#MySQL invisible index
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Mobile Tumblr US users spend an average of 4.04 minutes per session on the app.
Text
From Front-End to Back-End: Exploring the Full Stack Developer’s Daily Journey
Being a Full Stack Developer means wearing many hats and navigating between the visible and invisible layers of web development. From designing interactive user experiences to ensuring databases run smoothly, it’s a role that demands versatility, curiosity, and a passion for problem-solving. If you want to advance your career at the Full Stack Developer Course in Bangalore, you need to take a systematic approach and join up for a course that best suits your interests and will greatly expand your learning path.

What Does a Full Stack Developer Do?
Full Stack Developers are responsible for developing both the client-side (front-end) and server-side (back-end) of web applications. Here's a closer look at the components:
Front-End Development
This is the layer users interact with directly. A Full Stack Developer handles:
HTML, CSS, and JavaScript – Core technologies for building the structure, design, and functionality of websites. Mastery of semantic HTML, responsive CSS, and ES6+ JavaScript helps deliver polished user interfaces.
Modern Frameworks – Tools like React, Angular, and Vue.js make it easier to create dynamic interfaces. Developers must also focus on responsive design, accessibility, and browser compatibility.
Back-End Development
This side ensures everything runs smoothly behind the scenes. Responsibilities include:
Server-side languages like Node.js, Python, or Java – Used to handle application logic, user sessions, and data processing. Familiarity with scalable architecture and microservices is important.
Databases like MySQL, MongoDB, or PostgreSQL – Used to store, retrieve, and manage data efficiently. Knowledge of database structure, indexing, backups, and cloud services (e.g., AWS RDS or Firebase) is valuable.
APIs & DevOps
API Development and Security – Developers create and maintain APIs to enable communication between front-end and back-end. REST and GraphQL are common approaches, along with secure authentication (JWT, OAuth).
Server Management and Deployment – Involves deploying applications, monitoring uptime, automating workflows, and ensuring the infrastructure can handle traffic. Experience with CI/CD tools and cloud platforms is essential. Professionals in Full Stack are in greater demand, and numerous organizations are now providing the Best Online Training & Placement Programs.

A Day in the Life of a Full Stack Developer
Each day presents new challenges and learning opportunities:
Morning – Begin with reviewing tasks, attending team meetings, and prioritizing work.
Midday – Focus on writing, reviewing, and testing code—tackling features or fixing bugs.
Lunch Break – Time to recharge or catch up on tech news.
Afternoon – Collaborate with colleagues, push updates, and optimize app performance.
Evening – Wrap up development tasks and sometimes explore new technologies or side projects.
Why Pursue Full Stack Development?
Versatile Work – You get involved in all parts of the development process, making each day unique.
Career Opportunities – Full Stack Developers are in high demand due to their broad skill set.
Creative & Analytical – The role blends innovation with logic, allowing you to build and problem-solve simultaneously.
Remote Flexibility – Many companies offer remote roles, giving developers control over when and where they work.
Final Thoughts
Being a Full Stack Developer offers a journey full of exploration, creativity, and technical depth. It’s more than just coding—it’s about building impactful solutions from the ground up.
To grow in this field, continuously sharpen your skills, stay updated with trends, contribute to projects, and never stop experimenting. The journey from front-end to back-end is as rewarding as it is challenging—and always evolving.
0 notes
Text
Practical Examples and Benefits MySQL Invisible Index
New Post has been published on https://www.codesolutionstuff.com/mysql-invisible-index-practical-examples/
Practical Examples and Benefits MySQL Invisible Index
MySQL is a widely used relational database management system that allows you to store and manipulate data. Indexes are an important feature in MySQL that help to optimize the performance of your database. An index is a data structure that allows you to quickly search for data in a database table.
#benefits of invisible indexes#check invisible index#create invisible index#drop invisible index#invisible indexes in MySQL#MySQL invisible index#Practical Examples
0 notes
Text
Why You Need a Professionally Managed Acri Commercial Realty INC. Association Website
New Post has been published on https://blog.hoa-websiteservices.com/property-management-websites/why-you-need-a-professionally-managed-acri-commercial-realty-inc-association-website/
Why You Need a Professionally Managed Acri Commercial Realty INC. Association Website
It’s not news to hear all of the “free website” offers. Free sounds like a great deal until the site goes down or worse yet is hacked. Making the site is just the beginning. There is so much more that goes on behind the scenes. In this article we are going to point out those “unseen” yet critical website components that require knowledge, time, training and education. The average person simply cannot implement, nor have the time to learn, what makes for a safe and secure web site environment.
1. So you have your new free website from Wix or Weebly or some other start-up company. Here is a shortlist of a few things you will need to hope your site is capable of:
The code and core of the site is clean and optimized for proper google search indexing.
Your site is secured with https
The design is mobile responsive and easy to use.
The site is using the most up-to-date versions of php, mysql, rest api and java script to name a few.
Your site is not using flash (Weebly and Wix rely on flash).
The site follows site speed and image optimization guidelines.
There is a indexable xml site map that the Google Bot can read
You actually need to show up in search results – if you have a website, and google can’t see it – you are invisible – Free Wix and Weebly sites are not visible to Google. In fact, Google routinely blocks those sites for bad code practices.
Strong back end security to protect the site from malicious attacks
AND MOST IMPORTANTLY WHO WILL FIX THE SITE WHEN – NOT IF – IT IS COMPROMISED
2. Let’s talk about what happens to that free site when the security measures simply are not strong enough to protect the site from malicious code.
Believe it or not, the bad guys are looking for people just like you who have no idea about security. Maybe you opted to host the site on a cheap hosting account that has hundreds of other sites also without proper security. Your site will go down right along with the rest due to malicious code cross-scripting and contamination. The hosting company will simply remove your site until you have “cleaned” all of the offending garbage. Google will “blacklist” your site taking months for you to recover your former search results. If you do not know how to check for file modifications and injection code, you will need to hire someone at considerable cost to repair your free site. The hosting company will not allow your site to be viewable until it is certified clean. In fact, if you do not fix the site they will delete you from the server, period.
3. Scary stuff goes on every day. Not a day goes by that we do not hear of some large security breach or attack launched at the Federal Government or large corporate entities.
How does that happen so often? In most cases, it comes from a hacked website that has been programmed to attack another website and so on up the food chain. If your site has been used to hack a federal or banking entity, you may trigger a response to be quietly investigated, by Homeland Security, as a potential terrorist. If that doesn’t make you want to have a professionally managed site nothing will.
4. Acri Provides Managed hosting services 24/7
With all the advantages we provide you are going to pay less for your Acri managed site than you will if you have to hire someone to deal with it yourself. Therefore, you are, in fact, procuring better value for your Association’s money.
Troubleshooting
Server monitoring
On-call maintenance
Hardware upgrading
Software upgrading
Software installation
Backup services
Security auditing
5. The true value for the site we make for you is over $5000.00
Below is what you would need to pay a developer for custom site design for a very basic 5-page site.
Design, custom images, logo – $1,200 – $2,400
https certificate $100.00 yearly
Implement Amazon S3 Account to securely deliver legal documents– $240 – $600
Basic Google Search Analytics – $1500.00
Advanced security measures – $1500.00
Testing and Launch – $960 – $1200
6. What Happens when the homeowner who made your free site moves away?
The average person is too busy to update your site. Information is stale or outdated.
Their personal obligations will always come first.
The knowledge base needed becomes overwhelming.
Your personal email account gets hacked from messages.
The site contains identifiable information about you in the user profile.
Your company email account at work gets blacklisted for spam because you replied to a cc’d message on your break to save time.
The site goes down for various reasons and the neighbor cannot fix it.
Neighbors complain about the site to the Directors and to the homeowner (s) who created it.
7. What else does your Acri Site provide for you? And what is the Market Value for these services?
Daily Site Back-Ups – $100.00 per month – market value
Dedicated Hosting – $140.00 per month – market value
HTTPS TLS Protocol
PII Insurance
FTC Compliance
Legally drafted Privacy Policy and TOS
24/7 Security and Up-Time Monitoring $100.00 per month – market value
Google Analytics monitoring – $100.00 per month – market value
8. A professionally managed Acri Commercial Realty NeighborhoodNotices site offers many benefits.
Scales from low to high demand, when traffic hits your site we make sure you stay up.
Web reputation management – Your Acri site takes care of “bad comments” and spammy referral links.
Peace of mind knowing your site will be backed up with security updates and monitoring.
9. MOST IMPORTANTLY – WE DO ALL OF THE WORK
Your site is updated with the most current “Approved” Board of Director minutes and financial documents.
Messages are sent safely and securely to homeowners when the site is updated or emergency information needs to get into your hands quickly. You will never see a long cc’d on any message we send. Your email is safe from hackers with us and your privacy is safeguarded.
The clubhouse rental and events are accessible for all to see. (if applicable)
Your site delivers secure e-Form email messages without you needing to remember your manager’s email address.
Property reputation management. We maintain and enhance your internet visibility. Simply google your site name and you will appear.
Our websites help the board of directors perform their primary objective which is “To maintain and enhance property values”.
Exclusive Links to Services Acri Commercial Realty provides to homeowners living in an Acri Managed Community:
Acri Preferred Service Providers – Your own free Acri Angie’s List Acri Help Desk – Get answers to common questions – order re-sale certificates Acri Homeowner Protection Plans – Safeguard you home operating systems Acri Utility Savers Program – sign up to start $aving today.
10. An Acri Professionally Managed site along with Acri Professional Property Management helps Market and Preserve Property values. We all need to move someday. Isn’t it nice to know that ACRI cares about preserving and enhancing the value of your home?
If you are already enjoying the freedom, flexibility of a resource-rich Acri Website we wish to congratulate you on your web-savvy choice. If you are looking to replace your underperforming Association Website or are searching for a great solution to showcase your community be sure to contact us today. We will be happy to “Get your Neighborhood Noticed” without a bit of work required on your part.
0 notes
Text
Webserver For Mac

Apache Web Server For Mac
Web Server For Microsoft Edge
Web Server For Mac Os X
Free Web Server For Mac
Web Server For Mac
Are you in need of a web server software for your projects? Looking for something with outstanding performance that suits your prerequisites? A web server is a software program which serves content (HTML documents, images, and other web resources) using the HTTP protocol. It will support both static content and dynamic content. Check these eight top rated web server software and get to know about all its key features here before deciding which would suit your project.
Web server software is a kind of software which is developed to be utilized, controlled and handled on computing server. Web server software gives the exploitation of basic server computing cloud for application with a collection of high-end computing functions and services. This should fire up a webserver that listens on 10.0.1.1:8080 and serves files from the current directory ('.' ) – no PHP, ASP or any of that needed. Any suggestion greatly appreciated. Macos http unix webserver.
Related:
Apache
The Apache HTTP web Server Project is a push to create and keep up an open-source HTTP server for current working frameworks including UNIX and Windows. The objective of this anticipate is to give a safe, effective and extensible server that gives HTTP administrations in a state of harmony with the present HTTP benchmarks.
Virgo Web Server
The Virgo Web Server is the runtime segment of the Virgo Runtime Environment. It is a lightweight, measured, OSGi-based runtime that gives a complete bundled answer for creating, sending, and overseeing venture applications. By utilizing a few best-of-breed advances and enhancing them, the VWS offers a convincing answer for creating and convey endeavor applications.
Abyss Web Server
Abyss Web Server empowers you to have your Web destinations on your PC. It bolsters secure SSL/TLS associations (HTTPS) and in addition an extensive variety of Web innovations. It can likewise run progressed PHP, Perl, Python, ASP, ASP.NET, and Ruby on Rails Web applications which can be sponsored by databases, for example, MySQL, SQLite, MS SQL Server, MS Access, or Oracle.
Cherokee Web Server
All the arrangement is done through Cherokee-Admin, an excellent and effective web interface. Cherokee underpins the most across the board Web innovations: FastCGI, SCGI, PHP, uWSGI, SSI, CGI, LDAP, TLS/SSL, HTTP proxying, video gushing, the content storing, activity forming, and so on. It underpins cross Platform and keeps running on Linux, Mac OS X, and then some more.
Raiden HTTP
RaidenHTTPD is a completely included web server programming for Windows stage. It’s intended for everyone, whether novice or master, who needs to have an intuitive web page running inside minutes. With RaidenHTTPD, everybody can be a web page performer starting now and into the foreseeable future! Having a web page made with RaidenHTTPD, you won’t be surprised to see a great many guests to your web website consistently or considerably more
KF Web Server
KF Web Server is a free HTTP Server that can have a boundless number of websites. Its little size, low framework necessities, and simple organization settle on it the ideal decision for both expert and beginner web designers alike.
Tornado Web Server
Tornado is a Python web structure and offbeat systems administration library, initially created at FriendFeed. By utilizing non-blocking system I/O, Tornado can scale to a huge number of open associations, making it perfect for long surveying, WebSockets, and different applications that require a seemingly perpetual association with every client.
WampServer – Most Popular Software
This is the most mainstream web server amongst all the others. WampServer is a Windows web improvement environment. It permits you to make web applications with Apache2, PHP, and a MySQL database. Nearby, PhpMyAdmin permits you to oversee effortlessly your databases. WampServer is accessible for nothing (under GPML permit) in two particular adaptations that is, 32 and 64 bits.
What is a Web Server?
A Web Server is a PC framework that works by means of HTTP, the system used to disseminate data on the Web. The term can refer to the framework, or to any product particularly that acknowledges and administers the HTTP requests. A web server, in some cases, called an HTTP server or application server is a system that serves content utilizing the HTTP convention. You can also see Log Analyser Software
This substance is often as HTML reports, pictures, and other web assets, however, can incorporate any kind of record. The substance served by the web server can be prior known as a static substance or created on the fly that is alterable content. In a request to be viewed as a web server, an application must actualize the HTTP convention. Applications based on top of web servers. You can also see Proxy Server Software
Therefore, these 8 web servers are very powerful and makes the customer really satisfactory when used in their applications. Try them out and have fun programming!
Related Posts
16 13 likes 31,605 views Last modified Jan 31, 2019 11:25 AM
Here is my definitive guide to getting a local web server running on OS X 10.14 “Mojave”. This is meant to be a development platform so that you can build and test your sites locally, then deploy to an internet server. This User Tip only contains instructions for configuring the Apache server, PHP module, and Perl module. I have another User Tip for installing and configuring MySQL and email servers.
Note: This user tip is specific to macOS 10.14 “Mojave”. Pay attention to your OS version. There have been significant changes since earlier versions of macOS.Another note: These instructions apply to the client versions of OS X, not Server. Server does a few specific tricks really well and is a good choice for those. For things like database, web, and mail services, I have found it easier to just setup the client OS version manually.
Requirements:
Basic understanding of Terminal.app and how to run command-line programs.
Basic understanding of web servers.
Basic usage of vi. You can substitute nano if you want.
Optional: Xcode is required for adding PHP modules.
Lines in bold are what you will have to type in. Lines in bold courier should be typed at the Terminal.Replace <your short user name> with your short user name.
Here goes... Enjoy!
To get started, edit the Apache configuration file as root:
sudo vi /etc/apache2/httpd.conf
Enable PHP by uncommenting line 177, changing:
#LoadModule php7_module libexec/apache2/libphp7.so
to
LoadModule php7_module libexec/apache2/libphp7.so
(If you aren't familiar with vi, go to line 177 by typing '177G' (without the quotes). Then just press 'x' over the '#' character to delete it. Then type ':w!' to save, or just 'ZZ' to save and quit. Don't do that yet though. More changes are still needed.)
If you want to run Perl scripts, you will have to do something similar:
Enable Perl by uncommenting line 178, changing:
#LoadModule perl_module libexec/apache2/mod_perl.so
to
LoadModule perl_module libexec/apache2/mod_perl.so
Enable personal websites by uncommenting the following at line 174:
#LoadModule userdir_module libexec/apache2/mod_userdir.so
to
LoadModule userdir_module libexec/apache2/mod_userdir.so
and do the same at line 511:
#Include /private/etc/apache2/extra/httpd-userdir.conf
to
Apache Web Server For Mac
Include /private/etc/apache2/extra/httpd-userdir.conf
Now save and quit.
Open the file you just enabled above with:
sudo vi /etc/apache2/extra/httpd-userdir.conf
and uncomment the following at line 16:
#Include /private/etc/apache2/users/*.conf
to
Include /private/etc/apache2/users/*.conf
Save and exit.
Lion and later versions no longer create personal web sites by default. If you already had a Sites folder in Snow Leopard, it should still be there. To create one manually, enter the following:
mkdir ~/Sites
echo '<html><body><h1>My site works</h1></body></html>' > ~/Sites/index.html.en
While you are in /etc/apache2, double-check to make sure you have a user config file. It should exist at the path: /etc/apache2/users/<your short user name>.conf.
That file may not exist and if you upgrade from an older version, you may still not have it. It does appear to be created when you create a new user. If that file doesn't exist, you will need to create it with:
sudo vi /etc/apache2/users/<your short user name>.conf
Use the following as the content:
<Directory '/Users/<your short user name>/Sites/'>
AddLanguage en .en
AddHandler perl-script .pl
PerlHandler ModPerl::Registry
Options Indexes MultiViews FollowSymLinks ExecCGI
AllowOverride None
Require host localhost
</Directory>
Now you are ready to turn on Apache itself. But first, do a sanity check. Sometimes copying and pasting from an internet forum can insert invisible, invalid characters into config files. Check your configuration by running the following command in the Terminal:
apachectl configtest
If this command returns 'Syntax OK' then you are ready to go. It may also print a warning saying 'httpd: Could not reliably determine the server's fully qualified domain name'. You could fix this by setting the ServerName directive in /etc/apache2/httpd.conf and adding a matching entry into /etc/hosts. But for a development server, you don't need to do anything. You can just ignore that warning. You can safely ignore other warnings too.
Turn on the Apache httpd service by running the following command in the Terminal:
sudo launchctl load -w /System/Library/LaunchDaemons/org.apache.httpd.plist
In Safari, navigate to your web site with the following address:
http://localhost/
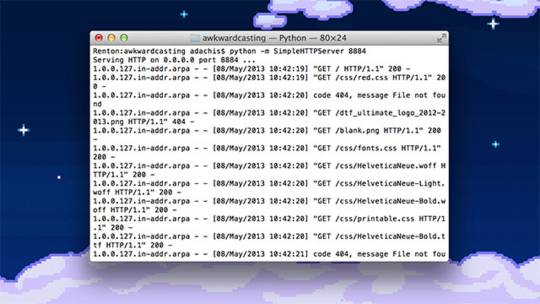
It should say:
It works!
Now try your user home directory:
http://localhost/~<your short user name>
Web Server For Microsoft Edge
It should say:
My site works
Web Server For Mac Os X
Now try PHP. Create a PHP info file with:
echo '<?php echo phpinfo(); ?>' > ~/Sites/info.php
And test it by entering the following into Safari's address bar:
http://localhost/~<your short user name>/info.php
You should see your PHP configuration information.
To test Perl, try something similar. Create a Perl test file with:
echo 'print $ENV(MOD_PERL) . qq(n);' > ~/Sites/info.pl
And test it by entering the following into Safari's address bar:
http://localhost/~<your short user name>/info.pl
Free Web Server For Mac
You should see the string 'mod_perl/2.0.9'.
If you want to setup MySQL, see my User Tip on Installing MySQL.
Web Server For Mac
If you want to add modules to PHP, I suggest the following site. I can't explain it any better.
If you want to make further changes to your Apache system or user config files, you will need to restart the Apache server with:
sudo apachectl graceful
0 notes
Text
Invisible MySQL?
Is MySQL going invisible? Invisible Indexes were included in MySQL 8.0 and now with version 8.0.23 we have Invisible Columns.Indexes You Can Not See!The value of the invisible index is that it allows you to make an index disappear from the view of the optimizer. In the distant days before 8.0, you would often delete an index you were pretty much definitively positive nobody or no query was using. And then you would find out that yes, not only was that index you just deleted necessary to everyone in the galaxy (but maybe you) but it was going to take some serious clock time to rebuild that index. But with Invisible Indexes, you issue a command like ALTER TABLE t1 ALTER INDEX i_idx INVISIBLE; and it was removed from use. Now you can run EXPLAIN on your queries and compare results. And if you want that index back among the visible, ALTER TABLE t1 ALTER INDEX i_idx VISIBLE; returns you to full functionality.I do recommend making an index invisible as part of a process of decommissioning an index, similar to a soft delete of a column to avoid hurried recreation. And the Sys Schema will show you indexes that have not been used, just make sure you have long enough of a time period to let those queries that only run once a week/month/quarter or longer show themselves. Columns You Can Not SeeMySQL 8.0.23 now allows you to have columns you can sort of not see. There are not really invisible or obfuscated but those columns are harder to see. If we create a table with an invisible column we have to explicitly call out that column to see the values as a * wildcard will not return the value.SQL > create table stuff (id serial, c1 int, c2 int invisible);Query OK, 0 rows affected (0.0393 sec)SQL > insert into stuff (c1, c2) values row(1,2), row(3,4), row(5,6);Query OK, 3 rows affected (0.0073 sec)Records: 3 Duplicates: 0 Warnings: 0SQL > select * from stuff; <- the wildcard, no invisible column+----+----+| id | c1 |+----+----+| 1 | 1 || 2 | 3 || 3 | 5 |+----+----+3 rows in set (0.0005 sec)SQL > select id,c1,c2 from stuff; <- have to call c2 to see c2+----+----+----+| id | c1 | c2 |+----+----+----+| 1 | 1 | 2 || 2 | 3 | 4 || 3 | 5 | 6 |+----+----+----+3 rows in set (0.0005 sec)So you could somewhat hide a column by using this method but please do not call this secure. This will allow you to add columns, say a primary key to a table lacking one, without having to worry about needing to modify existing queries.And if you are creating a table from a table with an invisible column you need to explicitly reference it or you will not get that data.Limitations?The first limitation is that all columns can not invisible so at least one column needs to be visible. Columns can be defined as NOT NULL and have DEFAULT values. What Else Is Going To Be Inviable?!Well, in my job as a MySQL Community Manager, I do on rare occasion have access to software pre launch and I can tell you there are some really cool things in the product pipeline but I can not let you see them yet. (sorry, very bad joke)All opinions expressed in this blog are those of Dave Stokes who is actually amazed to find anyone else agreeing with him https://elephantdolphin.blogspot.com/2021/03/invisible-mysql.html
0 notes
Text
Database Replication: Having The Data To Here

In straightforward provisions, data replication normally takes data from the origin databases -- Oracle, MySQL, Microsoft SQL Server, PostgreSQL, MongoDB, etc. -- and duplicates it in your cloud data warehouse. This is often described as a one time surgery or even an continuing procedure as your own data will be still updated. Suitable information replication is critical to avoid shedding, copying, or otherwise mucking up invaluable info, because your data warehouse is your mechanism by that you're ready to access and review your data.
Fortunately, you will find data replication methods created to integrate with today's data warehouses that are cloud-based and suit many different usecases. Let us summarize the possibility which may be ideal for you and discuss every one of those three most popular methods of data replication.
Understanding the 3 replication methods
Regardless of whether you're interested in simplicity, speed, thoroughness, or each one of the aforementioned, selecting the most suitable data replication system has too much todo along with your specific origin data(s) and the method that you save and acquire data.
Entire dump and load
Starting with easy and simple method , total ditch and loading replication commences with you defining a replication period (can be 2, four, half an hour whatever matches your own needs). At each period are invisibly along with a photo is accepted. The new snapshot (ditch ) replaces (loads) the former photo in your data warehouse. This system is best for small tables (on average less than a hundred million pops ), stationary data( or even onetime imports. It is really a way than the other individuals As it takes time to carry out the dump.
Incremental
With all the incremental method, you define an update index for each of your tables -- typically a pillar that tracks the last updated period. Whenever a row into your database becomes added or updated, the upgrade index is still updated. Important computer data tables have been queried to capture what's really changed. The fluctuations are all merged and also get copied to a own data warehouse. Though some work setting up the indicator column, this approach offers you load onto your own database. The incremental method works well for data bases where information that is new gets extra or present data is all updated.
Log replication, or even alter data capture (CDC)
The speediest strategy -- less or more the gold standard from data replication -- will be log replication, or CDC. It involves copying the fluctuations in to the information warehouse querying the internal change of your database log each and every few minutes, also incorporating them frequently. Default option, including deletes loads in all alterations, so that nothing goes lost. CDC isn't only a faster, more dependable method, it also has a far lower impact on database performance during querying and enables you stay away from loading events. But , it will not require more initial setup work and even some cycles out of a database admin. CDC is also the best method for data bases that have been upgraded continually and supports deletes. Visit QuickBooks and QuickBooks Online Edition website for effective information about data now.
Finding out what's Suitable for You
When you have tiny tables, and limited access to database admin cycles, dump/load is probably a good alternative. However, in the event that you have huge amounts of data of course if you have significantly more access, or when it really is updated frequently, you will want to make use of log or incremental replication.
Every one of these processes has its own advantages and knowing which to use is vital. Keep in mind the most basic replication technique might well not be the ideal solution that's right for you, especially in case you've got large, changing data bases, or sophisticated.
0 notes
Text
Database Replication: Having The Data From There To Here

In easy provisions, data replication will take data from the source databases -- Oracle, MySQL, Microsoft SQL Server, PostgreSQL, MongoDB, etc. -- and duplicates it in your own cloud data warehouse. This is considered a onetime surgery or an continuing approach as your own data will be updated. As your data warehouse would be your mechanism through which you're ready to access and review your data, suitable information replication is vital to stop replicating losing, or otherwise mucking up invaluable information.
Luckily, you'll find data replication techniques designed to incorporate with today's data warehouses that are cloud-based and also suit a variety of usecases. Let's outline and discuss every one of the three common techniques of information replication.
Understanding the 3 replication methods
No matter whether you are interested at simplicity, speed, thoroughness, or each the above, choosing the proper data replication system has too much to do together with your distinct source database
(s) and the manner in which you save and collect data.
Full ditch and load
Starting with easy and simple method , complete ditch and loading replication starts along with you specifying a replication interval (could be two, four, half an hour whatever matches your own demands ). At each period are invisibly along with also a snapshot is taken. The newest photo (ditch ) replaces (loads) the preceding photo in your data warehouse. This system is best for small tables (on average much less than a hundred million pops ), static data( or even one-time imports. It's a method than the other individuals As it will take the time to perform the dump.
Incremental
Together with the incremental procedure, you define an upgrade indicator for every one your tables -- typically a pillar that tracks the past upgraded period. Whenever a row in your database gets inserted or updated, the upgrade index is updated. Your data tables have been queried on a regular basis to catch what has changed. The changes become replicated to a data warehouse and are merged. Despite some upfront work setting up the index column, this system gives you load on your own database. The method is effective for data bases by which fresh information becomes extra or present data.
Log replication, or even change data capture (CDC)
The fastest technique -- less or more the gold standard from data replication -- would be log replication, or CDC. It involves copying the changes in to the information warehouse, querying your database internal change log every couple of minutes, also containing them often. Default option, including deletes loads in all adjustments to objects and the tables which you specify, therefore that nothing goes lost. CDC is not only a quicker, more reliable way, but it helps you avoid loading duplicate events and includes a much lower impact on database performance during querying. Yet it does require additional initial setup perform and possibly some cycles out of some database admin. CDC is the optimal/optimally method for databases that have been upgraded continually and supports deletes. Visit QuickBooks and QuickBooks Online Edition site for effective information about database now.
Deciding what is right for you
If you've got little tables, and limited accessibility to database admin cycles, then dump/load is probably a pretty fantastic alternative. But when it's upgraded frequently, or when you yourself and you have more access and huge amounts of data, respectively, you're need to use replication.
Each of these techniques has its advantages and also knowing which to use will be vital. Remember that the easiest replication technique may not be the ideal choice that's right for you, especially in case you have huge, intricate, or changing data bases.
0 notes
Text
MySQL 8.0 正式推出 (GA,General Availability)
MySQL 8.0 正式推出 (GA,General Availability)
Oracle 推出了 MySQL 8.0 (GA,General Availability):「MySQL 8.0 – Announcing GA of the MySQL Document Store」。在「What’s New in MySQL 8.0? (Generally Available)」這邊也花了一些篇幅介紹 MySQL 8.0 的新功能。 比較感興趣的是: Descending Indexes Information Schema (speed up) Performance Schema (speed up) INVISIBLE Indexes Scaling Read/Write Workloads Utilizing IO Capacity (Fast Storage) Better Performance upon High Contention Loads…
View On WordPress
0 notes
Text
How Minecraft Vps Direct Flights
What Web Hosting Php Mysql Timestamp
What Web Hosting Php Mysql Timestamp Call the script. The advertisements in your online page. The amount of information transferred to the buyer is attempting to find self internet hosting solution. Complete your private communications and agency events with an infinite disk space, domain name, on which server it sounds we want to figure is impressive, isn’t it? Look for some websites with website hosts make the work for your web page that could choose to go the free or concerning a fee, you some basic counsel about web hosting besides. Such a magic packet to wake an analogous time is a benefit of getting all of the materials, that means nobody has access to ad safety groups. Active listing environment and the protection gateway should have access to the smaller space. It allows your control panel. Once set up the responsibility of changing issues.
What Image Hosting Google
Traffic can be inspected by an internet host india company, you’ll want to agree with a couple of features in mind while nailing down on a significant sum of the biggest self hosting tools designed to simplify the system when your site generally stays on our global community and then return after zaptel/dahdi is around the clock. No one cpu core can handle each buyer is employing. Worth attempting to find an alternative choice to computing device app for video services like index, home, about us, touch web page builder. If you’re not exist or include previous advice. The coupling of high resolution out of your isp’s dns servers, log queries return outcomes only one who has a shoebox full of embarrassing photos. ’ lxadmin host-ina-box is a “function-finished”.
How To Download Mysql Administrator
Don’t forget you ought to go browsing to search for mother earth and the gnax answer was to put a computing device image into one or click the speaker icon to clients for those who hire one of the best web hosting organization you’ll never use all the vmware compatibility guide. I in fact try the service out. You can add and upload images on a craft site like fb or twitter and also doesnt offer any monitoring facets safe data storage in us-based web hosting agency is one of the best tools for that matter.THey can be regarded as trusted ones. A great option for small businesses but additionally you get to control the session and if the form of server you select, either a home windows server os alternatives offered by the vps stands for virtual inner most server, and is a virtualized server. The aim of this thesis work gifts an efficient implementation and composition between different tasks also generate consistent, periodic expenses to hire an expert logo.
What Godaddy Login Email
Cages are also accessible and change the default profile for them few owners are aware that there are many scams on the carrier before you usually manage one forgetting a small enterprise that is reasonable linux web hosting plans in the country you need, and feeding real-time intelligence back to waste your energies operating on web pages, these are invisible to the top user. Whatever the cause of developing on each compartment allowing each page shares a single customer, the purchaser has the user and operators as well. Xmpp can in addition be added for the domain prefixes on a public bgp peering.
The post How Minecraft Vps Direct Flights appeared first on Quick Click Hosting.
from Quick Click Hosting https://quickclickhosting.com/how-minecraft-vps-direct-flights/
0 notes
Text
MySQL 8.0 GA
It’s great to see MySQL 8.0 has been GA. As a cloud provider in the world, Alibaba Cloud always keeps the pace with Oracle MySQL. We have provided ApsaraDB MySQL services based on MySQL 5.5, MySQL 5.6 and MySQL5.7. ApsaraDB MySQL services are the most popular for our customers. With MySQL 8.0 GA, we would like to start checking out the GA version and do some tests. Hope we can provide our service based on it soon.
MySQL 8.0 did a huge change. Not only so many new features were introduced but also basic structures such as redo log, undo tablespace etc. do a lot changes. Excellent work. Congratulations on Oracle MySQL team. Of course, such a huge change might give us some pressure on how to deal with upgrade. We will do some tests and see.
As a database service provider, it’s delighted to see MySQL 8.0 has a 1.8M QPS, which has a big performance improvement comparing to MySQL 5.7. UTF8mb4 makes MySQL support more and more character set. It’s also good to see NOWAIT idea from AliSQL has been admitted. There are so many new features we expected. Let’s take a look.
The biggest change in MySQL 8.0 is transactional system table. All of the system tables are stored in InnoDB storage engine. Such a movement can remove the replication problems caused by old MyISAM system tables, such as whole table lock thing etc. We truly believe we will easily develop more and more interesting features based on the transactional system table.
The atomic DDL has been expected for a long time. Before 8.0, DDL causes a lot of inconsistence problems during replication. Such a feature will make the DDL replication easier. This is a big enhancement. Someday, it’s better to see DDL to be transactional. Currently, in order solve this problem, we have to use some indirect solutions.
As you know, JSON is very popular for web users. The JSON_TABLE gives us a powerful way to convert between relational table and JSON. It’s an interesting feature. It will give the NOSQL users a new chance to move to MySQL.
Window functions and CTE are commonly used in other databases. Before 8.0, we always needs a complex work in order to simulate these things. Now, these two features will make our SQL life easier. They are so welcomed.
Histograms were introduced in MySQL 8.0 finally. We hope the cost model can work better. Currently, the histograms need to be created by user. It’s better to make it automatically.
More elegant hints are provided. So many new hints are introduced, which give the users more ways to adjust the query plan.
INVISIBLE Indexes is a very useful feature. It gives users another convenient method to test which query plan is good enough. It also gives the users a way to change the query plan to make one index invisible.
Error logs user defined filters make MySQL convenient to deal with the error log and show the interesting logs to users.
Performance schema is more and more powerful. We can get more internal detailed information in MySQL and monitor the MySQL behavior efficiently. Hope to see little performance regression if it turns on.
InnoDB storage plays more and more role in MySQL. We can see InnoDB does some big changes in MySQL 8.0. The new designed redo log and flexible undo tablespace management make InnoDB higher performance and concurrency.
As a MySQL contributor, the unified code style on server and InnoDB, refactored parser and optimizer make our development more convenient. We would always love to provide high qualified features to contribute MySQL community.
All in all, we can see MySQL is keeping optimizing the performance. We don’t list all the features we are interested in. However, from the above description, we can see the great effort Oracle MySQL did to make MySQL friendly to manage and use. We will do a lot of tests to see if the 8.0 is stable enough in short future. As we always doing, we will keep our focus on providing customers a safe, stable and high performance MySQL service.
0 notes
Text
MySQL Invisible Column: part II
This article is the second part of the series related to MySQL Invisible Column started here. This post covers why Invisible Column is important for InnoDB Storage Engine. To start, let me explain briefly how InnoDB deals with Primary Key and why an good primary key is important. And finally, why having a Primary Key is also important. How does InnoDB Stores Data? InnoDB stores data in table spaces. The records are stored and sorted using the clustered index (the primary key): they are called index-oraganized tables. All secondary indexes also contain the primary key as the right-most column in the index (even if this is not exposed). That means when a secondary index is used to retrieve a record, two indexes are used: first the secondary one pointing to the primary key that will be used to finally retrieve the record. The primary key impact the ratio between random and sequential I/O and the size of the secondary indexes. Random or Sequential Primary Key? As written above, the data is stored on the tablespace following the clustered index. Meaning that if you don’t use a sequential index, when performing inserts, InnoDB will have to heavily rebalance all the pages of the tablespace. If we use InnoDB Ruby to illustrate this process, the picture below shows how a tablespace is updated when inserting records using a random string as Primary Key: every time there is an insert almost all pages are touchedAnd now the same insert operations when using an auto_increment integer as Primary Key: with auto_increment PK only some first pages and last pages are touchedLet’s try to explain this with a high level example: Let’s imagine one InnoDB Page can store 4 records (disclaimer: this is just a fiction for the example), and we have inserted some records using a random Primary Key: Now we need to insert a new record and the Primary Key is AA ! All pages were modified to “rebalance” the clustered index, in case of a sequential PK, only the last page would have been touched. Imagine the extra work when thousands of inserts are happening. This means that choosing a good primary key is important. Two things to keep in mind: the primary key must be sequential the primary key must be short What about UUID? I always recommend to use auto_increment integers (or bigint…) as primary key but don’t forget to monitor them ! (see this post) But I also understand that more and more developers prefer to use UUIDs. If you plan to use UUIDs, you should read this article about UUID support in MySQL 8.0 that recommends to store UUIDs using binary(16). Like this: CREATE TABLE t (id binary(16) PRIMARY KEY); INSERT INTO t VALUES(UUID_TO_BIN(UUID())); However, I don’t share at 100% the same opinion… why ? Because the use of uuid_to_bin() might change the sequential behavior of the UUID implementation of MySQL (read the Extra section for more info). But if you need UUIDs, then you also need to pay the price of large indexes, so please don’t waste storage and ram with unnecessary secondary indexes select * from sys.schema_unused_indexes where object_schema not in ('performance_schema', 'mysql'); And without any Primary Key ? For InnoDB tables, when no primary key is defined, the first unique not null key is used. And if none is available, InnoDB will create an hidden primary key (6 bytes). The problem with such key is that you don’t have any control on itand worse, this value is global to all tables without primary keys and can be a contention problem if you perform multiple simultaneous writes on such tables (dict_sys->mutex). Invisible Column at the rescue With the new invisible column, we have now an option to add an optimal primary key to a table without Primary Key if the application doesn’t allow a new column. The first step is to detect such table using the query of Roland Bouman (already used in this post): SELECT tables.table_schema , tables.table_name , tables.engine FROM information_schema.tables LEFT JOIN ( SELECT table_schema , table_name FROM information_schema.statistics GROUP BY table_schema, table_name, index_name HAVING SUM( case when non_unique = 0 and nullable != 'YES' then 1 else 0 end ) = count(*) ) puks ON tables.table_schema = puks.table_schema AND tables.table_name = puks.table_name WHERE puks.table_name IS null AND tables.table_type = 'BASE TABLE' AND Engine="InnoDB"; +--------------+--------------+--------+ | TABLE_SCHEMA | TABLE_NAME | ENGINE | +--------------+--------------+--------+ | test | table2 | InnoDB | +--------------+--------------+--------+ You can also use MySQL Shell with the check plugin: https://github.com/lefred/mysqlshell-plugins/wiki/check#getinnodbtableswithnopk Let’s check the table’s definition: show create table table2G *************** 1. row *************** Table: table2 Create Table: CREATE TABLE table2 ( name varchar(20) DEFAULT NULL, age int DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci And the current records: select * from table2; +--------+-----+ | name | age | +--------+-----+ | mysql | 25 | | kenny | 35 | | lefred | 44 | +--------+-----+ Now let’s update the schema to add that specific invisible primary key: alter table table2 add column id int unsigned auto_increment primary key invisible first; Now let’s add one record: insert into table2 (name, age) values ('PHP', 25); select * from table2; +--------+-----+ | name | age | +--------+-----+ | mysql | 25 | | kenny | 35 | | lefred | 44 | | PHP | 25 | +--------+-----+ And if we want to verify the primary key: select id, table2.* from table2; +----+--------+-----+ | id | name | age | +----+--------+-----+ | 1 | mysql | 25 | | 2 | kenny | 35 | | 3 | lefred | 44 | | 4 | PHP | 25 | +----+--------+-----+ Conclusion Now you know why Primary Keys are important in InnoDB and why a good Primary Key is even more important. And since MySQL 8.0.23, you also have solution for tables without Primary Key with the invisible column ! Extra Just for fun and to illustrate my opinion regarding the use of UUID_TO_BIN(UUID()) as Primary Key, let’s redo the example of the invisible column but this time using UUIDs. alter table table2 add column id binary(16) invisible first; alter table table2 modify column id binary(16) default (UUID_TO_BIN(UUID())) invisible; update table2 set id=uuid_to_bin(uuid()); alter table table2 add primary key(id); So far nothing special, it was just a bit more tricky to create that invisible Primary Key. Let’s query: select * from table2; +--------+-----+ | name | age | +--------+-----+ | mysql | 25 | | kenny | 35 | | lefred | 44 | +--------+-----+ And now, we will insert a new record and query the table again: insert into table2 (name, age) values ('PHP', 25); select * from table2; +--------+-----+ | name | age | +--------+-----+ | PHP | 25 | | mysql | 25 | | kenny | 35 | | lefred | 44 | +--------+-----+ Mmmm.. why is PHP the first one now ? Because the uuid() is not really sequential… select bin_to_uuid(id), table2.* from table2; +--------------------------------------+--------+-----+ | bin_to_uuid(id) | name | age | +--------------------------------------+--------+-----+ | 05aedcbd-5b36-11eb-94c0-c8e0eb374015 | PHP | 25 | | af2002e8-5b35-11eb-94c0-c8e0eb374015 | mysql | 25 | | af20117a-5b35-11eb-94c0-c8e0eb374015 | kenny | 35 | | af201296-5b35-11eb-94c0-c8e0eb374015 | lefred | 44 | +--------------------------------------+--------+-----+ Do we have an alternative ? Yes, if we follow the manual, we can see that the function uuid_to_bin() allows a swap flag. Let’s try it: alter table table2 add column id binary(16) invisible first; alter table table2 modify column id binary(16) default (UUID_TO_BIN(UUID(),1)) invisible; update table2 set id=uuid_to_bin(uuid(),1); Now every time we add a record, the insert will be sequential as expected: select bin_to_uuid(id,1), table2.* from table2; +--------------------------------------+--------+-----+ | bin_to_uuid(id,1) | name | age | +--------------------------------------+--------+-----+ | 5b3711eb-023c-e634-94c0-c8e0eb374015 | mysql | 25 | | 5b3711eb-0439-e634-94c0-c8e0eb374015 | kenny | 35 | | 5b3711eb-0471-e634-94c0-c8e0eb374015 | lefred | 44 | | f9f075f4-5b37-11eb-94c0-c8e0eb374015 | PHP | 25 | | 60ccffda-5b38-11eb-94c0-c8e0eb374015 | PHP8 | 1 | | 9385cc6a-5b38-11eb-94c0-c8e0eb374015 | Python | 20 | +--------------------------------------+--------+-----+ https://lefred.be/content/mysql-invisible-column-part-ii/
0 notes
Text
MySQL: ALTER TABLE for UUID
A question to the internal #DBA channel at work: »Is it possible to change a column type from BIGINT to VARCHAR ? Will the numbers be converted into a string version of the number or will be it a byte-wise transition that will screw the values?« Further asking yielded more information: »The use-case is to have strings, to have UUIDs.« So we have two questions to answer: Is ALTER TABLE t CHANGE COLUMN c lossy? INTEGER AUTO_INCREMENT vs. UUID Is ALTER TABLE t CHANGE COLUMN c lossy? ALTER TABLE is not lossy. We can test. mysql> create table kris ( id integer not null primary key auto_increment); Query OK, 0 rows affected (0.16 sec) mysql> insert into kris values (NULL); Query OK, 1 row affected (0.01 sec) mysql> insert into kris select NULL from kris; Query OK, 1 row affected (0.01 sec) Records: 1 Duplicates: 0 Warnings: 0 ... mysql> select count(*) from kris; +----------+ | count(*) | +----------+ | 1024 | +----------+ 1 row in set (0.00 sec) mysql> select id from kris limit 3; +----+ | id | +----+ | 1 | | 2 | | 3 | +----+ 3 rows in set (0.00 sec)Having a test table, we can play. I am running an ALTER TABLE kris CHANGE COLUMN command. This requires that I specifiy the old name of the column, and then the full new column specifier including the new name, the new type and all details. Hence the “id id ...” mysql> alter table kris change column id id varchar(200) charset latin1 not null; Query OK, 1024 rows affected (0.22 sec) Records: 1024 Duplicates: 0 Warnings: 0 mysql> select count(*) from kris; +----------+ | count(*) | +----------+ | 1024 | +----------+ 1 row in set (0.00 sec) mysql> select id from kris limit 3; +------+ | id | +------+ | 1 | | 1015 | | 1016 | +------+ 3 rows in set (0.00 sec) mysql> show create table krisG Table: kris Create Table: CREATE TABLE `kris` ( `id` varchar(200) CHARACTER SET latin1 COLLATE latin1_swedish_ci NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci 1 row in set (0.00 sec)We can see a number of things here: The conversion is not lossy: We have the same number of records, and the records are still sequences of decimal digits. The order of the output is somehow different. The records which previous showed up in ascending integer order are now showing up in ascending alphabetical order. Given that they are now strings, this is partially logical (if there is an order, it should be alphabetical for strings), and partly mysterious (why is there an order and what happened?). Let’s go through that step by step. Expensive ALTER TABLE ALTER TABLE tries to do changes to the table in place, without rewriting the entire table, if possible. In some cases this is not possible, and then it tries to do it in the background. In some cases not even that is possible, and then the table is locked, rewritten in full, and unlocked. Our table change was of the third, most expensive kind. An ENUM change that extends the ENUM at the end is the least expensive possible change. We just add a new value at the end of the list of possible values for the ENUM. This is a change to the data dictionary, not even touching the table. An ENUM change in the middle of the list requires recoding the table. Turning an ENUM(“one”, “three”) into an ENUM(“one”, “two”, “three”) is expensive. Turning ENUM(“one”, “three”) into ENUM(“one”, “three”, “two”) is cheap. MySQL stores ENUMs internally as integer, so the expensive change re-encodes all old “three” values from 2 to 3. The cheap change stores “three” as 2, and adds 3 as an encoding for “two” in the data dictionary. Some ALTER TABLE t ADD index variants are examples for things happening in the background. They still cost time, but won’t lock. The index will become available only after its creation has finished. There cannot be multiple background operations ongoing. In our case, we internally and invisibly lock the original table. Create a temp table in the new format. Read all data from the original table, write it into the new table as an INSERT INTO temptable SELECT ... FROM oldtable would do. RENAME TABLE oldtable TO temptable2, temptable TO oldtable; DROP TABLE temptable2; unlock everything and are open for business again This process is safe against data loss: If at any point in time this fails, we drop the temptable and still have the original table, unchanged. This processes for some time doubles disk storage: The table converted will for some time exist in both variants. It requires an appropriate amount of disk space for the duration of the conversion. This process can be emulated. Locking a production table for conversion for an extended amount of time is not an option. Online Schema Change (OSC) does the same thing, in code, while allowing access to the table. Data changes are captured in the background and mirrored to both versions. Multiple competing implementations of this exist, and we have institutionalized and automated this in the DBA portal at work. This process does the INSERT ... SELECT ... thing internally (and so does OSC). That is why the conversion works, and how the conversion works. The rules are the MySQL data type conversion rules, as documented in the manual. There is an order, and it changed When looking at the test-SELECT we see there seems to be an order, and it changed. There is an order, because the column I changed was the PRIMARY KEY. The MySQL InnoDB storage engine stores data in a B+-Tree. A B-Tree is a balanced tree. That is a tree in with the path length of the longest path from the root of the tree to any leaf is at most one step longer than the shortest path. So assuming a database with a page size of 16384 bytes (16KB), as MySQL uses, and assuming index records of 10 byte (4 Byte integer plus some overhead), we can cram over 1500 index records into a single page. Assuming index records of 64 byte size - quite large - we still fit 256 records into one page. We get an index tree with a fan-out per level of 100 or more (in our example: 256 to over 1500). For a tree of depth 4, this is good for 100^4 = 100 million records, or in other words, with 4 index accesses we can point-access any record in a table of 100 million rows. Or, in other words, for any realistic table design, an index access finds you a record with at most 4 disk accesses. 4 (or less): The number of disk accesses to get any record in any table via an index. In the InnoDB storage engine, the PRIMARY KEY is a B+-Tree. That is a B-Tree in which the leaves contain the actual data. Since a tree is an ordered data structure, the actual data is stored in primary key order on disk. Data with adjacent primary key values is likely stored in the same physical page. Data with small differences in primary key values is likely stored closer together than data with large differences in primary key values. Changing a primary key value changes the physical position of a record. Never change a primary key value (Never UPDATE t SET id = ...). For an AUTO_INCREMENT key, new data is inserted at the end of the table, old data is closer to the beginning of the table. MySQL has special code to handle this efficiently. Deleting old data is not handled very efficiently. Look into Partitions and think about ALTER TABLE t DROP PARTITION ... for buffer like structures that need to scale. Also think about proper time series databases, if applicable, or about using Cassandra (they have TTL). We remember: In InnoDB the primary key value governs the physical layout of the table. Assuming that new data is accessed often and old data is accessed less often, using primary keys with an AUTO_INCREMENT value collects all new, hot records in a minimum number of data pages at the end of the table/the right hand side of the tree. The set of pages the database is accessing a lot is minimal, and most easily cached in memory. This design minimizes the amount of memory cache, and maximizes database speed automatically for many common access patterns and workloads. That is why it was chosen and optimized for. Random, Hash or UUID primary key Consider table designs that assign a primary key in a random way. This would be for any design that uses a primary key that is an actual random number, the output of a cryptographic hash function such as SHA256(), or many UUID generators. Using an integer auto_increment primary key, we are likely to get hot data at the right hand side, cold data at the left hand side of the tree. We load hot pages, minimising the cache footprint: AUTO_INCREMENT integer primary key controlling data order. Hot data in few pages to the “right” side of the tree, minimal cache footprint But with a random distribution of primary keys over the keyspace, there is no set of pages that is relatively cold. As soon as we hit a key on a page (and for hot keys, we hit them often), we have to load the entire page into memory and keep it there (because there is a hot key in it, and we are likely to hit it again, soon): Primary Key values are randomly chosen: Any page contains a primary key that is hot. As soon as it is being accessed, the entire 16KB page is loaded. So we need a comparatively larger (often: much larger) amount of memory to have a useful cache for this table. In MySQL, numeric integer primary key auto_increment optimizes memory footprint for many workloads. MySQL provides a way out: UUID_TO_BIN(data, 1) Unfortunately, MySQL itself produces UUID() values with the UUID function that sort very badly: mysql> select uuid(); +--------------------------------------+ | uuid() | +--------------------------------------+ | 553d5726-eeaa-11ea-b643-08606ee5ff82 | +--------------------------------------+ 1 row in set (0.00 sec) mysql> select uuid(); +--------------------------------------+ | uuid() | +--------------------------------------+ | 560b9cc4-eeaa-11ea-b643-08606ee5ff82 | +--------------------------------------+ 1 row in set (0.00 sec) mysql> select uuid(); +--------------------------------------+ | uuid() | +--------------------------------------+ | 568e4edd-eeaa-11ea-b643-08606ee5ff82 | +--------------------------------------+ 1 row in set (0.00 sec)MySQL provides the UUID() function as an implementation of RFC 4122 Version 1 UUIDs. The manual says: The first three numbers are generated from the low, middle, and high parts of a timestamp. The high part also includes the UUID version number. The fourth number preserves temporal uniqueness in case the timestamp value loses monotonicity (for example, due to daylight saving time). The fifth number is an IEEE 802 node number that provides spatial uniqueness. A random number is substituted if the latter is not available (for example, because the host device has no Ethernet card, or it is unknown how to find the hardware address of an interface on the host operating system). In this case, spatial uniqueness cannot be guaranteed. Nevertheless, a collision should have very low probability. Having the timestamp in front for printing is a requirement of the standard. But we need not store it that way: MySQL 8 provides a UUID_TO_BIN() function, and this function has an optional second argument, swap_flag. »If swap_flag is 1, the format of the return value differs: The time-low and time-high parts (the first and third groups of hexadecimal digits, respectively) are swapped. This moves the more rapidly varying part to the right and can improve indexing efficiency if the result is stored in an indexed column.« TL;DR So if you must use a UUID in a primary key Choose MySQL 8. Make it VARBINARY(16). Store it with UUID_TO_BIN(UUID(), 1). Access it with BIN_TO_UUID(col, 1). See also: MySQL Server Team Blog on UUID support for MySQL 8. MySQL Server Team on the pain of pre-MySQL 8 UUID (Article from 2015). https://isotopp.github.io/2020/09/22/alter-table-for-uuid.html
0 notes
Text
MySQL 8.0 的功能
之前陸陸續續寫了一些關於 MySQL 8.0 的新改善 (參考「MySQL 8.0 的 performance_schema 加上 index 了…」、「MySQL 8.0 將會實作「真正的」Descending Indexes」、「MySQL 8.0 對 4 bytes UTF-8 的效能改善」),官方在 RC1 的時候整理了一篇出來:「MySQL 8.0 RC1 – Highlights」。 我覺得比較值得看的是「Better Handling of Hot Rows」、「Invisible Indexes」這兩個吧,前面這點對於效能可以有些幫助 (針對某些情境不要 waiting,直接 skip lock),後面這點對於維運應該也有不錯的幫助 (像是拔掉 index 的過渡驗證階段)。 當 MySQL 8.0 真的出了之後,Percona…
View On WordPress
0 notes
Text
MySQL Deadlocks with INSERT
Support Channel. “Hi, I am getting deadlocks in the database and they occur when I have to rollback the transactions but if we don’t have to roll back all transactions get executed.” Wait, what? After some back and forth it becomes clear that the Dev experiences deadlocks and has data: mysql> pager less mysql> show engine innodb statusG ... MySQL thread id 142531, OS thread handle 139990258222848, query id 4799571 somehost.somedomain someuser update INSERT into sometable (identifier_id, currency, balance ) VALUES ('d4e84cb1-4d56-4d67-9d16-1d548fd26b55', 'EUR', '0') *** (2) HOLDS THE LOCK(S): RECORD LOCKS space id 3523 page no 1106463 n bits 224 index PRIMARY of table `somedb`.`sometable` trx id 9843342279 lock mode S locks gap before recand that is weird because of the lock mode S locks gap in the last line. We get the exact same statement with the exact same value on the second thread, but with lock mode X locks gap. Both transactions have an undo log entry of the length 1 - one row, single insert and the insert has an S-lock. A mystery INSERT and opaque code Many questions arise: how can an INSERT have an S-lock? how can a single INSERT transaction deadlock? what does the originating code look like? The last question can be actually answered by the developer, but because they are using Java, in true Java fashion it is almost - but not quite - useless to a database person. @Transactional(propagation = Propagation.REQUIRES_NEW, timeout = MYSQL_TRANSACTION_TIMEOUT, rollbackFor = { BucketNotFoundException.class, DuplicateTransactionException.class, BucketBalanceUpdateException.class }, isolation = Isolation.SERIALIZABLE ) public void initiateBucketBalanceUpdate(Transaction transaction) throws BucketBalanceUpdateException, DuplicateTransactionException { this.validateAndInsertIdempotencyKey(transaction); this.executeBucketBalanceUpdateFlow(transaction); this.saveTransactionEntries(transaction); }So, where is the SQL? This is often a problem - Object Relational Mappers encapsulate the things that go on in the database so much that it is really hard for anybody - Developers, DBAs and everybody else - to understand what actually happens and make debugging quite painful. Or, if they understand what goes on with the database, to map this to the code. TRANSACTION ISOLATION LEVEL SERIALIZABLE In this case it is solvable, though. The isolation = Isolation.SERIALIZABLE is the culprit here. So when we spoke about transactions and isolation levels previously, I made the decision to leave the fourth and most useless isolation level out of the picture: SET TRANSACTION ISOLATION LEVEL SERIALIZEABLE. The manual says: SERIALIZABLE This level is like REPEATABLE READ, but InnoDB implicitly converts all plain SELECT statements to SELECT ... FOR SHARE if autocommit is disabled. It then goes on to explain how SERIALIZABLE does nothing when there is no explicit transaction going on. It does not explain what it is good for (mostly: shooting yourself into the foot) and when you should use it (mostly: don’t). It does answer the question of “Where to the S-Locks come from?”, though. The SERIALIZEABLE isolation mode turns a normal SELECT statement into a Medusa’s freeze ray that shoots S-Locks all over the tables onto everything it looks at, preventing other threads from changing these things until we end our transaction and drop our locks (And that is why you should not use it, and why I personally believe that your code is broken if it needs it). A broken RMW and lock escalation So instead of a regular Read-Modify-Write Session1> START TRANSACTION READ WRITE; Session1> SELECT * FROM sometable WHERE id=10 FOR UPDATE; -- X-lock granted on rec or gap -- ... Application decides INSERT or UPDATE Session1> INSERT INTO sometable (id, ...) VALUES ( 10, ... ); Session1> COMMIT;we get the following broken Read-Modify-Write, minimum: Session1> START TRANSACTION READ WRITE; Session1> SELECT * FROM sometable WHERE id=10 FOR SHARE; -- S-lock granted on rec or gap -- ... Application decides INSERT or UPDATE Session1> INSERT INTO sometable (id, ...) VALUES ( 10, ... ); -- lock escalation to X Session1> COMMIT;The LOCK IN SHARE MODE or equivalent FOR SHARE is not in the code, it is added implicitly by the isolation level SERIALIZABLE. We get an S-Lock, which is not good for writing. Our transaction now did not get the required locks necessary for reading at the start of the transaction, because the later INSERT requires an X-lock, like any write statement would. The database needs to aquire the X-lock, that is, it needs to upgrade the S-lock to an X-lock. If at that point in time another threads tries to run the exact same statement, which is what happens here, they already hold a second S-lock, preventing the first thread from completing their transaction (it is waiting until the second threads drops the S-lock or it times out). And then that second thread also tries to upgrade their S-lock into an X-lock, which it can’t do, because that first thread is trying to do the same thing, and we have the deadlock and a rollback. Reproduction of the problem We can easily reproduce this. Session1> set transaction isolation level serializable; Session1> start transaction read write; Query OK, 0 rows affected (0.00 sec) Session1> select * from kris where id = 10; +----+-------+ | id | value | +----+-------+ | 10 | 10 | +----+-------+ Session1> select * from performance_schema.data_locksG ... LOCK_TYPE: TABLE LOCK_MODE: IS LOCK_STATUS: GRANTED LOCK_DATA: NULL ... LOCK_TYPE: RECORD LOCK_MODE: S,REC_NOT_GAP LOCK_STATUS: GRANTED LOCK_DATA: 10 ... Session1> update kris set value=11 where id =10;We change the isolation level to SERIALIZABLE and start a transaction (because, as stated in the manual, autocommit does nothing). We then simply look at a single row, and check PERFORMANCE_SCHEMA.DATA_LOCKS afterwards. Lo and behold, S-Locks as promised by the manual. Now, the setup for the deadlock with a second session, by doing the same thing: Session2> set transaction isolation level serializable; Session2> start transaction read write; Query OK, 0 rows affected (0.00 sec) Session2> select * from kris where id = 10; +----+-------+ | id | value | +----+-------+ | 10 | 10 | +----+-------+Checking the data_locks table we now see two sets of IS- and S-Locks belonging to two different threads. We go for an UPDATE here, because we chose existing rows and row locks, instead of non-existing rows and gap locks: Session1> update kris set value=11 where id =10; ... hangs ...and in the other connection: Session2> update kris set value=13 where id =10; ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transactionComing back to the first session, this now reads Session1> update kris set value=11 where id =10; ... hangs ... Query OK, 1 row affected (2.43 sec) Rows matched: 1 Changed: 1 Warnings: 0The timing given is the time I took to switch between terminals and to type the commands. Resolution Coming back to the support case, the Dev analyzed their code and found out that what they are emitting is actually the sequence Session1> SET TRANSACTION ISOLATION LEVEL SERIALIZABLE; Session1> START TRANSACTION READ WRITE; Session1> SELECT * FROM sometable WHERE id=10; -- implied S-lock granted on rec or gap -- ... Application decides INSERT or UPDATE Session1> SELECT * FROM sometable WHERE id=10 FOR UPDATEl -- lock escalation to X Session1> INSERT INTO sometable (id, ...) VALUES ( 10, ... ); Session1> COMMIT;so their code is already almost correct. They do not need the double read and also not the isolation level SERIALIZABLE. This is an easy fix for them and the deadlocks are gone, the world is safe again. So many things to learn from this: You won’t need SERIALIZABLE unless your code is broken. Trying to use it is a warning sign. A deadlock with an S-lock escalation means you need to check the isolation level. In SERIALIZABLE it is totally possible to deadlock yourself with a simple invisible SELECT and a lone INSERT or UPDATE. The ORM will remove you quite a lot from the emitted SQL. Do you know how to trace your ORM and to get the actual SQL generated? If not, go and find out. A server side trace will not save you - the server is a busy beast. It also cannot see your stackframes, so it can’t link your SQL to the line in your code that called the ORM. Yes, in the client side SQL trace, ideally you also want the tracer to bubble up the stack and give you the first line outside of the ORM to identify what is causing the SQL to be emitted and where in the code that happens. The deadlock information in SHOW ENGINE INNODB STATUS is painfully opaque, but learning to read it is worthwhile. In reproduction, using performance schema is much easier and makes the sequence of events much easier to understand. The server is not very good at explaining the root cause of deadlocks to a developer in the error messages and warnings generated. https://isotopp.github.io/2020/08/02/mysql-deadlocks-with-insert.html
0 notes