#garbage collector node.js
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, 44% of users from Denmark used Tumblr daily.
Text
Technology is moving fast and so does Java technology. Java programming has completely changed in past decade. Millions of applications are developed using Java every day. Java is still one of the most popular programming languages among developers and employers. Since oracle acquired Sun Microsystems, there has been a significant change in the language. As a competent java developer, you need to stay on top of the latest trends and features to stay productive. I am a full-time java developer dealing with multiple applications in java. This article is based on my experience and interaction with other experienced developers in java technology. In this article, I have tried to cover java feature highlight, interesting libraries, frameworks and open source projects along with some career path options for new java developers. If you think I have missed out on something in this article please feel free to suggest it in comments. I will try to update the article to make it useful for our huge java developers community on the internet. I have been writing about java related technology for almost 10 years and most of the things are same in java technology. However, to learn java related latest technology any developer need to keep up with latest trends. The most important changes are as part of latest features in Java language itself and before you proceed, make sure you have the best laptop for programming to ensure you can work as efficiently as possible. Popular New Features In Java Recent versions of Java have introduced very powerful features. Some of my favorite features are listed below Lambda Expressions: Since Java 8 Lambda expressions in java are a way to achieve functional programming style code. These are good for some specific type of problems. Default and Static Methods In Interfaces Default methods are a powerful feature in java interfaces. This allows architects to redesign systems easily. Now you can easily add one more method to an existing interface without invalidating all implementing classes of it. Static methods can be now added to a java interface. This can avoid an explosion of utility classes in your project. Performance Improvements In Java 8 PermGen Space is Removed The PermGen space has been removed from Java 8 memory model. It has been replaced with an expandable metaspace to store JVM metadata in native memory. Garbage Collection : G1 Collector The G1 (Garbage-first collector) was introduced in JDK 7. It has been designed support larger heap size requirements of applications. Though this new Garbage collector is available in Java it is still not the default garbage collector. It may become the default collector in Java 9 Asynchronous IO vs Multi-Threaded IO in Java Java development is moving towards asynchronous IO. The latest recommended way to do IO in Java is using java.nio library. However, the programming using java.nio is still fairly complex. Therefore many developers prefer open source frameworks like netty Despite the availability of features and frameworks, asynchronous IO is still painful in java. Current abstractions are not easy enough to be used by inexperienced developers. This causes a lot of unwanted performance and code maintenance issues. Asynchronous IO is one of the strong reasons why many experienced web developers like Node.js - it is simple to do async IO in Node and it does it very well. Interesting Libraries and Frameworks Below are some interesting and noteworthy libraries, frameworks and open source projects that play an important part of java developers life these days. Big Data Technology in Java Java is still the leading language for big data analytics and map-reduce development. The two key open source projects to learn big data technology are listed below Hadoop Hadoop is still leading framework in big data computing technology. Map reduce development in java is very popular due to good support from apache. Spark Apache Spark is very popular big data computing framework that can run on top of Hadoop, Hbase, Mesos or Cassandra.
It is used due to faster development and better performance. It supports Java and many existing java developers like to use it for writing efficient MapReduce jobs. NOSQL Databases A large number of applications are now being developed using various NOSQL databases. The choice of database varies based on the needs of the project, however, some of the below listed NOSQL databases are reasonably popular now. MongoDB MongoDB is leading open source NOSQL database. It is popular due to its performance, JSON storage and other benefits of scaling. It is extremely easy to integrate. Therefore many java developers are quickly adopting it for REST web service development with JSON data input and output. Redis Redis is an open source in-memory database cache system. It is very powerful and used in many highly scalable systems. Cassandra Apache Cassandra is one of most flexible NOSQL database that provides tunable consistency. It is a popular choice for a scalable system that is developed using java. Couchbase Couchbase is an enterprise licensed NOSQL database. It is popular for extremely fast response time. Relational Databases Despite a lot of buzz around NOSQL databases, a relational database is still being used for a large number of applications. Some of the popular relational databases are listed below. MySQL Database Based on Github projects, MySQL database is the most popular choice for Java open source projects. Below snapshot shows the popularity of Postgres SQL database on Github open source projects. Postgres SQL Database Postgres relational database is also very popular open source relational database. This database is very popular among PHP open source community. It is also commonly used for Java-based open source projects. Below snapshot shows the popularity of Postgres SQL database on Github open source projects. Oracle Database Oracle is still the most popular enterprise relational database choice. This is not free however enterprise customers still rely heavily on it. Oracle is not as popular as MySQL and Postgres in open source community for obvious reasons. See the below snapshot of oracle usage in Github java projects. Popular JSON Libraries in Java JSON is the most popular format for REST based web service development. This is not different for Java technology either. Google GSON Google GSON is the most popular open source JSON library as of now. This is based on a number of open source projects on Github. Jackson The second most popular option for JSON parsing in java is Jackson. Functional Languages There are two leading functional programming languages that run on JVM These languages are being used by developers who like functional programming style. Scala Scala is an acronym of "Scalable language". It is a functional as well as object oriented language. It runs inside a JVM. It has inbuilt support to use java libraries. This makes it a powerful scripting language. I like to use it for test automation and load testing. Groovy Groovy is developed by Apache foundation. It is optionally typed and dynamic language. Many developers like to use groovy for scripting and automation. Java Developer Career Paths Java programming has been used for multiple types of projects. I have noticed 3 major types of a career path for java developers. Backend Developers / REST Service Developers Backend developers are responsible for writing java applications that can interact with a relational or NOSQL database and perform some business logic. Many applications are being developed with java as backend. This includes mobile apps as well. The job of backend developer is to create web enabled application that can be exposed as a web service. This service can be called from any client including web or mobile or any IOT device. Full Stack Developer Full Stack developers in java are primarily working on MVC frameworks like Spring MVC, Struts or similar. This requires an in-depth understanding of Core Java, Servlet API, and respective framework usage.
As per my observation, the need of full stack developer in java is reducing lately. This is happening mainly due to a reduction in Front End development using Java technology. Many companies are now moving to JavaScript based front-end development. This is forcing most java full stack developer to choose to move to JavaScript or become backed developers. There is still a ton of legacy applications that use traditional Java-based MVC frameworks. Therefore the job market is good for these developers. However, I foresee this will change very fast. If you find yourself working on Servlet, JSP, JSF or MVC based frameworks too long it may be a sign that you need to change your job to survive in the job market. Data Scientists / Big Data Analysts Many companies are doing big data analysis with the help of MapReduce developers. Data scientists are java developers who can write map reduce jobs in Hadoop or similar environment. This requires basic knowledge of core java and detailed understanding of the Hadoop ecosystem. Data scientist jobs are well paid and plenty in recent past. Many ETL developers are also moving toward this job role. Many java developers are learning to use Spark and quickly getting a high pay job as a data scientist. I see think the data scientists job market is still evolving and more jobs will be available for beginners as well. Summary I hope you find this article useful. Java development technology has changed over last decade. Staying up to date with latest java trends is key to survive in a good or bad developer job market. Article Updates Updated Broken Links and Added new reference links - January 24th 2017
0 notes
Text
Just Get Out between Ultimate battle of Node.js vs Go !
In application or website development, the front-end UI and backend logic is all that matters. Right? That means getting the right tools for server-side development that make the battle of Node.js vs Go interesting.
While both Go and Node.js are most favored among the developer community, the question is which one is preeminent for backend development? How do programming languages compare?
Let's see which one will be more suitable for your project.
Where is Golang used?
Go is mostly preferred in applications where the processor is hungry and needs to do multi-threaded tasks. The Golang programming language is more ideal for developing backend applications.
Where is Node.js used?
Node.js works more preferably while developing server-side applications as it can handle multiple requests. Moreover, asynchronous architecture in Node.js will build a stable connection with uniting client and server.
Performance
In the raw speed criteria, Go is faster than Node.js. Go is directly compiled in machine code as it does not require an interpreter. Due to this, Go performance is considered low-level languages such as C++, while in terms of IO operation, Go is much better than Node.js. In addition, Go and Node.js both have features of the garbage collector. That helps in staving off memory leaks and guarantee stability.
Node.js is one that was marginally trailing Golang in performance. The single-threaded and much-improved Node.js empower the efficiency and javascript V8 engine make sure that the application runs without requiring the interpreter.
Judgment: There is very few difference between Node.js and Go in real-life performance.
Concurrency
Like worker_thread, Node.js handles concurrency with API. These APIs will make sure that without running bottlenecks, Node.js processes incoming requests.
On the other hand, Go can handle concurrent tasks. Without making use of much RAM, GoRoutines allow applications to run with multi-threading functions. This makes Go pro in handling and processing- intense tasks without affecting other functions.
Judgment: Winner is Go.
Error Handling
Most developers are more familiar with the Node.js method of error handling. As it uses try-catch exceptions, that error will look instantly while handled at runtime.
However, God has different ways to check errors during its compilation and runtime. Compilation errors that are frequently syntax related can be rectified in code. Runtime errors need explicit handling so, the return value of the function is required manually inspected. The new version (Go 1.16) can work better on handling with the incorporation of work.
Judgment: hard to decide
Tools
Reducing development time plays a vital role, and reducing time can be possible with ready-to-use tools. In Node.js, developers get 836,000 open source tools and libraries to use via NPM. While there are many tools available in Node.js, choosing one is tough.
On the other hand, Go does not have more options in the tools, but Go has an authoritative standard library. Tools are limited in the Go. But each tool makes programming simpler. For instance, Test in Go allows developers to run a series of tests in code; however, Go vet filters unsecure constructs.
Judgment: Node.js have more quantity in tools.
Community
Node.js has backbone support such as Microsoft, Intel, and IBM from the Node.js foundation. In 2018 the number of Node.js downloads was around 1 billion. It shows the popularity of Node.js and the support of a community with a wide active size.
Go has matched it with Node.js popularity in a different way. Go has 83.2k users on Github, while Node.js has 77.6k. So, Go is beating Node.js from a different perspective.
Judgment: Both technologies have community support in different ways.
Take Away
It is really difficult to draw attention to the conclusion of which one is better and who won the battle of Node.js vs Go. Both are worthy in their own nature in building backend applications as Go offers needed computational power, and Node.js works well in asynchronous requests.
So, if you are planning to Hire Node js developer or Golang developer you need to find the best developer that understands the requirements of your application. And leverage you the utmost benefits of functionality of both the technologies.
0 notes
Text
WHY SHOULD YOU USE A GO BACKEND IN FLUTTER?

WHAT IS FLUTTER?
An open-source UI software development kit is called Flutter by Google. Using a single codebase, it is used to develop cross-platform applications for Linux, macOS, Windows, Android, iOS, and the web. Flutter's initial release, code-named "Sky," worked with the Android operating system. At the Dart developer summit in 2015, it was first made public. The framework's initial stable release, Flutter 1.0, was made available on December 4th of that year at the Flutter Live event. Version 2.10 of Flutter, the most latest stable version, was released on March 2, 2022.
WHAT IS GO BACKEND?
Programming language Go, commonly referred to as Golang, is open-source, statically typed, built, cross-platform, and blazingly quick. Google initially offered it in 2009. Go is a powerful language that is great for building backends. The goal of Google's developers was to incorporate the best aspects of already-existing languages while also fixing their most frequent problems. Go is a statically typed, high-efficiency language, similar to C++ and Java. Go is similar to C in terms of syntax and performance. It's an easy-to-use language that lets programmers create understandable, manageable code.
The first stable version of Go, which provided developers with a strong goroutine, a garbage collector, and an embedded testing environment, was published in 2011. The developer community has found Go to be very popular so far.
ADVANTAGES OF GO BACKEND IN FLUTTER
Go-based backends offer several non-technical and unnoticed benefits that Flutter frontends can take use of. Furthermore, you can avoid time-consuming rewrites of the business logic by employing Go modules directly in the Flutter project. Let's look at them now:
Trends, community and popularity:
Google has created two open source projects: Go and Flutter. The Google open source community, which contributes code, resources, and free community-based developer support, supports both projects. In 2012 and 2018, respectively, Google published Go v1 and Flutter v1, but by late 2019, both platforms have seen significant growth for cloud-based business apps. Both initiatives have a great reputation, strong community support, and cutting-edge technology that was developed by Google. They are both also growing in popularity quickly.
Identicalities in the development environment:
Go is the cross-platform programming language that Flutter uses. Both Flutter and Go have features for addressing different technological problems. However, the syntax, developer tools, and third-party libraries of Go and Flutter are very similar. As a result, the productivity of the same full-stack development team can be maintained while working on both backend and frontend projects. Flutter developers can simply begin backend work in Go thanks to its simple syntax. Additionally, all Flutter development tools' operating systems are entirely compatible with Go development tools. You may therefore build up a successful Go programming environment on your Flutter development PC.
Flutter uses Go backend logic:
On occasion, frontend applications must directly reuse backend code. If you use React Native for the frontend and Node.js for the backend, you can easily share common business logic by building a JavaScript package. You should think twice before choosing Dart to develop the backend because its server-side support is still in its early stages and is not yet comparable to the Go ecosystem. You might need to recreate the same existing business logic in Dart on the Flutter frontend if you design your backend in C#, Java, or Node.js. The Go mobile project offers a way for platform-specific mobile development environments, such Java and Android, to invoke Go code.
CONCLUSION
Therefore, it is safe to say that when it comes to high-load enterprise-level projects and even microservices, Go Backend is ideal for Flutter. If you’re looking for Flutter development services, then Stellar Digital is the right place to visit. Our App developers carry years of experience of working for various Flutter development projects and they offer the best of services. Reach out at us soon!
0 notes
Link
JavaScript is one of the most popular programming languages in the world. I believe it's a great language to be your first programming language ever. We mainly use JavaScript to create websites web applications server-side applications using Node.js but JavaScript is not limited to these things, and it can also be used to create mobile applications using tools like React Native create programs for microcontrollers and the internet of things create smartwatch applications It can basically do anything. It's so popular that everything new that shows up is going to have some kind of JavaScript integration at some point. JavaScript is a programming language that is: high level: it provides abstractions that allow you to ignore the details of the machine where it's running on. It manages memory automatically with a garbage collector, so you can focus on the code instead of managing memory like other languages like C would need, and provides many constructs which allow you to deal with highly powerful variables and objects. dynamic: opposed to static programming languages, a dynamic language executes at runtime many of the things that a static language does at compile time. This has pros and cons, and it gives us powerful features like dynamic typing, late binding, reflection, functional programming, object runtime alteration, closures and much more. Don't worry if those things are unknown to you - you'll know all of those at the end of the course. dynamically typed: a variable does not enforce a type. You can reassign any type to a variable, for example, assigning an integer to a variable that holds a string. loosely typed: as opposed to strong typing, loosely (or weakly) typed languages do not enforce the type of an object, allowing more flexibility but denying us type safety and type checking (something that TypeScript - which builds on top of JavaScript - provides) interpreted: it's commonly known as an interpreted language, which means that it does not need a compilation stage before a program can run, as opposed to C, Java or Go for example. In practice, browsers do compile JavaScript before executing it, for performance reasons, but this is transparent to you: there is no additional step involved. multi-paradigm: the language does not enforce any particular programming paradigm, unlike Java for example, which forces the use of object-oriented programming, or C that forces imperative programming. You can write JavaScript using an object-oriented paradigm, using prototypes and the new (as of ES6) classes syntax. You can write JavaScript in a functional programming style, with its first-class functions, or even in an imperative style (C-like). In case you're wondering, JavaScript has nothing to do with Java, it's a poor name choice but we have to live with it. Update: You can now get a PDF and ePub version of this JavaScript Beginner's Handbook.A little bit of history Created 20 years ago, JavaScript has gone a very long way since its humble beginnings. It was the first scripting language that was supported natively by web browsers, and thanks to this it gained a competitive advantage over any other language and today it's still the only scripting language that we can use to build Web Applications. Other languages exist, but all must compile to JavaScript - or more recently to WebAssembly, but this is another story. In the beginnings, JavaScript was not nearly powerful as it is today, and it was mainly used for fancy animations and the marvel known at the time as Dynamic HTML. With the growing needs that the web platform demanded (and continues to demand), JavaScript had the responsibility to grow as well, to accommodate the needs of one of the most widely used ecosystems of the world. JavaScript is now widely used also outside of the browser. The rise of Node.js in the last few years unlocked backend development, once the domain of Java, Ruby, Python, PHP and more traditional server-side languages. JavaScript is now also the language powering databases and many more applications, and it's even possible to develop embedded applications, mobile apps, TV sets apps and much more. What started as a tiny language inside the browser is now the most popular language in the world. Just JavaScript Sometimes it's hard to separate JavaScript from the features of the environment it is used in. For example, the console.log() line you can find in many code examples is not JavaScript. Instead, it's part of the vast library of APIs provided to us in the browser. In the same way, on the server it can be sometimes hard to separate the JavaScript language features from the APIs provided by Node.js. Is a particular feature provided by React or Vue? Or is it "plain JavaScript", or "vanilla JavaScript" as often called? In this book I talk about JavaScript, the language. Without complicating your learning process with things that are outside of it, and provided by external ecosystems. A brief intro to the syntax of JavaScript In this little introduction I want to tell you about 5 concepts: white space case sensitivity literals identifiers White space JavaScript does not consider white space meaningful. Spaces and line breaks can be added in any fashion you might like, even though this is in theory. In practice, you will most likely keep a well defined style and adhere to what people commonly use, and enforce this using a linter or a style tool such as Prettier. For example, I like to always 2 characters to indent. Case sensitive JavaScript is case sensitive. A variable named something is different from Something. The same goes for any identifier. Literals We define as literal a value that is written in the source code, for example, a number, a string, a boolean or also more advanced constructs, like Object Literals or Array Literals: 5 'Test' true ['a', 'b'] {color: 'red', shape: 'Rectangle'} Identifiers An identifier is a sequence of characters that can be used to identify a variable, a function, an object. It can start with a letter, the dollar sign $ or an underscore _, and it can contain digits. Using Unicode, a letter can be any allowed char, for example, an emoji 😄. Test test TEST _test Test1 $test The dollar sign is commonly used to reference DOM elements. Some names are reserved for JavaScript internal use, and we can't use them as identifiers. Comments are one of the most important part of any program. In any programming language. They are important because they let us annotate the code and add important information that otherwise would not be available to other people (or ourselves) reading the code. In JavaScript, we can write a comment on a single line using //. Everything after // is not considered as code by the JavaScript interpreter. Like this: // a comment true //another comment Another type of comment is a multi-line comment. It starts with /* and ends with */. Everything in between is not considered as code: /* some kind of comment */ Semicolons Every line in a JavaScript program is optionally terminated using semicolons. I said optionally, because the JavaScript interpreter is smart enough to introduce semicolons for you. In most cases, you can omit semicolons altogether from your programs, without even thinking about it. This fact is very controversial. Some developers will always use semicolons, some others will never use semicolons, and you'll always find code that uses semicolons and code that does not. My personal preference is to avoid semicolons, so my examples in the book will not include them. Values A hello string is a value. A number like 12 is a value. hello and 12 are values. string and number are the types of those values. The type is the kind of value, its category. We have many different types in JavaScript, and we'll talk about them in detail later on. Each type has its own characteristics. When we need to have a reference to a value, we assign it to a variable. The variable can have a name, and the value is what's stored in a variable, so we can later access that value through the variable name. Variables A variable is a value assigned to an identifier, so you can reference and use it later in the program. This is because JavaScript is loosely typed, a concept you'll frequently hear about. A variable must be declared before you can use it. We have 2 main ways to declare variables. The first is to use const: const a = 0 The second way is to use let: let a = 0 What's the difference? const defines a constant reference to a value. This means the reference cannot be changed. You cannot reassign a new value to it. Using let you can assign a new value to it. For example, you cannot do this: const a = 0 a = 1 Because you'll get an error: TypeError: Assignment to constant variable.. On the other hand, you can do it using let: let a = 0 a = 1 const does not mean "constant" in the way some other languages like C mean. In particular, it does not mean the value cannot change - it means it cannot be reassigned. If the variable points to an object or an array (we'll see more about objects and arrays later) the content of the object or the array can freely change. Const variables must be initialized at the declaration time: const a = 0 but let values can be initialized later: let a a = 0 You can declare multiple variables at once in the same statement: const a = 1, b = 2 let c = 1, d = 2 But you cannot redeclare the same variable more than one time: let a = 1 let a = 2 or you'd get a "duplicate declaration" error. My advice is to always use const and only use let when you know you'll need to reassign a value to that variable. Why? Because the less power our code has, the better. If we know a value cannot be reassigned, it's one less source for bugs. Now that we saw how to work with const and let, I want to mention var. Until 2015, var was the only way we could declare a variable in JavaScript. Today, a modern codebase will most likely just use const and let. There are some fundamental differences which I detail in this post but if you're just starting out, you might not care about. Just use const and let. Types Variables in JavaScript do not have any type attached. They are untyped. Once you assign a value with some type to a variable, you can later reassign the variable to host a value of any other type, without any issue. In JavaScript we have 2 main kinds of types: primitive types and object types. Primitive types Primitive types are numbers strings booleans symbols And two special types: null and undefined. Object types Any value that's not of a primitive type (a string, a number, a boolean, null or undefined) is an object. Object types have properties and also have methods that can act on those properties. We'll talk more about objects later on. Expressions An expression is a single unit of JavaScript code that the JavaScript engine can evaluate, and return a value. Expressions can vary in complexity. We start from the very simple ones, called primary expressions: 2 0.02 'something' true false this //the current scope undefined i //where i is a variable or a constant Arithmetic expressions are expressions that take a variable and an operator (more on operators soon), and result into a number: 1 / 2 i++ i -= 2 i * 2 String expressions are expressions that result into a string: 'A ' + 'string' Logical expressions make use of logical operators and resolve to a boolean value: a && b a || b !a More advanced expressions involve objects, functions, and arrays, and I'll introduce them later. Operators Operators allow you to get two simple expressions and combine them to form a more complex expression. We can classify operators based on the operands they work with. Some operators work with 1 operand. Most with 2 operands. Just one operator works with 3 operands. In this first introduction to operators, we'll introduce the operators you are most likely familar with: operators with 2 operands. I already introduced one when talking about variables: the assignment operator =. You use = to assign a value to a variable: let b = 2 Let's now introduce another set of binary operators that you already familiar with, from basic math. The addition operator (+) const three = 1 + 2 const four = three + 1 The + operator also serves as string concatenation if you use strings, so pay attention: const three = 1 + 2 three + 1 // 4 'three' + 1 // three1 The subtraction operator (-) const two = 4 - 2 The division operator (/) Returns the quotient of the first operator and the second: const result = 20 / 5 //result === 4 const result = 20 / 7 //result === 2.857142857142857 If you divide by zero, JavaScript does not raise any error but returns the Infinity value (or -Infinity if the value is negative). 1 / 0 //Infinity -1 / 0 //-Infinity The remainder operator (%) The remainder is a very useful calculation in many use cases: const result = 20 % 5 //result === 0 const result = 20 % 7 //result === 6 A reminder by zero is always NaN, a special value that means "Not a Number": 1 % 0 //NaN -1 % 0 //NaN The multiplication operator (*) Multiply two numbers 1 * 2 //2 -1 * 2 //-2 The exponentiation operator (**) Raise the first operand to the power second operand 1 ** 2 //1 2 ** 1 //2 2 ** 2 //4 2 ** 8 //256 8 ** 2 //64 Precedence rules Every complex statement with multiple operators in the same line will introduce precedence problems. Take this example: let a = 1 * 2 + 5 / 2 % 2 The result is 2.5, but why? What operations are executed first, and which need to wait? Some operations have more precedence than the others. The precedence rules are listed in this table: Operator Description * / % multiplication/dividision + - addition/subtraction = assignment Operations on the same level (like + and -) are executed in the order they are found, from left to right. Following these rules, the operation above can be solved in this way: let a = 1 * 2 + 5 / 2 % 2 let a = 2 + 5 / 2 % 2 let a = 2 + 2.5 % 2 let a = 2 + 0.5 let a = 2.5 Comparison operators After assignment and math operators, the third set of operators I want to introduce is conditional operators. You can use the following operators to compare two numbers, or two strings. Comparison operators always returns a boolean, a value that's true or false). Those are disequality comparison operators: < means "less than" <= means "minus than, or equal to" means "greater than" = means "greater than, or equal to" Example: = 1 //true In addition to those, we have 4 equality operators. They accept two values, and return a boolean: === checks for equality !== checks for inequality Note that we also have == and != in JavaScript, but I highly suggest to only use === and !== because they can prevent some subtle problems. Conditionals With the comparison operators in place, we can talk about conditionals. An if statement is used to make the program take a route, or another, depending on the result of an expression evaluation. This is the simplest example, which always executes: if (true) { //do something } on the contrary, this is never executed: if (false) { //do something (? never ?) } The conditional checks the expression you pass to it for true or false value. If you pass a number, that always evaluates to true unless it's 0. If you pass a string, it always evaluates to true unless it's an empty string. Those are general rules of casting types to a boolean. Did you notice the curly braces? That is called a block, and it is used to group a list of different statements. A block can be put wherever you can have a single statement. And if you have a single statement to execute after the conditionals, you can omit the block, and just write the statement: if (true) doSomething() But I always like to use curly braces to be more clear. You can provide a second part to the if statement: else. You attach a statement that is going to be executed if the if condition is false: if (true) { //do something } else { //do something else } Since else accepts a statement, you can nest another if/else statement inside it: if (a === true) { //do something } else if (b === true) { //do something else } else { //fallback } Arrays An array is a collection of elements. Arrays in JavaScript are not a type on their own. Arrays are objects. We can initialize an empty array in these 2 different ways: const a = [] const a = Array() The first is using the array literal syntax. The second uses the Array built-in function. You can pre-fill the array using this syntax: const a = [1, 2, 3] const a = Array.of(1, 2, 3) An array can hold any value, even value of different types: const a = [1, 'Flavio', ['a', 'b']] Since we can add an array into an array, we can create multi-dimensional arrays, which have very useful applications (e.g. a matrix): const matrix = [ [1, 2, 3], [4, 5, 6], [7, 8, 9] ] matrix[0][0] //1 matrix[2][0] //7 You can access any element of the array by referencing its index, which starts from zero: a[0] //1 a[1] //2 a[2] //3 You can initialize a new array with a set of values using this syntax, which first initializes an array of 12 elements, and fills each element with the 0 number: Array(12).fill(0) You can get the number of elements in the array by checking its length property: const a = [1, 2, 3] a.length //3 Note that you can set the length of the array. If you assign a bigger number than the arrays current capacity, nothing happens. If you assign a smaller number, the array is cut at that position: const a = [1, 2, 3] a //[ 1, 2, 3 ] a.length = 2 a //[ 1, 2 ] How to add an item to an array We can add an element at the end of an array using the push() method: a.push(4) We can add an element at the beginning of an array using the unshift() method: a.unshift(0) a.unshift(-2, -1) How to remove an item from an array We can remove an item from the end of an array using the pop() method: a.pop() We can remove an item from the beginning of an array using the shift() method: a.shift() How to join two or more arrays You can join multiple arrays by using concat(): const a = [1, 2] const b = [3, 4] const c = a.concat(b) //[1,2,3,4] a //[1,2] b //[3,4] You can also use the spread operator (...) in this way: const a = [1, 2] const b = [3, 4] const c = [...a, ...b] c //[1,2,3,4] How to find a specific item in the array You can use the find() method of an array: { //return true or false }) Returns the first item that returns true. Returns undefined if the element is not found. A commonly used syntax is: x.id === my_id) The above line will return the first element in the array that has id === my_id. findIndex() works similarly to find(), but returns the index of the first item that returns true, and if not found, it returns undefined: { //return true or false }) Another method is includes(): a.includes(value) Returns true if a contains value. a.includes(value, i) Returns true if a contains value after the position i. Strings A string is a sequence of characters. It can be also defined as a string literal, which is enclosed in quotes or double quotes: 'A string' "Another string" I personally prefer single quotes all the time, and use double quotes only in HTML to define attributes. You assign a string value to a variable like this: const name = 'Flavio' You can determine the length of a string using the length property of it: 'Flavio'.length //6 const name = 'Flavio' name.length //6 This is an empty string: ''. Its length property is 0: ''.length //0 Two strings can be joined using the + operator: "A " + "string" You can use the + operator to interpolate variables: const name = 'Flavio' "My name is " + name //My name is Flavio Another way to define strings is to use template literals, defined inside backticks. They are especially useful to make multiline strings much simpler. With single or double quotes you can't define a multiline string easily: you'd need to use escaping characters. Once a template literal is opened with the backtick, you just press enter to create a new line, with no special characters, and it's rendered as-is: const string = `Hey this string is awesome!` Template literals are also great because they provide an easy way to interpolate variables and expressions into strings. You do so by using the ${...} syntax: const var = 'test' const string = `something ${var}` //something test inside the ${} you can add anything, even expressions: const string = `something ${1 + 2 + 3}` const string2 = `something ${foo() ? 'x' : 'y'}` Loops Loops are one of the main control structures of JavaScript. With a loop we can automate and repeat indefinitely a block of code, for how many times we want it to run. JavaScript provides many way to iterate through loops. I want to focus on 3 ways: while loops for loops for..of loops while The while loop is the simplest looping structure that JavaScript provides us. We add a condition after the while keyword, and we provide a block that is run until the condition evaluates to true. Example: const list = ['a', 'b', 'c'] let i = 0 while (i < list.length) { console.log(list[i]) //value console.log(i) //index i = i + 1 } You can interrupt a while loop using the break keyword, like this: while (true) { if (somethingIsTrue) break } and if you decide that in the middle of a loop you want to skip the current iteration, you can jump to the next iteration using continue: while (true) { if (somethingIsTrue) continue //do something else } Very similar to while, we have do..while loops. It's basically the same as while, except the condition is evaluated after the code block is executed. This means the block is always executed at least once. Example: const list = ['a', 'b', 'c'] let i = 0 do { console.log(list[i]) //value console.log(i) //index i = i + 1 } while (i < list.length) for The second very important looping structure in JavaScript is the for loop. We use the for keyword and we pass a set of 3 instructions: the initialization, the condition, and the increment part. Example: const list = ['a', 'b', 'c'] for (let i = 0; i < list.length; i++) { console.log(list[i]) //value console.log(i) //index } Just like with while loops, you can interrupt a for loop using break and you can fast forward to the next iteration of a for loop using continue. for...of This loop is relatively recent (introduced in 2015) and it's a simplified version of the for loop: const list = ['a', 'b', 'c'] for (const value of list) { console.log(value) //value } Functions In any moderately complex JavaScript program, everything happens inside functions. Functions are a core, essential part of JavaScript. What is a function? A function is a block of code, self contained. Here's a function declaration: function getData() { // do something } A function can be run any times you want by invoking it, like this: getData() A function can have one or more argument: function getData() { //do something } function getData(color) { //do something } function getData(color, age) { //do something } When we can pass an argument, we invoke the function passing parameters: function getData(color, age) { //do something } getData('green', 24) getData('black') Note that in the second invokation I passed the black string parameter as the color argument, but no age. In this case, age inside the function is undefined. We can check if a value is not undefined using this conditional: function getData(color, age) { //do something if (typeof age !== 'undefined') { //... } } typeof is a unary operator that allows us to check the type of a variable. You can also check in this way: function getData(color, age) { //do something if (age) { //... } } although the conditional will also be true if age is null, 0 or an empty string. You can have default values for parameters, in case they are not passed: function getData(color = 'black', age = 25) { //do something } You can pass any value as a parameter: numbers, strings, booleans, arrays, objects, and also functions. A function has a return value. By default a function returns undefined, unless you add a return keyword with a value: function getData() { // do something return 'hi!' } We can assign this return value to a variable when we invoke the function: function getData() { // do something return 'hi!' } let result = getData() result now holds a string with the the hi! value. You can only return one value. To return multiple values, you can return an object, or an array, like this: function getData() { return ['Flavio', 37] } let [name, age] = getData() Functions can be defined inside other functions: {} dosomething() return 'test' } The nested function cannot be called from the outside of the enclosing function. You can return a function from a function, too. Arrow functions Arrow functions are a recent introduction to JavaScript. They are very often used instead of "regular" functions, the one I described in the previous chapter. You'll find both forms used everywhere. Visually, they allows you to write functions with a shorter syntax, from: function getData() { //... } to { //... } But.. notice that we don't have a name here. Arrow functions are anonymous. We must assign them to a variable. We can assign a regular function to a variable, like this: let getData = function getData() { //... } When we do so, we can remove the name from the function: let getData = function() { //... } and invoke the function using the variable name: let getData = function() { //... } getData() That's the same thing we do with arrow functions: { //... } getData() If the function body contains just a single statement, you can omit the parentheses and write all on a single line: console.log('hi!') Parameters are passed in the parentheses: console.log(param1, param2) If you have one (and just one) parameter, you could omit the parentheses completely: console.log(param) Arrow functions allow you to have an implicit return: values are returned without having to use the return keyword. It works when there is a on-line statement in the function body: 'test' getData() //'test' Like with regular functions, we can have default parameters: You can have default values for parameters, in case they are not passed: { //do something } and we can only return one value. Arrow functions can contain other arrow function, or also regular functions. The are very similar, so you might ask why they were introduced? The big difference with regular functions is when they are used as object methods. This is something we'll soon look into. Objects Any value that's not of a primitive type (a string, a number, a boolean, a symbol, null, or undefined) is an object. Here's how we define an object: const car = { } This is the object literal syntax, which is one of the nicest things in JavaScript. You can also use the new Object syntax: const car = new Object() Another syntax is to use Object.create(): const car = Object.create() You can also initialize an object using the new keyword before a function with a capital letter. This function serves as a constructor for that object. In there, we can initialize the arguments we receive as parameters, to setup the initial state of the object: function Car(brand, model) { this.brand = brand this.model = model } We initialize a new object using const myCar = new Car('Ford', 'Fiesta') myCar.brand //'Ford' myCar.model //'Fiesta' Objects are always passed by reference. If you assign a variable the same value of another, if it's a primitive type like a number or a string, they are passed by value: Take this example: let age = 36 let myAge = age myAge = 37 age //36 const car = { color: 'blue' } const anotherCar = car anotherCar.color = 'yellow' car.color //'yellow' Even arrays or functions are, under the hoods, objects, so it's very important to understand how they work. Object Properties Objects have properties, which are composed by a label associated with a value. The value of a property can be of any type, which means that it can be an array, a function, and it can even be an object, as objects can nest other objects. This is the object literal syntax we saw in the previous chapter: const car = { } We can define a color property in this way: const car = { color: 'blue' } here we have a car object with a property named color, with value blue. Labels can be any string, but beware special characters: if I wanted to include a character not valid as a variable name in the property name, I would have had to use quotes around it: const car = { color: 'blue', 'the color': 'blue' } Invalid variable name characters include spaces, hyphens, and other special characters. As you see, when we have multiple properties, we separate each property with a comma. We can retrieve the value of a property using 2 different syntaxes. The first is dot notation: car.color //'blue' The second (which is the only one we can use for properties with invalid names), is to use square brackets: car['the color'] //'blue' If you access an unexisting property, you'll get the undefined value: car.brand //undefined As said, objects can have nested objects as properties: const car = { brand: { name: 'Ford' }, color: 'blue' } In this example, you can access the brand name using car.brand.name or car['brand']['name'] You can set the value of a property when you define the object. But you can always update it later on: const car = { color: 'blue' } car.color = 'yellow' car['color'] = 'red' And you can also add new properties to an object: car.model = 'Fiesta' car.model //'Fiesta' Given the object const car = { color: 'blue', brand: 'Ford' } you can delete a property from this object using delete car.brand Object Methods I talked about functions in a previous chapter. Functions can be assigned to a function property, and in this case they are called methods. In this example, the start property has a function assigned, and we can invoke it by using the dot syntax we used for properties, with the parentheses at the end: const car = { brand: 'Ford', model: 'Fiesta', start: function() { console.log('Started') } } car.start() Inside a method defined using a function() {} syntax we have access to the object instance by referencing this. In the following example, we have access to the brand and model properties values using this.brand and this.model: const car = { brand: 'Ford', model: 'Fiesta', start: function() { console.log(`Started ${this.brand} ${this.model}`) } } car.start() It's important to note this distinction between regular functions and arrow functions: we don't have access to this if we use an arrow function: { console.log(`Started ${this.brand} ${this.model}`) //not going to work } } car.start() This is because arrow functions are not bound to the object. This is the reason why regular functions are often used as object methods. Methods can accept parameters, like regular functions: const car = { brand: 'Ford', model: 'Fiesta', goTo: function(destination) { console.log(`Going to ${destination}`) } } car.goTo('Rome') Classes We talked about objects, which are one of the most interesting parts of JavaScript. In this chapter we'll go up one level, introducing classes. What are classes? They are a way to define a common pattern for multiple objects. Let's take a person object: const person = { name: 'Flavio' } We can create a class named Person (note the capital P, a convention when using classes), that has a name property: class Person { name } Now from this class, we initialize a flavio object like this: const flavio = new Person() flavio is called an instance of the Person class. We can set the value of the name property: flavio.name = 'Flavio' and we can access it using flavio.name like we do for object properties. Classes can hold properties, like name, and methods. Methods are defined in this way: class Person { hello() { return 'Hello, I am Flavio' } } and we can invoke methods on an instance of the class: class Person { hello() { return 'Hello, I am Flavio' } } const flavio = new Person() flavio.hello() There is a special method called called constructor() that we can use to initialize the class properties when we create a new object instance. It works like this: class Person { constructor(name) { this.name = name } hello() { return 'Hello, I am ' + this.name + '.' } } Note how we use this to access the object instance. Now we can instantiate a new object from the class, passing a string, and when we call hello, we'll get a personalized message: const flavio = new Person('flavio') flavio.hello() //'Hello, I am flavio.' When the object is initialized, the constructor method is called, with any parameters passed. Normally methods are defined on the object instance, not on the class. You can define a method as static to allow it to be executed on the class instead: class Person { static genericHello() { return 'Hello' } } Person.genericHello() //Hello This is very useful, at times. Inheritance A class can extend another class, and objects initialized using that class inherit all the methods of both classes. Suppose we have a class Person: class Person { hello() { return 'Hello, I am a Person' } } We can define a new class Programmer that extends Person: class Programmer extends Person { } Now if we instantiate a new object with class Programmer, it has access to the hello() method: const flavio = new Programmer() flavio.hello() //'Hello, I am a Person' Inside a child class, you can reference the parent class calling super(): class Programmer extends Person { hello() { return super.hello() + '. I am also a programmer.' } } const flavio = new Programmer() flavio.hello() The above program prints Hello, I am a Person. I am also a programmer.. Asynchonous Programming and Callbacks Most of the time, JavaScript code is ran synchronously. This means that a line of code is executed, then the next one is executed, and so on. Everything is as you expect, and how it works in most programming languages. However there are times when you cannot just wait for a line of code to execute. You can't just wait 2 seconds for a big file to load, and halt the program completely. You can't just wait for a network resource to be downloaded, before doing something else. JavaScript solves this problem using callbacks. One of the simplest examples of how to use callbacks is timers. Timers are not part of JavaScript, but they are provided by the browser, and Node.js. Let me talk about one of the timers we have: setTimeout(). The setTimeout() function accepts 2 arguments: a function, and a number. The number is the milliseconds that must pass before the function is ran. Example: { // runs after 2 seconds console.log('inside the function') }, 2000) The function containing the console.log('inside the function') line will be executed after 2 seconds. If you add a console.log('before') prior to the function, and console.log('after') after it: { // runs after 2 seconds console.log('inside the function') }, 2000) console.log('after') You will see this happening in your console: before after inside the function The callback function is executed asynchronously. This is a very common pattern when working with the file system, the network, events, or the DOM in the browser. All of the things I mentioned are not "core" JavaScript, so they are not explained in this handbook, but you'll find lots of examples in my other handbooks available at https://flaviocopes.com. Here's how we can implement callbacks in our code. We define a function that accepts a callback parameter, which is a function. When the code is ready to invoke the callback, we invoke it passing the result: { //do things //do things const result = /* .. */ callback(result) } Code using this function would use it like this: { console.log(result) }) Promises Promises are an alternative way to deal with asynchronous code. As we saw in the previous chapter, with callbacks we'd be passing a function to another function call, that would be called when the function has finished processing. Like this: { console.log(result) }) When the doSomething() code ends, it calls the function received as a a parameter: { //do things //do things const result = /* .. */ callback(result) } The main problems with this approach is that the callback is executed asynchronously, so we don't have a way to do something, and then simply go on with our function. All our code must be nested inside the callback, and if we have to do 2-3 callbacks we enter in what is usually defined "callback hell" with many levels of functions indented into other functions: { console.log(result) }) }) }) Promises are one way to deal with this. Instead of doing: { console.log(result) }) We call a promise-based function in this way: { console.log(result) }) We first call the function, then we have a then() method that is called when the function ends. The indentation does not matter, but you'll often use this style for clarity. It's common to detect errors using a catch() method: { console.log(error) }) Now, to be able to use this syntax, the doSomething() function implementation must be a little bit special. It must use the Promises API. Instead of declaring it as a normal function: { } We declare it as a promise object: const doSomething = new Promise() and we pass a function in the Promise constructor: { }) This function receives 2 parameters. The first is a function we call to resolve the promise, the second a function we call to reject the promise. { }) Resolving a promise means complete it successfully (which results in calling the then() method in who uses it). Rejecting a promise means ending it with an error (which results in calling the catch() method in who uses it). Here's how: { //some code const success = /* ... */ if (success) { resolve('ok') } else { reject('this error occurred') } } ) We can pass a parameter to the resolve and reject functions, of any type we want. Async and Await Async functions are a higher level abstraction over promises. An async function returns a promise, like in this example: resolve('some data'), 2000) }) } Any code that want to use this function will use the async keyword right before the function: const data = await getData() and doing so, any data returned by the promise is going to be assigned to the data variable. In our case, the data is the "some data" string. With one particular caveat: whenever we use the await keyword, we must do so inside a function defined as async. Like this: { const data = await getData() console.log(data) } The Async/await duo allows us to have a cleaner code and a simple mental model to work with asynchronous code. As you can see in the example above, our code looks very simple. Compare it to code using promises, or callback functions. And this is a very simple example, the major benefits will arise when the code is much more complex. As an example, here's how you would get a JSON resource using the Fetch API, and parse it, using promises: response.json()) } getFirstUserData() And here is the same functionality provided using await/async: { // get users list const response = await fetch('/users.json') // parse JSON const users = await response.json() // pick first user const user = users[0] // get user data const userResponse = await fetch(`/users/${user.name}`) // parse JSON const userData = await user.json() return userData } getFirstUserData() Variables scope When I introduced variables, I talked about using const, let, and var. Scope is the set of variables that's visible to a part of the program. In JavaScript we have a global scope, block scope and function scope. If a variable is defined outside of a function or block, it's attached to the global object and it has a global scope, which mean it's available in every part of a program. There is a very important difference between var, let and const declarations. A variable defined as var inside a function is only visible inside that function. Similarly to a function arguments: A variable defined as const or let on the other hand is only visible inside the block where it is defined. A block is a set of instructions grouped into a pair of curly braces, like the ones we can find inside an if statement or a for loop. And a function, too. It's important to understand that a block does not define a new scope for var, but it does for let and const. This has very practical implications. Suppose you define a var variable inside an if conditional in a function function getData() { if (true) { var data = 'some data' console.log(data) } } If you call this function, you'll get some data printed to the console. If you try to move console.log(data) after the if, it still works: function getData() { if (true) { var data = 'some data' } console.log(data) } But if you switch var data to let data: function getData() { if (true) { let data = 'some data' } console.log(data) } You'll get an error: ReferenceError: data is not defined. This is because var is function scoped, and there's a special thing happening here, called hoisting. In short, the var declaration is moved to the top of the closest function by JavaScript, before it runs the code. More or less this is what the function looks like to JS, internally: function getData() { var data if (true) { data = 'some data' } console.log(data) } This is why you can also console.log(data) at the top of a function, even before it's declared, and you'll get undefined as a value for that variable: function getData() { console.log(data) if (true) { var data = 'some data' } } but if you switch to let, you'll get an error ReferenceError: data is not defined, because hoisting does not happen to let declarations. const follows the same rules as let: it's block scoped. It can be tricky at first, but once you realize this difference, then you'll see why var is considered a bad practice nowadays compared to let: they do have less moving parts, and their scope is limited to the block, which also makes them very good as loop variables, because they cease to exist after a loop has ended: function doLoop() { for (var i = 0; i < 10; i++) { console.log(i) } console.log(i) } doLoop() When you exit the loop, i will be a valid variable with value 10. If you switch to let, if you try to console.log(i) will result in an error ReferenceError: i is not defined. Conclusion Thanks a lot for reading this book. I hope it will inspire you to know more about JavaScript. For more on JavaScript, check out my blog flaviocopes.com. Note: You can get a PDF and ePub version of this JavaScript Beginner's Handbook
0 notes
Text
RT @v8js: 🚀 In Chrome 64 and Node.js v10, your JavaScript apps now continue execution while the @v8js garbage collector scans the heap to find and mark live objects! Free the main thread \o/ https://t.co/KbCZH9Epty https://t.co/ncDFxJr5el
🚀 In Chrome 64 and Node.js v10, your JavaScript apps now continue execution while the @v8js garbage collector scans the heap to find and mark live objects! Free the main thread \o/ https://t.co/KbCZH9Epty pic.twitter.com/ncDFxJr5el
— V8 (@v8js) June 11, 2018
nodejs
0 notes
Link
What Is Deno?

From the manual:
Deno is a JavaScript/TypeScript runtime with secure defaults and a great developer experience.
It's built on V8, Rust, and Tokio.
Deno is designed to be a replacement for our beloved Node.js, and it's led by Ryan Dahl, who started the Node.js project way back in 2009. The design stems from 10 things he regrets about Node.js.
So Deno aims to take on Node.js, which would be quite the moon shot if Ryan didn't lead it. So here's a couple of reasons to pay attention to Deno:
It's created by the person who started Node.js
It directly addresses shortcomings in Node.js
So it's off to a good start. But let's look at some of the technologies behind it and see if that matters.
What Powers Deno

So in the manual, it mentions V8, Rust, and Tokio. Not helpful if you don't know what those are.
V8 is Google's high-performance JavaScript (and now WebAssembly) engine. Node.js and Chrome use it now. It runs standalone, and it's rocket fast. The development on this engine has been very successful the last few years. Note: V8 compiles JavaScript into native machine code for ultra-fast performance. Here is some more great information about V8.
Rust is a systems programming language that's blazing fast. It has no runtime or garbage collector. Its primary focus is on performance and memory safety. Here are some other great things about Rust.
Tokio is asynchronous run-time for Rust. It's an event-driven platform for building fast, reliable, and lightweight network applications. It's also extremely fast and handles concurrency well.
So do you sense a pattern here? Deno is comprised of technologies that are fast, lightweight, and safe. We're off to a great start.
So Why Something New?

Well, JavaScript has changed a bit since 2009. Development, performance, and features have changed drastically in this amount of time, and Node.js has done it's best to keep up. Perhaps starting over fresh is a better approach.
According to Dahl, here are some design issues he's found with Node.js.
The module system and its distribution
Legacy APIs that must be supported
Security issues
Deno aims to address all of these.
If you've worked with Node.js for any amount of time, you know about NPM and its quirks. Personally, I think it's not too bad. It could certainly be improved. It uses a central repository model (npmjs.com), which has had its share of issues.
Deno modules can be hosted anywhere. Also, they're cached locally. You don't need to update them unless you want to. Pretty sweet.
Security in Deno is integrated. It has no access to file or network resources unless explicitly enabled. It dies on uncaught errors.
TypeScript is built-in - This is purely for developers. You can take full advantage of TypeScript for development and use all those fancy explicit types and other goodness from the language.
The Biggest Upside?

Deno promises performance and safety. That's a great benefit, but the most promise lies in the developer experience. It aims to make your life easier. Here's how:
You can use:
ES6
TypeScript
Remote repositories
Cool, those are great. But you can also:
Test with Deno - No scrambling to find random tools or argue about what's best, there's a test runner built into the core.
Format your Code - You can use "deno fmt" to format your files. This is one of the things I love about Go. Working in an opinionated environment has its downsides. It can also be a big time-saver for developers.
Debug - Deno has built-in Debugging so again, you don't have to go scouring the internet for the best debugger.
Compile and Bundle - I'm told this is still not complete, but it has a pretty decent bundler, and you can expect more improvements in the future.
These are all developer-focused improvements. While people will likely be raving about the speed and security, it's nice to know it won't be a massive headache for developers to create applications with Deno.
Oh, and it has a single executable to run. This is promising. Anyone who has fought dependencies and breaking changes knows the feeling of having a solid executable to run. You update it when you want, and don't have to fear what's going on with the dependencies at the time.
Final Word

Deno is going to shake things up. It's going to bring:
Performance
Security
Less developer pain
There's a lot of potential here. Deno also promises:
Adherence to web standards
Protection from deprecated APIs
TypeScript included
Built-in tooling
The future is bright for Deno, and I can't wait to dig in and build things with it. It looks very promising.
0 notes
Text
Introductory Go Programming Tutorial
by Jay Ts
How to get started with this useful new programming language.
You've probably heard of Go. Like any new programming language, it took a while to mature and stabilize to the point where it became useful for production applications. Nowadays, Go is a well established language that is used in web development, writing DevOps tools, network programming and databases. It was used to write Docker, Kubernetes, Terraform and Ethereum. Go is accelerating in popularity, with adoption increasing by 76% in 2017, and there now are Go user groups and Go conferences. Whether you want to add to your professional skills or are just interested in learning a new programming language, you should check it out.
Go History
A team of three programmers at Google created Go: Robert Griesemer, Rob Pike and Ken Thompson. The team decided to create Go because they were frustrated with C++ and Java, which through the years have become cumbersome and clumsy to work with. They wanted to bring enjoyment and productivity back to programming.
The three have impressive accomplishments. Griesemer worked on Google's ultra-fast V8 JavaScript engine used in the Chrome web browser, Node.js JavaScript runtime environment and elsewhere. Pike and Thompson were part of the original Bell Labs team that created UNIX, the C language and UNIX utilities, which led to the development of the GNU utilities and Linux. Thompson wrote the very first version of UNIX and created the B programming language, upon which C was based. Later, Thompson and Pike worked on the Plan 9 operating system team, and they also worked together to define the UTF-8 character encoding.
Why Go?
Go has the safety of static typing and garbage collection along with the speed of a compiled language. With other languages, "compiled" and "garbage collection" are associated with waiting around for the compiler to finish and then getting programs that run slowly. But Go has a lightning-fast compiler that makes compile times barely noticeable and a modern, ultra-efficient garbage collector. You get fast compile times along with fast programs. Go has concise syntax and grammar with few keywords, giving Go the simplicity and fun of dynamically typed interpreted languages like Python, Ruby and JavaScript.
The idea of Go's design is to have the best parts of many languages. At first, Go looks a lot like a hybrid of C and Pascal (both of which are successors to Algol 60), but looking closer, you will find ideas taken from many other languages as well.
Go is designed to be a simple compiled language that is easy to use, while allowing concisely written programs that run efficiently. Go lacks extraneous features, so it's easy to program fluently, without needing to refer to language documentation while programming. Programming in Go is fast, fun and productive.
Go to Full Article
http://bit.ly/2CISvqz via @johanlouwers . follow me also on twitter
0 notes
Photo

@nodejs : RT @v8js: 🚀 In Chrome 64 and Node.js v10, your JavaScript apps now continue execution while the @v8js garbage collector scans the heap to find and mark live objects! Free the main thread \o/ https://t.co/KbCZH9Epty https://t.co/ncDFxJr5el
0 notes
Text
WMS is Looking for a Las Vegas Software Developer
Are you a software developer looking for a position with a fantastic Las Vegas company? Contact Website Management Systems today! We are looking for a talented developer to add to our team. Are you the right candidate? Arrange an interview to meet with us to show us what you bring to the table.
We will consider any of the following languages and more: C, C++, D, Go, Rust, Python 2.x, Python 3.x, Perl, PHP, Ruby, C#, Bourne Shell, bash, zsh, csh, ECMAScript/JavaScript, Various SQL flavors: MySQL, Microsoft, Oracle, or any other language you are proficient with!
The main consideration for this program isn’t that you are an expert in the programming languages we use. Instead, this position demands that applicants can demonstrate proficiency in multiple languages and that you have experience in the technologies we use.
If you are familiar with the following technologies, we’d love to meet with you:
· Basic understanding of HTTP
· Passing familiarity with TCP
· Proficient in the operation and principles behind a DVCS like Mercurial or Git
· Advanced proficiency in the operation of a GNU/Linux operating system
· Know how to use a debugger
· Know what MVC is and when to use it
· Know what am O/RM is and when to use it
· Passing familiarity with asymmetric encryption principles
· Proficient understanding of HTML and CSS
· Basic proficiency in administration of MySQL server
While not required, it is helpful if you have experience with or knowledge of Apache administration, writing your own HTTP server, Windows Server administration, LDAP server administration, Linux MD RAID operation, PHP versions 5.2 and/or 5.4, debugging with XDebug, and debugging applications in node.js. It is also helpful if you know what a garbage collector is, what functional programming is (and what pure means), and what Object Oriented Programming is.
This is a full-time position with an established company. We are looking for good people, and references are a must! If you are the right candidate you will be able to start immediately, and please, no outsourcing. The salary is DOE, plus benefits.
If you would like to set up an interview, send us your work samples, salary requirements, and resume. Our beautiful offices are located in the Summerlin area near Charleston and Tenaya. Visit us at 7241 West Charleston Blvd, Las Vegas, Nevada 89117.
Call us at 702-720-1065 or send us an e-mail at [email protected]!
#WMS#Website Management Systems#WMS Las Vegas#Website Management Systems Las Vegas#7241 West Charleston Blvd Las Vegas#7241 w charleston blvd las vegas#las vegas marketing company#Las Vegas jobs#7241 W Charleston#West Charleston#W Charleston Blvd#West Charleston Blvd#West Charleston Las Vegas#W Charleston Blvd Las Vegas#West Charleston Blvd Las Vegas#West Charleston 89117#W Charleston Blvd 89117#West Charleston Blvd 89117#West Charleston Las Vegas 89117#W Charleston Blvd Las Vegas 89117#West Charleston Blvd Las Vegas 89117#West Charleston Las Vegas Nevada#W Charleston Blvd Las Vegas Nevada#West Charleston Blvd Las Vegas Nevada#West Charleston Las Vegas NV#W Charleston Blvd Las Vegas NV#West Charleston Blvd Las Vegas NV
0 notes
Text
The Future of Microservices Monitoring & Instrumentation
Monitoring gives us observability in our system and helps us to discover, understand, and address issues to minimize their impact on the business. It’s clear then, why you should aim for the best solutions out there; especially when you build a microservices architecture that has brought up new challenges in regards to observability.
The future of microservices monitoring depends on what kind of solutions become standardized in the industry and what new features will we see in the future that will make your applications much better. In this article I theorize what are these new monitoring features and what can we expect in 2018.
Microservices Monitoring and Instrumentation
To collect and analyze monitoring data, first, you need to extract metrics from your system - like the Memory usage of a particular application instance. The type of monitoring that provides details about the internal state of your application is called white-box monitoring, and the metrics extraction process is called instrumentation.
Current APM (Application Performance Monitoring) solutions on the market like NewRelic and Dynatrace rely heavily on different levels of instrumentations, this is why you have to install vendor specific agents to collect metrics into these products.
Agents can instrument your application at various places. They can extract low-level language specific metrics like Garbage Collector behavior or library specific things like RPC and database latencies as well.
Keep in mind that instrumentations can be very specific and usually need expertise and development time. As instrumentations are part of the running code, a bad instrumentation can introduce bugs into your system or generate an unreasonable performance overhead.
Instrumenting your system can also produce extra lines of code and bloat your application's codebase.
The Agent World of APM Vendors
We discussed earlier that current APM solutions provide agents to instrument our application and collect metrics. Creating and maintaining these agents need a lot of effort from the APM vendors side as they have to support multiple versions of languages and libraries that their customers use.
They need to continuously run tests against these different versions and benchmark their performance overhead to ensure that they won’t introduce any bug into the instrumented application.
If you check out collector agents from multiple APM vendors, you will realize that they are very similar from an implementation point of view. These companies put a tremendous amount of work to create the best agent for their customers while they reimplement the same thing and maintain their agent separately.
Having vendor specific agents can also lead to a situation when developers start to use multiple monitoring solutions and agents together as they miss some features from their current APM solution. Multiple agents usually mean multiple instrumentations on the same code piece, which can lead to an unnecessary performance overhead, false metrics or even bugs.
I think that the trend of using vendor-specific agents will change in the future and APM providers will join their efforts to create an open standard for instrumenting code. The future could lead to an era where agents are vendor-neutral, and all values will come from different backend and UI features.
Containers and Microservices Change the Game
Latest technology and architecture trends like containerization and microservices changed the way we write and run our applications.
The new era of these highly dynamic distributed systems brought new challenges to the art of observability. To monitor and debug these architectures, we need a new set of tools that are capable of storing and querying a large amount of multidimensional metrics series from different services and are also able to discover issues in microservices.
One of the new debugging methodologies is distributed tracing. It propagates transactions from distributed services and gains information from cross-process communication. To be able to track operations between applications, our instrumentation needs to share contextual information (like transaction ID’s) between processes in a standardized way. For example, when we create an RPC request to another service, it should share certain tracing information in meta headers to enable reverse engineering the transaction later.
With this kind of context sharing on the instrumentation level we can follow a request across the whole system; from the client through the underlying backend systems, network components, and databases. This kind of observability makes debugging in distributed systems, such as microservices, much easier. However, the popularity of microservices architectures is growing rapidly, distributed tracing is still in its early ages. Enterprise companies just started to evaluate the technology and discover its capabilities. We can expect an increasing amount of distributed tracing solutions in 2018 by early adopter companies.
Distributed tracing visualized
New Instrumentation Standards: OpenTracing
In the previous sections, we discussed that an optimal instrumentation should have a vendor-neutral standardized interface with cross-process context sharing capabilities and only a minimal performance impact.
This is the challenge that OpenTracing wants to address with providing a standard, vendor-neutral interface for distributed tracing instrumentations. OpenTracing provides a standard API to instrument your code and connects it with different tracing backends. It also makes it possible to instrument your code once and change the Tracing backend without trouble anytime.
Check out the following code snippet to understand OpenTracing’s approach to standardized instrumentation:
const server = http.createServer((req, res) => { const requestSpan = tracer.startSpan('http_request', { childOf: tracer.extract(FORMAT_HTTP_HEADERS, req.headers) }) const headers = {} metricsTracer.inject(requestSpan, FORMAT_HTTP_HEADERS, headers) requestSpan.setTag(Tags.HTTP_URL, req.url) requestSpan.setTag(Tags.HTTP_METHOD, req.method || 'GET') requestSpan.setTag(Tags.HTTP_STATUS_CODE, 200) requestSpan.setTag(Tags.SPAN_KIND_RPC_CLIENT, true) const childOperationSpan = tracer.startSpan('my_operation', { childOf: requestSpan }) childOperationSpan.finish() res.writeHead(200, headers) res.end('Ok') requestSpan.finish() })
OpenTracing example in Node.js
Node.js OpenTracing Instrumentation
In certain languages, such as Node.js, it’s also possible to do the instrumentation automatically via the OpenTracing API. In this case, you only need to specify which backends you want to use to collect metrics. The helper library will instrument your code and call the standard Tracer API for the necessary events, for example when an HTTP request or database call happens.
The following code demonstrates how you can use multiple OpenTracing compatible Tracer backends with automatic instrumentation:
const Instrument = require('@risingstack/opentracing-auto') const Tracer1 = require('tracer-1') const Tracer1 = require('tracer-2') const tracer1 = new Tracer1() const tracer2 = new Tracer2() const instrument = new Instrument({ tracers: [tracer1, tracer2] })
Using multiple OpenTracing Tracers with automatic instrumentation via opentracing-auto
As you can see, OpenTracing is a great first step to standardize instrumentation, but it requires a wider adoption to turn into the go-to monitoring solution. As it’s part of the Cloud Native Computing Foundation, we can expect some changes regarding its popularity in the upcoming months.
The future of standardized instrumentation also means that maintainers of open-source libraries and service providers can ship their solutions with built-in instrumentation. As they know the best how their libraries work and they have ownership of their internal behavior, this would be the optimal and the most risk-free solution.
I expect more and more standardized solutions for instrumentation in the future, and I hope one day all of the APM providers will work together to provide the best vendor-neutral agent. In this scenario, they will compete in who can provide the most insight and value on their backend and UI.
The One Microservices Instrumentation
OpenTracing is born to provide a vendor-neutral standard instrumentation for distributed tracing solutions, but it doesn’t mean that we cannot extract other kinds of information, like time-series metrics or error logs from it.
For example, by writing an OpenTracing compatible Tracer that calculates operation durations, we can measure request latency, throughput, and dependencies that can be consumed by monitoring solutions, like Prometheus. By collecting spans (events) with error flags to Elasticsearch or a similar storage, we can have an error tracker with only one instrumentation and multiple Tracer backends. In this way, we don’t have to double instrument our code per use-cases and deal with the performance overhead.
As OpenTracing also provides context about cross-process communications, we can use it to measure distributed operations in our system. For example, we can detect the throughput between two services, and we can also differentiate the metrics of traffic that comes from various sources.
Check out the following request throughout the metrics exported by OpenTracing to Prometheus. It contains the initiator parent_service label which we could determinate by the cross-process context sharing. The unknown value means that the source is not instrumented (in our case it’s the Prometheus scraper job that calls our service GET /metrics endpoint every 5 seconds):
Element Value {parent_service="my-server-1",service="my-server-3"} 10296 {parent_service="my-server-1",service="my-server-2"} 11166 {parent_service="unknown",service="my-server-1"} 10937 {parent_service="unknown",service="my-server-2"} 12 {parent_service="unknown",service="my-server-3"}
Throughput between specific services in an example microservices
Throughput between services*
Infrastructure topology visualization is a useful feature of APM solutions as we can see the system as a whole with all the dependencies. It makes easier to understand correlations during incidents and understand service boundaries.
With the special OpenTracing Metrics Tracer we extract the data about the initiator of a specific RPC call. Then, we can reverse engineer the whole infrastructure topology based on this information and visualize the dependencies between services. From these metrics, we can also gain information about throughput and latencies between applications and databases in our microservices architecture.
Check out the following image where we use Netflix’s vizceral engine to visualize a network topology:
Infrastructure topology reverse engineered from cross-process metrics
If you would like to learn more about how to extract infrastructure topology from your OpenTracing instrumentation, check out the http://ift.tt/2y8NKXf project.
Summary and Future of Instrumentation
To put microservices monitoring and observability to a next level and bring the era of the next APM tools, an open, vendor-neutral instrumentation standard would be needed like OpenTracing. This new standard needs to be applied by APM vendors, service providers, and open-source library maintainers as well.
Today you can use OpenTracing to collect different kind of metrics from your applications as it provides a flexible interface to use custom Tracer implementations through a standardized instrumentation API.
Key Takeaways
Vendor-specific agents are not optimal from an instrumentation point of view
A new open standard instrumentation would be needed
New architectures like microservices require new tools like distributed tracing
New tools like distributed tracing requires new kind of instrumentations
OpenTracing can be used beyond distributed tracing, we can also extract metrics from it
The Future of Microservices Monitoring & Instrumentation published first on http://ift.tt/2w7iA1y
0 notes
Text
The Future of Microservices Monitoring & Instrumentation

Monitoring gives us observability in our system and helps us to discover, understand, and address issues to minimize their impact on the business. It’s clear then, why you should aim for the best solutions out there; especially when you build a microservices architecture that has brought up new challenges in regards to observability.
The future of microservices monitoring depends on what kind of solutions become standardized in the industry and what new features will we see in the future that will make your applications much better. In this article I theorize what are these new monitoring features and what can we expect in 2018.
Microservices Monitoring and Instrumentation
To collect and analyze monitoring data, first, you need to extract metrics from your system - like the Memory usage of a particular application instance. The type of monitoring that provides details about the internal state of your application is called white-box monitoring, and the metrics extraction process is called instrumentation.
Current APM (Application Performance Monitoring) solutions on the market like NewRelic and Dynatrace rely heavily on different levels of instrumentations, this is why you have to install vendor specific agents to collect metrics into these products.
Agents can instrument your application at various places. They can extract low-level language specific metrics like Garbage Collector behavior or library specific things like RPC and database latencies as well.
Keep in mind that instrumentations can be very specific and usually need expertise and development time. As instrumentations are part of the running code, a bad instrumentation can introduce bugs into your system or generate an unreasonable performance overhead.
Instrumenting your system can also produce extra lines of code and bloat your application's codebase.
The Agent World of APM Vendors
We discussed earlier that current APM solutions provide agents to instrument our application and collect metrics. Creating and maintaining these agents need a lot of effort from the APM vendors side as they have to support multiple versions of languages and libraries that their customers use.
They need to continuously run tests against these different versions and benchmark their performance overhead to ensure that they won’t introduce any bug into the instrumented application.
If you check out collector agents from multiple APM vendors, you will realize that they are very similar from an implementation point of view. These companies put a tremendous amount of work to create the best agent for their customers while they reimplement the same thing and maintain their agent separately.
Having vendor specific agents can also lead to a situation when developers start to use multiple monitoring solutions and agents together as they miss some features from their current APM solution. Multiple agents usually mean multiple instrumentations on the same code piece, which can lead to an unnecessary performance overhead, false metrics or even bugs.
I think that the trend of using vendor-specific agents will change in the future and APM providers will join their efforts to create an open standard for instrumenting code. The future could lead to an era where agents are vendor-neutral, and all values will come from different backend and UI features.
Containers and Microservices Change the Game
Latest technology and architecture trends like containerization and microservices changed the way we write and run our applications.
The new era of these highly dynamic distributed systems brought new challenges to the art of observability. To monitor and debug these architectures, we need a new set of tools that are capable of storing and querying a large amount of multidimensional metrics series from different services and are also able to discover issues in microservices.
One of the new debugging methodologies is distributed tracing. It propagates transactions from distributed services and gains information from cross-process communication. To be able to track operations between applications, our instrumentation needs to share contextual information (like transaction ID’s) between processes in a standardized way. For example, when we create an RPC request to another service, it should share certain tracing information in meta headers to enable reverse engineering the transaction later.
With this kind of context sharing on the instrumentation level we can follow a request across the whole system; from the client through the underlying backend systems, network components, and databases. This kind of observability makes debugging in distributed systems, such as microservices, much easier. However, the popularity of microservices architectures is growing rapidly, distributed tracing is still in its early ages. Enterprise companies just started to evaluate the technology and discover its capabilities. We can expect an increasing amount of distributed tracing solutions in 2018 by early adopter companies.
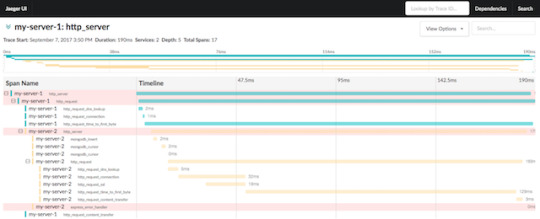
Distributed tracing visualized
New Instrumentation Standards: OpenTracing
In the previous sections, we discussed that an optimal instrumentation should have a vendor-neutral standardized interface with cross-process context sharing capabilities and only a minimal performance impact.
This is the challenge that OpenTracing wants to address with providing a standard, vendor-neutral interface for distributed tracing instrumentations. OpenTracing provides a standard API to instrument your code and connects it with different tracing backends. It also makes it possible to instrument your code once and change the Tracing backend without trouble anytime.
Check out the following code snippet to understand OpenTracing’s approach to standardized instrumentation:
const server = http.createServer((req, res) => { const requestSpan = tracer.startSpan('http_request', { childOf: tracer.extract(FORMAT_HTTP_HEADERS, req.headers) }) const headers = {} metricsTracer.inject(requestSpan, FORMAT_HTTP_HEADERS, headers) requestSpan.setTag(Tags.HTTP_URL, req.url) requestSpan.setTag(Tags.HTTP_METHOD, req.method || 'GET') requestSpan.setTag(Tags.HTTP_STATUS_CODE, 200) requestSpan.setTag(Tags.SPAN_KIND_RPC_CLIENT, true) const childOperationSpan = tracer.startSpan('my_operation', { childOf: requestSpan }) childOperationSpan.finish() res.writeHead(200, headers) res.end('Ok') requestSpan.finish() })
OpenTracing example in Node.js
Node.js OpenTracing Instrumentation
In certain languages, such as Node.js, it’s also possible to do the instrumentation automatically via the OpenTracing API. In this case, you only need to specify which backends you want to use to collect metrics. The helper library will instrument your code and call the standard Tracer API for the necessary events, for example when an HTTP request or database call happens.
The following code demonstrates how you can use multiple OpenTracing compatible Tracer backends with automatic instrumentation:
const Instrument = require('@risingstack/opentracing-auto') const Tracer1 = require('tracer-1') const Tracer1 = require('tracer-2') const tracer1 = new Tracer1() const tracer2 = new Tracer2() const instrument = new Instrument({ tracers: [tracer1, tracer2] })
Using multiple OpenTracing Tracers with automatic instrumentation via opentracing-auto
As you can see, OpenTracing is a great first step to standardize instrumentation, but it requires a wider adoption to turn into the go-to monitoring solution. As it’s part of the Cloud Native Computing Foundation, we can expect some changes regarding its popularity in the upcoming months.
The future of standardized instrumentation also means that maintainers of open-source libraries and service providers can ship their solutions with built-in instrumentation. As they know the best how their libraries work and they have ownership of their internal behavior, this would be the optimal and the most risk-free solution.
I expect more and more standardized solutions for instrumentation in the future, and I hope one day all of the APM providers will work together to provide the best vendor-neutral agent. In this scenario, they will compete in who can provide the most insight and value on their backend and UI.
The One Microservices Instrumentation
OpenTracing is born to provide a vendor-neutral standard instrumentation for distributed tracing solutions, but it doesn’t mean that we cannot extract other kinds of information, like time-series metrics or error logs from it.
For example, by writing an OpenTracing compatible Tracer that calculates operation durations, we can measure request latency, throughput, and dependencies that can be consumed by monitoring solutions, like Prometheus. By collecting spans (events) with error flags to Elasticsearch or a similar storage, we can have an error tracker with only one instrumentation and multiple Tracer backends. In this way, we don’t have to double instrument our code per use-cases and deal with the performance overhead.
As OpenTracing also provides context about cross-process communications, we can use it to measure distributed operations in our system. For example, we can detect the throughput between two services, and we can also differentiate the metrics of traffic that comes from various sources.
Check out the following request throughout the metrics exported by OpenTracing to Prometheus. It contains the initiator parent_service label which we could determinate by the cross-process context sharing. The unknown value means that the source is not instrumented (in our case it’s the Prometheus scraper job that calls our service GET /metrics endpoint every 5 seconds):
Element Value {parent_service="my-server-1",service="my-server-3"} 10296 {parent_service="my-server-1",service="my-server-2"} 11166 {parent_service="unknown",service="my-server-1"} 10937 {parent_service="unknown",service="my-server-2"} 12 {parent_service="unknown",service="my-server-3"}
Throughput between specific services in an example microservices

Throughput between services*
Infrastructure topology visualization is a useful feature of APM solutions as we can see the system as a whole with all the dependencies. It makes easier to understand correlations during incidents and understand service boundaries.
With the special OpenTracing Metrics Tracer we extract the data about the initiator of a specific RPC call. Then, we can reverse engineer the whole infrastructure topology based on this information and visualize the dependencies between services. From these metrics, we can also gain information about throughput and latencies between applications and databases in our microservices architecture.
Check out the following image where we use Netflix’s vizceral engine to visualize a network topology:

Infrastructure topology reverse engineered from cross-process metrics
If you would like to learn more about how to extract infrastructure topology from your OpenTracing instrumentation, check out the http://ift.tt/2y8NKXf project.
Summary and Future of Instrumentation
To put microservices monitoring and observability to a next level and bring the era of the next APM tools, an open, vendor-neutral instrumentation standard would be needed like OpenTracing. This new standard needs to be applied by APM vendors, service providers, and open-source library maintainers as well.
Today you can use OpenTracing to collect different kind of metrics from your applications as it provides a flexible interface to use custom Tracer implementations through a standardized instrumentation API.
Key Takeaways
Vendor-specific agents are not optimal from an instrumentation point of view
A new open standard instrumentation would be needed
New architectures like microservices require new tools like distributed tracing
New tools like distributed tracing requires new kind of instrumentations
OpenTracing can be used beyond distributed tracing, we can also extract metrics from it
The Future of Microservices Monitoring & Instrumentation published first on http://ift.tt/2fA8nUr
0 notes
Text
Progress#6 : Membuat API : Task List, menerapkan agile principles dan agile manifesto
Halo para developer,
kali ini saya akan menjelaskan apa yang telah saya kerjakan pada 2 minggu terakhir.
1. Membuat API : Task List
API task list adalah API yang digunakan untuk mengambil list tasks untuk diberikan pada courier
/GET tasks
Jika sukses akan mengembalikan list tasks

Potongan unit-test yang telah diambil

code coverage

PART A
1. Refactoring
https://www.csie.ntu.edu.tw/~r95004/Refactoring_improving_the_design_of_existing_code.pdf
https://refactoring.com/catalog/
Berdasarkan referensi, ada 2 definisi refactoring, based on verb and based on noun
Refactor (verb): to restructure software by applying a series of refactorings without changing its observable behavior.
Refactoring (noun): a change made to the internal structure of software to make it easier to understand and cheaper to modify without changing its observable behavior.
Implementasi
(Add Parameter)
https://gitlab.com/PPL2017csui/PPLB1/commit/e0487c65b4015693a2329bb555c58bc5c03f025e
(Don’t repeat yourself & Simplifying Conditional Expressions ) : https://gitlab.com/PPL2017csui/PPLB1/commit/278cab0ed6ee6148cede9a351c67c2953eaaa1fe?view=parallel
(Remove Parameter) :
https://gitlab.com/PPL2017csui/PPLB1/commit/dd6a604ec1515bf2df9ec2331d8a3617f16b1983
6. Agile manifesto
Agile Manifesto adalah sebuah metode alternatif dari pengembangan software yang memiliki 4 nilai utama:
http://agilemanifesto.org/
1. Individuals and interactions over processes and tools
Kelompok kami selalu memprioritaskan interaksi antar individu dan menghargai pendapat antar sesama dibanding hanya mengedepankan processes yang berjalan dan tools yang canggih.
2. Working software over comprehensive documentation
Kelompok kami memprioritaskan bekerja dan berfungsinya software dibanding dokumentasi yang sangat komprehensif. Tidak akan berguna dokumentasi baik, akan tetapi software berjalan tidak baik.
3. Customer collaborations over contract negotiation
Kami berkolaborasi dengan partner kami, yaitu cermati dengan cara menerima setiap input dari mereka, memberikan update pada mereka, meminta pendapat mengenai solusi efisien dari suatu permasalahan, dsb. Kolaborasi ini kami utamakan dibanding hanya sebuah kontrak dengan mereka yang menyatakan hubungan antar kita dengan partner hanya sebatas mereka minta kami kerjakan.
4. Responding to change over following a plan
Kelompok kami lebih mengutamakan perubahan signifikan yang lebih baik dibanding strict mengikuti rencana awal. Contohnya kami pernah melakukan alter database untuk mengubah beberapa atribut dari suatu tabel karena setelah berdiskusi dengan tim mobile (PPLB2), kami menemukan suatu hal yang dapat mengoptimasi penggunaan API.
7. Penerapan agile principle
Agile principles yang berdasarkan Agile Manifesto
https://www.agilealliance.org/agile101/12-principles-behind-the-agile-manifesto/
1. Our highest priority is to satisfy the customer through early and continous delivery
Prioritas kami untuk menyelesaikan software yang baik dan benar sampai partner kami puas dengan hasil software kami. Hal ini dilakukan secara continous dengan cara kami delivery fitur demi fitur agar setiap fitur yang ada telah sesuai dengan kriteria yang dibutuhkan.
2. Welcome changing requirements, even late in development. Agile processes harness change for the customer’s competitive advantage.
Kami menerima setiap perubahan requirements, walaupun sudah late in developmet, selama perubahan yang di-propose dapat meningkatkan competitive advantage partner kami. Hal ini terlihat dari ada beberapa user story tambahan seperti add multiple documents at once dan add tasks using json and API untuk kemudahan admin pengurus sistem.
3. Deliver working software frequently, from a couple of weeks to a couple of months, with a preference to the shorter timescale.
Kami terus deliver software kami melalui user story yang telah diselesaikan setiap individual review maupun sprint review secara berkala.
4. Business people and developers must work together daily throughout the project.
Kami selalu bekerja sama dengan product manager cermati untuk kolaborasi mengembangkan software ini dari perspektif bisnis dan teknis.
5. Build projects around motivated individuals. Give them the environment and support they need, and trust them to get the job done.
Kami membuat software ini secara berkelompok. Kelompok kami selalu bekerja sama dan saling membantu untuk menyelesaikan pekerjaan mereka. Kami sering berkumpul di kontrakan Akbar dan ngoding bersama untuk meningkatkan produktivitas.
6. The most efficient and effective method of conveying information to and within a development team is face-to-face conversation.
Kami pergi ke kantor Cermati di ruko dekat mall taman anggrek untuk menanyakan semua kebutuhan requirements yang masih tidak jelas sekaligus mereka memberikan pengetahuan node js mereka kepada kami.
7. Working software is the primary measure of progress.
Kami mengukur progress kami dari bekerjanya software yang kami kembangkan, dapat dilihat pada tiap kali sprint review.
8. Agile processes promote sustainable development. The sponsors, developers, and users should be able to maintain a constant pace indefinitely.
Dalam proses pengembangan, agar sustainable, pengembangan harus melihat secara berkelanjutan supaya setiap stakeholder software kami dapat maintain pace yang sama.
9. Continuous attention to technical excellence and good design enhances agility.
Kami selalu review sebelum menerima merge request dari branch user story ke branch develop supaya setiap kode yang di-merge telah didesain dengan baik dan benar.
10. Simplicity–the art of maximizing the amount of work not done–is essential.
Kami selalu melakukan refactoring agar kode-kode dapat reusable, simpel dan bebas redudansi.
11. The best architectures, requirements, and designs emerge from self-organizing teams.
Kami selalu bekerja sama dan mengevaluasi antar sesama pada proses pengembangan software.
12. At regular intervals, the team reflects on how to become more effective, then tunes and adjusts its behavior accordingly.
Pada momen sprint retrospective, kami selalu introspeksi diri dan orang lain dalam kelompok demi kemajuan pengembangan software secara baik. Introspeksi dilakukan dengan cara mengutarakan kelebihan dan kekurangan tim.
3. Error code and handling
Kami telah mendefine error code sebagai berikut

implementasi
pada terminal

12. Version control, git flow
git stash
Command ini berguna untuk menyimpan secara sementara pekerjaan yang telah kita kerjakan. Jika kita belum ingin commit, akan tetapi ingin ganti branch, supaya pekerjaan yang telah kita lakukan tidak hilang.
git pop
Command ini digunakan ketika ingin mengambil pekerjaan yang sudah kita stash sebelumnya. Jika sudah melakukan stash, maka lakukan command ini untuk mengambil yang sudah di stash.
git reset HEAD
Command ini digunakan untuk melakukan rollback terhadap commit. Command ini pernah saya gunakan ketika saya mau membatalkan git commit yang telah saya jalankan.
git log
Command ini memberikan daftar commit pada branch tertentu dengan detil dari commit tersebut. Command ini berguna untuk mengetahui list commit apa saja yang sudah dilakukan ketika kita ingin mengetahui dengan cepat dan detil siapa yang terakhir kali commit.
git gc
Command ini berguna mengaktifkan garbage collector pada repository, untuk membuang segala macam index-index yang sudah tidak terpakai supaya repository bersih.
13. Stress and penetration test
Kelompok kami telah mengakses website secara bersama-sama, pada halaman view task dan view courier. Hasilnya ternyata tergolong lambat.
Mencoba SQL injection pada login page sistem. Juga mencoba XSS pada form create task untuk cek apakah bisa disisipkan javascript dari luar sistem. Keduanya hasilnya sudah aman.
18. Development Framework
Komunitas dari expressJS paling berkembang dan memungkinan kita untuk mendapatkan informasi seputar pengembangan dari expressJS

24. Self Study
REST API node.js
REST memiliki kepanjangan REpresentational State Transfer. REST architecture adalah sebuah web standards yang menggunakan protokol http.
Verb HTTP yang paling sering digunakan adalah GET, POST.
RESTful web services adalah kumpulan open protocols dan standards yang digunakan untuk exchanging data antar aplikasi maupun sistem.
REST API pada node.js sebagai berikut

25. Self Study
express.js
Kami mengembangkan sistem web application ini menggunakan platform node.js dengan framework express.js. Untuk memudahkan dalam membangun struktur direktori, saya menggunakan express generator. Untuk menjalankan express generator, install terlebih dahulu dengan gunakan perintah:

Lalu jalankan perintah ini:

Maka akan terbuat directory awal dengan perubahan seperti ini:

Berikut konfigurasi aplikasi yang akan kita kembangkan:

Dan berikut konfigurasi server

PART D
2. Configure Code Coverage Tool
Kami menggunakan code coverage tool istanbul nyc. Code coverage telah secara otomatis berjalan ketika memasukkan perintah ‘npm test’, dan akan terlihat hasil dari code coveragenya.
Menjalankan code coverage

Hasil dari code coverage

3. Issue in Gitlab.
Bug tracking : open issue ketika ada bug atau error saat merge request, dengan adanya issue ini, kami jadi lebih aware terhadap masalah yang timbul dari code yang telah kami buat, serta issue yang kami buat tidak hanya masalah code, melainkan juga issue database pada staging yang perlu diperbaiki
https://gitlab.com/PPL2017csui/PPLB1/issues/50
https://gitlab.com/PPL2017csui/PPLB1/issues/56
4. Define Project Error Code
Kelompok kami telah men-define error code sebagai berikut

5. Software enviroment, platform selection
Heroku digunakan sebagai platform untuk hosting code yang kita buat ke cloud, sehingga product owner dapat melihat progress kami, Heroku sendiri tidak seperti hosting pada umumnya, heroku memiliki system GIT, dimana jika kita ingin upload diperlukan push ke Heroku dengan command misalnya ingin push ke master
git push heroku master
Diheroku juga kita dapat memilih bahasa/platform yang kita inginkan dalam hal tim kami, kita memilih node js sebagi webserver
Gitlab kami menggunakan gitlab sebagi hub untuk version control yang kami gunakan yakni git. Kami mengupload source code serta melakukan review terhadap code yang dibuat oleh tim kami
8. Product Packaging & Installer
Kami mengguanakan NPM (node package manager) untuk menginstall semua depedencies atau module yang kami gunakan dalam webapp yang kami buat
10. Scrum as framework for development team work
Kami sudah mengimplementasikan scrum sebagai framework dalam kerja tim, dengan cara menggunakan pivotal tracker sebagai tools dan mengadakan scrum daily meeting duakali dalam seminggu, Sprint planning yang dipimpin scrum master tiap bulan dalam menentukan task yang akan dikerjakan untuk satu sprint, scrum retrospective yang dipimpin juga oleh scrum masteruntuk mengevaluasi hasil kerja serta menilai teman sekelompok.
Dari Scrum ini kami memiliki proses development yang terarah dan sebagai tools untuk mengetahui progress serta memberikan evaluasi/review teman se-Tim
11. Role management, Authentication and Authorization
Role management : Sementara ini hanya ada admin dan super admin Authentication : Memverifikasi apakah orang yang ingin masuk kedalam sistem merupakan orang yg sudah dikenali (terdapat dalam database) dan memiliki izin untuk masuk kedalam sistem (account tersebut tidak di banned). Authorization : otoritas atau dengan kata lain merupakan fitur fitur apa saja yang dapat dipakai oleh suatu role. Contoh superadmin dapat membuka page create user sedangkan admin tida bisa membukanya.
Hal ini sangatlah penting dalam aspek security agar tidak sembarang orang dpt mengakses maupun edit data dari system. Authorization diberikan karena ada tujuan tertentu, misal superadmin dapat semua hal, sedangkan admin biasa hanya memiliki akses ke beberapa fitur saja, mungkin jika ada role data scientist, hanya bisa melihat fitur statistic saja
12. Additional Branching
Kami menerapkan brach hotfix jika ada userstory yang perlu direvisi berdasarkan evaluasi pada sprint review
0 notes
Photo

This week's JavaScript news, issue 322
This week's JavaScript news — Read this e-mail on the Web
JavaScript Weekly
Issue 322 — February 16, 2017
JavaScript's Journey Through 2016
The team at Telerik looks back at their predictions for JavaScript in 2016 and then ahead at what we might expect for the language in 2017.
Tara Manicsic
JavaScript Without Loops
If you find yourself reaching for while or for, think again - maybe map, reduce, filter, or find could result in more elegant, less complex code.
James Sinclair
An Update on ES6 Modules in Node.js
James, who wrote a great post on work on modules at TC-39, returns with an update on how things are progressing.
James M Snell
New Course: Make back-end developers jealous, with Elm 😉
Write bullet-proof, easily maintainable web applications with Elm, the functional programming language that is transforming web application development!
Frontend Masters Sponsor
One Small Step for Chrome, One Giant Heap for V8
Recent improvements to V8’s garbage collector allow larger heap sizes, and the latest Chrome Canary uses to this your advantage when debugging JavaScript memory leaks.
Michael Hablich
Interactive ES6 Feature Examples
Simple, live and editable ES6/ES2015 examples covering things from arrow functions and iterators to maps and proxies.
Rasmus Prentow
Managing State in Angular Applications
Covers six types of state, typical mistakes made managing them in Angular apps, and the patterns you should use instead.
Victor Savkin
Jobs
Senior Frontend Engineer - Angular/Node (London, UK)Ready for your next challenge? Join our rapidly expanding team in London and help define the future of a industry-leading Angular (2+) app. Avocet.io
Software Engineer, Web - Zürich, SwitzerlandCentralway is seeking an experienced programmer to come and join the team. The right candidate will be responsible for building and maintaining high performance web applications with cutting-edge technologies. Centralway Numbrs
Can't find the right job? Want companies to apply to you? Try Hired.com.
In Brief
Babel 6.23.0 Released news Improvements to react-constant-elements, codegen optimizations, and bug fixes. Babel
IBM #WatsonCodeChallenge news Compete against the best and test your coding skills during the IBM #WatsonCodeChallenge. Hurry, the contest ends Feb. 20th. IBM Watson Sponsor
Naive Infinite Scroll in Reactive Programming using RxJS Observables tutorial Ashwin Sureshkumar
Making Your Angular Apps Fast tutorial Packed with helpful tips to speed up your Angular apps. Pascal Precht
Writing JavaScript with Accessibility in Mind tutorial Manuel Matuzovic
Vue.js's Single File Components: Keeping It All In One Place tutorial Joe Zimmerman
Build, Test and Deploy Your Vue.js App Easily with GitLab tutorial Simon Tarchichi
Is Your Ember App Too Big? Split It Up with Ember Engines tutorial Todd Gandee
Native ECMAScript Modules: Dynamic import() tutorial Serg Hospodarets
A Comprehensive Look at jQuery DOM Traversal tutorial SitePoint
Dissecting Twitter’s Redux Store tutorial Ryan Johnson
Pusher Realtime Reddit API Pusher built a simple tool that lets you subscribe to realtime updates from any public subreddit. Pusher Sponsor
How to Profile and Optimize Your Angular 2 Apps video Programming with Mosh
The Evolution Of Asynchronous JavaScript video Alessandro Cinelli outlines how dealing with asynchrony in JavaScript has evolved. 25 minutes. Sessions by Pusher
Sazerac: Data-Driven Testing for JavaScript tools Mike Calvanese
A Catalog of Over 140 Angular 2+ Components and Libraries tools
webpack-chain: A Chaining API to Simplify Webpack 2 Config Modification tools Eli Perelman
Typewriter.js: A Simple, Dependency-Free 'Typewriting' Effect code
fmt-obj: Prettifies Any JavaScript Object in Your Console code Fabian Eichenberger
opentype.js: A Parser and Writer for OpenType and TrueType Fonts code Frederik De Bleser
Curated by Peter Cooper and published by Cooperpress.
Like this? You may also enjoy: FrontEnd Focus : Node Weekly : React Status
Stop getting JavaScript Weekly : Change email address : Read this issue on the Web
© Cooperpress Ltd. Office 30, Lincoln Way, Louth, LN11 0LS, UK
by via JavaScript Weekly http://ift.tt/2kXPPh8
0 notes