#aws cognito documentation
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The Tumblr app for Google Glass was released on May 16, 2013.
Text
Our step-by-step guide teaches how to replicate AWS Cognito user data across regions. Enhance data availability, disaster recovery, and seamless user experience. Read now for detailed instructions!
#aws cognito#aws cognito sso#aws cognito api#aws cognito documentation#aws services#aws cloud#cloud services#ethics first#habilelabs
0 notes
Text
FIDO Authentication Market Size, Share, and Business Outlook 2032
The FIDO Authentication Market Size was USD 1.5 billion in 2023 and is expected to Reach USD 9.90 billion by 2032 and grow at a CAGR of 23.33% over the forecast period of 2024-2032.
FIDO Authentication Market is expanding rapidly as organizations shift toward passwordless authentication solutions to enhance security and user experience. The rise in cyber threats, phishing attacks, and data breaches has accelerated the demand for FIDO (Fast Identity Online) standards. Leading companies and governments are adopting FIDO-based authentication to eliminate reliance on traditional passwords.
FIDO Authentication Market continues to gain traction as businesses prioritize secure and frictionless authentication methods. With biometric authentication, hardware security keys, and mobile-based authentication becoming mainstream, FIDO protocols provide a robust framework for ensuring password-free security. The adoption of FIDO2 and WebAuthn standards is driving the market forward, reducing authentication vulnerabilities and improving compliance with regulatory requirements.
Get Sample Copy of This Report: https://www.snsinsider.com/sample-request/3779
Market Keyplayers:
Yubico (YubiKey)
Auth0 (Identity Platform)
Okta (Okta Adaptive Authentication)
Gemalto (Thales) (SafeNet Trusted Access)
Microsoft (Windows Hello)
Google (Google Authenticator)
Apple (Apple Face ID, Touch ID)
Mastercard (ID Check Mobile)
Amazon Web Services (AWS) (AWS Cognito)
Ping Identity (PingOne)
SecureAuth (SecureAuth Identity Platform)
Ubisoft (Ubisoft Connect Authentication)
Duo Security (Duo Push)
(RSA SecurID)
BioConnect (BioConnect Authentication Platform)
Vasco Data Security (Digipass for FIDO)
OneLogin (OneLogin Adaptive Authentication)
Trustonic (Trustonic Secure User Authentication)
Deep Identity (Deep Identity Authentication Services)
HID Global (HID Approve, FIDO2 Authentication)
Market Trends Driving Growth
1. Increasing Adoption of Passwordless Authentication
Organizations are moving away from traditional passwords due to security concerns. FIDO authentication leverages biometrics, public key cryptography, and hardware-based security to provide a seamless login experience.
2. Expansion of Multi-Factor Authentication (MFA)
With cyberattacks on the rise, businesses are integrating FIDO-based authentication into their MFA strategies. This approach enhances security by combining biometric authentication with cryptographic keys.
3. Government Regulations and Compliance
Regulatory bodies are pushing for stronger authentication frameworks. FIDO standards align with global compliance requirements such as PSD2, GDPR, and Zero Trust security models.
4. Growth in Enterprise and Consumer Adoption
Enterprises, financial institutions, and tech companies are implementing FIDO authentication to enhance security while improving user convenience. Consumers are also embracing passwordless authentication through mobile devices and security keys.
Enquiry of This Report: https://www.snsinsider.com/enquiry/3779
Market Segmentation:
By Component
FIDO Authentication Devices
FIDO Authentication SDKs
FIDO Client SDK
FIDO Server SDK
Services
Technology Consulting
Integration & Deployment
FIDO Certification Services
Support Services
By Application
Payment Processing
PKI/Credential Management
Document Signing
User Authentication
Others
By Industry Vertical
BFSI
Healthcare & Life Sciences
IT & Telecom
Retail & CPG
Government & Defense
Energy & Utilities
Market Analysis and Current Landscape
Key factors influencing market growth include:
Rise in Cyber Threats: As phishing and credential theft increase, businesses are seeking more secure authentication solutions.
Advancements in Biometrics and Hardware Security: Fingerprint, facial recognition, and hardware-based authentication (e.g., YubiKey) are gaining widespread adoption.
Tech Giants Driving Adoption: Companies like Google, Microsoft, and Apple are integrating FIDO authentication into their platforms, making it a global standard.
Regulatory Push for Strong Authentication: Governments worldwide are enforcing stronger authentication measures to mitigate cyber risks.
Despite the positive outlook, challenges such as interoperability issues, integration complexities, and user adoption barriers remain. However, ongoing innovations in authentication technology are addressing these concerns.
Future Prospects: The Road Ahead
1. Expansion Across Industries
FIDO authentication is expected to witness significant adoption in banking, healthcare, e-commerce, and enterprise security as businesses prioritize cybersecurity.
2. Growth of Decentralized Authentication
The rise of decentralized identity solutions and blockchain-based authentication will further enhance the security and privacy of FIDO-based authentication systems.
3. Enhanced User Experience with AI and ML
AI-driven authentication and behavioral biometrics will refine FIDO implementations, reducing friction for users while maintaining high security.
4. Adoption of WebAuthn and FIDO2 in IoT Security
With the growing number of IoT devices, FIDO authentication will play a key role in securing connected ecosystems, preventing unauthorized access.
Access Complete Report: https://www.snsinsider.com/reports/fido-authentication-market-3779
Conclusion
The FIDO Authentication Market is set for exponential growth as businesses, governments, and consumers embrace passwordless authentication. With rising cyber threats and stricter regulations, FIDO standards are becoming the preferred choice for secure and user-friendly authentication. As technology advances, FIDO authentication will continue to evolve, providing a robust foundation for the future of digital security.
About Us:
SNS Insider is one of the leading market research and consulting agencies that dominates the market research industry globally. Our company's aim is to give clients the knowledge they require in order to function in changing circumstances. In order to give you current, accurate market data, consumer insights, and opinions so that you can make decisions with confidence, we employ a variety of techniques, including surveys, video talks, and focus groups around the world.
Contact Us:
Jagney Dave - Vice President of Client Engagement
Phone: +1-315 636 4242 (US) | +44- 20 3290 5010 (UK)
#FIDO Authentication Market#FIDO Authentication Market Scope#FIDO Authentication Market Growth#FIDO Authentication Market Trends
0 notes
Text
Looking to learn about AWS?
Of course! Amazon Web Services (AWS) is a comprehensive, evolving cloud computing platform provided by Amazon. It offers a wide range of services including computing power, storage solutions, networking, databases, machine learning, and more. Here's a brief overview of some key aspects of AWS:
Compute:
EC2 (Elastic Compute Cloud): Provides scalable virtual servers in the cloud, allowing you to run applications.
Lambda: A serverless computing service where you can run code in response to events without provisioning or managing servers.
Storage:
S3 (Simple Storage Service): Offers object storage that is highly scalable, secure, and durable. It's commonly used for hosting static websites, storing backups, and hosting media files.
EBS (Elastic Block Store): Provides persistent block storage volumes for use with EC2 instances.
Databases:
RDS (Relational Database Service): Managed relational databases including MySQL, PostgreSQL, Oracle, and SQL Server.
DynamoDB: A fully managed NoSQL database service, offering low-latency access to data at any scale.
Networking:
VPC (Virtual Private Cloud): Lets you provision a logically isolated section of the AWS Cloud where you can launch AWS resources in a virtual network.
Route 53: A scalable domain name system (DNS) web service designed to route end users to internet applications.
Security:
IAM (Identity and Access Management): Allows you to manage access to AWS services and resources securely.
Cognito: Provides authentication, authorization, and user management for web and mobile apps.
Machine Learning and AI:
SageMaker: A fully managed service for building, training, and deploying machine learning models.
Rekognition: A deep learning-based image and video analysis service for analyzing images and videos for content and metadata.
Developer Tools:
CodeCommit: A fully managed source control service that makes it easy for teams to host secure and highly scalable private Git repositories.
CodeDeploy: Automates software deployments to a variety of compute services such as EC2, Lambda, and ECS.
These are just a few highlights of the vast array of services AWS offers. Learning AWS involves understanding how these services work, how they integrate with each other, and best practices for deploying and managing applications in the cloud. AWS provides extensive documentation, tutorials, and training resources to help you get started. Additionally, there are many online courses, certifications, and communities where you can learn from others and deepen your understanding of AWS.
Watch Now:;- https://www.youtube.com/watch?v=bYYAejIfcNE
0 notes
Text
Integrating Okta as a SAML identity provider in an Amazon Cognito user pool
Posted on March 12, 2020, by Sandeep
Amazon Cognito user pool allows users to sign-in through an external identity provider (federation), such as Okta. A user pool integrated with Okta allows users in your Okta app to get user pool tokens from Amazon Cognito and authenticate apps that use Cognito.
Prerequisites 1. Cognito user pool created in the AWS account 2. Okta developer account
Steps 1. Create an app client in your user pool
a. When adding an app client, clear the Generate client secret checkbox. b. Select the required auth flows Select at least ALLOW_USER_SRP_AUTH and ALLOW_REFRESH_TOKEN_AUTH

Note: We are using the “Authorization code grant” authentication flow which does not require client secrets.
2. Create your Cognito user pool domain
a. Under the App Integration tab in the user pool console side menu, choose Domain name b. Enter your choice of unique domain prefix which is used to build Cognito login url for your SAML app.
3. Create a SAML app in Okta
a. Sign in to okta with admin access credentials and click on the “Admin” button on top right corner b. On the admin, menu chooses Applications and then choose Add Application. c. On the Add Application page, choose to Create a New App. d. In the Create a New Application Integration dialog, confirm that Platform is set to Web. e. For the Sign-on method, choose SAML 2.0. f. Choose to Create, this will open a General Settings page for saml app.
(i) Enter a name for your app. (ii) (Optional) Upload a logo and choose the visibility settings for your app. (iii) Choose Next.

(iv) Under GENERAL, for Single sign-on URL, enter https://yourDomainPrefix.auth.region.amazoncognito.com/saml2/idpresponse.
Note: Replace yourDomainPrefix and region with the values for your user pool. Find these values in the Amazon Cognito console on the Domain name page for your user pool.
(v) For Audience URI (SP Entity ID), enter urn:amazon:Cognito:sp:yourUserPoolId.
Note: Replace yourUserPoolId with your Amazon Cognito user pool ID. Find it in the Amazon Cognito console on the General settings page for your user pool.

(vi) Under ATTRIBUTE STATEMENTS (OPTIONAL- specifies which user attributes you want to export to Cognito), add a statement with the following information:
For Name, enter the SAML attribute name (attribute name by which you want to user attributes to be passed to Cognito in SAML response).

eg: if you want to pass user email in SAML response and you want to call it ‘Email Id’ enter ‘Email id’ in Name field and enter ‘user.email’ in Value field.
(vii) For all other settings on the page, leave them as their default values or set them according to your preferences. (viii) Choose Next. (ix) Choose a feedback response for Okta Support. (x) Choose Finish.
4. Assign a user to your Okta application
a. On the Assignments tab for your Okta app, for Assign, choose Assign to People. b. Next to the user that you want to assign, choose Assign.
Note: If this is a new account, the only option available is to choose yourself (the admin) as the user.
c. (Optional) For User Name, enter a user name, or leave it as the user’s email address, if you want. d. Choose Save and Go Back. Your user is assigned. e. Choose Done.
5. Get the IdP metadata for your Okta application
a. On Okta developer console, navigate to the Applications tab and select your application. b. On the Sign-On tab, find the Identity Provider metadata hyperlink (Look for text ‘Identity Provider metadata is available if this application supports dynamic configuration.’). Right-click the hyperlink (Identity Provider metadata), and then copy the URL.
6. Configure Okta as a SAML IdP in your user pool
a. In the Amazon Cognito console, choose to Manage user pools, and then choose your user pool. b. In the left navigation pane, under the Federation, choose Identity providers. c. Choose SAML. d. Under the Metadata document, paste the Identity Provider metadata URL that you copied. e. For Provider name, enter Okta. f. (Optional) Enter any SAML identifiers (Identifiers (Optional)) and enable sign-out from the IdP (Okta) when your users sign out from your user pool (Enable IdP sign out flow). g. Choose Create provider.

7. Map SAML attributes to user pool attributes
a. In the Amazon Cognito console, choose Manage user pools, and then choose your user pool. b. In the left navigation pane, under the Federation, choose Attribute mapping. c. On the attribute mapping page, choose the SAML tab. d. Choose Add SAML attribute. e. For the SAML attribute, enter the SAML attribute name (attribute name which you have mentioned in ATTRIBUTE STATEMENTS while creating the SAML app in Okta.

eg: we had specified ‘Email Id’ in the example above so mention ‘Email Id’ under SAML attribute and select Email under User pool attribute, continue and map all other attributes if you had mentioned any other in ATTRIBUTE STATEMENTS and Choose Save changes.
Note: Make sure all mapped attributes in cognito are readable and writable, you can set attribute permissions in General settings->App clients->Set read and write permissions.
8. Change app client settings for your user pool
a. In the Amazon Cognito console, choose Manage user pools, and then choose your user pool. b. In the left navigation pane, under App integration, choose App client settings. c. On the app client page, do the following: Under Enabled Identity Providers, select the Okta and Cognito User Pool checkboxes. For Callback URL(s), enter a URL where you want your users to be redirected after they log in. For testing, you can enter any valid URL, such as https://www.example.com/. For Sign out URL(s), enter a URL where you want your users to be redirected after they log out. For testing, you can enter any valid URL, such as https://www.example.com/. Under Allowed OAuth Flows, be sure to select Authorization code grant checkbox. Under Allowed OAuth Scopes, be sure to select the email and profile checkboxes. d. Choose Save changes.

9. Construct the endpoint URL
a. Using values from your user pool, construct this login endpoint URL: https://yourDomainPrefix.auth.region.amazoncognito.com/login?response_type=code&client_id=yourClientId&redirect_uri=redirectUrl b. Be sure to do the following:
(i) Replace yourDomainPrefix and region with the values for your user pool. Find these values in the Amazon Cognito console on the Domain name page for your user pool. (ii) Replace yourClientId with your app client’s ID, and replace redirectUrl with your app client’s callback URL. Find these in the Amazon Cognito console on the App client settings page for your user pool.
10. Test the endpoint URL
a. Enter the constructed login endpoint URL in your web browser. b. On your login endpoint webpage, choose Okta.
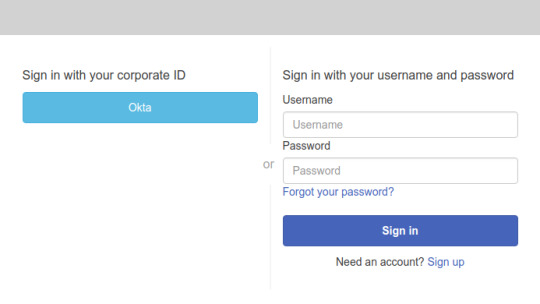
Note: If you’re redirected to your app client’s callback URL, you’re already logged in to your Okta account in your browser. The user pool tokens appear in the URL in your web browser’s address bar.
c. On the Okta Sign In page, enter the username and password for the user that you assigned to your app.
1 note
·
View note
Text

AWS Cognito is one of the offerings that had at the Amazon cloud app development platform. Using this provider without any difficulty can join it with different to be had offerings on AWS along with API Gateway, AppSync, or Lambdas. It can keep flutter development personal information like given name, own circle of relatives name, electronic mail, username, password, and some other information which your customers generally preserve within the web development or mobile software development.
📷
AWS cognito
If you need to permit customers check in and log into your app developers page, keep their information private, and a number of the capabilities like two-step authentication or password procedure, this app development provider is something well worth the use. Not best does it will let you keep away from writing a backend service, however, it additionally calls for less code at the frontend.
Getting started
Connection with AWS Cognito provider at the software development aspect may be accomplished with the aid of using uploading the AWS Amplify module, to be had to download as an NPM module. It offers your software development the cap potential to connect to the AWS Cognito provider and put in force the local person interface paperwork for authentication, password healing, etc.
AWS cognito pros
Fully configurable through the AWS manage panel.
Easy to connect to your software developers thru furnished AWS Amplify module.
No want for a further worldwide nation control answer on your app development. AWS Amplify will take a look at if the person is already logged for you. It presents its very own worldwide nation which may be used throughout the complete flutter development.
Out-of-the-field, UI paperwork for logging in, registration, password healing, password alternate, federated authentication, MFA.
All the information may be mechanically saved in the cloud AWS Cognito provider.
Confirmation emails may be mechanically despatched to the person in addition to textual content messages to confirm the phone quantity.
You can keep custom attributes for customers like address, phone quantity, town, and any custom discipline that you need.
Data despatched from the app developers is already encrypted and secured with the aid of using the AWS Amplify module.
Easy to connect to different AWS offerings like AWS AppSync.
UI Form validations controlled with the aid of using AWS manage panel.
Integration with Social identification vendors eg, “Log in with Google”.
Error messages already furnished with the aid of using web development provider.
Several approaches to deal with paperwork at the software development aspect.
AWS Amplify permits for making HTTP requests.
Out of the field protection capabilities like throttling or refresh tokens.
AWS cognito cons
It’s a paid solution.
Documentation is hardly ever up to date and now no longer a great deal detail.
Some of the alternatives may be best set for the duration of the introduction of an AWS Cognito person pool within the AWS management panel. After that, the alternatives are disabled, and in case you need to alternate them you want to delete the complete example and create a brand.
Aligning furnished UI paperwork with a number of the web designers can occasionally be problematic, then probable the quickest manner is to create your very own shape components.
Error messages furnished by using AWS Cognito aren’t very person-pleasant. Sometimes they’re too technical so that you want to offer a few types of a mistakes mapper within the flutter development, to reveal greater person-pleasant messages. For instance whilst a person attempts to log in with the incorrect password.
There aren’t any mistakes messages for precise shape fields, the best well-known mistakes messages.
Confirmation emails are very limited. You want to create custom HTML electronic mail templates in case you need greater than only undeniable textual content electronic mail with a verification link.
There are obstacles withinside the number of custom discipline attributes. You can’t create greater than 25 custom attributes.
AWS Amplify module is a touch heavy (minified + gzipped model is round a hundred and eighty kB).
Conclusion
Using AWS Cognito for authentication at the side of AWS amplify at the software development might be a solution than developing the complete authentication service on your very own. In addition, you don’t want to attend to the backend, due to the fact this can be already furnished by using AWS Cognito. But in case your software development no longer uses some other provider from AWS Cognito, connecting it with third-party offerings will make an effort and require custom web development solutions.
0 notes
Text
My Experience, Feedback, And Tips for the AWS Developer Associate Exam
I passed the AWS Certified Developer Associate test on my first try a few weeks ago. My second attempt at the trial was having previously obtained AWS Developer Associate certification around four years ago. Since then, the test has undoubtedly altered. In the past, you could easily pass the test using knowledge from the AWS Certified Solutions Architect Associate and a few extra facts about Amazon DynamoDB. The latest exam is unquestionably more developer-focused, with questions evaluating your grasp of Developer Tools, development best practices, and code examples.
I still don't think you need a solid background in development to pass this exam. Indeed, my experience is in Enterprise Solutions Architecture rather than programming. You will need to comprehend some basic code examples, such as JSON code, configuration files, and IAM policy documents, although these are pretty simple. This is a credential that anybody, regardless of background, may obtain with the proper training.
In this post, I'll go through the test blueprint, provide some input from my exam experience, and offer some advice on effectively preparing for this exam. Of course, all exam takers must sign a non-disclosure agreement (NDA) that precludes me from discussing exam subject specifics.
General Information About the Exam:
· AWS Certified Developer Associate is an abbreviation for Amazon Web Services Certified Developer Associate
· The length of the questionnaire is 65 questions.
· Duration: 130 minutes
· Passing grade: 720 points out of a possible 1000 points.
· On the test, there are two sorts of questions:
· Multiple-choice: There is one correct answer and three wrong answers (distractors)
· Multiple response: Has two or more accurate replies from a set of five or more possibilities. (I only saw four of them out of 65 questions.)
· Exam Guide for the AWS Certified Developer Associate
What should I study?
Here is a list of services and some crucial subjects I believe you should learn before taking the exam. There is a strong emphasis on serverless application development, so make sure you are well-versed in the first five services listed below.
Listed in ascending order of significance (the first five services made up over 50 percent of my exam)
AWS LAMBDA (10–15 % OF THE EXAM)
Types of invocation
· Using event source mappings and notifications
· X-Ray concurrency and throttling, as well as Amazon SQS DLLs
· Aliases and variants
· The use of blue and green deployment
· VPC connection packaging and deployment (with Internet/NAT GW)
· ELB target Lambda
· Dependencies
DYNAMODB AMAZON (10 percent OF THE EXAM)
· Query vs. Scans (and the APIs, parameters you can use)
· Secondary indices at the local and global levels
· Calculating RCUs (Read Capacity Units) and WCUs (Write Capacity Units) (WC)
· Best techniques for performance and optimization
· Case studies (for example, session state, key/value data storage, and scalability)
· Streams in DynamoDB
· Use with Lambda and API Gateway in a serverless app.
· Use cases for DynamoDB Accelerator (DAX)
AMAZON API GATEWAY (8%–10% OF THE EXAM)
· Authorizers for Lambda, IAM, and Cognito
· Cache invalidation
· Types of integration: proxy vs. bespoke / AWS vs. HTTP Caching
· importing and exporting Swagger standards for OpenAPI
· Variables at each stage
· Metrics of performance
AWS COGNITO (7%–8% OF THE EXAM)
· Identity pools vs. User pools
· An identity that has not been authenticated
· AWS Cognito Sync with Cognito Web Identity Federation Using MFA
AMAZON S3 (7%–8% OF THE EXAM)
· Encryption – needs to unmake sure you understand S3 encryption well before taking the exam!
· Versioning Data Copying Data Lifecycle Rules S3 Transfer Acceleration
IDENTITY AND ACCESS MANAGEMENT (IAM) ON AMAZON IAM POLICIES AND ROLES
· Access to multiple accounts
· API calls for multi-factor authentication (MFA)
· IAM Roles in EC2 (instance profiles)
· Roles vs. access keys
· Federation of IAM Best Practices
ELASTIC CONTAINER SERVICE ON AMAZON (ECS)
· Containers share storage space.
· Single-docker environments vs. multi-docker environments
· Using ECR to upload and download pictures
· Methods of placement (e.g., spread, binpack, random etc.)
· Mappings of ports
· Task definitions must be defined.
· Task Roles in IAM
ELASTIC BEANSTALK ON AMAZON
· Blue/green deployment policies
· extensions and configuration files
· Deployment updates
· Worker tier vs. web tier
· Deployment, packaging, and files, as well as code and commands, are all utilized.
· Case studies
CLOUD FORMATION ON AWS
· Anatomy of a CloudFormation template (e.g., mappings, outputs, parameters, etc.)
· AWS Serverless Application Model was utilized for packaging and deployment, including instructions (SAM)
#AWS Developer Associate Exam#AWS Certified Solutions Architect Associate#aws certified developer associate
0 notes
Text
Supercharge your knowledge graph using Amazon Neptune, Amazon Comprehend, and Amazon Lex
Knowledge graph applications are one of the most popular graph use cases being built on Amazon Neptune today. Knowledge graphs consolidate and integrate an organization’s information into a single location by relating data stored from structured systems (e.g., e-commerce, sales records, CRM systems) and unstructured systems (e.g., text documents, email, news articles) together in a way that makes it readily available to users and applications. In reality, data rarely exists in a format that allows us to easily extract and connect relevant elements. In this post we’ll build a full-stack knowledge graph application that demonstrates how to provide structure to unstructured and semi-structured data, and how to expose this structure in a way that’s easy for users to consume. We’ll use Amazon Neptune to store our knowledge graph, Amazon Comprehend to provide structure to semi-structured data from the AWS Database Blog, and Amazon Lex to provide a chatbot interface to answer natural language questions as illustrated below. Deploy the application Let’s discuss the overall architecture and implementation steps used to build this application. If you want to experiment, all the code is available on GitHub. We begin by deploying our application and taking a look at how it works. Our sample solution includes the following: A Neptune cluster Multiple AWS Lambda functions and layers that handle the reading and writing of data to and from our knowledge graph An Amazon API Gateway that our web application uses to fetch data via REST An Amazon Lex chatbot, configured with the appropriate intents, which interacts with via our web application An Amazon Cognito identity pool required for our web application to connect to the chatbot Code that scrapes posts from the AWS Database blog for Neptune, enhances the data, and loads it into our knowledge graph A React-based web application with an AWS Amplify chatbot component Before you deploy our application, make sure you have the following: A machine running Docker, either a laptop or a server, for running our web interface An AWS account with the ability to create resources With these prerequisites satisfied, let’s deploy our application: Launch our solution using the provided AWS CloudFormation template in your desired Region: us-east-1 us-west-2 Costs to run this solution depend on the Neptune instance size chosen with a minimal cost for the other services used. Provide the desired stack name and instance size. Acknowledge the capabilities and choose Create stack. This process may take 10–15 minutes. When it’s complete, the CloudFormation stack’s Outputs tab lists the following values, which you need to run the web front end: ApiGatewayInvokeURL IdentityPoolId Run the following command to create the web interface, providing the appropriate parameters: docker run -td -p 3000:3000 -e IDENTITY_POOL_ID= -e API_GATEWAY_INVOKE_URL= -e REGION= public.ecr.aws/a8u6m715/neptune-chatbot:latest After this container has started, you can access the web application on port 3000 of your Docker server (http://localhost:3000/). If port 3000 is in use on your current server, you can alter the port by changing -p :3000. Use the application With the application started, let’s try out the chatbot integration using the following phrases: Show me all posts by Ian Robinson What has Dave Bechberger written on Amazon Neptune? Have Ian Robinson and Kelvin Lawrence worked together Show me posts by Taylor Rigg (This should prompt for Taylor Riggan; answer “Yes”.) Show me all posts on Amazon Neptune Refreshing the browser clears the canvas and chatbox. Each of these phrases provides a visual representation of the contextually relevant connections with our knowledge graph. Build the application Now that we know what our application is capable of doing, let’s look at how the AWS services are integrated to build a full-stack application. We built this knowledge graph application using a common paradigm for developing these types of applications known as ingest, curate, and discover. This paradigm begins by first ingesting data from one or more sources and creating semi-structured entities from it. In our application, we use Python and Beautiful Soup to scrape the AWS Database blog website to generate and store semi-structured data, which is stored in our Neptune-powered knowledge graph. After we extract these semi-structured entities, we curate and enhance them with additional meaning and connections. We do so using Amazon Comprehend to extract named entities from the blog post text. We connect these extracted entities within our knowledge graph to provide more contextually relevant connections within our blog data. Finally, we create an interface to allow easy discovery of our newly connected information. For our application, we use a React application, powered by Amazon Lex and Amplify, to provide a web-based chatbot interface to provide contextually relevant answers to the questions asked. Putting these aspects together gives the following application architecture. Ingest the AWS Database blog The ingest portion of our application uses Beautiful Soup to scrape the AWS Database blog. We don’t examine it in detail, but knowing the structure of the webpage allows us to create semi-structured data from the unstructured text. We use Beautiful Soup to extract several key pieces of information from each post, such as author, title, tags, and images: { "url": "https://aws.amazon.com/blogs/database/configure-amazon-vpc-for-sparql-1-1-federated-query-with-amazon-neptune/", "img_src": "https://d2908q01vomqb2.cloudfront.net/887309d048beef83ad3eabf2a79a64a389ab1c9f/2020/10/02/VPCforSPARQL1.1.FederatedQueryNeptune2.png", "img_height": "395", "img_width": "800", "title": "Configure Amazon VPC for SPARQL 1.1 Federated Query with Amazon Neptune", "authors": [ { "name": "Charles Ivie", "img_src": "https://d2908q01vomqb2.cloudfront.net/887309d048beef83ad3eabf2a79a64a389ab1c9f/2020/08/06/charles-ivie-100.jpg", "img_height": "132", "img_width": "100" } ], "date": "12 OCT 2020", "tags": [ "Amazon Neptune", "Database" ], "post": "" } After we extract this information for all the posts in the blog, we store it in our knowledge graph. The following figure shows the what this looks like for the first five posts. Although this begins to show connections between the entities in our graph, we can extract more context by examining the data stored within each post. To increase the connectedness of the data in our knowledge graph, let’s look at additional methods to curate this semi-structured data. Curate our semi-structured data To extract additional information from our semi-structured data, we use the DetectEntity functionality in Amazon Comprehend. This feature takes a text input and looks for unique names of real-world items such as people, places, items, or references to measures such as quantities or dates. By default, the types of entities returned are provided a label of COMMERCIAL_ITEM, DATE, EVENT, LOCATION, ORGANIZATION, OTHER, PERSON, QUANTITY, or TITLE. To enhance our data, the input is required to be UTF-encoded strings of up to 5,000-byte chunks. We do this by dividing each post by paragraph and running each paragraph through the batch_detect_entities method in batches of 25. For each entity that’s detected, the score, type, text, as well as begin and end offsets are returned, as in the following example code: { "Score": 0.9177741408348083, "Type": "TITLE", "Text": "SPARQL 1.1", "BeginOffset": 13, "EndOffset": 23 } Associating each of these detected entities with our semi-structured data in our knowledge graph shows even more connections, as seen in a subset in the following graph. When we compare this to our previous graph, we see that a significant number of additional connections have been added. These connections not only link posts together, they allow us to provide additional relevant answers by linking posts based on contextual relevant information stored within the post. This brings us to the final portion of this sample application: creating a web-based chatbot to interact with our new knowledge graph. Discover information in our knowledge graph Creating a web application to discover information in our knowledge graph has two steps: defining our chatbot and integrating the chatbot into a web application. Defining our chatbot Our application’s chatbot is powered by Amazon Lex, which makes it easy to build conversational interfaces for applications. The building block for building any bot with Amazon Lex is an intent. An intent is an action that responds to natural language user input. Our bot has four different intents specified: CoAuthorPosts PostByAuthor PostByAuthorAndTag PostByTag Each intent is identified by defining a variety of short training phrases for that intent, known as utterances. Each utterance is unique and when a user speaks or types that phrase, the associated intent is invoked. The phrases act as training data for the Lex bot to identify user input and map it to the appropriate intent. For example, the PostsByAuthor intent has a few different utterances that can invoke it, as shown in the following screenshot. The best practice is to use 15–20 sample utterances to provide the necessary variations for the model to perform with optimum accuracy. One or more slot values are within each utterance, identified by the curly brackets, which represent input data that is needed for the intent. Each slot value can be required or not, has a slot type associated with it, and has a prompt that used by the chatbot for eliciting the slot value if it’s not present. In addition to configuring the chatbot to prompt the user for missing slot values, you can specify a Lambda function to provide a more thorough validation of the inputs (against values available in the database) or return potential options back to the user to allow them to choose. For our PostsByAuthor intent, we configure a validation check to ensure that the author entered a valid author in our knowledge graph. The final piece is to define the fulfillment action for the intents. This is the action that occurs after the intent is invoked and all required slots are filled or validation checks have occurred. When defining the fulfillment action, you can choose from either invoking a Lambda function or returning the parameters back to the client. After you define the intent, you build and test it on the provided console. Now that the chatbot is functioning as expected, let’s integrate it into our web application. Integrate our chatbot Integration of our chatbot into our React application is relatively straightforward. We use the familiar React paradigms of components and REST calls, so let’s highlight how to configure the integration between React and Amazon Lex. Amazon Lex supports a variety of different deployment options natively, including Facebook, Slack, Twilio, or Amplify. Our application uses Amplify, which is an end-to-end toolkit that allows us to construct full-stack applications powered by AWS. Amplify offers a set of component libraries for a variety of front-end frameworks, including React, which we use in our application. Amplify provides an interaction component that makes it simple to integrate a React front end to our Amazon Lex chatbot. To accomplish this, we need some configuration information, such as the chatbot name and a configured Amazon Cognito identity pool ID. After we provide these configuration values, the component handles the work of wiring up the integration with our chatbot. In addition to the configuration, we need an additional piece of code (available on GitHub) to handle the search parameters returned as the fulfillment action from our Amazon Lex intent: useEffect(() => { const handleChatComplete = (event) => { const { data, err } = event.detail; if (data) { props.setSearchParameter(data["slots"]); } if (err) console.error("Chat failed:", err); }; const chatbotElement = document.querySelector("amplify-chatbot"); chatbotElement.addEventListener("chatCompleted", handleChatComplete); return function cleanup() { chatbotElement.removeEventListener("chatCompleted", handleChatComplete); }; }, [props]); With the search parameters for our intent, we can now call our API Gateway as you would for other REST based calls. Clean up your resources To clean up the resources used in this post, use either the AWS Command Line Interface (AWS CLI) or the AWS Management Console. Delete the CloudFormation template that you used to configure the remaining resources generated as part of this application. Conclusion Knowledge graphs—especially enterprise knowledge graphs—are efficient ways to access vast arrays of information within an organization. However, doing this effectively requires the ability to extract connections from within a large amount of unstructured and semi-structured data. This information then needs to be accessible via a simple and user-friendly interface. NLP and natural language search techniques such as those demonstrated in this post are just one of the many ways that AWS powers an intelligent data extraction and insight platform within organizations. If you have any questions or want a deeper dive into how to leverage Amazon Neptune for your own knowledge graph use case, we suggest looking at our Neptune Workbench notebook (01-Building-a-Knowledge-Graph-Application). This workbook uses the same AWS Database Blog data used here but provides additional details on the methodology, data model, and queries required to build a knowledge graph based search solution. As with other AWS services, we’re always available through your Amazon account manager or via the Amazon Neptune Discussion Forums. About the author Dave Bechberger is a Sr. Graph Architect with the Amazon Neptune team. He used his years of experience working with customers to build graph database-backed applications as inspiration to co-author “Graph Databases in Action” by Manning. https://aws.amazon.com/blogs/database/supercharge-your-knowledge-graph-using-amazon-neptune-amazon-comprehend-and-amazon-lex/
0 notes
Text
RT @albertgao: Listening to the recent @syntaxfm learned that @MongoDB stitch added GraphQL support. Exciting. Just tried it. Awesome, love to be back finally. And TBH, its auth model is by far the easiest compare to AWS Cognito, Auth0. Especially for the documentation. DB + Serverless FTW! https://t.co/iXlQAsNMuQ
Listening to the recent @syntaxfm learned that @MongoDB stitch added GraphQL support. Exciting. Just tried it. Awesome, love to be back finally. And TBH, its auth model is by far the easiest compare to AWS Cognito, Auth0. Especially for the documentation. DB + Serverless FTW! pic.twitter.com/iXlQAsNMuQ
— Albert Gao (@albertgao) March 11, 2020
MongoDB
0 notes
Text
Urgent Requirement Head of Development and Cloud Lead in Singapore
Company Overview:
Intellect Minds is a Singapore-based company since 2008, specializing in talent acquisition, application development, and training. We are the Best Job Recruitment Agency and consultancy in Singapore serve BIG MNCs and well-known clients in talent acquisition, application development, and training needs for Singapore, Malaysia, Brunei, Vietnam, and Thailand.
Role overview:
This is a hybrid role in a leading company that combines responsibility as Lead Project Manager overseeing the development of the company’s web and app software while assuming full responsibility for the Cloud and Application infrastructure to support business and IT development needs.
Your primary responsibilities will be the following duties. Specifically:
• Technology team leader (project management, communication with senior management team, consult with potential B2B clients) • Cloud Architecture (High Availability, DR) • Cloud security (Network/Application/Database) • Cloud compliance (MAS TRM) • Ensure that the Company’s IT set up is fully compliant with the MAS Guidelines and Notice on Technology Risk Management, implementing new processes as required. IT Compliance consists of conducting and reviewing policies on business continuity and back up, and improvements to hardware and software as required, with a focus on security, data protection and scalability, as required. • Change Management • Continuous Integration/Deployment (CI/CD) • Automation • Backup & Recovery • Auditing Changes • Database design • Deploy application middleware (Apache/Tomcat) • Cloud Infrastructure monitoring & tuning • Cloud Cost optimization • Monitoring & Operations • Documenting policies and procedures around the IT systems in place and introducing best practice security measures and user controls etc.
Person Specification:
Education and Professional Qualifications: • Excellent interpersonal, communication and organizational skills • Strong attention to detail • Ability to work in a fast-paced, collaborative environment • Expert AWS Architect • Experience with Microservices, AWS Cognito, Postgres, MySQL, Apache, Tomcat Work Experience/ Skills and Knowledge • Candidates should ideally have 8 to 10 years previous experience in a similar role, preferably within a financial institution or Multi-National Corporation
All successful candidates can expect a very competitive remuneration package and a comprehensive range of benefits.
Interested Candidates, please submit your detailed resume online.
To your success!
The Recruitment Team
Intellect Minds Pte Ltd (Singapore)

0 notes
Photo

AWS SDK for Python(boto3)でAmazon Managed Blockchainのブロックチェーンネットワークを作成してみた http://bit.ly/2QO67Y5
Amazon Managed Blockchainでブロックチェーンネットワークを構築するのにAWS CloudFormationを利用したいなぁとドキュメントを読んでみたらリソースがありませんでした。oh… AWS CloudFormationのカスタムリソースを利用すれば管理できるので、まずはAWS SDKでAmazon Managed Blockchainが取り扱えるのか��認してみました。
AWS CloudFormationのカスタムリソースについては下記が参考になります。
カスタムリソース – AWS CloudFormation https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/template-custom-resources.html
CloudFormationで提供されていない処理をカスタムリソースで作ってみた。 | DevelopersIO https://dev.classmethod.jp/cloud/aws/cfn-api-custom/
AWS CloudFormationでCognitoユーザープールをMFAのTOTPを有効にして作成する – Qiita https://cloudpack.media/44573
Amazon Managed Blockchainってなんぞ?
Amazon Managed Blockchainってなんぞ?という方は下記をご参考ください。
Amazon Managed BlockchainがリリースされたのでHyperledger Fabricも合わせて情報をまとめてみた – Qiita https://cloudpack.media/46950
前提
今回はAmazon Managed Blockchainのネットワーク、メンバー、ノードがAWS SDKで作成できるかの確認のみとなります。セキュリティグループ、インタフェースVPCエンドポイントやHyperledger Fabricの設定などは行いません。
AWSアカウントがある
AWSアカウントに以下の作成権限がある
Managed Blockchainネットワーク
AWS CLIのaws configure コマンドでアカウント設定済み
ネットワーク構築して動作確認するまでの手順は下記が参考になります。
Amazon Managed BlockchainでHyperledger Fabricのブロックチェーンネットワークを構築してみた – Qiita https://cloudpack.media/46963
AWS SDK for Python(boto3)でAmazon Managed BlockchainのAPIが提供されてる
ドキュメントを確認してみたらAWS SDKでAmazon Managed BlockchainのAPIが提供されていました。
boto/boto3: AWS SDK for Python https://github.com/boto/boto3
ManagedBlockchain — Boto 3 Docs 1.9.152 documentation https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/managedblockchain.html
Python環境の用意
Pipenvを利用したことがなかったので、ついでに初利用します(趣味)。 仮想環境じゃなくてもOKです。
Pipenvを使ったPython開発まとめ – Qiita https://qiita.com/y-tsutsu/items/54c10e0b2c6b565c887a
# pipenvがインストールされてなかったら > pip install pipenv (略) Installing collected packages: virtualenv, virtualenv-clone, pipenv Successfully installed pipenv-2018.11.26 virtualenv-16.6.0 virtualenv-clone-0.5.3 # 仮想環境の作成 > pipenv --python 3.7 Creating a virtualenv for this project… Pipfile: /Users/xxx/dev/aws/managed-blockchain-use-sdk/Pipfile Using /Users/xxx/.anyenv/envs/pyenv/versions/3.7.0/bin/python3 (3.7.0) to create virtualenv… ⠴ Creating virtual environment... (略) ✓ Successfully created virtual environment! Virtualenv location: /Users/xxx/.local/share/virtualenvs/managed-blockchain-use-sdk-ijMKrYxz Creating a Pipfile for this project… # boto3のインストール > pipenv install boto3 Installing boto3… ⠴ Installing... (略) # 仮想環境へ入る > pipenv shell Launching subshell in virtual environment… Welcome to fish, the friendly interactive shell
AWS SDK for Python(boto3)を利用して実装
ドキュメントを参考にネットワークなどを作成、取得できるか確認します。
ManagedBlockchain — Boto 3 Docs 1.9.152 documentation https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/managedblockchain.html
ネットワークとメンバーの作成
create_network でネットワーク作成できます。パラメータはAWS CLIとほぼ同じなので下記が参考になります。 AWS CLIと同じく最初のメンバーも合わせて作成する必要があります。
Amazon Managed BlockchainでHyperledger Fabricのブロックチェーンネットワークを構築してみた – Qiita https://cloudpack.media/46963
create_network.py
import boto3 client = boto3.client("managedblockchain") def create_network(): new_network = client.create_network( ClientRequestToken="string", Name="TestNetwork", Description="TestNetworkDescription", Framework="HYPERLEDGER_FABRIC", FrameworkVersion="1.2", FrameworkConfiguration={ "Fabric": { "Edition": "STARTER" } }, VotingPolicy={ "ApprovalThresholdPolicy": { "ThresholdPercentage": 50, "ProposalDurationInHours": 24, "ThresholdComparator": "GREATER_THAN" } }, MemberConfiguration={ "Name": "org1", "Description": "Org1 first member of network", "FrameworkConfiguration": { "Fabric": { "AdminUsername": "AdminUser", "AdminPassword": "Password123" } } } ) print(new_network)
実行するとネットワークとメンバーの作成が開始されてNetworkId とMemberId が得られます。
> python create_network.py {'ResponseMetadata': {'RequestId': 'xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx', 'HTTPStatusCode': 200, 'HTTPHeaders': {'date': 'Tue, 21 May 2019 03:24:32 GMT', 'content-type': 'application/json', 'content-length': '86', 'connection': 'keep-alive', 'x-amzn-requestid': 'xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx', 'x-amz-apigw-id': 'xxxxxxxxxxxxxxx=', 'x-amzn-trace-id': 'Root=1-xxxxxxxx-xxxxxxxxxxxxxxxxxxxxxxxx; Sampled=0'}, 'RetryAttempts': 0}, 'NetworkId': 'n-XXXXXXXXXXXXXXXXXXXXXXXXXX', 'MemberId': 'm-XXXXXXXXXXXXXXXXXXXXXXXXXX'}
ネットワーク情報の取得
list_networks でネットワーク情報が取得できます。 パラメータ指定することで検索もできるみたいです。
list_network.py
import boto3 client = boto3.client("managedblockchain") def list_network(): networks = client.list_networks( # Name="Test" # Name="string", # Framework="HYPERLEDGER_FABRIC", # Status="CREATING"|"AVAILABLE"|"CREATE_FAILED"|"DELETING"|"DELETED", # MaxResults=123, # NextToken="string" ) print(networks) list_networks()
> python list_network.py [{'Id': 'n-XXXXXXXXXXXXXXXXXXXXXXXXXX', 'Name': 'TestNetwork', 'Description': 'TestNetworkDescription', 'Framework': 'HYPERLEDGER_FABRIC', 'FrameworkVersion': '1.2', 'Status': 'CREATING', 'CreationDate': datetime.datetime(2019, 5, 21, 3, 24, 31, 929000, tzinfo=tzutc())}]
ノードの作成
create_node でノード作成ができます。ClientRequestToken に関しては指定しない場合自動生成してくれるとのことでした。手動での生成方法は未調査です。
create_node.py
import boto3 client = boto3.client("managedblockchain") def create_node(): new_node = client.create_node( # ClientRequestToken='string', NetworkId='n-5QBOS5ULTVEZZG6EMIPLPRSSQA', MemberId='m-OMLBOQIAMJDDPJV3FVGIAVUGBE', NodeConfiguration={ 'InstanceType': 'bc.t3.small', 'AvailabilityZone': 'us-east-1a' } ) print(new_node) create_node()
> python create_node.py {'ResponseMetadata': {'RequestId': 'xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx', 'HTTPStatusCode': 200, 'HTTPHeaders': {'date': 'Tue, 21 May 2019 04:04:44 GMT', 'content-type': 'application/json', 'content-length': '42', 'connection': 'keep-alive', 'x-amzn-requestid': 'xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx', 'x-amz-apigw-id': 'xxxxxxxxxxxxxxx=', 'x-amzn-trace-id': 'Root=1-xxxxxxxx-xxxxxxxxxxxxxxxxxxxxxxxx;Sampled=0'}, 'RetryAttempts': 0}, 'NodeId': 'nd-XXXXXXXXXXXXXXXXXXXXXXXXXX'}
ネットワーク、メンバーが作成中(Status がCREATING )の場合は作成できませんでした。
ネットワーク、メンバー作成中に実行
> python create_node.py Traceback (most recent call last): File "main.py", line 43, in <module> 'AvailabilityZone': 'us-east-1a' File "/Users/xxx/.local/share/virtualenvs/managed-blockchain-use-sdk-ijMKrYxz/lib/python3.7/site-packages/botocore/client.py", line 357, in _api_call return self._make_api_call(operation_name, kwargs) File "/Users/xxx/.local/share/virtualenvs/managed-blockchain-use-sdk-ijMKrYxz/lib/python3.7/site-packages/botocore/client.py", line 661, in _make_api_call raise error_class(parsed_response, operation_name) botocore.errorfactory.ResourceNotReadyException: An error occurred (ResourceNotReadyException) when calling the CreateNode operation: Member m-XXXXXXXXXXXXXXXXXXXXXXXXXX is in CREATING. you cannot create nodes at this time..
メンバー情報の取得
list_members でメンバーが取得できます。NetworkId が必須となります。
list_members.py
import boto3 client = boto3.client("managedblockchain") def list_members(): members = client.list_members( NetworkId="n-XXXXXXXXXXXXXXXXXXXXXXXXXX" # Name="string", # Status="CREATING"|"AVAILABLE"|"CREATE_FAILED"|"DELETING"|"DELETED", # IsOwned=True|False, # MaxResults=123, # NextToken="string" ) print(members["Members"]) list_members()
> pyhton list_members.py [{'Id': 'm-XXXXXXXXXXXXXXXXXXXXXXXXXX', 'Name': 'demo', 'Description': 'demo member', 'Status': 'AVAILABLE', 'CreationDate': datetime.datetime(2019, 5, 21, 3, 24, 32, 271000, tzinfo=tzutc()), 'IsOwned': True}]
ノード情報の取得
list_nodes でノードが取得できます。NetworkId 、MemberId が必須となります。
list_nodes.py
import boto3 client = boto3.client("managedblockchain") def list_nodes(): nodes = client.list_nodes( NetworkId="n-XXXXXXXXXXXXXXXXXXXXXXXXXX", MemberId="m-XXXXXXXXXXXXXXXXXXXXXXXXXX" # Status="CREATING"|"AVAILABLE"|"CREATE_FAILED"|"DELETING"|"DELETED"|"FAILED", # MaxResults=123, # NextToken="string" ) print(nodes["Nodes"]) list_nodes()
> pyhton list_nodes.py [{'Id': 'nd-XXXXXXXXXXXXXXXXXXXXXXXXXX', 'Status': 'AVAILABLE', 'CreationDate': datetime.datetime(2019, 5, 21, 4, 4, 44, 468000, tzinfo=tzutc()), 'AvailabilityZone': 'us-east-1a', 'InstanceType': 'bc.t3.small'}]
特にハマることもなくboto3を利用してネットワーク、メンバー、ノードを作成することができました。 これで、AWS CloudFormationのカスタムリソースを利用してリソース管理することができそうです。 ただ、ネットワークとメンバー作成に20分程度かかるので、その待受処理などがAWS CloudFormationで実現できるのか、ちょっと心配です。(未調査)
参考
カスタムリソース – AWS CloudFormation https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/template-custom-resources.html
CloudFormationで提供されていない処理をカスタムリソースで作ってみた。 | DevelopersIO https://dev.classmethod.jp/cloud/aws/cfn-api-custom/
AWS CloudFormationでCognitoユーザープールをMFAのTOTPを有効にして作成する – Qiita https://cloudpack.media/44573
boto/boto3: AWS SDK for Python https://github.com/boto/boto3
ManagedBlockchain — Boto 3 Docs 1.9.152 documentation https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/managedblockchain.html
Amazon Managed BlockchainがリリースされたのでHyperledger Fabricも合わせて情報をまとめてみた – Qiita https://cloudpack.media/46950
Amazon Managed BlockchainでHyperledger Fabricのブロックチェーンネットワークを構築してみた – Qiita https://cloudpack.media/46963
Pipenvを使ったPython開発まとめ – Qiita https://qiita.com/y-tsutsu/items/54c10e0b2c6b565c887a
Amazon Managed BlockchainでHyperledger Fabricのブロックチェーンネットワークを構築してみた – Qiita https://cloudpack.media/46963
元記事はこちら
「AWS SDK for Python(boto3)でAmazon Managed Blockchainのブロックチェーンネットワークを作成してみた」
June 05, 2019 at 12:00PM
0 notes
Text
AWS Cloud Practitioner Training - What to Expect in the Exam
Last year Amazon Web Services exceeded $7 billion in fourth-quarter revenue, a jump of over 45% from the year before. With growth as exceptional as this, demand for cloud engineers is understandably increasing at a rapid rate.
Training and certification are a great way to get started in the cloud world and with typical salaries exceeding $100k p/a there has been a huge uptake in training in recent years. To get a job in a competitive market you need to be able to differentiate yourself and gaining several AWS certifications is a sensible way to get started.
Many aspiring cloud engineers will start their learning path by taking the AWS Certified Cloud Practitioner exam. This exam is the foundational level in the AWS training program and is a good first step on your path to cloud mastery.
In this article, I want to explore the AWS Cloud Practitioner Training path in more detail so you can get an idea of what to expect in the exam. I will discuss the recommended training, experience and practice that you should undertake before sitting the exam.
The AWS Exam Blueprint
As a foundational level exam, the AWS Certified Cloud Practitioner is intended for individuals who have the ability to, in Amazon’s words, "effectively demonstrate an overall understanding of the AWS Cloud". This certification is fairly generic and does not assess the skills required for specific job roles such as Developers, Sysops Administrators, and Solutions Architects.
AWS recommend you have a minimum of 6 months experience with the AWS Cloud. However, this does not need to be experience in a technical job role. Exposure to the AWS Cloud in a managerial, sales, purchasing or financial position is also acceptable.
The exam includes 65 questions and has a time limit of 90 minutes. You need to score a minimum of 700 out of 1000 points to pass the exam.
The question format of the exam is multiple-choice (one correct response from four options) and multiple-response (two correct responses from five options).
As you’ll see from the example questions later in this article, the questions are fairly straightforward and not scenario based like in other exams such as the Associate and Professional level certifications.
In the AWS Certified Cloud Practitioner exam blueprint, it is stated that the exam validates an examinee's ability to:
Define what the AWS Cloud is and the basic global infrastructure
Describe basic AWS Cloud architectural principles
Describe the AWS Cloud value proposition
Describe key services on the AWS platform and their common use cases(for example, compute and analytics)
Describe the basic security and compliance aspects of the AWS platform and the shared security model
Define the billing, account management, and pricing models
Identify sources of documentation or technical assistance (for example, whitepapers or support tickets)
Describe basic/core characteristics of deploying and operating in the AWS Cloud
Throughout the rest of this article, we’ll explore these knowledge requirements in more detail, and I’ll try to give you a clear idea of what to expect in the exam.
Domains, objectives and examples
The knowledge required is organized into four test "domains". Within each test domain there are several objectives that broadly describe the knowledge and experience expected to pass the exam.
Test Domain 1: Cloud Concepts
This domain makes up 28% of the exam and includes the following three objectives:
1.1 Define the AWS Cloud and its value proposition
1.2 Identify aspects of AWS Cloud economics
1.3 List the different cloud architecture design principles
What you need to know
You should be able to describe the benefits of public cloud services and be able to define what types of services are available on AWS (think IaaS, PaaS, SaaS). Make sure you understand the 6 advantages of cloud:
Trade capital expense for variable expense
Benefit from massive economies of scale
Stop guessing about capacity
Increase speed and agility
Stop spending money running and maintaining data centers
Go global in minutes
You need to know how cloud is beneficial from a financial perspective and should understand the difference between CAPEX and OPEX - this relates to item 1 in the list above.
You should understand the design principles of creating cloud architectures, this includes loose coupling, scaling (vertically and horizontally), bootstrapping and automation, to name just a few.
The AWS blog article "The 5 Pillars of the Well-Architected Framework" is essential reading, as is the whitepaper "Architecting for the Cloud: Best Practices".
Example questions
Question: Which feature of AWS allows you to deploy a new application for which the requirements may change over time?
Elasticity
Fault tolerance
Disposable resources
High availability
Answer: 1, elasticity allows you to deploy your application without worrying about whether it will need more or less resources in the future. With elasticity, the infrastructure can scale on-demand
Question: What advantages do you get from using the AWS cloud? (choose 2)
Trade capital expense for variable expense
Stop guessing about capacity
Increased capital expenditure
Gain greater control of the infrastructure layer
Comply with all local security compliance programs
Answer: 1+2, with public cloud services such as AWS you can pay on a variable (OPEX) basis for the resources you use and scale on-demand, so you never need to guess how much resources you need to deploy.
Resources
Architecting for the cloud best practices whitepaper
The 5 Pillar of the AWS Well-Architected Framework
Cloud Computing Concepts
Architecting for the Cloud
Test Domain 2: Security
This domain makes up 24% of the exam and includes the following four objectives:
2.1 Define the AWS Shared Responsibility mode
2.2 Define AWS Cloud security and compliance concepts
2.3 Identify AWS access management capabilities
2.4 Identify resources for security support
What you need to know
You should understand the AWS shared responsibility model which defines who is responsible for different aspects of the technology stack from the data centre through to servers, firewall rules and data encryption.
AWS provide tools and services for implementing security, assessing your security position, and generating alerts and compliance reports. You need to understand these services and tools well enough to describe their usage and benefits. This includes services such as KMS, CloudTrail and AWS Artifact.
You also need to understand the services that are used for authentication, authorization and access management. This includes services such as AWS IAM, and Amazon Cognito, and the usage of access keys, key pairs and signed URLs.
Support services include real-time insights through AWS Trusted Advisor and proactive support and advocacy with a Technical Account Manager (TAM). Make sure you know which support packages include a TAM.
Example questions
Question: Under the AWS shared responsibility model what is the customer responsible for?(choose 2)
Physical security of the data center
Replacement and disposal of disk drives
Configuration of security groups
Patch management of infrastructure
Encryption of customer data
Answer: 3+5, AWS are responsible for items such as the physical security of the DC, replacement of old disk drives, and patch management of the infrastructure whereas customers are responsible for items such as configuring security groups, network ACLs, patching their operating systems and encrypting their data.
Question: Which AWS service is used to enable multi-factor authentication?
Amazon STS
AWS IAM
Amazon EC2
AWS KMS
Answer: 2, IAM is used to securely control individual and group access to AWS resources and can be used to manage multi-factor authentication.
Resources
AWS Shared Responsibility Model
AWS Cloud Security
Identity and Access Management
AWS Billing and Pricing
Test Domain 3: Technology
This domain makes up 36% of the exam and includes the following four objectives:
3.1 Define methods of deploying and operating in the AWS Cloud
3.2 Define the AWS global infrastructure
3.3 Identify the core AWS services
3.4 Identify resources for technology support
What you need to know
You need to understand the core AWS services and what they are used for. You typically don't need a deep level of knowledge of the specifics of a service but do need to understand its purpose, benefits and use cases.
Core services include EC2, ECS, Lambda, LightSail, EBS, EFS, S3, RDS, DynamoDB, RedShift, ElastiCache, Elastic Load Balancing, Auto Scaling, CloudFront, Route 53, CloudWatch, CloudTrail, and SNS.
You should understand the underlying global infrastructure that makes up the AWS Cloud. This includes regions, availability zones, and edge locations. Make sure you understand which services are globally or regionally defined.
You should also know the customer configurable building blocks of cloud services including VPCs, and subnets, and connectivity options such as Internet Gateways, VPN and Direct Connect. Also, ensure you know the difference between NAT Instances and NAT Gateways and the relative benefits of each service.
Example questions
Question: What are the advantages of Availability Zones? (choose 2)
They allow regional disaster recovery
They provide fault isolation
They enable the caching of data for faster delivery to end users
They are connected by low-latency network connections
They enable you to connect your on-premises networks to AWS to form a hybrid cloud
Answer: 3+4, both Amazon EC2 and Amazon S3 are managed at a regional level. Note: Amazon S3 is a global namespace but you still create your buckets within a region.
Question: Which AWS support plans provide support via email, chat and phone? (choose 2)
Basic
Business
Developer
Global
Enterprise
Answer: 2+5, only the business and enterprise plans provide support via email, chat and phone.
Resources
AWS Global Infrastructure
Identity and Access Management
AWS Services: AWS Compute, AWS Storage, AWS Networking, AWS Databases, Elastic Load Balancing and Auto Scaling, Content Delivery and DNS, Monitoring and Logging, Notification Services, Additional AWS Services
Test Domain 4: Billing and Pricing
This domain makes up 12% of the exam and includes the following three objectives:
4.1 Compare and contrast the various pricing models for AWS
4.2 Recognize the various account structures in relation to AWS billing and pricing
4.3 Identify resources available for billing support
What you need to know
Most services on AWS are offered on a pay per use basis, but there are also options to reduce price by locking in to 1- or 3-year contracts with various options for payment. You need to understand these models and which services they apply to.
Make sure you understand what AWS charges you for and what is free of charge. For instance, inbound data transfer is free whereas outbound data transfer typically incurs costs.
Some services such as VPC, CloudFormation, and IAM are free but the resources you create with them may not be. You need to understand where costs may be incurred.
AWS accounts can be organized into Organizations for centralized management of policies and consolidated billing. You need to understand the various accounts structures and the benefits and use cases for implementing them.
For instance, you might want separate account structures to manage different policies for production and non-production resources, or you might implement consolidated billing to take advantage of volume discounts.
For billing support, you need to know the services and tools available to you and what levels of support you can get from AWS support plans.
Tools include AWS Cost Explorer, AWS Simple Monthly Calculator, and Total Cost of Ownership (TCO) calculator.
Example questions
Question: What are two ways an AWS customer can reduce their monthly spend? (choose 2)
Turn off resources that are not being used
Use more power efficient instance types
Reserve capacity where suitable
Be efficient with usage of Security Groups
Reduce the amount of data ingress charges
Answer: 1+3, turning off resources that are not used can reduce spend. You can also use reserved instances to reduce the monthly spend at the expense of having to lock into a 1 or 3-year contract - good for stable workloads.
Question: A company would like to maximize their potential volume and RI discounts across multiple accounts and also apply service control policies on member accounts. What can they use gain these benefits?
AWS Budgets
AWS Cost Explorer
AWS IAM
AWS Organizations
Answer: 4, AWS Organizations enables you to create groups of AWS accounts and then centrally manage policies across those accounts. AWS Organizations provides consolidated billing in both feature sets, which allows you set up a single payment method in the organization’s master account and still receive an invoice for individual activity in each member account. Volume pricing discounts can be applied to resources.
Resources
Check out the AWS FAQs for each service on the AWS website
AWS Billing and Pricing
AWS Cloud Practitioner Training
If you’re new to AWS, or cloud computing in general, and this is a bit overwhelming, fear not as there are some excellent and economical options for training.
The best way to get started is to head over to the aws.training website. AWS provide a number of free online courses including the “AWS Cloud Practitioner Essentials” course that are a great way to learn the fundamentals of the AWS Cloud.
However, I would like to note that many of our students have reported that the training on the aws.training website is not enough to pass the exam so you will need to find additional training resources.
Another learning tool is our Training Noteson the Digital Cloud Training website which provide a deeper level of detail for all test domains of the Cloud Practitioner exam. Get access here.
At Digital Cloud Training we also offer AWS Certified Cloud Practitioner Practice Exams which are designed to be representative of the question format and difficulty of the actual AWS exam. These are a great way not just of assessing your readiness, but also for learning the concepts as we provide detailed explanations and reference links for every question. But don’t leave it until the last minutes, get started with AWS Certified Cloud Practitioner Practice Exams early so you can ensure you’re on track.
Last but not least, make sure you get access to the AWS Cloud platform and start learning through practice. AWS provide a free-tier that you can use to spin up many services without incurring any costs. Get yourself signed up and start learning the fun way!
0 notes
Link
Zack Kanter Contributor
Zack Kanter is the co-founder of Stedi.
More posts by this contributor
Why Amazon is eating the world
While serverless is typically championed as a way to reduce costs and scale massively on demand, there is one extraordinarily compelling reason above all others to adopt a serverless-first approach: it is the best way to achieve maximum development velocity over time. It is not easy to implement correctly and is certainly not a cure-all, but, done right, it paves an extraordinary path to maximizing development velocity, and it is because of this that serverless is the most under-hyped, under-discussed tech movement amongst founders and investors today.
The case for serverless starts with a simple premise: if the fastest startup in a given market is going to win, then the most important thing is to maintain or increase development velocity over time. This may sound obvious, but very, very few startups state maintaining or increasing development velocity as an explicit goal.
“Development velocity,” to be specific, means the speed at which you can deliver an additional unit of value to a customer. Of course, an additional unit of customer value can be delivered either by shipping more value to existing customers, or by shipping existing value—that is, existing features—to new customers.
For many tech startups, particularly in the B2B space, both of these are gated by development throughput (the former for obvious reasons, and the latter because new customer onboarding is often limited by onboarding automation that must be built by engineers). What does serverless mean, exactly? It’s a bit of a misnomer. Just as cloud computing didn’t mean that data centers disappeared into the ether — it meant that those data centers were being run by someone else, and servers could be provisioned on-demand and paid for by the hour — serverless doesn’t mean that there aren’t any servers.
There always have to be servers somewhere. Broadly, serverless means that you aren’t responsible for all of the configuration and management of those servers. A good definition of serverless is pay-per-use computing where uptime is out of the developer’s control. With zero usage, there is zero cost. And if the service goes down, you are not responsible for getting it back up. AWS started the serverless movement in 2014 with a “serverless compute” platform called AWS Lambda.
Whereas a ‘normal’ cloud server like AWS’s EC2 offering had to be provisioned in advance and was billed by the hour regardless of whether or not it was used, AWS Lambda was provisioned instantly, on demand, and was billed only per request. Lambda is astonishingly cheap: $0.0000002 per request plus $0.00001667 per gigabyte-second of compute. And while users have to increase their server size if they hit a capacity constraint on EC2, Lambda will scale more or less infinitely to accommodate load — without any manual intervention. And, if an EC2 instance goes down, the developer is responsible for diagnosing the problem and getting it back online, whereas if a Lambda dies another Lambda can just take its place.
Although Lambda—and equivalent services like Azure Functions or Google Cloud Functions—is incredibly attractive from a cost and capacity standpoint, the truth is that saving money and preparing for scale are very poor reasons for a startup to adopt a given technology. Few startups fail as a result of spending too much money on servers or from failing to scale to meet customer demand — in fact, optimizing for either of these things is a form of premature scaling, and premature scaling on one or many dimensions (hiring, marketing, sales, product features, and even hierarchy/titles) is the primary cause of death for the vast majority of startups. In other words, prematurely optimizing for cost, scale, or uptime is an anti-pattern.
When people talk about a serverless approach, they don’t just mean taking the code that runs on servers and chopping it up into Lambda functions in order to achieve lower costs and easier scaling. A proper serverless architecture is a radically different way to build a modern software application — a method that has been termed a serverless, service-full approach.
It starts with the aggressive adoption of off-the-shelf platforms—that is, managed services—such as AWS Cognito or Auth0 (user authentication—sign up and sign in—as-a-service), AWS Step Functions or Azure Logic Apps (workflow-orchestration-as-a-service), AWS AppSync (GraphQL backend-as-a-service), or even more familiar services like Stripe.
Whereas Lambda-like offerings provide functions as a service, managed services provide functionality as a service. The distinction, in other words, is that you write and maintain the code (e.g., the functions) for serverless compute, whereas the provider writes and maintains the code for managed services. With managed services, the platform is providing both the functionality and managing the operational complexity behind it.
By adopting managed services, the vast majority of an application’s “commodity” functionality—authentication, file storage, API gateway, and more—is handled by the cloud provider’s various off-the-shelf platforms, which are stitched together with a thin layer of your own ‘glue’ code. The glue code — along with the remaining business logic that makes your application unique — runs on ultra-cheap, infinitely-scalable Lambda (or equivalent) infrastructure, thereby eliminating the need for servers altogether. Small engineering teams like ours are using it to build incredibly powerful, easily-maintainable applications in an architecture that yields an unprecedented, sustainable development velocity as the application gets more complex.
There is a trade-off to adopting the serverless, service-full philosophy. Building a radically serverless application requires taking an enormous hit to short term development velocity, since it is often much, much quicker to build a “service” than it is to use one of AWS’s off-the-shelf. When developers are considering a service like Stripe, “build vs buy” isn’t even a question—it is unequivocally faster to use Stripe’s payment service than it is to build a payment service yourself. More accurately, it is faster to understand Stripe’s model for payments than it is to understand and build a proprietary model for payments—a testament both to the complexity of the payment space and to the intuitive service that Stripe has developed.
But for developers dealing with something like authentication (Cognito or Auth0) or workflow orchestration (AWS Step Functions or Azure Logic Apps), it is generally slower to understand and implement the provider’s model for a service than it is to implement the functionality within the application’s codebase (either by writing it from scratch or by using an open source library). By choosing to use a managed service, developers are deliberately choosing to go slower in the short term—a tough pill for a startup to swallow. Many, understandably, choose to go fast now and roll their own.
The problem with this approach comes back to an old axiom in software development: “code isn’t an asset—code is debt.” Code requires an entry on both sides of the accounting equation. It is an asset that enables companies to deliver value to the customer, but it also requires maintenance that has to be accounted for and distributed over time. All things equal, startups want the smallest codebase possible (provided, of course, that developers aren’t taking this too far and writing clever but unreadable code). Less code means less surface area to maintain, and also means less surface area for new engineers to grasp during ramp-up.
Herein lies the magic of using managed services. Startups get the beneficial use of the provider’s code as an asset without holding that code debt on their “technical balance sheet.” Instead, the code sits on the provider’s balance sheet, and the provider’s engineers are tasked with maintaining, improving, and documenting that code. In other words, startups get code that is self-maintaining, self-improving, and self-documenting—the equivalent of hiring a first-rate engineering team dedicated to a non-core part of the codebase—for free. Or, more accurately, at a predictable per-use cost. Contrast this with using a managed service like Cognito or Auth0. On day one, perhaps it doesn’t have all of the features on a startup’s wish list. The difference is that the provider has a team of engineers and product managers whose sole task is to ship improvements to this service day in and day out. Their exciting core product is another company’s would-be redheaded stepchild.
If there is a single unifying principle amongst a startup’s engineering team, it should be to write as little code—and be responsible for as few non-core services—as humanly possible. By adopting this philosophy, a startup can build a platform that can process billions of transactions at an extremely predictable, purely-variable cost with nearly zero devops oversight.
Being this lazy takes a surprising amount of discipline. Getting good at managing a serverless codebase and serverless infrastructure is nontrivial. It means building extensive practices around testing and automation, which means an even larger upfront time investment. Integrating with a managed service can be unbelievably painful, with days spent trying to understand all of the gaps, gotchas, and edge cases. The temptation to implement a proprietary solution can be incredible, especially when it means a story can be done in a matter of minutes or hours instead of days or longer.
It means writing wonky workarounds when a service only accommodates 80% of a developer’s needs. And as the missing 20% of functionality is released, it means refactoring code to remove the workaround, even when it is working just fine and there is no near-term benefit to changing it. The substantial early time investment means that a serverless/managed-service-first approach is not right for every startup. The most important question to ask is, over what time scale do we need to be fast? If the answer is days or weeks, as is the case for many very early-stage startups, it is probably not the right approach.
But if the timescale for velocity optimization has shifted from days or weeks to months or years, it is worth taking a close look at going serverless.
Recruiting great engineers is extraordinarily hard—and only getting harder. It is a tremendous competitive advantage to task those engineers with building differentiated business functionality while your competitors build services that do commoditized, undifferentiated heavy lifting, and then remain stuck with the maintenance of those services for years to come. Of course, there are certain cases where serverless just doesn’t make sense, but those are disappearing at a rapid rate (for example, Lambda’s 5-minute timeout was recently tripled to 15 minutes)—and reasons such as lock-in or latency are generally nonsense or a thing of the past.
Ultimately, the job of a software startup—and therefore the job of the founder—is to deliver customer value above and beyond the capability of the competition. That job comes down to maximizing development velocity, which, in turn, comes down to mitigating complexity wherever possible. It may be that every codebase, and therefore every startup, is destined to become “a big ball of mud”—the term coined in a 1997 paper to describe the “haphazardly structured, sprawling, sloppy, duct-tape-and-baling-wire, spaghetti-code jungle” that every software project seems eventually destined to become.
One day, complexity will grow past a breaking point and development velocity will begin to decline irreversibly, and so the ultimate job of the founder is to push that day off as long as humanly possible. The best way to do that is to keep your ball of mud to the minimum possible size— serverless is the most powerful tool ever developed to do exactly that.
via TechCrunch
0 notes
Text
The business case for serverless
Zack Kanter Contributor
Zack Kanter is the co-founder of Stedi.
More posts by this contributor
Why Amazon is eating the world
While serverless is typically championed as a way to reduce costs and scale massively on demand, there is one extraordinarily compelling reason above all others to adopt a serverless-first approach: it is the best way to achieve maximum development velocity over time. It is not easy to implement correctly and is certainly not a cure-all, but, done right, it paves an extraordinary path to maximizing development velocity, and it is because of this that serverless is the most under-hyped, under-discussed tech movement amongst founders and investors today.
The case for serverless starts with a simple premise: if the fastest startup in a given market is going to win, then the most important thing is to maintain or increase development velocity over time. This may sound obvious, but very, very few startups state maintaining or increasing development velocity as an explicit goal.
“Development velocity,” to be specific, means the speed at which you can deliver an additional unit of value to a customer. Of course, an additional unit of customer value can be delivered either by shipping more value to existing customers, or by shipping existing value—that is, existing features—to new customers.
For many tech startups, particularly in the B2B space, both of these are gated by development throughput (the former for obvious reasons, and the latter because new customer onboarding is often limited by onboarding automation that must be built by engineers). What does serverless mean, exactly? It’s a bit of a misnomer. Just as cloud computing didn’t mean that data centers disappeared into the ether — it meant that those data centers were being run by someone else, and servers could be provisioned on-demand and paid for by the hour — serverless doesn’t mean that there aren’t any servers.
There always have to be servers somewhere. Broadly, serverless means that you aren’t responsible for all of the configuration and management of those servers. A good definition of serverless is pay-per-use computing where uptime is out of the developer’s control. With zero usage, there is zero cost. And if the service goes down, you are not responsible for getting it back up. AWS started the serverless movement in 2014 with a “serverless compute” platform called AWS Lambda.
Whereas a ‘normal’ cloud server like AWS’s EC2 offering had to be provisioned in advance and was billed by the hour regardless of whether or not it was used, AWS Lambda was provisioned instantly, on demand, and was billed only per request. Lambda is astonishingly cheap: $0.0000002 per request plus $0.00001667 per gigabyte-second of compute. And while users have to increase their server size if they hit a capacity constraint on EC2, Lambda will scale more or less infinitely to accommodate load — without any manual intervention. And, if an EC2 instance goes down, the developer is responsible for diagnosing the problem and getting it back online, whereas if a Lambda dies another Lambda can just take its place.
Although Lambda—and equivalent services like Azure Functions or Google Cloud Functions—is incredibly attractive from a cost and capacity standpoint, the truth is that saving money and preparing for scale are very poor reasons for a startup to adopt a given technology. Few startups fail as a result of spending too much money on servers or from failing to scale to meet customer demand — in fact, optimizing for either of these things is a form of premature scaling, and premature scaling on one or many dimensions (hiring, marketing, sales, product features, and even hierarchy/titles) is the primary cause of death for the vast majority of startups. In other words, prematurely optimizing for cost, scale, or uptime is an anti-pattern.
When people talk about a serverless approach, they don’t just mean taking the code that runs on servers and chopping it up into Lambda functions in order to achieve lower costs and easier scaling. A proper serverless architecture is a radically different way to build a modern software application — a method that has been termed a serverless, service-full approach.
It starts with the aggressive adoption of off-the-shelf platforms—that is, managed services—such as AWS Cognito or Auth0 (user authentication—sign up and sign in—as-a-service), AWS Step Functions or Azure Logic Apps (workflow-orchestration-as-a-service), AWS AppSync (GraphQL backend-as-a-service), or even more familiar services like Stripe.
Whereas Lambda-like offerings provide functions as a service, managed services provide functionality as a service. The distinction, in other words, is that you write and maintain the code (e.g., the functions) for serverless compute, whereas the provider writes and maintains the code for managed services. With managed services, the platform is providing both the functionality and managing the operational complexity behind it.
By adopting managed services, the vast majority of an application’s “commodity” functionality—authentication, file storage, API gateway, and more—is handled by the cloud provider’s various off-the-shelf platforms, which are stitched together with a thin layer of your own ‘glue’ code. The glue code — along with the remaining business logic that makes your application unique — runs on ultra-cheap, infinitely-scalable Lambda (or equivalent) infrastructure, thereby eliminating the need for servers altogether. Small engineering teams like ours are using it to build incredibly powerful, easily-maintainable applications in an architecture that yields an unprecedented, sustainable development velocity as the application gets more complex.
There is a trade-off to adopting the serverless, service-full philosophy. Building a radically serverless application requires taking an enormous hit to short term development velocity, since it is often much, much quicker to build a “service” than it is to use one of AWS’s off-the-shelf. When developers are considering a service like Stripe, “build vs buy” isn’t even a question—it is unequivocally faster to use Stripe’s payment service than it is to build a payment service yourself. More accurately, it is faster to understand Stripe’s model for payments than it is to understand and build a proprietary model for payments—a testament both to the complexity of the payment space and to the intuitive service that Stripe has developed.
But for developers dealing with something like authentication (Cognito or Auth0) or workflow orchestration (AWS Step Functions or Azure Logic Apps), it is generally slower to understand and implement the provider’s model for a service than it is to implement the functionality within the application’s codebase (either by writing it from scratch or by using an open source library). By choosing to use a managed service, developers are deliberately choosing to go slower in the short term—a tough pill for a startup to swallow. Many, understandably, choose to go fast now and roll their own.
The problem with this approach comes back to an old axiom in software development: “code isn’t an asset—code is debt.” Code requires an entry on both sides of the accounting equation. It is an asset that enables companies to deliver value to the customer, but it also requires maintenance that has to be accounted for and distributed over time. All things equal, startups want the smallest codebase possible (provided, of course, that developers aren’t taking this too far and writing clever but unreadable code). Less code means less surface area to maintain, and also means less surface area for new engineers to grasp during ramp-up.
Herein lies the magic of using managed services. Startups get the beneficial use of the provider’s code as an asset without holding that code debt on their “technical balance sheet.” Instead, the code sits on the provider’s balance sheet, and the provider’s engineers are tasked with maintaining, improving, and documenting that code. In other words, startups get code that is self-maintaining, self-improving, and self-documenting—the equivalent of hiring a first-rate engineering team dedicated to a non-core part of the codebase—for free. Or, more accurately, at a predictable per-use cost. Contrast this with using a managed service like Cognito or Auth0. On day one, perhaps it doesn’t have all of the features on a startup’s wish list. The difference is that the provider has a team of engineers and product managers whose sole task is to ship improvements to this service day in and day out. Their exciting core product is another company’s would-be redheaded stepchild.
If there is a single unifying principle amongst a startup’s engineering team, it should be to write as little code—and be responsible for as few non-core services—as humanly possible. By adopting this philosophy, a startup can build a platform that can process billions of transactions at an extremely predictable, purely-variable cost with nearly zero devops oversight.
Being this lazy takes a surprising amount of discipline. Getting good at managing a serverless codebase and serverless infrastructure is nontrivial. It means building extensive practices around testing and automation, which means an even larger upfront time investment. Integrating with a managed service can be unbelievably painful, with days spent trying to understand all of the gaps, gotchas, and edge cases. The temptation to implement a proprietary solution can be incredible, especially when it means a story can be done in a matter of minutes or hours instead of days or longer.
It means writing wonky workarounds when a service only accommodates 80% of a developer’s needs. And as the missing 20% of functionality is released, it means refactoring code to remove the workaround, even when it is working just fine and there is no near-term benefit to changing it. The substantial early time investment means that a serverless/managed-service-first approach is not right for every startup. The most important question to ask is, over what time scale do we need to be fast? If the answer is days or weeks, as is the case for many very early-stage startups, it is probably not the right approach.
But if the timescale for velocity optimization has shifted from days or weeks to months or years, it is worth taking a close look at going serverless.
Recruiting great engineers is extraordinarily hard—and only getting harder. It is a tremendous competitive advantage to task those engineers with building differentiated business functionality while your competitors build services that do commoditized, undifferentiated heavy lifting, and then remain stuck with the maintenance of those services for years to come. Of course, there are certain cases where serverless just doesn’t make sense, but those are disappearing at a rapid rate (for example, Lambda’s 5-minute timeout was recently tripled to 15 minutes)—and reasons such as lock-in or latency are generally nonsense or a thing of the past.
Ultimately, the job of a software startup—and therefore the job of the founder—is to deliver customer value above and beyond the capability of the competition. That job comes down to maximizing development velocity, which, in turn, comes down to mitigating complexity wherever possible. It may be that every codebase, and therefore every startup, is destined to become “a big ball of mud”—the term coined in a 1997 paper to describe the “haphazardly structured, sprawling, sloppy, duct-tape-and-baling-wire, spaghetti-code jungle” that every software project seems eventually destined to become.
One day, complexity will grow past a breaking point and development velocity will begin to decline irreversibly, and so the ultimate job of the founder is to push that day off as long as humanly possible. The best way to do that is to keep your ball of mud to the minimum possible size— serverless is the most powerful tool ever developed to do exactly that.
Via Jonathan Shieber https://techcrunch.com
0 notes
Text
The business case for serverless
Zack Kanter Contributor
Zack Kanter is the co-founder of Stedi.
More posts by this contributor
Why Amazon is eating the world
While serverless is typically championed as a way to reduce costs and scale massively on demand, there is one extraordinarily compelling reason above all others to adopt a serverless-first approach: it is the best way to achieve maximum development velocity over time. It is not easy to implement correctly and is certainly not a cure-all, but, done right, it paves an extraordinary path to maximizing development velocity, and it is because of this that serverless is the most under-hyped, under-discussed tech movement amongst founders and investors today.
The case for serverless starts with a simple premise: if the fastest startup in a given market is going to win, then the most important thing is to maintain or increase development velocity over time. This may sound obvious, but very, very few startups state maintaining or increasing development velocity as an explicit goal.
“Development velocity,” to be specific, means the speed at which you can deliver an additional unit of value to a customer. Of course, an additional unit of customer value can be delivered either by shipping more value to existing customers, or by shipping existing value—that is, existing features—to new customers.
For many tech startups, particularly in the B2B space, both of these are gated by development throughput (the former for obvious reasons, and the latter because new customer onboarding is often limited by onboarding automation that must be built by engineers). What does serverless mean, exactly? It’s a bit of a misnomer. Just as cloud computing didn’t mean that data centers disappeared into the ether — it meant that those data centers were being run by someone else, and servers could be provisioned on-demand and paid for by the hour — serverless doesn’t mean that there aren’t any servers.
There always have to be servers somewhere. Broadly, serverless means that you aren’t responsible for all of the configuration and management of those servers. A good definition of serverless is pay-per-use computing where uptime is out of the developer’s control. With zero usage, there is zero cost. And if the service goes down, you are not responsible for getting it back up. AWS started the serverless movement in 2014 with a “serverless compute” platform called AWS Lambda.
Whereas a ‘normal’ cloud server like AWS’s EC2 offering had to be provisioned in advance and was billed by the hour regardless of whether or not it was used, AWS Lambda was provisioned instantly, on demand, and was billed only per request. Lambda is astonishingly cheap: $0.0000002 per request plus $0.00001667 per gigabyte-second of compute. And while users have to increase their server size if they hit a capacity constraint on EC2, Lambda will scale more or less infinitely to accommodate load — without any manual intervention. And, if an EC2 instance goes down, the developer is responsible for diagnosing the problem and getting it back online, whereas if a Lambda dies another Lambda can just take its place.
Although Lambda—and equivalent services like Azure Functions or Google Cloud Functions—is incredibly attractive from a cost and capacity standpoint, the truth is that saving money and preparing for scale are very poor reasons for a startup to adopt a given technology. Few startups fail as a result of spending too much money on servers or from failing to scale to meet customer demand — in fact, optimizing for either of these things is a form of premature scaling, and premature scaling on one or many dimensions (hiring, marketing, sales, product features, and even hierarchy/titles) is the primary cause of death for the vast majority of startups. In other words, prematurely optimizing for cost, scale, or uptime is an anti-pattern.
When people talk about a serverless approach, they don’t just mean taking the code that runs on servers and chopping it up into Lambda functions in order to achieve lower costs and easier scaling. A proper serverless architecture is a radically different way to build a modern software application — a method that has been termed a serverless, service-full approach.
It starts with the aggressive adoption of off-the-shelf platforms—that is, managed services—such as AWS Cognito or Auth0 (user authentication—sign up and sign in—as-a-service), AWS Step Functions or Azure Logic Apps (workflow-orchestration-as-a-service), AWS AppSync (GraphQL backend-as-a-service), or even more familiar services like Stripe.
Whereas Lambda-like offerings provide functions as a service, managed services provide functionality as a service. The distinction, in other words, is that you write and maintain the code (e.g., the functions) for serverless compute, whereas the provider writes and maintains the code for managed services. With managed services, the platform is providing both the functionality and managing the operational complexity behind it.
By adopting managed services, the vast majority of an application’s “commodity” functionality—authentication, file storage, API gateway, and more—is handled by the cloud provider’s various off-the-shelf platforms, which are stitched together with a thin layer of your own ‘glue’ code. The glue code — along with the remaining business logic that makes your application unique — runs on ultra-cheap, infinitely-scalable Lambda (or equivalent) infrastructure, thereby eliminating the need for servers altogether. Small engineering teams like ours are using it to build incredibly powerful, easily-maintainable applications in an architecture that yields an unprecedented, sustainable development velocity as the application gets more complex.
There is a trade-off to adopting the serverless, service-full philosophy. Building a radically serverless application requires taking an enormous hit to short term development velocity, since it is often much, much quicker to build a “service” than it is to use one of AWS’s off-the-shelf. When developers are considering a service like Stripe, “build vs buy” isn’t even a question—it is unequivocally faster to use Stripe’s payment service than it is to build a payment service yourself. More accurately, it is faster to understand Stripe’s model for payments than it is to understand and build a proprietary model for payments—a testament both to the complexity of the payment space and to the intuitive service that Stripe has developed.
But for developers dealing with something like authentication (Cognito or Auth0) or workflow orchestration (AWS Step Functions or Azure Logic Apps), it is generally slower to understand and implement the provider’s model for a service than it is to implement the functionality within the application’s codebase (either by writing it from scratch or by using an open source library). By choosing to use a managed service, developers are deliberately choosing to go slower in the short term—a tough pill for a startup to swallow. Many, understandably, choose to go fast now and roll their own.
The problem with this approach comes back to an old axiom in software development: “code isn’t an asset—code is debt.” Code requires an entry on both sides of the accounting equation. It is an asset that enables companies to deliver value to the customer, but it also requires maintenance that has to be accounted for and distributed over time. All things equal, startups want the smallest codebase possible (provided, of course, that developers aren’t taking this too far and writing clever but unreadable code). Less code means less surface area to maintain, and also means less surface area for new engineers to grasp during ramp-up.
Herein lies the magic of using managed services. Startups get the beneficial use of the provider’s code as an asset without holding that code debt on their “technical balance sheet.” Instead, the code sits on the provider’s balance sheet, and the provider’s engineers are tasked with maintaining, improving, and documenting that code. In other words, startups get code that is self-maintaining, self-improving, and self-documenting—the equivalent of hiring a first-rate engineering team dedicated to a non-core part of the codebase—for free. Or, more accurately, at a predictable per-use cost. Contrast this with using a managed service like Cognito or Auth0. On day one, perhaps it doesn’t have all of the features on a startup’s wish list. The difference is that the provider has a team of engineers and product managers whose sole task is to ship improvements to this service day in and day out. Their exciting core product is another company’s would-be redheaded stepchild.
If there is a single unifying principle amongst a startup’s engineering team, it should be to write as little code—and be responsible for as few non-core services—as humanly possible. By adopting this philosophy, a startup can build a platform that can process billions of transactions at an extremely predictable, purely-variable cost with nearly zero devops oversight.
Being this lazy takes a surprising amount of discipline. Getting good at managing a serverless codebase and serverless infrastructure is nontrivial. It means building extensive practices around testing and automation, which means an even larger upfront time investment. Integrating with a managed service can be unbelievably painful, with days spent trying to understand all of the gaps, gotchas, and edge cases. The temptation to implement a proprietary solution can be incredible, especially when it means a story can be done in a matter of minutes or hours instead of days or longer.
It means writing wonky workarounds when a service only accommodates 80% of a developer’s needs. And as the missing 20% of functionality is released, it means refactoring code to remove the workaround, even when it is working just fine and there is no near-term benefit to changing it. The substantial early time investment means that a serverless/managed-service-first approach is not right for every startup. The most important question to ask is, over what time scale do we need to be fast? If the answer is days or weeks, as is the case for many very early-stage startups, it is probably not the right approach.
But if the timescale for velocity optimization has shifted from days or weeks to months or years, it is worth taking a close look at going serverless.
Recruiting great engineers is extraordinarily hard—and only getting harder. It is a tremendous competitive advantage to task those engineers with building differentiated business functionality while your competitors build services that do commoditized, undifferentiated heavy lifting, and then remain stuck with the maintenance of those services for years to come. Of course, there are certain cases where serverless just doesn’t make sense, but those are disappearing at a rapid rate (for example, Lambda’s 5-minute timeout was recently tripled to 15 minutes)—and reasons such as lock-in or latency are generally nonsense or a thing of the past.
Ultimately, the job of a software startup—and therefore the job of the founder—is to deliver customer value above and beyond the capability of the competition. That job comes down to maximizing development velocity, which, in turn, comes down to mitigating complexity wherever possible. It may be that every codebase, and therefore every startup, is destined to become “a big ball of mud”—the term coined in a 1997 paper to describe the “haphazardly structured, sprawling, sloppy, duct-tape-and-baling-wire, spaghetti-code jungle” that every software project seems eventually destined to become.
One day, complexity will grow past a breaking point and development velocity will begin to decline irreversibly, and so the ultimate job of the founder is to push that day off as long as humanly possible. The best way to do that is to keep your ball of mud to the minimum possible size— serverless is the most powerful tool ever developed to do exactly that.
The business case for serverless published first on https://timloewe.tumblr.com/
0 notes
Photo

New Post has been published on http://simplemlmsponsoring.com/attraction-marketing-formula/pinterest-marketing/amazon-web-services-how-big-is-aws/
Amazon Web Services: How Big Is AWS?

Working with technology companies, I’m amazed at how many are hosting their platforms on Amazon Web Services (AWS). Netflix, Reddit, AOL, and Pinterest are now running on Amazon services. Even GoDaddy is moving a majority of its infrastructure there.
Key to the popularity is the combination of the high availability and low cost. Amazon S3, for example, is designed to deliver 99.999999999% availability, serving trillions of objects worldwide. Amazon is notorious for its aggressive pricing and AWS’ is no different. That high availability and low cost has been attractive to startups who wish to scale quickly and efficiently.
$18 billion in revenue for 2017 and nearly 50% growth in the second quarter of 2018 show that the Amazon Cloud solution continues to attract new customers left and right.
Nick Galov, HostingTribunal
The downside, in my opinion, has been user experience and support. Sign into your Amazon Web Services panel and you’re met with dozens of options with very little detail on what platforms actually do and how they work together. Check out the list of products below the infographic… everything from hosting to AI have their own platforms on AWS.
Sure, you can dig and educate yourself. However, I’ve found that simple processes like setting up a website take way too much effort there. Of course, I’m not a full-time web developer. Many of the companies I work with give me a strange look when I tell them about the issues I have.
This infographic from HostingTribunal, AWS Web Hosting, does a great job in documenting the history of AWS, current growth statistics, alliances and partnerships, major outages, why you should host with AWS, key web hosting solutions on AWS, and success stories:

List of Amazon Web Services
AWS Server Solutions:
Amazon EC2 – Virtual Servers in the Cloud Amazon EC2 Auto Scaling – Scale Compute Capacity to Meet Demand Amazon Elastic Container Service – Run and Manage Docker Containers Amazon Elastic Container Service for Kubernetes – Run Managed Kubernetes on AWS Amazon Elastic Container Registry – Store and Retrieve Docker Images Amazon Lightsail – Launch and Manage Virtual Private Servers AWS Batch – Run Batch Jobs at Any Scale AWS Elastic Beanstalk – Run and Manage Web Apps AWS Fargate – Run Containers without Managing Servers or Clusters AWS Lambda – Run your Code in Response to Events AWS Serverless Application Repository – Discover, Deploy, and Publish Serverless Applications VMware Cloud on AWS – Build a Hybrid Cloud without Custom Hardware AWS Outposts – Run AWS services on-premises
AWS Storage Solutions
Amazon S3 – Scalable Storage in the Cloud Amazon EBS – Block Storage for EC2 Amazon Elastic File System – Managed File Storage for EC2 Amazon Glacier – Low-cost Archive Storage in the Cloud AWS Storage Gateway – Hybrid Storage Integration AWS Snowball – Petabyte-scale Data Transport AWS Snowball Edge – Petabyte-scale Data Transport with On-board Compute AWS Snowmobile – Exabyte-scale Data Transport Amazon FSx for Lustre – Fully managed compute-intensive file system Amazon FSx for Windows File Server – Fully managed Windows native file system
AWS Database Solutions
Amazon Aurora – High Performance Managed Relational Database Amazon RDS – Managed Relational Database Service for MySQL, PostgreSQL, Oracle, SQL Server, and MariaDB Amazon DynamoDB – Managed NoSQL Database Amazon ElastiCache – In-memory Caching System Amazon Redshift – Fast, Simple, Cost-effective Data Warehousing Amazon Neptune – Fully Managed Graph Database Service AWS Database Migration Service – Migrate Databases with Minimal Downtime Amazon Quantum Ledger Database (QLDB) – Fully managed ledger database Amazon Timestream – Fully managed time series database Amazon RDS on VMware – Automate on-premises database management
AWS Migration and Transfer Solutions
AWS Application Discovery Service – Discover On-Premises Applications to Streamline Migration AWS Database Migration Service – Migrate Databases with Minimal Downtime AWS Migration Hub – Track Migrations from a Single Place AWS Server Migration Service – Migrate On-Premises Servers to AWS AWS Snowball – Petabyte-scale Data Transport AWS Snowball Edge – Petabyte-scale Data Transport with On-board Compute AWS Snowmobile – Exabyte-scale Data Transport AWS DataSync – Simple, fast, online data transfer AWS Transfer for SFTP – Fully managed SFTP service
AWS Networking and Content Delivery Solutions
Amazon VPC – Isolated Cloud Resources Amazon VPC PrivateLink – Securely Access Services Hosted on AWS Amazon CloudFront – Global Content Delivery Network Amazon Route 53 – Scalable Domain Name System Amazon API Gateway – Build, Deploy, and Manage APIs AWS Direct Connect – Dedicated Network Connection to AWS Elastic Load Balancing – High Scale Load Balancing AWS Cloud Map – Application resource registry for microservices AWS App Mesh – Monitor and control microservices AWS Transit Gateway – Easily scale VPC and account connections AWS Global Accelerator – Improve application availability and performance
AWS Developer Tools
AWS CodeStar – Develop and Deploy AWS Applications AWS CodeCommit – Store Code in Private Git Repositories AWS CodeBuild – Build and Test Code AWS CodeDeploy – Automate Code Deployment AWS CodePipeline – Release Software using Continuous Delivery AWS Cloud9 – Write, Run, and Debug Code on a Cloud IDE AWS X-Ray – Analyze and Debug Your Applications AWS Command Line Interface – Unified Tool to Manage AWS Services
AWS Management and Governance Solutions
Amazon CloudWatch – Monitor Resources and Applications AWS Auto Scaling – Scale Multiple Resources to Meet Demand AWS CloudFormation – Create and Manage Resources with Templates AWS CloudTrail – Track User Activity and API Usage AWS Config – Track Resource Inventory and Changes AWS OpsWorks – Automate Operations with Chef and Puppet AWS Service Catalog – Create and Use Standardized Products AWS Systems Manager – Gain Operational Insights and Take Action AWS Trusted Advisor – Optimize Performance and Security AWS Personal Health Dashboard – Personalized View of AWS Service Health AWS Control Tower – Set up and govern a secure, compliant, multi-account environment AWS License Manager – Track, manage, and control licenses AWS Well-Architected Tool – Review and improve your workloads
AWS Media Services
Amazon Elastic Transcoder – Easy-to-use Scalable Media Transcoding Amazon Kinesis Video Streams – Process and Analyze Video Streams AWS Elemental MediaConvert – Convert File-based Video Content AWS Elemental MediaLive – Convert Live Video Content AWS Elemental MediaPackage – Video Origination and Packaging AWS Elemental MediaStore – Media Storage and Simple HTTP Origin AWS Elemental MediaTailor – Video Personalization and Monetization AWS Elemental MediaConnect – Reliable and secure live video transport
AWS Security, Identity, and Compliance Solutions
AWS Identity & Access Management – Manage User Access and Encryption Keys Amazon Cloud Directory – Create Flexible Cloud-native Directories Amazon Cognito – Identity Management for your Apps AWS Single Sign-On – Cloud Single Sign-On (SSO) Service Amazon GuardDuty – Managed Threat Detection Service Amazon Inspector – Analyze Application Security Amazon Macie -Discover, Classify, and Protect your Data AWS Certificate Manager – Provision, Manage, and Deploy SSL/TLS Certificates AWS CloudHSM – Hardware-based Key Storage for Regulatory Compliance AWS Directory Service – Host and Manage Active Directory AWS Firewall Manager – Central Management of Firewall Rules AWS Key Management Service – Managed Creation and Control of Encryption Keys AWS Organizations – Policy-based Management for Multiple AWS Accounts AWS Secrets Manager – Rotate, Manage, and Retrieve Secrets AWS Shield – DDoS Protection AWS WAF – Filter Malicious Web Traffic AWS Artifact – On-demand access to AWS compliance reports AWS Security Hub – Unified security and compliance center
AWS Analytics Solutions
Amazon Athena – Query Data in S3 using SQL Amazon CloudSearch – Managed Search Service Amazon Elasticsearch Service – Run and Scale Elasticsearch Clusters Amazon EMR – Hosted Hadoop Framework Amazon Kinesis – Work with Real-time Streaming Data Amazon Redshift – Fast, Simple, Cost-effective Data Warehousing Amazon Quicksight – Fast Business Analytics Service AWS Data Pipeline – Orchestration Service for Periodic, Data-driven Workflows AWS Glue – Prepare and Load Data Amazon Managed Streaming for Kafka – Fully managed Apache Kafka service AWS Lake Formation – Build a secure data lake in days
AWS Machine Learning Solutions
Amazon SageMaker – Build, Train, and Deploy Machine Learning Models at Scale Amazon Comprehend – Discover Insights and Relationships in Text Amazon Lex – Build Voice and Text Chatbots Amazon Polly – Turn Text into Lifelike Speech Amazon Rekognition – Analyze Image and Video Amazon Translate – Natural and Fluent Language Translation Amazon Transcribe – Automatic Speech Recognition AWS DeepLens – Deep Learning Enabled Video Camera AWS Deep Learning AMIs – Quickly Start Deep Learning on EC2 Apache MXNet on AWS – Scalable, High-performance Deep Learning TensorFlow on AWS – Open-source Machine Intelligence Library Amazon Personalize – Build real-time recommendations into your applications Amazon Forecast – Increase forecast accuracy using machine learning Amazon Inferentia – Machine learning inference chip Amazon Textract – Extract text and data from documents Amazon Elastic Inference – Deep learning inference acceleration Amazon SageMaker Ground Truth – Build accurate ML training datasets AWS DeepRacer – Autonomous 1/18th scale race car, driven by ML
AWS Mobile Solutions
AWS Amplify -Build and deploy mobile and web applications Amazon API Gateway – Build, Deploy, and Manage APIs Amazon Pinpoint – Push Notifications for Mobile Apps AWS AppSync – Real-time and Offline Mobile Data Apps AWS Device Farm – Test Android, FireOS, and iOS Apps on Real Devices in the Cloud AWS Mobile SDK – Mobile Software Development Kit
AWS Augmented Reality and Virtual Reality Solutions
Amazon Sumerian – Build and Run VR and AR Applications
AWS Application Integration Solutions
AWS Step Functions – Coordinate Distributed Applications Amazon Simple Queue Service (SQS) – Managed Message Queues Amazon Simple Notification Service (SNS) – Pub/Sub, Mobile Push and SMS Amazon MQ – Managed Message Broker for ActiveMQ
AWS Customer Engagement Solutions
Amazon Connect – Cloud-based Contact Center Amazon Pinpoint – Push Notifications for Mobile Apps Amazon Simple Email Service (SES) – Email Sending and Receiving
AWS Business Applications
Alexa for Business – Empower your Organization with Alexa Amazon Chime – Frustration-free Meetings, Video Calls, and Chat Amazon WorkDocs – Enterprise Storage and Sharing Service Amazon WorkMail – Secure and Managed Business Email and Calendaring
AWS Desktop and Application Streaming Solutions
Amazon WorkSpaces – Desktop Computing Service Amazon AppStream 2.0 – Stream Desktop Applications Securely to a Browser
AWS Internet of Things (IoT) Solutions
AWS IoT Core – Connect Devices to the Cloud Amazon FreeRTOS – IoT Operating System for Microcontrollers AWS Greengrass – Local Compute, Messaging, and Sync for Devices AWS IoT 1-Click – One Click Creation of an AWS Lambda Trigger AWS IoT Analytics – Analytics for IoT Devices AWS IoT Button – Cloud Programmable Dash Button AWS IoT Device Defender – Security Management for IoT Devices AWS IoT Device Management – Onboard, Organize, and Remotely Manage IoT Devices AWS IoT Events – IoT event detection and response AWS IoT SiteWise – IoT data collector and interpreter AWS Partner Device Catalog – Curated catalog of AWS-compatible IoT hardware AWS IoT Things Graph – Easily connect devices and web services
AWS Game Development Solutions
Amazon GameLift – Simple, Fast, Cost-effective Dedicated Game Server Hosting Amazon Lumberyard – A Free Cross-platform 3D Game Engine with Full Source, Integrated with AWS and Twitch
AWS Cost Management Solutions
AWS Cost Explorer – Analyze Your AWS Cost and Usage AWS Budgets – Set Custom Cost and Usage Budgets Reserved Instance Reporting – Dive Deeper into Your Reserved Instances (RIs) AWS Cost and Usage Report – Access Comprehensive Cost and Usage Information
AWS Blockchain Solutions
Amazon Managed Blockchain – Create and manage scalable blockchain networks
AWS Robotics Solutions
AWS RoboMaker – Develop, test, and deploy robotics applications
AWS Satellite Solutions
AWS Ground Station – Fully managed ground station as a service
Download a Sponsored Marketing Whitepaper: 8 Reasons Site Search Is Crucial to Your Digital Transformation
How site search provides a wealth of opportunities Download Now
The post Amazon Web Services: How Big Is AWS? appeared first on MarTech.
Read more: tracking.feedpress.it
0 notes
Text
Integrate your Amazon DynamoDB table with machine learning for sentiment analysis
Amazon DynamoDB is a non-relational database that delivers reliable performance at any scale. It’s a fully managed, multi-Region, multi-active database that provides consistent single-digit millisecond latency and offers built-in security, backup and restore, and in-memory caching. DynamoDB offers a serverless and event-driven architecture, which enables you to use other AWS services to extend DynamoDB capability. DynamoDB provides this capability using Kinesis Data Streams for DynamoDB and DynamoDB Streams with AWS Lambda. When you enable DynamoDB Streams on a DynamoDB table, it captures a time-ordered sequence of item-level modifications in the table and stores this information in a change log for up to 24 hours. Downstream AWS services can access these change logs and view the data items as they appeared before and after they were modified, in near-real time, using a Lambda function. This allows the DynamoDB table to integrate functionally for additional use cases like machine learning (ML), ad hoc queries, full text search, event alerting, and more, such as the following: Processing DynamoDB data with Apache Hive on Amazon EMR for data warehousing use cases Configuring AWS credentials using Amazon Cognito to authenticate access to DynamoDB tables for mobile application Using Amazon API Gateway and Lambda with DynamoDB for a front-end serverless architecture In this post, I show you how to integrate ML with Amazon DynamoDB using Amazon Comprehend to analyze sentiments on incoming product reviews. Serverless and event-driven architecture When you perform create, read, update, and delete (CRUD) operations on a DynamoDB table, DynamoDB Streams keep a 24-hour change log of all CRUD operations. The stream offers you four options of log attributes. For more information, see Enabling a Stream. Lambda functions process each incoming log event, extract the necessary information required for downstream services, and invoke said services, such as in the following situations: A function can loop back to a DynamoDB table to create or update the aggregate item, like a summary item or average of statistics in real time. You can use a function to send specific attributes to Amazon Elasticsearch Service (Amazon ES) for full text search use cases. For historical analysis or ad hoc queries, the function sends the updates to Amazon Simple Storage Service (Amazon S3) in optimized format through Amazon Kinesis Data Firehose, where you can run ad hoc queries or analytics using Amazon Athena You can use the recently announced option to export DynamoDB table data to Amazon S3 for the initial setup of data for analysis; however, you can’t use it for continuous read requirements. Additionally, using Kinesis Data Firehose for data export offers optimized Apache Parquet If you want to be updated on a specific event on the DynamoDB table like the deletion of a critical record, Lambda can notify you through Amazon Simple Notification Service (Amazon SNS). The following diagram illustrates this event-driven architecture. Using ML and analytics with the DynamoDB solution You can configure Amazon review analysis and analytics by running AWS CloudFormation on your own account. This solution uses a serverless event-driven architecture with automated steps. The solution checks the sentiment on the incoming Amazon product review, creates a product review summary based on the sentiment, and keeps updates in optimized format for future ad hoc queries and analytics. The following diagram illustrates this architecture. For this post, the solution uses the incoming Amazon product reviews by putting a review object in the S3 bucket in the form of JSON records. The S3 bucket publishes the s3:ObjectCreated:put event to Lambda by invoking the Lambda function, as specified in the bucket notification configuration. Lambda is meant for quick processing, so the solution limits the size of the product review object on Amazon S3 to smaller than 5 KB. If you want to run this solution in your account, follow these steps: Download the following artifacts: CloudFormation template – Part 1 CloudFormation template – Part 2 Sample gz file for testing – test.json.gz Deploy the CloudFormation Part 1 stack. Check the CloudFormation documentation for instructions. Once Part 1 stack deployment is complete, deploy the Part 2 stack. Once Part 2 stack deployment is complete, upload the sample gz file to the S3 bucket (-amazonreviewsbucket-*) with Server-side encryption option. Check Amazon S3 documentation for instructions. The CloudFormation Part 1 stack creates the following resources: A Glue database and table for cataloging, Two Lambda functions and associated permissions, Required roles and policies, CloudWatch LogStream and LogGroup, Kinesis Firehose for sending streams data to S3 for analysis, Two S3 buckets for incoming reviews and parquet output for analysis, DynamoDB table and associated Streams. The CloudFormation Part 2 stack imports the resources created and setup a managed policy. You can run the stacks on all regions where these services are supported. I tested it on US regions, North Virginia, Oregon and Ohio. Please note running this solution in your account will incur costs. The Lambda function amazon-review-processing runs and assumes the AWS Identity and Access Management (IAM) role created by AWS CloudFormation. The function reads the Amazon S3 events it receives as a parameter, determines where the review object is, reads the review object, and processes the records in the review object. The function breaks the incoming record into multiple records and DynamoDB items: a review item and product item (if it doesn’t already exist). This allows you to retrieve an individual item based on the partition key and sort key. If you want all the product items, you can query items based on just the product partition key. The following screenshot shows product summary item. The following screenshot shows review items associated with the product. The following Lambda code add the review data to DynamoDB table when review file is uploaded to S3 bucket. import io import os import gzip import json import boto3 def get_records(session, bucket, key): """ Generator for the bucket and key names of each CloudTrail log file contained in the event sent to this function from S3. (usually only one but this ensures we process them all). :param event: S3:ObjectCreated:Put notification event :return: yields bucket and key names """ s3 = session.client('s3') response = s3.get_object(Bucket=bucket, Key=key) with io.BytesIO(response['Body'].read()) as obj: with gzip.GzipFile(fileobj=obj) as logfile: records = json.load(logfile) return records def handler(event, context): """ Checks for API calls with RunInstances, TerminateInstances, and DeleteDBInstance in CloudTrail. if found, send specific records to SQS for processing :return: 200, success if records process successfully """ session = boto3.session.Session() dynamodb = boto3.resource("dynamodb", region_name='us-east-1') table = dynamodb.Table('AmazonReviews') # Get the S3 bucket and key for each log file contained in the event for event_record in event['Records']: try: bucket = event_record['s3']['bucket']['name'] key = event_record['s3']['object']['key'] print('Loading Amazon Reviews file s3://{}/{}'.format(bucket, key)) records = get_records(session, bucket, key) print('Number of records in log file: {}'.format(len(records))) for record in records: response = table.get_item(Key={'pk': record['product_id'], 'sk': '2099-12-31#PRODUCTSUMMARY'}) if 'Items' not in response: table.put_item( Item={ 'pk': record['product_id'], 'sk': '2099-12-31#PRODUCTSUMMARY', 'marketplace': record['marketplace'], 'product_parent': record['product_parent'], 'product_title': record['product_title'], 'product_category': record['product_category'], } ) table.put_item( Item={ 'pk': record['product_id'], 'sk': record['review_date'] + '#' + record['review_id'], 'customer_id': record['customer_id'], 'star_rating': record['star_rating'], 'helpful_votes': record['helpful_votes'], 'total_votes': record['total_votes'], 'vine': record['vine'], 'verified_purchase': record['verified_purchase'], 'review_headline': record['review_headline'], 'review_body': record['review_body'] } ) except Exception as e: print (e) return {'Exception status': e} else: print("records processed successfully!!") return { 'statusCode': 200, 'body': json.dumps('records inserted successfully to DynamoDB!!') } After the review records are added to the DynamoDB table, the items enter the DynamoDB stream in real time with new and old images. The amazon_reviews_summary Lambda function captures the stream records from the stream and processes them one by one. This Lambda function has multiple responsibilities: Capture review text from the stream record and call Amazon Comprehend for sentimental analysis. Amazon Comprehend limits review strings to fewer than 5,000 characters, so the code truncates review text to 4,999 characters before calling the Amazon Comprehend sentiment API. Add the sentiment response for the review record and create a product review summary record with sentiment counts. Flatten the DynamoDB streaming JSON logs and add the record to the Kinesis Data Firehose delivery stream. Invoke the Firehose delivery stream put_record API for putting updates in the S3 bucket. The following Lambda code processes the incoming DynamoDB Streams for sentiment analysis and save it to S3 for analytics. import json import boto3 import os def convert_file(f): out = {} def convert(element, name=''): if type(element) is dict: for sub in element: convert(element[sub], name + sub + '_') elif type(element) is list: ctr = 0 for sub in element: convert(sub, name + str(ctr) + '_') ctr += 1 else: out[name[:-1]] = element convert(f) return out def handler(event, context): cmphd = boto3.client(service_name='comprehend', region_name='us-east-1') fh = boto3.client('firehose') ddb = boto3.resource('dynamodb', region_name='us-east-1') dt=ddb.Table('AmazonReviews') FIREHOSE_URL = os.environ['FIREHOSE_URL'] for rec in event['Records']: if (rec['eventName'] == 'INSERT' and ('review_body' in rec['dynamodb']['NewImage'])): convt=convert_file(rec) response = fh.put_record( DeliveryStreamName=FIREHOSE_URL, Record={'Data': json.dumps(convt)} ) review_body=rec['dynamodb']['NewImage']['review_body']['S'] review_body=review_body[:4999] pk=rec['dynamodb']['Keys']['pk']['S'] sk=rec['dynamodb']['Keys']['sk']['S'] res=cmphd.detect_sentiment(Text=review_body, LanguageCode='en') st=res['Sentiment'] try: d_response = dt.put_item( Item={'pk': pk, 'sk': sk + '#' + 'SENTIMENT', 'sentiment': st} ) if st == "POSITIVE": d_s_response = dt.update_item( Key={'pk': pk,'sk': '2099-12-31#REVIEWSUMMARY'}, UpdateExpression="set positive_sentiment_count= if_not_exists(positive_sentiment_count, :start) + :inc",ExpressionAttributeValues={':inc': 1,':start': 0},ReturnValues="UPDATED_NEW" ) elif st == "NEGATIVE": d_s_response = dt.update_item( Key={'pk': pk,'sk': '2099-12-31#REVIEWSUMMARY'}, UpdateExpression="set negative_sentiment_count= if_not_exists(negative_sentiment_count, :start) + :inc",ExpressionAttributeValues={':inc': 1,':start': 0},ReturnValues="UPDATED_NEW" ) elif st == "NEUTRAL": d_s_response = dt.update_item( Key={'pk': pk,'sk': '2099-12-31#REVIEWSUMMARY'}, UpdateExpression="set neutral_sentiment_count= if_not_exists(neutral_sentiment_count, :start) + :inc",ExpressionAttributeValues={':inc': 1,':start': 0},ReturnValues="UPDATED_NEW" ) elif st == "MIXED": d_s_response = dt.update_item( Key={'pk': pk,'sk': '2099-12-31#REVIEWSUMMARY'}, UpdateExpression="set mixed_sentiment_count= if_not_exists(mixed_sentiment_count, :start) + :inc",ExpressionAttributeValues={':inc': 1,':start': 0},ReturnValues="UPDATED_NEW" ) else: print("No sentiment value: " + st) except Exception as e: return {'Exception status': e} else: print("record processed successfully") The amazon_reviews_summary Lambda function calls the Amazon Comprehend detect_sentiment API with the review text, and Amazon Comprehend returns one of the four sentiments: positive, negative, neutral, or mixed. If you want more granular sentiments, you can replace Amazon Comprehend with your own ML model. The amazon_reviews_summary Lambda function calls the DynamoDB table to update the sentiment response on the review item and create product review summary items (or update them if they already exist). The following screenshot shows sentiment item associated with review. The following screenshot shows review summary item. The amazon_reviews_summary Lambda function calls the Firehose delivery stream to flatten the DynamoDB streaming JSON payload. The delivery stream converts the record format to Parquet and adds these records to the S3 bucket. Kinesis Firehose is configured with Record format conversion enabled and Output format as Apache Parquet. You can now catalog the S3 bucket on Athena and run ad hoc queries. See the following query and result: SELECT * FROM "amazon_review"."amazon_reviews" where dynamodb_keys_pk_s ='B00004U2JW' eventid,eventname,eventversion,eventsource,awsregion,dynamodb_approximatecreationdatetime,dynamodb_keys_sk_s,dynamodb_keys_pk_s,dynamodb_newimage_total_votes_n,dynamodb_newimage_star_rating_n,dynamodb_newimage_sk_s,dynamodb_newimage_verified_purchase_s,dynamodb_newimage_pk_s,dynamodb_newimage_customer_id_n,dynamodb_newimage_helpful_votes_n,dynamodb_newimage_vine_s,dynamodb_newimage_review_body_s,dynamodb_newimage_review_headline_s,dynamodb_sequencenumber,dynamodb_sizebytes,dynamodb_streamviewtype,eventsourcearn 35f3c7ce3083aa72eb6b39cd56f3681d,INSERT,1.1,aws:dynamodb,us-east-1,1598908834,2000-09-07#R3MA96SRZSSBER,B00004U2JW,27,4,2000-09-07#R3MA96SRZSSBER,N,B00004U2JW,48308880,5,N,"cool camera with functions whitch i do need, but I cant buy her /and others from my wish list/ because I am not living in U.S. Amazon hurry, she is one of my favourite...",cool but to long way to get her to me,8.53782E+25,393,NEW_AND_OLD_IMAGES,arn:aws:dynamodb:us-east-1:080931190378:table/amazon-reviews-v1/stream/2020-08-14T06:28:33.219 Cleaning up To avoid incurring future costs, delete the resources you created with the CloudFormation stack: Delete the contents of the review bucket and Parquet analytics bucket. Delete the Part 2 CloudFormation stack first and then delete the Part 1 CloudFormation stack. Conclusion In this post, I showed how you can integrate your DynamoDB table with Amazon Comprehend for sentiment analysis and Athena for ad hoc queries across historical activities. You can use your own ML model instead of Amazon Comprehend if you want more granular sentiment analysis. You can also use other AWS services to integrate with DynamoDB by using DynamoDB Streams to extend DynamoDB features. I welcome your feedback, suggestions or questions on this post, please leave me comments below. About the author Utsav Joshi is a Technical Account Manager at AWS. He lives in New Jersey and enjoys working with AWS customers to solve architectural, operational, and cost optimization challenges. In his spare time, he enjoys traveling, road trips, and playing with his kids. https://aws.amazon.com/blogs/database/integrate-your-amazon-dynamodb-table-with-machine-learning-for-sentiment-analysis/
0 notes