#azure-documentdb
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
69% of Tumblr users are millennials.
Text
Sr DevOps Engineer - Remote

Company: Big Time A BIT ABOUT US We are a bold new game studio with a mission to build cutting edge AAA entertainment for the 21st century. Our founders are veterans in the online games, social games, and crypto fields. We are fully funded and building a dream team of developers who want to work with the best of the best and take their careers to the next level. See press coverage: Bloomberg, VentureBeat, CoinDesk. THE MISSION As a DevOps Engineer, you will join a small, fully remote team to work on backend infrastructure for an exciting Multiplayer Action RPG title as well as our marketplace infrastructure. In this role, you will work on game-supporting services and features as well as web facing products interacting with users directly. Our stack includes Docker, AWS Elastic Container Service, Terraform, Node.js, Typescript, MongoDB, React, PostgreSQL, and C++ among others. You will be working with the game and backend engineering teams to architect and maintain stable, reliable, and scalable backend infrastructure. RESPONSIBILITIES - Work closely with stakeholders company wide to provide services that enhance user experience for the development team, as well as our end-users. - Design and build operational infrastructure to support games and marketplace products for Big Time Studios. - Spearhead company wide security culture and architecture to keep our platform secure. - Own delivery, scalability, and reliability of our backend infrastructure. - Advise and collaborate with the rest of the engineering team to ensure we are building safe, secure, and reliable products. REQUIREMENTS - Ability to design and implement highly available and reliable systems. - Proven experience with Linux, Docker, and cloud technologies such as AWS, GCP, and Azure. - Extensive experience setting up and maintaining database infrastructure, including Postgres, Terraform, NoSQL, MongoDB, and DocumentDB. - Ability to be on-call during evenings and weekends when required. - Strong documentation skills. - Excellent communication and time management skills. DESIRABLE - Experience with Game Development. - Proficiency with C++.Proficiency with Typescript/Node.js. - Experience with DevOps tools such as Terraform, Ansible, Kubernetes, Redis, Jenkins. etc. - Experience with game server hosting. WHAT WE OFFER - Fully remote work, with a yearly company offsite. - Experience working with gaming veterans of game titles with a gross aggregate revenue well over $10B USD. - Flexible PTO. - Experience creating a new IP with franchise potential. APPLY ON THE COMPANY WEBSITE To get free remote job alerts, please join our telegram channel “Global Job Alerts” or follow us on Twitter for latest job updates. Disclaimer: - This job opening is available on the respective company website as of 2ndJuly 2023. The job openings may get expired by the time you check the post. - Candidates are requested to study and verify all the job details before applying and contact the respective company representative in case they have any queries. - The owner of this site has provided all the available information regarding the location of the job i.e. work from anywhere, work from home, fully remote, remote, etc. However, if you would like to have any clarification regarding the location of the job or have any further queries or doubts; please contact the respective company representative. Viewers are advised to do full requisite enquiries regarding job location before applying for each job. - Authentic companies never ask for payments for any job-related processes. Please carry out financial transactions (if any) at your own risk. - All the information and logos are taken from the respective company website. Read the full article
0 notes
Text
Is Azure CosmosDB really broken?
Microsoft has warned thousands of its Azure cloud computing customers, including many Fortune 500 companies, about a vulnerability that left their data completely exposed for the last two years.
A flaw in Microsoft’s Azure Cosmos DB database product left more than 3,300 Azure customers open to complete unrestricted access by attackers. The vulnerability was introduced in 2019 when Microsoft added a data visualization feature called Jupyter Notebook to Cosmos DB. The feature was turned on by default for all Cosmos DBs in February 2021.
A listing of Azure Cosmos DB clients includes companies like Coca-Cola, Liberty Mutual Insurance, ExxonMobil, and Walgreens, to name just a few.
“This is the worst cloud vulnerability you can imagine,” said Ami Luttwak, Chief Technology Officer of Wiz, the security company that discovered the issue. “This is the central database of Azure, and we were able to get access to any customer database that we wanted.”
Despite the severity and risk presented, Microsoft hasn’t seen any evidence of the vulnerability leading to illicit data access. “There is no evidence of this technique being exploited by malicious actors,” Microsoft told Bloomberg in an emailed statement. “We are not aware of any customer data being accessed because of this vulnerability.” Microsoft paid Wiz $40,000 for the discovery, according to Reuters. In an update posted to the Microsoft Security Response Center, the company said its forensic investigation included looking through logs to find any current activity or similar events in the past. “Our investigation shows no unauthorized access other than the researcher activity,” said Microsoft.
In a detailed blog post, Wiz says that the vulnerability introduced by Jupyter Notebook allowed the company’s researchers to gain access to the primary keys that secured the Cosmos DB databases for Microsoft customers. With said keys, Wiz had full read / write / delete access to the data of several thousand Microsoft Azure customers.
Wiz says that it discovered the issue two weeks ago and Microsoft disabled the vulnerability within 48 hours of Wiz reporting it. However, Microsoft can’t change its customers’ primary access keys, which is why the company emailed Cosmos DB customers to manually change their keys in order to mitigate exposure.
Today’s issue is just the latest security nightmare for Microsoft. The company had some of its source code stolen by SolarWinds hackers at the end of December, its Exchange email servers were breached and implicated in ransomware attacks in March, and a recent printer flaw allowed attackers to take over computers with system-level privileges. But with the world’s data increasingly moving to centralized cloud services like Azure, today’s revelation could be the most troubling development yet for Microsoft.
Protecting your environment
As described in their initial blog here on #chaosDB, Wiz Research team found an unprecedented critical vulnerability in the Azure Cosmos DB. The vulnerability gives any Azure user full admin access (read, write, delete) to another customers Cosmos DB instances without authorization.

How the vulnerability in CosmoDB is working
Outside the scope of the immediate remediation actions. It is important to review our networking & access strategy in the light of the #chaosDB vulnerability. The key question is what can we do to build our environments to be more bulletproof and completely avoid these kind of large scale vulnerabilities in the future.
Using RBAC: getting rid of secrets
The first and most important take away is that shared secrets such as ComosDB primary key are insecure and should be deprecated in favor of modern authentication methods.
The fact that CosmosDB has a primary key that can be shared across users and services, all using the same secret without any clear way to audit, monitor or revoke access is simply unacceptable from a security perspective.
The longer term goal should be to transition from these insecure primary/secondary keys to role based access that does not require any secrets at all. Role base access is already supported for Comsos DB and can in fact block the primary key to allow RBAC auth only. However, according to Microsoft documentation, the RBAC support is currently highly limited and doesn’t provide data plane access. Once fully supported, it should be high priority to transition into this new model.
Using private endpoints: minimizing cross-account exposure
The other exposure aspect which should be greatly improved is network exposure. Although Cosmos DB allows to activate an IP based firewall, in reality this doesn’t help to block cross account access since majority of services still require access. Even worse, services without static Ips require users to practically open their databases to the entire world (“Azure only” Ips is the same as saying “any attacker with an Azure tenant”).
The only valid approach to build CosmosDBs and other services with minimal network exposure is to leverage private endpoints to the extreme and ensure that no assets is externally exposed.
This approach as well is hard to implement as not all services actually support private endpoints. However this should be the goal of every organization as they plan the next network design.
The post Is Azure CosmosDB really broken? appeared first on PureSourceCode.
from WordPress https://www.puresourcecode.com/news/microsoft/is-azure-cosmosdb-really-broken/
0 notes
Link

Special Holiday Edition: Learning is patriotic!
#learning#learningneverstops#learningeveryday#continuouslearning#selflearning#keeplearning#happylearning#learningsomethingnew#learningisfun#quarntinediaries#cosmosdb#documentdb#azure#nosql
1 note
·
View note
Text
Linked Servers for Azure's NoSQL CosmosDB
Despite its reputation, I'm still a massive fan of linked servers. Microsoft developed it for a reason and it's ongoing presence on the platform since day one says it all. No one told you to pull back a gazillion rows on an inner join with a local table. So, when I saw it's now possible to use it with Azure's CosmosDB, a cloud based NoSQL database, wow, this could be useful and had to try it out myself. It's all possible through a simple ODBC Driver.
Despite its reputation, I’m still a massive fan of linked servers. Microsoft developed it for a reason and it’s ongoing presence on the platform since day one says it all. No one told you to pull back a gazillion rows on an inner join with a local table. So, when I saw it’s now possible to create a linked server to Azure’s CosmosDB, a cloud based NoSQL database, wow, this could be useful and had…
View On WordPress
2 notes
·
View notes
Text
ML For Dummies on iOs: https://apps.apple.com/us/app/aws-machine-learning-exam-prep/id1611600527
ML PRO without ADS on iOs: https://apps.apple.com/us/app/machine-learning-for-dummies-p/id1610947211
ML PRO without ADS on Windows: https://www.microsoft.com/en-ca/p/machine-learning-for-dummies-ml-ai-ops-on-aws-azure-gcp/9p6f030tb0mt?
ML PRO For Web/Android on Amazon: https://www.amazon.com/gp/product/B09TZ4H8V6
Use this App to learn about Machine Learning and Elevate your Brain with Machine Learning Quizzes, Cheat Sheets, Ml Jobs Interview Questions and Answers updated daily.
The App provides:
- 400+ Machine Learning Operation on AWS, Azure, GCP and Detailed Answers and References
- 100+ Machine Learning Basics Questions and Answers
- 100+ Machine Learning Advanced Questions and Answers
- Scorecard
- Countdown timer
- Machine Learning CheatSheets
- Machine Learning Interview Questions and Answers
- Machine Learning Latest News
The App covers: Azure AI Fundamentals AI-900 Exam Prep: Azure AI 900, ML, Natural Language Processing, Modeling, Data Engineering, Computer Vision, Exploratory Data Analysis, ML implementation and Operations, S3, SageMaker, Kinesis, Lake Formation, Athena, Kibana, Redshift, Textract, EMR, Glue, GCP PROFESSIONAL Machine Learning Engineer, Framing ML problems, Architecting ML solutions, Designing data preparation and processing systems, Developing ML models, Monitoring, optimizing, and maintaining ML solutions, NoSQL, Python, DocumentDB, linear regression, logistic regression, Sampling, dataset, statistical interaction, selection bias, non-Gaussian distribution, bias-variance trade-off, Normal Distribution, correlation and covariance, Point Estimates and Confidence Interval, A/B Testing, p-value, statistical power of sensitivity, over-fitting and under-fitting, regularization, Law of Large Numbers, Confounding Variables, Survivorship Bias, univariate, bivariate and multivariate, Resampling, ROC curve, TF/IDF vectorization, Cluster Sampling, etc.
#machinelearning #nlp #computervision #mlops #ml #dataengineering #hadoop #tensorflow #ai #mlsc01 #azurai900 #gcpml #awsml



0 notes
Text
<READ> Azure Cosmos DB and DocumentDB Succinctly by Ed Freitas
[Read] Kindle Azure Cosmos DB and DocumentDB Succinctly => https://themediaaesthetic.blogspot.com/book87.php?asin=B07B8FH59Z
Size: 36,445 KB
D0WNL0AD PDF Ebook Textbook Azure Cosmos DB and DocumentDB Succinctly by Ed Freitas
D0wnl0ad URL => https://themediaaesthetic.blogspot.com/away73.php?asin=B07B8FH59Z
Last access: 82949 user
Last server checked: 18 Minutes ago!
0 notes
Text
Amazon DocumentDB (with MongoDB compatibility) re:Invent 2020 recap
AWS re:Invent 2020 was a very different event than past re:Invents, given the travel shutdown imposed in response to COVID-19, but that didn’t stop the Amazon DocumentDB (with MongoDB capability) team from having a great time interacting with our customers at all of the AWS Database sessions and Ask-the-expert chat rooms! For us, the highlights are always seeing customer use cases for our services, and we had a great session this year from Zulily discussing how they use Amazon DocumentDB and Amazon Kinesis Data Analytics to show shoppers currently trending hot items and brands, and the Washington Post on how they migrated their MongoDB workload to Amazon DocumentDB. On top of that, we had several sessions from Amazon DocumentDB experts diving deep into the service and talking about some of the hot new features like MongoDB 4.0 compatibility, transactions, migrations, and much more! This post rounds up the Amazon DocumentDB recorded sessions from re:Invent 2020. Zulily drives shopping with Amazon DocumentDB and Kinesis Data Analytics Zulily is a global online retailer that applies a unique approach to ecommerce, launching thousands of new products every day. In this session, learn how Zulily delivers solutions for its customers by using AWS services such as Amazon DocumentDB and Kinesis Data Analytics to innovate faster and reduce total cost of ownership. Zulily built a search experience with Amazon DocumentDB and Kinesis Data Analytics that enables shoppers to see what top brands, categories, and keywords are currently trending. This fun new way of browsing gives shoppers an engaging way to discover unique finds, hot items, and debut brands. Full session video Amazon DocumentDB (with MongoDB compatibility) deep dive Developers have adopted the flexible schema and expressive query language of the MongoDB API because it enables them to build and evolve applications faster. However, some developers find that managing databases can be time-consuming, complicated, and challenging to scale. Amazon DocumentDB provides a fast, reliable, fully managed MongoDB-compatible database service that eliminates time-consuming setup and management tasks, allowing developers to focus on building high-performance, scalable applications. Watch this session to learn more about Amazon DocumentDB and how you can run MongoDB workloads at scale. Full session video Migrating databases to Amazon DocumentDB (with MongoDB compatibility) – featuring The Washington Post Amazon DocumentDB is a fast, reliable, fully managed MongoDB-compatible database service. What are the best practices to move your workloads to Amazon DocumentDB? What do you need to think about before, during, and after migration? Which tools and approaches should you use to ensure a successful migration? Watch this session to learn how to migrate database workloads to Amazon DocumentDB. Also learn how the Washington Post migrated their MongoDB workload to Amazon DocumentDB. Full session video Skip directly to Washington Post use case What’s new in Amazon DocumentDB (with MongoDB compatibility) Amazon DocumentDB is a fast, scalable, highly available, and fully managed document database service that supports MongoDB workloads. AWS continues to improve and add capabilities based on what customers actually use and ask for. This session provides an overview of new capabilities that launched in 2020, including demos from some of the most recently launched features. Full session video Leadership Sessions: Building for the future with AWS databases Data is at the core of every application, and companies are looking to use data as the foundation for future innovation in their applications and their organizations. In this session, Shawn Bice, VP of Databases, discusses how organizations are building for the future with fully managed purpose-built databases. From helping organizations move existing database-heavy applications to the cloud, to learning from some of the earliest adopters, Shawn shares strategies on how to get started building for the future. Watch Shawn go deep (with demos) on some of the newest database innovations. Full session video To learn more about Amazon DocumentDB, see the Developer Guide. We look forward to seeing you at AWS re:Invent 2021! About the Authors Chad Tindel is a DynamoDB Specialist Solutions Architect based out of New York City. He works with large enterprises to evaluate, design, and deploy DynamoDB-based solutions. Prior to joining Amazon he held similar roles at Red Hat, Cloudera, MongoDB, and Elastic. Meet Bhagdev is a Senior Product Manager at Amazon Web Services. Meet is passionate about all things data and spends his time working with customers to understand their requirements and building delightful experiences. Prior to his time at AWS, Meet worked on Azure databases at Microsoft. https://aws.amazon.com/blogs/database/amazon-documentdb-with-mongodb-compatibility-reinvent-2020-recap/
0 notes
Photo

Download Lynda NoSQL Development course with DocumentDB in Azure Description NoSQL Development with DocumentDB in Azure Lynda.com is a training course that teaches you how to quickly build NoSQL database applications using DocumentDB.
0 notes
Link
The news of Zeit Vercel raising $21m (slide deck here) is great occasion for taking stock of what is going on with cloud startups. As Brian Leroux (who runs Begin.com) observes, with reference to Netlify's $55m Series C last month:
Between just Netlify and Vercel the VC community has put over 70MM in cloud focused on frontend dev in 2020.
Haven't AWS/GCP/Azure owned the cloud space? What is the full potential of this new generation of startups basically reselling their services with some value add?
Cloud's Deployment Age
I am reminded, again, of Fred Wilson's beloved Carlota Perez framework that I wrote about in React Distros. First you have an Installation Age, with a lot of creative destruction. Then, with the base primitives sorted out, we then build atop the installed layer, in a Deployment Age:
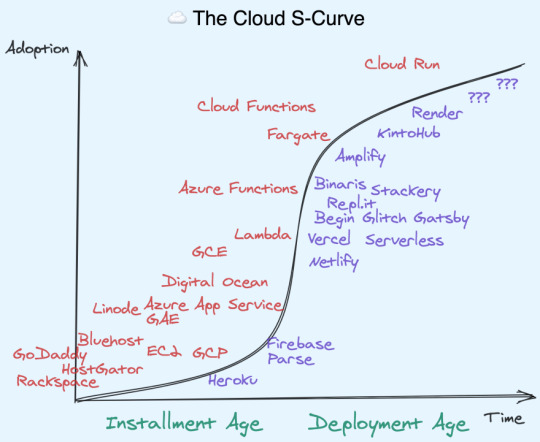
I think the same dynamics I outlined with frontend frameworks is happening here with cloud services. I'm obviously a LOT less well versed with the history of cloud, so please please take this with a grain of salt.
The "Failure" of PaaS
The argument is that the Big 3 Cloud Providers are mostly providing the new commoditized primitives on which the next generation of cloud services will be built. AWS is AWS, Azure maybe caters to the dotNet/Microsoft crowd better, whereas GCP maybe differentiates on Kubernetes and Machine Learning. Basically everyone has a container thing, a data thing, a file storage thing, a serverless thing, and so on.
A nice way to think about it, which I attribute to Guillermo (but I'm not sure about), is that these basic services are the new "Hardware". Instead of going to Fry's and picking up a motherboard, we now go to the AWS Console and pick up a t2.micro or to Azure for a Durable Function. Instead of debating Sandisk vs Western Digital we match up AWS Aurora vs Azure DocumentDB. The benefits are clear - we don't get our hands dirty, we can easily (too easily?) scale with a single API call, and thanks to Infra-as-Code we can truly treat our infra like cattle, not pets.
When the Big N clouds launched, the expectation was that Platform as a Service (PaaS) would win out over Infrastructure as a Service (IaaS). I mean - look at this chart! - if you were running a Software business, would you want to run it atop an IaaS or a PaaS? It made intuitive sense, and both Google App Engine and Azure originally launched with this vision, while Salesforce bought Heroku within 3 years of founding.
But this thesis was wrong. As Patrick McKenzie recently noted:
I'm surprised that Heroku's model didn't win over AWS' model and that DevOps is accordingly a core competence at most SaaS companies. This seems obviously terrible to me every time I'm doing DevOps, which probably took ~20% of all engineering cycles at my last company for surfacing very little customer value.
This rings true. As moderately successful as Heroku, Parse, and Firebase were, they are dwarfed by the size of the big clouds' IaaS businesses. It turns out that most people just wanted to lift and shift their workloads, rather than start new apps from scratch on underpowered platforms. Assisted by Docker, this acquired the rather unfortunate name of "cloud native". (Unfortunate, because there are now "more native" versions of building cloud-powered apps than "containerize everything and somehow mention agile")
But I don't think the PaaSes were wrong.
They were just early.
Developer Experience as a Differentiator
The thing about hardware providers is that they don't cater well to specific audiences. By nature, they build for general use. The best they can do is offer up a default "Operating System" to run them - the AWS Console, Google Cloud Console, Microsoft Azure Portal (Dave Cutler literally called Azure a Cloud OS when it began).
Meanwhile, the "undifferentiated heavy lifting" (aka Muck) of wrangling datacenters turned into "undifferentiated heavy lifting" of messing with 5 different AWS services just to set up a best practices workflow.
So increasingly, intermediate providers are rising up to provide a better developer experience and enforce opinionated architectures (like JAMstack):
Netlify
Vercel
Repl.it
Begin.com
Glitch
Render.com
Amplify
KintoHub
The working name for this new generation of cloud providers, used by Martin Casado, Amjad Masad, and Guillermo Rauch, is "second layer" or "higher level" cloud providers.
Nobody loves these names. It doesn't tell you the value add of having a second layer. Also the name implies that more layers atop these layers will happen, and that is doubtful.
Cloud Distros
I think the right name for this phenomenon is Cloud Distros (kinda gave this away in the title, huh). The idea is both that the default experience is not good enough, and that there are too many knobs and bells and whistles to tweak for the average developer to setup a basic best practices workflow.
Ok, I lied - there is no average developer. There are a ton of developers - ~40m, going by GitHub numbers. They don't all have the same skillset. The argument here is that cloud is going from horizontal, general purpose, off the shelf, to verticalized, opinionated, custom distributions. There are ~300,000 AWS Cloud Practitioners - yet, going by Vercel's numbers, there are 11 million frontend developers.
In order to cross this "chasm", the cloud must change shape. We need to develop custom "Distros" for each audience. For the Jamstack audience, we now have Netlify, Amplify, Begin and Vercel. For the Managed Containers crew, we have Render and KintoHub. For the Hack and Learn in the Cloud folks, we have Glitch and Repl.it. What the business nerds call verticalization or bundling, developers call "developer experience" - and it is different things to different people.
What's funny is these startups all basically run AWS or GCP under the hood anyway. They select the good parts, abstract over multiple services and give us better defaults. This is a little reminiscent of Linux Distros - you can like Ubuntu, and I can like Parrot OS, but it's all Linux under the hood anyway. We pick our distro based on what we enjoy, and our distros are made with specific developer profiles in mind too.
The Future of Cloud Distros
What we have now isn't the end state of things. It is still too damn hard to create and deploy full stack apps, especially with a serverless architecture. Serverless cannot proclaim total victory until we can recreate DHH's demo from 15 years ago in 15 minutes. I have yet to see a realistic demo replicating this. Our users and their frameworks want us to get there, but the platforms need to grow their capabilities dramatically. In our haste to go serverless, we broke apart the monolith - and suffered the consequences - now we must rebuild it atop our new foundations.
Begin and Amplify have made some great steps in this direction - offering integrated database solutions. Render and KintoHub buck the serverless trend, offering a great developer experience for those who need a running server.
There's probably no winner-takes-all effect in this market - but of course, there can be an Ubuntu. This generation of Cloud Distros is fighting hard to be the one-stop platform for the next wave (even the next generation) of developers, and we all win as a result.
0 notes
Text
Azure Cosmos DB now has support for built-in Jupyter notebooks

At Build 2017, Microsoft introduced Azure Cosmos DB as a multi-model and multi-API NoSQL database service. All Azure DocumentDB subscribers were upgraded to Cosmos DB at the time. Then, last year, a major UI upgrade in the form of a new Cosmos DB explorer was introduced to the cloud service. from Pocket https://www.neowin.net/news/azure-cosmos-db-now-has-support-for-built-in-jupyter-notebooks via IFTTT
0 notes
Text
AWS/Azure/GCPサービス比較 2019.05
from https://qiita.com/hayao_k/items/906ac1fba9e239e08ae8?utm_campaign=popular_items&utm_medium=feed&utm_source=popular_items

はじめに
こちら のAWSサービス一覧をもとに各クラウドで対応するサービスを記載しています
AWSでは提供されていないが、Azure/GCPでは提供されているサービスが漏れている場合があります
主観が含まれたり、サービス内容が厳密に一致していない場合もあると���いますが、ご容赦ください
Office 365やG SuiteなどMicrsoft/Googleとして提供されているものは括弧書き( )で記載しています
物理的なデバイスやSDKなどのツール群は記載していません
Analytics
AWS Azure GCP
データレイクへのクエリ Amazon Athena Azure Data Lake Analytics Google BigQuery
検索 Amazon CloudSearch Azure Search -
Hadoopクラスターの展開 Amazon EMR HD Insight/Azure Databricks CloudDataproc
Elasticsearchクラスターの展開 Amazon Elasticserach Service - -
ストリーミング処理 Amazon Kinesis Azure Event Hubs Cloud Dataflow
Kafkaクラスターの展開 Amazon Managed Streaming for Kafka - -
DWH Amazon Redshift Azure SQL Data Warehouse Google BigQuery
BIサービス Quick Sight (Power BI) (Goolge データーポータル)
ワークフローオーケストレーション AWS Data Pipeline Azure Data Factory Cloud Composer
ETL AWS Glue Azure Data Factory Cloud Data Fusion
データレイクの構築 AWS Lake Formation - -
データカタログ AWS Glue Azure Data Catalog Cloud Data Catalog
Application Integration
AWS Azure GCP
分散アプリケーションの作成 AWS Step Functions Azure Logic Apps -
メッセージキュー Amazon Simple Queue Service Azure Queue Storage -
Pub/Sub Amazon Simple Notification Service Azure Service Bus Cloud Pub/Sub
ActiveMQの展開 Amazon MQ
GraphQL AWS AppSync - -
イベントの配信 Amazon CloudWatch Events Event Grid -
Blockchain
AWS Azure GCP
ネットワークの作成と管理 Amazon Managed Blockchain Azure Blockchain Service -
台帳データベース Amazon Quantum Ledger Database - -
アプリケーションの作成 - Azure Blockchain Workbench -
Business Applications
AWS Azure GCP
Alexa Alexa for Business - -
オンラインミーティング Amazon Chime (Office 365) (G Suite)
Eメール Amazon WorkMail (Office 365) (G Suite)
Compute
AWS Azure GCP
仮想マシン Amazon EC2 Azure Virtual Machines Compute Engine
オートスケール Amazon EC2 Auto Scaling Virtual Machine Scale Sets Autoscaling
コンテナオーケストレーター Amazon Elastic Container Service Service Fabric -
Kubernetes Amazon Elastic Container Service for Kubernetes Azure Kubernetes Service Google Kubernetes Engine
コンテナレジストリ Amazon Elastic Container Registry Azure Container Registry Container Registry
VPS Amazon Lightsail - -
バッチコンピューティング AWS Batch Azure Batch -
Webアプリケーションの実行環境 Amazon Elastic Beanstalk Azure App Service App Engine
Function as a Service AWS Lambda Azure Functions Cloud Functions
サーバーレスアプリケーションのリポジトリ AWS Serverless Application Repository - -
VMware環境の展開 VMware Cloud on AWS Azure VMware Solutions -
オンプレミスでの展開 AWS Outposts Azure Stack Cloud Platform Service
バイブリットクラウドの構築 - - Anthos
ステートレスなHTTPコンテナの実行 - - Cloud Run
Cost Management
AWS Azure GCP
使用状況の可視化 AWS Cost Explorer Azure Cost Management -
予算の管理 AWS Budgets Azure Cost Management -
リザーブドインスタンスの管理 Reserved Instance Reporting Azure Cost Management -
使用状況のレポート AWS Cost & Usage Report Azure Cost Management -
Customer Engagement
AWS Azure GCP
コンタクトセンター Amazon Connect - Contact Center AI
エンゲージメントのパーソナライズ Amazon Pinpoint Notification Hubs -
Eメールの送受信 Amazon Simple Email Service - -
Database
AWS Azure GCP
MySQL Amazon RDS for MySQL/Amazon Aurora Azure Database for MySQL Cloud SQL for MySQL
PostgreSQL Amazon RDS for PostgreSQL/Amazon Aurora Azure Database for PostgreSQL Cloud SQL for PostgreSQL
Oracle Amazon RDS for Oracle - -
SQL Server Amazon RDS for SQL Server SQL Database Cloud SQL for SQL Server
MariaDB Amazon RDS for MySQL for MariaDB Azure Database for MariaDB -
NoSQL Amazon DynamoDB Azure Cosmos DB Cloud Datastore/Cloud Bigtable
インメモリキャッシュ Amazon ElastiCache Azure Cache for Redis Cloud Memorystore
グラフDB Amazon Neptune Azure Cosmos DB(API for Gremlin) -
時系列DB Amazon Timestream - -
MongoDB Amazon DocumentDB (with MongoDB compatibility) Azure Cosmos DB(API for MongoDB) -
グローバル分散RDB - - Cloud Spanner
リアルタイムDB - - Cloud Firestore
エッジに配置可能なDB - Azure SQL Database Edge -
Developer Tools
AWS Azure GCP
開発プロジェクトの管理 AWS CodeStar Azure DevOps -
Gitリポジトリ AWS CodeCommit Azure Repos Cloud Source Repositories
継続的なビルドとテスト AWS CodeBuild Azure Pipelines Cloud Build
継続的なデプロイ AWS CodeDeploy Azure Pipelines Cloud Build
パイプライン AWS CodePipeline Azure Pipelines Cloud Build
作業の管理 - Azure Boards -
パッケージレジストリ - Azure Artifacts -
テスト計画の管理 - Azure Test Plans -
IDE AWS Cloud9 (Visual Studio Online) -
分散トレーシング AWS X-Ray Azure Application Insights Stackdriver Trace
End User Computing
AWS Azure GCP
デスクトップ Amazon WorkSpaces Windows Virtual Desktop -
アプリケーションストリーミング Amazon AppStream 2.0 - -
ストレージ Amazon WorkDocs (Office 365) (G Suite)
社内アプリケーションへのアクセス Amazon WorkLink Azure AD Application Proxy -
Internet of Things
AWS Azure GCP
デバイスとクラウドの接続 AWS IoT Core Azure IoT Hub Cloud IoT Core
エッジへの展開 AWS Greengrass Azure IoT Edge Cloud IoT Edge
デバイスから任意の関数を実行 AWS IoT 1-Click - -
デバイスの分析 AWS IoT Analytics Azure Stream Analytics/Azure Time Series Insights -
デバイスのセキュリティ管理 AWS IoT Device Defender - -
デバイスの管理 AWS IoT Device Management Azure IoT Hub Cloud IoT Core
デバイスで発生するイベントの検出 AWS IoT Events - -
産業機器からデータを収集 AWS IoT SiteWise - -
IoTアプリケーションの構築 AWS IoT Things Graph Azure IoT Central -
位置情報 - Azure Maps Google Maps Platform
実世界のモデル化 - Azure Digital Twins
Machine Learning
AWS Azure GCP
機械学習モデルの構築 Amazon SageMaker Azure Machine Learning Service Cloud ML Engine
自然言語処理 Amazon Comprehend Language Understanding Cloud Natural Language
チャットボットの構築 Amazon Lex Azure Bot Service (Dialogflow)
Text-to-Speech Amazon Polly Speech Services Cloud Text-to-Speech
画像認識 Amazon Rekognition Computer Vision Cloud Vision
翻訳 Amazon Translate Translator Text Cloud Translation
Speech-to-Text Amazon Transcribe Speech Services Cloud Speech-to-Text
レコメンデーション Amazon Personalize - Recommendations AI
時系列予測 Amazon Forecast - -
ドキュメント検出 Amazon Textract - -
推論の高速化 Amazon Elastic Inference - -
データセットの構築 Amazon SageMaker Ground Truth - -
ビジョンモデルのカスタマイズ - Custom Vision Cloud AutoML Vision
音声モデルのカスタマイズ - Custom Speech -
言語処理モデルのカスタマイズ Amazon Comprehend - Cloud AutoML Natural Language
翻訳モデルのカスタマイズ - - Cloud AutoML Translation
Managemnet & Governance
AWS Azure GCP
モニタリング Amazon CloudWatch Azure Monitor Google Stackdriver
リソースの作成と管理 AWS CloudFormation Azure Resource Manager Cloud Deployment Manager
アクティビティの追跡 AWS CloudTrail Azure Activity Log
リソースの設定変更の記録、監査 AWS Config - -
構成管理サービスの展開 AWS OpsWorks(Chef/Puppet) - -
ITサービスカタログの管理 AWS Service Catalog - Private Catalog
インフラストラクチャの可視化と制御 AWS Systems Manager - -
パフォーマンスとセキュリティの最適化 AWS Trusted Advisor Azure Advisor -
使用しているサービスの状態表示 AWS Personal Health Dashboard Azure Resource Health -
基準に準拠したアカウントのセットアップ AWS Control Tower Azure Policy -
ライセンスの管理 AWS License Manager - -
ワークロードの見直しと改善 AWS Well-Architected Tool - -
複数アカウントの管理 AWS Organizations Subspricton+RBAC -
ディザスタリカバリ - Azure Site Recovery -
ブラウザベースのシェル AWS Systems Manager Session Manager Cloud Shell Cloud Shell
Media Services
AWS Azure GCP
メディア変換 Amazon Elastic Transcoder/AWS Elemental MediaConvert Azure Media Services - Encoding (Anvato)
ライブ動画処理 AWS Elemental MediaLive Azure Media Services - Live and On-demand Streaming (Anvato)
動画の配信とパッケージング AWS Elemental MediaPackage Azure Media Services (Anvato)
動画ファイル向けストレージ AWS Elemental MediaStore - -
ターゲティング広告の挿入 AWS Elemental MediaTailor - -
Migration & Transfer
AWS Azure GCP
移行の管理 AWS Migration Hub - -
移行のアセスメント AWS Application Discovery Service Azure Migrate -
データベースの移行 AWS Database Migration Service Azure Database Migration Service -
オンプレミスからのデータ転送 AWS DataSync - -
サーバーの移行 AWS Server Migration Service Azure Site Recovery -
大容量データの移行 Snowファミリー Azure Data box Transfer Appliance
SFTP AWS Transfer for SFTP - -
クラウド間のデータ転送 - - Cloud Storage Transfer Service
Mobile
AWS Azure GCP
モバイル/Webアプリケーションの構築とデプロイ AWS Amplify Mobile Apps (Firebase)
アプリケーションテスト AWS Device Farm (Xamarin Test Cloud) (Firebase Test Lab)
Networking & Content Delivery
AWS Azure GCP
仮想ネットワーク Amazon Virtual Private Cloud Azure Virtual Network Virtual Private Cloud
APIの管理 Amazon API Gateway API Management Cloud Endpoints/Apigee
CDN Amazon CloudFront Azure CDN Cloud CDN
DNS Amazon Route 53 Azure DNS Cloud DNS
プライベート接続 Amazon VPC PrivateLink Virtual Network Service Endpoints Private Access Options for Services
サービスメッシュ AWS App Mesh Azure Service Fabric Mesh Traffic Director
サービスディスカバリー AWS Cloud Map - -
専用線接続 AWS Direct Connect ExporessRoute Cloud Interconnect
グローバルロードバランサー AWS Global Accelerator Azure Traffic Manager Cloud Load Balancing
ハブ&スポーク型ネットワーク接続 AWS Transit Gateway - -
ネットワークパフォーマンスの監視 - Network Watcher -
Security, Identity & Compliance
AWS Azure GCP
ID管理 AWS Identity and Access Management Azure Active Directory Cloud IAM
階層型データストア Amazon Cloud Directory - -
アプリケーションのID管理 Amazon Cognito Azure Mobile Apps -
脅威検出 Amazon GuardDuty Azure Security Center Cloud Security Command Center
サーバーのセキュリティの評価 Amazon Inspector Azure Security Center Cloud Security Command Center
機密データの検出と保護 Amazon Macie Azure Information Protection -
コンプライアンスレポートへのアクセス AWS Artifact (Service Trust Portal) -
SSL/TLS証明書の管理 AWS Certificate Manager App Service Certificates Google-managed SSL certificates
ハードウェアセキュリティモジュール AWS Cloud HSM Azure Dedicated HSM Cloud HSM
Active Directory AWS Directory Service Azure Active Directory Managed Service for Microsoft Active Directory
ファイアウォールルールの一元管理 AWS Firewall Manager - -
キーの作成と管理 AWS Key Management Service Azure Key Vault Clou Key Management Service
機密情報の管理 AWS Secrets Manager Azure Key Vault -
セキュリティ情報の一括管理 AWS Security Hub Azure Sentinel -
DDoS保護 AWS Shield Azure DDoS Protection Cloud Armor
シングルサインオン AWS Single Sign-On Azure Active Directory B2C Cloud Identity
WAF AWS WAF Azure Application Gateway Cloud Armor
Storage
AWS Azure GCP
オブジェクトストレージ Amazon S3 Azure Blob Cloud Storage
ブロックストレージ Amazon EBS Disk Storage Persistent Disk
ファイルストレージ(NFS) Amazon Elastic File System Azure NetApp Files Cloud Filestore
ファイルストレージ(SMB) Amazon FSx for Windows File Server Azure Files -
HPC向けファイルシステム Amazon FSx for Lustre Azure FXT Edge Filer -
アーカイブストレージ Amazon S3 Glacier Storage archive access tier Cloud Storage Coldline
バックアップの一元管理 AWS Backup Azure Backup -
ハイブリットストレージ AWS Storage Gateway Azure StorSimple -
その他
AWS Azure GCP
AR/VRコンテンツの作成 Amazon Sumerian - -
ゲームサーバーホスティング Amazon GameLift - -
ゲームエンジン Amazon Lumberyard - -
ロボット工学 RoboMaker - -
人工衛星 Ground Station - -
参考情報
0 notes
Text
Data Persistence
Introduction to Data Persistence
Information systems process data and convert them into information.
The data should persist for later use;
To maintain the status
For logging purposes
To further process and derive knowledge
Data can be stored, read, updated/modified, and deleted.
At run time of software systems, data is stored in main memory, which is volatile.
Data should be stored in non-volatile storage for persistence.
Two main ways of storing data
- Files
- Databases
Data, Files, Databases and DBMSs
Data : Data are raw facts and can be processed and convert into meaningful information.
Data Arrangements
Un Structured : Often include text and multimedia content.
Ex: email messages, word processing documents, videos, photos, audio files, presentations, web pages and many other kinds of business documents.
Semi Structured : Information that does not reside in a relational database but that does have some organizational properties that make it easier to analyze.
Ex: CSV but XML and JSON, NoSQL databases
Structured : This concerns all data which can be stored in database SQL in table with rows and columns
Databases : Databases are created and managed in database servers
SQL is used to process databases
- DDL - CRUD Databases
- DML - CRUD data in databases
Database Types
Hierarchical Databases
In a hierarchical database management systems (hierarchical DBMSs) model, data is stored in a parent-children relationship nodes. In a hierarchical database model, data is organized into a tree like structure.
The data is stored in form of collection of fields where each field contains only one value. The records are linked to each other via links into a parent-children relationship. In a hierarchical database model, each child record has only one parent. A parent can have multiple children
Ex: The IBM Information Management System (IMS) and Windows Registry
Advantages : Hierarchical database can be accessed and updated rapidly
Disadvantages : This type of database structure is that each child in the tree may have only one parent, and relationships or linkages between children are not permitted
Network Databases
Network database management systems (Network DBMSs) use a network structure to create relationship between entities. Network databases are mainly used on a large digital computers.
A network database looks more like a cobweb or interconnected network of records.
Ex: Integrated Data Store (IDS), IDMS (Integrated Database Management System), Raima Database Manager, TurboIMAGE, and Univac DMS-1100
Relational Databases
In relational database management systems (RDBMS), the relationship between data is relational and data is stored in tabular form of columns and rows. Each column if a table represents an attribute and each row in a table represents a record. Each field in a table represents a data value.
Structured Query Language (SQL) is a the language used to query a RDBMS including inserting, updating, deleting, and searching records.
Ex: Oracle, SQL Server, MySQL, SQLite, and IBM DB2
Object Oriented model
Object DBMS's increase the semantics of the C++ and Java. It provides full-featured database programming capability, while containing native language compatibility.
It adds the database functionality to object programming languages.
Ex: Gemstone, ObjectStore, GBase, VBase, InterSystems Cache, Versant Object Database, ODABA, ZODB, Poet. JADE
Graph Databases
Graph Databases are NoSQL databases and use a graph structure for sematic queries. The data is stored in form of nodes, edges, and properties.
Ex: The Neo4j, Azure Cosmos DB, SAP HANA, Sparksee, Oracle Spatial and Graph, OrientDB, ArrangoDB, and MarkLogic
ER Model Databases
An ER model is typically implemented as a database.
In a simple relational database implementation, each row of a table represents one instance of an entity type, and each field in a table represents an attribute type.
Document Databases
Document databases (Document DB) are also NoSQL database that store data in form of documents.
Each document represents the data, its relationship between other data elements, and attributes of data. Document database store data in a key value form.
Ex: Hadoop/Hbase, Cassandra, Hypertable, MapR, Hortonworks, Cloudera, Amazon SimpleDB, Apache Flink, IBM Informix, Elastic, MongoDB, and Azure DocumentDB
DBMSs : DBMSs are used to connect to the DB servers and manage the DBs and data in them
Data Arrangements
Data warehouse
Big data
- Volume
- Variety
- Velocity
Applications to Files/DB
Files and DBs are external components
Software can connect to the files/DBs to perform CRUD operations on data
- File – File path, URL
- Databases – Connection string
To process data in DB
- SQL statements
- Prepared statements
- Callable statements
Useful Objects
o Connection
o Statement
o Reader
o Result set
SQL Statements - Execute standard SQL statements from the application
Prepared Statements - The query only needs to be parsed once, but can be executed multiple times with the same or different parameters.
Callable Statements - Execute stored procedures
ORM
Stands for Object Relational Mapping
Different structures for holding data at runtime;
- Application holds data in objects
- Database uses tables
Mismatches between relational and object models
o Granularity – Object model has more granularity than relational model.
o Subtypes – Subtypes are not supported by all types of relational databases.
o Identity – Relational model does not expose identity while writing equality.
o Associations – Relational models cannot determine multiple relationships while looking into an object domain model.
o Data navigations – Data navigation between objects in an object network is different in both models.
ORM implementations in JAVA
JavaBeans
JPA (JAVA Persistence API)
Beans use POJO
POJO stands for Plain Old Java Object.
It is an ordinary Java object, not bound by any special restriction
POJOs are used for increasing the readability and re-usability of a program
POJOs have gained most acceptance because they are easy to write and understand
A POJO should not;·
Extend pre-specified classes
Implement pre-specified interfaces
Contain pre-specified annotations
Beans
Beans are special type of POJOs
All JavaBeans are POJOs but not all POJOs are JavaBeans
Serializable
Fields should be private
Fields should have getters or setters or both
A no-arg constructor should be there in a bean
Fields are accessed only by constructor or getters setters
POJO/Bean to DB
Java Persistence API
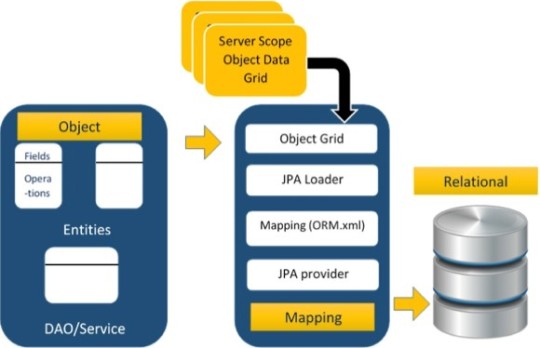
The above architecture explains how object data is stored into relational database in three phases.
Phase 1
The first phase, named as the Object data phase contains POJO classes, service interfaces and classes. It is the main business component layer, which has business logic operations and attributes.
Phase 2
The second phase named as mapping or persistence phase which contains JPA provider, mapping file (ORM.xml), JPA Loader, and Object Grid
Phase 3
The third phase is the Relational data phase. It contains the relational data which is logically connected to the business component.
JPA Implementations
Hybernate
EclipseLink
JDO
ObjectDB
Caster
Spring DAO
NoSQL and HADOOP
Relational DBs are good for structured data and for semi-structured and un-structured data, some other types of DBs can be used.
- Key value stores
- Document databases
- Wide column stores
- Graph stores
Benefits of NoSQL
Compared to relational databases, NoSQL databases are more scalable and provide superior performance
Their data model addresses several issues that the relational model is not designed to address
NoSQL DB Servers
o MongoDB
o Cassandra
o Redis
o Hbase
o Amazon DynamoDB
HADOOP
It is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models
It is designed to scale up from single servers to thousands of machines, each offering local computation and storage
HADOOP Core Concepts
HADOOP Distributed File System
- A distributed file system that provides high-throughput access to application data
HADOOP YARN
- A framework for job scheduling and cluster resource management
HADOOP Map Reduce
- A YARN-based system for parallel processing of large data sets
Information Retrieval
Data in the storages should be fetched, converted into information, and produced for proper use
Information is retrieved via search queries
1. Keyword Search
2. Full-text search
The output can be
1. Text
2. Multimedia
The information retrieval process should be;
Fast/performance
Scalable
Efficient
Reliable/Correct
Major implementations
Elasticsearch
Solr
Mainly used in search engines and recommendation systems
Additionally may use
Natural Language Processing
AI/Machine Learning
Ranking
References
https://www.tutorialspoint.com/jpa/jpa_orm_components.htm
https://www.c-sharpcorner.com/UploadFile/65fc13/types-of-database-management-systems/
0 notes
Text
Migrating relational databases to Amazon DocumentDB (with MongoDB compatibility)
Relational databases have been the foundation of enterprise data management for over 30 years. But the way we build and run applications today, coupled with unrelenting growth in new data sources and growing user loads, is pushing relational databases beyond their limits. This can inhibit business agility, limit scalability, and strain budgets, compelling more and more organizations to migrate to alternatives like NoSQL databases. Amazon DocumentDB (with MongoDB compatibility) is a fast, scalable, highly available, and fully managed document database service that supports MongoDB workloads. As a document database, Amazon DocumentDB makes it easy to store, query, and index JSON data. To get started with Amazon DocumentDB, see Getting Started with Amazon DocumentDB (with MongoDB compatibility). If your data is stored in existing relational databases, converting relational data structures to documents can be complex and involve constructing and managing custom extract, transform, and load (ETL) pipelines. Amazon Database Migration Service (AWS DMS) can manage the migration process efficiently and repeatably. With AWS DMS, you can perform minimal downtime migrations, and can replicate ongoing changes to keep sources and targets in sync. This post provides an overview on how you can migrate your relational databases like MySQL, PostgreSQL, Oracle, Microsoft SQL Server, and others to Amazon DocumentDB using AWS DMS. Data modeling Before addressing the mechanics of using AWS DMS to copy data from a relational database to Amazon DocumentDB, it’s important to understand the basic differences between relational databases and document databases. Relational databases Traditional relational database management system (RDBMS) platforms store data in a normalized relational structure and use structured query language (SQL) for database access. This reduces hierarchical data structures to a set of common elements that are stored across multiple tables. The following diagram provides an overview of the structure of the Employees sample database. This image was taken from MySQL’s employees sample database under the Creative Commons Attribution-ShareAlike license. No changes have been made. When developers need to access data in an application, you merge data from multiple tables together in a process called as join. You predefine your database schema and set up rules to govern the relationships between fields or columns in your tables. RDBMS platforms use an ad hoc query language (generally a type of SQL) to generate or materialize views of the normalized data to support application-layer access patterns. For example, to generate a list of departments with architects (sorted by hire date), you could issue the following query against the preceding schema: SELECT * FROM departments INNER JOIN dept_emp ON departments.dept_no = dept_emp.dept_no INNER JOIN employees ON employees.emp_no = dept_emp.emp_no INNER JOIN titles ON titles.emp_no = employees.emp_no WHERE titles.title IN (‘Architect’) ORDER BY employees.hire_date DESC; The preceding query initiates complex queries across a number of tables and then sorts and integrates the resulting data. One-time queries of this kind provide a flexible API for accessing data, but they require a significant amount of processing. If you’re running multiple complex queries, there can be considerable performance impact, leading to poor end-user experience. In addition, RDBMSs require up-front schema definition, and changing the schema later is very expensive. You may have use cases in which it’s very difficult to anticipate the schema of all the data that your business will eventually need. Therefore, RDBMS backends may not be appropriate for applications that work with a variety of data. However, NoSQL databases (like document databases) have dynamic schemas for unstructured data, and you can store data in many ways. They can be column-oriented, document-oriented, graph-based, or organized as a key-value store. This flexibility means that: You can create documents without having to first define their structure Each document can have its own unique structure The syntax can vary from database to database You can add fields as you go For more information, see What is NoSQL? Document databases Amazon DocumentDB is a fully managed document database service that makes it easy to store, query, and index JSON data. For more information, see What is a Document Database? and Understanding Documents. The following table compares terminology used by document databases with terminology used by SQL databases. SQL Amazon DocumentDB Table Collection Row Document Column Field Primary key ObjectId Index Index View View Nested table or object Embedded document Array Array Using Amazon DocumentDB, you can store semi-structured data as a document rather than normalizing data across multiple tables, each with a unique and fixed structure, as in a relational database. Fields can vary from document to document—you don’t need to declare the structure of documents to the system, because documents are self-describing. Development is simplified because documents map naturally to modern, object-oriented programming languages. The following is an example of a simple document. In the following document, the fields SSN, LName, FName, DOB, Street, City, State-Province, PostalCode, and Country are all siblings within the document: { "SSN": "123-45-6789", "LName": "Rivera", "FName": "Martha", "DOB": "1992-11-16", "Street": "125 Main St.", "City": "Anytown", "State-Province": "WA", "PostalCode": "98117", "Country": "USA" } For more information about adding, querying, updating, and deleting documents, see Working with Documents. Amazon DocumentDB is designed to work with your existing MongoDB applications and tools. Be sure to use drivers intended for MongoDB 3.4 or newer. Internally, Amazon DocumentDB implements the MongoDB API by emulating the responses that a MongoDB client expects from a MongoDB server. Therefore, you can use MongoDB APIs to query your Amazon DocumentDB database. For example, the following query returns all documents where the Item field is equal to Pen: db.example.find( { "Item": "Pen" } ).pretty() For more information about writing queries for Amazon DocumentDB, see Querying. Let’s say that you have a table in your relational database called Posts and another table called Comments, and the two are related because each post has multiple comments. The following is an example of the Posts table. post_id title 1 Post 1 2 Post 2 The following is an example of the Comments table. comment_id post_id author comment 1 1 Alejandro Rosalez Nice Post 2 1 Carlos Salazar Good Content 3 2 John Doe Improvement Needed in the post In order to get the comments of a post with title “Post 1”, you will need to execute an expensive JOIN query similar to below: SELECT author, comment FROM Comments INNER JOIN Posts ON Comments.post_id = Posts.post_id WHERE Posts.title LIKE “Post 1"; While modelling data for documents, you can create one collection of documents that represents a post with an array of comments. See the following output: { "_id" : NumberLong(1), "title" : "Post 1", "comments" : [ { "author" : "Alejandro Rosalez", "content" : " Nice Post" }, { "author" : "Carlos Salazar", "content" : " Good Content" } ] } { "_id" : NumberLong(2), "title" : "Post 2", "comments" : [ { "author" : "John Doe", "content" : " Improvement Needed in the post" } ] } The following query will provide the comments for the post with title as “Post 1”: rs0:PRIMARY> db.posts.find({ “title”: “Post 1” }, {“comments”: 1, _id: 0}) { “comments” : [ { “author” : “Alejandro Rosalez”, “content” : ” Nice Post” }, { “author” : “Carlos Salazar”, “content” : ” Good Content” } ] } For more information about data modeling, see Data Modeling Introduction. Solution overview You can use AWS DMS to migrate (or replicate) data from relational engines like Oracle, Microsoft SQL Server, Azure SQL Database, SAP ASE, PostgreSQL, MySQL and others to an Amazon DocumentDB database. You can also migrate the data from non-relational sources, but those are beyond the scope of this post. As depicted in the following architecture, you deploy AWS DMS via a replication instance within your Amazon Virtual Private Cloud (Amazon VPC). You then create endpoints that the replication instance uses to connect to your source and target databases. The source database can be on premises or hosted in the cloud. In this post, we create the source database in the same VPC as the target Amazon DocumentDB cluster. AWS DMS migrates data, tables, and primary keys to the target database. All other database elements are not migrated. This is because AWS DMS takes a minimalist approach and creates only those objects required to efficiently migrate the data. The following diagram shows the architecture of this solution. The walkthrough includes the following steps: Set up the source MySQL database. Set up the target Amazon DocumentDB database. Create the AWS DMS replication instance. Create the target AWS DMS endpoint (Amazon DocumentDB). Create the source AWS DMS endpoint (MySQL). Create the replication task. Start the replication task. Clean up your resources. As a pre-requisite, we just need an AWS Account and an IAM user which has appropriate access permissions. This walkthrough incurs standard service charges. For more information, see the following pricing pages: AWS Database Migration Service pricing Amazon DocumentDB (with MongoDB compatibility) pricing Amazon EC2 pricing Setting up the source MySQL database We first launch an Amazon Linux 2 EC2 instance and install MySQL server. For instructions, see Installing MySQL on Linux Using the MySQL Yum Repository. Then, we load the sample Employee database with the structure as shown in the beginning of the post. We used the following commands to load the sample database: git clone https://github.com/datacharmer/test_db.git cd test_db mysql -u root -p -t < employees.sql Setting up the target Amazon DocumentDB database For instructions on creating a new Amazon DocumentDB cluster and trying out some sample queries, see Setting up an Document Database. For this walkthrough, we create the cluster my-docdb-cluster with one instance my-docdb-instance. The following screenshot shows the cluster details. Creating an AWS DMS replication instance AWS DMS uses an Amazon Elastic Compute Cloud (Amazon EC2) instance to perform the data conversions as part of a given migration workflow. This EC2 instance is referred to as the replication instance. A replication instance is deployed within a VPC, and it must have access to the source and target databases. It’s a best practice to deploy the replication instance into the same VPC where your Amazon DocumentDB cluster is deployed. You also need to make other considerations in terms of sizing your replication instance. For more information, see Choosing the optimum size for a replication instance. To deploy a replication instance, complete the following steps: Sign in to the AWS DMS console within the AWS account and Region where your Amazon DocumentDB cluster is located. In the navigation pane, under Resource management, choose Replication instances. Choose Create replication instance. This brings you to the Create replication instance page. For Name, enter a name for your instance. For this walkthrough, we enter mysql-to-docdb-dms-instance. For Description, enter a short description. For Instance class, choose your preferred instance. For this walkthrough, we use a c4.xlarge instance. Charges may vary depending on your instance size, storage requirements, and certain data transfer usage. For more information, see AWS Database Migration Service Pricing. For Engine version, choose your AWS DMS version (prefer the latest stable version – not the beta versions). Select Publicly accessible option, if you want your instance to be publicly accessible. If you’re migrating from a source that exists outside of your VPC, you need to select this option. If the source database is within your VPC, accessible over an AWS Direct Connect connection, or via a VPN tunnel to the VPC, then you can leave this option unselected. In the Advanced security and network configuration section, select your suitable Security Group (that allows network traffic access to the source and target database). You can also define other options, such as specific subnets, Availability Zones, custom security groups, and if you want to use AWS Key Management Service (AWS KMS) encryption keys. For more information, see Working with an AWS DMS replication instance. For this post, we leave the remaining options at their defaults. Choose Create. For more details and screenshots, see Create a replication instance using the AWS DMS console. Provisioning your replication instance may take a few minutes. Wait until provisioning is complete before proceeding to the next steps. Creating a target AWS DMS endpoint After you provision a replication instance, you define the source and targets for migrating data. First, we define the connection to our target Amazon DocumentDB cluster. We do this by providing AWS DMS with a target endpoint configuration. On the AWS DMS console, under Resource management, choose Endpoints. Choose Create endpoint. This brings you to the Create endpoint page. For Endpoint type, select Target endpoint. For Endpoint Identifier, enter a name for your endpoint. For this walkthrough, we enter target-docdb-cluster For Target Engine, select docdb For Server name, enter the cluster endpoint for your target Amazon DocumentDB cluster (available in the Amazon DocumentDB cluster details on the Amazon DocumentDB console). To find the cluster endpoint of your Amazon DocumentDB cluster, refer to Finding a Cluster’s Endpoint. For Port, enter the port you use to connect to Amazon DocumentDB (the default is 27017). For SSL mode, choose verify-full. For CA certificate, do one of the following to attach the SSL certificate to your endpoint: If available, choose the existing rds-combined-ca-bundle certificate from the Choose a certificate drop-down menu. Download the new CA certificate bundle. This operation downloads a file named rds-combined-ca-bundle.pem. Then complete the following: In the AWS DMS endpoint page, choose Add new CA certificate. For Certificate identifier, enter rds-combined-ca-bundle. For Import certificate file, choose Choose file and navigate to the rds-combined-ca-bundle.pem file that you previously downloaded. Open the file and choose Import certificate. Choose rds-combined-ca-bundle from the Choose a certificate drop-down menu. For User name, enter the master user name of your Amazon DocumentDB cluster. For this walkthrough, we enter masteruser For Password, enter the master password of your Amazon DocumentDB cluster. For Database name, enter suitable value. For this walkthrough, we enter employees-docdb as the database name. In the Test endpoint connection section, ensure that your endpoint is successfully connected. This can be confirmed when status shows as successful as seen in the following screenshot. For more information on this step, see Creating source and target endpoints. Creating the source AWS DMS endpoint We now define the source endpoint for your source RDBMS. On the AWS DMS console, under Resource management, choose Endpoints. Choose Create endpoint. For Endpoint type¸ select Source endpoint. For Endpoint Identifier, enter a name. For this walkthrough, we enter source-ec2-mysql For Source engine, choose your source database engine. For this walkthrough, we used mysql. For Server name, enter your source endpoint. This can be the IP or DNS address of your source machine For Port, enter the DB port on the source machine (here 3306). For Secure Socket Layer, choose the value depending on user configurations set in your source mysql database. For this walkthrough, we used none. For User name, enter the user name of your source DB. For this walkthrough, we enter mysqluser. For Password, enter the master password of your source DB. For Database name, enter suitable value. For this walkthrough, we enter employees. In the Test endpoint connection section, ensure that your endpoint is successfully connected. This can be confirmed when status shows as successful as seen in the following screenshot. For more information on this step, see Creating source and target endpoints. Creating a replication task After you create the replication instance and source and target endpoints, you can define the replication task. For more information, see Creating a task. On the AWS DMS console, under Conversion & Migration, choose Database migration tasks. Choose Create database migration task. For Task identifier, enter your identifier. For this walkthrough, we enter dms-mysql-to-docDB Choose your replication instance and source and target database endpoints. For this walkthrough, we enter mysql-to-docdb-dms-instance, source-ec2-mysql and target-docdb-cluster Choose the Migration Type as per your requirements: Migrate existing data – This will migrate the existing data from source to target. This will not replicate the ongoing changes on the source. Migrate existing data and replicate ongoing changes – This will migrate the existing data from source to target and will also replicate changes on the source database that occur while the data is being migrated from the source to the target. Replicate data changes only – This will only replicate the changes on the source database and will not migrate the existing data from source to target. You may refer to Creating a task for more details on this option. For this walkthrough, we enter Migrate existing data. On the Task settings page, select Wizard as the Editing Mode. On the Task settings page, you can select Target table preparation mode. You can choose one of the following, depending on your requirements: Do nothing – This creates the table if a table isn’t on the target. If a table exists, this leaves the data and metadata unchanged. AWS DMS can create the target schema based on the default AWS DMS mapping of the data types. However, if you wish to pre-create the schema (or have a different data type) on the target database (Amazon DocumentDB), you can choose to create the schema and use this mode to perform the migration of data to your desired schema. You can also use mapping rules and transformation rules to support such use cases. Drop tables on target – This drops the table at the target and recreates the table. Truncate – This truncates the data and leaves the table and metadata intact. For this walkthrough, we enter Drop tables on target. On the Task settings page, you will have the option to select Include LOB columns in replication. For this walkthrough, we used Limited LOB mode with Max LOB size (KB) as 32. You can choose one of the following depending on your requirements: Don’t include LOB columns – LOB columns are excluded from the migration. Full LOB mode – Migrate complete LOBs regardless of size. AWS DMS migrates LOBs piecewise in chunks controlled by the Max LOB size parameter. This mode is slower than using Limited LOB mode. Limited LOB mode – Truncate LOBs to the value of the Max LOB size parameter. This mode is faster than using Full LOB mode. For this walkthrough, we unchecked Enable validations. AWS DMS provides support for data validation to ensure that your data was migrated accurately from the source to the target. This may slow down the migration. Refer to AWS DMS data validation for more details. On the Task settings page, select Enable CloudWatch logs. Amazon CloudWatch logs are useful if you encounter any issues when the replication task runs. You also need to provide IAM permissions for CloudWatch to write AWS DMS logs. Choose your values for Source Unload, Task Manager¸ Target Apply, Target Load, and Source Capture. For this walkthrough, we used Default. Initially, you may wish to keep the default values for logging levels. if you encounter problems, you can modify the task to select more detailed logging information that can help you to troubleshoot. To read more, refer to Logging task settings and How do I enable, access, and delete CloudWatch logs for AWS DMS? The Table Mapping configuration section of the replication task definition specifies the tables and columns that AWS DMS migrates from source MySQL database to Amazon DocumentDB. You can specify the required information two different ways: using a Guided UI or a JSON editor. For more information about sophisticated selection, filtering and transformation possibilities, including table and view selection and using wildcards to select schemas, tables, and columns, see Using table mapping to specify task settings. For this walkthrough, we used the following values: Editing mode – Wizard Schema – Enter a schema Schema name – employees Table name – % Action – Include Refer to Specifying table selection and transformations rules from the console for screenshots of this step. Choose Create task. Starting the replication task The definition of the replication task is now complete and you can start the task. The task status updates automatically as the process continues. For this post, we configured migration type as Migrate existing data, so the status of the task shows as Load Complete, which may differ depending on the migration type. If an error occurs, the error appears on the Overview details tab (see the following screenshot) under Last failure message. For more information about troubleshooting, see Troubleshooting migration tasks in AWS Database Migration Service. For our sample database, the AWS DMS process takes only a few minutes from start to finish. For more information about connecting to your cluster, see Developing with Amazon DocumentDB. For this post, we use the mongo shell to connect to the cluster. If you connect to the target cluster, you can observe the migrated data. The following query lists all the databases in the cluster: rs0:PRIMARY> show dbs; employees-docdb 1.095GB The following query switches to use the employees-docdb database: rs0:PRIMARY> use employees-docdb; switched to db employees-docdb The following query lists all the collections in the employees-docdb database: rs0:PRIMARY> db.getCollectionNames() [ "departments", "dept_emp", "dept_manager", "employees", "salaries", "titles" The following query selects one document from the departments collection: rs0:PRIMARY> db.departments.findOne() { "_id" : { "dept_no" : "d009" }, "dept_no" : "d009", "dept_name" : "Customer Service" } The following query selects one document from the employees collection: rs0:PRIMARY> db.employees.findOne() { "_id" : { "emp_no" : 10001 }, "emp_no" : 10001, "birth_date" : ISODate("1970-09-22T11:20:56.988Z"), "first_name" : "Georgi", "last_name" : "Facello", "gender" : "M", "hire_date" : ISODate("1986-06-26T00:00:00Z") } The following query counts the number of documents in the employees collection: rs0:PRIMARY> db.employees.count() 300024 Cleaning up When database migration is complete, you may wish to delete your AWS DMS resources. On the AWS DMS dashboard, choose Tasks in the navigation pane. Locate the migration task that you created earlier and click on drop-down Actions button and choose Delete. In the navigation pane, choose Endpoints. Choose the source and target endpoints that you created earlier and click on drop-down Actions button and choose Delete. In the navigation pane, choose Replication instances. Choose the replication instance that you created earlier and click on drop-down Actions button and choose Delete. Summary AWS DMS can quickly get you started with Amazon DocumentDB and your own data. This post discussed how to migrate a relational database to Amazon DocumentDB. We used an example MySQL database and migrated a sample database to Amazon DocumentDB. You can use similar steps for migration from a different supported RDBMS engine to Amazon DocumentDB. To learn more about Amazon DocumentDB, see What Is Amazon DocumentDB (with MongoDB Compatibility). To learn more about AWS DMS, see Sources for AWS Database Migration Service and Using Amazon DocumentDB as a target for AWS Database Migration Service. About the Author Ganesh Sawhney is a Partner Solutions Architect with the Emerging Partners team at Amazon Web Services. He works with the India & SAARC partners to provide guidance on enterprise cloud adoption and migration, along with building AWS practice through the implementation of well architected, repeatable patterns and solutions that drive customer innovation. Being an AWS Database Subject Matter Expert, he has also worked with multiple customers for their database and data warehouse migrations. https://aws.amazon.com/blogs/database/migrating-relational-databases-to-amazon-documentdb-with-mongodb-compatibility/
0 notes
Text
Doğuş Yayın Grubu, Microsoft Azure’a geçti
Türkiye’nin en büyük medya kuruluşlarından biri olan Doğuş Yayın Grubu, teknolojik altyapısını Microsoft çözümleriyle yeniledi. Microsoft’un Azure teknolojisiyle internet sayfalarını ve altyapısını yenileyen Doğuş Yayın Grubu, sıcak haberleri ve sporla ilgili son dakika gelişmeleri kesintisiz bir şekilde izleyicilerle paylaşacak.
Bireylerin ve kurumların daha fazlasını başarması için onlara güç…
View On WordPress
#Azure#Azure App Service#Azure PaaS#Azure Search#Azure SQL Database#Azure Stream Analytics#DocumentDB#Doğuş Yayın#Doğuş Yayın Grubu#Microsoft#Microsoft Azure#NTV#technologic
0 notes