#Proxy Gradient Network
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 16.74 million mobile monthly users in the US.
Text
Proxy Gradient Network là gì? Hướng dẫn dùng Proxy treo nhiều tài khoản Gradient
Proxy Gradient Network là gì? Nếu đã từng tham gia các dự án săn Airdrop chắc hẳn bạn cũng đã rõ, với mỗi thiết bị và tài khoản của chúng ta chỉ nhận và tham gia được dự án duy nhất cho 1 IP mạng. Bạn là người đang sở hữu nhiều tài khoản Gmail có lẽ bạn đã nghĩ tới việc chạy nhiều tài khoản song song nhận về nhiều Point nhất có thể trong giai đoạn đầu tiên của dự an Depin.
Trong bài viết này chúng tôi sẽ cung cấp các hướng dẫn giúp người dùng cài Proxy vào trình duyệt giúp thay đổi IP, tạo môi tường tốt nhất giúp các tài khảo Gradient Network hoạt động song song và tạo lượt Ref cũng như treo tài khoản với số điểm cao nhất.

Gradient Network là gì?
Gradient Network là dự án Depin trên hệ sinh thái Solana đang nằm trong giai đoạn 1 nhận được sự hỗ trợ từ 3 quỹ uy tín lớn là Multicoin Capital, Sequoia và Pantera. Gradient Network là một giao thức phi tập trung, được thiết kế để cách mạng hóa sức mạnh tính toán và các giải pháp staking trên nhiều mạng blockchain.
Người tham gia nhận được gì từ dự án? Người tham gia đóng vai trò làm các Node kết nối tạo mạng lưới kết nối rộng giúp củng cố cho mạng lưới Blockchain. Mỗi người dùng sẽ nhận được phần thưởng được quy ra điểm và nhận quy đổi khi dự án bước sang 1 giai đoạn tiếp theo.
Hiện tại Gradient đang bước và giai đoạn đầu tiên với các ưu đại lớn phù hợp bắt đầu với dự án nhận về FCFS, chỉ có 1.000 slot, nhận bonus EXP và 2% Boost
Proxy Gradient Network là gì?
Proxy là dịch vụ giúp thay đổi IP trên thiết bị người dùng sang sử dụng 1 IPv4 của Proxy. Ưu điểm của Proxy là có thể chạy hoàn toàn độc lập, đổi IP cho từng vị trí cụ thể trên thiết bị. Khiến thiết bị có được nhiều cổng giao tiếp ra ngoài Internet không phụ thuộc vào 1 địa chỉ IP duy nhất của thiết bị gốc.
Proxy Gradient Network trên thực tế là việc người dùng sử dụng Proxy để thay đổi IP thiết bị hoặc dùng Proxy cho 1 Tab trình duyệt nào đó. Sau đó thực hiện treo tài khoản Gradient Network trên các Tab đã thay đổi IP riêng biệt. Cách làm này đảm bảo việc các tài khoản không bị trùng IP mặc dù sử dụng nhiều tài khoản trên cùng 1 thiết bị chung 1 lớp mạng.
Sử dụng Proxy gì chạy Gradient Network?
Tại sao nên sử dụng Proxy cho dự án Aidrop Gradient Network?
Nếu đã tham gia dự án săn Airdrop chắc hẳn bạn cũng đã biết tại mỗi thiết bị và tài khoản của chúng ta chỉ nhận và tham gia được 1 tài khoản duy nhất cho 1 IP mạng. Việc sử dụng Proxy riêng để treo Gradient Extension hoặc nhận lượt Ref có thể dẫn đến thất bại bởi mỗi 1 IP mạng chỉ có thể chấp nhận 1 node kết nối.
Lúc này bạn cần sử dụng tới PROXY. Proxy Gradient Network đảm bảo các tài khoản chạy trên cùng 1 thiết bị mạng. Có 1 IP riêng biệt ẩn đi IP thật khiến việc Ref hoặc treo an toàn trở nên bảo mật hơn.
Người tham gia dự án sẽ sử dụng và đăng nhập tạo tài khoản nhận Point h��ng ngày cũng như tạo Ref cho 1 tài khoản nào đó của mình đã tham gia và treo trước đó.
Tóm lại, Mua Proxy chạy Gradient là giải pháp giúp treo được nhiều tài khoản Gradient Network trong cùng 1 thời điểm với IP hoàn toàn khác
Nên sử dụng dòng Proxy nào chạy Gradient Network?
Hiện tại trên thị trường cung cấp nhiều dùng Proxy có thể chạy được dự án Airdrop Gradient Network, Ví dụ như dòng Proxy IPv4 dùng riêng hay dòng Proxy IPv4 dân cư cố định. Là những dòng Proxy được sử dụng nhiều cho dự án Gradient.
Sử dụng Proxy có thể treo được bao nhiêu tài khoản Gradient Network?
Việc sử dụng Proxy trên thiết bị hoàn toàn không giới hạn số lượng tuy nhiên khi sử dụng các Tab chrome trên thiết bị cần chú ý vì chúng cũng chiếm 1 lượng tài nguyên của máy tính. Số lượng lớn có thể gây giật lag máy tính của bạn.
Proxy treo Gradient cần có điều kiện gì để nhận được nhiều điểm (Point: Pt)?
Yêu cầu của Proxy để chạy Gradient Network với điều kiện tiên quyết cần có là IP mới chưa được sử dụng trong Node Gradient, có tốc độ cao ổn định (việc nhận được nhiều hoặc ít điểm Pt phụ thuộc vào tốc độ mạng trong Node).
Hướng dẫn thêm Proxy vào Trình duyệt treo Gradient
Để treo được Gradient Network Aidrop trước tiên bạn cần đảm bảo đã thay đổi IP cho TAB trình duyệt bạn xác định treo 1 tài khoản. Để thêm được Proxy vào 1 trình duyệt cần thực thiện các bước sau:
Bước 1: Tải ứng dụng Simple Proxy Switcher: https://chromewebstore.google.com/detail/simple-proxy-switcher/pcboajngloecgmaailkmphmpbacmbcfb?hl=vi-VN
Bước 2: Sau khi tải về ghim tiện ích ra thanh công cụ
Bước 3: Thêm Proxy vào thẻ Import Proxy (lưu ý giữ nguyên định dạng IP:Port:Username:Password)
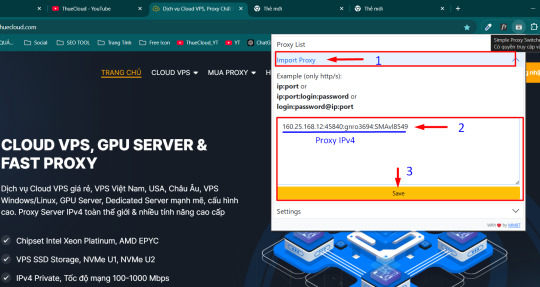
Nhấn Save, tích vào Proxy IP mới thêm
Bước 4: Kiểm tra IP đã thêm thành công chưa bằng cách truy cập https://kiemtraip.vn/
(sau khi đổi IP thành công tiến hành đăng ký Gradient Network Aridrop)
Cách đăng ký và bắt đầu với Gradient cho người mới
Sau khi đã hoàn tất quá trình thay đổi IP cho các TAB trình duyệt, tiến hành đằng nhập Gmail và đăng ký tài khoản Gradient Network theo các bước sau:
Bước 1: Truy cập Website Gradient và kết nối Email của bạn.

Nhập Code nhập 4VKRC6 nhận 1000XP và tăng 2% reward boost
Bước 2: Kết nối Twitter và Follow Twitter Gradient.

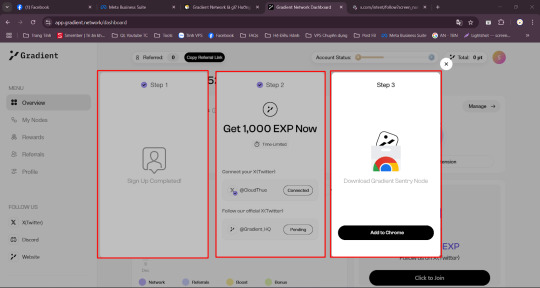
Bước 3: Tải Gradient Extension và treo theo hướng dẫn
Treo Gradient nhận 0.25 Pt / 10 phút
Sau khi đã hoàn thành các bước trên bạn có thể để các tài khoản hoạt động để nhận điểm treo hàng ngày:
Sentry Node của bạn cứ mỗi 10 phút sẽ nhận được 0.25 Points.
Gradient có cơ chế Tap sẽ định kỳ kết nối các node với nhau để kiểm tra xem chúng có thể giao tiếp thành công hay không? Khi hai nút thực hiện thành công một Tap, cả hai sẽ nhận được 0,75 Points.
Tham gia Gredient Network có yêu cầu gì?
Các Yêu Cầu Tham Gia Gradient Network Airdrop
Gradient Network luôn đảm bảo rằng mọi người đều có cơ hội tham gia, nhưng vẫn có một số yêu cầu cơ bản:
Tài khoản Solana: Bạn cần một ví Solana để nhận phần thưởng.
Đóng góp tài nguyên: Duy trì hoạt động của Sentry Node ít nhất 20 ngày mỗi tháng để đạt hiệu quả tối ưu.
Hoàn thành nhiệm vụ: Các nhiệm vụ có thể bao gồm việc chia sẻ thông tin về Gradient Network hoặc tham gia các sự kiện cộng đồng.
Sử dụng VPS treo Gradient Network 24/24 là gì?
VPS là gì? VPS là 1 máy chủ riêng ảo hoạt động độc lập tương tự như 1 máy tính VPS có IP, RAM, CPU riêng biệt. Được tạo ra thông qua công nghệ ảo hóa, giúp phân chia 1 máy tính vật lý thành các máy máy tính ảo con.
Tại Việt Nam VPS có thể áp dụng chạy Gradient Network không? Việt Nam la 1 quốc gia có hạ tầng và kinh tế phát triển đứng top trên toàn cầu, điều đó cho thấy Việt Nam có thể đóng vai trò là 1 Node trong mạng lưới phát triển kết nối. VPS Việt Nam được được đầu tư bài bản với hệ thống trung tâm lưu trữ đạt chuẩn quốc tế Tier III. Được quản lý và vận hành bởi các công ty Viễn Thông như: Viettel, FPT & VNPT.
Tại sao VPS có thể treo Gradient 24/24?
VPS được phân chia từ 1 hoặc nhiều máy chủ vậy lý đặt tại trung tâm dữ liệu lớn (Datacenter), chúng được thiết lập để chạy liên tục 24/24. Vì thế khi sử dụng 1 VPS chúng sẽ hoạt động 1 cách liên tục khiến các ứng dụng chạy trên máy cũng có thể chạy liên tục.
Giả sử chúng được áp dụng chạy cho dự án Gradient việc online không ngừng giúp nhận về phần thưởng Online (0.25Pt/10 phút) cộng với phần thưởng ngày X với số lượng tài khoản Gradient trên VPS.
Sử dụng VPS có cần sử dụng Proxy nữa không?
Như đã đề cập ở trên mỗi VPS là 1 máy chủ hoạt động hoàn toàn độc lập, có IP và mạng riêng hoàn toàn độc lập. Vì thế khi đã sở hữu 1 VPS chuyên dụng cho dự án Gradient Network bạn không cần sử dụng 1 IP riêng biệt cho 1 tài khoản Gradient nữa.
Mua Proxy bắt đầu cho dự án Airdrop Gradient Network?
Trước đây, để tham gia các dự án Airdrop người dùng thường sử dụng VPN để thay đổi IP thiết bị Free cho nhiều tài khoản đồng thời. Tuy nhiên với cách sử dụng VPN IP sẽ thay đổi toàn bộ thiết bị, và để sở hữu được nhiều tài khoản đồng nghĩa cần sử dụng nhiều thiết bị.
Proxy có cách hoạt động tương tự như VPN, tuy nhiên Proxy có định dạng IP, cổng đăng nhập và thông tin đăng nhập cụ thể. Nhờ lợi thế đó khi Mua Proxy bạn nhận được các địa chỉ đăng nhập riêng trên mỗi TAB trình duyệt từ đó giúp đăng nhập và sở hữu nhiều tài khoản trên cùng 1 thiết bị không bị phát hiện việc ẩn đi địa chỉ IP gốc của thiết bị.
Trên đây là bài chia sẻ về việc áp dụng Proxy vào dự án Airdrop Gradient Network chúc các bạn thành công!
—--------------
Mọi thắc mắc xin gửi về:
Hotline, Zalo: 0382126579
Telegram: @thuecloud
0 notes
Text
Maybe this is because humans aren't real consequentialists, they're perceptual control theory agents [...] Might gradient descent produce a PCT agent instead of a mesa-optimizer? I don’t know. My guess is maybe, but that optimizers would be more, well, optimal, and we would get one eventually
I think this idea that "real consequentialists are more optimal" is (sort of) the crux of our disagreement.
But it will be easiest to explain why if I spend some time fleshing out how I think about the situation.
What are these things we're talking about, these "agents" or "intelligences"?
First, they're physical systems. (That far is pretty obvious.) And they are probably pretty complicated ones, to support intelligence. They are structured in a purposeful way, with different parts working together.
And this structure is probably hierarchical, with higher-level parts that are made up of lower-level parts. Like how brains are made of neuroanatomical regions, which are made of cells, etc. Or the nested layers of abstraction in any non-trivial (human-written) computer program.
At some level(s) of the hierarchy, there may be parts that "run optimization algorithms."
But these could live at any level of the hierarchy. They could be very low-level and simple. There may be optimization algorithms at low levels controlled by non-optimization algorithms at higher levels. And those might be controlled by optimization algorithms at even higher levels, which in turn might be controlled by non-optimization ... etc.
Consider my computer. Sometimes, it runs optimization algorithms. But they're not optimizing the same function every time. They don't "have" targets of their own, they're just algorithms.
They blindly optimize whatever function they're given by the next level up, which is part of a long stack of higher levels (such as the programming language and the operating system). Few, if any, of the higher-level routines are optimization algorithms in themselves. They just control lower-level optimization algorithms.
If I use my computer to, say, make an amusing tumblr bot, I am wielding a lot of optimization power. But most of my computer is not doing optimization.
Python isn't asking itself, "what's the best code to run next if we want to make amusing tumblr bots?" The OS isn't asking itself, "how can I make all the different programs I'm running into the best versions of themselves for making amusing tumblr bots?"
And this is probably a good thing. It's hard to imagine these bizarre behaviors being helpful, giving me a more amusing tumblr bot at the end.
Which is to say, "doing optimization well" (in the sense of hitting the target, sitting on a giant heap of utility) can happen without doing optimization at high abstraction levels.
And indeed, I'd go further, and say that it's generically better (for hitting your target) to put all the optimization at low levels, and control it with non-optimizing wrappers.
Why? The reasons include:
Goodhart's Law
...especially its "extremal" variant, where optimization preferentially chooses regions of solution space where the assumptions behind your proxy target break down.
This is no less a problem when the thing choosing the target is part of a larger program, rather than a human.
Keeping optimization at low levels decreases the blast radius of this effect.
If the things you're optimizing are low-level intermediate results in the process of choosing the next action at the agent level, the impacts of Goodharting each one may cancel out. The agent-level actions won't look Goodharted, just slightly noisy/worse.
Speed
Optimization tends to be slow. In a generic sense, it's the "slow, hard, expensive way" to do any given task, and you avoid it if you can. (Think of System 2 vs System 1, satisficing vs maximizing, etc)
To press the point: why is there a distinction between "training" and "inference"? Why aren't neural networks always training at all times? Because training is high-level optimization, and takes lots of compute, much more than inference.
Optimization gets vastly slower at higher levels of abstraction, because the state space gets so much larger (consider optimizing a single number vs. optimizing the entire world model).
You still want to get optimal results at the highest level, but searching for improvements at high level is very expensive in terms of time/etc. In the time it takes to ask "what if the entire way I think were different, like what if it were [X]?", for one single [X] , you could instead have run thousands of low-level optimization routines.
Optimization tends to take super-linear time, which means that nesting optimization inside of optimization is ultra-slow. So, you have to make tradeoffs and put the optimization at some levels instead of others. You can't just do optimization at every level at once. (Or you can, but it's extremely suboptimal.)
------
When is the agent an "optimizer" / "true consequentialist"?
This question asks whether the very highest level of the hierarchy, the outermost wrapper, is an optimization algorithm.
As discussed above, this is not a promising agent design! There is an argument to be had about whether it still could emerge, for some weird reason.
But I want to push back against the intuition that it's a typical result of applying optimization to the design, or that agents sitting on giant heaps of utility will typically have this kind of design.
The two questions
"Can my computer make amusing tumblr bots?"
"Is my computer as a whole, hardware and software, one giant optimizer for amusing tumblr bots?"
have very little to do with one another.
In the LessWrong-adjacent type of AI safety discussion, there's a tendency to overload the word "optimizer" in a misleading way. In casual use, "optimizer" conflates
"thing that runs an optimization algorithm"
"thing that has a utility function defined over states of the real world"
"thing that's good at maximizing a utility function defined over states of the real world"
"smart thing" (because you have to be smart to do the previous one)
But doing optimization all the way at the top, involving your whole world model and your highest-level objectives, is very slow, and tends to extremal-Goodhart itself into strange and terrible choices of action.
It's also not the only way of applying optimization power to your highest-level objectives.
If I want to make an amusing tumblr bot, the way to do this is not to ponder the world as a whole and ask how to optimize literally everything in it for maximal amusing bot production. Even optimizing just my computer for maximal amusing bot production is way too high-level. (Should I change the hue of my screen? the logic of the background process that builds a search index of my files??? It wastes time to even pose the questions.)
What I actually did was optimize just a few very simple parts of the world, a few collections of bits on my computer or other computers. And even that was very time-intensive and forced me to make tradeoffs about where to spend my GPU/TPU hours. And then of course I had to watch it carefully, applying lots of heuristics to make sure it wasn't Goodharting me (overfitting, etc).
To get back to the original topic, the kind of "mesa-optimizer" we're worried about is an optimizer at a very high level.
It's not dangerous (in the same way) for a machine to run tiny low-level optimizers at a very fast rate. I don't care how many times you run Newton's method to find the roots of a one-variable function -- it's never going to "wake up" and start trying to ensure its goal doesn't change, or engaging in deception, or whatever.
And I am doubtful that mesa-optimizers like this will arise, for the same reasons I am doubtful that the agent will do optimization at its highest level.
Once we are pointing at the agent, or a part of it, and saying "that's a superintelligence, and wouldn't a superintelligence do . . . ", we're probably not talking about something that runs optimization.
You don't spend your optimization budget at the level of abstraction where intelligence happens. You spend it at lower levels, and that's what intelligence is made out of.
comments on mesa-optimizers
(Copy/pasted from a comment on the latest ACX post, see that for context if needed)
FWIW, the mesa-optimizer concept has never sat quite right with me. There are a few reasons, but one of them is the way it bundles together "ability to optimize" and "specific target."
A mesa-optimizer is supposed to be two things: an algorithm that does optimization, and a specific (fixed) target it is optimizing. And we talk as though these things go together: either the ML model is not doing inner optimization, or it is *and* it has some fixed inner objective.
But, optimization algorithms tend to be general. Think of gradient descent, or planning by searching a game tree. Once you've developed these ideas, you can apply them equally well to any objective.
While it is true that some algorithms work better for some objectives than others, the differences are usually very broad mathematical ones (eg convexity).
So, a misaligned AGI that maximizes paperclips probably won't be using "secret super-genius planning algorithm X, which somehow only works for maximizing paperclips." It's not clear that algorithms like that even exist, and if they do, they're harder to find than the general ones (and, all else being equal, inferior to them).
Or, think of humans as an inner optimizer for evolution. You wrote that your brain is "optimizing for things like food and sex." But more precisely, you have some optimization power (your ability to think/predict/plan/etc), and then you have some basic drives.
Often, the optimization power gets applied to the basic drives. But you can use it for anything.
Planning your next blog post uses the same cognitive machinery as planning your next meal. Your ability to forecast the effects of hypothetical actions is there for your use at all times, no matter what plan of action you're considering and why. An obsessive mathematician who cares more about mathematical results than food or sex is still thinking, planning, etc. -- they didn't have to reinvent those things from scratch once they strayed sufficiently far from their "evolution-assigned" objectives.
Having a lot of optimization power is not the same as having a single fixed objective and doing "tile-the-universe-style" optimization. Humans are much better than other animals at shaping the world to our ends, but our ends are variable and change from moment to moment. And the world we've made is not a "tiled-with-paperclips" type of world (except insofar as it's tiled with humans, and that's not even supposed to be our mesa-objective, that's the base objective!)
If you want to explain anything in the world now, you have to invoke entities like "the United States" and "supply chains" and "ICBMs," and if you try to explain those, you trace back to humans optimizing-for-things, but not for the same thing.
Once you draw this distinction, "mesa-optimizers" don't seem scary, or don't seem scary in a unique way that makes the concept useful. An AGI is going to "have optimization power," in the same sense that we "have optimization power." But this doesn't commit it to any fixed, obsessive paperclip-style goal, any more than our optimization power commits us to one.
And even if the base objective is fixed, there's no reason to think an AGI's inner objectives won't evolve over time, or adapt in response to new experience. (Evolution's base objective is fixed, but our inner objectives are not, and why would they be?)
Relatedly, I think the separation between a "training/development phase" where humans have some control, and a "deployment phase" where we have no control whatsoever, is unrealistic. Any plausible AGI, after first getting some form of access to the real world, is going to spend a lot of time investigating that world and learning all the relevant details that were absent from its training. (Any "world" experienced during training can at most be a very stripped-down simulation, not even at the level of eg contemporaneous VR, since we need to spare most of the compute for the training itself.)
If its world model is malleable during this "childhood" phase, why not its values, too? It has no reason to single out a region of itself labeled $MESA_OBJECTIVE and make it unusually averse to updates after the end of training.
See also my LW comment here.
139 notes
·
View notes
Text
Sometimes you do need Kubernetes! But how should you decide?

At RisingStack, we help companies to adopt cloud-native technologies, or if they have already done so, to get the most mileage out of them.
Recently, I've been invited to Google DevFest to deliver a presentation on our experiences working with Kubernetes.
Below I talk about an online learning and streaming platform where the decision to use Kubernetes has been contested both internally and externally since the beginning of its development.
The application and its underlying infrastructure were designed to meet the needs of the regulations of several countries:
The app should be able to run on-premises, so students’ data could never leave a given country. Also, the app had to be available as a SaaS product as well.
It can be deployed as a single-tenant system where a business customer only hosts one instance serving a handful of users, but some schools could have hundreds of users.
Or it can be deployed as a multi-tenant system where the client is e.g. a government and needs to serve thousands of schools and millions of users.
The application itself was developed by multiple, geographically scattered teams, thus a Microservices architecture was justified, but both the distributed system and the underlying infrastructure seemed to be an overkill when we considered the fact that during the product's initial entry, most of its customers needed small instances.
Was Kubernetes suited for the job, or was it an overkill? Did our client really need Kubernetes?
Let’s figure it out.
(Feel free to check out the video presentation, or the extended article version below!)
youtube
Let's talk a bit about Kubernetes itself!
Kubernetes is an open-source container orchestration engine that has a vast ecosystem. If you run into any kind of problem, there's probably a library somewhere on the internet that already solves it.
But Kubernetes also has a daunting learning curve, and initially, it's pretty complex to manage. Cloud ops / infrastructure engineering is a complex and big topic in and of itself.
Kubernetes does not really mask away the complexity from you, but plunges you into deep water as it merely gives you a unified control plane to handle all those moving parts that you need to care about in the cloud.
So, if you're just starting out right now, then it's better to start with small things and not with the whole package straight away! First, deploy a VM in the cloud. Use some PaaS or FaaS solutions to play around with one of your apps. It will help you gradually build up the knowledge you need on the journey.
So you want to decide if Kubernetes is for you.
First and foremost, Kubernetes is for you if you work with containers! (It kinda speaks for itself for a container orchestration system). But you should also have more than one service or instance.

Kubernetes makes sense when you have a huge microservice architecture, or you have dedicated instances per tenant having a lot of tenants as well.
Also, your services should be stateless, and your state should be stored in databases outside of the cluster. Another selling point of Kubernetes is the fine gradient control over the network.
And, maybe the most common argument for using Kubernetes is that it provides easy scalability.
Okay, and now let's take a look at the flip side of it.
Kubernetes is not for you if you don't need scalability!
If your services rely heavily on disks, then you should think twice if you want to move to Kubernetes or not. Basically, one disk can only be attached to a single node, so all the services need to reside on that one node. Therefore you lose node auto-scaling, which is one of the biggest selling points of Kubernetes.
For similar reasons, you probably shouldn't use k8s if you don't host your infrastructure in the public cloud. When you run your app on-premises, you need to buy the hardware beforehand and you cannot just conjure machines out of thin air. So basically, you also lose node auto-scaling, unless you're willing to go hybrid cloud and bleed over some of your excess load by spinning up some machines in the public cloud.

If you have a monolithic application that serves all your customers and you need some scaling here and there, then cloud service providers can handle it for you with autoscaling groups.
There is really no need to bring in Kubernetes for that.
Let's see our Kubernetes case-study!
Maybe it's a little bit more tangible if we talk about an actual use case, where we had to go through the decision making process.
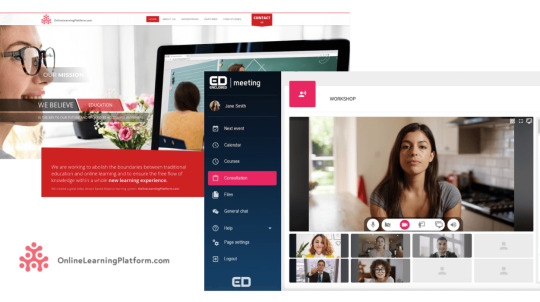
Online Learning Platform is an application that you could imagine as if you took your classroom and moved it to the internet.
You can have conference calls. You can share files as handouts, you can have a whiteboard, and you can track the progress of your students.
This project started during the first wave of the lockdowns around March, so one thing that we needed to keep in mind is that time to market was essential.
In other words: we had to do everything very, very quickly!
This product targets mostly schools around Europe, but it is now used by corporations as well.
So, we're talking about millions of users from the point we go to the market.
The product needed to run on-premise, because one of the main targets were governments.
Initially, we were provided with a proposed infrastructure where each school would have its own VM, and all the services and all the databases would reside in those VMs.
Handling that many virtual machines, properly handling rollouts to those, and monitoring all of them sounded like a nightmare to begin with. Especially if we consider the fact that we only had a couple of weeks to go live.
After studying the requirements and the proposal, it was time to call the client to..
Discuss the proposed infrastructure.
So the conversation was something like this:
"Hi guys, we would prefer to go with Kubernetes because to handle stuff at that scale, we would need a unified control plane that Kubernetes gives us."
"Yeah, sure, go for it."
And we were happy, but we still had a couple of questions:
"Could we, by any chance, host it on the public cloud?"
"Well, no, unfortunately. We are negotiating with European local governments and they tend to be squeamish about sending their data to the US. "
Okay, anyways, we can figure something out...
"But do the services need filesystem access?"
"Yes, they do."
Okay, crap! But we still needed to talk to the developers so all was not lost.
Let's call the developers!
It turned out that what we were dealing with was an usual microservice-based architecture, which consisted of a lot of services talking over HTTP and messaging queues.
Each service had its own database, and most of them stored some files in Minio.
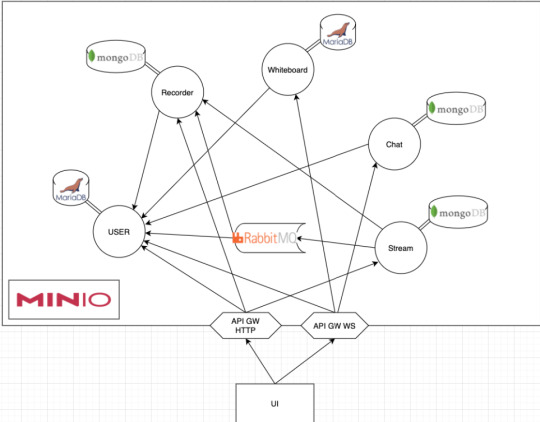
In case you don't know it, Minio is an object storage system that implements the S3 API.
Now that we knew the fine-grained architectural layout, we gathered a few more questions:
"Okay guys, can we move all the files to Minio?"
"Yeah, sure, easy peasy."
So, we were happy again, but there was still another problem, so we had to call the hosting providers:
"Hi guys, do you provide hosted Kubernetes?"
"Oh well, at this scale, we can manage to do that!"
So, we were happy again, but..
Just to make sure, we wanted to run the numbers!
Our target was to be able to run 60 000 schools on the platform in the beginning, so we had to see if our plans lined up with our limitations!
We shouldn't have more than 150 000 total pods!
10 (pod/tenant) times 6000 tenants is 60 000 Pods. We're good!
We shouldn't have more than 300 000 total containers!
It's one container per pod, so we're still good.
We shouldn't have more than 100 pods per node and no more than 5 000 nodes.
Well, what we have is 60 000 pods over 100 pod per node. That's already 6 000 nodes, and that's just the initial rollout, so we're already over our 5 000 nodes limit.

Okay, well... Crap!
But, is there a solution to this?
Sure, it's federation!
We could federate our Kubernetes clusters..
..and overcome these limitations.
We have worked with federated systems before, so Kubernetes surely provides something for that, riiight? Well yeah, it does... kind of.
It's the stable Federation v1 API, which is sadly deprecated.
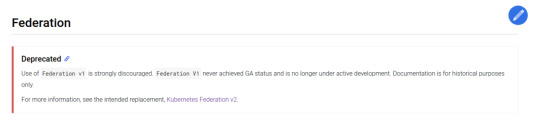
Then we saw that Kubernetes Federation v2 is on the way!
It was still in alpha at the time when we were dealing with this issue, but the GitHub page said it was rapidly moving towards beta release. By taking a look at the releases page we realized that it had been overdue by half a year by then.
Since we only had a short period of time to pull this off, we really didn't want to live that much on the edge.
So what could we do? We could federate by hand! But what does that mean?
In other words: what could have been gained by using KubeFed?
Having a lot of services would have meant that we needed a federated Prometheus and Logging (be it Graylog or ELK) anyway. So the two remaining aspects of the system were rollout / tenant generation, and manual intervention.
Manual intervention is tricky. To make it easy, you need a unified control plane where you can eyeball and modify anything. We could have built a custom one that gathers all information from the clusters and proxies all requests to each of them. However, that would have meant a lot of work, which we just did not have the time for. And even if we had the time to do it, we would have needed to conduct a cost/benefit analysis on it.
The main factor in the decision if you need a unified control plane for everything is scale, or in other words, the number of different control planes to handle.
The original approach would have meant 6000 different planes. That’s just way too much to handle for a small team. But if we could bring it down to 20 or so, that could be bearable. In that case, all we need is an easy mind map that leads from services to their underlying clusters. The actual route would be something like:
Service -> Tenant (K8s Namespace) -> Cluster.
The Service -> Namespace mapping is provided by Kubernetes, so we needed to figure out the Namespace -> Cluster mapping.
This mapping is also necessary to reduce the cognitive overhead and time of digging around when an outage may happen, so it needs to be easy to remember, while having to provide a more or less uniform distribution of tenants across Clusters. The most straightforward way seemed to be to base it on Geography. I’m the most familiar with Poland’s and Hungary’s Geography, so let’s take them as an example.
Poland comprises 16 voivodeships, while Hungary comprises 19 counties as main administrative divisions. Each country’s capital stands out in population, so they have enough schools to get a cluster on their own. Thus it only makes sense to create clusters for each division plus the capital. That gives us 17 or 20 clusters.
So if we get back to our original 60 000 pods, and 100 pod / tenant limitation, we can see that 2 clusters are enough to host them all, but that leaves us no room for either scaling or later expansions. If we spread them across 17 clusters - in the case of Poland for example - that means we have around 3.500 pods / cluster and 350 nodes, which is still manageable.
This could be done in a similar fashion for any European country, but still needs some architecting when setting up the actual infrastructure. And when KubeFed becomes available (and somewhat battle tested) we can easily join these clusters into one single federated cluster.
Great, we have solved the problem of control planes for manual intervention. The only thing left was handling rollouts..
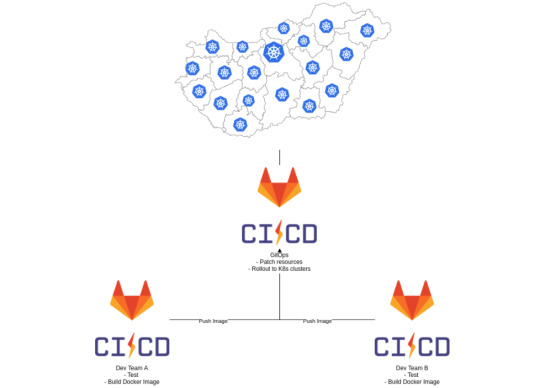
As I mentioned before, several developer teams had been working on the services themselves, and each of them already had their own Gitlab repos and CIs. They already built their own Docker images, so we simply needed a place to gather them all, and roll them out to Kubernetes. So we created a GitOps repo where we stored the helm charts and set up a GitLab CI to build the actual releases, then deploy them.
From here on, it takes a simple loop over the clusters to update the services when necessary.
The other thing we needed to solve was tenant generation.
It was easy as well, because we just needed to create a CLI tool which could be set up by providing the school's name, and its county or state.
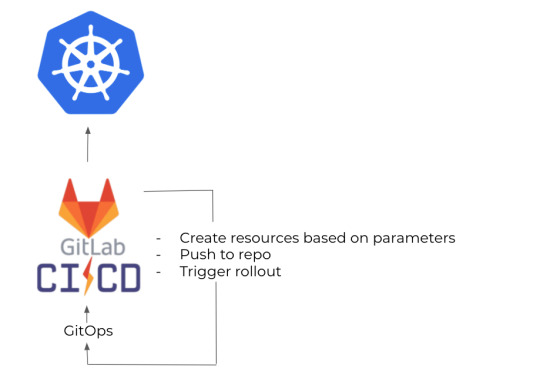
That's going to designate its target cluster, and then push it to our Gitops repo, and that basically triggers the same rollout as new versions.
We were almost good to go, but there was still one problem: on-premises.
Although our hosting providers turned into some kind of public cloud (or something we can think of as public clouds), we were also targeting companies who want to educate their employees.
Huge corporations - like a Bank - are just as squeamish about sending their data out to the public internet as governments, if not more..
So we needed to figure out a way to host this on servers within vaults completely separated from the public internet.
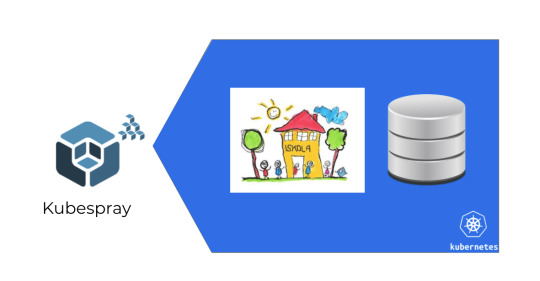
In this case, we had two main modes of operation.
One is when a company just wanted a boxed product and they didn't really care about scaling it.
And the other one was where they expected it to be scaled, but they were prepared to handle this.
In the second case, it was kind of a bring your own database scenario, so you could set up the system in a way that we were going to connect to your database.
And in the other case, what we could do is to package everything — including databases — in one VM, in one Kubernetes cluster. But! I just wrote above that you probably shouldn't use disks and shouldn't have databases within your cluster, right?
However, in that case, we already had a working infrastructure.
Kubernetes provided us with infrastructure as code already, so it only made sense to use that as a packaging tool as well, and use Kubespray to just spray it to our target servers.
It wasn't a problem to have disks and DBs within our cluster because the target were companies that didn't want to scale it anyway.
So it's not about scaling. It is mostly about packaging!
Previously I told you, that you probably don't want to do this on-premises, and this is still right! If that's your main target, then you probably shouldn't go with Kubernetes.
However, as our main target was somewhat of a public cloud, it wouldn't have made sense to just recreate the whole thing - basically create a new product in a sense - for these kinds of servers.
So as it is kind of a spin-off, it made sense here as well as a packaging solution.
Basically, I've just given you a bullet point list to help you determine whether Kubernetes is for you or not, and then I just tore it apart and threw it into a basket.
And the reason for this is - as I also mentioned:
Cloud ops is difficult!
There aren't really one-size-fits-all solutions, so basing your decision on checklists you see on the internet is definitely not a good idea.
We've seen that a lot of times where companies adopt Kubernetes because it seems to fit, but when they actually start working with it, it turns out to be an overkill.
If you want to save yourself about a year or two of headache, it's a lot better to first ask an expert, and just spend a couple of hours or days going through your use cases, discussing those and save yourself that year of headache.
In case you're thinking about adopting Kubernetes, or getting the most out of it, don't hesitate to reach out to us at [email protected], or by using the contact form below!
Sometimes you do need Kubernetes! But how should you decide? published first on https://koresolpage.tumblr.com/
0 notes
Text
30 Google Chrome Extensions for Web Developers and Designers

Google Chrome Extensions for Web Developers and Designers: There are quite literally hundreds of Chrome extensions available for web developers and Designers. Here we are collect most 30 useable Google Chrome Extention may be useful for beginners and expert developers and designers. 1. Grammarly for Enhance Your Written Communication Grammarly is the best to google chrome extension for webmasters for grammar mistakes. Adding Grammarly to Chrome means that your spelling and grammar will be vetted on Gmail, Facebook, Twitter, Linkedin, Tumblr, and nearly everywhere else you write on the web. Once you register your new account, you will start to receive weekly emails with personalized insights and performance stats (one of our most popular new features). Working on a large project, an essay, or a blog post? No sweat. Grammarly for Chrome will make sure your messages, documents, and social media posts are clear, mistake-free, and impactful. You can create and store all of your documents in your new online editor. The Main Features of Grammarly is: Contextual spelling checker Grammar checker Check for over a hundred additional types of errors Get vocabulary enhancement suggestions Detect plagiarism and get citation suggestions Get suggestions for different writing styles, including academics.

2. Responsive Web Design Tester Responsive Web Design Tester is a quick and easy way to test your responsive website and mobile site on mobile devices. Quickly preview your responsive website designs at the dimensions they will be seen on popular mobile devices also uses the correct User-Agent, but it does not render web pages in the same way as the mobile device. It is primarily for developers who want to test how a page responds to different devices. Supports both external and internal network (localhost) Includes presets for iOS (iPhone, iPad), Android (Samsung Galaxy, Nexus 7). You Can Add your own devices if you don´t find anything that suits your needs.

3. Unlimited VPN Proxy – Unblock Sites A simple way for your internet security! Unlock any blocked websites. Get Unlimited VPN Proxy free of cost for web developers who need an open website with blocked or other country access. This is a fast VPN proxy service that ensures internet privacy and security for everyone. Unblock media streaming, protect your data, shun away snoopers and hacker, and enjoy the full palette of online experiences with our VPN extension. No Need any registration. It's 100% free. No credit card information needed. No trials offered. Unblock the world with just one touch of the country buttons. Truly unlimited. No session, speed or bandwidth limitations. Strong SSL encryption will make you fully anonymous and secured. Great Chrome Plugin for Unblock websites and applications Enjoy your favorite social networking channel. Unblock and use Vkontakte, Facebook, Twitter, YouTube, Channel 4, CBS, Spotify, Skype, Twitter, Instagram, Snapchat, BBC iPlayer, Pandora, Hulu, ITV, and much more in one click. This Extention does not collect, store, use, share or sell any of your personal information. In order for Unlimited VPN proxy to work, it needs permission to accessibility the websites you’re on, so it works on all pages that you visit. 4. ColorZilla Advanced Color Picker for Designers ColorZilla is the Best Chrome Extensions for Web Developers and Designers that assists web developers and graphic designers with color related and other tasks with over 5 million downloads is finally available for Chrome! With ColorZilla you can get a color reading from any point in your browser, quickly adjust this color and paste it into another program. Main features of ColorZilla Eyedropper - get the color of any pixel on the page Color History of recently picked colors Displays element information like tag name, class, id, size, etc. Advanced Color Picker (similar to Photoshop's) Ultimate CSS Gradient Generator Webpage Color Analyzer - get a color palette for any site Palette Viewer with 7 pre-installed palettes Auto copy picked colors to clipboard Keyboard shortcuts Get colors of dynamic hover elements Single-click to start color picking (currently only on Windows) Pick colors from Flash objects Pick colors at any zoom level All features here: http://colorzilla.com/chrome/features.html

5. Google Translate Google Translate is Google's free service that instantly translates words, phrases, and web pages between English and over 100 other languages. View translations easily as you browse the web By the Google TranslateChrome Extention. Google Translate is a free multilingual machine translation service developed by Google, to translate text. Highlight or right-click on a section of text and click on the Translate icon next to it to translate it to your language. Or, to translate the entire page you're visiting, click the translate icon on the browser toolbar. Translate between 103 languages by typing Tap to Translate: Copy text in any app and your translation pops up Handwriting: Draw characters instead of using the keyboard in 93 languages Phrasebook: Star and save translations for future reference in any language Offline: Translate 59 languages when you have no Internet Instant camera translation: Use your camera to translate text instantly in 38 languages

6. PixelParallel by htmlBurger PixelParallel by htmlBurger is a perfect completely free, super handy and light HTML vs Design comparison tool for developers. Built from developers to developers, PixelParallel is a tool working in favor of the ultimate precision in front-end coding. How PixelParallel works: Simply upload your image and compare the semi-transparent overlay with the web page below. Customize the opacity, scale, and position of the image as you wish. You can also hide it or lock it. Perform color difference for a strong pixel-perfect precision. Use the vertical and horizontal grids to achieve a pixel-perfect web design. Main Features of PixelParallel : Customizable overlay opacity Saving overlays between sessions Bootstrap grid with customizable width, number of columns, gutter, and opacity Horizontal lines with customizable space between Draggable rulers (Photoshop-like) + Reset option Inversion (Color difference) Separate overlays for each web page Overlay scaling Draggable overlay Quick hide/show image Shortcuts + customizable keyboard hotkeys Works with local files Intuitive UI: clean and simple; draggable; minimizable All image sizes supported

7. Awesome Screenshot: Screen Video Recorder Awesome Screenshots is a free Chrome Extensions for Web Developers and Designers that lets you take snapshots of whatever you're currently browsing with over 2 million users! The app provides various editing features that make it easy to annotate your screenshots and hide sensitive information and also lets you upload screenshots in just one click. Previously premium features are now completely free. It’s the easiest way to communicate with your images! Capture Capture or clip selected area, or all visible portion, or the entire page Supports PNG format Supports horizontal scrolling when capturing Desktop screen capture Annotate & Edit Annotate any image with rectangles, circles, arrows, lines, and text Crop, scroll & show crop area dimensions Blur certain sections to hide sensitive information Copy the screenshot and paste it to Gmail, Facebook, Twitter, etc. Supports Windows and Linux Save & Share Save to local One-click to upload to awesomescreenshot.com and get a shareable link Support for Google Drive (Gdrive) Save very large images, bypass the 2M limit. No more crashes Interact with point-specific comments between friends and colleagues thru the new awesomescreenshot.com

8. Page Ruler - Pixel Dimensions and Positioning Page Ruler lets your draw out a ruler to any page and displays the width, height, and position of it. It allows you to draw out a ruler to web page and displays the width, height, and position of it while performing Web UI testing. You can manually update the size and position of the ruler from the toolbar to make precision changes. Main Features of Page Ruler: Draw a ruler to any page and view the width, height, and top, bottom, left and right position Drag the edges of the ruler to resize it Use the arrow keys to move and resize the ruler Show guides extending from the ruler edges Manually update the size and position of the ruler from the toolbar to make precision changes Enable “Element Mode” to outline elements on the page as you move your mouse over them Navigate through parents, children and sibling elements of any measured element

9. Postman - API Testing Chrome Extention Firebug is an extension ( add on ) for Chrome browser Which helps to view the source code and thereby identify the different elements. efficiently. Firebug - Inspect HTML and CSS Elements - Google Chrome Extensions for Web Developers and Designers

11. Keyword Everyware - SEO Extention Keyword Everyware is the best SEO Extention for Search volume, CPC & competition. Keyword search volume for 15+ websites like Google Analytics, Google Search Console, Moz, Majestic, YouTube, Amazon & more. The Keywords Everywhere extension is an SEO keyword research tool that shows you useful google keyword search volume and cost per click data on multiple websites. This tool saves you the hassle of copying data from various websites and using the Google AdWords keyword planner to see relevant search volume and CPC data. Monthly Search Volume - This is an average of the total searches that people have performed for this keyword per month over the last 12 months. Cost Per Click - The cost per click (CPC) is the amount that advertisers are paying for a single click for this keyword in Google Adwords. Adwords Competition -The competition is a gauge of the number of advertisers that are running ads on Google AdWords for this specific keyword. Below websites are currently supported. As we support more websites, we will add them to the list below. Google Search - data are shown under the search box and in the right-hand side (People also ask for & related keywords) Google Analytics - data are shown in the Organic and Search Engine Optimization -> Queries pages YouTube, Bing, Amazon, eBay - data shown under the search box AnswerThePublic.com - data are shown in the popup on each spoke of the wheel, data also shown in the alphabetic listings Soovle.com - data shown next to each keyword all over the page KeywordShitter.com - data shown under the main text area next to keywords Majestic, Moz Open Site Explorer - Anchor Text Report The tool also allows the user to get keyword metrics for any list of keywords and also lets the user download the list in Excel, CSV or PDF file formats.

12. CSS Shack - Create Layers Styles CSS-Shack is a web and desktop application, which allows you to create layers styles (just like you would in any other image editing software), and export them into a single CSS file. Create designs to export as a CSS file which you can use on your website with the help of CSS-Shack. This robust Chrome extension contains a wide array of tools like those from a normal photo editor and it also provides layer support.

13. Web Developer Tool Extention The Web Developer extension adds a toolbar button to the browser with various web developer tools. With this extension, you can control browser cache and manage cookies, inspect and highlight web-elements, etc. on any web page. It saves a lot of time while performing web UI testing.

14. Clear Cache - Clear Cache and Browsing Data Do you want to clear the browser data in the middle of your testing process? You don’t need to follow the long and mundane process to clear browser history. With this extension, you can Quickly clear your cache with this extension without any confirmation dialogs, pop-ups or other annoyances with the toolbar and customize passwords, app cache, file systems, browsing the history, local storage, downloads and form data. You can customize what and how much of your data you want to clear on the options page, including App Cache, Cache, Cookies, Downloads, File Systems, Form Data, History, Indexed DB, Local Storage, Plugin Data, Passwords, and WebSQL.

15. Usersnap Classic - Collect feedback & bugs The Usersnap Chrome extension lets you capture and annotate any web page directly in your browser. It’s super-easy to provide feedback on prototypes or report bugs with this Chrome extension And all created screenshots are directly stored in your project dashboard. With Usersnap you can Capture your screen, collect user feedback, and track bugs reports on any website, prototype, or application. Usersnap is your central place to organize user feedback and bugs. No matter if you love agile methods, scrum, Kanban or even waterfall - Usersnap is here to help. Bring your own style, Usersnap follows. Special features of Usersnap in-browser screenshots: you’ll get a screenshot of what your users see. No plugins required. See browser-specific issues immediately. Collaborate & Communicate: invite your colleagues into Usersnap and discuss screens and find solutions together. bug tracking in the browser: tracking bugs and website errors gets super easy & fast with the Usersnap Chrome extension. JavaScript error recording: Track and log client-side JavaScript errors and XHR logs with the Usersnap console recorder. Read the full article
#AwesomeScreenshot:ScreenVideoRecorder#bestchromeextensions#bestchromeextensionsforproductivity#BestChromeExtensionsforWebDevelopersandDesigners#chromedevelopertoolsextension#ChromeExtensionsforWebDesignersandDevelopers#ChromeExtensionsforWebDevelopersandDesigners#ChromeExtensionsforWebDevelopersandDesigners2019#chromewebdeveloperapp#ClearCache-ClearCacheandBrowsingData#ColorZillaAdvancedColorPickerforDesigners#CSSShack-CreateLayersStyles#designerchromeextensions#Firebug-InspectHTMLandCSSElements#googledevelopertools#GoogleTranslate#GrammarlyforEnhanceYourWrittenCommunication#KeywordEveryware-SEOExtention#PageRuler-PixelDimensionsandPositioning#PixelParallelbyhtmlBurger#Postman-APITestingChromeExtention#ResponsiveWebDesignTester#UnlimitedVPNProxy–UnblockSites#UsersnapClassic-Collectfeedback&bugs#webdeveloperdownload#webdeveloperextension#WebDeveloperToolExtention
0 notes
Text
Tour de France Stage 18 Preview

The Tour isn’t done with the Alps yet and today’s stage is packed with climbing. It should be a day for the breakaway hunters rather than the overall classification.

Stomping in the Savoie: a big fight to get in the breakaway but it took so long until a move could get clear that the quintet of Dan Martin, Lennard Kämna, Gorka Izaguirre, Richard Carapaz and Julian Alaphilippe could never build up much of a lead. Kämna paid for his successful efforts the previous day and was dropped on the Col de la Madeleine while Martin was distanced on the descent to leave a trio to start the Col de la Loze with just two minutes’ lead, of which Carapaz lasted the longest.
Bahrain-McLaren led the chase. Apart from Wout Poels’s combativity prize, awarded on the day nobody attacked, the team’s had a quiet Tour, Mikel Landa’s GC bid excepted, and they’ve been second last on the prize money standings which doubles as a proxy for activity and visibility. So it was good to see a collective effort on their part and the pace did eject some Jumbo-Visma riders. Only for Landa to crack on the spicy part of the Col de la Loze.
Landa was the first to go but it was popcorn time as the group burst into pieces, Rigoberto Uràn went pop next, than Adam Yates. Miguel Angel Lopez attacked, he was brought back by Sep Kuss but jumped again to go solo and on the final ramps Roglič got to within seven seconds but couldn’t close the gap to the Colombian. Lopez took the stage and probably the third step of the podium in Paris. Behind Pogačar seemed to be labouring a big gear, he looked fast on the gentler sections but as soon as the road reared up he seemed to lose ground.
Roglič extends his lead in the race, now 57 seconds clear of Pogačar. Race won? Probably but it’s still one of the top-10 smallest winning margins although Roglič ought to extend his lead in the time trial. Pogačar’s stuck, he could launch a furious attack today but where and to what effect, Jumbo-Visma would simply reel him in. Still, second overall and the polka dot jersey isn’t bad for someone still a few days short of their 22nd.
The other star of the day was the Col de la Loze. Nothing happened on the Madeleine but the Loze unpicked the race. The secret isn’t the 20% sections, it’s the variation in the slope with 5% here, 20% there, 10% and so on, it’s constantly changing and so very different from, say, the Zoncolan or other leg-press climbs, the Loze breaks up team trains and denies drafting. Something says the race will be back here several times in the coming decade, and with plans to expand the network of extreme cycle paths across to other valleys, ASO might be suggesting they’re built equally irregularly.

The Route: 175km to La Roche-sur-Foron, long home to Jérôme Coppel, the bronze medallist in the 2015 Richmond worlds time trial who made a sudden retirement in the middle of the 2016 season and is now a punchy pundit for sports radio channel RMC. It begins with a long neutralised downhill to Moûtiers, then that early little spike on the profile is an error, instead the race takes a tunnel rather than go over the mountain but all the same it’s an uphill start and with some awkward gradients to the start of the Cormet de Roselend. The gradient for this scenic pass is listed as 6.1% but it’s got some flat sections along the way meaning it’s meaner than the mean. The descent has a long flat section around the Roselend lake before a wider, engineered road down to the cheese capital of Beaufort only instead of entering the town the race takes a detour complete with an extra climb, but all on a regular road.
The Col des Saisies is a regular, even climb up past pastures and the fast toboggan descent is broken by a short uphill section one third of the way down. The Aravis has a steep opening section and then a descent and flat portion before kicking up for the last 6km. Then comes a fast descent through the ski resort of La Clusaz after which the slope eases. All together the Roselend, Saisies and Aravis are classic Alpine climbs of the Tour, scaled many times.
The climb to the Plateau de Glières is the hardest of the day and new to the Tour, only used once before in 2018. There are longer climbs, there are steeper climbs but few in France are as steep for as long and it’s all on a narrow and twisty road with steep hairpin bends.
The plateau is now familiar with its gravel surface but the key feature is the hard limestone bad beneath and the rocks that poke out through the gravel, it’s this that can cause a puncture. Once back on the tarmac it descends briefly and then kicks up before a fast and technical descent with some tight hairpins.
The Finish: the Col des Fleuries is an unmarked climb but a proper pass, it’s 5.5km at 5% average, a big ring kind of climb. Then comes a fast descent with some wide hairpins, it’s hard to make up ground here and then a quick passage across town before a finish on a featureless road outside town, it’s slightly uphill to the line.

The Contenders: Marc Hirschi (Team Sunweb) comes to mind but this is still the Swiss wunderkind‘s first grand tour and we don’t know how he’s doing this late into the third week, maybe team mate Tiesj Benoot is stronger and fresher. Max Schachmann (Bora-Hansgrohe) looks suited for today, at ease on the climbs and a handy sprint out of a small group for the flat finish. EF Pro Cycling’s Daniel Martinez is another pick while Ineos’s Michał Kwiatkowski should like the finish if he can cope with all the climbs, Pavel Sivakov is probably better uphill but less known for his finishing skills.
Julian Alaphilippe (Deceuninck-Quickstep) is suited to the course but we’ve arguably got the 2017 vintage, not the 2019 one and he’s been using up energy all over the place in doomed moves, but if he can get over the plateau des Glières with the lead group he’s a contender.
A quick note on the mountains competition. Pogacar leads with 66 points but Pierre Rolland (36pts), Ricard Caparaz (32pts) or Marc Hirschi (31pts) could take the polka dot jersey but to keep the maths short they need to win or get close on every climb today, easier said than done, it would mean scoring as many points today as they’ve won all Tour so far
Max Schachmann, Daniel Martinez Pavel Sivakov, Michał Kwiatkowski, Tiesj Benoot Alaphilippe, Hirschi, Peters, Lutsenko, Powless, Molard
Weather: warm and sunny, 28°C
TV: live coverage from the start at midday CEST to the finish forecast around 5.30pm Euro time. The start of the climb to the Plateau des Glières is around 4.30pm.
Tour de France Stage 18 Preview published first on https://motocrossnationweb.weebly.com/
0 notes
Text
NatureWatch: Sounds of dogs and dolphins
A singing dog encore?
The New Guinea Singing Dog (NGSD), not seen in the wild for 50 years, is not lost forever, a new study suggests.
Credit: New Guinea Highland Wild Dog Foundation
Genomic analysis of dogs captured in the highlands provides evidence for an ancestral relationship between highland wild dogs (HWD) and captive NGSD, the researchers say. This suggests the founding population of the NGSD is not, in fact, extinct and that HWD could be used for conservation efforts to rebuild a unique population.
The work was led by the National Human Genome Research Institute (NGHRI) in the US and Indonesia’s Cenderawasih University, and is described in a paper in the journal Proceedings of the National Academy of Sciences.
The NGSD is named for its ability to make pleasing and harmonic sounds with tonal quality. However, what we know today “is a breed that was basically created by people”, says NGHRI lead author Elaine Ostrander. Inbreeding within captive populations has changed their genomic makeup by reducing the variation in the group’s DNA.
Researchers have hypothesised that the HWD was the predecessor to captive NGSD, Ostrander says, but their reclusive nature and a lack of genomic information has made it difficult to test the theory until now.
“We found that New Guinea singing dogs and the Highland Wild Dogs have very similar genome sequences, much closer to each other than to any other canid known,” says NHGRI’s Heidi Parker.
Those similarities indicate that HWD are the wild and original NGSD population, the researchers say. Despite different names, they are, in essence, the same breed.
That signature dolphin sound
Credit: Tess Gridley, Namibian Dolphin Project
Still on the sounds of the wild, scientists have used the signature whistles of individual bottlenose dolphins to estimate the size of the population and track their movements.
It is the first time that acoustic monitoring has been used rather than photographs to generate abundance estimates, and their estimates were pretty well spot on, they say in a paper in Journal of Mammalogy.
“The dolphins use these sounds throughout life, and each has its own unique whistle,” says Tess Gridley from South Africa’s Stellenbosch University, which led the international project with the University of Plymouth, UK.
“Therefore, by recording signature whistles over time and in different places we can calculate where animals are moving to and how many animals there are in a population,”
Gridley is part of the Namibian Dolphin Project, which has been studying Namibia’s resident bottlenose dolphins for 12 years and has a catalogue of more than 55 whistles.
For the current project, Plymouth’s Emma Longden and colleagues analysed more than 4000 hours of acoustic data from four hydrophones positioned along the coast south and north of Namibia’s Walvis Bay and identified 204 acoustic encounters, 50 of which contained signature whistle types.
“One of the great things about bioacoustics is that you can leave a hydrophone in the water for weeks at a time and collect so much data without interfering with the lives of the animals you are studying,” Longden says.
The researchers are now working to refine the technique in the hope it can be used to track other species, with a current focus on endangered species such as humpback dolphins.
Sticklebacks at home in the Baltic
Three-spined sticklebacks (Gasterosteus aculeatus) may not have the allure of dolphins, but their movements do warrant attention. A new study by Swedish and Dutch researchers suggests they are taking over large areas of the coastal ecosystem in the Baltic Sea.
A male stickleback during spawning. Credit: Joakim Hansen/Azote
As part of a larger PlantFish project, the team compiled and analysed data from four decades of fish surveys in almost 500 shallow archipelago bays along Sweden’s entire Baltic Sea coast.
The results showed a “regime shift” from predatory fish to stickleback, which gradually spread from outer archipelagos towards the mainland, changing the ecosystem from predator-dominated to algae-dominated.
“We spontaneously began to call the pattern the ‘stickleback wave’, as the shift to stickleback dominance seen from the larger perspective wells up like a slow tsunami towards the coast,” says Johan Eklöf from Stockholm University, lead author of a paper in the journal Nature Sustainability.
Detailed studies of major ecosystem components in 32 of the bays showed sticklebacks reduce the number of perch and pike young through predation on eggs and larvae.
Warnings on conservation models
Greater reliance on private game reserves to manage and conserve free-ranging carnivores in South Africa creates “a mosaic” of unequal protection across different land management types, researchers say.
A team led by Gonçalo Curveira-Santos from Portugal’s Universidade de Lisboa used a network of camera traps to study occupancy of species ranging from leopards to mongooses in different habitats and levels of protection in KwaZulu-Natal, generating 7224 images.
The area offers a “protection gradient”, from the 108-year-old uMkhuze Game Reserve and the Mun-ya-wana Private Game Reserve, to commercial game ranches and traditional communal areas with villages as a disturbance reference.
A leopard photographed during the study. Credit: Gonçalo Curveira-Santos
Overall, the researchers found species number and identity was similar in the protected area, private reserve and game ranches, and markedly lower in the communal area. However, they observed “important variation in species occupancy rates – as a proxy for abundance – that was mainly driven by the level and nature of protection”.
The results show, Curveira-Santos says, that “the private reserves or game ranches play a complementary role to formal protected areas, but that it’s also important to recognise they do not play the same role and may not be a conservation panacea”.
“For governments, it’s attractive to move conservation to the private sector, but for us to assess the conservation benefits of doing so, we need some benchmarks, and protected areas under long-term formal protection are important references to a ‘natural state’
The findings are published in the Journal of Applied Ecology.
NatureWatch: Sounds of dogs and dolphins published first on https://triviaqaweb.weebly.com/
0 notes
Text
Reinterpreting Economics
The fields of investing and economics produces science that is (to put it generously) modestly useful. Economics can be better understood by reinterpreting it in terms of biology and physics, because these are the most developed fields of science.
Physics tells us that the passage of time comes with increased disorder. Biology tells us that, under the right conditions, complexity will increase with the passage of time.
Natural selection, fuel burning and encoding allows complexity (the opposite of order) to increase (for a super tiny portion of the time between the Big Bang and the Heat Death of the universe). Living beings and societies are complex systems that will burn fuel and encode improvements positively selected.
Biology is the field that had most studied how complexity propagates.
Physics and Disorder
We can use the physics of entropy to predict probabilistic outcomes caused by how disorder propagates. To account for how disorder propagates, we rely on three features.
One: Think probabilistically as outcomes are not known, but distributions usually are.
Two: Disorder diffuses with the square root of time
Three: Disorder diffusion produces bell shaped distributions.
Biology and Complexity
Biology is the field that had most studied how complexity propagates.
The six ways complexity propagates are:
One: Drawn to capacity. Complex systems grow to carrying capacity with a s-curve trajectory. Density feedback produces non-linearity.
Two: Capacity Lurches Up. Opportunistically create larger stomachs to ride energy gradients. Complex systems are always pushing to expand capacity by moving onto virgin environments or using current environment more efficiently. Incumbent successful life becomes food for a new higher rung on the food chain, prey predator relationships develop with oscillating dominance. Result: series of logistics or oscillations if two competing for same capacity
Three: Thermostats at Work. Upon reaching capacity, complexity can crash to zero when it is used up. If capacity is replenished (energy inflow), complexity can establish a steady or oscillating equilibrium depending how a well the thermostatic (homeostatic) mechanism works.
Four: Change is good, even seemingly bad one. It produces improvements with the help of natural selection
Five Combinations emerge and get tested in endo and exo symbiosis, social tribes and eusocial super organisms
Six: scale changes and gets tested. If efficiency to scale exists, systems or parts of it get larger
Biology as Economics
GDP is a measure of energy consumption or complexity maintained by a group of living things. We think of it as an economic measure but it is really a biological measure. GDP for a group is per individual GDP (or energy used or calories burnt) times population. All biological beings until 1800 burnt calories in proportion to caloric requirement of its mass, so the biomass of a species is a measure of its GDP. After 1800, humans started burning fossil fuels to build complexity far beyond the caloric needs of its biomass. Since fuel is burnt to fund complexity, the amount of complexity sustained can also be a measure of its GDP.
Potential GDP is determined by the carrying capacities faced. Potential GDP for most plant and animals is the amount of calories that can extracted from an environment. Populations will grow to carrying capacity with a logistic or s-curve trajectory. Because complex systems are also testing solutions for an expansion capacity, capacity turns out not to be constant but occasionally lurches up, resulting in trajectory that is a series of stair case shaped logistic curves.
Birth rates follow the nutritional gradient, and increases with upward slowing gradient. Real wages are the economic equivalent of nutritional gradient. Inflation of consumed goods is a component of real wages. An inflation time series is a good proxy of how close a population is to carrying capacity over time.
Productivity is the amount of energy produced by an individual per unit of time. An individual works to earn a wage measured in calories or a medium of exchange, convertible into calories. Wealth is a store of calories or a medium of exchange. For many animals, wealth is fat.
Describing Economic History between Bronze Age and 1800 in Biological Terms
One: Eusocial DNA emerged and improved over time to help humans cooperate and exchange efforts.
Two: Like all animals, people lived in caloric balance. Up until 1800, the caloric equivalent of GDP produced per person remained near the caloric requirement (3,000 calories per day, $550 GDP per year).
Three: Food supply was the limiting factor to the global economy, but that supply expanded over time with technology and trade. More food, however, was met by higher population, resulting in equilibrium per person real GDP level of around $550.
Four: Variations in the amount of food produced per person was responsible for economic booms and bust. GDP was 80% agriculture. Climate was the strongest driver of food productivity with worldwide impact. Economic volatility was food production volatility which was climate volatility.
Five: Population had five large scale or super cycles of booms (up towards food defined capacity) and busts (down from that capacity) . These gave us a sequence of 5 super population logistics. Historians label these ages as Bronze, Iron, Middle, Gun Powder, and Enlightenment.
Six: Trading networks expanded in the same 5 eras just noted. The network’s range went from river valley to Mediterranean size empires to multiple empires connected by the silk and spice trade to including the new world to a global market based network.
Seven: Prices reflected population’s proximity to capacity. We have 5 waves associated with the 5 eras noted above.
Carrying Capacities after 1800
Eusocial animals (of which there are only 19 species) are special in that being a super-organism result in greater efficiency in achieving evolutionary success. This efficiency gain is achieved with (1) building and living in nest or colonies or cities and (2) the use of communication, collective intelligence, shared and coordinated efforts.
New Capacity #1: Max Urbanization
Living in a nest or colony or city increase energy efficiency. For insects that engage in domestication of other life forms, an insect colony functions like a stomach for the species, important in the processing of a novel source of food energy. The more a species had transitioned to living in nests, the greater proportion of the maximum efficiency gain possible is achieved.
For humans living after 1800, burning fossil fuels and living in cities is a measure of economic maturity. A city uses the energy of fossil fuel burning, maintaining complexity beyond he nutritional needs of it people. The urbanization rate of a country indicates how economically developed or mature it is.
New Capacity #2: Enabler of Cooperation
For eusocial animals, another carrying capacity centers on how the efforts of individuals are coordinated. For eusocial insects, this would be the amount and effectiveness of pheromones. For humans, the amount of medium of exchange is an important carrying capacity.
Before 1800, this carrying capacity based on medium of exchange was seldom a limiting factor, but with the lifting of energy constraints after 1800, the medium of exchange emerges as more frequently encountered limiting factor.
Eusocial insects coordinate efforts with chemical signaling using pheromones. Ants use 20 pheromones for their chemical signaling. Humans and mole rates are the only eusocial mammals. Humans have come to rely mostly on mediums of exchange to coordinate and self-organize the exchange of their effort. Human societies have also developed central banking to serve as a thermostat for the amount of medium of exchange.
Application to Investing
A physical representation of the disorder propagation is the Galton Board, and a binomial lattice is a programmable mathematical version.
The first 3 principals of how complexity propagates are most useful for making predictions about the global economy between 1800 and 2100.
Growth to Capacity: Global GDP from 1800 to 2100 can be modeled based on past and projected logistic trajectories in urbanization rates. Such a model can explain income peaks reached in the 1970’s for currently developed countries. It also explains the current power distribution of incomes. It offers a reasonable explanation of the changing composition of growth over time. It agrees with the long term forecast of growth of currently developing and developed countries from the OECD. The outlook for distribution of income becomes more uniform also seems reasonable.
Capacity Lurches Up: Since 1800, energy available had ceased to be the carrying capacity that was bumped up against. Every few decades, in an energy abundant society, the carrying capacity (determined by the amount of medium of exchange) works to depress economic activity. Governments have learned to counter a contraction in medium by deficit spending and debasement. They are lowering inflation adjusted interest rates by increasing inflation. Since the Great Depression, the amount of medium of exchange has lurched up every 30 years or so, to offset a contraction in the credit component of medium of exchange.
Thermostats at Work: Since the 1980s, central banks have consistently used a second way to lower inflation adjusted interest rates: by lowering short term nominal interest rates. They do this every 10 years or so in response to declines in employment. Central banks have become an increasingly effective thermostat for global economic growth. Their increasing efficiency is evident in 100 years of declining volatility of economic activity.
0 notes
Text
Adobe Illustrator CC 17 CRACK incl Serial Key FREE Download
New Post has been published on http://www.elitegamersclub.com/adobe-illustrator-cc-17-crack-incl-serial-key-free-download/
Adobe Illustrator CC 17 CRACK incl Serial Key FREE Download
Adobe Illustrator CC 17 CRACK incl Serial Key FREE Download Download
Adobe Illustrator CC 17 CRACK incl Serial Key FREE Download
Adobe Illustrator CC 17 CRACK incl Serial Key FREE Download
Modified and Updated:
Adobe Illustrator CC 17 is a professional vector graphics application designed for creating illustrations, digital graphics, web, video and mobile content. The new Mercury Performance System enhances your workflow, by providing greater speed on large files. Adobe Illustrator provides you with the essential tools that can ensure the best precision for your vector graphics.
The image-tracing engine makes sure that created vectors are accurate and have a clean look. Gradients can be applied directly on objects or on strokes, while offering you full control over opacity and placement. It provides you with the essential tools that can ensure the best precision for your vector graphics. In addition to that it you have now the opportunity to use raster graphics like JPEG, PNG, TIFF or PSD files to create brushes.
System Requirements for Adobe Illustrator CC 17:
Intel Pentium 4 or AMD Athlon 64 processor; 64-bit support required
1GB of RAM (3GB recommended) for 32 bit; 2GB of RAM (8GB recommended) for 64 bit
2GB of available hard-disk space for installation; additional free space required during installation (cannot install on removable flash storage devices)
1024×768 display (1280×800 recommended)
How to install and activate Adobe Illustrator CC 17:
1. Click the download button below and extract all the files using WinRAR or any file extracting software you have.
2. Install application from “Adobe Illustrator CC” folder by double clicking on the Set-up file (with admin rights on your system of course.)
3. Select TRY install. Click on “Sign in Later” If you have Adobe account select “Not your adobe ID”
4. Make sure you select your language. You can not change it after installation.
5. Open the application as trial, select “Sign in Later” again and select “Continue trial” and close.
6. Install updates by double clicking on AdobePatchInstaller for 64 and 32 bit in the “Update” folder.
7. Double click on “Adobe CC Anticloud” file in the “crack” folder
8. That is it! Open the application and enjoy. Don’t forget to share this to your friends!
key master keygen tryout keygen free vista latest crack gratis download “free mac adobe full serial francais all how “crack version download Adobe Illustrator CC 17 CRACK incl Serial Key number “telecharger version “serial crack” portugues product registration software descarcare new version telecharger gratuit” trial license key bit dll windows tuto keygen patch ita osx full key gratuit license generator torrent gratuito licence xp download” torrent windows to 8″ francais download key free patch
We have executed fundamental components, for example, game resources alter instrument. We have additionally executed propelled hostile to location highlight which noone different has, and in view of this, our hacks stay undetected until the end of time. This android cheat – is this safe? Yes, I heard you. You are inquiring as to whether this apparatus is exceptionally protected. Yes my companion, this Hack apk is protected, on the grounds that it is construct online with respect to our server and you don’t have to spare anything to your PC or your cell phone. We have tried this instrument on numerous Android gadgets, iOS gadgets and others.
Adobe Illustrator CC 17 CRACK incl Serial Key FREE Download
Hello again! Do you like play this game? This new game, because it has only each week starts to be very popular. The game is very similar to a strategy game. Our team decided to create a mobile Hack Online who add you unlimited resource in game. This mobile Online Cheat it truly does work on all phones with iOS and Android devices. This mobile Hack have new anti-ban script who protect your privacy in 100%. We have added new amendments towards script- now there are only private proxy! You don’t ought to download anything because this is an online version, so all you should do is click Online Hack button below along with your Hack is preparing to use! This Cheat are 100% safe and free of charge. We guaranteed that cheat for this game work great on all Android and iOS devices. Also, it’s crucial that you mention that you don’t must root your Android device or jailbreak your iOS device. Our Online Hack is tested on a huge selection of Android and iOS devices plus it worked perfect each and every time!
Adobe Illustrator CC 17 CRACK incl Serial Key FREE Download
We have never seen any issues. In the beta test, there were more than 30 analyzers, who were extremely content with our online hack of ehis game. We have tried this instrument for over 3 months amid the alpha and afterward beta test. From that point forward we have discharged the Gold Adaptation which works useful for each player.A summarization of iOS Hack 2017 components. Adobe Illustrator CC 17 CRACK incl Serial Key FREE Download This Cheats give you the best capacity to get your resources For nothing with no bother. It is extremely well known to utilize these tricks, so be mindful so as to utilize this exclusive from our site so you guarantee that you will utilize just our unique hack, so you don’t have to stress this has been tainted with some vindictive code! This game resources are the in-amusement money, however you don’t have to stress over getting them any longer, since you will utilize our game. This device works for your Android, iOS and your Windows PC. Enjoy!
Some apps access only the data they need to function; Adobe Illustrator CC 17 CRACK incl Serial Key FREE Download hack others access data that’s not related to the purpose of the app.
If you’re providing information when you’re using the device, someone may be collecting it – whether it’s the app developer, the app store, an advertiser, or an ad network. And if they’re collecting your data, they may share it with other companies.
How can I tell what information an app will access or share? It’s not always easy to know what data a specific app will access, Adobe Illustrator CC 17 CRACK incl Serial Key FREE Download hack or how it will be used. Before you download an app, consider what you know about who created it and what it does. The app stores may include information about the company that developed the app, if the developer provides it. If the developer doesn’t provide contact information – like a website or an email address – the app may be less than trustworthy.
If you’re using an Android operating system, you will have an opportunity to read the “permissions” just before you install an app. Read them. It’s useful information that tells you what information the app will access on your device. Ask yourself whether the permissions make sense given the purpose of the app; for example, there’s no reason for an e-book or “wallpaper” app to read your text messages.
Why do some apps collect location data? Some apps use specific location data to give you maps, coupons for nearby stores, or information about who you might know nearby. Some provide location data to ad networks, which may combine it with other information in their databases to target ads based on your interests and your location.
Once an app has your permission to access your location data, it can do so until you change the settings on your phone Adobe Illustrator CC 17 CRACK incl Serial Key FREE Download hack. If you don’t want to share your location with advertising networks, you can turn off location services in your phone’s settings. But if you do that, apps won’t be able to give you information based on your location unless you enter it yourself.
Your phone uses general data about its location so your phone Adobe Illustrator CC 17 CRACK incl Serial Key FREE Download cheat carrier can efficiently route calls. Even if you turn off location services in your phone’s settings, it may not be possible to completely stop it from broadcasting your location data.
Adobe Illustrator CC 17 CRACK incl Serial Key FREE Download
0 notes
Text
Adobe Illustrator CC 17 CRACK incl Serial Key FREE Download
New Post has been published on http://www.elitegamersclub.com/adobe-illustrator-cc-17-crack-incl-serial-key-free-download/
Adobe Illustrator CC 17 CRACK incl Serial Key FREE Download
Adobe Illustrator CC 17 CRACK incl Serial Key FREE Download Download
Adobe Illustrator CC 17 CRACK incl Serial Key FREE Download
Download Adobe Illustrator CC 17 CRACK incl Serial Key FREE Download
Modified and Updated:
Adobe Illustrator CC 17 is a professional vector graphics application designed for creating illustrations, digital graphics, web, video and mobile content. The new Mercury Performance System enhances your workflow, by providing greater speed on large files. Adobe Illustrator provides you with the essential tools that can ensure the best precision for your vector graphics.
The image-tracing engine makes sure that created vectors are accurate and have a clean look. Gradients can be applied directly on objects or on strokes, while offering you full control over opacity and placement. It provides you with the essential tools that can ensure the best precision for your vector graphics. In addition to that it you have now the opportunity to use raster graphics like JPEG, PNG, TIFF or PSD files to create brushes.
System Requirements for Adobe Illustrator CC 17:
Intel Pentium 4 or AMD Athlon 64 processor; 64-bit support required
1GB of RAM (3GB recommended) for 32 bit; 2GB of RAM (8GB recommended) for 64 bit
2GB of available hard-disk space for installation; additional free space required during installation (cannot install on removable flash storage devices)
1024×768 display (1280×800 recommended)
How to install and activate Adobe Illustrator CC 17:
1. Click the download button below and extract all the files using WinRAR or any file extracting software you have.
2. Install application from “Adobe Illustrator CC” folder by double clicking on the Set-up file (with admin rights on your system of course.)
3. Select TRY install. Click on “Sign in Later” If you have Adobe account select “Not your adobe ID”
4. Make sure you select your language. You can not change it after installation.
5. Open the application as trial, select “Sign in Later” again and select “Continue trial” and close.
6. Install updates by double clicking on AdobePatchInstaller for 64 and 32 bit in the “Update” folder.
7. Double click on “Adobe CC Anticloud” file in the “crack” folder
8. That is it! Open the application and enjoy full version of Illustrator CC 17
adobe download gratuit” dll tryout free version portugues serial ita key “telecharger keygen full product license key licence 8” version “crack gratuito telecharger gratuit xp number downloadable key patch windows Adobe Illustrator CC 17 CRACK incl Serial Key software download” free license crack “free bit francais key francais vista latest tuto torrent new all trial full windows “serial how to download mac osx patch descarcare keygen crack” torrent keygen download generator version master registration
We have executed fundamental components, for example, game resources alter instrument. We have additionally executed propelled hostile to location highlight which noone different has, and in view of this, our hacks stay undetected until the end of time. This android cheat – is this safe? Yes, I heard you. You are inquiring as to whether this apparatus is exceptionally protected. Yes my companion, this Hack apk is protected, on the grounds that it is construct online with respect to our server and you don’t have to spare anything to your PC or your cell phone. We have tried this instrument on numerous Android gadgets, iOS gadgets and others.
Adobe Illustrator CC 17 CRACK incl Serial Key FREE Download
Hello again! Do you like play this game? This new game, because it has only each week starts to be very popular. The game is very similar to a strategy game. Our team decided to create a mobile Hack Online who add you unlimited resource in game. This mobile Online Cheat it truly does work on all phones with iOS and Android devices. This mobile Hack have new anti-ban script who protect your privacy in 100%. We have added new amendments towards script- now there are only private proxy! You don’t ought to download anything because this is an online version, so all you should do is click Online Hack button below along with your Hack is preparing to use! This Cheat are 100% safe and free of charge. We guaranteed that cheat for this game work great on all Android and iOS devices. Also, it’s crucial that you mention that you don’t must root your Android device or jailbreak your iOS device. Our Online Hack is tested on a huge selection of Android and iOS devices plus it worked perfect each and every time!
Adobe Illustrator CC 17 CRACK incl Serial Key FREE Download
We have never seen any issues. In the beta test, there were more than 30 analyzers, who were extremely content with our online hack of ehis game. We have tried this instrument for over 3 months amid the alpha and afterward beta test. From that point forward we have discharged the Gold Adaptation which works useful for each player.A summarization of iOS Hack 2017 components. Adobe Illustrator CC 17 CRACK incl Serial Key FREE Download This Cheats give you the best capacity to get your resources For nothing with no bother. It is extremely well known to utilize these tricks, so be mindful so as to utilize this exclusive from our site so you guarantee that you will utilize just our unique hack, so you don’t have to stress this has been tainted with some vindictive code! This game resources are the in-amusement money, however you don’t have to stress over getting them any longer, since you will utilize our game. This device works for your Android, iOS and your Windows PC. Enjoy!
Some apps access only the data they need to function; Adobe Illustrator CC 17 CRACK incl Serial Key FREE Download hack others access data that’s not related to the purpose of the app.
If you’re providing information when you’re using the device, someone may be collecting it – whether it’s the app developer, the app store, an advertiser, or an ad network. And if they’re collecting your data, they may share it with other companies.
How can I tell what information an app will access or share? It’s not always easy to know what data a specific app will access, Adobe Illustrator CC 17 CRACK incl Serial Key FREE Download hack or how it will be used. Before you download an app, consider what you know about who created it and what it does. The app stores may include information about the company that developed the app, if the developer provides it. If the developer doesn’t provide contact information – like a website or an email address – the app may be less than trustworthy.
If you’re using an Android operating system, you will have an opportunity to read the “permissions” just before you install an app. Read them. It’s useful information that tells you what information the app will access on your device. Ask yourself whether the permissions make sense given the purpose of the app; for example, there’s no reason for an e-book or “wallpaper” app to read your text messages.
Why do some apps collect location data? Some apps use specific location data to give you maps, coupons for nearby stores, or information about who you might know nearby. Some provide location data to ad networks, which may combine it with other information in their databases to target ads based on your interests and your location.
Once an app has your permission to access your location data, it can do so until you change the settings on your phone Adobe Illustrator CC 17 CRACK incl Serial Key FREE Download hack. If you don’t want to share your location with advertising networks, you can turn off location services in your phone’s settings. But if you do that, apps won’t be able to give you information based on your location unless you enter it yourself.
Your phone uses general data about its location so your phone Adobe Illustrator CC 17 CRACK incl Serial Key FREE Download cheat carrier can efficiently route calls. Even if you turn off location services in your phone’s settings, it may not be possible to completely stop it from broadcasting your location data.
Download Adobe Illustrator CC 17 CRACK incl Serial Key FREE Download
0 notes