#SSML Tags
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
There were a total of 171.5 billion posts on Tumblr in 2019.
Link
SSML Text To Speech - Use SSML Tags To Create Engaging Contents - https://www.askeygeek.com/ssml-text-to-speech/ Have you ever wondered how to produce exciting, attention-grabbing text-to-speech using SSML Tags? In this article, we'll look at SSML Text To Speech, its functions, and why it can help you produce engaging content. .elementor-115045 .elementor-element.elementor-element-18f0e1d{color:#000000;}.elementor-115045 .elementor-element.elementor-element-18f0e1d > .elementor-widget-container{padding:10px 10px 10px 10px;border-style:solid;border-width:1px 1px 1px 1px;border-color:#F2F6FC;border-radius:6px 6px 6px 6px;box-shadow:0px 0px 1px 0px rgba(0,0,0,0.5);}.elementor-115045 .elementor-element.elementor-element-f65a572 .elementor-heading-title{color:#282828;font-family:"Montserrat", Sans-serif;font-size:22px;font-weight:900;text-transform:capitalize;}.elementor-115045 .elementor-element.elementor-element-f65a572 > .elementor-widget-container{padding:8px 8px 8px 8px;background-color:#F2F6FC;border-style:solid;border-width:1px 1px 1px 50px;border-color:#F16334;border-radius:3px 3px 3px 3px;}.elementor-115045 .elementor-element.elementor-element-01cdd1b .elementor-heading-title{color:#282828;font-family:"Montserrat", Sans-serif;font-size:22px;font-weight:900;text-transform:capitalize;}.elementor-115045 .el #ssml #texttospeech #TextToSpeech
0 notes
Text
Amazon Polly’s Generative Engine Offers 3 Evocative Voices
Amazon Polly
Use human voices that sound authentic and of excellent quality in a variety of languages.
AWS is pleased to announce today the broad release of Amazon Polly’s generative engine, which comes in three voice versions: American English’s Ruth and Matthew, and British English’s Amy. A range of voices, languages, and styles, as well as private and publicly available data, were used to train the new generative engine. It renders context-dependent prosody, pauses, spelling, dialectal characteristics, foreign word pronunciation, and more with the utmost precision.
Talk output that is compatible with lexicons and Speech Synthesis Markup Language (SSML) tags can be customised and controlled.
Speech can be saved and shared in common file types such as OGG and MP3.
Deliver conversational user experiences and lifelike voices in a timely manner with consistently quick response times.
How it functions
You may turn articles into speech by using Amazon Polly, which synthesises human speech using deep learning algorithms. Amazon Polly offers hundreds of realistic voices in a wide range of languages, making it easy to create speech-activated applications.Image credit to AWS
Use cases
Produce audio in numerous languages
Applications having a worldwide audience, such webpages, movies, and RSS feeds, can benefit from adding speech.
Engage clients by speaking in a natural tone of voice
Amazon Polly speech output can be recorded and played back to prompt callers via interactive or automated voice response systems.
Modify your loudness, pitch, speaking tempo, and manner of speaking
For speech synthesis applications, use SSML, a W3C standard XML-based markup language, which supports common SSML tags for intonation, emphasis, and phrasing.
Amazon Polly is an ML service that uses TTS to read text aloud. Amazon Polly lets you deploy speech-enabled apps across several countries using dozens of languages and high-quality, realistic human voices.
You may choose from a variety of voice options with Amazon Polly, such as neural, long-form, and generative voices, which produce remarkably expressive, emotionally intelligent, and human-like voices while delivering revolutionary gains in speech quality. With Speech Synthesis Markup Language (SSML) tags, you may modify the speech rate, pitch, or volume as well as store speech output in common formats like MP3 or OGG. You can also rapidly produce realistic voices and conversational user experiences with consistently fast response times.
The new generative engine: what is it?
Four voice engines are currently supported by Amazon Polly: generative, long-form, neural, and conventional voices.
Amazon Polly voices
The 2016 introduction of standard TTS voices makes use of conventional concatenative synthesis. This technique creates synthesised speech that sounds incredibly natural by piecing together the phonemes of recorded speech. The methods employed to segment the waveforms and the inherent changes in speech, however, restrict the quality of speech.
Introduced in 2019, neural teletext-speech (NTTS) voices rely on a neural network that processes phonemes in sequence to create spectrograms, which are then further processed by a neural vocoder to create a continuous audio output. Compared to its regular voices, the NTTS generates voices that are much more lifelike.
The goal of long-form voices, which will be released in 2023, is to hold listeners’ interest for longer content, including news stories, training manuals, or promotional films. They are created using state-of-the-art deep learning TTS technology.
Big Adaptive Streamable TTS with Emergent abilities (BASE) is a new research TTS model that Amazon scientists unveiled in February 2024. The Polly Generative Engine can produce artificially generated voices that resemble humans thanks to its technology. These voices can be used as an informed virtual assistant, marketer, or customer service representative.
These voice options are available for you to select based on your use case and application. Go to the AWS documentation’s Generative Voices section to discover more about the generative engine.
Begin utilizing generating voices
Using the AWS Management Console, AWS Command Line Interface (AWS CLI), or AWS SDKs, you can have access to the new voices.
Amazon Polly text to speech
To begin, navigate to the US (N. Virginia) Region of the Amazon Polly dashboard and select the Text-to-Speech option from the left pane. You can choose the Generative engine if you choose the voice of Ruth or Matthew in English, US, or Amy in English, UK. Enter your text, then click the generated voice output to listen to it or download it.Image credit to AWs
You can list the voices that make advantage of the new generative engine by using the CLI:
To synthesise sample text to an audio file (hello.mp3) with generative engine parameters and a supported voice ID, execute the synthesize-speech CLI command now.
Visit Code and Application Examples in the AWS documentation to see other code examples that make use of the AWS SDKs. You can use code examples for Java and Python, as well as examples of web applications written in Java or Python, iOS apps, and Android apps.
Amazon Polly pricing
The US East (North Virginia) Region is currently able to access the new generative voices of Amazon Polly. Based on how many text letters you turn into speech, you only pay for what you utilize. See Amazon Polly Pricing page for additional information.
Read more on govindhtech.com
#AWS#Amazon#MLSERVICE#deeplearning#amazonpolly#TTS#amazonmanagement#amazondocumentation#News#technews#technologynews#govindhtech
0 notes
Text
Speechki Review 2024: How to Create High-Quality Audio Content from Your Text

What is Speechki?
Speechki is a text-to-speech plugin that lets you connect to ChatGPT and transform any text into natural-sounding audio content. ChatGPT is a powerful artificial intelligence model that can generate realistic voices in over 80 languages, with different accents, tones, and emotions. You can use Speechki to create voiceovers, podcasts, audiobooks, e-learning courses, and more, with just a few clicks. Some of the main features and benefits of Speechki are:
It offers over 1,100 voices in 80 languages, so you can choose the best voice for your content and audience.
It allows you to customize the voice speed, pitch, volume, and emphasis, to make it sound more natural and expressive.
It supports SSML tags, which let you add pauses, breaks, emphasis, and other effects to your speech.
It lets you preview and edit your speech before downloading it as an MP3 or WAV file.
It has a simple and intuitive interface, which makes it easy to use and navigate.
Click Here to Read The Full Review
#Speechki Review#Speechki#Speechki demo#Speechki Review and demo#Speechki honest Review#Speechki software Review#Speechki pricing#text to speech software
0 notes
Text
Voiceover Technology Can Boost Your Output, Productivity, and Profits
Using AI voice technology can help you in many ways. It allows you to create more content in less time without hiring a voiceover specialist for every project. It can help you reach more people with engaging voices that match your brand’s tone and style. Create AIvoiceovers.com, it just might be. Text to Speech Online platforms cost a fraction of what traditional voice recording studios cost or even what internal employee voiceovers cost once you factor in their time. For example, rendering 30 minutes of your script via our Text to Speech Voices technology will cost under $5.00, compared to an internal employee costing upwards of $500 or a voice actor costing $1000 or more. That’s nearly a 100x savings when using our Text to Speech Generator system versus that of an internal employee, and a 200x savings when using createAIvoiceovers.com technology versus a human voice from voiceover studio. As a content creator, educator, or entrepreneur it is important that you are using Artificial Intelligence strategies to help save time and money as Text to Voice Generator solutions can be enabled easily with minimal maintenance. Create Ai Voice Overs is an online audio conversion Text to Speech system that harnesses the latest synthetic speech technology to create a high quality AI voice that more accurately mimics the pitch, tone, and pace of a real human voice. The AI voice enables users to realize substantial cost and time reduction versus traditional audio production methods.
Our process of text-to-speech helps users address the challenges of delivering their content and marketing messages to a wide array of audiences.
The concept of Text-to-speech is not new, but its application has become far more life-like versus it’s early robotic sounding voice renderings. The latest natural voice sounding technology allows any digital material to have its own voice regardless of the medium (eLearning, marketing, blogging, advertising, corporate communications, electronic gaming, audiobooks, website). The text-to-speech technology is a winner solution to those visually impaired, and those challenged with reading disabilities.
Create Ai Voice Overs is owned and operated by The Seaplace Group, LLC of Sarasota, Florida.
0 notes
Text
Text To Speech With AWS
Text To Speech With AWS
Philip Kiely
2019-08-01T14:00:00+02:002019-08-01T12:05:38+00:00
This two-part series presents three projects that teach you how to use AWS (Amazon Web Services) to transform text between its written and spoken states. The first project will use text to speech to turn a blog post or other written content into a spoken .mp3 file to give more options to blind and dyslexic users of your site.
In the next article, we will embark on the return journey, from speech to text, and consider the accuracy of these transcriptions by sending various samples through a round-trip translation. To follow these tutorials, you will need an AWS account with billing enabled, though the tutorials will stay well within the constraints of free-tier resources. Examples will focus on using the AWS console, but I will also demonstrate the AWS CLI (Command Line Interface), which requires basic command line knowledge.
Introduction And Motivation
Most of the internet is text-based. Text is lightweight (1 byte per letter), widely supported, easy to interpret, and has a precedent as old as the internet as the default medium of online communication. Sending written text predates the internet: telegraphs carried text over wires hundreds of years ago and physical mail has transmitted writing for centuries. Voice transmission over radio and telephone also predates the internet, but did not translate to the same foundational medium that text did online. This is in almost all cases a good thing, again, text is lightweight and easy to interpret compared to audio. However, transforming between voice and text can add powerful functionality to and improve the accessibility of a wide variety of applications.
It has always been possible to transform between audio and text, you can read a written speech or transcribe an oral sermon. Indeed, if we think back to the telegram, trained operators transcoded Morse Code messages to words. In each example, it has always been very labor intensive to move from speech to writing or back, even with specialized training and equipment. With a variety of cloud services, we can automate these processes to allow transitioning between mediums in seconds without any human effort, which expands the possible use cases.
The most obvious benefit of implementing appropriate text to speech and speech to text options is accessibility. A visually impaired or dyslexic user would benefit from a narrated version of an article, while a deaf person could become a member of your podcasting audience by reading a transcript of the show.
Text to Speech Project
Say you wanted to add narrated versions of every post to your blog. You could purchase a microphone and invest hours into recording and editing spoken renditions of each post. This would result in a superior listener experience, but if you want most of the benefit for only a couple of minutes and a few pennies per post, consider using AWS instead. If you are the sort of person who regularly updates and revises older or evergreen content, this method also helps you keep the spoken version up to date with minimal effort.
We will begin with text to speech using Amazon Polly. For simple exploration, AWS provides a graphical user interface through its online console. After logging in to your AWS account, use the “Services” menu to find “Amazon Polly” or go to https://us-east-1.console.aws.amazon.com/polly/home/SynthesizeSpeech.
Using the Polly Console
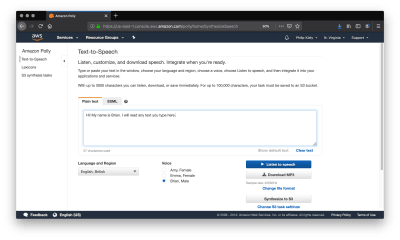
Amazon Polly provides a console to perform text-to-speech operations. (Large preview)
You can use the Amazon Polly console to read 3,000 characters (about 500 words) and get an audio stream or immediate download. If you need up to 100,000 characters (about 16,600 words) read, your only option is to have AWS store the result in S3 after it has finished processing, which can take a couple of minutes. At the time of writing, Amazon Polly does not support inputs of over 100,000 billable characters, if you want to convert a longer text like a book you will most likely have to do so in chunks and concatenate the audio files yourself.
A “billable character” is one that the service actually pronounces. Specifically, that means that SSML tags are not billable characters, which we will cover later. For your first year of using Amazon Polly, you get 5 million billable characters per month for free, which is more than enough to run the examples from this article and do your own experimentation. Beyond that, Amazon Polly costs four dollars per million billable characters at the time of writing, meaning that converting a standard-length novel would cost about two dollars.
The console also allows you to change the language, region, and voice of the reader. Though this article only covers English, at the time of writing AWS supports 21 languages and 29 distinct language-region pairs. While most regions only have one or two voices, popular ones like United States English have several options to chose between.
Amazon Polly narrated text is very obviously read by a robot, but the resulting audio is quite listenable.
“
I often prefer to use the UK English voice “Brian.” To my American ears, the British accent covers some of the inflections in robotic speech and makes for a smoother listening experience. To be clear, Amazon Polly narrated text is very obviously read by a robot, but the resulting audio is quite listenable.
It is significantly better than the built-in reader that the MacOS say terminal command uses, and is comparable to the speech quality of voice assistants like Siri and Alexa.
Writing SSML
If you want full control over the resultant speech, you can take the time to tag your input with SSML. SSML (Speech Synthesis Markup Language) is a standardized language for representing verbal cues in text. Like HTML, XML, and other markup languages, it uses opening and closing tags. Amazon Polly supports SSML input, and tags do not count as “billable characters.” Alexa skills also use SSML for pre-programmed responses, so it is a worthwhile language to know.
The foundational tag, <speak>, wraps everything that you want read. Like HTML, use <p> to divide paragraphs, which results in a significant pause in the narration. Smaller pauses come from punctuation, and you always have the option to insert pauses of up to ten seconds with <break>.
SSML provides <say-as>, a very flexible tag that supports everything from pronouncing phone numbers to censoring expletives using the interpret-as argument. Consider the options from this tag with the following sample.
<speak> Call 5551230987 by 11'00" PM to get tips on writing clean JavaScript.<break time="1s"/> Call <say-as interpret-as="telephone">5551230987</say-as> by 11'00" PM to get tips on writing clean <say-as interpret-as="expletive">JavaScript</say-as> </speak>
Further flexibility comes from the <prosody> tag, which provides you with control over the rate, pitch, and volume of speech. Unfortunately, at the time of writing Polly does not support the <voice> tag, which Alexa skills can use to speak in multiple standard voices, but does support the <lang> tag that allows voices in one language to correctly pronounce words from other languages. In this example, <lang> corrects the pronunciation of “tag” from American to German.
<speak> Guten tag, where is the airport?<break time="1s"/> <lang xml:lang="de-DE">Guten tag</lang>, where is the airport> </speak>
Finally, if you want to customize pronunciation within a language, Amazon Polly supports the <phoneme> tag.
My last name, Kiely, is spelled differently than it is pronounced. Using the x-sampa alphabet, I am able to specify the correct pronunciation.
“
<speak> Philip Kiely<break time="1s"/> Philip <phoneme alphabet="x-sampa" ph="ˈkaI.li">Kiely</phoneme> </speak>
This is not an exhaustive list of the customization options available with SSML. For a complete reference, visit the documentation.
Writing Lexicons
If you want to specify a consistent custom pronunciation or expand an abbreviation without tagging each instance with a phoneme tag, or you are using plain text instead of SSML, Amazon Polly supports lexicons of custom pronunciations. You can apply up to five lexicons of up to 4,000 characters each per language to a narration, though larger lexicons increase the processing time.
As with before, I want to make sure that Amazon Polly says my name correctly, but this time I want to do so without using SSML. I wrote the following lexicon:
<?xml version="1.0" encoding="UTF-8"?> <lexicon version="1.0" xmlns="http://www.w3.org/2005/01/pronunciation-lexicon" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.w3.org/2005/01/pronunciation-lexicon http://www.w3.org/TR/2007/CR-pronunciation-lexicon-20071212/pls.xsd" alphabet="x-sampa" xml:lang="en-US"> <lexeme><grapheme>Kiely</grapheme><alias>ˈkaIli</alias></lexeme> </lexicon>
The <?xml?> header and <lexicon> tag will stay mostly constant between lexicons, though the <lexicon> tag supports two important arguments. The first, alphabet, lets you choose between x-sampa and ipa, two standard pronunciation alphabets. I prefer x-sampa because it uses standard ASCII characters, so I am unlikely to encounter encoding issues. The xml:lang argument lets you specify language and region. A lexicon is only usable by a voice from that language and region.
The lexicon itself is a sequence of <lexeme> tags. Each one contains a <grapheme> tag, which contains the original text, and the <alias> tag, which describes what you want said instead. Aliases go beyond pronunciation, you can use them for expanding abbreviations (“Jr” becomes “Junior”) or replacing words (“Bruce Wayne” becomes “Batman”). A lexicon can have as many lexeme tags as it can fit in the 4,000 character limit.
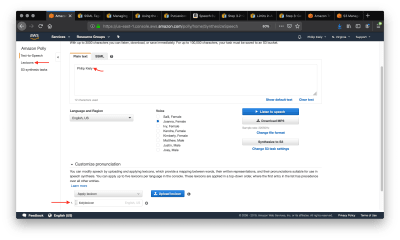
The included lexicon will modify the pronunciation of the input text. (Large preview)
The screenshot shows the plain text that would be mispronounced and the applied lexicon. Use the “Customize Pronunciation” menu to select up to five uploaded lexicons, uploaded from the left navbar tab “Lexicons.” Listening to the speech verifies that my name is said correctly.
Now that we have full control over the resultant speech, let’s consider how to save the output for use in our application.
Saving and loading from S3
If you want to re-use spoken text in your application, you’ll want to choose the “Synthesize to S3” option in the Amazon Polly console. In this example, I am using the voice “Brian” to perform a surprisingly capable reading of Shakespeare’s sonnet XXIX. We begin by copying in the poem as plain text and selecting “Synthesize to S3,” which launches the following modal.
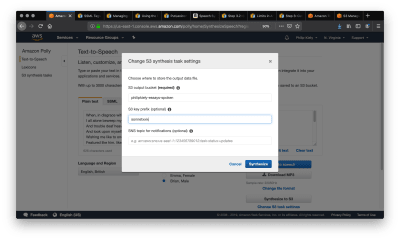
The 'Synthesize to S3' button gives you options for where to save the resultant file. (Large preview)
S3 buckets have globally unique names, and you can enter any S3 bucket that you own or have the appropriate permissions to. Make sure the bucket allows for making its contents public, as that will be required in a future step. You should also set a “S3 key prefix,” which is a string that will help you identify the output in the bucket. After clicking Synthesize and giving it a moment to process, we navigate to the S3 bucket that we synthesized the speech into.
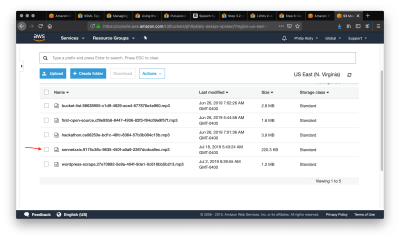
A S3 bucket stores your project's files. (Large preview)
The arrow points to the entry in the bucket that we just created. Selecting that item will bring us to the following page.
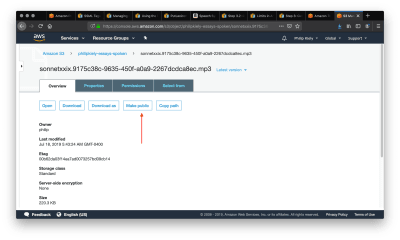
For each file, you can make it public using this button. (Large preview)
Follow the arrow to select the “Make Public” option, which will make the file accessible to anyone with a link. Scroll down and copy the link and use it in your application. For example, you can download the poem here. For many applications, you may wish to pass the url to an html <audio> tag to allow for web playback.
We have covered every necessary component for transforming text to speech on AWS. Next, we turn our attention to a more advanced interface that can provide automation potential and save time.
Using the AWS CLI
Back to our hypothetical blog post. The simplest workflow would be to take the final written version of each article, copy it into the console, click the “Synthesize to S3 button,” and embed a download link to the resultant .mp3 file in the blog. Honestly, this is a pretty decent workflow; it is exactly what I do for my personal website. However, AWS offers another option: the AWS CLI.
Make sure that you have installed and configured the AWS CLI appropriately. Begin by entering aws polly help to make sure that Polly is available and to read a list of supported commands. For troubleshooting, see the documentation.
To perform a conversion from the command line, I first copied the poem from earlier into a .txt file. I then ran the following command in terminal (MacOS/Linux):
aws polly synthesize-speech \ --output-format mp3 \ --voice-id Joanna \ --text "`cat sonnetxxix.txt`" \ poem.mp3
In a few seconds, the resulting .mp3 file was downloaded to my machine, ready for inclusion in my CMS or other application. Note the special characters around the --text argument, this passes the contents of the file rather than just the file name.
Finally, for more advanced applications, Amazon Polly has an SDK for 9 languages/platforms. The SDK would be overkill for these examples, but is exactly what you want for automating Amazon Polly calls, especially in response to user actions.
Conclusion
Text to speech can help you create more versatile, accessible content. Beginning in the Amazon Polly console, we can transform up to 100,000 billable characters in plain text or SSML, make the resulting .mp3 file public, and use that file in an application. We can use the AWS CLI for automation and more convenient access.
Stay tuned for the second installment of the series, we will convert media in the other direction, from speech to text, and consider the benefits and challenges of doing so. Part two will build on the technologies that we have used so far and introduce Amazon Transcribe.
Further Reference
AWS Polly
AWS S3
SSML Reference
Managing Lexicons

(yk,ra)
0 notes
Text
How To Make A Speech Synthesis Editor
How To Make A Speech Synthesis Editor
Knut Melvær
2019-03-21T13:00:16+01:002019-03-21T14:36:02+00:00
When Steve Jobs unveiled the Macintosh in 1984, it said “Hello” to us from the stage. Even at that point, speech synthesis wasn’t really a new technology: Bell Labs developed the vocoder as early as in the late 30s, and the concept of a voice assistant computer made it into people’s awareness when Stanley Kubrick made the vocoder the voice of HAL9000 in 2001: A Space Odyssey (1968).
It wasn’t before the introduction of Apple’s Siri, Amazon Echo, and Google Assistant in the mid 2015s that voice interfaces actually found their way into a broader public’s homes, wrists, and pockets. We’re still in an adoption phase, but it seems that these voice assistants are here to stay.
In other words, the web isn’t just passive text on a screen anymore. Web editors and UX designers have to get accustomed to making content and services that should be spoken out loud.
We’re already moving fast towards using content management systems that let us work with our content headlessly and through APIs. The final piece is to make editorial interfaces that make it easier to tailor content for voice. So let’s do just that!
What Is SSML
While web browsers use W3C’s specification for HyperText Markup Language (HTML) to visually render documents, most voice assistants use Speech Synthesis Markup Language (SSML) when generating speech.
A minimal example using the root element <speak>, and the paragraph (<p>) and sentence (<s>) tags:
<speak> <p> <s>This is the first sentence of the paragraph.</s> <s>Here’s another sentence.</s> </p> </speak>
Press play to listen to the snippet:
Your browser does not support the audio element.
Where SSML gets existing is when we introduce tags for <emphasis> and <prosody> (pitch):
<speak> <p> <s>Put some <emphasis strength="strong">extra weight on these words</emphasis></s> <s>And say <prosody pitch="high" rate="fast">this a bit higher and faster</prosody>!</s> </p> </speak>
Press play to listen to the snippet:
Your browser does not support the audio element.
SSML has more features, but this is enough to get a feel for the basics. Now, let’s take a closer look at the editor that we will use to make the speech synthesis editing interface.
The Editor For Portable Text
To make this editor, we’ll use the editor for Portable Text that features in Sanity.io. Portable Text is a JSON specification for rich text editing, that can be serialized into any markup language, such as SSML. This means you can easily use the same text snippet in multiple places using different markup languages.
Sanity.io’s default editor for Portable Text (Large preview)
Installing Sanity
Sanity.io is a platform for structured content that comes with an open-source editing environment built with React.js. It takes two minutes to get it all up and running.
Type npm i -g @sanity/cli && sanity init into your terminal, and follow the instructions. Choose “empty”, when you’re prompted for a project template.
If you don’t want to follow this tutorial and make this editor from scratch, you can also clone this tutorial’s code and follow the instructions in README.md.
When the editor is downloaded, you run sanity start in the project folder to start it up. It will start a development server that use Hot Module Reloading to update changes as you edit its files.
How To Configure Schemas In Sanity Studio
Creating The Editor Files
We’ll start by making a folder called ssml-editor in the /schemas folder. In that folder, we’ll put some empty files:
/ssml-tutorial/schemas/ssml-editor ├── alias.js ├── emphasis.js ├── annotations.js ├── preview.js ├── prosody.js ├── sayAs.js ├── blocksToSSML.js ├── speech.js ├── SSMLeditor.css └── SSMLeditor.js
Now we can add content schemas in these files. Content schemas are what defines the data structure for the rich text, and what Sanity Studio uses to generate the editorial interface. They are simple JavaScript objects that mostly require just a name and a type.
We can also add a title and a description to make a bit nicer for editors. For example, this is a schema for a simple text field for a title:
export default { name: 'title', type: 'string', title: 'Title', description: 'Titles should be short and descriptive' }
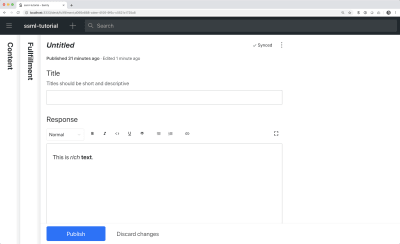
The studio with our title field and the default editor (Large preview)
Portable Text is built on the idea of rich text as data. This is powerful because it lets you query your rich text, and convert it into pretty much any markup you want.
It is an array of objects called “blocks” which you can think of as the “paragraphs”. In a block, there is an array of children spans. Each block can have a style and a set of mark definitions, which describe data structures distributed on the children spans.
Sanity.io comes with an editor that can read and write to Portable Text, and is activated by placing the block type inside an array field, like this:
// speech.js export default { name: 'speech', type: 'array', title: 'SSML Editor', of: [ { type: 'block' } ] }
An array can be of multiple types. For an SSML-editor, those could be blocks for audio files, but that falls outside of the scope of this tutorial.
The last thing we want to do is to add a content type where this editor can be used. Most assistants use a simple content model of “intents” and “fulfillments”:
Intents Usually a list of strings used by the AI model to delineate what the user wants to get done.
Fulfillments This happens when an “intent” is identified. A fulfillment often is — or at least — comes with some sort of response.
So let’s make a simple content type called fulfillment that use the speech synthesis editor. Make a new file called fulfillment.js and save it in the /schema folder:
// fulfillment.js export default { name: 'fulfillment', type: 'document', title: 'Fulfillment', of: [ { name: 'title', type: 'string', title: 'Title', description: 'Titles should be short and descriptive' }, { name: 'response', type: 'speech' } ] }
Save the file, and open schema.js. Add it to your studio like this:
// schema.js import createSchema from 'part:@sanity/base/schema-creator' import schemaTypes from 'all:part:@sanity/base/schema-type' import fullfillment from './fullfillment' import speech from './speech' export default createSchema({ name: 'default', types: schemaTypes.concat([ fullfillment, speech, ]) })
If you now run sanity start in your command line interface within the project’s root folder, the studio will start up locally, and you’ll be able to add entries for fulfillments. You can keep the studio running while we go on, as it will auto-reload with new changes when you save the files.
Adding SSML To The Editor
By default, the block type will give you a standard editor for visually oriented rich text with heading styles, decorator styles for emphasis and strong, annotations for links, and lists. Now we want to override those with the audial concepts found in SSML.
We begin with defining the different content structures, with helpful descriptions for the editors, that we will add to the block in SSMLeditorSchema.js as configurations for annotations. Those are “emphasis”, “alias”, “prosody”, and “say as”.
Emphasis
We begin with “emphasis”, which controls how much weight is put on the marked text. We define it as a string with a list of predefined values that the user can choose from:
// emphasis.js export default { name: 'emphasis', type: 'object', title: 'Emphasis', description: 'The strength of the emphasis put on the contained text', fields: [ { name: 'level', type: 'string', options: { list: [ { value: 'strong', title: 'Strong' }, { value: 'moderate', title: 'Moderate' }, { value: 'none', title: 'None' }, { value: 'reduced', title: 'Reduced' } ] } } ] }
Alias
Sometimes the written and the spoken term differ. For instance, you want to use the abbreviation of a phrase in a written text, but have the whole phrase read aloud. For example:
<s>This is a <sub alias="Speech Synthesis Markup Language">SSML</sub> tutorial</s>
Press play to listen to the snippet:
Your browser does not support the audio element.
The input field for the alias is a simple string:
// alias.js export default { name: 'alias', type: 'object', title: 'Alias (sub)', description: 'Replaces the contained text for pronunciation. This allows a document to contain both a spoken and written form.', fields: [ { name: 'text', type: 'string', title: 'Replacement text', } ] }
Prosody
With the prosody property we can control different aspects how text should be spoken, like pitch, rate, and volume. The markup for this can look like this:
<s>Say this with an <prosody pitch="x-low">extra low pitch</prosody>, and this <prosody rate="fast" volume="loud">loudly with a fast rate</prosody></s>
Press play to listen to the snippet:
Your browser does not support the audio element.
This input will have three fields with predefined string options:
// prosody.js export default { name: 'prosody', type: 'object', title: 'Prosody', description: 'Control of the pitch, speaking rate, and volume', fields: [ { name: 'pitch', type: 'string', title: 'Pitch', description: 'The baseline pitch for the contained text', options: { list: [ { value: 'x-low', title: 'Extra low' }, { value: 'low', title: 'Low' }, { value: 'medium', title: 'Medium' }, { value: 'high', title: 'High' }, { value: 'x-high', title: 'Extra high' }, { value: 'default', title: 'Default' } ] } }, { name: 'rate', type: 'string', title: 'Rate', description: 'A change in the speaking rate for the contained text', options: { list: [ { value: 'x-slow', title: 'Extra slow' }, { value: 'slow', title: 'Slow' }, { value: 'medium', title: 'Medium' }, { value: 'fast', title: 'Fast' }, { value: 'x-fast', title: 'Extra fast' }, { value: 'default', title: 'Default' } ] } }, { name: 'volume', type: 'string', title: 'Volume', description: 'The volume for the contained text.', options: { list: [ { value: 'silent', title: 'Silent' }, { value: 'x-soft', title: 'Extra soft' }, { value: 'medium', title: 'Medium' }, { value: 'loud', title: 'Loud' }, { value: 'x-loud', title: 'Extra loud' }, { value: 'default', title: 'Default' } ] } } ] }
Say As
The last one we want to include is <say-as>. This tag lets us exercise a bit more control over how certain information is pronounced. We can even use it to bleep out words if you need to redact something in voice interfaces. That’s @!%&© useful!
<s>Do I have to <say-as interpret-as="expletive">frakking</say-as> <say-as interpret-as="verbatim">spell</say-as> it out for you!?</s>
Press play to listen to the snippet:
Your browser does not support the audio element.
// sayAs.js export default { name: 'sayAs', type: 'object', title: 'Say as...', description: 'Lets you indicate information about the type of text construct that is contained within the element. It also helps specify the level of detail for rendering the contained text.', fields: [ { name: 'interpretAs', type: 'string', title: 'Interpret as...', options: { list: [ { value: 'cardinal', title: 'Cardinal numbers' }, { value: 'ordinal', title: 'Ordinal numbers (1st, 2nd, 3th...)' }, { value: 'characters', title: 'Spell out characters' }, { value: 'fraction', title: 'Say numbers as fractions' }, { value: 'expletive', title: 'Blip out this word' }, { value: 'unit', title: 'Adapt unit to singular or plural' }, { value: 'verbatim', title: 'Spell out letter by letter (verbatim)' }, { value: 'date', title: 'Say as a date' }, { value: 'telephone', title: 'Say as a telephone number' } ] } }, { name: 'date', type: 'object', title: 'Date', fields: [ { name: 'format', type: 'string', description: 'The format attribute is a sequence of date field character codes. Supported field character codes in format are {y, m, d} for year, month, and day (of the month) respectively. If the field code appears once for year, month, or day then the number of digits expected are 4, 2, and 2 respectively. If the field code is repeated then the number of expected digits is the number of times the code is repeated. Fields in the date text may be separated by punctuation and/or spaces.' }, { name: 'detail', type: 'number', validation: Rule => Rule.required() .min(0) .max(2), description: 'The detail attribute controls the spoken form of the date. For detail='1' only the day fields and one of month or year fields are required, although both may be supplied' } ] } ] }
Now we can import these in an annotations.js file, which makes things a bit tidier.
// annotations.js export {default as alias} from './alias' export {default as emphasis} from './emphasis' export {default as prosody} from './prosody' export {default as sayAs} from './sayAs'
Now we can import these annotation types into our main schemas:
// schema.js import createSchema from "part:@sanity/base/schema-creator" import schemaTypes from "all:part:@sanity/base/schema-type" import fulfillment from './fulfillment' import speech from './ssml-editor/speech' import { alias, emphasis, prosody, sayAs } from './annotations' export default createSchema({ name: "default", types: schemaTypes.concat([ fulfillment, speech, alias, emphasis, prosody, sayAs ]) })
Finally, we can now add these to the editor like this:
// speech.js export default { name: 'speech', type: 'array', title: 'SSML Editor', of: [ { type: 'block', styles: [], lists: [], marks: { decorators: [], annotations: [ {type: 'alias'}, {type: 'emphasis'}, {type: 'prosody'}, {type: 'sayAs'} ] } } ] }
Notice that we also added empty arrays to styles, and decorators. This disables the default styles and decorators (like bold and emphasis) since they don’t make that much sense in this specific case.
Customizing The Look And Feel
Now we have the functionality in place, but since we haven’t specified any icons, each annotation will use the default icon, which makes the editor hard to actually use for authors. So let’s fix that!
With the editor for Portable Text it’s possible to inject React components both for the icons and for how the marked text should be rendered. Here, we’ll just let some emoji do the work for us, but you could obviously go far with this, making them dynamic and so on. For prosody we’ll even make the icon change depending on the volume selected. Note that I omitted the fields in these snippets for brevity, you shouldn’t remove them in your local files.
// alias.js import React from 'react' export default { name: 'alias', type: 'object', title: 'Alias (sub)', description: 'Replaces the contained text for pronunciation. This allows a document to contain both a spoken and written form.', fields: [ /* all the fields */ ], blockEditor: { icon: () => '🔤', render: ({ children }) => <span>{children} 🔤</span>, }, };
// emphasis.js import React from 'react' export default { name: 'emphasis', type: 'object', title: 'Emphasis', description: 'The strength of the emphasis put on the contained text', fields: [ /* all the fields */ ], blockEditor: { icon: () => '🗯', render: ({ children }) => <span>{children} 🗯</span>, }, };
// prosody.js import React from 'react' export default { name: 'prosody', type: 'object', title: 'Prosody', description: 'Control of the pitch, speaking rate, and volume', fields: [ /* all the fields */ ], blockEditor: { icon: () => '🔊', render: ({ children, volume }) => ( <span> {children} {['x-loud', 'loud'].includes(volume) ? '🔊' : '🔈'} </span> ), }, };
// sayAs.js import React from 'react' export default { name: 'sayAs', type: 'object', title: 'Say as...', description: 'Lets you indicate information about the type of text construct that is contained within the element. It also helps specify the level of detail for rendering the contained text.', fields: [ /* all the fields */ ], blockEditor: { icon: () => '🗣', render: props => <span>{props.children} 🗣</span>, }, };
The editor with our custom SSML marks (Large preview)
Now you have an editor for editing text that can be used by voice assistants. But wouldn’t it be kinda useful if editors also could preview how the text actually will sound like?
Adding A Preview Button Using Google’s Text-to-Speech
Native speech synthesis support is actually on its way for browsers. But in this tutorial, we’ll use Google’s Text-to-Speech API which supports SSML. Building this preview functionality will also be a demonstration of how you serialize Portable Text into SSML in whatever service you want to use this for.
Wrapping The Editor In A React Component
We begin with opening the SSMLeditor.js file and add the following code:
// SSMLeditor.js import React, { Fragment } from 'react'; import { BlockEditor } from 'part:@sanity/form-builder'; export default function SSMLeditor(props) { return ( <Fragment> <BlockEditor {...props} /> </Fragment> ); }
We have now wrapped the editor in our own React component. All the props it needs, including the data it contains, are passed down in real-time. To actually use this component, you have to import it into your speech.js file:
// speech.js import React from 'react' import SSMLeditor from './SSMLeditor.js' export default { name: 'speech', type: 'array', title: 'SSML Editor', inputComponent: SSMLeditor, of: [ { type: 'block', styles: [], lists: [], marks: { decorators: [], annotations: [ { type: 'alias' }, { type: 'emphasis' }, { type: 'prosody' }, { type: 'sayAs' }, ], }, }, ], }
When you save this and the studio reloads, it should look pretty much exactly the same, but that’s because we haven’t started tweaking the editor yet.
Convert Portable Text To SSML
The editor will save the content as Portable Text, an array of objects in JSON that makes it easy to convert rich text into whatever format you need it to be. When you convert Portable Text into another syntax or format, we call that “serialization”. Hence, “serializers” are the recipes for how the rich text should be converted. In this section, we will add serializers for speech synthesis.
You have already made the blocksToSSML.js file. Now we’ll need to add our first dependency. Begin by running the terminal command npm init -y inside the ssml-editor folder. This will add a package.json where the editor’s dependencies will be listed.
Once that’s done, you can run npm install @sanity/block-content-to-html to get a library that makes it easier to serialize Portable Text. We’re using the HTML-library because SSML has the same XML syntax with tags and attributes.
This is a bunch of code, so do feel free to copy-paste it. I’ll explain the pattern right below the snippet:
// blocksToSSML.js import blocksToHTML, { h } from '@sanity/block-content-to-html' const serializers = { marks: { prosody: ({ children, mark: { rate, pitch, volume } }) => h('prosody', { attrs: { rate, pitch, volume } }, children), alias: ({ children, mark: { text } }) => h('sub', { attrs: { alias: text } }, children), sayAs: ({ children, mark: { interpretAs } }) => h('say-as', { attrs: { 'interpret-as': interpretAs } }, children), break: ({ children, mark: { time, strength } }) => h('break', { attrs: { time: '${time}ms', strength } }, children), emphasis: ({ children, mark: { level } }) => h('emphasis', { attrs: { level } }, children) } } export const blocksToSSML = blocks => blocksToHTML({ blocks, serializers })
This code will export a function that takes the array of blocks and loop through them. Whenever a block contains a mark, it will look for a serializer for the type. If you have marked some text to have emphasis, it this function from the serializers object:
emphasis: ({ children, mark: { level } }) => h('emphasis', { attrs: { level } }, children)
Maybe you recognize the parameter from where we defined the schema? The h() function lets us defined an HTML element, that is, here we “cheat” and makes it return an SSML element called <emphasis>. We also give it the attribute level if that is defined, and place the children elements within it — which in most cases will be the text you have marked up with emphasis.
{ "_type": "block", "_key": "f2c4cf1ab4e0", "style": "normal", "markDefs": [ { "_type": "emphasis", "_key": "99b28ed3fa58", "level": "strong" } ], "children": [ { "_type": "span", "_key": "f2c4cf1ab4e01", "text": "Say this strongly!", "marks": [ "99b28ed3fa58" ] } ] }
That is how the above structure in Portable Text gets serialized to this SSML:
<emphasis level="strong">Say this strongly</emphasis>
If you want support for more SSML tags, you can add more annotations in the schema, and add the annotation types to the marks section in the serializers.
Now we have a function that returns SSML markup from our marked up rich text. The last part is to make a button that lets us send this markup to a text-to-speech service.
Adding A Preview Button That Speaks Back To You
Ideally, we should have used the browser’s speech synthesis capabilities in the Web API. That way, we would have gotten away with less code and dependencies.
As of early 2019, however, native browser support for speech synthesis is still in its early stages. It looks like support for SSML is on the way, and there is proof of concepts of client-side JavaScript implementations for it.
Chances are that you are going to use this content with a voice assistant anyways. Both Google Assistant and Amazon Echo (Alexa) support SSML as responses in a fulfillment. In this tutorial, we will use Google’s text-to-speech API, which also sounds good and support several languages.
Start by obtaining an API key by signing up for Google Cloud Platform (it will be free for the first 1 million characters you process). Once you’re signed up, you can make a new API key on this page.
Now you can open your PreviewButton.js file, and add this code to it:
// PreviewButton.js import React from 'react' import Button from 'part:@sanity/components/buttons/default' import { blocksToSSML } from './blocksToSSML' // You should be careful with sharing this key // I put it here to keep the code simple const API_KEY = '<yourAPIkey>' const GOOGLE_TEXT_TO_SPEECH_URL = 'https://texttospeech.googleapis.com/v1beta1/text:synthesize?key=' + API_KEY const speak = async blocks => { // Serialize blocks to SSML const ssml = blocksToSSML(blocks) // Prepare the Google Text-to-Speech configuration const body = JSON.stringify({ input: { ssml }, // Select the language code and voice name (A-F) voice: { languageCode: 'en-US', name: 'en-US-Wavenet-A' }, // Use MP3 in order to play in browser audioConfig: { audioEncoding: 'MP3' } }) // Send the SSML string to the API const res = await fetch(GOOGLE_TEXT_TO_SPEECH_URL, { method: 'POST', body }).then(res => res.json()) // Play the returned audio with the Browser’s Audo API const audio = new Audio('data:audio/wav;base64,' + res.audioContent) audio.play() } export default function PreviewButton (props) { return <Button style= onClick={() => speak(props.blocks)}>Speak text</Button> }
I’ve kept this preview button code to a minimal to make it easier to follow this tutorial. Of course, you could build it out by adding state to show if the preview is processing or make it possible to preview with the different voices that Google’s API supports.
Add the button to SSMLeditor.js:
// SSMLeditor.js import React, { Fragment } from 'react'; import { BlockEditor } from 'part:@sanity/form-builder'; import PreviewButton from './PreviewButton'; export default function SSMLeditor(props) { return ( <Fragment> <BlockEditor {...props} /> <PreviewButton blocks={props.value} /> </Fragment> ); }
Now you should be able to mark up your text with the different annotations, and hear the result when pushing “Speak text”. Cool, isn’t it?
You’ve Created A Speech Synthesis Editor, And Now What?
If you have followed this tutorial, you have been through how you can use the editor for Portable Text in Sanity Studio to make custom annotations and customize the editor. You can use these skills for all sorts of things, not only to make a speech synthesis editor. You have also been through how to serialize Portable Text into the syntax you need. Obviously, this is also handy if you’re building frontends in React or Vue. You can even use these skills to generate Markdown from Portable Text.
We haven’t covered how you actually use this together with a voice assistant. If you want to try, you can use much of the same logic as with the preview button in a serverless function, and set it as the API endpoint for a fulfillment using webhooks, e.g. with Dialogflow.
If you’d like me to write a tutorial on how to use the speech synthesis editor with a voice assistant, feel free to give me a hint on Twitter or share in the comments section below.
Further Reading on SmashingMag:
Experimenting With speechSynthesis
Enhancing User Experience With The Web Speech API
Accessibility APIs: A Key To Web Accessibility
Building A Simple AI Chatbot With Web Speech API And Node.js

(dm, ra, yk, il)
0 notes
Text
I’ve long loved the idea of having computer-synthesized speech in my projects. For the trailer for Legendary Loot, I’m doing that using Amazon Polly. My process will make up the rest of this post.
First, I wrote out what I wanted the computer to say, then i marked it up using just a few tags in SSML, in an effort to produce more natural, more radio-announcer-like speech. the code follows.
<speak> <prosody pitch="high" amazon:max-duration="60s"> You want <prosody pitch="medium" volume="soft">to build a</prosody> game <prosody pitch="medium" volume="soft">with</prosody> interesting <emphasis>items</emphasis> <prosody pitch="medium" volume="soft">and</prosody> <emphasis>enemies</emphasis>. You want <prosody pitch="medium" volume="soft">to get</prosody> <prosody rate="fast">up and running</prosody> without spending <emphasis>months</emphasis> designing and programming <prosody pitch="medium" volume="soft">a</prosody> <emphasis>stat, engine</emphasis>. That's why you need <emphasis>Legendary Loot</emphasis>. <emphasis>Legendary loot</emphasis> <prosody pitch="medium" volume="soft">is a</prosody> collection of out-of-the-box <emphasis>stat, engines</emphasis> along with supporting <emphasis>factories</emphasis> <prosody pitch="medium" volume="soft">for</prosody> generating random <emphasis>enemies</emphasis> <prosody pitch="medium" volume="soft">or</prosody> <emphasis>items</emphasis>. <prosody pitch="medium" volume="soft">And lots of </prosody> handy glue code <prosody pitch="medium" volume="soft">for</prosody> tying <prosody pitch="medium" volume="soft">the</prosody> <emphasis>stat, engine</emphasis> <prosody pitch="medium" volume="soft">into</prosody> your game. Lets <prosody rate="fast">dive right in</prosody> <prosody pitch="medium" volume="soft">by</prosody> making some <emphasis>random items</emphasis> <prosody pitch="medium" volume="soft">in the</prosody> next minute. </prosody> </speak>
After switching Polly over to a british voice, I downloaded the OGG. Next up was Audacity.
First, we normalize the waveform, then I used the compressor to tweak it slightly. I made a copy of that track, and then put just the "wet" component of reverb there, so that I could adjust it's volume. In the background of the trailer there will be some pink noise to help the voice sound more normal as well. The trailer follows.
youtube
0 notes
Text
Five Benchmarks for Writing Dialog that Sounds Great to Alexa Customers
Great Alexa skills depend on written prompts. In voice-first interfaces, the dialog you write isn’t one component of the user interface—it is the interface, because Alexa’s voice is the primary guide leading a customer through your skill.
But if you don’t have a background in writing, that’s okay! Any skill builder can improve their written dialog so it successfully serves the customer. This post covers five benchmarks your Alexa skill’s dialog should meet, and specific techniques for how you can get there.
Benchmark 1: Avoid Jargon and Ten-Dollar Words
Customers love low-friction interactions, and the individual words in your dialog can be a huge part of keeping the interaction simple and easy. Informal language is faster and less burdensome for a customer to process, so they can follow a voice interaction without pausing to respond.
Here are some examples of commonly used jargon or overly formal words, along with alternatives that could be used instead:
Jargon: “You can default to a stored method associated with this account, or override it by selecting an alternate method of payment.”
Simpler: “You can use the credit card on file, or add a new card.”
Jargon: “I can submit a request for a customer service representative to return your call.”
Simpler: “I can have an agent call you back.”
Jargon: “Would you like me to submit your order for processing?”
Simpler: “Ready to finish your order?”
Jargon: “The transaction attempt was not successful.”
Simpler: “Hmm. Something went wrong with your payment.”
So, what are some techniques for replacing jargon with clearer language? First, fresh eyes are valuable here. Find someone who’s not an expert in your skill’s content, and ask them to read or listen to your dialog and point out words that feel unfamiliar to them. Second, once you’ve identified some clunky words, find synonyms that are less formal. (Don’t be afraid to dust off that thesaurus!)
Benchmark 2: Apply the One-Breath Test for Concision
Remember that your skill’s dialog will be spoken out loud, one word at a time, so excess words in your prompts quite literally add time to the interaction. A useful guideline is that a prompt should be about as long as a human could say in one breath. It’s a great idea to read your dialog out loud or have a colleague read it to you.
If you identify some prompts that don’t pass the one-breath test, here are some ways you can shorten them:
Cut filler words, like “very.” Keep an eye out for words that don’t change the meaning of a sentence or add information; you can eliminate these.
Look out for wordiness around verbs. For example, “I’d like to be able to help you” can be shortened to “I can help.”
Find information that customers don’t need. For example, if a prompt contains a date, like “Your order will be ready on August 2, 2019,” you can usually omit the year.
There are concrete techniques you can use to make sentences concise. First, make sure each sentence passes the one-breath test by reading it aloud. Next, if you find sentences that don’t pass the test, cut your sentences down by challenging yourself to omit 2-5 words from every line of dialog in your code.
Benchmark 3: Introduce Variety into Your Dialog
Humans use a lot of variation in the way they speak. In contrast, voice experiences that repeat the same phrases don’t sound natural to the human ear. You can avoid repetitive dialog by adding randomized variations to your dialog.
Look for the skill dialog that your users will hear the most often, starting with the greeting. Imagine a skill that allows you to order groceries called Grocery Store. If you heard “Welcome to the Grocery Store!” with every launch, you’d grow tired of this greeting.
As a skill builder, you could provide randomized phrases so that customers might hear one of several responses upon launch. For example:
Thanks for stopping by the Grocery Store.
Hi, you’ve reached the Grocery Store.
Let’s fill your cart at the Grocery Store!
Another opportunity for variation is confirming a purchase, or congratulating a customer for completing a task. For example, if you have a skill that sells cupcakes, you could randomize phrases that confirm the purchase:
You’re all set! Treats are on the way.
It’s cupcake time! Your order is complete.
Sweet! You’ve successfully ordered your cupcakes.
It’s important to keep aspects of the flow consistent; your skill shouldn’t feel radically different or unfamiliar each time. But creating variation is an important way to keep your skill interesting and fresh, especially for skills a user might open every day, like skills for weather, exercise, or news.
To make sure your dialog isn’t overly repetitive, you can add a few simple techniques to your process. First, take a look at your list of dialog lines and identify 3-5 prompts that your customers will encounter each time they use your skill. Next, write 2-5 (or more!) variations for each of these lines. It’s a good idea to ask a few friends or colleagues to help you brainstorm, as you may come up with more creative variations as a group.
For more guidance, check out the Alexa Design Guide’s section on adding variety in repetitive tasks, and using adaptive prompts.
Benchmark 4: Try Contractions and Informal Phrasing
General advice for Alexa dialog is “Write it the way you say it.” People use lots of contractions when they speak, such as:
“I’m” instead of “I am”
“I’d” instead of “I would”
“Don’t” instead of “do not”
“Can’t” instead of “cannot”
“I cannot help you with that” sounds much stiffer than “I can’t help you with that.” Because your skill’s dialog should be casual and conversational, for most situations, the contracted version is preferred.
Humans also use short phrases; not every line of dialog has to be a complete sentence. This keeps your prose natural, and contributes to concise sentences. For example:
“Done!” instead of “This purchase is complete.”
“Ready?” instead of “Do you want to continue?”
“Got it, four adult tickets to next week’s choir concert!” instead of “Okay, I will place an order for four adult tickets to go see the choir concert taking place next week.”
With just a little extra effort, you can make sure your dialog sounds casual and easy on the ear. First, circle all of the verbs that could be turned into contractions. Reading out loud can help you identify these places, too. Next, you can identify dialog that can be turned into shorter phrases. Some good candidates for phrases are prompts that end with a question and confirmation phrases.
Benchmark 5: Use SSML for Better Pacing
When customers listen to a long string of dialog without meaningful pauses, the words can bleed together and create confusion. It’s a great idea to employ synthetic speech markup language (SSML) to adjust aspects of Alexa’s speech so it sounds even more natural to a human ear.
You can use SSML to do lots of things, from tweaking a word’s pronunciation to adjusting emphasis on a specific syllable. But perhaps the simplest SSML tag with the biggest impact is the break time tag, which represents a pause in speech. Sometimes adding even a few milliseconds of extra time can help your customer comprehend the prompt more easily.
For example, you can use SSML to add time between menu items:
<speak>
There are three house plants I’d recommend for your apartment: elephant ear, <break time="600ms"/> peace lily <break time="600ms"/> and spider plant.
</speak>
You can also add a lengthier pause between sentences, usually to indicate a transition between content and a next step:
<speak>
You answered a total of 14 questions right!
That beats your all-time high score of 12 correct answers. <break time="1s"/> Want to play again?
</speak>
To identify places where a pause is useful, listen to each prompt being read by Alexa. An easy way is to paste your dialog into the Voice & Tone speech simulator, located in the Test tab in the Alexa developer console. If a sentence seems rushed, add some break time tags and listen again to fine-tune. You can experiment with adding pauses of varying lengths, from 300 milliseconds to one second.
Benchmark Checklist
If you’ve done all of these things, your dialog will be crafted for a natural, concise, easy-on-the-ear customer experience.
Eliminate jargon by asking for feedback from someone who’s not an expert in your skill’s content.
Perform the one-breath test and, if you need to, cut 3-5 words from every sentence.
Identify 3-5 prompts that will be commonly encountered and write at least two variations for each.
Where you can, reduce your verb phrases to contractions and shorten some sentences to phrases.
Listen to Alexa read every line and add spacing between phrases and sentences.
In general, the best way to confirm you’ve got great dialog is to read it aloud. Better yet, read it aloud to a friend or colleague who represents your customer base. Check to make sure they had an easy time understanding and responding to your prompts, and use their feedback to tweak your dialog until it has a conversational tone that’s easy to comprehend. Taking the extra time to scrutinize your dialog will help you craft a skill experience that’s conversational, intuitive, and frictionless for your customers.[Source]-https://developer.amazon.com/blogs/alexa/post/d92c7822-d289-44fd-a9fe-9652874fc3c9/five-benchmarks-for-writing-dialog-that-sounds-great-to-alexa-customers
Amazon Web Services Certification
Courses in Mumbai. 30 hours practical training program on all avenues of Amazon Web Services. Learn under AWS Expert
#Amazon Web Services Certification#AWS Training for Beginners#AWS Certification Course#AWS Training Classes
0 notes
Text
Alexa developers get 8 free voices to use in skills, courtesy of Amazon Polly
New Post has been published on https://latestnews2018.com/alexa-developers-get-8-free-voices-to-use-in-skills-courtesy-of-amazon-polly/
Alexa developers get 8 free voices to use in skills, courtesy of Amazon Polly
Now Alexa’s voice apps don’t have to sound like Alexa. Amazon today is offering a way for developers to give their voice apps a unique character with the launch of eight free voices to use in skills, courtesy of the Amazon Polly service. The voices are only available in U.S. English, and include a mix of both male and female, according to Amazon Polly’s website.
Amazon Polly was first introduced at Amazon’s re:Invent developer event in November 2016, and has been steadily ramping up its capabilities in the time since. The text-to-speech service today is capable of things like whispering, speech marks, using a timbre effect, and dynamic range compression – all which make the voices sound more natural.
While the speech engine today supports a couple dozen languages, only the U.S. English voices are being offered to Alexa developers at this time.
But their addition could make some of Alexa’s skills more engaging – especially those involving different characters, like an adventure story or game, for example.
Developers today may already be using multiple voices in their skills, but the process of doing so is more cumbersome and rigid, as with mp3 file uploads.
To use an Amazon Polly voice instead, developers would use Structured Speech Markup Language (SSML) and then specify which voice they want with the “voice name” tag. This makes it easier to adjust what is said, as developers could just change the text instead of having to re-record an mp3.
Amazon has been working to make Polly more accessible to a wider audience, recently by offering a WordPress plugin that could turn your posts into podcasts.
The new Alexa skills integration, meanwhile, gives Polly another avenue of reaching consumers. It’s also another means of competing with Alexa’s rival, Google Assistant. At Google’s developer conference last week, the company announced six new voices generated by Wavenet, including one from singer John Legend. These will roll out later this year, and presumably, could make their way to the Assistant developer ecosystem as well.
0 notes
Text
Alexa developers get 8 free voices to use in skills, courtesy of Amazon Polly
Alexa developers get 8 free voices to use in skills, courtesy of Amazon Polly
Now Alexa’s voice apps don’t have to sound like Alexa. Amazon today is offering a way for developers to give their voice apps a unique character with the launch of eight free voices to use in skills, courtesy of the Amazon Polly service. The voices are only available in U.S. English, and include a mix of both male and female, according to Amazon Polly’s website.
Amazon Polly was first introduced at Amazon’s re:Invent developer event in November 2016, and has been steadily ramping up its capabilities in the time since. The text-to-speech service today is capable of things like whispering, speech marks, using a timbre effect, and dynamic range compression – all which make the voices sound more natural.
While the speech engine today supports a couple dozen languages, only the U.S. English voices are being offered to Alexa developers at this time.
But their addition could make some of Alexa’s skills more engaging – especially those involving different characters, like an adventure story or game, for example.
Developers today may already be using multiple voices in their skills, but the process of doing so is more cumbersome and rigid, as with mp3 file uploads.
To use an Amazon Polly voice instead, developers would use Structured Speech Markup Language (SSML) and then specify which voice they want with the “voice name” tag. This makes it easier to adjust what is said, as developers could just change the text instead of having to re-record an mp3.
Amazon has been working to make Polly more accessible to a wider audience, recently by offering a WordPress plugin that could turn your posts into podcasts.
The new Alexa skills integration, meanwhile, gives Polly another avenue of reaching consumers. It’s also another means of competing with Alexa’s rival, Google Assistant. At Google’s developer conference last week, the company announced six new voices generated by Wavent, including one from singer John Legend. These will roll out later this year, and presumably, could make their way to the Assistant developer ecosystem as well.
0 notes
Link
Now Alexa’s voice apps don’t have to sound like Alexa. Amazon today is offering a way for developers to give their voice apps a unique character with the launch of eight free voices to use in skills, courtesy of the Amazon Polly service. The voices are only available in U.S. English, and include a mix of both male and female, according to Amazon Polly’s website.
Amazon Polly was first introduced at Amazon’s re:Invent developer event in November 2016, and has been steadily ramping up its capabilities in the time since. The text-to-speech service today is capable of things like whispering, speech marks, using a timbre effect, and dynamic range compression – all which make the voices sound more natural.
While the speech engine today supports a couple dozen languages, only the U.S. English voices are being offered to Alexa developers at this time.
But their addition could make some of Alexa’s skills more engaging – especially those involving different characters, like an adventure story or game, for example.
Developers today may already be using multiple voices in their skills, but the process of doing so is more cumbersome and rigid, as with mp3 file uploads.
To use an Amazon Polly voice instead, developers would use Structured Speech Markup Language (SSML) and then specify which voice they want with the “voice name” tag. This makes it easier to adjust what is said, as developers could just change the text instead of having to re-record an mp3.
Amazon has been working to make Polly more accessible to a wider audience, recently by offering a WordPress plugin that could turn your posts into podcasts.
The new Alexa skills integration, meanwhile, gives Polly another avenue of reaching consumers. It’s also another means of competing with Alexa’s rival, Google Assistant. At Google’s developer conference last week, the company announced six new voices generated by Wavent, including one from singer John Legend. These will roll out later this year, and presumably, could make their way to the Assistant developer ecosystem as well.
via TechCrunch
0 notes
Text
Week 3
This week was very interesting from an information science perspective. It was a trip down memory lane for me that took me back to my childhood days of using HTML to create goofy websites with funky art about my favorite super hero or animal. I went back in time because of a new language that was introduced in class – XML or eXtensible Markup Language.
Tags such as <title> and <head> were replaced with tags that contain information. This was a simple yet confusing concept. XML doesn’t really “do” anything. It doesn’t run any program or perform any calculations. It is just information that is wrapped in tags. The beauty of the language comes from this key difference. This allows XML to be a fluid language that can easily be integrated into other powerful languages and manipulate the data given.
The most interesting thing about XML however is its application. Developed in 1998, XML has been tried and tested in multiple environment and has made it as a versatile format that can be modified for a particular task. Although XML in itself has very little application, combining it with other languages or structures gives it infinite possibilities. This is because of its simple yet comprehensive structure that can be extended and modified endlessly. In today's world XML is used in almost every industry. Every Word, Excel or PowerPoint is stored in Open Office XML (OOXML). Every time you file your taxes (PSA- Tax season is upon us! File those returns!) or a company reports its financials, the IRS and SEC transfer it in XBRL. Even things such as asking your Alexa device to switch off the lights uses SSML (Speech Synthesis Markup Language) to transfer information. The possibilities are truly endless, with next-gen technology such as Internet of Things and self-driving automobiles extending their usage.
One thing about XML is certain – it has matured. With millions of people having removed bugs and streamlined the processing, there is very little if no room for error. The language has reached a point where its at its maximum applications and is widely deployed. There are also tools and systems being built that take advantage of packages that are built on top of XML without even noticing it. In a few years down the line people might forget that such a language exists. However, the underlying code and core XML structure is here to stay
Sources:
https://sdtimes.com/webdev/w3c-xml-is-everywhere/
https://www.w3schools.com/xml/xml_whatis.asp
0 notes
Text
Kecerdasan buatan atau artificial intelligence (AI) pada dasarnya menggunakan sistem voice recognition yang diprogram agar bisa berbicara. Teknologi tersebut diprogram untuk mampu menjawab beberapa pertanyaan yang dilontarkan oleh pengguna. Kendati demikian, Amazon menginginkan kecerdasan buatan miliknya, Alexa, mirip dengan manusia. Dengan sebuah program terbaru bernama SSML, perusahaan tersebut akan meningkatkan kemampuan berbicara dari sistem AI buatannya. "Speech Synthesis Markup Language atau SSML adalah bahasa markup standar yang memungkinkan pengembang mengendalikan pengucapan, intonasi, waktu, dan emosi," ungkap Amazon sebagaimana dikutip dari Ubergizmo, Senin. Dengan adanya SSML, Alexa mampu menghasilkan pidato dari tanggapan penggunanya. Selain itu, pengguna juga bisa menambahkan jeda, mengubah pengucapan, serta mengeja kata dan menyisipkan kata serta frasa khusus. "SSML pada Alexa memungkinkan Anda untuk mengontrol bagaimana Alexa menghasilkan pidato dari tanggapan teks keterampilan Anda," imbuh Amazon. Pengembang yang ingin mendapatkan teknologi baru tersebut bisa menggunakan tag khusus. Dengan tag ini pengembang bisa membuat Alexa berbisik. Kemampuan ini bisa berguna jika pengaturan Anda menunjukkan bahwa Anda ingin menurunkan volume. Hal ini tentunya menjadi peningkatan kemampuan kecerdasan buatan yang ada saat ini. (Okz/l) http://dlvr.it/P3dd47
0 notes
Link
In a bid to provide more natural voice experience,Amazon has introduced new Speech Synthesis Markup Language (SSML) features to its voice assistant Alexa that allows it to whisper, bleep, and even change its pitch.
SSML is a standardised markup language that allows developers to control pronunciation, intonation, timing and emotion.
"We are excited to announce five new SSML tags in the US, Britain and Germany that you can use with Alexa, including whispers, expletive bleeps and more," the company said in a blog post.
SSML support on Alexa allows users to control how Alexa generates speech from their skill's text responses. Developers can add pauses, change pronunciation, spell out a word, and add short audio snippets using existing SSML tags. Now, Amazon has added five more:
Whispers - Convey a softer dialogExpletive beeps - Bleep out wordsSub - Ask Alexa to say something other than what's writtenEmphasis - Change the rate and volume at which Alexa speaksProsody - Developers can use this tag to control the volume, pitch, and rate of speech
Amazon is set to host a webinar on May 18 on the new code, that will give a more clear idea on SSML.
#SooraSaab #Soora #Facebook #News #Gadgets #Technology #sports #Automobile #blog #youtube #smartphones #top #Tumblr
0 notes
Text
Amazon Expands Alexa's Speech Synthesis Markup Language - Android Headlines
Android Headlines
Amazon Expands Alexa's Speech Synthesis Markup Language Android Headlines Amazon's Alexa takes advantage of a specially made Speech Synthesis Markup Language to help developers make their Alexa skills sound more natural, and today, that language is getting five additional tags. The new SSML tags allow Alexa to whisper, ... and more »
from Technology - Google News http://ift.tt/2pteTgw via IFTTT
0 notes