#java'd script
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Women make up for the other 50% of Tumblr’s audience.
Text
You know what, I'll bother making this post. It's long overdue.
PSA: Please don't install uBlock Origin rules for Tumblr that use :nth-of-type(), and please remove or fix any you have installed. They can and will hide the wrong things. I'll show you a few alternatives below.
First, an example of how we get here. I've used the uBlock Origin element picker to try to hide the "Get a Domain" sidebar item:
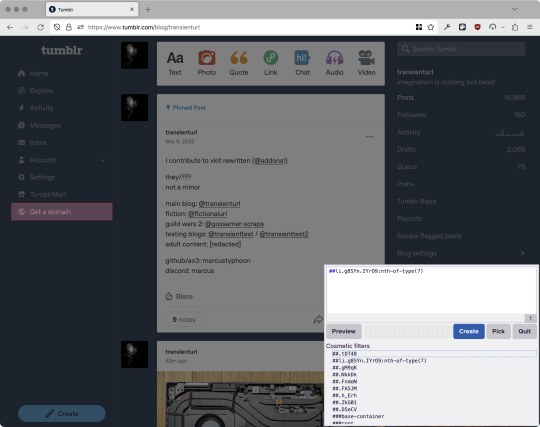
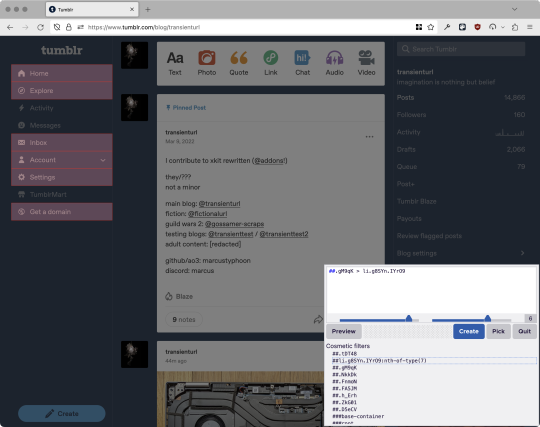
With some different adjustments of the sliders, it gave me these two snippets, one of which targeted a whole bunch of sidebar items, and the other of which selected the right one. Great, right? Read on.
www.tumblr.com##li.g8SYn.IYrO9:nth-of-type(7) www.tumblr.com##.gM9qK > li.g8SYn.IYrO9
As you can see, these both target a particular kind of sidebar item via "li.g8SYn.IYrO9"—fine—and as you can probably guess, the second one counts them all up and hides the seventh it finds.
This is bad, because what it actually hides depends on exactly how many sidebar items there are! Users can "snooze" Tumblr Live, which will make an item appear or disappear, and users with/without Ad-Free subscriptions will have or not have another. I have seen many, many people accidentally hide their activity, messages, inbox, etc using someone else's rule that's supposed to hide Live. Worse, some rules intended for e.g. recommended post carousels that use nth-of-type translate to something like "hide item number three on the dashboard no matter what it is," which will lead to a seemingly random post on your dashboard disappearing!
This isn't a problem specific to Tumblr, of course—I personally think uBlock Origin should never autogenerate these rules—but Tumblr has a ton of elements that aren't in fixed positions, so I feel comfortable wording that PSA the way I did. On a very static site, those rules might be fine. Here they almost always aren't.
So how do we fix this? First of all, as a developer of XKit Rewritten (check out @addons!), I must suggest you check if it has a feature to do what you want. Plenty of times it won't, though, and if not, we want to make a rule that hides an element based on what it is, not where it is. Here are three ways to make a robust rule:
First, I'll right-click the element I want and use the inspect element tool in my browser's developer tools to look at the element I really want (Firefox and Chrome/Edge/Opera have different but overall similar interfaces for this):
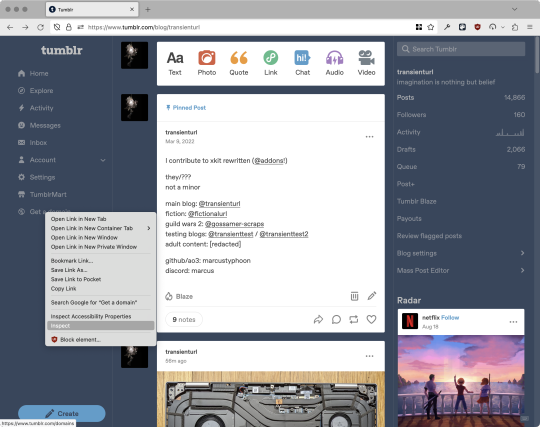
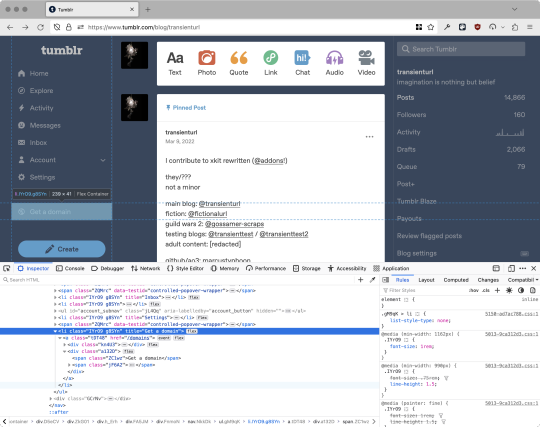
The HTML looks, for reference, like this (Tumblr sucks at code blocks but I'll try):
<li class="IYrO9 g8SYn" title="Get a domain"> <a class="tDT48" href="/domains"> <div class="kn4U3"> <svg> <use href="#managed-icon__earth"></use> </svg> </div> <div class="a132D"> <span class="ZC1wz">Get a domain</span> <!-- other unimportant stuff removed--> </div> </a> </li>
What's something unique about this element, preferably about the outermost element, and preferably contained within the <angle brackets> (HTML tags)? In this case, we have it easy: title="Get a domain" is definitely unambiguous and fulfills all of those three. If you're very familiar with web design using CSS, you'll know how to target that; if you've vaguely heard of CSS, you may be able to look at a reference sheet of CSS selectors, see [attribute=value], and figure it out, and if neither is true, I'll spoil it for you and say that we just put it in square brackets in this case.
So—taking the rule uBlock Origin made, removing the :nth-of-type() and replacing it with our better selector—here's our first working, bug-free uBlock Origin rule:
##li.g8SYn.IYrO9[title="Get a domain"]
Okay, great. But what if we didn't have that attribute to target? What if our top-level element looks the same as the other ones? What if we want this rule to work if we change our Tumblr language to Spanish? Let's move on to :has().
:has() is a CSS selector (supported in uBlock Origin even in browsers where you can't use it for web development yet, i.e. Firefox), that lets you check the contents of an element for whatever is in the parentheses. Let's assume that Tumblr would never make two sidebar items with the same icon, and target that href="#managed-icon__earth" property:
##li.g8SYn.IYrO9:has([href="#managed-icon__earth"])
Yep, that works too!
Finally, what if we couldn't use either of those because we need to target the content of the page that's not contained within the <angle brackets>? We can take a look at the uBlock Origin documentation and find that it has something for that too: :has-text(). You can do very powerful things with this (e.g. you can sort of implement Blacklist entirely using uBlock Origin using something like article:has-text), but it doesn't perform well and can pretty easily be used incorrectly, so I'd suggest you avoid it when possible.
However, let's try using it here to target the "Get a domain" label text:
##li.g8SYn.IYrO9:has-text(Get a domain)
And that also works!
With these techniques, you should be able to target any specific thing you'd want to hide without using any fragile positional selectors. If you're going to share your uBlock Origin rules with others, please make use of this! If you're just using your rules for yourself, then hopefully I've given you enough information so that you can understand what a rule does and decide for yourself if it's worth bothering to fix (menu item order might not change that often, so maybe you're fine with certain rules being a bit prone to breakage; if your rule hides the first post in your timeline you really do need to fix that one!)
-
And, of course, a note for you web developers out there: :has() isn't natively supported in Firefox quite yet, so you can't really use it (I would not recommend using JQuery's simulated version—it's not quite the same). And :has-text() is just not a thing for CSS at all. Just use javascript at that point! Edit: No longer true in 2024; style away!
Final note: any rule with a random 5-character string like g8SYn will eventually break when Tumblr rebuilds its CSS map, though they haven't done that in ages. But when they do: no, it's not "Tumblr devs breaking our rules because they hate us." (Yes, I hear that sentiment a lot in contexts when it almost always makes zero sense.) If you're fairly experienced with CSS you can sometimes make Stylus/uBlock Origin rules that don't reference any, but it's usually convoluted and more trouble than it's worth.
81 notes
·
View notes
Note
I see people questioning why "not working on a lot of posts" is a justifiable reason not to implement a feature. It's a logical question, but one with a number of good answers. I'm definitely not an expert—I've never worked in professional web and app dev—but I was the one who implemented about half (iirc) of the XKit Rewritten interactive UI for Trim Reblogs, so it's not like I have no idea.
Obviously the real reason you wouldn't work on this is because it would take a bunch of developer time to write and then, crucially, to test for bugs in the at least six different weird edge cases hinted at by the complex date range quoted in the original post (trust me, this part I know extremely well), and because Tumblr doesn't, last time we were made aware of its finances, even make enough money to pay its devs market rate to keep the site from blowing up and developing features that will get used more than a small percentage of the time. (Roleplayers are a valued part of the site, I think I can speak for the devs in saying, but I think you guys make up a very, very small portion of site revenue, and Money Can Be Exchanged For Features And Bugfixes). This applies to a lot of potential cool site features.
But there is also something to be said, specifically, about how difficult it is to responsibly implement a feature that doesn't necessarily work. For one, you have to write a failure UI that reflects both what failed and the current state after the failure, which often takes a ton more code than just having a success UI and a minimal error popup most users will never see.
Additionally—possibly the more difficult part—if you're officially blessing a feature, it's your responsibility to explain when and why it doesn't work and what its caveats are, and to keep that explanation comprehensible, up-to-date, and translated into all 18 UI languages Tumblr supports. Here's some of XKit Rewritten's explanation code:

(source)
That took us probably multiple hours, it's not fully comprehensive, and we only have it in English. Do you want to try to explain to an Indonesian translator what the hell any of this means? I, for one, do not.
XKit gets to shirk some of these responsibilities because there is an expectation that it's a user addon and it's therefore not for everyone and it won't always work or make sense to a non-veteran Tumblr user. Tumblr's official website and app cannot make these tradeoffs: a mysterious or ill-documented feature erodes user trust in the platform itself, and this userbase has quite the hair trigger for distrusting the platform itself on the tiniest provocation, take my goddamn word for it; I have years of receipts. (Now, I'm not saying there haven't been a fair number of Tumblr feature rollouts I have taken issue with the public messaging on—I have a long list of those too—but the point remains, and arguments that one invalidates the other are just not convincing if you think them fully through).
Was there any point to this post? I dunno. I guess hopefully it helps a few people see things a bit more from a "person that has to do the work if you want a feature" perspective. That seems like a valuable thing to try to cultivate!
Hi!
Are there any plans to improve how users can prune a reblog chain before reblogging it themselves?
Right now, we either have to remove all the additional posts, or find a reblog from before a particular part was added. That's tricky, and being able to just snip the rest of the chain off at more points would make life a lot easier.
Answer: Hey, @tartrazeen!
Good news! This is already supported in the API via the “exclude_trail_items” parameter when creating or editing a reblog. However, it only really works for posts stored in our Neue Post Format (NPF), which excludes all posts made before 2016 and many posts on web before August 2023. For that reason, we don’t expect this will ever be made a “real” feature that you can access in our official clients. It wouldn’t be too wise of us to design, build, and ship an interface for something we know won’t even work on the majority of posts.
If you don’t fancy doing this via the API yourself, there are other solutions to leverage this feature—namely, third-party browser extensions. For example, XKit Rewritten has something called “Trim Reblogs,” which allows you to do exactly what you ask… though with all the caveats about availability mentioned above.
Thanks for your question. We hope this helps!
113 notes
·
View notes
Text
whoa they're really doing it. wild.
(also interesting to see the faq post about why they picked golang, and all of its comments from c# programmers going, "really? but... you are microsoft employees... help...")
2 notes
·
View notes
Text
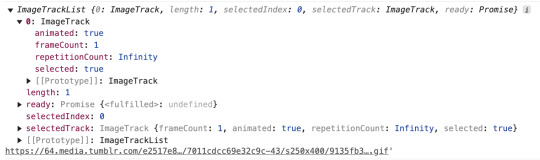
philosophical question: is an animation with a frame count of 1 animated?
#every time I say I'm done working on this animation pausing thing for now there's one more thing#java'd script
3 notes
·
View notes
Text
this is, obviously, the kind of thing you ideally never use, and thus probably shouldn't really know?
however: I finally bothered to figure out how to use git rebase --onto to sync changes between multiple git branches that depend on one another.
normally, one runs git rebase [new base branch] to change the base of the the currently checked out branch to the target. typically this is git rebase main or git rebase master. there's a second argument that can go after the new base branch that defaults to the currently checked out branch; that argument makes following the documentation/examples I could find confusing and I always check out the branch I'm working on so I'm going to ignore it.
the --onto argument takes two inputs: the first is the same as the regular argument; the second is the last commit on the current checked out feature branch we want to drop because it is now obsolete.
I think the way git diagrams usually show branches is unhelpful here; here's mine. say I have this:
A---B---C---D feature1 A---B---C---D---E---F feature2
I realize that I have a bug in commit C in feature1, and the fix will merge conflict with D. I rewrite history on feature1 to fix it:
A---B---C*--D* feature1 A---B---C---D---E---F feature2
now I check out feature2, wanting to update it. I can't just do git rebase feature1, because git will try to make A---B---C*--D*--C---D---E---F. I can make a temporary branch based on feature1, cherry pick E and F onto it, then hard reset feature2 to the temporary branch, but that's silly. (I could probably do a number of other things; there are like eleven billion git commands. please comment if you know an even better way to do this.)
what I want to do here is git rebase --onto feature1 D (where D is the sha of commit D, the last commit I do not want to keep on feature2 because I am replacing it with the new base branch).
I have no idea why this command is not git rebase feature1 --onto D or something. replacing the first argument you would normally use with a flag and then the argument you would normally use and then another different argument makes precisely zero sense? but, whatever, fine. sure wasted me a lot of time in between the first time I read that manpage, gave up, did temporary branches for years, then finally figured it out, but you do you, git devs.
edit: oh, this probably goes without saying if you know enough git to read this, but this is only necessary if one does rewrite history on feature1. if you just commit a fix on it normally, git rebase feature1 (and then handling any merge conflicts in E and F) will work fine. that's why you generally don't need to know this; it's only necessary if you're manipulating your commit history because you think it'll provide useful clarity and think that's worth the complexity in your git workflow. I do it a fair amount because I tend to juggle multiple potential changes to the same code at once more than is probably wise, but I definitely lean toward not doing it, particularly in a codebase that uses squash merging for PRs and discards all of this history in the end anyway.
3 notes
·
View notes
Text
okay there has to be a oneliner way to make a command line command (npm package script) use environment variables that will either use a .env file or the github actions environment secrets. right? no? maybe no.
sighs. at some point I'm going to publish a template repository for "web extension that's not listed in the extension stores but is signed" and it is going to have to come with a three page long instruction manual. this is all so stupid
4 notes
·
View notes
Text
ever find yourself wanting to make a git commit that results in the file contents of one branch exactly matching the file contents of another branch? no? well, whatever, I sometimes do and somehow never bothered to look up the correct way to (I've been doing squash merge shenanigans). turns out it's as simple as
git diff currentbranch branchtocopy | git apply -
(and then, you know, adding and committing the changes. I use github desktop because I love interactive staging like it's one of my nonexistent children, so I'm not including that in the oneliner, but you could.)
2 notes
·
View notes
Text
TypeScript 5.3 now can perform narrowing based on conditions in each case clause within a switch (true).
in each case clause in a what now
...huh. that's actually. pretty clever.
2 notes
·
View notes
Text
fun fact: according to my first experiment with the chromium css selector performance tooling that I just found, the most expensive selector (by a massive margin) on a tumblr page running xkit is, drum roll please... row > :nth-child(2), a style from tumblr itself that's part of the code for the blog activity graph on the activity page.
so, uh, a) yeah I am not going to worry about xkit selector performance, and b) I guess in the future I will be careful about using an otherwise unqualified relative position selector as the last selector in a descendent selector tree. except for the part where I wouldn't have done that anyway
2 notes
·
View notes
Text
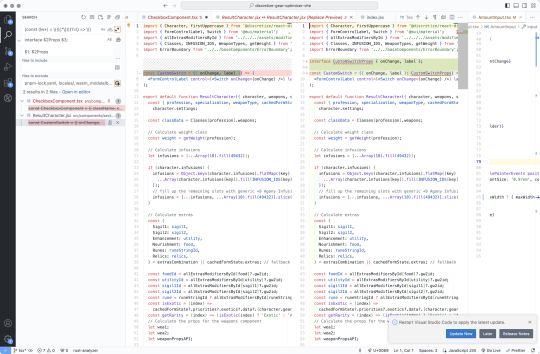
Is this regex replace (to save time converting jsx components to tsx)... good? No, not even a little bit. But I can't be bothered to figure out a better way to make a VS Code Macro and I'm not paying for Copilot, so.
edit: slightly improved
(.*const (\w+) = \((\{.*\}))(?=\) =>) (.*function (\w+)\((\{.*\}))(?=\) \{)
interface $2Props $3; $1: $2Props
3 notes
·
View notes
Text
I love that ancient, fundamentally pointless bits of the web standard like "html elements with id or name attributes automatically become globals in the javascript context for absolutely no reason" repeatedly become security issues
I'll give you one guess where this particular behavior was first implemented. actually I'll give you zero guesses it's internet explorer
4 notes
·
View notes
Text
Little post I wrote in my XKit Rewritten notes. I don't expect this to be that interesting to anyone, but I take some pride in trying to explain the details of things like this.
---
An unfortunate small performance regression:
Some of the experimental virtual scroller code makes use of requestAnimationFrame. This is cool! Unfortunately for us, what this means is that Redpop is doing DOM mutations inside an rAF callback.
Recall that our pageModifications engine, as per #407 (and its predecessor #275):
will compile an array of every mutation between frames, and queue onBeforeRepaint() for before the next frame using Window.requestAnimationFrame()
There is a subtle condition here: requestAnimationFrame will queue its callback to run right before the next frame is rendered... unless you're already in the rAF callback "right before" said frame, at which point it will queue its callback for right before the one after that. This, of course, makes sense: a user repeatedly calling rAF is trying to step through each frame in order to, you know, run an animation.
This means, though, that in the case where the DOM mutations we're trying to react to are called using rAF, and are thus in an rAF callback, we have no way* of scheduling pageModifications after all Redpop mutations but before the DOM gets painted, rendered, etc like we used to. If we use rAF, our modifications will occur one frame later, so the user will see one frame of unmodified content before the modified view (causing a double reflow, etc, as we used to always have before 454b268 and #416 and stuff). If we don't use rAF, we basically have to just handle the mutations "now,"* which would mean running all of the pageModifications callbacks multiple times.
Having a choice between a few milliseconds of wasteful javascript and a frame of UI flicker isn't the worst thing in the world—it's really only noticeable in certain circumstances, like when using Scroll to Bottom—but it is too bad to lose the "best of both worlds" option for such a subtle reason.
*I have a trick involving repeatedly queueing a new microtask; it doesn't really help here.

14 notes
·
View notes
Text
Hrmmmm.
I have a piece of code that (simplified) takes an array of values, runs a fetch corresponding to each value, and does something with the results (in order). The naive way to do this runs all of the fetches in sequence, which is of course slow.
for (const value of someValues) { const result = await fetch(value); console.log(result); }
The slightly less naive way to do this (Promise.all) fires all of the fetches at the same time, which is fine if you have a small number, but not so much if you have a big number. Ideally you would want to do a specific configurable number of fetches at once.
Obviously this isn't hard to do if you write your code that way in advance. I was trying to think of a way to do a helper function that could be used to replace the naive way with a minimal change to the code, though.
In a way, I actually already had one of these (this gist needs more comments; the technique is quite cool imho but it's a bit of a fun puzzle to understand):
This is nice for medium-sized arrays where you're okay with waiting until all of the fetches to resolve before you do anything else with them. But for really large arrays, it's nice to be able to do stuff with the results incrementally. I had this idea:
const batchCallAsync = (inputValues, cb, batchSize) => { const results = []; const values = [...inputValues]; let waitForPreviousBatch = Promise.resolve(); while (values.length) { const resultBatch = values.splice(0, batchSize).map( (value) => new Promise((resolve) => { waitForPreviousBatch.finally(() => resolve(cb(value))); }) ); waitForPreviousBatch = Promise.allSettled(resultBatch); results.push(...resultBatch); } return results; };
This, when run, instantly generates an array of promises, but the promises execute fetches and resolve in batches. You can thus do e.g.
for await (const result of batchCallAsync(someValues, fetch, 5)) { console.log(result) }
and the log statements will come out in real time as the fetches occur. Neat. Could use some refactoring (and a performance improvement to match that gist), but whatever.
Problem, though: you can't cancel this. If you call this on an array of length 3500, you are getting 3500 fetches executed even if you break that for loop (unless you close node/your browser tab). That's not true of the original snippet.
I'm pretty sure it's possible to solve that, too? This seems like the ideal use case for an async generator function. Haven't bothered to write it, yet, but it should be quite simple in principle.
2 notes
·
View notes
Text
can't imagine this will be useful for anyone, but... my updated browser version api support notes:
sticky thead: firefox 59, chrome 91 es2020 ?. : firefox 74, chrome 80 ''.replaceAll(): firefox 77, chrome 85 regex lookbehind: firefox 78, chrome 62
MacOS 10.11 (~2008 Macs): Firefox 78; Chrome 103
es2021 ??= : firefox 79, chrome 85 overflow:clip: firefox 81, chrome 90 not(a, b): firefox 84, chrome 88 top-level await: firefox 89, chrome 89 dynamic import in content script: firefox 89, chrome ???? [].at(): firefox 90, chrome 92
avif images: firefox 93, chrome 85 storage.local.onChanged.addListener: firefox 101, chrome 73 mv2 scripting api: firefox 102 pale moon is firefox 102 mv2 non-persistent background page: firefox 106 mv3 basic support: firefox 109, chrome 88 [].findLast: firefox 104, chrome 97 manifest.json gecko_android: firefox 113 module workers: firefox 114, chrome 80 link rel=modulepreload: firefox 115, chrome 66
MacOS 10.12 (2009-2010): Firefox 115; Chrome 103
media query range: firefox 63, chrome 104
Windows 7/8: Firefox 115; Chrome 109
[].toSorted(): firefox 115, chrome 110 non-buggy image-set: firefox 113, chrome 113 color-mix: firefox 113, chrome 111
MacOS 10.13 (2009-2010): Firefox 115; Chrome 116
object.groupby: firefox 119, chrome 117 css &: firefox 117, chrome 120? css masks: firefox 53, chrome 120 permissions.request: fenix 120? :has(): firefox 121, chrome 105 mv3 service_worker and scripts: firefox 121, chrome 121
css color from: firefox 128, chrome 119? mv3 optional_host_permissions, many fixes: firefox 128, chrome 102 mv3 world: "MAIN": firefox 128, chrome 102 mv3 world: "MAIN" (in manifest): firefox 128, chrome 111
most firefox forks: Firefox 128
1 note
·
View note
Text
oh. huh. I think I've used a combination of setTimeout and Promise.race to do this at least once in the past; I guess that was overly convoluted.
2 notes
·
View notes