#especially on technical websites where a deep level of knowledge is required. However
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Mobile US users spent an average of 115.8 minutes on Tumblr app monthly.
Text
Essential Guide to Finding Quality Detroit Motor Parts for Your Detroit 60 Series Engine
When it comes to maintaining the performance and longevity of heavy-duty engines, sourcing the right components is critical. For those who rely on the proven power of the Detroit 60 Series engine, finding dependable Detroit Motor Parts is more than a preference—it’s a necessity. Whether you are conducting routine maintenance or addressing specific mechanical issues, choosing high-quality parts tailored to the Detroit 60 Series is crucial to keeping your engine running at optimal efficiency. If you're looking for a trustworthy place to shop, shop.nadieselparts.com provides a comprehensive selection of products designed to meet your engine’s unique demands.
The Detroit 60 Series is widely recognized for its robust design and reliability across various commercial and industrial applications. Since its debut, this engine series has earned a strong reputation for fuel efficiency, power, and durability, making it a favorite among fleet operators and independent truckers alike. However, even the most reliable engine will eventually require parts replacement or upgrades to continue delivering peak performance. That’s where access to genuine Detroit Motor Parts becomes essential.
One of the key advantages of using genuine or high-quality aftermarket parts specifically made for the Detroit 60 Series is that they are engineered to meet or exceed OEM specifications. This ensures a perfect fit and compatibility, reducing the risk of mechanical failure due to improper installations or substandard components. Everything from cylinder heads and turbochargers to water pumps and injectors must be selected with care to preserve the engine’s integrity.
What separates the Detroit 60 Series from many other heavy-duty engines is its advanced engineering and modular design. As a result, not every generic part will suit its configuration. Choosing parts that are designed for this engine ensures better performance, fuel economy, and reduced downtime. This makes the sourcing process even more significant and reinforces the importance of choosing a reputable supplier.
Online platforms have revolutionized the way we buy parts for our vehicles, especially for specialized equipment. shop.nadieselparts.com offers an intuitive and secure platform where you can find a wide range of parts compatible with the Detroit 60 Series. From individual gaskets to complete overhaul kits, the website is stocked with components that are clearly listed for specific engine models, simplifying the process for both experienced mechanics and do-it-yourselfers.
Another aspect to consider is customer support and technical assistance. When you're dealing with complex engines like the Detroit 60 Series, having access to expert advice can make a big difference in ensuring that you get the right part the first time. Platforms that focus exclusively on diesel engine parts are often staffed by individuals with deep knowledge of diesel engines and their components, making your purchasing decision much more informed.
Price is also a factor, and while it may be tempting to go for the cheapest option, this can often lead to more significant problems down the line. Poor-quality parts can lead to breakdowns, costly repairs, and even complete engine failure. Investing in reliable Detroit Motor Parts ensures that your engine remains in excellent working condition, thus safeguarding your long-term operational costs.
In conclusion, keeping your Detroit 60 Series engine in prime condition demands thoughtful selection of replacement parts. Whether you're looking for preventative maintenance items or critical engine components, choosing the right supplier makes all the difference. With its extensive inventory and commitment to quality, shop.nadieselparts.com stands out as a dependable source for those who need authentic or high-grade aftermarket parts. Equip your engine with components that match its level of excellence and keep it running strong for years to come.
For more info:-
Facebook
0 notes
Text
Maximizing Visibility - How SEO Drives Business Growth in Vancouver
In Vancouver, Canada’s bustling west coast city, the competition for online visibility is fierce. With a growing number of businesses shifting to digital platforms, the need for strong search engine optimization (SEO) has never been more crucial. As consumers rely heavily on search engines like Google to find local services, products, and businesses, mastering SEO is key to gaining a competitive edge in Vancouver’s diverse business landscape.
Why SEO is Essential for Vancouver Businesses
Search engine optimization is a digital marketing strategy that involves enhancing a website’s visibility on search engines like Google. SEO helps businesses appear higher in search results when potential customers search for related keywords. In Vancouver, where industries range from tourism and tech to real estate and retail, SEO is not just a tool for online success—it’s a necessity.
The online marketplace in Vancouver is booming, and local consumers increasingly use search engines to find businesses nearby. This trend has made local SEO particularly valuable for companies in Vancouver. Whether someone is looking for a local restaurant, a real estate agent, or a nearby tech service, appearing at the top of the search results page is critical. When a website ranks higher in local searches, it attracts more organic traffic, which often leads to higher conversion rates and business growth.
SEO in Vancouver also helps businesses build credibility. When a website ranks high on Google, it is often perceived as more trustworthy by users. This level of trust is invaluable, especially in competitive markets like Vancouver, where customers have plenty of options. A well-optimized website not only draws visitors but also provides a seamless user experience, further boosting your brand’s reputation.
The Role of SEO Agencies in Vancouver’s Digital Growth
SEO is a complex and evolving field that requires specialized knowledge, constant attention, and a deep understanding of search engine algorithms. That’s why many Vancouver businesses choose to partner with professional SEO agencies. A reliable SEO agency in Vancouver can take the guesswork out of optimizing your website, providing expert strategies tailored to the local market.
One of the key advantages of working with a local SEO agency in Vancouver is their knowledge of the city’s specific search trends. These agencies understand the local culture, consumer behavior, and competition, allowing them to create targeted campaigns that resonate with the Vancouver audience. Moreover, SEO agencies can stay on top of algorithm changes and SEO best practices, ensuring that your business stays competitive in search rankings.
An SEO agency in Vancouver doesn’t just optimize for search engines—it helps businesses thrive in a digital-first world. By employing tactics like keyword research, technical SEO audits, and content optimization, an agency ensures that your website ranks for the most relevant and valuable keywords in your industry. The right agency will also focus on improving user experience, boosting mobile compatibility, and increasing the speed of your site, all of which contribute to higher rankings.
Finding the Best SEO Firm in Vancouver
With numerous SEO firms in Vancouver, selecting the right partner for your business can be overwhelming. However, a few key considerations can help narrow down your options. First, it’s important to look for an SEO firm with proven experience. An experienced agency will have case studies, testimonials, and a portfolio of successful SEO campaigns that demonstrate their ability to deliver results.
Another important factor is transparency. A trustworthy SEO firm in Vancouver will communicate openly about their processes and strategies, ensuring that you understand how they are improving your website’s rankings. They will also provide regular reports to show how your SEO efforts are paying off in terms of traffic, leads, and conversions.
Lastly, a good SEO firm will offer a customized approach. Vancouver businesses vary widely in their goals, industries, and target audiences, so a one-size-fits-all SEO strategy won’t work. The best SEO agencies in Vancouver will take the time to understand your business, your competition, and your specific SEO needs. Whether you’re a small local business or a large corporation, a personalized SEO plan is essential for achieving meaningful results.
The Power of Local SEO in Vancouver
Local SEO is one of the most impactful aspects of digital marketing for Vancouver-based businesses. Local SEO focuses on optimizing your website to rank for location-based searches, which is particularly important for businesses that rely on foot traffic or serve a specific geographic area. By optimizing your website for local search terms, like “SEO agency Vancouver” or “best coffee shop in Vancouver,” you increase your chances of being discovered by potential customers in your area.
One effective local SEO tactic is optimizing your Google My Business (GMB) profile. A well-optimized GMB listing helps your business appear in Google’s local pack, the map that appears at the top of search results for location-specific queries. Vancouver SEO agencies can help manage and optimize your GMB profile, ensuring that your business appears prominently in local searches. Encouraging customer reviews and managing online directories are other crucial aspects of local SEO that agencies can handle to further boost your visibility.
SEO: The Future of Digital Marketing in Vancouver
As Vancouver continues to grow as a hub for innovation, tech, and commerce, the importance of SEO will only increase. New developments in search technology, such as voice search and AI-powered algorithms, are transforming the way people search for information online. To stay competitive, Vancouver businesses must adapt to these changes by ensuring their SEO strategies are up-to-date.
Partnering with a forward-thinking SEO firm in Vancouver will allow your business to stay ahead of the curve. By continuously optimizing your website and adjusting your strategy to meet the latest search trends, you can ensure that your business remains visible and competitive in Vancouver’s dynamic online landscape.
In conclusion, SEO is an invaluable tool for Vancouver businesses looking to increase their online visibility, drive traffic, and grow their customer base. Investing in a reputable SEO agency in Vancouver can set your business up for long-term success in the ever-evolving digital world.
If you are looking for SEO firm in Vancouver, visit Mandreel (SEO Vancouver)
0 notes
Text
How to Find the Right DUI Lawyer for You

If you’ve been charged with driving under the influence (DUI), the legal consequences can be severe, including license suspension, fines, and possibly jail time. To navigate the complexities of DUI law, it’s crucial to have the right legal representation. Finding the right DUI lawyer is key to building a strong defense and achieving the best possible outcome for your case. However, with so many options available, it can be challenging to know where to begin. This guide will help you understand how to find the right DUI lawyer for your needs, ensuring that you receive expert legal advice and support.
1. Start with Research
The first step in finding the right DUI lawyer is conducting thorough research. Start by creating a list of potential lawyers in your area who specialize in DUI defense. You can begin by searching online, asking for recommendations from friends or family, or checking local bar associations. When researching, focus on DUI lawyers with a proven track record of handling similar cases and a reputation for success.
Where to Start Your Search:
Online directories: Websites like Avvo, Justia, and FindLaw provide detailed profiles of DUI lawyers, including client reviews, credentials, and practice areas.
Referrals: Personal recommendations from friends, family members, or colleagues who have been through similar experiences can be valuable.
Local bar associations: Many bar associations offer referral services that can help you find reputable DUI lawyers in your area.
Lawyer websites: Check the websites of potential lawyers to get an idea of their specialization, experience, and success rates in DUI cases.
2. Look for Specialization in DUI Law
One of the most important factors to consider is whether the lawyer specializes in DUI law. DUI defense requires a deep understanding of specific laws, procedures, and scientific evidence, such as breathalyzer results and field sobriety tests. Lawyers who specialize in DUI defense are more likely to be familiar with the nuances of these cases, including potential defenses and the best strategies for negotiating with prosecutors.
Why Specialization Matters:
DUI cases involve complex laws and technical aspects, such as breathalyzer accuracy, blood alcohol content (BAC) levels, and sobriety testing procedures.
A specialized lawyer will stay updated on changes in DUI laws and can use this knowledge to your advantage.
DUI lawyers are often familiar with local court systems, prosecutors, and judges, giving them insight into how to approach your case effectively.
3. Consider Experience and Track Record
Experience is key when choosing the right DUI lawyer. An experienced lawyer will have handled numerous DUI cases and will be well-versed in strategies to challenge evidence and negotiate with prosecutors. When assessing a lawyer’s experience, look for their success rate in DUI cases, especially those similar to yours. Lawyers with a strong track record of winning or reducing DUI charges can give you confidence in their ability to handle your case.
Questions to Ask About Experience:
How long have you been practicing DUI law?
How many DUI cases have you handled, and what were the outcomes?
Do you have experience with cases similar to mine, such as first-time offenses, high BAC levels, or accidents involving DUI?
Have you taken DUI cases to trial, and if so, what was the result?
4. Evaluate Reputation and Reviews
A lawyer’s reputation is another crucial factor when choosing the right DUI lawyer. A good reputation can give you insight into their professionalism, competence, and success rate. Look for client reviews and testimonials to see what previous clients have to say about their experiences. You can also check the lawyer’s standing with the local bar association to ensure they have no disciplinary issues.
How to Evaluate Reputation:
Check online reviews on platforms like Google, Avvo, and Yelp.
Look for testimonials or success stories on the lawyer’s website.
Ask for references from past clients during your consultation.
Check if the lawyer has been recognized with awards or accolades for their work in DUI defense.
5. Schedule Initial Consultations
Most DUI lawyers offer free initial consultations, which provide an opportunity for you to discuss your case and assess whether the lawyer is the right fit for you. During the consultation, ask specific questions about how they would approach your case, their legal strategy, and their fees. This meeting is also a chance to evaluate how comfortable you feel with the lawyer and whether they communicate clearly.
What to Ask During a Consultation:
What is your approach to handling DUI cases like mine?
What potential outcomes do you see for my case?
How do you charge for your services (hourly or flat fee), and what is included in the fee?
Will you be personally handling my case, or will it be assigned to another lawyer in your firm?
How often will we communicate, and how will you keep me updated on the progress of my case?
6. Assess Communication and Personal Compatibility
Effective communication is crucial when working with a DUI lawyer. You need a lawyer who is responsive, listens to your concerns, and explains legal concepts in a way that’s easy to understand. Additionally, personal compatibility is essential for building a strong attorney-client relationship. You want to feel comfortable discussing your case openly with your lawyer and trust that they have your best interests in mind.
Signs of Good Communication:
The lawyer answers your questions clearly and patiently during the consultation.
They respond to phone calls or emails promptly.
They keep you informed throughout the legal process and provide regular updates on your case.
7. Understand Legal Fees and Payment Options
Before committing to a DUI lawyer, make sure you fully understand their fee structure. DUI defense can be expensive, so it’s important to know what you’ll be paying for and how much it will cost. Some lawyers charge a flat fee, while others bill by the hour. Additionally, there may be extra costs for things like court fees, expert witnesses, or trial representation. Make sure to ask about payment plans or flexible payment options if needed.
Questions to Ask About Fees:
Do you charge a flat fee or an hourly rate?
What is included in your fee, and are there any additional costs?
Do you offer payment plans or other flexible payment options?
Will there be extra charges if my case goes to trial?
8. Evaluate Local Knowledge
Finally, consider whether the lawyer has local knowledge. A DUI lawyer who practices in your area will be familiar with the local court system, judges, and prosecutors, which can be an advantage in your case. Local lawyers may also be aware of any regional nuances in DUI laws that could impact your defense.
Benefits of Local Knowledge:
Familiarity with local judges and prosecutors can help the lawyer tailor their approach to the specifics of your case.
Local lawyers are often better equipped to navigate regional court procedures and practices.
They may have relationships with law enforcement or other key players that can be beneficial in negotiations.
Conclusion
Choosing the right DUI lawyer for your case is a critical decision that can significantly impact the outcome of your legal situation. By conducting thorough research, considering a lawyer’s specialization, experience, reputation, and communication skills, and understanding their fee structure, you can make an informed choice that provides you with the best chance for a favorable outcome. Taking the time to find a DUI lawyer who meets your needs and understands your case will give you the confidence and peace of mind needed to navigate this challenging legal process.
0 notes
Text
HOW TO BECOME AN ONLINE TUTOR IN 7 EASY STEPS
With technology creeping into almost all aspects of our everyday lives, more people are now taking classes online. The advent of Covid-19 even emphasized the need for virtual classes, and teachers are now harnessing this opportunity to make money from the comforts of their home.
Fortunately, you see yourself as someone with relevant knowledge or skills to do the same. But your problem is, how do you become an online tutor? What are the things you need to do to start teaching online?
The good thing is, you can become an online tutor even when you currently have a regular job.
Whether you’re a teacher or a retired one, a professional in any industry with sought-after skills such as music, or even an undergraduate, becoming an online tutor is an excellent way to make money online simply by sharing knowledge.
This blog post, therefore, discusses the steps you need to take to become an online tutor.
7 STEPS TO BECOMING AN ONLINE TUTOR
Determine what to offer based on your strengths
Knowing where your strength lies is vital to being optimally impactful to your students. You may be knowledgeable in diverse areas, but you want to choose a subject of which you can deliver to your best capacity. This will help you stand out more among other tutors in that given field.
Pro tip: Having a certification on your chosen subject is often required to build credibility, but it’s not a conclusive determinant. You could become an online tutor even while in school or just newly graduated. To start teaching online, what’s essential is that you have the requisite subject knowledge, some level of experience, a passion for learning and imparting knowledge, and a cordial, professional attitude.
Know your target audience
Perhaps, you’ve chosen to teach math or guitar online. The next step to becoming an online tutor is identifying your potential students and the challenges they face in that subject matter.
So you want to ask yourself the following questions:
Who is my target audience?
What are their needs?
How do I persuade them to choose me as their teacher amidst the competition?
How do I express myself as an expert in this given field?
Choose an online tutoring platform
You may be tempted to create your own website as an online tutor, but it’s far easier to sign up on an online tutoring marketplace like Skiedo.
At Skiedo, you can become an online tutor with or without any certification, as long as your knowledge can be an asset to someone else. Sign up for free, design your course according to your schedule, set your own price, and get paid 100% of the fees due to you.
Interestingly, Skiedo has a live video chat feature in addition to text messaging. With the video chat, you can discuss with your students face-to-face, get a more personable experience, understand their needs, and hold your online classes.
With Skiedo becoming an online tutor is fast and easy, and registration is free! You can register right away and become an online tutor in minutes by login to skiedo.com and following the instructions below:
Click on Become a Tutor. On the drop-down menu that appears, click Register.
A page will open where you get to type in your name, email, and password. Read Skiedo's Terms & Conditions, Agree, and then click Next.
You will then receive a verification email to verify your email ID.
Once verified, you can log in back by entering your email ID and password. Then click LOGIN.
Now you need to fill in your basic information on the page that opens. Kindly fill in the data at your convenience and to your best knowledge.
Click Next and select the subjects you wish to teach. You can choose multiple subjects but are not advised to choose more than three subjects in which you're best versed.
Once you're done filling your subjects, complete inputting your information and ensure all fields have been filled. Kindly select your hourly rate as well. Then click Next.
Time to personalize your profile. It's always best to use a smiling picture to express friendliness to your students. On creating your profile, click Next.
You will then arrive at the Terms & Conditions Page. If you've read it, click Accept, which then takes you to your tutor profile. Here you will find all your information. You can edit and update at your convenience. Also, include your bank details where you'll receive your payments.
Add your 'slots of booking,' which tells students about your availability. Each slot should be an hour each.
If the subject you wish to offer is not on the list of subjects, you can 'suggest' a subject by clicking on the left bar of 'teaching subjects'.
Once you Register, your profile will appear when students search. When they book the class, you will receive a notification to approve the class. It's best to do so as soon as possible.
Once you've accepted the booking, you need to Initiate the Class on your dashboard on 'My Schedule'.
Once a class is finished, click Complete the Class.
You can also watch the video on how to become a tutor on Skiedo here.
Get your technical requirements set
As an online tutor, you will conduct your classes on a computer via the Internet. Hence, you need the following technical requirements to ensure you and your students don’t suffer glitches in the middle of an exciting course:
A fast and reliable computer: Although you may already have a computer, ensure it has at least a 1 GHz processor and 2 GB of ram for optimal speed. Skiedo works on Windows, Android, and Ios, so you can easily download the app. If you're using a web browser, however, ensure it's up-to-date.
High-speed Internet of at least 1 Mbps: You do not want your video conversation cutting off every minute. To know if your Internet connection is up to speed, go to www.speedtest.net.
HD Webcam: Being able to hear each other is great, but seeing each other brings that deep human connection that creates a whole new experience. Fortunately, Skiedo comes with a video chat feature. To get an optimal experience, ensure your webcam is HD. If yours is of a lower quality, purchase and install a better one.
The following are not mandatory but can give you a better experience:
Microphone: This is most especially important for music classes. However, if you want your students to hear you more efficiently, you'd need to get one if your in-built microphone isn't that great. Plug it into the microphone slot in your computer and set it up just beside the computer, with the mouthpiece close to your face. Blue Microphone Yeti and Rode NTK are some of the best microphones for online classes.
Headphones
Whiteboards.
Set up your course outline
As an online tutor, your course shouldn’t be bland. Ensure you design your course to be engaging and different from those of your competitors.
Additionally, structure the outline and direction of the lesson based on the subject matter, number of students in the session, and how much you want them to gain during the course. If it would be best to teach students individually, then do so.
Depending on the niche you’re into, you can also create written materials to back up the live video session.
And most importantly, it’s always a great idea to include interactive and gaming sessions to keep your students engaged. This fun environment helps to build a personal connection with them (many students complain of lack of personal connection in virtual learning).
Spice up your online course with quizzes, instructive videos, and other interactive activities. Make your learning more engaging, and users will rush to become your students.
Set your price and payment system
Setting an hourly rate is often a daunting task for online tutors. You may not want to set a price that looks too high, neither do you want to charge something unworthy. One way to go is to browse through other tutors in your chosen field. Notably, online tutors can charge anything between $20 and $100 per hour, depending on the course.
On fixing your price, you should then decide how you wish for students to make payments. PayPal, Google Pay, and Payoneer are some fast, reliable methods.
But Skiedo makes it so much easier. On Skiedo, you can enter your bank details and get your fees straight into your bank account.
Time to have your first class!
You’ve covered virtually all you need to do in your journey to becoming an online tutor. Now for the exciting part: your first class!
You will most likely have some worries and may even feel nervous, but preparation is key!
Have a game plan ready. It’s helpful to write out your introduction and the order of things for that particular session so that you always know what to do or say.
As you have your technical requirements all sorted out, you also need to make sure your students have theirs. Ask questions to know if their system is up to speed and what learning pattern they’re most comfortable with. It’s also a great idea to prepare a written material for your students to go through before the first class.
Putting your students on the same page with you is imperative for success as an online tutor.
If you feel nervous, rehearse with a friend or family member. This can help put you at ease before the actual class.
Pro tip: Be flexible. As an online tutor, you must be flexible. Your students may live in another time zone entirely, so you want to be available when you’re needed.
📷
CONCLUSION
Now you know the steps to take to become an online tutor and start teaching online. It’s time to take action and start. As you move on, you will find your teaching skills getting sharpened.
Teaching online is an incredible way for you to make extra money doing the things you love. Take charge of this digital learning revolution, and the sky’s your limit.
2 notes
·
View notes
Text
The Evolution of Artificial Intelligence: From Expert Systems to Deep Learning
Despite its many evocative depictions in science fiction films, the question of AI isn’t just one to be entertained by. It is a real and important issue that has the potential to change our world forever if we don’t manage it properly.
The Evolution of Artificial Intelligence: From Expert Systems to Deep Learning Over the past few decades, computers have been developing increasingly intelligent abilities. They can now learn, process information, and interact with people and other machines like never before. But that progress has come with a lot of pitfalls.

First of all, there is the problem of how to define "intelligence" in an ethical way that is appropriate for modern society and our environment. There are various definitions, including a broad one that includes the ability to reason. Others are more specific, defining "intelligence" as a set of skills and abilities that enable an individual to solve problems and make decisions.
Second, there is the problem of how to implement such capabilities in real-world applications. This What is metaverse and is it the future? requires the development of AI systems that are robust and flexible enough to respond to changing circumstances.
Third, there is the problem of how to measure an AI system’s performance. This is often complicated and difficult, requiring the use of data, and sometimes a combination of multiple data sets.
Fourth, there is the problem of how to interpret such results. This is especially true in the case of decision making, where a machine’s conclusions can be very complex.
Fifth, there is the problem of how to explain such decisions. This can be a major concern in industries where the resulting AI decisions are subject to strict regulatory compliance requirements.
Sixth, there is the problem of how to manage inconsistencies or contradictions in a system’s knowledge base. This is particularly challenging in specialised fields such as medicine and law.
Seventh, there is the problem of how to convert all this data into meaningful information for a machine. This is a complex and time-consuming task that requires a lot of human expertise.
Eighth, there is the problem of how to ensure that a system can evolve and improve its intelligence over time. This is a complicated and time-consuming task that requires a very high level of technical expertise, often involving artificial neural networks and other specialized algorithms.
Nineth, there is the problem of how to determine when an AI should be deemed "fully autonomous." This website technology can be complicated and requires a highly skilled and experienced team that can interpret how such systems operate.
Historically, research on AI has been divided between the academic and industrial camps, with the former focusing on the theoretical analysis of intelligence and the latter concentrating on the systems point of view. The former has emphasized the idea that some formalized combination of deductive reasoning mechanisms will pave the road to progress, while the latter has favored an evolutionary rather than revolutionary approach.
Today, however, we are at a crossroads. We have the opportunity to move forward and create powerful technologies that will change our world for the better. The key is to stay focused on what works and not what doesn’t.
1 note
·
View note
Text
Messaging Extra-Terrestrial Intelligence (METI) – A Local Search
Abstract: This paper examines the feasibility of an amateur approach to METI using cheaply available lasers and optics. We suggest a novel variation in the search methodology, concentrating on contacting any interstellar extraterrestrial probes that may be present in the solar system. Specifically, the Lunar poles and Lagrange points L4 and L5. It is assumed that such a probe incorporates advanced artificial intelligence (AI) at or beyond human level. Additionally, that it is able to communicate in all major languages and common communications protocols. The paper is written in non-technical language with sufficient information to act as a “how to” source for technically knowledgeable people.
Note: Any portion of this may be reproduced and used in any manner provided attributions “Dirk Bruere” and the organization “Zero State” are included. Other more technical versions of this are available.
[ DOWNLOAD PDF ]
Historical Introduction
On 16 November 1974 The radio telescope at Arecibo sent a brief message to the M13 star cluster some 25,000 light years distant. It comprised some 210 bytes of data sent at a bitrate of 10 bits per second and a power of around one megawatt. The (colored) pictorial representation is shown here. It is probably the best known attempt at contacting extraterrestrial intelligence (ETI), even though it was not serious, was not the first and by no means the last.
The first was a Morse code message sent from the USSR to Venus in 1962 which was even shorter. It is known in Russian as the Radio Message “MIR, LENIN, SSSR”.
Latterly, in 2016 on 10 October 2016, at 20:00 UTC the Cebreros (DSA2) deep-space tracking station of the European Space Agency sent a radio signal towards Polaris, the Pole Star, which is approximately 434 light years from Earth. The message consisted of a single 27,653,733 byte, 866 second transmission. Again, it was not a serious contact attempt, and was rather more a work of performance art by Paul Quast.
A few, more serious, attempts have been made in the intervening years i, targeted at more plausible planetary systems but none for any sustained period of time.
So, enter METI ii or “Messaging Extra-Terrestrial Intelligence” who aim to start a serious and comprehensive program of signaling various star systems some time in 2018 if they can raise the estimated $1million per year needed to run the program. For once, judging by their website, they intend to do it properly with a great deal of effort going into the communications protocols of the messages themselves.
Laser Communication
And that is where we were until June 2017 and a paper iii written by Michael Hippke examining the possible role of using the gravitational lensing effect of our sun to amplify laser signals across interstellar distances. The surprising conclusion was that using optical wavelength lasers and mirrors of only one-meter diameter, data could potentially be transferred at a megabit per second rates using around one Watt of power over 4 light years. This, to put it mildly, is spectacular especially since the receiving technology is potentially within our ability, assuming we could locate a telescope some 600 astronomical units (AU) from the sun. Unfortunately, our most distant spacecraft is Voyager 1 at about 140AU. He also showed in a previous paper that the data rate drops to bits per second per watt using a 39-meter receiving telescope and no lensing.
However, if we turn that around and assume that ETI has superior technology to us and can implement suitable receivers, then to contact them we need only very modest laser transmitters. Ones that are well within the budget of hobbyists and amateur astronomers. The advantage of using lasers is more apparent, especially for amateurs, when we consider beam divergence. Lasers can quite easily achieve divergences of less than one milli-radian (mrad) which corresponds to one meter per kilometer. To achieve that with microwaves at (say) 6GHz would necessitate a transmitter dish of approximately 65 meters diameter. A very expensive piece of radio astronomy kit. This also means that power levels can be significantly less than would be needed for radio communication. Nevertheless, there are serious caveats. These mostly concern the location and type of transmitter. For example, to limit beam spread Hippke assumes a one-meter diameter mirror and a beam spread of considerably less than a milliradian, so we are going to assume a rather larger receiver at the ETI end in order to minimize beam requirements at our end.
A much more serious problem is that the mirrors have to be aligned with each other. Specifically, the transmitter should be relatively stationary in space, and not on a rotating planet which is in turn circling its sun. If the latter is the case, the receiver will probably only align at fixed intervals lasting no more than a few tens of milliseconds unless very precise aiming technology is used.
However, there is a more interesting search regime far better suited to low budget than attempting interstellar communications.
Exploratory Scenario
This is a METI search that will be primarily focused on contact with self-replicating Von Neumann (VN) style interstellar probes iv. There are strong arguments that over a time scale of the order of thousands to a few million years, these are the best way of exploring the galaxy by any intelligent technology-oriented species. Once one of these devices arrives in a solar system it sets about creating sufficient infrastructure to both report back to its home system (as well as possible siblings) and create a replica of itself for onward launch to multiple other stars. Reasonably conservative capabilities are as follows:
They are very likely to outlive the species that sent them
They would almost certainly embody an artificial intelligence (AI) at or beyond Human level capability
They would be self-repairing and possibly have a lifetime in the tens of millions of years, barring accidents
They could exist around just about every star in the galaxy within ten million years
Using the kind of technology we might reasonably expect to appear sometime in the next century or two, such as placing observatories at the gravitational focal point of our sun, some 600AU out, we could view details on nearby extra-solar planets. And anyone out there could do the same to us. As a consequence, Earth has likely been an interesting place to view for the past 300 million years or so with its oxygen atmosphere and vegetation. And vastly more interesting in the past 10,000 years since rectangular shapes started appearing in the form of cities and fields. Rectangles generally do not occur naturally. Then in the past 300 years, the atmosphere started to show signs of industrial pollution followed 200 years later by radio and TV signals, intense radar pulses and the unmistakable sign of nuclear bombs whose output peaked at around 1% of the total output power of our sun.
If ETI exists, or has existed, within a few thousand light years there is a strong possibility that their probes are already here, and have been for a considerable length of time. This leads to a number of massively simplifying assumptions, again quite reasonable given the scenario above. These are:
Since we are now searching within our solar system power levels can be vastly reduced.
Message transit times, in both directions, are no more than a few hours maximum and possible only seconds.
Any intelligent VN probe that has been examining Earth will have been monitoring our technological development and radio/TV output. As a consequence, it will almost certainly understand all the major languages both written and spoken as well as our communications protocols.
We need to consider beaming our messages at likely locations within our own solar systems. For example, where would we place intelligent probes to wait out the ages and watch developments on Earth? Among strong possibilities are the Lunar poles, Lunar caverns which we now know exist v and the Lagrange points vi associated with Earth’s orbit, particularly L4 and L5, where position can be held with little expenditure of energy. We intend to beam laser messages to these points as part of the Zero State program.
But what messages? People have given much thought to creating a communications system that can be decoded by ETI, as mentioned above with METI. However, we contend that the answer is simple – we use English, and code in simple ASCII.
What has been lacking from Earth is a specific invitation to communicate or visit. It is this that forms the core of our project.
How Far Can We Be Seen?
Suppose we want to do the crudest communication system possible – a laser doing Morse Code. To the unaided Human eye, how far away could we see the beam? This depends on several factors:
Beam Divergence
Beam power
Wavelength
Eye sensitivity
Taking these in turn…
The power we will assume to be one Watt since this level of power is quite economical, and the wavelength to be either 532nm or 520nm, the latter being a pure diode output, not frequency doubled.
It is also the approximate wavelength where the eye peaks in sensitivity, and in our project is partly chosen for this reason. We could have gone for high power infrared in the tens of watts, or maybe towards the blue/violent end of the spectrum. However, green is not only easier and safer to work with, being highly visible, but is quite photogenic. From a safety point of view you seriously do not want an invisible beam of blinding intensity sweeping about. That would also be more difficult to aim and focus.
So we have an intensity of approximately one Watt per square meter at a distance of one kilometer, with the intensity dropping off as the square of the distance. At 2 km we have 0.25W per square meter, and so on.
Finally, what is the maximum sensitivity of the dark adapted Human eye? It appears to be about 100 photons per secondvii, but for the sake of argument we shall assume a level ten times lower, or 1000 photons per second in a dark adapted eye whose aperture is 100 square millimeters. That gives us a minimum intensity requirement of 10^7 photons per square meter per second. With each green photon carrying an energy of approximately 3.5e-19 Joules we get a required power density of 3.5e-12 Watts.
So, how far can our 1W green laser with a divergence of 1 mRad travel before we hit that value? The answer is a little over 500,000km – further than the Earth-Moon separation. By the time the beam gets there it will be illuminating a circle some 500km in diameter. If we are looking back from the Moon via a modest telescope such a beam would appear as a bright flickering point of monochromatic light. Even a 100mm diameter telescope would improve visibility by more than 100 times.
If we wish to improve the numbers there are certain things we can do. If we increase the power, it scales linearly in intensity at a given distance. If we increase the collimation to (say) 0.5mRad the intensity quadruples, but the illuminated area decreases 75% as the spot size halves.
Proof of Principle Equipment – Stage 1
The setup described below is an absolute minimum and has been put together simply to illustrate how easy it can be, and how cheap.
WARNING! – The lasers described should be treated like a loaded firearms with the safety off. Anyone around it should have eye protection goggles when it is operating or being worked on. If it sweeps across your eyes it will cause instant permanent blindness. It can also start fires. These are Class 4viii. You should also assume they will cause eye damage out to 1km if the beam is not expanded.
The basic equipment list is relatively straightforward – example sources are UK but may be obtained cheaply elsewhere:
• A computer with a USB interface • A terminal emulator program such as Realtermix or similar • A USB to TTL converter cable x • A battery based stabilized power supply for the laser module • High power laser module 1 Watt or greater xi • A telescopic rifle sight (scope) • A GOTO telescope • Various Weaver rail fittings and adapters • A low power sighting laser • Laser safety goggles
Less straightforward is any metalwork or optical interfacing of the laser module, however, the use of a scope with integral Weaver rails simplifies things considerably. The scope needs an attachment to the GOTO telescope, and the rest of the equipment attaches to the scope.
The next problem is that of holding the telescopic sight on target, which is where a motorized equatorial mount, or GOTO mount is required. Both will compensate for the rotation of the Earth and hold on a previously acquired target with accuracy much better than the assumed mrad (for scale, the diameter of the full moon in the sky is about 9 mrad) A GOTO telescope is fully computerized and will automatically move to designated targets either by name or celestial coordinates.
The first step is to securely attach the laser module co-axially to the telescopic sight so that you can see through the scope where the beam strikes. To do this you need a deserted area where you can aim the beam at a target some 100 meters distant and adjust optics and mechanical attachment so that the beam is aligned and parallel to the cross-hairs.
At this point you can examine the beam quality. With modules such as the above it will not be around spot. More likely it will be an image of the emission diode structure. Not ideal, but good enough for now.
The pictures below show the scope, sighting laser and Class 4 laser complete with a DIN rail that is used to attach all this to the telescope. In this instance, it is mounted on a camera tripod for alignment work.
Illustration 1: Left Side of the Lasers and Optics
Illustration 2: Right Side of the Lasers and Optics
Illustration 3: Front view of the Lasers and Optics
Proof of Principle Equipment – Stage 2
So, how do we improve upon this? Well, the answer is obvious. Rather than relying on the beam straight from the laser passing through the supplied focusing lens we use custom optics to expand and collimate the beam. This at once gives us better control over the divergence and by expanding the beam makes it somewhat safer by reducing areal power density.
Next, we add a receiver to the telescope eyepiece.
This consists of a bandpass optical filter centered at the wavelength of the laser transmitter. Again, this assumes that any VN probe is quite capable of transmitting on the received wavelength at a power level comparable to, or greater than, our own. The necessary electronics, including a high sensitivity photodiode, is not prohibitively expensive.
Final equipment and Message Format
The above describes a minimal setup both from a cost and capability point of view. A more suitable laser system would be one using a far higher power, and a receiving telescope with a mirror at least 200mm diameter (8” reflector).
The choice of lasers is wide, but if we limit the choice to minimize atmospheric absorption and costly optics that leaves visible and near infrared (NIR).
One possibility stands out. That is a Q-switched Nd:YAG laserxii, with around a 200W continuous,
1MW pulsed, output at 1064nm normally used as an industrial cutter. The output can if necessary be frequency doubled to 532nm green but with loss of power.
This should be able to communicate with its equivalent to a distance beyond the orbit of Jupiter.
Such systems typically cost under $15k, although the optics, beam guides and alignment equipment will add significantly to this price. Needless to say, such a beam in free space is spectacularly dangerous if mishandled.
Additional requirements will include an electric generator or power source in the kilowatt region, water cooling and a trailer if the equipment has to be moved to an open air site before use.
All together we intend to budget around $30,000 for the hardware. Location is as yet undecided, although a strong possibility is Provo, Utah in the USA given its clear skies and weather. Britain is a poor second in this respect. Plus, we may locate it at the TransHumanist Housexiii available to Zero State House Adar. However, much depends on location and local laws.
The message format with Q-switched pulses would be somewhat different from the existing setup. The coding would be provided by the timing between the pulses, or by the timing between successive pulse trains. Again, data rate would be low because we are not attempting to communicate anything complex. Just attract attention.
Zero State seeks collaboration from like-minded engineers and scientists, and sponsorship for this project, which after initial hardware costs are met should incur very low running costs.
Ethical Considerations
On 13 February 2015, scientists (including Geoffrey Marcy, Seth Shostak, Frank Drake, Elon Musk and David Brin) at a convention of the American Association for the Advancement of Science, discussed Active SETI and whether transmitting a message to possible intelligent extraterrestrials in the Cosmos was a good idea; one result was a statement, (which was not signed by Seth Shostak or Frank Drake), that a “worldwide scientific, political and humanitarian discussion must occur before any message is sent” xiv . We believe that this is not, and should not be the case for local METI. We should issue the invitation to communicate now. It is beyond reasonable doubt that if any ETI capable of receiving these messages lies within our solar system or a few tens of light years, then they already know of our existence.
References:
i https://en.wikipedia.org/wiki/List_of_interstellar_radio_messages ii http://meti.org/mission iii https://arxiv.org/abs/1706.05570 iv Journal of the British Interplanetary Society, Vol.33, pp. 251-264 1980 v https://en.wikipedia.org/wiki/Lunar_lava_tube vi https://en.wikipedia.org/wiki/Lagrangian_point vii S. Hecht, S. Schlaer and M.H. Pirenne, “Energy, Quanta and vision.” Journal of the Optical Society of America, 38, 196-208 (1942) viii http://www.lasersafetyfacts.com/4/ ix https://sourceforge.net/projects/realterm/ x https://www.maplin.co.uk/p/usb-to-ttl-serial-cable-cable-n74de xi http://odicforce.com/epages/05c54fb6-7778-4d36-adc0-0098b2af7c4e.sf/en_GB/?ObjectPath=/Shops/05c54fb6- 7778-4d36-adc0-0098b2af7c4e/Products/OFL365-5-TTL xii https://en.wikipedia.org/wiki/Nd:YAG_laser xiii https://hpluspedia.org/wiki/Transhuman_House xiv https://en.wikipedia.org/wiki/List_of_interstellar_radio_messages
Messaging Extra-Terrestrial Intelligence (METI) – A Local Search was originally published on transhumanity.net
#arecibo#download#ETI#Lenin#MIR#pdf#research#SETI#SSSR#USSR#ZeroState#zs#ZS Houses#crosspost#transhuman#transhumanitynet#transhumanism#transhumanist#thetranshumanity
1 note
·
View note
Text
The Five Major Platforms For Machine Learning Model Development
New Post has been published on https://perfectirishgifts.com/the-five-major-platforms-for-machine-learning-model-development-2/
The Five Major Platforms For Machine Learning Model Development
Over the past two decades, the biggest evolution of Artificial Intelligence has been the maturation of deep learning as an approach for machine learning, the expansion of big data and the knowledge of how to effectively manage big data systems, and affordable and accessible compute power that can handle some of the most challenging machine learning model development. Today’s data scientists and machine learning engineers now have a wide range of choices for how they build models to address the various patterns of AI for their particular needs.
However, The diversity in options is actually part of the challenge for those looking to build machine learning models. There are just too many choices. This, compounded by the fact that there are different ways you can go about developing a machine learning model, is the issue that many AI software vendors do a particularly poor job of explaining what their products actually do. Marketing skills and websites that actually explain what the product and/or company actually does are clearly lacking for many AI vendors. This makes it difficult for those looking to implement machine learning models to choose the best vendor option for them.
Untangling the complexity of machine learning model development
Machine learning is the cornerstone of AI. Without a way for systems to learn from experience and example, they aren’t able to achieve higher order cognitive tasks that require learning patterns from data. Without machine learning, machines need instructions and rules programmed and developed by humans to tell them what to do which isn’t intelligence – that’s just programming.
There are three primary approaches to machine learning: supervised learning in which machines learn from human-tagged examples, unsupervised learning in which machines discover patterns in the data, and reinforcement learning where machines learn from trial-and-error with a reward-based system. Each of these approaches are applicable and appropriate for different learning scenarios.
Furthermore, there are a wide range of algorithms that machine learning practitioners can use to implement those various learning approaches. These algorithms have different tradeoffs and performance characteristics. In addition, the end result of training a particular algorithm on particular training data is a machine learning model. The model represents what the machine has learned for a particular task. People seem to often confuse the machine learning algorithm, which tells machines the approach they should use to encode learning, and the machine learning model, which is the outcome of that learning. New algorithms are not frequently developed as new approaches to learning are few and far between. New models, however, are developed all the time since each new learning is encoded in a model, which can happen an infinite amount of times.
In addition to the above challenges, building machine learning models can be particularly challenging, especially for those that have limited data science and machine learning skills and understanding. Those with deep technical capabilities and strong statistical understanding can optimize and tweak models and choose appropriate algorithms with the right settings (“hyperparameters”) with their experience, while others that are fairly new to model creation might be stumped by all the choices that need to be made to select the right modeling approach. Tools on the market to develop machine learning models cater to a wide range of needs from novice to expert, making tool selection that much more challenging.
Five Major Approaches to ML Model Development
A recent report by AI market research and advisory firm Cognilytica identifies five major approaches to machine learning model development:
The Five Machine Learning Platforms
Machine Learning Toolkits
The field of machine learning and data science is not new, with decades of research from academicians, researchers, and data scientists. As a result, there are a large collection of toolkits that enable knowledgeable machine learning practitioners to implement a wide range of algorithms with low-level configurability. These machine learning toolkits are very popular and many are open source. Some toolkits are focused on specific machine learning algorithms and applications, most notably Keras, Tensorflow, and PyTorch which are focused on deep learning models, while others such as Apache Mahout and SciKit Learn provide a range of machine algorithms and tools. These toolkits are in turn embedded in many larger machine learning platforms including those mentioned below. In addition, many of the machine learning toolkits have the support and ongoing development resources of large technology companies. For example, Facebook supports PyTorch, Google supports Keras and TensorFlow, Amazon supports MXNet, Microsoft supports CNTK Toolkit, and others are supported by companies like IBM, Baidu, Apple, Netflix, and others.
Data Science Notebooks
The realm of machine learning is that of data science, since after all, we’re trying to derive higher value insights from big data. The primary environment for data science is the “notebook”, which is a collaborative, interactive, document-style environment that combines aspects of coding, data engineering, machine learning modeling, data visualization, and collaborative data sharing. Open source notebooks such as Jupyter and Apache Zeppelin have become widely adopted and have also found their way into the commercial platform offerings.
Data science notebooks offer the full breadth of machine learning algorithms through support and embedding of many of the popular machine learning toolkits mentioned above. While data science notebooks can be used to develop models of any type, they are primarily used during the experimentation and iteration phases of model development, since data science notebooks are optimized for that sort of iterative experimentation versus being focused on organization-wide aspects of management and deployment.
Machine Learning Platforms
Organizations that are looking to make mission-critical use of machine learning know that simply building a machine learning model is not all that needs to be taken into consideration for ML model needs. The full lifecycle of machine learning model development includes aspects of data preparation and engineering, machine learning model iteration including the use of “AutoML” to automatically identify the best algorithms and settings to achieve desired outcomes, machine learning model evaluation, and ML model iteration and versioning including the emerging area of “ML Ops”.
As a result, the last decade has seen the explosive emergence of full-lifecycle machine learning platform solutions that aim to not only simplify ML model development but also address these other areas of managing the ML model lifecycle. Many companies in this space have emerged as small startups to become major powerhouses in the industry with ever-increasing solutions that tackle a wider array of needs for data scientists and machine learning engineers.
Analytics Platforms
Before data science was called data science, there was the field of analytics and business intelligence. Many tools that were once used for non-machine learning analytics have since added machine learning model development to their capabilities. Most of the analytics field is dominated by a few large commercial analytics firms, which are increasingly broadening their offerings. As such, data scientists that might have experience with those tools will find increasing capabilities for machine learning model development and broader lifecycle capabilities.
These solutions traditionally aimed at data analytics, statistics, and mathematics applications have realized the power of adding machine learning capabilities to their existing statistical and/or analytics offerings. Organizations that have already invested in analytics solutions will find that they can retain the skill, experience, and investment in their existing tools that now support machine learning development and deployment.
Cloud-based ML-as-a-Service (MLaaS)
In addition to the above approaches, most of the large cloud providers have jumped in with both feet into the machine learning space. Amazon, Google, IBM, and Microsoft have all added core capabilities for machine learning model development, management, and iteration as well as capabilities for data preparation, engineering, and augmentation. These cloud vendors also support and use many of the open source ML toolkits as well as the Data Science Notebooks popular in the field. As a result, the decision to use the cloud for ML model development is rarely an “either/or” decision, but more of a tactical decision on whether the use of cloud-based resources for computing, data storage, and value-added ML lifecycle capabilities is needed.
The growth of machine learning model markets
No doubt the field of machine learning model development continues to expand. Cognilytica expects the market for machine learning platforms to reach over $120 Billion USD by 2025, growing at a fast and furious rate. (Disclosure: I’m a principal analyst with Cognilytica) While there might be questions as to how long this latest wave of AI will last, there’s no doubt that the future of machine learning development and implementation looks bright.
From CIO Network in Perfectirishgifts
0 notes
Text
YouTube Dominates Google Video in 2020
New Post has been published on https://tiptopreview.com/youtube-dominates-google-video-in-2020/
YouTube Dominates Google Video in 2020

In a study of 2.1M searches and 766K videos, YouTube accounted for 94% of all video carousel results on page one of Google, leaving little room for competition.
Even the most casual video aficionado knows YouTube (acquired by Google in 2006). As a Google search user, you may even feel like you encounter more YouTube videos than videos from other sources, but does the data back this up?
A Wall Street Journal article in June 2020 measured a strong advantage of YouTube in Google search results, but that article focused on 98 hand-selected videos to compare YouTube to other platforms.
Using a set of over two million Google.com (US) desktop searches captured in early October 2020, we were able to extract more than 250,000 results with video carousels on page one. Most organic video results in 2020 appear in a carousel, like this one:

This carousel appeared on a search for “How to be an investor” (Step 1: Find a bag of money). Notice the arrow on the far-right — currently, searchers can scroll through up to ten videos. While our research tracked all ten positions, most of this report will focus on the three visible positions.
How dominant is YouTube?
Anecdotally, we see YouTube pop up a lot in Google results, but how dominant are they in the visible three video carousel results across our data set? Here’s a breakdown:

YouTube’s presence across the first three video slots was remarkably consistent, at (1) 94.1%, (2) 94.2% and (3) 94.2%. Khan Academy and Facebook took the #2 and #3 rankings for each carousel slot, with Facebook gaining share in later slots.
Obviously, this is a massive drop from the first to second largest share, and YouTube’s presence only varied from 94.1% to 95.1% across all ten slots. Across all visible videos in the carousel, here are the top ten sites in our data set:
YouTube (94.2%)
Khan Academy (1.5%)
Facebook (1.4%)
Microsoft (0.4%)
Vimeo (0.1%)
Twitter (0.1%)
Dailymotion (<0.1%)
CNBC (<0.1%)
CNN (<0.1%)
ESPN (<0.1%)
Note that, due to technical limitations with how search spiders work, many Facebook and Twitter videos require a login and are unavailable to Google. That said, the #2 to #10 biggest players in the video carousel — including some massive brands with deep pockets for video content — add up to only 3.7% of visible videos.
How about how-to?
Pardon my grammar, but “How to…?” questions have become a hot spot for video results, and naturally lend themselves to niche players like HGTV. Here’s a video carousel from a search for “how to organize a pantry”:

It looks promising on the surface, but does this niche show more diversity of websites at scale? Our data set included just over 45,000 “How to …” searches with video carousels. Here’s the breakdown of the top three sites for each slot:

In our data set, YouTube is even more dominant in the how-to niche, taking up from 97-98% of each of the three visible slots. Khan Academy came in second, and Microsoft (specifically, the Microsoft support site) rounded out the third position (but at <1% in all three slots).
Is this just a fluke?
Most of this analysis was based on a snapshot of data in early October. Given that Google frequently makes changes and runs thousands of tests per year, could we have just picked a particularly unusual day? To answer that, we pulled YouTube’s prevalence across all videos in the carousel on the first day of each month of 2020:
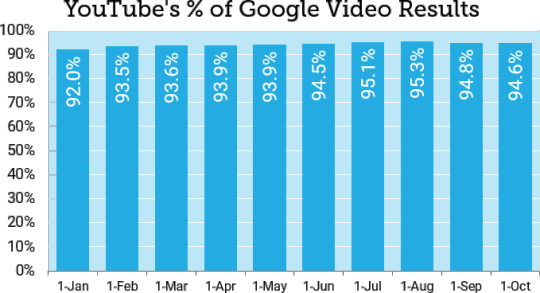
YouTube’s dominance was fairly steady across 2020, ranging from 92.0% to 95.3% in our data set (and actually increasing a bit since January). Clearly, this is not a temporary nor particularly recent condition.
Another challenge in studying Google results, even with large data sets, is the possibility of sampling bias. There is no truly “random” sample of search results (more on that in Appendix A), but we’re lucky enough to have a second data set with a long history. While this data set is only 10,000 keywords, it was specifically designed to evenly represent the industry categories in Google Ads. On October 9, we were able to capture 2,390 video carousels from this data set. Here’s how they measured up:
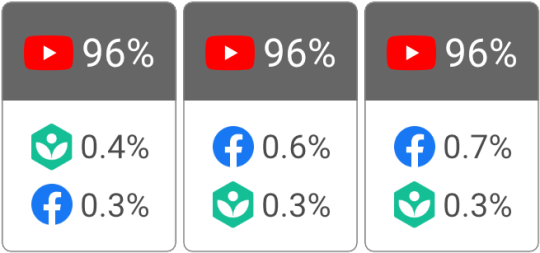
The top three sites in each of the carousel slots were identical to the 2M-keyword data set, and YouTube’s dominance was even higher (up from 94% to 96%). We have every confidence that the prevalence of YouTube results measured in this study is not a fluke of a single day or a single data set.
How level is the field?
Does YouTube have an unfair advantage? “Fair” is a difficult concept to quantify, so let’s explore Google’s perspective.
Google’s first argument would probably be that YouTube has the lion’s share of video results because they host the lion’s share of videos. Unfortunately, it’s hard to get reliable numbers across the entire world of video hosting, and especially for social platforms. YouTube is undoubtedly a massive player and likely hosts the majority of non-social, public videos in the United States, but 94% seems like a big share even for the lion.
The larger problem is that this dominance becomes self-perpetuating. Over the past few years, more major companies have hosted videos on YouTube and created YouTube channels because it’s easier to get results in Google search than hosting on smaller platforms or their own site.
Google’s more technical argument is that the video search algorithm has no inherent preference for YouTube. As a search marketer, I’ve learned to view this argument narrowly. There’s probably not a line of code in the algorithm that says something like:
IF site = ‘YouTube’ THEN ranking = 1
Defined narrowly, I believe that Google is telling the truth. However, there’s no escaping the fact that Google and YouTube share a common backbone and many of the same internal organs, which provides advantages that may be insurmountable.
For example, Google’s video algorithm might reward speed. This makes sense — a slow-loading video is a bad customer experience and makes Google look bad. Naturally, Google’s direct ownership over YouTube means that their access to YouTube data is lightning fast. Realistically, how can a competitor, even with billions in investment, produce an experience that’s faster than a direct pipeline to Google? Likewise, YouTube’s data structure is naturally going to be optimized for Google to easily process and digest, relying on inside knowledge that might not be equally available to all players.
For now, from a marketing perspective, we’re left with little choice but to cover our bases and take the advantage YouTube seems to offer. There’s no reason we should expect YouTube’s numbers to decrease, and every reason to expect YouTube’s dominance to grow, at least without a paradigm-shifting disruption to the industry.
Many thanks to Eric H. and Michael G. on our Vancouver team for sharing their knowledge about the data set and how to interpret it, and to Eric and Rob L. for trusting me with Athena access to a treasure trove of data.
Appendix A: Data and methodology
The bulk of the data for this study was collected in early October 2020 from a set of just over two million Google.com, US-based, desktop search results. After minor de-duplication and clean-up, this data set yielded 258K searches with video carousels on page one. These carousels accounted for 2.1 million total video results/URLs and 767K visible results (Google displays up to three per carousel, without scrolling).
The how-to analysis was based on a smaller data set of 45K keywords that explicitly began with the words “how to”. Neither data set is a randomly selected sample and may be biased toward certain industries or verticals.
The follow-up 10K data set was constructed specifically as a research data set and is evenly distributed across 20 major industry categories in Google Ads. This data set was specifically designed to represent a wide range of competitive terms.
Why don’t we use true random sampling? Outside of the textbook, a truly random sample is rarely achieved, but theoretically possible. Selecting a random sample of adults in The United States, for example, is incredibly difficult (as soon as you pick up the phone or send out an email, you’ve introduced bias), but at least we know that, at any particular moment, the population of adults in the United States is a finite set of individual people.
The same isn’t true of Google searches. Searches are not a finite set, but a cloud of words being conjured out of the void by searchers every millisecond. According to Google themselves: “There are trillions of searches on Google every year. In fact, 15 percent of searches we see every day are new.” The population of searches is not only in the trillions, but changing every minute.
Ultimately, we rely on large data sets, where possible, try to understand the flaws in any given data set, and replicate our work across multiple data sets. This study was replicated against two very different data sets, as well as a third set created by a thematic slice of the first set, and validated against multiple dates in 2020.
Source link
0 notes
Text
YouTube Dominates Google Video in 2020
Posted by Dr-Pete
In a study of 2.1M searches and 766K videos, YouTube accounted for 94% of all video carousel results on page one of Google, leaving little room for competition.
Even the most casual video aficionado knows YouTube (acquired by Google in 2006). As a Google search user, you may even feel like you encounter more YouTube videos than videos from other sources, but does the data back this up?
A Wall Street Journal article in June 2020 measured a strong advantage of YouTube in Google search results, but that article focused on 98 hand-selected videos to compare YouTube to other platforms.
Using a set of over two million Google.com (US) desktop searches captured in early October 2020, we were able to extract more than 250,000 results with video carousels on page one. Most organic video results in 2020 appear in a carousel, like this one:
This carousel appeared on a search for “How to be an investor” (Step 1: Find a bag of money). Notice the arrow on the far-right — currently, searchers can scroll through up to ten videos. While our research tracked all ten positions, most of this report will focus on the three visible positions.
How dominant is YouTube?
Anecdotally, we see YouTube pop up a lot in Google results, but how dominant are they in the visible three video carousel results across our data set? Here’s a breakdown:
YouTube’s presence across the first three video slots was remarkably consistent, at (1) 94.1%, (2) 94.2% and (3) 94.2%. Khan Academy and Facebook took the #2 and #3 rankings for each carousel slot, with Facebook gaining share in later slots.
Obviously, this is a massive drop from the first to second largest share, and YouTube’s presence only varied from 94.1% to 95.1% across all ten slots. Across all visible videos in the carousel, here are the top ten sites in our data set:
YouTube (94.2%)
Khan Academy (1.5%)
Facebook (1.4%)
Microsoft (0.4%)
Vimeo (0.1%)
Twitter (0.1%)
Dailymotion (<0.1%)
CNBC (<0.1%)
CNN (<0.1%)
ESPN (<0.1%)
Note that, due to technical limitations with how search spiders work, many Facebook and Twitter videos require a login and are unavailable to Google. That said, the #2 to #10 biggest players in the video carousel — including some massive brands with deep pockets for video content — add up to only 3.7% of visible videos.
How about how-to?
Pardon my grammar, but “How to…?” questions have become a hot spot for video results, and naturally lend themselves to niche players like HGTV. Here’s a video carousel from a search for “how to organize a pantry”:
It looks promising on the surface, but does this niche show more diversity of websites at scale? Our data set included just over 45,000 “How to …” searches with video carousels. Here’s the breakdown of the top three sites for each slot:
In our data set, YouTube is even more dominant in the how-to niche, taking up from 97-98% of each of the three visible slots. Khan Academy came in second, and Microsoft (specifically, the Microsoft support site) rounded out the third position (but at <1% in all three slots).
Is this just a fluke?
Most of this analysis was based on a snapshot of data in early October. Given that Google frequently makes changes and runs thousands of tests per year, could we have just picked a particularly unusual day? To answer that, we pulled YouTube’s prevalence across all videos in the carousel on the first day of each month of 2020:
YouTube’s dominance was fairly steady across 2020, ranging from 92.0% to 95.3% in our data set (and actually increasing a bit since January). Clearly, this is not a temporary nor particularly recent condition.
Another challenge in studying Google results, even with large data sets, is the possibility of sampling bias. There is no truly “random” sample of search results (more on that in Appendix A), but we’re lucky enough to have a second data set with a long history. While this data set is only 10,000 keywords, it was specifically designed to evenly represent the industry categories in Google Ads. On October 9, we were able to capture 2,390 video carousels from this data set. Here’s how they measured up:
The top three sites in each of the carousel slots were identical to the 2M-keyword data set, and YouTube’s dominance was even higher (up from 94% to 96%). We have every confidence that the prevalence of YouTube results measured in this study is not a fluke of a single day or a single data set.
How level is the field?
Does YouTube have an unfair advantage? “Fair” is a difficult concept to quantify, so let’s explore Google’s perspective.
Google’s first argument would probably be that YouTube has the lion’s share of video results because they host the lion’s share of videos. Unfortunately, it’s hard to get reliable numbers across the entire world of video hosting, and especially for social platforms. YouTube is undoubtedly a massive player and likely hosts the majority of non-social, public videos in the United States, but 94% seems like a big share even for the lion.
The larger problem is that this dominance becomes self-perpetuating. Over the past few years, more major companies have hosted videos on YouTube and created YouTube channels because it’s easier to get results in Google search than hosting on smaller platforms or their own site.
Google’s more technical argument is that the video search algorithm has no inherent preference for YouTube. As a search marketer, I’ve learned to view this argument narrowly. There’s probably not a line of code in the algorithm that says something like:
IF site = ‘YouTube’ THEN ranking = 1
Defined narrowly, I believe that Google is telling the truth. However, there’s no escaping the fact that Google and YouTube share a common backbone and many of the same internal organs, which provides advantages that may be insurmountable.
For example, Google’s video algorithm might reward speed. This makes sense — a slow-loading video is a bad customer experience and makes Google look bad. Naturally, Google’s direct ownership over YouTube means that their access to YouTube data is lightning fast. Realistically, how can a competitor, even with billions in investment, produce an experience that’s faster than a direct pipeline to Google? Likewise, YouTube’s data structure is naturally going to be optimized for Google to easily process and digest, relying on inside knowledge that might not be equally available to all players.
For now, from a marketing perspective, we’re left with little choice but to cover our bases and take the advantage YouTube seems to offer. There’s no reason we should expect YouTube’s numbers to decrease, and every reason to expect YouTube’s dominance to grow, at least without a paradigm-shifting disruption to the industry.
Many thanks to Eric H. and Michael G. on our Vancouver team for sharing their knowledge about the data set and how to interpret it, and to Eric and Rob L. for trusting me with Athena access to a treasure trove of data.
Appendix A: Data and methodology
The bulk of the data for this study was collected in early October 2020 from a set of just over two million Google.com, US-based, desktop search results. After minor de-duplication and clean-up, this data set yielded 258K searches with video carousels on page one. These carousels accounted for 2.1 million total video results/URLs and 767K visible results (Google displays up to three per carousel, without scrolling).
The how-to analysis was based on a smaller data set of 45K keywords that explicitly began with the words “how to”. Neither data set is a randomly selected sample and may be biased toward certain industries or verticals.
The follow-up 10K data set was constructed specifically as a research data set and is evenly distributed across 20 major industry categories in Google Ads. This data set was specifically designed to represent a wide range of competitive terms.
Why don’t we use true random sampling? Outside of the textbook, a truly random sample is rarely achieved, but theoretically possible. Selecting a random sample of adults in The United States, for example, is incredibly difficult (as soon as you pick up the phone or send out an email, you’ve introduced bias), but at least we know that, at any particular moment, the population of adults in the United States is a finite set of individual people.
The same isn’t true of Google searches. Searches are not a finite set, but a cloud of words being conjured out of the void by searchers every millisecond. According to Google themselves: “There are trillions of searches on Google every year. In fact, 15 percent of searches we see every day are new.” The population of searches is not only in the trillions, but changing every minute.
Ultimately, we rely on large data sets, where possible, try to understand the flaws in any given data set, and replicate our work across multiple data sets. This study was replicated against two very different data sets, as well as a third set created by a thematic slice of the first set, and validated against multiple dates in 2020.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
0 notes
Text
YouTube Dominates Google Video in 2020
Posted by Dr-Pete
In a study of 2.1M searches and 766K videos, YouTube accounted for 94% of all video carousel results on page one of Google, leaving little room for competition.
Even the most casual video aficionado knows YouTube (acquired by Google in 2006). As a Google search user, you may even feel like you encounter more YouTube videos than videos from other sources, but does the data back this up?
A Wall Street Journal article in June 2020 measured a strong advantage of YouTube in Google search results, but that article focused on 98 hand-selected videos to compare YouTube to other platforms.
Using a set of over two million Google.com (US) desktop searches captured in early October 2020, we were able to extract more than 250,000 results with video carousels on page one. Most organic video results in 2020 appear in a carousel, like this one:
This carousel appeared on a search for “How to be an investor” (Step 1: Find a bag of money). Notice the arrow on the far-right — currently, searchers can scroll through up to ten videos. While our research tracked all ten positions, most of this report will focus on the three visible positions.
How dominant is YouTube?
Anecdotally, we see YouTube pop up a lot in Google results, but how dominant are they in the visible three video carousel results across our data set? Here’s a breakdown:
YouTube’s presence across the first three video slots was remarkably consistent, at (1) 94.1%, (2) 94.2% and (3) 94.2%. Khan Academy and Facebook took the #2 and #3 rankings for each carousel slot, with Facebook gaining share in later slots.
Obviously, this is a massive drop from the first to second largest share, and YouTube’s presence only varied from 94.1% to 95.1% across all ten slots. Across all visible videos in the carousel, here are the top ten sites in our data set:
YouTube (94.2%)
Khan Academy (1.5%)
Facebook (1.4%)
Microsoft (0.4%)
Vimeo (0.1%)
Twitter (0.1%)
Dailymotion (<0.1%)
CNBC (<0.1%)
CNN (<0.1%)
ESPN (<0.1%)
Note that, due to technical limitations with how search spiders work, many Facebook and Twitter videos require a login and are unavailable to Google. That said, the #2 to #10 biggest players in the video carousel — including some massive brands with deep pockets for video content — add up to only 3.7% of visible videos.
How about how-to?
Pardon my grammar, but “How to…?” questions have become a hot spot for video results, and naturally lend themselves to niche players like HGTV. Here’s a video carousel from a search for “how to organize a pantry”:
It looks promising on the surface, but does this niche show more diversity of websites at scale? Our data set included just over 45,000 “How to …” searches with video carousels. Here’s the breakdown of the top three sites for each slot:
In our data set, YouTube is even more dominant in the how-to niche, taking up from 97-98% of each of the three visible slots. Khan Academy came in second, and Microsoft (specifically, the Microsoft support site) rounded out the third position (but at <1% in all three slots).
Is this just a fluke?
Most of this analysis was based on a snapshot of data in early October. Given that Google frequently makes changes and runs thousands of tests per year, could we have just picked a particularly unusual day? To answer that, we pulled YouTube’s prevalence across all videos in the carousel on the first day of each month of 2020:
YouTube’s dominance was fairly steady across 2020, ranging from 92.0% to 95.3% in our data set (and actually increasing a bit since January). Clearly, this is not a temporary nor particularly recent condition.
Another challenge in studying Google results, even with large data sets, is the possibility of sampling bias. There is no truly “random” sample of search results (more on that in Appendix A), but we’re lucky enough to have a second data set with a long history. While this data set is only 10,000 keywords, it was specifically designed to evenly represent the industry categories in Google Ads. On October 9, we were able to capture 2,390 video carousels from this data set. Here’s how they measured up:
The top three sites in each of the carousel slots were identical to the 2M-keyword data set, and YouTube’s dominance was even higher (up from 94% to 96%). We have every confidence that the prevalence of YouTube results measured in this study is not a fluke of a single day or a single data set.
How level is the field?
Does YouTube have an unfair advantage? “Fair” is a difficult concept to quantify, so let’s explore Google’s perspective.
Google’s first argument would probably be that YouTube has the lion’s share of video results because they host the lion’s share of videos. Unfortunately, it’s hard to get reliable numbers across the entire world of video hosting, and especially for social platforms. YouTube is undoubtedly a massive player and likely hosts the majority of non-social, public videos in the United States, but 94% seems like a big share even for the lion.
The larger problem is that this dominance becomes self-perpetuating. Over the past few years, more major companies have hosted videos on YouTube and created YouTube channels because it’s easier to get results in Google search than hosting on smaller platforms or their own site.
Google’s more technical argument is that the video search algorithm has no inherent preference for YouTube. As a search marketer, I’ve learned to view this argument narrowly. There’s probably not a line of code in the algorithm that says something like:
IF site = ‘YouTube’ THEN ranking = 1
Defined narrowly, I believe that Google is telling the truth. However, there’s no escaping the fact that Google and YouTube share a common backbone and many of the same internal organs, which provides advantages that may be insurmountable.
For example, Google’s video algorithm might reward speed. This makes sense — a slow-loading video is a bad customer experience and makes Google look bad. Naturally, Google’s direct ownership over YouTube means that their access to YouTube data is lightning fast. Realistically, how can a competitor, even with billions in investment, produce an experience that’s faster than a direct pipeline to Google? Likewise, YouTube’s data structure is naturally going to be optimized for Google to easily process and digest, relying on inside knowledge that might not be equally available to all players.
For now, from a marketing perspective, we’re left with little choice but to cover our bases and take the advantage YouTube seems to offer. There’s no reason we should expect YouTube’s numbers to decrease, and every reason to expect YouTube’s dominance to grow, at least without a paradigm-shifting disruption to the industry.
Many thanks to Eric H. and Michael G. on our Vancouver team for sharing their knowledge about the data set and how to interpret it, and to Eric and Rob L. for trusting me with Athena access to a treasure trove of data.
Appendix A: Data and methodology
The bulk of the data for this study was collected in early October 2020 from a set of just over two million Google.com, US-based, desktop search results. After minor de-duplication and clean-up, this data set yielded 258K searches with video carousels on page one. These carousels accounted for 2.1 million total video results/URLs and 767K visible results (Google displays up to three per carousel, without scrolling).
The how-to analysis was based on a smaller data set of 45K keywords that explicitly began with the words “how to”. Neither data set is a randomly selected sample and may be biased toward certain industries or verticals.
The follow-up 10K data set was constructed specifically as a research data set and is evenly distributed across 20 major industry categories in Google Ads. This data set was specifically designed to represent a wide range of competitive terms.
Why don’t we use true random sampling? Outside of the textbook, a truly random sample is rarely achieved, but theoretically possible. Selecting a random sample of adults in The United States, for example, is incredibly difficult (as soon as you pick up the phone or send out an email, you’ve introduced bias), but at least we know that, at any particular moment, the population of adults in the United States is a finite set of individual people.
The same isn’t true of Google searches. Searches are not a finite set, but a cloud of words being conjured out of the void by searchers every millisecond. According to Google themselves: “There are trillions of searches on Google every year. In fact, 15 percent of searches we see every day are new.” The population of searches is not only in the trillions, but changing every minute.
Ultimately, we rely on large data sets, where possible, try to understand the flaws in any given data set, and replicate our work across multiple data sets. This study was replicated against two very different data sets, as well as a third set created by a thematic slice of the first set, and validated against multiple dates in 2020.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
0 notes
Text
YouTube Dominates Google Video in 2020
Posted by Dr-Pete
In a study of 2.1M searches and 766K videos, YouTube accounted for 94% of all video carousel results on page one of Google, leaving little room for competition.
Even the most casual video aficionado knows YouTube (acquired by Google in 2006). As a Google search user, you may even feel like you encounter more YouTube videos than videos from other sources, but does the data back this up?
A Wall Street Journal article in June 2020 measured a strong advantage of YouTube in Google search results, but that article focused on 98 hand-selected videos to compare YouTube to other platforms.
Using a set of over two million Google.com (US) desktop searches captured in early October 2020, we were able to extract more than 250,000 results with video carousels on page one. Most organic video results in 2020 appear in a carousel, like this one:
This carousel appeared on a search for “How to be an investor” (Step 1: Find a bag of money). Notice the arrow on the far-right — currently, searchers can scroll through up to ten videos. While our research tracked all ten positions, most of this report will focus on the three visible positions.
How dominant is YouTube?
Anecdotally, we see YouTube pop up a lot in Google results, but how dominant are they in the visible three video carousel results across our data set? Here’s a breakdown:
YouTube’s presence across the first three video slots was remarkably consistent, at (1) 94.1%, (2) 94.2% and (3) 94.2%. Khan Academy and Facebook took the #2 and #3 rankings for each carousel slot, with Facebook gaining share in later slots.
Obviously, this is a massive drop from the first to second largest share, and YouTube’s presence only varied from 94.1% to 95.1% across all ten slots. Across all visible videos in the carousel, here are the top ten sites in our data set:
YouTube (94.2%)
Khan Academy (1.5%)
Facebook (1.4%)
Microsoft (0.4%)
Vimeo (0.1%)
Twitter (0.1%)
Dailymotion (<0.1%)
CNBC (<0.1%)
CNN (<0.1%)
ESPN (<0.1%)
Note that, due to technical limitations with how search spiders work, many Facebook and Twitter videos require a login and are unavailable to Google. That said, the #2 to #10 biggest players in the video carousel — including some massive brands with deep pockets for video content — add up to only 3.7% of visible videos.
How about how-to?
Pardon my grammar, but “How to…?” questions have become a hot spot for video results, and naturally lend themselves to niche players like HGTV. Here’s a video carousel from a search for “how to organize a pantry”:
It looks promising on the surface, but does this niche show more diversity of websites at scale? Our data set included just over 45,000 “How to …” searches with video carousels. Here’s the breakdown of the top three sites for each slot:
In our data set, YouTube is even more dominant in the how-to niche, taking up from 97-98% of each of the three visible slots. Khan Academy came in second, and Microsoft (specifically, the Microsoft support site) rounded out the third position (but at <1% in all three slots).
Is this just a fluke?
Most of this analysis was based on a snapshot of data in early October. Given that Google frequently makes changes and runs thousands of tests per year, could we have just picked a particularly unusual day? To answer that, we pulled YouTube’s prevalence across all videos in the carousel on the first day of each month of 2020:
YouTube’s dominance was fairly steady across 2020, ranging from 92.0% to 95.3% in our data set (and actually increasing a bit since January). Clearly, this is not a temporary nor particularly recent condition.
Another challenge in studying Google results, even with large data sets, is the possibility of sampling bias. There is no truly “random” sample of search results (more on that in Appendix A), but we’re lucky enough to have a second data set with a long history. While this data set is only 10,000 keywords, it was specifically designed to evenly represent the industry categories in Google Ads. On October 9, we were able to capture 2,390 video carousels from this data set. Here’s how they measured up:
The top three sites in each of the carousel slots were identical to the 2M-keyword data set, and YouTube’s dominance was even higher (up from 94% to 96%). We have every confidence that the prevalence of YouTube results measured in this study is not a fluke of a single day or a single data set.
How level is the field?
Does YouTube have an unfair advantage? “Fair” is a difficult concept to quantify, so let’s explore Google’s perspective.
Google’s first argument would probably be that YouTube has the lion’s share of video results because they host the lion’s share of videos. Unfortunately, it’s hard to get reliable numbers across the entire world of video hosting, and especially for social platforms. YouTube is undoubtedly a massive player and likely hosts the majority of non-social, public videos in the United States, but 94% seems like a big share even for the lion.
The larger problem is that this dominance becomes self-perpetuating. Over the past few years, more major companies have hosted videos on YouTube and created YouTube channels because it’s easier to get results in Google search than hosting on smaller platforms or their own site.
Google’s more technical argument is that the video search algorithm has no inherent preference for YouTube. As a search marketer, I’ve learned to view this argument narrowly. There’s probably not a line of code in the algorithm that says something like:
IF site = ‘YouTube’ THEN ranking = 1
Defined narrowly, I believe that Google is telling the truth. However, there’s no escaping the fact that Google and YouTube share a common backbone and many of the same internal organs, which provides advantages that may be insurmountable.
For example, Google’s video algorithm might reward speed. This makes sense — a slow-loading video is a bad customer experience and makes Google look bad. Naturally, Google’s direct ownership over YouTube means that their access to YouTube data is lightning fast. Realistically, how can a competitor, even with billions in investment, produce an experience that’s faster than a direct pipeline to Google? Likewise, YouTube’s data structure is naturally going to be optimized for Google to easily process and digest, relying on inside knowledge that might not be equally available to all players.
For now, from a marketing perspective, we’re left with little choice but to cover our bases and take the advantage YouTube seems to offer. There’s no reason we should expect YouTube’s numbers to decrease, and every reason to expect YouTube’s dominance to grow, at least without a paradigm-shifting disruption to the industry.
Many thanks to Eric H. and Michael G. on our Vancouver team for sharing their knowledge about the data set and how to interpret it, and to Eric and Rob L. for trusting me with Athena access to a treasure trove of data.
Appendix A: Data and methodology
The bulk of the data for this study was collected in early October 2020 from a set of just over two million Google.com, US-based, desktop search results. After minor de-duplication and clean-up, this data set yielded 258K searches with video carousels on page one. These carousels accounted for 2.1 million total video results/URLs and 767K visible results (Google displays up to three per carousel, without scrolling).
The how-to analysis was based on a smaller data set of 45K keywords that explicitly began with the words “how to”. Neither data set is a randomly selected sample and may be biased toward certain industries or verticals.
The follow-up 10K data set was constructed specifically as a research data set and is evenly distributed across 20 major industry categories in Google Ads. This data set was specifically designed to represent a wide range of competitive terms.
Why don’t we use true random sampling? Outside of the textbook, a truly random sample is rarely achieved, but theoretically possible. Selecting a random sample of adults in The United States, for example, is incredibly difficult (as soon as you pick up the phone or send out an email, you’ve introduced bias), but at least we know that, at any particular moment, the population of adults in the United States is a finite set of individual people.
The same isn’t true of Google searches. Searches are not a finite set, but a cloud of words being conjured out of the void by searchers every millisecond. According to Google themselves: “There are trillions of searches on Google every year. In fact, 15 percent of searches we see every day are new.” The population of searches is not only in the trillions, but changing every minute.
Ultimately, we rely on large data sets, where possible, try to understand the flaws in any given data set, and replicate our work across multiple data sets. This study was replicated against two very different data sets, as well as a third set created by a thematic slice of the first set, and validated against multiple dates in 2020.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
0 notes
Text
YouTube Dominates Google Video in 2020
Posted by Dr-Pete
In a study of 2.1M searches and 766K videos, YouTube accounted for 94% of all video carousel results on page one of Google, leaving little room for competition.
Even the most casual video aficionado knows YouTube (acquired by Google in 2006). As a Google search user, you may even feel like you encounter more YouTube videos than videos from other sources, but does the data back this up?
A Wall Street Journal article in June 2020 measured a strong advantage of YouTube in Google search results, but that article focused on 98 hand-selected videos to compare YouTube to other platforms.
Using a set of over two million Google.com (US) desktop searches captured in early October 2020, we were able to extract more than 250,000 results with video carousels on page one. Most organic video results in 2020 appear in a carousel, like this one:
This carousel appeared on a search for “How to be an investor” (Step 1: Find a bag of money). Notice the arrow on the far-right — currently, searchers can scroll through up to ten videos. While our research tracked all ten positions, most of this report will focus on the three visible positions.
How dominant is YouTube?
Anecdotally, we see YouTube pop up a lot in Google results, but how dominant are they in the visible three video carousel results across our data set? Here’s a breakdown:
YouTube’s presence across the first three video slots was remarkably consistent, at (1) 94.1%, (2) 94.2% and (3) 94.2%. Khan Academy and Facebook took the #2 and #3 rankings for each carousel slot, with Facebook gaining share in later slots.
Obviously, this is a massive drop from the first to second largest share, and YouTube’s presence only varied from 94.1% to 95.1% across all ten slots. Across all visible videos in the carousel, here are the top ten sites in our data set:
YouTube (94.2%)
Khan Academy (1.5%)
Facebook (1.4%)
Microsoft (0.4%)
Vimeo (0.1%)
Twitter (0.1%)
Dailymotion (<0.1%)
CNBC (<0.1%)
CNN (<0.1%)
ESPN (<0.1%)
Note that, due to technical limitations with how search spiders work, many Facebook and Twitter videos require a login and are unavailable to Google. That said, the #2 to #10 biggest players in the video carousel — including some massive brands with deep pockets for video content — add up to only 3.7% of visible videos.
How about how-to?
Pardon my grammar, but “How to…?” questions have become a hot spot for video results, and naturally lend themselves to niche players like HGTV. Here’s a video carousel from a search for “how to organize a pantry”:
It looks promising on the surface, but does this niche show more diversity of websites at scale? Our data set included just over 45,000 “How to …” searches with video carousels. Here’s the breakdown of the top three sites for each slot:
In our data set, YouTube is even more dominant in the how-to niche, taking up from 97-98% of each of the three visible slots. Khan Academy came in second, and Microsoft (specifically, the Microsoft support site) rounded out the third position (but at <1% in all three slots).
Is this just a fluke?
Most of this analysis was based on a snapshot of data in early October. Given that Google frequently makes changes and runs thousands of tests per year, could we have just picked a particularly unusual day? To answer that, we pulled YouTube’s prevalence across all videos in the carousel on the first day of each month of 2020:
YouTube’s dominance was fairly steady across 2020, ranging from 92.0% to 95.3% in our data set (and actually increasing a bit since January). Clearly, this is not a temporary nor particularly recent condition.
Another challenge in studying Google results, even with large data sets, is the possibility of sampling bias. There is no truly “random” sample of search results (more on that in Appendix A), but we’re lucky enough to have a second data set with a long history. While this data set is only 10,000 keywords, it was specifically designed to evenly represent the industry categories in Google Ads. On October 9, we were able to capture 2,390 video carousels from this data set. Here’s how they measured up:
The top three sites in each of the carousel slots were identical to the 2M-keyword data set, and YouTube’s dominance was even higher (up from 94% to 96%). We have every confidence that the prevalence of YouTube results measured in this study is not a fluke of a single day or a single data set.
How level is the field?
Does YouTube have an unfair advantage? “Fair” is a difficult concept to quantify, so let’s explore Google’s perspective.
Google’s first argument would probably be that YouTube has the lion’s share of video results because they host the lion’s share of videos. Unfortunately, it’s hard to get reliable numbers across the entire world of video hosting, and especially for social platforms. YouTube is undoubtedly a massive player and likely hosts the majority of non-social, public videos in the United States, but 94% seems like a big share even for the lion.
The larger problem is that this dominance becomes self-perpetuating. Over the past few years, more major companies have hosted videos on YouTube and created YouTube channels because it’s easier to get results in Google search than hosting on smaller platforms or their own site.
Google’s more technical argument is that the video search algorithm has no inherent preference for YouTube. As a search marketer, I’ve learned to view this argument narrowly. There’s probably not a line of code in the algorithm that says something like:
IF site = ‘YouTube’ THEN ranking = 1
Defined narrowly, I believe that Google is telling the truth. However, there’s no escaping the fact that Google and YouTube share a common backbone and many of the same internal organs, which provides advantages that may be insurmountable.
For example, Google’s video algorithm might reward speed. This makes sense — a slow-loading video is a bad customer experience and makes Google look bad. Naturally, Google’s direct ownership over YouTube means that their access to YouTube data is lightning fast. Realistically, how can a competitor, even with billions in investment, produce an experience that’s faster than a direct pipeline to Google? Likewise, YouTube’s data structure is naturally going to be optimized for Google to easily process and digest, relying on inside knowledge that might not be equally available to all players.
For now, from a marketing perspective, we’re left with little choice but to cover our bases and take the advantage YouTube seems to offer. There’s no reason we should expect YouTube’s numbers to decrease, and every reason to expect YouTube’s dominance to grow, at least without a paradigm-shifting disruption to the industry.
Many thanks to Eric H. and Michael G. on our Vancouver team for sharing their knowledge about the data set and how to interpret it, and to Eric and Rob L. for trusting me with Athena access to a treasure trove of data.
Appendix A: Data and methodology
The bulk of the data for this study was collected in early October 2020 from a set of just over two million Google.com, US-based, desktop search results. After minor de-duplication and clean-up, this data set yielded 258K searches with video carousels on page one. These carousels accounted for 2.1 million total video results/URLs and 767K visible results (Google displays up to three per carousel, without scrolling).
The how-to analysis was based on a smaller data set of 45K keywords that explicitly began with the words “how to”. Neither data set is a randomly selected sample and may be biased toward certain industries or verticals.
The follow-up 10K data set was constructed specifically as a research data set and is evenly distributed across 20 major industry categories in Google Ads. This data set was specifically designed to represent a wide range of competitive terms.
Why don’t we use true random sampling? Outside of the textbook, a truly random sample is rarely achieved, but theoretically possible. Selecting a random sample of adults in The United States, for example, is incredibly difficult (as soon as you pick up the phone or send out an email, you’ve introduced bias), but at least we know that, at any particular moment, the population of adults in the United States is a finite set of individual people.
The same isn’t true of Google searches. Searches are not a finite set, but a cloud of words being conjured out of the void by searchers every millisecond. According to Google themselves: “There are trillions of searches on Google every year. In fact, 15 percent of searches we see every day are new.” The population of searches is not only in the trillions, but changing every minute.
Ultimately, we rely on large data sets, where possible, try to understand the flaws in any given data set, and replicate our work across multiple data sets. This study was replicated against two very different data sets, as well as a third set created by a thematic slice of the first set, and validated against multiple dates in 2020.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
0 notes
Text
YouTube Dominates Google Video in 2020
Posted by Dr-Pete
In a study of 2.1M searches and 766K videos, YouTube accounted for 94% of all video carousel results on page one of Google, leaving little room for competition.
Even the most casual video aficionado knows YouTube (acquired by Google in 2006). As a Google search user, you may even feel like you encounter more YouTube videos than videos from other sources, but does the data back this up?
A Wall Street Journal article in June 2020 measured a strong advantage of YouTube in Google search results, but that article focused on 98 hand-selected videos to compare YouTube to other platforms.
Using a set of over two million Google.com (US) desktop searches captured in early October 2020, we were able to extract more than 250,000 results with video carousels on page one. Most organic video results in 2020 appear in a carousel, like this one:
This carousel appeared on a search for “How to be an investor” (Step 1: Find a bag of money). Notice the arrow on the far-right — currently, searchers can scroll through up to ten videos. While our research tracked all ten positions, most of this report will focus on the three visible positions.
How dominant is YouTube?
Anecdotally, we see YouTube pop up a lot in Google results, but how dominant are they in the visible three video carousel results across our data set? Here’s a breakdown:
YouTube’s presence across the first three video slots was remarkably consistent, at (1) 94.1%, (2) 94.2% and (3) 94.2%. Khan Academy and Facebook took the #2 and #3 rankings for each carousel slot, with Facebook gaining share in later slots.
Obviously, this is a massive drop from the first to second largest share, and YouTube’s presence only varied from 94.1% to 95.1% across all ten slots. Across all visible videos in the carousel, here are the top ten sites in our data set:
YouTube (94.2%)
Khan Academy (1.5%)
Facebook (1.4%)
Microsoft (0.4%)
Vimeo (0.1%)
Twitter (0.1%)
Dailymotion (<0.1%)
CNBC (<0.1%)
CNN (<0.1%)
ESPN (<0.1%)
Note that, due to technical limitations with how search spiders work, many Facebook and Twitter videos require a login and are unavailable to Google. That said, the #2 to #10 biggest players in the video carousel — including some massive brands with deep pockets for video content — add up to only 3.7% of visible videos.
How about how-to?
Pardon my grammar, but “How to…?” questions have become a hot spot for video results, and naturally lend themselves to niche players like HGTV. Here’s a video carousel from a search for “how to organize a pantry”:
It looks promising on the surface, but does this niche show more diversity of websites at scale? Our data set included just over 45,000 “How to …” searches with video carousels. Here’s the breakdown of the top three sites for each slot:
In our data set, YouTube is even more dominant in the how-to niche, taking up from 97-98% of each of the three visible slots. Khan Academy came in second, and Microsoft (specifically, the Microsoft support site) rounded out the third position (but at <1% in all three slots).
Is this just a fluke?
Most of this analysis was based on a snapshot of data in early October. Given that Google frequently makes changes and runs thousands of tests per year, could we have just picked a particularly unusual day? To answer that, we pulled YouTube’s prevalence across all videos in the carousel on the first day of each month of 2020:
YouTube’s dominance was fairly steady across 2020, ranging from 92.0% to 95.3% in our data set (and actually increasing a bit since January). Clearly, this is not a temporary nor particularly recent condition.
Another challenge in studying Google results, even with large data sets, is the possibility of sampling bias. There is no truly “random” sample of search results (more on that in Appendix A), but we’re lucky enough to have a second data set with a long history. While this data set is only 10,000 keywords, it was specifically designed to evenly represent the industry categories in Google Ads. On October 9, we were able to capture 2,390 video carousels from this data set. Here’s how they measured up:
The top three sites in each of the carousel slots were identical to the 2M-keyword data set, and YouTube’s dominance was even higher (up from 94% to 96%). We have every confidence that the prevalence of YouTube results measured in this study is not a fluke of a single day or a single data set.
How level is the field?
Does YouTube have an unfair advantage? “Fair” is a difficult concept to quantify, so let’s explore Google’s perspective.
Google’s first argument would probably be that YouTube has the lion’s share of video results because they host the lion’s share of videos. Unfortunately, it’s hard to get reliable numbers across the entire world of video hosting, and especially for social platforms. YouTube is undoubtedly a massive player and likely hosts the majority of non-social, public videos in the United States, but 94% seems like a big share even for the lion.
The larger problem is that this dominance becomes self-perpetuating. Over the past few years, more major companies have hosted videos on YouTube and created YouTube channels because it’s easier to get results in Google search than hosting on smaller platforms or their own site.
Google’s more technical argument is that the video search algorithm has no inherent preference for YouTube. As a search marketer, I’ve learned to view this argument narrowly. There’s probably not a line of code in the algorithm that says something like:
IF site = ‘YouTube’ THEN ranking = 1
Defined narrowly, I believe that Google is telling the truth. However, there’s no escaping the fact that Google and YouTube share a common backbone and many of the same internal organs, which provides advantages that may be insurmountable.
For example, Google’s video algorithm might reward speed. This makes sense — a slow-loading video is a bad customer experience and makes Google look bad. Naturally, Google’s direct ownership over YouTube means that their access to YouTube data is lightning fast. Realistically, how can a competitor, even with billions in investment, produce an experience that’s faster than a direct pipeline to Google? Likewise, YouTube’s data structure is naturally going to be optimized for Google to easily process and digest, relying on inside knowledge that might not be equally available to all players.
For now, from a marketing perspective, we’re left with little choice but to cover our bases and take the advantage YouTube seems to offer. There’s no reason we should expect YouTube’s numbers to decrease, and every reason to expect YouTube’s dominance to grow, at least without a paradigm-shifting disruption to the industry.
Many thanks to Eric H. and Michael G. on our Vancouver team for sharing their knowledge about the data set and how to interpret it, and to Eric and Rob L. for trusting me with Athena access to a treasure trove of data.
Appendix A: Data and methodology
The bulk of the data for this study was collected in early October 2020 from a set of just over two million Google.com, US-based, desktop search results. After minor de-duplication and clean-up, this data set yielded 258K searches with video carousels on page one. These carousels accounted for 2.1 million total video results/URLs and 767K visible results (Google displays up to three per carousel, without scrolling).
The how-to analysis was based on a smaller data set of 45K keywords that explicitly began with the words “how to”. Neither data set is a randomly selected sample and may be biased toward certain industries or verticals.
The follow-up 10K data set was constructed specifically as a research data set and is evenly distributed across 20 major industry categories in Google Ads. This data set was specifically designed to represent a wide range of competitive terms.
Why don’t we use true random sampling? Outside of the textbook, a truly random sample is rarely achieved, but theoretically possible. Selecting a random sample of adults in The United States, for example, is incredibly difficult (as soon as you pick up the phone or send out an email, you’ve introduced bias), but at least we know that, at any particular moment, the population of adults in the United States is a finite set of individual people.
The same isn’t true of Google searches. Searches are not a finite set, but a cloud of words being conjured out of the void by searchers every millisecond. According to Google themselves: “There are trillions of searches on Google every year. In fact, 15 percent of searches we see every day are new.” The population of searches is not only in the trillions, but changing every minute.
Ultimately, we rely on large data sets, where possible, try to understand the flaws in any given data set, and replicate our work across multiple data sets. This study was replicated against two very different data sets, as well as a third set created by a thematic slice of the first set, and validated against multiple dates in 2020.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
#túi_giấy_epacking_việt_nam #túi_giấy_epacking #in_túi_giấy_giá_rẻ #in_túi_giấy #epackingvietnam #tuigiayepacking
0 notes
Text
YouTube Dominates Google Video in 2020
Posted by Dr-Pete
In a study of 2.1M searches and 766K videos, YouTube accounted for 94% of all video carousel results on page one of Google, leaving little room for competition.
Even the most casual video aficionado knows YouTube (acquired by Google in 2006). As a Google search user, you may even feel like you encounter more YouTube videos than videos from other sources, but does the data back this up?
A Wall Street Journal article in June 2020 measured a strong advantage of YouTube in Google search results, but that article focused on 98 hand-selected videos to compare YouTube to other platforms.
Using a set of over two million Google.com (US) desktop searches captured in early October 2020, we were able to extract more than 250,000 results with video carousels on page one. Most organic video results in 2020 appear in a carousel, like this one:
This carousel appeared on a search for “How to be an investor” (Step 1: Find a bag of money). Notice the arrow on the far-right — currently, searchers can scroll through up to ten videos. While our research tracked all ten positions, most of this report will focus on the three visible positions.
How dominant is YouTube?
Anecdotally, we see YouTube pop up a lot in Google results, but how dominant are they in the visible three video carousel results across our data set? Here’s a breakdown:
YouTube’s presence across the first three video slots was remarkably consistent, at (1) 94.1%, (2) 94.2% and (3) 94.2%. Khan Academy and Facebook took the #2 and #3 rankings for each carousel slot, with Facebook gaining share in later slots.
Obviously, this is a massive drop from the first to second largest share, and YouTube’s presence only varied from 94.1% to 95.1% across all ten slots. Across all visible videos in the carousel, here are the top ten sites in our data set:
YouTube (94.2%)
Khan Academy (1.5%)
Facebook (1.4%)
Microsoft (0.4%)
Vimeo (0.1%)
Twitter (0.1%)
Dailymotion (<0.1%)
CNBC (<0.1%)
CNN (<0.1%)
ESPN (<0.1%)
Note that, due to technical limitations with how search spiders work, many Facebook and Twitter videos require a login and are unavailable to Google. That said, the #2 to #10 biggest players in the video carousel — including some massive brands with deep pockets for video content — add up to only 3.7% of visible videos.
How about how-to?
Pardon my grammar, but “How to…?” questions have become a hot spot for video results, and naturally lend themselves to niche players like HGTV. Here’s a video carousel from a search for “how to organize a pantry”:
It looks promising on the surface, but does this niche show more diversity of websites at scale? Our data set included just over 45,000 “How to …” searches with video carousels. Here’s the breakdown of the top three sites for each slot:
In our data set, YouTube is even more dominant in the how-to niche, taking up from 97-98% of each of the three visible slots. Khan Academy came in second, and Microsoft (specifically, the Microsoft support site) rounded out the third position (but at <1% in all three slots).
Is this just a fluke?
Most of this analysis was based on a snapshot of data in early October. Given that Google frequently makes changes and runs thousands of tests per year, could we have just picked a particularly unusual day? To answer that, we pulled YouTube’s prevalence across all videos in the carousel on the first day of each month of 2020:
YouTube’s dominance was fairly steady across 2020, ranging from 92.0% to 95.3% in our data set (and actually increasing a bit since January). Clearly, this is not a temporary nor particularly recent condition.
Another challenge in studying Google results, even with large data sets, is the possibility of sampling bias. There is no truly “random” sample of search results (more on that in Appendix A), but we’re lucky enough to have a second data set with a long history. While this data set is only 10,000 keywords, it was specifically designed to evenly represent the industry categories in Google Ads. On October 9, we were able to capture 2,390 video carousels from this data set. Here’s how they measured up:
The top three sites in each of the carousel slots were identical to the 2M-keyword data set, and YouTube’s dominance was even higher (up from 94% to 96%). We have every confidence that the prevalence of YouTube results measured in this study is not a fluke of a single day or a single data set.
How level is the field?
Does YouTube have an unfair advantage? “Fair” is a difficult concept to quantify, so let’s explore Google’s perspective.
Google’s first argument would probably be that YouTube has the lion’s share of video results because they host the lion’s share of videos. Unfortunately, it’s hard to get reliable numbers across the entire world of video hosting, and especially for social platforms. YouTube is undoubtedly a massive player and likely hosts the majority of non-social, public videos in the United States, but 94% seems like a big share even for the lion.
The larger problem is that this dominance becomes self-perpetuating. Over the past few years, more major companies have hosted videos on YouTube and created YouTube channels because it’s easier to get results in Google search than hosting on smaller platforms or their own site.
Google’s more technical argument is that the video search algorithm has no inherent preference for YouTube. As a search marketer, I’ve learned to view this argument narrowly. There’s probably not a line of code in the algorithm that says something like:
IF site = ‘YouTube’ THEN ranking = 1
Defined narrowly, I believe that Google is telling the truth. However, there’s no escaping the fact that Google and YouTube share a common backbone and many of the same internal organs, which provides advantages that may be insurmountable.
For example, Google’s video algorithm might reward speed. This makes sense — a slow-loading video is a bad customer experience and makes Google look bad. Naturally, Google’s direct ownership over YouTube means that their access to YouTube data is lightning fast. Realistically, how can a competitor, even with billions in investment, produce an experience that’s faster than a direct pipeline to Google? Likewise, YouTube’s data structure is naturally going to be optimized for Google to easily process and digest, relying on inside knowledge that might not be equally available to all players.
For now, from a marketing perspective, we’re left with little choice but to cover our bases and take the advantage YouTube seems to offer. There’s no reason we should expect YouTube’s numbers to decrease, and every reason to expect YouTube’s dominance to grow, at least without a paradigm-shifting disruption to the industry.
Many thanks to Eric H. and Michael G. on our Vancouver team for sharing their knowledge about the data set and how to interpret it, and to Eric and Rob L. for trusting me with Athena access to a treasure trove of data.
Appendix A: Data and methodology
The bulk of the data for this study was collected in early October 2020 from a set of just over two million Google.com, US-based, desktop search results. After minor de-duplication and clean-up, this data set yielded 258K searches with video carousels on page one. These carousels accounted for 2.1 million total video results/URLs and 767K visible results (Google displays up to three per carousel, without scrolling).
The how-to analysis was based on a smaller data set of 45K keywords that explicitly began with the words “how to”. Neither data set is a randomly selected sample and may be biased toward certain industries or verticals.
The follow-up 10K data set was constructed specifically as a research data set and is evenly distributed across 20 major industry categories in Google Ads. This data set was specifically designed to represent a wide range of competitive terms.
Why don’t we use true random sampling? Outside of the textbook, a truly random sample is rarely achieved, but theoretically possible. Selecting a random sample of adults in The United States, for example, is incredibly difficult (as soon as you pick up the phone or send out an email, you’ve introduced bias), but at least we know that, at any particular moment, the population of adults in the United States is a finite set of individual people.
The same isn’t true of Google searches. Searches are not a finite set, but a cloud of words being conjured out of the void by searchers every millisecond. According to Google themselves: “There are trillions of searches on Google every year. In fact, 15 percent of searches we see every day are new.” The population of searches is not only in the trillions, but changing every minute.
Ultimately, we rely on large data sets, where possible, try to understand the flaws in any given data set, and replicate our work across multiple data sets. This study was replicated against two very different data sets, as well as a third set created by a thematic slice of the first set, and validated against multiple dates in 2020.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
0 notes
Text
The Five Major Platforms For Machine Learning Model Development
New Post has been published on https://perfectirishgifts.com/the-five-major-platforms-for-machine-learning-model-development/
The Five Major Platforms For Machine Learning Model Development
In the last two decades, the biggest evolution of Artificial Intelligence has been the maturation of deep learning as an approach for machine learning, the expansion of big data and the knowledge of how to effectively manage big data systems, and compute power that can handle some of the most challenging machine learning model development. Today’s data scientists and machine learning engineers now have a wide range of choices for how they build models to address the various patterns of AI for their particular needs.
The diversity in options is actually part of the challenge for those looking to build machine learning models. There are just too many choices. Compounded by the fact that there are different ways you can go about developing a machine learning model is the issue that many AI software vendors do a particularly poor job of explaining what their products do. Marketing skills and clear websites are clearly lacking for many AI vendors, which makes it difficult for those looking to implement machine learning models to choose which vendor option is best for them.
Untangling the complexity of machine learning model development
Machine learning is the cornerstone of AI. Without a way for systems to learn from experience and example, they aren’t able to achieve higher order cognitive tasks that require learning patterns from data. Without machine learning, machines need instructions and rules programmed and developed by humans to tell them what to do. This isn’t intelligence – that’s just programming.
There are three primary approaches to machine learning: supervised learning in which machines learn from human-tagged examples, unsupervised learning in which machines discover patterns in the data, and reinforcement learning where machines learn from trial-and-error with a reward-based system. Each of these approaches are applicable and appropriate for different learning scenarios.
Furthermore, there are a wide range of algorithms that machine learning practitioners can use to implement those various learning approaches. These algorithms have different tradeoffs and performance characteristics. In addition, the end result of training a particular algorithm on particular training data is a machine learning model. The model represents what the machine has learned for a particular task. People seem to often confuse the machine learning algorithm, which tells machines the approach they should use to encode learning, and the machine learning model, which is the outcome of that learning. New algorithms are not frequently developed as new approaches to learning are few and far between. New models, however, are developed all the time since each new learning is encoded in a model, which can happen an infinite amount of times.
In addition to the above challenges, building machine learning models can be particularly challenging, especially for those that have limited data science and machine learning skills and understanding. Those with deep technical capabilities and statistics understanding can optimize and tweak models and choose appropriate algorithms with the right settings (“hyperparameters”) with their experience, while others that are fairly new to model creation might be stumped by all the choices that need to be made to select the right modeling approach. Tools on the market to develop machine learning models cater to a wide range of needs from novice to expert, making tool selection that much more challenging.
Five Major Approaches to ML Model Development
A recent report by AI market research and advisory firm Cognilytica identifies five major approaches to machine learning model development:
Five Major Platforms for Machine Learning Model Development
Machine Learning Toolkits
The field of machine learning and data science is not new, with decades of research from academicians, researchers, and data scientists. As a result, there are a large collection of toolkits that enable knowledgeable machine learning practitioners to implement a wide range of algorithms with low-level configurability. These machine learning toolkits are very popular and many are open source. Some toolkits are focused on specific machine learning algorithms and applications, most notably Keras, Tensorflow, and PyTorch which are focused on deep learning models, while others such as Apache Mahout and SciKit Learn provide a range of machine algorithms and tools. These toolkits are in turn embedded in many larger machine learning platforms including those mentioned below. In addition, many of the machine learning toolkits have the support and ongoing development resources of large technology companies. For example, Facebook supports PyTorch, Google supports Keras and TensorFlow, Amazon supports MXNet, Microsoft supports CNTK Toolkit, and others are supported by companies like IBM, Baidu, Apple, Netflix, and others.
Data Science Notebooks
The realm of machine learning is that of data science, since after all, we’re trying to derive higher value insights from big data. The primary environment for data science is the “notebook”, which is a collaborative, interactive, document-style environment that combines aspects of coding, data engineering, machine learning modeling, data visualization, and collaborative data sharing. Open source notebooks such as Jupyter and Apache Zeppelin have become widely adopted and have also found their way into the commercial platform offerings.
Data science notebooks offer the full breadth of machine learning algorithms through support and embedding of many of the popular machine learning toolkits mentioned above. While data science notebooks can be used to develop models of any type, they are primarily used during the experimentation and iteration phases of model development, since data science notebooks are optimized for that sort of iterative experimentation versus being focused on organization-wide aspects of management and deployment.
Machine Learning Platforms
Organizations that are looking to make mission-critical use of machine learning know that simply building a machine learning model is not all that needs to be taken into consideration for ML model needs. The full lifecycle of machine learning model development includes aspects of data preparation and engineering, machine learning model iteration including the use of “AutoML” to automatically identify the best algorithms and settings to achieve desired outcomes, machine learning model evaluation, and ML model iteration and versioning including the emerging area of “ML Ops”.
As a result, the last decade has seen the explosive emergence of full-lifecycle machine learning platform solutions that aim to not only simplify ML model development but also address these other areas of managing the ML model lifecycle. Many companies in this space have emerged as small startups to become major powerhouses in the industry with ever-increasing solutions that tackle a wider array of needs for data scientists and machine learning engineers.
Analytics Platforms
Before data science was data science, there was the field of analytics and business intelligence. Many tools that were used for non-machine learning analytics have since added machine learning model development to their capabilities. Most of the analytics field is dominated by a few large commercial analytics firms, which are increasingly broadening their offerings. As such, data scientists that might have experience with those tools will find increasing capabilities for machine learning model development and broader lifecycle capabilities.
These solutions traditionally aimed at data analytics, statistics, and mathematics applications have realized the power of adding machine learning capabilities to their existing statistical and/or analytics offerings. Organizations that have already invested in analytics solutions will find that they can retain the skill, experience, and investment in their existing tools that now support machine learning development and deployment.
Cloud-based ML-as-a-Service (MLaaS)
In addition to the above approaches, most of the large cloud providers have jumped in with both feet into the machine learning space. Amazon, Google, IBM, and Microsoft have all added core capabilities for machine learning model development, management, and iteration as well as capabilities for data preparation, engineering, and augmentation. These cloud vendors also support and use many of the open source ML toolkits as well as the Data Science Notebooks popular in the field. As a result, the decision to use the cloud for ML model development is rarely an “either / or” decision, but more of a tactical decision on whether the use of cloud-based resources for computing, data storage, and value-added ML lifecycle capabilities is needed.
The growth of machine learning model markets
No doubt the field of machine learning model development continues to expand. Cognilytica expects the market for machine learning platforms to reach over $120 Billion by 2025, growing at a fast and furious rate. (Disclosure: I’m a principal analyst with Cognilytica) While there might be questions as to how long this latest wave of AI will last, there’s no doubt that the future of machine learning development and implementation looks bright.
From AI in Perfectirishgifts
0 notes
Text
YouTube Dominates Google Video in 2020
Posted by Dr-Pete
In a study of 2.1M searches and 766K videos, YouTube accounted for 94% of all video carousel results on page one of Google, leaving little room for competition.
Even the most casual video aficionado knows YouTube (acquired by Google in 2006). As a Google search user, you may even feel like you encounter more YouTube videos than videos from other sources, but does the data back this up?
A Wall Street Journal article in June 2020 measured a strong advantage of YouTube in Google search results, but that article focused on 98 hand-selected videos to compare YouTube to other platforms.
Using a set of over two million Google.com (US) desktop searches captured in early October 2020, we were able to extract more than 250,000 results with video carousels on page one. Most organic video results in 2020 appear in a carousel, like this one:
This carousel appeared on a search for “How to be an investor” (Step 1: Find a bag of money). Notice the arrow on the far-right — currently, searchers can scroll through up to ten videos. While our research tracked all ten positions, most of this report will focus on the three visible positions.
How dominant is YouTube?
Anecdotally, we see YouTube pop up a lot in Google results, but how dominant are they in the visible three video carousel results across our data set? Here’s a breakdown:
YouTube’s presence across the first three video slots was remarkably consistent, at (1) 94.1%, (2) 94.2% and (3) 94.2%. Khan Academy and Facebook took the #2 and #3 rankings for each carousel slot, with Facebook gaining share in later slots.
Obviously, this is a massive drop from the first to second largest share, and YouTube’s presence only varied from 94.1% to 95.1% across all ten slots. Across all visible videos in the carousel, here are the top ten sites in our data set:
YouTube (94.2%)
Khan Academy (1.5%)
Facebook (1.4%)
Microsoft (0.4%)
Vimeo (0.1%)
Twitter (0.1%)
Dailymotion (<0.1%)
CNBC (<0.1%)
CNN (<0.1%)
ESPN (<0.1%)
Note that, due to technical limitations with how search spiders work, many Facebook and Twitter videos require a login and are unavailable to Google. That said, the #2 to #10 biggest players in the video carousel — including some massive brands with deep pockets for video content — add up to only 3.7% of visible videos.
How about how-to?
Pardon my grammar, but “How to…?” questions have become a hot spot for video results, and naturally lend themselves to niche players like HGTV. Here’s a video carousel from a search for “how to organize a pantry”:
It looks promising on the surface, but does this niche show more diversity of websites at scale? Our data set included just over 45,000 “How to …” searches with video carousels. Here’s the breakdown of the top three sites for each slot:
In our data set, YouTube is even more dominant in the how-to niche, taking up from 97-98% of each of the three visible slots. Khan Academy came in second, and Microsoft (specifically, the Microsoft support site) rounded out the third position (but at <1% in all three slots).
Is this just a fluke?
Most of this analysis was based on a snapshot of data in early October. Given that Google frequently makes changes and runs thousands of tests per year, could we have just picked a particularly unusual day? To answer that, we pulled YouTube’s prevalence across all videos in the carousel on the first day of each month of 2020:
YouTube’s dominance was fairly steady across 2020, ranging from 92.0% to 95.3% in our data set (and actually increasing a bit since January). Clearly, this is not a temporary nor particularly recent condition.
Another challenge in studying Google results, even with large data sets, is the possibility of sampling bias. There is no truly “random” sample of search results (more on that in Appendix A), but we’re lucky enough to have a second data set with a long history. While this data set is only 10,000 keywords, it was specifically designed to evenly represent the industry categories in Google Ads. On October 9, we were able to capture 2,390 video carousels from this data set. Here’s how they measured up:
The top three sites in each of the carousel slots were identical to the 2M-keyword data set, and YouTube’s dominance was even higher (up from 94% to 96%). We have every confidence that the prevalence of YouTube results measured in this study is not a fluke of a single day or a single data set.
How level is the field?
Does YouTube have an unfair advantage? “Fair” is a difficult concept to quantify, so let’s explore Google’s perspective.
Google’s first argument would probably be that YouTube has the lion’s share of video results because they host the lion’s share of videos. Unfortunately, it’s hard to get reliable numbers across the entire world of video hosting, and especially for social platforms. YouTube is undoubtedly a massive player and likely hosts the majority of non-social, public videos in the United States, but 94% seems like a big share even for the lion.
The larger problem is that this dominance becomes self-perpetuating. Over the past few years, more major companies have hosted videos on YouTube and created YouTube channels because it’s easier to get results in Google search than hosting on smaller platforms or their own site.
Google’s more technical argument is that the video search algorithm has no inherent preference for YouTube. As a search marketer, I’ve learned to view this argument narrowly. There’s probably not a line of code in the algorithm that says something like:
IF site = ‘YouTube’ THEN ranking = 1
Defined narrowly, I believe that Google is telling the truth. However, there’s no escaping the fact that Google and YouTube share a common backbone and many of the same internal organs, which provides advantages that may be insurmountable.
For example, Google’s video algorithm might reward speed. This makes sense — a slow-loading video is a bad customer experience and makes Google look bad. Naturally, Google’s direct ownership over YouTube means that their access to YouTube data is lightning fast. Realistically, how can a competitor, even with billions in investment, produce an experience that’s faster than a direct pipeline to Google? Likewise, YouTube’s data structure is naturally going to be optimized for Google to easily process and digest, relying on inside knowledge that might not be equally available to all players.
For now, from a marketing perspective, we’re left with little choice but to cover our bases and take the advantage YouTube seems to offer. There’s no reason we should expect YouTube’s numbers to decrease, and every reason to expect YouTube’s dominance to grow, at least without a paradigm-shifting disruption to the industry.
Many thanks to Eric H. and Michael G. on our Vancouver team for sharing their knowledge about the data set and how to interpret it, and to Eric and Rob L. for trusting me with Athena access to a treasure trove of data.
Appendix A: Data and methodology
The bulk of the data for this study was collected in early October 2020 from a set of just over two million Google.com, US-based, desktop search results. After minor de-duplication and clean-up, this data set yielded 258K searches with video carousels on page one. These carousels accounted for 2.1 million total video results/URLs and 767K visible results (Google displays up to three per carousel, without scrolling).
The how-to analysis was based on a smaller data set of 45K keywords that explicitly began with the words “how to”. Neither data set is a randomly selected sample and may be biased toward certain industries or verticals.
The follow-up 10K data set was constructed specifically as a research data set and is evenly distributed across 20 major industry categories in Google Ads. This data set was specifically designed to represent a wide range of competitive terms.
Why don’t we use true random sampling? Outside of the textbook, a truly random sample is rarely achieved, but theoretically possible. Selecting a random sample of adults in The United States, for example, is incredibly difficult (as soon as you pick up the phone or send out an email, you’ve introduced bias), but at least we know that, at any particular moment, the population of adults in the United States is a finite set of individual people.
The same isn’t true of Google searches. Searches are not a finite set, but a cloud of words being conjured out of the void by searchers every millisecond. According to Google themselves: “There are trillions of searches on Google every year. In fact, 15 percent of searches we see every day are new.” The population of searches is not only in the trillions, but changing every minute.
Ultimately, we rely on large data sets, where possible, try to understand the flaws in any given data set, and replicate our work across multiple data sets. This study was replicated against two very different data sets, as well as a third set created by a thematic slice of the first set, and validated against multiple dates in 2020.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
0 notes