema can contain tables, views, etc.
2. Q: How can you unload data from Snowflake to an external location?
A: You can use the COPY INTO command to unload data from Snowflake to an external location, such as an Amazon S3 bucket or Azure Data Lake Storage.
3. Q: Explain how data sharing works in Snowflake.
A: Data sharing in Snowflake allows sharing data between different accounts. A provider account can share a database or schema, and a consumer account can access the shared data using a share.
Security:
Q: What are Snowflake’s security features?
A: Snowflake provides features such as encryption at rest and in transit, multi-factor authentication, role-based access control (RBAC), and virtual private snowflake (VPS) for additional security.
Miscellaneous:
Q: How does Snowflake handle concurrency?
A: Snowflake’s multi-cluster, shared data architecture allows it to handle high levels of concurrency by scaling out compute resources. Each virtual warehouse operates independently and can be scaled up or down based on workload.
2.Q: Can you explain Snowflake’s time travel feature?
A: Snowflake’s time travel feature allows you to query data at a specific point in the past. There are two types: Time Travel (Data) lets you query historical data within a time window, and Time Travel (Schema) allows you to recover dropped or changed objects.
This course is designed to provide students with a solid understanding of the architecture and functionality of MuleSoft’s integration platform.
Advanced SQL and Performance Optimization:
1. Q: Explain Snowflake’s automatic clustering feature.
A: Snowflake’s automatic clustering optimizes data storage and query performance by organizing data based on usage patterns. It reduces the need for manual clustering and enhances query efficiency.
2. Q: How does Snowflake handle semi-structured data, and what are the benefits of using VARIANT data type?
A: Snowflake supports semi-structured data using the VARIANT data type, which allows storage of JSON, Avro, or XML data. VARIANT provides flexibility and performance benefits for handling nested and dynamic structures.
3. Q: Discuss the role of metadata in Snowflake and how it contributes to performance.
A: Snowflake uses metadata extensively to manage and optimize queries. Metadata includes information about data distribution, statistics, and storage, enabling the query optimizer to make informed decisions for efficient query execution.
Data Loading and Integration:
1. Q: Compare and contrast Snowflake’s different data loading options: COPY INTO, Snowpipe, and External Tables.
A: COPY INTO is used for batch loading, Snowpipe is a continuous data ingestion service, and External Tables allow querying data directly from external storage. Each option has specific use cases based on data volume and latency requirements.
2. Q: How does Snowflake handle data deduplication during data loading?
A: Snowflake’s automatic deduplication occurs during the data loading process. Duplicate records are identified based on the clustering key, and only unique records are stored, optimizing storage and improving query performance.
Administration and Monitoring:
1. Q: Explain the role of a Snowflake Virtual Warehouse. How can you optimize its performance?
A: A Virtual Warehouse (VW) is a compute resource in Snowflake. To optimize performance, consider adjusting the size of the virtual warehouse based on workload, using multiple warehouses for concurrency, and monitoring resource usage to make informed scaling decisions.
2. Q: What tools and techniques are available for monitoring and managing performance in Snowflake?
A: Snowflake provides features like Query Profile, Query History, and Resource Monitors for monitoring performance. External tools, such as Snowflake’s Snowsight or third-party tools, can also be used for performance analysis and optimization.
Case-Specific Scenarios:
1.Q: Describe a scenario where you might choose to use Snowflake’s secure data sharing feature.
A: Secure data sharing can be beneficial in scenarios where two organizations need to collaborate on analytics without physically moving data. For example, a retailer sharing sales data with a supplier for demand forecasting without exposing sensitive information.
2. Q: How would you design a data warehouse schema in Snowflake for a complex business analytics application with diverse data sources?
A: Consider factors such as data normalization, performance requirements, and access patterns. Leverage Snowflake’s features like clustering, semi-structured data types, and secure data sharing to design a schema that meets the application’s needs.
0 notes
Text
From REST to GraphQL: Enhancing API Development with DataGraph in MuleSoft by NexGen Architects
The power of a Traditional REST API has revolutionized client-server interaction. By utilizing standardized HTTP protocols and versatile data formats like JSON, XML, text, and HTML, it effortlessly bridges the gap between clients and servers.
1 note
·
View note
Text
Using Faker with Mulesoft
Faker is one of those tools that can save you a lot of time. It generates for you massive amounts of fake data for testing taking that out of your headspace.
Basically it is Lorem Ipsum for software development.
So, when I finally got this thing to work it boiled down to:
Adding the dependency on the project POM file, it looks like this:
<dependency> <groupId>com.github.blocoio</groupId> <artifactId>faker</artifactId> <version>1.2.7</version> </dependency>
Generating the Expression Language global functions to use, here is an example:
<configuration doc:name=“Faker"> <expression-language autoResolveVariables="true"> <import class="io.bloco.faker.Faker"/> <global-functions> def fakerFirstName() { return new Faker().name.firstName().toString() }; def fakerLastName() { return new Faker().name.lastName().toString() }; </global-functions> </expression-language> </configuration>
Using the new functions in DataWeave, here is an example:
%dw 1.0 %output application/json --- { batch: payload.batch, paymentTerm: payload.paymentTerm, billToContact: { firstName: fakerFirstName(), lastName: fakerLastName(), address1: fakerStreetAddress(), address2: fakerSecondaryAddress(), zipCode: fakerZipCode(), city: fakerCity(), state: fakerState(), country: fakerCountry() } }
Maybe there’s better ways to get this done, let me know if you have a better approach.
1 note
·
View note
Text
Cenit IO Lifetime Deal | Apps Integration Platform
Hello, my valuable readers, today’s review is about the ‘Cenit IO Lifetime Deal.’
I always try to provide information not available on the appsumo deal page in my article. This article will help you to decide to purchase the product. So, I think you will get value from my writing. Let us start.
There’s nothing worse than realizing that all your business tools are as incompatible as tuna and jam in a sandwich.
You can’t afford to stop using all your favorite apps, and you don’t have time to build an integrated solution from scratch.
Imagine if there was an integration platform that allowed you to connect any tool you want to create the workflows you need
Say hello to Cenit IO.
Finding a tool that integrates all your favorite applications can feel like one boss fight after another in Super Mario.
With Cenit IO, you can seamlessly connect your entire technology stack to an open-source integration platform to fully customize your workflows.
Meet Cenit IO Lifetime Deal
Category - Cloud, SaaS, Web-Based
Technical Support - Email/Help Desk, FAQs/Forum, Knowledge Base
Recommend - Certainly Yes
Founded 2015
About Cenit IO:
Cenit IO is the world’s top open-source integration platform iPaaS, designed to orchestrate data flows that may involve several endpoints.
It is possible to deploy it on-premises in your data center or use it in the cloud. Cenit IO makes possible complete business automation of all operational processes in a company, connecting the organization’s infrastructure and cloud provider services.
It allows the creation of custom data pipelines for process, storage, and data movement between APIs.
What Is Cenit IO:
Cenit IO is an open-source integration platform that lets you connect your tech stack to build automation and speed up workflows. Get API access to your entire technology stack to create custom integrations.
Implement integration capabilities with your own SaaS product in the cloud or on-premises.
Alternative To:
MuleSoft and Zapier
Who Uses Cenit IO?
Agencies, SMBs, and SaaS product teams looking to automate custom workflows.
Meet Cenit IO Lifetime Deal
Cenit IO Introduction:
Learn More About Cenit IO:
Cenit IO makes it easy to automate business processes and gives you everything you need to customize your workflows.
Get API access to your entire technology stack and stay competitive in today’s API economy.
You can set up instructions for importing, analyzing, and exporting data so that your data is automatically transferred between different systems.
Implement integration capabilities into your own SaaS product, with the freedom to work in the cloud or move on-premises anytime.
For example, a modern application, such as a one-page application, can use this platform as a backend to create a curated user experience.
Cenit IO also offers a multi-user feature, so you can serve multiple customers from the same database and isolate all data to ensure data protection.
The best part is that your customers don’t have to pay for third-party subscriptions to use the integrations.
Retrieve data from APIs in various file formats, including JSON, XML, EDI, and PDF.
From there, it’s easy to export this data to many formats for further processing and even create PDFs by automating workflows.
Cenit IO supports industry data standards such as EDIFACT, X12, and UBL, as well as protocol connectors in HTTP (S), FTP, and SFTP so that you can configure different types of integrations.
Cenit IO keeps a complete record of all actions, including any deletion of files or logs.
On the Tracks tab, you can view all data requests, updates, and your destination location.
You can also set up notifications when a task is completed, or user input is requested, so your team is always on the same page.
Key Features:
Backendless
A new data type is created using a JSON schema. It then generates a full REST API and a CRUD user interface to manage the data.
Data Integration
Data Validation, Transformation, and Mapping Coverage: Supports multiple data formats and communication protocols.
Third-Party Service
Share integration settings and connect services such as ERP/Fulfillment/Marketing/Communication.
Routing & orchestrations
The configuration of a multilevel integration is done through atomic functions such as connection, transformation, webhook, and flow.
Integration Services
Performs cloud service integration to publish and manage APIs to meet requirements
Multi-tenant
Convenient addition of new tenants. Each customer’s data is isolated and invisible to other customers.
Why Choose This Platform?
Platform
The power of a modern multi-user iPaaS. Designed to solve unique integration requirements and support a wide range of use cases.
Deploy anywhere
Choose the deployment model that fits your business needs and is ready to run on-premises, in the cloud or in a hybrid environment.
Open Source
Open source and free to use locally. It also allows you to customize the center. A possible starting point for a new SaaS company.
Shared resources
Hundreds of shared collections covering many popular APIs are a good starting point for creating your custom integration.
Pro-service
Hire our experienced integration specialists to help you implement a successful integration
Partners
Partners who create B2B integration services and use a Cenit server as their backbone.
Community
A successful open source project gives confidence that everyone can contribute.
Support
You get guided support with multiple support channels (Slack, email, video call).
Is Cenit IO 100% Open Source?
The Cenit IO engine platform is 100% open source with an MIT license.
You can visit our repository https://github.com/cenit-io/cenit.
The React front-end application, which connects to the CENIT server through the API, is available as a compiled version.
However, Cenit IO does offer an annual license to access the source code in case you need to change it.
We Love Cenit IO Because It:
Sets up data importing, parsing, and exporting instructions
It Offers a multi-tenant capability.
Notifies you when a task is completed or user input is requested.
Specialties:
iPaaS, APIs Integration, EDI Integration, Cloud Integration, Integration Platform, API, and open source
Cenit IO Lifetime Deal
There is a lifetime exclusive deal of Cenit IO on appsumo for $89. Appsumo is full of high quality digital products. I think it is the best appsumo deal ever. You can get up to 97% off in appsumo. Among all the lifetime deal sites, appsumo is the best.
Most of these lifetime Appsumo offerings will sell out on AppSumo within a week of their release. So take advantage of the fantastic offer while you still can.
Click here to find similar apps if the Cenit IO lifetime deal has expired.
Key Features of Lifetime Deal
Lifetime access to Cenit IO
All future Growth up Plan updates
Unlimited connected systems, workflows, app/API access, and custom integrations
License Tier 1
All of the above features included
All Growth up Plan features
One tenant(s)
5,000 total task executions (per tenant)
Unlimited users
License Tier 2
All of the above features included
All Growth up Plan features
Three tenant(s)
15,000 total task executions (per tenant)
Unlimited users
License Tier 3
All of the above features included
All Growth up Plan features
Ten tenant(s)
60,000 total task executions (per tenant)
Unlimited users
See More Deal Terms
Get Lifetime Access To Cenit IO Today!
Lifetime access would usually cost $228
Additional plans with more features are available for $179
ONE-TIME PURCHASE OF $89 $228
Cenit IO Lifetime Deal: How To Get An Extra $10 Discount For New Users?
Visit the “Cenit IO appsumo lifetime deal” page.
Wait for some seconds, and a Discount popup will appear.
Enter your Email to receive the exclusive benefits.
Continue with the same email id.
Get a $10 discount at the end.
Discount valid for new users only.
Get Cenit IO Lifetime Deal At $89
Most of these deals will be sold out within one week of their launch on AppSumo, So be sure to grab the best appsumo deals while you can. If the Cenit IO lifetime latest deal has expired, click here to find similar apps.
Join
Appsumo Plus
: With Appsumo Plus Membership, You Can Save More Valuable Money And Grow Faster.
#Cenit IO Lifetime Deal#AppSumoLTDLifetime DealMarketing ToolDigital MarketingSoftwareSoftware DealsSEOEntrepreneurMarketplaceUIUX
0 notes
Text
Dataweave in Mule expression language
The implementation of Data Weave as our main speech-language is one of the big improvements in Mule 4. Although this will sound like a dramatic move, I will discuss some of the reasoning behind our decision, and why it is a big leap forward. I will also share a few explanations and answer a question that is sure to be on the minds of many readers.
Why We Pick Dataweave for Mule?
Let us begin with a case. I wanted to build a Slack app a few weeks ago to review the status of our experiments on Jenkins. This meant that to build a customized experience for our squad, I had to combine Slack and Jenkins APIs- just what MuleSoft is all about. I decided to begin developing the app after reading some docs on each API.
First, to receive Slack commands, I used an HTTP listener and a selection router that determines which action to take depending on the input; in this case, I either get the status.
Then, to retrieve the test data from Jenkins, I generated my key logic, returning XML data that I converted to JSON.
Quite fast
MEL was required for all my routing logic and Data Weave was required for all my transformation logic. But hey, why? If Data Weave is strong enough to manage it all, why was I compelled to use and study two languages? Ok, just timing is the key to that. The mule was very Java-oriented when MEL was implemented. There were several evaluators to manage various inputs, such as Groovy and JSON, up to that point. As a consequence, when working with these expressions, MEL was developed to construct a seamless experience. Transformations, on the other hand, were considered separate; only transformers and DataMapper were used at the time, for the most part.
Data Weave became a success with a well-functioning transformation engine and rich query functionality. So, there we were, inside our network of two languages, and one so dominant that the other had a feature to name it: dw (). Using Data Weave does mean using all of its power.
You must turn everything into Java artifacts in Mule 3 to test some expressions (e.g. when routing payloads or logging data). The specifications of each transformer you will have to understand. But, with Data Weave as the language for expression, you might easily explicitly query the data and forget all those transformations.
With Data Weave, rather than its style, our expressions could be based on the structure of our knowledge. Since a Java array is the same as a Data Weave JSON array, we don't need separate expressions to manage it.
Entry to binary data can be achieved wherever you need it and you can get larger than memory, random, due to some excellent streaming upgrades.
That is why, with a single, new, consolidated language that has success at its heart, Mule 4 unifies expressions and transitions, rendering all of the above reality.
Why Mule 4 Revolutionizes Data Weave
Data Weave now offers a service for testing expressions used by the Mule Runtime engine. In turn, the runtime gives Data Weave all data, including payload, variables, planned performance, and metadata, about the current execution. For eg, this helps Data Weave to know whether a string or a map is needed, how each variable should be treated, whether a type is coerced, etc. Then, as in the example below, one can write expressions:
Variables #[payload ++ variables .myStatus]
The keywords for payload, variables, and attributes will be translated as such in this case. Mule 4 Now, many can question how this one-liner Data Weave term works, especially because the output format requires users to announce Data Weave. Where appropriate, the output form is assumed, so you can apply it to the one-liner as well. We use a JSON payload in the example below to set the headers of an HTTP request, take the current map of headers and add one to it with the expression:
Payload ++ { host:'httpbin.org '}] #[output application/java —- payload ++ { host:'httpbin.org'
The backend will respond with the received headers containing the values sent as the body to our HTTP listener and the host one that we have inserted.
Full Incorporation for Mule
We have only spoken about Data Weave phrases as a one-liner for routers and basic attributes so far. Flows are another simplification that we made. By encouraging users to identify "inline" content, we have reduced the number of necessary transformation elements. For example, inside the 'write' portion of the File connector, you can create the content of a file, there is no need to use a 'transform' component to get the payload you need beforehand. In the above case, you do not need any additional steps to iterate the obtained JSON payload, and the new file path is defined by the following expression:
#[payload.name ++ '.' ++ dataType.mime-type name ++.' ++ dataType.mimeType .subType]
In the writing operation, we also add a desired "date" attribute, exactly where it is expected, setting the content to:
#[payload ++ { date: now() }] { date: now() }]
A fine example of the output from being assumed is the last expression. Since we know the payload is JSON, the output does not need to be specified and the files generated will also be in that format. This functions with all new connectors since our new Mule SDK supports it. The HTTP body of a request is sent with a script in the example below, where I may take advantage of all the features of Data Weave, as in any transformation part script.
#[
Percentage dw 2.0
Application/json performance
——
Payload ++ {place:' LATAM', office:' BA'}}
]
Additionally, the listener response body can be modified with the expression.
#[Payload Payload .data]
This is because a JSON would be returned by the backend server, where the value reflects the payload sent to it. So, to add any more attributes, the data collected by the listener would be updated and then forwarded back.
For eg, the data that the HTTP listener receives is application/x-www-form-urlencoded. Data Weave performs the out-of-the-box-no parsing needed now. The outcome would have been the same even though I had sent a JSON payload. This is because Data Weave helps us, rather than its format, to concentrate on the structure of the data.
Compatibility for Mule
But enough about Data Weave, let's talk to the elephant in the post, compatibility with Mule 3 and MEL. Oh, there's always MEL, it's all deprecated. Since the main and default speech-language is Data Weave, each expression will have the prefix "Mel:" to indicate that it should be evaluated with MEL. The HTTP listener in the example below.
Users adjust more readily, but I would make the Data Weave leap as quickly as possible if I were you, to begin taking advantage of all its wonderful features!
A bit more
The team carried out intensive efforts on the language version 2.0.0. The team assisted not only in the integration of the runtime but also sought to develop the language itself. In a future column, I'll leave it to them to tell you all about that, but you can know more through MuleSoft online training.
● Imports and modules
● You can now box and import scripts into others so that the code can be reused and shared.
#mulesoft self learning#mule 4 online training#mulesoft online training in India#mulesoft online training india#mulesoft online training in Hyderabad
0 notes
Text
Splunk Integration With MuleSoft

Integrating Splunk with MuleSoft enables organizations to enhance monitoring, logging, and analytics capabilities across their Mule applications. Splunk is a powerful platform for searching, monitoring, and analyzing machine-generated big data via a web-based interface. When combined with MuleSoft, it provides deep insights into the performance and usage of APIs and integrations, helping teams to identify and troubleshoot issues quickly, understand data flows, and optimize performance.
Use Cases for Splunk Integration with MuleSoft
Real-time Monitoring and Alerting: Track the health and performance of Mule applications in real time, setting up alerts for specific events or metrics that indicate issues.
Log Management: Aggregate logs from Mule applications and APIs for centralized analysis, search, and troubleshooting.
Security Analysis: Monitor and analyze security events across your MuleSoft deployments to detect and respond to threats.
Operational Intelligence: Gain insights into API usage patterns, transaction volumes, and system performance to drive operational efficiencies and improve user experiences.
Strategies for Integrating Splunk with MuleSoft
Using Splunk Forwarders:
Install Splunk Universal Forwarders on the servers hosting Mule applications to forward logs directly to Splunk for analysis.
Configure MuleSoft to log events and transactions in a format easily consumed by Splunk, such as JSON, and ensure that critical data points are included in the logs for detailed analysis.
HTTP Event Collector (HEC):
Utilize Splunk’s HTTP Event Collector to send data directly from Mule applications to Splunk over HTTP/HTTPS.
Implement a logging strategy in your Mule applications, including sending log data to Splunk via HEC. This can be achieved through custom components or by integrating with MuleSoft’s logging framework.
Splunk App for MuleSoft:
Explore if there’s a Splunk App or Add-on specifically designed for MuleSoft. Such an app would facilitate easier integration and provide pre-built dashboards and analytics tailored to MuleSoft environments.
Custom Integration Solutions:
Develop custom integration solutions using MuleSoft to send data to Splunk. This could involve using MuleSoft’s HTTP Connector to post data to Splunk’s HEC or writing data to a middleware layer that forwards data to Splunk.
Best Practices
Secure Data Transmission: Ensure that the data transmission between MuleSoft and Splunk is secure, using HTTPS for HTTP Event Collector communications and securing Splunk Universal Forwarders.
Efficient Data Indexing: Structure log data to make it efficient for Splunk to index and search. This includes using consistent log formats and including relevant metadata for filtering and analysis.
Monitor Performance Impact: Keep an eye on the performance impact of logging and data forwarding on your Mule applications. Optimize logging levels and data forwarding rates to balance detailed monitoring and system performance.
Leverage Splunk Dashboards: Utilize Splunk dashboards to visualize data from MuleSoft. Create custom dashboards that align with your operational, security, and business analytics needs.
Demo Day 1 Video:
youtube
You can find more information about Mulesoft in this Mulesoft Docs Link
Conclusion:
Unogeeks is the №1 Training Institute for Mulesoft Training. Anyone Disagree? Please drop in a comment
You can check out our other latest blogs on Mulesoft Training here — Mulesoft Blogs
You can check out our Best in Class Mulesoft Training details here — Mulesoft Training
Follow & Connect with us:
— — — — — — — — — — — -
For Training inquiries:
Call/Whatsapp: +91 73960 33555
Mail us at: [email protected]
Our Website ➜ https://unogeeks.com
Follow us:
Instagram: https://www.instagram.com/unogeeks
Facebook: https://www.facebook.com/UnogeeksSoftwareTrainingInstitute
Twitter: https://twitter.com/unogeeks
#MULESOFT #MULESOFTTARINING #UNOGEEKS #UNOGEEKS TRAINING
0 notes
Text
MuleSoft integration pattern models
Learn Mulesoft Today the use of MuleSoft integration is to extract, transform, and use data. It is at the top of the mind. MuleSoft integration patterns can help streamline the MuleSoft integration process. Besides, the flows are crucial to understanding.
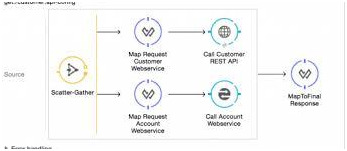
Models for MuleSoft integration
It is one or more separate sources to proceed. In other words, how the MuleSoft integration will happen must decide. This refers to also the type of incorporation.
Invocation by remote procedure
MuleSoft integration space, Remote Procedure Invocation (RPI) was the go-to way. In this method, a provider would allow an external mechanism. This is to make requests into a closed program. The external caller has the requirements for making the request. Then an understanding of what the answer will be, but using a black-box approach, all the logic takes place. RPI is the mechanism used in this case to conduct an operation against the target device.
Find an application to treat financial transactions. The vendor can offer an API to allow transactions to post from an external source. This is before the popularity of RESTful APIs. Using RPI, it introduces API.
The developer will write a program to collect the information he needs. Then use RPI to connect to the application. In reply, the results of the RPI/API requests pack. Then the calling application processes the information.
The Database Shared
The MuleSoft integration style of the shared database leverages a database. This is for synchronization between two or more apps. As a result, a link to share the database containing the information. Thus, it will incorporate will maintain in the application.
Using an INSERT statement to a staging table in the database, for example. This might activate a store procedure that would conduct business logic. Then update attributes elsewhere in the database for other applications. Besides, you can use the same mutual MuleSoft integration of the database.
The messaging
With service SOA implementations, the messaging MuleSoft integration style began to gain popularity. This is by using an enterprise service bus (ESB) as the basis for the message itself.
In the example of a financial transaction, the custom application can place a message. Then demand the posting of a certain transaction on the ESB. To manage any remaining tasks, this device submits the message. Then relies on the style of messaging MuleSoft integration.
On the financial system hand, depending on the essence of the message, the message is on the bus causes. Then the event that absorbs the message and takes the necessary action. The financial system recognizes the mission that needs the message queue used. Then metadata inside the message itself.
The financial system may place a new message on the bus when complete. Then you can consume the original system. In this case, adding to the original request for auditor validation purpose. Thus, you could relate to specific transaction information.
The Concept of Messages
The MuleSoft integration Courier is primarily based on the principle of messaging. This is not unlike other technology-driven solutions, since something you use. This is to relay crucial information to the solution at hand. The courier is often the payload that transfers to a POST request or from a GET request. This is by using RESTful APIs as an example.
The Messaging Systems
A major advantage of messaging is both systems do not need asynchronous messages. This is to be online and accessible at the same time. One system may position a message with an ESB. Thus, you can immediately process hours later by another system or on a schedule. Either way, without affecting the other, treat all situations.
The message system employs channels (or queues) to coordinate the information that needs to be integrated and categorize it. For example, the messages will use different channels for each message form if the source system wants to communicate with a financial system and an HR system.
Routing of Message
In more complex MuleSoft integration cases, the concept of message routing is also applied, where a message might be needed to route through several channels before reaching the target destination.
In this case, a message router will aid, allowing messages to be sent to a dedicated component that analyses the message and uses business logic to decide where the message is routed based on the message content itself.
The source system would simply need to post a transaction in the financial transaction example. The source system does not have a detailed understanding of which system manages which transactions if the company maintains several financial systems. The message router would become the source of the message and would have the necessary skills to send the message to the correct channel.
Message routing goes much further and can use a large array of patterns that support the process of routing. Such widespread developments include:
Message Filter:
Allows messages to be filtered within the message based on attributes.
Scatter-Gather:
Enables synchronous messages to simultaneously be sent to various sources.
Message Aggregator:
Enables the sorting and pushing of messages from different sources into a single resulting message, perhaps to process the scatter-gather results.
Transforming Message
Connecting various systems also makes it clear that a given response does not fit the source system's intended or preferred response. The transformation of messages is a process that can perform the necessary data transfer between the two systems.
Using the example of a financial system, the source system may wish to submit data in JSON, but XML is required by the financial system. The incoming JSON data will be processed and converted(i.e. transformed) into XML using message translation to prepare for processing by a SOAP web Server. This is essentially the pattern of normalizer MuleSoft integration in use.
Some proven patterns of message transformation include:
● Content Enricher:
Enables the alteration of metadata in order to fulfill the target system's expectations.
● Claim Check:
Momentarily streamlines the message to delete metadata that is not required but available for later processing at that point in time.
● Content Filter:
Fully delete metadata from the post, more permanently than the above-noted argument check approach.
Control of Systems
The management of MuleSoft integration is the center of the solution, building on the MuleSoft integration styles and the flow and delivery of a given message.
Bus Control
The management tier within the MuleSoft integration system is the control bus pattern. The control bus uses, as one would imagine, the same principles applied by the MuleSoft integration method.
If the administration layer needs information for the user to send to the system administrator, the message data captured by the MuleSoft integration system is used to report the status of any known problems found.
Store Message
Any level of historical knowledge or metrics is often needed to operate any system. The difficulty of looking at the messages with metrics without disturbing the transient existence of the messages themselves. By sending a duplicate copy of the message to the message store, the message store pattern satisfies this need. The requisite metrics can be retained and transferred to the control bus for processing and reporting until a copy of the message is stored inside the message store.
Proxy Smart
Usually, messages flow to a fixed output channel. There are instances, however, in which a part needs to post reply messages back to a channel specified in the original request. The smart proxy pattern can be utilized when this need arises.
In order to capture the return address specified by the sender, the smart proxy integrates logic to intercept messages. Upon completion of processing, the smart proxy replaces the destination of the fixed output channel with the address captured when the original request was sent.
Conclusion
Having an understanding of MuleSoft integration types, message principles, and system management trends will help direct developers of MuleSoft integration to employ activities that translate irrespective of the industry through any MuleSoft integration project. In doing so, when additional resources help and sustain current MuleSoft integration programs, the ramp-up period would be decreased. You can learn more about the models through MuleSoft online training.
For more information About this course Please go through this link
Mulesoft Online Training
Contact Information
USA: +1 7327039066
INDIA: +91 8885448788, 9550102466
Email: [email protected]
Mulesoft Online Training at Onlineitguru in Hyderabad, India, and Chennai. Enroll for the course for a free demo today from live industry experts with live projects. For more information Contact us@ +91 9550102466.
#Mulesoft Training#Mulesoft Online Training#Learn Mulesoft#Mule Training#Mulesoft Self Learning#Mulesoft Online Training in Hyderabad#Mulesoft Online Course#Learn Mulesoft Online#Mulesoft Training in Hyderabad#Mulesoft Training Hyderabad#Mulesoft Course Online
0 notes
Text
Mulesoft — an ESB Solution
Enterprise Service Bus (ESB) is a pattern/middleware which allows systems (applications) implemented in incompatible technologies to communicate with each other. Hence an ESB can be thought of as a pluggable backbone where one can plug incompatible applications, and expect them to communicate with each other without any hassle.

Point to Point Integration (P2P)
Point to point integration is integrating systems or applications with each other directly. This is a legacy integration pattern which has many disadvantages and obstacles as listed below:

Single Points Of Failure
No Course Of Action For Emergencies
Exponential Increase in Complexity
Loss of Agility
Enterprise Service Bus Pattern (ESB)
ESB pattern is a more flexible approach for application integration. This integration is achieved by encapsulating and exposing each application functionality as a set of discrete reusable capabilities. Hence applications do not integrate directly with each other instead, they integrate through an ESB infrastructure, as illustrated below:

Anypoint Studio
MuleSoft’s Eclipse-based development environment for designing and testing Mule ESB applications is known as Anypoint Studio. With Anypoint Studio one can develop their message flows between application to application with a graphical drag-and-drop editor (or edit the XML file if preferred). The designer can select all of the different components offered by Mulesoft in their message flows and configure them easily.
Out-of-the-box Components
Anypoint studio has hundreds of built-in components which are needed for integration development:
Message Sources/Endpoints — HTTP, FTP, TCP, UDP, File, Database
Message Processors — Components (REST, SOAP, Java, Python, javascript…), Filters, Routers (aggregators, splitters, round-robin…), Scopes (Flows, sub-flows, for-each, a-synchronous…), Transformers (convert XML, JSON, File, Byte Array, Object, String…)
Connectors — Anypoint studio comes with numerous connectors to third-party applications such as Amazon, Facebook, Google products, Sharepoint, MongoDB, Salesforce...
Dataweave Language
DataWeave is an expression language for accessing and then transform the data that travels through a Mule app.
In a mule message flow, the data being transferred from a component to the next component is called a Message. Hence mostly DW (Dataweave) is used to access and transform data in this Message. For example, after a source component in your flow gets a Message from one system, you can use DW to modify and output selected fields in that Message to a new data format, then use the next component in your flow to pass on that data to another system.
Mulesoft Message Structure
As stated earlier data transferred between components in a mule flow is called Messages. So one component will change/filter the input Message that it receives and export them to the next component so that it’s input Message will be that changed data.

Example 1: Listen to a Post Request from an HTTP Listener, Change the payload structure and save in a MySQL DB.

HTTP Listener Component
Here you should configure the HTTP Listener on what port is this Listener will be listening on and on what path should the caller call to invoke this Mule flow. For example, Listener Configuration would look like below:


So according to the above configuration of HTTP Listener, it would be listening via port 8081 and on path /insert-path .

And above code snippet shows the generated XML code for the configured HTTP Listener. So for every component that we configure in Mulesoft can be edited, created in XML too.
Logger Components
Loggers are used for logging the output message (mostly the payload) from the previous component. This is very helpful when you want to know and debug the output from a component.
Transform Message Component
This is one of the important components in Mulesoft. For all of the message transformations, this component is used mainly. And for doing the transformations, the Dataweave language is used.
DB Insert Component
This component is used to make a connection to the DB and insert the relevant data passed through the mule flow.
Example 2: Listen to a Post Request from an HTTP Listener, Invoke a Java method by passing the received payload, do the necessary changes to the payload from the java method, send the output from java method to another API Endpoint.

0 notes
Text
Urgent Requirement Java Developer in Singapore
Company Overview:
Intellect Minds is a Singapore-based company since 2008, specializing in talent acquisition, application development, and training. We are the Best Job Recruitment Agency and consultancy in Singapore serve BIG MNCs and well-known clients in talent acquisition, application development, and training needs for Singapore, Malaysia, Brunei, Vietnam, and Thailand.
Job Responsibilities: • Hands on Design, Development, Deployment & Support of Software products • Interact with Product Owners to design and deliver technical solutions to support various business functions • Provide thought leadership and lead innovation by exploring, investigating, recommending, benchmarking and implementing tools and frameworks. • Work in a Globally Distributed Development team environment to enable successful delivery with a minimal supervision • Advocate, document, and follow best design and development practices
It is you, if: • You are passionate, creative and self-driven • You are curious and collaborative, and a believer in the power of teams and team work • You are flexible and have a broad set of capabilities to wear multiple hats • You thrive in a dynamic and a fast paced environment • You pursue speed and simplicity relentlessly • You are a natural leader in everything you do
Experience:
• BS/MS CS/SE/EE degree or equivalent with 8+ years of experience in the field of Software Engineering and Development using Java/JEE/JavaScript • Minimum 5+ years of strong hands-on development experience with Java (7.0/8.0), JEE and related technologies • Minimum 5+ years of experience in building Platforms, Frameworks & API’s using Open Source Java & JavaScript Frameworks (SpringBoot, Hibernate, Play, Akka, Netty.IO, Node.js etc.) • Strong working experience in micro services API first development • Experience in AWS is added advantage • Experience in large scale data management using Big Data, Elastic Search • Working Knowledge on Reactive/Functional Programming is highly desirable • Knowledge of NO-SQL technologies like Cassandra, MongoDB • Excellent understanding of Micro services based architectures, Service oriented design & architecture, Application Integration & Messaging, Security and Web 2.0. • Strong understanding of design patterns and best practices in Java/JEE platform including UI, Application & Frameworks development. • Extensive hands-on development experience with frameworks and tools including Apache Stack, Web Services. • Strong Experience/Knowledge on Data modeling (RDBMS, XSD, JSON), Database/XML interaction, SQL, Stored Procedure and ORM. • Experience with web servers & application servers such as Tomcat & JBoss • Must have prior experience in leading Technical deliverables. Must be able to effectively communicate & work with fellow team members and other functional team members to coordinate & meet deliverables. • Exceptional communication, organization and presentation skills • Experience working with Open Source API Gateway Frameworks, Mulesoft/Apigee API Gateway is a huge plus • Good understanding of CI/CD systems and Container based deployments on Docker.
All successful candidates can expect a very competitive remuneration package and a comprehensive range of benefits.
Interested Candidates, please submit your detailed resume online.
To your success!
The Recruitment Team
Intellect Minds Pte Ltd (Singapore)
https://www.intellect-minds.com/job/java-developer-5/

0 notes
Text
MuleSoft Lead
Title : MuleSoft Lead Location : Pocatello, Idaho Duration : 12+ Months Rate : Market Technical Skills & Knowledge: Primary Skills: MuleSoft, Java, API, architecture exp Responsibilities: · Overall 10+ Years of experience in MuleSoft, Java and API with strong architecture experience. · 5+ years of experience implementing solutions based on developing services in MuleSoft ESB using AnyPoint Studio. Must have strong experience in integration& API architecture; on various Mule connectors / adapters, developing API, API management and developing services on CloudHub. Must have hands-on experience with production deployment and post production support. · Good Exposure and understanding of Anypoint platform products like API Manager, Design Center etc. · Good hands-on experience in writing RAML / Swagger. · Strong concepts of typical Integrations & api solutions, principles, best practices; must have good analytical, solutioning and effort estimation capabilities. · Good understanding of typical integration technologies such as HTTP, XML/XSLT, JMS, JDBC, REST, SOAP, WebServices and APIs · Must have strong knowledge of SOA and ESB and must have experience on at least one large scale ESB implementation. · 4+ years of core Java experience (preferred) or another object-oriented language or any other Middleware platform · Good understanding of data formats such as XML, CSV, EDI and JSON · Experience with ESB implementation with any platform would be added advantage. · Good oral and written communication is mandatory. Reference : MuleSoft Lead jobs Source: http://jobrealtime.com/jobs/technology/mulesoft-lead_i5077
0 notes
Text
JSON to XML Transformation Using DataWeave 2.0 in Mule 4.0
Nowadays, most of the data would be like JSON or XML as the input/output to every system. To get the required format for downstream system bit complex to transform but MuleSoft will do that easily and push into the target system. This post will explain the simple way to do a JSON to XML transformation in MuleSoft. This can be done by using DataWeave, and not only JSON, but others like Java, CSV, and XML format. Step1: Select the Mule project from Anypoint Studio and write the project name. Then, click ok. https://goo.gl/CFDDUz #DataIntegration #ML
0 notes
Text
Achieving Event-Driven Architecture with Solace PubSub+ Event Broker and MuleSoft
One of the benefits of my current job is that I get to work with companies from different industries. As someone who had only worked in financial services before, it has been a very rewarding experience to understand the kinds of challenges companies face in other industries and how they compare to challenges commonly found in financial services. Additionally, I also get to learn about their technology stack.
Recently, I had the opportunity to work with a popular iPaaS (integration platform as a service) solution called MuleSoft which was acquired by Salesforce. MuleSoft, like other integration solutions, makes it as easy as dragging and dropping connectors to connect your applications. Such tools are heavily used to integrate applications from different domains together. For example, you can link your CRM app to your marketing app, invoice app, and analytics app with a simple drag-and-drop.
As you can probably guess, iPaaS tools are built on synchronous RESTful APIs. For your marketing app to be integrated with your CRM app, you need to have appropriate RESTful endpoints. While this works fine, we know that synchronous REST calls have their limitations when compared with the asynchronous calls of event-driven architecture. Instead of polling for data, you would rather have your apps sharing messages via the publish/subscribe messaging that enables event-driven architecture as part of your Mulesoft environment.
What are the advantages of event-driven architecture and publish/subscribe messaging?
You have undoubtedly heard of these terms before because, in the last few years, both have gotten extremely popular. Our world is full of events so your applications need to be event-driven. When a credit card is swiped, an event is fired which triggers a bunch of other downstream events. For example, your phone gets a real-time notification informing you that your card was just swiped, your credit card balance is updated, and so forth.
I have previously written a post about the nature and advantages of event-driven architecture, but here are the main ones:
Perform analytics and actions on real-time data as opposed to stale data obtained from batch processing
Identify issues in real-time instead of waiting till the batch is executed
Push vs pull – events are pushed to your applications as opposed to constantly polling for updates
Loosely coupled applications
Easier to scale
Typical pub/sub benefits such as the efficient distribution of data, persistence, replay, and migration to the cloud
Implementing Event-Driven Architecture with MuleSoft and Solace PubSub+
Now that we have a better idea of why you should consider using pub/sub messaging with your iPaaS, let’s look at how to achieve Mulesoft event-driven architecture. We will use MuleSoft’s Anypoint Studio which you can download for free (there may be a 30-day limit).
For our broker, we will be using PubSub+ Event Broker deployed via Docker container on my laptop, but you can also use PubSub+ Event Broker: Cloud which has a free tier. PubSub+ supports open APIs and protocols, so it’s really easy to use it with other products. For example, to integrate it with Mulesoft, we will be using Mulesoft’s JMS module.
Use Case
We have a CRM system such as Salesforce which pushes updates to a REST endpoint whenever there is an account update such as an account being created. The update contains high-level information about the account itself (name, website etc.), contact information, contract information, and location information (address). We have downstream applications such as marketing app, invoice app, and analytics app which are interested in one or more of these types of information contained in the entire account update.
Here is what our downstream applications are interested in:
Analytics app – interested in high-level account and contract information
Invoice app – interested in contract information only
Marketing app – interested in contact and location information
Our goal is to digest the original payload (XML schema), parse it, and split it into 4 different smaller payloads:
High-level account information
Contact information
Location information
Contract information
Then, we need to publish this data on different topics and have different consumers subscribe to this data depending on their interest.
Notice that despite having multiple apps subscribing to the same data (both analytics and invoice apps are interested in contract data), we only need to publish it once. This is one of the key benefits of using pub/sub messaging pattern. While it may not seem like a major benefit in our use case, it definitely makes a difference when you are dealing with high data volumes.
Additionally, we are able to dynamically filter the dataset using PubSub+’s rich hierarchical topics instead of having all our applications consume the same data and then having to filter themselves.
Schemas and Topics
One of the benefits of using an iPaaS such as MuleSoft is that it allows you to transform your data, which can come in very handy in event-driven architecture. In our case, we will be ingesting XML payload but the output will be in JSON.
Here is the schema of the original payload (topic: company/sales/salesforce/customerAccount/all/created/v1/{accountId}):
<xs:schema attributeFormDefault="unqualified" elementFormDefault="qualified" xmlns:xs="http://www.w3.org/2001/XMLSchema"> <xs:element name="AccountId" type="xs:string"/> <xs:element name="AccountName" type="xs:string"/> <xs:element name="AccountSource" type="xs:string"/> <xs:element name="AnnualRevenue" type="xs:int"/> <xs:element name="BillingCountryCode" type="xs:string"/> <xs:element name="BillingState" type="xs:string"/> <xs:element name="CreatedDate" type="xs:dateTime"/> <xs:element name="CurrencyIsoCode" type="xs:string"/> <xs:element name="IsActive" type="xs:string"/> <xs:element name="IsArchived" type="xs:string"/> <xs:element name="IsDeleted" type="xs:string"/> <xs:element name="LastModifiedById" type="xs:string"/> <xs:element name="LastModifiedDate" type="xs:dateTime"/> <xs:element name="LastReferencedDate" type="xs:dateTime"/> <xs:element name="LastViewedDate" type="xs:dateTime"/> <xs:element name="ContactName" type="xs:string"/> <xs:element name="ContactId" type="xs:int"/> <xs:element name="ContactEmail" type="xs:string"/> <xs:element name="Description" type="xs:string"/> <xs:element name="Industry" type="xs:string"/> <xs:element name="NumberOfEmployees" type="xs:short"/> <xs:element name="Type" type="xs:string"/> <xs:element name="BillingAddress" type="xs:string"/> <xs:element name="Website" type="xs:anyURI"/> <xs:element name="ProductCode" type="xs:int"/> <xs:element name="ContractNumber" type="xs:int"/> <xs:element name="ContractAddress" type="xs:string"/> <xs:element name="Sum_Units_Sold__c" type="xs:float"/> <xs:element name="SystemModstamp" type="xs:dateTime"/> </xs:schema>
Here are the schemas for the 4 payloads after they have been parsed:
High-level account (topic: company/sales/salesforce/customerAccount/account/created/v1/{accountId}):
{ "$schema": "http://json-schema.org/draft-04/schema#", "type": "object", "properties": { "Body": { "type": "object", "properties": { "AccountId": { "type": "string" }, "AccountName": { "type": "string" }, "Website": { "type": "string" } }, "required": [ "AccountId", "AccountName", "Website" ] } }, "required": [ "Body" ] }
Contact (topic: company/sales/salesforce/customerAccount/contact/created/v1/{accountId}):
{ "$schema": "http://json-schema.org/draft-04/schema#", "type": "object", "properties": { "Body": { "type": "object", "properties": { "ContactName": { "type": "string" }, "ContactId": { "type": "string" }, "ContactEmail": { "type": "string" } }, "required": [ "ContactName" "ContactId", "ContactEmail" ] } }, "required": [ "Body" ] }
Location (topic: company/sales/salesforce/customerAccount/location/created/v1/{accountId}):
{ "$schema": "http://json-schema.org/draft-04/schema#", "type": "object", "properties": { "Body": { "type": "object", "properties": { "BillingCountryCode": { "type": "string" }, "BillingState": { "type": "string" }, "BillingAddress": { "type": "string" } }, "required": [ "BillingCountryCode", "BillingState", "BillingAddress", ] } }, "required": [ "Body" ] }
Contract (topic: company/sales/salesforce/customerAccount/contract/created/v1/{accountId}):
{ "$schema": "http://json-schema.org/draft-04/schema#", "type": "object", "properties": { "Body": { "type": "object", "properties": { "ContractNumber": { "type": "string" }, "ContractAddress": { "type": "string" } }, "required": [ "ContractNumber", "ContractAddress" ] } }, "required": [ "Body" ] }
Phew, that’s a lot of information to keep track of. We need to know our downstream applications, which events they are interested in, and what the schemas will be for those events. If only there was a design tool which allowed us to do that!
How PubSub+ Event Portal Helps You Manage Event-Driven Architecture
The “event gods” have heard your pleas and granted your wish! Solace recently launched new product called PubSub+ Event Portal that is, as we like to say, “the market’s first event management toolset to design, create, discover, catalog, share, visualize, secure and manage all the events in your enterprise”.
I used it to design the flow of our steps in our Mulesoft event-driven architecture, and here is what it looks like:
As you can see, the Salesforce app at the top publishes the original event containing raw payload, which is then parsed by MuleSoft, and published to PubSub+ for downstream applications to consume — event-driven architecture in action!
We can also create specific events and associate schemas in the Event Portal. For example, as you can see from the image above, our MuleSoft app is publishing accountContractUpdates event which is being subscribed to by InvoicingSystem application. Expanding that event shows us who created it, which topic it is published to, what the associated schema is, and which applications are subscribing and publishing this event.
Again, while they may not seem very impressive right now, imagine how useful Event Portal would be to an organization with hundreds of applications and thousands of events!
Implementing MuleSoft Event-Driven Architecture
Now that we have our events documented, we can start implementing them.
Here is what my Mule workspace looks like:
It consists of two flows: Publisher and Consumer.
The Publisher flow has an http listener which is listening to my endpoint localhost:5001/solace. When I issue a POST request against this endpoint, the listener will capture the payload and pass it to 4 different JMS Publish modules for publishing 4 different events to 4 different topics.
Here is the connection setting for JMS Publish module:
<jms:config name="Solace" doc:name="JMS Config" doc:id="635cb4d0-a727-4723-8d5f-6da38b806745" > <jms:generic-connection username="mule" password="mule"> <jms:connection-factory > <jms:jndi-connection-factory connectionFactoryJndiName="/jms/cf/default"> <jms:custom-jndi-name-resolver > <jms:simple-jndi-name-resolver jndiInitialFactory="com.solacesystems.jndi.SolJNDIInitialContextFactory" jndiProviderUrl="tcp://mule:mule@localhost:55555"> <jms:jndi-provider-properties > <jms:jndi-provider-property key="Solace_JMS_VPN" value="default" /> </jms:jndi-provider-properties> </jms:simple-jndi-name-resolver> </jms:custom-jndi-name-resolver> </jms:jndi-connection-factory> </jms:connection-factory> </jms:generic-connection> </jms:config>
And here is the config xml for one of the JMS Publish modules:
<jms:publish doc:name="Publish Account to Solace" doc:id="1a24df7f-c33d-4ca1-a551-0d097d85bb65" config-ref="Solace" destination='#[output text ns ns0 http://schemas.xmlsoap.org/soap/envelope/ --- "company/sales/salesforce/customerAccount/account/created/v1/" ++ payload.ns0#Envelope.ns0#Body.AccountId]' destinationType="TOPIC"> <jms:message > <jms:body ><![CDATA[#[output application/xml ns ns0 http://schemas.xmlsoap.org/soap/envelope/ --- { ns0#Envelope: { ns0#Body: { AccountName: payload.ns0#Envelope.ns0#Body.AccountName, Website: payload.ns0#Envelope.ns0#Body.Website } } }]]]></jms:body> </jms:message> </jms:publish>
I have a second flow called Consumer which has a simple JMS Consume module listening to a queue followed by a JMS ack module for acknowledging messages. Here is its configuration:
<flow name="Consumer" doc:id="e705a269-7978-40c5-a0d2-7279567278ad" > <jms:listener doc:name="Listener" doc:id="2c76ddb5-07ff-41aa-9496-31897f19d378" config-ref="Solace" destination="mule" ackMode="MANUAL"> <jms:consumer-type > <jms:queue-consumer /> </jms:consumer-type> </jms:listener> <logger level="INFO" doc:name="Logger" doc:id="cb53890f-9bc7-4bad-8512-55586aa61e8d" /> <jms:ack doc:name="Ack" doc:id="c2b197a8-2fcb-4954-b748-071ffde36da5" ackId="#[%dw 2.0 output application/java --- attributes.ackId]"/> </flow> You will need to create a queue for the consumer to bind to. In my case, I have created a queue called <code>mule</code> using Solace’s UI and mapped a topic to it: <code>company/sales/salesforce/customerAccount/></code> <img src="https://solace.com/wp-content/uploads/2020/07/pubsubplus-mulesoft_pic-04.png" alt="" width="1024" height="316" class="alignnone size-full wp-image-41324" /> Notice that instead of specifying an exact topic, I have used Solace’s wildcard > to select any topic that falls under that hierarchy. In our case, subscribing to this topic will allow us to consume all of the four events. Now we are ready to test our setup. Using Postman, I have sent a POST request: <img src="https://solace.com/wp-content/uploads/2020/07/pubsubplus-mulesoft_pic-05.png" alt="" width="1024" height="499" class="alignnone size-full wp-image-41323" /> And here is the output of my Mule flow: INFO 2020-05-21 13:02:55,528 [[MuleRuntime].uber.03: [solace].Consumer.CPU_LITE @85a5ceb] [processor: Consumer/processors/0; event: ea2e4270-9b84-11ea-9fe8-a483e79ba806] org.mule.runtime.core.internal.processor.LoggerMessageProcessor: org.mule.runtime.core.internal.message.DefaultMessageBuilder$MessageImplementation { payload=<?xml version='1.0' encoding='UTF-8'?> <ns0:Envelope xmlns:ns0="http://schemas.xmlsoap.org/soap/envelope/"> <ns0:Body> <AccountName>Solace</AccountName> <Website>www.solace.com</Website> </ns0:Body> </ns0:Envelope> mediaType=application/xml; charset=UTF-8 attributes=org.mule.extensions.jms.api.message.JmsAttributes@460bec31 attributesMediaType=application/java } INFO 2020-05-21 13:02:55,536 [[MuleRuntime].uber.03: [solace].Consumer.CPU_LITE @85a5ceb] [processor: Consumer/processors/0; event: ea2e4270-9b84-11ea-9fe8-a483e79ba806] org.mule.runtime.core.internal.processor.LoggerMessageProcessor: org.mule.runtime.core.internal.message.DefaultMessageBuilder$MessageImplementation { payload={ "Envelope": { "Body": { "ContactName": "Himanshu", "ContactId": "2309402", "ContactEmail": "[email protected]" } } } mediaType=application/json; charset=UTF-8 attributes=org.mule.extensions.jms.api.message.JmsAttributes@395abcae attributesMediaType=application/java } INFO 2020-05-21 13:02:55,566 [[MuleRuntime].uber.03: [solace].Consumer.CPU_LITE @85a5ceb] [processor: Consumer/processors/0; event: ea2e4270-9b84-11ea-9fe8-a483e79ba806] org.mule.runtime.core.internal.processor.LoggerMessageProcessor: org.mule.runtime.core.internal.message.DefaultMessageBuilder$MessageImplementation { payload={ "Envelope": { "Body": { "ContractNumber": "123456", "ContractAddress": "535 Legget Drive, 3rd Floor, Ottawa, Canada" } } } mediaType=application/json; charset=UTF-8 attributes=org.mule.extensions.jms.api.message.JmsAttributes@6a4910db attributesMediaType=application/java } INFO 2020-05-21 13:02:55,574 [[MuleRuntime].uber.03: [solace].Consumer.CPU_LITE @85a5ceb] [processor: Consumer/processors/0; event: ea2e4270-9b84-11ea-9fe8-a483e79ba806] org.mule.runtime.core.internal.processor.LoggerMessageProcessor: org.mule.runtime.core.internal.message.DefaultMessageBuilder$MessageImplementation { payload={ "Envelope": { "Body": { "BillingCountryCode": "US", "BillingState": "NY", "BillingAddress": "535 Legget Drive, 3rd Floor, Ottawa, Canada" } } } mediaType=application/json; charset=UTF-8 attributes=org.mule.extensions.jms.api.message.JmsAttributes@130e6e64 attributesMediaType=application/java }
As you can see, our single consumer in our Consumer Mule flow was able to consume all the messages from our queue (mule) which was subscribing to just one topic.
Of course, to fully leverage the power of pub/sub messaging, event-driven architecture and Mulesoft, you can show having multiple consumers using Solace’s rich hierarchal topics to consume select events.
Get on the road to event-driven architecture!
That’s it for this post! I wanted to show you how you can make iPaaS tools such as MuleSoft even more powerful by adding pub/sub messaging to enable event-driven architecture. With Solace PubSub+, you can easily use JMS standard to connect to it and publish/consume messages.
If you work with an iPaaS, I highly recommend considering PubSub+ to make your applications event-driven. PubSub+ Standard Edition is free to use, even in production!
The post Achieving Event-Driven Architecture with Solace PubSub+ Event Broker and MuleSoft appeared first on Solace.
Achieving Event-Driven Architecture with Solace PubSub+ Event Broker and MuleSoft published first on https://jiohow.tumblr.com/
0 notes
Text
MuleSoft C#

It sounds like you’re interested in learning about how MuleSoft can be integrated with C#. MuleSoft, known for its integration capabilities through its Anypoint Platform, allows different applications, systems, and services to connect and interact. Although MuleSoft primarily uses Java and is more commonly associated with technologies like Java and XML for configuring integrations, you can still interact with MuleSoft APIs or services from a C# application.
Here are some general steps and considerations for integrating MuleSoft with C#:
Use of HTTP Requests: Since MuleSoft exposes its APIs over HTTP, you can use C#’s built-in HttpClient class to send and receive data from MuleSoft APIs. This involves making GET, POST, PUT, or DELETE requests to the API endpoints exposed by your Mule applications.
APIKit and RAML: If you’re developing APIs in MuleSoft, you might use APIKit and RAML to design and implement your APIs. Ensure your API is well documented, with clear information on endpoints, request types, and payloads. C# applications can consume these APIs by making HTTP requests per the API contract.
Handling JSON or XML: MuleSoft APIs typically exchange data in JSON or XML format. In C#, you can use libraries like Newtonsoft.Json for JSON serialization and deserialization or the built-in XmlDocument and XDocument for XML handling. This will allow you to efficiently work with the data returned by MuleSoft APIs or send data to these APIs.
Security and Authentication: Make sure to implement proper authentication and authorization mechanisms. If your MuleSoft API requires OAuth, Basic Authentication, or any other form of security, ensure your C# application includes the necessary headers or tokens in its HTTP requests.
Error Handling: Implement robust error handling in your C# application to manage any errors the MuleSoft API returns. This includes checking the HTTP response status code and parsing error messages or codes returned in the response body.
Asynchronous Programming: Given the network-bound nature of calling external APIs, consider using asynchronous programming patterns in C# (async/await) to make your API calls. This will help improve the performance of your application by not blocking threads while waiting for API responses.
Demo Day 1 Video:
youtube
You can find more information about Mulesoft in this Mulesoft Docs Link
Conclusion:
Unogeeks is the №1 Training Institute for Mulesoft Training. Anyone Disagree? Please drop in a comment
You can check out our other latest blogs on Mulesoft Training here — Mulesoft Blogs
You can check out our Best in Class Mulesoft Training details here — Mulesoft Training
Follow & Connect with us:
— — — — — — — — — — — -
For Training inquiries:
Call/Whatsapp: +91 73960 33555
Mail us at: [email protected]
Our Website ➜ https://unogeeks.com
Follow us:
Instagram: https://www.instagram.com/unogeeks
Facebook: https://www.facebook.com/UnogeeksSoftwareTrainingInstitute
Twitter: https://twitter.com/unogeeks
#MULESOFT #MULESOFTTARINING #UNOGEEKS #UNOGEEKS TRAINING
1 note
·
View note