#entryset
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs




Fun Fact
Tumblr.com rank in the US is 25.
Text
PB Entryset (Conjunto De Móveis Diversos Para The Sims 2)
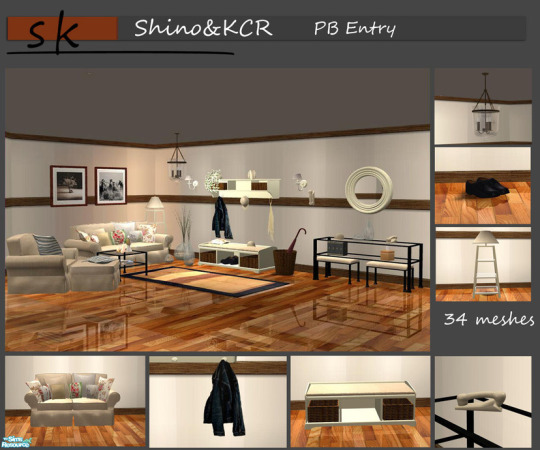
Você Pode Encontrar Esse Conjunto Aqui:
The Sims Resource - PB Entryset
8 notes
·
View notes
Text
How to Iterate Over a HashMap in Java
HashMap is a commonly used data structure in Java that allows key-value pairs to be stored efficiently. Iterating over a HashMap is an essential skill for Java developers, as it enables data manipulation, retrieval, and processing. In this article, we will explore iterate hashmap java over .
1. Using for-each Loop with EntrySet
The entrySet() method returns a set of key-value pairs, which can be iterated using a for-each loop. This is one of the most efficient ways to traverse a HashMap.
import java.util.HashMap; import java.util.Map;
public class HashMapIteration { public static void main(String[] args) { HashMap map = new HashMap<>(); map.put(1, "Apple"); map.put(2, "Banana"); map.put(3, "Cherry"); for (Map.Entry<Integer, String> entry : map.entrySet()) { System.out.println("Key: " + entry.getKey() + ", Value: " + entry.getValue()); } }
}
2. Using keySet() for Iterating Keys
If you only need to iterate over keys, you can use the keySet() method.
for (Integer key : map.keySet()) { System.out.println("Key: " + key); }
3. Using values() for Iterating Values
Similarly, if only values are required, values() can be used.
for (String value : map.values()) { System.out.println("Value: " + value); }
Conclusion
There are multiple ways to iterate over a HashMap in Java, each with its own use case. The for-each loop with entrySet() is commonly used for its simplicity, while forEach() and Streams provide modern and efficient alternatives. Choosing the right method depends on the specific requirements of your program.
0 notes
Text
Java Map: A Comprehensive Overview

The Java Map interface is a crucial part of the Java Collections Framework, providing a structure for storing key-value pairs. Among its popular implementations is the HashMap, which offers efficient performance for basic operations like insertion and retrieval by using a hash table.
For developers looking to dive deeper into this topic, resources such as JAVATPOINT offer comprehensive guides and tutorials on HashMap and other map implementations.
Understanding how to use HashMap and other Java Map types can significantly enhance your ability to manage and access data effectively in your Java applications.
Basic Concepts
A Map does not allow duplicate keys; each key can map to only one value. If you insert a new value for an existing key, the old value is overwritten. The primary operations that Map provides include adding entries, removing entries, and retrieving values based on keys. It also supports checking if a key or value is present and getting the size of the map.
Key Implementations
Several classes implement the Map interface, each with its own characteristics:
HashMap: This is the most commonly used Map implementation. It uses a hash table to store the key-value pairs, which provides average constant-time performance for basic operations such as get and put. However, HashMap does not guarantee the order of its entries. It is ideal for scenarios where performance is critical, and the order of elements is not important.
LinkedHashMap: This implementation extends HashMap and maintains a linked list of entries to preserve the insertion order. This means that when iterating over the entries of a LinkedHashMap, they will appear in the order they were inserted. This implementation is useful when you need predictable iteration order and can afford a slight performance trade-off compared to HashMap.
TreeMap: A TreeMap is a sorted map that uses a Red-Black tree to store its entries. It sorts the keys in their natural order or according to a specified comparator. This implementation is suitable when you need a map that maintains sorted order and supports range views. However, it has a higher overhead compared to HashMap and LinkedHashMap due to the tree-based structure.
Common Operations
The Map interface provides a variety of methods to interact with the data:
put(K key, V value): Adds a key-value pair to the map. If the key already exists, it updates the value.
get(Object key): Retrieves the value associated with the specified key. Returns null if the key does not exist.
remove(Object key): Removes the key-value pair associated with the specified key.
containsKey(Object key): Checks if the map contains the specified key.
containsValue(Object value): Checks if the map contains the specified value.
keySet(): Returns a set view of the keys contained in the map.
values(): Returns a collection view of the values contained in the map.
entrySet(): Returns a set view of the key-value pairs (entries) contained in the map.
Use Cases
Map implementations are versatile and can be used in a variety of scenarios:
Caching: Store frequently accessed data for quick retrieval.
Counting: Track the occurrence of elements or events.
Lookup Tables: Create efficient lookup tables for quick access to data.
Conclusion
Understanding the Map interface and its implementations is essential for effective Java programming. The HashMap is a popular choice for its efficiency in handling key-value pairs with average constant-time performance, making it ideal for various applications.
For those interested in delving deeper into data structures and their uses, resources like TpointTech offer valuable insights and tutorials on concepts such as the hashmap java.
Mastery of these tools allows developers to write more efficient and effective code, leveraging the strengths of each Map implementation to meet their specific needs.
0 notes
Text
Distinctive Design - Antique Architectural Doors and Artifacts
Distinctive Design – Antique Architectural Doors and Artifacts
istinctive Design – Antique Architectural Doors and Artifacts
Restoring old historical homes gives the design and architectural potential to add character with reclaimed architectural doors and salvaged woods. The quality and workmanship of traditional and authentic Haveli doors, handcrafted in teak wood in old world designs, elaborately carved headers and finials, these beautiful majestic doors…
View On WordPress
#antiquedoor#brassdoor#consciousedoor#DOOR#entryset#farmhousedoor#frontdoor#gardendoor#gate#homedoor#industrial#rusticdoor#teakdoor#vintagedoor#woodendoor
0 notes
Photo

@baldwinhardware captures the opulence of #versailles. Lifetime Satin Brass in its timeless glory. A project we worked on in 1996 located in a 20 million dollar estate in Hillsborough California stands perfect untouched in #class and #elegance. Photo Credit: @charahgg Baldwin Dealer: @designersbrass Product Feature: 6933 Finish: 044 Lifetime Satin Brass #whitedecor #brushedbrass #goldentouch #whiteinterior #style #grandentrance #architecturaldesign #curateddesign #oppulence #baldwin #designersbrass #designersbrassinc #sanbruno #baldwinhardware #decorativehardware #design #architecture #architecturalhardware #doorhardware #architect #designer #luxuryhome #designerhardware #entrylock #entryhardware #entryset #doorhandle (at Hillsborough, California) https://www.instagram.com/p/CTz983jPrMV/?utm_medium=tumblr
#versailles#class#elegance#whitedecor#brushedbrass#goldentouch#whiteinterior#style#grandentrance#architecturaldesign#curateddesign#oppulence#baldwin#designersbrass#designersbrassinc#sanbruno#baldwinhardware#decorativehardware#design#architecture#architecturalhardware#doorhardware#architect#designer#luxuryhome#designerhardware#entrylock#entryhardware#entryset#doorhandle
0 notes
Text
Creating Amazon Timestream interpolated views using Amazon Kinesis Data Analytics for Apache Flink
Many organizations have accelerated their adoption of stream data processing technologies in an effort to more quickly derive actionable insights from their data. Frequently, it is required that data from streams be computed into metrics or aggregations and stored in near real-time for analysis. These computed values should be generated and stored as quickly as possible; however, in instances where late arriving data is in the stream, the values must be recomputed and the original records updated. To accommodate this scenario, Amazon Timestream now supports upsert operations, meaning records are inserted into a table if they don’t already exist, or updated if they do. The default write behavior of Timestream follows the first writer wins semantics, wherein data is stored as append only and any duplicate records are rejected. However, in some applications, last writer wins semantics or the update of existing records are required. This post is part of a series demonstrating a variety of techniques for collecting, aggregating, and streaming data into Timestream across a variety of use cases. In this post, we demonstrate how to use the new upsert capability in Timestream to deal with late arriving data. For our example use case, we ingest streaming data, perform aggregations on the data stream, write records to Timestream, and handle late arriving data by updating any existing partially computed aggregates. We will also demonstrate how to use Amazon QuickSight for dashboarding and visualizations. Solution overview Time series is a common data format that describes how things change over time. Some of the most common sources of time series data are industrial machines and internet of things (IoT) devices, IT infrastructure stacks (such as hardware, software, and networking components), and applications that share their results over time. Timestream makes it easy to ingest, store, and analyze time series data at any scale. One common application of time series data is IoT data, where sensors may emit data points at a very high frequency. IoT sensors can often introduce noise into the data source, which may obfuscate trends. You may be pushing metrics at second or sub-second intervals, but want to query data at a coarser granularity to smooth out the noise. This is often accomplished by creating aggregations, averages, or interpolations over a longer period of time to smooth out and minimize the impact of noisy blips in the data. This can present a challenge, because performing interpolations and aggregations at read time can often increase the amount of computation necessary to complete a query. To solve this problem, we show you how to build a streaming data pipeline that generates aggregations when writing source data into Timestream. This enables more performant queries, because Timestream no longer has to calculate these values at runtime. The following diagram illustrates our solution’s architecture. In this post, we use synthetic Amazon Elastic Compute Cloud (Amazon EC2) instance data generated by a Python script. The data is written from an EC2 instance to an Amazon Kinesis Data Streams stream. Next, a Flink application (running within Amazon Kinesis Data Analytics for Apache Flink) reads the records from the data stream and writes them to Timestream. Inside the Flink application is where the magic of the architecture really happens. We then query and analyze the Timestream data using QuickSight. Prerequisites This post assumes the following prerequisites: QuickSight is set up within your account. If QuickSight is not yet set up within your account, refer to Getting Started with Data Analysis in Amazon QuickSight for a comprehensive walkthrough. You have an Amazon EC2 key pair. For information on creating an EC2 key pair, see Amazon EC2 key pairs and Linux instances. Setting up your resources To get started with this architecture, complete the following steps: Note: This solution may incur costs; please check the pricing pages related to the services we’re using. Run the following AWS CloudFormation template in your AWS account: For Stack name¸ enter a name for your stack. For VPC, enter a VPC for your EC2 instance. For Subnet, enter a subnet in which to launch your instance. For KeyName, choose an EC2 key pair that may be used to connect to the instance. Leave all other parameters at the default value and create the stack. The template starts by setting up the necessary AWS Identity and Access Management (IAM) policies and roles to ensure a secure environment. It then sets up an EC2 instance and installs the necessary dependencies (Maven, Flink, and code resources) onto the instance. We also set up a Kinesis data stream and a Kinesis Data Analytics application. Later in this post, you build the Flink application and deploy it to the Kinesis Data Analytics application. The CloudFormation template also deploys the Timestream database and its corresponding Timestream table. QuickSight is not deployed via CloudFormation; we configure it manually in a later step. The entire process of creating the infrastructure takes approximately 5 minutes. After the CloudFormation template is deployed, we have an EC2 instance, Kinesis data stream, empty Kinesis Data Analytics application, Timestream database, and Timestream table. In the following steps, we go through setting up, compiling, and deploying the Flink application from the EC2 instance to Kinesis Data Analytics, starting the Kinesis Data Analytics application, streaming data to the Kinesis data stream, and reading the data from Timestream via interactive queries and QuickSight. Throughout this guide, we refer to a few values contained in the Outputs section of the CloudFormation template, including how to connect to the instance, as well as the Amazon Simple Storage Service (Amazon S3) bucket used. Building the Flink application Let’s begin by connecting to the instance. On the Outputs tab of the CloudFormation template, choose the link associated with ConnectToInstance. This opens a browser-based terminal session to the instance.The EC2 instance has undergone some initial configuration. Specifically, the CloudFormation template downloads and installs Java, Maven, Flink, and clones the amazon-timestream-tools repository from GitHub. The GitHub repo is a set of tools to help you ingest data and consume data from Timestream. We use the Flink connector included in this repository as the starting point for our application. Navigate to the correct directory, using the following command: sudo su - ec2-user cd /home/ec2-user/amazon-timestream-tools/integrations/flink_connector_with_upserts Examine the contents of the main class of the Flink job using the following command: cat src/main/java/com/amazonaws/services/kinesisanalytics/StreamingJob.java This code reads in the input parameters and sets up the environment. We set up the Kinesis consumer configuration, configure the Kinesis Data Streams source, and read records from the source into the input object, which contain non-aggregated records. To produce the aggregated output, the code filters the records to only those where the measure value type is numeric. Next, timestamps and watermarks are assigned to allow for Flink’s event time processing. Event time processing allows us to operate on an event’s actual timestamp, as opposed to system time or ingestion time. For more information about event time, see Tracking Events in Kinesis Data Analytics for Apache Flink Using the DataStream API. The keyBy operation then groups records by the appropriate fields—much like the SQL GROUP BY statement. For this dataset, we aggregate by all dimensions (such as instance_name, process_name, and jdk_version) for a given measure name (such as disk_io_writes or cpu_idle). The aggregation window and the allowed lateness of data within our stream is then set before finally applying a custom averaging function. This code generates average values for each key, as defined in the keyBy function, which is written to a Timestream table at the end of every window (with a default window duration of 5 minutes). If data arrives after the window has already passed, the allowedLateness method allows us to keep that previous window in state for the duration of the window plus the duration of allowed lateness—for example, a 5-minute window plus 2 minutes of allowed lateness. When data arrives late but within the allowed lateness, the aggregate value is recomputed to include the newly added data. The previously computed aggregate stored within Timestream must then be updated.To write data from both the non-aggregated and aggregated streams to Timestream, we use a TimestreamSink. To see how data is written and upserted within Timestream, examine the TimestreamSink class using to following command: cat src/main/java/com/amazonaws/services/timestream/TimestreamSink.java Towards the bottom of the file, you can find the invoke method (also provided below). Within this method, records from the data stream are buffered and written to Timestream in batch to optimize the cost of write operations. The primary thing of note is the use of the withVersion method when constructing the record to be written to Timestream. Timestream stores the record with the highest version. When you set the version to the current timestamp and include the version in the record definition, any existing version of a given record within Timestream is updated with the most recent data. For more information about inserting and upserting data within Timestream, see Write data (inserts and upserts). @Override public void invoke(TimestreamPoint value, Context context) throws Exception { List dimensions = new ArrayList<>(); for(Map.Entry entry : value.getDimensions().entrySet()) { Dimension dim = new Dimension().withName(entry.getKey()).withValue(entry.getValue()); dimensions.add(dim); } //set vesion to current time long version = System.currentTimeMillis(); Record measure = new Record() .withDimensions(dimensions) .withMeasureName(value.getMeasureName()) .withMeasureValueType(value.getMeasureValueType()) .withMeasureValue(value.getMeasureValue()) .withTimeUnit(value.getTimeUnit()) .withTime(String.valueOf(value.getTime())) //by setting the version to the current time, latest record will overwrite any existing earlier records .withVersion(version); bufferedRecords.add(measure); if(shouldPublish()) { WriteRecordsRequest writeRecordsRequest = new WriteRecordsRequest() .withDatabaseName(this.db) .withTableName(this.table) .withRecords(bufferedRecords); try { WriteRecordsResult writeRecordsResult = this.writeClient.writeRecords(writeRecordsRequest); LOG.debug("writeRecords Status: " + writeRecordsResult.getSdkHttpMetadata().getHttpStatusCode()); bufferedRecords.clear(); emptyListTimetamp = System.currentTimeMillis(); } catch (RejectedRecordsException e){ List rejectedRecords = e.getRejectedRecords(); LOG.warn("Rejected Records -> " + rejectedRecords.size()); for (int i = rejectedRecords.size()-1 ; i >= 0 ; i-- ) { LOG.warn("Discarding Malformed Record ->" + rejectedRecords.get(i).toString()); LOG.warn("Rejected Record Reason ->" + rejectedRecords.get(i).getReason()); bufferedRecords.remove(rejectedRecords.get(i).getRecordIndex()); } } catch (Exception e) { LOG.error("Error: " + e); } } } Now that we have examined the code, we can proceed with compiling and packaging for deployment to our Kinesis Data Analytics application. Enter the following commands to create a JAR file we will deploy to our Flink application: mvn clean compile -Dflink.version=1.11.2 mvn package -Dflink.version=1.11.2 Deploying, configuring, and running the application Now that the application is packaged, we can deploy it. Copy it to the S3 bucket created as part of the CloudFormation template (substitute with the OutputBucketName from the CloudFormation stack outputs): aws s3 cp /home/ec2-user/amazon-timestream-tools/integrations/flink_connector_with_upserts/target/timestreamsink-1.0-SNAPSHOT.jar s3:///timestreamsink/timestreamsink-1.0-SNAPSHOT.jar We can now configure the Kinesis Data Analytics application. On the Kinesis console, choose Analytics applications. You should see the Kinesis Data Analytics application created via the CloudFormation template. Choose the application and choose Configure. We now set the code location for the Flink application. For Amazon S3 bucket, choose the bucket created by the CloudFormation template. For Path to Amazon S3 object, enter timestreamsink/timestreamsink-1.0-SNAPSHOT.jar. Under Properties, expand the key-value pairs associated with FlinkApplicationProperties. The Kinesis data stream, Timestream database, and table parameters for your Flink application have been prepopulated by the CloudFormation template. Choose Update. With the code location set, we can now run the Kinesis Data Analytics application. Choose Run. Choose Run without snapshot. The application takes a few moments to start, but once it has started, we can see the application graph on the console. Now that the application is running, we can start pushing data to the Kinesis data stream. Generating and sending data To generate synthetic data to populate the Timestream table, you utilize a script from Amazon Timestream Tools. This Git repository contains sample applications, plugins, notebooks, data connectors, and adapters to help you get started with Timestream and enable you to use Timestream with other tools and services. The Timestream Tools repository has already been cloned to the EC2 instance. From your EC2 instance, navigate to the Timestream Tools Kinesis ingestor directory: cd /home/ec2-user/amazon-timestream-tools/tools/kinesis_ingestor The timestream_kinesis_data_gen.py script generates a continuous stream of EC2 instance data and sends this data as records to the Kinesis data stream. Note the percent-late and late-time parameters—these send 5% of all records 75 seconds late, leading some aggregate values to be recomputed and upserted within Timestream: python3 timestream_kinesis_data_gen.py --percent-late 5 --late-time 75 --stream --region > writer.log & The Flink application starts to continuously read records from the Kinesis data stream and write them to your Timestream table. Non-aggregated records are written to Timestream immediately. Aggregated records are processed and written to Timestream every 5 minutes, with aggregates recomputed and upserted when late arriving data is generated by the Python script. Querying and visualizing your data We can now visualize the data coming in and explore it via the Timestream console. On the Timestream console, choose Query editor. For Database, choose your database. Run a quick query to verify we’re pushing both real-time and aggregated metrics: SELECT * FROM "InterpolatedBlogDB-"."EC2MetricTable-" WHERE measure_name IN ('cpu_idle', 'avg_cpu_idle') LIMIT 100 The following screenshot shows our output. In addition to simply querying the data, you can use QuickSight to analyze and publish data dashboards that contain your Timestream data. First, we need to ensure QuickSight has access to Timestream. Navigate to the QuickSight console. Choose your user name on the application bar and ensure you’re in the same Region as your Timestream database. Choose Manage QuickSight. Choose Security & permissions. Ensure that Timestream is listed under QuickSight access to AWS services. If Timestream is not listed, choose Add or remove to add Timestream. After you validate that QuickSight is configured to access Timestream, navigate to Datasets. Choose New dataset. Select Timestream. For Data source name, enter the Timestream database that was created as part of the CloudFormation template. Choose Create data source. For Database, choose the database created as part of the CloudFormation template. For Tables, select the table created as part of the CloudFormation template. Choose Select. In the following window, choose Visualize. When your data has loaded, choose Line chart under Visual types. Drag the time field to the X axis For Aggregate, choose Minute. For Value, choose measure_value::double. For Aggregate, select Average. For Color, choose measure_name. Because our Timestream data is structured as a narrow table, we need to apply filters to the dataset to select the measures of interest. On the navigation pane, choose Filter. Choose Create one. Choose measure_name. Choose the newly created filter and select avg_cpu_system and cpu_system. Choose Apply. The filter is now reflected in the visualization. Conclusion In this post, we demonstrated how to generate aggregations of streaming data, write streaming data and aggregations to Timestream, and generate visualizations of time series data using QuickSight. Through the use of Kinesis Data Streams and Kinesis Data Analytics, we deployed a data pipeline that ingests source data, and consumes this data into a Flink application that continuously reads and processes the streaming data and writes the raw and aggregated data to Timestream. We aggregated the data stream as it’s written to Timestream to reduce the amount of computation required when querying the data. With QuickSight, we rapidly developed visualizations from data stored in Timestream. We invite you to try this solution for your own use cases and to read the following posts, which contain further information and resources: What Is Amazon Kinesis Data Analytics for Apache Flink? Build and run streaming applications with Apache Flink and Amazon Kinesis Data Analytics for Java Applications Amazon Timestream Developer Guide: Amazon Kinesis Data Analytics for Apache Flink Amazon Timestream Developer Guide: Amazon QuickSight Amazon Timestream Tools and Samples Amazon Kinesis Analytics Taxi Consumer This post is part of a series describing techniques for collecting, aggregating, and streaming data to Timestream across a variety of use cases. This post focuses on challenges associated with late arriving data, partial aggregates, and upserts into Timestream. Stay tuned for the next post in the series where we focus on Grafana integration and a Kotlin based connector for Timestream. About the Authors Will Taff is a Data Lab Solutions Architect at AWS based in Anchorage, Alaska. Will helps customers design and build data, analytics, and machine learning solutions to meet their business needs. As part of the AWS Data Lab, he works with customers to rapidly develop and deploy scalable prototypes through joint engineering engagements. John Gray is a Data Lab Solutions Architect at AWS based out of Seattle. In this role, John works with customers on their Analytics, Database and Machine Learning use cases, architects a solution to solve their business problems and helps them build a scalable prototype. https://aws.amazon.com/blogs/database/creating-amazon-timestream-interpolated-views-using-amazon-kinesis-data-analytics-for-apache-flink/
0 notes
Text
Certified Python Training institute in South Delhi with 100% placement

Programmers will basically optimize the performance of the applying by specializing in some easy cryptography techniques while writing Java code.
Easy coding Tricks to Optimize Performance in Java
1) Use String Builder slightly than + Operator
While writing Java code, programmers of times use the + operator. However, the operator consumes extra memory of the heap and therefore affects the application's performance. The developers will cut back the memory consumption drastically by exploitation String Builder rather than + operators. They'll any modify the creation of complicated strings by exploitation the String Builder reference across totally different ways. They'll even substitute String Buffer instances with String Builder to cut back extra memory consumption.
2) Avoid Regular Expressions
Often Java developers realize it convenient to use regular expressions. However, the employment of standard expressions will have an associated adverse impact on the application's performance. in order that they should avoid exploitation of regular expressions in computation-intensive code sections. just in case a developer decides to use regular expressions in computation-intensive code sections, he should not forget to cache the pattern reference. The pattern reference cache can forestall the regular expressions from being compiled ofttimes.
3) Avoid the Iterator and For-Each loop:
Both Iterator and the for-Each loop have the power to create Java code easy and decipherable. However, the programmers should avoid exploitation Iterator () whereas a string is being whorled. Once the string is ready to retell a replacement Iterator instance on the heap is formed anytime. That the combination of the for-each loop and Iterator will increase memory consumption. The Advanced Java Training in Bangalore programmers will simply scale back memory consumption by exploitation index-based iterations.
4) Avoid calling high-priced strategies directly
Some ways will have an effect on the Java application's performance by intense additional memory. that the programmers should determine and avoid job such ways directly. for example, the JDBC driver would force overtime to calculate the worth of the worth of the ResultSet.wasNull() operate. Rather than the job the dearly-won ways directly, they'll decide the cache.
5) Use Primitive sorts
The wrapper sorts will have an effect on Java code's performance by swing extra pressure of the server. That the developers should explore ways that to avoid exploitation wrapper sorts in their code. They'll replace wrapper sorts by employing a variety of primitive sorts and making one-dimensional arrays of them. Likewise, they'll use delimiter variables to point the precise location of the encoded object within the array. It's conjointly honest to apply to require advantage of an honest assortment of primitive collections obtainable within the market.
6) Avoid rule
While exploitation fashionable practical programming languages, programmers usually used rule. However, the employment of recursions will have a negative impact on the Java code process supported the compiler. There also are possibilities that the tail-recursive of the rule can have an effect on the rule negatively. If the compiler fails to spot the tail-recursive, the complete code can select a toss. Therefore it's invariably better for Java programmers to use iteration rather than the rule.
7) Use entrySet() with Maps
While operating with maps, Java developers usually use a spread of map access operations. However several programmers retell through maps exploitation keys and values. The developer will simply boost the performance of the Java application by selecting the proper map access operations. He should use entrySet() with keys and values to retell through the map additional expeditiously. Alternately, he will use the Map. Entry instance to access the map while not moving the performance of the Java code.
8) Replace HashMap with EnumMap
Sometimes Java programmers use maps with predefined values. For example, they grasp the doable keys during a map whereas employing a configuration map. In such situations, the programmers Java Courses in Bangalore will boost the application's performance by exploitation EnumSet or EnumMap rather than HashSet or HashMap. The array of indexed values makes it easier for Java compiler to spot and insert new values at the time of compilation. EnumMap can increase the map access speed considerably, whereas intense lesser memory than HashMap.
9) Enhance hashCode() and equals() ways
If a coder decides to not use HashMap, it becomes essential for him to optimize the hashCode() and equals() ways. The optimized hashCode() methodology can facilitate programmers to stop calls to equals(). The calls to equals () methodology consume additional memory. Thus, the calls to the dearly-won methodology should be reduced to optimize the Java application's performance.
10) Adopt practical Programming ideas
Java isn't a 100 percent practical programming language nevertheless. However, the programmers should write Java code in practical programming vogue to boost the Java application's performance. They need to attempt to write the code that's additional decipherable and reusable. At a similar time, they conjointly got to profit of sets, collections, lists and similar choices provided by the programming language and Java/J2ee Classes Bangalore numerous frameworks. The usage of sets can create the rule of additional taciturn and code additional decipherable.
Oracle Corporation ofttimes updates Java programming language with new options and enhancements. However several studies have disclosed that the Java version adoption rate is way slower. Several enterprises still use older versions of the programming language. That the Java application developers should select the performance improvement techniques in keeping with the version of Java they're using.
High technologies solutions is the well-known Python Training Center in Delhi with high tech infrastructure and lab facilities. We also provide online access to servers so that candidates will implement the projects at their homes easily. High technologies solutions in Delhi mentored more than 3000+ candidates with Python Certification Training in Delhi at a very reasonable fee. All the trainers have 10+ years of experience in the fields. Course curriculum is customized as per the requirement of candidates/corporates. For free demo class call at +919311002620 or visit our website. https://www.htsindia.com/Courses/python/python-training-institute-in-south-delhi
0 notes
Photo

Working with Maps in Java
//Map Interface has three implementations ie. HashMap, LinkedHashMap and TreeMap.
//Map stores elements in key value pair. Each key and value pair is known as entry. Keys are always unique.
//Retrieving of elements in HashMap is in random order of keys.
//Retrieving of elements in LinlkedHashMap is in insertion order of keys.
// Retrieving of elements in TreeMap is in ascending order of keys.
//Following is a sample of implementation of java HashMappublic class MapExample {public static void main(String[] args) {
Map mapObj = new HashMap();
mapObj.put(100, "amit");
mapObj.put(101,"Vijay");
mapObj.put(102,"Rahul");
mapObj.put(500,"Vijay"); //Here value is replaced for already existing key.
mapObj.put(99,"sumit");
mapObj.put(99,"rahul");
mapObj.put(99,"luke");//one null key is allowed in HashMap and LinkedHashMap but not in TreeMap.
mapObj.put(null,"Rahul2");
mapObj.put(null,"Rahul1");//duplicate values are allowed in map.
mapObj.put(933,null);
mapObj.put(993,null);
// iterate map object with keySet() method of Map interface. This returns set of keys.
Set ks = mapObj.keySet();
for(Integer object : ks){
System.out.println(object+" "+mapObj.get(object));
}
System.out.println();// iterate map object with entrySet() method of Map interface. This returns set of entries. Each entry is object of Map.Entry interface.
Set> entrySet = mapObj.entrySet();
for(Map.Entry sampleEntry: entrySet){
System.out.println(sampleEntry.getKey()+" "+sampleEntry.getValue());
}
System.out.println();
}
}
// Output will be:
null Rahul1
993 null
99 luke
100 amit
500 Vijay
101 Vijay
933 null
102 Rahul
null Rahul1
993 null
99 luke
100 amit
500 Vijay
101 Vijay
933 null
102 Rahul
***************************************************************************************
QACult Best Software Testing Courses in Chandigarh tricity.- We love to enhance your knowledge.
QACult is the premier institute catering to the requirements of experienced and fresh pass-out that gives leaders like you a new way to experience Quality engineering—while you work and giving you the flexibility to both advance your career. Our faculty have 12+ years of industrial experience and have developed many automation testing frameworks in java using TestNG or BDD (cucumber) methodology. We expertise in developing automation testing frameworks in java, python, javascript, php, ruby(WATIR-webdriver & Capybara) and Appium. please subscribe our channel for more such updates:
https://www.youtube.com/channel/UC0xat537YITJbN_9GSMUALA
And visit for website: www.qacult.com for various blogs and Upcoming Events.
0 notes
Text
Fun with Java Deserialization
Down the Rabbit Hole
I’ve just been scrambling down the rabbit hole to patch an app that Qualys is complaining has a deserialization vulnerability. What should have been a simple effort has turned into a mystery because, while we appear to have the correct libraries already in place, Qualys is still complaining about the error. A report that should be clean, to indicate compliance with GDPR, is instead “yellow”, or “orange”, or “red”, so fingers point, tempers flare, e-mails fly about, cc’ing higher and higher ups, so now we have assumptions, and based on those assumptions, tersely written orders, involvement by 3rd party vendors. Time to panic? Shall we be careful and tip-toe through the eggs?[0]
Well, it turns out to be a rather interesting mystery.
What is Java serialization?
First, some definitions are in order. What is Java serialization and why is it important? Perhaps Wikipedia[1] defines it the simplest:
A method for transferring data through the wires
Java serialization is a mechanism to store an object in a non-object form, i.e. a flat, serial stream rather than an object, so that it can be easily sent somewhere, such as to a filesystem, for example. It is also known as “marshaling”, “pickling”, “freezing” or “flattening”. Java programmers should be familiar with the concept, and with the Serializable interface, since it is required in various situations. For example, this technique is used for Oracle Coherence’s “Portable Object Format” to improve performance and support language independence.
Early Days of Java Serialization
Amazing to think that, back in the day, we used all the various tools required for distributed communication, whether simple like RMI and JMX, or more involved specs like CORBA and EJB, and we never thought much about the security aspects. I’m sure if I peruse my copy Henning and Vinoski’s definitive work on C++ and CORBA, I’ll find a chapter or so focusing on security[1], but I’m figuring, we, like everyone else, focused on the business details, getting the apps to communicate reliably, adding features, improving stability, etc, and not on whether there were any security holes, such as tricking a server into running cryptocurrency mining malware[2]. Yes, Bitcoin and the like did not even exist then.
The Biggest Wave of Remote Execution Bugs in History
Well, times change, and the twenty-year-old Java deserialization capability is the source of “nearly half of the vulnerabilities that have been patched in the JDK in the last 2 years” [3], so Oracle has plans in the works to completely revamp object serialization. Further note that this is not solely Oracle’s issue, nor is it limited to Java. Many other software vendors, and open source projects, whether tools or languages, have this weakness, such as Apache Commons Collections, Google Guava, Groovy, Jackson, and Spring.
It seems all the excitement, at least in the Java world, started when Chris Frohoff and Garbriel Lawrence presented their research on Java serialization “ultimately resulting in what can be readily described as the biggest wave of remote code execution bugs in Java history.” [6] However, it is important to note that this flaw is not limited to Java. While Frohoff and Lawrence focused on Java deserialization, Moritz Bechler wrote a paper that focuses on various Java open-source marshalling libraries:
Research into that matter indicated that these vulnerabilities are not exclusive to mechanisms as expressive as Java serialization or XStream, but some could possibly be applied to other mechanisms as well.
I think Moritz describes the heart of the issue the best:
Giving an attacker the opportunity to specify an arbitrary type to unmarshal into enables him to invoke a certain set of methods on an object of that type. Clearly the expectation is that these will be well-behaved – what could possibly go wrong?
Java deserialization
For our purposes, we focused on Java serialization and Apache Commons Collections. From the bug report COLLECTIONS-580[4]:
With InvokerTransformer serializable collections can be build that execute arbitrary Java code. sun.reflect.annotation.AnnotationInvocationHandler#readObject invokes #entrySet and #get on a deserialized collection.
If you have an endpoint that accepts serialized Java objects (JMX, RMI, remote EJB, …) you can combine the two to create arbitrary remote code execution vulnerability.
The Qualys report didn’t have much in the way of details, other than a port and the commons-collections payloads that illustrated the vulnerability, but I guessed from that info that the scanner simply uses the work done by the original folks (Frohoff and Lawrence) [5] that discovered the flaw available as the ysoserial project below.
https://www.youtube.com/watch?v=KSA7vUkXGSg
Source code here: https://github.com/frohoff/ysoserial
Now, in the flurry of trying to fix this error, given the annoyingly vague details from Qualys, I had looked at all sorts of issues, after noticing a few extra JVM arguments in the Tomcat configuration that happened to be set for the instances that were failing with this error, but were not set on other instances. Apparently someone had decided to add these, without informing our team. Interesting.
Now, remember that according to the original bug report, this exploit requires (1) untrusted deserialization, it (2) some way to send a payload, i.e. something listening on a port, such as a JMX service. In fact, These extra JVM args were for supporting remote access via JMX, so unraveling the thread, I researched Tomcat 8 vulnerabilities especially related to JMX. While it turns out that JMX is a weak point (JBoss in particular had quite a well-known major JMX flaw), I did have any luck convincing the customer that they should shut down the port. It is used to gather monitoring metrics useful in determining application performance such as CPU load, memory, and even cache information. Ok, easy but drastic solutions were off the table. I was back to the drawing board.
Next, I tried to see why it was flagging Apache collections in the first place. Going back to the ysoserial project, was it incorrectly flagging Apache Commons Collections 3.2.2, or Collections4-4.1, despite the fact that the libs were fixed? Further looking at the specific payloads, Qualys/Ysoserial was complaining about Collections 3.2.1, which limited the test scenarios to try to get working
Now here’s the interesting part: with ysoserial, I was unable to get the exploit to work, as depicted in the Marshalling Pickles video. It was failing with a strange error I hadn’t seen before, something about filter setting a “rejected” status. Now, this led me to finding info about Oracle’s critical patch update (_121). I was running with latest & greatest JDK, release _192, however our production servers were running a very out-of-date version - surprise surprise.
Apparently, with Oracle JDK at release 121 or later, Oracle has started to address this vulnerability in an official way, rather than what exists currently which is a bunch of ad-hoc solutions, mainly whitelisting/blacklisting, which is a difficult without library support. Some would call this ‘whack-a-mole’, but I think this illustrates quite well the idea of a “patch”, i.e. there’s a leak, so run over and put some tape over it, but we aren’t solving the fundamental issue. In other words, the current defense against this attach is limited because we can’t possibly know what libraries customers will use, so the library maintainer has to scramble to plug the holes whenever they are discovered. Note that even the best of libraries like Groovy, Apache and Spring have had to fix this flaw.
So kudos to Oracle for taking some much needed steps in solving this problem. Here’s a little detail on the new feature that works to make the deserialization process more secure:
The core mechanism of deserialization filtering is based on an ObjectInputFilter interface which provides a configuration capability so that incoming data streams can be validated during the deserialization process. The status check on the incoming stream is determined by Status.ALLOWED, Status.REJECTED, or Status.UNDECIDED arguments of an enum type within ObjectInputFilter interface.
https://access.redhat.com/blogs/766093/posts/3135411
While it is the “official” way to deal with the deserialization issue, it remains to be seen how well this strategy will work. As a further research project, I’m curious whether this model might be used beyond Java serialization, i.e. in projects like Jackson. Does it add anything more than Jackson already has, or does it simplify it, etc.
This feature is targeted for Java 9, but was backported to 8, though it looks like it doesn’t have all the functionality that Java 9 supports.
So you are probably wondering what happened? Did we fix all of the above, and even throw in an upgrade Tomcat, like the Monty Python “Meaning of Life” movie “everything, with a cherry on top!” Well, finally, given a little guidance on where to look, the 3rd party developers - turned out that not only had they added the JVM args, they had also added in some extra code to handle the authentication. Which used - you guessed it - the _old_ 3.2.1 version of commons-collections. This code was also manually maintained, so while the app our team maintained received the updated commons jar in an automated fashion along with all the other updates, this little bit of code, tucked away on the server, was never updated.
Lessons learned? Off-the-wall custom authentication? Don’t do this. But if you do, don’t leave manually updated chunks of code lying around, and further, keep up with the patches!
[0] Yes, I’m reading William Finnegan’s “Barbarian Days: The Surfing Life”, Finnegan’s hilarious and fascinating account of being a surfer in the early days of the sport. At one point, he complains to his friend and fellow surfer, who is getting on his nerves, that he is tired of walking on eggs around him. Of course, in his anger, he mixed up the quote, and meant “walking on eggshells”.
[1] https://en.wikipedia.org/wiki/Serialization
[2] A quick look at the omniORB doc shows it has a feature called the “Dynamic Invocation Interface…Thus using the DII applications may invoke operations on any CORBA object, possibly determining the object’s interface dynamically by using an Interface Repository.” Sounds like reflection doesn’t it? I’m not aware of any specific vulnerabilities, but it does seem we’ve traded a bit of the security that invoking statically-compiled objects brings for convenience.
https://www.cl.cam.ac.uk/research/dtg/attarchive/omniORB/doc/3.0/omniORB/omniORB011.html
[3] https://www.siliconrepublic.com/enterprise/cryptocurrency-malware-monero-secureworks
The Java Object Serialization Specification for Java references a good set of guidelines on how to mitigate the vulnerability:
https://www.oracle.com/technetwork/java/seccodeguide-139067.html#8
[4] https://www.securityinfowatch.com/cybersecurity/information-security/article/12420169/oracle-plans-to-end-java-serialization-but-thats-not-the-end-of-the-story
[5] https://issues.apache.org/jira/browse/COLLECTIONS-580
[6]Which seems to be a pretty standard strategy these days, i.e. proprietary companies like Qualys leveraging open source and adding it to their toolset. AWS does this to great effect, and we, as the consumer, benefit by getting simple interfaces. However, we should not forget that much of the code we use today is Open-source software, in some way or another.
Stratechery, as usual, has a very thoughtful post about this very idea:
It’s hard to not be sympathetic to MongoDB Inc. and Redis Labs: both spent a lot of money and effort building their products, and now Amazon is making money off of them. But that’s the thing: Amazon isn’t making money by selling software, they are making money by providing a service that enterprises value, and both MongoDB and Redis are popular in large part because they were open source to begin with.
[snip]
That, though, should give pause to AWS, Microsoft, and Google. It is hard to imagine them ever paying for open source software, but at the same time, writing (public-facing) software isn’t necessarily the core competency of their cloud businesses. They too have benefited from open-source companies: they provide the means by which their performance, scalability, and availability are realized. Right now everyone is winning: simply following economic realities could, in the long run, mean everyone is worse off.
https://stratechery.com/2019/aws-mongodb-and-the-economic-realities-of-open-source/
[7] https://www.github.com/mbechler/marshalsec/blob/master/marshalsec.pdf?raw=true
[8] https://medium.com/@cowtowncoder/on-jackson-cves-dont-panic-here-is-what-you-need-to-know-54cd0d6e8062
0 notes
Photo

Today on "Things I didn't know if be passionate about": #doorhardware Why? I have no idea, I just know I've fallen in love with @baldwinhardware recently. I love the quality builds and all. I don't even own a house, but one day... One day. Thanks @italycahardwarecom For the new passion. . . . . . #EntrySets #DreamDoor #Brass #Baldwin #PerfectFinish https://www.instagram.com/p/BrF78hfAO_W/?utm_source=ig_tumblr_share&igshid=tyjx1qdgyxjt
0 notes
Text
California Ranch Home for Sale
Be prepared to fall in love with this California ranch-style home! Located in La Jolla, CA, and built by The Meter Company and interiors by AGK Design Studio (make sure to check the builder’s and the designer’s work at their website), this home perfectly blends elegance and craftsmanship in a very special way.
You would be impressed by the gorgeous exterior if you went for a walk and saw this stunning home. Featuring Modern Farmhouse influences with a metal roof and an inviting Portico, this home seems to invite you into its bright and airy interiors.
This home beautifully represents the essence of life in California and I am honored to be sharing this house tour on Home Bunch. Enjoy!
California Ranch Home for Sale
Isn’t this the most beautiful exterior color scheme? It features my favorite colors! Exterior paint is Sherwin Williams Alabaster SW 7008.
Garage Door: Garage Door Enterprises – Custom Build 16 Lite With X Paneling.
Door Paint Color
Front Door & Shutters Paint: Benjamin Moore Van Courtland Blue HC 145.
Entry Door Hardware: Emtek Entryset in Satin Nickel Finish.
Exterior Lighting
Exterior Lights: Princeton 19’’ High Black Outdoor Wall Light Style – Other Affordable Options: here, here, here & here.
Doors & Windows
Doors are custom-made by The Meter Company (builder).
Windows: Dixieline.
Foyer
This home is impressive from every angle! The Entry features paneled walls and stunning wide plank hardwood flooring with a custom design.
Chandelier
Chandelier: Capital Lighting Greyson five lite 29” wide taper candle chandelier.
Ceiling Paint: Sherwin Williams Pure White SW 7005.
Paint Color
Wainscotting & Front Door Paint: Benjamin Moore HC-145 Van Courtland Blue in semi-gloss.
Kitchen
What a breathtaking home!!! It’s impossible to not love it, right?! The kitchen features marble countertops, European French Oak hardwood flooring and a design that will stand the test of time.
Great Room
The kitchen opens into a very spacious Great Room, which features a sliding glass wall to the backyard.
Ceiling Color: Sherwin Williams Pure White SW 7005.
New Idea!
Box Beams are wrapped in wide plank hardwood flooring – (California Classics Mediterranean Collection French Oak Item # Mckw517 Color: Kerrew).
Counterstools
The Chippendale Rattan Counterstools are painted Naval By Sherwin Williams SW 6244 – similar here & here – Other Styles: here, here, here, here & here.
Kitchen Pendants
These pendants work perfectly with the kitchen hood. Great choice! Pendants are Visual Comfort & Co.
Countertop
Countertop is Statuario Marble Amazon Stone.
Vase: Serena & Lily.
Hutch
The Kitchen also features a gorgeous built-in Hutch with herringbone tile. Countertop is Statuario Marble.
Custom cabinetry by The Meter Company.
Hutch Paint Color
Built-in Hutch Cabinet Color: Sherwin Williams Pure White.
Layout
View of Kitchen towards the Mudroom.
Kitchen Range
This large kitchen range is a dream!
Range: Wolf Range 48′ – Other more affordable options: here, here & here.
Backsplash
Backsplash tile: Bedrosians 2 x 10 white clay, Staggered Lay – similar here – Others: here, here, here, here & here.
All grout is #361 Bright White CBP.
Pulls
Cabinet Pulls: Top Knobs Ascendra pull 9′ in Honey Bronze.
Kitchen Hood
The custom white kitchen hood with brass trim is by The Meter Company.
Hood liner is Zephyr stainless steel.
Pot Filler: Newport Brass Pot Filler Kitchen Faucet in Satin Brass.
Cutting Board: Serena & Lily.
Dutch Oven: Staub.
Kitchen Cabinet Paint Color
Kitchen Cabinet Color: Sherwin Williams SW 7064 Passive.
Kitchen Faucet
Kitchen Faucet: Newport Brass in Satin Brass.
Stems
Faux stems instantly give a fresher feel to a kitchen.
Beautiful Faux Stems: here, here & here.
Shelves
Glass shelving are Restoration Hardware – 1930s French Bistro Shelving.
Cabinetry
The kitchen cabinets were custom-designed by the builder. I love this light grey color and the inset glass doors with latch pulls.
Latches
Cabinet Latches: Top Knobs item TK729HB Transcend cabinet latch in Honey Bronze.
Refrigerator
Paneled refrigerators are also in “Passive by Sherwin Williams”. What a gorgeous color for cabinetry!
Vase: Serena & Lily.
Refrigerator Pulls
Appliance Pulls: Top Knobs.
Paint Color
Walls/ Moulding Color: Sherwin Williams Pure White SW 7005 – Notice the stunning Marble fireplace in the Great Room.
Hardwood Flooring
Hardwood Flooring: California Classics Mediterranean Collection French Oak Item # Mckw517 Color: Kerrew – Others: here, here & here .
Wet Bar
This wet bar is a shower apart! Cabinet color is Sherwin Williams Grays Harbor.
Countertop & Backsplash
Countertop: Bedrosians- Sequel Quartz – Brilliant White 2 cm.
Backsplash: Bedrosians – Provincetown 3” x 6” Tile – similar here, here & here.
Wire Mesh Grille
Cabinet Insert: Kent Design- 114 1/4f 1″ Round Flat Crimped Wire Grille -16″ X 42.
Wallpaper: Phillip Jefferies Borderline 1338 – available through the designer.
Cabinet Pulls: Top Knobs.
Latches: Top Knobs.
Faucet & Sink
Faucet: Newport Brass.
Powder Room
Wall & Moulding Color: Sherwin Williams Stardew.
Mirror: RH – Other Beautiful Mirrors: here, here, here & here.
Vanity: Pottery Barn.
Countertop
Countertop is Honed carrara marble top and ceramic sink top (it comes with the vanity).
Bathroom Faucet
Faucet: Newport Brass.
Towel Ring: Kohler.
Grey Shiplap Bedroom
Wall paneling is TH&H #2003LDF (San Diego, CA store) – Accent wall color is Sherwin Williams Passive SW 7064 in semi-gloss.
Guest Bath
What a fresh and beautiful design. The soothing color scheme is also a huge plus!
Paneling
Wall paneling is TH&H # 2003LDF. Paneling color is Sherwin Williams Foggy London SW 8642 in Satin.
Vanity
Vanity is from All Modern , 30 inch Carrera marble single bathroom vanity in Polished Nickel.
Mirror: Rejuvenation – Rounded Rectangle Yaquina Mirror Polished Nickel.
Shower Threshold Tile: Emser.
Lighting: Quoizel.
Faucet
Vanity faucet is by Signature Hardware.
Bath & Tile
Tub: Kohler – Archer Soaking Tub.
Shower Faucet: Kohler – Margaux Shower Faucet Trim Kit.
Shower tile is basket weave mosaic Thassos white marble with blue gray dots – similar here.
Robe Hook: Kohler – Margaux Robe Hook Vibrant Polished Nickel.
Guest Bedroom
Box Panelling Accent Wall Color: Sherwin Williams Foggy London SW 8642.
Ceiling Color: Sherwin Williams Pure White SW 7005.
It’s all on the Details
Door Hardware: Rejuvenation Putnam classic knob Interior Door Set in polished nickel.
Jack & Jill
The Guest Bedrooms are connected to a large Jack & Jill bathroom.
Cabinetry Paint Color
Vanity & Built-ins Paint Color: Sherwin Williams Stardew.
Floor Tile
Flooring: Walker Zanger – Pietra Bello Penny Round Bianco Bella – similar here.
Pocket Door Hardware (Same Throughout House): Emtek.
Countertop
Vanity Countertop & Backsplash: Bedrosians- Sequel Quartz – Brilliant White 2 cm.
Towel Rings: Kohler – Margaux Collection Towel Ring Vibrant Polished Nickel.
Hardware: RH- similar here.
Mirrors & Faucets
Mirrors: Pottery Barn – Hewitt Pivot Mirror.
Faucets: Kohler – Elliston Widespread Bathroom Faucet.
Vanity Lights: Quoizel.
Shower
Shower Flooring: Walker Zanger – similar here.
Shower Threshold Tile: Emser Marble – Thassos White Polished 12’ X 24’.
Shower Wall Tile
Shower Wall Tile: MSI Pinwheel Bianco Dolomite Marble Mosaic Tile.
Shower Faucet: Kohler – Margaux Collection Vibrant Polished Nickel.
Kid’s Bedroom
Moulding Detail Wall Color: Sherwin Williams SW 7652 Mineral Deposit.
Walls Color: Sherwin Williams Pure White SW 7005.
Paneling Paint Color
White Wall Paneling Paint Color: Sherwin Williams Pure White SW 7005 in semi-gloss.
Lighting: Pendants: Birch Lane – Cranton 4 Light Square/Rectangle Pendant #Mcrr6428 Polished Nickel.
Oh, “Henri”!
Flooring: California Classics Mediterranean Collection French Oak Item # Mckw517 Color: Kerrew in Herringbone Lay.
Master Bedroom
The large Master Bedroom features sliding doors to the backyard. Walls and wall paneling are in Sherwin Williams Pure White.
Beautiful Bedroom Decor Ideas:
(Scroll to see more)
!function(w,i,d,g,e,t){d.getElementById(i)||(element=d.createElement(t),element.id=i,element.src="https://widgets.rewardstyle.com"+e,d.body.appendChild(element)),w.hasOwnProperty(g)===!0&&"complete"===d.readyState&&w[g].init()}(window,"shopthepost-script",document,"__stp","/js/shopthepost.js","script")
JavaScript is currently disabled in this browser. Reactivate it to view this content.
Master Bathroom
The master bathroom is simply gorgeous! It features a spacious shower and bathtub area ensconced in stone tile.
Door: 8‘0“ door unit in glass is from Jeld Wen.
Towel Bar: Kohler.
Vanity Paint Color
Vanity Color: Sherwin Williams Pure White SW 7005 – All cabinets in the entire home are custom-made by the The Meter company (builder).
Vanity Lights: Quoizel – Union 3 Light 23 Inch Back Light Wall Light.
Mirrors: Rejuvenation.
Vanity Hardware: Rejuvenation.
Countertop & Faucets
Countertop: Bardiglio Marble.
Faucets: Kohler Artifacts in Vibrant Polished Nickel.
Sinks are Mirabelle Undermount.
Wall Paint Color
Wall Color: Sherwin Williams Passive.
Floor Tile
The large open shower accommodates a sleek freestanding tub.
Floor Tile: MSI Geometrica Bianco Dolomite Marble Mosaic Tile – also available here.
Ceiling Color: Sherwin Williams Pure White SW 7005.
Wall Tile
Shower Wall Tile is Emser 12×24 Thassos Tile.
Tub
Freestanding Tub: Signature Hardware – Boyce Acrylic Freestanding Tub 65”.
Tub Faucet: Kohler Artifacts Collection Vibrant Polished Nickel with Valve Trim.
Shower Faucet
Niche Tile Inserts: Thassos And Carrara Polished Basketweave Mosaic Tile – similar here.
Shower Plumbing: Kohler Artifacts Collection.
Laundry Room/Mudroom
This is one of my favorite places in this house. I am loving everything about it, including the Dog Wash Station.
Wall Color: Sherwin Williams Pure White SW 7005.
Flooring: Emser Marble – Thassos White Polished 12’ X 24’.
Paint Color
Cabinet paint color is Sherwin Williams African Gray SW 9162.
Countertop is Amazon Stone – Bardiglio Marble.
Backsplash: Bedrosian Costa Allergra in White Sand.
Faucet: Rohl Wall-mounted Faucet.
Dog Shower
Elevated dog showers are definitely a better choice for our back.
Tile: Bedrosian Costa Allergra in White Sand.
Valve Trim: Kohler Artifacts.
Hand Shower: Kohler.
Sconce: RH – similar here.
Awwww
This puppy melts my heart! What a cute little face!!!
Store it in Style
This Laundry room/Mudroom also features plenty of storage space.
Mudroom Cubbies
Custom built-in cabinets flank a large Mudroom bench with cubbies. Wall is accentuated with shiplap.
Hardware: Top Knobs.
Backyard
Although not seen here, this home also features a rooftop deck with a breathtaking view of the city and ocean.
Vegetable Garden
Raised garden beds are perfect to create the most delicious and healthy vegetable garden! Cheers to the builder for having this great idea!!!
Pergola
The Pergola was custom-built by the builder and paint color is Sherwin Williams Pure White SW 7005.
Many thanks to the builder & designer for sharing the details above!
Builder: The Meter Company.
Interior Design: AGK Design Studio (Instagram).
Photography: Ryan Garvin.
Click on items to shop!
!function(w,i,d,g,e,t){if (!d.getElementById(i)) {element = d.createElement(t);element.id = i;element.src = 'https://widgets.rewardstyle.com' + e;d.body.appendChild(element);} if (typeof w[g] === 'object') { if (d.readyState === 'complete') { w[g].init(); }}}(window, 'moneyspot-script', document, '__moneyspot', '/js/widget.js', 'script');
JavaScript is currently disabled in this browser. Reactivate it to view this content.
Best Sales of the Month:
Thank you for shopping through Home Bunch. For your shopping convenience, this post may contain AFFILIATE LINKS to retailers where you can purchase the products (or similar) featured. I make a small commission if you use these links to make your purchase, at no extra cost to you, so thank you for your support. I would be happy to assist you if you have any questions or are looking for something in particular. Feel free to contact me and always make sure to check dimensions before ordering. Happy shopping!
Wayfair: Up to 70% off on Kitchen Renovation.
Pottery Barn: Up to 40% off Outdoor Furniture.
Serena & Lily: Enjoy 20% Off with code: ATHOME.
Joss & Main: Under $200: Large Area Rugs.
West Elm: Premier Event Up to 70% Off.
Verishop: Mother’s Day Sale.
Popular Posts:
Classic Home with Wrap-around Porch.
New-construction Florida Home.
New-construction Modern Farmhouse Home.
White Home with Front Porch.
Riverside Modern Farmhouse Tour.
Reinvented Traditional Kitchen Design Ideas.
Modern Farmhouse Lake House.
New Modern Farmhouse.
Lake House Renovation.
California Fixer Upper.
Beautiful Homes of Instagram: Florida.
California Home Interior Design Ideas.
Florida House for Sale.
California Modern Farmhouse for Sale.
Beautiful Homes of Instagram: Modern Farmhouse.
Black & White Modern Farmhouse.
Follow me on Instagram: @HomeBunch
You can follow my pins here: Pinterest/HomeBunch
See more Inspiring Interior Design Ideas in my Archives.
“Dear God,
If I am wrong, right me. If I am lost, guide me. If I start to give-up, keep me going.
Lead me in Light and Love”.
Have a wonderful day, my friends and we’ll talk again tomorrow.”
with Love,
Luciane from HomeBunch.com
from Home https://www.homebunch.com/california-ranch-home-for-sale/ via http://www.rssmix.com/
0 notes
Text
How to Iterate Over a HashMap in Java
A HashMap in Java is a part of the java.util package and is one of the most commonly used data structures for storing key-value pairs. Iterating over a HashMap efficiently is essential for performing operations like searching, updating, or processing data stored in the map. In this article, we will explore different ways to iterate over hashmap java.
Different Ways to Iterate Over a HashMap
Using entrySet() and a For-Each Loop
This is the most common and recommended approach. The entrySet() method returns a set view of the mappings contained in the map. import java.util.HashMap; import java.util.Map;
public class HashMapIteration { public static void main(String[] args) { HashMap map = new HashMap<>(); map.put(1, "Apple"); map.put(2, "Banana"); map.put(3, "Cherry"); for (Map.Entry<Integer, String> entry : map.entrySet()) { System.out.println("Key: " + entry.getKey() + ", Value: " + entry.getValue()); } }
}
Using keySet() to Iterate Over Keys
If you only need the keys, you can use keySet() to retrieve a set of keys and loop through them. for (Integer key : map.keySet()) { System.out.println("Key: " + key + ", Value: " + map.get(key)); } This approach requires an additional lookup (map.get(key)) to retrieve values, making it less efficient than entrySet().
Using values() to Iterate Over Values
If you only need to iterate over values without keys, you can use values(). for (String value : map.values()) { System.out.println("Value: " + value); }
Using Java 8 Streams
With Java 8, you can use streams to iterate over a HashMap in a more functional style. map.forEach((key, value) -> System.out.println("Key: " + key + ", Value: " + value)); Alternatively, using streams: map.entrySet().stream().forEach(entry -> System.out.println("Key: " + entry.getKey() + ", Value: " + entry.getValue())); 5. Using an Iterator
You can use an Iterator to iterate over a HashMap, especially when you need to remove elements while iterating. Iterator> iterator = map.entrySet().iterator(); while (iterator.hasNext()) { Map.Entry entry = iterator.next(); System.out.println("Key: " + entry.getKey() + ", Value: " + entry.getValue()); } Conclusion
Java provides multiple ways to iterate over a HashMap, each with its own advantages. The entrySet() method is the most efficient for iterating over both keys and values, while Java 8 streams offer a modern, concise approach. Using an iterator is useful when modifications are needed during iteration. Choosing the right method depends on your specific use case and performance considerations
0 notes
Text
Exploring the Benefits of Java Map

Exploring the Benefits of Java Map reveals its significant advantages, particularly with hashmap java. Java Map efficiently stores key-value pairs, ensuring fast data retrieval, unique keys, and easy integration into programs.
Implementations like `HashMap` offer constant-time performance for basic operations, enhancing application speed. Versatile and memory-efficient, Java Map simplifies data management in various real-world applications such as caching and configuration management.
For a detailed understanding of hashmap java, resources like TpointTech provide comprehensive tutorials and examples, making it easier for developers to leverage Java Map's full potential.
Efficient Data Retrieval
One of the primary benefits of using Java Map is its efficient data retrieval capability. Maps allow you to store data in key-value pairs, where each key is unique. This structure enables fast retrieval of values based on their keys, often in constant time, O(1), using hash-based implementations like HashMap. This efficiency is crucial for applications that require quick access to data, such as caching mechanisms and real-time data processing systems.
No Duplicate Keys
In Java Map, each key must be unique, which ensures that there are no duplicate keys in the collection. This feature is particularly useful when you need to maintain a unique set of identifiers and their associated values. For instance, in a database application, you can use a map to store user IDs and their corresponding information, ensuring that each user ID is unique.
Versatile Implementations
Java provides several implementations of the Map interface, each with its own strengths and use cases. The most commonly used implementations include:
HashMap: Offers constant-time performance for basic operations and is not synchronized, making it faster but not thread-safe.
LinkedHashMap: Maintains the insertion order of elements, making it useful for applications that require ordered iterations.
TreeMap: Implements the NavigableMap interface and ensures that the keys are sorted according to their natural order or a specified comparator, making it suitable for applications that require sorted data.
ConcurrentHashMap: Provides a thread-safe alternative to HashMap with improved concurrency, making it ideal for multithreaded applications.
This versatility allows developers to choose the most appropriate implementation based on their specific requirements.
Easy to Use
Java Maps are easy to use and integrate into your programs. The standard methods provided by the Map interface, such as put(), get(), remove(), and containsKey(), make it straightforward to perform common operations. Additionally, the enhanced for loop and the entrySet() method allow for easy iteration over the map's entries, simplifying the process of traversing and manipulating key-value pairs.
Memory Efficiency
Maps can be more memory-efficient compared to other data structures, especially when dealing with large datasets. By using keys to access values directly, you avoid the need for complex searching algorithms, which can save both time and memory. Implementations like HashMap use hash codes to distribute entries evenly across buckets, minimizing the likelihood of collisions and reducing the overhead associated with handling them.
Improved Code Readability
Using a Map can significantly improve the readability of your code. By clearly defining the relationship between keys and values, you make your data structures more intuitive and easier to understand. This clarity is particularly beneficial in large codebases, where maintaining readability and simplicity is crucial for effective collaboration and maintenance.
Real-World Applications
Java Maps are widely used in real-world applications across various domains. Some common use cases include:
Caching: Storing frequently accessed data for quick retrieval.
Database indexing: Mapping primary keys to database records.
Configuration management: Storing application settings and configurations.
Associative arrays: Implementing dictionaries or lookup tables.
Conclusion
Java Map, particularly the `HashMap`, offers an efficient and versatile way to manage key-value pairs, making it an essential tool for Java developers.
Its ability to provide fast data retrieval, ensure unique keys, and support various implementations makes it suitable for a wide range of applications, from caching to database indexing.
The ease of use and memory efficiency further enhance its appeal, contributing to improved code readability and maintainability. For a deeper understanding of `hashmap java`, exploring resources like TpointTech can provide valuable insights and practical examples.
0 notes
Video
youtube
Antique Carved Architectural Haveli Door Antique Carved Architectural Haveli Door Designers and architects, understand the appeal of the unique and one of a kind elements for prospective buyers, …
#antiquedoor#DOOR#entryset#exteriordoor#frontdoor#gate#rusticdoor#teakdoor#vintagedoor#welcomegate#woodendoor
0 notes
Text
Java executor
Interfaces. Executor is a simple standardized interface for defining custom thread-like subsystems, including thread pools, asynchronous I/O, and lightweight task frameworks. Depending on which concrete Executor class is being used, tasks may execute in a newly created thread, an existing task-execution thread, or the thread calling execute, and may execute sequentially or concurrently. ExecutorService provides a more complete asynchronous task execution framework. An ExecutorService manages queuing and scheduling of tasks, and allows controlled shutdown. The ScheduledExecutorService subinterface and associated interfaces add support for delayed and periodic task execution. ExecutorServices provide methods arranging asynchronous execution of any function expressed as Callable, the result-bearing analog of Runnable. A Future returns the results of a function, allows determination of whether execution has completed, and provides a means to cancel execution. A RunnableFuture is a Future that possesses a run method that upon execution, sets its results. How to get sublist from arraylist in java? How to sort arraylist using comparator in java? How to reverse contents of arraylist java? How to shuffle elements in an arraylist in java? How to swap two elements in an arraylist java? how to read all elements in linkedlist by using iterator in java? How to copy or clone linked list in java? How to add all elements of a list to linkedlist in java? How to remove all elements from a linked list java? How to convert linked list to array in java? How to sort linkedlist using comparator in java? How to reverse linked list in java? How to shuffle elements in linked list in java? How to swap two elements in a linked list java? How to add an element at first and last position of linked list? How to get first element in linked list in java? How to get last element in linked list in java? How to iterate through linked list in reverse order? Linked list push and pop in java How to remove element from linkedlist in java? How to iterate through hashtable in java? How to copy map content to another hashtable? How to search a key in hashtable? How to search a value in hashtable? How to get all keys from hashtable in java? How to get entry set from hashtable in java? How to remove all elements from hashtable in java? Hash table implementation with equals and hashcode example How to eliminate duplicate keys user defined objects with Hashtable? How to remove duplicate elements from arraylist in java? How to remove duplicate elements from linkedlist in java? how to iterate a hashset in java? How to copy set content to another hashset in java? How to remove all elements from hashset in java? How to convert a hashset to an array in java? How to eliminate duplicate user defined objects from hashset in java? How to iterate a linkedhashset in java? How to convert linkedhashset to array in java? How to add all elements of a set to linkedhashset in java? How to remove all elements from linkedhashset in java? How to delete specific element from linkedhashset? How to check if a particular element exists in LinkedHashSet? How to eliminate duplicate user defined objects from linkedhashset? How to create a treeset in java? How to iterate treeset in java? How to convert list to treeset in java? How to remove duplicate entries from an array in java? How to find duplicate value in an array in java? How to get least value element from a set? How to get highest value element from a set? How to avoid duplicate user defined objects in TreeSet? How to create a hashmap in java? How to iterate hashmap in java? How to copy map content to another hashmap in java? How to search a key in hashmap in java? How to search a value in hashmap in java? How to get list of keys from hashmap java? How to get entryset from hashmap in java? How to delete all elements from hashmap in java? How to eliminate duplicate user defined objects as a key from hashmap? How to create a treemap in java? How to iterate treemap in java? How to copy map content to another treemap? How to search a key in treemap in java? How to search a value in treemap in java? How to get all keys from treemap in java? How to get entry set from treemap in java? How to remove all elements from a treeMap in java? How to sort keys in treemap by using comparator? How to get first key element from treemap in java? How to get last key element from treemap in java? How to reverse sort keys in a treemap? How to create a linkedhashmap in java? How to iterate linkedhashmap in java? How to search a key in linkedhashmap in java? How to search a value in linkedhashmap in java? How to remove all entries from linkedhashmap? How to eliminate duplicate user defined objects as a key from linkedhashmap? How to find user defined objects as a key from linkedhashmap? Java 8 functional interface. Java lambda expression. Java lambda expression hello world. Java lambda expression multiple parameters. Java lambda expression foreach loop. Java lambda expression multiple statements. Java lambda expression create thread. Java lambda expression comparator. Java lambda expression filter. Java method references. Java default method. Java stream api. Java create stream. Java create stream using list. Java stream filter. Java stream map. Java stream flatmap. Java stream distinct. Java forEach. Java collectors class. Java stringjoiner class. Java optional class. Java parallel array sorting. Java Base64. Java 8 type interface improvements. Java 7 type interface. Java 8 Date Time API. Java LocalDate class. Java LocalTime class. Java LocalDateTime class. Java MonthDay class. Java OffsetTime class. Java OffsetDateTime class. Java Clock class. Java ZonedDateTime class. Java ZoneId class. Java ZoneOffset class. Java Year class. Java YearMonth class. Java Period class. Java Duration class. Java Instant class. Java DayOfWeek class. Java Month enum. Java regular expression. Regex character classes. Java Regex Quantifiers. Regex metacharacters. Regex validate alphanumeric. Regex validate 10 digit number. Regex validate number. Regex validate alphabets. Regex validate username. Regex validate email. Regex validate password. Regex validate hex code. Regex validate image file extension. Regex validate ip address. Regex validate 12 hours time format. Regex validate 24 hours time format. Regex validate date. Regex validate html tag. Java Date class example. Java DateFormat class. Java SimpleDateFormat class. Java Calendar class. Java GregorianCalendar class. Java TimeZone class. Java SQL date class. Java get current date time. Java convert calendar to date. Java compare dates. Java calculate elapsed time. Java convert date and time between timezone. Java add days to current date. Java variable arguments. Java string in switch case. Java try-with-resources. Java binary literals. Numeric literals with underscore. Java catch multiple exceptions.
0 notes
Text
Emtek EMTouch Electronic Touch screen Keypad Deadbolts on Huge Sale
Emtek Single Cylinder Cast Bronze Electronic Deadbolt:
Residential keyless security has never looked better than Emtek's low profile Modern Keypad Entryset. Leave your keys behind as you ride a bike or walk the dog with the freedom and security that Emtek Keypad Locks provide.
Features:
Cast Bronze
Standard Door Prep
Height: 6-1/8'
Width: 3'
Door Thickness: 1-3/4' to 2-1/4'

Emtek EMTouch Electronic Touchscreen Keypad Deadbolt:
Emtek's EMTouch Deadbolt is a combination of style; function and security all wrapped up into a perfect addition to any home. No more digging for keys or making dozens of copies; the electronic keypad deadbolt comes factory programmed with 2 unique; secure codes right out of the box and can be programmed for up to 20 additional codes of your choice.
Features:
Installs easily with only a Phillips head screwdriver.
Factory programmed with 2 unique; secure user codes for use right out of the box.
Can be programmed with up to 20 user codes of your choice.
Programming changes can be made easily using the keypad.
Illuminated keypad for easy and quick operation after dark.
Low battery indicator lets you know when it's time to change the battery.
For more products and information visit here: https://www.lockinghardware.com
Call us: (800) 604-1922
Facebook Page || Twitter || Pinterest
0 notes