#Stringmatching
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In February 2021, Tumblr had 518.6 million blog accounts.
Text
Fuzzy Match
Unveiling Fuzzy Match: Revolutionizing Data Matching with Advanced Algorithms
In today's data-driven world, the ability to accurately match and analyze textual data is paramount. Whether it's for identifying relationships, detecting anomalies, or optimizing search results, the need for precise data matching solutions is more critical than ever. Enter Fuzzy Match – the cutting-edge platform set to revolutionize how we handle and interpret textual data.
What is Fuzzy Match?

Fuzzy Match is an innovative platform developed by Radix Analytics that leverages advanced algorithms and machine learning to provide unparalleled accuracy in data matching. Designed to handle even the most challenging datasets, Fuzzy Match ensures you can efficiently search, match, and analyze data with ease.
How Does Fuzzy Match Work?
Fuzzy Match employs a sophisticated methodology combining advanced text matching techniques with state-of-the-art machine learning algorithms. Here’s a glimpse into how it works:
Data Upload: Users begin by uploading CSV or Excel files containing textual data to the Fuzzy Match platform.
Search Query Processing: When a search query is received, Fuzzy Match's machine learning models analyze the query to identify relevant patterns within the dataset.
Column Selection: Users can select specific columns on which they want to search, and the search text can be a combination of multiple columns.
Fuzzy Matching and Semantic Analysis: The platform intelligently compares the query against the selected columns of the uploaded data, accounting for variations in spelling, formatting, and semantics.
Results: Fuzzy Match delivers highly precise search results, even when dealing with diverse and inconsistently formatted datasets.
Why Choose Fuzzy Match?
Fuzzy Match is not just another data matching tool; it’s a comprehensive solution designed to address the most complex data challenges. Here’s why you should consider Fuzzy Match:
Accuracy: Our machine learning algorithms ensure you get the most accurate matches possible, saving you time and reducing errors.
Efficiency: The platform is designed to handle large volumes of data quickly and efficiently, making it ideal for organizations of all sizes.
User-Friendly: With an intuitive interface, Fuzzy Match is easy to use, even for those without a technical background.
Continuous Improvement: The platform continually refines its matching capabilities through feedback loops and iterative learning, ensuring it stays adaptable to evolving user needs and data structures.
Get Started with Fuzzy Match
Ready to experience the power of Fuzzy Match? Visit https://fuzzymatch.in and sign up for our beta program today. Discover how Fuzzy Match can transform the way you handle textual data and unlock new insights for your organization.
#FuzzyMatch#DataMatching#DataScience#FuzzyLogic#DataCleaning#TextMatching#StringMatching#DataProcessing#Algorithm#MachineLearning#PatternMatching#DataAnalysis#DataQuality#DataIntegration#DataEngineering
0 notes
Text
Anti-Plagiarism Checker vs Rogeting - How do they work?

As you might already know, plagiarism detection is the process - or the technique, if you prefer - of locating instances of plagiarism within an abstract, a document or any other text-based work. Plagiarism is something that has always existed since ancient times: however, thanks to the advent of modern technologies - the web in the first place - and Content Management Systems, which make it easier to plagiarize the work of others, it quickly escalated to a widespread phenomenon. Plagiarism detection processes can be either manual or software-assisted: manual detection is not ideal, though, as it often requires substantial effort and excellent memory - which mean, high costs, especially for a huge amount of documents to check; for this very reason, software-assisted detection is almost always the way to go, as it allows vast collections of documents to be compared to each other, making successful detection much more likely. However, both control systems can be easily countered by manual or automatic techniques that rely on word substitutions and/or word order changes within the various sentences, thus making the plagiarism detection a much harder task: such anti-antiplagiarism technique is called rogeting. The battle between plagiarism detection and rogeting kind of resembles the "eternal" struggle between viruses and antivirus software and is mostly fought by very powerful algorithms. In this post, we'll try to briefly explain the most common approaches implemented by most systems for text-plagiarism detection, and also spend a couple of words about rogeting techniques. If you're looking for free plagiarism checker tools, we strongly suggest taking a look at our 10 free anti-plagiarism detection tools list. In case you've been looking for rogeting tools instead, sadly we can't help you: you should definitely write your own, original text instead (especially if you're a student) or seek the help of a certified professional writing service such as UkEssay.
Anti-Plagiarism
Anti-plagiarism solutions are typically split into two different detection approaches: external and intrinsic. External detection systems compare a suspicious document with a reference collection, which is a set of documents assumed to be genuine: the submitted text is compared with each one of these documents to produce one or multiple metrics (words, paragraphs, sentences, and so on) that calculates how much "distance" there is between the two. Intrinsic detection systems analyze the submitted text without performing comparisons to external documents trying to to recognize changes in the unique writing style of an author, which could be an indicator for potential plagiarism: such an approach is often used in mixed analyses - where humans and computers work together - since it's arguably not capable of reliably identifying plagiarism without human judgment. The figure below (source: Wikipedia) depicts all detection approaches in use nowadays for computer-assisted plagiarism detection:
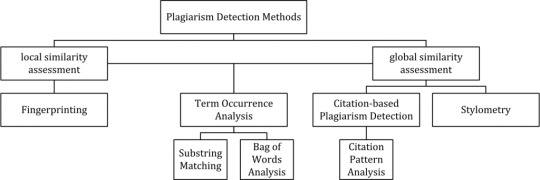
As we can see, the various approaches are split into two main "branches", characterized by the type of similarity assessment they undertake: global or local. Global similarity assessment approaches use the characteristics taken from larger parts of the text or the document as a whole to compute similarity. Local assessment approaches only examine pre-selected text segments as input. In the next paragraphs, we'll briefly summarize each one of them (source: Wikipedia). Fingerprinting Fingerprinting is currently the most widely applied approach to plagiarism detection: this method forms representative digests of documents by selecting a set of multiple substrings (n-grams) from them. The sets represent the fingerprints and their elements are called minutiae. A suspicious document is checked for plagiarism by computing its fingerprint and querying minutiae with a precomputed index of fingerprints for all documents of a reference collection. Minutiae matching with those of other documents indicate shared text segments and suggest potential plagiarism if they exceed a chosen similarity threshold. Computational resources and time are limiting factors to fingerprinting, which is why this method typically only compares a subset of minutiae to speed up the computation and allow for checks in very large collections, such as the Internet. String matching String matching is a prevalent approach used in computer science. When applied to the problem of plagiarism detection, documents are compared for verbatim text overlaps. Numerous methods have been proposed to tackle this task, of which some have been adapted to external plagiarism detection. Checking a suspicious document in this setting requires the computation and storage of efficiently comparable representations for all documents in the reference collection to compare them pairwise. Generally, suffix document models, such as suffix trees or suffix vectors, have been used for this task. Nonetheless, substring matching remains computationally expensive, which makes it a non-viable solution for checking large collections of documents. Bag of words Bag of words analysis represents the adoption of vector space retrieval, a traditional IR concept, to the domain of plagiarism detection. Documents are represented as one or multiple vectors, e.g. for different document parts, which are used for pairwise similarity computations. Similarity computation may then rely on the traditional cosine similarity measure, or on more sophisticated similarity measures. Citation analysis Citation-based plagiarism detection (CbPD) relies on citation analysis and is the only approach to plagiarism detection that does not rely on the textual similarity. CbPD examines the citation and reference information in texts to identify similar patterns in the citation sequences. As such, this approach is suitable for scientific texts, or other academic documents that contain citations. Citation analysis to detect plagiarism is a relatively young concept. It has not been adopted by commercial software, but a first prototype of a citation-based plagiarism detection system exists. Similar order and proximity of citations in the examined documents are the main criteria used to compute citation pattern similarities. Citation patterns represent subsequences non-exclusively containing citations shared by the documents compared. Factors, including the absolute number or relative fraction of shared citations in the pattern, as well as the probability that citations co-occur in a document are also considered to quantify the patterns’ degree of similarity. Stylometry Stylometry subsumes statistical methods for quantifying an author’s unique writing style and is mainly used for authorship attribution or intrinsic CaPD. By constructing and comparing stylometric models for different text segments, passages that are stylistically different from others, hence potentially plagiarized, can be detected.
Rogeting
Rogeting is a neologism created to describe the act of using a synonym listing (such as the Roget's Thesaurus, a famous synonym listing) to "swap" the words of a source text with their synonyms to create an entirely different abstract with the same content. Here's a quick example: Today I saved a family of cats from the street. A while ago I rescued a household of mices from the road. As we can see, it's a rather simple (and highly automatable or scriptable) technique consisting in replacing words with their synonyms, often chosen from a thesaurus or a synonym collection or website. Although anti-plagiarism detection tools would arguably have a hard time trying to detect the original source, the resulting text is often much more complex or difficult to read, especially when the replacement is performed using an automated tool: for this very reason, such attempts often require the subsequent action of human operators to "fix" the rewritten sentences. The rogeting technique has been developed with the precise intent of "not being detected" by the anti-plagiarism software and it's often used by students (using automatic or even manual approaches) to "cheat" these kinds of tools. The first use of such term has been attributed to Chris Sadler, principal lecturer in business information systems at Middlesex University, who had to deal with various rogeting attempts performed by his students.
Conclusion
That's it, at least for now. In case you're looking for some of the best free plagiarism checker tools available on the web, feel free to check our 10 free anti-plagiarism detection tools article. Read the full article
0 notes
Text
Version 324
youtube
windows
zip
exe
os x
app
tar.gz
linux
tar.gz
source
tar.gz
I had a great week. The downloader overhaul is almost done.
pixiv
Just as Pixiv recently moved their art pages to a new phone-friendly, dynamically drawn format, they are now moving their regular artist gallery results to the same system. If your username isn't switched over yet, it likely will be in the coming week.
The change breaks our old html parser, so I have written a new downloader and json api parser. The way their internal api works is unusual and over-complicated, so I had to write a couple of small new tools to get it to work. However, it does seem to work again.
All of your subscriptions and downloaders will try to switch over to the new downloader automatically, but some might not handle it quite right, in which case you will have to go into edit subscriptions and update their gallery manually. You'll get a popup on updating to remind you of this, and if any don't line up right automatically, the subs will notify you when they next run. The api gives all content--illustrations, manga, ugoira, everything--so there unfortunately isn't a simple way to refine to just one content type as we previously could. But it does neatly deliver everything in just one request, so artist searching is now incredibly faster.
Let me know if pixiv gives any more trouble. Now we can parse their json, we might be able to reintroduce the arbitrary tag search, which broke some time ago due to the same move to javascript galleries.
twitter
In a similar theme, given our fully developed parser and pipeline, I have now wangled a twitter username search! It should be added to your downloader list on update. It is a bit hacky and may be ultimately fragile if they change something their end, but it otherwise works great. It discounts retweets and fetches 19/20 tweets per gallery 'page' fetch. You should be able to set up subscriptions and everything, although I generally recommend you go at it slowly until we know this new parser works well. BTW: I think twitter only 'browses' 3200 tweets in the past, anyway. Note that tweets with no images will be 'ignored', so any typical twitter search will end up with a lot of 'Ig' results--this is normal. Also, if the account ever retweets more than 20 times in a row, the search will stop there, due to how the clientside pipeline works (it'll think that page is empty).
Again, let me know how this works for you. This is some fun new stuff for hydrus, and I am interested to see where it does well and badly.
misc
In order to be less annoying, the 'do you want to run idle jobs?' on shutdown dialog will now only ask at most once per day! You can edit the time unit under options->maintenance and processing.
Under options->connection, you can now change max total network jobs globally and per domain. The defaults are 15 and 3. I don't recommend you increase them unless you know what you are doing, but if you want a slower/more cautious client, please do set them lower.
The new advanced downloader ui has a bunch of quality of life improvements, mostly related to the handling of example parseable data.
full list
downloaders:
after adding some small new parser tools, wrote a new pixiv downloader that should work with their new dynamic gallery's api. it fetches all an artist's work in one page. some existing pixiv download components will be renamed and detached from your existing subs and downloaders. your existing subs may switch over to the correct pixiv downloader automatically, or you may need to manually set them (you'll get a popup to remind you).
wrote a twitter username lookup downloader. it should skip retweets. it is a bit hacky, so it may collapse if they change something small with their internal javascript api. it fetches 19-20 tweets per 'page', so if the account has 20 rts in a row, it'll likely stop searching there. also, afaik, twitter browsing only works back 3200 tweets or so. I recommend proceeding slowly.
added a simple gelbooru 0.1.11 file page parser to the defaults. it won't link to anything by default, but it is there if you want to put together some booru.org stuff
you can now set your default/favourite download source under options->downloading
.
misc:
the 'do idle work on shutdown' system will now only ask/run once per x time units (including if you say no to the ask dialog). x is one day by default, but can be set in 'maintenance and processing'
added 'max jobs' and 'max jobs per domain' to options->connection. defaults remain 15 and 3
the colour selection buttons across the program now have a right-click menu to import/export #FF0000 hex codes from/to the clipboard
tag namespace colours and namespace rendering options are moved from 'colours' and 'tags' options pages to 'tag summaries', which is renamed to 'tag presentation'
the Lain import dropper now supports pngs with single gugs, url classes, or parsers--not just fully packaged downloaders
fixed an issue where trying to remove a selection of files from the duplicate system (through the advanced duplicates menu) would only apply to the first pair of files
improved some error reporting related to too-long filenames on import
improved error handling for the folder-scanning stage in import folders--now, when it runs into an error, it will preserve its details better, notify the user better, and safely auto-pause the import folder
png export auto-filenames will now be sanitized of \, /, :, *-type OS-path-invalid characters as appropriate as the dialog loads
the 'loading subs' popup message should appear more reliably (after 1s delay) if the first subs are big and loading slow
fixed the 'fullscreen switch' hover window button for the duplicate filter
deleted some old hydrus session management code and db table
some other things that I lost track of. I think it was mostly some little dialog fixes :/
.
advanced downloader stuff:
the test panel on pageparser edit panels now has a 'post pre-parsing conversion' notebook page that shows the given example data after the pre-parsing conversion has occurred, including error information if it failed. it has a summary size/guessed type description and copy and refresh buttons.
the 'raw data' copy/fetch/paste buttons and description are moved down to the raw data page
the pageparser now passes up this post-conversion example data to sub-objects, so they now start with the correctly converted example data
the subsidiarypageparser edit panel now also has a notebook page, also with brief description and copy/refresh buttons, that summarises the raw separated data
the subsidiary page parser now passes up the first post to its sub-objects, so they now start with a single post's example data
content parsers can now sort the strings their formulae get back. you can sort strict lexicographic or the new human-friendly sort that does numbers properly, and of course you can go ascending or descending--if you can get the ids of what you want but they are in the wrong order, you can now easily fix it!
some json dict parsing code now iterates through dict keys lexicographically ascending by default. unfortunately, due to how the python json parser I use works, there isn't a way to process dict items in the original order
the json parsing formula now uses a string match when searching for dictionary keys, so you can now match multiple keys here (as in the pixiv illusts|manga fix). existing dictionary key look-ups will be converted to 'fixed' string matches
the json parsing formula can now get the content type 'dictionary keys', which will fetch all the text keys in the dictionary/Object, if the api designer happens to have put useful data in there, wew
formulae now remove newlines from their parsed texts before they are sent to the StringMatch! so, if you are grabbing some multi-line html and want to test for 'Posted: ' somewhere in that mess, it is now easy.
next week
After slaughtering my downloader overhaul megajob of redundant and completed issues (bringing my total todo from 1568 down to 1471!), I only have 15 jobs left to go. It is mostly some quality of life stuff and refreshing some out of date help. I should be able to clear most of them out next week, and the last few can be folded into normal work.
So I am now planning the login manager. After talking with several users over the past few weeks, I think it will be fundamentally very simple, supporting any basic user/pass web form, and will relegate complicated situations to some kind of improved browser cookies.txt import workflow. I suspect it will take 3-4 weeks to hash out, and then I will be taking four weeks to update to python 3, and then I am a free agent again. So, absent any big problems, please expect the 'next big thing to work on poll' to go up around the end of October, and for me to get going on that next big thing at the end of November. I don't want to finalise what goes on the poll yet, but I'll open up a full discussion as the login manager finishes.
1 note
·
View note
Text
Version 456
youtube
windows
zip
exe
macOS
app
linux
tar.gz
I had an ok week. With luck, the client should have less UI lag, and I also fixed a bunch of stuff and improved some quality of life.
basic highlights
I removed some very hacky memory management code this week. It was eating far more CPU than it was worth, particularly for large clients. If you have a very heavy client, particularly if it has lots of heavy subscriptions, please let me know if you A) have fewer UI lockups, and B) see any crazy memory spikes while running subs. As bad as the old routine was, it was aggressive and effective at what it did, so I may have to revisit this.
All multi-column lists across the program now catch enter/return keystrokes and trigger an 'activate' call, as if you had double-clicked. Should be easy to navigate and highlight a downloader page list just with the keyboard now.
advanced highlights
The 'file log' window now lets you see and copy an import item's hashes, tags, and urls from its right-click menu. I hope this will help debug some weirder downloader problems and generally inform on how the downloaders work.
The Edit URL Class dialog has had a layout makeover. Also, URL Classes now support matching and normalising 'single value' parameters (this is where you have a token/keyword parameter rather than the traditional key=value pair).
The hydrus server now remembers custom update and anonymisation periods! Previously, it was resetting to defaults on a restart! Thank you for the reports here--I apologise for the inconvenience and delay.
I added an 'mpv report mode' to the debug menu. If mpv loads for you but you have silent audio or similar (and perhaps some crashes, but we'll see if this catches useful info in time), this'll dump a huge amount of mpv debug information to the log.
full list
misc:
the client no longer regularly commits a full garbage collection during memory maintenance. this debug-tier operation can take up to 15s on very large clients, resulting in awful lag. various instances of forcing it after big operations complete (e.g. to encourage post-subscription memory cleanup), are now replaced with regular pauses to allow python to clean itself more granularly. this may result in temporary memory bloat for some very subscription-heavy clients, so feedback would be appreciated
right-clicking on a single url import item in a 'file log' now shows you all the known hashes, parsed urls, and parsed tags for that item. I hope this will help debug some weird problems!
all multi-column lists across the program now convert an enter/return key press into an 'activate' command, as if you had double-clicked. this should make it easier to, for instance, highlight a downloader or shift/ctrl select a bunch of sibling rows and mass-delete (issue #933)
the subscription gap filler button now propagates file import options and tag import options from the subscription to the downloader it creates (issue #910)
a new 'mpv report mode' now prints a huge amount of mpv debug information to the hydrus log when activated
improved how mpv prints log messages to the hydrus log, including immediate log flushing
fixed a bug that meant the hydrus server was not saving custom update period or anonymisation period for next boot. thank you for the reports, and sorry for the trouble! (issue #976)
cleaned up some database savepoint handling after a serious transaction error occurs
the client api now ignores any parameter with a value of null, as if it were not there, rather than moaning about invalid datatypes (issue #922)
.
url classes:
the edit url class dialog is now broken into two notebook pages--'match rules', which strictly covers how to recognise a url, and 'options', which handles url storage, conversion, and normalisation
url classes can now support single-value parameters (a parameter with just a value, not a key/value pair). if turned on, then at least one single-value parameter is required to match the url, and multiple are permitted. a checkbox in the dialog turns this on and a string match lets you determine if the url class matches the received single value params
added unit tests to test the new single-value parameter matching
fixed an issue where StringMatch buttons were not emitting their valueChanged signal, guess how I discovered that bug this week
fixed the insertion of default parameter values when the URL Class has non-alphabetised params
refactored and cleaned up some related parsing and string convertion code into new ClientString module
next week
More small jobs and bug fixes. I would also like to seriously explore and plan out an important downloader pipeline rewrite that will reduce UI lag significantly and allow for hundreds of downloaders working simultaneously.
0 notes
Text
Version 309
youtube
windows
zip
exe
os x
app
tar.gz
linux
tar.gz
source
tar.gz
I had a good week with a bunch of unusual work.
tumblr GDPR
When GDPR hit, tumblr introduced a click-through page for all European Union and European Economic Area users. Unfortunately, this page applies (likely unintentionally) to their old JSON API as well as regular pages, so it broke the current hydrus tumblr downloader.
I have written a simple 'login script' to perform this click-through manually, so if you are an EU/EEA user, please hit network->DEBUG: misc->tumblr click-through. The magic cookie you get lasts a year, so we have plenty of time to come up with a better solution. I understand this click-through event is linked to tumblr logins, so as I roll out a proper login system, we'll have more control here.
I live in the US, so testing for this was not super convenient. It appeared to work for a couple of EU/EEA users, but it may not for certain countries or may suddenly no longer be needed if tumblr changes how or where it applies to their CDN. I don't know enough about the implementation or the law's details to know for sure, so please send your feedback. This--and any other sites that might be forced to switch in the coming weeks--is likely something we'll just have to keep a continuing eye on.
video thumbnails
Videos (but not gif yet) now generate their thumbnails 35% in by default! You can also change the 35% value under options->media. You should see far fewer black-frame thumbnails for your videos now!
This was a highly requested feature. While I had originally planned to wait for a full overhaul of the system that would introduce animated thumbnails and maybe even an 'interestingness' scanner to pick the 'best' frame and discard blank ones entirely, after thinking about it more and talking with several users the past few months, I decided to have a brief look at the actual code and saw I could hack in some simple support. I cannot promise it works for files with unusual/inaccurate frame counts, so please link/send in any video files that error out.
I will eventually write an automated maintenance routine to regenerate all your old videos' thumbnails (and some other stuff that still needs a rescan) in idle time, but if you can't wait, turn on help->advanced mode and right click the selection of files you want to regenerate--there should be an option at the bottom to reparse and rethumbnail them.
downloader stuff
I've added parsers for inkbunny and gelbooru 0.2.0 (by default in the client, that means rule34.xxx, tbib, and xbooru), so they now support drag-and-drop and, for gelbooru, parse a little more info than before.
The multiple watcher now has a pause button, better sorting, and will prefer to accept url drag-and-drops on the current multiple watcher page, if multiple are open but one is currently selected.
The way the client performs its 'Have I seen this URL before?' test is now much more strict. False positives should now be far less common when some booru attaches a bare username/artist twitter/patreon/whatever URL as the source for a file. If you have been hit by this, let me know if it all magically fixes this week if you 'try again' the affected URLs, and if it doesn't, please let me know the details. I am still working on this and will roll out more tools to control url-checking behaviour.
Advanced users: The HTML parsing formula's tag rules can now search for tags that have certain 'string' content, like 'Original image'. This is very helpful in certain situations--check out my new gelbooru 0.2.0 file url content parser if you want to see an example!
siblings and parents logic improve
Much like the video thumbnails above, I decided to hack-in some better sibling and parents logic this week rather than wait for a neater complete overhaul.
So: now, if you create a new parent pair c->p, c will now also get any parents of p, and and parents of them (i.e. grandparents are now added to children recursively). Also, if you add a sibling pair a->b, a and all of a's siblings will get all the parents and grandparents (etc...) of b and b's siblings, and vice versa. Basically, parents now add recursively and all the siblings get all the parents they are supposed to. It isn't perfect yet, but it is better.
And again, I expect to write a maintenance routine in the future to retroactively fill in the gaps here.
Linux stability
I have put a bunch of time into improving Linux stability, which has, on-and-off, been randomly horrible since the wx update. I haven't caught everything, but I think things are better. Please continue to give feedback--whether you notice any difference at all, and if any activity in particular is still likely to cause a crash a few minutes later.
full list
wrote a fix for the tumblr GDPR issue under _network->DEBUG: misc->do tumblr GDPR click-through_. you will also get a popup about this on update
the tumblr downloader will try to detect the GDPR problem and present a similar popup guiding you to the GDPR click-through solution
the client and server now generate video (but not gif yet) thumbnails 35% in by default. the client can now change this percentage value under options->media. this was highly requested and was being put off for a longer rewrite, but I figured out a simple way to hack it in. please let me know if you get failures
on adding a parent, all files with the child tag will now also get all applicable grandparents (with no limit on recursive generations and dealing with accidental loops)
on adding a sibling, all files with any of the siblings will now also get all applicable parents and grandparents for the whole group. a maintenance call to retroactively fill in the sibling/parent gaps that are now filled will also come soon
this logic still does not apply in cross-service situations, which _will_ likely have to wait for a big data/gui overhaul and us figuring out what we actually want here
added a simple pause/play button to the multiple watcher
if the multiple watcher is set to catch watchable url drag and drop events and the current page is a multiple watcher, this current page will catch those new urls (as opposed to the _leftmost_ multiple watcher)
improved some thread unpause logic which was failing to lock pause during 404 status
the multiple watcher should now ignore case when it sorts by subject
added url class and file page parser for inkbunny (so this site is now supported in drag and drop!). it fetches creator tag, some artist-made unnamespaced tags, source time, and md5
added file page parser for gelbooru 0.2.0, which by default works for rule34.xxx, tbib, xbooru but certainly should work for a bunch of others. it fetches source time and source url
html formula parsing rules can now additionally test the tag 'string' using a standard StringMatch object. this greatly helps to parse otherwise indistinguishable 'a' tags that have string 'Original image' and so on
the 'have I seen this url's file before?' pre-import test is now much more strict and will cause fewer accidental false-positive 'already in db'/'deleted' results:
the url pre-import test now does not trust source urls if they do not have a url class
the url pre-import test now no longer trusts urls that are supposed to only be mapped to one file but are actually mapped to multiple
this url pre-import test now treats url-classless original post urls and intended file urls with a special level of trust
urls are now stored in the db in a more powerful and in-future easily searchable way--your db will take a moment to convert to the new format on update
did some prep work for multi-file post urls (like pixiv manga) but did not have time to finish it
the filename tagging options panel (in the 'add tags based on filename' of file import dialog and import folder dialog) now updates its tags/list 0.5s after the last change event, which means typing on a giant list will not cause megalag
improved stability of some client-screen coordinate conversion
misc bmp handling stability improvements
improved some parsing ui stability when example data gets set after the dialog is closed
improved some misc dialog close stability
converted all but one final ui update timer to the new job scheduling system
there are still problems with linux stability--I will continue to work on it
an ugly (but basically harmless) shutdown exception sometimes caused by Animations being a bit slow on deleting their underlying bmps _should_ be fixed
the export files dialog now generates its paths in sort order, meaning (1), (2) de-dupe filename suffixes should now be generated nicely in order
the network domain manager should now always chase API URL links to get the right parser
made some 'the db is broke, let's try to fix it' tag recovery code more forgiving
misc improvements to some media indexing backend, which may fix some unusual session ghost files
fixed the 'sure it is ok to close this importing page' dialog to also veto on a 'cancel' event, rather than just a 'no'
added a guide to database_migration.html on how to move the db from just an HDD to straddle both an SSD and HDD.
cleaned up the help->debug menu a bunch
added run fast/slow memory maintenance calls to help->debug->data actions
misc cleanup
next week
I would like to take the week from the 6th to 13th easy so I can shitpost E3, so I'd like to concentrate on tying up loose ends. I'd love to get pixiv manga pages working along with other multi-page Post URLs like tweets and Artstation posts--I did a little on this this week, but then ten other things like GDPR swamped me.
2 notes
·
View notes
Text
Version 305
youtube
windows
zip
exe
os x
app
tar.gz
linux
tar.gz
source
tar.gz
I had a great week with a bunch more downloader overhaul work done. The new parsing system now kicks in in a few more places and some sites now support url drag-and-drop by default.
new gallery parsers
I have tightened up last week's improvements on the new gallery page downloader and integrated it into regular downloader pages and subscriptions. Now, if the client recognises a url in any downloader or sub and knows how to parse it in the new system, it will use that new parser seamlessly.
I have also written new parsers for pixiv, danbooru, safebooru, and e621 for exactly this, so if you use any of those, you may notice they now populate the 'source time' column of the file import status window (which is useful for subscription check timing calculations) or that these parsers now pull and associate additional 'source urls' from the files' pages (so although you may download from danbooru, you might also get a new known pixiv url along the way).
A neat thing about these parsers is that if one of these additional source urls has already been seen by the client, the client can use that to pre-determine if the file is 'already in db' or 'previously deleted' before the file is downloaded, just like it would the main post url, saving time and bandwidth. The danbooru and e621 ones even pull md5/sha1 hashes and check those, so if everything works right, you should never have to redownload anything from danbooru or e621 again!
I also fixed the pixiv downloader more generally, which I had broken in last week's url normalisation update (and due to some other pixiv-specific stuff). I apologise for the inconvenience--everything should be working again (although you may have some useless bad urls from v304 that are missing the 'mode=medium' component that you may wish to skip/delete rather than let error-out), and the new pixiv parser fetches the romaji versions of tags now as well. Manga pages aren't supported yet, and tag searching is still down, but as I roll out some more gallery stuff here, I think I'll be able to figure something out.
Another upshot of the new parsers is that the client can now receive these sites' post urls as drag-and-drop events. Try dragging and dropping a danbooru file post url (like this https://danbooru.donmai.us/posts/2689241 ) on the client--it should all get imported in a new 'urls downloader' automatically, with all the new url association and everything! (You might want to check the new 'manage default tag import options' under the 'network' menu before you try this--the whole download system has a foot in two worlds at the moment, and while some parts pull TIO from the old system, the new url-based auto-stuff looks there.)
And lastly, with the help of @cuddlebear on the discord, there is a comprehensive yiff.party API parser in place, also with drag-and-drop support. Due to the shape of the data that yiff.party presents, this creates a thread watcher. You can even set these watchers to check like every 30 days or so, _and they should work_ and keep up with new files as they come in, but I recommend you just leave them as [DEAD] one-time imports for now: I expect to integrate 'watchable' import sources into the proper subscription system by the time this overhaul is done, which I think is probably the better place for more permanent and longer-period watchables to go.
I am pleased with these changes and with how the entire new downloader system is coming together. There is more work to do--gallery parsing and some kind of search object are the next main things--but we are getting there. Over the next weeks, I will add new parsers for all the rest of the default downloaders in the client (and then I can start deleting the old downloader code!).
other stuff
Import pages now report their total file progress after their name! They now give "(x, y/z)", where x=number of files in page, y=number of queue items processed, z=number of queue items unknown. If y=z, only "(x)" is reported. Furthermore, this y/z progress adds up through layers of page of pages!
If you try to close a page of pages (or the whole application), and multiple import pages want to protest that they are now yet finished importing, are you sure you want to close y/n, the client now bundles all their protests into a single yes/no dialog!
If manage subs takes more than a second to load, it'll now make a little popup telling you how it is doing.
full list
fixed the pixiv url class, which was unintentionally removing a parameter
wrote a pixiv parser in the new system, fixing a whole bunch of tag parsing along the way, and also parses 'source time'! by default, pixiv now fetches the translated/romaji versions of tags
finished a safebooru parser that also handles source time and source urls
finished an e621 parser that also handles source time and source urls and hash!
wrote a danbooru parser that also handles source time and source urls and hash!
as a result, danbooru, safebooru, e621, and pixiv post urls are now drag-and-droppable onto the client!
finished up a full yiff.party watcher from another contribution by @cuddlebear on the discord, including url classes and a full parser, meaning yiff.party artist urls are now droppable onto the client and will spawn thread watchers (I expect to add some kind of subscription support for watchers in the future). inline links are supported, and there is source time and limited filename: and hash parsing
fixed some thread watcher tag association problems in the new system
when pages put an (x) number after their name for number of files, they will now also put an (x/y) import total (if appropriate and not complete) as well. this also sums up through page of pages!
if a call to close a page of pages or the application would present more than one page's 'I am still importing' complaint, all the complaints are now summarised in a single yes/no dialog
url downloader pages now run a 'are you sure you want to close this page' when their import queues are unfinished and unpaused
if the subscriptions for 'manage subscriptions' take more than a second to load, a popup will come up with load progress. the popup is cancellable
added a prototype 'open in web browser' to the thumbnail right-click share menu. it will only appear in windows if you are in advanced mode, as atm it mostly just launches the file in the default program, not browser. I will keep working on this
harmonised more old download code into a single location in the new system
created a neater network job factory system for generalised network requests at the import job level
created a neater presentation context factory system for generalised and reliable set/clear network job ui presentation at the import job level
moved the new downloader simple-file-download-and-import to the new file object and harmonised all downloader code to call this single location where possible
did the same thing with download-post-and-then-fetch-tags-and-file job and added hooks for in the subscription and gallery downloader loops (where a parser match for the url is found)
the simple downloader and urls downloader now use 'downloader instance' network jobs, so they obey a couple more bandwidth rules
harmonised how imported media is then presented to pages as thumbnails through the new main import object
the new post downloader sets up referral urls for the file download (which are needed for pixiv and anything else picky) automatically
improved file download/import error reporting a little
entering an invalid regex phrase in the stringmatch panel (as happens all the time as you type it) will now present the error in the status area rather than spamming popups
fixed a bug in the new parsing gui that was prohibiting editing a date decode string transformation
fixed enabling of additional date decode controls in the string transformations edit panel
added a hyperlink to date decoding controls that links to python date decoding explainer
if a source time in the new parsing system suggests a time in the future, it will now clip to 30s ago
misc downloader refactoring and cleanup
fixed an issue where new file lookup scripts were initialising with bad string transformation rows and breaking the whole dialog in subsequent calls, fugg
hid the 'find similar files' menu entry for images that have duration (gifs and apngs), which are not yet supported
added 'flip_debug_force_idle_mode_do_not_set_this' to main_gui shortcut set. only set it if you are an advanced user and prepared for the potential consequences
silenced a problem with newgrounds gallery parser--will fix it properly next week
fixed some old busted unit test code
rejiggered some thumb dupe menu entry layout
next week
I will try to fit in some more parsers, and I might take a stab at a 'multiple thread watcher' page for advanced users. There's also an experimental new 'open file in web browser' that I had mixed luck with this week and would like to pin down a good multiplat solution for.
2 notes
·
View notes
Text
Version 283
youtube
windows
zip
exe
os x
app
tar.gz
linux
tar.gz
source
tar.gz
I had a tough week, but it worked out ok in the end. There are a variety of different improvements this week.
highlights
Subscriptions now deal with and present their new multiple queries a little better. They will also notify you when a query dies. I improved the timing check calculations, but some queries are still dying after their initial check--if this happens to you, please tell them to 'check now' again, and they should revive. I am going to keep working on this.
The different time periods in subscription and thread watcher check options can now stretch to a maximum of ten years! If you want to quietly watch an artist or thread only once per year or more, just in case it is updated, please check this out.
The pixiv 'artist' downloader is turned back on! I made a mistake last week--it was only the tag gallery that has changed. If the artist gallery updates in the future, I will turn it off again, so I suggest you get your artist stuff now!
I added support for an unusual type of flash file. If you have a number of broken 'ZWS' .swf files in a folder somewhere, please try importing them again and let me know how you get on.
I fixed a bug with editing import folders that have existing 'quick namespaces' entries. Also, if you have multiple import folders, you can now manually check them all at once with a new menu entry.
The new StringMatch parsing object is done. I've added it to the 'html formula', so you can quietly filter parsed texts if they do not fit some common character limits or lengths or even a regex. It will appear in several other places in the future to do similar filtering and veto condition testing.
full list
subscription popups show a bit more info about their individual queries
subscription popups hide the sub-query info in text and file buttons if it is the same as the subscription name
subscriptions now work through their queries' downloading phases in random order (so a heavy query named 'aardvark' won't repeatedly choke the sub's other queries if bandwidth is tight)
if a subscription query dies, a notification popup will now be made
changed a logical edge case that may have been killing some subscription queries after the first sync
re-enabled pixiv artist search, as it still uses the old gallery style
added tentative support for 'ZWS' flash files
if there is more than one import folder, the 'check import folder now' submenu now has a 'check all' entry
TimeDelta controls that have the 'days' entry (as in thread/subscription checker options panels) now have a max period of 10 years for those _really_ slow threads
fixed an issue where the 'quick namespaces' section of the new filename tagging options panel was not initialising correctly when it loaded data from a previously serialised import folder (this was the "unhashable type: 'list'" bug in the edit import folder panel)
the filename tagging dialog now works on the new panel system. it also has an entry under options->gui: 'local_import_filename_tagging'
polished StringMatch object
polished EditStringMatchPanel
html formulas now have a string match object
improved parsing error system
miscellaneous improvements to the parsing system
misc fixes to StringMatch and parsing system
the main gui will no longer interpret text drops on child frames as url drops. this fix just quashes the drop--it doesn't allow the initially desired drop on the child frame to occur. I will keep thinking about this
the dupe filter's 'no media to display' text now says 'Looking for more pairs--please wait'
the 'remove' media action is now labelled 'remove from view' to reduce 'is it a delete?' confusion
fixed an icon initialisation order problem that meant pre-boot errors were unable to display
fixed a graceful-shutdown-on-boot-error bug
the custom 'listboxtags' controls now post an event on their contents changing
the tag censorship panel now updates its status text when its listboxes change due to a mouse double-click event
fixed file import 'source time' column sometimes showing '3e-05 years' kind of garbage that was due to a missed float->int conversion
cleaned up how some page names are thrown around, which should stop some stray [USER] prefixes slipping though
the adminside petition management checklistbox will now escape mnemonic characters (typically '&') and hence display them correctly on sibling pairs and so on
wrote a 'help my client will not boot.txt' that explains the new debug builds and some other common fixes to try
'all known files' file search domain is now hidden behind advanced mode
fixed another instance of flashwin causing a failed boot
cleaned up some old broken unit tests
some misc help improvements
updated Windows build to new version of sqlite
next week
I will now work on a 'URLMatch' object, which will let the client think about domains and URLs in a more clever way, which will be of use to the new downloader engine and login manager.
2 notes
·
View notes
Text
Version 398
youtube
windows
zip
exe
macOS
app
linux
tar.gz
source
tar.gz
I had a good work week. Tag autocomplete gets some new search options, and advanced users who make downloaders get some new text processing tools.
tag autocomplete
When I recently overhauled the tag autocomplete pipeline, I eliminated some unusual logical hoops where you could accidentally fire off expensive searches that would fetch all tags. Now the code is clean, I am adding them back in as real options.
The main thing here is that services->tag display is now services->tag display and search. It has several new options to change search based on what the autocomplete's current 'tag domain' is (i.e. what the button on the dropdown says, "all known tags" or "my tags" or whatever else). The options are available for every specific tag domain and the "all known tags" domain, and only apply there.
There are three new search options: You can have full namespace lookup, so an input of 'ser' also finds 'series:metroid' and all other series tags; you can have an explicit input of 'series:*' show all 'series' tags; and you can have '*' show all tags. These queries are extremely expensive for a large service like the public tag repository (they could take minutes to complete, and eat a ton of memory and CPU), but they may be appropriate for a smaller domain like "my tags". Please feel free to play with them.
There are also a couple of clever options setting how 'write' autocompletes (the ones that add tags, like in the manage tags dialog) start up, based on the tag service of the page they are on. You can set them to start with a different file or tag domain. Most users will be happy with the defaults, which is to stick with the current tag domain and "all known files", but if you want to change that (e.g. some users like to get suggestions for "my tags" from the PTR, or they don't want tag counts from files not in "my files"), you now can. The old option under options->tags that did the "all known files" replacement for all write autocompletes is now removed.
I have optimised the database autocomplete search code to work better with '*' 'get everything' queries. In the right situation, these searches can be very fast. This logic is new, the first time I have supported it properly, so let me know if you discover any bugs.
string processing
This is only important for advanced users who write downloaders atm. It will come to the filename tagging panel in future.
I am plugging the new String Processor today into all parsing formulae. Instead of the old double-buttons of String Match and String Converter, these are now merged into one button that can have any combination of ordered Matches and Converters, so if you want to filter after you convert, this is now easy. There is new UI to manage this and test string processing at every step.
The String Processor also provides the new String Splitter object, which takes a single string like '1,2,3' and lets you split it by something like ',' to create three strings [ '1', '2', '3' ]. So, if your HTML or JSON parsing provides you with a line with multiple things to parse, you should now be able to split, convert, and match it all, even if it is awkward, without voodoo regex hackery.
I also did some background work on improving how the parsing example/test data is propagated to different panels, and several bugs and missed connections are fixed. I will keep working here, with the ideal being that every test panel shows multiple test data, so if you are parsing fifty URLs, a String Processor working on them will show how all fifty are being converted, rather than the current system of typically just showing the first. After that, I will get to work on supporting proper multiline parsing so we can parse notes.
the rest
Double-clicking a page tab now lets you rename it!
system:time imported has some quick buttons for 'since 1/7/30 days ago'.
I cleaned out the last of the behind-the-scenes mouse shortcut hackery from the media viewer. Everything there now works on the new shortcuts system. There aren't many front-end changes here, but a neat thing is that clicking to focus an unfocused media window no longer activates the shortcut for that click! So, if you have an archive/delete filter, feel free to left-click it to activate it--it won't 'keep and move on' on that first click any more. I will continue to push on shortcuts in normal weekly work, adding mouse support to more things and adding more command types.
You can now enter percent-encoded characters into downloader queries. A couple of sites out there have tags with spaces, like '#simple background', which would normally be broken in hydrus into two tags [ '#simple', 'background' ]. You can now search for this with '#simple%20background' or '%23simple%20background'. Generally, if you are copy/pasting any percent-encoded query, it should now work in hydrus. The only proviso here is %25, which actually is %. If you paste this, it may work or not, all bets are off.
I am rolling out updated Gelbooru and Newgrounds parsers this week. Gelbooru searching should work again, and Newgrounds should now get static image art.
full list
new tag search options:
there are several new options for tag autocomplete under the newly renamed _services->tag display and search_:
for 'manage tags'-style 'write' autocompletes, you can now set which file service and tag service each tag service page's autocomplete starts with (e.g. some users have wanted to say 'start my "my tags" service looking at "all known files" and "ptr"' to get more suggestions for "my tags" typing). the default is 'all known files' and the same tag service
the old blanket 'show "all known files" in write autocompletes' option under _options->tags_ is removed
you now can enable the following potentially very slow and expensive searches on a per-tag-domain basis:
- you can permit namespace-autocompleting searches, so 'ser' also matches 'ser*:*', i.e. 'series:metroid' and every other series tag
- you can permit 'namespace:*', fetching all tags for a namespace
- you can permit '*', fetching all tags (╬ಠ益ಠ)
'*' and 'namespace:*' wildcard searches are now significantly faster on smaller specific tag domains (i.e. not "all known tags")
short explicit wildcard searches like "s*" now fire off that actual search, regardless of the 'exact match' character threshold
queries in the form "*:xxx" are now replaced with "xxx" in logic and display
improved the reliability of various search text definition logic to account for wildcard situations properly when doing quick-enter tag broadcast and so on
fixed up autocomplete db search code for wildcard namespaces with "*" subtags
simplified some autocomplete database search code
.
string processing:
the new string processor is now live. all parsing formulae now use a string processor instead of the string match/transformer pair, with existing matches and transformers that do work being integrated into the new processor
thus, all formulae parsing now supports the new string splitter object, which allows you to split '1,2,3' into ['1','2','3']
all formulae panels now have the combined 'string processing' button, which launches a new edit panel and will grow in height to list all current processing steps
the stringmatch panel now hides its controls when they are not relevent to the current match type. also, setting fixed match type (or, typically, mouse-scrolling past it), no longer resets min/max/example fields)
the string conversion step edit panel now clearly separates the controls vs the test results
improved button and summary labelling for string tools across the program
some differences in labelling between string 'conversion' and 'transformation' are unified to 'conversion' across the program
moved the test data used in parsing edit panels to its own object, and updated some of the handling to support passing up of multiple example texts
the separation formula of a subsidiary page parser now loads with current test data
the string processing panel loads with the current test data, and passes the first example string of the appropriate processing step to its sub-panels. this will be expanded in future to multiple example testing for each panel, and subsequently for note parsing, multiline testing
added safety code and unit tests to test string processing for hex/base64 bytes outcomes. as a reminder, I expect to eliminate the bytes issue in future and just eat hashes as hex
cleaned up a variety of string processing code
misc improvements to string processing controls
.
the rest:
double-clicking a page tab now opens up the rename dialog
system:time imported now has quick buttons for 'since 1/7/30 days ago'
all hydrus downloaders now accept percent-encoded characters in the query field, so if you are on a site that has tags with spaces, you can now enter a query like "simple%20background red%20hair" to get the input you want. you can also generally now paste encoded queries from your address bar into hydrus and they should work, with the only proviso being "%25", which is "%", when all bets are off
duplicates shut down work (both tree rebalancing and dupe searching) now quickly obeys the 'cancel shutdown work' splash button
fixed a signal cleanup bug that meant some media windows in the preview viewer were hanging on to and multiplying a 'launch media' signal and a shortcut handler, which meant double-clicking on the preview viewer successively on a page would result in multiple media window launches
fixed an issue opening the manage parsers dialog for users with certain unusual parsers
fixed the 'hide the preview window' setting for the new page layout method
updated the default gelbooru gallery page parser to fix gelb gallery parsing
updated the newgrounds parser to the latest on the github. it should support static image art now
if automatic vacuum is disabled in the client, forced vacuum is no longer prohibited
updated cloudscraper for all builds to 1.2.38
.
boring code cleanup:
all final mouse event processing hackey is removed from the media viewers, and the shortcut system is now fully responsible. left click (now with no or any modifier) is still hardcoded to do drag but does not interfere with other mapped left-click actions
the duplicates filter no longer hardcodes mouse wheel to navigate--whatever is set for the normal browser, it now obeys
cleaned up some mouse move tracking code
clicking to focus an unfocused media viewer window will now not trigger the associated click action, so you can now click on archive/delete filters without moving on!
the red/green on/off buttons on the autocomplete dropdown are updated from the old wx pubsub to Qt signalling
updated wx hacks to proper Qt event processing for splash window, mouse move events in the media viewer and the animation scanbar
cleaned up how some event filtering and other processing propagates in the media viewer
deleted some old unused mouse show/hide media viewer code
did some more python imports cleanup
cleaned up some unit test selection code
refactored the media code to a new directory module
refactored the media result and media result cache code to their own files
refactored some qt colour functions from core to gui module
misc code cleanup
next week
I will be taking my week vacation after next week, and I don't want to accidentally create any big problems for the break, so I will try to mostly do small cleanup work and bug fixes.
0 notes
Text
Version 282
youtube
windows
zip
exe
os x
app
tar.gz
linux
tar.gz
source
tar.gz
I had a great week. I fixed some things and added regex tag parsing to import folders.
flash fixed and debug exes
I accidentally broke flash embed windows for Windows users last week. It seems the new version of the program I use to make the Windows build was not linking something correctly, so many users were unable to play flash without a stream of errorspam, and some users could not even boot.
I have rolled back my PyInstaller to the old version and everything flash seems to be working again. I will be testing flash embeds every week from now on to make sure this doesn't slip through again.
Also: I think I have figured a way to include the debug executables in the regular builds. They are just called client_debug and server_debug. If you cannot boot the client in future, please try running the debug exe and screenshotting the additional error information it provides. (I'll write a .txt file in the base directory next week or so to explain this further)
faster thumbnails
This is just a little thing really, but I 'smoothed' out the thumbnail rendering pipeline a bit. The client should generate some thumbnails much faster, particularly when they are first viewed.
pixiv broken
It seems that Pixiv recentishly changed how their gallery pages work (they now load in a stream as you scroll down, via some javascript or json thing). Unfortunately, the existing hydrus pixiv parser cannot deal with this and was as a result not parsing these results (I think it was just getting a handful in the 'popular' row and then quitting).
I have hidden the pixiv downloader links in the client and paused any existing pixiv subscriptions. You'll also get a little popup about it on update.
I would like to say that the new hydrus downloading engine will be able to handle the new system, but I have not looked into it deep enough to be certain. I hope it can, and will look into it more when it finally comes time for us to rebuild the existing parsers in the new engine.
Pixiv do have an official json API, but it is an OAuth thing, which is an entirely different kettle of fish for our purposes.
EDIT: Someone just told me that artist pages are still using the old system, so I will revisit this next week to make sure and reactivate them if they are all ok.
filename tagging options
As has been long-planned, I have extracted the regex and other 'filename' tagging options you can set after the 'import files' dialog into their own object and applied them to import folders!
If you are into import folders or the regex parsing, please check it out under the manage import folders dialog--a new simple listctrl replaces the old '.txt parsing' button. You can't set 'tags for some files' or the '#'-based tags (because those require manual input), but you should be able to set anything else on a per-service basis.
I have tested this and it all seems to work correctly, but it was a complicated and semi-big rewrite, so please let me know if you run into trouble. Maybe try it out on a small example before you go full on!
string converter
This is an advanced thing for people interested in making scripts and downloaders with the parsing engine.
I realised this week that the login manager and downloader overhaul actually have a lot of overlap in the work that needs to be done, particluarly in the parsing engine. Rather than finish the login and domain managers first and then move on to the downloader overhaul, I have decided to work on all three at the same time, making small improvements as the new parsing engine can do more things.
So, this week, I finished a new 'StringConverter' class, that does simple string transformations--adding or removing text, encoding to hex, reversing, that sort of thing. I added it to the html formulas in the existing scripting system and expect it to put it in a couple of other places for when you are in the situation of, 'I can parse this data, but I don't need the first six characters.' I don't expect the existing file lookup scripts need this too much, but feel free to play around with it. I think I'll add a 'regex' transformation type in future.
I also added it to the 'file identifier' section of the initial file lookup request. Now, rather than the file's hash bytes being encoded to hex or base64 from the dropdown, it occurs through a string converter. There has been a persistent issue of wanting to generate an 'md5:[md5_hash]' argument, and I believe this will now fix it. I do not know the exact specifics here so I won't write the script myself, but I'm happy to work with people on the discord or email or whatever to figure out a solution here.
full list
rolled back to an older version of pyinstaller that does not seem to have the embedded flash window problems windows users experienced
added an error handler to wx.lib.flashwin import--if it fails to import, the client will print the error to the log and thereafter show 'open externally' buttons instead of the embedded flash window
created a 'filename tagging options' object to handle the instance-non-specific auto-tagging parts of the filename tagging dialog
moved all the appropriate tag generation code to this new object
extracted the simple and advanced panels in the filename tagging dialog to a separate panel
wrote a new wrapper panel to edit filename tagging options objects directly
cleaned up some tag generation code--it'll now all be siblinged/parented/censored the same way
import folders now use the filename tagging options object, harmonising this tag parsing code
edit import folder gui now has an add/edit/delete listctrl to manage the new tag_service->filename_tagging_object relationship (this replaces the old .txt management button and summary text)
finished the StringConverter class in the new parsing engine. it applies a series of transformations to text
wrote a panel to edit string converters
wrote a panel to edit string converters' individual transformations
updated html formulas to use string converters instead of the old cull_and_add system
html formula edit panels can now edit their new string converters
file lookup scripts now 'stringconvert' their file identifier strings--this should allow the 'md5:md5_hash' fix we've been talking about (i.e. by first encoding to hex and then prepending 'md5:')
the help->about window now shows the client's default temp directory
thumbnail regeneration--particularly full-size regen and resized png gen--should be much faster in the client
the debug exes are now included in the windows build
the debug exes are now included in the non-windows builds
the test exe is no longer included in the windows install (can't remember it ever being useful, and it is like 10MB now)
unfortunately, a recentish change to how pixiv serves gallery page results has broken the hydrus pixiv downloader. this will have to wait for the downloader overhaul, and even then, it might be _slightly_ tricky. pixiv downloader entries are now hidden, and existing pixiv subscriptions will be paused on update
the thumbnail select submenu now clarifies 'all (all in x)' if all are in the inbox or archive
you can now archive/delete filter from the thumbnail menu on a single file
lowered the http session inactivity timeout even more, to 45 minutes
fixed a couple of instances of the new subscription dialogs being unable to mass-retry failures
ffmpeg parsing errors now print more info about broken file path
some daemons will be snappier about shutting down on application shutdown
took out the sometimes invalid 'booting' phrase in the during disk cache population status report
the client will now warn you about page instability at 165 pages after one user reported instability at 175. 200 is still the strict limit.
downloader pages and subscriptions will fail more gracefully if their downloaders cannot be loaded (e.g. they used a since-deleted booru)
fixed listctrl panel button enabled/disabled status when the child listctrl starts empty
the new listctrl can now select data in a cleverer way
misc fixes
misc refactoring
next week
I want to get the 'StringMatch' object finished, and maybe the accompanying 'URLMatch' done as well. These will verify that strings and urls match certain rules, and will help with login and domain and downloader verification and veto states.
0 notes